Post Syndicated from Sol Kavanagh original https://aws.amazon.com/blogs/security/forensic-investigation-environment-strategies-in-the-aws-cloud/
When a deviation from your secure baseline occurs, it’s crucial to respond and resolve the issue quickly and follow up with a forensic investigation and root cause analysis. Having a preconfigured infrastructure and a practiced plan for using it when there’s a deviation from your baseline will help you to extract and analyze the information needed to determine the impact, scope, and root cause of an incident and return to operations confidently.
Time is of the essence in understanding the what, how, who, where, and when of a security incident. You often hear of automated incident response, which has repeatable and auditable processes to standardize the resolution of incidents and accelerate evidence artifact gathering.
Similarly, having a standard, pristine, pre-configured, and repeatable forensic clean-room environment that can be automatically deployed through a template allows your organization to minimize human interaction, keep the larger organization separate from contamination, hasten evidence gathering and root cause analysis, and protect forensic data integrity. The forensic analysis process assists in data preservation, acquisition, and analysis to identify the root cause of an incident. This approach can also facilitate the presentation or transfer of evidence to outside legal entities or auditors. AWS CloudFormation templates—or other infrastructure as code (IaC) provisioning tools—help you to achieve these goals, providing your business with consistent, well-structured, and auditable results that allow for a better overall security posture. Having these environments as a permanent part of your infrastructure allows them to be well documented and tested, and gives you opportunities to train your teams in their use.
This post provides strategies that you can use to prepare your organization to respond to secure baseline deviations. These strategies take the form of best practices around Amazon Web Services (AWS) account structure, AWS Organizations organizational units (OUs) and service control policies (SCPs), forensic Amazon Virtual Private Cloud (Amazon VPC) and network infrastructure, evidence artifacts to be collected, AWS services to be used, forensic analysis tool infrastructure, and user access and authorization to the above. The specific focus is to provide an environment where Amazon Elastic Compute Cloud (Amazon EC2) instances with forensic tooling can be used to examine evidence artifacts.
This post presumes that you already have an evidence artifact collection procedure or that you are implementing one and that the evidence can be transferred to the accounts described here. If you are looking for advice on how to automate artifact collection, see How to automate forensic disk collection for guidance.
Infrastructure overview
A well-architected multi-account AWS environment is based on the structure provided by Organizations. As companies grow and need to scale their infrastructure with multiple accounts, often in multiple AWS Regions, Organizations offers programmatic creation of new AWS accounts combined with central management and governance that helps them to do so in a controlled and standardized manner. This programmatic, centralized approach should be used to create the forensic investigation environments described in the strategy in this blog post.
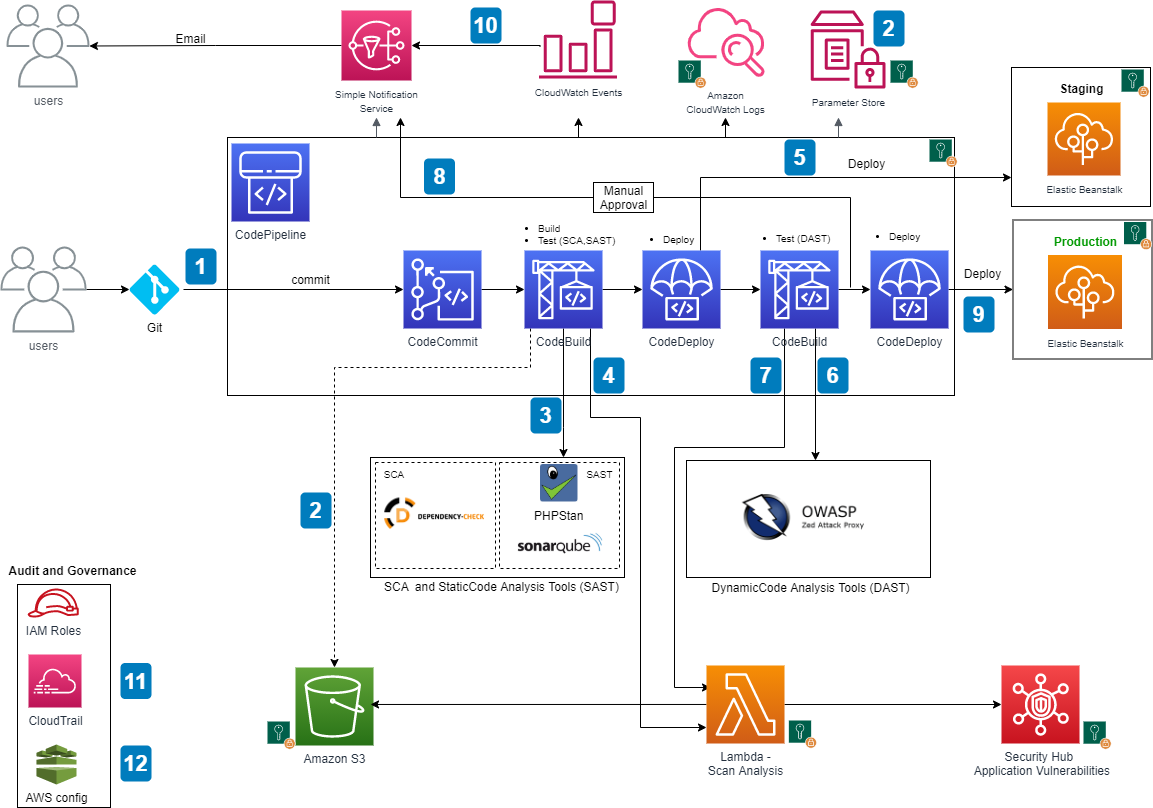
The example in this blog post uses a simplified structure with separate dedicated OUs and accounts for security and forensics, shown in Figure 1. Your organization’s architecture might differ, but the strategy remains the same.
Note: There might be reasons for forensic analysis to be performed live within the compromised account itself, such as to avoid shutting down or accessing the compromised instance or resource; however, that approach isn’t covered here.

Figure 1: AWS Organizations forensics OU example
The most important components in Figure 1 are:
- A security OU, which is used for hosting security-related access and services. The security OU and the associated AWS accounts should be owned and managed by your security organization.
- A forensics OU, which should be a separate entity, although it can have some similarities and crossover responsibilities with the security OU. There are several reasons for having it within a separate OU and account. Some of the more important reasons are that the forensics team might be a different team than the security team (or a subset of it), certain investigations might be under legal hold with additional access restrictions, or a member of the security team could be the focus of an investigation.
When speaking about Organizations, accounts, and the permissions required for various actions, you must first look at SCPs, a core functionality of Organizations. SCPs offer control over the maximum available permissions for all accounts in your organization. In the example in this blog post, you can use SCPs to provide similar or identical permission policies to all the accounts under the forensics OU, which is being used as a resource container. This policy overrides all other policies, and is a crucial mechanism to ensure that you can explicitly deny or allow any API calls desired. Some use cases of SCPs are to restrict the ability to disable AWS CloudTrail, restrict root user access, and ensure that all actions taken in the forensic investigation account are logged. This provides a centralized way to avoid changing individual policies for users, groups, or roles. Accessing the forensic environment should be done using a least-privilege model, with nobody capable of modifying or compromising the initially collected evidence. For an investigation environment, denying all actions except those you want to list as exceptions is the most straightforward approach. Start with the default of denying all, and work your way towards the least authorizations needed to perform the forensic processes established by your organization. AWS Config can be a valuable tool to track the changes made to the account and provide evidence of these changes.
Keep in mind that once the restrictive SCP is applied, even the root account or those with administrator access won’t have access beyond those permissions; therefore, frequent, proactive testing as your environment changes is a best practice. Also, be sure to validate which principals can remove the protective policy, if required, to transfer the account to an outside entity. Finally, create the environment before the restrictive permissions are applied, and then move the account under the forensic OU.
Having a separate AWS account dedicated to forensic investigations is best to keep your larger organization separate from the possible threat of contamination from the incident itself, ensure the isolation and protection of the integrity of the artifacts being analyzed, and keeping the investigation confidential. Separate accounts also avoid situations where the threat actors might have used all the resources immediately available to your compromised AWS account by hitting service quotas and so preventing you from instantiating an Amazon EC2 instance to perform investigations.
Having a forensic investigation account per Region is also a good practice, as it keeps the investigative capabilities close to the data being analyzed, reduces latency, and avoids issues of the data changing regulatory jurisdictions. For example, data residing in the EU might need to be examined by an investigative team in North America, but the data itself cannot be moved because its North American architecture doesn’t align with GDPR compliance. For global customers, forensics teams might be situated in different locations worldwide and have different processes. It’s better to have a forensic account in the Region where an incident arose. The account as a whole could also then be provided to local legal institutions or third-party auditors if required. That said, if your AWS infrastructure is contained within Regions only in one jurisdiction or country, then a single re-creatable account in one Region with evidence artifacts shared from and kept in their respective Regions could be an easier architecture to manage over time.
An account created in an automated fashion using a CloudFormation template—or other IaC methods—allows you to minimize human interaction before use by recreating an entirely new and untouched forensic analysis instance for each separate investigation, ensuring its integrity. Individual people will only be given access as part of a security incident response plan, and even then, permissions to change the environment should be minimal or none at all. The post-investigation environment would then be either preserved in a locked state or removed, and a fresh, blank one created in its place for the subsequent investigation with no trace of the previous artifacts. Templating your environment also facilitates testing to ensure your investigative strategy, permissions, and tooling will function as intended.
Accessing your forensics infrastructure
Once you’ve defined where your investigative environment should reside, you must think about who will be accessing it, how they will do so, and what permissions they will need.
The forensic investigation team can be a separate team from the security incident response team, the same team, or a subset. You should provide precise access rights to the group of individuals performing the investigation as part of maintaining least privilege.
You should create specific roles for the various needs of the forensic procedures, each with only the permissions required. As with SCPs and other situations described here, start with no permissions and add authorizations only as required while establishing and testing your templated environments. As an example, you might create the following roles within the forensic account:
Responder – acquire evidence
Investigator – analyze evidence
Data custodian – manage (copy, move, delete, and expire) evidence
Analyst – access forensics reports for analytics, trends, and forecasting (threat intelligence)
You should establish an access procedure for each role, and include it in the response plan playbook. This will help you ensure least privilege access as well as environment integrity. For example, establish a process for an owner of the Security Incident Response Plan to verify and approve the request for access to the environment. Another alternative is the two-person rule. Alert on log-in is an additional security measure that you can add to help increase confidence in the environment’s integrity, and to monitor for unauthorized access.
You want the investigative role to have read-only access to the original evidence artifacts collected, generally consisting of Amazon Elastic Block Store (Amazon EBS) snapshots, memory dumps, logs, or other artifacts in an Amazon Simple Storage Service (Amazon S3) bucket. The original sources of evidence should be protected; MFA delete and S3 versioning are two methods for doing so. Work should be performed on copies of copies if rendering the original immutable isn’t possible, especially if any modification of the artifact will happen. This is discussed in further detail below.
Evidence should only be accessible from the roles that absolutely require access—that is, investigator and data custodian. To help prevent potential insider threat actors from being aware of the investigation, you should deny even read access from any roles not intended to access and analyze evidence.
Protecting the integrity of your forensic infrastructures
Once you’ve built the organization, account structure, and roles, you must decide on the best strategy inside the account itself. Analysis of the collected artifacts can be done through forensic analysis tools hosted on an EC2 instance, ideally residing within a dedicated Amazon VPC in the forensics account. This Amazon VPC should be configured with the same restrictive approach you’ve taken so far, being fully isolated and auditable, with the only resources being dedicated to the forensic tasks at hand.
This might mean that the Amazon VPC’s subnets will have no internet gateways, and therefore all S3 access must be done through an S3 VPC endpoint. VPC flow logging should be enabled at the Amazon VPC level so that there are records of all network traffic. Security groups should be highly restrictive, and deny all ports that aren’t related to the requirements of the forensic tools. SSH and RDP access should be restricted and governed by auditable mechanisms such as a bastion host configured to log all connections and activity, AWS Systems Manager Session Manager, or similar.
If using Systems Manager Session Manager with a graphical interface is required, RDP or other methods can still be accessed. Commands and responses performed using Session Manager can be logged to Amazon CloudWatch and an S3 bucket, this allows auditing of all commands executed on the forensic tooling Amazon EC2 instances. Administrative privileges can also be restricted if required. You can also arrange to receive an Amazon Simple Notification Service (Amazon SNS) notification when a new session is started.
Given that the Amazon EC2 forensic tooling instances might not have direct access to the internet, you might need to create a process to preconfigure and deploy standardized Amazon Machine Images (AMIs) with the appropriate installed and updated set of tooling for analysis. Several best practices apply around this process. The OS of the AMI should be hardened to reduce its vulnerable surface. We do this by starting with an approved OS image, such as an AWS-provided AMI or one you have created and managed yourself. Then proceed to remove unwanted programs, packages, libraries, and other components. Ensure that all updates and patches—security and otherwise—have been applied. Configuring a host-based firewall is also a good precaution, as well as host-based intrusion detection tools. In addition, always ensure the attached disks are encrypted.
If your operating system is supported, we recommend creating golden images using EC2 Image Builder. Your golden image should be rebuilt and updated at least monthly, as you want to ensure it’s kept up to date with security patches and functionality.
EC2 Image Builder—combined with other tools—facilitates the hardening process; for example, allowing the creation of automated pipelines that produce Center for Internet Security (CIS) benchmark hardened AMIs. If you don’t want to maintain your own hardened images, you can find CIS benchmark hardened AMIs on the AWS Marketplace.
Keep in mind the infrastructure requirements for your forensic tools—such as minimum CPU, memory, storage, and networking requirements—before choosing an appropriate EC2 instance type. Though a variety of instance types are available, you’ll want to ensure that you’re keeping the right balance between cost and performance based on your minimum requirements and expected workloads.
The goal of this environment is to provide an efficient means to collect evidence, perform a comprehensive investigation, and effectively return to safe operations. Evidence is best acquired through the automated strategies discussed in How to automate incident response in the AWS Cloud for EC2 instances. Hashing evidence artifacts immediately upon acquisition is highly recommended in your evidence collection process. Hashes, and in turn the evidence itself, can then be validated after subsequent transfers and accesses, ensuring the integrity of the evidence is maintained. Preserving the original evidence is crucial if legal action is taken.
Evidence and artifacts can consist of, but aren’t limited to:
Access to the control plane logs mentioned above—such as the CloudTrail logs—can be accessed in one of two ways. Ideally, the logs should reside in a central location with read-only access for investigations as needed. However, if not centralized, read access can be given to the original logs within the source account as needed. Read access to certain service logs found within the security account, such as AWS Config, Amazon GuardDuty, Security Hub, and Amazon Detective, might be necessary to correlate indicators of compromise with evidence discovered during the analysis.
As previously mentioned, it’s imperative to have immutable versions of all evidence. This can be achieved in many ways, including but not limited to the following examples:
- Amazon EBS snapshots, including hibernation generated memory dumps:
- Original Amazon EBS disks are snapshotted, shared to the forensics account, used to create a volume, and then mounted as read-only for offline analysis.
- Amazon EBS volumes manually captured:
- Linux tools such as dc3dd can be used to stream a volume to an S3 bucket, as well as provide a hash, and then made immutable using an S3 method from the next bullet point.
- Artifacts stored in an S3 bucket, such as memory dumps and other artifacts:
- S3 Object Lock prevents objects from being deleted or overwritten for a fixed amount of time or indefinitely.
- Using MFA delete requires the requestor to use multi-factor authentication to permanently delete an object.
- Amazon S3 Glacier provides a Vault Lock function if you want to retain immutable evidence long term.
- Disk volumes:
- Linux: Mount in read-only mode.
- Windows: Use one of the many commercial or open-source write-blocker applications available, some of which are specifically made for forensic use.
- CloudTrail:
- AWS Systems Manager inventory:
- AWS Config data:
- By default, AWS Config stores data in an S3 bucket, and can be protected using the above methods.
Note: AWS services such as KMS can help enable encryption. KMS is integrated with AWS services to simplify using your keys to encrypt data across your AWS workloads.
An example use case of Amazon EBS disks being shared as evidence to the forensics account, the following figure—Figure 2—is a simplified S3 bucket folder structure you could use to store and work with evidence.
Figure 2 shows an S3 bucket structure for a forensic account. An S3 bucket and folder is created to hold incoming data—for example, from Amazon EBS disks—which is streamed to Incoming Data > Evidence Artifacts using dc3dd. The data is then copied from there to a folder in another bucket—Active Investigation > Root Directory > Extracted Artifacts—to be analyzed by the tooling installed on your forensic Amazon EC2 instance. Also, there are folders under Active Investigation for any investigation notes you make during analysis, as well as the final reports, which are discussed at the end of this blog post. Finally, a bucket and folders for legal holds, where an object lock will be placed to hold evidence artifacts at a specific version.

Figure 2: Forensic account S3 bucket structure
Considerations
Finally, depending on the severity of the incident, your on-premises network and infrastructure might also be compromised. Having an alternative environment for your security responders to use in case of such an event reduces the chance of not being able to respond in an emergency. Amazon services such as Amazon Workspaces—a fully managed persistent desktop virtualization service—can be used to provide your responders a ready-to-use, independent environment that they can use to access the digital forensics and incident response tools needed to perform incident-related tasks.
Aside from the investigative tools, communications services are among the most critical for coordination of response. You can use Amazon WorkMail and Amazon Chime to provide that capability independent of normal channels.
Conclusion
The goal of a forensic investigation is to provide a final report that’s supported by the evidence. This includes what was accessed, who might have accessed it, how it was accessed, whether any data was exfiltrated, and so on. This report might be necessary for legal circumstances, such as criminal or civil investigations or situations requiring breach notifications. What output each circumstance requires should be determined in advance in order to develop an appropriate response and reporting process for each. A root cause analysis is vital in providing the information required to prepare your resources and environment to help prevent a similar incident in the future. Reports should not only include a root cause analysis, but also provide the methods, steps, and tools used to arrive at the conclusions.
This article has shown you how you can get started creating and maintaining forensic environments, as well as enable your teams to perform advanced incident resolution investigations using AWS services. Implementing the groundwork for your forensics environment, as described above, allows you to use automated disk collection to begin iterating on your forensic data collection capabilities and be better prepared when security events occur.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on one of the AWS Security, Identity, and Compliance forums or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.



















































 Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.
Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.