A malware campaign uses the unusual method of locking users in their browser’s kiosk mode to annoy them into entering their Google credentials, which are then stolen by information-stealing malware.
Specifically, the malware “locks” the user’s browser on Google’s login page with no obvious way to close the window, as the malware also blocks the “ESC” and “F11” keyboard keys. The goal is to frustrate the user enough that they enter and save their Google credentials in the browser to “unlock” the computer.
Once credentials are saved, the StealC information-stealing malware steals them from the credential store and sends them back to the attacker.
I’m sure this works often enough to be a useful ploy.
Класическите консерватори в САЩ преживяват тежки времена. Гласуването за Републиканската партия, която би трябвало да изразява ценностите им, върви в комплект с популизма на Доналд Тръмп. А самият Тръмп, вместо да се концентрира върху важните за избирателите си приоритети, разпространява конспиративните теории за хаитянски имигранти, които ядат домашни любимци и деца, които се връщат от училище със сменен пол. Затова вече над двеста високопоставени републиканци, включително бившият вицепрезидент Дик Чейни, призовават да се гласува за кандидатката на демократите Камала Харис. Загубата на Тръмп би дала шанс за възраждане на нормалния консерватизъм.
Американците, които не харесват популизма обаче, поне имат избор. За съжаление, същото не може да се каже за българските избиратели. Според различни социологически изследвания повече от половината гласоподаватели в България споделят ценностите на либералната демокрация. Ала партиите и коалициите в Народното събрание се държат така, сякаш всички техни потенциални избиратели са тръмписти или путинисти (които в ценностно отношение са сходни). Същото се отнася впрочем и за извънпарламентарните партии, особено след като Зелено движение отказа да се включи в предизборната надпревара.
Ценностният компас на парламентарните партии
„Възраждане“, „Има такъв народ“ и отломките от „Величие“ са националпопулистки по дефиниция, от тях не може да се очаква защита на либералната демокрация. БСП е в период на полуразпад. Но борбата в най-старата партия в България е не за ценности, а за власт. Няма заявка, че тези, които идват след Корнелия Нинова, ще се опитат да направят от БСП нормална европейска левица, която защитава правата на жените и уязвимите групи и се противопоставя на популизма и омразата.
По-интересен е въпросът с парламентарните партии и коалиции, които се идентифицират като проевропейски и демократични. Това са ГЕРБ, в чието име присъстват думите „европейско развитие“, ДПС, които поне според заглавието си са за права и свободи, и коалицията между „Продължаваме промяната“ и „Демократична България“. От ПП–ДБ винаги са декларирали евроатлантическа ориентация.
В последните месеци в Народното събрание се нарояват все повече законодателни инициативи, които са в унисон с руските закони. Това са т.нар. забрана на „пропагандата на нетрадиционна сексуална ориентация“ в училище по инициатива на „Възраждане“, предложението за „чуждестранните агенти“ – отново на „Възраждане“, за забрана на смяната на пола на непълнолетни – на ИТН и по-мекият вариант на същото – на ПП–ДБ.
Тъй като, за разлика от останалите предложения, промените в Закона за предучилищното и училищното образование, прочули се като „закон за пропагандата“, са вече приети, в тази статия се обръща внимание специално на него. Акцентът е върху действията на т.нар. демократични партии, тъй като останалите са последователни в преследването на дневния си ред.
Законопроектът беше приет на три гласувания. Първото четене се отнася за предложението като цяло.
Второто четене е параграф по параграф. Първо се гласува текстът, според който се забранява „извършване на пропаганда, популяризиране или подстрекаване по какъвто и да е начин, пряко или косвено, на идеи и възгледи, свързани с нетрадиционна сексуална ориентация и/или определяне на полова идентичност, различна от биологичната“.
След това идва ред на приемането на самата дефиниция за „нетрадиционна сексуална ориентация“ – „различни от общоприетите и заложените в българската правна традиция схващания за емоционално, романтично, сексуално или чувствено привличане между лица от противоположни полове“.
ГЕРБ и евроатлантизмът, който сменя полове
Парламентарната група на ГЕРБ–СДС е най-голямата в парламента. Без нейната подкрепа промените в образователния закон нямаше да се приемат. На първо четене 55 от общо 60 присъстващи в залата депутати от коалицията подкрепят законопроекта на „Възраждане“. Против е само един – Тервел Георгиев. Той е и единственият, който и при трите гласувания е против. Въздържат се четирима – Георг Георгиев, Георги Георгиев, Екатерина Захариева и Йорданка Фандъкова.
При гласуването на дефиницията към противопоставилия се Тервел Георгиев се присъединява и Георги Георгиев, а останалите трима, които на първо четене се въздържат, запазват позицията си. 56 депутати гласуват за. Що се отнася до дефиницията на ориентацията, против са вече 6 народни представители от най-голямата група, 8 се въздържат, а 47 гласуват за.
По време на дебатите Тервел Георгиев обръща внимание, че законопроектът на „Възраждане“ повтаря руски закон:
През 2013 г. администрацията на Владимир Путин прие такъв закон в Руската федерация и той съответно се прилага оттогава в тази държава. Той ще бъде първият обаче такъв законопроект, ако бъде и се превърне в закон, който ще е приет в държава, която принадлежи към европейската ценностна система и разбирания.
Георгиев е репликиран от съпартийците си Петър Николов и Красимир Вълчев. Според Николов „в Европа няма по-полезни хора за Владимир Путин и за Русия от хората, които започнаха да слагат знак на равенство между нетрадиционната сексуална ориентация и европейските ценности! Хората, които замениха националните си флагове или флага на Европейския съюз със знамето на дъгата, са най-вредните хора за Европа!“.
Вълчев изразява несъгласието си по-меко. Той казва, че с колегите си от Образователната комисия е подкрепил законопроекта поради консервативните си разбирания:
Не защото не сме толерантни, не сме европейци, не защото сме пропутинисти, а защото това е нашето разбиране в какво общество трябва да живеем.
Председателят на ГЕРБ Бойко Борисов обаче, който не участва в гласуването на закона, поставя самия евроатлантизъм под въпрос. В отговор на питане на журналистка как се връзва подкрепата на партията за законопроекта на „Възраждане“ с евроатлантическите ценности, той отговаря:
Ако евроатлантизмът, уважаема госпожо, е да ме направи жена, значи тогава – давам Ви заглавие – не съм евроатлантик. […] Няма да го направя по никакъв начин. Нито желая внуците ми да го направят.
Освен „откритието“, че евроатлантизмът означава принудителна смяна на пола, в същото си изказване Борисов изразява увереност, че може да преценява пола на участниците в Олимпиадата на око. В подкрепа на тезата си, че тайванската боксьорка Лин Ю-Тин, победила българката Светлана Каменова на ринга в Париж, не е жена, той казва: „Аз вярвам на очите си. Гледах го мача“ и добавя, че Ю-Тин се биела „като мъж“, като не пропуска да пусне хомофобски майтап – в случая, че задният вход всъщност бил изход.
Как ДПС – Пеевски гласува срещу себе си
В Европейския парламент ДПС е част от групата на либералите. Това обаче не проличава в дебатите по законопроекта. Единственият представител на парламентарната група, взел участие в тях, е Йордан Цонев. Той заявява, че групата ще подкрепи законопроекта с аргумента:
Традиционните религии са изключително консервативни по тази тема и има защо да са консервативни, тъй като устоите на човешкия род се крепят върху това – върху семейството, брака между мъж и жена и продължаването на човешкия род и човешкия вид на тази основа.
След това Цонев, който е с докторат по богословие, продължава изказването си с цитати от Библията.
На първите две гласувания групата на ДПС е дружно за. Ала на третото всички изведнъж стават против, като внезапно да са се сетили, че са либерали. Йордан Цонев впрочем гласува само на първо четене, а Пеевски, също като Борисов, не се включва изобщо.
Що се отнася до ДПС – Доган, изключените депутати от парламентарната група на ДПС гласуват в подкрепа на законопроекта и трите пъти. Изглежда, на тях е нямало #кой да им напомни, че са либерали.
Еволюцията на ПП–ДБ в рамките на един парламентарен ден
Парламентарната група на ПП–ДБ също преживява интересна трансформация между трите гласувания, макар и не толкова рязка, колкото тази на ДПС – Пеевски.
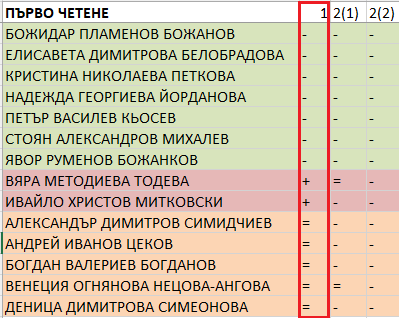
На първо четене гласуват едва 15 народни представители – по-малко от половината от групата. Сред невключилите се са и съпредседателите на ПП Кирил Петков и Асен Василев. Законопроектът е отхвърлен от 7 депутати: Божидар Божанов, Елисавета Белобрадова, Кристина Петкова, Надежда Йорданова, Петър Кьосев, Стоян Михалев и Явор Божанков. Те са и единствените, които и трите пъти гласуват по един и същи начин.
Същевременно двама подкрепят предложението на „Възраждане“ – Вяра Тодева и Ивайло Митковски, а петима се въздържат – Александър Симидчиев, Андрей Цеков, Богдан Богданов, Венеция Нецова-Ангелова и Деница Симеонова.
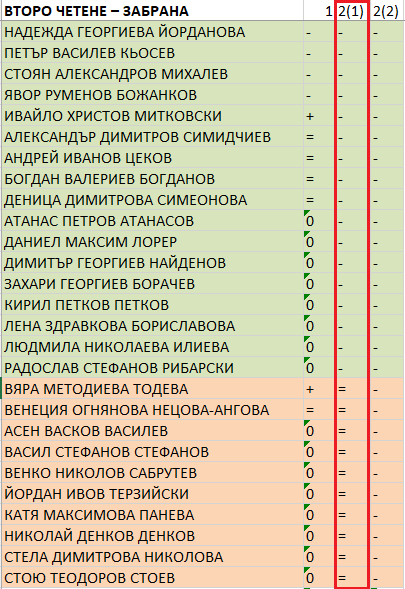
При гласуването на забраната на „пропагандата, подстрекаването и популяризирането“ броят на участвалите депутати от ПП–ДБ се удвоява. Никой не гласува за. 20 депутати от групата отхвърлят предложението, включително Ивайло Митковски, който на първо четене го подкрепя. 10 народни представители от групата обаче се въздържат. Сред тях са съпредседателят на ПП Асен Василев и бившият премиер Николай Денков.
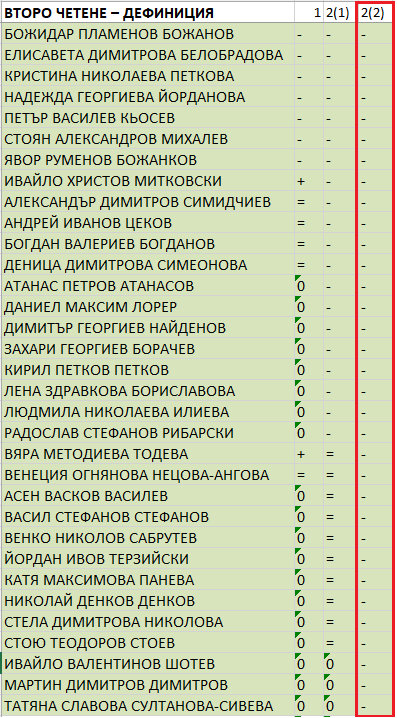
На третото гласуване обаче всички от ПП–ДБ, които този път са 33, гласуват против. Това оставя общественото мнение с впечатлението, че на второ четене всички депутати от групата са отхвърлили законопроекта на „Възраждане“. Но това не е вярно. Една трета от гласувалите не са се противопоставили на забраната на „пропагандата, подстрекаването и популяризирането“ на теми, свързани със сексуалната ориентация и половата идентичност в училище. Те само не са били съгласни с дефиницията за „нетрадиционна сексуална ориентация“.
Има основания и хипотезата, че между първото и третото гласуване нещо се е променило. Че от ПП–ДБ са очаквали общественото мнение да застане в подкрепа на хомофобския закон и бурните реакции срещу него са довели до мобилизация и обрат в позициите на народните представители, които при предишните гласувания са били за, въздържали са се или изобщо са отказали да участват.
По време на обсъжданията на предложението четирима депутати от парламентарната група вземат думата. Това са Елисавета Белобрадова, Андрей Цеков, Явор Божанков и Петър Кьосев, който се включва с кратка реплика. От тях само Божанков казва от трибуната, че „този законопроект има аналог в Руската федерация и той е станал основание за едни съвсем други процеси по-късно в тяхното общество“.
Вятърничава политика
И по повод на предстоящите избори – седми поред за три години – ще се говори за ниската избирателна активност. Но партиите и коалициите все така няма да забелязват, че една от основните причини хората да не гласуват е, че се чувстват непредставени. Включително заради това, че продемократичните и проевропейските избиратели, които са мнозинство, не виждат политически субект, който да защитава ценностите им.
За сметка на това продемократичните избиратели виждат, че избраниците им в парламента гласуват според както духа вятърът (или според както си мислят, че вятърът духа). И че ценностите им могат да бъдат пожертвани на всяка крачка от всяка партия и коалиция. Било заради някаква моментна политическа изгода, било защото партиите и коалициите просто не знаят какви хора гласуват за тях. И вместо да си направят труда да разберат, си въобразяват някакъв абстрактен избирател, който по дефиниция е консервативен популист. Така обаче се борят за електората на популистките партии, не за собствения си.
Чували сте една от дефинициите на лудостта – всеки път да повтаряш едно и също и да очакваш различен резултат. Докато смятащите се за демократични партии пробутват на гласоподавателите все същия вятърничав продукт, докато държат в мъгла какво точно отстояват, за да не отблъснат някого, ще се въртим в абсурдната спирала от избори след избори. И все повече хора ще се питат за какво им е тази демокрация, след като няма кой да припомня смисъла от нея.
Over the past 14 years, Cloudflare has evolved far beyond a Content Delivery Network (CDN), expanding its offerings to include a comprehensive Zero Trust security portfolio, network security & performance services, application security & performance optimizations, and a powerful developer platform. But customers also continue to rely on Cloudflare for caching and delivering static website content. CDNs are often judged on their ability to return content to visitors as quickly as possible. However, the speed at which content is removed from a CDN’s global cache is just as crucial.
When customers frequently update content such as news, scores, or other data, it is essential they avoid serving stale, out-of-date information from cache to visitors. This can lead to a subpar experience where users might see invalid prices, or incorrect news. The goal is to remove the stale content and cache the new version of the file on the CDN, as quickly as possible. And that starts by issuing a “purge.”
In May 2022, we released the first partof the series detailing our efforts to rebuild and publicly document the steps taken to improve the system our customers use, to purge their cached content. Our goal was to increase scalability, and importantly, the speed of our customer’s purges. In that initial post, we explained how our purge system worked and the design constraints we found when scaling. We outlined how after more than a decade, we had outgrown our purge system and started building an entirely new purge system, and provided purge performance benchmarking that users experienced at the time. We set ourselves a lofty goal: to be the fastest.
Today, we’re excited to share that we’ve built the fastest cache purge in the industry. We now offer a global purge latency for purge by tags, hostnames, and prefixes of less than 150ms on average (P50), representing a 90% improvement since May 2022. Users can now purge from anywhere, (almost) instantly. By the time you hit enter on a purge request and your eyes blink, the file is now removed from our global network — including data centers in 330 cities and 120+ countries.
But that’s not all. It wouldn’t be Birthday Week if we stopped at just being the fastest purge. We are alsoannouncing that we’re opening up more purge options to Free, Pro, and Business plans. Historically, only Enterprise customers had access to the full arsenal of cache purge methods supported by Cloudflare, such as purge by cache-tags, hostnames, and URL prefixes. As part of rebuilding our purge infrastructure, we’re not only fast but we are able to scale well beyond our current capacity. This enables more customers to use different types of purge. We are excited to offer these new capabilities to all plan types once we finish rolling out our new purge infrastructure, and expect to begin offering additional purge capabilities to all plan types in early 2025.
Why cache and purge?
Caching content is like pulling off a spectacular magic trick. It makes loading website content lightning-fast for visitors, slashes the load on origin servers and the cost to operate them, and enables global scalability with a single button press. But here’s the catch: for the magic to work, caching requires predicting the future. The right content needs to be cached in the right data center, at the right moment when requests arrive, and in the ideal format. This guarantees astonishing performance for visitors and game-changing scalability for web properties.
Cloudflare helps make this caching magic trick easy. But regular users of our cache know that getting content into cache is only part of what makes it useful. When content is updated on an origin, it must also be updated in the cache. The beauty of caching is that it holds content until it expires or is evicted. To update the content, it must be actively removed and updated across the globe quickly and completely. If data centers are not uniformly updated or are updated at drastically different times, visitors risk getting different data depending on where they are located. This is where cache “purging” (also known as “cache invalidation”) comes in.
One-to-many purges on Cloudflare
Back in part 2 of the blog series, we touched on how there are multiple ways of purging cache: by URL, cache-tag, hostname, URL prefix, and “purge everything”, and discussed a necessary distinction between purging by URL and the other four kinds of purge — referred to as flexible purges — based on the scope of their impact.
The reason flexible purge isn’t also fully coreless yet is because it’s a more complex task than “purge this object”; flexible purge requests can end up purging multiple objects – or even entire zones – from cache. They do this through an entirely different process that isn’t coreless compatible, so to make flexible purge fully coreless we would have needed to come up with an entirely new multi-purge mechanism on top of redesigning distribution. We chose instead to start with just purge by URL, so we could focus purely on the most impactful improvements, revamping distribution, without reworking the logic a data center uses to actually remove an object from cache.
We said our next steps included a redesign of flexible purges at Cloudflare, and today we’d like to walk you through the resulting system. But first, a brief history of flexible cache purges at Cloudflare and elaboration on why the old flexible purge system wasn’t “coreless compatible”.
Just in time
“Cache” within a given data center is made up of many machines, all contributing disk space to store customer content. When a request comes in for an asset, the URL and headers are used to calculate a cache key, which is the filename for that content on disk and also determines which machine in the datacenter that file lives on. The filename is the same for every data center, and every data center knows how to use it to find the right machine to cache the content. A purge request for a URL (plus headers) therefore contains everything needed to generate the cache key — the pointer to the response object on disk — and getting that key to every data center is the hardest part of carrying out the purge.
Purging content based on response properties has a different hardest part. If a customer wants to purge all content with the cache-tag “foo”, for example, there’s no way for us to generate all the cache keys that will point to the files with that cache-tag at request time. Cache-tags are response headers, and the decision of where to store a file is based on request attributes only. To find all files with matching cache-tags, we would need to look at every file in every cache disk on every machine in every data center. That’s thousands upon thousands of machines we would be scanning for each purge-by-tag request. There are ways to avoid actually continuously scanning all disks worldwide (foreshadowing!) but for our first implementation of our flexible purge system, we hoped to avoid the problem space altogether.
An alternative approach to going to every machine and looking for all files that match some criteria to actively delete from disk was something we affectionately referred to as “lazy purge”. Instead of deleting all matching files as soon as we process a purge request, we wait to do so when we get an end user request for one of those files. Whenever a request comes in, and we have the file in cache, we can compare the timestamp of any recent purge requests from the file owner to the insertion timestamp of the file we have on disk. If the purge timestamp is fresher than the insertion timestamp, we pretend we didn’t find the file on disk. For this to work, we needed to keep track of purge requests going back further than a data center’s maximum cache eviction age to be sure that any file a customer sends a matching flex purge to clear from cache will either be naturally evicted, or forced to cache MISS and get refreshed from the origin. With this approach, we just needed a distribution and storage system for keeping track of flexible purges.
Purge looks a lot like a nail
At Cloudflare there is a lot of configuration data that needs to go “everywhere”: cache configuration, load balancer settings, firewall rules, host metadata — countless products, features, and services that depend on configuration data that’s managed through Cloudflare’s control plane APIs. This data needs to be accessible by every machine in every datacenter in our network. The vast majority of that data is distributed via a system introduced several years ago called Quicksilver. The system works very, very well (sub-second p99 replication lag, globally). It’s extremely flexible and reliable, and reads are lightning fast. The team responsible for the system has done such a good job that Quicksilver has become a hammer that when wielded, makes everything look like a nail… like flexible purges.
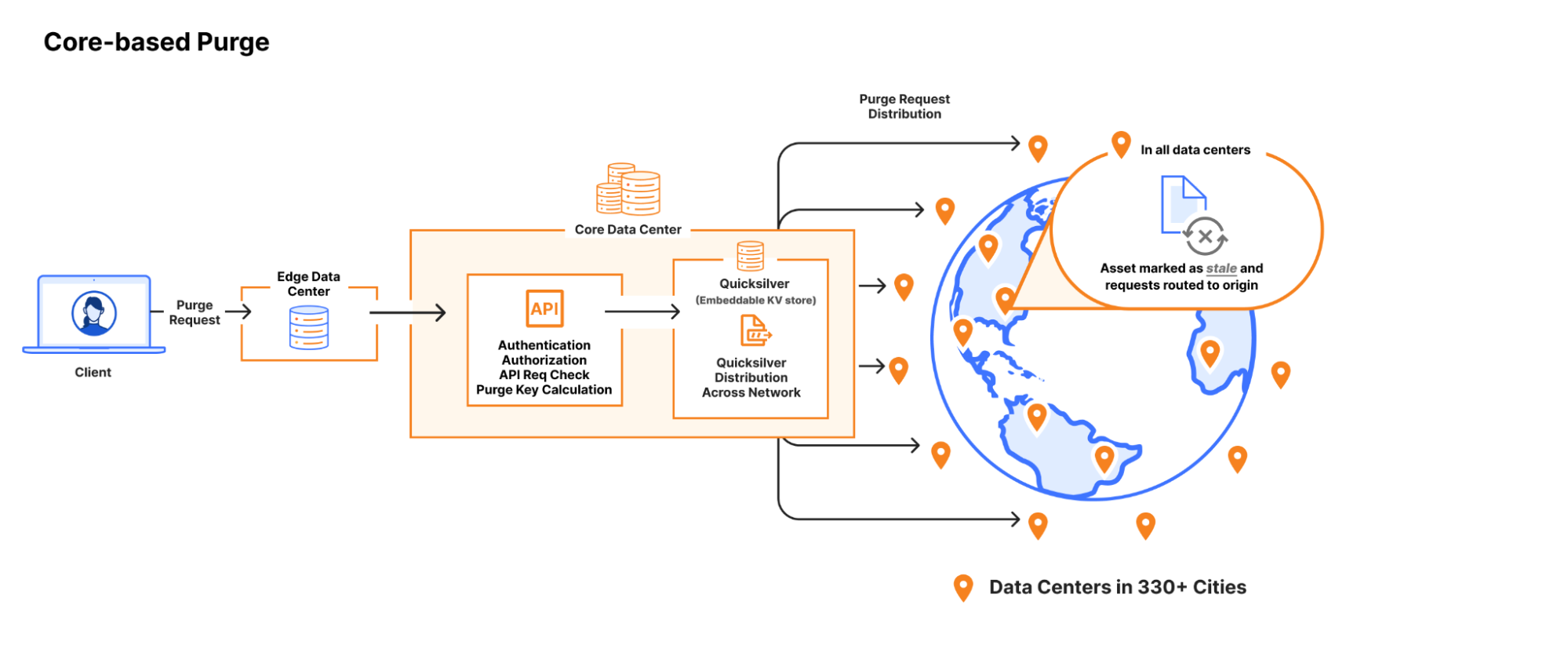
Core-based purge request entering a data center and getting backhauled to a core data center where Quicksilver distributes the request to all network data centers (hub and spoke).
Our first version of the flexible purge system used Quicksilver’s spoke-hub distribution to send purges from a core data center to every other data center in our network. It took less than a second for flexible purges to propagate, and once in a given data center, the purge key lookups in the hot path to force cache misses were in the low hundreds of microseconds. We were quite happy with this system at the time, especially because of the simplicity. Using well-supported internal infrastructure meant we weren’t having to manage database clusters or worry about transport between data centers ourselves, since we got that “for free”. Flexible purge was a new feature set and the performance seemed pretty good, especially since we had no predecessor to compare against.
Victims of our own success
Our first version of flexible purge didn’t start showing cracks for years, but eventually both our network and our customer base grew large enough that our system was reaching the limits of what it could scale to. As mentioned above, we needed to store purge requests beyond our maximum eviction age. Purge requests are relatively small, and compress well, but thousands of customers using the API millions of times a day adds up to quite a bit of storage that Quicksilver needed on each machine to maintain purge history, and all of that storage cut into disk space we could otherwise be using to cache customer content. We also found the limits of Quicksilver in terms of how many writes per second it could handle without replication slowing down. We bought ourselves more runway by putting Kafka queues in front of Quicksilver to buffer and throttle ourselves to even out traffic spikes, and increased batching, but all of those protections introduced latency. We knew we needed to come up with a solution without such a strong correlation between usage and operational costs.
Another pain point exposed by our growing user base that we mentioned in Part 2 was the excessive round trip times experienced by customers furthest away from our core data centers. A purge request sent by a customer in Australia would have to cross the Pacific Ocean and back before local customers would see the new content.
To summarize, three issues were plaguing us:
Latency corresponding to how far a customer was from the centralized ingest point.
Latency due to the bottleneck for writes at the centralized ingest point.
Storage needs in all data centers correlating strongly with throughput demand.
Coreless purge proves useful
The first two issues affected all types of purge. The spoke-hub distribution model was problematic for purge-by-URL just as much as it was for flexible purges. So we embarked on the path to peer-to-peer distribution for purge-by-URL to address the latency and throughput issues, and the results of that project were good enough that we wanted to propagate flexible purges through the same system. But doing so meant we’d have to replace our use of Quicksilver; it was so good at what it does (fast/reliable replication network-wide, extremely fast/high read throughput) in large part because of the core assumption of spoke-hub distribution it could optimize for. That meant there was no way to write to Quicksilver from “spoke” data centers, and we would need to find another storage system for our purges.
Flipping purge on its head
We decided if we’re going to replace our storage system we should dig into exactly what our needs are and find the best fit. It was time to revisit some of our oldest conclusions to see if they still held true, and one of the earlier ones was that proactively purging content from disk would be difficult to do efficiently given our storage layout.
But was that true? Or could we make active cache purge fast and efficient (enough)? What would it take to quickly find files on disk based on their metadata? “Indexes!” you’re probably screaming, and for good reason. Indexing files’ hostnames, cache-tags, and URLs would undoubtedly make querying for relevant files trivial, but a few aspects of our network make it less straightforward.
Cloudflare has hundreds of data centers that see trillions of unique files, so any kind of global index — even ignoring the networking hurdles of aggregation — would suffer the same type of bottlenecking issues with our previous spoke-hub system. Scoping the indices to the data center level would be better, but they vary in size up to several hundred machines. Managing a database cluster in each data center scaled to the appropriate size for the aggregate traffic of all the machines was a daunting proposition; it could easily end up being enough work on its own for a separate team, not something we should take on as a side hustle.
The next step down in scope was an index per machine. Indexing on the same machine as the cache proxy had some compelling upsides:
The proxy could talk to the index over UDS (Unix domain sockets), avoiding networking complexities in the hottest paths.
As a sidecar service, the index just had to be running anytime the machine was accepting traffic. If a machine died, so would the index, but that didn’t matter, so there wasn’t any need to deal with the complexities of distributed databases.
While data centers were frequently adding and removing machines, machines weren’t frequently adding and removing disks. An index could reasonably count on its maximum size being predictable and constant based on overall disk size.
But we wanted to make sure it was feasible on our machines. We analyzed representative cache disks from across our fleet, gathering data like the number of cached assets per terabyte and the average number of cache-tags per asset. We looked at cache MISS, REVALIDATED, and EXPIRED rates to estimate the required write throughput.
After conducting a thorough analysis, we were convinced the design would work. With a clearer understanding of the anticipated read/write throughput, we started looking at databases that could meet our needs. After benchmarking several relational and non-relational databases, we ultimately chose RocksDB, a high-performance embedded key-value store. We found that with proper tuning, it could be extremely good at the types of queries we needed.
Putting it all together
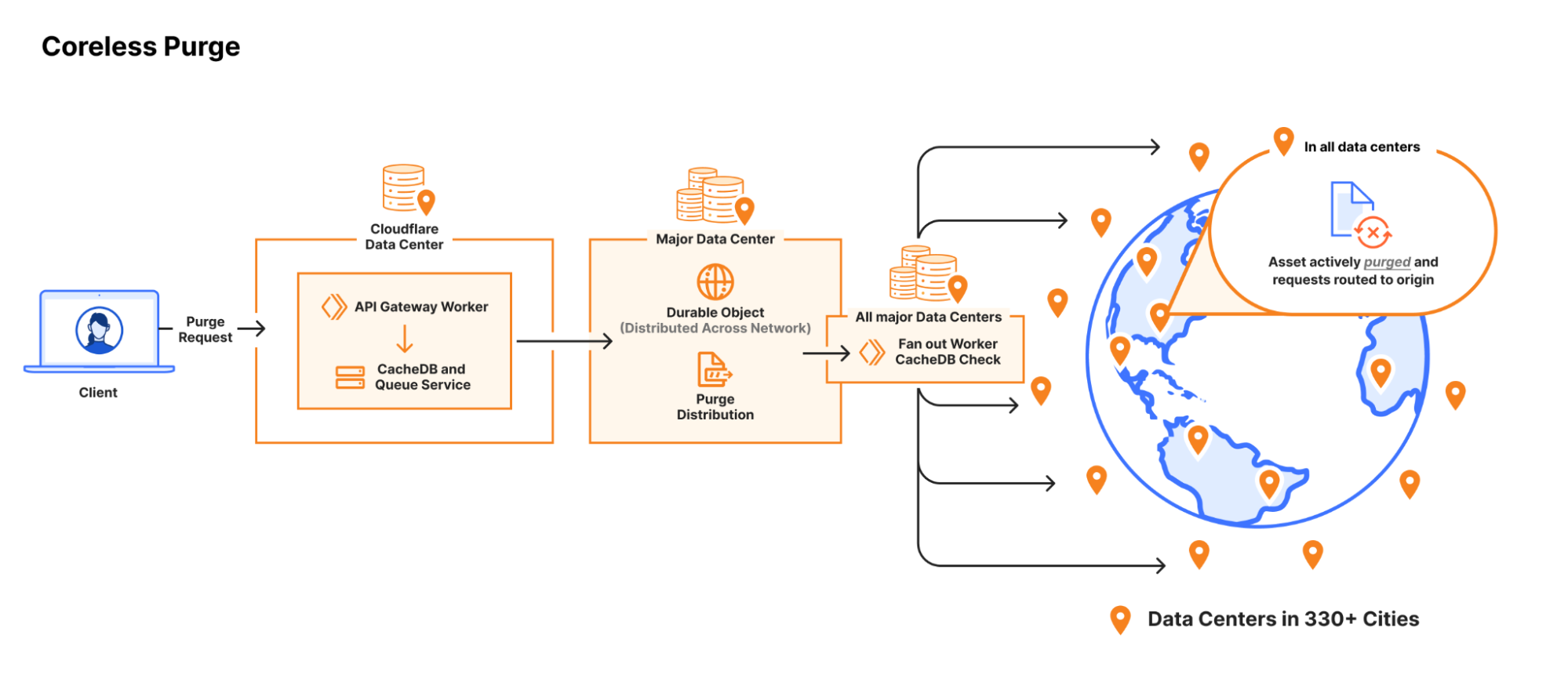
And so CacheDB was born — a service written in Rust and built on RocksDB, which operates on each machine alongside the cache proxy to manage the indexing and purging of cached files. We integrated the cache proxy with CacheDB to ensure that indices are stored whenever a file is cached or updated, and they’re deleted when a file is removed due to eviction or purging. In addition to indexing data, CacheDB maintains a local queue for buffering incoming purge operations. A background process reads purge operations in the queue, looking up all matching files using the indices, and deleting the matched files from disk. Once all matched files for an operation have been deleted, the process clears the indices and removes the purge operation from the queue.
To further optimize the speed of purges taking effect, the cache proxy was updated to check with CacheDB — similar to the previous lazy purge approach — when a cache HIT occurs before returning the asset. CacheDB does a quick scan of its local queue to see if there are any pending purge operations that match the asset in question, dictating whether the cache proxy should respond with the cached file or fetch a new copy. This means purges will prevent the cache proxy from returning a matching cached file as soon as a purge reaches the machine, even if there are millions of files that correspond to a purge key, and it takes a while to actually delete them all from disk.
Coreless purge using CacheDB and Durable Objects to distribute purges without needing to first stop at a core data center.
The last piece to change was the distribution pipeline, updated to broadcast flexible purges not just to every data center, but to the CacheDB service running on every machine. We opted for CacheDB to handle the last-mile fan out of machine to machine within a data center, using consul to keep each machine informed of the health of its peers. The choice let us keep the Workers largely the same for purge-by-URL (more here) and flexible purge handling, despite the difference in termination points.
The payoff
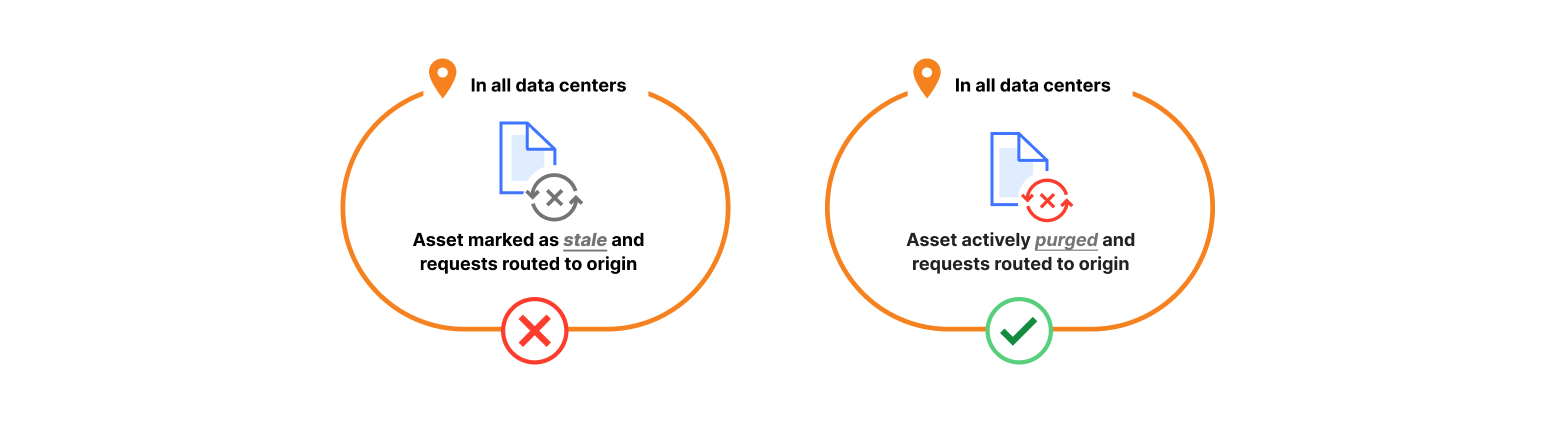
Our new approach reduced the long tail of the lazy purge, saving 10x storage. Better yet, we can now delete purged content immediately instead of waiting for the lazy purge to happen or expire. This new-found storage will improve cache retention on disk for all users, leading to improved cache HIT ratios and reduced egress from your origin.
The shift from lazy content purging (left) to the new Coreless Purge architecture allows us to actively delete content (right). This helps reduce storage needs and increase cache retention times across our service.
With the new coreless cache purge, we can now get a purge request into any datacenter, distribute the keys to purge, and instantly purge the content from the cache database. This all occurs in less than 150 milliseconds on P50 for tags, hostnames, and prefix URL, covering all 330 cities in 120+ countries.
Benchmarks
To measure Instant Purge, we wanted to make sure that we were looking at real user metrics — that these were purges customers were actually issuing and performance that was representative of what we were seeing under real conditions, rather than marketing numbers.
The time we measure represents the period when a request enters the local datacenter, and ends with when the purge has been executed in every datacenter. When the local data center receives the request, one of the first things we do is to add a timestamp to the purge request. When all data centers have completed the purge action, another timestamp is added to “stop the clock.” Each purge request generates this performance data, and it is then sent to a database for us to measure the appropriate quantiles and to help us understand how we can improve further.
In August 2024, we took purge performance data and segmented our collected data by region based on where the local data center receiving the request was located.
Region
P50 Aug 2024 (Coreless)
P50 May 2022 (Core-based)
Improvement
Africa
303ms
1,420ms
78.66%
Asia Pacific Region (APAC)
199ms
1,300ms
84.69%
Eastern Europe (EEUR)
140ms
1,240ms
88.70%
Eastern North America (ENAM)
119ms
1,080ms
88.98%
Oceania
191ms
1,160ms
83.53%
South America (SA)
196ms
1,250ms
84.32%
Western Europe (WEUR)
131ms
1,190ms
88.99%
Western North America (WNAM)
115ms
1,000ms
88.5%
Global
149ms
1,570ms
90.5%
Note: Global latency numbers on the core-based measurements (May 2022) may be larger than the regional numbers because it represents all of our data centers instead of only a regional portion, so outliers and retries might have an outsized effect.
What’s next?
We are currently wrapping up the roll-out of the last throughput changes which allow us to efficiently scale purge requests. As that happens, we will revise our rate limits and open up purge by tag, hostname, and prefix to all plan types! We expect to begin rolling out the additional purge types to all plans and users beginning in early 2025.
In addition, in the process of implementing this new approach, we have identified improvements that will shave a few more milliseconds off our single-file purge. Currently, single-file purges have a P50 of 234ms. However, we want to, and can, bring that number down to below 200ms.
If you want to come work on the world’s fastest purge system, check out our open positions.
Cross-Region deployments provide increased resilience to maintain business continuity during outages, natural disasters, or other operational interruptions. Many large enterprises, design and deploy special plans for readiness during such situations. They rely on solutions built with AWS services and features to improve their confidence and response times. Amazon OpenSearch Service is a managed service for OpenSearch, a search and analytics engine at scale. OpenSearch Service provides high availability within an AWS Region through its Multi-AZ deployment model and provides Regional resiliency with cross-cluster replication. Amazon OpenSearch Serverless is a deployment option that provides on-demand auto scaling, to which we continue to bring in many features.
With the existing cross-cluster replication feature in OpenSearch Service, you designate a domain as a leader and another as a follower, using an active-passive replication model. Although this model offers a way to continue operations during Regional impairment, it requires you to manually configure the follower. Additionally, after recovery, you need to reconfigure the leader-follower relationship between the domains.
In this post, we outline two solutions that provide cross-Region resiliency without needing to reestablish relationships during a failback, using an active-active replication model with Amazon OpenSearch Ingestion (OSI) and Amazon Simple Storage Service (Amazon S3). These solutions apply to both OpenSearch Service managed clusters and OpenSearch Serverless collections. We use OpenSearch Serverless as an example for the configurations in this post.
Solution overview
We outline two solutions in this post. In both options, data sources local to a region write to an OpenSearch ingestion (OSI) pipeline configured within the same region. The solutions are extensible to multiple Regions, but we show two Regions as an example as Regional resiliency across two Regions is a popular deployment pattern for many large-scale enterprises.
You can use these solutions to address cross-Region resiliency needs for OpenSearch Serverless deployments and active-active replication needs for both serverless and provisioned options of OpenSearch Service, especially when the data sources produce disparate data in different Regions.
After you complete these steps, you can create two OSI pipelines one in each Region with the configurations detailed in the following sections.
Use OpenSearch Ingestion (OSI) for cross-Region writes
In this solution, OSI takes the data that is local to the Region it’s in and writes it to the other Region. To facilitate cross-Region writes and increase data durability, we use an S3 bucket in each Region. The OSI pipeline in the other Region reads this data and writes to the collection in its local Region. The OSI pipeline in the other Region follows a similar data flow.
While reading data, you have choices: Amazon SQS or Amazon S3 scans. For this post, we use Amazon SQS because it helps provide near real-time data delivery. This solution also facilitates writing directly to these local buckets in the case of pull-based OSI data sources. Refer to Source under Key concepts to understand the different types of sources that OSI uses.
The following diagram shows the flow of data.
The data flow consists of the following steps:
Data sources local to a Region write their data to the OSI pipeline in their Region. (This solution also supports sources directly writing to Amazon S3.)
OSI writes this data into collections followed by S3 buckets in the other Region.
OSI reads the other Region data from the local S3 bucket and writes it to the local collection.
Collections in both Regions now contain the same data.
The following snippets shows the configuration for the two pipelines.
#pipeline config for cross region writes
version: "2"
write-pipeline:
source:
http:
path: "/logs"
processor:
- parse_json:
sink:
# First sink to same region collection
- opensearch:
hosts: [ "https://abcdefghijklmn.us-east-1.aoss.amazonaws.com" ]
aws:
sts_role_arn: "arn:aws:iam::1234567890:role/pipeline-role"
region: "us-east-1"
serverless: true
index: "cross-region-index"
- s3:
# Second sink to cross region S3 bucket
aws:
sts_role_arn: "arn:aws:iam::1234567890:role/pipeline-role"
region: "us-east-2"
bucket: "osi-cross-region-bucket"
object_key:
path_prefix: "osi-crw/%{yyyy}/%{MM}/%{dd}/%{HH}"
threshold:
event_collect_timeout: 60s
codec:
ndjson:
The code for the write pipeline is as follows:
#pipeline config to read data from local S3 bucket
version: "2"
read-write-pipeline:
source:
s3:
# S3 source with SQS
acknowledgments: true
notification_type: "sqs"
compression: "none"
codec:
newline:
sqs:
queue_url: "https://sqs.us-east-1.amazonaws.com/1234567890/my-osi-cross-region-write-q"
maximum_messages: 10
visibility_timeout: "60s"
visibility_duplication_protection: true
aws:
region: "us-east-1"
sts_role_arn: "arn:aws:iam::123567890:role/pipe-line-role"
processor:
- parse_json:
route:
# Routing uses the s3 keys to ensure OSI writes data only once to local region
- local-region-write: "contains(/s3/key, \"osi-local-region-write\")"
- cross-region-write: "contains(/s3/key, \"osi-cross-region-write\")"
sink:
- pipeline:
name: "local-region-write-cross-region-write-pipeline"
- pipeline:
name: "local-region-write-pipeline"
routes:
- local-region-write
local-region-write-cross-region-write-pipeline:
# Read S3 bucket with cross-region-write
source:
pipeline:
name: "read-write-pipeline"
sink:
# Sink to local-region managed OpenSearch service
- opensearch:
hosts: [ "https://abcdefghijklmn.us-east-1.aoss.amazonaws.com" ]
aws:
sts_role_arn: "arn:aws:iam::12345678890:role/pipeline-role"
region: "us-east-1"
serverless: true
index: "cross-region-index"
local-region-write-pipeline:
# Read local-region write
source:
pipeline:
name: "read-write-pipeline"
processor:
- delete_entries:
with_keys: ["s3"]
sink:
# Sink to cross-region S3 bucket
- s3:
aws:
sts_role_arn: "arn:aws:iam::1234567890:role/pipeline-role"
region: "us-east-2"
bucket: "osi-cross-region-write-bucket"
object_key:
path_prefix: "osi-cross-region-write/%{yyyy}/%{MM}/%{dd}/%{HH}"
threshold:
event_collect_timeout: "60s"
codec:
ndjson:
To separate management and operations, we use two prefixes, osi-local-region-write and osi-cross-region-write, for buckets in both Regions. OSI uses these prefixes to copy only local Region data to the other Region. OSI also creates the keys s3.bucket and s3.key to decorate documents written to a collection. We remove this decoration while writing across Regions; it will be added back by the pipeline in the other Region.
This solution provides near real-time data delivery across Regions, and the same data is available across both Regions. However, although OpenSearch Service contains the same data, the buckets in each Region contain only partial data. The following solution addresses this.
Use Amazon S3 for cross-Region writes
In this solution, we use the Amazon S3 Region replication feature. This solution supports all the data sources available with OSI. OSI again uses two pipelines, but the key difference is that OSI writes the data to Amazon S3 first. After you complete the steps that are common to both solutions, refer to Examples for configuring live replication for instructions to configure Amazon S3 cross-Region replication. The following diagram shows the flow of data.
The data flow consists of the following steps:
Data sources local to a Region write their data to OSI. (This solution also supports sources directly writing to Amazon S3.)
This data is first written to the S3 bucket.
OSI reads this data and writes to the collection local to the Region.
Amazon S3 replicates cross-Region data and OSI reads and writes this data to the collection.
The following snippets show the configuration for both pipelines.
version: "2"
s3-read-pipeline:
source:
s3:
acknowledgments: true
notification_type: "sqs"
compression: "none"
codec:
newline:
# Configure SQS to notify OSI pipeline
sqs:
queue_url: "https://sqs.us-east-2.amazonaws.com/1234567890/my-s3-crr-q"
maximum_messages: 10
visibility_timeout: "15s"
visibility_duplication_protection: true
aws:
region: "us-east-2"
sts_role_arn: "arn:aws:iam::1234567890:role/pipeline-role"
processor:
- parse_json:
# Configure OSI sink to move the files from S3 to OpenSearch Serverless
sink:
- opensearch:
hosts: [ "https://abcdefghijklmn.us-east-1.aoss.amazonaws.com" ]
aws:
# Role must have access to S3 OpenSearch Pipeline and OpenSearch Serverless
sts_role_arn: "arn:aws:iam::1234567890:role/pipeline-role"
region: "us-east-1"
serverless: true
index: "cross-region-index"
The configuration for this solution is relatively simpler and relies on Amazon S3 cross-Region replication. This solution makes sure that the data in the S3 bucket and OpenSearch Serverless collection are the same in both Regions.
Impairment scenarios and additional considerations
Let’s consider a Regional impairment scenario. For this use case, we assume that your application is powered by an OpenSearch Serverless collection as a backend. When a region is impaired, these applications can simply failover to the OpenSearch Serverless collection in the other Region and continue operations without interruption, because the entirety of the data present before the impairment is available in both collections.
When the Region impairment is resolved, you can failback to the OpenSearch Serverless collection in that Region either immediately or after you allow some time for the missing data to be backfilled in that Region. The operations can then continue without interruption.
You can automate these failover and failback operations to provide a seamless user experience. This automation is not in scope of this post, but will be covered in a future post.
The existing cross-cluster replication solution, requires you to manually reestablish a leader-follower relationship, and restart replication from the beginning once recovered from an impairment. But the solutions discussed here automatically resume replication from the point where it last left off. If for some reason only Amazon OpenSearch service that is collections or domain were to fail, the data is still available in a local buckets and it will be back filled as soon the collection or domain becomes available.
You can effectively use these solutions in an active-passive replication model as well. In those scenarios, it’s sufficient to have minimum set of resources in the replication Region like a single S3 bucket. You can modify this solution to solve different scenarios using additional services like Amazon Managed Streaming for Apache Kafka (Amazon MSK), which has a built-in replication feature.
In this post, we outlined two solutions that achieve Regional resiliency for OpenSearch Serverless and OpenSearch Service managed clusters. If you need explicit control over writing data cross Region, use solution one. In our experiments with few KBs of data majority of writes completed within a second between two chosen regions. Choose solution two if you need simplicity the solution offers. In our experiments replication completed completely in a few seconds. 99.99% of objects will be replicated within 15 minutes. These solutions also serve as an architecture for an active-active replication model in OpenSearch Service using OpenSearch Ingestion.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.