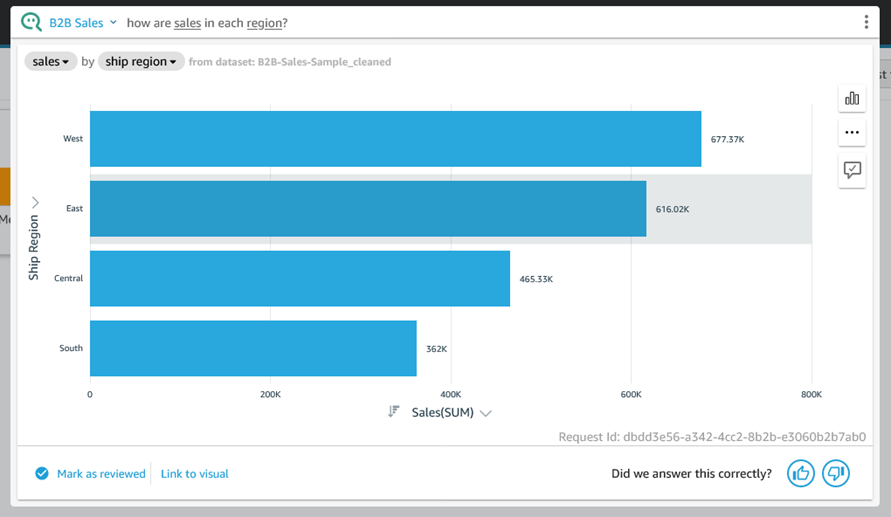
Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/new-replication-for-amazon-elastic-file-system-efs/
Amazon Elastic File System (Amazon EFS) allows EC2 instances, AWS Lambda functions, and containers to share access to a fully-managed file system. First announced in 2015 and generally available in 2016, Amazon EFS delivers low-latency performance for a wide variety of workloads and can scale to thousands of concurrent clients or connections. Since the 2016 launch we have continued to listen and to innovate, and have added many new features and capabilities in response to your feedback. These include on-premises access via Direct Connect (2016), encryption of data at rest (2017), provisioned throughput and encryption of data in transit (2018), an infrequent access storage class (2019), IAM authorization & access points (2020), lower-cost one zone storage classes (2021), and more.
Introducing Replication
Today I am happy to announce that you can now use replication to automatically maintain copies of your EFS file systems for business continuity or to help you to meet compliance requirements as part of your disaster recovery strategy. You can set this up in minutes for new or existing EFS file systems, with replication either within a single AWS region or between two AWS regions in the same AWS partition.
Once configured, replication begins immediately. All replication traffic stays on the AWS global backbone, and most changes are replicated within a minute, with an overall Recovery Point Objective (RPO) of 15 minutes for most file systems. Replication does not consume any burst credits and it does not count against the provisioned throughput of the file system.
Configuring Replication
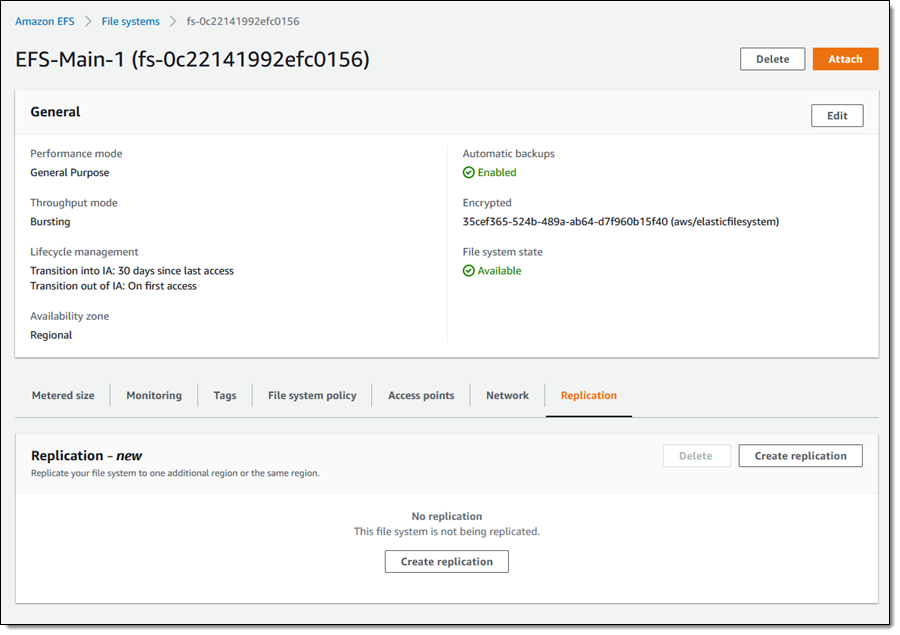
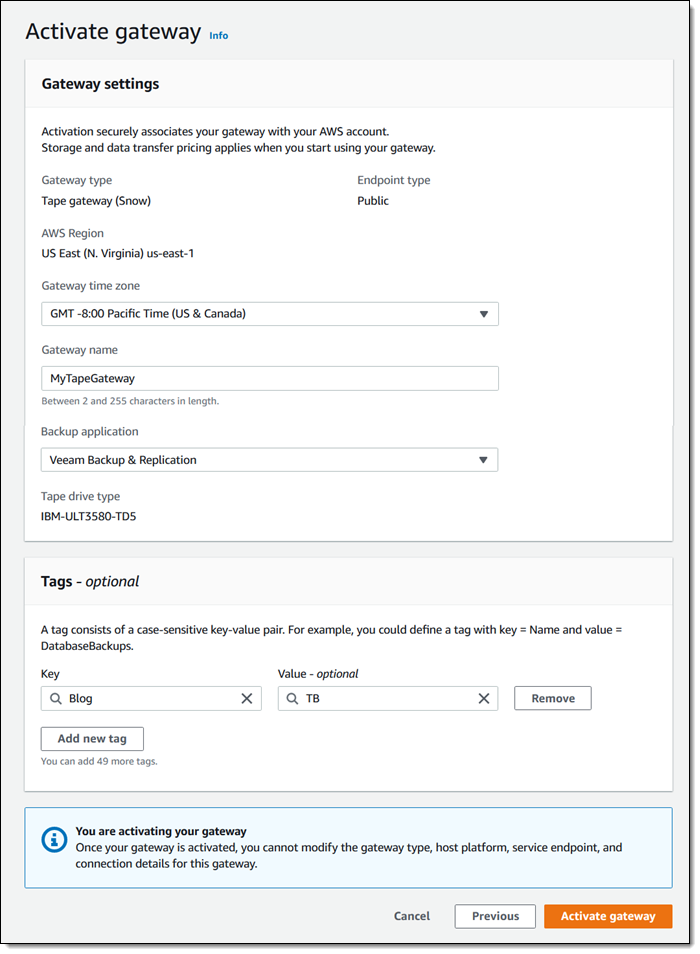
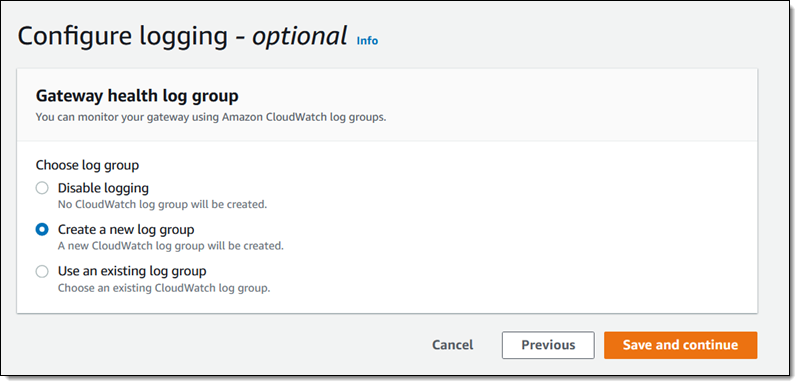
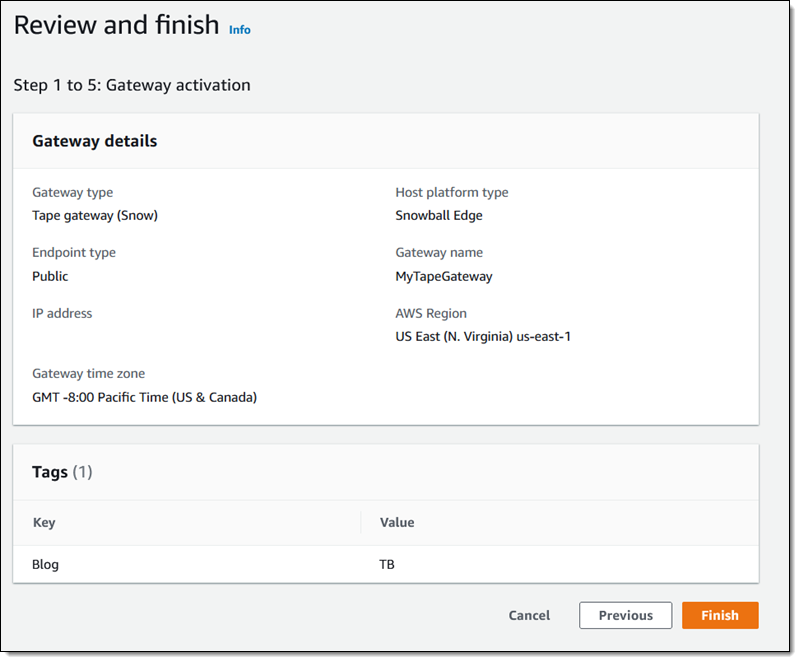
To configure replication, I open the Amazon EFS Console , view the file system that I want to replicate, and select the Replication tab:
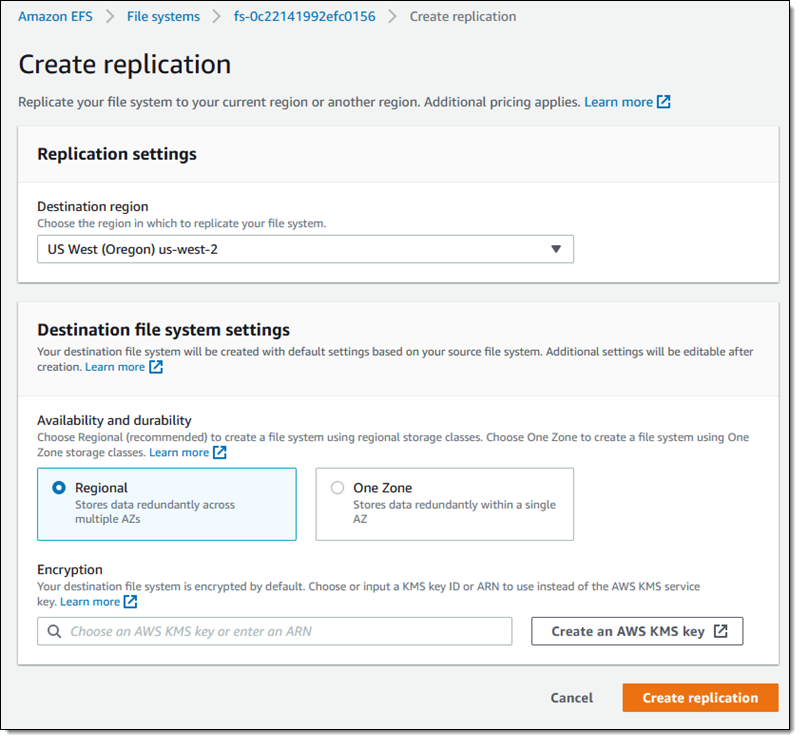
I click Create replication, choose the desired destination region, and select the desired storage (Regional or One Zone). I can use the default KMS key for encryption or I can choose another one. I review my settings and click Create replication to proceed:
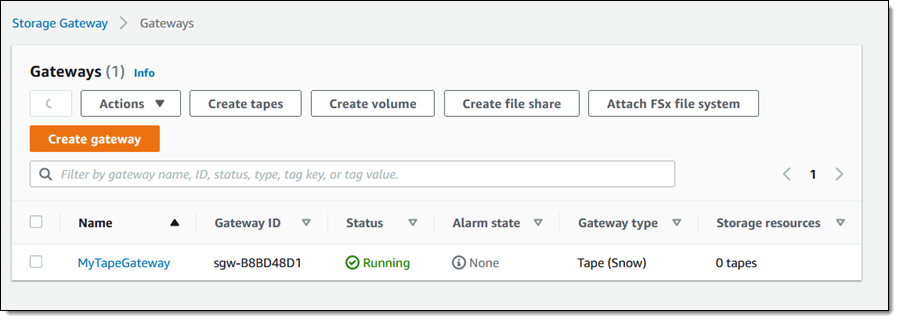
Replication begins right away and I can see the new, read-only file system immediately:
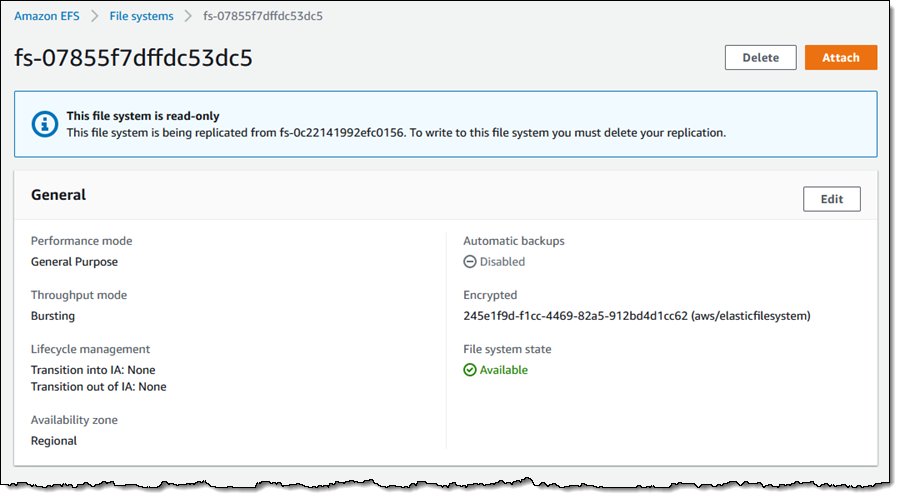
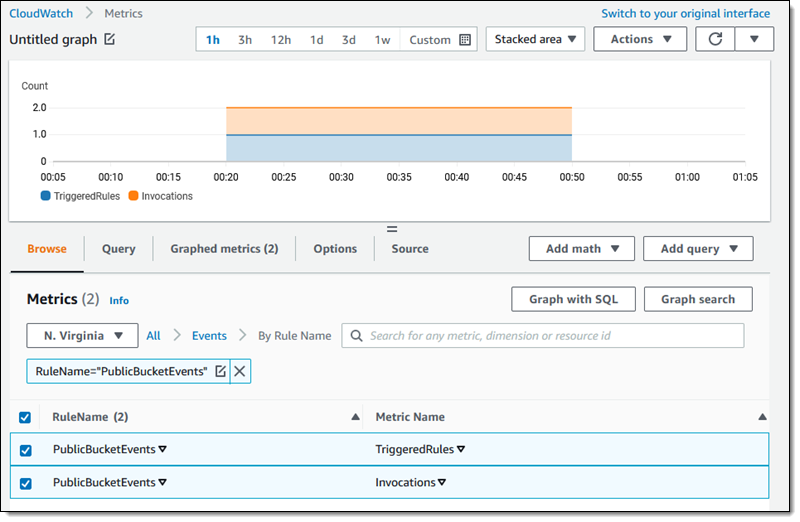
A new CloudWatch metric, TimeSinceLastSync, is published when the initial replication is complete, and periodically after that:
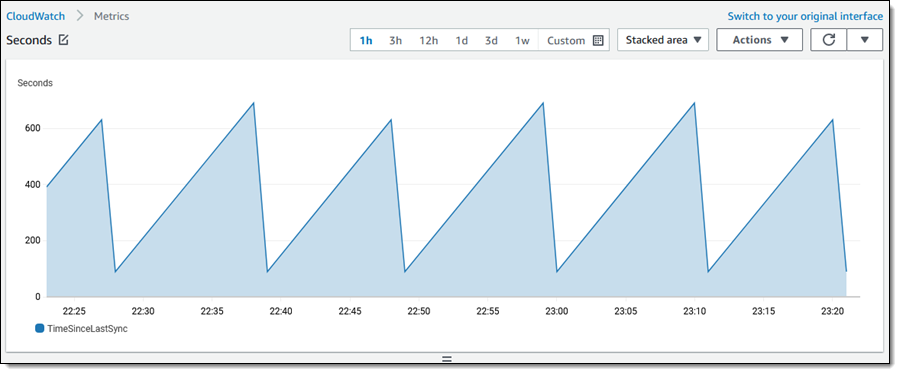
The replica is created in the selected region. I create any necessary mount targets and mount the replica on an EC2 instance:
EFS tracks modifications to the blocks (currently 4 MB) that are used to store files and metadata, and replicates the changes at a rate of up to 300 MB per second. Because replication is block-based, it is not crash-consistent; if you need crash-consistency you may want to take a look at AWS Backup.
After I have set up replication, I can change the lifecycle management, intelligent tiering, throughput mode, and automatic backup setting for the destination file system. The performance mode is chosen when the file system is created, and cannot be changed.
Initiating a Fail-Over
If I need to fail over to the replica, I simply delete the replication. I can do this from either side (source or destination), by clicking Delete and confirming my intent:
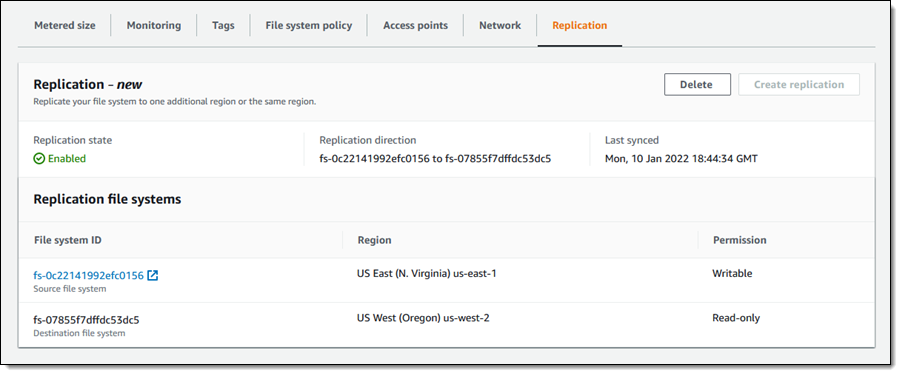
I enter delete, and click Delete replication to proceed:
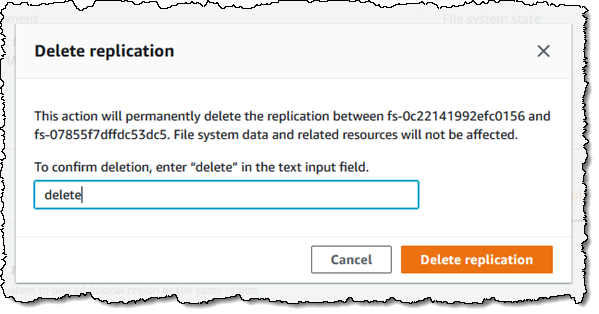
The former read-only replica is now a writable file system that I can use as part of my recovery process. To fail-back, I create a replica in the original location, wait for replication to finish, and delete the replication.
I can also use the command line and the EFS APIs to manage replication. For example:
createreplication-configuration / CreateReplicationConfiguration – Establish replication for an existing file system.
describe-replication-configurations / DescribeReplicationConfigurations – See the replication configuration for a source or destination file system, or for all replication configurations in an AWS account. The data returned for a destination file system also includes LastReplicatedTimestamp, the time of the last successful sync.
delete-replication-configuration / DeleteReplicationConfiguration – End replication for a file system.
Available Now
This new feature is available now and you can start using it today in the AWS US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), South America (São Paulo), and GovCloud Regions.
You pay the usual storage fees for the original and replica file systems and any applicable cross-region or intra-region data transfer charges.
— Jeff;
















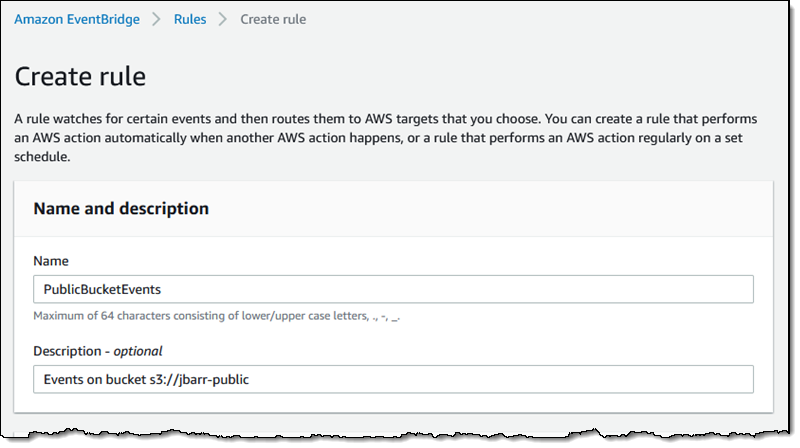 Then I define a pattern that matches the bucket and the events of interest:
Then I define a pattern that matches the bucket and the events of interest: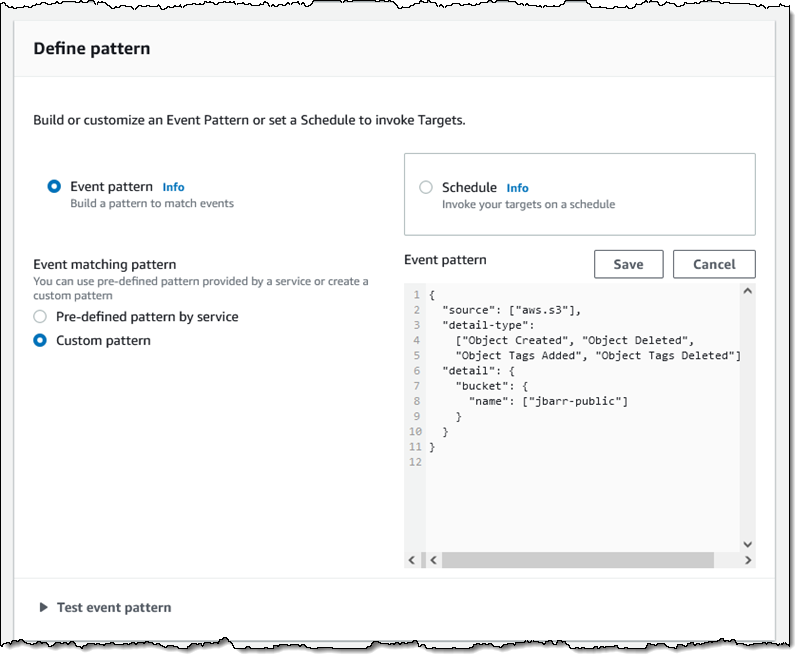 One pattern can match one or more buckets and one or more events; the following events are supported:
One pattern can match one or more buckets and one or more events; the following events are supported: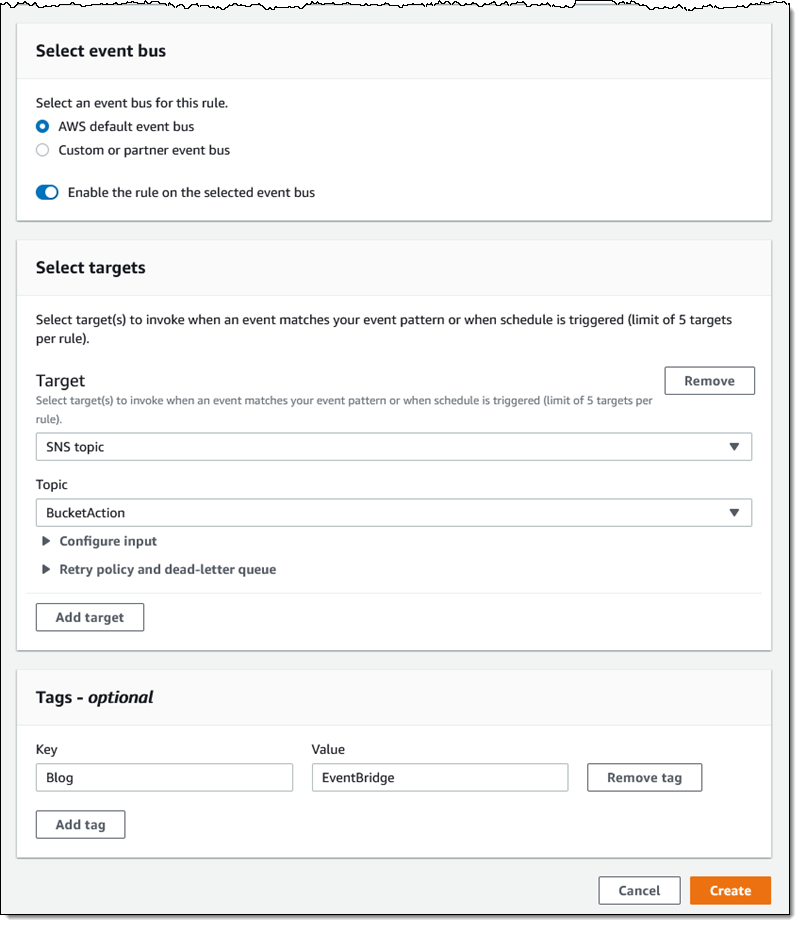

 I add a tag (User) to the rule, and click Create retention rule:
I add a tag (User) to the rule, and click Create retention rule: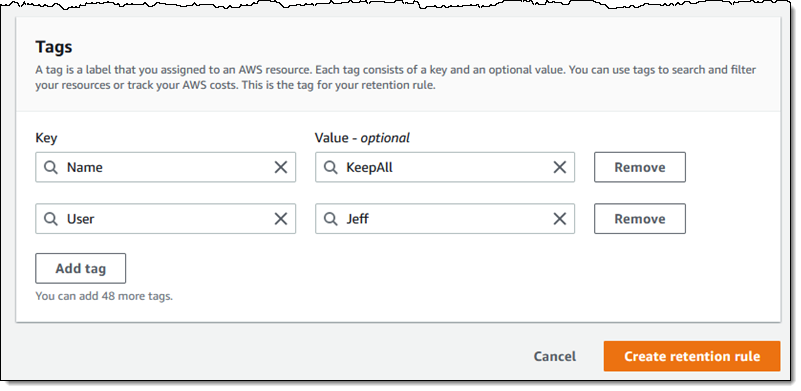














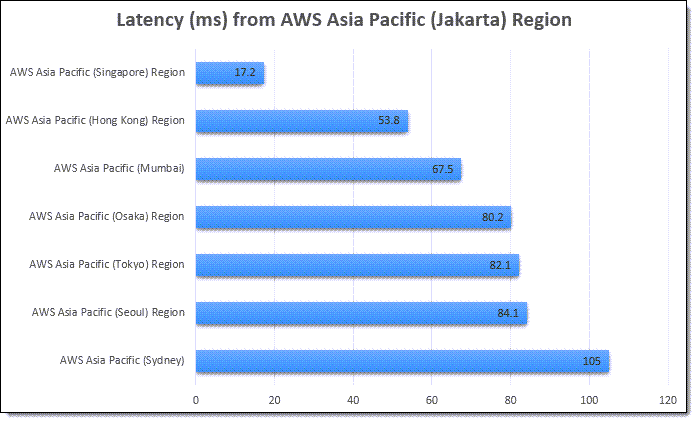
 Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to: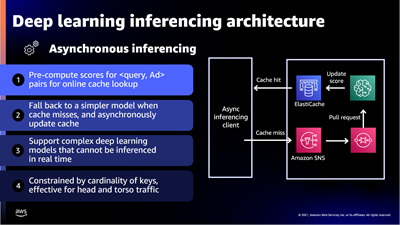 The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
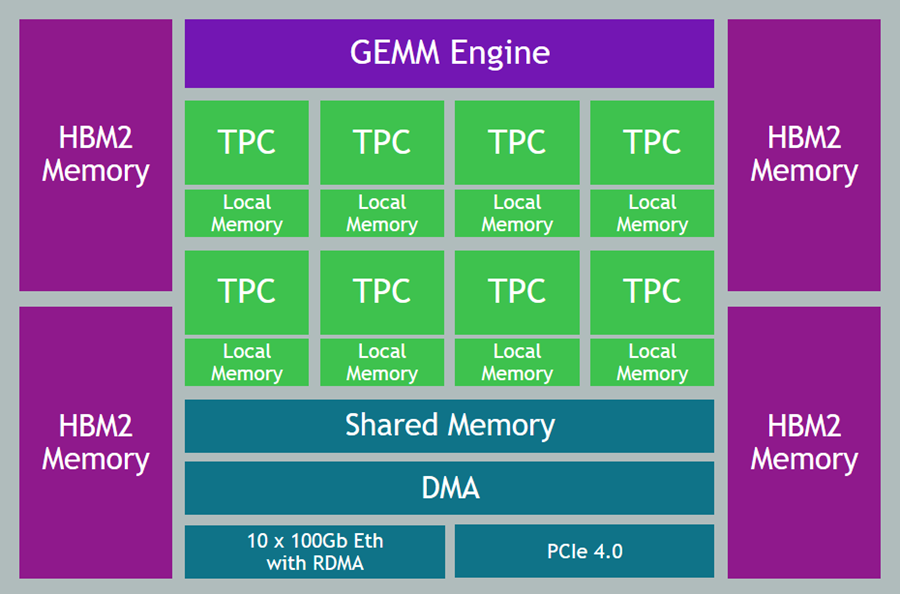
The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations. The
The 

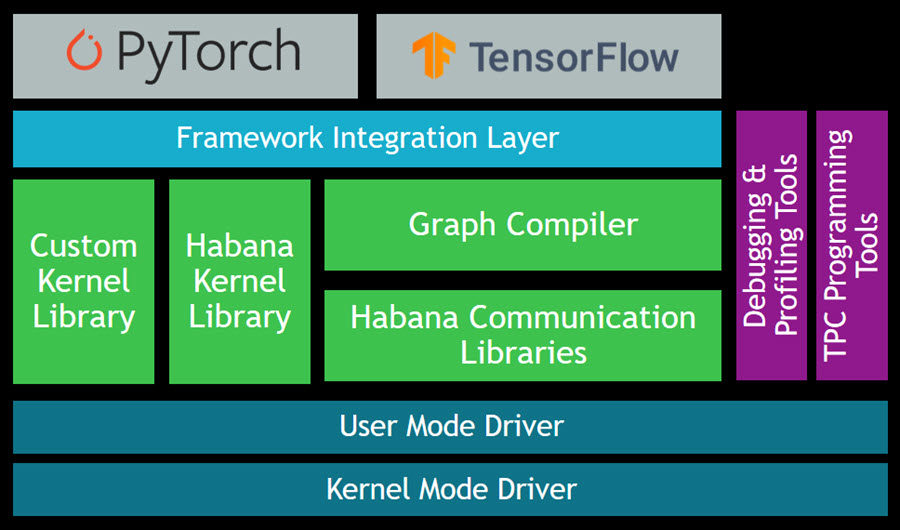





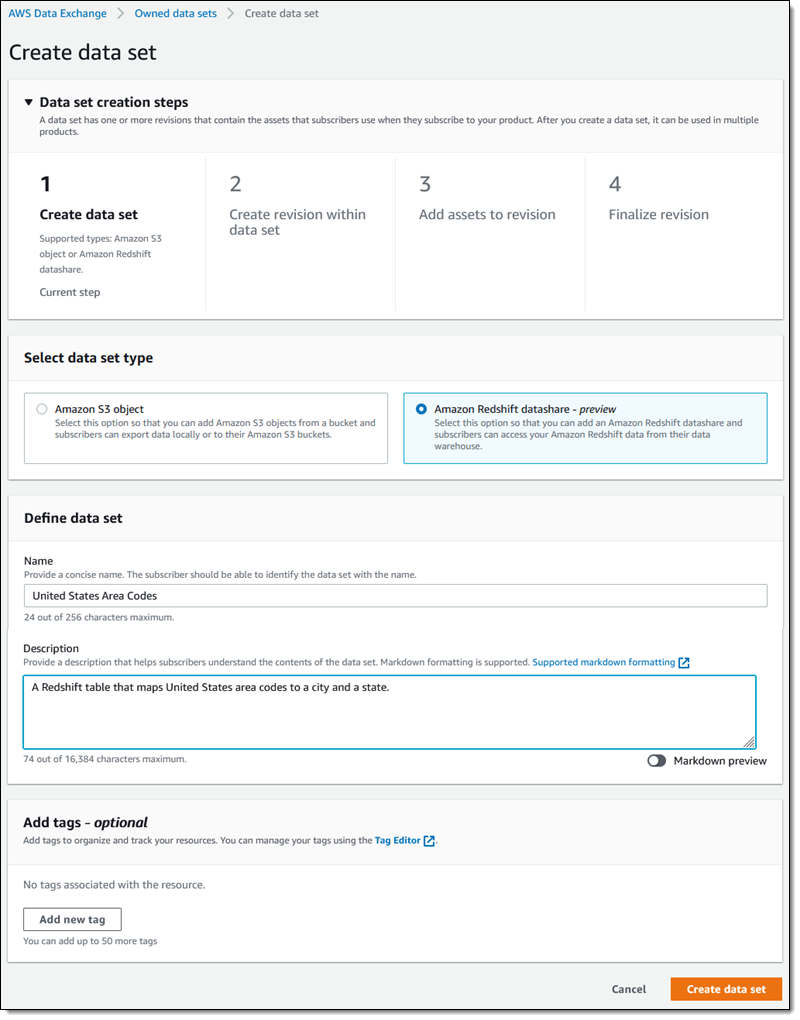

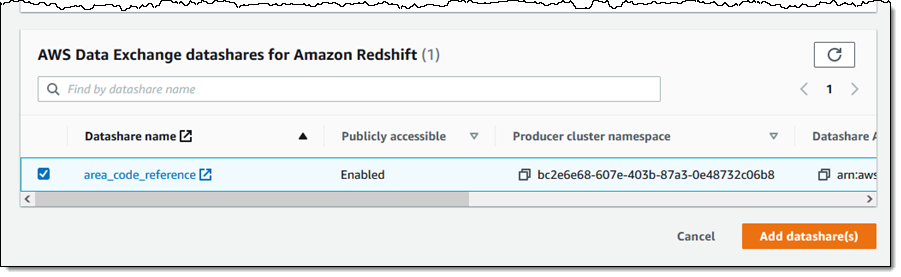

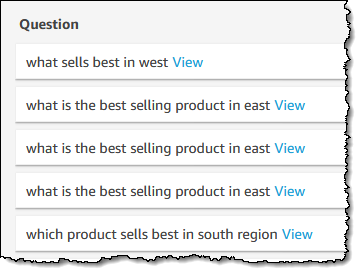 To recap, Q is a natural language query tool for the Enterprise Edition of
To recap, Q is a natural language query tool for the Enterprise Edition of