We anticipate FreeBSD 15.0 will not include the armv6, i386, and powerpc platforms, and FreeBSD 16.0 will not include armv7. Support for executing 32-bit binaries on 64-bit kernels will be retained through at least the lifetime of the stable/16 branch if not longer.
The announcement notes that support for some 32-bit platforms “may be extended if there is both demand and commitment to increased developer resources“. More details about the current plans for 32-bit platforms are available in the FreeBSD 14.0-RELEASE Release Notes.
Public health organizations need access to data insights that they can quickly act upon, especially in times of health emergencies, when data needs to be updated multiple times daily. For example, during the COVID-19 pandemic, access to timely data insights was critically important for public health agencies worldwide as they coordinated emergency response efforts. Up-to-date information and analysis empowered organizations to monitor the rapidly changing situation and direct resources accordingly.
This is the second post in this series; we recommend that you read this first post before diving deep into this solution. In our first post, Enable data collaboration among public health agencies with AWS Clean Rooms – Part 1 , we showed how public health agencies can create AWS Clean Room collaborations, invite other stakeholders to join the collaboration, and run queries on their collective data without either party having to share or copy underlying data with each other. As mentioned in the previous blog, AWS Clean Rooms enables multiple organizations to analyze their data and unlock insights they can act upon, without having to share sensitive, restricted, or proprietary records.
However, public health organizations leaders and decision-making officials don’t directly access data collaboration outputs from their Amazon Simple Storage Service (Amazon S3) buckets. Instead, they rely on up-to-date dashboards that help them visualize data insights to make informed decisions quickly.
To ensure these dashboards showcase the most updated insights, the organization builders and data architects need to catalog and update AWS Clean Rooms collaboration outputs on an ongoing basis, which often involves repetitive and manual processes that, if not done well, could delay your organization’s access to the latest data insights.
Manually handling repetitive daily tasks at scale poses risks like delayed insights, miscataloged outputs, or broken dashboards. At a large volume, it would require around-the-clock staffing, straining budgets. This manual approach could expose decision-makers to inaccurate or outdated information.
Automating repetitive workflows, validation checks, and programmatic dashboard refreshes removes human bottlenecks and help decrease inaccuracies. Automation helps ensure continuous, reliable processes that deliver the most current data insights to leaders without delays, all while streamlining resources.
In this post, we explain an automated workflow using AWS Step Functions and Amazon QuickSight to help organizations access the most current results and analyses, without delays from manual data handling steps. This workflow implementation will empower decision-makers with real-time visibility into the evolving collaborative analysis outputs, ensuring they have up-to-date, relevant insights that they can act upon quickly
Solution overview
The following reference architecture illustrates some of the foundational components of clean rooms query automation and publishing dashboards using AWS services. We automate running queries using Step Functions with Amazon EventBridge schedules, build an AWS Glue Data Catalog on query outputs, and publish dashboards using QuickSight so they automatically refresh with new data. This allows public health teams to monitor the most recent insights without manual updates.
The architecture consists of the following components, as numbered in the preceding figure:
A scheduled event rule on EventBridge triggers a Step Functions workflow.
The Step Functions workflow initiates the run of a query using the StartProtectedQueryAWS Clean Rooms API. The submitted query runs securely within the AWS Clean Rooms environment, ensuring data privacy and compliance. The results of the query are then stored in a designated S3 bucket, with a unique protected query ID serving as the prefix for the stored data. This unique identifier is generated by AWS Clean Rooms for each query run, maintaining clear segregation of results.
When the AWS Clean Rooms query is successfully complete, the Step Functions workflow calls the AWS Glue API to update the location of the table in the AWS Glue Data Catalog with the Amazon S3 location where the query results were uploaded in Step 2.
Amazon Athena uses the catalog from the Data Catalog to query the information using standard SQL.
QuickSight is used to query, build visualizations, and publish dashboards using the data from the query results.
An AWS Clean rooms collaboration. For this post, we use the membership ID for the collaboration created in Part 1 of this series. You can locate this on the AWS Clean Rooms console, on your collaboration Details tab.
Launch the CloudFormation stack
In this post, we provide a CloudFormation template to create the following resources:
An EventBridge rule that triggers the Step Functions state machine on a schedule
An AWS Glue database and a catalog table
An Athena workgroup
Three S3 buckets:
For AWS Clean Rooms to upload the results of query runs
For Athena to upload the results for the queries
For storing access logs of other buckets
A Step Functions workflow designed to run the AWS Clean Rooms query, upload the results to an S3 bucket, and update the table location with the S3 path in the AWS Glue Data Catalog
To create the necessary resources, complete the following steps:
Choose Launch Stack:
Enter cleanrooms-query-automation-blog for Stack name.
Enter the membership ID from the AWS Clean Rooms collaboration you created in Part 1 of this series.
Choose Next.
Choose Next again.
On the Review page, select I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create stack.
After you run the CloudFormation template and create the resources, you can find the following information on the stack Outputs tab on the AWS CloudFormation console:
AthenaWorkGroup – The Athena workgroup
EventBridgeRule – The EventBridge rule triggering the Step Functions state machine
GlueDatabase – The AWS Glue database
GlueTable – The AWS Glue table storing metadata for AWS Clean Rooms query results
S3Bucket – The S3 bucket where AWS Clean Rooms uploads query results
StepFunctionsStateMachine – The Step Functions state machine
Test the solution
The EventBridge rule named cleanrooms_query_execution_Stepfunctions_trigger is scheduled to trigger every 1 hour. When this rule is triggered, it initiates the run of the CleanRoomsBlogStateMachine-XXXXXXX Step Functions state machine. Complete the following steps to test the end-to-end flow of this solution:
On the Step Functions console, navigate to the state machine you created.
On the state machine details page, locate the latest query run.
The details page lists the completed steps:
The state machine submits a query to AWS Clean Rooms using the startProtectedQuery API. The output of the API includes the query run ID and its status.
The state machine waits for 30 seconds before checking the status of the query run.
After 30 seconds, the state machine checks the query status using the getProtectedQuery API. When the status changes to SUCCESS, it proceeds to the next step to retrieve the AWS Glue table metadata information. The output of this step contains the S3 location to which the query run results are uploaded.
The state machine retrieves the metadata of the AWS Glue table named patientimmunization, which was created via the CloudFormation stack.
The state machine updates the S3 location (the location to which AWS Clean Rooms uploaded the results) in the metadata of the AWS Glue table.
After a successful update of the AWS Glue table metadata, the state machine is complete.
“SELECT * FROM "cleanrooms_patientdb "."patientimmunization" limit 10;"
Visualize the data with QuickSight
Now that you can query your data in Athena, you can use QuickSight to visualize the results. Let’s start by granting QuickSight access to the S3 bucket where your AWS Clean Rooms query results are stored.
Grant QuickSight access to Athena and your S3 bucket
First, grant QuickSight access to the S3 bucket:
Sign in to the QuickSight console.
Choose your user name, then choose Manage QuickSight.
Choose Security and permissions.
For QuickSight access to AWS services, choose Manage.
For Amazon S3, choose Select S3 buckets, and choose the S3 bucket named cleanrooms-query-execution-results -XX-XXXX-XXXXXXXXXXXX (XXXXX represents the AWS Region and account number where the solution is deployed).
Choose Save.
Create your datasets and publish visuals
Before you can analyze and visualize the data in QuickSight, you must create datasets for your Athena tables.
On the QuickSight console, choose Datasets in the navigation pane.
Choose New dataset.
Select Athena.
Enter a name for your dataset.
Choose Create data source.
Choose the AWS Glue database cleanrooms_patientdb and select the table PatientImmunization.
Select Directly query your data.
Choose Visualize.
On the Analysis tab, choose the visual type of your choice and add visuals.
Clean up
Complete the following steps to clean up your resources when you no longer need this solution:
Manually delete the S3 buckets and the data stored in the bucket.
In this post, we demonstrated how to automate running AWS Clean Rooms queries using an API call from Step Functions. We also showed how to update the query results information on the existing AWS Glue table, query the information using Athena, and create visuals using QuickSight.
The automated workflow solution delivers real-time insights from AWS Clean Rooms collaborations to decision makers through automated checks for new outputs, processing, and Amazon QuickSight dashboard refreshes. This eliminates manual handling tasks, enabling faster data-driven decisions based on latest analyses. Additionally, automation frees up staff resources to focus on more strategic initiatives rather than repetitive updates.
AWS Clean Rooms helps companies and their partners more easily and securely analyze and collaborate on their collective datasets—without sharing or copying one another’s underlying data. With AWS Clean Rooms, you can create a secure data clean room in minutes, and collaborate with any other company on the AWS Cloud to generate unique insights about advertising campaigns, investment decisions, and research and development.
The AWS Clean Rooms team is continually building new features to help you collaborate. Watch this video to learn more about privacy-enhanced collaboration with AWS Clean Rooms.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Java archive files (JAR, WAR, and EAR) are widely used for packaging Java applications and libraries. These files can contain various dependencies that are required for the proper functioning of the application. In some cases, a JAR file might include other JAR files within its structure, leading to nested dependencies. To help maintain the security and stability of Java applications, you must identify and manage nested dependencies.
In this post, I will show you how to navigate the challenges of uncovering nested Java dependencies, guiding you through the process of analyzing JAR files and uncovering these dependencies. We will focus on the vulnerabilities that Amazon Inspector identifies using the Amazon Inspector SBOM Generator.
The challenge of uncovering nested Java dependencies
Nested dependencies in Java applications can be outdated or contain known vulnerabilities linked to Common Vulnerabilities and Exposures (CVEs). A crucial issue that customers face is the tendency to overlook nested dependencies during analysis and triage. This oversight can lead to the misclassification of vulnerabilities as false positives, posing a security risk.
This challenge arises from several factors:
Volume of vulnerabilities — When customers encounter a high volume of vulnerabilities, the sheer number can be overwhelming, making it challenging to dedicate sufficient time and resources to thoroughly analyze each one.
Lack of tools or insufficient tooling — There is often a gap in the available tools to effectively identify nested dependencies (for example, mvn dependency:tree, OWASP Dependency-Check). Without the right tools, customers can miss critical dependencies hidden deep within their applications.
Understanding the complexity — Understanding the intricate web of nested dependencies requires a specific skill set and knowledge base. Deficits in this area can hinder effective analysis and risk mitigation.
Overview of nested dependencies
Nested dependencies occur when a library or module that is required by your application relies on additional libraries or modules. This is a common scenario in modern software development because developers often use third-party libraries to build upon existing solutions and to benefit from the collective knowledge of the open-source community.
In the context of JAR files, nested dependencies can arise when a JAR file includes other JAR files as part of its structure. These nested files can have their own dependencies, which might further depend on other libraries, creating a chain of dependencies. Nested dependencies help to modularize code and promote code reuse, but they can introduce complexity and increase the potential for security vulnerabilities if they aren’t managed properly.
Why it’s important to know what dependencies are consumed in a JAR file
Consider the following examples, which depict a typical file structure of a Java application to illustrate how nested dependencies are organized:
This structure includes the following files and dependencies:
mywebapp-1.0-SNAPSHOT.jar is the main application JAR file.
Within mywebapp-1.0-SNAPSHOT.jar, there’s spring-boot-3.0.2.jar, which is a dependency of the main application.
Nested within spring-boot-3.0.2.jar, there’s spring-boot-autoconfigure-3.0.2.jar, a transitive dependency.
Within spring-boot-autoconfigure-3.0.2.jar, there’s log4j-to-slf4j.jar, which is our nested Log4J dependency.
This structure illustrates how a Java application might include nested dependencies, with Log4J nested within other libraries. The actual nesting and dependencies will vary based on the specific libraries and versions that you use in your project.
This structure includes the following files and dependencies:
myfinanceapp-2.5.jar is the primary application JAR file.
Within myfinanceapp-2.5.jar, there is jackson-databind-2.9.10.1.jar, which is a library that the main application relies on for JSON processing.
Nested within jackson-databind-2.9.10.1.jar, there are other Jackson components such as jackson-core-2.9.10.jar and jackson-annotations-2.9.10.jar. These are dependencies that jackson-databind itself requires to function.
This structure is an example for Java applications that use Jackson for JSON operations. Because Jackson libraries are frequently updated to address various issues, including performance optimizations and security fixes, developers need to be aware of these nested dependencies to keep their applications up-to-date and secure. If you have detailed knowledge of where these components are nested within your application, it will be easier to maintain and upgrade them.
This structure includes the following files and dependencies:
myerpsystem-3.1.jar as the primary JAR file of the application.
Within myerpsystem-3.1.jar, hibernate-core-5.4.18.Final.jar serves as a dependency for object-relational mapping (ORM) capabilities.
Nested dependencies such as hibernate-validator-6.1.5.Final.jar and hibernate-entitymanager-5.4.18.Final.jar are crucial for the validation and entity management functionalities that Hibernate provides.
In instances where MyERPSystem encounters operational issues due to a mismatch between the Hibernate versions and another library (that is, a newer version of Spring expecting a different version of Hibernate), developers can use the detailed insights that Amazon Inspector SBOM Generator provides. This tool helps quickly pinpoint the exact versions of Hibernate and its nested dependencies, facilitating a faster resolution to compatibility problems.
Here are some reasons why it’s important to understand the dependencies that are consumed within a JAR file:
Security — Nested dependencies can introduce vulnerabilities if they are outdated or have known security issues. A prime example is the Log4J vulnerability discovered in late 2021 (CVE-2021-44228). This vulnerability was critical because Log4J is a widely used logging framework, and threat actors could have exploited the flaw remotely, leading to serious consequences. What exacerbated the issue was the fact that Log4J often existed as a nested dependency in various Java applications (see Example 1), making it difficult for organizations to identify and patch each instance.
Compliance — Many organizations must adhere to strict policies about third-party libraries for licensing, regulatory, or security reasons. Not knowing the dependencies, especially nested ones such as in the Log4J case, can lead to non-compliance with these policies.
Maintainability — It’s crucial that you stay informed about the dependencies within your project for timely updates or replacements. Consider the Jackson library (Example 2), which is often updated to introduce new features or to patch security vulnerabilities. Managing these updates can be complex, especially when the library is a nested dependency.
Troubleshooting — Identifying dependencies plays a critical role in resolving operational issues swiftly. An example of this is addressing compatibility issues between Hibernate and other Java libraries or frameworks within your application due to version mismatches (Example 3). Such problems often manifest as unexpected exceptions or degraded performance, so you need to have a precise understanding of the libraries involved.
These examples underscore that you need to have deep visibility into JAR file contents to help protect against immediate threats and help ensure long-term application health and compliance.
Existing tooling limitations
When analyzing Java applications for nested dependencies, one of the main challenges is that existing tools can’t efficiently narrow down the exact location of these dependencies. This issue is particularly evident with tools such as mvn dependency:tree, OWASP Dependency-Check, and similar dependency analysis solutions.
Although tools are available to analyze Java applications for nested dependencies, they often fall short in several key areas. The following points highlight common limitations of these tools:
Inadequate depth in dependency trees — Although other tools provide a hierarchical view of project dependencies, they often fail to delve deep enough to reveal nested dependencies, particularly those that are embedded within other JAR files as nested dependencies. Nested dependencies are repackaged within a library and aren’t immediately visible in the standard dependency tree.
Lack of specific location details — These tools typically don’t offer the granularity needed to pinpoint the exact location of a nested dependency within a JAR file. For large and complex Java applications, it may be challenging to identify and address specific dependencies, especially when they are deeply embedded.
Complexity in large projects — In projects with a vast and intricate network of dependencies, these tools can struggle to provide clear and actionable insights. The output can be complicated and difficult to navigate, leaving customers without a clear path to identifying critical dependencies.
Address tooling limitations with Amazon Inspector SBOM Generator
The Amazon Inspector SBOM Generator (Sbomgen) introduces a significant advancement in the identification of nested dependencies in Java applications. Although the concept of monitoring dependencies is well-established in software development, AWS has tailored this tool to enhance visibility into the complexities of software compositions. By generating a software bill of materials (SBOM) for a container image, Sbomgen provides a detailed inventory of the software installed on a system, including hidden nested dependencies that traditional tools can overlook. This capability enriches the existing toolkit, offering a more granular and actionable understanding of the dependency structure of your applications.
Sbomgen works by scanning for files that contain information about installed packages. Upon finding such files, it extracts essential data such as package names, versions, and other metadata. Then it transforms this metadata into a CycloneDX SBOM, providing a structured and detailed view of the dependencies.
In this output, the amazon:inspector:sbom_collector:path property is particularly significant. It provides a clear and complete path to the location of the specific dependency (in this case, log4j-to-slf4j) within the application’s structure. This level of detail is crucial for several reasons:
Precise location identification — It helps you quickly and accurately identify the exact location of each dependency, which is especially useful for nested dependencies that are otherwise hard to locate.
Effective risk management — When you know the exact path of dependencies, you can more efficiently assess and address security risks associated with these dependencies.
Time and resource efficiency — It reduces the time and resources needed to manually trace and analyze dependencies, streamlining the vulnerability management process.
Enhanced visibility and transparency — It provides a clearer understanding of the application’s dependency structure, contributing to better overall management and maintenance.
Comprehensive package information — The detailed package information, including name, version, hashes, and package URL, of Sbomgen equips you with a thorough understanding of each dependency’s specifics, aiding in precise vulnerability tracking and software integrity verification.
Mitigate vulnerable dependencies
After you identify the nested dependencies in your Java JAR files, you should verify whether these dependencies are outdated or vulnerable. Amazon Inspector can help you achieve this by doing the following:
Comparing the discovered dependencies against a database of known vulnerabilities.
Providing a list of potentially vulnerable dependencies, along with detailed information about the associated CVEs.
Offering recommendations on how to mitigate the risks, such as updating the dependencies to a newer, more secure version.
By integrating Amazon Inspector into your software development lifecycle, you can continuously monitor your Java applications for vulnerable nested dependencies and take the necessary steps to help ensure that your application remains secure and compliant.
Conclusion
To help secure your Java applications, you must manage nested dependencies. Amazon Inspector provides an automated and efficient way to discover and mitigate potentially vulnerable dependencies in JAR files. By using the capabilities of Amazon Inspector, you can help improve the security posture of your Java applications and help ensure that they adhere to best practices.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
After winning Super Bowl LVII in 2023, the Kansas City Chiefs entered Super Bowl LVIII with an opportunity to pull off back-to-back wins, a feat last achieved by the New England Patriots two decades earlier, in 2003 and 2004. They faced the San Francisco 49ers, five-time Super Bowl champions, although their last win was nearly three decades ago, in 1995. The game started slowly, remaining scoreless until the start of the second quarter, after which both teams traded the lead until a tie score at the end of the game made it only the second Super Bowl to go into overtime. And if you weren’t watching it for the football, the advertisements certainly didn’t disappoint. And if you weren’t watching it for the football or the advertisements, but instead were waiting to see how many times CBS cut away to a shot of Taylor Swift during the game, the answer is… 16. (By my count, at least.)
In this blog post, we will explore which Super Bowl advertisements drove the largest spikes in traffic, as well as examine how traffic to food delivery services, social media, sports betting, and video platform websites and applications changed during the game. In addition, we look at local traffic trends seen during the game, as well as email threat volume across related categories in the weeks ahead of the game.
Cloudflare Radar uses a variety of sources to provide aggregate information about Internet traffic and attack trends. In this blog post, as we did last year and the year before, we use DNS name resolution data from our 1.1.1.1 resolver to estimate traffic to websites. We can’t see who visited the websites mentioned, or what anyone did on the websites, but DNS can give us an estimate of the interest generated by the ads or across a set of sites in the categories listed above.
Ads: URLs are no longer cool
In last year’s blog post, we asked “Are URLs no longer cool?”, noting that many of the advertisements shown during Super Bowl LVII didn’t include a URL. The trend continued into 2024, as over 100 ads were shown throughout Super Bowl LVIII, but only about one-third of them contained URLs — some were displayed prominently, some were in very small type. A few of the advertisements contained QR codes, and a few suggested downloading an app from Apple or Google’s app stores, but neither approach appears to be a definitive replacement for including a link to a website in the ad. And although Artificial Intelligence (AI) has all but replaced cryptocurrency as the thing that everyone is talking about, the lone AI ad during this year’s game was for Microsoft Copilot, which the company is positioning as an “everyday AI companion”.
As we did last year, we again tracked DNS request traffic to our 1.1.1.1 resolver in United States data centers for domains associated with the advertised products or brands. Traffic growth is plotted against a baseline calculated as the mean request volume for the associated domains between 12:00-15:00 EST on Sunday, February 11 (Super Bowl Sunday). The brands highlighted below were chosen because their advertisements drove some of the largest percentage traffic spikes observed during the game.
TurboTax
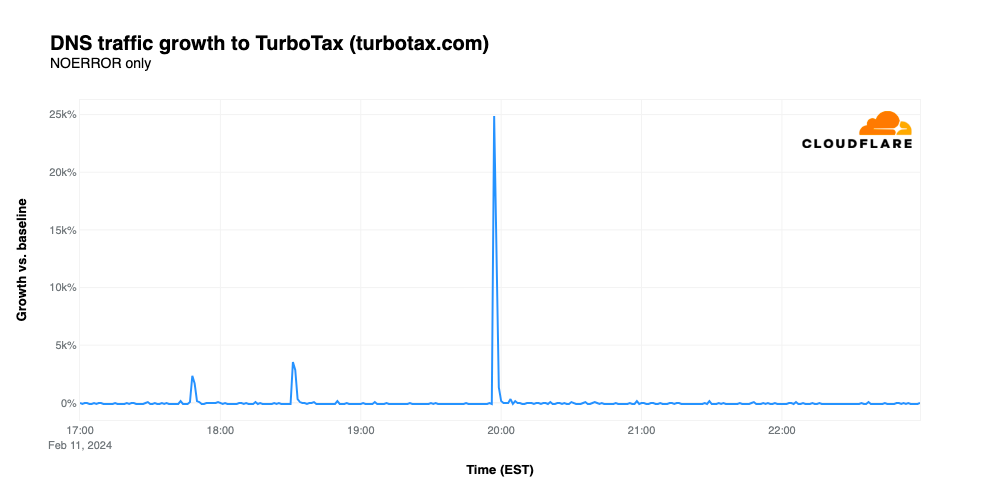
Although most Americans dislike having to pay taxes, they apparently feel that winning a million dollars would make doing so a little less painful. The Intuit TurboTax Super Bowl File ad, starring Emmy Award winner Quinta Brunson, included a URL pointing visitors to turbotax.com, where they could register to win one million dollars. The promotion aired a couple of times before the game began, visible as small spikes in the graph below, but it paid off for Intuit when it was shown at 19:56, driving traffic 24,875% above baseline and placing it as the ad that drove the largest increase in traffic.
DoorDash
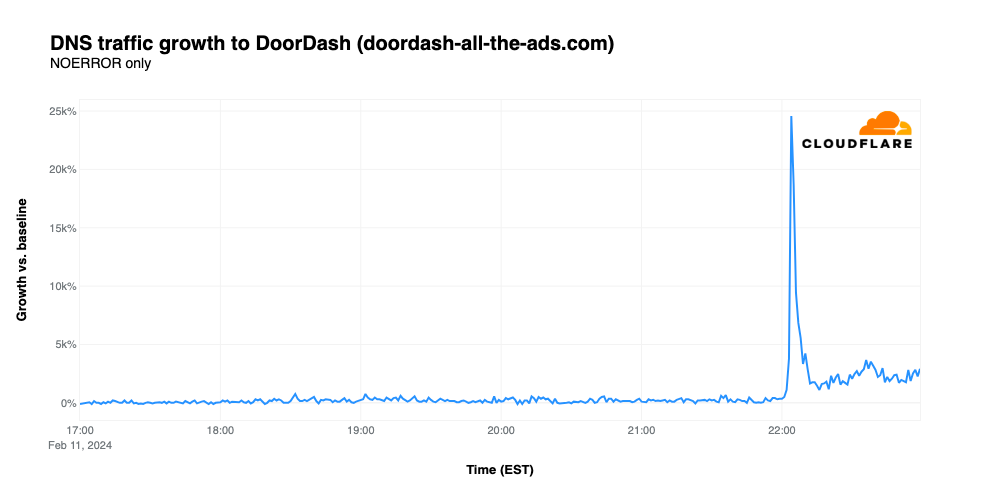
Most DoorDash deliveries are fairly nominal, and should be able to easily fit in the Dasher’s car. However, in a twist, the delivery for the “DoorDash all the ads” promotion includes several cars, as well as candy, cosmetics, trips, mayonnaise, and a myriad of other items, all of which appeared in Super Bowl advertisements, as a way for the company to demonstrate that they deliver more than. The ad, which prominently featured a URL for the contest site, aired at 22:03 EST and drove traffic 24,574% above baseline. The graph below shows that prominent spike, but it also shows traffic remaining 1700-2500% above baseline after the ad aired. This elevated traffic is likely due to efforts to transcribe the full promo code needed to enter the contest. The promo code, as crowdsourced in a Reddit thread, clocks in at a whopping 1,813 characters.
Poppi
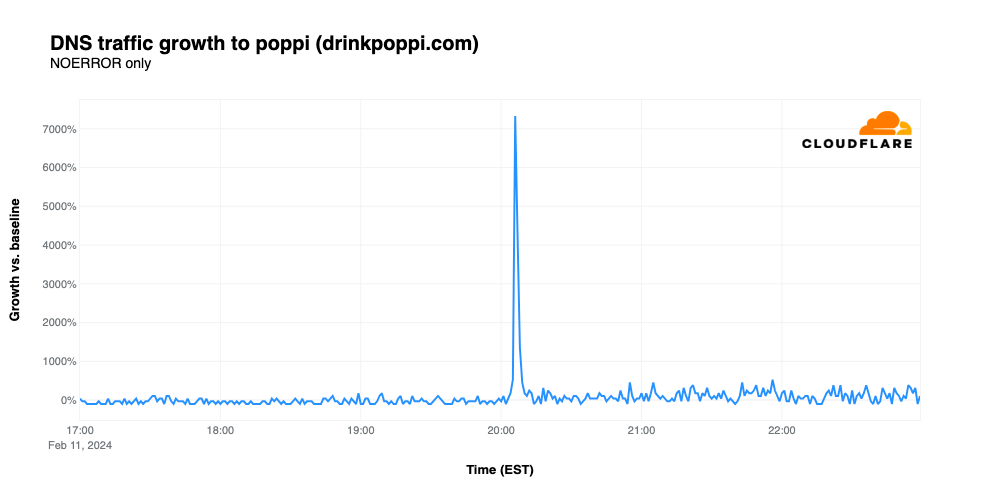
Super Bowl ads for “new” drink brands have frequently driven significant amounts of traffic, such as the growth seen by Cutwater Spirits in 2022. Relative newcomer Poppi, a brand of soda that contains prebiotics, continued the trend, with traffic spiking 7,329% above baseline after its ad appeared at 20:04 EST, despite no URL appearing in the advertisement. However, it appears that not everyone was a fan of the ad, as critics complained that it “food shamed” those who choose to drink traditional sodas.
e.l.f. Cosmetics
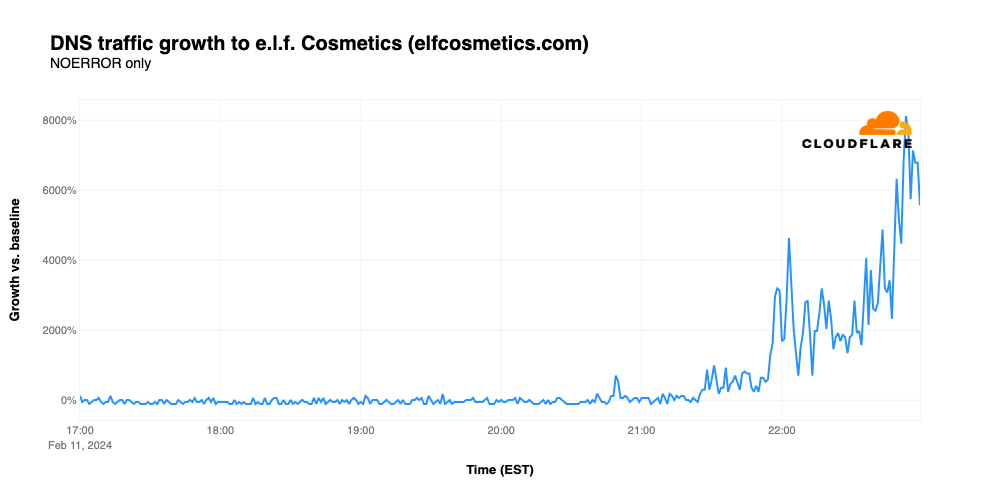
The cosmetic brand’s second Super Bowl advertisement featured Judge Judy presiding over a courtroom scene featuring musician Meghan Trainor and the cast of the USA Network legal drama Suits. While the ad drove traffic for elfcosmetics.com to 8,118% over baseline despite lacking a URL, the timing of the growth is unusual as it doesn’t align with the time the ad aired (20:22 EST). The traffic starts to tick up around 21:24 EST, just after a Chiefs touchdown put them in the lead, peaking at 22:53, several minutes after the Chiefs won the game. It isn’t clear why e.l.f. appears to buck the trend seen for most Super Bowl ads, showing a gradual ramp in traffic before peaking, as opposed to a large spike aligned with the time that the ad was broadcast.
In addition to the advertisements discussed above, a number of others also experienced traffic spikes greater than 1,000% above baseline, including ads for the NFL, Hallow, He Gets Us, homes.com, Kawasaki, Robert F. Kennedy, Jr. 2024, Snapchat, Skechers, and Volkswagen.
App traffic sees mixed impacts
Using the same baseline calculations described above, we also looked at traffic for domains associated with several groups of sites, including food delivery, messaging, social media, and sports betting to see how events that occurred during the game impacted traffic. Traffic shifts among most of these groups remained fairly nominal during the game, with sports betting seeing the largest movement. Halftime is clearly visible within the graphs, as viewers apparently focused on the musical performance, which featured R&B singer Usher, joined by guests Alicia Keys, H.E.R., will.i.am, Ludacris, and Lil Jon.
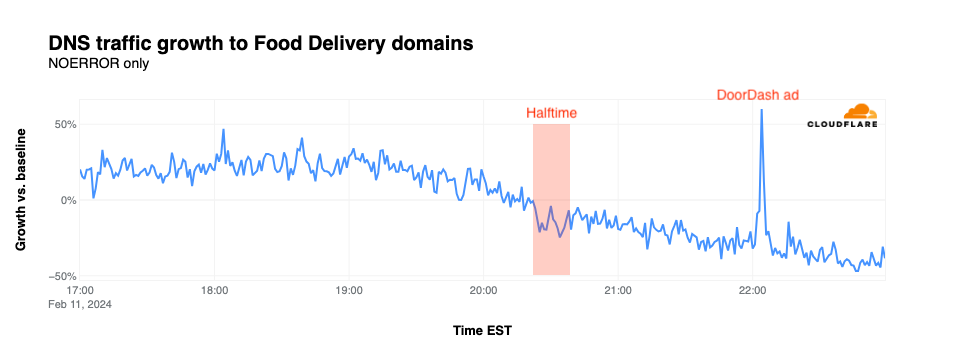
Food delivery
Traffic for food delivery sites remained relatively constant, on average, through the first quarter of the game, and started to decline as the second quarter started. A more significant dip is visible during halftime, with the drop continuing through the end of overtime. The outlier, of course, is the spike that occurred when the DoorDash advertisement aired, even though it featured a domain other than doordash.com, which is a member of this group.
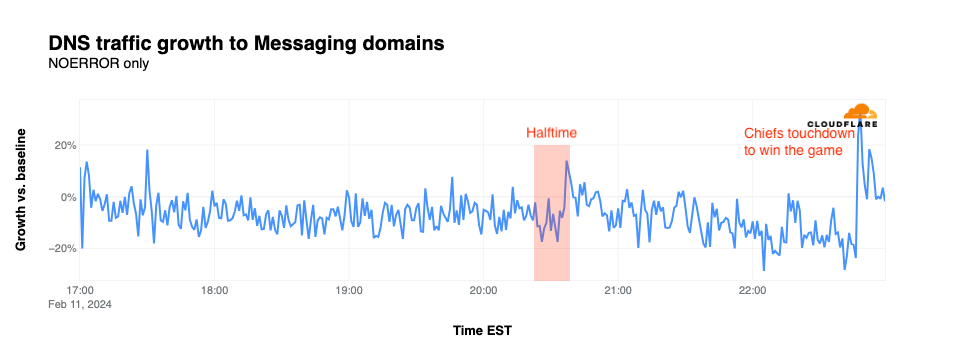
Messaging
Traffic to domains associated with messaging applications generally remained just below baseline throughout the first half of the game. The spikes above baseline during the first half were nominal, and don’t appear to be associated with any notable in-game events. Traffic picked back up briefly as the halftime show ended, jumping to 14% above baseline. After that, traffic continued to drop until 22:46 EST, when the Chiefs sealed their victory with an overtime touchdown, causing traffic for messaging sites to spike to 34% above baseline.
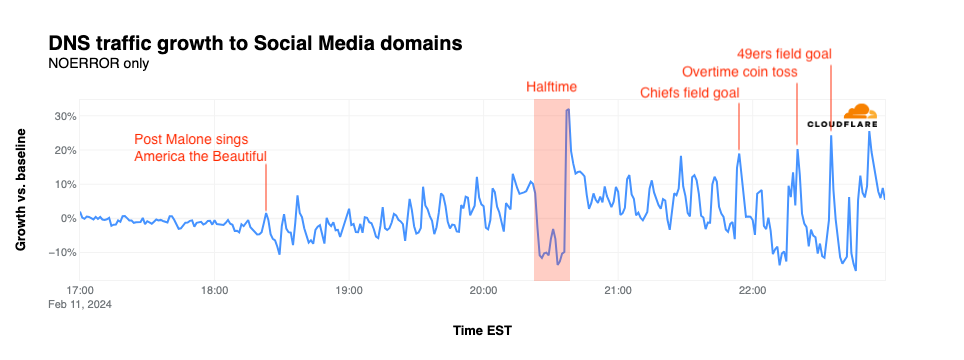
Social media
Traffic for social media sites often spikes in conjunction with major plays, such as fumbles or touchdowns, as fans take to their favorite sites and apps to share photos or videos, or to celebrate or vent, depending on the team they support. Although social media traffic was fairly flat ahead of the start of the game, it began to see some spikiness as Post Malone sang America the Beautiful. This nominal spikiness continued through halftime, although none of the peaks were clearly correlated with major plays during the first half. Similar to messaging, a notable drop in traffic occurred during halftime followed by a spike as Usher’s halftime show ended. In the second half, traffic spiked as the Chiefs tied the game with a field goal, for the overtime coin toss, and as the 49ers took the lead with an overtime field goal. Interestingly, that final spike visible in the graph occurs approximately six minutes after the Chiefs’ game-winning touchdown during an ad break ahead of the post-game show.
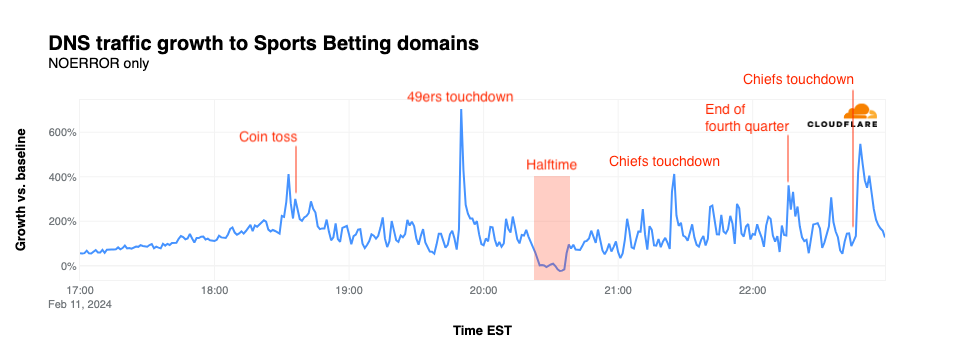
Sports betting
Compared to the relatively anemic traffic growth (when it was actually above baseline) seen for the categories above, traffic for domains associated with sports betting sites and apps remained significantly above baseline throughout the game with the exception of the dip during halftime, similar to what was also seen in the categories above. The first spike occurred just minutes before the coin toss, jumping to 412% above baseline. The game’s first touchdown, scored by the 49ers, caused traffic to spike 705% above baseline. A 413% spike occurred when the Chiefs took the lead late in the third quarter, with a slightly smaller one occurring at the end of regulation play as the game entered overtime. The final spike occurred just a couple of minutes after the Chiefs scored the game-winning touchdown, reaching 548% above baseline.
Zooming in to Kansas City and San Francisco
Using the same baseline calculations highlighted in the previous two sections, we also looked at changes in DNS traffic for the domains associated with the Kansas City Chiefs (chiefs.com) and the San Francisco 49ers (49ers.com). In addition, we looked at HTTP traffic from these two cities, using traffic levels from one week prior as a baseline.
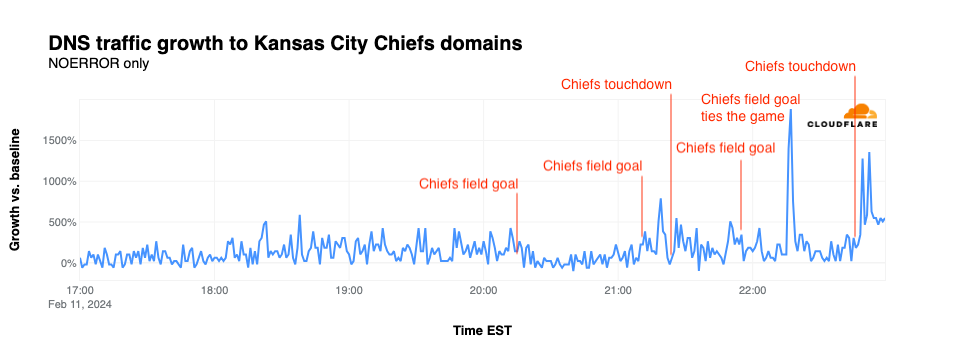
By and large, DNS traffic for chiefs.com did not appear to be significantly impacted by most of the team’s field goals or touchdowns during the game, as seen in the graph below. The exception is the traffic spike seen as the team tied the game towards the end of the fourth quarter, forcing the game into overtime. That play resulted in a spike of traffic for the team’s website that reached 1,887% above baseline. Traffic spiked again after the Chiefs won the game, spiking to 1,360% above baseline.
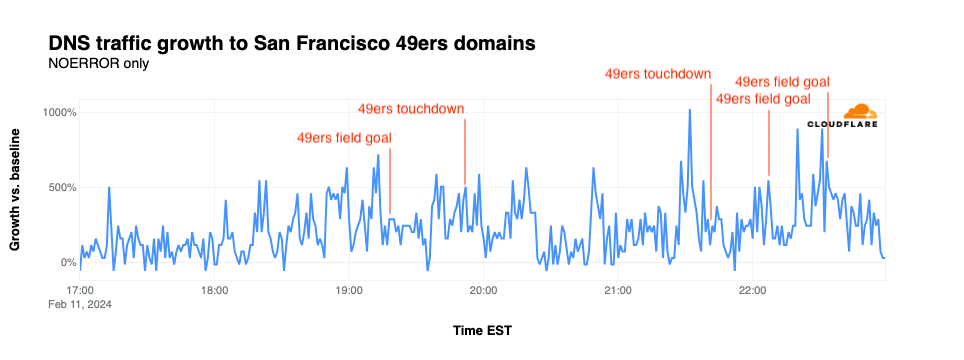
DNS traffic for 49ers.com did not exhibit significant shifts correlated with field goals or touchdowns. The most significant spike reached 1,023% over baseline at the end of the third quarter, minutes after the team called for a timeout.
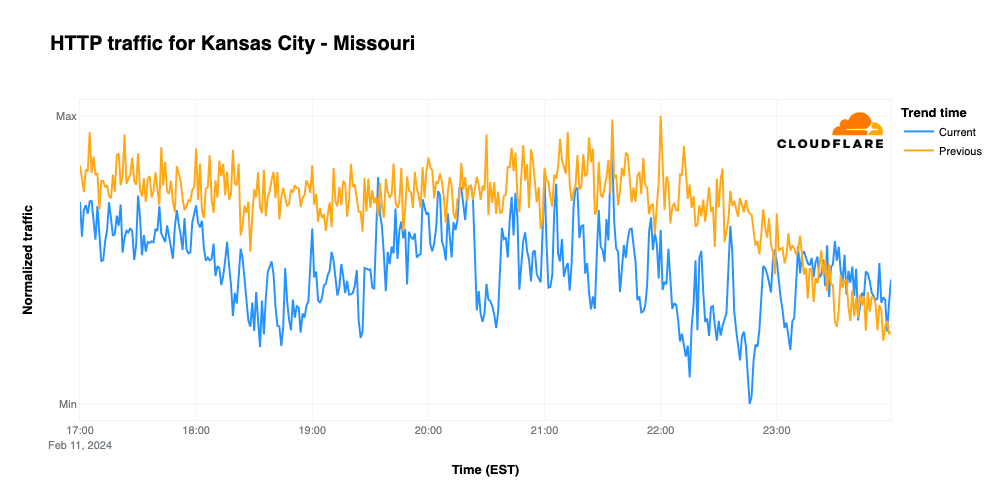
When comparing traffic trends for Kansas City and San Francisco, they could hardly be more different. Looking at request traffic from Kansas City, we find that it remains below traffic seen during the same time frame on February 4, with notable drops at the start of the game, during halftime, and when the Chiefs tied the game with a field goal late in the fourth quarter. Traffic hit its lowest point when the Chiefs won the game, but then recovered to meet/exceed the prior week’s traffic levels once the broadcast had concluded.
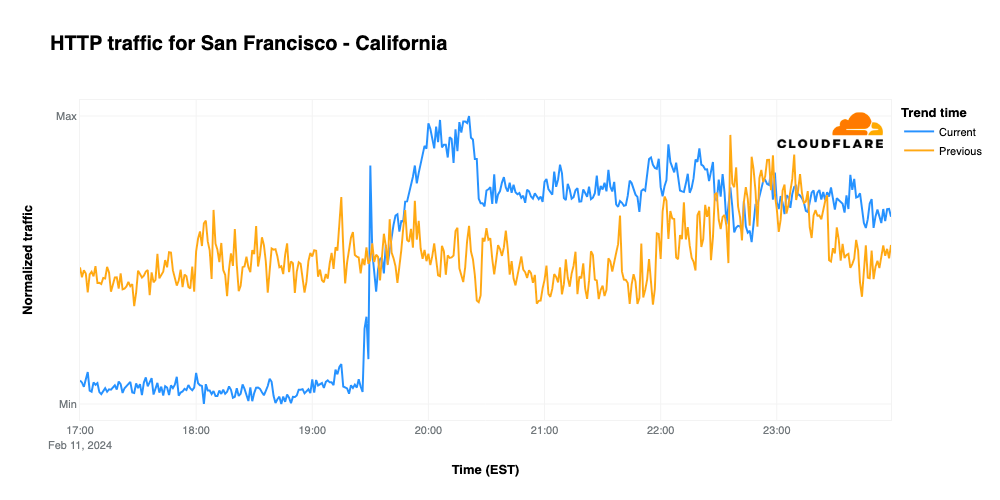
In contrast, traffic from San Francisco remained well below traffic levels seen the previous Sunday before unexpectedly spiking around 19:30 EST. Request traffic then remained well above the previous week’s levels until San Francisco kicked a field goal to take the initial lead during overtime play. Traffic remained roughly in line with the previous week until the broadcast ended, and then remained slightly higher.
Email threats and “The Big Game”
As we noted in last year’s blog post, spammers and scammers will frequently try to take advantage of the popularity of major events when running their campaigns, hoping the tie-in will entice the user to open the message and click on a malicious link, or visit a malicious website where they give up a password or credit card number. The Cloudflare Area 1 Email Security team once again analyzed the subject lines of email messages processed by the service in the weeks leading up to the Super Bowl to identify malicious, suspicious, and spam messages across four topic areas: Super Bowl/football, sports media/websites, sports gambling, and food delivery.
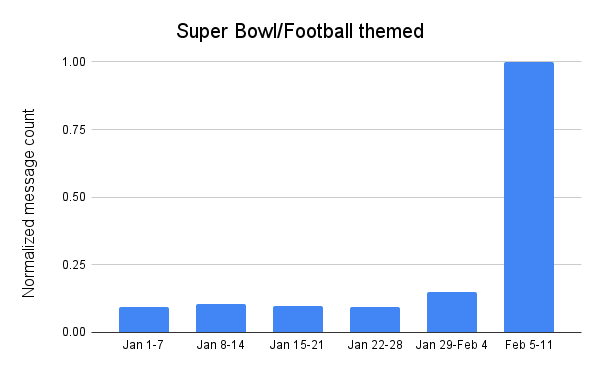
Super Bowl/Football
Spammers and scammers apparently didn’t feel that the “Super Wild Card Weekend” nor the divisional playoffs were sufficiently interesting to use as bait for their campaigns, as the volume of Super Bowl and football themed unwanted and potentially malicious email messages throughout January remained relatively low and fairly consistent. However, they apparently knew that the big game itself would draw interest, as the volume of such messages increased more than 6x over the prior week in the days ahead of the game.
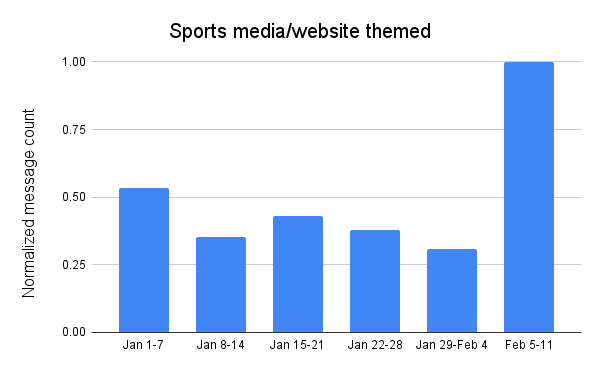
Sports media/websites
Attackers appeared to lose interest in using messages with subject lines related to sports media and websites as January progressed, with the volume of related messages peaking the first week of the month. However, similar to Super Bowl and football themed messages, this theme took on renewed interest in the week leading up to the Super Bowl, with message volume reaching over 3x the previous week, and 1.8x the peak seen durinthe first week of the year.
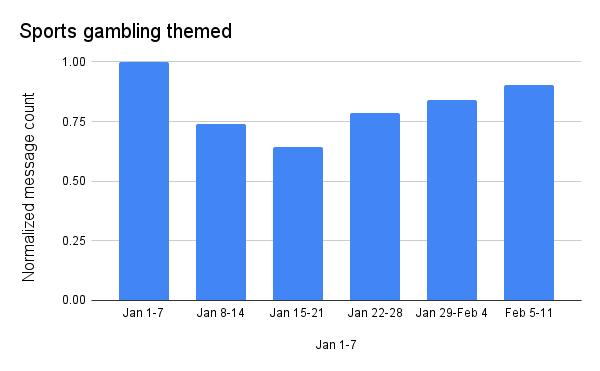
Sports gambling
The final weekend of regular season games (on January 6 & 7) again drove the highest volume of sports gambling themed messages, similar to the pattern seen in 2023. Message volume dropped by about a third over the next two weeks, but picked back up around the divisional and conference playoff games and into the Super Bowl. Even with the growth into the Super Bowl, gambling-themed spam and malicious message volume remained 10% lower than the peak seen a month earlier.
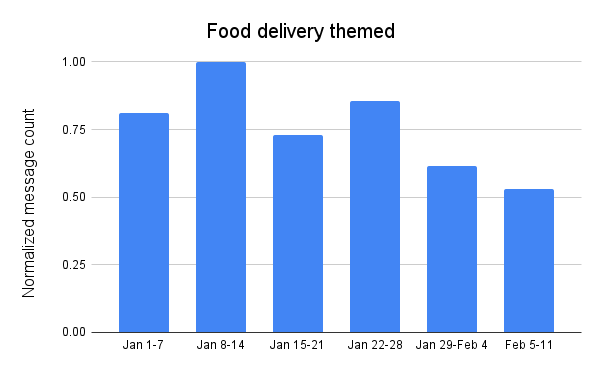
Food delivery
Peak volume of food delivery themed messages was an order of magnitude (10x) higher than the Super Bowl and football themed peak, which was the next largest. Due to the popularity of such services, it appears that it is a regular theme for spam and potentially malicious messages, as volume remained extremely high throughout January. After peaking the week of January 8-14, message volume was lower each of the following weeks, reaching its nadir in the week leading up to the Super Bowl, 47% lower than the peak volume.
Conclusion
Likely peaking during the so-called “dot.com” Super Bowls nearly a quarter-century ago, most Super Bowl ads no longer drive traffic to associated websites by including a URL in their ad. However, as our DNS traffic analysis found, it appears that viewers don’t seem to have much trouble finding these sites. We also found that in-game events had a mixed impact on traffic across domains associated with multiple types of apps, as well as traffic for the websites associated with the teams playing in the Super Bowl.
Once again, runc—a tool
for spawning and running OCI containers—is drawing attention due to a high
severity container breakout attack. This vulnerability is interesting for
several reasons: its potential for widespread impact, the continued difficulty
in actually containing containers, the dangers of running containers
as a privileged user, and the fact that this vulnerability is made possible
in part by a response to a previous
container breakout flaw in runc.
Once again, runc—a tool
for spawning and running OCI containers—is drawing attention due to a high
severity container breakout attack. This vulnerability is interesting for
several reasons: its potential for widespread impact, the continued difficulty
in actually containing containers, the dangers of running containers
as a privileged user, and the fact that this vulnerability is made possible
in part by a response to a previous
container breakout flaw in runc.
For almost seven years, Cloudflare has been fighting against patent trolls. We’ve been doing this successfully through the efforts of our own legal team, external counsel, and the extraordinary efforts of people on the Internet looking for prior art (and getting rewarded for it) through our Project Jengo.
While we refuse to pay trolls for their meritless claims, we’ve been happy to awardprizes to Project Jengo participants who help stop the trolls through prior art that invalidates their patents or claims. Project Jengo participants helped us in the past roundly beat the patent troll Blackbird (who subsequently went out of business).
Today, we’re back to talk about yet another win thanks to a lot of work by us, our external counsel, and Project Jengo participants.
Sable
Last Thursday, on a clear, sunny morning in Waco, Texas, a jury returned a verdict after less than two hours of deliberation. The jury found that Cloudflare did not infringe the patent asserted against Cloudflare by patent trolls Sable IP and Sable Networks.
And while that would have been enough to decide the case by itself, the jury went further and found that Sable’s old and broadly-written patent claim was invalid and never should have been granted in the first place–meaning they can no longer assert the claim against anyone else. Since Sable first sued us, we’ve invalidated significant parts of three Sable patents, hamstringing their ability to bring lawsuits against other companies.
It’s worth noting that very few lawsuits ever reach a jury. Most non-lawyers are shocked to learn that only about 1% of civil cases make it to trial, because trials are generally what they see on TV or in film. But professional litigators know that almost all cases are resolved much earlier through procedures that are much less entertaining to watch on screen: written motions, delay, or settlement. A big reason for this is that taking a case to trial–even on simple matters–is extremely costly. In patent cases, that means millions of dollars.
As we described in our first Project Jengo blog post, these costs are the threat that patent trolls rely on to extract sizable settlements out of innovative technology companies. It’s often easier for technology companies to pay a settlement rather than pay millions more in litigation costs that likely can’t be recovered even if the technology company wins. Patent trolls usually don’t want to incur the costs of going to trial either, but they typically wait for the other side to blink first and pay up–especially because the company accused of infringement is the one that faces the risk of a bad verdict and damages award.
But every once in a while the target doesn’t blink. Cloudflare’s hard fought victory, the culmination of three years of litigation, is a strong warning to all patent trolls–we will not be intimidated into playing your game.
Background
Let’s recap how we got here. This case began in March 2021 when Sable Networks and Sable IP filed a complaint against Cloudflare in federal court. Sable asserted around 100 claims spanning four patents against multiple Cloudflare products and features. The patents relied on by Sable were filed around the turn of the century, and they addressed the hardware-based router technology of the day. More specifically, they addressed a particular type of hardware focused on “flows” composed of multiple linked packets. This approach is not used by modern-day software-defined services delivered on the cloud, particularly not services like Cloudflare that handle traffic on a packet-by-packet basis. But that didn’t stop Sable from arguing its broadly-worded patents covered essentially all router operations, including Cloudflare’s cutting edge technology–well beyond what the asserted patent claims were ever intended to cover.
As with many patent trolls, Sable IP has never made or sold products and doesn’t employ a single person to create or design actual technology. Sable IP was created as a shell entity in 2020 to monetize the patent portfolio of Sable Networks, which itself was formed in 2006 and allegedly acquired the assets–including the patents–of Caspian Networks, a router company that had shuttered its operations. Sable IP is one of many such shell entities formed to “monetize” patents through lawyer-driven litigation campaigns.
Cloudflare wasn’t Sable’s only target. Sable sued a number of other companies, including Cisco, Fortinet, Check Point, SonicWall, Juniper Networks, and others, each of which eventually resolved the lawsuit against them out of court. Cloudflare took a different approach.
To kick off our fight against Sable, we launched another round of Project Jengo, crowdsourcing submissions of prior art for all of Sable’s active patents–including patents not asserted against Cloudflare–and committing a $100,000 award to be split among winners that submitted strong prior art. Dedicated readers will remember Cloudflare’s first round of Project Jengo, which helped put the notorious patent troll Blackbird out of business. We’ve received dozens of submissions since we launched this Sable-focused round of Project Jengo, and have awarded \$70,000 since 2021. We will distribute the remaining \$30,000 to winners of the Final Awards which we will announce after the official conclusion of the case per the Project Jengo Rules.
Relying on prior art, we filed petitions for inter partes review to the U.S. Patent and Trademark Office (“USPTO”) seeking to invalidate Sable’s patents. The inter partes process is an administrative proceeding that involves filing briefs for administrative patent judges at the USPTO to determine if a patent should have been issued in the first place. In many cases it’s a helpful process available to try and limit the threat of patent trolls. In May 2022, to avoid responding to one of those petitions–and to avoid the risk that its patent would be canceled altogether–Sable voluntarily canceled all of the claims asserted against Cloudflare under one of its patents. And in January 2023, we were successful in invalidating the portions of a second Sable patent that had been asserted against us.
Two patents down, Sable refused to give up. By December 2023, through its petitions to the USPTO and related motions before the court, Cloudflare had successfully narrowed the number of patents and claims at issue from approximately 100 claims across four, to just five claims from two patents. Then, at the pretrial conference on December 13, 2023, the court issued summary judgment in our favor on a third Sable patent. Summary judgment is a process where the court determines that an argument is so clear that no reasonable jury could rule otherwise. This further narrowed the case to a single asserted claim on a single patent–claim 25 of U.S. Patent No. 7,012,919.
Through years of hard work, we’d successfully whittled down Sable’s case from about 100 claims across four patents to just one claim of one patent. But despite all that success, the fact remained…we were heading to trial, and it can be difficult to know what a jury will decide–and what damages they may award–on heavily technical issues.
Trials and tribulations for Sable IP and Sable Networks
We weren’t just heading to trial, we were heading to the Western District of Texas. Waco, Texas, to be precise, where Sable chose to file its lawsuit. The Western District of Texas has in recent years become a popular venue for patent plaintiffs, as it has a reputation for being a friendly jurisdiction for patent holders.
Sable’s trial story was not compelling. On the technical merits, Sable had the unenviable task of trying to map decades-old flow-based hardware router technology onto Cloudflare’s modern, software-defined packet-by-packet architecture. They attempted to do so through a series of hand waving exercises, equating the “line cards” required by the patent to various different software and hardware used by Cloudflare, and suggesting that any flow of packets across Cloudflare’s network could be construed as the specific “micro-flows” at the center of its patent.
Beyond the technical issues, Sable’s story was simple, though not very attractive–Sable wanted money. Having acquired rights to the patents of a failed hardware company, they were seeking to “monetize” those patents to the greatest extent possible. If that meant leveraging a patent related to decades-old router hardware to sue a cloud-based service provider, so be it. And if it required leaps of logic and untethered claims that might make a toddler blush, oh well.
When it was our turn, we told the jury our story. How Cloudflare was founded to help build a better Internet by moving past old, hardware-based solutions to new, cloud-based solutions delivered through our global network. We explained the hard work put into building our network, and all the services that sit on top of it. One of our outstanding engineers described what it’s like to create a new product, working with teams of engineers, product managers, and others to bring something exciting to the market for the first time.
We drilled down into Sable’s twenty-year old patent, explaining the many reasons why the patent does not describe anything that Cloudflare actually does. Among other things, the patent requires various steps to be performed at a “line card,” and Cloudflare’s accused edge servers don’t include a single such line card. And while the patent focused on flow-based routing, Cloudflare designed its system to perform packet-by-packet inspection to protect against malicious traffic. We also explained that the patent claim asserted against Cloudflare is invalid–and never should have been issued–because it was obvious in view of the prior art and lacked the required written description. In fact, Sable’s patent covered, at best, only technology that had already been described by inventors at Nortel Networks and Lucent Technologies–leading routing technology companies at the time.
During closing arguments, Cloudflare’s trial lawyer made one thing clear–this case was about more than Sable or Cloudflare. The patent system was designed to foster innovation and promote the progress of science, but what Sable was doing was exactly the opposite: bringing meritless cases in an effort to turn a buck, and stifling progress in the process. That distortion and abuse of the patent system has to stop and, ultimately, only the jury had the power to end it.
To our great satisfaction, the jury answered that call. The jury’s decision did not take long. Less than two hours after leaving the courtroom to deliberate, the jury returned with a verdict that sends a message far beyond the courthouse. No infringement by Cloudflare, andSable’s patent is invalid.
What’s next
We’ll enjoy this verdict for a long time, but the hard work doesn’t stop here. Cloudflare is dedicated to rebalancing a system that is being distorted by trolls like Sable. As part of our efforts, we look forward to announcing the final awards for Project Jengo on this blog following the conclusion of the case. We’ll also plan to share additional thoughts and insights we’ve gleaned from facing down a troll at trial.
For now, we want to express our sincere gratitude to the judge and jury for the hard work they put in at trial, including the jury weighing the evidence and understanding the complex technology at issue in the case. Cloudflare is deeply grateful for the jury’s time and efforts over the past week, its careful consideration of all the facts, and for its verdict. We also again want to thank our amazing trial lawyers from Charhon Callahan Robson & Garza PLLC, and The Dacus Firm. If you end up with a patent troll problem, we recommend them highly.
On February 8, 2024 Fortinet disclosed multiple critical vulnerabilities affecting FortiOS, the operating system that runs on Fortigate SSL VPNs. The critical vulnerabilities include CVE-2024-21762, an out-of-bounds write vulnerability in SSLVPNd that could allow remote unauthenticated attackers to execute arbitrary code or commands on Fortinet SSL VPNs via specially crafted HTTP requests.
According to Fortinet’s advisory for CVE-2024-21762, the vulnerability is “potentially being exploited in the wild.” The U.S. Cybersecurity and Infrastructure Security Agency (CISA) added CVE-2024-21762 to their Known Exploited Vulnerabilities (KEV) list as of February 9, 2024, confirming that exploitation has occurred.
Zero-day vulnerabilities in Fortinet SSL VPNs have a history of being targeted by state-sponsored and other highly motivated threat actors. Other recent Fortinet SSL VPN vulnerabilities (e.g., CVE-2022-42475, CVE-2022-41328, and CVE-2023-27997) have been exploited by adversaries as both zero-day and as n-day following public disclosure.
Affected products
FortiOS versions vulnerable to CVE-2024-21762 include:
FortiOS 7.4.0 through 7.4.2
FortiOS 7.2.0 through 7.2.6
FortiOS 7.0.0 through 7.0.13
FortiOS 6.4.0 through 6.4.14
FortiOS 6.2.0 through 6.2.15
FortiOS 6.0 all versions
FortiProxy 7.4.0 through 7.4.2
FortiProxy 7.2.0 through 7.2.8
FortiProxy 7.0.0 through 7.0.14
FortiProxy 2.0.0 through 2.0.13
FortiProxy 1.2 all versions
FortiProxy 1.1 all versions
FortiProxy 1.0 all versions
Note: Fortinet’s advisory did not originally list FortiProxy as being vulnerable to this issue, but the bulletin was updated after publication to add affected FortiProxy versions.
Mitigation guidance
According to the Fortinet advisory, the following fixed versions remediate CVE-2024-21762:
FortiOS 7.4.3 or above
FortiOS 7.2.7 or above
FortiOS 7.0.14 or above
FortiOS 6.4.15 or above
FortiOS 6.2.16 or above
FortiOS 6.0 customers should migrate to a fixed release
FortiProxy 7.4.3 or above
FortiProxy 7.2.9 or above
FortiProxy 7.0.15 or above
FortiProxy 2.0.14 or above
FortiProxy 1.2, 1.1, and 1.0 customers should migrate to a fixed release
As a workaround, the advisory instructs customers to disable the SSL VPN with the added context that disabling the webmode is not a valid workaround. For more information and the latest updates, please refer to Fortinet’s advisory.
Rapid7 customers
InsightVM and Nexpose customers can assess their exposure to FortiOS CVE-2024-21762 with a vulnerability check available in the Friday, February 9 content release.
Проектът „Ускорител за балкански преводи“ на фондация „Следваща страница“ е насочен не към авторите и преводачите, които сме свикнали да виждаме като основни лица на литературната сцена, а към уж второстепенните герои – агенти, литературни организации, издатели, организатори на фестивали, панаири и други. Неговата цел е да ускори потока на балкански преводи. „Тези участници са много важни за цялата книжна екосистема, но често остават в сянка и са пренебрегвани. Особено на малки книжни пазари, каквито са Западните Балкани и България“, казва Юлия Рафаилович, изпълнителен директор на фондацията.
Смисълът на ускорителя за преводи е да се засилят уменията и капацитетът на хората, решили да се занимават професионално с литература, но не в ролята на автори или преводачи. Според Юлия целта е да се изгради и самочувствие, че западнобалканските професионалисти от книжния сектор могат да имат тежест в международния литературен обмен. За съжаление, голяма част от тях поради ограничената си роля през годините и липсата на ресурси нямат опита и актуалните умения, с които са свързани професиите в по-развитите книжни пазари.
С тази цел фондация „Следваща страница“ инициира тригодишен международен проект, част от който е Академията за литературен мениджмънт и промотиране на превода с участници от над 30 литературни организации от Западните Балкани, които по някакъв начин се включват в процеса на международно издаване чрез превод. В рамките на програмата участниците обсъждат наболели проблеми, обменят истории и опит, слушат лектори от цяла Европа, имат и възможност да направят кратък стаж. Идеята е да се създаде мека инфраструктура от агенти, фестивали, преводачи в ролята на агенти. „Тази мека инфраструктура по обективни причини е много слаба в региона, доскоро и липсваше. Така че нашата работа е насочена към тях – да засилим и укрепим капацитета им“, казва Юлия.
Снимка: Соня Ставрова
Балканска литература, световна литература?
С проекта фондацията си поставя за цел да изследва начини за преодоляване на дисбаланса в потока на художествения превод в Европа. „Отдавна знаем и от България, и от други страни, чийто език е от т.нар. периферни, или по-рядко употребявани езици, че те много по-трудно пробиват на чуждоезични пазари. Обикновено пробивът на книжен пазар е на някой от големите езици, сред които на първо място е английският. Това означава, че ако романът ви е преведен на английски, е доста по-вероятно той да стигне до някой издател от по-малък език, който да иска да го издаде, което пък ще доведе до превеждането му на този език“, казва Юлия. Преводът на една книга на повече езици ѝ дава повече видимост, което означава, че тя може да бъде забелязана по-лесно в света. Затова, логично, подобряването на връзките между балканските държави е важно за техните автори и литератури. „Не съм сигурна доколко литературите от Балканите мислят себе си като балканска литература“, казва Юлия.
Има сръбска, македонска и прочее литератури, но те не са една литература. Разбира се, всеки поглед отвън ще се опита да генерализира или стереотипизира и да ги мисли като части от едно цяло. Но тук идва ролята на литературните агенти: именно те са тези, които познават и общуват с двете страни, и медиаторската им функция е безценна.
Програми като „Ускорител за балкански преводи“ подпомагат именно такива професионалисти. При по-периферните езици ролята на агента впрочем често е в ръцете на преводачите. Понякога между два езика има не повече от един-двама действащи литературни преводачи. В такива случаи (а те не са изключението, напротив) литературният обмен между два езика съществува и се оформя изцяло благодарение на тази шепа преводачи. А „чуждестранните издатели“ и „навън“ също е трудно да се обяснят.
„Всяка страна е различна, отделно издателствата в рамките на всяка държава се различават помежду си. Така че няма една монолитна чужбина със стройни очаквания, които, стига да съвпаднат с нашите намерения, ще подсигурят литературата да тръгне като на поточна линия към чуждоезичните пазари.“
Сложната роля на професионалистите от книжния сектор
Освен литературен човек, работещият в сферата на книгите е и дипломат, културен аташе, медиатор, преводач, познавач на другата култура, организатор, пиар… Какво би означавала подкрепата за такива хора „Личното ми мнение е, че тези литератури – особено от нашия регион – по условие са нишови литератури и ще си намират читателите, които търсят такива книги. В това няма нищо пораженско, напротив – за литературите ни има много читатели на всякакви езици, въпросът е да се намерим. Това е все едно да се питаме защо киното ни не може да произведе филм, който да вземе „Оскар“ за най-добър филм – не чуждестранен, а филм. Няма да го направи, но в това няма нищо драматично. Проблемите започват, щом се объркат очакванията.“
В рамките на проекта се публикуват изследвания на пазарите на литература в превод в държавите участнички – Северна Македония, Сърбия, Албания, Косово, Черна гора и Босна и Херцеговина. Всички шест изследвани държави, освен Косово, имат програми за подкрепа на преводите извън страната, макар и тези програми да имат своите недостатъци, както се отбелязва и в изследванията.
Снимка: Соня Ставрова
„Ролята на държавата е да подкрепя онези сектори, за които има обществен консенсус, че са значими, но които не могат да оцелеят сами в чисто пазарни условия. Културният сектор е един от тях. Изработването на адекватни политики, които да отразяват този консенсус, е изключително важно. Те правят много неща, но в крайна сметка се свеждат до разпределяне на ресурс. За да е качествен и смислен процесът, трябва най-вече да има яснота какво искаме и да имаме идея как да го постигнем. Тази роля е жизненоважна и принципно няма как да се изпълнява от друг, тя е по условие публичен въпрос. Оттам нататък важно е онези, които произвеждат културен продукт, както и експертите, които разбират нуждите на сектора и проблемите в регулаторните рамки, от една страна, и представителите на публичния сектор, да не стоят едни срещу други, а да са наясно, че трябва да работят заедно и да допринасят за целите, които сме припознали вече като общи“, смята Юлия.
Успешната балканска литература
Двама от партньорите в проекта – писателят Владимир Янковски от македонската издателска къща „Готен“ и сръбската поетеса Ана Мария Гърбич от Argh – споделят каква е тяхната дефиниция за успешна национална литература. Преводът е приоритет (Гърбич посочва, че преводите на големите езици са най-важни), но той е едва началото – намирането на добър издател, който „ще се погрижи“ за книгата, също е много важно. Авторите трябва да присъстват на фестивали, но тези фестивали трябва да бъдат организирани и представени от някого, и то на ниво, което е съвременно, сравнимо с нивото на други места по света. Отзивите за книгата, дори рекламата изискват своите професионалисти.
Успехът на един автор навън го прави успешен и на националния пазар. Това означава, че интересът от професионализация на средата е свързан не само с литературен износ, но и с развитието на литературната култура у дома. Възможно ли е балканската литература да има своя запазена марка като скандинавската, пита Владимир Янковски.
Проектът „Ускорител за балкански преводи“ е съфинансиран от програма „Творческа Европа“ на Европейския съюз и от Национален фонд „Култура”.
Тази статия е публикувана с финансовата подкрепа на фондация „Следваща страница”.
The 6.8-rc4 kernel prepatch is out for
testing. “Commit counts and contents look normal for this phase of the
release, nothing here really stands out.“
The 6.8-rc4 kernel prepatch is out for
testing. “Commit counts and contents look normal for this phase of the
release, nothing here really stands out.”
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.







 Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS. Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.