Post Syndicated from arp242.net original https://www.arp242.net/why-zsh.html
You would expect this to work, no?
bash% echo $(( .1 + .2 ))
bash: .1 + .2 : syntax error: operand expected (error token is ".1 + .2 ")
Well, bash says no, but zsh just works:
zsh% echo $(( .1 + .2 ))
0.30000000000000004 # Well, "works" insofar IEEE-754 works.
There is simply no way you can do calculations with fractions in bash without
relying on bc, dc, or some hacks. Compared to simply being able to use a +
b it’s ugly, slow, and difficult.
There are other pretty frustrating omissions in bash; NUL bytes is another fun
one:
zsh% x=$(printf 'N\x00L'); printf $x | xxd -g1 -c3
00000000: 4e 00 4c N.L
bash% x=$(printf 'N\x00L'); printf $x | xxd -g1 -c3
bash: warning: command substitution: ignored null byte in input
00000000: 4e 4c NL
It looks like bash added a warning recently-ish (4.4-patch 2); this one
bit me pretty hard a few years ago; back then it would just get silently
discarded without warning; I guess a warning is an “improvement” of sorts
(fixing it, however, would be an actual improvement).
NUL bytes aren’t that uncommon, think of e.g. find -print0, xargs -0, etc.
That all works grand, right up to the point you try to assign it to a variable.
You can use NUL bytes for array assignments though, if you evoke the right
incantation:
bash% read -rad arr < <(find . -print0)
There are all sorts of edge-cases where you need to resort to read or
readarray rather than being able to just assign in. In zsh it’s just
arr=($(find . -print0)).
Don’t even think of doing something like:
img=$(curl https://example.com/image.png)
if [[ $cond ]]; then
optpng <<<"$img" > out.png
else
cat <<<"$img" > out.png
fi
Of course you can refactor this to avoid the variable (and the example is a bit
contrived), but it really ought to work. I once wrote a script to import emails
from the Mailgun API. It worked great, yet sometimes images were mangled and I
just couldn’t figure out why. Turns out Mailgun “helpfully” decodes attachments
(i.e. removes the base64) and sends binary content, which bash (at the time)
would silently discard. It took me a very long time to figure out. I forgot why,
but it was hard to avoid storing the response in a variable. I ended up
rewriting it to Python because of this, which was just a waste of time really.
It’s this, specifically, that really soured me on bash and prompted The shell
scripting trap in 2017. However, many items listed there are solved by
zsh, including this one.
zsh also fixes most of the quoting:
zsh% for f in *; ls -l $f
-rw-rw-r-- 1 martin martin 0 Oct 19 06:51 asd.txt
-rw-rw-r-- 1 martin martin 0 Oct 19 06:51 with space.txt
bash% for f in *; do ls -l $f; done
-rw-rw-r-- 1 martin martin 0 Oct 19 06:51 asd.txt
ls: cannot access 'with': No such file or directory
ls: cannot access 'space.txt': No such file or directory
It’s not POSIX compatible, but who cares? bash doesn’t follow POSIX in all
sorts of ways by default either because it just makes more sense, and with
both you can still tell them to be POSIX-compatible if you must for one reason
or the other.
Also note the convenient short version of the
for loop: no need for do, done and muckery with ; before the done,
which is much more convenient for quick one-liners you interactively type in.
You can still do word splitting, but you need to do it explicitly:
zsh% for i in *; ls -l $=i
-rw-rw-r-- 1 martin martin 0 Oct 19 06:51 asd.txt
ls: cannot access 'with': No such file or directory
ls: cannot access 'space.txt': No such file or directory
[[ is supposed to fix [, but it still has weird quoting quirks:
zsh% a=foo; b=*;
zsh% if [[ $a = $b ]]; then
print 'Equal!'
else
print 'Nope!'
fi
Nope!
bash% a=foo; b=*
bash% if [[ $a = $b ]]; then
echo 'Equal!'
else
echo 'Nope!'
fi
Equal!
This is equal because without quotes it still interprets the right-hand side as
a pattern (i.e. glob). In zsh you need to use $~var to explicitly enable
pattern matching, which is a much better model than remembering when you do and
don’t need to quote things – sometimes you do want the pattern matching and
then you don’t want quotes; it’s not always immediately obvious if an if [[ ...
statement is correct if it’s lacking quotes.
“But Martin, you should always quote things, you’re being disingenuous!” Well, I
could make a comfortable living if I were paid to add quotes to other people’s
shell scripts. Telling people to “always quote things” is what we’ve been doing
for 40 years now and irrefutable observational evidence has demonstrated that it
just does not work.
Most people aren’t shell scripting wizards; they make a living writing Python or
C or Go or PHP programs, or maybe they’re sysadmins or scientists, and oh,
occasionally they also write a shell script. They just see something that works
and assume it has sane behaviour and don’t realize the subtle differences
between $@, $*, and "$@". I think that’s actually quite reasonable,
because the behaviour is odd, surprising, and confusing.
It’s also a lot more complex than just “quote your variables”, especially if you
use $(..) since command substitution often needs quotes too, as well as any
variables inside it. Before you know it you’ve got double, triple, or more
levels of nested quotes and if you forget one set of them you’re in trouble.
It’s such a fertile source of real-world bugs that it would merit entomologist
examination. If there’s a system that causes this many bugs then that system is
at fault, and not the people using it. Computers and software should adapt to
humans, not the other way around.
And “always quote things!” isn’t even right either, because you should always
quote things except when you shouldn’t:
zsh% a=foo; b=.*;
zsh% if [[ "$a" =~ "$b" ]]; then
print 'Equal!'
else
print 'Nope!'
fi
Equal!
bash% a=foo; b=.*
bash% if [[ "$a" =~ "$b" ]]; then
echo 'Equal!'
else
echo 'Nope!'
fi
Nope!
If there are quotes around a regexp then it’s treated as a literal string. I
mean, it’s consistent with = pattern matching, but also confusing because I
explicitly use =~ to match a regular expression.
Another famous quoting trap is $@ vs. "$@" vs. $* vs. "$*":
zsh% cat args
echo "unquoted @:"
for a in $@; do echo " => $a"; done
echo "quoted @:"
for a in "$@"; do echo " => $a"; done
echo "quoted *:"
for a in $*; do echo " => $a"; done
echo "quoted *:"
for a in "$*"; do echo " => $a"; done
bash% bash args
unquoted @:
=> hello
=> world
=> test
=> space
=> Guust1129.jpg
=> IEEESTD.2019.8766229.pdf
[.. rest of my $HOME ..]
quoted @:
=> hello
=> world
=> test space
=> *
unquoted *:
=> hello
=> world
=> test
=> space
=> Guust1129.jpg
=> IEEESTD.2019.8766229.pdf
[.. rest of my $HOME ..]
quoted *:
=> hello world test space *
Experiences shellers will know to (almost) always use "$@", but how often do
you see it being done wrong? It’s not that strange people do it wrong either; if
you learned about quoting and word splitting then $@ without quotes is
actually the logical thing to use because you would expect "$@" to be
treated as one argument (as "$*"). You tell people to “always add quotes to
prevent word splitting and treat things as a single argument”, and then you tell
them “oh, except in this one special case when the addition of quotes invokes
a special kind of splitting and doesn’t follow any of the rules we previously
told you about”.
In zsh, $@ and $* (and $argv) are all (read-only) arrays and it all
behaves identical as you would expect with no surprises:
zsh% zsh args hello world 'test space' '*'
unquoted @:
=> hello
=> world
=> test space
=> *
quoted @:
=> hello
=> world
=> test space
=> *
unquoted *:
=> hello
=> world
=> test space
=> *
quoted *:
=> hello world test space *
Actually in bash you can do argv=("$@") and then you have an array. This is
really how it should work by default.
You still need to loop over it with:
bash% for a in "${argv[@]}"; do
echo "=> $a"
done
Rather than just for a in $argv like in zsh. Aside from the pointless [@],
why would you ever want to word-split every element of an array? There is
probably some use case somewhere, but it’s exceedingly rare. Better to just skip
all of that by default unless explicitly enabled with = and/or ~.
Oh, here’s another interesting tidbit:
zsh% n=3; for i in {1..$n}; print $i
1
2
3
bash% n=3; for i in {1..$n}; do echo "$i"; done
{1..3}
bash% n=3; for i in {1..3}; do echo "$i"; done
1
2
3
Why does it work like that? That’s left as an exercise for the reader 😉
Aside from all sorts caveats that are handled much better, a lot of common
things are just much easier in zsh:
zsh% arr=(123 5 1 9)
zsh% echo ${(o)arr} # Lexical order
1 123 5 9
zsh% echo ${(on)arr} # Numeric order
1 5 9 123
bash% IFS=$'\n'; echo "$(sort <<<"${arr[*]}")"; unset IFS
1 123 5 9
bash% IFS=$'\n'; echo "$(sort -n <<<"${arr[*]}")"; unset IFS
1 5 9 123
I had to look up how to do it in bash; the Stack Overflow answer for that one
starts with “you don’t really need all that much code”. lol? I guess that’s in
reply to some of the other horrendously complex answers which implement “pure
bash” sorting algorithms and the like. I guess compared to that this is “not
that much code”. And of course the entire thing is a minefield of expansion
again; and if you forget a set of nested quotes you end up in trouble.
Arrays in general are just awkward in bash:
bash% arr=(first second third fourth)
bash% echo ${arr[0]}
first
bash% echo ${arr[@]::2}
first second
I mean, it works, and it’s not that much typing, but why do I need that [@]?
Probably some (historical) reason, but zsh implements it much more readable and
easier:
zsh% arr=(first second third fourth)
zsh% print ${arr[1]} # Yeah, it's 1-based. Deal with it.
first
zsh% print ${arr[1,2]}
first second
The bash array syntax was copied from ksh; so I guess we have to blame David
Korn (zsh supports it too, if you must use it). But regular subscripts are just
so much easier.
And then there’s the useful features:
zsh% ls *.go
format.go format_test.go gen.go old.go uni.go uni_test.go
zsh% ls *.go~*_test.go
format.go gen.go old.go uni.go
zsh% ls *.go~*_test.go~f*
gen.go old.go uni.go
*.go gets expanded, and filters the pattern after the ~; *_test.go in this
case. Looks a bit obscure at first glance, but bash’s ksh-style extglobs are far
harder:
bash% ls !(*_test).go
format.go gen.go old.go uni.go
bash% ls !(*_test|f*).go
gen.go old.go uni.go
!(..) is “match anything except the pattern”; the * is implied here (zsh
supports !(..) if you set ksh_glob). While it works, the the
pattern~filter~filter model is much easier, and also more flexible since you
don’t need to start with all matches.
There are many useful things you can do with globbing; you can replace many uses
of find with it, and you don’t need to worry about the caveats, -print0
hacks, etc. For example to recursively list all regular files:
zsh% ls **/*(.)
LICENSE go.sum unidata/gen.go wasm/make*
README.md old.go unidata/gen_codepoints.go wasm/srv*
[..]
Or directories:
zsh% ls -d /etc/**/*(/)
/etc/OpenCL/ /etc/runit/runsvdir/default/dnscrypt-proxy/log/
/etc/OpenCL/vendors/ /etc/runit/runsvdir/default/ntpd/log/
/etc/X11/ /etc/runit/runsvdir/default/postgresql/supervise/
[..]
Or files that were changed in the last week:
zsh% ls -l /etc/***(.m-7) # *** is a shortcut for **/*; needs GLOB_STAR_SHORT
-rw-r--r-- 1 root root 28099 Oct 13 03:47 /etc/dnscrypt-proxy.toml.new-2.1.1_1
-rw-r--r-- 1 root root 97 Oct 13 03:47 /etc/environment
-rw-r--r-- 1 root root 37109 Oct 17 10:34 /etc/ld.so.cache
-rw-r--r-- 1 root root 77941 Oct 19 01:01 /etc/public-resolvers.md
-rw-r--r-- 1 root root 6011 Oct 19 01:01 /etc/relays.md
-rw-r--r-- 1 root root 142 Oct 19 07:57 /etc/shells
You can even order them by modified date with om (***(.m-7om)), although
that’s a bit pointless here as ls will reorder them again, but if you’re
looping over files it’s useful.
There is no way to do any of this in bash, you’ll have to use something like:
bash% find /etc -type f -mtime 7 -exec ls -l {} +
find: ‘/etc/sv/docker/supervise’: Permission denied
find: ‘/etc/sv/docker/log/supervise’: Permission denied
find: ‘/etc/sv/bluetoothd/log/supervise’: Permission denied
find: ‘/etc/sv/postgresql/supervise’: Permission denied
find: ‘/etc/sv/runsvdir-martin/supervise’: Permission denied
find: ‘/etc/wpa_supplicant/supervise’: Permission denied
find: ‘/etc/lvm/cache’: Permission denied
-rw-rw-r-- 1 root root 167 Oct 12 22:17 /etc/default/postgresql
-rw-r--r-- 1 root root 817 Oct 12 09:11 /etc/fstab
-rw-r--r-- 1 root root 1398 Oct 12 22:19 /etc/passwd
-rw-r--r-- 1 root root 1397 Oct 12 22:19 /etc/passwd.OLD
-rw-r--r-- 1 root root 307 Oct 12 23:10 /etc/public-resolvers.md.minisig
-rw-r--r-- 1 root root 297 Oct 12 23:10 /etc/relays.md.minisig
-r-------- 1 root root 932 Oct 12 09:57 /etc/shadow
-rwxrwxr-x 1 root root 397 Oct 12 22:23 /etc/sv/postgresql/run
Not sure how to make it ignore these errors too without redirecting stderr (more
typing!) And if you think adding single letters in (..) after a pattern is
hard then try understanding find’s weird flag syntax. Glob qualifies are
great.
csh-style parameter substitution is pretty useful:
zsh% for f in ~/photos/*.png; convert $f ${f:t:r}.jpeg
:t to get the tail, and :r to get the root (without extension). csh could do
this before I was even born, but bash can’t (it can for history expansion, but
not variables). According to the bash FAQ “Posix has specified a more powerful,
albeit somewhat more cryptic, mechanism cribbed from ksh”, which I find a
somewhat curious statement as the above in bash is:
bash% for f in ~/photos/*.png; do convert "$f" "$(basename "${f%%.*}")"; done
Technically “more powerful” in the sense that you can do other things with it,
but not really “more useful for common operations” (zsh, of course, implements
% and # as well).
Note you can’t nest ${..} in bash; e.g. "${${f%%.*}##*/}" is an error:
zsh% f=~/asd.png; print "${${f%%.*}##*/}"
asd
bash% f=~/a.png; echo "${${f%%.*}##*/}"
bash: ${${f%%.*}##*/}: bad substitution
While this can quickly lead to very unreadable ASCII vomit, it’s useful on
occasion, when used with care and wisdom. You can click below for a more
advanced example if the children are already in bed.
There are many more things. I’m not going to list them all here. None of this is
new; much (if not all?) of this has around for 20 years, if not longer. I don’t
know why bash is the de-facto default, or why people spend time on complex
solutions to work around bash problems when zsh solves them. I guess because
Linux used a lot of GNU stuff and bash was came with it, and GNU stuff was (and
is) using bash. Not a very good reason, certainly not one 30 years later.
zsh still has plenty of limitations; the syntax isn’t always something you’d
want to show your mother for starters, as well as a number of other things.
Still, it’s clearly better. I genuinely can’t find a single thing bash does
better beyond “it’s installed on many systems already”.
Ubiquitousness is overrated anyway; zsh has no dependencies beyond libc and
curses and is 970K on my system and is available for pretty much all
systems. Compared to most other interpreters it’s tiny, with only Lua being
smaller (275K). “Stick to POSIX sh for compatibility” was good advice in 1990
when you had some SunOS system with some sun-sh and that’s what you were stuck
with. Those days are long gone, and while there are a few poor souls still suck
on those systems (sometimes even with csh!) chances are they’re not going to try
and run your Docker or Arch Linux shell script or whatnot on those systems
anyway.
Contorting yourself in all sorts of strange bends to perhaps possibly maybe make
it work for a tiny fraction of users who are unlikely to use your script anyway
does not seem like a good trade-off, especially since these kind of limitations
tend to be organisational rather than technical, which is not my problem anyway
to be honest.
Using zsh is also more portable; since it allows you to avoid many shell tools
and the (potential) incompatibilities, and by explicitly setting zsh as the
interpreter you can rely on zsh behaviour, rather than hoping the /bin/sh on
$random_system behaves the same (even dash has some extensions to POSIX sh, such
as local).
What I typically do is save files as script.zsh with:
#!/usr/bin/env zsh
[ "${ZSH_VERSION:-}" = "" ] && echo >&2 "Only works with zsh" && exit 1
This makes sure it gets run by zsh when used as ./script.zsh, and gives an
error in case people type sh script.zsh or bash script.zsh in case the .zsh
extension isn’t enough of a clue.
So in conclusion: s/bash/zsh/g and everything will be just a little bit
better.
P.S. maybe fish is even better by the way, but I could never get over the bright
colouring and all these things popping in and out of my screen; it’s such a
“busy” chaotic experience! I’d have to spend time disabling all that stuff to
make it usable for me, and I never bothered – and if you’re disabling the key
selling points of a program then it’s probably not intended for you anyway.
Maybe I’ll have a crack at it at some point though.
Footnotes
-
Which I assume isn’t so easy, otherwise it would have been done already.
The reason it doesn’t work is an artifact from C’s NUL-terminated strings,
but this kind of stuff really shouldn’t be exposed in a high-level language
like the shell. It’s also a bit ironic since one of Stephen Bourne’s
original goals with his shell was to get rid of arbitrary size limits on
strings, which were common at the time.
-
A full install if ~8M, mostly in the optional completion functions it
ships with. Bash is about 1.3M by the way.










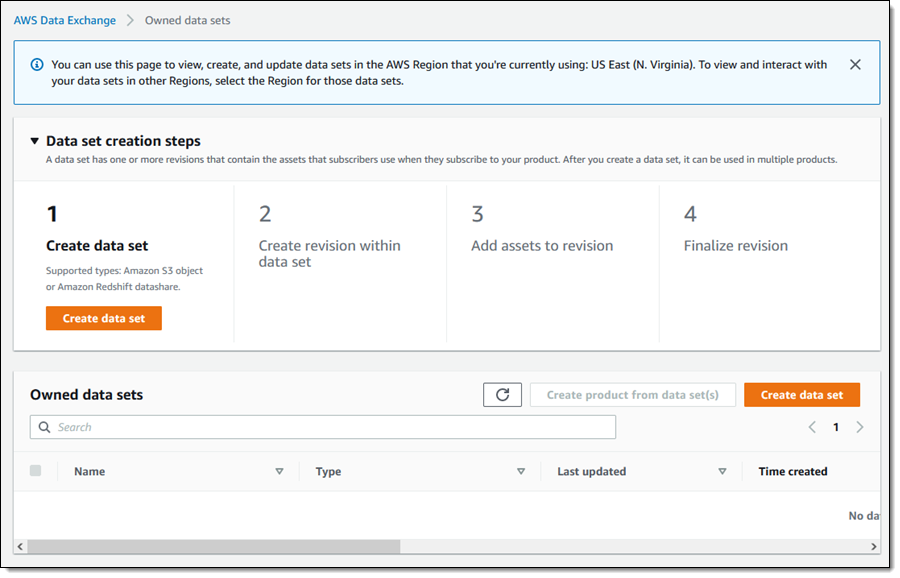
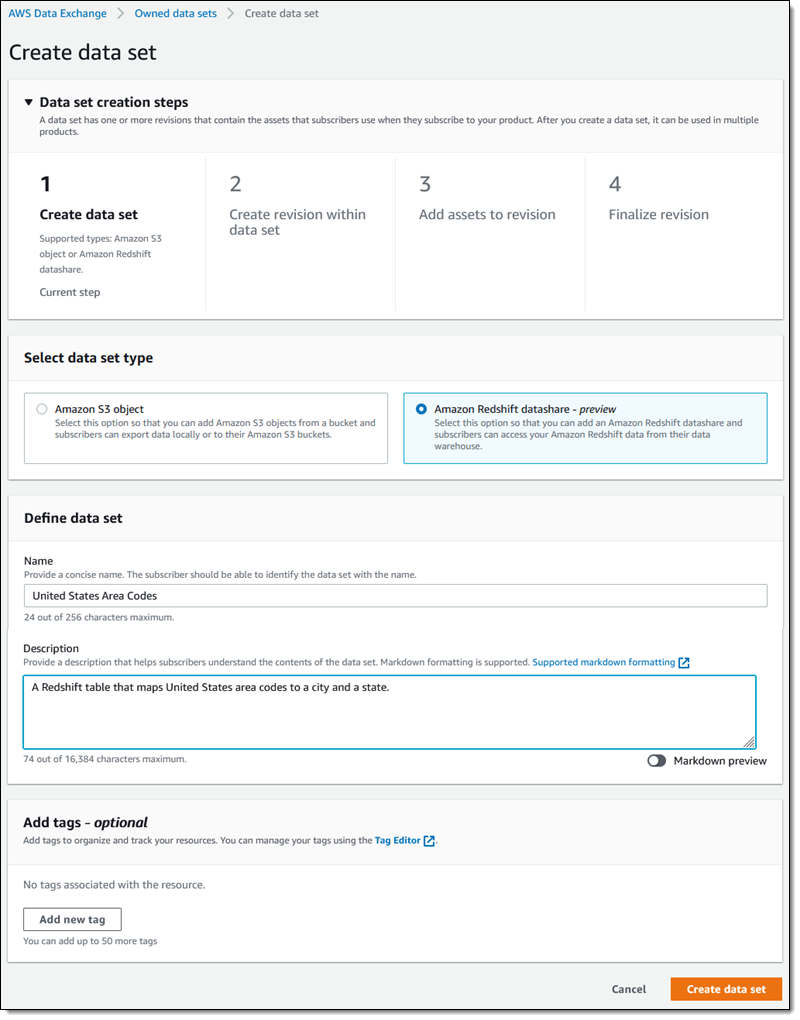

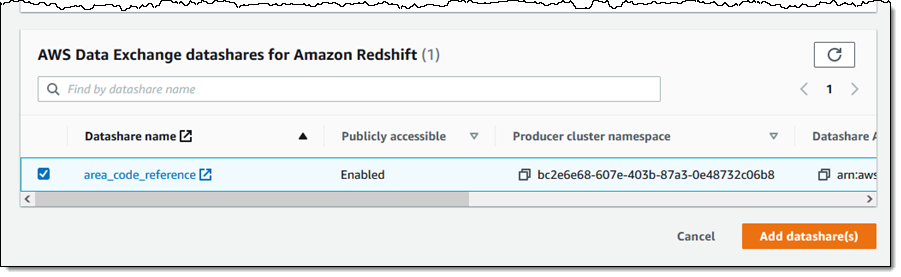








 Syed Ali Abbas Gardezi is a Sr. Solution Architect for AWS based in London, United Kingdom. He works with AWS GSI Partners architecting, designing and implementing various large-scale IT solution. Before joining AWS he worked in several Architecture roles in a tier 1 financial organisation in London.
Syed Ali Abbas Gardezi is a Sr. Solution Architect for AWS based in London, United Kingdom. He works with AWS GSI Partners architecting, designing and implementing various large-scale IT solution. Before joining AWS he worked in several Architecture roles in a tier 1 financial organisation in London.

