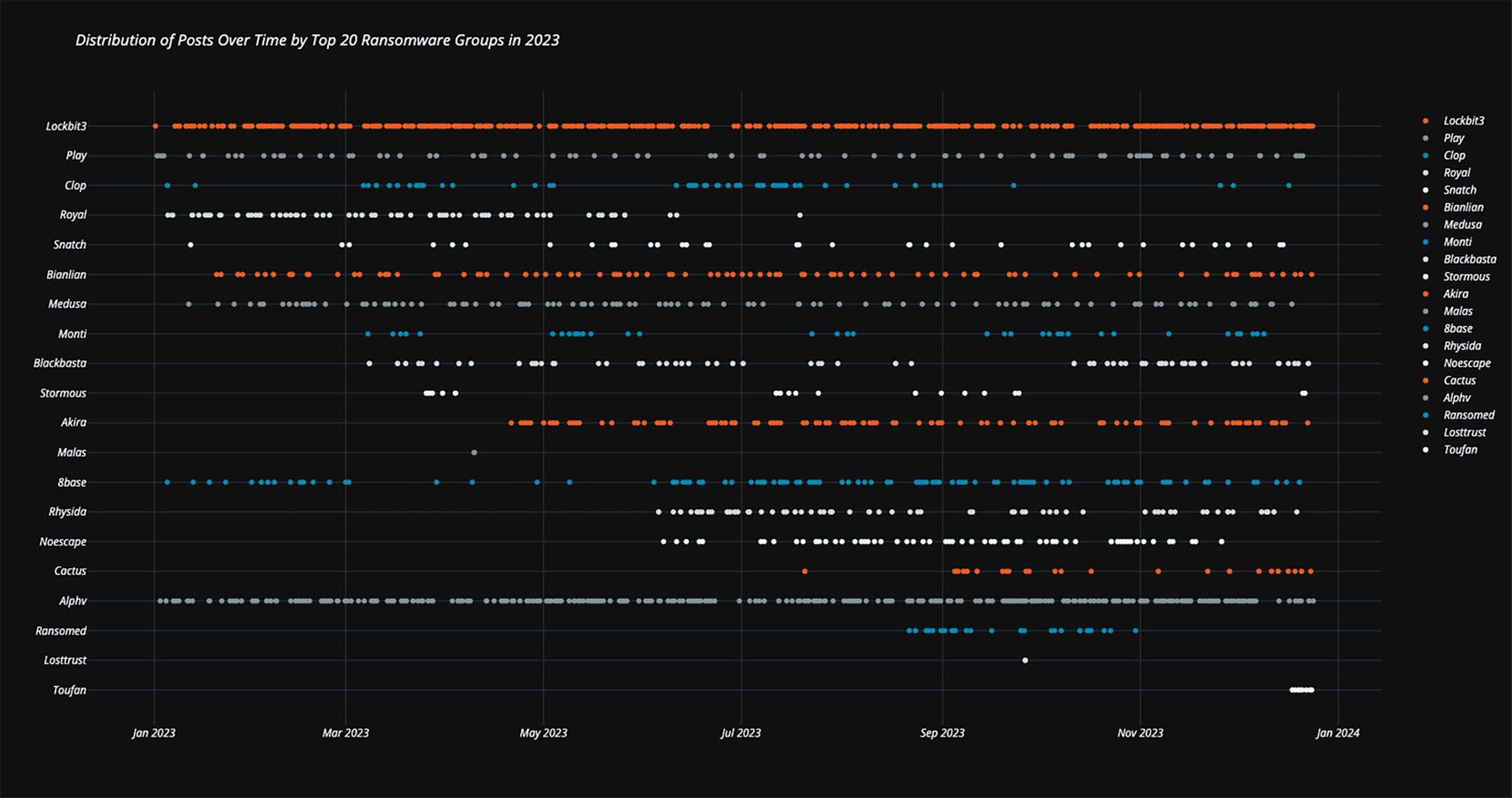
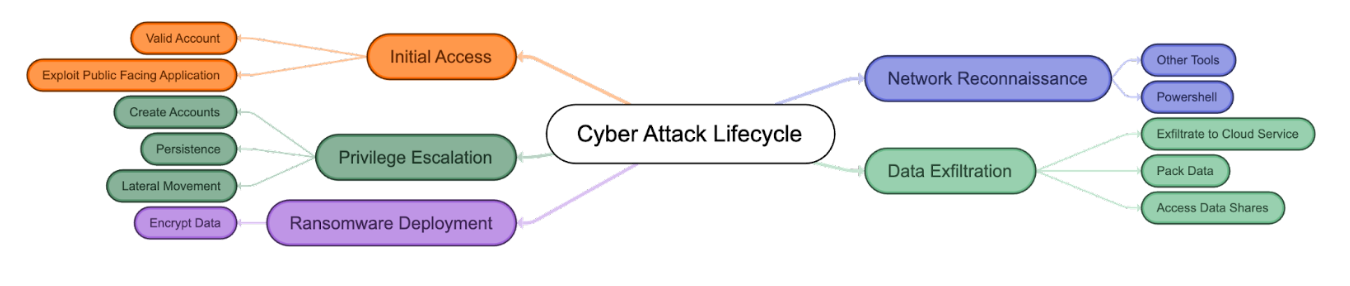
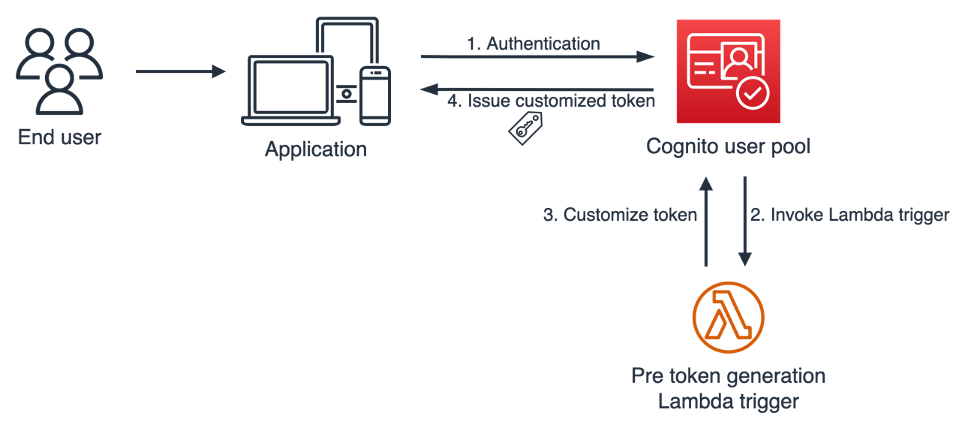
Post Syndicated from Александър Нуцов original https://www.toest.bg/nevidimata-detsentralizatsiya-v-bulgaria/

Кой движи света напред? Кой води войните? Къде е концентрирана властта? В индивида, държавата, наднационалните институции? В политическите науки и международните отношения това са философски въпроси, от чиито корени черпят своето начало различни научни течения и школи. Но едва ли има единствен, цялостен и правилен отговор на тях. Докато хората на власт изпълват управленските структури със своята идентичност, позиции и идеи, същите структури влияят на хората в тях и ги ограничават с установените си рамки, инструменти и норми на съществуване.
Безспорно обаче най-голям властови ресурс – административен, финансов и военен – е съсредоточен в националната държава. Държавата съществува със своите структури, модели на поведение и „инстинкти“. Подобно на човека, първичното стремление на всяка власт е самосъхранението и възпроизвеждането. Държавите и техните структури също като нас се адаптират към променящата се среда и трансформират елементи от себе си, за да оцелеят. Така историческите събития ги подтикват да делегират част от правомощията си нагоре, към наднационални институции като ООН и Европейския съюз, и надолу – към местната власт, гражданите и частния сектор.
Вълни на децентрализация
Процеси по децентрализация текат навсякъде по света още от времето на Студената война. Първоначално те се състоят преди всичко в предаване на правомощия и функции от централната към местната власт и различни локални структури с идеята да предоставят по-качествени и ефективни услуги на своите граждани. Тук можем да включим и случаите на федерализация и засилване на федералните власти в страни с такова управление.
С падането на желязната завеса – особено в страните от бившия Източен блок – децентрализацията поема към по-значително включване на частния сектор в публичните дела и икономиката заради масовата приватизация. Отварянето на пазарите и стимулирането на частната инициатива се осъществява в по-широкия контекст на демократизация на обществата.
Впоследствие „разпръскването“ на власт придобива все по-широк смисъл. Вече говорим за включване на все повече обществени кръгове във вземането на политически решения – граждани, неправителствени организации, бизнес. Тоест от тясното разбиране за делегиране на правомощия от централната към местната власт постепенно стигаме до по-широката тема за създаване на по-справедливо и ефективно държавно управление. Именно в този по-общ смисъл ще си поговорим за децентрализацията в България.
Предпоставките на средата
За разлика от много други страни по света, в България липсва държавна стратегия или целенасочена държавна политика за децентрализация на властта. У нас тя се развива по-скоро по естествен път, в съзвучие със сложните социално-икономически, политически и исторически обстоятелства на средата.
Парадоксално, политическата нестабилност през последните години, незначителната избирателна активност и ниската легитимност на властта от белег за немощ на българската демокрация могат да се превърнат в първопричината за нейното надграждане.
Фрагментираният парламент без единствена доминираща партия доведе до няколко ключови последици. Първата е липсата на единен център, който да създава и променя законодателството. Това, от една страна, създава поле за битка на повече и различни гледни точки. От друга обаче, означава невъзможност за водене на единна и стабилна политика, тъй като твърде многото интереси и компромиси водят до забавяне на законодателния процес или до осакатяване на реформите.
Вторият важен момент е, че немалка част от политическите фигури, като Бойко Борисов и Румен Радев, които дълго време концентрираха огромна власт в ръцете си, постепенно загубиха този свой прерогатив. И докато самият парламент се разпокъса отвътре, конфронтацията между парламента и Президентството доведе до конституционните промени, които орязват някои правомощия на президента.
При тази липса на единни самодостатъчни властови ядра законодателният процес и политиците се нуждаят от обединяващ фактор, който да надмогне кавгите и управленската разпокъсаност. И тук все по-съществена роля играят частният и гражданският сектор. Защото бизнесите и гражданските организации предлагат надпартийни решения отвъд институционалните борби, които нямат цвят, а решават проблеми на обществената среда.
На този фон администрацията остава изключително ретроградна, а политиците често нямат време, експертност и воля да реформират закостенялото законодателство. Тези дефицити все повече се запълват от активната роля на бизнес асоциациите, неправителствените организации и гражданите с експертни познания в различни области.
Освен това държавният апарат изостава драстично от технологичното развитие на глобално ниво, което забавя модернизацията на всички сектори от обществено значение – от образование и здравеопазване до електронно правителство и дигитализация на обществените услуги. Оттам идва и нарастващата зависимост на държавата от предприемачите, които създават, развиват и предоставят технологиите.
В условията на глобализация и ускорено технологично развитие частният и гражданският сектор придобиват все по-голяма тежест и лостове за влияние върху политиците.
Ефектът върху демокрацията
Нарастващата роля на бизнеса и гражданите трябва да се превърне в тенденция, така че те да участват все по-активно в политическите процеси и вземането на стратегически решения. Тук говорим за „разпръскване“ на власт от парламента и партиите, както и от правителството и министерствата надолу – към обществото.
По-силният глас на модерните бизнеси и гражданския сектор гарантира повече контрол върху дейността на политиците, повече и по-добри идеи за реформи от хора и организации с експертно знание и по-ефективни решения на конкретни проблеми на средата. А колкото по-силни и разпознаваеми сред обществото са добрите примери на хора и организации от неправителствения сектор, толкова по-голямо внимание получават те от медиите. И ако политиците откажат да се съобразяват с тях, именно медиите са тези, които могат да разобличат нередностите и да осъществяват натиск, което неизбежно води до загуба на доверие и електорат.
Къде бизнесът покрива дефицити?
По отношение на дигитализацията бизнесът предоставя технологии и ноу-хау в най-различни сектори, част от които вече споменахме. През миналата година например България най-накрая създаде своя национален електронен идентификатор благодарение на разработената от Evrotrust Technologies дигитална схема Evrotrust eID.
Най-големите пробойни на държавата бизнесът се опитва да попълни в образованието. За първи път 25 бизнес организации излязоха с обща позиция за нуждата от дълбока реформа в образованието. Все повече предприемачи споделят за развитието на собствени академии, стажове и семинари, с които да обучават собствени кадри поради липса на добра подготовка на кандидатите. Инвестициите в учебната инфраструктура, като например научни лаборатории, също говорят за големия принос на бизнеса. Социални предприемачи пък развиват собствени платформи за обучение и осигуряват финансов стимул за успелите ученици и студенти.
В здравеопазването имаме все повече дигитални платформи, които улесняват достъпа до специалисти в най-различни области, осигуряват ценна информация, дигитализират работата на институциите, помагат при подбора на персонал и т.н.
В земеделието български компании предоставят технологични решения за нуждите на земеделците. Например произвеждат високотехнологична роботика за най-различни дейности, като умно косене и плевене, разработват автоматизиране на капковото напояване, осъществяват контрол на климата в закрити и открити площи при отглеждането на култури, осигуряват софтуер и специалисти, които правят измервания и анализи и прилагат добри практики за устойчиво развитие на земеделието и оптимизиране на разходите.
Сигурността и отбраната също все по-силно зависят от модерните предприемачи, най-вече при надпреварата в иновациите. НАТО има собствен иновационен акселератор – DIANA, който предоставя ресурси и тестова база за иновативните стартъпи и ги свързва с учените и крайните потребители при създаването на „дълбоки технологии“ (deep tech) с т.нар. двойна употреба за страните от Съюза. Един от ключовите партньори на DIANA в България като тестов център е институтът „Големи данни в полза на интелигентно общество“ (GATE) към СУ „Св. Климент Охридски“, който осъществява и връзката между българските компании и натовската акселераторска програма.
Това са само няколко примера за нарастващата роля на бизнеса в традиционни за държавата сфери, което постепенно ще се превърне в тенденция в контекста на технологичното развитие.
Стабилна децентрализация в политическа нестабилност
На фона на политическата нестабилност и слабата държавност българските граждани и предприемачи ще придобиват все по-ключова позиция, която ще им позволи да държат политиците отговорни и да изсветляват управленските нередности и корупционни схеми.
Децентрализацията обаче не е лек сама по себе си. Тя трябва да улесни процеса на реформиране на законодателството и модернизиране на средата, като подпомогне комуникацията между политиците и експертите/практиците от частния и гражданския сектор, така че всички да участват дейно в политическите и публичните дела.
Необходимо е създаването на повече профилирани неправителствени и граждански организации, които обединяват широки обществени кръгове, застъпват се за каузи и черпят креативни идеи и решения от практиката. Те трябва да инициират и улесняват разговора между по-широк кръг лица от гражданския, частния и държавния сектор, за да се отговори на нуждите на обществото по най-смислен и ефективен начин. И най-важното – трябва да предоставят конкретни решения на конкретни проблеми, издигайки на пиедестал идеята всяка отделна сфера от живота ни да е по-добра за всички.
Децентрализацията в България ще продължи да се реализира по-скоро по естествен път, движен от нестабилната политическа обстановка и ускореното технологично развитие. Това е шанс за създаване на по-устойчива, макар и несъвършена демокрация, с повече съвестни управленци в по-благоприятна среда за правене на политика.