Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=x5IYfpawZys
PHOBOS: MARS’ DOOMED MOON?
Post Syndicated from Geographics original https://www.youtube.com/watch?v=9jJQgl5IPh0
The Philadelphia Eagles Make Real-Time Content Production a Reality
Post Syndicated from Laquie Campbell original https://www.backblaze.com/blog/how-to-migrate-mam-to-cloud/

Media and entertainment professionals have long debated how and where cloud services best fit in their workflows. Archive was initially seen as the most natural fit. But end-to-end cloud workflows and cloud-based production were viewed with skepticism due to the network bandwidth required to edit full resolution content. Now, as more organizations lean into REMI workflows, and new cloud-oriented creative tools enable real-time content production, the cloud is playing a role at every step of creative workflows.
Of course, it’s one thing to talk about real-time production in the cloud and it’s another thing to show how the cloud has transformed an actual workflow from end-to-end. But that’s exactly what the Philadelphia Eagles media team did by building a streamlined work-from-anywhere solution with cloud storage and cloud-delivered asset management. The best part was that rolling out the new cloud workflow was just as painless as it was transformative for their business.
We went from frequent LTO crashes and long restore times to near-instant access for every stored clip.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
Archive availability sidelines production efforts
The Eagles were using a portfolio of different storage systems to store petabytes of content with different availability for each tier. The best they could hope for when restoring clips from LTO, for example, was half real-time. So, a three hour clip might take an hour and half to restore—and that’s if the LTO system was working at all. It became so problematic that they stopped archiving content to LTO altogether, opting to max out their SAN to ensure fast access.
The desire for faster file-sharing led the business requirements for overhauling their storage infrastructure. They needed to:
- Consolidate their storage infrastructure.
- Improve remote access faster for sharing content internally or even monetizing it outside the organization.
- Improve the reliability of their backup and archive solution.
But migrating data and setting up a new system is no small feat.
Migration can’t run down the clock
Anyone who’s ever done a legacy migration knows moving to a new system is a quagmire. You can’t tell IT: You need to stop syncs and backups for three weeks while we do a migration.
—Ryan Lakey, Principal Lead, Solutions, CHESA
There’s a reason folks in the media and entertainment space dread a migration. It’s slow. It’s semi-painful. And, everything has to port over correctly.
The Eagles approached their migration in the off season. They needed some flexibility to consolidate their multiple SANs, stadium production operations, and LTO system into something that helped them fly higher.
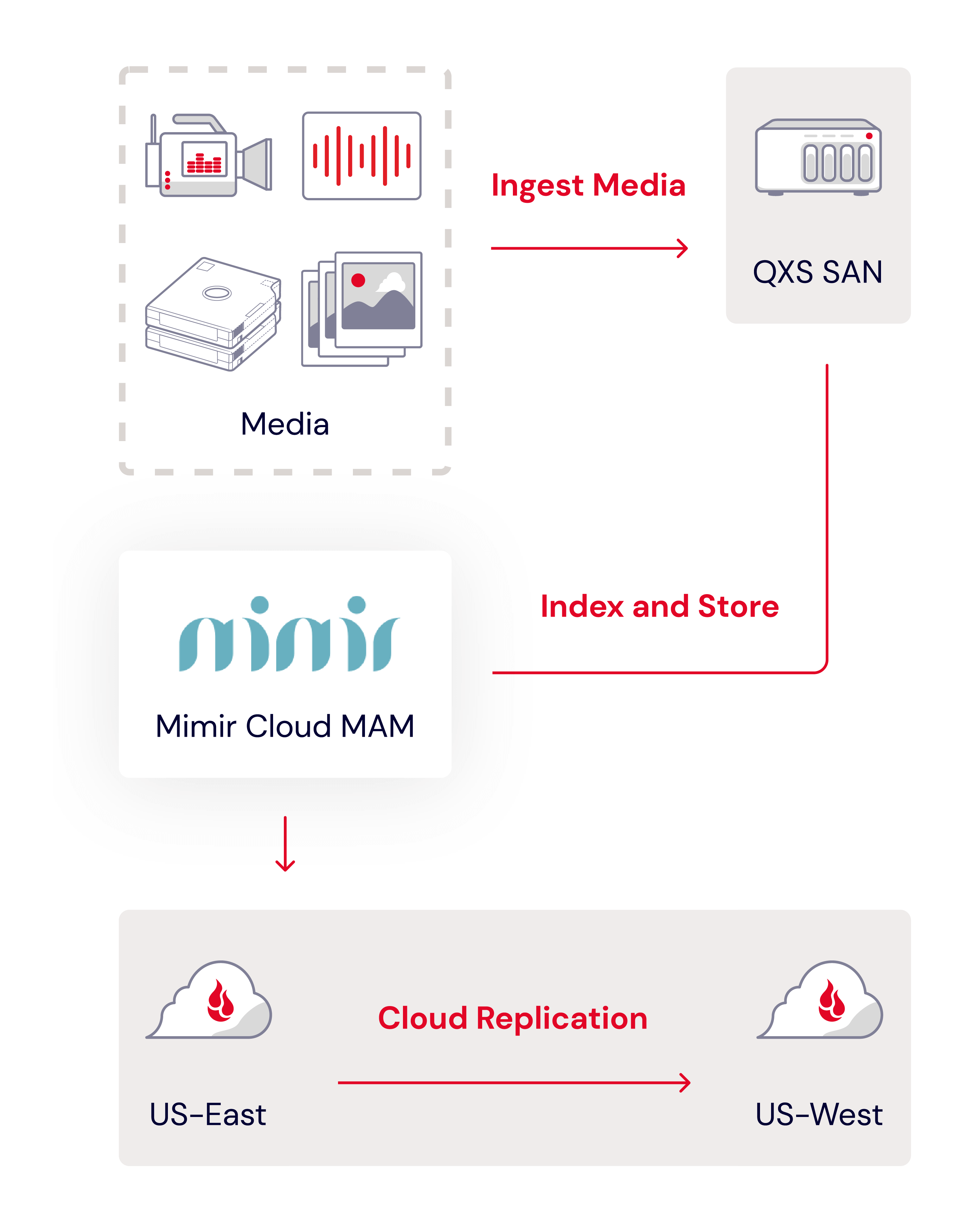
They consolidated the data into one single tier with a Quantum QSX on site for nearline storage and shifted hundreds of terabytes from their SAN and LTO system to Backblaze as their off-site storage for backup and archive.
Cloud MAM for the win
With storage sorted, the Eagles then integrated Mimir, a video collaboration and production platform that includes production asset management, archive, and object-store integration, to keep everything organized and on time. Whenever a file is uploaded to Mimir, it’s automatically stored in Backblaze B2 via Mimir’s file indexer system Kelda. This covered the game day action—their production team had fast access to recently recorded content, providing flexibility to work from home after those late night games.
Getting our sponsored, highest-performing content out quickly drives more views and boosts revenue, so efficiency on game day is critical. Our newly streamlined workflows ensure our editors can deliver while the content is still relevant and engaging.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
The final score
The new system empowers their production team by giving them instant access and fast workflows so they can work without slowdowns. Kelleher noted that restoring a clip is nearly instant.
They have the ability to share links directly from Mimir to users outside the organization for things like pre-season broadcasts, which comes in handy especially when those users don’t want, need, or have the equipment to download the entire broadcast file. Stacy can just copy and paste a Mimir link into an email, and outside agencies or users can watch entire games at speed.
Finally, they freed up IT staff time spent managing all that tape and old hardware, not to mention physical space. It all added up to a big win for the IT team, the franchise, and the fans.
Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
The post The Philadelphia Eagles Make Real-Time Content Production a Reality appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
LibreOffice 25.2 released
Post Syndicated from corbet original https://lwn.net/Articles/1008342/
Version 25.2 of the LibreOffice productivity suite is out. Changes include
the ability to remove all personal information from any document, support
for ODF version 1.4, a number of accessibility improvements, and more;
see the
release notes for details.
OpenWrt 24.10.0 released
Post Syndicated from corbet original https://lwn.net/Articles/1008339/
Version
24.10.0 of the OpenWrt router-oriented distribution has been released.
Changes include an update to the 6.6 kernel, use of access control lists on
larger systems, multipath TCP support, better WiFi6 support, the
beginning of WiFi7 support, and more.
Big Screen Battle! 100" QLED TV vs Projector vs UST
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=vPikt0UbhPk
Tailscale Setup on GL.iNet: Remote Access Made Easy
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=JQLXMNibLHs
Handle errors in Apache Flink applications on AWS
Post Syndicated from Alexis Tekin original https://aws.amazon.com/blogs/big-data/error-handling-in-apache-flink-applications/
Data streaming applications continuously process incoming data, much like a never-ending query against a database. Unlike traditional database queries where you request data one time and receive a single response, streaming data applications constantly receive new data in real time. This introduces some complexity, particularly around error handling. This post discusses the strategies for handling errors in Apache Flink applications. However, the general principles discussed here apply to stream processing applications at large.
Error handling in streaming applications
When developing stream processing applications, navigating complexities—especially around error handling—is crucial. Fostering data integrity and system reliability requires effective strategies to tackle failures while maintaining high performance. Striking this balance is essential for building resilient streaming applications that can handle real-world demands. In this post, we explore the significance of error handling and outline best practices for achieving both reliability and efficiency.
Before we can talk about how to handle errors in our consumer applications, we first need to consider the two most common types of errors that we encounter: transient and nontransient.
Transient errors, or retryable errors, are temporary issues that usually resolve themselves without requiring significant intervention. These can include network timeouts, temporary service unavailability, or minor glitches that don’t indicate a fundamental problem with the system. The key characteristic of transient errors is that they’re often short-lived and retrying the operation after a brief delay is usually enough to successfully complete the task. We dive deeper into how to implement retries in your system in the following section.
Nontransient errors, on the other hand, are persistent issues that don’t go away with retries and may indicate a more serious underlying problem. These could involve things such as data corruption or business logic violations. Nontransient errors require more comprehensive solutions, such as alerting operators, skipping the problematic data, or routing it to a dead letter queue (DLQ) for manual review and remediation. These errors need to be addressed directly to prevent ongoing issues within the system. For these types of errors, we explore DLQ topics as a viable solution.
Retries
As previously mentioned, retries are mechanisms used to handle transient errors by reprocessing messages that initially failed due to temporary issues. The goal of retries is to make sure that messages are successfully processed when the necessary conditions—such as resource availability—are met. By incorporating a retry mechanism, messages that can’t be processed immediately are reattempted after a delay, increasing the likelihood of successful processing.
We explore this approach through the use of an example based on the Amazon Managed Service for Apache Flink retries with Async I/O code sample. The example focuses on implementing a retry mechanism in a streaming application that calls an external endpoint during processing for purposes such as data enrichment or real-time validation
The application does the following:
- Generates data simulating a streaming data source
- Makes an asynchronous API call to an Amazon API Gateway or AWS Lambda endpoint, which randomly returns success, failure, or timeout. This call is made to emulate the enrichment of the stream with external data, potentially stored in a database or data store.
- Processes the application based on the response returned from the API Gateway endpoint:
-
- If the API Gateway response is successful, processing will continue as normal
- If the API Gateway response times out or returns a retryable error, the record will be retried a configurable number of times
- Reformats the message in a readable format, extracting the result
- Sends messages to the sink topic in our streaming storage layer
In this example, we use an asynchronous request that allows our system to handle many requests and their responses concurrently—increasing the overall throughput of our application. For more information on how to implement asynchronous API calls in Amazon Managed Service for Apache Flink, refer to Enrich your data stream asynchronously using Amazon Kinesis Data Analytics for Apache Flink.
Before we explain the application of retries for the Async function call, here is the AsyncInvoke implementation that will call our external API:
This example uses an AsyncHttpClient to call an HTTP endpoint that is a proxy to calling a Lambda function. The Lambda function is relatively straightforward, in that it merely returns SUCCESS. Async I/O in Apache Flink allows for making asynchronous requests to an HTTP endpoint for individual records and handles responses as they arrive back to the application. However, Async I/O can work with any asynchronous client that returns a Future or CompletableFuture object. This means that you can also query databases and other endpoints that support this return type. If the client in question makes blocking requests or can’t support asynchronous requests with Future return types, there isn’t any benefit to using Async I/O.
Some helpful notes when defining your Async I/O function:
- Increasing the
capacityparameter in your Async I/O function call will increase the number of in-flight requests. Keep in mind this will cause some overhead on checkpointing, and will introduce more load to your external system. - Keep in mind that your external requests are saved in application state. If the resulting object from the Async I/O function call is complex, object serialization may fall back to Kryo serialization which can impact performance.
The Async I/O function can process multiple requests concurrently without waiting for each one to be complete before processing the next. Apache Flink’s Async I/O function provides functionality for both ordered and unordered results when receiving responses back from an asynchronous call, giving flexibility based on your use case.
Errors during Async I/O requests
In the case that there is a transient error in your HTTP endpoint, there could be a timeout in the Async HTTP request. The timeout could be caused by the Apache Flink application overwhelming your HTTP endpoint, for example. This will, by default, result in an exception in the Apache Flink job, forcing a job restart from the latest checkpoint, effectively retrying all data from an earlier point in time. This restart strategy is expected and typical for Apache Flink applications, built to withstand errors without data loss or reprocessing of data. Restoring from the checkpoint should result in a fast restart with 30 seconds (P90) of downtime.
Because network errors could be temporary, backing off for a period and retrying the HTTP request could have a different result. Network errors could mean receiving an error status code back from the endpoint, but it could also mean not getting a response at all, and the request timing out. We can handle such cases within the Async I/O framework and use an Async retry strategy to retry the requests as needed. Async retry strategies are invoked when the ResultFuture request to an external endpoint is complete with an exception that you define in the preceding code snippet. The Async retry strategy is defined as follows:
When implementing this retry strategy, it’s important to have a solid understanding of the system you will be querying. How will retries impact performance? In the code snippet, we’re using a FixedDelayRetryStrategy that retries requests upon error one time every second with a delay of one second. The FixedDelayRetryStrategy is only one of several available options. Other retry strategies built into Apache Flink’s Async I/O library include the ExponentialBackoffDelayRetryStrategy, which increases the delay between retries exponentially upon every retry. It’s important to tailor your retry strategy to the specific needs and constraints of your target system.
Additionally, within the retry strategy, you can optionally define what happens when there are no results returned from the system or when there are exceptions. The Async I/O function in Flink uses two important predicates: isResult and isException.
The isResult predicate determines whether a returned value should be considered a valid result. If isResult returns false, in the case of empty or null responses, it will trigger a retry attempt.
The isException predicate evaluates whether a given exception should lead to a retry. If isException returns true for a particular exception, it will initiate a retry. Otherwise, the exception will be propagated and the job will fail.
If there is a timeout, you can override the timeout function within the Async I/O function to return zero results, which will result in a retry in the preceding block. This is also true for exceptions, which will result in retries, depending on the logic you determine to cause the .compleExceptionally() function to trigger.
By carefully configuring these predicates, you can fine-tune your retry logic to handle various scenarios, such as timeouts, network issues, or specific application-level exceptions, making sure your asynchronous processing is robust and efficient.
One key factor to keep in mind when implementing retries is the potential impact on overall system performance. Retrying operations too aggressively or with insufficient delays can lead to resource contention and reduced throughput. Therefore, it’s crucial to thoroughly test your retry configuration with representative data and loads to make sure you strike the right balance between resilience and efficiency.
A full code sample can be found at the amazon-managed-service-for-apache-flink-examples repository.
Dead letter queue
Although retries are effective for managing transient errors, not all issues can be resolved by reattempting the operation. Nontransient errors, such as data corruption or validation failures, persist despite retries and require a different approach to protect the integrity and reliability of the streaming application. In these cases, the concept of DLQs comes into play as a vital mechanism for capturing and isolating individual messages that can’t be processed successfully.
DLQs are intended to handle nontransient errors affecting individual messages, not system-wide issues, which require a different approach. Additionally, the use of DLQs might impact the order of messages being processed. In cases where processing order is important, implementing a DLQ may require a more detailed approach to make sure it aligns with your specific business use case.
Data corruption can’t be handled in the source operator of the Apache Flink application and will cause the application to fail and restart from the latest checkpoint. This issue will persist unless the message is handled outside of the source operator, downstream in a map operator or similar. Otherwise, the application will continue retrying and retrying.
In this section, we focus on how DLQs in the form of a dead letter sink can be used to separate messages from the main processing application and isolate them for a more focused or manual processing mechanism.
Consider an application that is receiving messages, transforming the data, and sending the results to a message sink. If a message is identified by the system as corrupt, and therefore can’t be processed, merely retrying the operation won’t fix the issue. This could result in the application getting stuck in a continuous loop of retries and failures. To prevent this from happening, such messages can be rerouted to a dead letter sink for further downstream exception handling.
This implementation results in our application having two different sinks: one for successfully processed messages (sink-topic) and one for messages that couldn’t be processed (exception-topic), as shown in the following diagram. To achieve this data flow, we need to “split” our stream so that each message goes to its appropriate sink topic. To do this in our Flink application, we can use side outputs.
The diagram demonstrates the DLQ concept through Amazon Managed Streaming for Apache Kafka topics and an Amazon Managed Service for Apache Flink application. However, this concept can be implemented through other AWS streaming services such as Amazon Kinesis Data Streams.

Side outputs
Using side outputs in Apache Flink, you can direct specific parts of your data stream to different logical streams based on conditions, enabling the efficient management of multiple data flows within a single job. In the context of handling nontransient errors, you can use side outputs to split your stream into two paths: one for successfully processed messages and another for those requiring additional handling (i.e. routing to a dead letter sink). The dead letter sink, often external to the application, means that problematic messages are captured without disrupting the main flow. This approach maintains the integrity of your primary data stream while making sure errors are managed efficiently and in isolation from the overall application.
The following shows how to implement side outputs into your Flink application.
Consider the example that you have a map transformation to identify poison messages and produce a stream of tuples:
Based on the processing result, you know whether you want to send this message to your dead letter sink or continue processing it in your application. Therefore, you need to split the stream to handle the message accordingly:
First create an OutputTag to route invalid events to a side output stream. This OutputTag is a typed and named identifier you can use to separately manage and direct specific events, such as invalid ones, to a distinct stream for further handling.
Next, apply a ProcessFunction to the stream. The ProcessFunction is a low-level stream processing operation that gives access to the basic building blocks of streaming applications. This operation will process each event and decide its path based on its validity. If an event is marked as invalid, it’s sent to the side output stream defined by the OutputTag. Valid events are emitted to the main output stream, allowing for continued processing without disruption.
Then retrieve the side output stream for invalid events using getSideOutput(invalidEventsTag). You can use this to independently access the events that were tagged and send them to the dead letter sink. The remainder of the messages will remain in the mainStream , where they can either continue to be processed or be sent to their respective sink:
The following diagram shows this workflow.

A full code sample can be found at the amazon-managed-service-for-apache-flink-examples repository.
What to do with messages in the DLQ
After successfully routing problematic messages to a DLQ using side outputs, the next step is determining how to handle these messages downstream. There isn’t a one-size-fits-all approach for managing dead letter messages. The best strategy depends on your application’s specific needs and the nature of the errors encountered. Some messages might be resolved though specialized applications or automated processing, while others might require manual intervention. Regardless of the approach, it’s crucial to make sure there is sufficient visibility and control over failed messages to facilitate any necessary manual handling.
A common approach is to send notifications through services such as Amazon Simple Notification Service (Amazon SNS), alerting administrators that certain messages weren’t processed successfully. This can help make sure that issues are promptly addressed, reducing the risk of prolonged data loss or system inefficiencies. Notifications can include details about the nature of the failure, enabling quick and informed responses.
Another effective strategy is to store dead letter messages externally from the stream, such as in an Amazon Simple Storage Service (Amazon S3) bucket. By archiving these messages in a central, accessible location, you enhance visibility into what went wrong and provide a long-term record of unprocessed data. This stored data can be reviewed, corrected, and even re-ingested into the stream if necessary.
Ultimately, the goal is to design a downstream handling process that fits your operational needs, providing the right balance of automation and manual oversight.
Conclusion
In this post, we looked at how you can leverage concepts such as retries and dead letter sinks for maintaining the integrity and efficiency of your streaming applications. We demonstrated how you can implement these concepts through Apache Flink code samples highlighting Async I/O and Side Output capabilities:
To supplement, we’ve included the code examples highlighted in this post in the above list. For more details, refer to the respective code samples. It’s best to test these solutions with sample data and known results to understand their respective behaviors.
About the Authors
 Alexis Tekin is a Solutions Architect at AWS, working with startups to help them scale and innovate using AWS services. Previously, she supported financial services customers by developing prototype solutions, leveraging her expertise in software development and cloud architecture. Alexis is a former Texas Longhorn, where she graduated with a degree in Management Information Systems from the University of Texas at Austin.
Alexis Tekin is a Solutions Architect at AWS, working with startups to help them scale and innovate using AWS services. Previously, she supported financial services customers by developing prototype solutions, leveraging her expertise in software development and cloud architecture. Alexis is a former Texas Longhorn, where she graduated with a degree in Management Information Systems from the University of Texas at Austin.
 Jeremy Ber has been in the software space for over 10 years with experience ranging from Software Engineering, Data Engineering, Data Science and most recently Streaming Data. He currently serves as a Streaming Specialist Solutions Architect at Amazon Web Services, focused on Amazon Managed Streaming for Apache Kafka (MSK) and Amazon Managed Service for Apache Flink (MSF).
Jeremy Ber has been in the software space for over 10 years with experience ranging from Software Engineering, Data Engineering, Data Science and most recently Streaming Data. He currently serves as a Streaming Specialist Solutions Architect at Amazon Web Services, focused on Amazon Managed Streaming for Apache Kafka (MSK) and Amazon Managed Service for Apache Flink (MSF).
[$] The selfish contributor revisited
Post Syndicated from jzb original https://lwn.net/Articles/1007426/
Open source is often described as a “gift economy”—an
ecosystem where contributors are motivated by a desire to make the
world a better place. That is, sometimes, true. However, James
Bottomley used his main
track slot at FOSDEM 2025,
on February 1, to make the case that it is better to bank on the
selfish motivations of individuals to drive community success than to
rely on their altruism.
Security updates for Thursday
Post Syndicated from jake original https://lwn.net/Articles/1008275/
Security updates have been issued by Debian (asterisk and chromium), Fedora (FlightGear, java-1.8.0-openjdk, java-11-openjdk, java-17-openjdk, java-latest-openjdk, and SimGear), Mageia (bind, chromium-browser-stable, python-django, and vim), Oracle (buildah, bzip2, firefox, keepalived, mariadb:10.11, and podman), Slackware (curl, mariadb, and mozilla), SUSE (cargo-audit-advisory-db-20250204 and python311-scikit-learn), and Ubuntu (ckeditor, krb5, and ruby2.7).
Comic for 2025.02.06 – Duck
Post Syndicated from Explosm.net original https://explosm.net/comics/duck
New Cyanide and Happiness Comic
4 Reasons Why MSPs & MSSPs Need to Enhance Attack Surface Management
Post Syndicated from Sid Nanda original https://blog.rapid7.com/2025/02/06/4-reasons-why-msps-and-mssps-need-attack-surface-management/

In today’s rapidly evolving digital landscape, Managed Service Providers (MSPs) and Managed Security Service Providers (MSSPs) face increasing challenges. As businesses expand their digital footprints, MSPs and MSSPs are under pressure to deliver comprehensive security services while managing costs, streamlining operations, and addressing client-specific vulnerabilities. Operating without a robust Attack Surface Management (ASM) solution can leave significant gaps in security, efficiency, and scalability—limiting growth and leaving clients vulnerable to modern threats.
Here are four key reasons why enhancing attack surface management should be a top priority for MSPs and MSSPs:
1. Streamlined Onboarding with Automated Asset Discovery
The Challenge: For many MSPs and MSSPs, onboarding new clients can be a time-consuming process, particularly when it comes to manual asset discovery and correlation. Without automation, teams often spend weeks sorting, deduplicating, and organizing data across different tools, delaying time-to-value for clients.
Why ASM Matters: An effective ASM solution automates asset discovery and provides near real-time insights into a client’s digital footprint. This reduces onboarding times significantly, allowing MSPs and MSSPs to bring more clients on board faster. By eliminating manual inefficiencies, teams can focus on delivering strategic services, enhancing client satisfaction, and scaling operations.
2. Improved Risk Assessment and Cost Predictability
The Challenge: Accurately predicting operational expenditures (OpEx) can be challenging without full visibility into a client’s vulnerabilities and risks. This uncertainty often leads to unexpected costs during service delivery, affecting both profitability and client relationships.
Why ASM Matters: With a comprehensive ASM solution, MSPs and MSSPs can assess risks upfront and forecast potential costs with greater accuracy. Knowing the full scope of vulnerabilities before committing to a client engagement allows for better resource allocation and informed decision-making.
The Opportunity: Risk assessment powered by ASM not only helps avoid financial surprises but also builds trust with clients. By providing clear, data-driven projections, MSPs and MSSPs can confidently structure pricing, demonstrating their value as proactive and reliable partners.
3. Enhanced Service Offerings and Revenue Opportunities
The Challenge: Many MSPs and MSSPs struggle to differentiate their services in a crowded market. Without advanced tools to uncover vulnerabilities or prioritize remediation efforts, security offerings may appear standardized , making it harder to justify premium pricing.
Why ASM Matters: An ASM solution enables providers to offer more advanced, proactive services such as continuous monitoring, exposure mitigation, and tailored remediation plans. These capabilities not only enhance the value of core services but also create opportunities to upsell additional offerings like managed detection and response (MDR) or threat intelligence services.
The Opportunity: By leveraging ASM, MSPs and MSSPs can position themselves as strategic partners, delivering measurable results that align with client objectives. This differentiation fosters client loyalty and opens the door to new revenue streams.
4. Breaking Down Operational Silos for Better Collaboration
The Challenge: Operational silos between NetOps, SecOps, and CloudOps can hinder effective communication and delay incident response. When teams work in isolation, identifying and addressing vulnerabilities becomes a fragmented process, increasing response times and risks.
Why ASM Matters: A unified ASM platform provides a single pane of glass for all operational teams, enabling seamless collaboration. With shared access to real-time data, teams can align on priorities, streamline workflows, and coordinate remediation efforts effectively.
The Opportunity: Better collaboration leads to faster response times, reduced operational friction, and stronger client outcomes. By eliminating silos, MSPs and MSSPs can deliver a more cohesive and reliable service, strengthening their reputation and competitiveness.
Why Consider Rapid7 Exposure Command?
While the need for a robust ASM solution is clear, not all platforms are created equal. Rapid7’s Exposure Command delivers advanced capabilities designed to meet the unique challenges faced by MSPs and MSSPs, including:
- Comprehensive Visibility: A continuous 360° view of attack surfaces across hybrid environments.
- Proactive Mitigation: Threat-aware risk context to prioritize and eliminate high-priority exposures.
- Enhanced Scalability: Automation and integrations that support efficient scaling as your business grows.
By adopting these solutions, MSPs and MSSPs can future-proof their services, providing clients with the security and reliability they need in today’s threat landscape.
The Bottom Line
Incorporating a strong ASM strategy is no longer optional for MSPs and MSSPs. It’s a necessity for staying competitive, delivering exceptional client value, and unlocking new revenue opportunities. By addressing onboarding inefficiencies, improving risk predictability, enhancing service offerings, and fostering cross-functional collaboration, ASM empowers providers to rise to the challenges of modern cybersecurity.
If you’re ready to take your attack surface management capabilities to the next level, consider Rapid7’s Exposure Command. With this tool, you can confidently navigate today’s complex threat landscape and set your business apart as a leader in managed security services.
Близнаците от NASA и ключът към живота ни в Космоса
Post Syndicated from original https://www.toest.bg/bliznatsite-ot-nasa-i-klyuchut-kum-zhivota-ni-v-kosmosa/
Изследването с близнаците

Засега познанията ни за взаимодействията на човешкото тяло с космическата околна среда на молекулярно ниво са сравнително ограничени. Космическата радиация, специфичната диета в Космоса, намалената физическа активност, нарушеният биологичен часовник и безтегловността влияят на имунитета и метаболизма на човека.
Информация за здравословното състояние на астронавтите биха дали биомаркерите (гени, свързани с функциите на имунната система, с поправката на ДНК, с развитието на рак – т.нар. протоонкогени, и др.). Биомаркерите, които представляват научен интерес, са част от генома, епигенома и метаболома. Освен за здравето на астронавтите, те биха могли да дадат и насоки за изготвяне на персонализирани планове за превенция на заболявания, свързани със средата в Космоса.
Въпреки че познанията ни за последствията от престоя в Космоса на физиологично ниво се увеличават непрекъснато през последните над 20 години, те са в резултат на краткосрочни мисии – 4 до 6 месеца престой на Международната космическа станция (МКС). До момента само четирима души са участвали в космически мисии с голяма продължителност (една година и повече). Погледът към бъдещето предполага по-дълги космически мисии (до три години), включително и до Марс, за които е необходима сериозна подготовка.
NASA избира еднояйчните близнаци Скот и Марк Кели за уникална мисия, за да се проучи влиянието на околната среда в Космоса (микрогравитацията и радиацията) при дълги космически полети (над една година). Двамата близнаци са астронавти на NASA, но не са били изпращани на мисии в Космоса четири години преди проучването. Скот е избран да престои една година на Международната космическа станция, а неговото генетично копие – брат му Марк, е т.нар. контрола на експеримента и остава на Земята. Мисията е с продължителност почти година – от 27 март 2015 г. до 1 март 2016 г.
Биологичните проби от близнаците, събрани за периода на експеримента са 317 (кръв, урина, изпражнения). Проведени са изследвания, свързани с епигенетични промени, и са подложени на молекулярна диагностика на различни омикс нива – метаболом, транскриптом, протеом, микробиом и геном (виж фиг. 1). Освен това Скот и Марк Кели са били тествани преди и след космическата мисия.
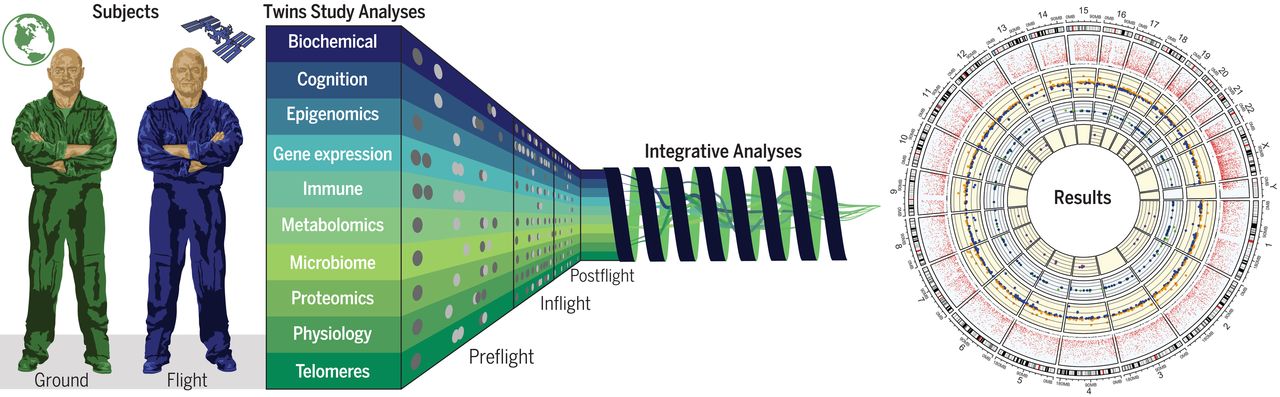
Човешкият геном в космически условия
Част от изследванията са фокусирани върху нарушения в хромозомите в резултат на излагане на йонизираща радиация по време на полет в Космоса. Нарушенията могат да бъдат транслокации вътре в хромозомата (пренареждане на сегменти от хромозомите) и инверсии (сегменти от хромозомата с обърната посока). Транслокациите са отговорни за развитието на заболявания като рак, стерилитет, синдром на Даун и др. Инверсиите могат да доведат до промени в експресията на гените, например някои протеини да не се произвеждат, както и до генетични заболявания, като хемофилия.
Резултатите от изследването сочат, че при Скот Кели (близнака в Космоса) инверсиите се увеличават в сравнение с транслокациите. Тези данни съвпадат със силата на излагането на радиация в Космоса, тоест знаем, че при излагането на космическа радиация се случва именно това.
Наблюдават се и промени в експресията на някои гени. С повишена експресия са гените, отговорни за поправка на ДНК. Причината е, че е необходимо да произвеждат повече белтъци, които отговарят за поправката на ДНК при възникнали грешки. Това означава, че тялото е изложено на по-голямо количество мутагенни фактори. Честотата на хромозомните инверсии се повишава дори и след полета, което би могло да се обясни с повреди в ДНК на стволовите клетки след излагане на космическа радиация. Други данни от изследването сочат, че втората половина на полета (от 6-тия до 12-тия месец) води до увеличаване на промените в генома.
Част от гените не възстановяват нормалната си експресия шест месеца след връщането на Скот на Земята. Тези гени (811 на брой в различни видове клетки) са свързани с функциите на имунната система и поправката на ДНК.
Стареенето на Земята и в Космоса
Теломерите са повтарящи се структури в краищата на хромозомите. Те са изключително важни за поддържането на целостта на генома, тъй като защитават физическите краища на ДНК от разграждане. Теломерите се скъсяват с клетъчното делене и с възрастта, както и при различни фактори на начина на живот, като стрес, замърсяване на въздуха и радиация.
В изследването на близнаците от NASA средната дължина на теломерите е оценена преди, по време и след космическия полет на Скот Кели. Най-съществено увеличение на дължината на теломерите се наблюдава по време на космическия полет (в сравнение с дължината им преди и след него, както и в сравнение с теломерите на Марк, който остава на Земята). Изненадващо, при завръщането на Скот дължината на теломерите се скъсява до средните стойности преди полета само за 48 часа. С други думи, в Космоса стареенето се е забавило и после за 48 часа се е върнало към обичайното за Земята, което при всички положения е страшно интересно, и предстои да научим защо става точно така.
Специфичното за космическите полети удължаване на теломерите, наблюдавано в това проучване, е в съответствие с подобни открития при астронавти, които са имали по-кратък престой (около 6 месеца) на МКС. Въпреки това механизмите и последиците от удължаването на теломерите в космически условия не са изяснени. С по-дълги теломери се свързват здравословният начин на живот, включващ състоянието на метаболизма, диетата, физическата активност и телесното тегло. В тази връзка, по време на полета Скот Кели е бил с намалено телесно тегло и повишени нива на фолат в серума, което може да обясни удължаването на теломерите.
Изводи от проучването и поглед към бъдещето
Установените промени в човешкото тяло на молекулярно ниво при продължителен престой в Космоса биха могли да дадат насоки за предпазване на здравето при дълги мисии. Недостатък на изследването с близнаците е, че не e статистически значимо, защото в него участват само един обект и една контрола и не е изключено установените различия да се дължат на случайни събития.
Изследването е първа крачка към още подобни проучвания с други астронавти. От NASA планират да изпращат по десет астронавти за различни периоди (шест месеца, една година), а на Земята да има контролни индивиди в изолирана среда.
Междувременно Скот Кели ще бъде наблюдаван и тестван веднъж годишно, докато е жив, с надеждата да получим отговор на непрекъснато възникващите въпроси, свързани с живота на човека в Космоса.
AIs and Robots Should Sound Robotic
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/02/ais-and-robots-should-sound-robotic.html
Most people know that robots no longer sound like tinny trash cans. They sound like Siri, Alexa, and Gemini. They sound like the voices in labyrinthine customer support phone trees. And even those robot voices are being made obsolete by new AI-generated voices that can mimic every vocal nuance and tic of human speech, down to specific regional accents. And with just a few seconds of audio, AI can now clone someone’s specific voice.
This technology will replace humans in many areas. Automated customer support will save money by cutting staffing at call centers. AI agents will make calls on our behalf, conversing with others in natural language. All of that is happening, and will be commonplace soon.
But there is something fundamentally different about talking with a bot as opposed to a person. A person can be a friend. An AI cannot be a friend, despite how people might treat it or react to it. AI is at best a tool, and at worst a means of manipulation. Humans need to know whether we’re talking with a living, breathing person or a robot with an agenda set by the person who controls it. That’s why robots should sound like robots.
You can’t just label AI-generated speech. It will come in many different forms. So we need a way to recognize AI that works no matter the modality. It needs to work for long or short snippets of audio, even just a second long. It needs to work for any language, and in any cultural context. At the same time, we shouldn’t constrain the underlying system’s sophistication or language complexity.
We have a simple proposal: all talking AIs and robots should use a ring modulator. In the mid-twentieth century, before it was easy to create actual robotic-sounding speech synthetically, ring modulators were used to make actors’ voices sound robotic. Over the last few decades, we have become accustomed to robotic voices, simply because text-to-speech systems were good enough to produce intelligible speech that was not human-like in its sound. Now we can use that same technology to make robotic speech that is indistinguishable from human sound robotic again.
A ring modulator has several advantages: It is computationally simple, can be applied in real-time, does not affect the intelligibility of the voice, and—most importantly—is universally “robotic sounding” because of its historical usage for depicting robots.
Responsible AI companies that provide voice synthesis or AI voice assistants in any form should add a ring modulator of some standard frequency (say, between 30-80 Hz) and of a minimum amplitude (say, 20 percent). That’s it. People will catch on quickly.
Here are a couple of examples you can listen to for examples of what we’re suggesting. The first clip is an AI-generated “podcast” of this article made by Google’s NotebookLM featuring two AI “hosts.” Google’s NotebookLM created the podcast script and audio given only the text of this article. The next two clips feature that same podcast with the AIs’ voices modulated more and less subtly by a ring modulator:
Raw audio sample generated by Google’s NotebookLM
Audio sample with added ring modulator (30 Hz-25%)
Audio sample with added ring modulator (30 Hz-40%)
We were able to generate the audio effect with a 50-line Python script generated by Anthropic’s Claude. One of the most well-known robot voices were those of the Daleks from Doctor Who in the 1960s. Back then robot voices were difficult to synthesize, so the audio was actually an actor’s voice run through a ring modulator. It was set to around 30 Hz, as we did in our example, with different modulation depth (amplitude) depending on how strong the robotic effect is meant to be. Our expectation is that the AI industry will test and converge on a good balance of such parameters and settings, and will use better tools than a 50-line Python script, but this highlights how simple it is to achieve.
Of course there will also be nefarious uses of AI voices. Scams that use voice cloning have been getting easier every year, but they’ve been possible for many years with the right know-how. Just like we’re learning that we can no longer trust images and videos we see because they could easily have been AI-generated, we will all soon learn that someone who sounds like a family member urgently requesting money may just be a scammer using a voice-cloning tool.
We don’t expect scammers to follow our proposal: They’ll find a way no matter what. But that’s always true of security standards, and a rising tide lifts all boats. We think the bulk of the uses will be with popular voice APIs from major companies—and everyone should know that they’re talking with a robot.
This essay was written with Barath Raghavan, and originally appeared in IEEE Spectrum.
Purge Now, Pay Later
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=8_qVH8rHlpY
На второ четене: „Коларят на Смъртта“
Post Syndicated from Стефан Иванов original https://www.toest.bg/na-vtoro-chetene-kolaryat-na-smurtta/
„Коларят на Смъртта“ от Селма Лагерльоф

превод от шведски Меглена Боденска, София: изд. „Лист“, 2021
Вместо въведение – писателски спиритичен сеанс. Представете си, че сте на вечеря с духовете на Достоевски, Дикенс и Едгар Алън По. Те пият тежко червено вино, обсъждат моралните падения на човечеството и някъде между диалектиката на вината и херменевтиката на покаянието изведнъж влиза една фина, но неумолима и волева скандинавка – Селма Лагерльоф. Оставя на масата тънък том със заглавието Körkarlen („Коларят на Смъртта“), оглежда всички с онзи особен поглед на човек, който знае, че разказът му е по-силен от тяхната логорея (надменно и снизходително, но може да си го позволи, знае си цената), и сяда, оставяйки произведението си да говори вместо нея.
Но защо този роман, публикуван през 1912 г., продължава да резонира и в XXI век? Защо той се нарежда сред тези литературни произведения, които не само разказват история, а изискват читателят да се превърне в техен съучастник?
Лагерльоф оставя след себе си внушително творчество, което смесва фолклор, мистицизъм и социална критика. Тя често изследва границите между реалността и фантастичното, превръщайки я в нещо като северен еквивалент на Габриел Гарсия Маркес, но с далеч по-суров климат и без тропически плодове.
Нужен е малко биографичен фон, който да препотвърди за пореден път, че с лични демони почти винаги се пише по-добре. Селма Лагерльоф не е единствено писателка от канона – тя е явление. В края на XIX и началото на XX век шведската литература изпитва силна нужда от нови гласове, които да избягат от натурализма и неговата непоколебима обсесия с мизерията и клетостта.
Влиза Лагерльоф, която – въпреки че разказва истории за несретници – ги превръща във всекидневни и архетипни герои, способни на трансформация в една магическа реалност.
„Коларят на Смъртта“ до голяма степен черпи вдъхновение от личния ѝ живот. Алкохолизмът на баща ѝ, смъртта на нейната сестра Анна от туберкулоза, както и дълбокият ѝ интерес към социалните проблеми на времето са вградени в тъканта на романа. И ако се замислим, цялата ѝ кариера е един бунт срещу структурите, които потискат индивидуалния дух: тя е първата жена, получила Нобелова награда за литература (1909), активно се бори за правата на жените, а като автор не се побира в удобните рамки на шведската академична традиция.
Но да се върнем на сюжета. Той е чист, ясен и мрачен – Смъртта кара нощна смяна. В медийното пространство е новина кое е първото бебе за годината, а в литературното пространство е важно кой е последният покойник за годината.
Историята започва с класическата сцена на умираща светица – сестра Едит, член на Армията на спасението, която на смъртния си одър настоява да повикат най-големия грешник, когото някога е срещала: пияницата и побойник Давид Холм. Само че съдбата – както знаем – обича добрите обрати и вместо да се разиграе стандартната драматична среща, Холм умира точно в полунощ на Нова година, ставайки новият Колар на Смъртта. Това означава, че ще трябва цяла година да събира душите на починалите – точно както предишният колар, негов стар познайник, е правил преди него.
В този момент Лагерльоф натиска бутона „свръхестествено“ и разказът се превръща в бавна разходка през моралния разпад на героя. Холм е класически персонаж от епохата на реализма – паднал мъж, който, по всички канони на литературата, е обречен. Но тук идва голямото „но“: чрез поредица от видения, връщания в миналото и финален акт на осъзнаване той намира спасение.
Темите и мотивите, с които Лагерльоф джазира виртуозно, варират от Данте до Дикенс и обратно. Тя представя изкуплението и вината като екзистенциален и жизненонеобходим душевен аксесоар. Лагерльоф се заиграва с християнската концепция за покаянието, но го прави по начин, който би накарал дори и най-закоравелия атеист да преглътне тежко. Холм е повече от типичен грешник – той е прамъжът, изгубил себе си в разрушителната сила на алкохола, насилието и безразличието. Но романът отказва да го демонизира напълно. Вместо това го оставя да страда, докато сам не разбере, че вината е безполезна, ако не води до действие.
Смъртта от своя страна е разгледана като бюрократична институция. Коларят, освен митична фигура, е и работник. Един уморен, леко отчаян, но неизменно задължен към своята работа персонаж, който напомня за готическите видения на По, но с нотка на институционален цинизъм. Лагерльоф не представя смъртта като трагичен или епичен акт – тя е неотменна част от процеса.

Романът се занимава с два основни социални кошмара на своето време – туберкулозата и алкохолизма.
И двете са представени като епидемии, но с една съществена разлика – докато болестта е безмилостна, пиянството е и избор. Давид Холм не е жертва, той е активен участник в своята деградация.
Но на кого му пука за още един алкохолизиран неудачник, би си казал някой читател, след като вече е чел Лоури, Буковски, Селби и Венедикт Ерофеев? Ако сложим „Коларят на Смъртта“ в диалог с други произведения, ще видим, че той си комуникира с класики от различни традиции. И изпъква. Скрудж от „Коледна песен“ на Дикенс и Давид Холм са братовчеди по дух, но докато Скрудж намира спасение чрез духове, Холм го намира чрез смъртта си. Холм може да се разглежда и като по-лузърска версия на герой на Достоевски или дори на Фауст – човек, който без много размисъл продава душата си, но за бутилка ракия, а не за вселенската мъдрост.
Нужно е да се припомни и че филмовата адаптация на Виктор Шьострьом (1921) е сред най-влиятелните филми на нямото кино и любима творба на Ингмар Бергман. Мотиви от романа присъстват и в пиесата „Майсторите на образи“ на П. У. Енквист, поставена от Бергман през 1998 г.
Това очевидно е разказ за смъртта, но и разказ за живота, за границите на човешката промяна и за това, че дори най-изгубените души може би не са толкова изгубени. В този смисъл романът е нещо повече от готическа притча. Той е метафора за неизбежния сблъсък между миналото и бъдещето, между греха и опрощението, между човека и самия него.
Или казано по-просто: ако някога чуете скрибуцането на стара каруца в новогодишната нощ, може би е време да преразгледате житейските си решения и да си кажете:
Боже, позволи на душата ми да узрее, преди да бъде прибрана!“
Активните дарители на „Тоест“ получават постоянна отстъпка в размер нa 20% от коричната цена на всички заглавия от каталога на издателство „Лист“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
The "Belly Flopper."
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=x4TS_th-3Ws
Army oddity
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Cn0VUqGPAXA
[$] LWN.net Weekly Edition for February 6, 2025
Post Syndicated from corbet original https://lwn.net/Articles/1007000/
Inside this week’s LWN.net Weekly Edition:
- Front: Finding concurrency bugs with sched_ext; Rust abstractions; 6.14 Merge window; Sealed system mappings; OpenSUSE board; Julia; Site tour.
- Briefs: Binutils 2.44; Firefox 135.0; Freedesktop GitLab; GNU C Library 2.41; GTK; Servo; Thunderbird updates; Sanctions; Quotes; …
- Announcements: Newsletters, conferences, security updates, patches, and more.
AWS CodeBuild for macOS adds support for Fastlane
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/codebuild-for-macos-adds-support-for-fastlane/
I’m pleased to announce the availability of Fastlane in your AWS CodeBuild for macOS environments. AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces ready-to-deploy software packages.
Fastlane is an open source tool suite designed to automate various aspects of mobile application development. It provides mobile application developers with a centralized set of tools to manage tasks such as code signing, screenshot generation, beta distribution, and app store submissions. It integrates with popular continuous integration and continuous deployment (CI/CD) platforms and supports both iOS and Android development workflows. Although Fastlane offers significant automation capabilities, developers may encounter challenges during its setup and maintenance. Configuring Fastlane can be complex, particularly for teams unfamiliar with the syntax and package management system of Ruby. Keeping Fastlane and its dependencies up to date requires ongoing effort, because updates to mobile platforms or third-party services may necessitate adjustments to existing workflows.
When we introduced CodeBuild for macOS in August 2024, we knew that one of your challenges was to install and maintain Fastlane in your build environment. Although it was possible to manually install Fastlane in a custom build environment, at AWS, we remove the undifferentiated heaving lifting from your infrastructure so you can spend more time on the aspects that matter for your business. Starting today, Fastlane is installed by default, and you can use the familiar command fastlane buildin your buildspec.yaml file.
Fastlane and code signing
To distribute an application on the App Store, developers must sign their binary with a private key generated on the Apple Developer portal. This private key, along with the certificate that validates it, must be accessible during the build process. This can be a challenge for development teams because they need to share the development private key (which allows deployment on selected test devices) among team members. Additionally, the distribution private key (which enables publishing on the App Store) must be available during the signing process before uploading the binary to the App Store.
Fastlane is a versatile build system in that it also helps developers with the management of development and distribution keys and certificates. Developers can use fastlane match to share signing materials in a team and make them securely and easily accessible on individual developers’ machines and on the CI environment. match allows the storage of private keys, the certificates, and the mobile provisioning profiles on a secured share storage. It makes sure that the local build environment, whether it’s a developer laptop or a server machine in the cloud, stays in sync with the shared storage. At build time, it securely downloads the required certificates to sign your app and configures the build machine to allow the codesign utility to pick them up.
match allows the sharing of signing secrets through GitHub, GitLab, Google Cloud Storage, Azure DevOps, and Amazon Simple Storage Service (Amazon S3).
If you already use one of these and you’re migrating your projects to CodeBuild, you don’t have much to do. You only need to make sure your CodeBuild build environment has access to the shared storage (see step 3 in the demo).
Let’s see how it works
If you’re new to Fastlane or CodeBuild, let’s see how it works.
For this demo, I start with an existing iOS project. The project is already configured to be built on CodeBuild. You can refer to my previous blog post, Add macOS to your continuous integration pipelines with AWS CodeBuild, to learn more details.
I’ll show you how to get started in three steps:
- Import your existing signing materials to a shared private GitHub repository
- Configure
fastlaneto build and sign your project - Use
fastlanewith CodeBuild
Step 1: Import your signing materials
Most of the fastlane documentation I read explains how to create a new key pair and a new certificate to get started. Although this is certainly true for new projects, in real life, you probably already have your project and your signing keys. So, the first step is to import these existing signing materials.
Apple App Store uses different keys and certificates for development and distribution (there are also ad hoc and enterprise certificates, but these are outside the scope of this post). You must have three files for each usage (that’s a total of six files):
- A
.mobileprovisionfile that you can create and download from the Apple developer console. The provisioning profile links your identity, the app identity, and the entitlements the app might have. - A
.cerfile, which is the certificate emitted by Apple to validate your private key. You can download this from the Apple Developer portal. Select the certificate, then select Download. - A
.p12file, which contains your private key. You can download the key when you create it in the Apple Developer portal. If you didn’t download it but have it on your machine, you can export it from the Apple Keychain app. Note that the KeyChain.app is hidden in macOS 15.x. You can open it withopen /System/Library/CoreServices/Applications/Keychain\ Access.app. Select the key you want to export and right click to select Export.
 |
 |
When you have these files, create a fastlane/Matchfile file with the following content:
git_url("https://github.com/sebsto/secret.git")
storage_mode("git")
type("development")
# or use appstore to use the distribution signing key and certificate
# type("appstore")Be sure to replace the URL of your GitHub repository and make sure this repository is private. It will serve as a storage for your signing key and certificate.
Then, I import my existing files with the fastlane match import --type appstore command. I repeat the command for each environment: appstore and development.
The very first time, fastlane prompts me for my Apple Id username and password. It connects to App Store Connect to verify the validity of the certificates or to create new ones when necessary. The session cookie is stored in ~/.fastlane/spaceship/<your apple user id>/cookie.
fastlane match also asks for a password. It uses this password to generate a key to crypt the signing materials on the storage. Don’t forget this password because it will be used at build time to import the signing materials on the build machine.
Here is the command and its output in full:
fastlane match import --type appstore
[✔] 🚀
[16:43:54]: Successfully loaded '~/amplify-ios-getting-started/code/fastlane/Matchfile' 📄
+-----------------------------------------------------+
| Detected Values from './fastlane/Matchfile' |
+--------------+--------------------------------------+
| git_url. | https://github.com/sebsto/secret.git |
| storage_mode | git |
| type | development |
+--------------+--------------------------------------+
[16:43:54]: Certificate (.cer) path:
./secrets/sebsto-apple-dist.cer
[16:44:07]: Private key (.p12) path:
./secrets/sebsto-apple-dist.p12
[16:44:12]: Provisioning profile (.mobileprovision or .provisionprofile) path or leave empty to skip
this file:
./secrets/amplifyiosgettingstarteddist.mobileprovision
[16:44:25]: Cloning remote git repo...
[16:44:25]: If cloning the repo takes too long, you can use the `clone_branch_directly` option in match.
[16:44:27]: Checking out branch master...
[16:44:27]: Enter the passphrase that should be used to encrypt/decrypt your certificates
[16:44:27]: This passphrase is specific per repository and will be stored in your local keychain
[16:44:27]: Make sure to remember the password, as you'll need it when you run match on a different machine
[16:44:27]: Passphrase for Match storage: ********
[16:44:30]: Type passphrase again: ********
security: SecKeychainAddInternetPassword <NULL>: The specified item already exists in the keychain.
[16:44:31]: 🔓 Successfully decrypted certificates repo
[16:44:31]: Repo is at: '/var/folders/14/nwpsn4b504gfp02_mrbyd2jr0000gr/T/d20250131-41830-z7b4ic'
[16:44:31]: Login to App Store Connect ([email protected])
[16:44:33]: Enter the passphrase that should be used to encrypt/decrypt your certificates
[16:44:33]: This passphrase is specific per repository and will be stored in your local keychain
[16:44:33]: Make sure to remember the password, as you'll need it when you run match on a different machine
[16:44:33]: Passphrase for Match storage: ********
[16:44:37]: Type passphrase again: ********
security: SecKeychainAddInternetPassword <NULL>: The specified item already exists in the keychain.
[16:44:39]: 🔒 Successfully encrypted certificates repo
[16:44:39]: Pushing changes to remote git repo...
[16:44:40]: Finished uploading files to Git Repo [https://github.com/sebsto/secret.git]
I verify that Fastlane imported my signing material to my Git repository.

I can also configure my local machine to use these signing materials during the next build:
» fastlane match appstore
[✔] 🚀
[17:39:08]: Successfully loaded '~/amplify-ios-getting-started/code/fastlane/Matchfile' 📄
+-----------------------------------------------------+
| Detected Values from './fastlane/Matchfile' |
+--------------+--------------------------------------+
| git_url | https://github.com/sebsto/secret.git |
| storage_mode | git |
| type | development |
+--------------+--------------------------------------+
+-------------------------------------------------------------------------------------------+
| Summary for match 2.226.0 |
+----------------------------------------+--------------------------------------------------+
| type | appstore |
| readonly | false |
| generate_apple_certs | true |
| skip_provisioning_profiles | false |
| app_identifier | ["com.amazonaws.amplify.mobile.getting-started"] |
| username | xxxx@xxxxxxxxx |
| team_id | XXXXXXXXXX |
| storage_mode | git |
| git_url | https://github.com/sebsto/secret.git |
| git_branch | master |
| shallow_clone | false |
| clone_branch_directly | false |
| skip_google_cloud_account_confirmation | false |
| s3_skip_encryption | false |
| gitlab_host | https://gitlab.com |
| keychain_name | login.keychain |
| force | false |
| force_for_new_devices | false |
| include_mac_in_profiles | false |
| include_all_certificates | false |
| force_for_new_certificates | false |
| skip_confirmation | false |
| safe_remove_certs | false |
| skip_docs | false |
| platform | ios |
| derive_catalyst_app_identifier | false |
| fail_on_name_taken | false |
| skip_certificate_matching | false |
| skip_set_partition_list | false |
| force_legacy_encryption | false |
| verbose | false |
+----------------------------------------+--------------------------------------------------+
[17:39:08]: Cloning remote git repo...
[17:39:08]: If cloning the repo takes too long, you can use the `clone_branch_directly` option in match.
[17:39:10]: Checking out branch master...
[17:39:10]: Enter the passphrase that should be used to encrypt/decrypt your certificates
[17:39:10]: This passphrase is specific per repository and will be stored in your local keychain
[17:39:10]: Make sure to remember the password, as you'll need it when you run match on a different machine
[17:39:10]: Passphrase for Match storage: ********
[17:39:13]: Type passphrase again: ********
security: SecKeychainAddInternetPassword <NULL>: The specified item already exists in the keychain.
[17:39:15]: 🔓 Successfully decrypted certificates repo
[17:39:15]: Verifying that the certificate and profile are still valid on the Dev Portal...
[17:39:17]: Installing certificate...
+-------------------------------------------------------------------------+
| Installed Certificate |
+-------------------+-----------------------------------------------------+
| User ID | XXXXXXXXXX |
| Common Name | Apple Distribution: Sebastien Stormacq (XXXXXXXXXX) |
| Organisation Unit | XXXXXXXXXX |
| Organisation | Sebastien Stormacq |
| Country | US |
| Start Datetime | 2024-10-29 09:55:43 UTC |
| End Datetime | 2025-10-29 09:55:42 UTC |
+-------------------+-----------------------------------------------------+
[17:39:18]: Installing provisioning profile...
+-------------------------------------------------------------------------------------------------------------------+
| Installed Provisioning Profile |
+---------------------+----------------------------------------------+----------------------------------------------+
| Parameter | Environment Variable | Value |
+---------------------+----------------------------------------------+----------------------------------------------+
| App Identifier | | com.amazonaws.amplify.mobile.getting-starte |
| | | d |
| Type | | appstore |
| Platform | | ios |
| Profile UUID | sigh_com.amazonaws.amplify.mobile.getting-s | 4e497882-d80f-4684-945a-8bfec1b310b9 |
| | tarted_appstore | |
| Profile Name | sigh_com.amazonaws.amplify.mobile.getting-s | amplify-ios-getting-started-dist |
| | tarted_appstore_profile-name | |
| Profile Path | sigh_com.amazonaws.amplify.mobile.getting-s | /Users/stormacq/Library/MobileDevice/Provis |
| | tarted_appstore_profile-path | ioning |
| | | Profiles/4e497882-d80f-4684-945a-8bfec1b310 |
| | | b9.mobileprovision |
| Development Team ID | sigh_com.amazonaws.amplify.mobile.getting-s | XXXXXXXXXX |
| | tarted_appstore_team-id | |
| Certificate Name | sigh_com.amazonaws.amplify.mobile.getting-s | Apple Distribution: Sebastien Stormacq |
| | tarted_appstore_certificate-name | (XXXXXXXXXX) |
+---------------------+----------------------------------------------+----------------------------------------------+
[17:39:18]: All required keys, certificates and provisioning profiles are installed 🙌Step 2: Configure Fastlane to sign your project
I create a Fastlane build configuration file in fastlane/Fastfile (you can use fastlane init command to get started):
default_platform(:ios)
platform :ios do
before_all do
setup_ci
end
desc "Build and Sign the binary"
lane :build do
match(type: "appstore", readonly: true)
gym(
scheme: "getting started",
export_method: "app-store"
)
end
end
Make sure that the setup_ci action is added to the before_all section of Fastfile for the match action to function correctly. This action creates a temporary Fastlane keychain with correct permissions. Without this step, you may encounter build failures or inconsistent results.
And I test a local build with the command fastlane build. I enter the password I used when importing my keys and certificate, then I let the system build and sign my project. When everything is correctly configured, it produces a similar output.
...
[17:58:33]: Successfully exported and compressed dSYM file
[17:58:33]: Successfully exported and signed the ipa file:
[17:58:33]: ~/amplify-ios-getting-started/code/getting started.ipa
+---------------------------------------+
| fastlane summary |
+------+------------------+-------------+
| Step | Action | Time (in s) |
+------+------------------+-------------+
| 1 | default_platform | 0 |
| 2 | setup_ci | 0 |
| 3 | match | 36 |
| 4 | gym | 151 |
+------+------------------+-------------+
[17:58:33]: fastlane.tools finished successfully 🎉Step 3: Configure CodeBuild to use Fastlane
Next, I create a project on CodeBuild. I’m not going into the step-by-step guide to help you to do so. You can refer to my previous post or to the CodeBuild documentation.
There is just one Fastlane-specific configuration. To access the signing materials, Fastlane requires access to three secret values that I’ll pass as environment variables:
MATCH_PASSWORD, the password I entered when importing the signing material. Fastlane uses this password to decipher the encrypted files in the GitHub repositoryFASTLANE_SESSION, the value of the Apple Id session cookie, located at~/.fastlane/spaceship/<your apple user id>/cookie. The session is valid from a couple of hours to multiple days. When the session expires, reauthenticate with the commandfastlane spaceauthfrom your laptop and update the value ofFASTLANE_SESSIONwith the new value of the cookie.MATCH_GIT_BASIC_AUTHORIZATION, a base 64 encoding of your GitHub username, followed by a colon, followed by a personal authentication token (PAT) to access your private GitHub repository. You can generate PAT on the GitHub console in Your Profile > Settings > Developers Settings > Personal Access Token. I use this command to generate the value of this environment variable:echo -n my_git_username:my_git_pat | base64.
Note that for each of these three values, I can enter the Amazon Resource Name (ARN) of the secret on AWS Secrets Manager or the plain text value. We strongly recommend using Secrets Manager to store security-sensitive values.
I’m a security-conscious user, so I store the three secrets in Secrets Manager with these commands:
aws --region $REGION secretsmanager create-secret --name /CodeBuild/MATCH_PASSWORD --secret-string MySuperSecretPassword
aws --region $REGION secretsmanager create-secret --name /CodeBuild/FASTLANE_SESSION --secret-string $(cat ~/.fastlane/spaceship/my_appleid_username/cookie)
aws --region $REGION secretsmanager create-secret --name /CodeBuild/MATCH_GIT_BASIC_AUTHORIZATION --secret-string $(echo -n my_git_username:my_git_pat | base64)
If your build project refers to secrets stored in Secrets Manager, the build project’s service role must allow the secretsmanager:GetSecretValue action. If you chose New service role when you created your project, CodeBuild includes this action in the default service role for your build project. However, if you chose Existing service role, you must include this action to your service role separately.
For this demo, I use this AWS Identity and Access Management (IAM) policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:secretsmanager:us-east-2:012345678912:secret:/CodeBuild/*"
]
}
]
}After I created the project in the CodeBuild section of the AWS Management Console, I enter the three environment variables. Notice that the value is the name of the secret in Secrets Manager.

You can also define the environment variables and their Secrets Manager secret name in your buildpsec.yaml file.
Next, I modify the buildspec.yaml file at the root of my project to use fastlane to build and sign the binary. My buildspec.yaml file now looks like this one:
# buildspec.yml
version: 0.2
phases:
install:
commands:
- code/ci_actions/00_install_rosetta.sh
pre_build:
commands:
- code/ci_actions/02_amplify.sh
build:
commands:
- (cd code && fastlane build)
artifacts:
name: getting-started-$(date +%Y-%m-%d).ipa
files:
- 'getting started.ipa'
base-directory: 'code'The Rosetta and Amplify scripts are required to receive the Amplify configuration for the backend. If you don’t use AWS Amplify in your project, you don’t need these.
Notice that there is nothing in the build file that downloads the signing key or prepares the keychain in the build environment; fastlane match will do that for me.
I add the new buildspec.yaml file and my ./fastlane directory to Git. I commit and push these files. git commit -m "add fastlane support" && git push
When everything goes well, I can see the build running on CodeBuild and the Succeeded message.

Pricing and availability
Fastlane is now pre-installed at no extra cost on all macOS images that CodeBuild uses, in all Regions where CodeBuild for macOS is available. At the time of this writing, these are US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt).
In my experience, it takes a bit of time to configure fastlane match correctly. When it’s configured, having it working on CodeBuild is pretty straightforward. Before trying this on CodeBuild, be sure it works on your local machine. When something goes wrong on CodeBuild, triple-check the values of the environment variables and make sure CodeBuild has access to your secrets on AWS Secrets Manager.
Now go build (on macOS)!