Post Syndicated from Samuel Macleod original https://blog.cloudflare.com/connecting-to-production-the-architecture-of-remote-bindings/
Remote bindings are bindings that connect to a deployed resource on your Cloudflare account instead of a locally simulated resource – and recently, we announced that remote bindings are now generally available.
With this launch, you can now connect to deployed resources like R2 buckets and D1 databases while running Worker code on your local machine. This means you can test your local code changes against real data and services, without the overhead of deploying for each iteration.
In this blog post, we’ll dig into the technical details of how we built it, creating a seamless local development experience.
A key part of the Cloudflare Workers platform has been the ability to develop your code locally without having to deploy it every time you wanted to test something – though the way we’ve supported this has changed greatly over the years.
We started with wrangler dev running in remote mode. This works by deploying and connecting to a preview version of your Worker that runs on Cloudflare’s network every time you make a change to your code, allowing you to test things out as you develop. However, remote mode isn’t perfect — it’s complex and hard to maintain. And the developer experience leaves a lot to be desired: slow iteration speed, unstable debugging connections, and lack of support for multi-worker scenarios.
Those issues and others motivated a significant investment in a fully local development environment for Workers, which was released in mid-2023 and became the default experience for wrangler dev. Since then, we’ve put a huge amount of work into the local dev experience with Wrangler, the Cloudflare Vite plugin (alongside @cloudflare/vitest-pool-workers) & Miniflare.
Still, the original remote mode remained accessible via a flag: wrangler dev --remote. When using remote mode, all the DX benefits of a fully local experience and the improvements we’ve made over the last few years are bypassed. So why do people still use it? It enables one key unique feature: binding to remote resources while locally developing. When you use local mode to develop a Worker locally, all of your bindings are simulated locally using local (initially empty) data. This is fantastic for iterating on your app’s logic with test data – but sometimes that’s not enough, whether you want to share resources across your team, reproduce bugs tied to real data, or just be confident that your app will work in production with real resources.
Given this, we saw an opportunity: If we could bring the best parts of remote mode (i.e. access to remote resources) to wrangler dev, there’d be one single flow for developing Workers that would enable many use cases, while not locking people out of the advancements we’ve made to local development. And that’s what we did!
As of Wrangler v4.37.0 you can pick on a per-binding basis whether a binding should use remote or local resources, simply by specifying the remote option. It’s important to re-emphasise this—you only need to add remote: true! There’s no complex management of API keys and credentials involved, it all just works using Wrangler’s existing Oauth connection to the Cloudflare API.
{
"name": "my-worker",
"compatibility_date": "2025-01-01",
"kv_namespaces": [{
"binding": "KV",
"id": "my-kv-id",
},{
"binding": "KV_2",
"id": "other-kv-id",
"remote": true
}],
"r2_buckets": [{
"bucket_name": "my-r2-name",
"binding": "R2"
}]
}The eagle-eyed among you might have realised that some bindings already worked like this, accessing remote resources from local dev. Most prominently, the AI binding was a trailblazer for what a general remote bindings solution could look like. From its introduction, the AI binding always connected to a remote resource, since a true local experience that supports all the different models you can use with Workers AI would be impractical and require a huge upfront download of AI models.
As we realised different products within Workers needed something similar to remote bindings (Images and Hyperdrive, for instance), we ended up with a bit of a patchwork of different solutions. We’ve now unified under a single remote bindings solution that works for all binding types.
We wanted to make it really easy for developers to access remote resources without having to change their production Workers code, and so we landed on a solution that required us to fetch data from the remote resource at the point of use in your Worker.
const value = await env.KV.get("some-key")The above code snippet shows accessing the “some-key” value in the env.KV KV namespace, which is not available locally and needs to be fetched over the network.
So if that was our requirement, how would we get there? For instance, how would we get from a user calling env.KV.put(“key”, “value”) in their Worker to actually storing that in a remote KV store? The obvious solution was perhaps to use the Cloudflare API. We could have just replaced the entire env locally with stub objects that made API calls, transforming env.KV.put() into PUT http:///accounts/{account_id}/storage/kv/namespaces/{namespace_id}/values/{key_name}.
This would’ve worked great for KV, R2, D1, and other bindings with mature HTTP APIs, but it would have been a pretty complex solution to implement and maintain. We would have had to replicate the entire bindings API surface and transform every possible operation on a binding to an equivalent API call. Additionally, some binding operations don’t have an equivalent API call, and wouldn’t be supportable using this strategy.
Instead, we realised that we already had a ready-made API waiting for us — the one we use in production!
Most bindings on the Workers platform boil down to essentially a service binding. A service binding is a link between two Workers that allows them to communicate over HTTP or JSRPC (we’ll come back to JSRPC later).
For example, the KV binding is implemented as a service binding between your authored Worker and a platform Worker, speaking HTTP. The JS API for the KV binding is implemented in the Workers runtime, and translates calls like env.KV.get() to HTTP calls to the Worker that implements the KV service.

Diagram showing a simplified model of how a KV binding works in production
You may notice that there’s a natural async network boundary here — between the runtime translating the env.KV.get() call and the Worker that implements the KV service. We realised that we could use that natural network boundary to implement remote bindings. Instead of the production runtime translating env.KV.get() to an HTTP call, we could have the local runtime (workerd) translate env.KV.get() to an HTTP call, and then send it directly to the KV service, bypassing the production runtime. And so that’s what we did!

Diagram showing a locally run worker with a single KV binding, with a single remote proxy client that communicates to the remote proxy server, which in turn communicates with the remote KV
The above diagram shows a local Worker running with a remote KV binding. Instead of being handled by the local KV simulation, it’s now being handled by a remote proxy client. This Worker then communicates with a remote proxy server connected to the real remote KV resource, ultimately allowing the local Worker to communicate with the remote KV data seamlessly.
Each binding can independently either be handled by a remote proxy client (all connected to the same remote proxy server) or by a local simulation, allowing for very dynamic workflows where some bindings are locally simulated while others connect to the real remote resource, as illustrated in the example below:

The above diagram and config shows a Worker (running on your computer) bound to 3 different resources—two local (KV & R2), and one remote (KV_2)
The above section deals with bindings that are backed by HTTP connections (like KV and R2), but modern bindings use JSRPC. That means we needed a way for the locally running workerd to speak JSRPC to a production runtime instance.
In a stroke of good luck, a parallel project was going on to make this possible, as detailed in the Cap’n Web blog. We integrated that by making the connection between the local workerd instance and the remote runtime instance communicate over websockets using Cap’n Web, enabling bindings backed by JSRPC to work. This includes newer bindings like Images, as well as JSRPC service bindings to your own Workers.
We didn’t want to limit this exciting new feature to only wrangler dev. We wanted to support it in our Cloudflare Vite Plugin and vitest-pool-workers packages, as well as allowing any other potential tools and use cases from the JavaScript ecosystem to also benefit from it.
In order to achieve this, the wrangler package now exports utilities such as startRemoteProxySession that allow tools not leveraging wrangler dev to also support remote bindings. You can find more details in the official remote bindings documentation.
Just use wrangler dev! As of Wrangler v4.37.0 (@cloudflare/vite-plugin v1.13.0, @cloudflare/vitest-pool-workers v0.9.0), remote bindings are available in all projects, and can be turned on a per-binding basis by adding remote: true to the binding definition in your Wrangler config file.

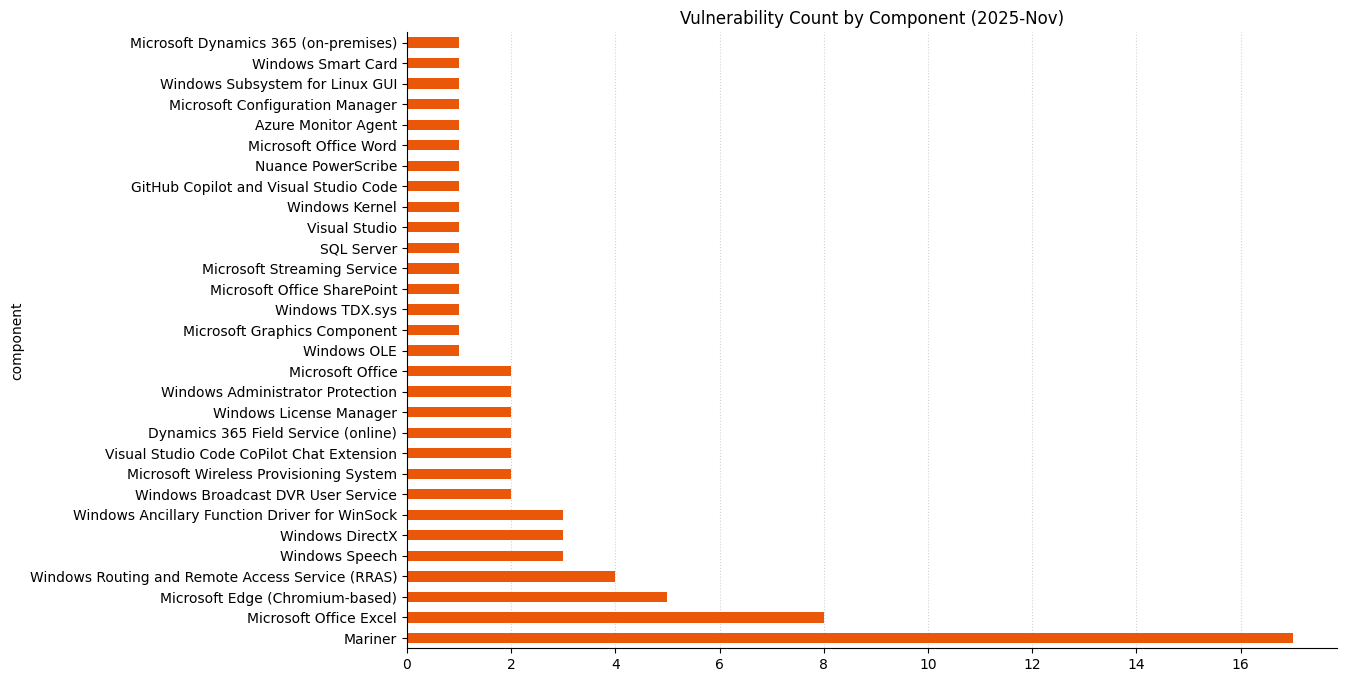

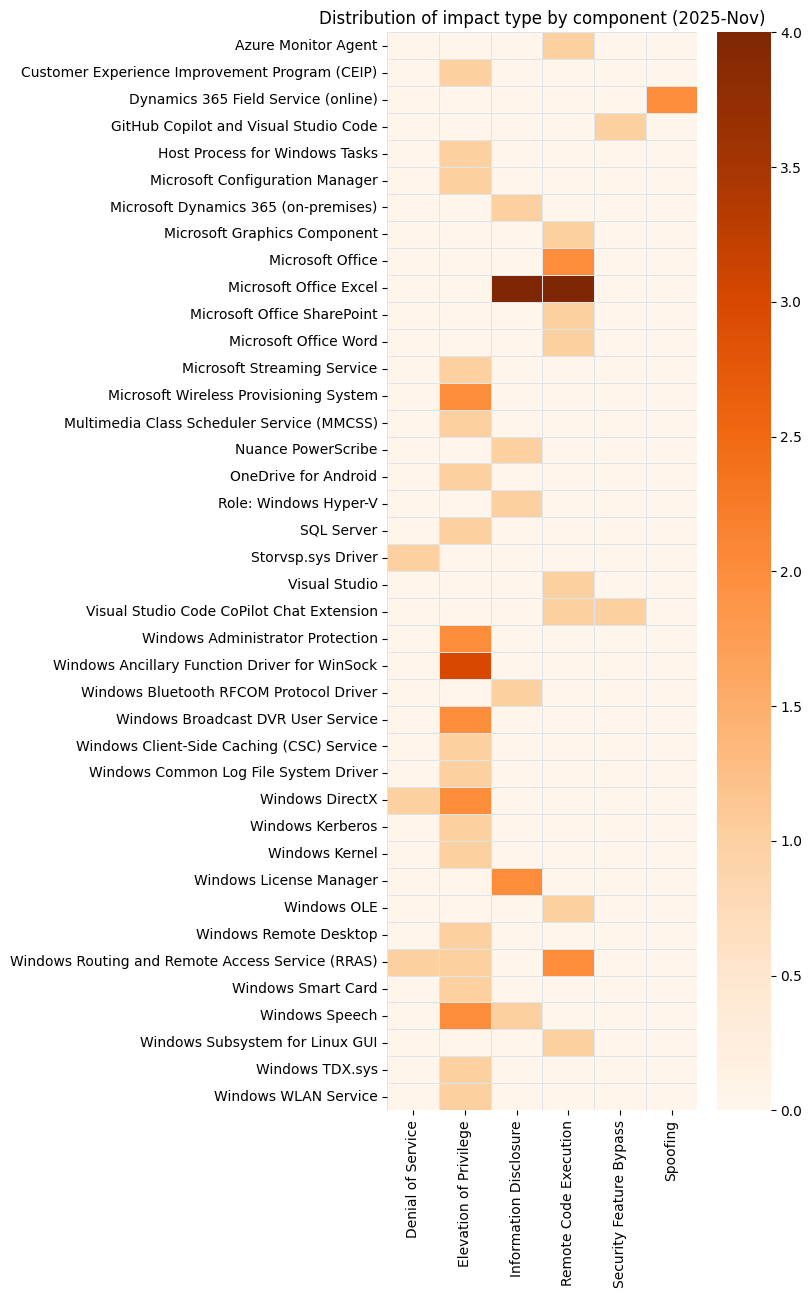
















{kind=link}