On June 12, 2025, Cloudflare suffered a significant service outage that affected a large set of our critical services. As explained in our blog post about the incident, the cause was a failure in the underlying storage infrastructure used by our Workers KV service. Workers KV is not only relied upon by many customers, but serves as critical infrastructure for many other Cloudflare products, handling configuration, authentication and asset delivery across the affected services. Part of this infrastructure was backed by a third-party cloud provider, which experienced an outage on June 12 and directly impacted availability of our KV service.
Today we’re providing an update on the improvements that have been made to Workers KV to ensure that a similar outage cannot happen again. We are now storing all data on our own infrastructure. We are also serving all requests from our own infrastructure in addition to any third-party cloud providers used for redundancy, ensuring high availability and eliminating single points of failure. Finally, the work has meaningfully improved performance and set a clear path for the removal of any reliance on third-party providers as redundant back-ups.
Background: The Original Architecture
Workers KV is a global key-value store that supports high read volumes with low latency. Behind the scenes, the service stores data in regional storage and caches data across Cloudflare’s network to deliver exceptional read performance, making it ideal for configuration data, static assets, and user preferences that need to be available instantly around the globe.
Workers KV was initially launched in September 2018, predating Cloudflare-native storage services like Durable Objects and R2. As a result, Workers KV’s original design leveraged object storage offerings from multiple third-party cloud service providers, maximizing availability via provider redundancy. The system operated in an active-active configuration, successfully serving requests even when one of the providers was unavailable, experiencing errors, or performing slowly.
Requests to Workers KV were handled by Storage Gateway Worker (SGW), a service running on Cloudflare Workers. When it received a write request, SGW would simultaneously write the key-value pair to two different third-party object storage providers, ensuring that data was always available from multiple independent sources. Deletes were handled similarly, by writing a special tombstone value in place of the object to mark the key as deleted, with these tombstones garbage collected later.
Reads from Workers KV could usually be served from Cloudflare’s cache, providing reliably low latency. For reads of data not in cache, the system would race requests against both providers and return whichever response arrived first, typically from the geographically closer provider. This racing approach optimized read latency by always taking the fastest response while providing resilience against provider issues.
Given the inherent difficulty of keeping two independent storage providers synchronized, the architecture included sophisticated machinery to handle data consistency issues between backends. Despite this machinery, consistency edge cases remained more frequent than consumers required due to the inherently imperfect availability of upstream object storage systems and the challenges of maintaining perfect synchronization across independent providers.
Over the years, the system’s implementation evolved significantly, includinga variety of performance improvements we discussed last year, but the fundamental dual-provider architecture remained unchanged. This provided a reliable foundation for the massive growth in Workers KV usage while maintaining the performance characteristics that made it valuable for global applications.
Scaling Challenges and Architectural Trade-offs
As Workers KV usage scaled dramatically and access patterns became more diverse, the dual-provider architecture faced mounting operational challenges. The providers had fundamentally different limits, failure modes, APIs, and operational procedures that required constant adaptation.
The scaling issues extended beyond provider reliability. As KV traffic increased, the total number of IOPS exceeded what we could write to local cache infrastructure, forcing us to rely on traditional caching approaches when data was fetched from origin storage. This shift exposed additional consistency edge cases that hadn’t been apparent at smaller scales, as the caching behavior became less predictable and more dependent on upstream provider performance characteristics.
Eventually, the combination of consistency issues, provider reliability disparities, and operational overhead led to a strategic decision to reduce complexity by moving to a single object storage provider earlier this year. This decision was made with awareness of the increased risk profile, but we believed the operational benefits outweighed the risks and viewed this as a temporary intermediate state while we developed our own storage infrastructure.
Unfortunately, on June 12, 2025, that risk materialized when our remaining third-party cloud provider experienced a global outage, causing a high percentage of Workers KV requests to fail for a period that lasted over two hours. The cascading impact to customers and to other Cloudflare services was severe: Access failed all identity-based logins, Gateway proxy became unavailable, WARP clients couldn’t connect, and dozens of other services experienced significant disruptions.
Designing the Solution
The immediate goal after the incident was clear: bring at least one other fully redundant provider online such that another single-provider outage would not bring KV down. The new provider needed to handle massive scale along several dimensions: hundreds of billions of key-value pairs, petabytes of data stored, millions of GET requests per second, tens of thousands of steady-state PUT/DELETE requests per second, and tens of gigabits per second of throughput—all with high availability and low single-digit millisecond internal latency.
One obvious option was to bring back the provider that we had disabled earlier in the year. However, we could not just flip the switch back. The infrastructure to run in the dual backend configuration on the prior third-party storage provider was gone and the code had experienced some bit rot, making it infeasible to quickly revert to the previous dual-provider setup.
Additionally, the other provider had frequently been a source of their own operational problems, with relatively high error rates and concerningly low request throughput limits, that made us hesitant to rely on it again. Ultimately, we decided that our second provider should be entirely owned and operated by Cloudflare.
The next option was to build directly on top of Cloudflare R2. We already had a private beta version of Workers KV running on R2, but this experience helped us better understand Workers KV’s unique storage requirements. Workers KV’s traffic patterns are characterized by hundreds of billions of small objects with a median size of just 288 bytes—very different from typical object storage workloads that assume larger file sizes.
For workloads dominated by sub-1KB objects at this scale, database storage becomes significantly more efficient and cost-effective than traditional object storage. When you need to store billions of very small values with minimal per-value overhead, a database is a natural architectural fit. We’re working on optimizations for R2 such as inlining small objects with metadata to eliminate additional retrieval hops that will improve performance for small objects, but for our immediate needs, a database-backed solution offered the most promising path forward.
After thorough evaluation of possible options, we decided to use a distributed database already in production at Cloudflare. This same database is used behind the scenes by both R2 and Durable Objects, giving us several key advantages: we have deep in-house expertise and existing automation for deployment and operations, and we knew we could depend on its reliability and performance characteristics at scale.
We sharded data across multiple database clusters, each with three-way replication for durability and availability. This approach allows us to scale capacity horizontally while maintaining strong consistency guarantees within each shard. We chose to run multiple clusters rather than one massive system to ensure a smaller blast radius if any cluster becomes unhealthy and to avoid pushing the practical limits of single-cluster scalability as Workers KV continues to grow.
Implementing the Solution
One immediate challenge that we ran into when implementing the system was connectivity. The SGW needed to communicate with database clusters running in our core datacenters, but databases typically use binary protocols over persistent TCP connections—not the HTTP-based communication patterns that work efficiently across our global network.
We built KV Storage Proxy (KVSP) to bridge this gap. KVSP is a service that provides an HTTP interface that our SGW can use while managing the complex database connectivity, authentication, and shard routing behind the scenes. KVSP stripes namespaces across multiple clusters using consistent hashing, preventing hotspotting where popular namespaces could overwhelm single clusters, eliminating noisy neighbor issues, and ensuring capacity limitations are distributed rather than concentrated.
The biggest downside of using a distributed database for Workers KV’s storage is that, while it excels at handling the small objects that dominate KV traffic, it is not optimal for the occasional large values of up to 25 MiB that some users store. Rather than compromise on either use case, we extended KVSP to automatically route larger objects to Cloudflare R2, creating a hybrid storage architecture that optimizes the backend choice based on object characteristics. From the perspective of SGW, this complexity is completely transparent—the same HTTP API works for all objects regardless of size.
We also restored our dual-provider capabilities between storage providers from KV’s prior architecture and adapted them to work well in tandem with the changes that had been made to KV’s implementation since it dropped down to a single provider. The modified system now operates by racing writes to both backends simultaneously, but returns success to the client as soon as the first backend confirms the write.
This improvement minimizes latency while ensuring durability across both systems. When one backend succeeds but the other fails—due to temporary network issues, rate limiting, or service degradation—the failed write is queued for background reconciliation, which serves as part of our synchronization machinery that is described in more detail below.
Deploying the Solution
With the hybrid architecture implemented, we began a careful rollout process designed to validate the new system while maintaining service availability.
The first step was introducing background writes from SGW to the new Cloudflare backend. This allowed us to validate write performance and error rates under real production load without affecting read traffic or user experience. It also was a necessary step in copying all data over to the new backend.
Next, we copied existing data from the third-party provider to our new backend running on Cloudflare infrastructure, routing the data through KVSP. This brought us to a critical milestone: we were now in a state where we could manually failover all operations to the new backend within minutes in the event of another provider outage. The single point of failure that caused the June incident had been eliminated.
With confidence in the failover capability, we began enabling our first namespaces in active-active mode, starting with internal Cloudflare services where we had sophisticated monitoring and deep understanding of the workloads. We dialed up traffic very slowly, carefully comparing results between backends. The fact that SGW could see responses from both backends asynchronously—after already returning a response to the user—allowed us to perform detailed comparisons and catch any discrepancies without impacting user-facing latency.
During testing, we discovered an important consistency regression compared to our single provider setup, which caused us to briefly roll back the change to put namespaces in active-active mode. While Workers KVis eventually consistent by design, with changes taking up to 60 seconds to propagate globally as cached versions time out, we had inadvertently regressed read-your-own-write (RYOW) consistency for requests routed through the same Cloudflare point of presence.
In the previous dual provider active-active setup, RYOW was provided within each PoP because we wrote PUT operations directly to a local cache instead of relying on the traditional caching system in front of upstream storage. However, KV throughput had outscaled the number of IOPS that the caching infrastructure could support, so we could no longer rely on that approach. This wasn’t a documented property of Workers KV, but it is behavior that some customers have come to rely on in their applications.
To understand the scope of this issue, we created an adversarial test framework designed to maximize the likelihood of hitting consistency edge cases by rapidly interspersing reads and writes to a small set of keys from a handful of locations around the world. This framework allowed us to measure the percentage of reads where we observed a violation of RYOW consistency—scenarios where a read immediately following a write from the same point of presence would return stale data instead of the value that was just written. This allowed us to design and verify a new approach to how KV populates and invalidates data in cache, which restored the RYOW behavior that customers expect while maintaining the performance characteristics that make Workers KV effective for high-read workloads.
How KV Maintains Consistency Across Multiple Backends
With writes racing to both backends and reads potentially returning different results, maintaining data consistency across independent storage providers requires a sophisticated multi-layered approach. While the details have evolved over time, KV has always taken the same basic approach, consisting of three complementary mechanisms that work together to reduce the likelihood of inconsistencies and minimize the window for data divergence.
The first line of defense happens during write operations. When SGW sends writes to both backends simultaneously, we treat the write as successful as soon as either provider confirms persistence. However, if a write succeeds on one provider but fails on the other—due to network issues, rate limiting, or temporary service degradation—the failed write is captured and sent to a background reconciliation system. This system deduplicates failed keys and initiates a synchronization process to resolve the inconsistency.
The second mechanism activates during read operations. When SGW races reads against both providers and notices different results, it triggers the same background synchronization process. This helps ensure that keys that become inconsistent are brought back into alignment when first accessed rather than remaining divergent indefinitely.
The third layer consists of background crawlers that continuously scan data across both providers, identifying and fixing any inconsistencies missed by the previous mechanisms. These crawlers also provide valuable data on consistency drift rates, helping us understand how frequently keys slip through the reactive mechanisms and address any underlying issues.
The synchronization process itself relies on version metadata that we attach to every key-value pair. Each write automatically generates a new version consisting of a high-precision timestamp plus a random nonce, stored alongside the actual data. When comparing values between providers, we can determine which version is newer based on these timestamps. The newer value is then copied to the provider with the older version.
In rare cases where timestamps are within milliseconds of each other, clock skew could theoretically cause incorrect ordering, though given the tight bounds we maintain on our clocks throughCloudflare Time Services and typical write latencies, such conflicts would only occur with nearly simultaneous overlapping writes.
To prevent data loss during synchronization, we use conditional writes that verify that the last timestamp is older before writing instead of blindly overwriting values. This allows us to avoid introducing new inconsistency issues in cases where requests in close proximity succeed to different backends and the synchronization process copies older values over newer values.
Similarly, we can’t just delete data when the user requests it because if the delete only succeeded to one backend, the synchronization process would see this as missing data and copy it from the other backend. Instead, we overwrite the value with a tombstone that has a newer timestamp and no actual data. Only after both providers have the tombstone do we proceed with actually removing the keys from storage.
This layered consistency architecture doesn’t guarantee strong consistency, but in practice it does eliminate most mismatches between backends while maintaining a performance profile that makes Workers KV attractive for latency-sensitive, high-read workloads while also providing high availability in the case of any backend errors. In distributed systems terms, KV chooses availability (AP) over consistency (CP) in the CAP theorem, and more interestingly also chooses latency over consistency in the absence of a partition, meaning it’s PA/EL under the PACELC theorem. Most inconsistencies are resolved within seconds through the reactive mechanisms, while the background crawlers ensure that even edge cases are typically corrected over time.
The above description applies to both our historical dual-provider setup and today’s implementation, but two key improvements in the current architecture lead to significantly better consistency outcomes. First, KVSP maintains a much lower steady-state error rate compared to our previous third-party providers, reducing the frequency of write failures that create inconsistencies in the first place. Second, we now race all reads against both backends, whereas the previous system optimized for cost and latency by preferentially routing reads to a single provider after an initial learning period.
In the original dual-provider architecture, each SGW instance would initially race reads against both providers to establish baseline performance characteristics. Once an instance determined that one provider consistently outperformed the other for its geographic region, it would route subsequent reads exclusively to the faster provider, only falling back to the slower provider when the primary experienced failures or abnormal latency. While this approach effectively controlled third-party provider costs and optimized read performance, it created a significant blind spot in our consistency detection mechanisms—inconsistencies between providers could persist indefinitely if reads were consistently served from only one backend.
Results: Performance and Availability Gains
With these consistency mechanisms in place and our careful rollout strategy validated through internal services, we continued expanding active-active operation to additional namespaces across both internal and external workloads, and we were thrilled with what we saw. Not only did the new architecture provide the increased availability we needed for Workers KV, it also delivered significant performance improvements.
These performance gains were particularly pronounced in Europe, where our new storage backend is located, but the benefits extended far beyond what geographic locality alone could explain. The internal latency improvements compared to the third-party object store we were writing to in parallel were remarkable.
For example, p99 internal latency for reads to KVSP were below 5 milliseconds. For comparison, non-cached reads to the third-party object store from our closest location—after normalizing for transit time to create an apples-to-apples comparison—were typically around 80ms at p50 and 200ms at p99.
The graphs below show the closest thing that we can get to an apples-to-apples comparison: our observed internal latency for requests to KVSP compared with observed latency for requests that are cache misses and end up being forwarded to the external service provider from the closest point of presence, which includes an additional 5-10 milliseconds of request transit time.
These performance improvements translated directly into faster response times for the many internal Cloudflare services that depend on Workers KV, creating cascading benefits across our platform. The database-optimized storage proved particularly effective for the small object access patterns that dominate Workers KV traffic.
After seeing these positive results, we continued expanding the rollout, copying data and enabling groups of namespaces for both internal and external customers. The combination of improved availability and better performance validated our architectural approach and demonstrated the value of building critical infrastructure on our own platform.
What’s next?
Our immediate plans focus on expanding this hybrid architecture to provide even greater resilience and performance for Workers KV. We’re rolling out the KVSP solution to additional locations, creating a truly global distributed backend that can serve traffic entirely from our own infrastructure while also working to further improve how quickly we reach consistency between providers and in cache after writes.
Our ultimate goal is to eliminate our remaining third-party storage dependency entirely, achieving full infrastructure independence for Workers KV. This will remove the external single points of failure that led to the June incident while giving us complete control over the performance and reliability characteristics of our storage layer.
Beyond Workers KV, this project has demonstrated the power of hybrid architectures that combine the best aspects of different storage technologies. The patterns we’ve developed—using KVSP as a translation layer, automatically routing objects based on size characteristics, and leveraging our existing database expertise—can be leveraged by other services that need to balance global scale with strong consistency requirements. The journey from a single-provider setup to a resilient hybrid architecture running on Cloudflare infrastructure demonstrates how thoughtful engineering can turn operational challenges into competitive advantages. With dramatically improved performance and active-active redundancy, Workers KV is well positioned to serve as an even more reliable foundation for the growing set of customers that depend on it.
Правосъдният министър предлага да се спре възможността да се вадят незаверени копия от актове вписани в имотния регистър. Като причини дава борба с имотните измами, която сега води предимно с PR съобщения. Разбра се защо реално е подхванал темата. Тази промяна е крайно опасна – всъщност помага на имотните измамници като страничен ефект, но в основата си цели нещо съвсем друго.
Достъп до актовете в имотния регистър сега има всеки. За целта обаче трябва да се идентифицираш с електронен подпис, така че да е видно както за собствениците, така и за съдебната система кой е гледал какви документи и кога. Всичко е проследимо и ясно. Т.е. ако искаха да се борят с измамници, „просто“ трябва да имаме работеща прокуратура и разследване, липса на чадъри в правосъдното министерство и съда. Това го няма и си го казват.
В момента този свободен, но проследим достъп до актовете се използва именно за борба с измамите – всеки от нас може да види ясно дали и кой притежава имот, от който се интересуваме, дали документът пред нас е подправен и е спирачка за редица други схеми, за които чуваме в медиите. Георгиев се опитва да махне именно безценен инструмент в ръцете на обикновените граждани, с който се пазим. Това обаче е само страничен ефект.
Още по-ценен е този инструмент е за журналисти, активисти и дори съвестни държавни служители, които така следят за корупция, връзки между политици, бизнес, прокурори, съдии, нездрави интереси и схеми каквито прозират в продажбата на 4400-те държавни имота. Използвам го дори аз в разследвания си. Именно тази публичност позволена и уредена нормативно се опитва да затрие Георгиев. За всеки обръщал внимание на нещо в държавата е ясно, че ще е в полза на ГЕРБ НН и ДПС НН.
Не можах да тагна и попитам за тези неща самия Георгиев, защото ме е блокирал още от времето, когато беше общински съветник в София. Тогава правеше същите схеми и обръщане на обективни факти с главата надолу, за да лобира за вредни за обществото решения в услуга на конкретен интерес. Сега го прави на национално ниво.
Твърденията на министерството и Георгиев ще намерите на страницата им. Проектът за промените ще намерите пак там. Призовавам да подавате становища в консултациите в Strategy.bg. Те продължават до 9-ти септември и макар да не очаквам Георгиев да отчете каквато и да е външна критика или искания за корекции, важно е да се покаже, че намеренията му са прозрачни и промяната е опасна.
Google’s vulnerability finding team is again pushing the envelope of responsible disclosure:
Google’s Project Zero team will retain its existing 90+30 policy regarding vulnerability disclosures, in which it provides vendors with 90 days before full disclosure takes place, with a 30-day period allowed for patch adoption if the bug is fixed before the deadline.
However, as of July 29, Project Zero will also release limited details about any discovery they make within one week of vendor disclosure. This information will encompass:
The vendor or open-source project that received the report
The affected product
The date the report was filed and when the 90-day disclosure deadline expires
I have mixed feelings about this. On the one hand, I like that it puts more pressure on vendors to patch quickly. On the other hand, if no indication is provided regarding how severe a vulnerability is, it could easily cause unnecessary panic.
The problem is that Google is not a neutral vulnerability hunting party. To the extent that it finds, publishes, and reduces confidence in competitors’ products, Google benefits as a company.
Cold starts are an important consideration when building applications on serverless platforms. In AWS Lambda, they refer to the initialization steps that occur when a function is invoked after a period of inactivity or during rapid scale-up. While typically brief and infrequent, cold starts can introduce additional latency, making it essential to understand them, especially when optimizing performance in responsive and latency-sensitive workloads.
In this article, you’ll gain a deeper understanding of what cold starts are, how they may affect your application’s performance, and how you can design your workloads to reduce or eliminate their impact. With the right strategies and tools provided by AWS, you can efficiently manage cold starts and deliver consistent, low-latency experience for your users.
What is a cold start?
Cold starts occur because serverless platforms like AWS Lambda are designed for cost-efficiency – you don’t pay for compute resources when your code isn’t running. As a result, Lambda only provisions resources when needed. A cold start happens when there isn’t an existing execution environment available and a new one must be created. This can happen, for example, when a function is invoked for the first time after a period of inactivity or during a burst in traffic that triggers scale-up.
When this occurs, Lambda rapidly provisions and initializes a new execution environment for running your function code. This initialization adds a small amount of latency to the request, but it only occurs once for the lifecycle of that execution environment.
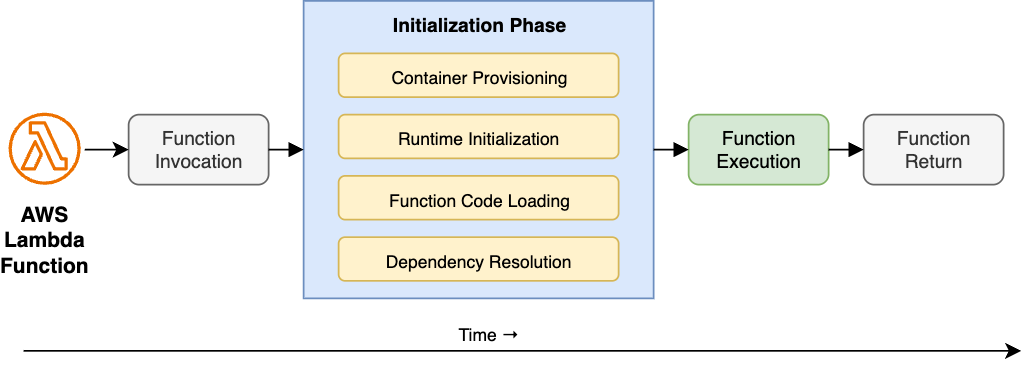
Cold starts consist of several steps that make up the Initialization Phase, which occurs before the function begins running. These steps take place when the Lambda service creates a new execution environment, contributing to the latency commonly referred to as the INIT duration of the function, as illustrated in a following diagram:
Figure 1: Lambda Function Execution Lifecycle: Cold Start Components
Container Provisioning: Lambda allocates the necessary compute resources to run the function, based on its configured memory.
Function Code Loading: Lambda downloads and unpacks the function code into the container.
Dependency Resolution: Lambda loads required libraries and packages so the function can execute successfully.
While cold starts typically affect less than 1% of requests, they can introduce performance variability in workloads where Lambda needs to create new execution environments more frequently, such as after periods of inactivity or during rapid scaling. This variability can impact perceived response times, especially in latency-sensitive applications such as user-facing APIs.
Why do cold starts occur?
Cold starts are a natural aspect of the serverless computing model due to its core design principles:
Resource Efficiency: To optimize cost and resource usage, AWS Lambda automatically shuts down idle execution environments after a period of inactivity. When the function is invoked again, a new environment must be provisioned.
Security and Isolation: Each Lambda execution environment runs in an isolated container to ensure strong security boundaries between invocations. This container-level isolation requires a fresh initialization process, which adds startup latency.
Auto-Scaling: Lambda automatically creates new environments to handle increased traffic or concurrent invocations. Each new environment requires provisioning and initialization, which contributes to cold start latency.
Understanding and optimizing cold start factors
The following sections explore factors contributing to cold starts, and optimization techniques to initialize your functions faster.
Runtime selection
Lambda supports multiple programming languages through runtimes, including the ability to create custom runtimes. A runtime handles core responsibilities such as relaying invocation events, context, and responses between the Lambda service and your function code. The time it takes to initialize a runtime can vary depending on the language. Interpreted languages, such as Python and Node.js, typically initialize faster, while compiled languages like Java or .NET may take longer due to additional startup steps such as loading classes. Custom, or OS-only runtimes commonly provide fastest cold start performance as they typically run compiled binaries on the underlying Linux environment.
Runtimes are regularly maintained and updated by AWS, with newer versions typically offering improvements in performance, security, and startup latency. To take advantage of these enhancements, AWS recommends keeping your functions up to date with the latest supported runtimes.
Packaging and layers
AWS Lambda supports two packaging options for deploying your function code – ZIP archives and container images. Each approach offers unique advantages and may influence cold start latency depending on how it’s used.
For ZIP-based deployments, you can upload your function code directly (up to 50MB) or via Amazon Simple Storage Service (Amazon S3) (up to 250MB unzipped). To promote reusability, Lambda also supports Lambda layers, allowing you to share common code, libraries, or runtime dependencies across multiple functions. However, larger packages can impact cold start latency due to factors such as increased S3 download time, ZIP extraction overhead, layer mounting and initialization. The size and number of dependencies directly affects initialization time – each added dependency increases the deployment artifact size, which Lambda must download, unpack, and initialize during the INIT phase.
To optimize cold start performance, keep your deployment ZIP packages small, remove unused dependencies with techniques like tree shaking, prioritize lightweight libraries, exclude unnecessary files like tests or docs, and structure your layers efficiently.
When using container-based deployments, you push your function image to Amazon Elastic Container Registry (Amazon ECR) first. This option provides greater flexibility and control over the runtime environment, especially useful when your function code exceeds 250MB or when you require specific language version or system libraries not included in the AWS-managed runtimes. While container images allow for highly customized deployments, pulling large images from ECR might contribute to cold start latency. Similar to ZIP-based approach, make sure to keep your image sizes minimal by removing unnecessary artifacts.
Resource allocation
Memory allocation plays a key role in both the performance and cost of your Lambda functions. When you assign more memory to a function, Lambda also allocates more CPU power, which can help reduce the time it takes to initialize and run your code – often improving cold start performance.
Use the AWS Lambda Power Tuning tool to balance performance benefits with added cost of allocating more memory. This tool runs your function with different memory settings and analyzes the trade-offs between speed and cost. This makes it easier to find the most cost-effective configuration for your workload.
Network configuration
By default, your Lambda functions are connected to the public internet, however you can attach them to your own Amazon Virtual Private Cloud (Amazon VPC) instead, for example when your functions need to access VPC-hosted resources such as databases. When this happens, the Lambda service creates an Elastic Network Interface (ENI) to attach your functions to. This process involves multiple steps, such as creation of network interfaces, subnets, security groups, route table and so on. While Lambda service tries to minimize added latency, applying this configuration might introduce additional latency, therefore you should only use it when access to VPC resources is necessary.
Design considerations
Optimizing your function initialization code can help to reduce cold start latencies. Streamline your function code to load and prepare quickly, alongside its runtime environment and dependencies. Employ lightweight libraries and implement lazy loading for resources to further cut initialization time. Minimize code size by eliminating unnecessary dependencies. Consider your architecture carefully: break down large functions into smaller, more focused units based on invocation patterns. This approach allows for quicker initialization of individual components. These smaller, task-specific functions offer the added benefits of improved modularity, easier testing, and simpler maintenance. However, always strike a balance between function size and functionality to maintain overall system efficiency. By implementing these optimization strategies, you can substantially mitigate cold start impacts while preserving your application’s core functionality and performance.
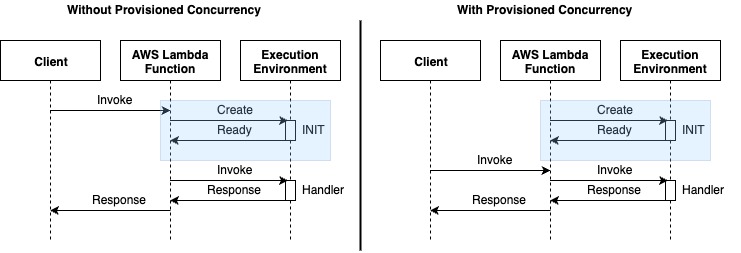
Provisioned Concurrency
Provisioned Concurrency addresses cold starts by pre-initializing function environments and keeping them “warm”, always ready to respond to incoming function invocations. By maintaining pre-initialized execution environments, Provisioned Concurrency delivers consistent performance for frequently invoked functions while eliminating throttling during peak loads. Provisioned Concurrency results in predictable performance for a function by providing consistent latency at some cost for reserved instances. Provisioned Concurrency is beneficial for high-traffic applications that requires consistent performance during heavy traffic and latency sensitive applications that requires fast responses for an interactive application, thereby reducing cold starts benefitting overall performance. The customer success story from Smartsheet demonstrates significant improvement in user experience with reduced latencies and better cost efficiency.
Figure 2: AWS Lambda execution flow comparison: standard vs. Provisioned Concurrency
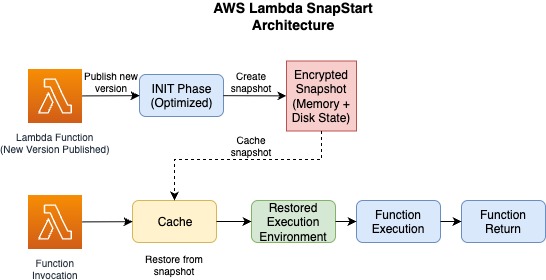
SnapStart
Lambda SnapStart improves cold invoke latency by reducing the time it takes for a function to initialize and become ready to handle incoming requests. When SnapStart is enabled for a function, Lambda creates an encrypted snapshot of the initialized execution environment when you publish a new function version. This triggers an optimized INIT phase of the function where an immutable, encrypted snapshot of the memory and disk is taken. This snapshot is cached for reuse later. When a SnapStart-enabled function is invoked again, Lambda restores the execution environment from the cached snapshot instead of creating a new environment, thus moderating a cold invoke. SnapStart minimizes the invocation latency of a function, since creating a new execution environment no longer requires a dedicated INIT phase.
SnapStart is an efficient cold start solution, currently available for Java, Python, and .NET functions. It is particularly useful for functions with long initialization times. Inactive snapshots are automatically removed after 14 days without invocation. For detailed pricing information, check out our pricing page.
Use out-of-the-box observability facilities provided by AWS Lambda to investigate whether your functions or user experience are affected by cold starts and identify most impactful optimization areas. Monitoring Lambda cold start performance using built-in metrics such as INIT duration, invocation duration, and error rates is crucial for identifying bottlenecks and refining the function for optimal performance and cost-effectiveness. Use the following metrics:
INIT duration: The INIT duration metric, found in the REPORT section of function logs, measures the time taken for the function to initialize and become ready to handle invocation.
REPORT Message: Lambda reports total invocation time, such as initialization, in the REPORT log message at the end of each invocation. Monitoring this metric helps identify potential bottlenecks within the function code.
Error Rates: Monitoring error rates helps identify issues within the function, thus guaranteeing reliability and stability.
Concurrency Metrics: Concurrency metrics help understand if a function is hitting the concurrency limits that can contribute to potential increases in cold start durations and throttling.
Conclusion
In this post you’ve learned a detailed breakdown and insights about various aspects of Lambda cold starts, offering a comprehensive understanding of the challenges and solutions in this space. While cold starts commonly affect less than 1% of requests, understanding their nature and implementing appropriate remediation strategies early can help to minimizing their impact in the most latency-sensitive applications.
Disaster recovery (DR) is a top-line priority for enterprise organizations facing increasingly complex threats—sophisticated ransomware attacks, widespread cloud outages, and regulatory risks. The ability to recover quickly and maintain business continuity isn’t just a technical necessity—it’s a competitive imperative.
Today, I’m breaking down foundational strategies for enterprise DR readiness. You’ll find practical guidance on infrastructure design, site strategy, backup best practices, and more to help you take immediate action.
Get the full guide
Our “Essential Guide to Disaster Recovery Planning” offers a comprehensive framework for designing a DR plan that protects your business across multiple threat vectors.
Comprehensive DR requires a multi-tiered approach. Your DR strategy should encompass four critical stages: prevention, preparation, mitigation, and recovery.
Choose the right infrastructure: Beyond legacy limitations
Many enterprises still rely on legacy storage technologies like tape, which create delays in restoration and introduce hardware failure risks. Shifting to cloud-first infrastructure reduces these vulnerabilities while unlocking scalability and location diversity. It also supports immutability features—critical for ransomware resilience—and simplifies compliance with evolving regulations.
Cloud platforms also unlock new options for data governance and sovereignty. Enterprises operating across regions or industries governed by strict data residency laws can configure cloud storage to maintain compliance while reducing operational overhead.
As enterprise backup and archive needs grow, it becomes vital to distinguish between long-term cold storage and actively accessible data. With clear infrastructure planning, organizations can streamline operations and ensure faster recovery without overspending on high-performance systems for archival workloads.
What is Object Lock?
Object Lock is the feature in cloud platforms that enables immutability. With immutability, your data cannot be changed, deleted, or encrypted. This is the ultimate protection against ransomware.
DR site temperatures: Hot, warm, or cold?
Depending on your recovery time objective (RTO), different types of recovery sites offer different benefits:
Hot sites: Fully mirrored and ready for instant failover—great for mission-critical apps but expensive.
Warm sites: Pre-configured but not fully live—strike a balance between cost and speed.
Cold sites: Infrastructure is ready but requires manual configuration—most affordable, but slowest to recover.
Enterprises evaluating DR readiness should consider whether their current configuration meets their recovery time goals—and whether they’re optimizing for the right workloads. Comparing hot, warm, and cold site models can help strike the right balance between performance and budget.
Build vs. buy vs. cloud: Finding the right fit
Selecting a DR site is fundamental to your strategy. There are four main approaches to establishing a DR site: building your own, buying services from a co-location provider, buying public cloud storage, or leveraging a disaster recovery as a service (DRaaS) solution. Each approach offers distinct advantages and drawbacks.
Building an on-premises DR site
Pros: It provides complete control over the DR environment, offering greater customization and security.
Cons: Significant upfront investment in hardware, software, and facility infrastructure and management. Requires ongoing maintenance and staffing costs. Limited scalability to accommodate future growth.
Buying co-located DR storage
Pros: It offers a cost-effective alternative to building your own site. Co-location providers manage aspects of the physical infrastructure, reducing your IT team’s workload.
Cons: Less control over the environment compared to an on-premises solution. May require additional investment for network connectivity and configuration. Potential vendor lock-in with specific co-location providers.
Buying public cloud-based DR storage
Pros: Highly scalable and cost-effective. CSPs manage the physical infrastructure, reducing your IT team’s workload. Features like Object Lock help address security concerns versus on-premises storage.
Cons: Retrieving large volumes of data may be slow due to bandwidth constraints.
Buying disaster recovery as a service (DRaaS)
Pros: Highly scalable and cost-effective solution. Eliminates the need for upfront infrastructure investment. DRaaS providers manage the entire DR environment and provide technical support, freeing up your IT staff.
Cons: Reliance on a third-party provider for critical data and infrastructure. Potential concerns over network latency and vendor lock-in. Security considerations require a careful evaluation of the cloud provider’s practices.
Backup vs. replication: Know the difference
Replication copies data in real-time, but that also means it can copy infected or corrupted data. Backups, on the other hand, offer point-in-time recoveries so you can restore data even after a ransomware attack.
The optimal approach to DR depends on your specific needs.
For frequently accessed data requiring near-instantaneous recovery, consider a combination of hot site methodology and real-time data replication. This offers the fastest failover, but can come at a higher cost.
For critical data with acceptable downtime, a warm site with replicated immutable backups at a secondary location (either on-premises or in the cloud) provides a good balance between cost and recovery time. While requiring some manual intervention, it offers protection against malware replicating to the DR site.
For less critical data or archival purposes, cold storage with periodic backups is a cost-effective option. Backups offer a historical record and are less susceptible to malware infection compared to replicated data, particularly if Object Lock is enabled for immutability.
SaaS outages are a threat you can’t ignore
Although built for high availability, SaaS apps don’t guarantee protection against data loss. Tools like Microsoft 365 and Google Workspace are built for uptime, not recovery. Misconfigurations, insider threats, and accidental deletions remain common risks. Enterprises should take control of their own retention policies with dedicated SaaS backup strategies, including regular point-in-time snapshots and recovery testing.
Additionally, planning for SaaS outages should include identifying local alternatives for core business functions. Can teams temporarily revert to offline workflows? Are key contacts available outside of email or Slack? Defining fallback protocols ensures that productivity doesn’t grind to a halt even if your primary tools go dark.
Assembling your incident response team
The incident response team (IRT) is the backbone of your DR response and is responsible for leading the recovery efforts during a disaster. Here’s a breakdown of possible key IRT roles:
Incident commander: Oversees the entire incident response process, making critical decisions and delegating tasks to team members.
Technical lead: Provides technical expertise, directing recovery efforts for IT infrastructure and data restoration.
Communications lead: Handles external and internal communication, ensuring timely updates for stakeholders and mitigating potential reputational damage.
Documentation lead: Maintains the DR runbook, ensuring its accuracy and updating it with post-incident findings.
Legal counsel: Provides legal guidance and ensures compliance with relevant regulations during the response and recovery process.
Objectives, priorities, and KPIs: The compass of your DR strategy
A robust DR strategy starts with clearly defined objectives and priorities. These guide your approach and decision-making during a disaster recovery event. Your strategy should prioritize rapid recovery of critical systems and applications to minimize operational downtime and resume normal functions swiftly.
Prioritization: Not all data (or systems) are created equal
Prioritizing your critical business applications depends on a deep understanding of your business. Collaborate with internal partners to identify critical business applications that are essential for ongoing operations. Not all applications require immediate restoration. Prioritize systems based on their impact on core business functions.
Documentation is key
A popular mantra for DR specialists is “Test the plan; don’t plan the test.” Your DR plans must be clearly documented as working recipes for application and data recovery, including dependencies and prerequisites. Document the recovery procedures for each critical application, outlining the steps required to bring them back online. This ensures your IT team can efficiently restore essential services during a disaster.
Primary DR objectives
Minimize data loss: The primary objective is to minimize data loss through regular backups and secure storage practices.
Ensure business continuity: The DR plan aims to rapidly recover operation of critical functions during a disaster, minimizing disruption to the business goals.
Optimize costs: Application and data recovery needs to balance speed and costs to ensure recoverability without unnecessarily increasing IT spending.
Compliance considerations
Compliance regulations might influence your DR priorities. Understand any industry-specific regulations or data privacy laws that might dictate specific data protection and recovery timeframes.
Collaborative RTO and RPO setting
Working with internal partners to set RTOs and RPOs ensures alignment across the organization.
Recovery Time Objective (RTO) defines the acceptable timeframe for restoring critical applications to a functional state.
The Recovery Point Objective (RPO) defines the maximum tolerable amount of data loss acceptable in the event of a disaster.
Stakeholders need to understand the realistic trade-offs involved in setting RTOs and RPOs, balancing the need for quick recovery with resource and cost limitations. Achieving extremely short RTOs, such as recovery within minutes, might require substantial investments in advanced infrastructure, redundant systems, and skilled personnel. Setting achievable RTOs and RPOs that effectively balance the need for swift recovery with the financial limitations of the organization requires open communication and collaboration.
Restore vs. recovery: Understanding the nuances
It’s important to distinguish between data restoration and system recovery. Data restoration specifically involves retrieving data from backups. On the other hand, system recovery encompasses the comprehensive restoration of data, applications, configurations, and user accounts to fully restore system functionality.
Your RTOs should focus on the time it takes to bring an application to a usable state, not just the time to recover the data.
Setting expectations
Employees might have unrealistic expectations regarding recovery times during a disaster. Educate the organization on the DR process and the inherent complexities involved.
Developing measurable KPIs
Tracking your progress Key performance indicators (KPIs) are your guiding metric for measuring the effectiveness of your DR strategy. Here are some key DR-related KPIs to consider:
RTO achievement rate: Tracks the percentage of times critical applications are restored within the established RTO.
RPO achievement rate: Measures the percentage of data recovered that meets the defined RPO.
DR plan testing frequency: Monitors how often the DR plan is tested to ensure its effectiveness.
Mean time to recovery (MTTR): Tracks the average time taken to recover critical applications after a disaster.
Data loss rate: Measures the amount of data lost during a disaster compared to the established RPO.
These KPIs provide valuable insights into your DR preparedness and help identify areas for improvement.
Strengthen your RTO and RPO goals with the cloud
Recovery time objectives (RTOs) and recovery point objectives (RPOs) are the backbone of any DR plan. Yet many organizations set unrealistic targets without fully accounting for infrastructure, bandwidth, or cost constraints.
Establishing tiers of RTO and RPO based on data type or application criticality helps organizations avoid overengineering. Not every workload needs sub-hour recovery—archived legal files or marketing collateral may tolerate 24+ hour RTOs. Grouping systems into priority tiers ensures efficient use of budget and infrastructure while keeping SLAs aligned to business risk.
Improving these metrics often comes down to using the right storage architecture. By offloading backup workloads to cost-effective cloud storage with integrated immutability and replication, enterprises can improve RTO and RPO without the overhead of traditional DR environments.
A proactive, iterative approach
A DR plan isn’t a one-time project—it’s a living process that should evolve with the business. Every test, every incident, and every infrastructure change is an opportunity to improve.
Strong DR programs rely on frequent validation, leadership alignment, role clarity, and avoiding common missteps. As IT leaders face new threats and shifting architectures, resiliency comes from readiness—not just recovery.
Testing is everything
Even the most comprehensive DR plans can falter if they aren’t regularly validated. Testing ensures that backup data is restorable, that systems behave as expected under stress, and that team roles are clearly understood.
Testing also gives stakeholders across departments a shared language for discussing DR. Finance understands the cost implications of downtime, Legal sees the impact of non-compliance, and Security can stress-test assumptions about containment and escalation. When testing is multidisciplinary, recovery isn’t just possible—it’s predictable.
Organizations that incorporate routine DR drills and testing into their operations tend to recover faster and more confidently. Effective exercises can include walk-throughs, tabletop simulations, and full-scale failover tests. The goal isn’t just compliance—it’s ensuring the organization can execute when it matters most.
Cost transparency and budgeting for DR
Budget uncertainty often limits the scope and effectiveness of DR plans. Legacy vendors may impose hidden fees for egress, API operations, or early deletion, making it difficult to forecast the total cost of a recovery event. Cloud-native solutions with transparent pricing models allow IT and finance teams to plan confidently.
Establishing a clear TCO framework—including hardware, licensing, testing, and human resources—can help justify DR investments and avoid budget shortfalls when they matter most. DR isn’t just insurance—it’s a measurable part of digital operational excellence.
Final thoughts
Disaster recovery isn’t optional—it’s essential. With threats ranging from cyberattacks to cloud outages, every organization needs a plan that’s tested, documented, and designed for rapid recovery.
Backblaze B2 helps you implement affordable, scalable, and secure DR strategies with:
Immutable backups
Flexible recovery options
Transparent pricing (no egress fees)
Seamless integrations with backup tools like Veeam, MSP360, and more
By some appearances, at least, the kernel community has been relatively
insulated from the onslaught of AI-driven software-development tools.
There has not been a flood of vibe-coded memory-management patches — yet.
But kernel development is, in the end, software development, and these
tools threaten to change many aspects of how software development is done.
In a world where companies are actively pushing their developers to use
these tools, it is not surprising that the topic is increasingly prominent
in kernel circles as well. There are currently a number of ongoing
discussions about how tools based on large language models (LLMs) fit into
the kernel-development community.
The release of Rust 1.89 has been announced. Changes this time include
support for inferring the length of certain arrays, lint messages suggesting how to clarify potentially confusing uses of lifetime elision in function signatures, and improvements to the C ABI. The full changelog is also available.
Security updates have been issued by AlmaLinux (glibc, kernel, libxml2, python-requests, and python-setuptools), Debian (chromium), Fedora (chromium, firefox, gdk-pixbuf2, iputils, libsoup3, libssh, perl, perl-Devel-Cover, perl-PAR-Packer, polymake, and poppler), Gentoo (Composer and Spreadsheet-ParseExcel), Oracle (glibc, kernel, libxml2, python-setuptools, sqlite, and virt:rhel and virt-devel:rhel), Red Hat (libxml2), SUSE (grub2, libarchive, libgcrypt, and python311), and Ubuntu (cifs-utils and poppler).
Zabbix has been the backbone of my infrastructure for over ten years, a journey I’ve been on from version 3.2 to 7.4. It’s a robust and reliable tool. However, in the age of intelligent assistants, I posed a question to myself: Why can’t I interact with my monitoring system as naturally as I talk with Maria, my generative AI assistant?
Table of Contents
What is MCP?
MCP (Model Context Protocol) is a universal protocol that helps generative AI systems interact with global data securely, reliably, and at scale.
Imagine this: It’s 3 AM, and you receive a critical alert on your phone. Instead of opening multiple dashboards and manually correlating data, you simply type: “What’s happening with the production server?”
You get a response like this:
“The web-prod-01 server is experiencing high memory usage (94%). This started 15 minutes ago, coinciding with a traffic spike. I recommend checking the database connection pool and considering a restart of the Apache service. Would you like me to show you the related logs?”
This is no longer science fiction!
Design principle
The main objective is to enhance Zabbix without altering its core. The solution is based on an architecture that adheres to the following principles:
Zabbix intact: The original installation remains unchanged.
API-first: All communication is done through Zabbix’s robust JSON-RPC API.
Intelligent bridge: An intermediary service is created to translate between human language and Zabbix metrics.
Scalability: The design is prepared to grow alongside the infrastructure.
AI server (MCP): Rocky Linux 9, Gemini AI, Express.js, Winston (Logging), Gemini CLI, Redis, Nginx, PM2
Webhooks
We process Zabbix alerts through a webhook that sends the data to our generative AI service.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import json
import requests
import sys
from datetime import datetime
def send_to_mcp(args):
""" Sends alerts to MCP server"""
# SETTINGS - EDIT ACCORDING TO YOUR ENVIRONMENT
mcp_endpoint = "http://TU_IP_MCP_SERVER:3001/alerts" # Change to the MCP server IP
mcp_token = "TU_MCP_AUTH_TOKEN" # Exchange for your MCP authentication token
zabbix_server_ip = "TU_IP_ZABBIX_SERVER" # Change to the Zabbix server IP
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {mcp_token}'
}
# Extracting arguments from the Zabbix webhook
eventid = args[0] if len(args) > 0 else "unknown"
severity = args[1] if len(args) > 1 else "0"
message = args[2] if len(args) > 2 else "No message"
host = args[3] if len(args) > 3 else "unknown"
value = args[4] if len(args) > 4 else ""
payload = {
"timestamp": datetime.now().isoformat(),
"source": "zabbix",
"eventid": eventid,
"severity": severity,
"message": message,
"host": host,
"value": value,
"zabbix_server": zabbix_server_ip
}
try:
print(f"Sending alert to MCP: {mcp_endpoint}")
print(f"Payload: {json.dumps(payload, indent=2)}")
response = requests.post(mcp_endpoint, json=payload, headers=headers, timeout=15)
response.raise_for_status()
print(f"Alert sent successfully: HTTP {response.status_code}")
print(f"Response: {response.text}")
return True
except requests.exceptions.Timeout:
print("? Error: Timeout connecting to MCP server", file=sys.stderr)
return False
except requests.exceptions.ConnectionError:
print("? Error: Cannot connect to MCP server", file=sys.stderr)
return False
except requests.exceptions.HTTPError as e:
print(f"? HTTP Error: {e}", file=sys.stderr)
print(f"Response: {response.text}", file=sys.stderr)
return False
except Exception as e:
print(f"? Unexpected error: {e}", file=sys.stderr)
return False
if __name__ == "__main__":
# The arguments come from Zabbix
args = sys.argv[1:]
print(f"Script called with args: {args}")
success = send_to_mcp(args)
sys.exit(0 if success else 1)
Use cases
Scenario 1: Monday morning
Cesar: Good morning, how is the infrastructure looking?
Gemini CLI: Good morning! Everything is calm. 14 active hosts, 0 critical problems. There was a scheduled reboot on ‘proxmox-desarrollo’ over the weekend which completed successfully. The average CPU usage is at 23%. Do you need details on any specific system?
Scenario 2: Proactive planning
Cesar: What worrying trends are you seeing this week?
Gemini CLI: I’ve noticed three patterns that require attention:
1. storage-01: Growth of 2GB/day in /var/log.
Projection: 90% capacity in 12 days.
Recommendation: Configure a more aggressive log rotate.
2. mikrotik: Gradually increasing temperature (+3°C over the last 7 days).
Recommendation: Check ventilation.
3. base-datos-01: Slow queries increasing by 15%.
Recommendation: Review indexes and optimize frequent queries.
MCP implementation
Server (Rocky Linux 9)
bash
#create the project
mkdir /opt/mcp-zabbix
cd /opt/mcp-zabbix
#Install dependencies
sudo dnf install -y nodejs npm redis nginx
sudo npm install -g pm2
#Set up the project
npm init -y
npm install express axios @google/generative-ai winston helmet cors dotenv
Complete installation: Scripts for Rocky Linux and Debian
Zabbix configuration: Media types and actions
API reference: Endpoints and examples
Use cases
Basic monitoring: Hosts, items, triggers
Intelligent alerts: Automatic analysis
Ad-hoc queries: Quick investigation
Automated reports: Periodic summaries
Future integrations
The goal is to develop an application that allows natural interaction with an AI assistant called “Maria.” The idea is that based on what’s happening, Maria suggests actions and executes them proactively.
To achieve this, the assistant will integrate with Gemini’s command-line interface (CLI) and establish an additional secure communication channel. The recommended architecture will consist of several servers capable of understanding each other, including a Zabbix Server, the MCP (Model Context Protocol), and the personal assistant.You can follow the development of the base integration in this repository.
Conclusion
Zabbix will continue to be the reliable engine we all know. The difference is that it now becomes more intuitive and conversational. The goal is not to replace human experience, but to empower it. AI will allow us to create solutions that were previously unthinkable.
To fully leverage this potential, it is essential that we, as experts, continue to train and deepen our knowledge of the tool. This way, we will not only depend on what the AI suggests, but we will be able to validate and authorize its actions with our own judgment.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.