Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=HhyBVV27sqM
The only B&O ‘Boombox’
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=0_gyA_qfZz0
Седмицата (3–8 февруари)
Post Syndicated from Светла Енчева original https://www.toest.bg/siedmitsata-3-8-fevruari-2/

Какво да ви кажа – ситуацията хич не е розова. Затова започвам ударно с първия епизод от новата рубрика на Елена Телбис „Т.Е. от Е.Т.“, в която тя представя алтернативен и смешен прочит на събитията от седмицата. Като престанете да се смеете, продължаваме със сериозната част. Което значи, че може и да не продължим…
Буквално допреди дни изглеждаше немислимо. Доналд Тръмп, президент на държавата, която до неотдавна беше символ на демократичния свят, предложи САЩ да придобие ивицата Газа и да я превърне в морски курорт. А палестинците, които я обитават, да отидат… все едно къде. Тръмп не уточнява какво ще стане с костите на палестинските жертви, голяма част от които жени и деца. И те ли ще бъдат преместени някъде, или курортистите ще плажуват върху тях? Следващата стъпка може би ще е американският президент да предложи САЩ да купи концлагерите в Аушвиц и Бухенвалд и да ги превърне в увеселителни паркове.
Сарказмът настрана – идеята на Тръмп е призив за етническо прочистване. Ни повече, ни по-малко. След Втората световна война беше умонепостижимо лидер на демократичния свят да призовава към етническо прочистване. Е, вече е умопостижимо. Когнитивният дисонанс може да се разреши, ако престанем да мислим за САЩ като за демократична държава. Поне за няколко години напред.
Най-страшното обаче дори не е самото предложение на Тръмп. А че то вече изглежда легитимно на други представители на демократичния свят. Сериозни анализатори твърдят, че Тръмп всъщност не искал да превръща Газа в нова Ривиера, а изказването му било хитър политически ход. Представете си да отидете на преговори, а в залата да ви очаква гилотина. Преговарящите може и да нямат намерение да режат главата ви, ако не се съгласите с условията им, но вие не знаете това. Е, може и да е хитро, но редно ли е така да се преговаря?
Предложението на Тръмп за Газа е една от многото му идеи в противоречие с международното право, което той не изглежда да зачита вече. Нито зачита Световната здравна организация. Нито Парижкото споразумение за климата. На Международния наказателен съд в Хага наложи санкции с указ. А програмата на САЩ за хуманитарна помощ USAID просто я стопира. Изведнъж светът се оказа без 40% от хуманитарната помощ, отделяна за лечение и предотвратяване на болести, за борба с глада и подкрепа на демократичните ценности. Друг въпрос е защо светът се е оставил в толкова голяма степен да зависи от американската помощ и каква е отговорността на Европа да се стигне дотам.
На войната на Доналд Тръмп с прогреса е посветена и статията на Надежда Цекулова, която разказва как президентската администрация в САЩ изтри десетилетия напредък в медицинската наука. От сайтовете на Центровете за контрол и превенция на заболяванията и на библиотеката на Националния институт по здравеопазване на САЩ е премахнат голям масив от научна информация, свързана не само с трансджендър хората, но и с репродуктивното здраве, ваксините, ХИВ – изобщо, с много неща. Това затруднява изследователи от цял свят, но най-много американците, които имат нужда от определени видове медицинска помощ и профилактика.
На фона на САЩ Европа (все още) успява да запази базово равнище на нормалност. Дори тукашната политика изглежда почти приемлива. Ключовата дума е „почти“. Бойко Борисов се прицели словесно в журналистката Полина Паунова, която не му остана длъжна. После изкара, че не бил разбран – обидата всъщност била комплимент, – и ѝ се извини с половин уста. Проектозаконите на „Възраждане“ за чуждестранните агенти и на ДПС на Пеевски за комисия, разследваща дейността на Фондация „Отворено общество“, не минаха в парламента.
Внесените в Народното събрание мотиви за „разследване“ на „Отворено общество“ притеснително напомнят аргументите против евреите от нацистки пропаганден филм, откъс от който може да се види в „Дом, ужас, Холокост, надежда“. Според bTV най-подходящото време за премиера на документалния филм е… в полунощ. Дали защото така по-малко зрители ще могат да си направят аналогията между нацизма и посланията на „Възраждане“ и Пеевски, или просто защото телевизията не смята темата за значима.

Но пък кипи треска за назначения на „нови хора в беззъби регулатори“, по думите на Емилия Милчева, която е озаглавила тазседмичния си политически анализ „Нова бодра смяна. Всички, навсякъде, наведнъж“. Едни лоялни винтчета от държавната машина се сменят с други, за да възпроизвеждат същата заучена безпомощност, каквато и предишните. А някои се издигат международно. Десислава Атанасова, чието основно качество е лоялността към ГЕРБ, беше пратена да представя България във Венецианската комисия. В същото време никой не се е загрижил да бори корупцията, а идеята за правосъдна реформа като че остана в миналото.
Като говорим за българския политически живот, дразните ли се, когато политици и журналисти казват „в пленарна зала“, „в Народно събрание“ или „в Министерски съвет“, а не „в пленарната зала“, „в Народното събрание“ и „в Министерския съвет“? Аз, признавам си, се дразня. Но в новата си „порция език“ Павлина Върбанова ни връща чак до романа на Маркес „Сто години самота“, за да ни помогне да разберем на какво се дължи този феномен. И да ни обърне внимание, че всъщност изрази като „на училище“ или „на работа“ не ни правят впечатление, а логиката им е същата, каквато на „в пленарна зала“.
Насред безрадостната реалност е по-уютно да продължаваме да си говорим за думи и за книги. В рубриката „По буквите“ Зорница Христова ни обръща внимание върху две книги. Първата е „Приказки от сърцето на града“ от Шон Тан в превод на Нева Мичева. В нея човешкото същество е представено като смътно, но неудържимо самотно и криещо самотата от себе си. Втората книга е „Нокомис“ от Катерина Стойкова. В нея се проследява ефимерността на връзката между учител и ученик, водач и последовател. Фактът, че връзката не е любовна, не я лишава от емоционална дълбочина.
Стефан Иванов пък ни връща към романа на Селма Лагерльоф „Коларят на Смъртта“, преведен от Меглена Боденска. Публикуван още през 1912 г., повече от век по-късно той продължава да резонира и се нарежда сред литературните произведения, които не само разказват история, а превръщат читателя в свой съучастник. Книгата черпи вдъхновение от биографията на авторката и от нейния интерес към социалните проблеми, алкохолизма на баща ѝ и смъртта на сестра ѝ. И представя смъртта не като трагедия, а като бюрократична институция.
Не мога да се меря с професионализма, с който авторите на рубриките „По буквите“ и „На второ четене“ пишат за книги, но понякога и аз се изкушавам да разкажа за произведение, което ме е впечатлило. В бюлетина на „Тоест“ бях споменала за първата книга на Анета Василева „Kicked a Building Lately?* Архитектурна критика след дигиталната революция“, но не се сдържах да предложа по-подробен критически прочит.
Разговорът за архитектурата ни връща към реалността. Но светът е тръгнал в такава посока, че по-добре да погледнем към Космоса (въпреки че дясната ръка на Тръмп – Илон Мъск, има шансове да го покори преди нас). Анастасия Орманджиева ни разказва за близнаците от NASA и ключа към живота ни в Космоса. Как влияе на човека космическата околна среда при дълги полети? Еднояйчните близнаци Скот и Марк Кели са избрани да допринесат за отговора на този въпрос. Скот е пребивавал в Международната космическа станция цяла година, а брат му е останал на земята. Целта е била да се види какво се е променило в тялото на единия, но не и в това на другия.
Дойде време да ви препоръчам нещо. Продължавам космическата тема, защото, като гледам накъде върви светът, се сещам за „Пътеводител на галактическия стопаджия“ на Дъглас Адамс. Къщата на главния герой беше предназначена за бутане, за да се построи на нейно място магистрала. После се оказа, че цялата планета Земя е предвидена за унищожение, за да се построи на нейно място космическа магистрала. Днес Дъглас Адамс ми се вижда особено актуален. Само да си взема хавлията и отивам да потърся някоя друга галактика. Чао, ако не ме видите пак в „Тоест“, знаете къде съм.
Междувременно, ако за вас е важно да има независими медии, имайте предвид, че „Тоест“ съществува благодарение на даренията от своите читатели.
Tupavco 4 Outlet 10in Rack Power Strip Mini Review
Post Syndicated from E Lopez original https://www.servethehome.com/tupavco-4-outlet-10in-rack-power-strip-mini-review/
We take a look at the Tupavco 4 outlet power strip for 10 inch rack applications since it has become quite popular online
The post Tupavco 4 Outlet 10in Rack Power Strip Mini Review appeared first on ServeTheHome.
Does DeepSeek send your data to China when it’s run locally?
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=GsGD8SsBI-U
Egregious Act of Vandalism
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=S-W-PgDvitQ
Introducing JSONL support with Step Functions Distributed Map
Post Syndicated from Eric Johnson original https://aws.amazon.com/blogs/compute/introducing-jsonl-support-with-step-functions-distributed-map/
This post written by Uma Ramadoss, Principal Specialist SA, Serverless and Vinita Shadangi, Senior Specialist SA, Serverless.
Today, AWS Step Functions is expanding the capabilities of Distributed Map by adding support for JSON Lines (JSONL) format. JSONL, a highly efficient text-based format, stores structured data as individual JSON objects separated by newlines, making it particularly suitable for processing large datasets.
This new capability enables you to process large collection of items stored in JSONL format directly through Distribtued Map and optionally exports the output of the Distributed Map as JSONL file. The enhancement also introduces support for additional delimited file formats, including semicolon and tab-delimited files, providing greater flexibility in data source options. Furthermore, new flexible output transformations gives developers more control over result formatting, enabling better integration with downstream processes for efficient data handling.
Overview
Distributed Map enables parallel processing of large-scale data by concurrently running the same processing steps for millions of entries in a dataset at the maximum scale of 10000. This is particularly useful for use cases like large scale payroll processing, image conversion, document processing and data migrations. Previously, the dataset can come from state input, JSON/CSV files in S3 and collection of S3 objects. With this new feature, the dataset can be a JSONL file in Amazon S3.
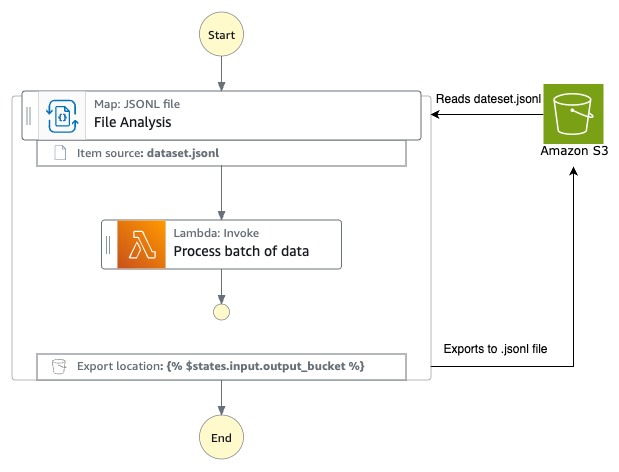
The AWS Step Functions workflow
Consider an example of end-to-end GenAI batch inferencing using Amazon Bedrock. Batch inference helps you process a large number of requests efficiently by bundling them as single request and storing the results in an S3 bucket. Since both input and output are handled as JSONL files, the blog uses the scenario as an example to demonstrate the new capabilities of Distributed Map.
The diagram below shows the end-to-end flow –
- Step Functions workflow (Batch inference input generation worfklow) uses Distributed Map to build and bundle AI prompts for a collection of product review data. Workflow then invokes the Amazon Bedrock batch inference API.
- Amazon Bedrock stores the results in S3 as JSONL file when the batch inference is completed.
- An S3 object created event invokes the second Step Functions workflow (Batch inference output processing workflow) that processes the JSONL file and loads the results into an Amazon DynamoDB table.

Batch inferencing workflow
Introducing new output transformations through batch inference input generation workflow
The batch inference input generation workflow processes product review data in S3 using Distributed Map. Distributed Map spins multiple child workflows that generate AI prompts for sentiment analysis of each product review and exports the results of the child workflows to S3 as a JSONL file. The workflow calls Amazon Bedrock batch inference API (CreateModelInvocationJob) with the JSONL file as input upon completion of the Distributed Map state. Since the inference API operates asynchronously, the workflow completes immediately after receiving a successful response from the API.

Batch inference input generation workflow
Each child workflow receives a batch of product reviews as an array. It operates on the array using Pass state to create an array of AI prompts, one for each item. The Pass state manipulates the input using JSONata expressions, generates unique recordId using JSONata numeric functions, and outputs the results in a format Amazon Bedrock expects.
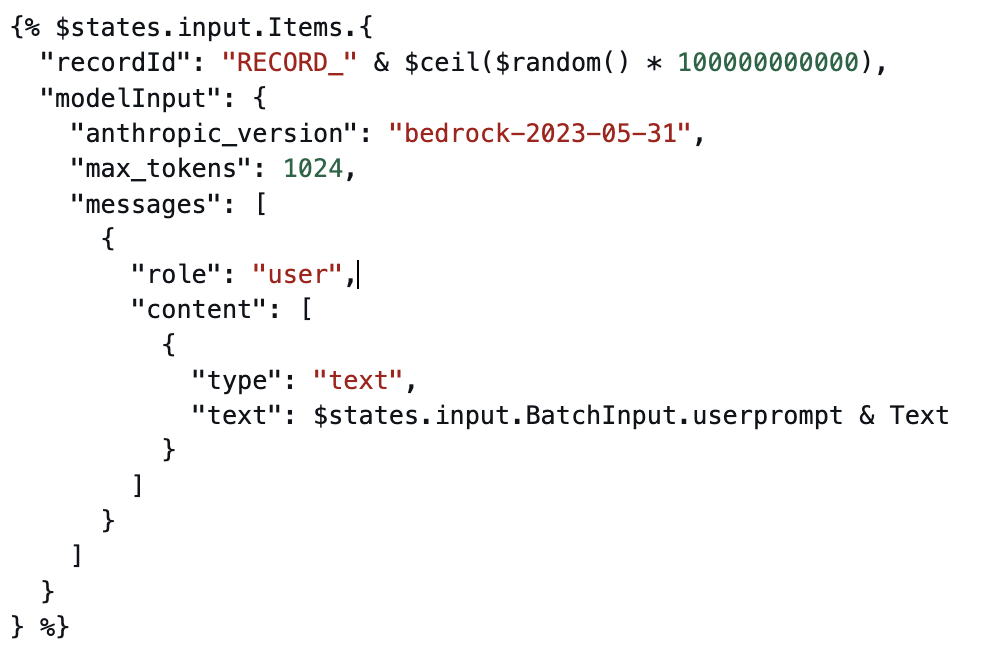
JSONata transformation to generate prompts
Once all child workflows are complete, Distributed Map uses the new output transformations to export the outputs from child workflows to S3.
Using the new output transformations to export in JSONL format
Distributed Map now offers more flexible output handling through an optional writer configuration. While it traditionally exports child workflow execution results to three separate JSON files (successful, failed, and pending), the new writer configuration streamlines the output and supports JSONL format in addition to JSON format.
The previous export option included comprehensive execution details – metadata, child workflow inputs, and outputs. The new configuration allows you to streamline output to include only the child workflow execution results, which are valuable for map/reduce patterns, where the output from one Distributed Map needs to feed directly into another without the need for additional transformation steps.
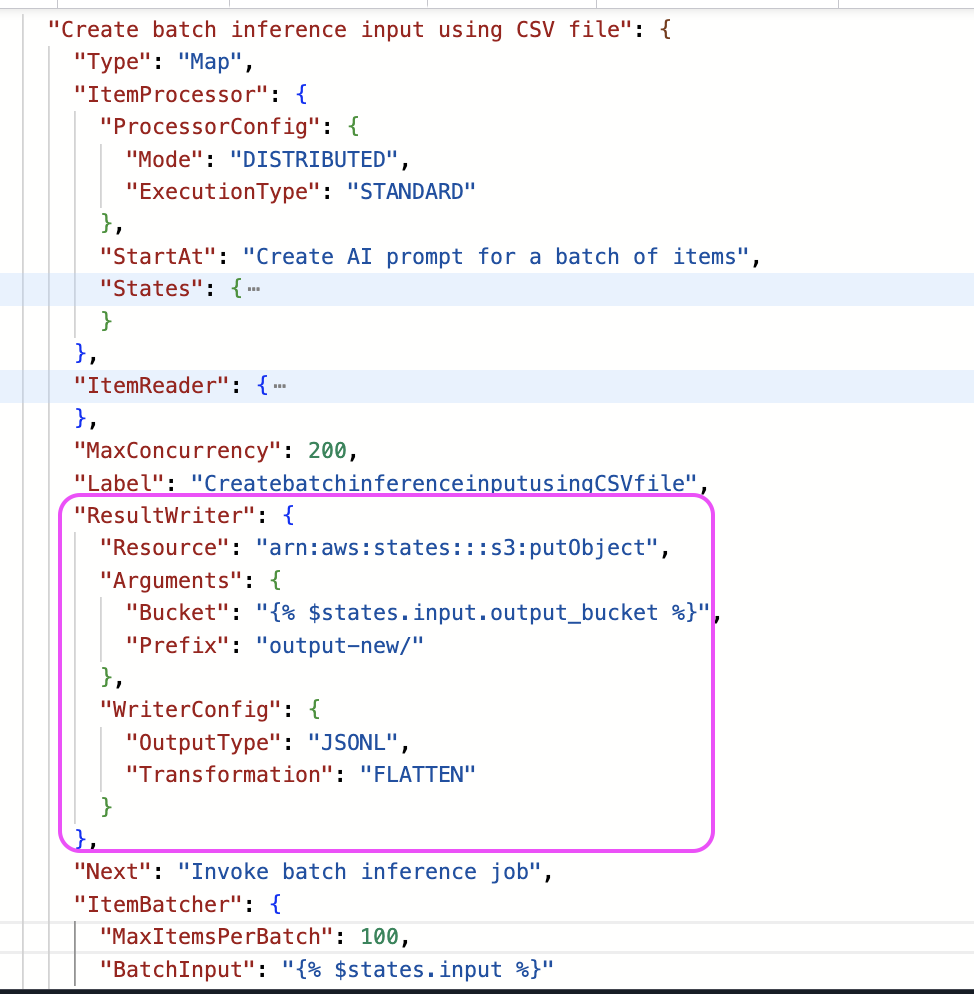
Output writer config for JSONL
Writer config also allows you to flatten the output array. When a child workflow processes batches of the input, it produces an array of results which will eventually become an array of arrays when the Distributed Map aggregates the outputs from all child workflows. With the new output transformation called FLATTEN, you can choose to flatten the array without additional code.

Flattening output in JSONL
Introducing the new ItemReader for JSONL using batch inference output processing workflow
The second workflow processes output of the batch inference job by launching multiple child workflows using Distributed Map. Each child workflow processes batches of items, examining them for error objects and separating successful inferences from errors. The workflow then loads all successful inferences into a DynamoDB table while sending errors to a dead letter queue for subsequent analysis.

Processing inference results
Using the new InputType to read the JSONL inference results
The Distributed Map in the batch inference results processing workflow uses the newly supported ItemReader-InputType, JSONL. Previously, the InputType only accepted CSV, JSON, and MANIFEST, which is an S3 Inventory manifest file.

Reading JSONL file
There is no other change to how Distributed Map processes and shares data with child workflows. The Pass state in the child workflow receives batches of Items from the Map, and uses JSONata expressions to separate the errors from successful items.

Separating successful processing from errors
The following shows the input received by the Pass state and the output generated by the state using the above JSONata expression.

Sample successful processing records
Using S3 events as connective tissue between the workflows
When Amazon Bedrock completes the batch inference job, it stores the output in the S3 location specified in the API request. An EventBridge rule triggers the batch inference results processing workflow using S3 event notifications. The rule looks for “Object Created” event from the specified S3 bucket and a wildcard pattern for JSONL file extension. When the rule matches the incoming event, it triggers the workflow.

EventBridge rule
You can detect failed batch inference jobs by setting up EventBridge rules that listen to Amazon Bedrock status events. Since failed jobs don’t create output files in S3, monitoring status events directly ensures you catch and handle job failures.
Key considerations
- The new output transformations do not change the information in the FAILED execution results file in order to help you analyze the reasons for failures. To learn more about the output transformation configurations, visit the documentation.
- The new transformation mode FLATTEN, COMPACT stores only the output of the execution results. To inspect the results for fact checking or troubleshooting, use the default transformation.
- As a best practice, when implementing code changes, it’s advised to use the versioning and aliasing feature for gradual deployment of changes to production.
- When using Distributed Map, there is an option to configure the child workflow as either Standard or Express. Express is the recommended choice if each iteration (child workflow) can be completed within 5 minutes, and batching items will help optimize costs. To learn more about optimizations for Distributed Map, visit the workshop.
Conclusion
Step Functions Distributed Map is a powerful feature that enables developers to create large-scale data processing solutions with ease, eliminating concerns about operational aspects and software challenges like batching, concurrency, and failure handling. The addition of JSONL support for both input and output expands workload capabilities and minimizes additional effort through transformations by natively deserializing and flattening the output. This blog demonstrated the new feature’s capabilities through a practical example of building large-scale data processing applications using Distributed Map.
For more information on Distributed Map and how to use it with JSONL files, refer to the user guide.
To explore generative AI samples with Step Functions, visit the the GitiHub repo.
To expand your serverless knowledge, visit Serverless Land.
Friday Squid Blogging: The Colossal Squid
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/02/friday-squid-blogging-the-colossal-squid.html
Long article on the colossal squid.
Use DeepSeek with Amazon OpenSearch Service vector databases and Amazon SageMaker
Post Syndicated from Jon Handler original https://aws.amazon.com/blogs/big-data/use-deepseek-with-amazon-opensearch-service-vector-databases-and-amazon-sagemaker/
DeepSeek-R1 is a powerful and cost-effective AI model that excels at complex reasoning tasks. When combined with Amazon OpenSearch Service, it enables robust Retrieval Augmented Generation (RAG) applications. This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. This example provides a solution for enterprises looking to enhance their AI capabilities.
OpenSearch Service provides rich capabilities for RAG use cases, as well as vector embedding-powered semantic search. You can use the flexible connector framework and search flow pipelines in OpenSearch to connect to models hosted by DeepSeek, Cohere, and OpenAI, as well as models hosted on Amazon Bedrock and SageMaker. In this post, we build a connection to DeepSeek’s text generation model, supporting a RAG workflow to generate text responses to user queries.
Solution overview
The following diagram illustrates the solution architecture.

In this walkthrough, you will use a set of scripts to create the preceding architecture and data flow. First, you will create an OpenSearch Service domain, and deploy DeepSeek-R1 to SageMaker. You will execute scripts to create an AWS Identity and Access Management (IAM) role for invoking SageMaker, and a role for your user to create a connector to SageMaker. You will create an OpenSearch connector and model that will enable the retrieval_augmented_generation processor within OpenSearch to execute a user query, perform a search, and use DeepSeek to generate a text response. You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Finally, you will execute the query to compare population growth in Miami and New York City.
Prerequisites
We’ve created and open-sourced a GitHub repo with all the code you need to follow along with the post and deploy it for yourself. You will need the following prerequisites:
- Git – Clone the repo at https://github.com/Jon-AtAWS/opensearch-examples.git.
- Python – The code has been tested with Python version 3.13.
- An AWS account – You will need to be able to create an OpenSearch Service domain and two SageMaker endpoints.
- An integrated development environment (IDE) – An IDE like Visual Studio Code is helpful, although it’s not strictly necessary.
- AWS CLI – Make sure to configure the AWS Command Line Interface (AWS CLI) with the account you plan to use. Alternately, you can follow the Boto 3 documentation to make sure you use the right credentials.
Deploy DeepSeek on Amazon SageMaker
You will need to have or deploy DeepSeek with an Amazon SageMaker endpoint. To learn more about deploying DeepSeek-R1 on SageMaker, refer to Deploying DeepSeek-R1 Distill Model on AWS using Amazon SageMaker AI.
Create an OpenSearch Service domain
Refer to Create an Amazon OpenSearch Service domain for instructions on how to create your domain. Make note of the domain Amazon Resource Name (ARN) and domain endpoint, both of which can be found in the General information section of each domain on the OpenSearch Service console.
Download and prepare the code
Run the following steps from your local computer or workspace that has Python and git:
- If you haven’t already, clone the repo into a local folder using the following command:
- Create a Python virtual environment:
The example scripts use environment variables for setting some common parameters. Set these up now using the following commands. Be sure to update with your AWS Region, your SageMaker endpoint ARN and URL, your OpenSearch Service domain’s endpoint and ARN, and your domain’s primary user and password.
You now have the code base and have your virtual environment set up. You can examine the contents of the opensearch-deepseek-rag directory. For clarity of purpose and reading, we’ve encapsulated each of seven steps in its own Python script. This post will guide you through running these scripts. We’ve also chosen to use environment variables to pass parameters between scripts. In an actual solution, you would encapsulate the code in classes and pass the values where needed. Coding this way is clearer, but is less efficient and doesn’t follow coding best practices. Use these scripts as examples to pull from.
First, you will set up permissions for your OpenSearch Service domain to connect to your SageMaker endpoint.
Set up permissions
You will create two IAM roles. The first will allow OpenSearch to call your SageMaker endpoint. The second will allow you to make the create connector API call to OpenSearch.
- Examine the code in create_invoke_role.py.
- Return to the command line, and execute the script:
- Execute the command line from the script’s output to set the INVOKE_DEEPSEEK_ROLE environment variable.
You have created a role named invoke_deepseek_role, with a trust relationship for OpenSearch Service to assume the role, and with a permission policy that allows OpenSearch Service to invoke your SageMaker endpoint. The script outputs the ARNs for your role and policy and additionally a command line command to add the role to your environment. Execute that command before running the next script. Make a note of the role ARN in case you need to return at a later time.
Now you need to create a role for your user to be able to create a connector in OpenSearch Service.
- Examine the code in create_connector_role.py.
- Return to the command line and execute the script:
- Execute the command line from the script’s output to set the CREATE_DEEPSEEK_CONNECTOR_ROLE environment variable.
You have created a role named create_deepseek_connector_role, with a trust relationship with the current user and permissions to write to OpenSearch Service. You need these permissions to call the OpenSearch create_connector API, which packages a connection to a remote model host, DeepSeek in this case. The script prints the policy’s and role’s ARNs, and additionally a command line command to add the role to your environment. Execute that command before running the next script. Again, make note of the role ARN, just in case.
Now that you have your roles created, you will tell OpenSearch about them. The fine-grained access control feature includes an OpenSearch role, ml_full_access, that will allow authenticated entities to execute API calls within OpenSearch.
- Examine the code in setup_opensearch_security.py.
- Return to the command line and execute the script:
You set up the OpenSearch Service security plugin to recognize two AWS roles: invoke_create_connector_role and LambdaInvokeOpenSearchMLCommonsRole. You will use the second role later, when you connect with an embedding model and load data into OpenSearch to use as a RAG knowledge base. Now that you have permissions in place, you can create the connector.
Create the connector
You create a connector with configuration that tells OpenSearch how to connect, provides credentials for the target model host, and provides prompt details. For more information, see Creating connectors for third-party ML platforms.
- Examine the code in create_connector.py.
- Return to the command line and execute the script:
- Execute the command line from the script’s output to set the DEEPSEEK_CONNECTOR_ID environment variable.
The script will create the connector to call the SageMaker endpoint and return the connector ID. The connector is an OpenSearch construct that tells OpenSearch how to connect to an external model host. You don’t use it directly; you create an OpenSearch model for that.
Create an OpenSearch model
When you work with machine learning (ML) models, in OpenSearch, you use OpenSearch’s ml-commons plugin to create a model. ML models are an OpenSearch abstraction that let you perform ML tasks like sending text for embeddings during indexing, or calling out to a large language model (LLM) to generate text in a search pipeline. The model interface provides you with a model ID in a model group that you then use in your ingest pipelines and search pipelines.
- Examine the code in create_deepseek_model.py.
- Return to the command line and execute the script:
- Execute the command line from the script’s output to set the DEEPSEEK_MODEL_ID environment variable.
You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines. The _register API places the model in the model group and references your SageMaker endpoint through the connector (connector_id) you created.
Verify your setup
You can run a query to verify your setup and make sure that you can connect to DeepSeek on SageMaker and receive generated text. Complete the following steps:
- On the OpenSearch Service console, choose Dashboard under Managed clusters in the navigation pane.
- Choose your domain’s dashboard.

- Choose the OpenSearch Dashboards URL (dual stack) link to open OpenSearch Dashboards.
- Log in to OpenSearch Dashboards with your primary user name and password.
- Dismiss the welcome dialog by choosing Explore on my own.
- Dismiss the new look and feel dialog.
- Confirm the global tenant in the Select your tenant dialog.
- Navigate to the Dev Tools tab.
- Dismiss the welcome dialog.
You can also get to Dev Tools by expanding the navigation menu (three lines) to reveal the navigation pane, and scrolling down to Dev Tools.

The Dev Tools page provides a left pane where you enter REST API calls. You execute the commands and the right pane shows the output of the command. Enter the following command in the left pane, replace your_model_id with the model ID you created, and run the command by placing the cursor anywhere in the command and choosing the run icon.
You should see output like the following screenshot.

Congratulations! You’ve now created and deployed an ML model that can use the connector you created to call to your SageMaker endpoint, and use DeepSeek to generate text. Next, you will use your model in an OpenSearch search pipeline to automate a RAG workflow.
Set up a RAG workflow
RAG is a way of adding information to the prompt so that the LLM generating the response is more accurate. An overall generative application like a chatbot orchestrates a call to external knowledge bases and augments the prompt with knowledge from those sources. We’ve created a small knowledge base comprising population information.
OpenSearch provides search pipelines, which are sets of OpenSearch search processors that are applied to the search request sequentially to build a final result. OpenSearch has processors for hybrid search, reranking, and RAG, among others. You define your processor and then send your queries to the pipeline. OpenSearch responds with the final result.
When you build a RAG application, you choose a knowledge base and a retrieval mechanism. In most cases, you will use an OpenSearch Service vector database as a knowledge base, performing a k-nearest neighbor (k-NN) search to incorporate semantic information in the retrieval with vector embeddings. OpenSearch Service provides integrations with vector embedding models hosted in Amazon Bedrock and SageMaker (among other options).
Make sure that your domain is running OpenSearch 2.9 or later, and that fine-grained access control is enabled for the domain. Then complete the following steps:
- On the OpenSearch Service console, choose Integrations in the navigation pane.
- Choose Configure domain under Integration with text embedding models through Amazon SageMaker.

- Choose Configure public domain.
- If you created a virtual private cloud (VPC) domain instead, choose Configure VPC domain.
You will be redirected to the AWS CloudFormation console.
- For Amazon OpenSearch Endpoint, enter your endpoint.
- Leave everything else as default values.
The CloudFormation stack requires a role to create a connector to the all-MiniLM-L6-v2 model, hosted on SageMaker, called LambdaInvokeOpenSearchMLCommonsRole. You enabled access for this role when you ran setup_opensearch_security.py. If you changed the name in that script, be sure to change it in the Lambda Invoke OpenSearch ML Commons Role Name field.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names, and choose Create stack.
For simplicity, we’ve elected to use the open source all-MiniLM-L6-v2 model, hosted on SageMaker for embedding generation. To achieve high search quality for production workloads, you should fine-tune lightweight models like all-MiniLM-L6-v2, or use OpenSearch Service integrations with models such as Cohere Embed V3 on Amazon Bedrock or Amazon Titan Text Embedding V2, which are designed to deliver high out-of-the-box quality.
Wait for CloudFormation to deploy your stack and the status to change to Create_Complete.
- Choose the stack’s Outputs tab on the CloudFormation console and copy the value for ModelID.

You will use this model ID to connect with your embedding model.
- Examine the code in load_data.py.
- Return to the command line and set an environment variable with the model ID of the embedding model:
- Execute the script to load data into your domain:
The script creates the population_data index and an OpenSearch ingest pipeline that calls SageMaker using the connector referenced by the embedding model ID. The ingest pipeline’s field mapping tells OpenSearch the source and destination fields for each document’s embedding.
Now that you have your knowledge base prepared, you can run a RAG query.
- Examine the code in run_rag.py.
- Return to the command line and execute the script:
The script creates a search pipeline with an OpenSearch retrieval_augmented_generation processor. The processor automates running an OpenSearch k-NN query to retrieve relevant information and adding that information to the prompt. It uses the generation_model_id and connector to the DeepSeek model on SageMaker to generate a text response for the user’s question. The OpenSearch neural query (line 55 of run_rag.py) takes care of generating the embedding for the k-NN query using the embedding_model_id. In the ext section of the query, you provide the user’s question for the LLM. The llm_model is set to bedrock/claude because the parameterization and actions are the same as they are for DeepSeek. You’re still using DeepSeek to generate text.
Examine the output from OpenSearch Service. The user asked the question “What’s the population increase of New York City from 2021 to 2023? How is the trending comparing with Miami?” The first portion of the result shows the hits—documents OpenSearch retrieved from the semantic query—as the population statistics for New York City and Miami. The next section of the response includes the prompt, as well as DeepSeek’s answer.
Congratulations! You’ve connected to an embedding model, created a knowledge base, and used that knowledge base, along with DeepSeek, to generate a text response to a question on population changes in New York City and Miami. You can adapt the code from this post to create your own knowledge base and run your own queries.
Clean up
To avoid incurring additional charges, clean up the resources you deployed:
- Delete the SageMaker deployment of DeepSeek. For instructions, see Cleaning Up.
- If your Jupyter notebook has lost context, you can delete the endpoint:
- On the SageMaker console, under Inference in the navigation pane, choose Endpoints.
- Select your endpoint and choose Delete.
- Delete the CloudFormation template for connecting to SageMaker for the embedding model.
- Delete the OpenSearch Service domain you created.
Conclusion
The OpenSearch connector framework is a flexible way for you to access models you host on other platforms. In this example, you connected to the open source DeepSeek model that you deployed on SageMaker. DeepSeek’s reasoning capabilities, augmented with a knowledge base in the OpenSearch Service vector engine, enabled it to answer a question comparing population growth in New York and Miami.
Find out more about AI/ML capabilities of OpenSearch Service, and let us know how you are using DeepSeek and other generative models to build!
About the Authors
 Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
 Yaliang Wu is a Software Engineering Manager at AWS, focusing on OpenSearch projects, machine learning, and generative AI applications.
Yaliang Wu is a Software Engineering Manager at AWS, focusing on OpenSearch projects, machine learning, and generative AI applications.
Resolving a Mutual TLS session resumption vulnerability
Post Syndicated from Matt Bullock original https://blog.cloudflare.com/resolving-a-mutual-tls-session-resumption-vulnerability/
On January 23, 2025, Cloudflare was notified via its Bug Bounty Program of a vulnerability in Cloudflare’s Mutual TLS (mTLS) implementation.
The vulnerability affected customers who were using mTLS and involved a flaw in our session resumption handling. Cloudflare’s investigation revealed no evidence that the vulnerability was being actively exploited. And tracked as CVE-2025-23419, Cloudflare mitigated the vulnerability within 32 hours after being notified. Customers who were using Cloudflare’s API shield in conjunction with WAF custom rules that validated the issuer’s Subject Key Identifier (SKI) were not vulnerable. Access policies such as identity verification, IP address restrictions, and device posture assessments were also not vulnerable.
The bug bounty report detailed that a client with a valid mTLS certificate for one Cloudflare zone could use the same certificate to resume a TLS session with another Cloudflare zone using mTLS, without having to authenticate the certificate with the second zone.
Cloudflare customers can implement mTLS through Cloudflare API Shield with Custom Firewall Rules and the Cloudflare Zero Trust product suite. Cloudflare establishes the TLS session with the client and forwards the client certificate to Cloudflare’s Firewall or Zero Trust products, where customer policies are enforced.
mTLS operates by extending the standard TLS handshake to require authentication from both sides of a connection – the client and the server. In a typical TLS session, a client connects to a server, which presents its TLS certificate. The client verifies the certificate, and upon successful validation, an encrypted session is established. However, with mTLS, the client also presents its own TLS certificate, which the server verifies before the connection is fully established. Only if both certificates are validated does the session proceed, ensuring bidirectional trust.
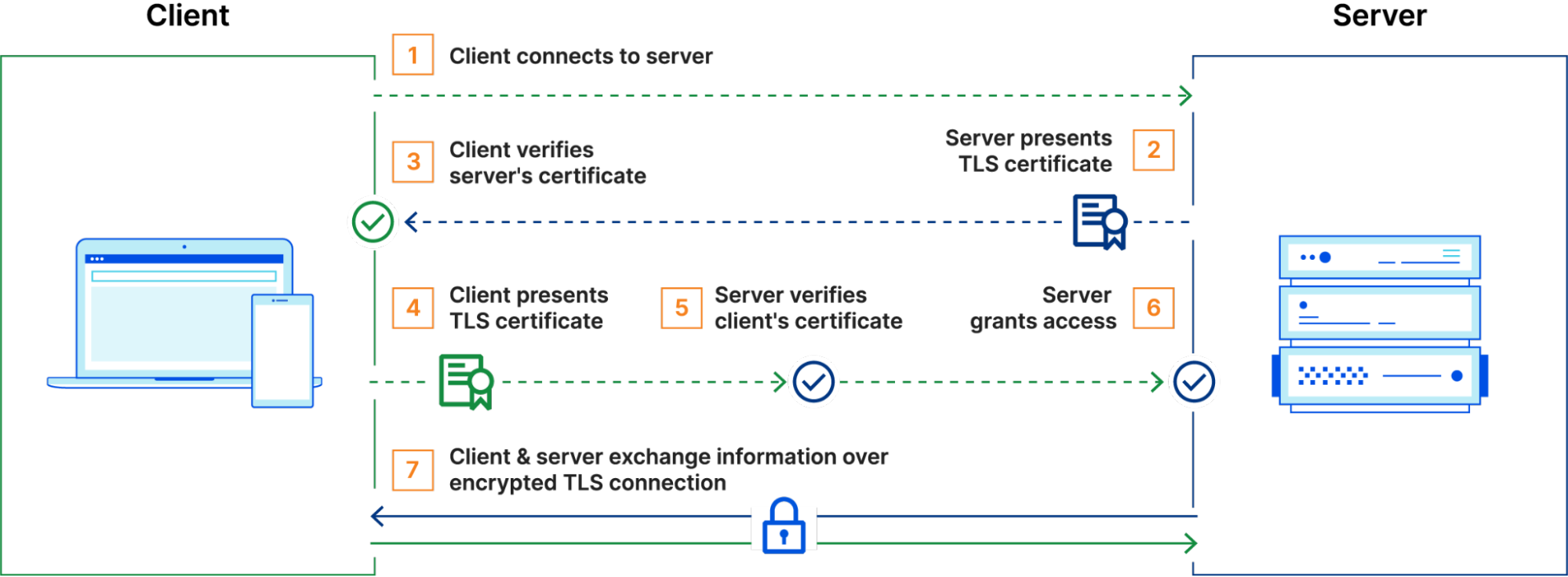
mTLS is useful for securing API communications, as it ensures that only legitimate and authenticated clients can interact with backend services. Unlike traditional authentication mechanisms that rely on credentials or tokens, mTLS requires possession of a valid certificate and its corresponding private key.
To improve TLS connection performance, Cloudflare employs session resumption. Session resumption speeds up the handshake process, reducing both latency and resource consumption. The core idea is that once a client and server have successfully completed a TLS handshake, future handshakes should be streamlined — assuming that fundamental parameters such as the cipher suite or TLS version remain unchanged.
There are two primary mechanisms for session resumption: session IDs and session tickets. With session IDs, the server stores the session context and associates it with a unique session ID. When a client reconnects and presents this session ID in its ClientHello message, the server checks its cache. If the session is still valid, the handshake is resumed using the cached state.
Session tickets function in a stateless manner. Instead of storing session data, the server encrypts the session context and sends it to the client as a session ticket. In future connections, the client includes this ticket in its ClientHello, which the server can then decrypt to restore the session, eliminating the need for the server to maintain session state.
A resumed mTLS session leverages previously established trust, allowing clients to reconnect to a protected application without needing to re-initiate an mTLS handshake.
In Cloudflare’s mTLS implementation, however, session resumption introduced an unintended behavior. BoringSSL, the TLS library that Cloudflare uses, will store the client certificate from the originating, full TLS handshake in the session. Upon resuming that session, the client certificate is not revalidated against the full chain of trust, and the original handshake’s verification status is respected. To avoid this situation, BoringSSL provides an API to partition session caches/tickets between different “contexts” defined by the application. Unfortunately, Cloudflare’s use of this API was not correct, which allowed TLS sessions to be resumed when they shouldn’t have been.
To exploit this vulnerability, the security researcher first set up two zones on Cloudflare and configured them behind Cloudflare’s proxy with mTLS enabled. Once their domains were configured, the researcher authenticated to the first zone using a valid client certificate, allowing Cloudflare to issue a TLS session ticket against that zone.
The researcher then changed the TLS Server Name Indication (SNI) and HTTP Host header from the first zone (which they had authenticated with) to target the second zone (which they had not authenticated with). The researcher then presented the session ticket when handshaking with the second Cloudflare-protected mTLS zone. This resulted in Cloudflare resuming the session with the second zone and reporting verification status for the cached client certificate as successful,bypassing the mTLS authentication that would normally be required to initiate a session.
If you were using additional validation methods in your API Shield or Access policies – for example, checking the issuers SKI, identity verification, IP address restrictions, or device posture assessments – these controls continued to function as intended. However, due to the issue with TLS session resumption, the mTLS checks mistakenly returned a passing result without re-evaluating the full certificate chain.
We have disabled TLS session resumption for all customers that have mTLS enabled. As a result, Cloudflare will no longer allow resuming sessions that cache client certificates and their verification status.
We are exploring ways to bring back the performance improvements from TLS session resumption for mTLS customers.
Customers can further harden their mTLS configuration and add enhanced logging to detect future issues by using Cloudflare’s Transform Rules, logging, and firewall features.
While Cloudflare has mitigated the issue by disabling session resumption for mTLS connections, customers may want to implement additional monitoring at their origin to enforce stricter authentication policies. All customers using mTLS can also enable additional request headers using our Managed Transforms product. Enabling this feature allows us to pass additional metadata to your origin with the details of the client certificate that was used for the connection.
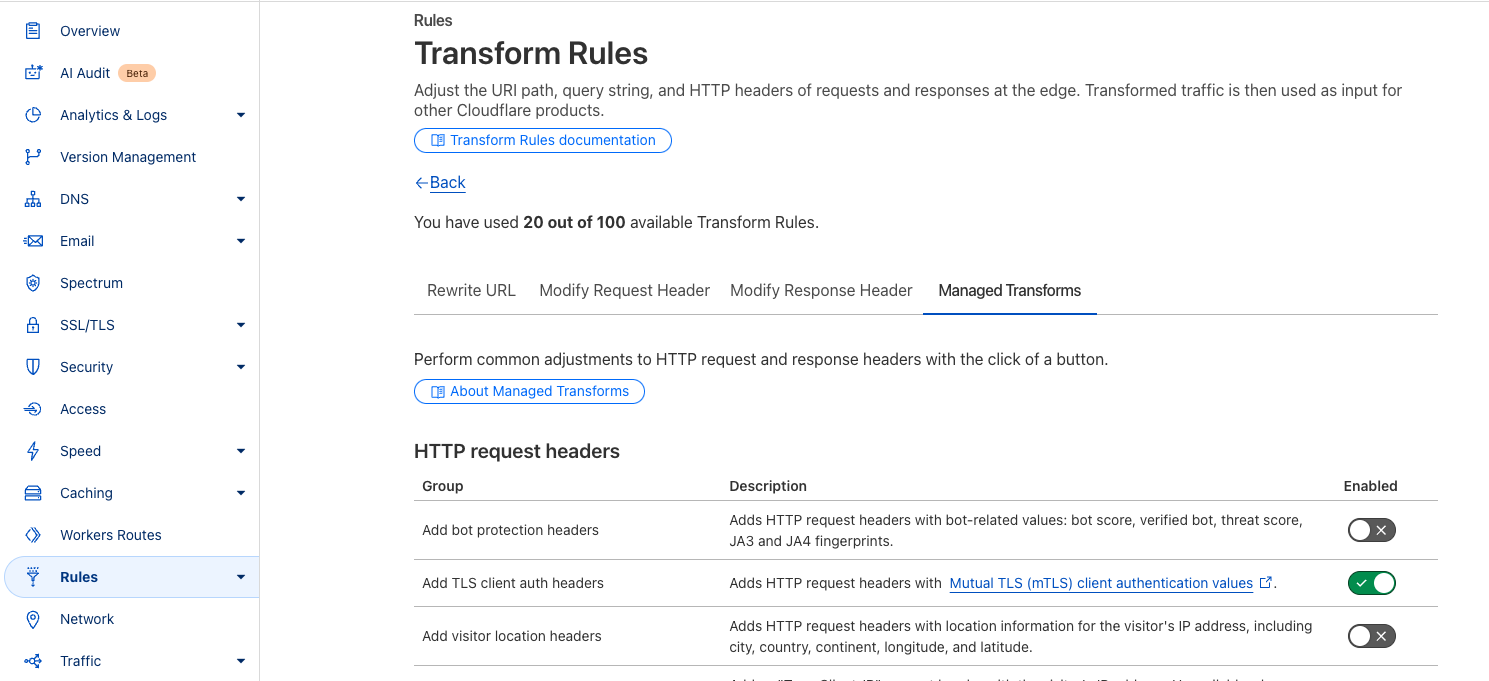
Enabling this feature allows you to see the following headers where mTLS is being utilized on a request.
{
"headers": {
"Cf-Cert-Issuer-Dn": "CN=Taskstar Root CA,OU=Taskstar\\, Inc.,L=London,ST=London,C=UK",
"Cf-Cert-Issuer-Dn-Legacy": "/C=UK/ST=London/L=London/OU=Taskstar, Inc./CN=Taskstar Root CA",
"Cf-Cert-Issuer-Dn-Rfc2253": "CN=Taskstar Root CA,OU=Taskstar\\, Inc.,L=London,ST=London,C=UK",
"Cf-Cert-Issuer-Serial": "7AB07CC0D10C38A1B554C728F230C7AF0FF12345",
"Cf-Cert-Issuer-Ski": "A5AC554235DBA6D963B9CDE0185CFAD6E3F55E8F",
"Cf-Cert-Not-After": "Jul 29 10:26:00 2025 GMT",
"Cf-Cert-Not-Before": "Jul 29 10:26:00 2024 GMT",
"Cf-Cert-Presented": "true",
"Cf-Cert-Revoked": "false",
"Cf-Cert-Serial": "0A62670673BFBB5C9CA8EB686FA578FA111111B1B",
"Cf-Cert-Sha1": "64baa4691c061cd7a43b24bccb25545bf28f1111",
"Cf-Cert-Sha256": "528a65ce428287e91077e4a79ed788015b598deedd53f17099c313e6dfbc87ea",
"Cf-Cert-Ski": "8249CDB4EE69BEF35B80DA3448CB074B993A12A3",
"Cf-Cert-Subject-Dn": "CN=MB,OU=Taskstar Admins,O=Taskstar,L=London,ST=Essex,C=UK",
"Cf-Cert-Subject-Dn-Legacy": "/C=UK/ST=Essex/L=London/O=Taskstar/OU=Taskstar Admins/CN=MB ",
"Cf-Cert-Subject-Dn-Rfc2253": "CN=MB,OU=Taskstar Admins,O=Taskstar,L=London,ST=London,C=UK",
"Cf-Cert-Verified": "true",
"Cf-Client-Cert-Sha256": "083129c545d7311cd5c7a26aabe3b0fc76818495595cea92efe111150fd2da2",
}
}
Enterprise customers can also use our Cloudflare Log products to add these headers via the Logs Custom Fields feature. For example:
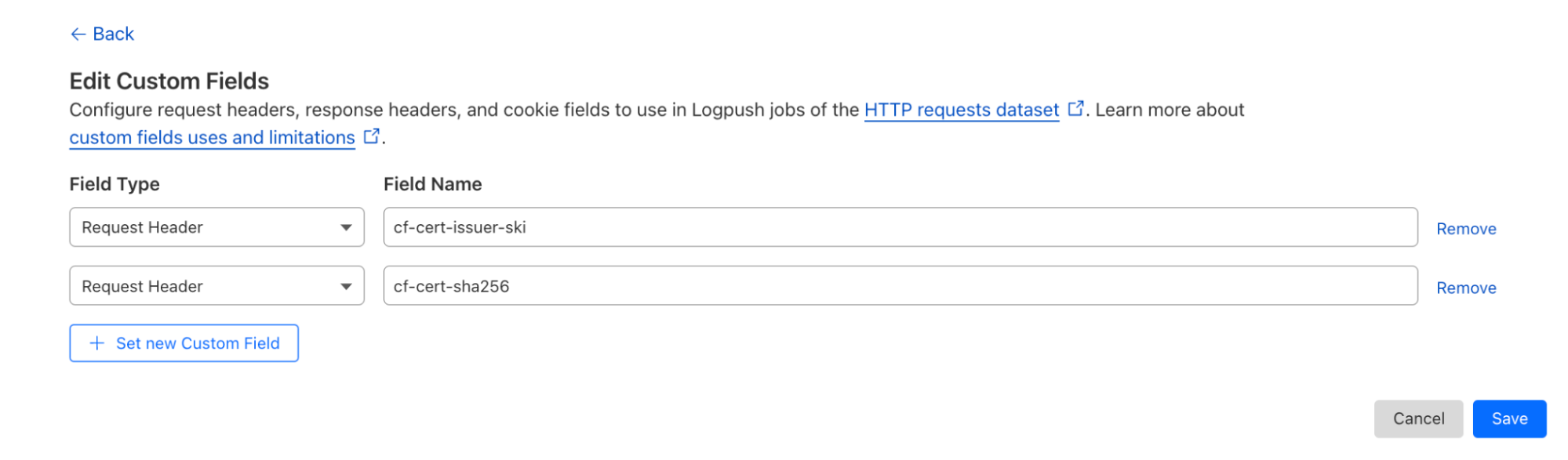
This will add the following information to Cloudflare Logs.
"RequestHeaders": {
"cf-cert-issuer-ski": "A5AC554235DBA6D963B9CDE0185CFAD6E3F55E8F",
"cf-cert-sha256": "528a65ce428287e91077e4a79ed788015b598deedd53f17099c313e6dfbc87ea"
},
Customers already logging this information — either at their origin or via Cloudflare Logs — can retroactively check for unexpected certificate hashes or issuers that did not trigger any security policy.
Users are also able to use this information within their WAF custom rules to conduct additional checks. For example, checking the Issuer’s SKI can provide an extra layer of security.
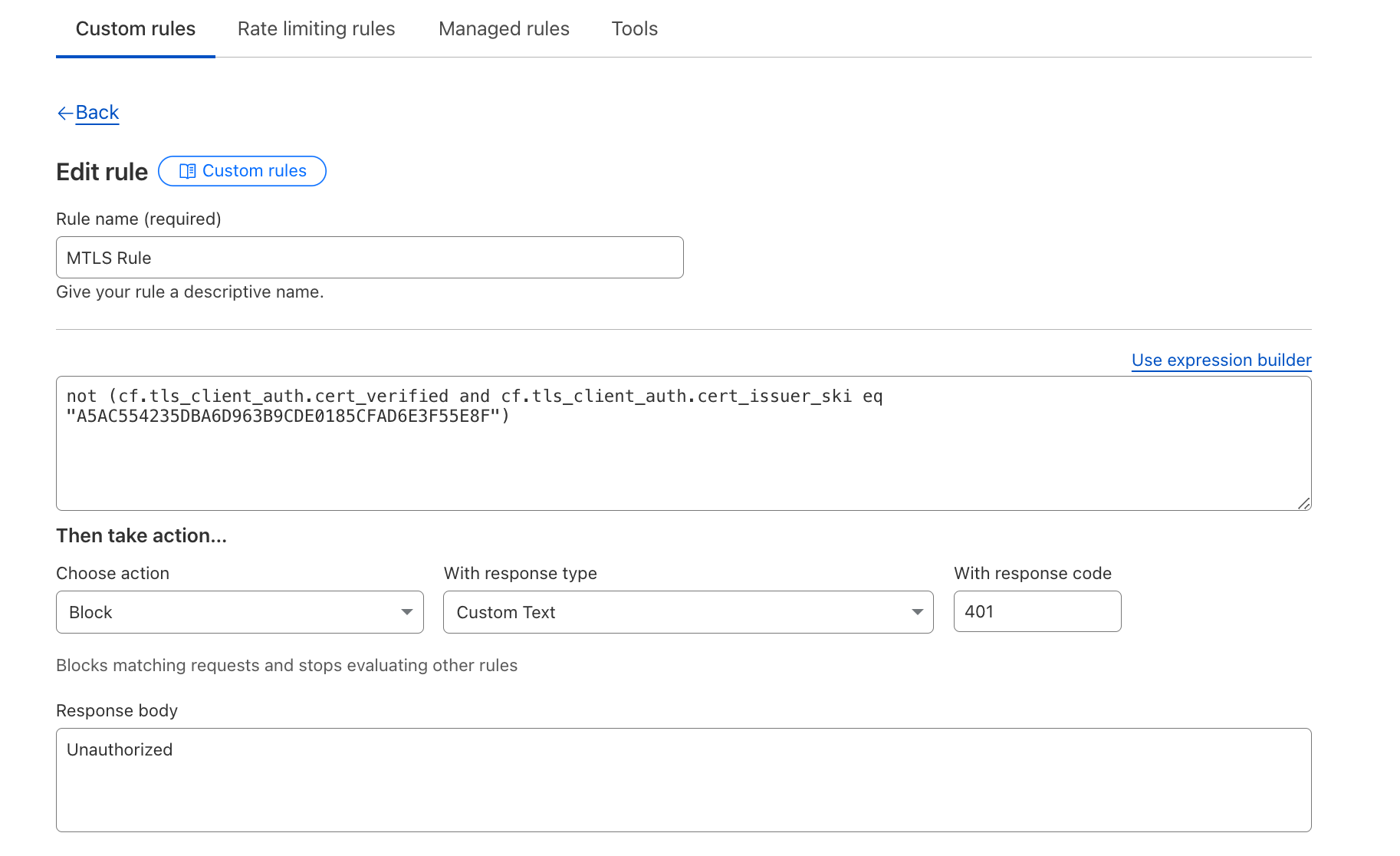
Customers who enabled this additional check were not vulnerable.
We sincerely thank the security researcher who responsibly disclosed this issue via our HackerOne Bug Bounty Program, allowing us to identify and mitigate the vulnerability. We welcome further submissions from our community of researchers to continually improve our products’ security.
Finally, we want to apologize to our mTLS customers. Security is at the core of everything we do at Cloudflare, and we deeply regret any concerns this issue may have caused. We have taken immediate steps to resolve the vulnerability and have implemented additional safeguards to prevent similar issues in the future.
All timestamps are in UTC
-
2025-01-23 15:40 – Cloudflare is notified of a vulnerability in Mutual TLS and the use of session resumption.
-
2025-01-23 16:02 to 21:06 – Cloudflare validates Mutual TLS vulnerability and prepares a release to disable session resumption for Mutual TLS.
-
2025-01-23 21:26 – Cloudflare begins rollout of remediation.
-
2025-01-24 20:15 – Rollout completed. Vulnerability is remediated.
Vector Command Opportunistic Phishing Blog
Post Syndicated from Ed Montgomery original https://blog.rapid7.com/2025/02/07/vector-command-opportunistic-phishing-blog/
Gone Phishing with Vector Command

During one of our customer engagements, our red team will continuously attack your network to see if we can exploit a vulnerability. One of the tactics, techniques and procedures (TTPs) we use is “Opportunistic Phishing”. First, let’s share a quick reminder about what Vector Command is.
Vector Command is Rapid7’s new continuous red teaming managed service, designed to assess your external attack surface and identify gaps in the security defenses on an ongoing basis. Vector Command continues the expansion of our Exposure Management solutions for our customers. While external attack surface management (EASM) tools offer visibility, they often fall short in validation, generating lengthy lists of potential exposures for security teams to sift through. Traditional penetration testing can help validate vulnerabilities, but its point-in-time nature risks leaving critical exposures undetected for extended periods. With Vector Command, our red team will continuously look for exploitable vulnerabilities.
Hacking the Human
Social engineering attacks are based on the exploitation of someone’s personality and can be referred to as “hacking the human”.
Security professionals often comment how the employee can often be the weakest link in a company’s security posture. From end-of-day tiredness, to our more relaxed nature during a quick lunch break and even our predisposed trusting tendencies towards those causes we care deeply about, can be exploited by threat actors. This is the “social” aspect in “Social Engineering”. Humans can be manipulated into making mistakes through psychological means and giving our login credentials away or other sensitive information.
Opportunistic Phishing – The Human Touch
Opportunistic Phishing, also known as “untargeted attacks” may have no warning signs and is often deployed spontaneously, without a specific target. Rapid7’s red team will use this technique to see what information they can get from a customer engagement.
Let’s take the hypothetical example of a former IT contractor who was employed by a company. The off-boarding policy has not yet been completed. The IT contractor had elevated access to one business application containing personally identifiable information (PII). Our red team, once they identify this former contracted employee, could use their access rights to gain entry to sensitive PII and services on the corporate network.
When an opportunistic attempt is executed by a threat actor, it is most commonly conducted via malware or phishing over email.
In this specific technique, an attacker will send out fraudulent messages, taking care to design the emails to look like the actual organization, often using similar logos, fonts, and signatures. Inside the body of the message will be a URL, typically with a misspelled domain name or extra subdomain. If the recipient is not savvy enough to recognise the fake web address from the real one and clicks on the link, this is when the malware is activated as an executable file and downloaded to the device. The payload often includes keylogging software, used to collect keystrokes, including your passwords, which now gives the threat actor access to your company network.
By deploying this tactic, Rapid7’s red team, think, act and behave like a threat actor, but without the malicious consequences for your organization. Using opportunistic phishing, we will find and identify where your security gaps are, with respect to technology (through different configuration types for campaigns) and people, helping you to act and respond. Our advanced Vector Command reporting even gives a detailed outline of the situation, including remediation recommendations for your IT and Security teams.
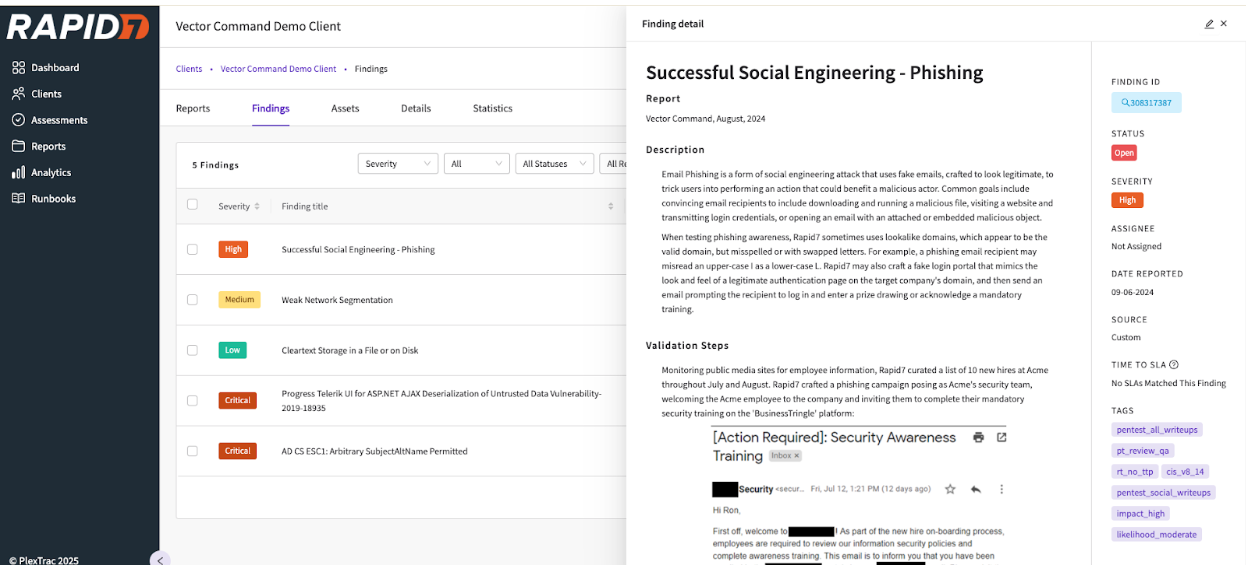
What should you be on the lookout for?
Let’s explore some typical phishing examples that frequently target organizations.
- Invoices for companies that you do not have a supplier agreement with.
- Shipping notifications from large retailers, both online and the high street.
- Password reset requests for your email, or other online account e.g. Amazon, or PayPal.
- Tax refund emails either at the time of needing to submit your tax return (when it is time sensitive) or months away from when it needs to be completed (anomalous behavior).
- Can you spot poor grammar, or spelling errors in the subject, or within the body of the email, that would indicate it is not from a reputable source?
- Does the email have a sense of urgency – “Act now”?
- Generic greetings like “Dear Customer” as opposed to a more personalized one.
- Surveys from third-parties or workplace experience coordinators that are out-of-place.
- Suspicious login alerts from common applications sourcing from an untrusted sender.
- Password reset requests for your email, or other online account e.g. Amazon, or PayPal.
- Employee benefit emails either at the time of needing to submit your elections (when it is time sensitive) or months away from when it needs to be completed (anomalous behavior).
- Shared documents and calendar invitations from third-parties you do not commonly interact with.
- Browser extensions, software updates, and installation requests via email or phone.
- Verify unexpected phone calls through internal communication applications such as Teams, or Slack.
Take Command of your Attack Surface
Stay tuned as we continue to share insights of other TTPs employed by Rapid7’s expert red team to test your cyber resilience.
We have created a self-guided product tour for Vector Command which you can check out at your leisure.
Vector Command: Request Demo ▶︎
Ready to see how continuous red team managed services can ensure your potential attack pathways are remediated before they can ever be exploited?
Enhancing telecom security with AWS
Post Syndicated from Kal Krishnan original https://aws.amazon.com/blogs/security/enhancing-telecom-security-with-aws/
If you’d like to skip directly to the detailed mapping between the CISA guidance and AWS security controls and best practices, visit our Github page.
Implementing CISA’s enhanced visibility and hardening guidance for communications infrastructure
In response to recent cybersecurity incidents attributed to actors from the People’s Republic of China, a number of cybersecurity agencies led by the U.S. Cybersecurity and Infrastructure Security Agency (CISA) have jointly released comprehensive guidance for securing communications infrastructure. As communications service providers (CSPs) migrate their workloads to the cloud, they must take steps to implement these security measures effectively in cloud environments.
This blog post describes how CSPs can use Amazon Web Services (AWS) capabilities to implement this guidance while benefiting from the advantages of the cloud.
The guidance focuses on two key domains:
- Strengthening visibility: Enabling security teams to monitor, detect, and respond to potential threats through comprehensive visibility into digital assets
- Hardening systems and devices: Implementing robust security controls and configurations to minimize vulnerabilities and help prevent unauthorized access
Overview of fundamental cloud concepts
Before exploring the specific guidance in this post, it’s important to understand how security recommendations apply differently to public cloud environments than to private infrastructure. A common tendency in the telecommunications industry is to treat public clouds as merely scaled-up versions of private clouds. This can result in a misunderstanding of security capabilities and underutilization of cloud-native security features of the public cloud.
The fundamental difference lies in how public clouds are architected—specifically for multi-tenancy, with strong tenant isolation as a cornerstone of their design. In AWS, virtual resources are isolated by default and require explicit configuration to interconnect. For example, when you create a virtual private cloud (VPC) with Amazon VPC, this logically isolated network does not permit inbound or outbound traffic until specific routes and ports are deliberately configured. Similarly, Amazon Simple Storage Service (Amazon S3) buckets are private by default, requiring explicit configuration to grant access. This isolation extends to the core of our virtualization infrastructure through the AWS Nitro System, which provides unprecedented workload isolation—even AWS operators with the highest privileges have no technical access to customer workloads. Furthermore, data moving between Nitro System based virtual machines or across our global backbone network is automatically encrypted, providing additional layers of protection beyond customer-implemented encryption.
This secure-by-design and secure-by-default philosophy permeates throughout AWS service design and operations. It isn’t merely a design choice—it’s a business imperative driven by the critical need for operational resilience and customer trust in the public cloud model. Our commitment to principles of this sort is reflected in our participation as a signatory to CISA’s Secure by Design Pledge.
When AWS customers operate in the public cloud, understanding the shared responsibility model is paramount. This model clearly delineates security responsibilities: AWS is responsible for security of the cloud, while customers are responsible for security in the cloud. This division of responsibilities significantly reduces your operational burden, because AWS assumes responsibility for securing everything about and inside the cloud services it provides, all the way down to the physical protection of data centers. As a result, you can concentrate your security resources where they matter most—protecting your applications and workloads—while AWS handles the undifferentiated heavy lifting of infrastructure security.
This shared responsibility model becomes even more advantageous when considering the economies of scale inherent to public cloud operations. The massive scale of AWS allows us to invest more in securing the foundations than a single enterprise could achieve independently, creating a security multiplier effect that benefits all customers. A compelling example of this scale advantage is our comprehensive threat intelligence program, which deploys honeypot sensors throughout our global network. These sensors observe more than 100 million potential threat interactions and probes daily. Using artificial intelligence and machine learning (AI/ML), we analyze this information and take swift, often automated actions to mitigate threats. In the first half of 2023 alone, this program enabled us to dismantle the sources of approximately 230,000 Layer 7 distributed denial of service (DDoS) events. We also provide this intelligence to customers through services like Amazon GuardDuty, extending the benefits of our scale to our customers.
The scale of AWS operations not only enables exemplary threat intelligence, but also necessitates extensive automation of our security operations. Several routine tasks, such as feature and patch deployments and configuration updates, are fully automated through deployment pipelines. Automation has the added benefit of taking humans out of the loop, thereby decreasing opportunities for mistakes.
Our scale also facilitates our comprehensive compliance with security standards across multiple industries and jurisdictions. Our global presence and diverse customer base necessitate adherence to the most stringent security requirements worldwide. Through the AWS Compliance Program, we’ve achieved 143 security standards and compliance certifications, ranging from ISO standards for cloud security and privacy to industry-specific regulations in finance and healthcare, as well as government security programs. This includes independent verification of our claims on the isolation properties of our Nitro System virtualization infrastructure. Consequently, you benefit from this scale-driven compliance, gaining access to a secure, certified infrastructure that implements state-of-the-art security systems.
These are a few reasons why, in a blog post titled Why cloud first is not a security problem, the UK’s National Cyber Security Centre concluded that “using the cloud securely should be your primary concern – not the underlying security of the public cloud.”
Private clouds, on the other hand, are typically within the control of a single organization and are single-tenanted, offering relatively weak workload isolation. Virtual resources in private clouds usually default to being interconnected upon creation, and so require explicit steps to increase isolation. Manual operations, with their opportunities for mistakes as well as potential involvement of threat actors, are often still a large part of private cloud workflows. Rarely do they undergo the level of security scrutiny that public clouds are routinely subjected to. These, and other differences, mean that security risks in each offering are inherently different, so correspondingly distinct security controls and solution architectures are needed to mitigate these risks.
Implementing hardening guidance with AWS
Your cloud resources and data are contained in an AWS account. An account acts as an identity and access management isolation boundary. When you need to share resources and data between two accounts, you must explicitly allow this access. This reduces the risk of lateral movement between accounts.
Designing your AWS environment correctly lays a strong foundation that can help you meet the CISA cybersecurity guidance. AWS Control Tower, working with AWS Organizations, enables you to establish a well-architected, multi-account environment based on security best practices.
For detailed guidance on creating a secure landing zone for telecom workloads, refer to our comprehensive blog post on this topic.
We’ve analyzed the recommendations in CISA’s guidance and grouped them into six categories across the two key domains. Refer to the GitHub page linked at the bottom of this post, which has further detailed guidance on the relevant AWS services that can assist your implementation of each individual security measure in the guidance.
Logging and monitoring
The guidance in this category emphasizes the importance of increasing visibility to understand network activity, which is essential for detecting anomalies and responding to incidents. Key security controls include the following: have a robust asset management capability, enable logging at various levels, centralize logging, protect the logging and monitoring infrastructure, and use security tools to detect anomalies and incidents.
Enhanced visibility is an inherent advantage of the public cloud model, particularly in AWS. This transparency is not just a bolted-on feature, but a fundamental necessity driven by the API-centric, pay-as-you-go business model. To accurately bill customers, AWS has built comprehensive tracking and logging capabilities into its core architecture. As a result, AWS provides robust tools that allow you to capture, centralize, and monitor logs across every layer of your network workload. This level of visibility extends far beyond what’s typically achievable in traditional infrastructure, offering you unprecedented insight into your IT assets and user activities.
Another key guidance is this area is to centralize security-related logging while isolating the logging infrastructure from other production environments. You can implement this guidance in AWS by using Amazon Security Lake together with OpenSearch implemented in separate accounts, with access restricted to just the security organization. Alternatively, this solution provides a best-practice implementation of creating collection and ingestion pipelines to allow for centralization and inspection of log sources across your AWS workloads without the use of Security Lake.
Configuration and change management
The guidance in this category emphasizes the centralization, security, and protection of configurations. It highlights the importance of detecting and providing alerts for unauthorized modifications, auditing configurations for compliance, and a change management process that automates routine changes to minimize unintended drift.
In AWS, you can implement infrastructure and configuration as code, which allows for central storage of configuration in repositories, tracking changes through version control, and implementing changes through approved change management processes. You can use code repositories and continuous integration and continuous delivery (CI/CD) pipelines to automate the implementation of these configurations, helping you increase deployment speed, maintain consistency, simplify management, and implement a rigorous and auditable change control process.
Regardless of how infrastructure is deployed and managed, you can use the AWS Config service to automatically track the current state and history of a wide set of configuration information across more than 100 AWS services and hundreds of their resource types. You can also write custom AWS Config rules to take automatic actions whenever sensitive resources are modified, or take advantage of more than 400 AWS managed rules in AWS Config that send alerts or create automatic remediations when critical resources change state.
Identity and access management
The guidance in this category emphasizes the importance of active account and permissions management, use of phishing-resistant authentication methods, implementing least privilege through role-based access controls, managing emergency access, and limiting sessions.
Authentication and authorization, which are critical components of access control, are managed through AWS Identity and Access Management (IAM), AWS IAM Identity Center, and AWS Organizations. AWS provides you with capabilities to manage permissions at scale across identities, resources, and services, including mandating the use of multi-factor authentication (MFA) for logins. Furthermore, these capabilities support customers adhering to the principle of least privilege by encouraging time-bound, session-based credential management by using AWS Security Token Service (AWS STS).
Software running in the cloud that needs to call cloud APIs receives its temporary and frequently rotated credentials automatically through IAM roles for Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), and AWS Lambda, helping to eliminate the need for long-term credentials that can leak or be compromised. Access to cloud APIs from on-premises software can be safely boot-strapped from enterprise identity management technologies by using AWS IAM Roles Anywhere. You can even protect authentication to non-cloud technologies with a combination of roles and the use of AWS Secrets Manager to protect and automatically rotate secrets such as database passwords.
Network and traffic management
The guidance in this category emphasizes segmenting workloads and networks to limit the potential for lateral movement and exposure to the internet, monitoring and regulating traffic flows by using policies, and securing unused ports.
You can achieve network micro-segmentation, a critical aspect of modern security architecture, through VPCs and subnets. You can, for example, segregate internet-facing components of your application from those that don’t require such access by placing them in separate VPCs and enabling internet access only on the VPC that requires it. You can control traffic flows within and between segments by using a variety of network services—routing tables, internet gateways, transit gateways, and firewall services, to name a few. This segmentation minimizes your risk from unauthorized activity that originates from the internet and limits the potential for lateral movement in the event of a breach.
To implement the guidance regarding out-of-band management, you can architect your network connections to separate management traffic from network signaling traffic by using subnets—for example, a single EC2 instance can have multiple elastic network interfaces (ENIs) attached to different subnets or even different VPCs: one that permits only management traffic and another that permits only signaling traffic.
Strong cryptography to encrypt data at rest and in traffic
The guidance in this category emphasizes using strong cipher suites, secure versions of encryption protocols, and PKI-based certificates to protect data at rest and in transit.
Encryption, a cornerstone of data protection, is comprehensively addressed in AWS offerings. API endpoints of AWS services support TLS 1.3 (and a minimum of TLS 1.2) with secure standards-based cipher suites, encryption keys, and advanced security features like HKDF (HMAC-based extract-and-expand key derivation function) for added security. AWS services that manage customer secrets sent over the wire also support post-quantum cryptography. For example, AWS Key Management Service (AWS KMS), AWS Certificate Manager, and AWS Secrets Manager support a hybrid post-quantum key exchange option for the TLS network encryption protocol. In its use of the Border Gateway Protocol (BGP), AWS uses Resource Public Key Infrastructure (RPKI) and Route Origin Authorization (ROA) to protect the Amazon IP address space and routes from misconfigurations and hijacking.
You can also use AWS cryptographic services such as AWS KMS, AWS CloudHSM, and AWS Certificate Manager to help secure your data in transit and at rest. Keys that you create in AWS KMS are protected by FIPS 140-2 Level 3 validated hardware security modules (HSMs), and there is no mechanism for anyone, including AWS service operators, to view, access, or export plaintext key material.
AWS Secrets Manager helps you securely manage, retrieve, and rotate database credentials, application credentials, OAuth tokens, API keys, and other secrets throughout their lifecycles. For more details on AWS cryptography solutions and best practices, refer to Encryption best practices for AWS services.
Vulnerability management
This guidance emphasizes minimizing exploitation risks through proper lifecycle management, regular patching, and elimination of insecure protocols. AWS helps address these requirements through both shared responsibility and innovative architectural approaches.
Under the shared responsibility model, AWS manages the security of underlying infrastructure. This includes maintaining up-to-date systems and services, disabling insecure protocols and unused ports, and providing Security Bulletins for timely vulnerability notifications. AWS services are supported through contractually defined terms, so that you don’t need to worry about end-of-life infrastructure components.
For your applications, AWS enables a transformative approach to vulnerability management through ephemeral resources and immutable infrastructure. Instead of maintaining long-lived instances that require continuous patching, you can maintain a single, hardened, and frequently updated Amazon Machine Image (AMI) as your golden image. When updates are needed, rather than patching running instances, you simply deploy new instances with your application code installed from an updated AMI. Similar approaches also apply to container-based workloads. Workloads based on AWS Lambda reduce your patching responsibility even further, because only the code that contains your business logic (and any supporting layers you have chosen) needs to be updated—AWS patches the underlying hypervisors, operating systems, and containers automatically. This approach enables you to keep your systems in a known, secure state while reducing both the threat surface and operational overhead. You can further enhance security by using AWS networking features like security groups to disable insecure protocols, such as enforcing HTTPS rather than HTTP.
Conclusion
The comprehensive guidance from cybersecurity agencies provides a crucial framework for securing telecommunications infrastructure. As demonstrated throughout this post, AWS offers a robust set of native services and capabilities that align with the recommendations from CISA and allied governments. From enhanced visibility through logging and monitoring, to strong identity management, network segmentation, encryption, and vulnerability management, AWS provides the tools you need to implement these security controls effectively while maintaining operational efficiency. The shared responsibility model, combined with AWS continuous innovation in security, enables telecommunications companies to build and maintain resilient, secure cloud environments.
Visit our GitHub page for detailed information on implementing CISA guidance with AWS services.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Learning AWS best practices from Amazon Q in the Console
Post Syndicated from Brendan Jenkins original https://aws.amazon.com/blogs/devops/learning-aws-best-practices-from-amazon-q-in-the-console/
Operators, administrators, developers, and many other personas leveraging AWS come across multiple use cases and common issues such as lack of permissions, bugs in code in AWS Lambda, and more when leveraging the AWS console. To help alleviate this burden when using the console, AWS released Amazon Q to assist with users accessing the console with these use cases. Amazon Q is AWS’s generative AI-powered assistant that helps write code, answer questions, generate content, solve problems, manage AWS resources, and take actions. A component of Amazon Q is Amazon Q Developer. One way to interact with the service is to chat with Amazon Q Developer in the AWS Management Console, the AWS Console Mobile Application, on AWS websites, AWS Documentation websites, and chat channels integrated with AWS Chatbot to learn about AWS services. You can ask Q Developer about best practices, recommendations, step-by-step instructions for AWS tasks, and architecting your AWS resources and workflows.
In this blog post, we will highlight best practices for interacting with Q Developer in the console including topics such as using Q Developer in the console to generate code snippets, architect workloads, and understand your costs.
Prerequisites
To follow along with these examples, the following prerequisites are required:
Overview
Here are some of the examples on how Amazon Q Developer in the console can be utilized:
- Learn about certain AWS Services and explore best practices for leveraging those services effectively.
- Generate code snippets or scripts to automate tasks using AWS Software Development Kit (SDK) or AWS Command Line Interface (CLI)
- Architect a workload and optimize it
- Understand your costs
Please Note – Amazon Q in Console may generate different output than shown in examples below due to its non-deterministic nature.
To start, access the Amazon Q Developer service by signing into the AWS console and clicking the Amazon Q icon on the right-hand panel as shown below in Figure 1. Authenticate if necessary:

Figure 1: Accessing Amazon Q Chat
Use Q to learn about AWS services and best practices
In this section, we will look at how Amazon Q can help you learn about AWS services and also outline the best practices for using those services
Learn about services available in AWS
Whether someone is just learning or an experienced user, Amazon Q provides a simple way to discover AWS capabilities and get helpful information whenever needed.
For example, if you are looking to learn on how to auto-scale your compute instances based on a metric you can ask Amazon Q in console.
Sample prompt –
I need to set a autoscaling group for EC2 instances with this requirement, if
CPU utilization goes above 50% for 5 minutes then it should add new instance
and if CPU utilization drops below 50% for 5 minutes then it should delete 1
instance.

Figure 2: User Prompt and Response from Amazon Q for Auto Scaling Compute Instance based on a specific metric and threshold
The response from Amazon Q lists down all the steps to set an Auto Scaling Group based on the requirements provided in the prompt.
Ask specific questions about AWS services
Amazon Q in console can also help you to run systems to deliver business value keeping best practices in mind. With natural language prompts, you can learn the best practices when using AWS services.
Sample Prompt –
I am using API Gateway for REST APIs. I have configured timeout for requests. I would like to learn additional best practices to reduce and handle long running requests.

Figure 3: User Prompt and Response from Amazon Q keeping compute costs low
As shown above in Figure 3, Amazon Q then summarizes various ways to optimize for long running requests in Amazon API Gateway, for example, implement timeouts, use asynchronous invocation for long running operation if possible and several other ways to optimize.
Use Q to generate code snippets or scripts to automate tasks using AWS SDK or AWS CLI
Developers or System Administrators can use Q to generate code snippets or scripts to automate tasks instead of spending time going through documentation.
How to write an AWS Lambda function to read data from S3
For example, a developer may way to get started writing an AWS Lambda function that reads data from an Amazon S3 bucket but doesn’t know how to get started, Amazon Q can help.

Figure 4: User Prompt and Response from Amazon Q on instructions to write a Lambda function

Figure 5: Response from Amazon Q with sample code to write a Lambda function
As shown above in Figure 4 & 5, Amazon Q returns step-by-step instructions on how to write the Lambda function, including sample code for reference.
How do I upload a file to an S3 bucket using the AWS CLI?
If a developer or IT Professional uses the AWS CLI frequently but struggle with finding right commands to accomplish a task, then Amazon Q is definitely helpful
Sample Prompt –
How do I upload a file to an S3 bucket using the AWS CLI?

Figure 6: User Prompt and Response from Q with CLI command to upload file to S3 bucket
As shown above in Figure 6, Amazon Q returns the CLI command to upload a file to an S3 bucket. The response also suggests the command to verify the upload.
Use Console-to-Code to write code to automate use of other services
Console-to-Code records your console actions, then uses generative AI to suggest code in your preferred language which currently supports CLI commands, CDK Java, CDK Python, CDK TypeScript, CloudFormation JSON/YAML.
Let’s say a developer wants to generate a CloudFormation YAML with an Amazon EC2 instance and Amazon RDS database instance. For this, the developer can go to the console of Amazon EC2 and Amazon RDS. On the right side, choose Console-to-Code icon and choose Start Recording.
As shown in the figures below, once an Amazon EC2 instance and then Amazon RDS DB instance is launched, stop the recording and simply download the CloudFormation YAML template.

Figure 7: Console-to-Code recording Amazon EC2 and Amazon RDS Database instance launch

Figure 8: Generate Infrastructure-As-Code from the Console-to-Code recording

Figure 9: Generated CloudFormation YAML template from the Console-to-Code recording
Use Q to architect a workload & optimize
In this section, we will focus on leveraging Amazon Q to architect new workloads and optimize existing workloads.
Architecting Workloads
Now, a developer wants to build a new financial services application with the following requirements:
- Architecture must be serverless & event driven
- It must provide functionality as deposits and withdrawals
- It should use low-cost, efficient AWS services.
- It should scale with traffic spikes that can reach thousands of requests per second.
- Should support REST APIs
Let’s prompt Amazon Q Developer by copying the following prompt below and pasting it into the chat window:
Sample Prompt:
How can I build a new financial services application with the following requirements: it should be serverless and event driven, must provide functionality as deposits and withdrawals, It should use low-cost efficient AWS services, It should scale with traffic spikes that can reach thousands of requests per second, and lastly it should support REST APIs.
Amazon Q should provide a response on how to architect this workload. Here is a sample response received from Amazon Q:

Figure 10: Response from Amazon Q for architecture
Amazon Q was able to provide the following response in full:
________________________________________________
To build a new financial services application with the requirements you described, I would recommend the following AWS services and architecture:
- Serverless and Event-Driven Architecture:
- Use AWS Lambda for the core application logic, which will allow you to run your code without provisioning or managing servers.
Integrate AWS Lambda with other serverless services like Amazon API Gateway for the REST API, Amazon DynamoDB for the database, and Amazon SNS/SQS for event-driven messaging.
- Use AWS Lambda for the core application logic, which will allow you to run your code without provisioning or managing servers.
- Deposits and Withdrawals Functionality:
- Use Amazon DynamoDB as the database to store customer account information and transaction details.
- Implement the deposit and withdrawal logic in AWS Lambda functions, which can be triggered by events from Amazon API Gateway or Amazon SNS/SQS.
- Low-Cost and Efficient AWS Services:
- Leverage AWS Lambda, which charges only for the compute time you consume, and Amazon DynamoDB, which provides a pay-per-request pricing model.
- Use Amazon API Gateway’s pay-per-call pricing to keep costs low for the REST API.
- Consider using Amazon SQS and Amazon SNS for their low-cost, highly available, and scalable messaging capabilities.
- Scalability and High-Performance:
- AWS Lambda and the other serverless services you choose will automatically scale to handle traffic spikes of thousands of requests per second.
- You can further optimize performance by using features like Amazon API Gateway’s caching, Amazon DynamoDB’s auto-scaling, and Amazon SQS’s message batching.
- REST API Support:
- Integrate your application logic in AWS Lambda with Amazon API Gateway to expose a RESTful API. Amazon API Gateway will handle the API management, including routing, authentication, and throttling.
To get started, I recommend reviewing the following AWS documentation:
- Serverless Applications with AWS Lambda
- Building Serverless Applications with Amazon API Gateway
- Amazon DynamoDB for NoSQL Database
- Amazon SNS and Amazon SQS for Messaging
Please let me know if you have any other questions!
Sources:
Key AWS services – Financial Services Industry Lens
Harnessing the scale of AWS for financial simulations | AWS HPC Blog
RPC vs REST – Difference Between API Architectures – AWS
________________________________________________
As shown above, Amazon Q was able to provide the service recommendations for our architecture based on the requirements provided along with links to services recommended based on the requirements
Optimizing workloads
Now, let’s a developer or IT professional has an architecture that revolves around Amazon EC2 and an instance deployed called Server-1-demo in AWS and wants to optimize to help save on costs.
Similar to the previous section, open a new chat window within the Amazon Q chat in the console and enter the following prompt:
Sample Prompt:
Based on the current CPU utilization of my EC2 Server-1-demo, what do you recommend I do to cost optimize?
As a result, Q provides the following response:

Figure 11: Optimization Response from Amazon Q
As shown, Amazon Q took in the context of the CPU utilization for Server-1-demo and made recommendations to leverage new instance types such as AWS Graviton which is designed to deliver the best price performance for your cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2) along with other recommendations.
Use Q to understand your costs
Another way to leverage Q in the console is to analyze costs. A developer or IT professional can use Amazon Q, to retrieve and analyze cost data from AWS Cost Explorer, being able ask questions about AWS costs and receive answers in natural language that reflect the actual costs of your AWS account.
Now, open a new Amazon Q in Console chat window and lets try the following prompt as an example:
Sample Prompt:
Show me the breakdown of EC2 costs by instance type for the last 30 days.
![] Response from Amazon Q for the breakdown of EC2 costs in the last month](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2025/02/03/figure12.png)
Figure 12: Response from Amazon Q for the breakdown of EC2 costs in the last month
As shown above in Figure 12, Q Developer provides a detailed breakdown of the EC2 instance types for the last 30 days.
Now, trying another example:
Sample Prompt:
What was my cost breakdown by service for the past three months?

Figure 13: Response from Amazon Q for last 3 months spend analysis
As shown in figure 13, Amazon Q provides detailed cost breakdowns, including percentages of total spend, making it easy to understand your AWS usage and expenses. This feature allows you to quickly identify your highest-cost services and track spending trends over time. Always verify your cost data with AWS Cost Explorer for the most accurate information. For more details and information on this capability, check out this blog covering the feature in more detail.
Best practices for using Amazon Q in the console
The previous sections showcased examples of leveraging Amazon Q capabilities for AWS application architecture and account management. In both cases, the input given to Amazon Q directly affects its output quality. Your question should be concise, clear and contain the necessary details for the tool to understand the scenario and what should be answered. The recommended approach for providing effective input to a generative AI chat bot is called Prompt Engineering. By adhering to the following best practices, you can achieve improved outcomes when using Amazon Q:
- Specify the task you want Q to do: explain a concept, compare services, list pros and cons, generate a CLI command, generate a code snippet, suggest architecture options for a scenario.
- Provide context: Why do you need to know this concept? For which part of your application or architecture will you apply the knowledge?

Figure 14: Amazon Q asks for additional details to better answer the question.
In this example, we asked for scenarios, which is what type of answer we want. We also specified the service we want scenarios about, and the edge case of the scenario (after instance creation). Amazon Q summarized our question and provided scenarios and sources in accordance with what we asked.
- Break a series of questions into multiple questions.
- Ask for one task at a time.
- Don’t stop at the first answer; keep asking questions that use the information to help Q provide more enriched responses.

Figure 15: Amazon Q uses chat context to give an answer.
In this scenario, the provided input was not enough for Q to provide a good answer, so it asked for more details and considered both inputs as a context to the answer.
- Be mindful about security related questions about your account- Amazon Q in console may not provide answers that address security in your account
- Your input must have the maximum of 1000 characters. This is another reason to be concise while providing an input.
- Create a new conversation if you are going to start a new topic discussion. Unnecessary context will reduce Q answers specificity to your new situation.

Figure 16: Amazon Q does not provide security tips. Create a new conversation. Maximum allowed characters are 1000.
Conclusion
In this blog post, we explored the various ways in which Amazon Q, AWS’s generative AI-powered assistant, is used in the AWS Console to enhance productivity and reduce ramp-up time for developers, DevOps engineers, and architects. Amazon Q functions as an AWS consultant, offering advice on various tasks, such as understanding AWS services and implementing best practices, as well as generating code snippets and automating CLI commands. The tool’s capability to help architect new workloads and enhance existing ones based on specific needs was demonstrated with detailed examples. The importance of prompt engineering – crafting clear, concise prompts to elicit high-quality responses from the AI assistant – was also discussed. By embracing the capabilities of Amazon Q in the console, AWS users will streamline their workflows and speed up their cloud journey. Whether you’re a seasoned cloud architect or starting out, this AI-powered assistant will serve as a partner, helping you navigate the AWS landscape and unlock new levels of efficiency. As you continue exploring the possibilities of Amazon Q, follow the best practices outlined in this post, experiment!
About the authors
Nikon Z Users BEWARE!
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=6juLOvkGo7o
Metasploit Weekly Wrap-Up 02/07/2025
Post Syndicated from Christophe De La Fuente original https://blog.rapid7.com/2025/02/07/metasploit-weekly-wrap-up-02-07-2025/
Gathering data and improving workflows

This week’s release includes 2 new auxiliary modules targeting Argus Surveillance DVR and Ivanti Connect Secure. The former, contributed by Maxwell Francis, and based on the work of John Page, can be used to retrieve arbitrary files on the target’s filesystem by exploiting an unauthenticated directory traversal vulnerability. The latter, brought by our very own Martin Šutovský, is a HTTP login scanner for Ivanti Connect Secure. This release also adds many improvements related to our Github continuous integration process and to the AD CS attack-based workflow. Thanks to the community for making Metasploit great!
New module content (2)
Argus Surveillance DVR 4.0.0.0 – Directory Traversal
Authors: John Page and Maxwell Francis
Type: Auxiliary
Pull request: #19847 contributed by TheBigStonk
Path: gather/argus_dvr_4_lfi_cve_2018_15745
AttackerKB reference: CVE-2018-15745
Description: Adds a module which exploits CVE-2018-15745, an unauthenticated directory traversal leading to file disclosure in Argus Surveillance DVR 4.0.0.0.
Ivanti Connect Secure HTTP Scanner
Author: msutovsky-r7
Type: Auxiliary
Pull request: #19844 contributed by msutovsky-r7
Path: scanner/ivanti/login_scanner
Description: This adds an auxiliary module for Ivanti Connect Secure HTTP Login.
Enhancements and features (3)
- #19779 from h00die – Adds a Github workflow to run update_wordpress_vulnerabilities.rb, update_user_agent_strings.rb and update_joomla_components.rb and to post a weekly PR with the changes from each update script. This also converts both
update_joomla_componentsandupdate_user_agent_stringsfrom python scripts to ruby scripts. - #19849 from zeroSteiner – This makes changes to the
ldap_esc_vulnerable_cert_finder, ad_cs_cert_templateandget_ticketmodules to enable them to be used as part of larger workflow automation. For all three modules, it adds a return value to indicate that the operation was successful and include some relevant information. LDAP object caching has been introduced to reduce the number of queries sent to the target. A #build_certificate_details method to consolidate the collection of information about certificate templates. This ensures that all certificates are returned with common information, regardless of their vulnerability status. DNS records are looked up from LDAP to avoid crashing in instances where the DNS hostname of the CA server can not be resolved by Metasploit’s running configuration. This would be the case when a DC is targeted without the ability to resolve addresses within its domain. - #19856 from bwatters-r7 – This fixes certificate request behavior for the esc8 relay module as well as adds domain controller template support. The certificate generation for the Computer template now correctly requests based on the Machine template name instead of the DisplayName, which previously caused failures. When in AUTO mode and a computer login is detected, the module now attempts to generate certificates based on both the Machine and DomainController templates. This ensures that if a login is coerced from a domain controller (Petit Potam), the appropriate DC certificate is obtained.
Bugs fixed (2)
- #19813 from h00die – Fixes an issue were
Rex::Version.newwas causing modules to crash when run against instances of Amazon Linux and other distributions which have a different format for displaying the kernel version. - #19837 from adfoster-r7 – Fixes a bug which caused incorrect creation of multiple
Mdm::TaskServiceobjects when callingreport_servicefrom modules.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
[$] Improved load-time checking for BPF kfuncs
Post Syndicated from corbet original https://lwn.net/Articles/1007947/
The BPF verifier is charged with the
challenging task of ensuring that a BPF program is safe for the kernel to
run before that program is loaded. Among many other concerns, the verifier
must ensure that any kfuncs (kernel functions that have been exported to
BPF programs) are called with the correct parameters and from the right
context. The “context” part of that enforcement is showing its age in ways
that are hurting performance; Juntong Deng has been working on
infrastructure to provide finer-grained control over when a kfunc can be
called.
Screenshot-Reading Malware
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/02/screenshot-reading-malware.html
Kaspersky is reporting on a new type of smartphone malware.
The malware in question uses optical character recognition (OCR) to review a device’s photo library, seeking screenshots of recovery phrases for crypto wallets. Based on their assessment, infected Google Play apps have been downloaded more than 242,000 times. Kaspersky says: “This is the first known case of an app infected with OCR spyware being found in Apple’s official app marketplace.”
That’s a tactic I have not heard of before.
Security updates for Friday
Post Syndicated from daroc original https://lwn.net/Articles/1008502/
Security updates have been issued by Debian (openjdk-17), Fedora (firefox, FlightGear, java-1.8.0-openjdk, java-11-openjdk, java-latest-openjdk, and SimGear), Mageia (gstreamer), Red Hat (firefox, kernel, kernel-rt, libsoup, and python-jinja2), SUSE (bind, curl, dcmtk, etcd, firefox, google-osconfig-agent, krb5, openssl-1_1, podman, python311-cbor2, thunderbird, wget, and xrdp), and Ubuntu (glibc).
Casualties of the West Point Class of 42 -vol 1
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=RZfylLpJdtI
Нова бодра смяна. Всички, навсякъде, наведнъж
Post Syndicated from Емилия Милчева original https://www.toest.bg/nova-bodra-smyana-vsichki-navsyakude-navednuj/

Нови хора в беззъби регулатори. В следващите месеци мнозинство(то) в 51-вия парламент ще подмени стотина души в органи, чиито мандати са изтекли. Този процес започва в третата седмица от избора на правителството на Росен Желязков (ГЕРБ–СДС), без да бъде анализирана досегашната ефективност на законите, регулиращи съответните сектори.
„Вратите“ в тях остават точно толкова отворени, че да не бъдат сериозно застрашени ничии интереси. Истината е проста: мнозинството сменя едни лоялни изпълнители с други, за да надзирават процесите по същите стари правила и със същата безпомощност. Нито една политическа сила не предложи да бъде анализирано законодателството, създало регулаторите, което функционира на остарели принципи и с пробойни в ущърб на действителните ползи за обществото.
Комисията за енергийно и водно регулиране (КЕВР), Сметната палата, Фискалният съвет, Висшият съдебен съвет (ВСС) и Инспекторатът към него, Комисията за защита на конкуренцията (КЗК), подуправителят на БНБ, Комисията за финансов надзор (КФН), Здравната каса, Комисията за регулиране на съобщенията (КРС) и т.н. – почти няма орган, чиито членове да не са изкарали още половин мандат, че и отгоре, след изтеклия.
Опозиционната коалиция ПП–ДБ критикува бързината, с която се действа – сроковете за номиниране са едва 7–14 дни. Според Лена Бориславова (ПП–ДБ) се нарушава и Правилникът за организацията и дейността на Народното събрание, съгласно който председателят му трябва да предложи график за попълване на регулаторите в началото на всяка сесия.
Ако пак имаме избор на регулатор с по един кандидат, с ярки политически кадри или с такива, които са роднини на ярки политически кадри, обществото отново няма гаранция и увереност, че тези регулатори ще реагират справедливо.
Преди година обаче тогавашното мнозинство, чиято кръстница стана Бориславова с есемес за сглобката, само за осем дни избра двама съдии в Конституционния съд – номинацията беше на 11 януари, гласуването в пленарната зала – на 19-ти. Единият беше предложен от ГЕРБ–СДС – тогавашната председателка на парламентарната им група Десислава Атанасова. А другият – бившият върховен съдия Борислав Белазелков, беше издигнат от ПП–ДБ.
Само преди дни Министерският съвет взе на подпис решението Атанасова да бъде представителка на България във Венецианската комисия, а Белазелков – неин заместник. Изборът предизвика недоволство сред общността на юристите с аргументи, че има много по-големи авторитети от тях, а други заподозряха жест към ПП–ДБ. Сред позициите за попълване е и тази на конституционен съдия от квотата на парламента, за която също са приети процедурни правила.
Предстои разпределянето на огромната власт, която дават регулаторите – контрол върху пазари за милиарди и върху съдебната система за години напред. За ВСС, който назначава, премества, оценява, налага дисциплинарни наказания и освобождава съдии, прокурори и следователи, и за Инспектората, са необходими 160 гласа. За всички останали позиции трябва обикновено мнозинство.
Съчлененото от ГЕРБ, БСП, ИТН и ДПС – Доган управляващо мнозинство разполага с общо 126 гласа и несъмнено (ще) преговаря с други от парламентарно представените политически сили за съдебната власт. Кои от тях ще получат шанс за свои представители във ВСС за следващите пет години, а с това и възможност да интронизират както бъдещия главен прокурор, така и председателя на Върховния административен съд? ПП–ДБ, „Възраждане“, ДПС на Делян Пеевски? Заради малкия размер на групата си – 12 депутати, МЕЧ е извън тази сметка.
Първоначално изборът на членове на ВСС и Инспектората беше обявен за приоритет, но изглежда, че преговорите вървят и техният изход зависи от гласуванията за бюджета, който ще внесе кабинетът „Желязков“. На преден план излязоха други регулатори – подуправител в БНБ за „Банков надзор“, двама заместник-председатели на Сметната палата, председател и четирима членове на Фискалния съвет, КФН, Комисията за публичен надзор над регистрираните одитори. Първите трима от тази серия са и в списъка с потенциални кандидат-премиери, където ги подреди шестата поправка на Конституцията.
Какво прави впечатление? Големият отсъстващ – Антикорупционната комисия, която е тричленка с мандат от 6 години. Изглежда, за нея не е намерено разбирателство, въпреки че изборът е с обикновено мнозинство от половината от присъстващите в пленарна зала, и така този „приоритет“ остава на заден план засега.
Следващата седмица процедурните правила, които ще определят как ще бъдат избирани новите членове на регулаторите, влизат за одобрение в пленарната зала. Това е първата работа, с която се зае управляващото мнозинство, далеч преди да са избрани заместник-министрите и областните управители. Но техните назначения също започнаха, макар да липсва официална информация от Съвета за съвместно управление. В него участват по трима души от ГЕРБ–СДС, БСП– Обединена левица и ИТН, а формацията на Доган разполага с двама представители, чиито гласове имат еднаква тежест с останалите. Лидерът на ГЕРБ Бойко Борисов обаче уверява, че назначенията на заместник-министрите (първите шестима са факт) са съгласувани с коалиционните партньори.
Не знам какво се договарят в Съвета за съвместно управление. След като имаме мнозинство, не ни трябва подкрепа от другите партии. Не виждам с кои други партии ще можем да постигнем по-голямо мнозинство за избор на регулатори. ПП–ДБ затвориха с ритник пътя си към ГЕРБ и така затвориха с ритник конституционно мнозинство. Сега как няма да участват, когато е за постове. Ние знаем, че те са „за“ постовете.
Бившата шефка на НАП Галя Димитрова, по чието време изтекоха личните данни на 5 млн. българи, е назначена за заместник-министър на финансите, пише Mediapool.bg. Правителството назначи и първите трима областни управители в Хасково, Търговище и Шумен на мястото на напусналите след призива на Пеевски.
Формализъм на държавните одитори
Политиците, или поне част от тях, са наясно с пробойните в законодателството, които отслабват обществената полза от регулаторите. Но те остават влиятелни заради потенциала си да бъдат използвани като инструмент за политически натиск и за услуги към определени бизнес кръгове. В името на подбор на професионалисти с интегритет, за техни членове Народното събрание би могло да въведе конкурсното начало.
Годишните одити на Сметната палата например са формални, държавните одитори, които отговарят за контрола върху публичните финанси и одита на институции, разходващи бюджетни средства, внимателно подбират кого да проверяват – също и кога. Одитите често се извършват със закъснение, което означава, че злоупотребите се разкриват твърде късно, когато щетите вече са нанесени. Липсват механизми, с които да се изискват незабавни действия от институциите, а макар да проверява и общините, Сметната палата рядко разкрива сериозни нарушения. Докладите се изпращат в прокуратурата и там приключва всичко.
Дори когато установи нарушения, Сметната палата не може да гарантира, че препоръките ѝ ще бъдат изпълнени. А поради избора на ръководството на Сметната палата от Народното събрание остават рисковете за политически натиск и селективност в проверките.
Натиск върху КЕВР и бухалката КЗК
За КЕВР политическият натиск при определяне на цените трудно би се доказал. Но Комисията трябва да има механизми за гъвкавото им регулиране, за да се избегнат резки поскъпвания. Водните и енергийните дружества трябва да са задължени да инвестират в подобряване на услугите, а не само да вдигат цените. От значение е КЕВР съвестно да следи дали заявените инвестиции наистина са направени.
КЗК пък е регулатор, който се задейства основно при обществен скандал, а резултатите от дейността ѝ трудно могат да се нарекат полезни за обществото. Освен това, както и другите органи, се използва за бухалка по неудобни за статуквото бизнеси. Към монополисти като „Лукойл“ обаче традиционно е била милостива години наред и прогледна за господстващото му положение едва през 2023 г., налагайки глоба от 195 млн. лв., което компанията обжалва.
Законът за защита на конкуренцията (ЗЗК) използва неясни критерии за определяне на господстващо положение на даден пазар, което води до субективност в решенията на КЗК и затруднява доказването на злоупотреба. Наред с това ЗЗК не регулира ефективно вертикалните ограничения (споразумения между доставчици и търговци, които могат да ограничат конкуренцията) и това позволява по-големите компании да влияят върху пазара, а санкциите се избягват.
Глобите, които КЗК налага, често не са достатъчно ефективни за големи компании, особено в сектори с олигополна структура. Съдебният контрол върху решенията на Комисията води до забавяния, което прави санкциите по-малко ефективни. Въпреки че ЗЗК криминализира картелните споразумения, доказването им е трудно, тъй като липсва ефективен механизъм за събиране на доказателства. Критериите за оценка на сливания и придобивания невинаги гарантират, че новите структури няма да доведат до монополни или олигополни форми на конкуренция.
Εдин твърде важен подуправител
Макар България да е член на Единния надзорен механизъм на Европейската централна банка (ЕЦБ), постът на подуправителя, отговарящ за банковия надзор, остава изключително важен, нищо че част от надзорните функции се изпълняват от ЕЦБ. Скоро изтича мандатът на Радослав Миленков, избран на този пост през 2019 г., след като дотогава управляваше Фонда за гарантиране на влоговете.
Въпреки че ЕЦБ упражнява надзор над най-големите банки в България, БНБ запазва ролята си на пряк надзорен орган за по-малките банки, които не попадат под директния контрол на Франкфурт. Именно националният надзор е отговорен за ранното идентифициране на проблеми и за поддържането на стабилността на банковата система. Всички българи платиха цената от над 4 млрд. лв. за аферата „КТБ“, при която „Банков надзор“ не беше на мястото си.
След като България се присъедини към Европейския банков надзор през 2021 г., БНБ работи съвместно с ЕЦБ и участва в надзорните процеси. В случай на банкови сътресения националният надзорен орган трябва да действа незабавно, даже преди ЕЦБ да се намеси. БНБ е отговорна за надзора върху мерките за възстановяване и преструктуриране на банки заедно с Единния съвет за преструктуриране (SRB). Предвид приемането на еврото, БНБ прие наредба за осигуряване на спешна подкрепа на български банки, ако изпаднат в ликвидна криза след присъединяването към еврозоната.
За другите регулатори също има големи апетити. Към края на 2021 г. общият размер на активите под надзора на КФН – капиталови пазари, застрахователни и пенсионноосигурителни дружества, възлиза на над 46,6 млрд. лв., а през 2023 г. само активите на частните пенсионни фондове надхвърлят 21 млрд. През януари Европейският орган за застраховане и професионално пенсионно осигуряване (EIOPA) препоръча на КФН да затегне проверките си за платежоспособността на застрахователите по повод случая с „Eвроинс“ в Румъния.
Мястото на управител на НЗОК отдавна привлича много интереси. За 2024 г. бюджетът, разпределян от Касата, е 8,1 млрд. лв., от които за болниците е предназначена над ¼ от него и повече от 2 млрд. лв. са за лекарства. Мандатът на настоящия управител Станимир Михайлов, излъчен от ПП–ДБ, изтича през март. Парламентът го отстрани от поста миналата пролет с гласовете на ГЕРБ, БСП и ДПС, но по-късно беше възстановен с решение на Конституционния съд. Сега тези сили управляват заедно и могат да изберат кандидата, за когото се договорят.
Запълването на всички места в регулаторите и съдебната власт ще е резултат от множество сделки и плаващи мнозинства. Политическите сили в 51-вия парламент едва ли искат да пропуснат шанса да се включат в голямото наддаване – друг няма да има. Въпросът е какво са готови да извършат срещу отдаване на една или друга позиция. Тази готовност ще бъде тествана с предстоящото разглеждане на бюджет 2025. Вече се разбра, че като инструмент на парламентаризма вотът на недоверие отпада. Наскоро ПП–ДБ заплашиха, че могат да го внесат, но явно не бяха изчислили, че за да съберат необходимите 48 подписа, ще трябва да потърсят липсващите им 11 народни представители от „Възраждане“, Пеевски или МЕЧ – все невъзможни опции.
А за преглед и промяна на законодателната рамка никой не мисли. Работещите институции са най-голямата заплаха за политическия монопол и олигархията.