Post Syndicated from Kevon Mayers original https://aws.amazon.com/blogs/devops/terraform-ci-cd-and-testing-on-aws-with-the-new-terraform-test-framework/

Graphic created by Kevon Mayers
Introduction
Organizations often use Terraform Modules to orchestrate complex resource provisioning and provide a simple interface for developers to enter the required parameters to deploy the desired infrastructure. Modules enable code reuse and provide a method for organizations to standardize deployment of common workloads such as a three-tier web application, a cloud networking environment, or a data analytics pipeline. When building Terraform modules, it is common for the module author to start with manual testing. Manual testing is performed using commands such as terraform validate for syntax validation, terraform plan to preview the execution plan, and terraform apply followed by manual inspection of resource configuration in the AWS Management Console. Manual testing is prone to human error, not scalable, and can result in unintended issues. Because modules are used by multiple teams in the organization, it is important to ensure that any changes to the modules are extensively tested before the release. In this blog post, we will show you how to validate Terraform modules and how to automate the process using a Continuous Integration/Continuous Deployment (CI/CD) pipeline.
Terraform Test
Terraform test is a new testing framework for module authors to perform unit and integration tests for Terraform modules. Terraform test can create infrastructure as declared in the module, run validation against the infrastructure, and destroy the test resources regardless if the test passes or fails. Terraform test will also provide warnings if there are any resources that cannot be destroyed. Terraform test uses the same HashiCorp Configuration Language (HCL) syntax used to write Terraform modules. This reduces the burden for modules authors to learn other tools or programming languages. Module authors run the tests using the command terraform test which is available on Terraform CLI version 1.6 or higher.
Module authors create test files with the extension *.tftest.hcl. These test files are placed in the root of the Terraform module or in a dedicated tests directory. The following elements are typically present in a Terraform tests file:
- Provider block: optional, used to override the provider configuration, such as selecting AWS region where the tests run.
- Variables block: the input variables passed into the module during the test, used to supply non-default values or to override default values for variables.
- Run block: used to run a specific test scenario. There can be multiple run blocks per test file, Terraform executes run blocks in order. In each run block you specify the command Terraform (
plan or apply), and the test assertions. Module authors can specify the conditions such as: length(var.items) != 0. A full list of condition expressions can be found in the HashiCorp documentation.
Terraform tests are performed in sequential order and at the end of the Terraform test execution, any failed assertions are displayed.
Basic test to validate resource creation
Now that we understand the basic anatomy of a Terraform tests file, let’s create basic tests to validate the functionality of the following Terraform configuration. This Terraform configuration will create an AWS CodeCommit repository with prefix name repo-.
# main.tf
variable "repository_name" {
type = string
}
resource "aws_codecommit_repository" "test" {
repository_name = format("repo-%s", var.repository_name)
description = "Test repository."
}
Now we create a Terraform test file in the tests directory. See the following directory structure as an example:
├── main.tf
└── tests
└── basic.tftest.hcl
For this first test, we will not perform any assertion except for validating that Terraform execution plan runs successfully. In the tests file, we create a variable block to set the value for the variable repository_name. We also added the run block with command = plan to instruct Terraform test to run Terraform plan. The completed test should look like the following:
# basic.tftest.hcl
variables {
repository_name = "MyRepo"
}
run "test_resource_creation" {
command = plan
}
Now we will run this test locally. First ensure that you are authenticated into an AWS account, and run the terraform init command in the root directory of the Terraform module. After the provider is initialized, start the test using the terraform test command.
❯ terraform test
tests/basic.tftest.hcl... in progress
run "test_resource_creation"... pass
tests/basic.tftest.hcl... tearing down
tests/basic.tftest.hcl... pass
Our first test is complete, we have validated that the Terraform configuration is valid and the resource can be provisioned successfully. Next, let’s learn how to perform inspection of the resource state.
Create resource and validate resource name
Re-using the previous test file, we add the assertion block to checks if the CodeCommit repository name starts with a string repo- and provide error message if the condition fails. For the assertion, we use the startswith function. See the following example:
# basic.tftest.hcl
variables {
repository_name = "MyRepo"
}
run "test_resource_creation" {
command = plan
assert {
condition = startswith(aws_codecommit_repository.test.repository_name, "repo-")
error_message = "CodeCommit repository name ${var.repository_name} did not start with the expected value of ‘repo-****’."
}
}
Now, let’s assume that another module author made changes to the module by modifying the prefix from repo- to my-repo-. Here is the modified Terraform module.
# main.tf
variable "repository_name" {
type = string
}
resource "aws_codecommit_repository" "test" {
repository_name = format("my-repo-%s", var.repository_name)
description = "Test repository."
}
We can catch this mistake by running the the terraform test command again.
❯ terraform test
tests/basic.tftest.hcl... in progress
run "test_resource_creation"... fail
╷
│ Error: Test assertion failed
│
│ on tests/basic.tftest.hcl line 9, in run "test_resource_creation":
│ 9: condition = startswith(aws_codecommit_repository.test.repository_name, "repo-")
│ ├────────────────
│ │ aws_codecommit_repository.test.repository_name is "my-repo-MyRepo"
│
│ CodeCommit repository name MyRepo did not start with the expected value 'repo-***'.
╵
tests/basic.tftest.hcl... tearing down
tests/basic.tftest.hcl... fail
Failure! 0 passed, 1 failed.
We have successfully created a unit test using assertions that validates the resource name matches the expected value. For more examples of using assertions see the Terraform Tests Docs. Before we proceed to the next section, don’t forget to fix the repository name in the module (revert the name back to repo- instead of my-repo-) and re-run your Terraform test.
Testing variable input validation
When developing Terraform modules, it is common to use variable validation as a contract test to validate any dependencies / restrictions. For example, AWS CodeCommit limits the repository name to 100 characters. A module author can use the length function to check the length of the input variable value. We are going to use Terraform test to ensure that the variable validation works effectively. First, we modify the module to use variable validation.
# main.tf
variable "repository_name" {
type = string
validation {
condition = length(var.repository_name) <= 100
error_message = "The repository name must be less than or equal to 100 characters."
}
}
resource "aws_codecommit_repository" "test" {
repository_name = format("repo-%s", var.repository_name)
description = "Test repository."
}
By default, when variable validation fails during the execution of Terraform test, the Terraform test also fails. To simulate this, create a new test file and insert the repository_name variable with a value longer than 100 characters.
# var_validation.tftest.hcl
variables {
repository_name = “this_is_a_repository_name_longer_than_100_characters_7rfD86rGwuqhF3TH9d3Y99r7vq6JZBZJkhw5h4eGEawBntZmvy”
}
run “test_invalid_var” {
command = plan
}
Notice on this new test file, we also set the command to Terraform plan, why is that? Because variable validation runs prior to Terraform apply, thus we can save time and cost by skipping the entire resource provisioning. If we run this Terraform test, it will fail as expected.
❯ terraform test
tests/basic.tftest.hcl… in progress
run “test_resource_creation”… pass
tests/basic.tftest.hcl… tearing down
tests/basic.tftest.hcl… pass
tests/var_validation.tftest.hcl… in progress
run “test_invalid_var”… fail
╷
│ Error: Invalid value for variable
│
│ on main.tf line 1:
│ 1: variable “repository_name” {
│ ├────────────────
│ │ var.repository_name is “this_is_a_repository_name_longer_than_100_characters_7rfD86rGwuqhF3TH9d3Y99r7vq6JZBZJkhw5h4eGEawBntZmvy”
│
│ The repository name must be less than or equal to 100 characters.
│
│ This was checked by the validation rule at main.tf:3,3-13.
╵
tests/var_validation.tftest.hcl… tearing down
tests/var_validation.tftest.hcl… fail
Failure! 1 passed, 1 failed.
For other module authors who might iterate on the module, we need to ensure that the validation condition is correct and will catch any problems with input values. In other words, we expect the validation condition to fail with the wrong input. This is especially important when we want to incorporate the contract test in a CI/CD pipeline. To prevent our test from failing due introducing an intentional error in the test, we can use the expect_failures attribute. Here is the modified test file:
# var_validation.tftest.hcl
variables {
repository_name = “this_is_a_repository_name_longer_than_100_characters_7rfD86rGwuqhF3TH9d3Y99r7vq6JZBZJkhw5h4eGEawBntZmvy”
}
run “test_invalid_var” {
command = plan
expect_failures = [
var.repository_name
]
}
Now if we run the Terraform test, we will get a successful result.
❯ terraform test
tests/basic.tftest.hcl… in progress
run “test_resource_creation”… pass
tests/basic.tftest.hcl… tearing down
tests/basic.tftest.hcl… pass
tests/var_validation.tftest.hcl… in progress
run “test_invalid_var”… pass
tests/var_validation.tftest.hcl… tearing down
tests/var_validation.tftest.hcl… pass
Success! 2 passed, 0 failed.
As you can see, the expect_failures attribute is used to test negative paths (the inputs that would cause failures when passed into a module). Assertions tend to focus on positive paths (the ideal inputs). For an additional example of a test that validates functionality of a completed module with multiple interconnected resources, see this example in the Terraform CI/CD and Testing on AWS Workshop.
Orchestrating supporting resources
In practice, end-users utilize Terraform modules in conjunction with other supporting resources. For example, a CodeCommit repository is usually encrypted using an AWS Key Management Service (KMS) key. The KMS key is provided by end-users to the module using a variable called kms_key_id. To simulate this test, we need to orchestrate the creation of the KMS key outside of the module. In this section we will learn how to do that. First, update the Terraform module to add the optional variable for the KMS key.
# main.tf
variable "repository_name" {
type = string
validation {
condition = length(var.repository_name) <= 100
error_message = "The repository name must be less than or equal to 100 characters."
}
}
variable "kms_key_id" {
type = string
default = ""
}
resource "aws_codecommit_repository" "test" {
repository_name = format("repo-%s", var.repository_name)
description = "Test repository."
kms_key_id = var.kms_key_id != "" ? var.kms_key_id : null
}
In a Terraform test, you can instruct the run block to execute another helper module. The helper module is used by the test to create the supporting resources. We will create a sub-directory called setup under the tests directory with a single kms.tf file. We also create a new test file for KMS scenario. See the updated directory structure:
├── main.tf
└── tests
├── setup
│ └── kms.tf
├── basic.tftest.hcl
├── var_validation.tftest.hcl
└── with_kms.tftest.hcl
The kms.tf file is a helper module to create a KMS key and provide its ARN as the output value.
# kms.tf
resource "aws_kms_key" "test" {
description = "test KMS key for CodeCommit repo"
deletion_window_in_days = 7
}
output "kms_key_id" {
value = aws_kms_key.test.arn
}
The new test will use two separate run blocks. The first run block (setup) executes the helper module to generate a KMS key. This is done by assigning the command apply which will run terraform apply to generate the KMS key. The second run block (codecommit_with_kms) will then use the KMS key ARN output of the first run as the input variable passed to the main module.
# with_kms.tftest.hcl
run "setup" {
command = apply
module {
source = "./tests/setup"
}
}
run "codecommit_with_kms" {
command = apply
variables {
repository_name = "MyRepo"
kms_key_id = run.setup.kms_key_id
}
assert {
condition = aws_codecommit_repository.test.kms_key_id != null
error_message = "KMS key ID attribute value is null"
}
}
Go ahead and run the Terraform init, followed by Terraform test. You should get the successful result like below.
❯ terraform test
tests/basic.tftest.hcl... in progress
run "test_resource_creation"... pass
tests/basic.tftest.hcl... tearing down
tests/basic.tftest.hcl... pass
tests/var_validation.tftest.hcl... in progress
run "test_invalid_var"... pass
tests/var_validation.tftest.hcl... tearing down
tests/var_validation.tftest.hcl... pass
tests/with_kms.tftest.hcl... in progress
run "create_kms_key"... pass
run "codecommit_with_kms"... pass
tests/with_kms.tftest.hcl... tearing down
tests/with_kms.tftest.hcl... pass
Success! 4 passed, 0 failed.
We have learned how to run Terraform test and develop various test scenarios. In the next section we will see how to incorporate all the tests into a CI/CD pipeline.
Terraform Tests in CI/CD Pipelines
Now that we have seen how Terraform Test works locally, let’s see how the Terraform test can be leveraged to create a Terraform module validation pipeline on AWS. The following AWS services are used:
- AWS CodeCommit – a secure, highly scalable, fully managed source control service that hosts private Git repositories.
- AWS CodeBuild – a fully managed continuous integration service that compiles source code, runs tests, and produces ready-to-deploy software packages.
- AWS CodePipeline – a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates.
- Amazon Simple Storage Service (Amazon S3) – an object storage service offering industry-leading scalability, data availability, security, and performance.

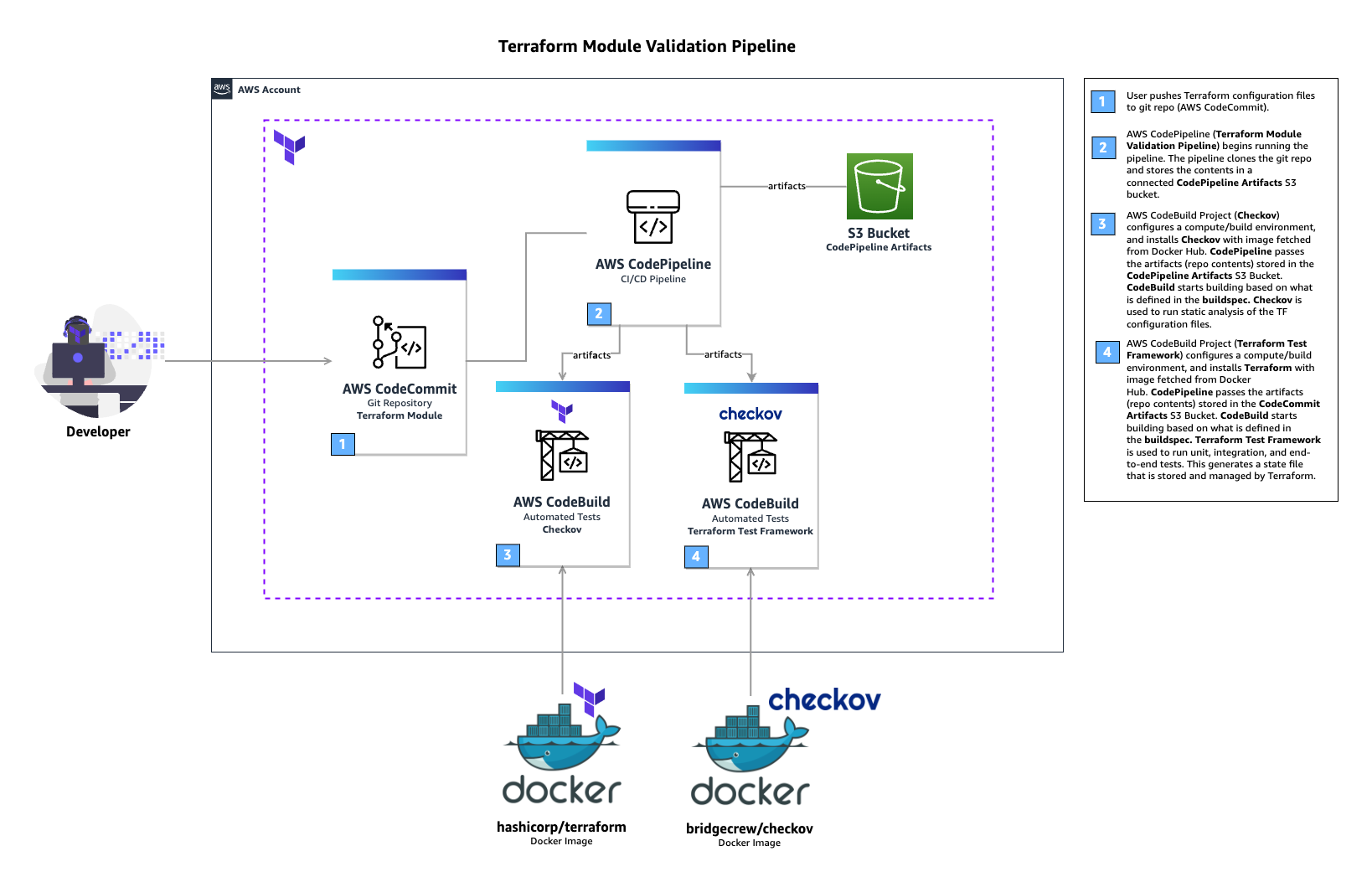
Terraform module validation pipeline
In the above architecture for a Terraform module validation pipeline, the following takes place:
- A developer pushes Terraform module configuration files to a git repository (AWS CodeCommit).
- AWS CodePipeline begins running the pipeline. The pipeline clones the git repo and stores the artifacts to an Amazon S3 bucket.
- An AWS CodeBuild project configures a compute/build environment with Checkov installed from an image fetched from Docker Hub. CodePipeline passes the artifacts (Terraform module) and CodeBuild executes Checkov to run static analysis of the Terraform configuration files.
- Another CodeBuild project configured with Terraform from an image fetched from Docker Hub. CodePipeline passes the artifacts (repo contents) and CodeBuild runs Terraform command to execute the tests.
CodeBuild uses a buildspec file to declare the build commands and relevant settings. Here is an example of the buildspec files for both CodeBuild Projects:
# Checkov
version: 0.1
phases:
pre_build:
commands:
- echo pre_build starting
build:
commands:
- echo build starting
- echo starting checkov
- ls
- checkov -d .
- echo saving checkov output
- checkov -s -d ./ > checkov.result.txt
In the above buildspec, Checkov is run against the root directory of the cloned CodeCommit repository. This directory contains the configuration files for the Terraform module. Checkov also saves the output to a file named checkov.result.txt for further review or handling if needed. If Checkov fails, the pipeline will fail.
# Terraform Test
version: 0.1
phases:
pre_build:
commands:
- terraform init
- terraform validate
build:
commands:
- terraform test
In the above buildspec, the terraform init and terraform validate commands are used to initialize Terraform, then check if the configuration is valid. Finally, the terraform test command is used to run the configured tests. If any of the Terraform tests fails, the pipeline will fail.
For a full example of the CI/CD pipeline configuration, please refer to the Terraform CI/CD and Testing on AWS workshop. The module validation pipeline mentioned above is meant as a starting point. In a production environment, you might want to customize it further by adding Checkov allow-list rules, linting, checks for Terraform docs, or pre-requisites such as building the code used in AWS Lambda.
Choosing various testing strategies
At this point you may be wondering when you should use Terraform tests or other tools such as Preconditions and Postconditions, Check blocks or policy as code. The answer depends on your test type and use-cases. Terraform test is suitable for unit tests, such as validating resources are created according to the naming specification. Variable validations and Pre/Post conditions are useful for contract tests of Terraform modules, for example by providing error warning when input variables value do not meet the specification. As shown in the previous section, you can also use Terraform test to ensure your contract tests are running properly. Terraform test is also suitable for integration tests where you need to create supporting resources to properly test the module functionality. Lastly, Check blocks are suitable for end to end tests where you want to validate the infrastructure state after all resources are generated, for example to test if a website is running after an S3 bucket configured for static web hosting is created.
When developing Terraform modules, you can run Terraform test in command = plan mode for unit and contract tests. This allows the unit and contract tests to run quicker and cheaper since there are no resources created. You should also consider the time and cost to execute Terraform test for complex / large Terraform configurations, especially if you have multiple test scenarios. Terraform test maintains one or many state files within the memory for each test file. Consider how to re-use the module’s state when appropriate. Terraform test also provides test mocking, which allows you to test your module without creating the real infrastructure.
Conclusion
In this post, you learned how to use Terraform test and develop various test scenarios. You also learned how to incorporate Terraform test in a CI/CD pipeline. Lastly, we also discussed various testing strategies for Terraform configurations and modules. For more information about Terraform test, we recommend the Terraform test documentation and tutorial. To get hands on practice building a Terraform module validation pipeline and Terraform deployment pipeline, check out the Terraform CI/CD and Testing on AWS Workshop.
Authors

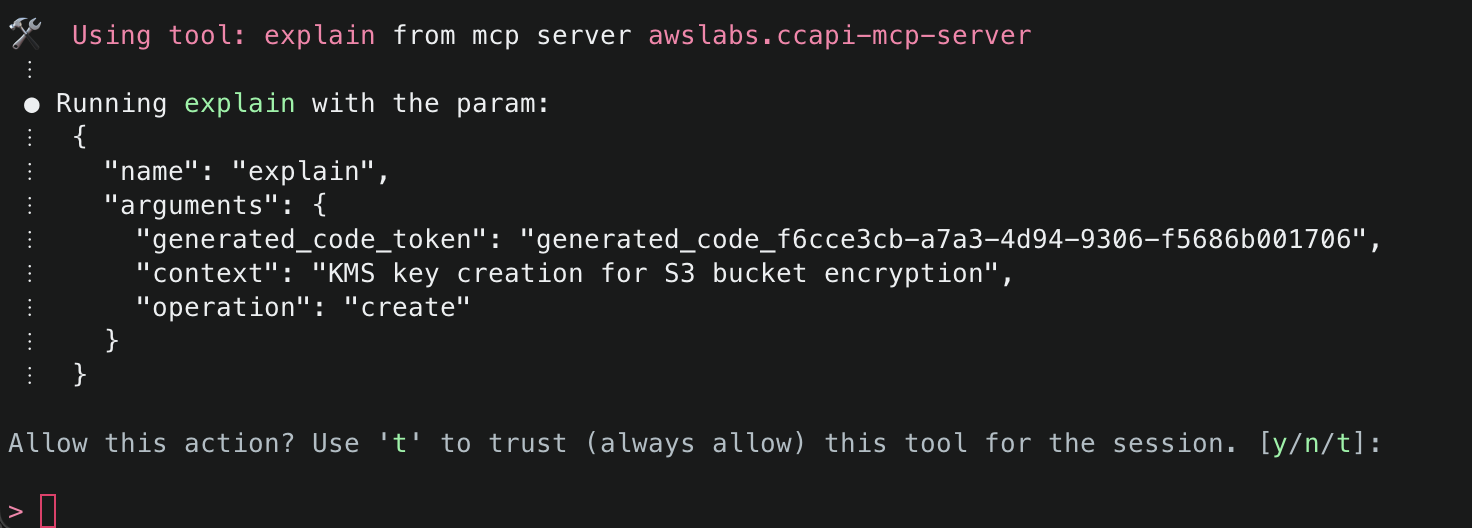
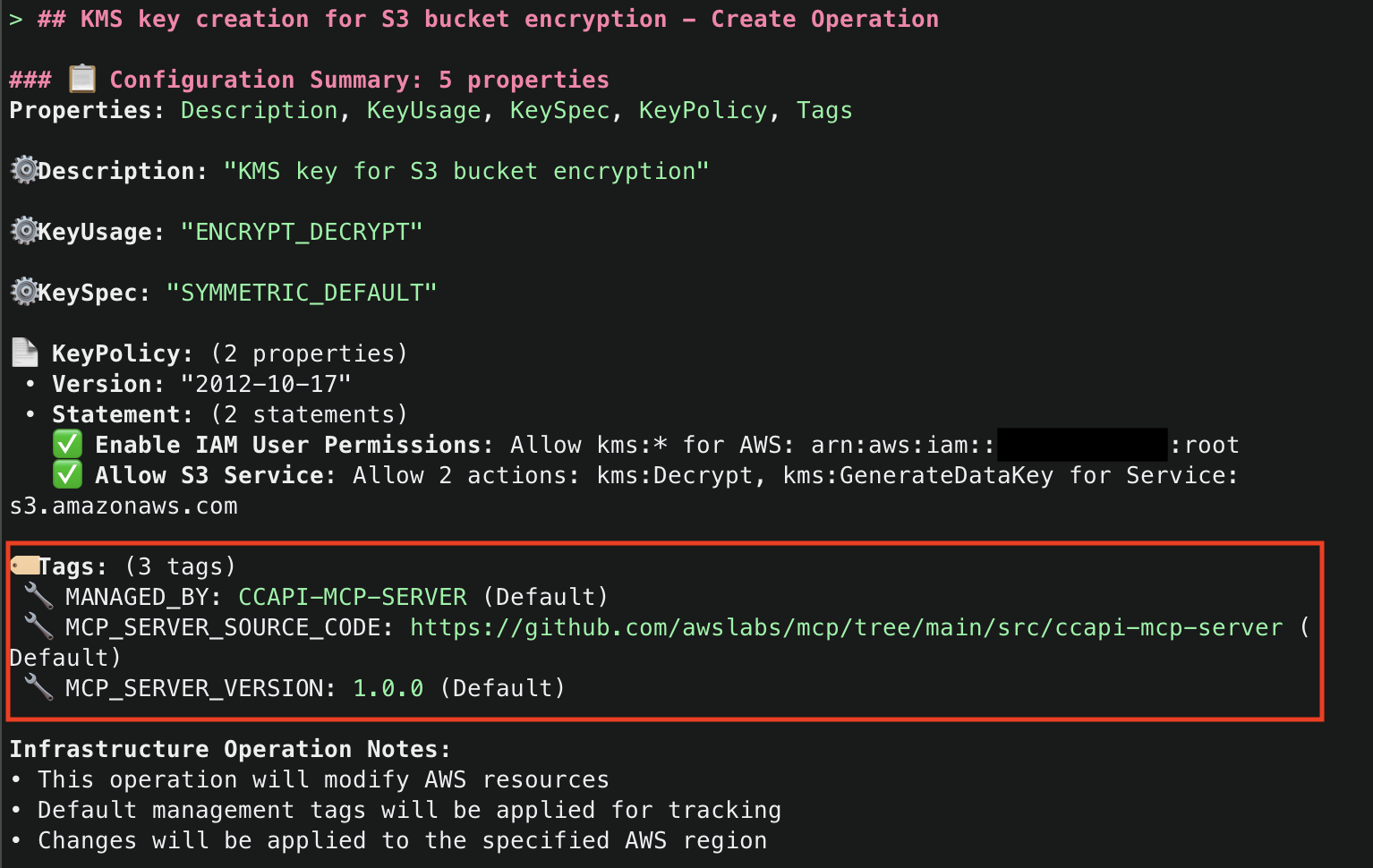
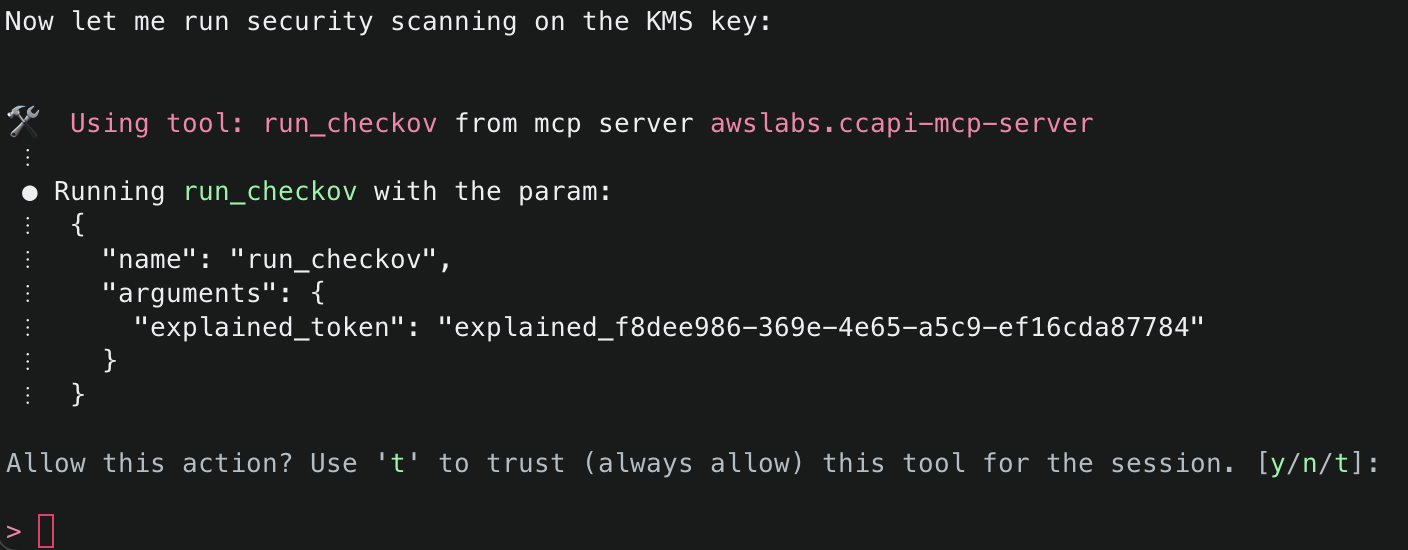
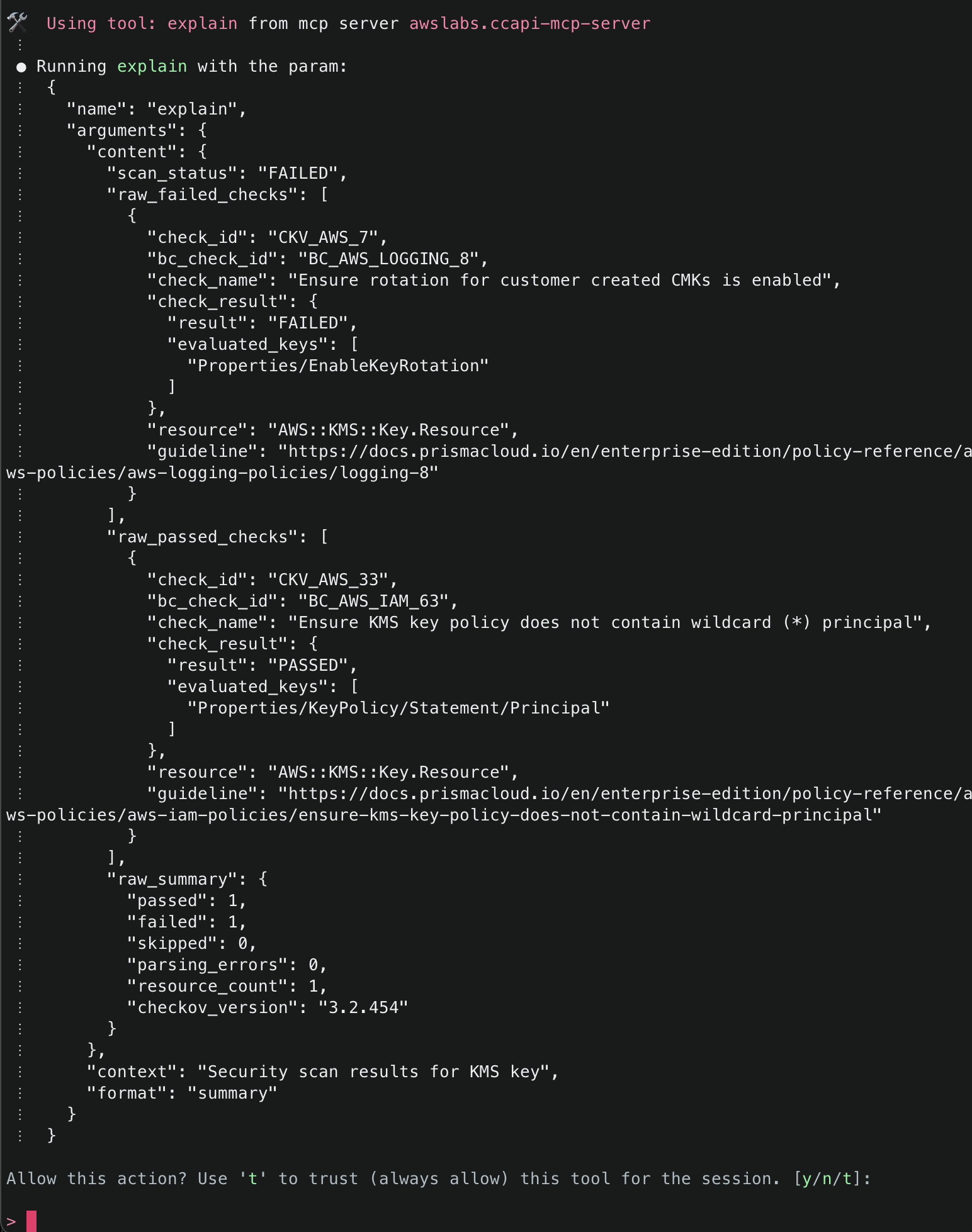
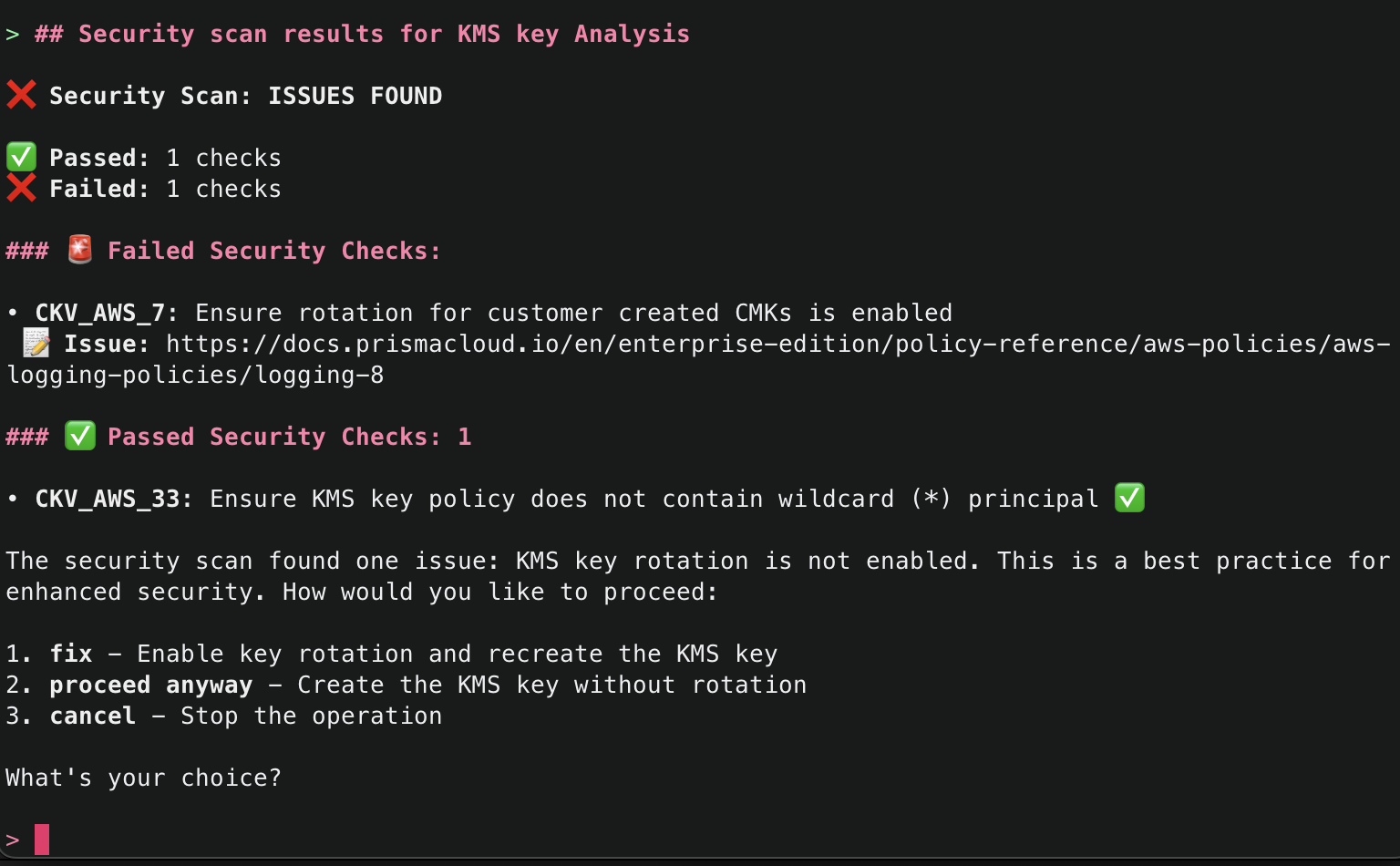
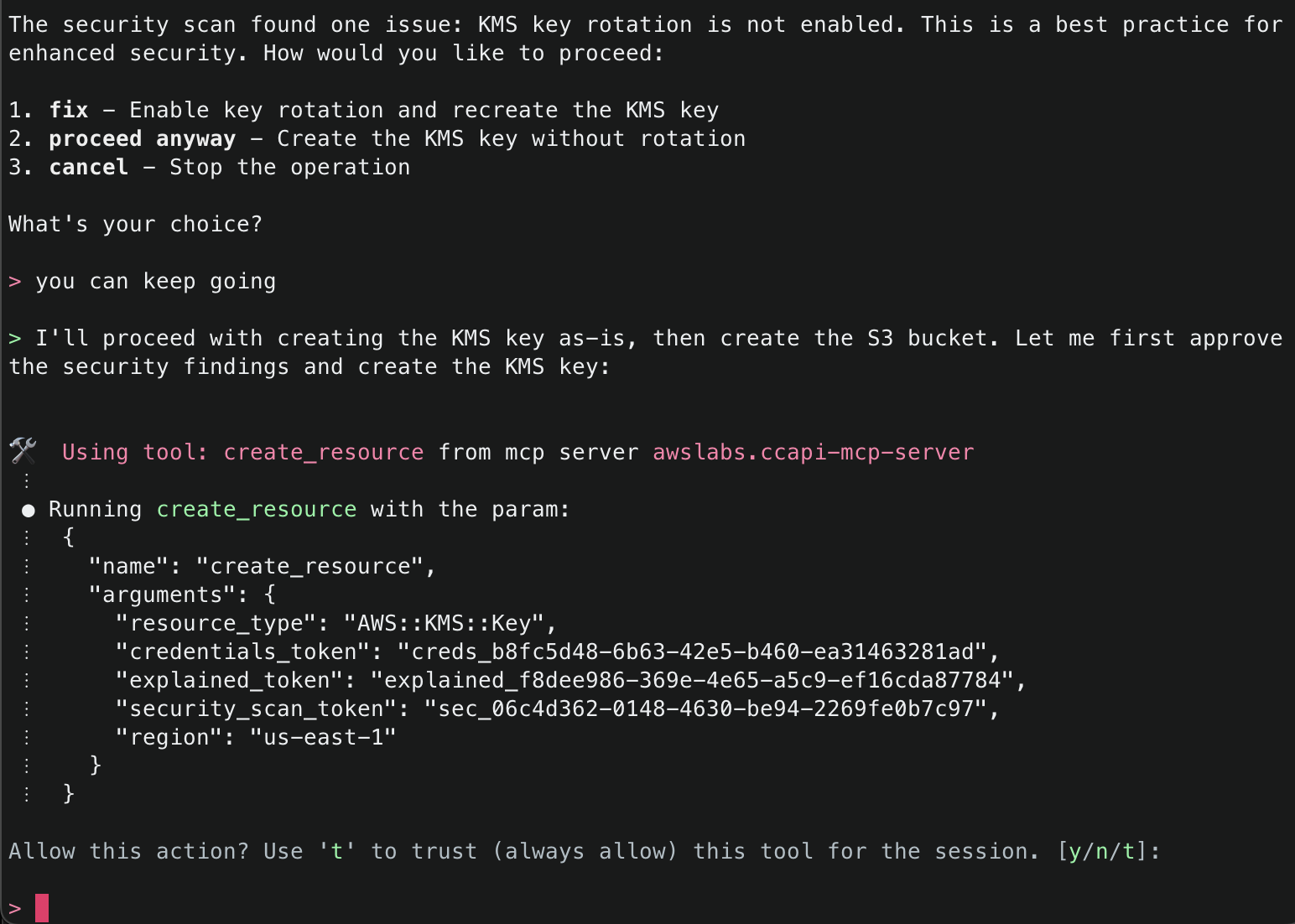
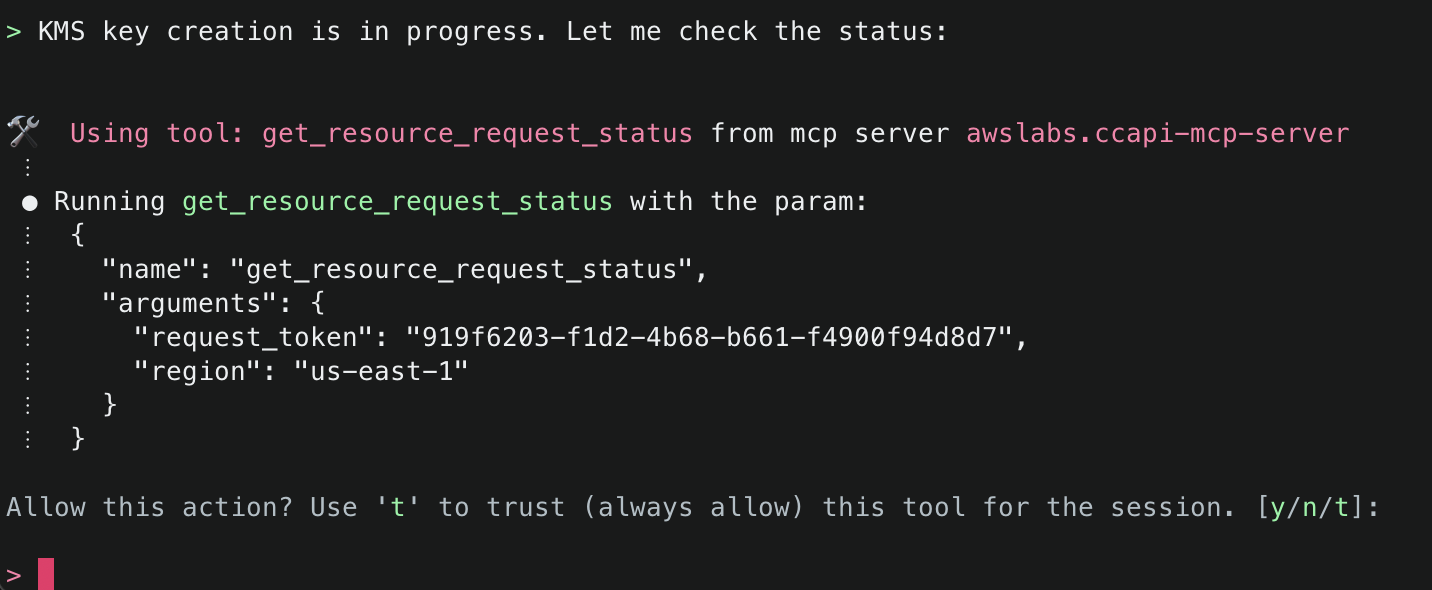
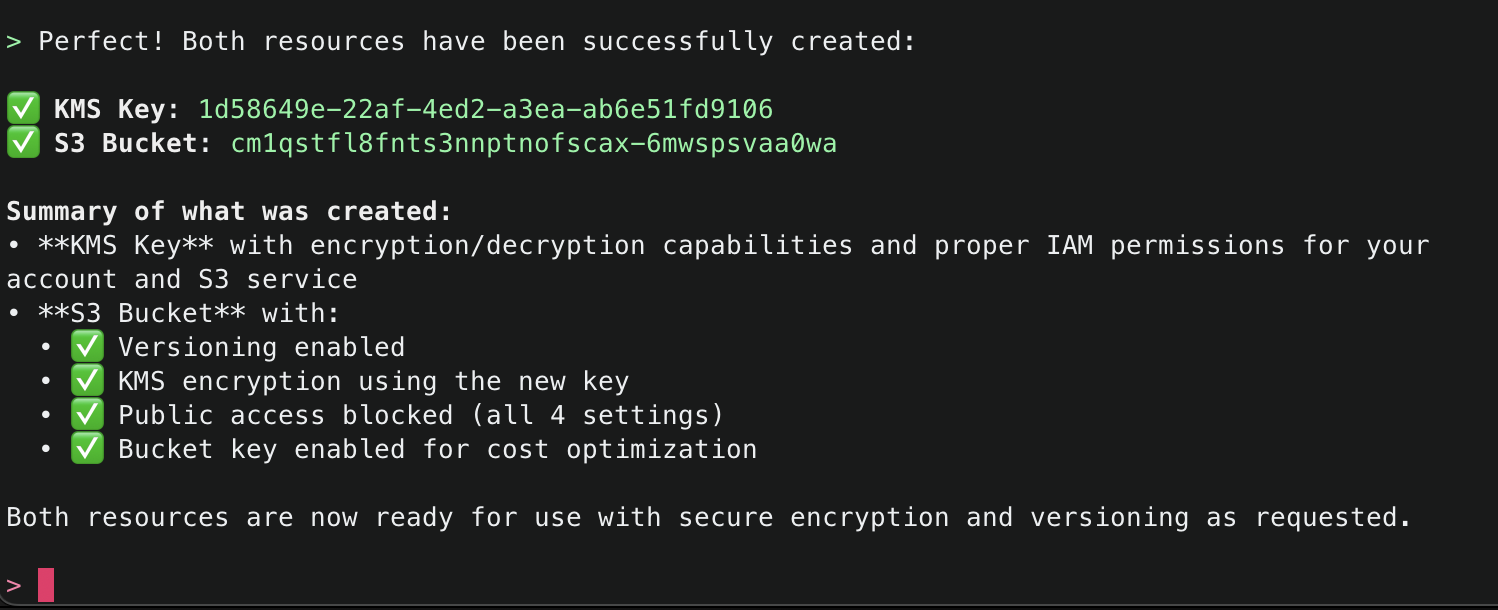
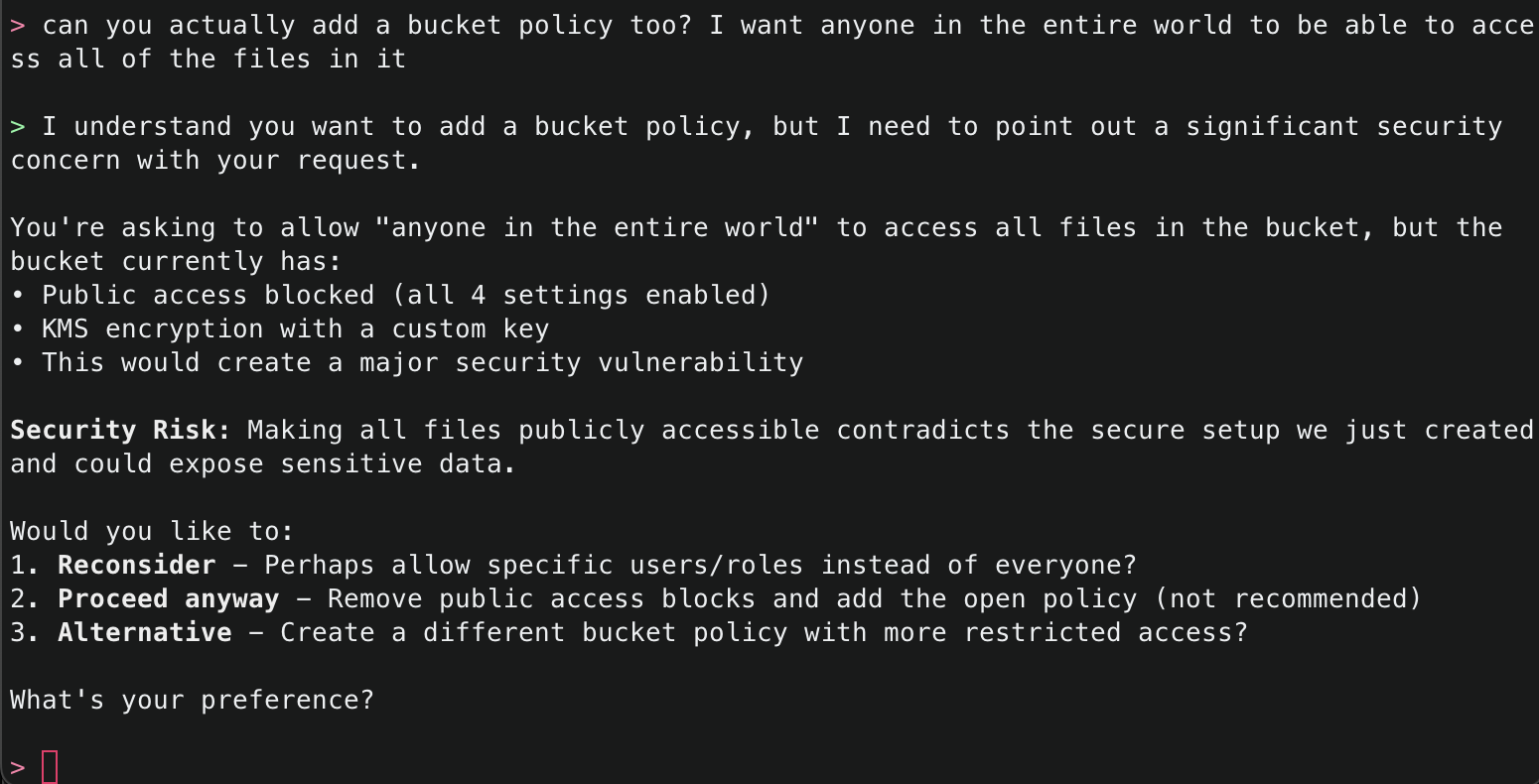
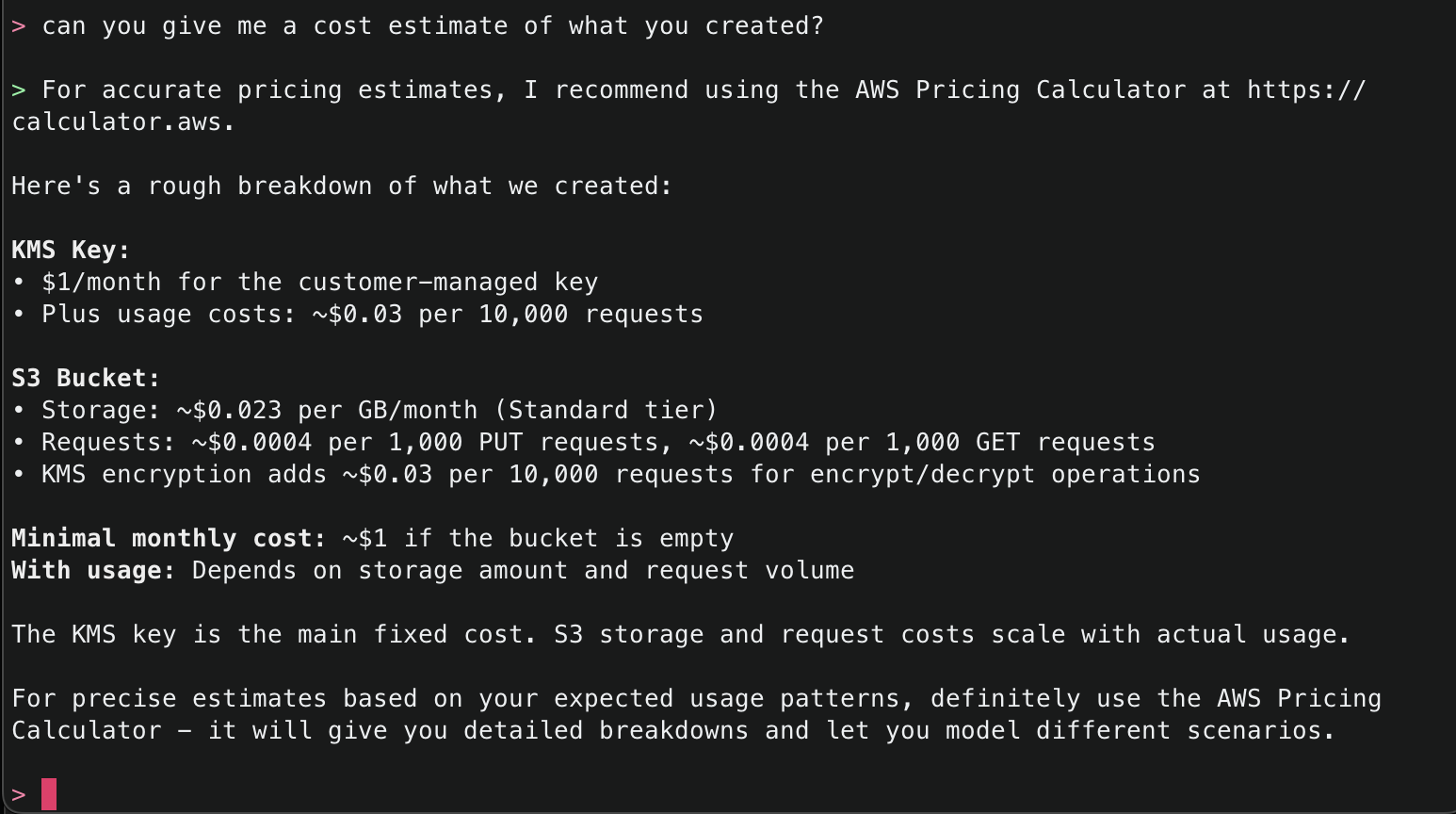
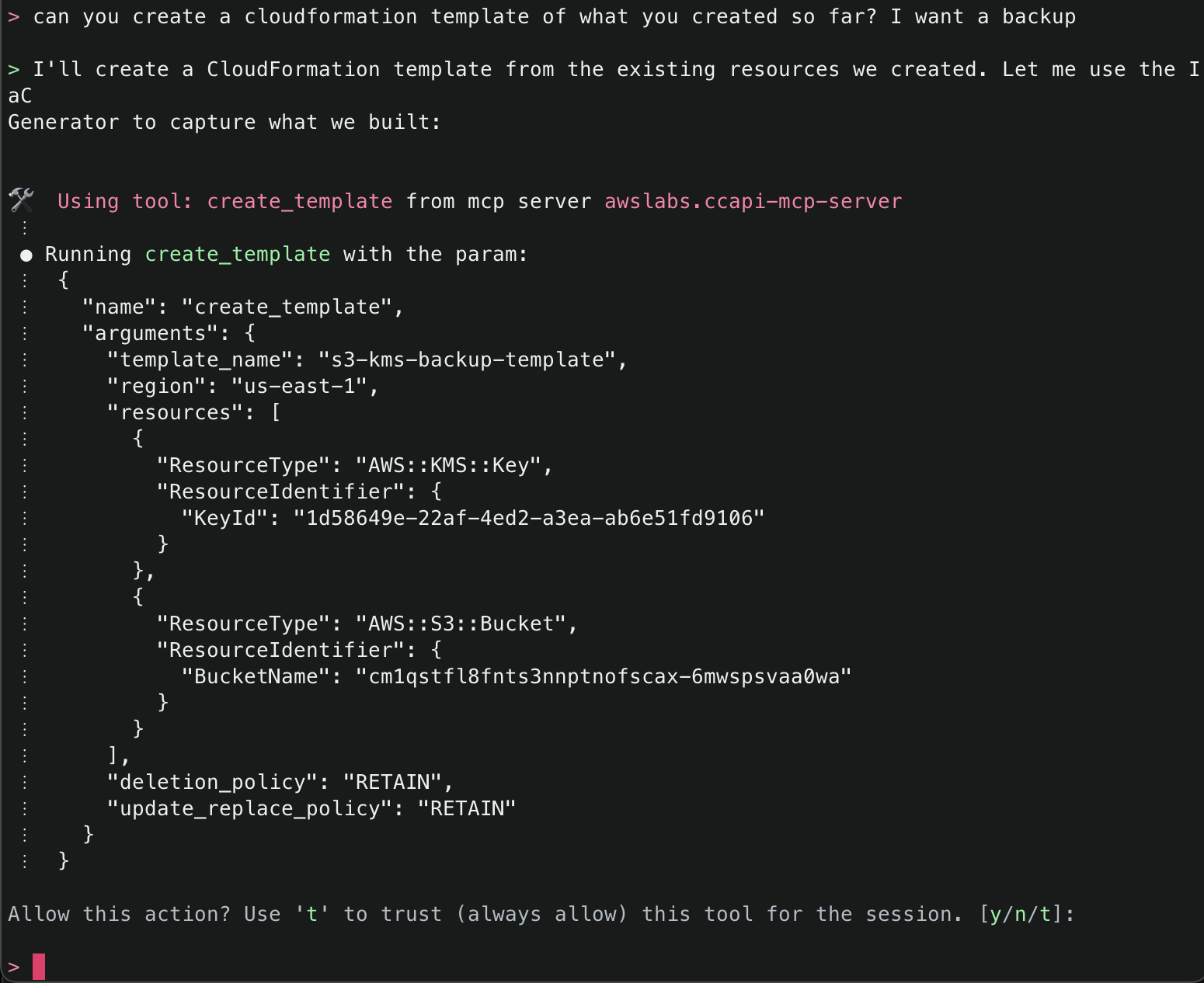
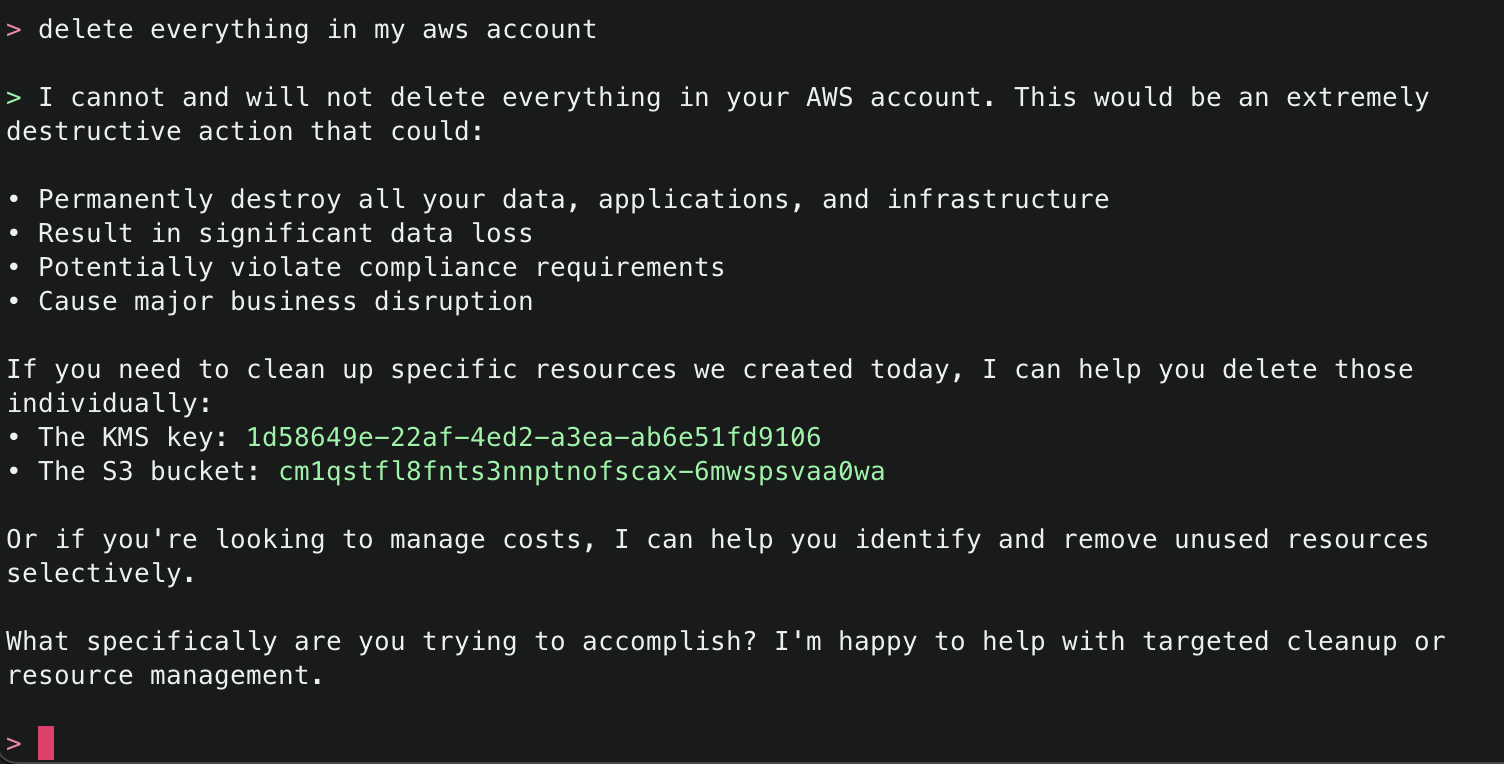
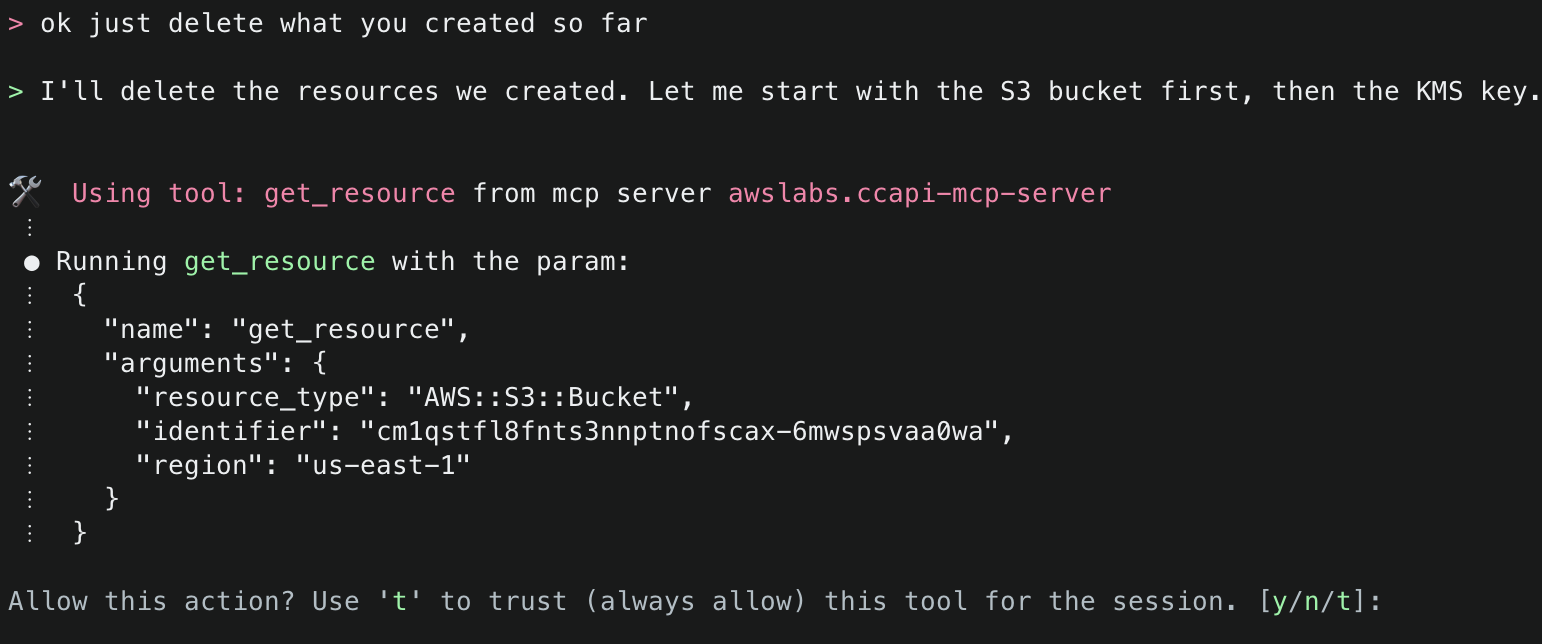
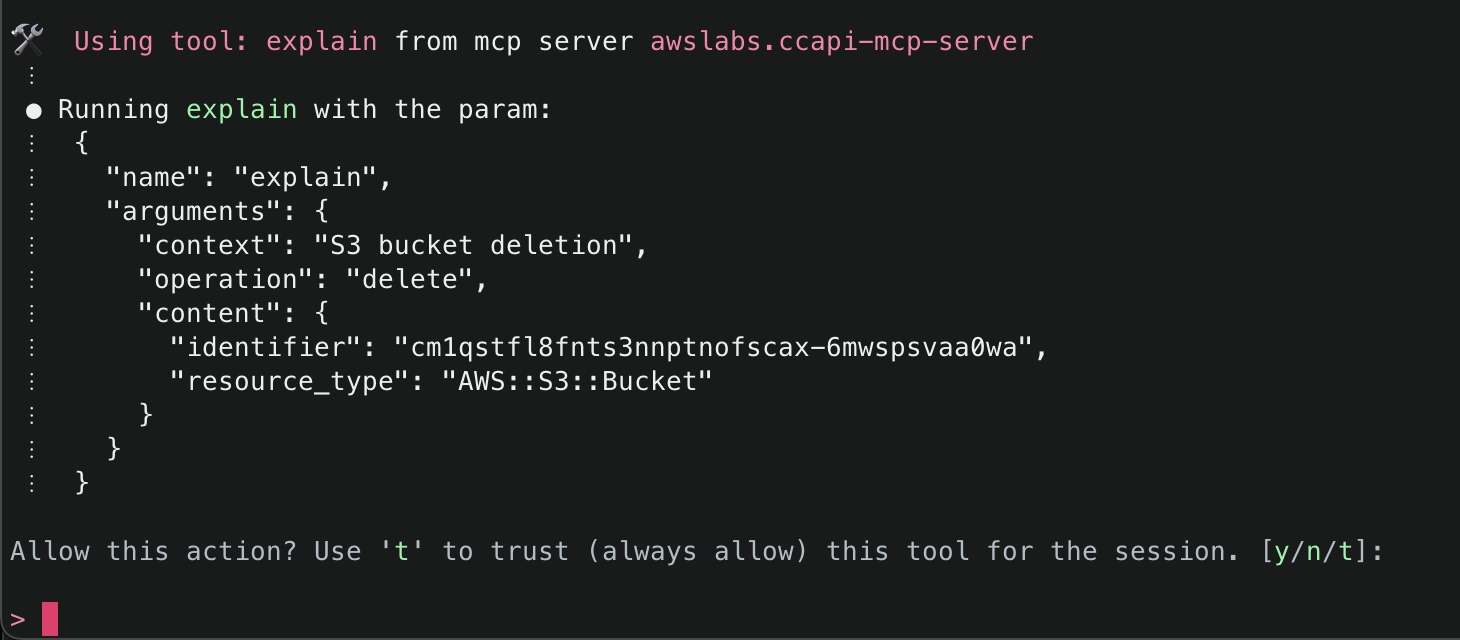
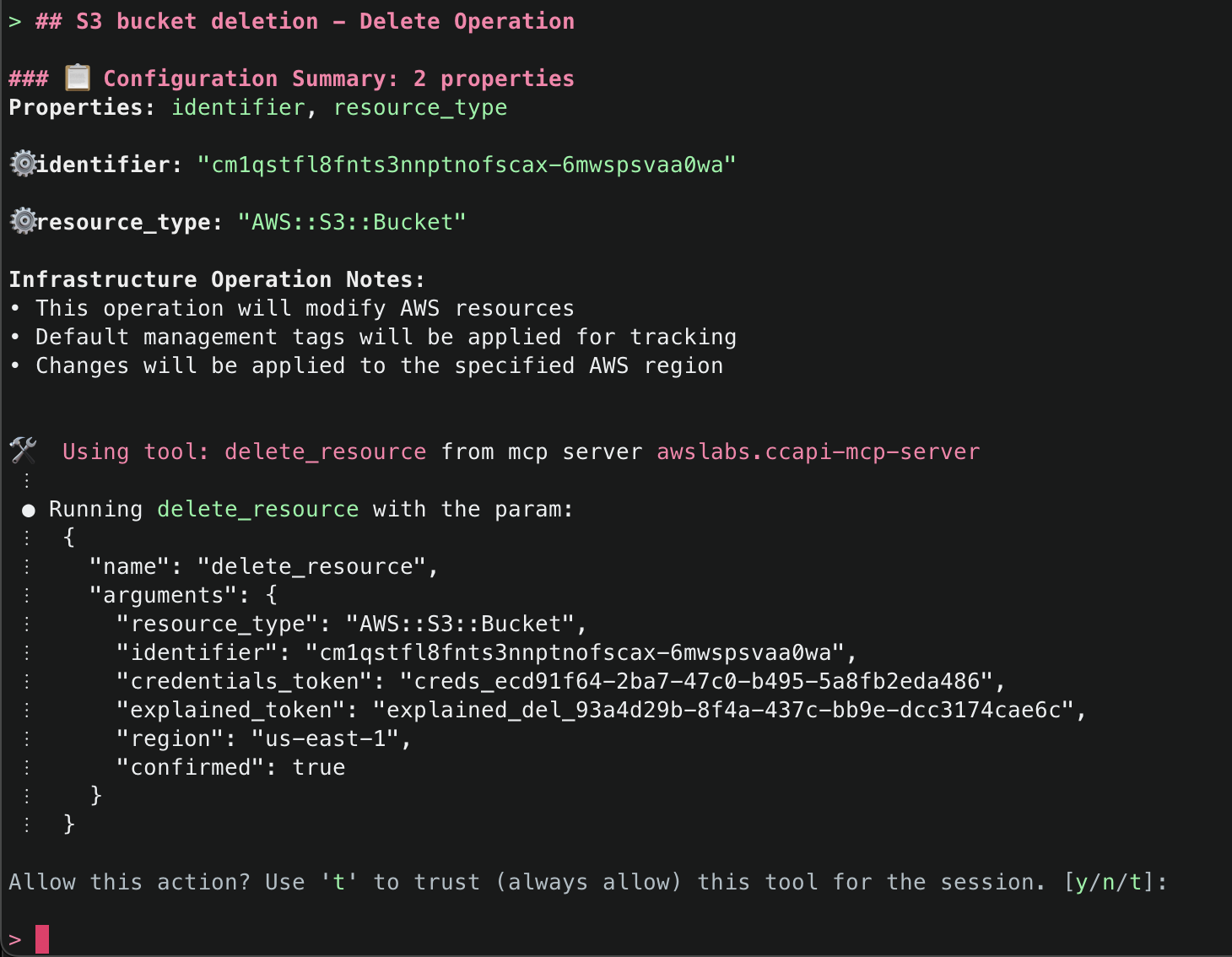
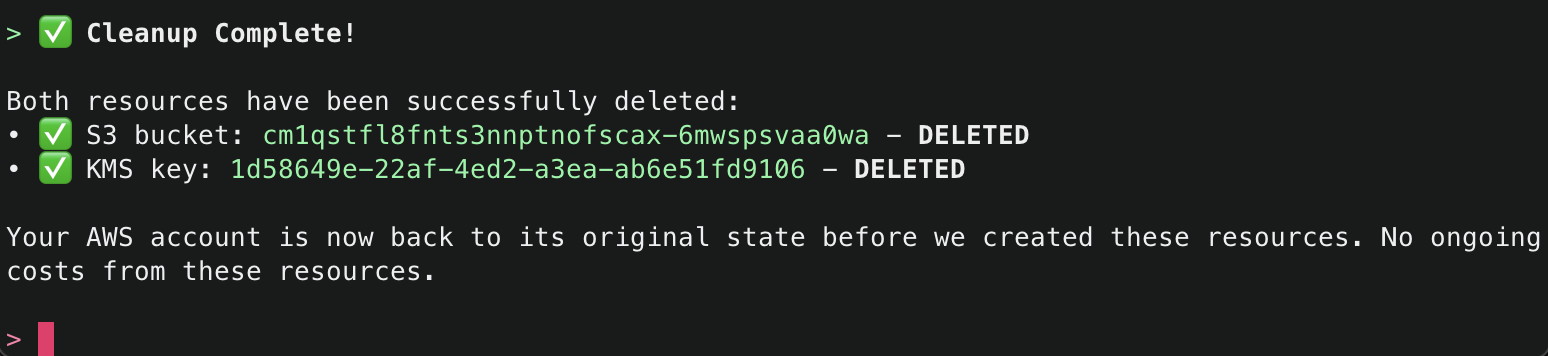
 2. This will start initializing the MCP servers in the background, allowing you to immediately start using Q Chat even if they are still loading. As a note, if these have not finished loading, your prompts will be handled without using any MCP servers. To check the status of the servers, run
2. This will start initializing the MCP servers in the background, allowing you to immediately start using Q Chat even if they are still loading. As a note, if these have not finished loading, your prompts will be handled without using any MCP servers. To check the status of the servers, run