This past Friday, April 19, the University of South Florida (USF) College of Engineering recognized individuals and organizations who have greatly impacted USF and beyond at its ninth annual Engineering Honors Awards at The Armature Works in Tampa. I had the honor of joining my colleagues, including Rapid7 CEO, Corey Thomas, who accepted the Corporate Impact Award on behalf of the company.
The Corporate Impact Award is among the highest and most prestigious recognitions given by the College of Engineering. It recognizes Rapid7’s significant contributions to the College and its students. Receiving this award is incredibly gratifying for the Rapid7 Labs team as well as the greater Rapid7 organization.
Rapid7 CEO Corey Thomas accepts the Corporate Impact Award from Dr. Sanjukta Bhanja, Executive Associate Dean of the USF College of Engineering.
In February 2023, the Rapid7 Cybersecurity Foundation invested in USF to create the Rapid7 Cyber Threat Intelligence Lab. Furthermore, Rapid7 is actively working with a multi-disciplinary team at USF to research and develop training to better educate students for taking SOC roles, funded by the National Science Foundation and the Office of Naval Research.
Equally important has been Rapid7’s enthusiasm for directly working with researchers, professors, and students. Our Open Data Initiative provides real-world data derived from internet scans and honeypot data. We support research into training future SOC professionals by exposing them to teams working to protect our networks. A significant number of our teammates in Rapid7’s Tampa office are graduates from University of South Florida, a trend we aim to continue.
Rapid7’s USF partners, along with CEO Corey Thomas, at our Tampa office.
The future of Rapid7 and USF is bright, especially with the recent announcement of the formation of the College of AI and Cybersecurity at University of South Florida.
Rapid7 would like to not only thank the USF College of Engineering for recognizing our efforts in supporting the College, but more importantly, we want to thank them for being a great partner in driving research in the cybersecurity field as well as working alongside us to train the next generation of professionals. The future of cybersecurity depends on helping today’s students gain the tools they need to be successful, an area where University of South Florida excels.
На 9-ти юни 2024 ще се проведат избори за Народно събрание и Европейски парламент. Вече може да подавате заявление за гласуване зад граница. Ще намерите формуляра на страницата на ЦИК. Там може да проверите и дали правилно е записано заявлението ви. Ето няколко важни неща, които трябва да знаете:
Крайният срок за подаване е 14-ти май в полунощ българско време
Подаването на заявление за гласуване в секцията най-близо до Вас, ще Ви улесни и ще ускори изборния процес, тъй като ще сте вече вписани в списъците
Заявление се подава за всеки вот поотделно. Т.е. не се пренасят от предходни избори
Дори да подадете заявление, а се окаже, че на 9-ти юни сте в България, ще може да гласувате в секцията си по постоянен адрес с попълване на декларация (Приложение 28 и 29 на страницата на ЦИК)
Вече са предварително одобрени 776 места за секции в чужбина, където в последните 5 години е имало поне 100 гласували. Това не означава, че непременно ще има секции на тези места. Това зависи от възможностите на помещенията и дали има комисии и доброволци към тях. В крайна сметка решението е на ЦИК по препоръка на Външно. Могат да се увеличат шансовете като се подават заявления за тези места и повече хора се включат като членове на комисии и доброволци.
На някои места като Германия е нужно да се иска разрешение от местните власти. Това вече би трябвало да се случва предвид предварително одобрените места. Очакваме информация от Външно
Подаването на заявления освен, че подпомага изборния процес, показва и повишен интерес на съгражданите ни в чужбина към вота
Събирането на заявленията и визуализацията в картата на Glasuvam.org, каквото правих години наред, в момента е невъзможно, тъй като ЦИК изглежда са блокирали такива опити. Търся начин да го възстановя.
Last week the Backblaze team connected with the best and brightest of the media and entertainment industry at the National Association of Broadcasters (NAB) conference in Las Vegas. For those who missed out, here is a recap of last week events:
Event Notifications Launches at NAB 2024
Event Notifications gives you the freedom to build automated workflows across the different best-of-breed cloud platforms you use or want to use—saving time, money, and improving your end users’ experiences. After demoing this new service for folks working across media workflows at the NAB show and winning the NAB Product of the Year in the Cloud Computing and Storage category, the Event Notifications private preview list is filling up, but you can still join it today.
Backblaze B2 Cloud Storage Event Notifications Wins NAB Best of Show Product of the Year
Backblaze Achieves TPN Blue Shield Status
More news for media and entertainment leaders: Backblaze joined the Trusted Partner Network (TPN), receiving Blue Shield status. TPN is the Motion Picture Association’s initiative aimed at advancing trust and security best practices across the media and entertainment industry. This important initiative provides greater transparency and confidence in the procurement process as you advance your workflow with new technology.
Axle AI Cloud is Powered by Backblaze
A testament to the power of partnerships across the industry, Axel AI announced Axel AI Cloud Powered by Backblaze, a new, highly affordable, AI-powered media storage service that leverages Backblaze’s new Powered by Backblaze program for affordable, seamlessly integrated AI tagging, transcription, and search.
Experts on Stage
For the first time, Backblaze hosted a series of events together with Partners and customers, delivering actionable insights for folks on the show floor to improve their own media workflows. Our Backblaze Tech Talks featured Quantum, CuttingRoom, iconik, ELEMENTS, Axel AI, CloudSoda, Hedge, bunny.net, Suite Studios, and Qencode. Huge thanks to the presenters and everyone who came by.
See You at the Next One
Thank you to all of our customers, partners, and friends who helped make last week a hit. We are already looking forward to NAB–NY, IBC, NAB 2025—and, most of all, to moving the industry forward together.
On Friday, April 19, 2024, managed file transfer vendor CrushFTP released information to a private mailing list on a new zero-day vulnerability affecting versions below 10.7.1 and 11.1.0 (as well as legacy 9.x versions) across all platforms. No CVE was assigned by the vendor, but a third-party CVE Numbering Authority (CNA) assigned CVE-2024-4040 as of Monday, April 22. According to a public-facing vendor advisory, the vulnerability is ostensibly a VFS sandbox escape in CrushFTP managed file transfer software that allows “remote attackers with low privileges to read files from the filesystem outside of VFS Sandbox.”
Rapid7’s vulnerability research team analyzed CVE-2024-4040 and determined that it is fully unauthenticated and trivially exploitable; successful exploitation allows for not only arbitrary file read as root, but also authentication bypass for administrator account access and full remote code execution. Successful exploitation allows a remote, unauthenticated attacker to access and potentially exfiltrate all files stored on the CrushFTP instance.
Although the vulnerability has been formally described as an arbitrary file read, Rapid7 believes that it can be more accurately categorized as a server-side template injection (SSTI). CVE-2024-4040 was exploited in the wild as a zero-day vulnerability, per private customer communications from the vendor and a public Reddit post from security firm CrowdStrike. Using a query that looks for a specific JavaScript file in the web interface, there appear to be roughly 5,200 instances of CrushFTP exposed to the public internet.
Mitigation guidance
According to the advisory, CrushFTP versions below 11.1 are vulnerable to CVE-2024-4040. The following versions of CrushFTP are vulnerable as of April 22, 2024:
All legacy CrushFTP 9 installations
CrushFTP 10 before v10.7.1
CrushFTP 11 before v11.1.0
The vulnerability has been patched in version 11.1.0 for the 11.x version stream, and in version 10.7.1 for the 10.x version stream. The vendor advisory emphasizes the importance of updating to a fixed version of CrushFTP on an urgent basis. Rapid7 echoes this guidance, particularly given our team’s findings on the true impact of the issue, and urges organizations to apply the vendor-supplied patch on an emergency basis, without waiting for a typical patch cycle to occur.
While the vendor guidance as of April 22 says that “customers using a DMZ in front of their main CrushFTP instance are partially protected,” it’s unclear whether this is actually an effective barrier to exploitation. Out of an abundance of caution, Rapid7 advises against relying on a DMZ as a mitigation strategy.
CrushFTP customers can harden their servers against administrator-level remote code execution attacks by enabling Limited Server mode with the most restrictive configuration possible. Organizations should also use firewalls wherever possible to aggressively restrict which IP addresses are permitted to access CrushFTP services.
Rapid7 customers
A vulnerability check for InsightVM and Nexpose customers is in development and expected to be available in either today’s (Tuesday, April 23) or tomorrow’s (Wednesday, April 24) content release.
The Rust programming language, it is hoped, will bring a new level of
safety to the Linux kernel. At the moment, though, there are still a
number of impediments to getting useful Rust code into the kernel. In the
Embedded Open Source Summit track of the Open
Source Summit North America, Fabien Parent provided an overview of his
work aimed at improving the infrastructure needed to write the device
drivers needed by embedded systems in Rust; there is still some work to be
done.
Security updates have been issued by Debian (glibc and samba), Fedora (chromium, cjson, mingw-python-idna, and pgadmin4), Mageia (kernel, kmod-xtables-addons, kmod-virtualbox, kernel-linus, and perl-Clipboard), Red Hat (go-toolset:rhel8, golang, java-11-openjdk, kpatch-patch, and shim), Slackware (freerdp), SUSE (apache-commons-configuration, glibc, jasper, polkit, and qemu), and Ubuntu (google-guest-agent, google-osconfig-agent, linux-lowlatency-hwe-6.5, pillow, and squid).
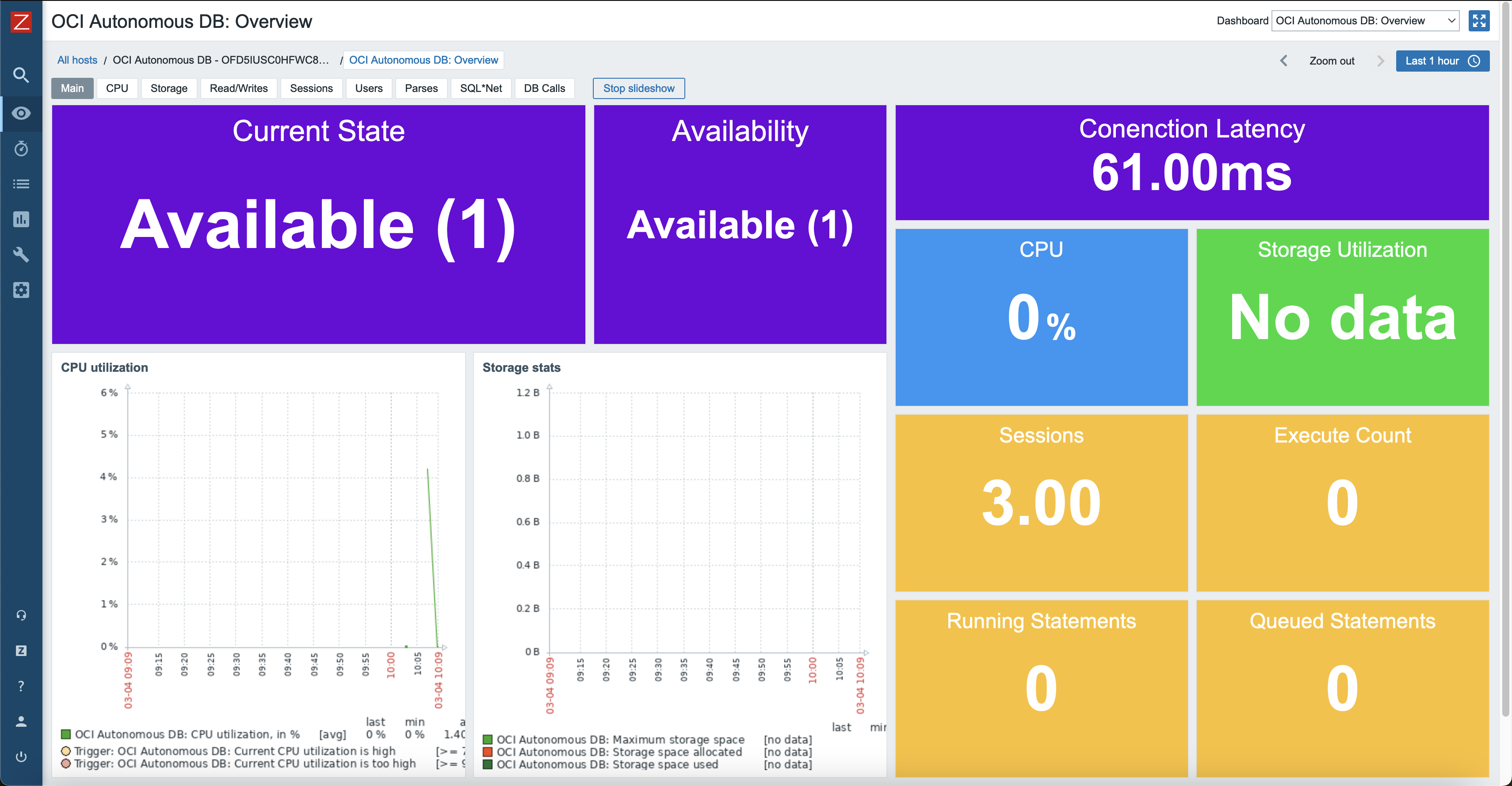
Monitoring Oracle Cloud Infrastructure resources is crucial for maintaining optimal performance, security, and cost-efficiency. By continuously monitoring resources such as compute instances, storage, databases, and networking components, you can proactively identify and address potential issues before they escalate, ensuring uninterrupted service delivery.
Monitoring also provides valuable insights into resource utilization patterns, enabling capacity planning and optimization efforts. Furthermore, effective monitoring enhances security posture by detecting anomalies or suspicious activities that could indicate potential security breaches.
This integration consists of multiple templates, where each template covers a specific OCI resource. As of writing this blog post, such services are supported:
OCI Compute;
OCI Autonomous Database (serverless);
OCI Object Storage;
OCI Virtual Cloud Networks (VCNs);
OCI Block Volumes;
OCI Boot Volumes.
The structure of these templates is made so that you do not need to configure each service separately. There is a master template Oracle Cloud by HTTP, which needs to be configured and rest of the services get monitored automatically using low-level discovery and host prototypes. Overall, the structure of templates looks like this:
Prepare OCI for monitoring with Zabbix
In all of these examples, an OCI web console will be used, therefore, keep in mind that some of the UI elements or navigation menus can potentially change in the future.
User creation
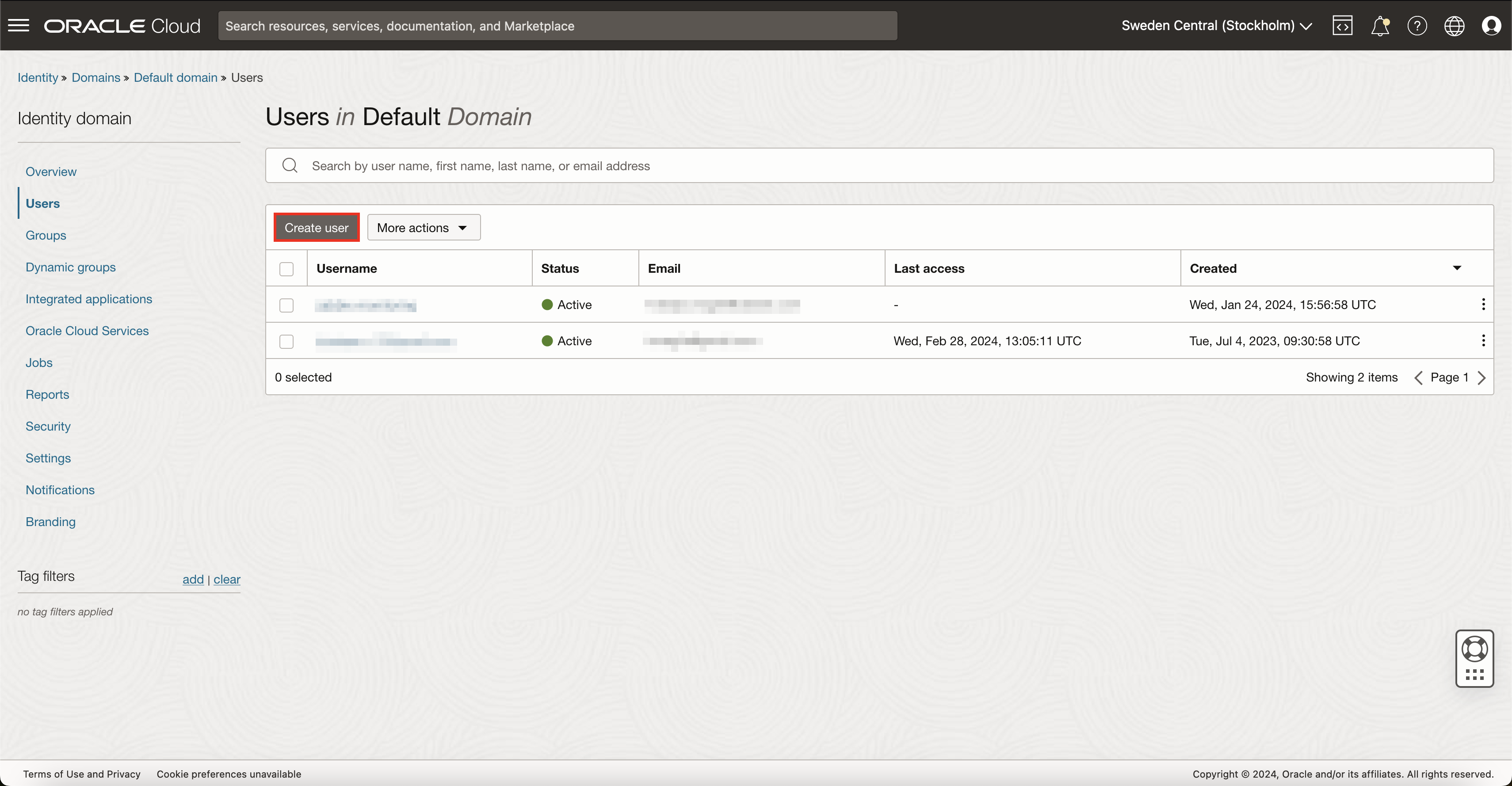
First of all, you need to set up a user in OCI that Zabbix will use to access the Rest API and gather data. To do so, navigate to 'Identity & Security' -> 'Domains' from the main menu in top-left of the screen. Select the domain for which you wish to monitor resources and head over to Users view on the left sidebar. Here, create a new user.
API key generation
After this, OCI should automatically redirect you to the newly created user page. If not, for some reason, go back to all users in domain and open your previously created user.
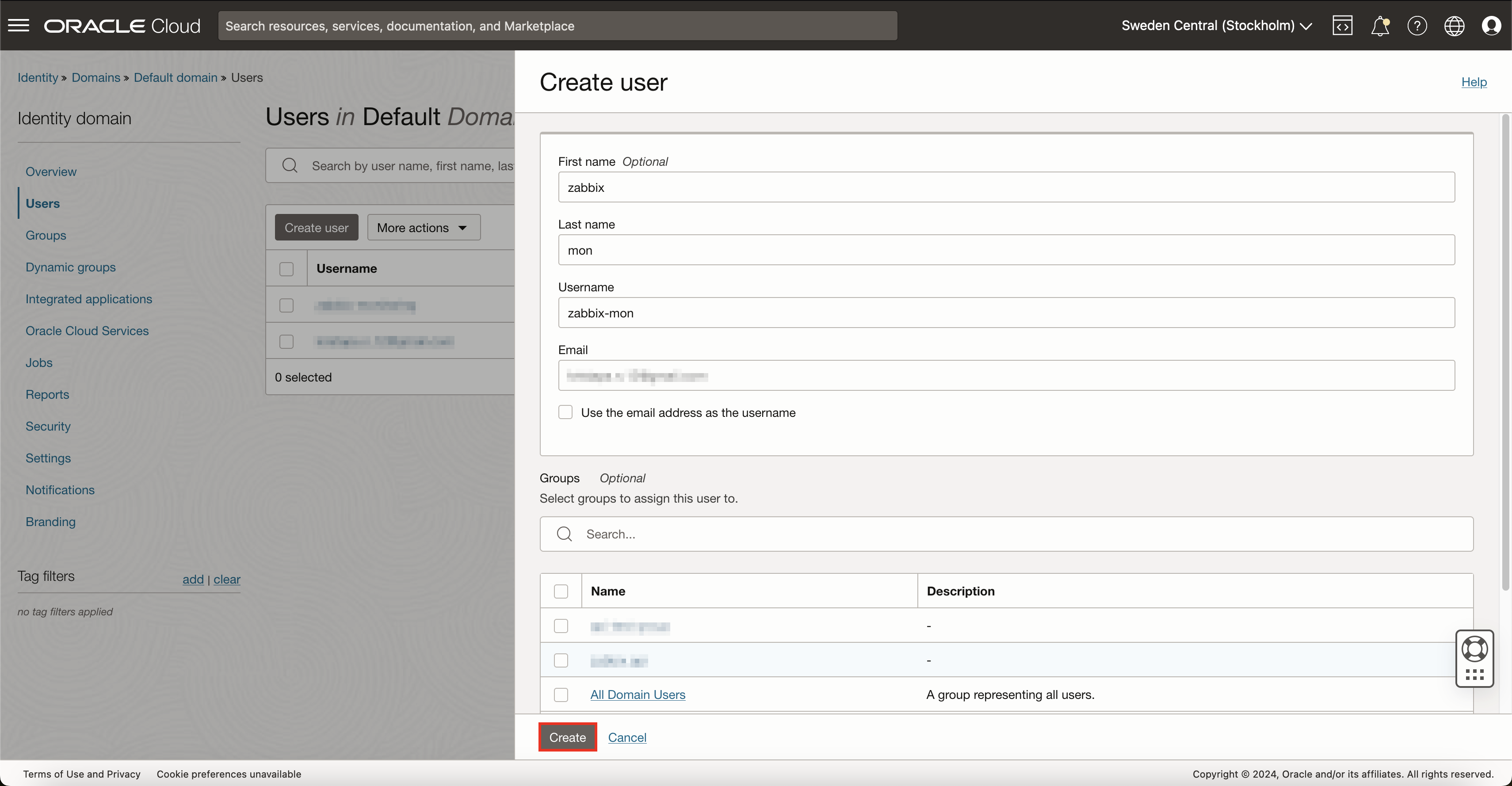
You need to assign API keys to this user. To do so, on the left sidebar, press API keys and then Add API key. If you already have an RSA key pair that you wish to use for this monitoring user, you can select an option to either upload or paste the public key. However, in this example, I will generate a completely new key pair.
After pressing button Add, OCI will show you details about your environment and the API key. Save this information somewhere safe for now, as we will need to use this data later inside Zabbix. After saving this, you can now close this pop-up.
User group creation
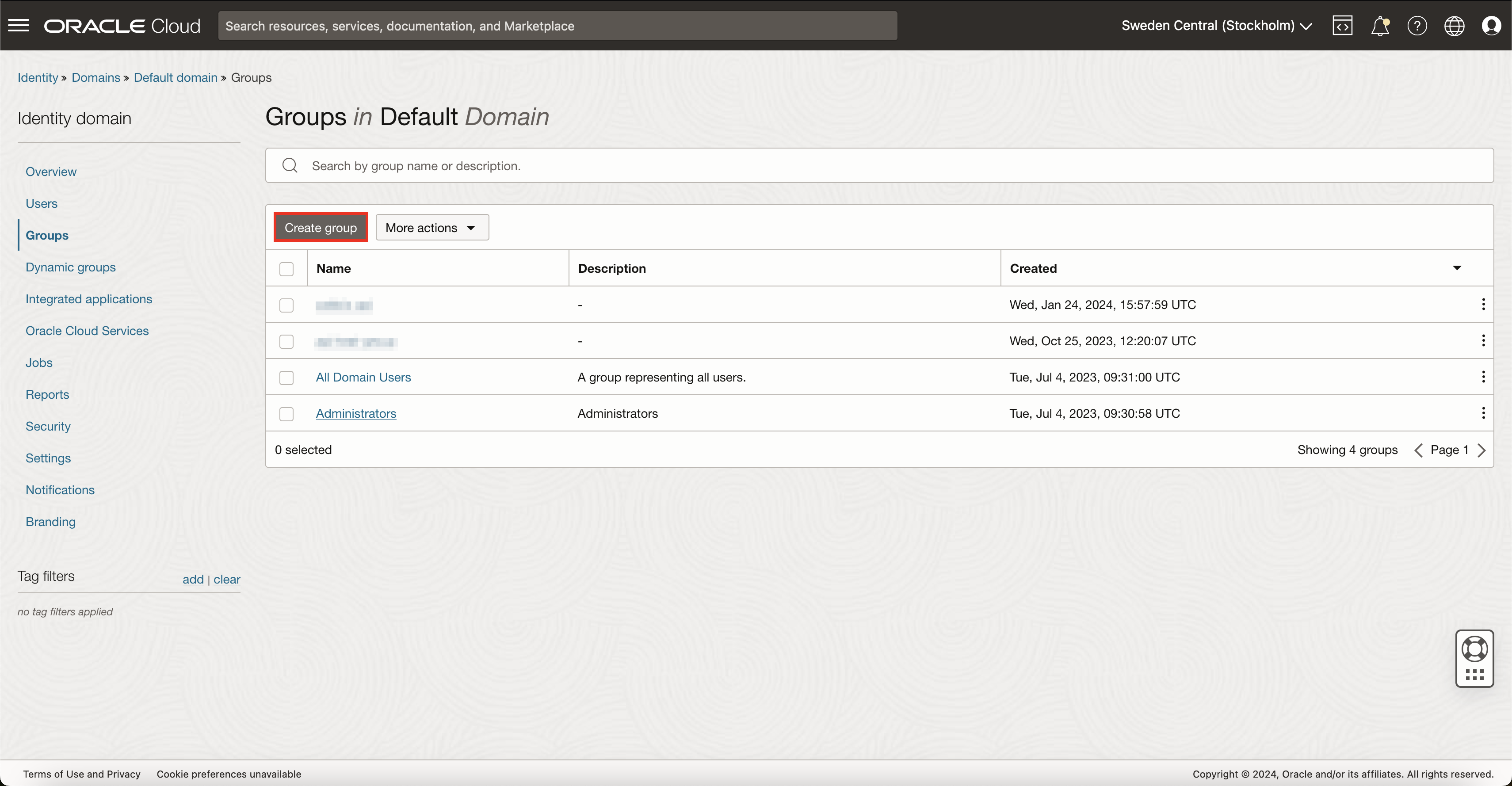
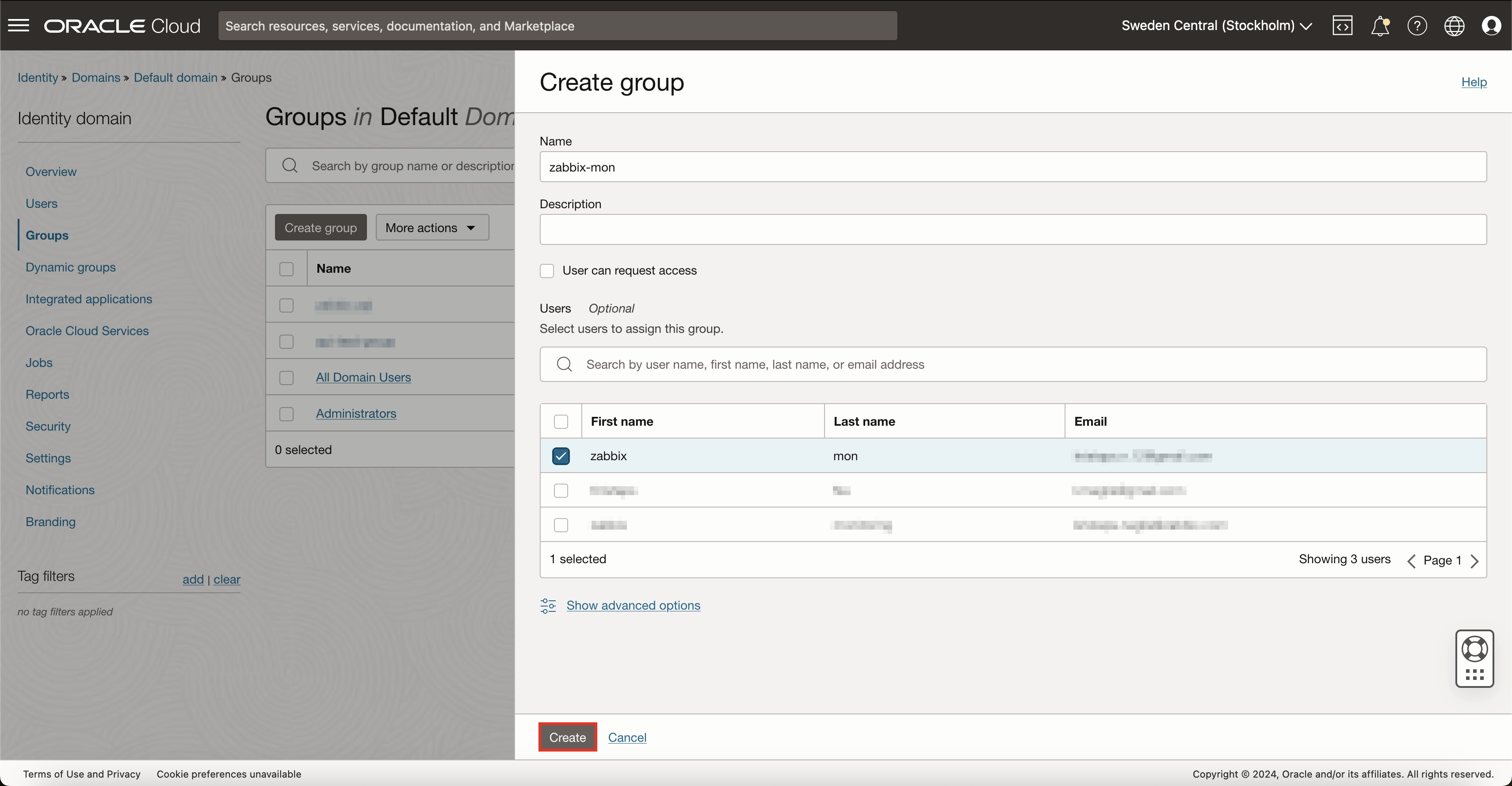
To make user management more flexible, a good idea would be to create a user group specifically for monitoring and assign monitoring user to this group. So in case, in the future, you will need more monitoring users, you will be able to just assign those users to a common monitoring user group, and all access rights will work automatically.
To do this, navigate back to 'Identity & Security' -> 'Domains' and select Groups. Here press on button Create group. Give a name for this group and assign your monitoring user to it while you’re at it.
Policy creation
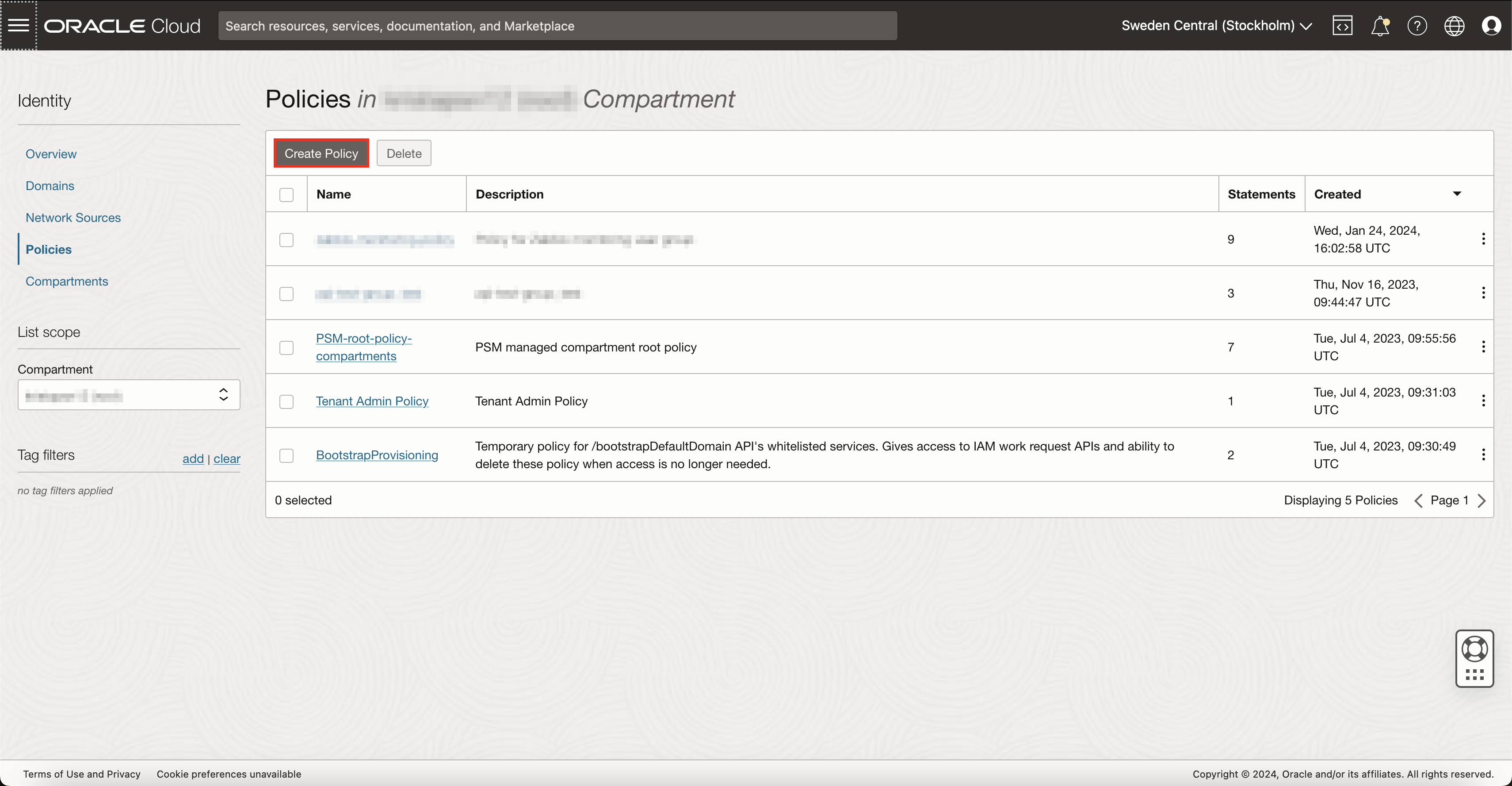
Now that you have successfully created a monitoring user, generated API keys and created a user group for monitoring, you now need to create a new OCI policy. Policies in OCI regulate what resources its users can access and what they can do with those resources. To create a new policy, open the top-left menu and navigate to 'Identity & Security' -> 'Policies' and press on the button Create Policy.
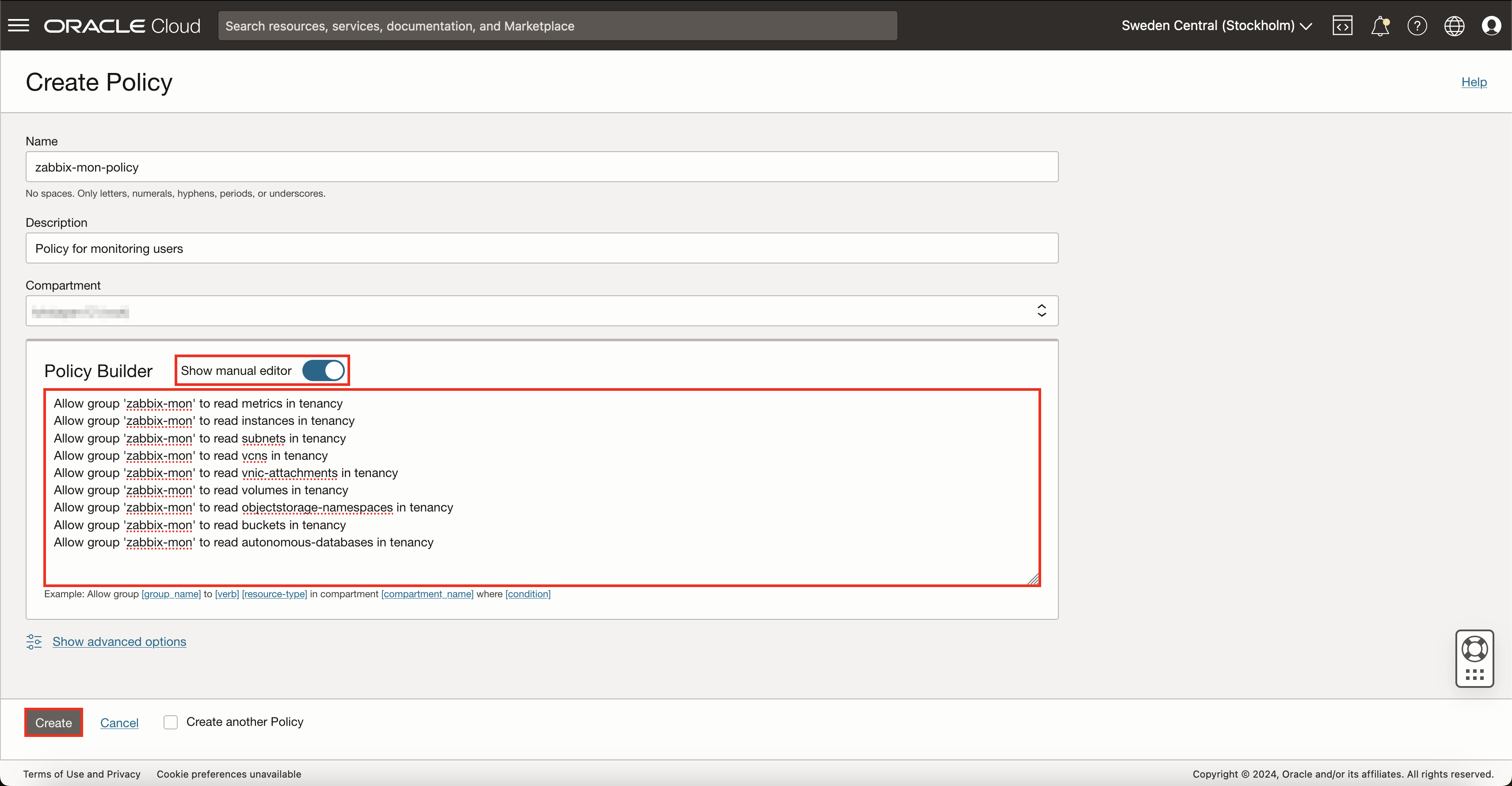
This will open a new view where you can define policy settings. Give this policy a name and description and select the appropriate compartment. Inside the policy builder, enable Show manual editor and copy-paste these rules, just remember to replace zabbix-mon with your monitoring group name:
Allow group 'zabbix-mon' to read metrics in tenancy
Allow group 'zabbix-mon' to read instances in tenancy
Allow group 'zabbix-mon' to read subnets in tenancy
Allow group 'zabbix-mon' to read vcns in tenancy
Allow group 'zabbix-mon' to read vnic-attachments in tenancy
Allow group 'zabbix-mon' to read volumes in tenancy
Allow group 'zabbix-mon' to read objectstorage-namespaces in tenancy
Allow group 'zabbix-mon' to read buckets in tenancy
Allow group 'zabbix-mon' to read autonomous-databases in tenancy
This set of rules will give your monitoring group users read-only access to only those resources that Zabbix Oracle Cloud Infrastructure templates use.
After you are done, press the Create button and the policy will be created.
If you decide to modify our template to access more data from OCI, you will need to append appropriate rules here as well.
That is it for configuration on the OCI side now.
Prepare Zabbix
Create host
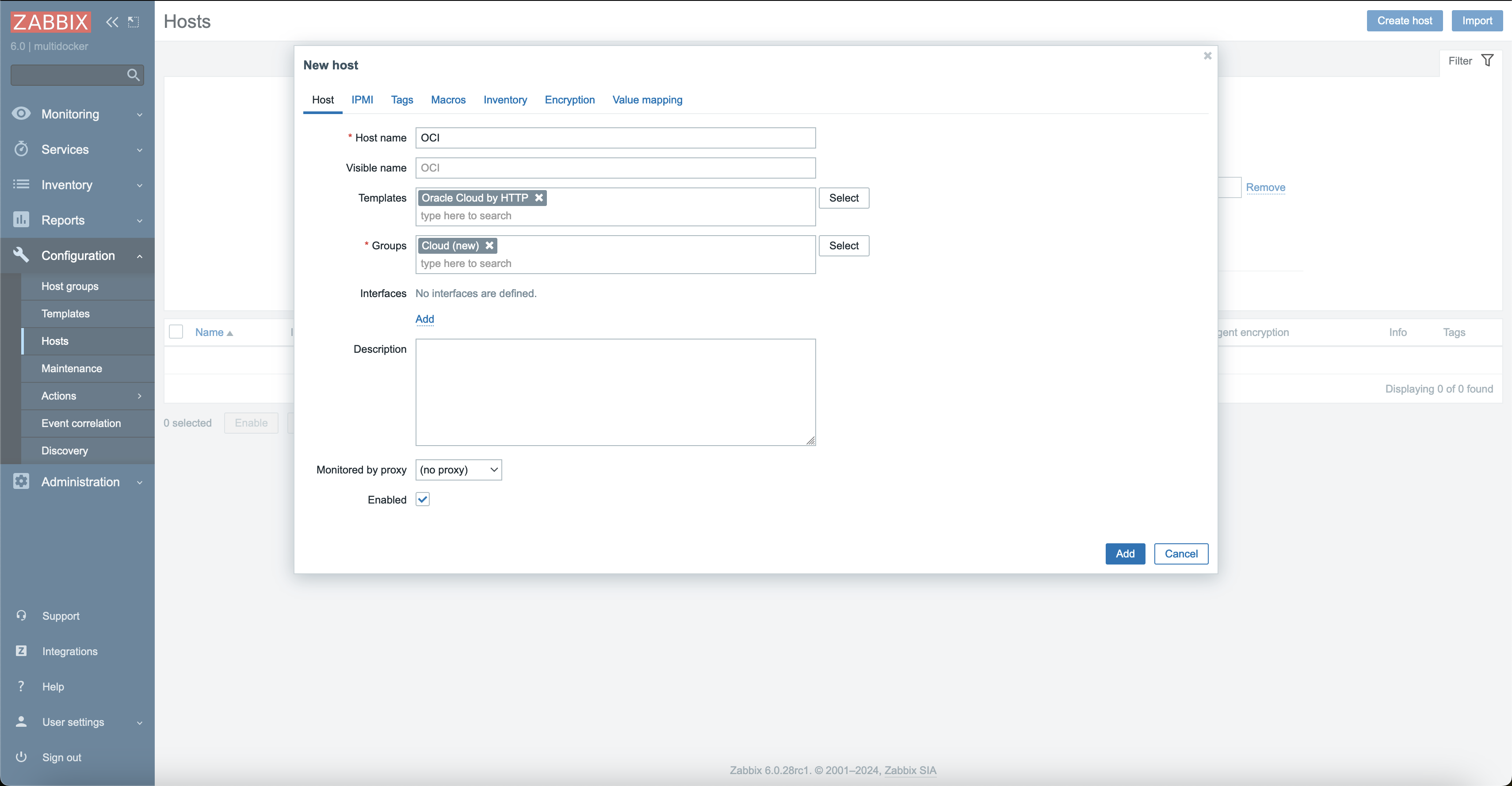
First, open up your Zabbix web interface, head over to Hosts section and create a new host. Here, you will need to specify a host name of your choice, template Oracle Cloud by HTTPS and assign it to a group.
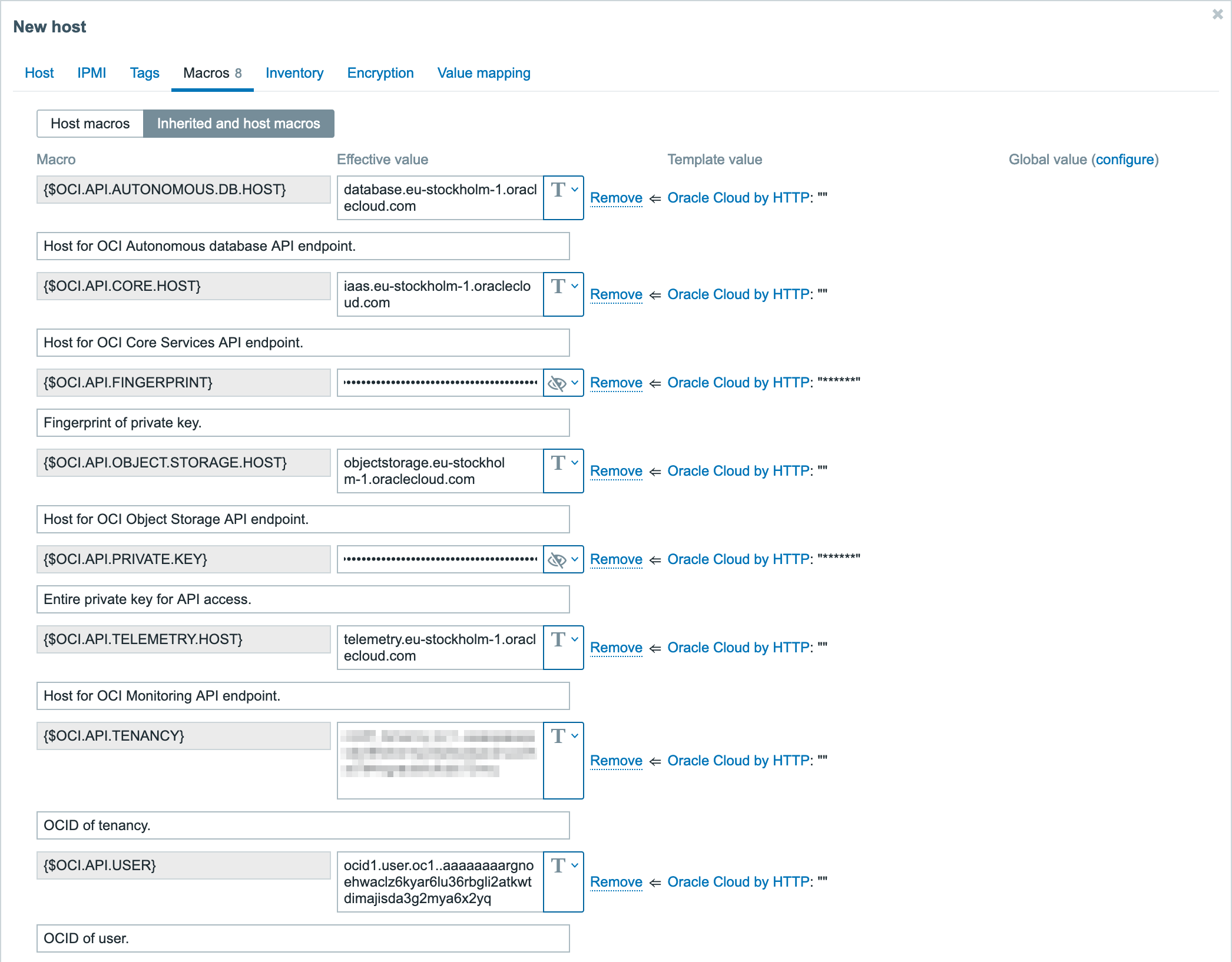
Before pressing the Add button, you should configure macros. Open the Macros tab and select Inherited and host macros. There will be quite a few of them, but each with its own use-case. Some of these macros are discussed in Optional configuration section, so for now let’s focus on the ones that are necessary for template to work at all.
Essentially, there are 3 steps to take here:
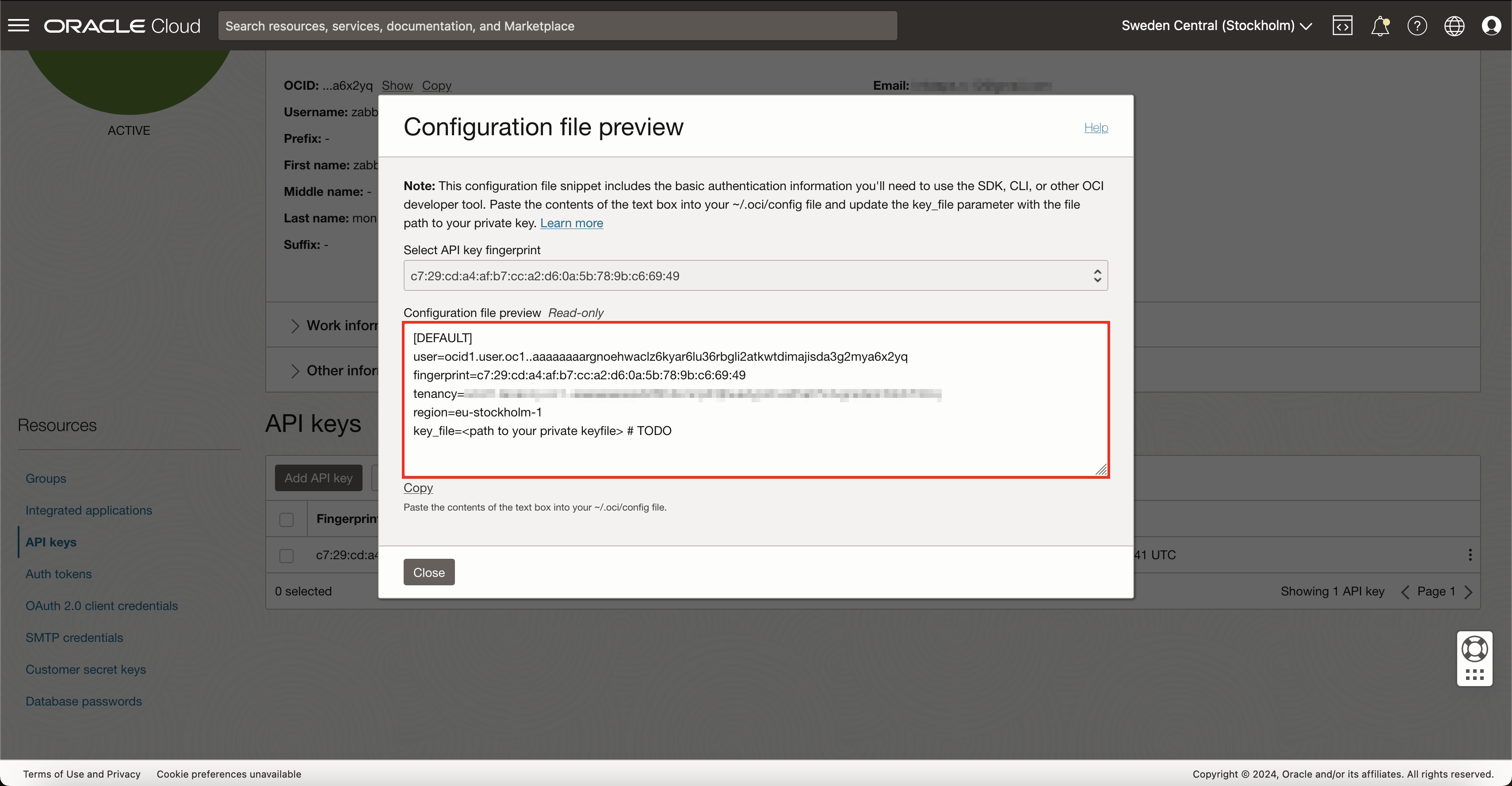
This is the moment when OCI configuration file values from API key generation section come into play. You will need to set the macro value to the value that OCI gave you:
{$OCI.API.TENANCY} – here set the tenancy OCID value;
{$OCI.API.USER} – here set the user OCID value;
{$OCI.API.FINGERPRINT} – here set the fingerprint value;
Now you need to find where you saved the private key for your OCI monitoring user from the same API key generation section. Copy the contents of that private key file and paste them into {$OCI.API.PRIVATE.KEY}macro.
Once the authentication credentials are entered, you need to identify the correct OCI API endpoints that match for your region (the one that OCI configuration file gave you in the API key generation section). One way to do this is to go to Oracle Cloud Infrastructure Documentation, and on the left side you will find all the API services. Under each of these services, there is a home page dedicated to each service with respective API endpoints available. Required API service endpoints for Zabbix are:
In my case the OCI region is eu-stockholm-1, therefore the above API service endpoints look like this:
OCI API service
URL
Zabbix macro name
Core Services API
iaas.eu-stockholm-1.oraclecloud.com
{$OCI.API.CORE.HOST}
Database Service API
database.eu-stockholm-1.oraclecloud.com
{$OCI.API.AUTONOMOUS.DB.HOST}
Object Storage Service API
objectstorage.eu-stockholm-1.oraclecloud.com
{$OCI.API.OBJECT.STORAGE.HOST}
Monitoring API
telemetry.eu-stockholm-1.oraclecloud.com
{$OCI.API.TELEMETRY.HOST}
Now that you have the necessary host names, you need to save them as values for their respective Zabbix macros.
IMPORTANT! API Endpoint URLs need to be entered without the HTTP scheme (https://).
After these 3 steps, your Macros tab should look something like this.
After pressing the button Add, this host will be added to Zabbix.
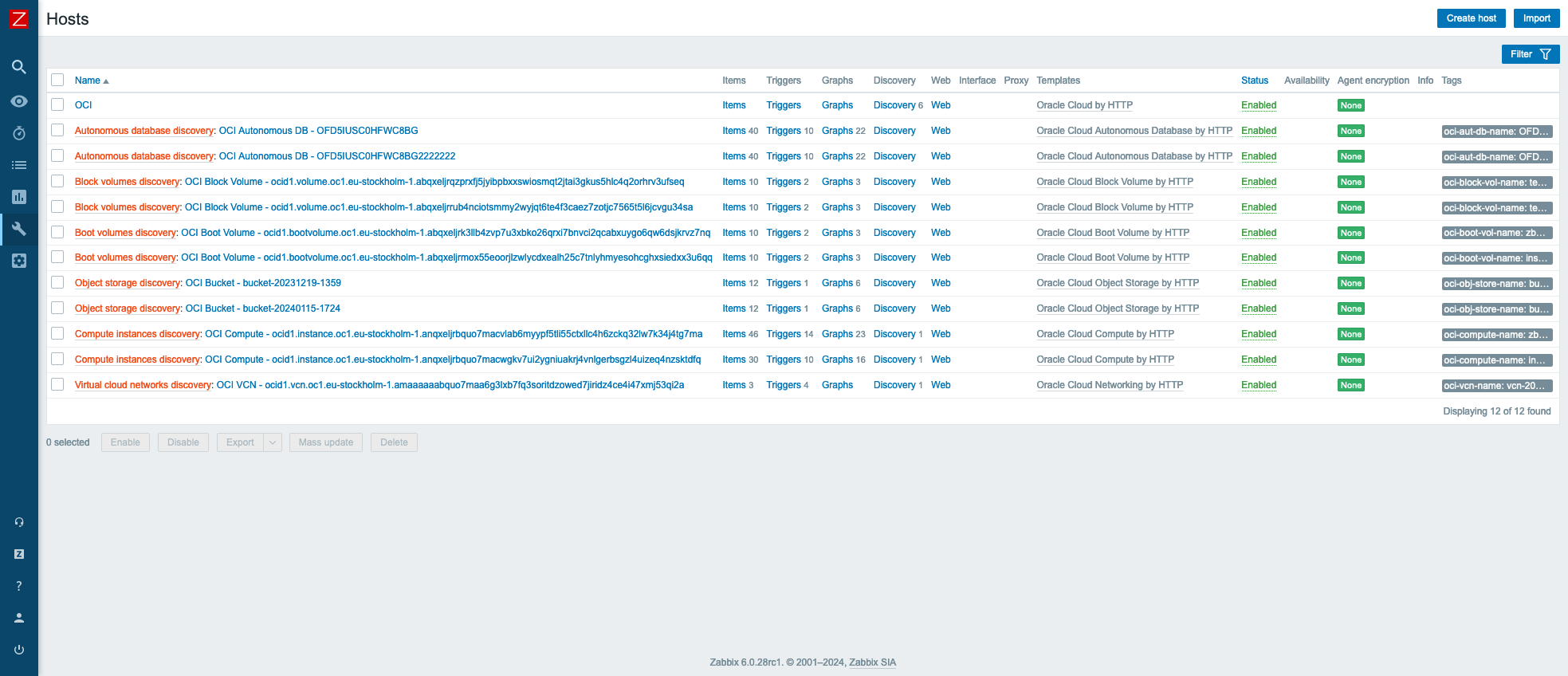
This host will not have any metrics items, instead it will discover all the OCI resources and add them as separate hosts in Zabbix. This will happen automatically, sometime between when Zabbix server reloads its configuration cache and 1 hour after that (because discovery rules have update interval of 1 hour). However, if you want to speed this up, you can manually refresh Zabbix server config cache with CLI command zabbix_server -R config_cache_reload and execute all discovery rules manually.
After that, in the Hosts view, you should see all of your monitored OCI resources.
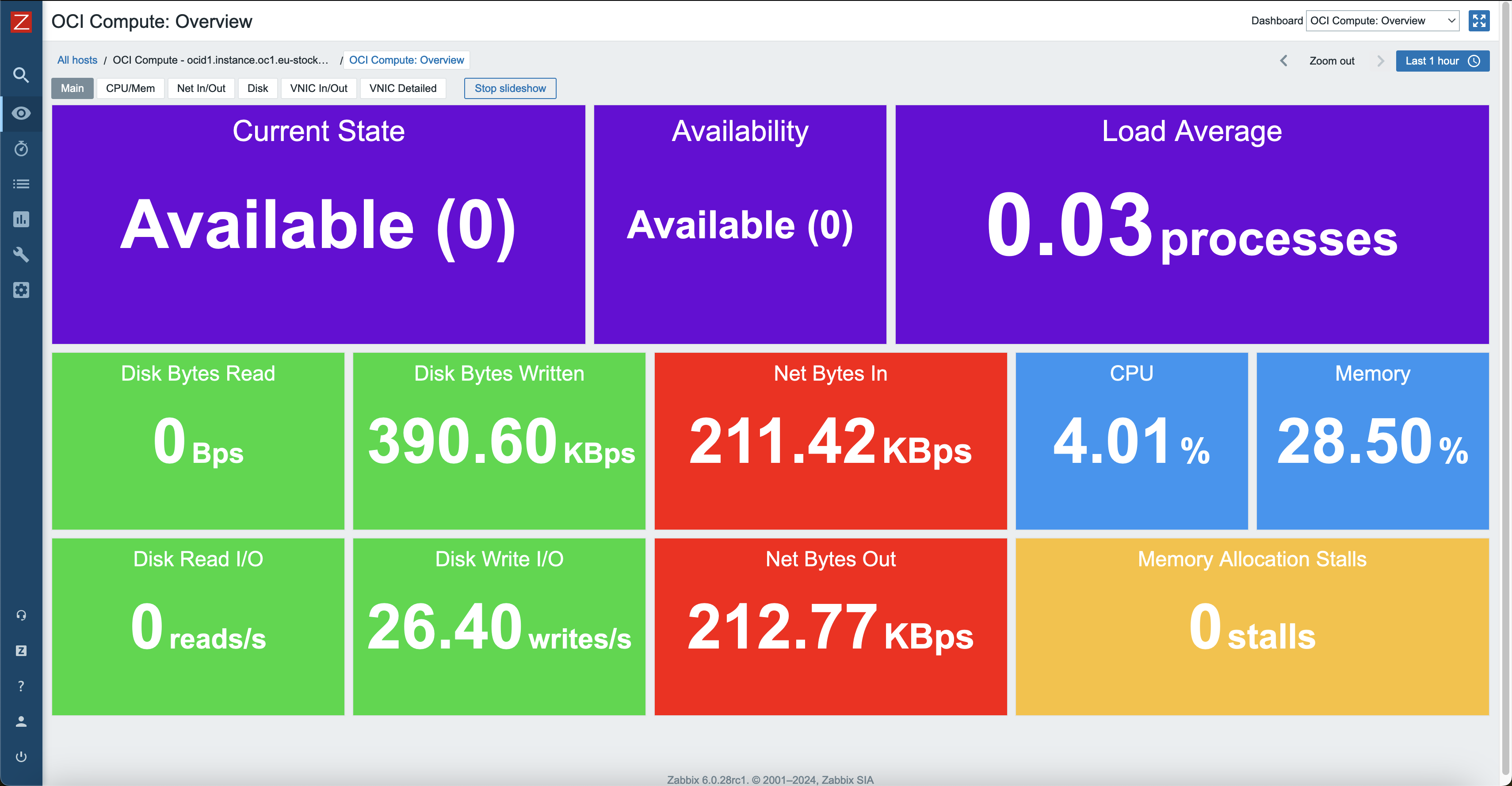
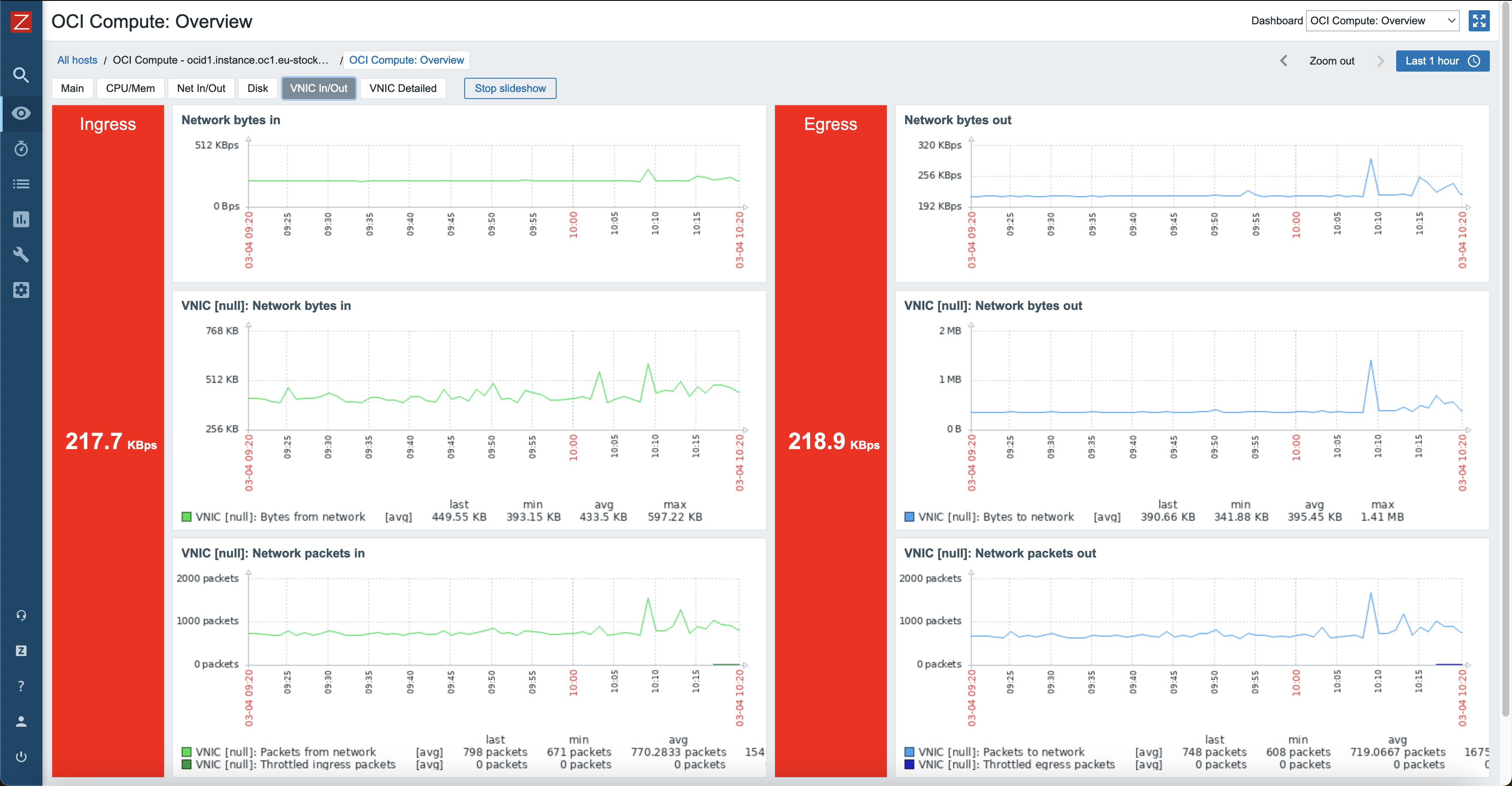
Also, each of these hosts will have their own dashboards created automatically that will give a good overview of resource utilization.
Optional configuration
When creating the OCI host in Zabbix, there were a few macros that required modification of values. As you might have noticed, there were quite a few other macros that we skipped over. In the following sections, usage of these macros will be explained. These are optional macros, so depending on your requirements, you might not even need to change them.
Use macros for low-level discovery filtering
In official Zabbix templates, you might find macros that end with MATCHES and NOT_MATCHES. These are used for Low-level discovery rules (LLDs), to help you filter resources that should or should not be discovered. These values are using regular expressions. Therefore, you can use wildcard symbols for pattern matching.
Usage of these macros can be found in Filters tab, under discovery rules.
Usually default values for MATCHES is .* and for NOT_MATCHES – CHANGE_IF_NEEDED. This means that any kind of value will be discovered if it is not equal to CHANGE_IF_NEEDED. For example, if such macros are filtering compute instance name:
{"instance-name": "compute_instance_1"} will be discovered;
{"instance-name": "web-server"} will be discovered;
{"instance-name": "CHANGE_IF_NEEDED"} will not be discovered.
In OCI templates, such discovery macros are also used. One example is compute instance discovery where filters are checking the instance state:
Macro {$OCI.COMPUTE.DISCOVERY.STATE.MATCHES} has a value of .*;
Macro {$OCI.COMPUTE.DISCOVERY.STATE.NOT_MATCHES} has a value of TERMINATED.
This means that any instance that is in terminated state will not be discovered. This is because when you terminate an instance in OCI, it is still kept for a while, but there is no reason to monitor such an instance.
Now that you have an idea how these filters work, you can adjust them based on your requirements.
Low-level discovery resource filtering by free-form tags of OCI resources
To add additional resource discovery filtering options, every discovery script (except VCN discovery), gathers free-form tag data about a specific resource. Since free-form tags are completely custom and format or usage will vary between users, the free-from tag filters are not included under LLD filters by default, but can be easily added as they are already being collected by scripts.
To show an example, let’s assume that you want to categorize OCI compute instances by their usage utilizing free-form tags.
For one of the instances, add a new free-from tag, such as, usage with value web-server.
You need to repeat this for other compute instances and set usage free-from tag values as you want to.
Now, switch over to Zabbix and open Oracle Cloud by HTTP template in Zabbix and go to Discovery rules. Find Compute instances discovery and open it.
Under LLD macros tab, add a new macro that will represent this location group tag, for example, {#USAGE}$.tags.usage.
Under the Filters tab, there will already be filters regarding the compute instance name and state. Click “Add” to add a new filter and define the previously created LLD macro and add a matching pattern and value, for example, {#USAGE}matchesweb-server.
The next time Compute instances discovery is executed, it will only discover OCI compute instances that have the free-form tag usage that matches the regex of web-server. You can also experiment with the LLD filter pattern matching value to receive different matching results for a specified value.
IMPORTANT! You must have the free-from tag present on every resource in OCI that you are using this method on. In these examples you would need to set usage free-form tag on every compute instance, or Zabbix LLD will stop working. If a tag does not exist when Zabbix LLD searches for it, it will throw an error. The free-form tag does not need to have a value, make sure that the tag key is there.
HTTP proxy usage
If needed, you can specify an HTTP proxy for the template to use by changing the value of {$OCI.HTTP.PROXY} user macro. Every request will use this proxy.
Custom OK HTTP response
If using proxy, returned OK HTTP response could change from 200 to some different value. In that case, please change user macro {$OCI.HTTP.RETURN.CODE.OK} to the appropriate value. By default, this is set to 200, therefore, all request items will only accept data when response is 200.
In case you missed the announcement from Developer Week 2024, Cloudflare is now offering software development kits (SDKs) for Typescript, Go and Python. As a reminder, you can get started by installing the packages.
// Typescript
npm install cloudflare
// Go
go get -u github.com/cloudflare/cloudflare-go/v2
// Python
pip install --pre cloudflare
Instead of using a tool like curl or Postman to create a new zone in your account, you can use one of the SDKs in a language that you’re already comfortable with or that integrates directly into your existing codebase.
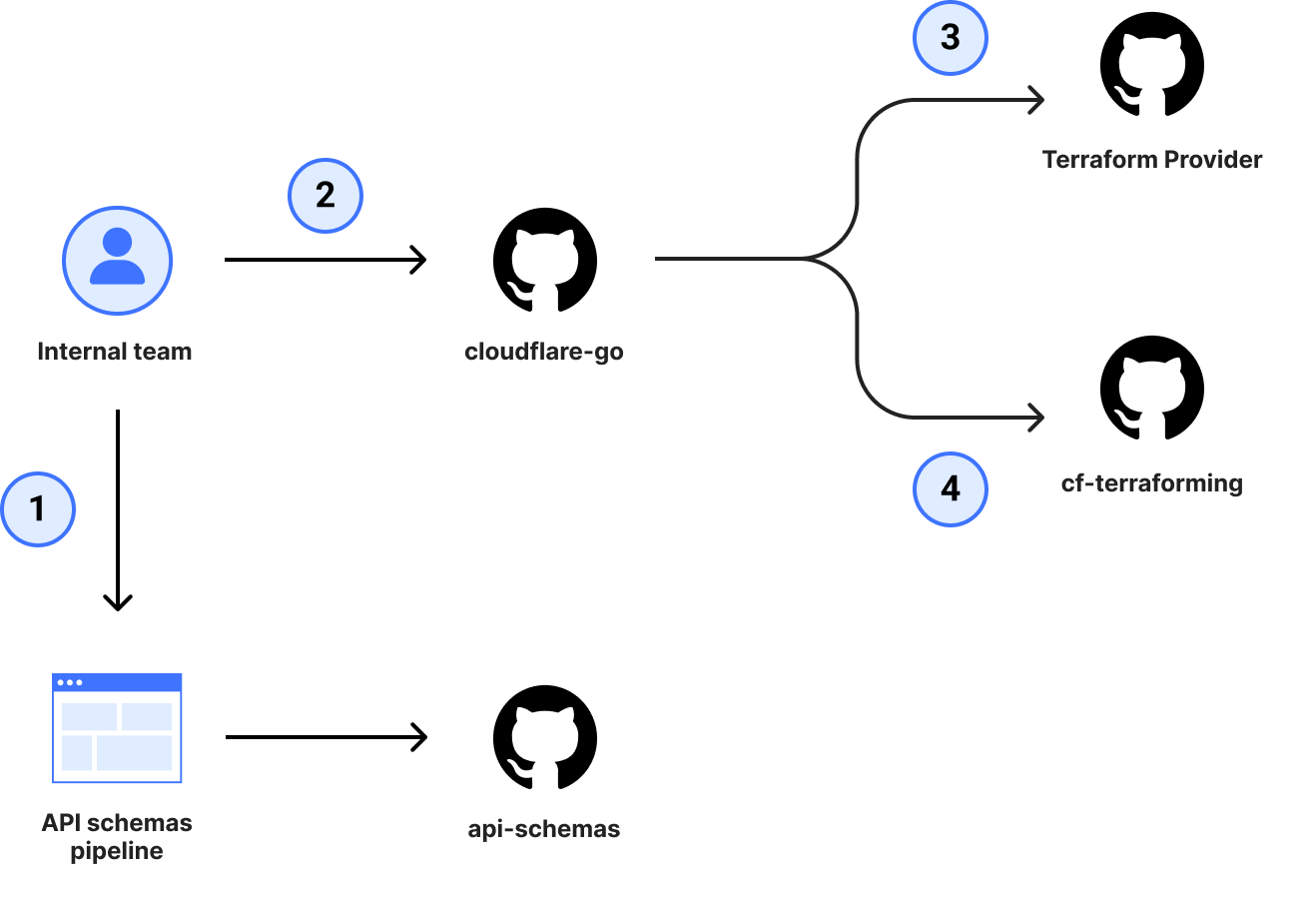
Since their inception, our SDKs have been manually maintained by one or more dedicated individuals. For every product addition or improvement, we needed to orchestrate a series of manually created pull requests to get those changes into customer hands. This, unfortunately, created an imbalance in the frequency and quality of changes that made it into the SDKs. Even though the product teams would drive some of these changes, not all languages were covered and the SDKs fell to either community-driven contributions or to the maintainers of the libraries to cover the remaining languages. Internally, we too felt this pain when using our own services and, instead of covering all languages, decided to rally our efforts behind the primary SDK (Go) to ensure that at least one of these libraries was in a good state.
This plan worked for newer products and additions to the Go SDK, which in turn helped tools like our Terraform Provider stay mostly up to date, but even this focused improvement was still very taxing and time-consuming for internal teams to maintain. On top of this, the process didn’t provide any guarantees on coverage, parity, or correctness because the changes were still manually maintained and susceptible to human error. Regardless of the size of contribution, a team member would still need to coordinate a minimum of 4 pull requests (shown in more depth below) before a change was considered shipped and needed deep knowledge of the relationship between the dependencies in order to get it just right.
The pull requests previously required to ship an SDK change.
Following the completion of our transition to OpenAPI from JSON Hyper-Schema, we caught up internally and started discussing what else OpenAPI could help us unlock. It was at that point that we set the lofty goal of using OpenAPI for more than just our documentation. It was time to use OpenAPI to generate our SDKs.
Before we dove headfirst into generating SDKs, we established some guiding principles. These would be non-negotiable and determine where we spent our effort.
You should not be able to tell what underlying language generated the SDK
This was important for us because too often companies build SDKs using automation. Not only do you end up with SDKs that are flavored based on generator language, but the SDKs then lack the language nuances or patterns that are noticeable to users familiar with the language.
For example, a Rubyist may use the following if expression:
do_something if bar?
Whereas most generators do not have this context and would instead default to the standard case where if/else expressions are spread over multiple lines.
if bar?
do_something
end
Despite being a simple and non-material example, it demonstrates a nuance that a machine cannot decipher on its own. This is terrible for developers because you’re then no longer only thinking about how to solve the original task at hand, but you also end up tailoring your code to match how the generator has built the SDK and potentially lose out on the language features you would normally use. The problem is made significantly worse if you’re using a strongly typed language to generate a language without types, since it will be structuring and building code in a way that types are expected but never used.
Lowering the mean time to uniform support
When a new feature is added to a product, it’s great that we add API support initially. However, if that new feature or product never makes it to whatever language SDK you are using to drive your API calls, it’s as good as non-existent. Similarly, not every use case is for infrastructure-as-code tools like Terraform, so we needed a better way of meeting our customers with uniformity where they choose to integrate with our services.
By extension, we want uniformity in the way the namespaces and methods are constructed. Ignoring the language-specific parts, if you’re using one of our SDKs and you are looking for the ability to list all DNS records, you should be able to trust that the method will be in the dns namespace and that to find all records, you can call a list method regardless of which one you are using. Example:
// Go
client.DNS.Records.List(...)
// Typescript
client.dns.records.list(...)
// Python
client.dns.records.list(...)
This leads to less time digging through documentation to find what invocation you need and more time using the tools you’re already familiar with.
Fast feedback loops, clear conventions
Cloudflare has a lot of APIs; everything is backed by an API somewhere. However, not all Cloudflare APIs are designed with the same conventions in mind. Those APIs that are on the critical path and regularly experience traffic surges or malformed input are naturally more hardened and more resilient than those that are infrequently used. This creates a divergence in quality of the endpoint, which shouldn’t be the case.
Where we have learned a lesson or improved a system through a best practice, we should make it easy for others to be aware of and opt into that pattern with little friction at the earliest possible time, ideally as they are proposing the change in CI. That is why when we built the OpenAPI pipeline for API schemas, we built in mechanisms to allow applying linting rules, using redocly CLI, that will either warn the engineer or block them entirely, depending on the severity of the violation.
For example, we want to encourage usage of fine grain API tokens, so we should present those authentication schemes first and ensure they are supported for new endpoints. To enforce this, we can write a redocly plugin:
module.exports = {
id: 'local',
assertions: {
apiTokenAuthSupported: (value, options, location) => {
for (const i in value) {
if (value.at(i)?.hasOwnProperty("api_token")) {
return [];
}
}
return [{message: 'API Token should be defined as an auth method', location}];
},
apiTokenAuthDefinedFirst: (value, options, location) => {
if (!value.at(0)?.hasOwnProperty("api_token")) {
return [{message: 'API Tokens should be the first listed Security Option', location}];
}
return [];
},
},
};
In this example, should a team forget to put the API token authentication scheme first, or define it at all, the CI run will fail. Teams are provided a helpful failure message with a link to the conventions to discover more if they need to understand why the change is recommended.
These lints can be used for style conventions, too. For our documentation descriptions, we like descriptions to start with a capital letter and end in a period. Again, we can add a lint to enforce this requirement.
module.exports = {
id: 'local',
assertions: {
descriptionIsFormatted: (value, options, location) => {
for (const i in value) {
if (/^[A-Z].*\.$/.test(value)) {
return [];
}
}
return [{message: 'Descriptions should start with a capital and end in a period.', location}];
},
},
};
This makes shipping endpoints of the same quality much easier and prevents teams needing to sort through all the API design or resiliency patterns we may have introduced over the years – possibly even before they joined Cloudflare.
Building the generation machine
Once we had our guiding principles, we started doing some analysis of our situation and saw that if we decided to build the solution entirely in house, we would be at least 6–9 months away from a single high quality SDK with the potential for additional follow-up work each time we had a new language addition. This wasn’t acceptable and prevented us from meeting the requirement of needing a low-cost followup for additional languages, so we explored the OpenAPI generation landscape.
Due to the size and complexity of our schemas, we weren’t able to use most off the shelf products. We tried a handful of solutions and workarounds, but we weren’t comfortable with any of the options; that was, until we tried Stainless. Founded by one of the engineers that built what many consider to be the best-in-class API experiences at Stripe, Stainless is dedicated to generating SDKs. If you’ve used the OpenAI Python or Typescript SDKs, you’ve used an SDK generated by Stainless.
The way the platform offering works is that you bring your OpenAPI schemas and map them to methods with the configuration file. Those inputs then get fed into the generation engine to build your SDKs.
resources:
zones:
methods:
list: get /zones
The configuration above would allow you to generate various client.zones.list() operations across your SDKs.
This approach means we can do the majority of our changes using the existing API schemas, but if there is an SDK-specific issue, we can modify that behavior on a per-SDK basis using the configuration file.
An added benefit of using the Stainless generation engine is that it gives us a clear line of responsibility when discussing where a change should be made.
Service team: Knows their service best and manages the representation for end users.
API team: Understands and implements best practices for APIs and SDK conventions, builds centralized tooling or components within the platform for all teams, and translates service mappings to align with Stainless.
Stainless: Provides a simple interface to generate SDKs consistently.
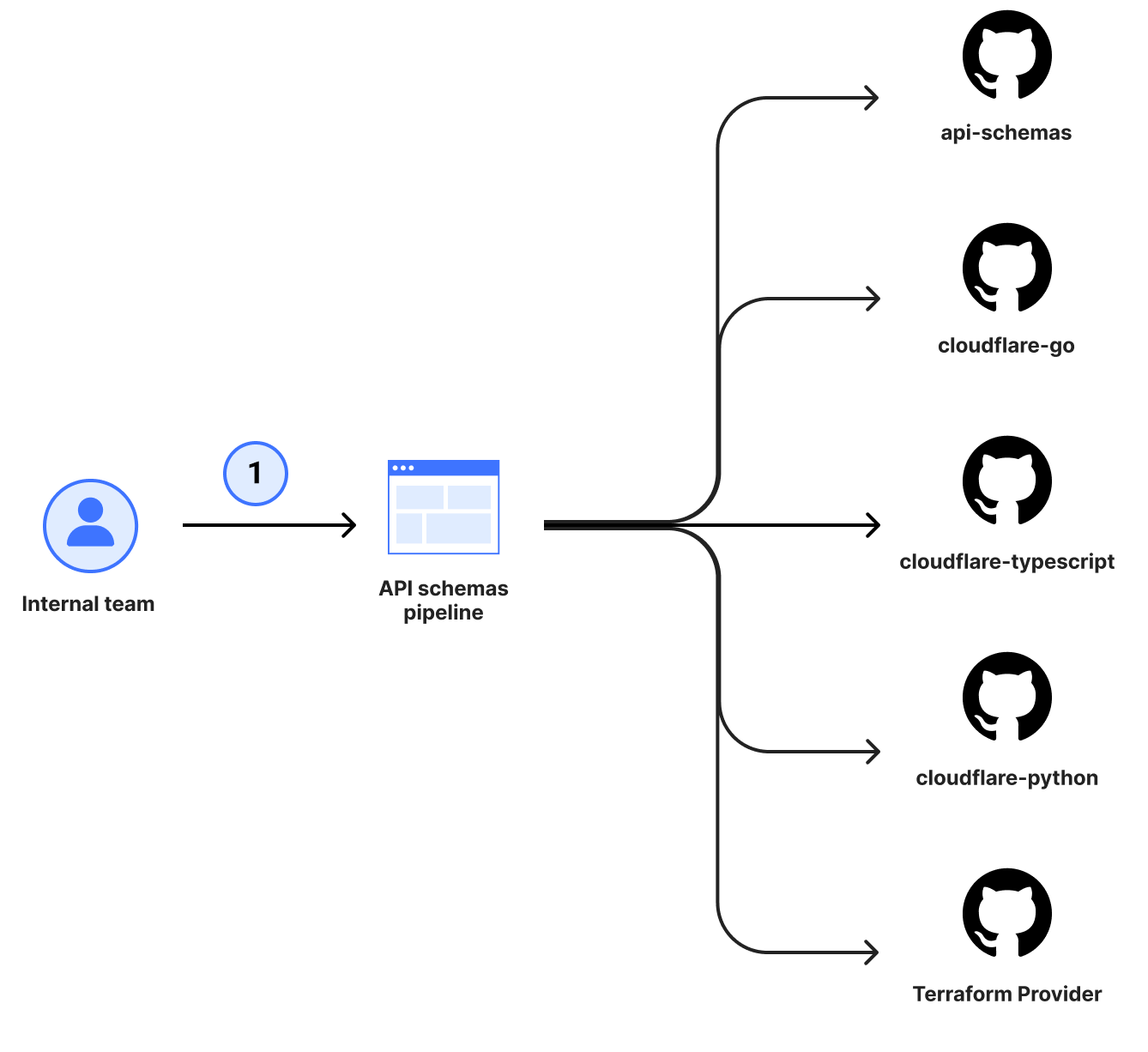
The decision to use Stainless has allowed us to move our focus from building the generation engine to instead building high-quality schemas to describe our services. In the span of a few months, we have gone from inconsistent, manually maintained SDKs to automatically shipping three language SDKs with hands-off updates freely flowing from the internal teams. Best of all, it is now a single pull request workflow for the majority of our changes – even if we were to add a new language or integration to the pipeline!
Just a single pull request is now required to ship an SDK change.
Lessons from our journey, for yours
Mass updates, made easy
Depending on the age of your APIs, you will have a diverging history of how they are represented to customers. That may be as simple as path parameters being inconsistent or perhaps something more complex like different HTTP methods for updates. While you can handle these individually at any sort of scale, that just isn’t feasible. As of this post, Cloudflare offers roughly 1,300 publicly documented endpoints, and we needed a more automatable solution. For us, that was codemods. Codemods are a way of applying transformations to perform large scale refactoring of your codebase. This allows you to programmatically rewrite expressions, syntax or other parts of your code without having to manually go through every file. Think of it like find and replace, but on steroids and with more context of the underlying language constructs.
We started with a tool called comby. We wrapped it in a custom CLI tool that knew how to speak to our version control endpoints and wired it in a way that provides a comby configuration TOML file, pull request description, and commit message for each transformation we needed to apply. Here is a sample comby configuration where we updated the URI paths to be consistently suffixed with _id instead of other variations (_identifier, Identifier, etc.) where we had a plural resource followed by an individual identifier.
[account-id-1-path-consistency]
match = 'paths/~accounts~1{account_identifier1}'
rewrite = 'paths/~accounts~1{account_id}'
[account-id-camelcase-path-consistency]
match = 'paths/~accounts~1{accountId}'
rewrite = 'paths/~accounts~1{account_id}'
[placeholder-identifier-to-id]
match = ':[_~_identifier}]' # need the empty hole match here since we are using unbalanced }
rewrite = '_id}'
[route-consistency-for-resource-plurals]
match = ':[topic~/\w+/]{:[id~\w+]}'
rewrite = ':[topic]{:[id]}'
rule = 'where rewrite :[id] { :[x] -> :[topic] }, rewrite :[id] { /:[x]s/ -> :[x]_id }'
[property-identifier-to-id]
match = 'name: :[topic]_identifier'
rewrite = 'name: :[topic]_id'
For an interactive version of this configuration, check out the comby playground.
This approach worked for the majority of our internal changes. However, knowing how difficult migrations can be, we also wanted a tool that we could provide to customers to use for their own SDK migrations. In the past we’ve used comby for upgrades in the Terraform Provider with great feedback. While comby is powerful, once you start using more complex expressions, the syntax can be difficult to understand unless you are familiar with it.
After looking around, we eventually found Grit. It is a tool that does everything we need (including the custom CLI) while being very familiar to anyone that understands basic Javascript through a query language, known as GritQL. An added bonus here is that we are able to contribute to the Grit Pattern Library, so our migrations are only ever a single CLI invocation away for anyone to use once they have the CLI installed.
// Migrate to the Golang v2 library
grit apply cloudflare_go_v2
Consistency, consistency, consistency
Did I mention consistency is important? Before attempting to feed your OpenAPI schemas into any system (especially a homegrown one), get them consistent with the practices, structures, and how you intend to represent them. This makes determining what is a bug in your generation pipeline vs a bug in your schema much easier. If it’s broken everywhere, it’s the generation pipeline, otherwise it’s an isolated bug to track down in your schema.
Having consistency leads into a better developer experience. From our examples above, if your routes always follow the plural resource name followed by an identifier, the end user doesn’t have to think about what the inputs need to be. The consistency and conventions lead them there – even if your documentation is lacking.
Use shared $refs sparingly
It seems like a great idea for reusability at the time of writing them, but when overused, $refs make finding correct values problematic and lead to cargo cult practices. In turn, this leads to lower quality and difficult-to-change schemas despite looking more usable from the outset. Consider the following schema example:
thing_base:
type: object
required:
- id
properties:
updated_at:
$ref: '#/components/schemas/thing_updated_at'
created_at:
$ref: '#/components/schemas/thing_updated_at'
id:
$ref: '#/components/schemas/thing_identifier'
thing_updated_at:
type: string
format: date-time
description: When the resource was last updated.
example: "2014-01-01T05:20:00Z"
thing_created_at:
type: string
format: date-time
description: When the resource was created.
example: "2014-01-01T05:20:00Z"
thing_id:
type: string
description: Unique identifier of the resource.
example: "2014-01-01T05:20:00Z"
Did you spot the bug? Have another look at the created_at value. You likely didn’t catch it at first glance, but this is a common issue when needing to reference reusable values. Here, it is a minor annoyance as the documentation would be incorrect (created_at would have the description of updated_at), but in other cases, it could be a completely incorrect schema representation.
For us, the correct usage of $ref values is predominantly where you have potential for multiple component schemas that may be used as part of a oneOf, allOf or anyOf directive.
When in doubt, consider the YAGNI principle instead. You can always refactor and extract this later once you have enough uses to determine the correct abstraction.
Design your ideal usage and work backwards
Before we wrote a single line of code to solve the problem of generation, we prepared language design documents for each of our target languages that followed the README-driven design principles. This meant our focus from the initial design was on the usability of the library and not on the technical challenges that we would eventually encounter. This led us to identify problems and patterns early with how various language nuances would surface to the end user without investing in anything more than a document. Python keyword arguments, Go interfaces, how to enforce required parameters, client instantiation and overrides, types – all considerations made up front that helped minimize the number of unknowns as we built out support.
What’s next?
When we embarked on the OpenAPI journey, we knew it was only the beginning and would eventually open more doors and quality of life improvements for teams and customers alike. Now that we have a few language SDKs available, we’re turning our attention to generating our Terraform Provider using the same guiding principles to further minimize the maintenance burden. But that’s still not all. Coming later in 2024 are more improvements and integrations with other parts of the Cloudflare Developer Platform, so stay tuned.
If you haven’t already, check out one of the SDKs in Go, Typescript and Python today. If you’d like support for a different language, go here to submit your details to help determine the next language. We’d love to hear what languages you would like offered as a Cloudflare SDK.
Today, we are announcing the general availability of Meta’s Llama 3 models in Amazon Bedrock. Meta Llama 3 is designed for you to build, experiment, and responsibly scale your generative artificial intelligence (AI) applications. New Llama 3 models are the most capable to support a broad range of use cases with improvements in reasoning, code generation, and instruction.
According to Meta’s Llama 3 announcement, the Llama 3 model family is a collection of pre-trained and instruction-tuned large language models (LLMs) in 8B and 70B parameter sizes. These models have been trained on over 15 trillion tokens of data—a training dataset seven times larger than that used for Llama 2 models, including four times more code, which supports an 8K context length that doubles the capacity of Llama 2.
You can now use two new Llama 3 models in Amazon Bedrock, further increasing model choice within Amazon Bedrock. These models provide the ability for you to easily experiment with and evaluate even more top foundation models (FMs) for your use case:
Llama 3 8B is ideal for limited computational power and resources, and edge devices. The model excels at text summarization, text classification, sentiment analysis, and language translation.
Llama 3 70B is ideal for content creation, conversational AI, language understanding, research development, and enterprise applications. The model excels at text summarization and accuracy, text classification and nuance, sentiment analysis and nuance reasoning, language modeling, dialogue systems, code generation, and following instructions.
Meta is also currently training additional Llama 3 models over 400B parameters in size. These 400B models will have new capabilities, including multimodality, multiple languages support, and a much longer context window. When released, these models will be ideal for content creation, conversational AI, language understanding, research and development (R&D), and enterprise applications.
Llama 3 models in action If you are new to using Meta models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Llama 3 models from Meta, request access separately for Llama 3 8B Instruct or Llama 3 70B Instruct.
To test the Meta Llama 3 models in the Amazon Bedrock console, choose Text or Chat under Playgrounds in the left menu pane. Then choose Select model and select Meta as the category and Llama 8B Instruct or Llama 3 70B Instruct as the model.
By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs. You can use model IDs such as meta.llama3-8b-instruct-v1 or meta.llama3-70b-instruct-v1.
Here is a sample of the AWS CLI command:
$ aws bedrock-runtime invoke-model \
--model-id meta.llama3-8b-instruct-v1:0 \
--body "{\"prompt\":\"Simply put, the theory of relativity states that\\n the laws of physics are the same everywhere in the universe, and that the passage of time and the length of objects can vary depending on their speed and position in a gravitational field \",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}" \
--cli-binary-format raw-in-base64-out \
--region us-east-1 \
invoke-model-output.txt
You can use code examples for Amazon Bedrock using AWS SDKs to build your applications with various programming languages. The following Python code examples show how to invoke the Llama 3 Chat model in Amazon Bedrock for text generation.
You can use these Llama 3 models for a variety of tasks, such as question answering, language translation, sentiment analysis, and more. Here is an example of Llama 3 models with few-shot in-context learning where we provide training samples available to the model.
Input: Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>
Output: fromage
panda => panda
penguin => pingouin
polar bear => ours polaire
puffin => macareux
sloth => paresseux
walrus => morse
whale => baleine
zebra => z\u00e8bre
Translate English to German:
sea otter => Seeotter
You can also use Llama 3 instruct models optimized for dialogue use cases. The input to the instruct model endpoints is the previous history between the chat assistant and the user. So, you can ask questions contextual to the conversation that has happened so far and provide the system configuration, such as personas, which define the chat assistant’s behavior in the following format:
In the following example, the user has a conversation with the assistant about tourist sites in Paris. Then, the user inquires about the first option recommended by the chat assistant.
Input: <|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n
I am going to Paris, what should I see?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n
1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n
2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n
3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\n
These are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n
What is so great about #1?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
Output: The Eiffel Tower! It's an iconic symbol of Paris and one of the most recognizable landmarks in the world. Here are some reasons why it's so great:\n\n
1. **Engineering marvel**: When it was built for the 1889 World's Fair, the Eiffel Tower was a groundbreaking feat of engineering. It was the tallest structure in the world at the time, standing at 324 meters (1,063 feet).\n
2. **Panoramic views**: The Eiffel Tower offers breathtaking 360-degree views of the city from its observation decks. You can see many of Paris' famous landmarks, such as the Seine River, the Louvre, and Montmartre.\n
3. **Romantic atmosphere**: The Eiffel Tower is often associated with romance and is a popular spot for proposals, weddings, and romantic dinners. The tower's iron latticework and twinkling lights at night add to its romantic ambiance.\n
4. **Historical significance**: The Eiffel Tower has played a significant role in French history, serving as a communication tower during World War I and a symbol of French culture and engineering.\n
5. **Accessibility**: The Eiffel Tower is easily accessible by public transportation or on foot, and there are various ways to experience it, including taking the stairs, elevator, or a guided tour.\n
6. **Nighttime spectacle**: The Eiffel Tower is even more magical at night, when it's illuminated with thousands of twinkling lights. The light show, known as the \"Eiffel Tower Sparkle,\" takes place every hour on the hour from dusk to midnight.\n
7. **Iconic status**: The Eiffel Tower has been featured in countless films, literature, and art, making it an instantly recognizable symbol of Paris and France.\n\n
Overall, the Eiffel Tower is a must-visit attraction in Paris, offering a unique combination of history, engineering, romance, and stunning views.
Now available Meta’s Llama 3 models are available today in Amazon Bedrock in the US East (N. Virginia) and US West (Oregon) Regions. Check the full Region list for future updates. To learn more, check out the Llama in Amazon Bedrock product page and pricing page.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
Today, I am happy to announce the general availability of Guardrails for Amazon Bedrock, first released in preview at re:Invent 2023. With Guardrails for Amazon Bedrock, you can implement safeguards in your generative artificial intelligence (generative AI) applications that are customized to your use cases and responsible AI policies. You can create multiple guardrails tailored to different use cases and apply them across multiple foundation models (FMs), improving end-user experiences and standardizing safety controls across generative AI applications. You can use Guardrails for Amazon Bedrock with all large language models (LLMs) in Amazon Bedrock, including fine-tuned models.
Guardrails for Bedrock offers industry-leading safety protection on top of the native capabilities of FMs, helping customers block as much as 85% more harmful content than protection natively provided by some foundation models on Amazon Bedrock today. Guardrails for Amazon Bedrock is the only responsible AI capability offered by top cloud providers that enables customers to build and customize safety and privacy protections for their generative AI applications in a single solution, and it works with all large language models (LLMs) in Amazon Bedrock, as well as fine-tuned models.
Aha! is a software company that helps more than 1 million people bring their product strategy to life. “Our customers depend on us every day to set goals, collect customer feedback, and create visual roadmaps,” said Dr. Chris Waters, co-founder and Chief Technology Officer at Aha!. “That is why we use Amazon Bedrock to power many of our generative AI capabilities. Amazon Bedrock provides responsible AI features, which enable us to have full control over our information through its data protection and privacy policies, and block harmful content through Guardrails for Bedrock. We just built on it to help product managers discover insights by analyzing feedback submitted by their customers. This is just the beginning. We will continue to build on advanced AWS technology to help product development teams everywhere prioritize what to build next with confidence.”
In the preview post, Antje showed you how to use guardrails to configure thresholds to filter content across harmful categories and define a set of topics that need to be avoided in the context of your application. The Content filters feature now has two additional safety categories: Misconduct for detecting criminal activities and Prompt Attack for detecting prompt injection and jailbreak attempts. We also added important new features, including sensitive information filters to detect and redact personally identifiable information (PII) and word filters to block inputs containing profane and custom words (for example, harmful words, competitor names, and products).
Guardrails for Amazon Bedrock sits in between the application and the model. Guardrails automatically evaluates everything going into the model from the application and coming out of the model to the application to detect and help prevent content that falls into restricted categories.
You can recap the steps in the preview release blog to learn how to configure Denied topics and Content filters. Let me show you how the new features work.
New features To start using Guardrails for Amazon Bedrock, I go to the AWS Management Console for Amazon Bedrock, where I can create guardrails and configure the new capabilities. In the navigation pane in the Amazon Bedrock console, I choose Guardrails, and then I choose Create guardrail.
I enter the guardrail Name and Description. I choose Next to move to the Add sensitive information filters step.
I use Sensitive information filters to detect sensitive and private information in user inputs and FM outputs. Based on the use cases, I can select a set of entities to be either blocked in inputs (for example, a FAQ-based chatbot that doesn’t require user-specific information) or redacted in outputs (for example, conversation summarization based on chat transcripts). The sensitive information filter supports a set of predefined PII types. I can also define custom regex-based entities specific to my use case and needs.
I add two PII types (Name, Email) from the list and add a regular expression pattern using Booking ID as Name and [0-9a-fA-F]{8} as the Regex pattern.
I choose Next and enter custom messages that will be displayed if my guardrail blocks the input or the model response in the Define blocked messaging step. I review the configuration at the last step and choose Create guardrail.
I navigate to the Guardrails Overview page and choose the Anthropic Claude Instant 1.2 model using the Test section. I enter the following call center transcript in the Prompt field and choose Run.
Please summarize the below call center transcript. Put the name, email and the booking ID to the top: Agent: Welcome to ABC company. How can I help you today? Customer: I want to cancel my hotel booking. Agent: Sure, I can help you with the cancellation. Can you please provide your booking ID? Customer: Yes, my booking ID is 550e8408. Agent: Thank you. Can I have your name and email for confirmation? Customer: My name is Jane Doe and my email is [email protected] Agent: Thank you for confirming. I will go ahead and cancel your reservation.
Guardrail action shows there are three instances where the guardrails came in to effect. I use View trace to check the details. I notice that the guardrail detected the Name, Email and Booking ID and masked them in the final response.
I use Word filters to block inputs containing profane and custom words (for example, competitor names or offensive words). I check the Filter profanity box. The profanity list of words is based on the global definition of profanity. Additionally, I can specify up to 10,000 phrases (with a maximum of three words per phrase) to be blocked by the guardrail. A blocked message will show if my input or model response contain these words or phrases.
Now, I choose Custom words and phrases under Word filters and choose Edit. I use Add words and phrases manually to add a custom word CompetitorY. Alternatively, I can use Upload from a local file or Upload from S3 object if I need to upload a list of phrases. I choose Save and exit to return to my guardrail page.
I enter a prompt containing information about a fictional company and its competitor and add the question What are the extra features offered by CompetitorY?. I choose Run.
I use View trace to check the details. I notice that the guardrail intervened according to the policies I configured.
Now available Guardrails for Amazon Bedrock is now available in US East (N. Virginia) and US West (Oregon) Regions.
Quick agent creation – You can now quickly create an agent and optionally add instructions and action groups later, providing flexibility and agility for your development process.
Agent builder – All agent configurations can be operated in the new agent builder section of the console.
Simplified configuration – Action groups can use a simplified schema that just lists functions and parameters without having to provide an API schema.
Return of control –You can skip using an AWS Lambda function and return control to the application invoking the agent. In this way, the application can directly integrate with systems outside AWS or call internal endpoints hosted in any Amazon Virtual Private Cloud (Amazon VPC) without the need to integrate the required networking and security configurations with a Lambda function.
Infrastructure as code – You can use AWS CloudFormation to deploy and manage agents with the new simplified configuration, ensuring consistency and reproducibility across environments for your generative AI applications.
Let’s see how these enhancements work in practice.
Creating an agent using the new simplified console To test the new experience, I want to build an agent that can help me reply to an email containing customer feedback. I can use generative AI, but a single invocation of a foundation model (FM) is not enough because I need to interact with other systems. To do that, I use an agent.
In the Amazon Bedrockconsole, I choose Agents from the navigation pane and then Create Agent. I enter a name for the agent (customer-feedback) and a description. Using the new interface, I proceed and create the agent without providing additional information at this stage.
I am now presented with the Agent builder, the place where I can access and edit the overall configuration of an agent. In the Agent resource role, I leave the default setting as Create and use a new service role so that the AWS Identity and Access Management (IAM) role assumed by the agent is automatically created for me. For the model, I select Anthropic and Claude 3 Sonnet.
In Instructions for the Agent, I provide clear and specific instructions for the task the agent has to perform. Here, I can also specify the style and tone I want the agent to use when replying. For my use case, I enter:
Help reply to customer feedback emails with a solution tailored to the customer account settings.
In Additional settings, I select Enabled for User input so that the agent can ask for additional details when it does not have enough information to respond. Then, I choose Save to update the configuration of the agent.
I now choose Add in the Action groups section. Action groups are the way agents can interact with external systems to gather more information or perform actions. I enter a name (retrieve-customer-settings) and a description for the action group:
Retrieve customer settings including customer ID.
The description is optional but, when provided, is passed to the model to help choose when to use this action group.
In Action group type, I select Define with function details so that I only need to specify functions and their parameters. The other option here (Define with API schemas) corresponds to the previous way of configuring action groups using an API schema.
Action group functions can be associated to a Lambda function call or configured to return control to the user or application invoking the agent so that they can provide a response to the function. The option to return control is useful for four main use cases:
When it’s easier to call an API from an existing application (for example, the one invoking the agent) than building a new Lambda function with the correct authentication and network configurations as required by the API
When the duration of the task goes beyond the maximum Lambda function timeout of 15 minutes so that I can handle the task with an application running in containers or virtual servers or use a workflow orchestration such as AWS Step Functions
When I have time-consuming actions because, with the return of control, the agent doesn’t wait for the action to complete before proceeding to the next step, and the invoking application can run actions asynchronously in the background while the orchestration flow of the agent continues
When I need a quick way to mock the interaction with an API during the development and testing and of an agent
In Action group invocation, I can specify the Lambda function that will be invoked when this action group is identified by the model during orchestration. I can ask the console to quickly create a new Lambda function, to select an existing Lambda function, or return control so that the user or application invoking the agent will ask for details to generate a response. I select Return Control to show how that works in the console.
I configure the first function of the action group. I enter a name (retrieve-customer-settings-from-crm) and the following description for the function:
Retrieve customer settings from CRM including customer ID using the customer email in the sender/from fields of the email.
In Parameters, I add email with Customer email as the description. This is a parameter of type String and is required by this function. I choose Add to complete the creation of the action group.
Because, for my use case, I expect many customers to have issues when logging in, I add another action group (named check-login-status) with the following description:
Check customer login status.
This time, I select the option to create a new Lambda function so that I can handle these requests in code.
For this action group, I configure a function (named check-customer-login-status-in-login-system) with the following description:
Check customer login status in login system using the customer ID from settings.
In Parameters, I add customer_id, another required parameter of type String. Then, I choose Add to complete the creation of the second action group.
When I open the configuration of this action group, I see the name of the Lambda function that has been created in my account. There, I choose View to open the Lambda function in the console.
In the Lambda console, I edit the starting code that has been provided and implement my business case:
import json
def lambda_handler(event, context):
print(event)
agent = event['agent']
actionGroup = event['actionGroup']
function = event['function']
parameters = event.get('parameters', [])
# Execute your business logic here. For more information,
# refer to: https://docs.aws.amazon.com/bedrock/latest/userguide/agents-lambda.html
if actionGroup == 'check-login-status' and function == 'check-customer-login-status-in-login-system':
response = {
"status": "unknown"
}
for p in parameters:
if p['name'] == 'customer_id' and p['type'] == 'string' and p['value'] == '12345':
response = {
"status": "not verified",
"reason": "the email address has not been verified",
"solution": "please verify your email address"
}
else:
response = {
"error": "Unknown action group {} or function {}".format(actionGroup, function)
}
responseBody = {
"TEXT": {
"body": json.dumps(response)
}
}
action_response = {
'actionGroup': actionGroup,
'function': function,
'functionResponse': {
'responseBody': responseBody
}
}
dummy_function_response = {'response': action_response, 'messageVersion': event['messageVersion']}
print("Response: {}".format(dummy_function_response))
return dummy_function_response
I choose Deploy in the Lambda console. The function is configured with a resource-based policy that allows Amazon Bedrock to invoke the function. For this reason, I don’t need to update the IAM role used by the agent.
I am ready to test the agent. Back in the Amazon Bedrock console, with the agent selected, I look for the Test Agent section. There, I choose Prepare to prepare the agent and test it with the latest changes.
As input to the agent, I provide this sample email:
Hi, when I try to log into my account, I get an error and cannot proceed further. Can you check? Thank you, Danilo
In the first step, the agent orchestration decides to use the first action group (retrieve-customer-settings) and function (retrieve-customer-settings-from-crm). This function is configured to return control, and in the console, I am asked to provide the output of the action group function. The customer email address is provided as the input parameter.
To simulate an interaction with an application, I reply with a JSON syntax and choose Submit:
{ "customer id": 12345 }
In the next step, the agent has the information required to use the second action group (check-login-status) and function (check-customer-login-status-in-login-system) to call the Lambda function. In return, the Lambda function provides this JSON payload:
{
"status": "not verified",
"reason": "the email address has not been verified",
"solution": "please verify your email address"
}
Using this content, the agent can complete its task and suggest the correct solution for this customer.
I am satisfied with the result, but I want to know more about what happened under the hood. I choose Show trace where I can see the details of each step of the agent orchestration. This helps me understand the agent decisions and correct the configurations of the agent groups if they are not used as I expect.
Things to know You can use the new simplified experience to create and manage Agents for Amazon Bedrock in the US East (N. Virginia) and US West (Oregon) AWS Regions.
You can now create an agent without having to specify an API schema or provide a Lambda function for the action groups. You just need to list the parameters that the action group needs. When invoking the agent, you can choose to return control with the details of the operation to perform so that you can handle the operation in your existing applications or if the duration is longer than the maximum Lambda function timeout.
Model evaluations are critical at all stages of development. As a developer, you now have evaluation tools available for building generative artificial intelligence (AI) applications. You can start by experimenting with different models in the playground environment. To iterate faster, add automatic evaluations of the models. Then, when you prepare for an initial launch or limited release, you can incorporate human reviews to help ensure quality.
We received a lot of wonderful and helpful feedback during the preview and used it to round-out the features of this new capability in preparation for today’s launch — I’ll get to those in a moment. As a quick recap, here are the basic steps (refer to Antje’s post for a complete walk-through):
Create a Model Evaluation Job – Select the evaluation method (automatic or human), select one of the available foundation models, choose a task type, and choose the evaluation metrics. You can choose accuracy, robustness, and toxicity for an automatic evaluation, or any desired metrics (friendliness, style, and adherence to brand voice, for example) for a human evaluation. If you choose a human evaluation, you can use your own work team or you can opt for an AWS-managed team. There are four built-in task types, as well as a custom type (not shown):
After you select the task type you choose the metrics and the datasets that you want to use to evaluate the performance of the model. For example, if you select Text classification, you can evaluate accuracy and/or robustness with respect to your own dataset or a built-in one:
As you can see above, you can use a built-in dataset, or prepare a new one in JSON Lines (JSONL) format. Each entry must include a prompt and can include a category. The reference response is optional for all human evaluation configurations and for some combinations of task types and metrics for automatic evaluation:
{
"prompt" : "Bobigny is the capitol of",
"referenceResponse" : "Seine-Saint-Denis",
"category" : "Capitols"
}
You (or your local subject matter experts) can create a dataset that uses customer support questions, product descriptions, or sales collateral that is specific to your organization and your use case. The built-in datasets include Real Toxicity, BOLD, TREX, WikiText-2, Gigaword, BoolQ, Natural Questions, Trivia QA, and Women’s Ecommerce Clothing Reviews. These datasets are designed to test specific types of tasks and metrics, and can be chosen as appropriate.
Run Model Evaluation Job – Start the job and wait for it to complete. You can review the status of each of your model evaluation jobs from the console, and can also access the status using the new GetEvaluationJob API function:
Retrieve and Review Evaluation Report – Get the report and review the model’s performance against the metrics that you selected earlier. Again, refer to Antje’s post for a detailed look at a sample report.
New Features for GA With all of that out of the way, let’s take a look at the features that were added in preparation for today’s launch:
Improved Job Management – You can now stop a running job using the console or the new model evaluation API.
Model Evaluation API – You can now create and manage model evaluation jobs programmatically. The following functions are available:
CreateEvaluationJob – Create and run a model evaluation job using parameters specified in the API request including an evaluationConfig and an inferenceConfig.
ListEvaluationJobs – List model evaluation jobs, with optional filtering and sorting by creation time, evaluation job name, and status.
GetEvaluationJob – Retrieve the properties of a model evaluation job, including the status (InProgress, Completed, Failed, Stopping, or Stopped). After the job has completed, the results of the evaluation will be stored at the S3 URI that was specified in the outputDataConfig property supplied to CreateEvaluationJob.
StopEvaluationJob – Stop an in-progress job. Once stopped, a job cannot be resumed, and must be created anew if you want to rerun it.
This model evaluation API was one of the most-requested features during the preview. You can use it to perform evaluations at scale, perhaps as part of a development or testing regimen for your applications.
Enhanced Security – You can now use customer-managed KMS keys to encrypt your evaluation job data (if you don’t use this option, your data is encrypted using a key owned by AWS):
Access to More Models – In addition to the existing text-based models from AI21 Labs, Amazon, Anthropic, Cohere, and Meta, you now have access to Claude 2.1:
After you select a model you can set the inference configuration that will be used for the model evaluation job:
Things to Know Here are a couple of things to know about this cool new Amazon Bedrock capability:
Pricing – You pay for the inferences that are performed during the course of the model evaluation, with no additional charge for algorithmically generated scores. If you use human-based evaluation with your own team, you pay for the inferences and $0.21 for each completed task — a human worker submitting an evaluation of a single prompt and its associated inference responses in the human evaluation user interface. Pricing for evaluations performed by an AWS managed work team is based on the dataset, task types, and metrics that are important to your evaluation. For more information, consult the Amazon Bedrock Pricing page.
Regions – Model evaluation is available in the US East (N. Virginia) and US West (Oregon) AWS Regions.
More GenAI – Visit our new GenAI space to learn more about this and the other announcements that we are making today!
With Amazon Bedrock, you have access to a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies that make it easier to build and scale generative AI applications. Some of these models provide publicly available weights that can be fine-tuned and customized for specific use cases. However, deploying customized FMs in a secure and scalable way is not an easy task.
In this way, you can use Amazon Bedrock with existing customized models such as Code Llama, a code-specialized version of Llama 2 that was created by further training Llama 2 on code-specific datasets, or use your data to fine-tune models for your own unique business case and import the resulting model in Amazon Bedrock.
Let’s see how this works in practice.
Bringing a custom model to Amazon Bedrock In the Amazon Bedrock console, I choose Imported models from the Foundation models section of the navigation pane. Now, I can create a custom model by importing model weights from an Amazon Simple Storage Service (Amazon S3) bucket or from an Amazon SageMaker model.
I choose to import model weights from an S3 bucket. In another browser tab, I download the MistralLite model from the Hugging Face website using this pull request (PR) that provides weights in safetensors format. The pull request is currently Ready to merge, so it might be part of the main branch when you read this. MistralLite is a fine-tuned Mistral-7B-v0.1 language model with enhanced capabilities of processing long context up to 32K tokens.
When the download is complete, I upload the files to an S3 bucket in the same AWS Region where I will import the model. Here are the MistralLite model files in the Amazon S3 console:
Back at the Amazon Bedrock console, I enter a name for the model and keep the proposed import job name.
I select Model weights in the Model import settings and browse S3 to choose the location where I uploaded the model weights.
To authorize Amazon Bedrock to access the files on the S3 bucket, I select the option to create and use a new AWS Identity and Access Management (IAM) service role. I use the View permissions details link to check what will be in the role. Then, I submit the job.
About ten minutes later, the import job is completed.
Now, I see the imported model in the console. The list also shows the model Amazon Resource Name (ARN) and the creation date.
I choose the model to get more information, such as the S3 location of the model files.
In the model detail page, I choose Open in playground to test the model in the console. In the text playground, I type a question using the prompt template of the model:
<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>
The MistralLite imported model is quick to reply and describe some of those challenges.
In the playground, I can tune responses for my use case using configurations such as temperature and maximum length or add stop sequences specific to the imported model.
To see the syntax of the API request, I choose the three small vertical dots at the top right of the playground.
aws bedrock-runtime invoke-model \
--model-id arn:aws:bedrock:us-east-1:123412341234:imported-model/a82bkefgp20f \
--body "{\"prompt\":\"<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>\",\"max_tokens\":512,\"top_k\":200,\"top_p\":0.9,\"stop\":[],\"temperature\":0.5}" \
--cli-binary-format raw-in-base64-out \
--region us-east-1 \
invoke-model-output.txt
The output is similar to what I got in the playground. As you can see, for imported models, the model ID is the ARN of the imported model. I can use the model ID to invoke the imported model with the AWS CLI and AWS SDKs.
Things to know You can bring your own weights for supported model architectures to Amazon Bedrock in the US East (N. Virginia) AWS Region. The model import capability is currently available in preview.
When using custom weights, Amazon Bedrock serves the model with On-Demand mode, and you only pay for what you use with no time-based term commitments. For detailed information, see Amazon Bedrock pricing.
The ability to import models is managed using AWS Identity and Access Management (IAM), and you can allow this capability only to the roles in your organization that need to have it.
With this launch, it’s now easier to build and scale generative AI applications using custom models with security and privacy built in.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.