One reason the early years of squids has been such a mystery is because squids’ lack of hard shells made their fossils hard to come by. Undeterred, the team instead focused on finding ancient squid beaks—hard mouthparts with high fossilization potential that could help the team figure out how squids evolved.
With that in mind, the team developed an advanced fossil discovery technique that completely digitized rocks with all their embedded fossils in complete 3D form. Upon using that technique on Late Cretaceous rocks from Japan, the team identified 1,000 fossilized cephalopod beaks hidden inside the rocks, which included 263 squid specimens and 40 previously unknown squid species.
The team said the number of squid fossils they found vastly outnumbered the number of bony fishes and ammonites, which are extinct shelled relatives of squids that are considered among the most successful swimmers of the Mesozoic era.
“Forty previously unknown squid species.” Wow.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Amazon Web Services (AWS) is pleased to announce that the Spring 2025 System and Organization Controls (SOC) 1, 2, and 3 reports are now available. The reports cover 184 services over the 12-month period from April 1, 2024, to March 31, 2025, giving customers a full year of assurance. The reports demonstrate our continuous commitment to adhering to the heightened expectations for cloud service providers.
AWS strives to continuously bring services into the scope of its compliance programs to help customers meet their architectural and regulatory needs. You can view the current list of services in scope on our Services in Scope page. You can also reach out to your AWS account team if you have any questions or feedback about SOC compliance.
To learn more about AWS compliance and security programs, see AWS Compliance Programs. As always, we value feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Amazon Redshift materialized views enables you to significantly improve performance of complex queries. Materialized views store precomputed query results that future similar queries can utilize, offering a powerful solution for data warehouse environments where applications often need to execute resource-intensive queries against large tables. This optimization technique enhances query speed and efficiency by allowing many computation steps to be skipped, with precomputed results returned directly. Materialized views are particularly useful for speeding up predictable and repeated queries, such as those used to populate dashboards or generate reports. Instead of repeatedly performing resource-intensive operations, applications can query a materialized view and retrieve precomputed results, leading to significant performance gains and improved user experience. Additionally, materialized views can be incrementally refreshed, applying logic only to changed data when data manipulation language (DML) changes are made to the underlying base tables, further optimizing performance and maintaining data consistency.
This post demonstrates how to maximize your Amazon Redshift query performance by effectively implementing materialized views. We’ll explore creating materialized views and implementing nested refresh strategies, where materialized views are defined in terms of other materialized views to expand their capabilities. This approach is particularly powerful for reusing precomputed joins with different aggregate options, significantly reducing processing time for complex ETL and BI workloads. Let’s explore how to implement this powerful feature in your data warehouse environment.
Introduction to Nested Materialized Views
Nested materialized views in Amazon Redshift allow you to create materialized views based on other materialized views. This capability enables a hierarchical structure of precomputed results, significantly enhancing query performance and data processing efficiency. With nested materialized views, you can build multi-layered data abstractions, creating increasingly complex and specialized views tailored to specific business needs.This layered approach offers several advantages:
Improved Query Performance: Each level of the nested materialized view hierarchy serves as a cache, allowing queries to quickly access pre-computed data without the need to traverse the underlying base tables.
Reduced Computational Load: By offloading the computational work to the materialized view refresh process, you can significantly reduce the runtime and resource utilization of your day-to-day queries.
Simplified Data Modeling: Nested materialized views enable you to create a more modular and extensible data model, where each layer represents a specific business concept or use case.
Incremental Refreshes: The Redshift materialized views support incremental refreshes, allowing you to update only the changed data within the nested hierarchy, further optimizing the refresh process.
Cascading Materialized Views: The Redshift materialized views support automatic handling of Extract, Load, and Transform (ELT) style workloads, minimizing the need for manual creation and management of these processes.
You can implement nested materialized views using the CREATE MATERIALIZED VIEW statement, which allows referencing other materialized views in the definition. Common use cases include:
Modular data transformation pipelines
Hierarchical aggregations for progressive analysis
Multi-level data validation pipelines
Historical data snapshot management
Optimized BI reporting with precomputed results
Architecture
Architectural diagram depicting Amazon Redshift’s nested materialized view structure. Shows multiple base tables (orange) connecting to materialized views (red), with connections to a nested view layer and data sharing table (green). Includes integration points for users and QuickSight visualization.
Base Table(s): These are the underlying base tables that contain the raw data for your data warehouse. It can be local tables or data sharing tables.
Base Materialized View(s): These are the first-level materialized views that are created directly on top of the base tables. These views encapsulate common data transformations and aggregations. This can serve as the base for the nested materialized view and also be accessed by users directly.
Nested Materialized View(s): These are the second level (or higher) materialized views that are created based on the base materialized views. The nested materialized view can further aggregate, filter, or transform the data from the base materialized views.
Application/Users/BI Reporting: The application or business intelligence (BI) tools interact with the nested materialized views to generate reports and dashboards. The nested views provide a more optimized and precomputed data structure for efficient querying and reporting.
Creating and using nested materialized views
To demonstrate how nested materialized views work in Amazon Redshift, we’ll use the TPC-DS dataset. We’ll create three queries using the STORE, STORE_SALES, CUSTOMER, and CUSTOMER_ADDRESS tables to simulate data warehouse reports. This example will illustrate how multiple reports can share result sets and how materialized views can improve both resource efficiency and query performance.Let’s consider the following queries as dashboard queries:
SELECT cust.c_customer_id,
cust.c_first_name,
cust.c_last_name,
sales.ss_item_sk,
sales.ss_quantity,
cust.c_current_addr_sk
FROM store_sales sales INNER JOIN customer cust
ON sales.ss_customer_sk = cust.c_customer_sk;
SELECT cust.c_customer_id,
cust.c_first_name,
cust.c_last_name,
sales.ss_item_sk,
sales.ss_quantity,
cust.c_current_addr_sk,
store.s_store_name
FROM store_sales sales INNER JOIN customer cust
ON sales.ss_customer_sk = cust.c_customer_sk
INNER JOIN store store
ON sales.ss_store_sk = store.s_store_sk;
SELECT cust.c_customer_id,
cust.c_first_name, cust.c_last_name,
sales.ss_item_sk,
sales.ss_quantity,
addr.ca_state
FROM store_sales sales INNER JOIN customer cust
ON sales.ss_customer_sk = cust.c_customer_sk
INNER JOIN store store
ON sales.ss_store_sk = store.s_store_sk
INNER JOIN customer_address addr
ON cust.c_current_addr_sk = addr.ca_address_sk;
Notice that the join between STORE_SALES and CUSTOMER tables is present at all 3 queries (dashboards).
The second query adds a join with STORE table and the third query is the second one with an extra join with CUSTOMER_ADDRESS table. This pattern is common in business intelligence scenarios. As mentioned earlier, using a materialized view can speed up queries because the result set is stored and ready to be delivered to the user, avoiding reprocessing of the same data. In cases like this, we can use nested materialized views to reuse already processed data.When transforming our queries into a set of nested materialized views, the result would be as below:
CREATE MATERIALIZED VIEW StoreSalesCust as
SELECT cust.c_customer_id,
cust.c_first_name,
cust.c_last_name,
sales.ss_item_sk,
sales.ss_store_sk,
sales.ss_quantity,
cust.c_current_addr_sk
FROM store_sales sales INNER JOIN customer cust
ON sales.ss_customer_sk = cust.c_customer_sk;
CREATE MATERIALIZED VIEW StoreSalesCustStore as
SELECT storesalescust.c_customer_id,
storesalescust.c_first_name,
storesalescust.c_last_name,
storesalescust.ss_item_sk,
storesalescust.ss_quantity,
storesalescust.c_current_addr_sk,
store.s_store_name
FROM StoreSalesCust storesalescust INNER JOIN store store
ON storesalescust.ss_store_sk = store.s_store_sk;
CREATE MATERIALIZED VIEW StoreSalesCustAddress as
SELECT storesalescuststore.c_customer_id,
storesalescuststore.c_first_name,
storesalescuststore.c_last_name,
storesalescuststore.ss_item_sk,
storesalescuststore.ss_quantity,
addr.ca_state
FROM StoreSalesCustStore storesalescuststore INNER JOIN customer_address addr
ON storesalescuststore.c_current_addr_sk = addr.ca_address_sk;
Nested materialized views can improve performance and resource efficiency by reusing initial view results, minimizing redundant joins, and working with smaller result sets. This creates a hierarchical structure where materialized views depend on one another. Due to these dependencies, you must refresh the views in a specific order.
SQL query result indicating dependency issue for REFRESH MATERIALIZED VIEW StoreSalesCustAddress.
With the new option “REFRESH MATERIALIZED VIEW mv_name CASCADE” you will be able to refresh the entire chain of dependencies for the materialized views you have. Note that in this example we are using the third materialized view, StoreSalesCustAddress, and this will refresh all 3 materialized views because they are dependent on each other.
SQL query showing successful CASCADE refresh of StoreSalesCustAddress materialized view in Amazon Redshift.
If we use the second materialized view with the CASCADE option, we will refresh only the first and second materialized views, leaving the third unchanged. This may be useful when we need to keep some materialized views with less current data than others.
The SVL_MV_REFRESH_STATUS system view reveals the refresh sequence of materialized views. When triggering a cascade refresh on StoreSalesCustAddress, the system follows the dependency chain we established: StoreSalesCust refreshes first, followed by StoreSalesCustStore, and finally StoreSalesCustAddress. This demonstrates how the refresh operation respects the hierarchical structure of our materialized views.
SQL query result from SVL_MV_REFRESH_STATUS showing successful recomputation of three materialized views.
Considerations
Consider a dependency chain where StoreSalesCust (A) → StoreSalesCustStore (B) → StoreSalesCustAddress (C).
The CASCADE refresh behavior works as follows:
When refreshing C with CASCADE: A, B, and C will all be refreshed.
When refreshing B with CASCADE: Only A and B will be refreshed.
When refreshing A with CASCADE: Only A will be refreshed.
If you specifically need to refresh A and C but not B, you must perform separate refresh operations without using CASCADE—first refresh A, then refresh C directly.
Best Practices for Materialized View
Improve the source query: Start with a well-optimized SELECT statement for your materialized view. This is especially important for views that need full rebuilds during each refresh.
Plan refresh strategies: When creating materialized views that depend on other materialized views, you cannot use AUTO REFRESH YES. Instead, implement orchestrated refresh mechanisms using Redshift Data API with Amazon EventBridge for scheduling and AWS Step Functions for workflow management.
Leverage distribution and sort keys: Properly configure distribution and sort keys on materialized views based on their query patterns to optimize performance. Well-chosen keys improve query speed and reduce I/O operations.
Consider incremental refresh capability: When possible, design materialized views to support incremental refresh, which only updates changed data rather than rebuilding the entire view, greatly improving refresh performance.
To learn more about the Automated materialized view (auto-MV) feature to boost your workload performance, this intelligent system monitors your workload and automatically creates materialized views to enhance overall performance. For more detailed information on this feature, please refer to Automated materialized views.
Clean up
Complete the following steps to clean up your resources:
Delete the Redshift provisioned replica cluster or the Redshift serverless endpoints created for this exercise
or
Drop only the Materialized view which you have created for testing
Conclusion
This post showed how to create nested Amazon Redshift materialized views and refresh the child materialized views using the new REFRESH CASCADE option. You can quickly build and maintain efficient data processing pipelines and seamlessly extend the low latency query execution benefits of materialized views to data analysis.
About the authors
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
Ricardo Serafim is a Senior Analytics Specialist Solutions Architect at AWS. He has been helping companies with Data Warehouse solutions since 2007.
Популярен мем от интернет фолклора гласи: „Мислех, че роботите ще готвят и перат, за да мога да рисувам и творя, а то пак аз пера и готвя, а те рисуват и творят.“ Смятам, че е много подходящо да продължим във втората част на темата за изкуствения интелект именно с тази шега.
В първата част изяснихме, че благодарение на изчислителните възможности на днешните процесори и големите масиви от информация, с които можем да захраним моделите на ИИ, те всъщност вече превъзхождат човешките способности за осмисляне и преработване на информация. Тези способности на ИИ обаче са изчислителни. Машината не разбира какво изчислява. Колкото и парадоксално да звучи, тя не знае какво прави.
Има фундаментална разлика между това да знаеш, че нещо е вярно като факт – защото така са те учили в училище или са ти го поднесли наготово, както в случая на ИИ, – и да знаеш защо то е вярно.
Разликата е в съзнателното разбиране. Все още не е ясно дали ИИ някога ще бъде способен на това.
(Тук по-добре да спестим колебанията си колко от хората биха могли да прескочат същата летва.)
Нужно ли му е обаче на ИИ да разбира по този начин? За да прави това, което може да прави към днешна дата – не. За да бъде наистина автономен интелект – вероятно да. Смята се, че ако се сдобие с такива способности, ИИ следва да може сам да създава ново знание, надграждайки това, с което вече сме го захранили. Предвид сериозните му изчислителни възможности, човечеството може да има огромни ползи… но и да се изправи пред страховити проблеми. И това, че някаква част от хората биха останали без работа, е най-малкият от тях. Все пак нека не подминаваме повече тази тема.
ИИ и бъдещите професии
Миналата седмица една от компаниите, които се борят за лидерско място в областта на ИИ – Microsoft, – обяви, че уволнява 9000 души. Заедно с други 6000, които бяха освободени предишните два месеца, съкратените служители на корпорацията стават 15 000 само за първата половина на 2025 г. През юни Google, друг лидер в областта на ИИ, анонсира програма за „доброволно напускане“ на служители заради преструктуриране на бизнеса.
Виновен ли е ИИ за това? В известен смисъл – да. Но не точно този, който първосигнално ни идва наум. Знам, че за мнозина би изглеждало справедливо възмездие ИТ хората да понесат част от щетите, които причиняват – не е невъзможно да се случи, разбира се, но… ИИ все още има нужда от хора около себе си, които знаят какво искат от него и как да го напътстват. Причината за горните съкращения е, че големите корпорации се готвят за огромни разходи с едничката цел да останат фактор в надпреварата за по-по-най ИИ. И в следващите месеци ще стягат колана, за да могат да посрещнат безумните инвестиции, които планират да направят за мащабиране на инфраструктурата си за ИИ и… за електроенергията за тази инфраструктура.
Иначе е факт, че ИИ вече програмира доста прилично, но също така е вярно, че прави грешки,
може да сътвори безумни проблеми, особено със сигурността… и най-важното – не е в състояние да носи отговорност за действията си.
Неотдавна самият изпълнителен директор на Google Сундар Пичай сподели, че ИИ вече пише около 30% от кода им, но това води до едва 10% инженерна ефективност. Надали има по-добро признание, че действителността е много по-различна от медийните фанфари по темата. Така че не, програмистите все още не са станали излишни. Даже онези компании, които избързаха да освобождават разработчици, започнаха да връщат част от тях. Но важната думичка е част. А по-важният въпрос е коя част.
Има и друго – в технологичната индустрия през последния четвърт век влязоха твърде много хора, които не носят професията в сърцето си. Те бяха привлечени от парите. Иначе биха се занимавали с друго и в други сфери. Появиха се много церемониални роли, директори на водопади, препращачи на имейли, мениджъри на щастие… След пандемията през 2020 г. някои компании назначиха прекалено много персонал.
Секторът има нужда от отрезвяване и приземяване, но съм скептичен, че точно ИИ ще го побутне в правилната посока. По-скоро се надува нов балон.
Има и структурен проблем. Не само в ИТ сегмента, а почти навсякъде ИИ за момента застрашава предимно роли, заемани от младши специалисти. Формулата за внедряването му често се заключава около концепцията, че увеличената производителност на опитен експерт, въоръжен с ИИ, елиминира необходимостта от млади кадри. Проблемът тук е стратегически, а именно, че перспективата пред младите специалисти да се развият и придобият опит драстично се свива. И съвсем резонен е въпросът какво ще правим, когато старшите експерти с опит станат недостатъчни, а не сме обучили навреме младши. За разлика от ИИ, ние, хората, не се раждаме обучени и ни е нужно време, за да натрупаме знания и най-вече опит.
Ако индустриалните революции дотук влияеха предимно върху ръчния труд, то ИИ поне засега има повече потенциал за приложение в офисите, автоматизирайки предимно интелектуален труд, особено във функции и роли с по-ниска добавена стойност.
Затова опасенията на част от хората за бъдещето, при това за съвсем непосредственото бъдеще, не са нито смешни, нито пренебрежими.
В човешката история винаги са изчезвали едни професии и са се появявали други, съвсем нови. През януари в доклада на Световния икономически форум за бъдещето на работните места се прогнозира, че през следващите пет години се очаква да бъдат създадени 170 млн. нови работни места и да бъдат закрити 92 млн. стари, което означава структурно текучество на пазара на труда от 22% (от 1,2 млрд. официални работни места в изследваната извадка данни). Според прогнозата ИИ няма да е единственият виновник за това, но е основен. И ако изглежда като добра новина това, че се очаква нетно увеличение на заетостта от 7%, или ръст от 78 млн. работни места, то проблемната част е колко души ще са подготвени да ги заемат, както и че всеки четвърти-пети човек на планетата ще бъде пряко засегнат от този процес.
Съвсем скорошно изследване на Станфорд показва, че хората възприемат най-позитивно автоматизацията чрез ИИ, когато тя освобождава време за друга работа с висока стойност (това твърдят 69,4% от анкетираните). Други най-приемливи приложения на ИИ са разтоварване от досадно повторяеми задачи (46,6%) и от стрес (25,5%) или пък когато има възможности за подобряване на качеството (46,6%). Мнозинството от хората предпочитат сътрудничеството между ИИ и човека (45,2%) или автоматизация чрез ИИ, която обаче разчита на ключова намеса от човека (35,6%).
Конвенционалната мъдрост предполага вслушване в нагласите на хората. Не само на теория.
Разбира се, ако правителствата, бизнесът и технологичната индустрия не са окончателно забравили, че всъщност смисълът на всичко е хората да водят по-добър, щастлив и качествен живот. С правилно внедряване, адекватен контрол и нужната етика ИИ може да бъде в хармонична симбиоза с човечеството и да помага за решаване на много и разнообразни проблеми. За съжаление обаче, като всеки инструмент, с него може и да се злоупотребява и рисковете това да се случва не бива да се пренебрегват. Изобщо не е нужно да чакаме ИИ да стане свръхинтелигентен, за да се борим с последствията, които приложенията му вече причиняват.
ИИ, медии и истина
В доклада за дигиталните новини на Института „Ройтерс“ за 2025 г. се твърди, че 73% от американците споделят как не се ориентират или трудно се ориентират какво е истина и какво – лъжа. В Европа този процент засега е само 46.
Но сега изгледайте този новинарски репортаж…
В него няма нищо истинско. Това не се е случило. Нито един от показаните образи не съществува. Лицата, казаното, дори журналистите са компютърно генерирани от ИИ. Нищо че изглеждат като съвсем реални хора, които споделят свои възгледи – добронамерени и позитивни впрочем. Ами ако не бяха?
От технологична гледна точка наистина е впечатляващо колко реалистично изглежда всичко. Но е и точно толкова проблематично. Защото не просто е трудно, а вече става невъзможно да се отличи реалното от виртуално генерираното. И това отваря врати за всякакви злоупотреби.
Технологията е чудесна сама по себе си – проблемът е кой и за какви цели би могъл да я използва.
Инструментът, с който е генериран горният новинарски псевдорепортаж, е достъпен за всички, не струва много и с него може да бъде скалъпена всякаква ужасна новина, която да накара множество хора да повярват, че е истина.
Телефонни измамници и телемаркетинг компании ползват ИИ, за да синтезират човешки гласове. Появиха се фалшиви реклами, промотиращи продукти с лицата на известни личности, които нямат представа за това.
Големият въпрос е как ще живеем в свят, в който е невъзможно да отличим лъжа от истина.
Това не е всичко. Откакто Google започна да предлага т.нар. AI overviews (българският превод е тромав – „общ преглед, създаден от ИИ“, или иначе казано, генерирано от ИИ резюме на всяко търсене в търсачката), медиите се оплакват от огромен спад в трафика към сайтовете си. Очевидно е защо – ако потребителите търсят нещо и получат кратко резюме още в началото, колко от тях биха продължили да четат надолу?
Първият проблем е, че хората се доверяват на резюмето безкритично. Вторият е, че това е директен удар върху и бездруго крехкия и неефективен модел за финансиране на медиите чрез реклама. Защото по-малко трафик означава по-малко показана реклама, по-малко интерес от рекламодателите и съответно по-малко директни приходи.
Интернет и бездруго вече съсипа модела на печатните издания, като буквално нулира приходите на огромна част от тях. Онлайн рекламата и до днес не може да компенсира това. Сега Google издърпва и спасителния пояс на удавниците.
А големият проблем е, че без медии няма демокрация.
Спадът в трафика на онлайн медиите няма как да не доведе пък до съкращаване на журналисти и дори до разпускане на цели екипи и закриване на медии. Някои от тях ще се опитат да компенсират със създадено от ИИ съдържание, което само ще ускори тяхната смърт, защото няма как това да бъде добре прието от публиката.
А погледнато от позитивната страна, ИИ може да има много широко приложение в медиите – като помощник в превода от и на различни езици, в резюмирането и (с много уговорки) редактирането на текстове или в преобразуването на съдържание от един формат в друг (например текст в аудио). Подчертавам помощник – ролята и намесата впоследствие на редактор човек остават неотменими. В „Тоест“ например напоследък ползваме генерирани от ИИ илюстрации за заглавни изображения към материалите, тъй като бюджетът ни не позволява да ползваме услугите на илюстратор или фотограф за всяка публикация. Със сигурност не бихме допуснали обаче генерирани от ИИ статии.
Много е вероятно като съпротивителен механизъм на навлизането на ИИ в различни области да се появят и утвърдят занаятчийски алтернативи, при които не се използва ИИ, а само човешки умения и сили. И това да се превърне в символ на качество, както сега възприемаме ръчно изработените стоки, крафтбирата, домашната лютеница или произведените по поръчка дрехи или мебели. И да сме склонни да плащаме повече за тях – заради личното отношение и човешката връзка. Вече започнаха да се появяват книги, чиито автори декларират на корицата, че не са ползвали ИИ за написването ѝ. (И аз бях сложил изречение, че за написването на тази статия не е използван ИИ, но редакторката ми го изтри.)
ИИ и образованието
В сферата на образованието приложението на ИИ е буквално безгранично – като започнем от чуждоезиковото обучение, визуалните изкуства, точните науки, индивидуалните обучения, различни игровизации (геймификации), особено за деца и хора със специални потребности.
Но в неотдавнашен разтърсващ материал на 404 media преподаватели споделят наблюденията и тревогите си как ИИ буквално е сринал смисъла на преподаването. И не защото технологията е „лоша“, а защото е внедрена или възприета без замисляне и стратегия, без някакви премерени граници. Педагозите разказват с тъга за есета и домашни, написани частично или изцяло от ИИ, и за времето, похабено в търсене и доказване на такива опити за измама, вместо да бъде вложено в работа с наистина мотивираните ученици и студенти. Споделят, че сред възпитаниците им има такива, които не се опитват да разсъждават, а очакват и дори разчитат да консумират съдържание наготово. Разказват за напълно изгубеното доверие, диалог и смисъл.
Най-страшното е не че ИИ пише домашните на учениците или курсовите работи на студентите, а че те самите спират да мислят.
„ChatGPT не е самостоятелен, специфичен проблем. Той е симптом на повсеместна културна парадигма, в която пасивното потребление и преповтаряне на съдържание се превръща в статукво“, казва един от анкетираните преподаватели.
ИИ и власт
Няма спор, че позиционирането на ИИ като новата космическа надпревара е сполучлива медийна метафора и хитроумна бизнес стратегия. Но както някои метафори, хем шуми повече от необходимото, хем не казва същественото. Горчивата истина е, че не разполагаме с механизъм, който да възпре тази технологична битка да се превърне в ожесточена борба за власт. Тя вече е – включително в геополитически смисъл. И проблемът отново е не ИИ, а хората. С онези същите смъртни грехове – алчност, леност, завист, гордост, гняв…
We will use Grok 3.5 (maybe we should call it 4), which has advanced reasoning, to rewrite the entire corpus of human knowledge, adding missing information and deleting errors.
Then retrain on that.
Far too much garbage in any foundation model trained on uncorrected data.
„Ще ползваме Grok – заяви Илън Мъск преди три седмици [Grok е генеративният ИИ на неговата компания xAI – б.а.], – и ще пренапишем целия масив от човешко знание, ще добавим липсващата информация и ще премахнем грешките. И ще го обучим наново с това. Има твърде много боклук в некоректните данни, с които сме обучили основните модели досега.“
Дали не е прекалил с някоя субстанция? Не е ясно. Възможно ли е това да е неовладян импулс за привличане на прожекторите, понеже напоследък остана в леко засенчения ъгъл на историята? Възможно е. Но също така е напълно вероятна хипотезата той просто да е безпардонно откровен, защото горното е нищо по-малко от признание, че тази надпревара е за власт. И залогът е висок.
Мъск буквално казва, че който я спечели, ще дефинира реалността за човечеството.
На хора като него не им пука за ефективността на труда ни или за качеството на нашия живот – той иска да оформя начина, по който мислим. И нека си представим последствията. Защото неговите инвеститори си представят точно това, но политически коректно го назовават възможности. И инвеститорите на OpenAI – също, както и крупните акционери в Microsoft, Google и други. Предвид разрушените обществени механизми за колективна съпротива остава да се надяваме да спечели по-малкото зло.
ИИ е толкова интересна концепция, защото е нещо като думата „транспорт“. Има велосипеди, има камиони, има ракети. Всички те са форми на транспорт, но служат за различни цели и представляват различен компромис между разходи и ползи. За мен стремежът към ИИ е най-лошият компромис, защото се опитват да изградят фундаментална машина за всичко, но в крайна сметка тя не може да прави всички неща. Така не само объркват обществото какво всъщност може да се прави с тези технологии – което нанася вреди, защото хората започват да я питат например за медицинска информация, а насреща да получават медицинска дезинформация. Но за капак всичко това е за сметка на колосално потребление на ресурси и колосална експлоатация на труда.
Това каза преди няколко седмици журналистката на „Ню Йорк Таймс“ Карън Хао в телевизионно интервю по повод току-що излязлата ѝ книга Empire of AI. Хао е имала възможността да изследва отвътре OpenAI, компанията създателка на ChatGPT, при това продължително, имайки директен достъп до служителите, до ключови хора в екипа, както и до самия изпълнителен директор Сам Олтман. Наблюдавала е взаимоотношенията помежду им буквално „от пилотската кабина на компанията, която движи лудостта“, както пише в рецензията на корицата Шошана Зубоф. Ще бъде истински пропуск, ако книгата не излезе на български език, защото е крайъгълен камък в историята на развитието на ИИ. До този момент не съществува друга толкова прецизна и обстойна критика по темата.
В първата част на статията споменах, че една от целите ми е да акцентирам върху приглушените гласове – Карън Хао е един от най-важните сред тях, защото пази интегритета и смисъла на журналистиката да служи на хората. Подминавам Джефри Хинтън и Иля Суцкевер, защото ми се струва по-важно да припомня едно доста дълго, но изключително смислено и човешко интервю на Стивън Бартлет с Мо Гаудат, един от напусналите мениджъри на полусекретното развойно звено на Google – X Development.
Две години са изминали от този разговор, но той не е загубил смисъла си. И продължава да съдържа всичко, което е нужно да имаме наум в тревогите си за бъдещето – но също и възможните отговори за него. Игнорирайте лепкавото заглавие, отделете два часа от някой горещ летен уикенд и чуйте какво споделя Мо Гаудат.
ИИ и ние
Дали ИИ е заплаха, или надежда, всъщност е глупав въпрос. Защото поне засега няма изгледи отговорът да не е в ръцете на… човечеството. Разбира се, съмненията в собствените ни способности за етични и рационални избори са валидни и трудно оборими.
Да използваме ИИ, но не и да му се доверяваме сляпо, особено за вземане на критични решения. Да проверяваме всичко. Дори когато ползваме специализиран ИИ, пак трябва да имаме наум, че вероятността да сгреши или да ни заблуди никога не е нулева. Ползвайки ИИ, всъщност е препоръчително да си припомним поне основите на теорията на вероятностите.
Да внимаваме какво споделяме с ИИ – особено ако го ползваме безплатно. Нека си спомним, че сметката все още не излиза. ИИ е скъпо удоволствие и има твърде малко причини някой да ни го предлага твърде евтино или безплатно.
Да приемаме с резерви новините, че ИИ е направил уебсайт за три минути, спечелил е дело, заменил е цяла счетоводна кантора или е проектирал сграда, която е спечелила конкурс. Не защото не е възможно, а защото… надали искаме бизнесът ни да разчита на сайт, направен за три минути. Скорост без стратегия е просто шумотевица. Да забавим. Да премислим. И да се погрижим за последствията и за човешкото отношение помежду си. Не защото само това ще остане да ни отличава от машините, а защото… носим отговорността. Ние, не ИИ.
Времето за критична дискусия между сферите на технологиите, образованието и етиката винаги е сега. Този път – повече от всякога.
The kernel’s perf
events subsystem can produce high-quality profiles, with full
function-call chains, of resource usage
within the kernel itself. Developers, however, often would like to see
profiles of the whole system in one integrated report with, for example,
call-stack information that crosses the boundary between the kernel and
user space. Support for unwinding user-space call stacks in the perf
events subsystem is currently inefficient at best. A long-running effort
to provide reliable, user-space call-stack unwinding within the kernel,
which will improve that situation considerably, appears to be reaching
fruition.
България е управлявана от трима премиери – избрания, явния и тайния. Росен Желязков подписва, Бойко Борисов се показва, Делян Пеевски решава.
В този абсурден режим на триъгълна стабилност всеки от тях действа, както намери за добре. Конституционно начело е Желязков, без реална политическа тежест, но пък е европейското лице на България на високи форуми. Лидерът на ГЕРБ все още държи контрола върху партията, част от кадровите назначения и коалиционния бизнес, той капитализира и успеха от присъединяването на България като 21-ви член на еврозоната от 1 януари 2026 г. Председателят на ДПС – Ново начало Делян Пеевски е неофициалният координатор на службите, прокуратурата и „дълбоката“ държава, апотеоз на Красьо Черничкия на институционално ниво с власт, легитимация и без нужда да се крие.
Консенсус между страха и сделката
В това триединство е трудно да се открие смислено бъдеще, по-скоро държавата бива задържана в цикъл на подчинена стабилност. България формално изглежда демократична и стабилна – с многопартиен парламент, коалиционно правителство и евро на хоризонта. Всеки може да протестира – било срещу единната европейска валута, произвола на репресивния държавен апарат или срещу недостойното заплащане на младите медици и медицински специалисти и рязко повишените такси за студенти. В действителност държавата се управлява от фасада, посредник и задкулисие, при което антикорупционните действия са политическо оръжие, а не инструмент на правосъдието.
Доверието в съдебната система е под 30%, констатира излезлият тази седмица доклад за върховенството на закона в България. Документът за пореден път не отчете напредък – липсващи присъди за корупция по високите етажи на властта, неефективни разследвания, не е избегнато дългосрочното командироване на съдии за заемане на свободни длъжности и др.
Акциите на Антикорупционната комисия срещу управленски кадри на „Продължаваме промяната“ в София и Варна са доказателство за избирателното прилагане на закона, а не за системен контрол над обществените поръчки, които са за над 36 млрд. лв. за 2024 г. Избирателното правоприлагане означава репресия и беззаконие. ГЕРБ и ДПС са монополисти в местната власт от десетилетия, но борците с корупцията избраха да ударят две от четирите общини (София, Варна, Пазарджик и Благоевград), в които от есента на 2023 г. управляват кметове на ПП–ДБ. Разкритията на Антикорупционния фонд за злоупотреби с публични средства за стотици милиони не представляват интерес за Комисията за противодействие на корупцията (КПК), чиито действия биват съобразявани с политическата конюнктура.
След ареста на заместник-кмета на София Никола Барбутов, предшестван от разпространен от анонимен подател запис на негов разговор с кмета на район „Люлин“, съпредседателят на ПП Кирил Петков подаде оставка. Петков също така отказа да бъде предлаган за преизбиране на предстоящия в края на септември конгрес, а ПП обеща да бъде по-стриктна в кадровия си подбор. На записа се чуват предложения за схеми, при които 5–6% от стойността на обществени поръчки да отиват в партийните каси и за кметския екип. Софийският апелативен съд остави за постоянно в ареста Барбутов и експерта Петър Рафаилов, обвинени в участие в организирана престъпна група за корупция и предлагане на подкупи.
Но ако при задържането на Барбутов нямаше инициирани протести, то арестът на кмета на Варна Благомир Коцев доведе в крайморския град депутатите от „Промяната“ заедно с техни колеги от „Демократична България“. Барбутов е назначен от кмета Васил Терзиев от квотата на ПП, докато Коцев е мажоритарно избран с листата на ПП–ДБ и задържането му нанася по-големи репутационни щети. Пред сградата на Общината се събраха стотици граждани на Варна в знак на протест срещу политическата репресия с плакати „Днес е Благо, утре си ти“, „Няма да стане“, „Събуди се и измети мафията“, „Коцев е виновен за това, че не се продава“.
Според Николай Денков (ПП) хората са били хиляди, според лидера на „Възраждане“ Костадин Костадинов, който ги е броил – не повече от 350. Подкрепа за Коцев обяви и най-малката парламентарно представена партия – „Величие“, с лидер Ивелин Михайлов. Граждани излязоха и в София, пред сградата на КПК.
Арестът на Коцев е свързан със сигнал за обществена поръчка за над 1,5 млн. лв. за изхранване на деца в неравностойно положение, подаден от Пламенка Димитрова, която твърди, че ѝ е поискан 15% подкуп. Нейната фирма „Залива 47-СП“ не е спечелила поръчката, но е печелила 17 други от 2000 г. насам за близо 15 млн. лв. Когато е класирана втора през 2024 г., Димитрова обжалва решението пред Комисията за защита на конкуренцията и Върховния административен съд (ВАС), но отново губи.
Оказа се, че делото срещу Коцев е заведено през 2024 г., акцията е разрешена на 2 юли, но Антикорупционната комисия и Софийската градска прокуратура (СГП) се задействат шест дни по-късно – на 8 юли. При това обискираха служебния кабинет и дома на кмета в условия на неотложност, тоест без предварително съдебно разрешение. Съпругата на Коцев публикува емоционален разказ в профила на съпруга си във Facebook за нахлуването на 15 агенти в дома им и грубото им отношение.
По-късно стана ясно, че Коцев, двама общински съветници и един бизнесмен (съдружник във фирмата, спечелила спорната поръчка за хранене) са с повдигнати от СГП обвинения за престъпления по служба, подкупи и пране на пари. Те бяха докарани в София.
Оказа се обаче, че ключовият свидетел в разследването срещу кмета е не Пламенка Димитрова, а неговият бивш заместник и дългогодишен семеен адвокат Диан Иванов. Соченият за дясната ръка на Коцев юрист изненадващо напусна поста на 5 май, като мотивира решението си със „здравословни причини“. Като заместник-кмет в ресора му са влизали дирекциите „Европейски и национални оперативни програми“, „Контрол и санкции“, „Правнонормативно обслужване“ и „Общинска собственост“, както и предприятието „Инвестиционна политика“. Твърденията му били като при случая с Барбутов – кметът искал да се събират комисиони от обществени поръчки за издръжка на ПП.
Усещане за Пеевски…
За лидера на националпопулистката партия „Възраждане“ Костадин Костадинов в акцията „има усещане за намесата на Пеевски, това само слепец може да го отрече“. Кирил Петков и Асен Василев също виждат поръчка от Пеевски, но според Петков има и друга причина – неприетия бюджет на Варна с разходи за над 857 млн. лв.
Не е случайна датата, всички знаят, че бюджетът на Варна ще се разглежда утре [четвъртък, 10 юли – б.а.], и ако искат да сгънат един демократично избран кмет, за да включат техните сметки и далавери, сега е моментът. Само че, първо, Благо не е човек, който ще се сгъне, и второ, Варна не е град, в който те могат да си правят каквото си искат,
каза Петков.
Бюджетът беше приет, при това без особени пререкания. Но макар лидерът на ПП Асен Василев да увери, че протестите в подкрепа на кмета ще продължат, втори още не се е състоял.
От една страна, акцията съживи в политически план ПП, изваждайки я от дефанзивната тактика, предприета след ареста на Барбутов и отлива от партията на общински съветници и активисти. Като жертва на политическа репресия „Промяната“ събира повече симпатии, а и се мобилизират твърдите ядра на ПП–ДБ. От друга страна, акцията потвърди за обществото, че институциите работят само когато им наредят да работят. Същинска черна комедия! Санкциониран за корупция от САЩ и Великобритания се бори срещу корупцията, а оглавяваната от Антон Славчев КПК удря все по негови противници – било то доскорошни съратници в ДПС, или други.
Все същото за последните 15–20 години. Един изпарил се от публичната среда високопоставен чиновник като Филип Златанов, бивш шеф на Комисията за предотвратяване и установяване на конфликт на интереси, пишеше в тефтерче кого да опраска по директивите на „ИФ→ЦЦ→ББ“. Накрая и тефтерите изчезнаха, и Златанов се отърва с условна присъда, и никой от хората с инициалите, в т.ч. ДП, не беше разпитан. Само Искра Фидосова изчезна от политиката и ГЕРБ след историята със Златанов, по-късно я последва и Цветан Цветанов.
Но дали временният председател Славчев, сочен от ПП–ДБ за свързан с Пеевски, ще изчезне от Антикорупционната комисия, или напротив – ще я оглави, стремейки се да заслужи подкрепата на третия премиер? Изборът на нов състав на КПК е условие за получаването на втория транш по Плана за възстановяване и устойчивост (ПВУ). Управляващото мнозинство възнамерява да свърши тази работа, преди Народното събрание да излезе във ваканция през август, с година и половина закъснение. Като за начало парламентът промени закона, като заличи предвиденото мнозинство от ⅔ за избор на членове на Комисията. Изборът вече ще е с обикновено мнозинство от половината народни представители.
А номинационната комисия, която трябва да изслуша, оцени и препоръча кандидатите за КПК на депутатите, ще взема решения с мнозинство от четирима души, тоест в непълен състав, тъй като парламентът още не е избрал омбудсман. Кандидатите за обществен защитник минаха през селекцията на Народното събрание още през април, но причината да не се състои същинският избор е или в липсата на съгласие в управляващата коалиция, или се изчакват резултатите от конституционното дело по оспорването на т.нар. домова книга, от която се избира служебен премиер (в нея е и омбудсманът). Другите членове на номинационната комисия са представители на Върховния касационен съд, Висшия адвокатски съвет, Министерството на правосъдието и Сметната палата.
А след като правилата за избор на Антикорупционната комисия бъдат приети, към Брюксел може да потегли искането за второто плащане по ПВУ. Председателката на парламента Наталия Киселова защити промените:
Трябва да сме реалисти. Трябваше да се съобразим с решението на Конституционния съд и да се промени мнозинството – да стане обикновено от квалифицирано. По отношение дали номинационната комисия винаги трябва да бъде в пълен състав, това също е усложняване на процедурата, защото в никой друг случай по отношение на никой друг орган нямаме такава процедура.
А по повод акцията във Варна напомни, че именно ПП–ДБ са настоявали КПК да има разследващи функции – „и сега виждаме плодовете от труда им“.
Зад пушилката, която „антикорупционните“ акции вдигнаха, на поста си беше бетониран кадър, верен на тройката премиери, особено на един от тях. Прокурорската колегия на Висшия съдебен съвет закрепи настоящия и.ф. главен прокурор Борислав Сарафов на поста въпреки ограничението в Закона за съдебната власт за 6 месеца на тази позиция. Според прокурорите обаче това не важи за заварените случаи, какъвто е този със Сарафов, временно изпълняващ от юни 2023 г. Очакванията са и Съдийската колегия на ВСС да постъпи така с Георги Чолаков, който управлява ВАС като и.ф., след като изтече мандатът му.
Така след утвърждаването на новите състави на регулаторите, попълнени с хора на ГЕРБ, Пеевски и по някой и друг представител на БСП и ИТН, статуквото не изпуска контрола и върху съдебната система, занитвайки лоялния си персонал.
Наред с това удобно игнорира критиките за „липса на напредък“ в утвърждаване на върховенството на правото в България, избирайки фанфарите за приемането в еврозоната от 1 януари 2026 г.
Гарнитурата „Боташ“
В опит да омекоти обвиненията за политическа репресия, Антикорупционната комисия поде акция срещу подписалите вредната за България сделка с турската компания „Боташ“(Boru Hatları ile Petrol Taşıma Anonim Şirketi). Тя е договорена по време на служебното правителство, назначено от президента Румен Радев, в което министър на енергетиката беше Росен Христов. В 13-годишния договор, задължаващ „Булгаргаз“ да плаща над 1 млн. лв. на ден за 53 200 мегаватчаса, независимо дали пренася газ от Турция, няма клауза за предоговаряне. Контрактът може да се развали само ако България заплати накуп 4-те милиарда лева. Българската компания е спряла да плаща на „Боташ“ и е задлъжняла с над 250 млн. лв.
За „Булгаргаз“ щетите са огромни – 267 млн. лв. е загубата от неизползвания капацитет с Турция, което е почти 85% от загубите, регистрирани в търговския отчет на дружеството за 2024 г. на обща стойност 315 млн. лв.
Антикорупционната комисия влезе за обиск в дома на Христов две години и половина след подписването на споразумението с „Боташ“ и след доклад на временна парламентарна комисия, изпратен на ДАНС и прокуратурата преди близо 15 месеца. Христов заедно с бившата шефка на „Булгаргаз“ Деница Златева бяха извикани и на изслушване в парламента заради договора с „Боташ“.
След обиска в дома на Христов обаче се разбра, че както и в случая с Коцев делото е било образувано преди година и претърсването е извършено „в условията на неотложност“. Иззети са телефон и лаптоп, намерени са 80 000 евро, но обвинения не са повдигнати. Обискиран е бил и домът на Деница Златева, където са открити 100 000 лв.
Бившият министър на енергетиката заплаши да съди държавата и дори да си търси политическо убежище. На следващия ден обаче беше разпитван 6 часа в Антикорупционната комисия, а на излизане повтори пред журналисти тезата си за договора с „Боташ“ – не се използвал „пълноценно“. Христов обича да дава съвети как резервираният капацитет трябва да се продаде. Проблемът е обаче, че никой не го иска, тъй като е скъп. На разпит беше извикана и Златева, която си намери извинение с високо кръвно, за да не се яви.
Едва 11% от капацитета на договора е използван, заяви енергийният министър Жечо Станков.
Усилията за предоговаряне на клаузите продължават. Имаме право веднъж да го предоговорим, и то трябва да бъде много внимателно договорено, така че да излезем от този омагьосан кръг.
Едва ли някой очаква да бъде проведено сериозно разследване на сделката с „Боташ“, което да доведе до обвинения и присъди. Съвсем не е сигурно, че и Коцев ще бъде осъден, но може да се стигне до предсрочни избори за кмет на Варна, ако мандатът му бъде прекратен.
Вместо страж на закона Антикорупционната комисия е превърната в боен реквизит. Върховенството на правото да върви на… в Брюксел – важното е какво ще заповядат премиерите. Изобщо, България е в стабилен театрален режим – с декори на демокрация, сценарий от задкулисието и публика, която все по-често напуска залата, защото представлението е криндж.
Е.Т. ще ви обясни правилата. Трябва да си изберете един Делян, да хвърлите зарчето и да си изтеглите от тестето с карти политическа фигура, удобна за арестуване.
We love hearing from members of the community and sharing stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
It’s especially inspiring to hear about young people who are not only passionate about technology, but who are also driven to share that passion with others. Meet Matthew, a 15-year-old creator and youth mentor at Code Club, who builds his own projects and inspires peers by organising hackathons.
Matthew and his team at Cool as Hack at the RPF offices
Matthew’s early experience with coding
Matthew’s journey into the world of coding began at a young age. His initial exposure was through Scratch at school in Singapore. From there, he began exploring self-learn platforms in his own time, getting to grips with HTML and basic web development.
His enthusiasm for creating led him to participate in a technology week in Year 6, where he took on a BBC micro:bit challenge. He dedicated his summer holiday to developing a token system that encouraged community recycling, using an ultrasonic sensor to award points for good behaviour. This early project showcased his knack for problem-solving and innovation.
What truly captivated Matthew was the possibility of combining the logical challenges of competitive programming with the joy of project creation.
Matthew with his device developed in Year 6 to promote recycling behaviour in his residential community
Connecting with the community
Through YouthHacks, an initiative he co-founded to support teenage hackathon organisers, Matthew aims to expand access to hackathons across the UK (a hackathon is an event where individuals or teams work intensively over a relatively short time period to build software, hardware, or other kinds of technology). Matthew wants to offer advice and support, making it easier for young people to run their own hackathons. He puts a lot of time into ensuring that the content and atmosphere truly resonate with the participants.
“So, we made YouthHacks basically as an idea to be able to support these teenage organisers, you know, like hackathons for teenagers by teenagers.”
Matthew’s connection with the Raspberry Pi Foundation came from his keen interest in the hackathon community and a need for a local venue. Having previously toured the Foundation’s offices for a school robotics club, he decided to reach out when organising a satellite hackathon called Counterspell.
This initial collaboration led to further events at the Foundation, including Scrapyard Cambridge and, more recently, Cool as Hack.
Coolest Projects hackathon: A new approach to collaborative coding
Cool as Hack was Matthew’s third event held at the Raspberry Pi Foundation offices. Unlike traditional hackathons with intense time pressure, this event, inspired by the spirit of Coolest Projects, aimed to be more relaxed and collaborative.
“For this, people could bring in their own project scraps and then they could put it together with a team, finalise it, and then enter it to Coolest Projects.”
The focus was on showcasing creativity and sharing projects globally, rather than competitive prizes. Everyone then entered their creations into the Coolest Projects online showcase.
Cool as Hack in progress at RPF HQ. Credit: W O Wallace
Cool as Hack was a huge success. The atmosphere was incredible — there was even a karaoke session and a “swag shop” where participants could exchange tokens earned for innovative ideas or project milestones. This token system, designed by Matthew and harking back to his own recycling project from years ago, created a fun and engaging reward system.
Inspiring the next generation
Matthew’s drive to organise these events and encourage other young people to code stems from his enjoyment of project creation and the community aspect of hackathons.
“Well, I suppose it links back to me enjoying making projects and when you attend a hackathon, it’s not a competition really. It’s more of a social event. So, you’re making a project and then you’re meeting quite a lot of coders, or even artists and musicians, and so many other people.”
All of the creators that took part in Cool as Hack. Credit: W O Wallace
Now a regular volunteer at the Raspberry Pi Foundation’s monthly Code Club in Cambridge, Matthew remains focused on encouraging others into tech. For aspiring young coders, he says that coding is far more diverse and creative than many might initially perceive, encompassing art, storytelling, and problem-solving. Matthew’s advice is simple:
“Enjoy the process and as you learn new things you’ll realise that all of this is like super interesting, and that there are so many ways to make what you want. Just enjoy it and continue meeting new people and, yeah, be creative.”
Matthew’s journey shows how an intro to computing at a young age can lead to an incredible amount of impact. With his continued dedication, he’s sure to inspire many more young minds to start on their own coding adventures.
If you would like to explore coding, you can get started at home with over 250 free projects.
Looking for a little extra support in your own coding journey or open to mentoring others? Join a Code Club near you to meet a like-minded and supportive community.
Изкуствен интелект (ИИ) е леко претенциозно название на доста разнообразна палитра от технологии. Част от тях са съвсем нови, но са стъпили на вече достигнала зрялост технологична основа. Други се развиват с колебливо ускорение от години и дори десетилетия. А трети, нищо че може би и за тях сте чули съвсем наскоро, вече излизат от т.нар. пик на завишени очаквания, където развитието им често е стремглаво, и се предполага, че в период от няколко месеца до година-две ще се превърнат в част от обичайното. Или пък няма. Предстои да видим.
Напълно разбираемо е любопитството към ИИ, както и тревогите за бъдещето, в което той ще се намеси. Много въпроси обаче нямат нито лесни, нито очевидни отговори, без значение кой и какво твърди с непоклатима убеденост. Спекулациите и опитите за пророкуване какво ни чака и как ще се промени животът ни, са част от медийния буламач, който съпътства всяка нова и сложна технология. Така беше и с интернет, електронната търговия, облачните технологии, социалните мрежи, блокчейн и криптовалутите.
Голяма част от прогнозите не се сбъднаха. Сега на дневен ред е ИИ.
Понеже интернет и социалните мрежи дадоха възможност (за съжаление – и самочувствие) на всеки да се чувства компетентен да обсъжда всичко, гласовете на онези, които наистина имат какво да кажат, остават нечути. И това далеч не са Сатя Надела(Microsoft), Сундар Пичай(Google), а още по-малко Сам Олтман (OpenAI, които стоят зад разработката на ChatGPT).
Те, разбира се, винаги имат какво да кажат, но нека не забравяме, че като бизнесмени трябва да продават – очаквания, мечти, страхове или каквото е нужно за положителните резултати във финансовите отчети на компаниите, които управляват. Или пък да влияят на нашите мечти, очаквания и страхове, пак заради същите финансови отчети. Това не прави твърденията им безпочвени. Поне не всички. Но измества акцента върху по-съществени въпроси – например кога казват нещо, какво не казват и най-вече защо.
За жалост, дори експерти, които работят в сферата, също невинаги са благонадежден източник на информация. Те са твърде фокусирани върху детайлите и емоционално увлечени от работата си. Някои според мен дори се нуждаят от специализирана помощ. Мнозина са продукт (и жертва) на една силно конкурентна среда, която фаворизира трескавото създаване на технологии без много замисляне върху последиците. Среда, в която техническата надпревара е удобно и всепризнато извинение да не се поема и носи отговорност. А целта – пари, надвиване на конкуренцията, власт – оправдава всички средства.
Трудно е да се оцени ИИ еднозначно, при това без да се залита в крайности като технооптимизъм или параноя.
Всяка технология има своите силни страни и своите недостатъци. Заедно с това, малцина съобразяват оценките си с хуманизма, който днешният пазарно ориентиран технологичен свят има навика напълно да игнорира. С този текст ще насоча вниманието към приглушените гласове – с надеждата повече хуманитаристи и интелектуалци да навлязат в темата.
Независимо от това какво ще е съвместното бъдеще на ИИ и хората, разговорът за това бъдеще е вече закъснял. Защото скоростта, с която ИИ навлиза в живота ни, може да причини такъв световъртеж, че дори при най-позитивното развитие на технологиите те да са твърде сложни за възприемане и осмисляне. Голямото предизвикателство пред човечеството е доколко то ще е способно да се адаптира към тези промени – в икономически, обществен и дори психологически план.
Болезненият въпрос е не дали някои хора ще загубят работата си – това се случва и без ИИ. А каква част ще съумеят да следват промените с нужното темпо. Защото отговорът, че тези, които не успяват, не са подготвени за новите реалности (и както обикновено сами са си виновни), сега няма да ни свърши работа. За да водим обаче адекватен разговор по темата, е нужно поне базово да познаваме технологиите от семейството на ИИ. Ще се опитам да обобщя най-важното от развитието им, без да прекалявам с техническите подробности.
Кратък хронологичен разбор на ИИ
Едва ли е голяма изненада, че модерните днес ChatGPT, Gemini AI, CoPilot и подобни са стъпили на раменете на купчина предхождащи ги технологии – като невронните мрежи, големите масиви от данни, машинното (само)обучение, обработката на естествени езици като част от компютърната лингвистика и дори математическата статистика. Тези технологии не са се появили вчера, някои от тях се развиват от десетилетия.
Една от първите софтуерни програми, които (с известни уговорки) са в състояние да издържат теста на Тюринг, тоест да заблудят някого, че разговаря с човек, е ELIZA – чатбот, създаден още през 60-те години на миналия век, който имитира психотерапевт. ELIZA е програмирана да разпознава ключови думи и шаблони, на които реагира по предварително зададен начин съгласно система от правила. Един от недостатъците на този подход е, че програмата всъщност няма никакво понятие за контекста на разговора, който „води“ (а всъщност симулира). Компетенциите ѝ се изчерпват със системата от правила и сферата, от която са. Няма и механизъм за някакво самообучение или разширяване на тези „компетенции“.
В отговор на недостатъците се появяват технологиите за т.нар. подсилващо обучение (reinforcement learning, или RL), които дават възможност на системата да се адаптира към контекста, в който е поставена, и да се учи от масиви от данни и от предходен опит („проба–грешка“ впрочем е един от основните подходи – както е при хората). Много от текстово базираните компютърни игри прилагат тези технологии от години. Недостатъците на подхода са, че компетенциите отново са ограничени до някаква област (от която са данните, използвани за обучението), ефективността на обучаване е ниска и отнема много време, а нюансите на естествените човешки езици добавят цели нива на сложност.
Така опираме до необходимостта от технологии, които да осигурят някакво ниво на универсалност и обобщаване на знанията. Иначе казано, софтуерът, обучен с едни данни, да е в състояние да прилага „наученото“ в друг контекст, област или ситуация, която не е изрично разписана и подадена предварително. Големите езикови модели (large language model, или LLM) се превърнаха в повратна точка в компютърната обработка на човешки езици. Те ползват многослойни невронни мрежи, за да възприемат и представят големите данни, с които биват обучавани. Всъщност именно те са в основата на днешните чат базирани платформи, които постепенно (и погрешно) приравнихме с ИИ.
Английската абревиатура за изкуствен интелект е AI, от artificial intelligence. Има критики, че и двете думи не са коректни. За първата има предложение (предвид сегашното ниво на развитие) AI да се разчита като assistive intelligence, подпомагащ интелект. За втората дума критиката е по-скоро фундаментална – че не може да съществува интелект без осмисляне, тоест без съзнание, а на този етап ИИ, строго погледнато, е изчислителна технология.
Добре е да се има предвид, че езиковите модели всъщност имат едно ключово умение, и то е да предполагат най-вероятната следваща дума в изречението, така че то да стане част от смислово свързан текст. Наричат се още предвиждащи машини. И това не е ирония, а термин. Захранени с голям масив от данни, те боравят с вероятностни разпределения и успяват чудесно да комбинират най-сполучливите (тоест най-вероятните), подредени в правилен словоред думички по такъв начин, че да заговорят (и пишат) като нас. Даже по-добре от нас. На почти всеки език.
В действителност езиковите модели са едни високотехнологични папагали, които повтарят заучени фрази – нищо повече.
Но това все пак е революция в областта на компютърната обработка на човешките езици, която от години беше затънала в опити да описва лексика и граматика със сложни системи от правила.
Внимателно избягвах думата знание и вместо нея ползвах компетенции, защото дотук разполагахме основно с комплект от специализирани умения за съставяне и съпоставяне на текстове. Масивите от данни, с които захранваме езиковите модели обаче, са знание. Нещо повече, това е част от натрупаното общочовешко знание. И тук стигаме до първородния грях – това знание в повечето случаи е събрано и ползвано за обучение на езиковите модели незаконно, без позволение, без компенсации за авторство, без дори признание за авторите му. Хилядолетното знание на човечеството бе откъснато от създателите му и предоставено на машините на тепсия – от търговците на мечти и страхове. Но ще се върнем на това престъпление малко по-нататък.
Именно езиковите модели са това, което направи популярни ChatGPT и подобните нему. GPT всъщност е съкращение от generative pre-trained transformer, което се предполага да преведем като предварително обучен генеративен преобразувател. Именно GPT системите се появиха и се утвърдиха като най-добрите езикови модели (понеже не всички езикови модели са GPT).
Преобразувателите обаче също не са съвършени – това, че са в състояние да сглобят правдоподобен текст и да върнат най-вероятния отговор от голямата си, но все пак ограничена база със знания, съвсем не означава, че това, което твърдят, е истина или е правилно. Точно затова е изключително глупаво да се допитват до тях за здравни или пък романтични съвети, за политиката, бъдещето и т.н. Моделите могат да бъдат изключително некомпетентни в някои области – особено в онези, в които и самите ние, хората, сме боси или пък по някаква причина натрупаното знание не е леснодостъпно. Актуални и очевидни неща, като днешните новини, какво е времето навън или колко е часът, ги затрудняват, защото са обучени с по-стара информация.
Или поне доскоро беше така. Сега те вече разполагат с механизми и инструменти да търсят в интернет и дори да се питат и да си помагат едни на други. Чрез технологии като RAG, допълнителни интерфейси и добавяне на различни инструменти,
ИИ платформите отдавна не са само голи езикови модели.
По сходен начин се появиха и моделите, специализирани в създаването на изображения, глас, музика, видео.
И тук опираме до един вододел, който е много важен за разбирането на контекста на темата. Невронните мрежи, стоящи в основата на езиковите модели, не са нова идея. Техният възход точно сега е резултат от комбинирането им с големите масиви от данни и наличието на изчислителни мощности, каквито доскоро не бяха възможни.
За една група експерти и учени това е доказателство, че технологията не е ефективна, а разхищението на ресурси не води до желаното мащабиране. В другата посока са онези, които вярват, че понеже невронните мрежи се опитват да копират човешкия мозък (доколкото изобщо знаем как функционира той), ако те бъдат захранени с достатъчно данни и изчислителна мощ и продължаваме да ги развиваме, в някакъв момент ще разполагаме с т.нар. общ изкуствен интелект(ОИИ) – artificial general intelligence,илиAGI, който ще може да се справя автономно с всяка интелектуална задача, без ние да трябва да му помагаме.
По тази тема всякакви хора напоследък се упражняват да гадаят – между как това никога няма да стане и как т.нар. технологична сингулярност буквално ни дебне зад ъгъла. В интерес на истината, и двата лагера имат своите валидни аргументи.
Днес обаче, колкото и да са добри в това, което правят, моделите преизползват прагматично информацията, без да я разбират в някаква дълбочина. Този проблем се опитват да решат т.нар. разсъждаващи модели (reasoning language model, или RLM), които могат да анализират ситуации, да правят логически изводи и да вземат информирани решения на базата на това, с което са обучени, и на допълнителните данни, до които могат да получат достъп. Подобно на ученик, който не само запаметява факти, но и прилага критично мислене при решаване на реален проблем.
Те са доста нова технология, която, разбира се, също има своите ограничения и проблеми. Невинаги успяват да разглобят правилно сложните задачи на по-прости и решими проблеми. Провалят се при по-заплетени казуси – точно като нас, хората. Загубват се в някои логически взаимовръзки, когато нямат достатъчно контекст да ги подредят по приоритет или пък им липсва достатъчно информация, за да вземат решение. Страдат от предубеждения в зависимост от данните, с които са обучавани…
Познато, нали? Всъщност никак не е случайно, че толкова много си приличаме, дори в недостатъците.
Нека не забравяме, че като продукт на първородния грях те разполагат с огромен комплект от знания и правят дедуктивни заключения на базата на нашите решения и действия от миналото, които сме документирали и предоставили. В този смисъл те доста добре ни познават и копират. Включително в това да имитират страдание, болка, съчувствие и разбиране. Затова, когато прочетете някъде, че някакъв изкуствен интелект страдал или се страхувал да не бъде изключен, моля… намерете си друго четиво.
Една от актуалните новости са т.нар. ИИ агенти. Те представляват софтуер, който, разчитайки на моделите и на допълнителни инструменти и данни, включително постъпващи в реално време, може да извършва напълно автономно някаква специализирана дейност – да управлява машина, да пише софтуер, да шофира, да приема и обработва поръчки в електронен магазин, да помага или даже да замени служител в колцентър или отдел за поддръжка – и да прави това бързо, неуморно, на множество езици и едновременно за много клиенти. Агенти с разсъждаващи модели могат да анализират данни за пациенти, да диагностицират болести и да препоръчват терапии, като в някои случаи успяват даже да са по-прецизни от лекарите.
Важно е обаче да правим разлика между това, че специализиран ИИ e в състояние да анализира и сравнява резултати от ядрено-магнитен резонанс и да бъде дори по-прецизен от лекар при диагностицирането на дадено онкологично заболяване – и това да се допитваме до папагала ChatGPT за медицински съвет, който с огромна вероятност може да е непрецизен и дори погрешен.
Горе-долу тук се намираме днес. И независимо как е прозвучал текстът ми досега, тези технологии са страхотни. Имат огромен потенциал и приложения и би било глупаво да не ги използваме. Първо, те наистина могат да ни помагат за много неща и да ни спестят досадна дейност, усилия и време. Могат дори да спасяват човешки живот. Освен това, искаме или не, те са тук и който не ги познава и използва, рискува да изостане в личното и професионалното си развитие. И не на последно място, ако опасенията, които технологиите пораждат, се оправдаят в бъдеще, тези, които ги познават по-добре, ще имат по-добри шансове – защото, ползвайки силните им страни, интуитивно ще са опознали и слабостите им.
Слабости на ИИ? Разбира се, че има – и те не са малко
Огромен проблем е, че ИИ е гигантски консуматор на електроенергия и изчислителни ресурси. Неотдавна Сам Олтман каза пред Сената, че цената и изобилието на ИИ ще зависят пряко от цената и изобилието на енергия. Иначе казано, без инвестиции в енергийна инфраструктура нуждите на ИИ може да надскочат развитието на електроснабдителните мрежи.
ИИ вече се определя като „космическата надпревара на ХХI век“ и поне засега тя се основава на енергия и ресурси. Това може сериозно да размести баланса на силите в световен мащаб – но пък прекрасно устройва играчи като Сам Олтман, чиято цел е максимално да придърпат темата за ИИ към себе си. Ако Илън Мъск в последно време успя да се превърне в злодея на всички злодеи, изчакайте още малко Сам Олтман.
Икономически сметката все още не излиза. Инвестициите в ИИ са огромни, а възвръщаемостта е ниска. Някои скорошни анализи даже сигнализират, че е достигната фаза на намаляваща възвръщаемост, когато добавянето на ресурси (данни и изчислителна мощ) не увеличава ефективността. Очакванията са огромна част (над 90–95%) от стартъпите за ИИ да фалират бързо и да се получи поредна концентрация около няколко от най-големите технологични играчи.
Скоростта е другият проблем. Като всяка нова технология ИИ се развива много бързо и това не е новина. Различното този път е, че потенциалът му да променя най-различни области от човешкото ежедневие е огромен. При това по-бързо, отколкото са обичайните човешки способности за адаптация. Много по-бързо отколкото процесите, заложени в социално-политическите ни системи от десетилетия преди появата му, могат да реагират. Не е случайно, че наричаме тези характеристики на технологиите разрушителни или подривни. Не непременно с негативна конотация, защото очакваме те да водят до положителни резултати, но такива промени с висока скорост имат всички шансове да увеличат общото усещане за глобален хаос и несигурност, което и бездруго не липсва.
Дали ИИ/ОИИ някога ще бъде в състояние да създава ново знание, да трупа опит и да се самоусъвършенства без човешка намеса, предстои да видим. Това, предполага се, би ускорило още повече всичко. Но дори да не се развие по този начин, някои от тревогите по отношение на днешния ИИ не са неоснователни – за екологията, за разхищаването на енергия, за бъдещите обществено-икономически отношения. За отговорността. Защото кой носи отговорността за дадено решение, действие или бездействие на ИИ като част от една или друга система, не е само юридически или философски въпрос.
Затова отсъствието на хуманитаристите от този сложен разговор е много тревожно.
Разговорът, както и решенията, не бива да остават единствено в кръга и властта на технократите и технооптимистите. Те вече сътвориха достатъчно бели с наивността или с алчността си, с бруталната си самоувереност, пълна липса на критично мислене и неспособност да носят отговорност. Достатъчен пример са социалните мрежи, които уж трябваше да свързват хората, а се превърнаха в терен за културни войни и инструмент за радикализация. И така са на път да счупят демокрациите.
ИИ създава предизвикателства, каквито не познаваме и за които не изглежда да сме готови – нито като индивиди, нито като общества. Правителствата не разбират добре какво става, подценяват евентуалните проблеми и пропиляват безценно време за подготовка. А тривиалните решения няма да сработят. Регулацията не помага особено, защото нерегулираният ИИ (например в Китай) би се развил повече и би надделял над регулирания. В ситуация на глобална технологична надпревара това ще е самоубийствено.
Макар че поне някаква регулация е необходима – високи данъци върху ИИ например биха помогнали да се компенсират някои щети, но само на теория, защото колко ще са политиците с гръбнак да се преборят за това. А и без общо съгласие в глобален мащаб ефектът ще е по-скоро обратен. Колко вероятно е да постигнем такова съгласие в света, който споделяме днес? Освен ако точно ИИ не ни научи най-накрая, че всички на планетата сме в една лодка…
Разбира се, че полза от вторачване в евентуални негативни сценарии няма. Но да не сме подготвени за тях би било безотговорно – защото, ако през предното стъкло изглежда, че сме се засилили с мръсна газ към бетонна стена, решението не е нито да стискаме очи, нито да се надяваме стената да се отмести. Някак трябва да вземем завоя.
П.П. Преди точно 20 години, на 12 юни 2005 г., Стив Джобс произнесе реч пред завършващите „Станфорд“, която и до днес има силно въздействие с възгледа си за пресичането на сферите на хуманизма и технологиите. Дано той не е бил един от последните технологични лидери, за когото това е имало значение.
This is a guest post authored by Akira Mikami, a technical expert at Furuno Electric. The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
Since successfully commercializing the world’s first fish finder in 1948, Furuno Electric has been developing unique ultrasonic and electronic technologies in the marine electronics field. Under the company motto of “making the invisible visible”, they’ve have expanded their business centered on marine sensing technology and are now extending into subscription-based data businesses using Internet of Things (IoT) data. They’re are actively promoting the planning and development of data businesses to realize their new management vision outlined in FURUNO GLOBAL VISION NAVI NEXT 2030.
Like many manufacturing companies, Furuno Electric faced significant changes in revenue structure and technical architecture as they transitioned from traditional business to data-driven business. To succeed in this transformation, it was essential to build a foundation that promotes data utilization across the entire organization.
This post demonstrates how Furuno Electric built their system using Amazon DataZone and other Amazon Web Services (AWS) services to address technical infrastructure fragmentation, establish proper security governance, and develop an effective data business promotion system as part of their journey transitioning from a traditional manufacturing company to a data-driven business.
Challenges
Furuno Electric faced three specific challenges in promoting their data business: technical infrastructure fragmentation and duplication, lack of security governance, and underdeveloped data business promotion system.
Project managers in the data business were independently designing and building data infrastructure, resulting in duplication of components for data collection, processing, and storage. This situation created wasteful development investments, hindered effective use of common data, and caused inefficient states that took time to launch businesses. Marine data services including fishing vessel data collection and sharing system, FWC, and Furuno Open Platform (FOP) had similar functions implemented separately for each project along the functional axes of data collection, processing, visualization, and analysis, resulting in unnecessary workload across the organization.
Security measures were considered and implemented separately by each department, and although checklists existed, they weren’t applied uniformly. This resulted in a lack of consistency in security measures, duplicate consideration costs for each department, and uncertainty in the comprehensiveness of measures. Integrated risk management was also difficult.
The organizational structure wasn’t prepared for the iterative development processes and long-term revenue models specific to data businesses, and there was a lack of mechanisms for cross-departmental data utilization and joint development. The distributed operational structure across departments made it difficult to rapidly deploy and continuously improve data businesses. In the process of creating data businesses, it became necessary to build entirely different customer relationships compared to traditional product sales businesses. In terms of organizational management and talent strategy, there was a need to transition from a top-down, risk-averse, specialized skill-focused structure to a bottom-up, challenge-oriented structure that emphasizes communication skills and diversity.
Solution overview
Furuno Electric built a data management foundation centered on Amazon DataZone, Amazon Simple Storage Service (Amazon S3), AWS Glue, and AWS Control Tower, a comprehensive solution designed to address each of the three challenges mentioned in the preceding section.
Building the integrated data platform JuBuRaw
To address technical infrastructure fragmentation and duplication, they built Junction Architecture of Business Raw Data (JuBuRaw), a platform that consolidates common components for data collection, storage, management, and authentication. Using AWS Cloud Development Kit (AWS CDK) to code the infrastructure, they achieved standardization and automation of environment construction. This provides consistency and reproducibility, making it easier to add new systems and migrate existing systems to the common platform. Merely by executing CDK, a standard data pipeline (using AWS IoT Core, Amazon S3, AWS Glue, Amazon Kinesis, Amazon API Gateway, and AWS Lambda) for a specific system is automatically built. This eliminates duplicate design and development within the organization, reducing business launch time and improving fixed cost management. By standardizing common functions, they reduced the management and operation costs of existing systems and enabled the launch of new systems in half the time compared to before.
The following diagram is the overall JuBuRaw architecture.
Security control with AWS Control Tower
To address the lack of security governance, they implemented a comprehensive security framework centered on AWS Control Tower to apply consistent security policies across multiple accounts. With automated monitoring systems using AWS Security Hub, AWS Config, and AWS CloudTrail and an integrated authentication system using AWS IAM Identity Center, they provide security consistency while reducing operational costs and management burden.
With the organization’s management account at the top, they placed AWS Control Tower, AWS Organizations, and AWS IAM Identity Center to achieve hierarchical security management. By adopting a multi-layered defense structure consisting of account baselines with AWS CloudTrail and AWS Config enabled, log archive environments, and audit and security operation environments, consistent security policies are applied to all accounts, enabling early detection and response to security incidents. This integrated approach has reduced the workload for security responses. This configuration is shown in the following diagram.
Establishing a data democratization foundation with Amazon DataZone
To address the underdeveloped data business promotion system, they introduced Amazon DataZone to streamline data discovery, sharing, and governance across the organization. They clarified the role division between the infrastructure management team and the data management team, centralizing data security policies, quality management, and metadata standardization. With a project-based collaboration environment, they promoted cross-departmental data utilization, establishing a foundation to support the creation and continuous monetization of data businesses.
Organizational reform and operational structure establishment
In parallel with the introduction of technical solutions, they implemented organizational reforms to support medium- to long-term data utilization. The new organizational structure consists of three main roles: the infrastructure management team, the data management team, and the chief data officer. The following chart shows this organizational structure.
The infrastructure management team is responsible for maintaining and developing the technical foundation of the platform, managing multiple accounts using AWS Control Tower, applying and monitoring security baselines, and tracking infrastructure version management and changing history. By specializing in common technologies, they can provide a stable platform.
The data management team is responsible for data quality management and continual improvement using AWS Glue Data Quality, standardization and maintenance of metadata, definition and application of data security policies, management of Amazon DataZone data Catalog, and providing data governance using Amazon DataZone. To maximize the value of data, they focus on deeply understanding business requirements and data characteristics and performing appropriate data management.
The chief data officer is responsible for formulating data business strategies and determining direction, promoting coordination and collaboration between teams, making decisions regarding the evolution of the data management foundation, and fostering a data utilization culture throughout the organization. From a strategic perspective, they oversee the whole and bridge business goals and technology.
This clear division of roles has established an operational structure for effective data utilization, accelerating the data business creation process. Additionally, clarifying data ownership has improved data quality and reliability, promoting data utilization across the organization. This structure is sustainable and can flexibly respond to technological changes and changes in the business environment.
Benefits of the modernized platform
As a concrete application example of the integrated data platform JuBuRaw and organizational structure explained in the previous section, we introduce the migration project of the existing service SHIPS. This use case is a comprehensive migration case that uses all three solution elements of data collection, management, and utilization mentioned earlier.
Furuno Electric provides a system called SHIPS that plots ship position information and monitors the status of equipment installed on ships. By migrating this existing service to the JuBuRaw foundation, the several functional enhancements are expected.
In terms of data integration enhancement, by using the data catalog function of Amazon DataZone, it becomes easier to integrate not only ship position information but also various data sources such as internal systems, IoT devices, other company systems, automatic identification system (AIS) data, and weather and sea condition data. This enables swift data analysis and comprehensive ship management, which means operators can detect potential issues and implement preventive measures before they develop into serious problems. Particularly important is that by storing this data in a common data lake and retaining them as master data, they create an environment where the data can be easily used by other applications.
For security enhancement, organizations can use Amazon DataZone federated governance with publish-subscribe (pubsub) workflow mechanism and fine-grained access control capabilities. This means they can implement detailed permissions management specifically for data assets, rows, and columns while maintaining unified access control and data governance across multiple AWS accounts and organizational boundaries.
In this case, by using the new integrated data management foundation, it becomes possible to integrate individually designed and built data foundations, improving both efficiency and functionality. A consistent data flow from data sources to the data platform and then to individual applications is realized, enabling flexible data utilization centered on the data lake. Linkage with each application can also be easily realized from the data lake, providing expandability for future data utilization.
This SHIPS migration case is a comprehensive approach using the solution elements of the JuBuRaw foundation and is expected to serve as a reference model for future system migrations. It’s expected to achieve both service quality improvement and operational cost reduction.
Future vision and next steps
Based on the data management foundation they’ve built, Furuno Electric aims to further expand and deepen data utilization. As part of their plan to continue and expand digital transformation, they’re currently starting with the migration of SHIPS, but plan to gradually migrate other IoT-related services (such as FOP, FWC, and Ichidake) to the new data management foundation in the future. This is expected to further strengthen the foundation for company-wide data utilization and enhance synergies between services.
Continuous enhancement of secure data sharing and access control is also essential. With the increase in data and expansion of utilization scope, the importance of security and access control will further increase. They’ll optimize the balance between data protection and utilization while incorporating practices accumulated through operations.
Additionally, Furuno Electric is exploring the expansion of their data management capabilities to Amazon SageMaker, specifically using Amazon SageMaker Catalog integrated with Amazon DataZone. This integration will enable them to seamlessly extend their existing data analytics governance workflows into artificial intelligence and machine learning (AI/ML) workloads. By applying the same data discovery, data sharing, and access control foundation across both data analytics and AI model development, they can accelerate the development of new AI-powered services. The unified governance framework will also provide secure and efficient AI adoption throughout the organization.
Through these initiatives, Furuno Electric is realizing their company motto of “making the invisible visible” in the field of data business as well. The integrated data platform JuBuRaw isn’t just an integration of technical foundations but serves as a foundation to support organizational culture transformation and the creation of new business models. As seen in the SHIPS migration case, using this foundation not only enhances existing services but also expands possibilities for new data utilization.
Through building a data foundation that can flexibly respond to business growth and changes while using a cloud-based environment, Furuno Electric has successfully led their digital transformation. They’ll continue to provide new value to customers through the democratization of marine data and accelerate the transition to data-driven business.
This case serves as a reference for many manufacturing companies promoting data utilization, showing that approaches from both technical and organizational perspectives are key to success. As Furuno Electric’s initiatives demonstrate, data democratization and effective utilization play an important role in the digital transformation of manufacturing.
About the Authors
Akira Mikami is a technical expert who played a central role in the FURUNO Data Platform (JuBuRaw) Construction Project at Furuno Electric Co., Ltd. Specializing in data platform construction and architecture, he led the implementation of cloud solutions utilizing AWS. He contributed to achieving efficient data management and strengthening team collaboration, leading the project to success.
Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at Amazon Web Services (AWS) in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including data mesh, data lakehouse, and generative AI, so customers can build scalable and innovative solutions on Amazon Web Services (AWS).
Mitsuhiko Nishida is an Enterprise Solutions Architecture Automotive & Manufacturing Group Solutions Architect at Amazon Web Services (AWS) in Japan. He serves as a field Solutions Architect for manufacturing customers, helping them solve their business challenges. With expertise in generative AI and manufacturing IT, he guides the design and implementation of innovative solutions leveraging cutting-edge technologies. He supports manufacturing customers in building efficient architecture powered by AWS services to accelerate their cloud transformation journey and contribute to their digital transformation initiatives.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.















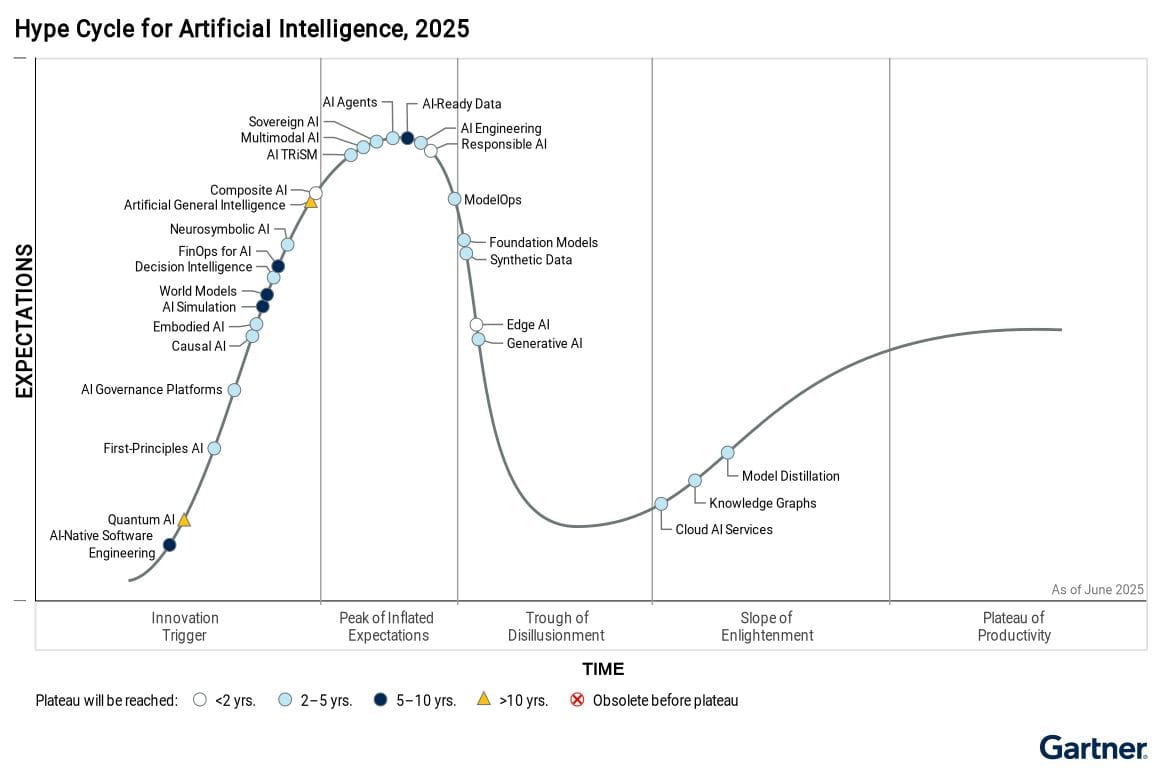




 Akira Mikami is a technical expert who played a central role in the FURUNO Data Platform (JuBuRaw) Construction Project at Furuno Electric Co., Ltd. Specializing in data platform construction and architecture, he led the implementation of cloud solutions utilizing AWS. He contributed to achieving efficient data management and strengthening team collaboration, leading the project to success.
Akira Mikami is a technical expert who played a central role in the FURUNO Data Platform (JuBuRaw) Construction Project at Furuno Electric Co., Ltd. Specializing in data platform construction and architecture, he led the implementation of cloud solutions utilizing AWS. He contributed to achieving efficient data management and strengthening team collaboration, leading the project to success. Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at Amazon Web Services (AWS) in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including data mesh, data lakehouse, and generative AI, so customers can build scalable and innovative solutions on Amazon Web Services (AWS).
Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at Amazon Web Services (AWS) in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including data mesh, data lakehouse, and generative AI, so customers can build scalable and innovative solutions on Amazon Web Services (AWS). Mitsuhiko Nishida is an Enterprise Solutions Architecture Automotive & Manufacturing Group Solutions Architect at Amazon Web Services (AWS) in Japan. He serves as a field Solutions Architect for manufacturing customers, helping them solve their business challenges. With expertise in generative AI and manufacturing IT, he guides the design and implementation of innovative solutions leveraging cutting-edge technologies. He supports manufacturing customers in building efficient architecture powered by AWS services to accelerate their cloud transformation journey and contribute to their digital transformation initiatives.
Mitsuhiko Nishida is an Enterprise Solutions Architecture Automotive & Manufacturing Group Solutions Architect at Amazon Web Services (AWS) in Japan. He serves as a field Solutions Architect for manufacturing customers, helping them solve their business challenges. With expertise in generative AI and manufacturing IT, he guides the design and implementation of innovative solutions leveraging cutting-edge technologies. He supports manufacturing customers in building efficient architecture powered by AWS services to accelerate their cloud transformation journey and contribute to their digital transformation initiatives.