Post Syndicated from Umesh Dangat original https://aws.amazon.com/blogs/big-data/how-yelp-modernized-its-data-infrastructure-with-a-streaming-lakehouse-on-aws/
This is a guest post by Umesh Dangat, Senior Principal Engineer for Distributed Services and Systems at Yelp, and Toby Cole, Principle Engineer for Data Processing at Yelp, in partnership with AWS.
Yelp processes massive amounts of user data daily—over 300 million business reviews, 100,000 photo uploads, and countless check-ins. Maintaining sub-minute data freshness with this volume presented a significant challenge for our Data Processing team. Our homegrown data pipeline, built in 2015 using then-modern streaming technologies, scaled effectively for many years. As our business and data needs evolved, we began to encounter new challenges in managing observability and governance across an increasingly complex data ecosystem, prompting the need for a more modern approach. This affected our outage incidents, making it harder to both assess impact and restore service. At the same time, our streaming framework struggled with Kafka for data streaming and permanent data storage. In addition, our connectors to analytical data stores experienced latencies exceeding 18 hours.
This came to a head when our efforts to comply with General Data Protection Regulation (GDPR) requirements revealed gaps in our infrastructure that would require us to clean up our data, while simultaneously maintaining operational reliability and reducing data processing times. Something had to change.
In this post, we share how we modernized our data infrastructure by embracing a streaming lakehouse architecture, achieving real-time processing capabilities at a fraction of the cost while reducing operational complexity. With this modernization effort, we reduced analytics data latencies from 18 hours to mere minutes, while also removing the need for using Kafka as a permanent storage for our change log streams.
The problem: Why we needed change
We started this transformation by initiating a migration from self-managed Apache Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK), which significantly reduced our operational overhead and enhanced security. Amazon MSK’s express brokers also provided better elasticity for our Apache Kafka clusters. While these improvements were a promising start, we recognized the need for a more fundamental architectural change
Legacy architecture pain points
Let’s examine the specific challenges and limitations of our previous architecture that prompted us to seek a modern solution.
The following diagram depicts Yelp’s original data architecture.
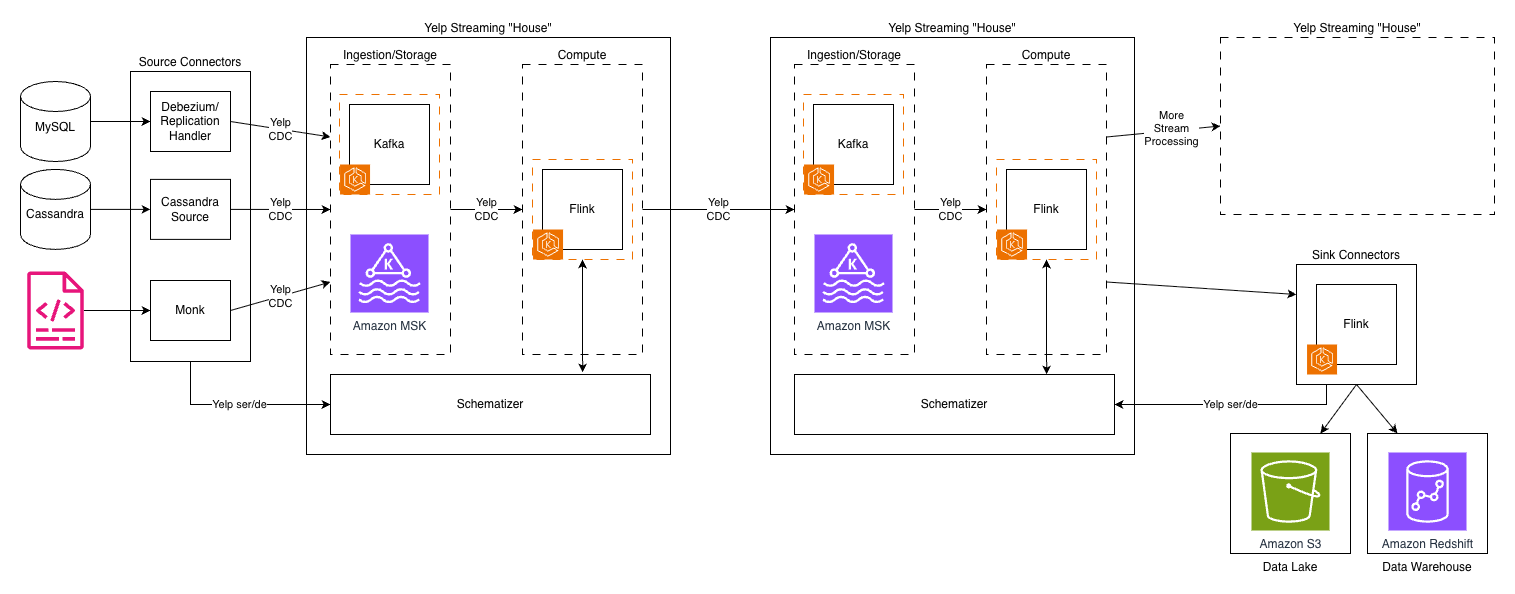
Kafka topics proliferated across our infrastructure, creating long processing chains. As a result, each hop added latency, operational overhead, and storage costs. The system’s reliance on Kafka for both ingestion and storage created a fundamental bottleneck—Kafka’s architecture, optimized for high-throughput messaging, wasn’t designed for long-term storage and to handle complex querying patterns.
Another challenge was our custom “Yelp CDC” format—a proprietary change data capture language—was powerful and tailored to our needs. However, as our team grew and our use cases expanded, it introduced complexity and a steeper learning curve for new engineers. It also made integrations with off-the-shelf systems more complex and maintenance intensive.
The cost and latency trade-off
The traditional trade-off between real-time processing and cost efficiency had us caught in an expensive bind. Real-time streaming systems demand significant resources to maintain state within compute engines like Apache Flink, keep multiple copies of data across Kafka clusters, and run always-on processing jobs. Our infrastructure costs were growing, and it was largely driven by:
- Long Kafka chains: Data often traversed 4-5 Kafka topics before reaching its destination and each topic was replicated for reliability
- Duplicate data storage: The same data existed in multiple formats across different systems—raw in Kafka, processed in intermediate topics, and final forms in data warehouses and Flink RocksDB for join-like use cases
- Complex custom tooling maintenance: The proprietary nature of our tools meant engineering resources were focused on maintenance rather than building new capabilities
Meanwhile, our business requirements became more demanding. Teams at Yelp needed faster insights, near-real-time results, and the ability to quickly run complex historical analyses without delay. This pushed us to shape our new architecture to improve streaming discovery and metadata visibility, provide more flexible transformation tooling, and simplify operational workflows with faster recovery times.
Understanding the streamhouse concept
To understand how we solved our data infrastructure challenges, it’s important to first grasp the concept of a streamhouse and how it differs from traditional architectures.
Evolution of data architecture
To understand why a streaming lakehouse or streamhouse was the answer to our challenges, it’s helpful to trace the evolution of data architectures. The journey from data warehouses to modern streaming systems reveals why each generation solved certain problems while creating new ones.
Data warehouses like Amazon Redshift and Snowflake brought structure and reliability to analytics, but their batch-oriented nature meant accepting hours or days of latency. Data lakes emerged to handle the volume and variety of big data, using low-cost object storage like Amazon S3, but often became “data swamps” without proper governance. The lakehouse architecture, pioneered by technologies like Apache Iceberg and Delta Lake, promised to combine the best of both, the structure of warehouses with the flexibility and economics of lakes.
But even lakehouses were designed with batch processing in mind. While they added streaming capabilities, these were often bolted on rather than fundamental to the architecture. What we needed was something different: a reimagining that treated streaming as a first-class citizen while maintaining lakehouse economics.
What makes a streamhouse different
A streamhouse, as we define it, is “a stream processing framework with a storage layer that leverages a table format, making intermediate streaming data directly queryable.” This seemingly simple definition represents a fundamental shift in how we think about data processing.
Traditional streaming systems maintain dynamic tables like materialized views in databases, but these aren’t directly queryable. You can only consume them as streams, limiting their utility for ad-hoc analysis or debugging. Lakehouses, conversely, excel at queries but struggle with low-latency updates and complex streaming operations like out-of-order event handling or partial updates.
The streamhouse bridges this gap by:
- Treating batch as a special case of streaming, rather than a separate paradigm
- Making data, including intermediate processing results, queryable via SQL
- Providing streaming-native features like database change-data capture (CDC) and temporal joins
- Leveraging cost-effective object storage while maintaining minute-level latencies
Core capabilities we needed
Our requirements for a streaming lakehouse were shaped by years of operating at scale:
Real-time processing with minute-level latency: While sub-second latency wasn’t necessary for most use cases, our previous hours-long delays weren’t acceptable. The sweet spot was processing latencies measured in minutes fast enough for real-time decision-making but relaxed enough to leverage cost-effective storage.
Efficient CDC handling: With numerous MySQL databases powering our applications, the ability to efficiently capture and process database changes was crucial. The solution needed to handle both initial snapshots and ongoing changes seamlessly, without manual intervention or downtime.
Cost-effective scaling: The architecture had to break the linear relationship between data volume and cost. This meant leveraging tiered storage, with hot data on fast storage and cold data on low-cost object storage, all while maintaining query performance.
Built-in data management: Schema evolution, data lineage, time travel queries, and data quality controls needed to be first-class features, not afterthoughts. Our experience maintaining our custom Schematizer taught us that these capabilities were essential for operating at scale.
The solution architecture
Our modernized data infrastructure combines several key technologies into a cohesive streamhouse architecture that addresses our core requirements while maintaining operational efficiency.
Our technology stack selection
We carefully selected and integrated several proven technologies to build our streamhouse solution.The following diagram depicts Yelp’s new data architecture.
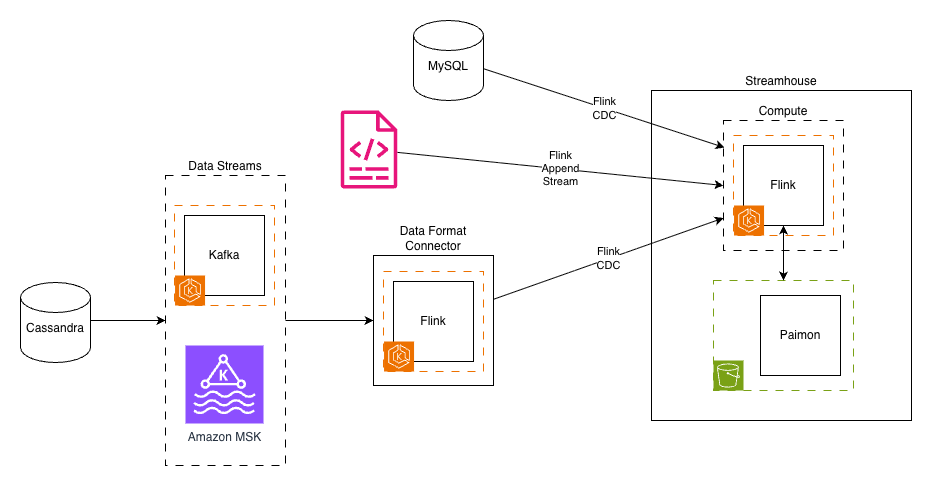
After extensive evaluation, we assembled a modern streaming lakehouse stack, streamhouse, built on proven open source technologies:
Amazon MSK continues to deliver existing streams as they did before from source applications and services.
Apache Flink on Amazon EKS served as our compute engine, a natural choice given our existing expertise and investment in Flink-based processing. Its powerful stream processing capabilities, exactly-once semantics, and mature framework made it ideal for the computational layer.
Apache Paimon emerged as the key innovation, providing the streaming lakehouse storage layer. Born from the Flink community’s FLIP-188 proposal for built-in dynamic table storage, Paimon was designed from the ground up for streaming workloads. Its LSM-tree-based architecture provided the high-speed ingestion capabilities we needed.
Amazon S3 serves as our streamhouse storage layer, offering highly scalable capacity at a fraction of the cost. The shift from compute-coupled storage (Kafka brokers) to object storage represented a fundamental architectural change that unlocked massive cost savings.
Flink CDC connectors replaced our custom CDC implementations, providing battle-tested integrations with databases like MySQL. These connectors handled the complexity of initial snapshots, incremental updates, and schema changes automatically.
Architectural transformation
The transformation from our legacy architecture to the streamhouse model involved three key architectural shifts:
1. Decoupling ingestion from storage
In our old world, Kafka handled both data ingestion and storage, creating an expensive coupling. Every byte ingested had to be stored on Kafka brokers with replication for reliability. Our new architecture separated these concerns: Flink CDC handled ingestion by immediately writing to Paimon tables backed by S3. This separation reduced our storage costs by over 80% and improved reliability through the 11 nines of durability of S3.
2. Unified data format
The migration from our proprietary CDC format to the industry-standard Debezium format was more than a technical change. It reflected a broader move toward community-supported standards. We built a Data Format Converter that bridged the gap, allowing legacy streams to continue functioning while new streams leveraged standard formats. This approach facilitated backward compatibility while paving the way for future simplification.
3. Streamhouse tables
Perhaps the most radical change was replacing some of our Kafka topics with Paimon tables. These weren’t just storage locations—they were dynamic, versioned, queryable entities that supported:
- Time travel queries in the table’s snapshot retention period
- Automatic schema evolution without downtime
- SQL-based access for both streaming and batch workloads
- Built-in compaction and optimization
Key design decisions
Several key design decisions shaped our implementation:
SQL as the primary interface: Rather than requiring developers to write Java or Scala code for every transformation, SQL became our lingua franca. This democratized access to streaming data, allowing analysts and data scientists to work with real-time data using familiar tools.
Separation of compute and storage: By decoupling these layers, we could scale them independently. A spike in processing needs no longer meant provisioning more storage, and historical data could be kept indefinitely without impacting compute costs.
Embracing open source standards: The shift from home-grown formats and tools to community-supported projects reduced our maintenance burden and accelerated feature development. When issues arose, our engineers could leverage community knowledge rather than debugging in isolation.
Implementation journey
Our transition to the new streamhouse architecture followed a carefully planned path, encompassing prototype development, phased migration, and systematic validation of each component.
Migration strategy
Our migration to the streamhouse architecture required careful planning and execution. The strategy had to balance the need for transformation with the reality of maintaining critical production systems.
1. Prototype development
Our journey began with building foundational components:
- Pure Java client library: Removing Scala dependencies were crucial for broader adoption. Our new library removed reliance on Yelp-specific configurations, allowing it to run in many environments.
- Data Format Converter: This bridge component translated between our proprietary CDC format and the standard Debezium format, making sure existing consumers could continue operating during the migration.
- Paimon ingestor: A Flink job that could ingest data from Kafka sources into Paimon tables, handling schema evolution automatically.
2. Phased rollout approach
Rather than attempting a “big bang” migration, we adopted a per-use case approach—moving a vertical slice of data rather than the entire system at once. Our phased rollout followed these steps:
- Select a representative, real-world use case that provides broad coverage of the existing feature set.
- Re-implement the use case on the new stack in a development environment using sample data to test the logic
- Shadow-launch the new stack in production to test it at scale
- This was a critical step for us, as we had to iterate through various configuration tweaks before the system could reliably sustain our production traffic.
- Verify the new production deployment against the legacy system’s output
- Switch live traffic to the new system only after both the Yelp Platform team and data owners are confident in its performance and reliability
- Decommission the legacy system for that use case once the migration is complete
This phased approach allowed our team to build confidence, identify issues early, and refine our processes before touching business-critical systems in production.
Technical challenges we overcame
The migration surfaced several technical challenges that required innovative solutions:
System integration: We developed comprehensive monitoring to track end-to-end latencies and built automated alerting to detect any degradation in performance.
Performance tuning: Initial write performance to Paimon tables was suboptimal for our higher-throughput streams. After careful analysis, we identified that Paimon was re-reading manifest files from S3 on every commit. To alleviate this, we enabled Paimon’s sink writer coordinator cache setting, which is disabled by default. This massively reduced the number of S3 calls during commits. We also found that writing parallelism in Paimon is limited by the number of “buckets” within a partition. Selecting the right number of buckets to allow you to scale horizontally, but also not spread your data too thinly is important for balancing write performance against query performance.
Data validation: Validating data consistency between our legacy Yelp CDC streams and the new Debezium-based format presented notable challenges. During the parallel run phase, we implemented comprehensive validation frameworks to make sure the Data Format Convertor accurately transformed messages, while maintaining data integrity, ordering guarantees, and schema compatibility across both systems.
Data migration complexity: For consistency, we developed custom tooling to verify ordering guarantees and implemented parallel running of old and new systems. We chose Spark as the framework to implement our validations as every data source and sink in our framework has mature connectors, and Spark is a well-supported system at Yelp.
Practical wins we achieved
Our implementation delivered transformative results:
Simplified streaming stack: By replacing multiple custom components with standardized tools, we avoided years of technical debt in one migration. We reduced our complexity and thereby simplified our entire streaming architecture, leading to higher reliability and less maintenance overhead. Our Schematizer, encryption layer, and custom CDC format were all replaced by built-in features from Paimon and standard Kafka, along with IAM controls across S3 and MSK.
Fine-grained access management: Moving our analytical use cases read via Iceberg unlocked a huge win for us: the ability to enable AWS Lake Formation on our data lake. Previously, our access management relied on large, complex S3 bucket policy documents that were approaching their size limits. By moving to Lake Formation we could build an access request lifecycle into our in-house Access Hub to automate access granting and revocation.
Built-in data management features: Capabilities that would have required months of custom development came out-of-the-box, such as automatic schema evolution, time travel queries, and incremental snapshots for efficient processing.
Potential for reduced operational costs: We anticipate that transitioning from Kafka storage to S3 in a streamhouse architecture will significantly reduce storage costs. Avoiding long Kafka chains will also simplify data pipelines and reduce compute costs.
Enhanced troubleshooting capabilities: The streamhouse architecture promises built-in observability features that will make debugging easier. Rather than having to manually look through event streams for problematic data, which can be time-consuming and complex for multi-stream pipelines, engineers can now query live data directly from tables using standard SQL.
Lessons learned and best practices
Throughout this transformation, we gained valuable insights about both technical implementation and organizational change management that can benefit others undertaking similar modernization efforts.
Technical insights
Our journey revealed several crucial technical lessons:
Battle-tested open source wins: Choosing Apache Paimon and Flink CDC over custom solutions proved wise. The community support, continuous improvements, and shared knowledge base accelerated our development and reduced risk.
SQL interfaces democratize access: Making streaming data accessible via SQL transformed who could work with real-time data. Engineers and analysts familiar with SQL can now understand how streaming pipelines work. The barrier to entry has been significantly lowered as engineers no longer need to understand Flink-specific APIs to create a streaming application.
Separation of storage and compute is fundamental: This architectural principle unlocked cost savings and operational flexibility that wouldn’t have been possible otherwise. Our teams can now optimize storage and compute independently based on their specific needs.
Organizational learnings
The human side of the transformation was equally important:
Phased migration reduces risk: Our gradual approach allowed teams to build confidence and expertise, while maintaining business continuity. Each successful phase created momentum for the next. Building trust with newer systems helps gain velocity in later stages of migrations.
Backward compatibility enables progress: By maintaining compatibility layers, our teams could migrate at their own pace without forcing synchronized changes across the organization.
Investment in learning pays dividends: Giving our teams space to learn new technologies like Paimon and streaming SQL had some opportunity cost, but they paid off through increased productivity and reduced operational burden.
Conclusion
Our transformation to a streaming lakehouse architecture (streamhouse) has revolutionized Yelp’s data infrastructure, delivering impressive results across multiple dimensions. By implementing Apache Paimon with AWS services like Amazon S3 and Amazon MSK, we reduced our analytics data latencies from 18 hours to just minutes while cutting storage costs by 80%. The migration also simplified our architecture by replacing multiple custom components with standardized tools, significantly reducing maintenance overhead and improving reliability.
Key achievements include the successful implementation of real-time processing capabilities, streamlined CDC handling, and enhanced data management features like automatic schema evolution and time travel queries. The shift to SQL-based interfaces has democratized access to streaming data, while the separation of compute and storage has given us unprecedented flexibility in resource optimization. These improvements have transformed not just our technology stack, but also how our teams work with data.
For organizations facing similar challenges with data processing latency, operational costs, and infrastructure complexity, we encourage you to explore the streamhouse approach. Start by evaluating your current architecture against modern streaming solutions, particularly those leveraging cloud services and open-source technologies like Apache Paimon. Make sure to leverage security best practices when implementing your solution. You can find AWS security best practices here. Visit the Apache Paimon website or AWS documentation to learn more about implementing these solutions in your environment.