Post Syndicated from Explosm.net original https://explosm.net/comics/independence-day
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/independence-day
New Cyanide and Happiness Comic
Post Syndicated from original https://0pointer.net/blog/asg-2023-cfp-closes-soon.html
The Call for Participation (CFP) for All Systems Go!
2023 will close in three days, on 7th of
July! We’d like to invite you to submit your proposals for
consideration to the CFP submission
site quickly!
![]()
All topics relevant to foundational open-source Linux technologies are
welcome. In particular, however, we are looking for proposals
including, but not limited to, the following topics:
The CFP will close on July 7th, 2023. A response will be sent to all
submitters on or before July 14th, 2023. The conference takes place in
🗺️ Berlin, Germany 🇩🇪 on Sept. 13-14th.
All Systems Go! 2023 is all about foundational open-source Linux
technologies. We are primarily looking for deeply technical talks by
and for developers, engineers and other technical roles.
We focus on the userspace side of things, so while kernel topics are
welcome they must have clear, direct relevance to userspace. The
following is a non-comprehensive list of topics encouraged for 2023
submissions:
For more information please visit our conference
website!
Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/aws-week-in-review-generative-ai-with-llm-hands-on-course-amazon-sagemaker-data-wrangler-updates-and-more-july-3-2023/
In last week’s AWS Week in Review post, Danilo mentioned that it’s summer in London. Well, I’m based in Singapore, and it’s mostly summer here. But, June is a special month here as it marks the start of durian season.
Starting next week, I’ll be travelling to Thailand, Malaysia, and the Philippines. But before I go, I want to share some interesting updates from last week for you.
Let’s get started.
Last Week’s Launches
Here are some launches that caught my attention:
New Hands-on Course: Generative AI with Large Language Models – Generative AI has been a technology highlight for the past few months. If you are on your journey to learn large language models (LLM), then you can try the new hands-on course Generative AI with LLMs at Coursera. Antje wrote a post to announce this collaboration course between DeepLearning.AI and AWS. This course is designed to prepare data scientists and engineers to become experts in selecting, training, fine-tuning, and deploying LLMs for real-world applications.

Amazon SageMaker Data Wrangler direct connection to Snowflake – With this announcement, you can now browse databases, tables, schemas, and query data from Snowflake in SageMaker Data Wrangler. This unlocks the possibility for you to join your data with other popular data sources, such as S3, Amazon Athena, Amazon Redshift, Amazon EMR and over 50 SaaS applications to create the right data set for machine learning.
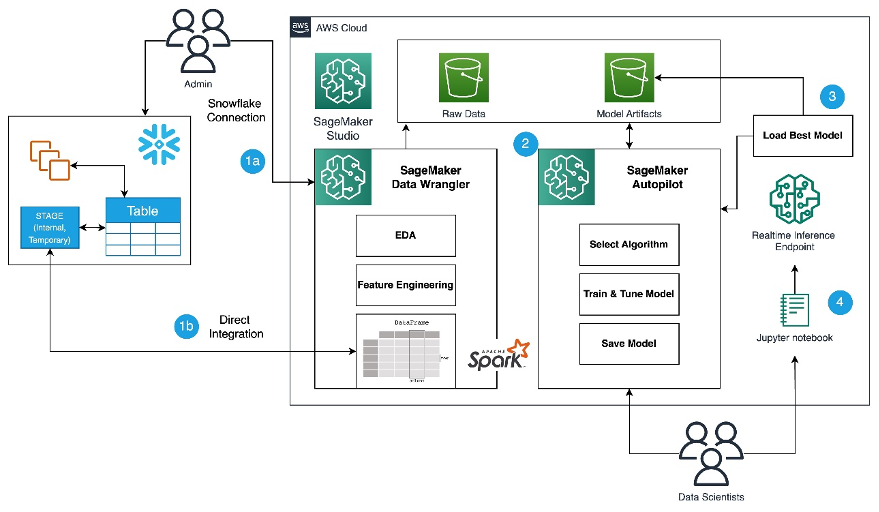
Amazon SageMaker Role Manager now provides CDK library to create fine-grained permissions — The CDK support for Amazon SageMaker Role Manager lets you define permissions with fine-grained access for SageMaker users, jobs, and SageMaker pipelines programmatically. This will reduce manual efforts and consistent permissions management. For example, the following code grants permissions with a set of related machine learning activities specific to a persona.
export class myCDKStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const persona = new Persona(this, 'example-persona-id', {
activities: [
Activity.runStudioAppsV2(this, 'example-id1', {}),
Activity.accessS3Buckets(this, 'example-id2', {s3buckets: [s3.S3Bucket.fromBucketName('DOC-EXAMPLE-BUCKET')]})
Activity.accessAwsServices(this, 'example-id3', {})
]
});
const role = persona.createRole(this, 'example-IAM-role-id', 'example-IAM-role-name');
}
}
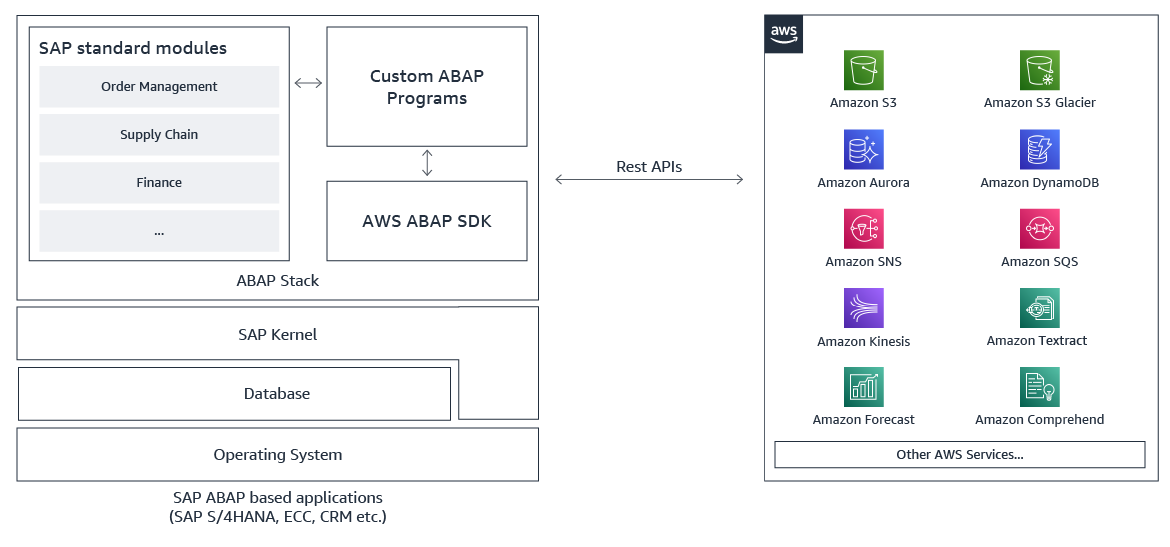
AWS SDK for SAP ABAP – Great news for SAP ABAP developers! We just recently announced the general availability of the AWS SDK for SAP ABAP. With this, ABAP developers can use simple, secure and configurable connections between ABAP environments and 200+ supported AWS services in all AWS Regions, including AWS GovCloud (US) Regions. This AWS SDK helps ABAP developers to modernize their business processes with AWS services.
Amazon OpenSearch Ingestion now supports ingesting events from Amazon Security Lake – Amazon OpenSearch Ingestion now lets you bring data in the Apache Parquet format. As Amazon Security Lake also uses Open Cybersecurity Schema Framework (OCSF) in Apache Parquet format, it means you can easily ingest data from Amazon Security Lake.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
AWS Open-Source Updates
As always, my colleague Ricardo has curated the latest updates for open-source news at AWS. Here are some of the highlights.
lightsail-miab-installer – This handy command-line tool developed by my colleague Rio Astamal was designed to simplify the process of setting up Mail-in-a-Box on Amazon Lightsail. With lightsail-miab-installer, you can effortlessly streamline the installation and configuration of Mail-in-a-Box, making it even more accessible and user-friendly.
rdsconn – This amazing tool, created by AWS Hero Aidan Steele, simplifies the process of connecting to an AWS RDS instance within a VPC directly from your laptop. Using the recently launched EC2 Instance Connect, rdsconn eliminates the need for cumbersome SSH tunnels.
cdk-appflow – If you’re using AWS CDK to build your applications and Amazon AppFlow to create bidirectional data transfer integrations between various SaaS applications and AWS, then you’re going to love cdk-appflow, a new AWS CDK construct for Amazon AppFlow. It’s currently in technical preview, but you’re more than welcome to try it and provide us with your feedback.
Upcoming AWS Events
There are also upcoming events that you can join to learn. Let’s start with AWS Summit events:
And, let’s learn from our fellow builders and join AWS Community Days:
Open for Registration for AWS re:Invent
Before I end this post, AWS re:Invent registration is now open!

This learning conference hosted by AWS for the global cloud computing community will be held from Nov 27 to Dec 1, 2023 in Las Vegas.
Pro-tip: You can use information on the Justify Your Trip page to prove the value of your trip to AWS re:Invent.
That’s all for this week. Check back next Monday for another Week in Review.
Happy building.
— Donnie
Post Syndicated from Guy Bachar original https://aws.amazon.com/blogs/big-data/backtesting-index-rebalancing-arbitrage-with-amazon-emr-and-apache-iceberg/
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance.
Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to minimize index tracking error. Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600). The arbitrage trade looks to profit from going long on stocks added to an index and shorting the ones that are removed, with the aim of generating profit from these price differences.
In this post, we look into the process of using backtesting to evaluate the performance of an index arbitrage profitability strategy. We specifically explore how Amazon EMR and the newly developed Apache Iceberg branching and tagging feature can address the challenge of look-ahead bias in backtesting. This will enable a more accurate evaluation of the performance of the index arbitrage profitability strategy.
Let’s first discuss some of the terminology used in this post:
For our testing purposes, consider the following example, in which a change to the S&P Dow Jones Indices is announced on September 2, 2022, becomes effective on September 19, 2022, and doesn’t become observable in the ETF holdings data that we will be using in the experiment until September 30, 2022. We use Iceberg tags to label market data snapshots to avoid look-ahead bias in the research data lake, which will enable us to test various trade entry and exit scenarios and assess the respective profitability of each.
As part of our experiment, we utilize a paid, third-party data provider API to identify SPY ETF holdings changes and construct a portfolio. Our model portfolio will buy stocks that are added to the index, known as going long, and will sell an equivalent amount of stocks removed from the index, known as going short.
We will test short-term holding periods, such as 1 day and 1, 2, 3, or 4 weeks, because we assume that the rebalancing effect is very short-lived and new information, such as macroeconomics, will drive performance beyond the studied time horizons. Lastly, we simulate different entry points for this trade:
To run our experiment, we have have used the following research data lake environment.
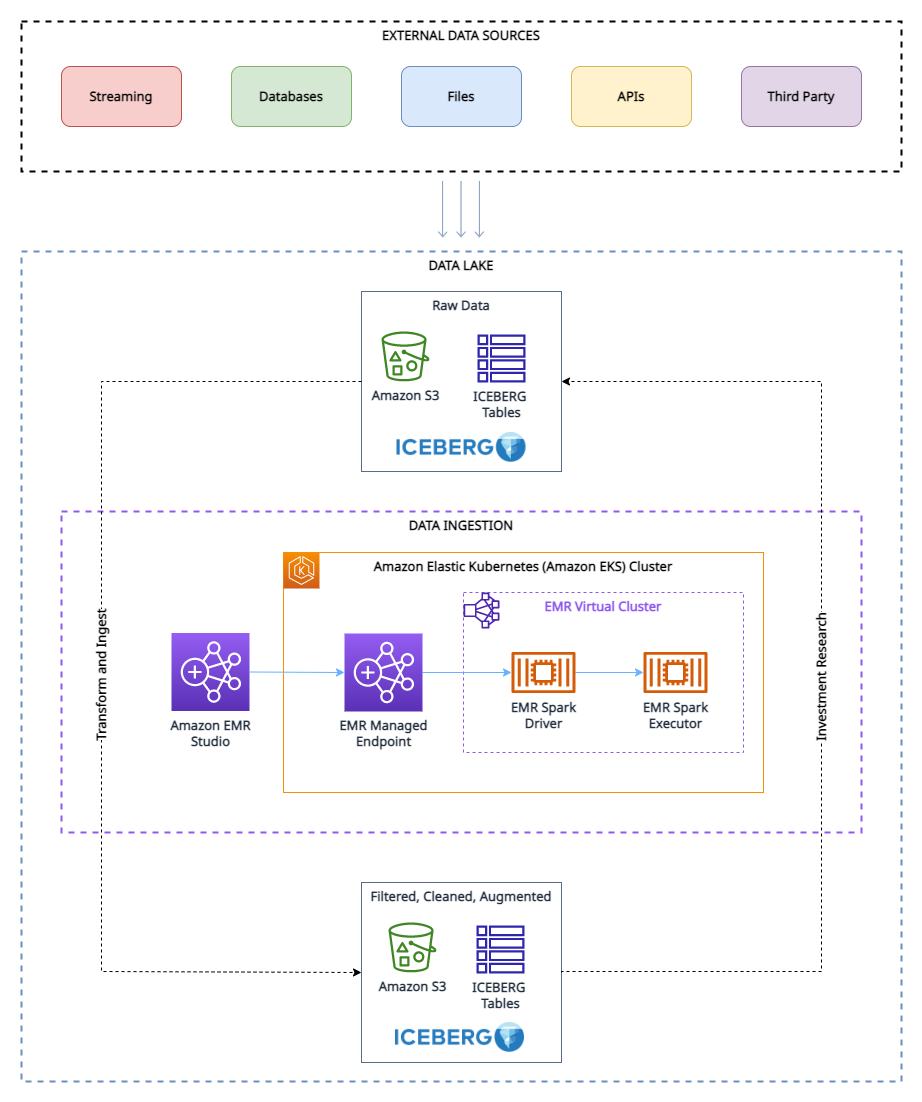
As shown in the architecture diagram, the research data lake is built on Amazon S3 and managed using Apache Iceberg, which is an open table format bringing the reliability and simplicity of relational database management service (RDBMS) tables to data lakes. To avoid look-ahead bias in backtesting, it’s essential to create snapshots of the data at different points in time. However, managing and organizing these snapshots can be challenging, especially when dealing with a large volume of data.
This is where the tagging feature in Apache Iceberg comes in handy. With tagging, researchers can create differently named snapshots of market data and track changes over time. For example, they can create a snapshot of the data at the end of each trading day and tag it with the date and any relevant market conditions.
By using tags to organize the snapshots, researchers can easily query and analyze the data based on specific market conditions or events, without having to worry about the specific dates of the data. This can be particularly helpful when conducting research that is not time-sensitive or when looking for trends over long periods of time.
Furthermore, the tagging feature can also help with other aspects of data management, such as data retention for GDPR compliance, and maintaining lineages of the table via different branches. Researchers can use Apache Iceberg tagging to ensure the integrity and accuracy of their data while also simplifying data management.
To follow along with this walkthrough, you must have the following:
To set up and test this experiment, we complete the following high-level steps:
We can get up and running with Iceberg by creating a table via Spark SQL from an existing view, as shown in the following code:
Now that we’ve created an Iceberg table, we can use it for investment research. One of the key features of Iceberg is its support for scalable data versioning. This means that we can easily track changes to our data and roll back to previous versions without making additional copies. Because this data gets updated periodically, we want to be able to create named snapshots of the data so that quant traders have easy access to consistent snapshots of data that have their own retention policy. In this case, let’s tag the dataset to indicate that it represents the ETF holdings data as of Q1 2022:
As we move forward in time and new data becomes available by Q3, we may need to update existing datasets to reflect these changes. In the following example, we first use an UPDATE statement to mark the stocks as expired in the existing ETF holdings dataset. Then we use the MERGE INTO statement based on matching conditions such as ISIN code. If a match is not found between the existing dataset and the new dataset, the new data will be inserted as new records in the table and status code will be set to ‘new’ for these records. Similarly, if the existing dataset has stocks that are not present in the new dataset, those records will remain expired with a status code of ‘expired’. Finally, for records where a match is found, the data in the existing dataset will be updated with the data from the new dataset, and record will have an unchanged status code. With Iceberg’s support for efficient data versioning and transactional consistency, we can be confident that our data updates will be applied correctly and without data corruption.
Because we now have a new version of the data, we use Iceberg tagging to provide isolation for each new version of data. In this case, we tag this as Q3_2022 and allow quant traders and other users to work on this snapshot of the data without being affected by ongoing updates to the pipeline:
This makes it very easy to see which stocks are being added and deleted. We can use Iceberg’s time travel feature to read the data at a given quarterly tag. First, let’s look at which stocks are added to the index; these are the rows that are in the Q3 snapshot but not in the Q1 snapshot. Then we will look at which stocks are removed; these are the rows that are in the Q1 snapshot but not in the Q3 snapshot:
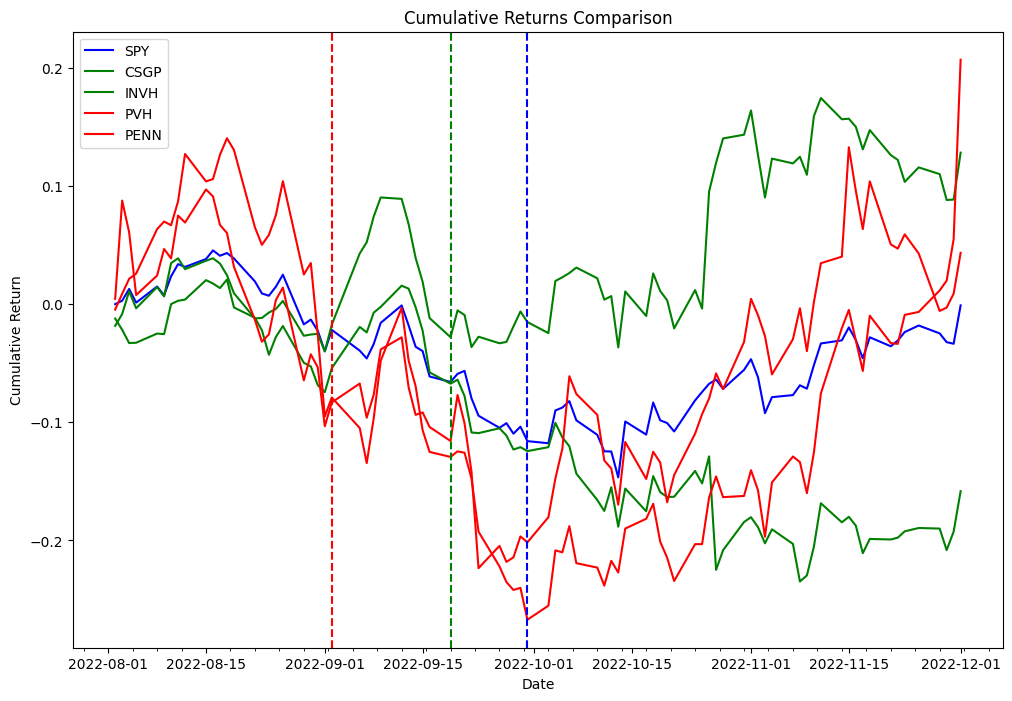
Now we use the delta obtained in the preceding code to backtest the following strategy. As part of the index rebalancing arbitrage process, we’re going to long stocks that are added to the index and short stocks that are removed from the index, and we’ll test this strategy for both the effective date and announcement date. As a proof of concept from the two different lists, we picked PVH and PENN as removed stocks, and CSGP and INVH as added stocks.
To follow along with the examples below, you will need to use the notebook provided in the Quant Research example GitHub repository.
The following table represent the portfolio orders records:
| Order Id | Column | Timestamp | Size | Price | Fees | Side |
|---|---|---|---|---|---|---|
| 0 | (PENN, PENN) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Sell |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Sell |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Buy |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Buy |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Sell |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Sell |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Buy |
| 7 | (PENN, PENN) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Buy |
The following table shows Sharpe Ratios for various holding periods and two different trade entry points: announcement and effective dates.
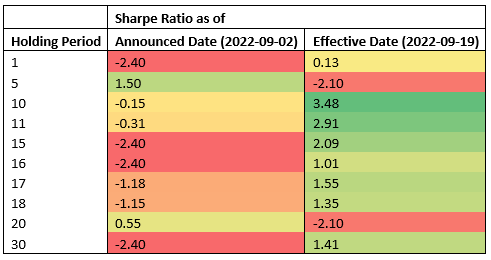
The data suggests that the effective date is the most profitable entry point across most holding periods, whereas the announcement date is an effective entry point for short-term holding periods (5 calendar days, 2 business days). Because the results are obtained from testing a single event, this is not statistically significant to accept or reject a hypothesis that index rebalancing events can be used to generate consistent alpha. The infrastructure we used for our testing can be used to run the same experiment required to do hypothesis testing at scale, but index constituents data is not readily available.
In this post, we demonstrated how the use of backtesting and the Apache Iceberg tagging feature can provide valuable insights into the performance of index arbitrage profitability strategies. By using a scalable Amazon EMR on Amazon EKS stack, researchers can easily handle the entire investment research lifecycle, from data collection to backtesting. Additionally, the Iceberg tagging feature can help address the challenge of look-ahead bias, while also providing benefits such as data retention control for GDPR compliance and maintaining lineage of the table via different branches. The experiment findings demonstrate the effectiveness of this approach in evaluating the performance of index arbitrage strategies and can serve as a useful guide for researchers in the finance industry.
 Boris Litvin is Principal Solution Architect, responsible for financial services industry innovation. He is a former Quant and FinTech founder, and is passionate about systematic investing.
Boris Litvin is Principal Solution Architect, responsible for financial services industry innovation. He is a former Quant and FinTech founder, and is passionate about systematic investing.
 Guy Bachar is a Solutions Architect at AWS, based in New York. He accompanies greenfield customers and helps them get started on their cloud journey with AWS. He is passionate about identity, security, and unified communications.
Guy Bachar is a Solutions Architect at AWS, based in New York. He accompanies greenfield customers and helps them get started on their cloud journey with AWS. He is passionate about identity, security, and unified communications.
 Noam Ouaknine is a Technical Account Manager at AWS, and is based in Florida. He helps enterprise customers develop and achieve their long-term strategy through technical guidance and proactive planning.
Noam Ouaknine is a Technical Account Manager at AWS, and is based in Florida. He helps enterprise customers develop and achieve their long-term strategy through technical guidance and proactive planning.
 Sercan Karaoglu is Senior Solutions Architect, specialized in capital markets. He is a former data engineer and passionate about quantitative investment research.
Sercan Karaoglu is Senior Solutions Architect, specialized in capital markets. He is a former data engineer and passionate about quantitative investment research.
 Jack Ye is a software engineer in the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
Jack Ye is a software engineer in the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
 Amogh Jahagirdar is a Software Engineer in the Athena Data Lake team. He is an Apache Iceberg Committer.
Amogh Jahagirdar is a Software Engineer in the Athena Data Lake team. He is an Apache Iceberg Committer.
Post Syndicated from Bryan Young original https://www.servethehome.com/sodola-8-port-2-5gbe-and-1-port-10gbe-switch-review/
In our Sodola SL-SWTG018AS review, we check out this 8x 2.5GbE and 1x SFP+ 10GbE switch to see just how low the power consumption can be
The post Sodola 8-port 2.5GbE and 1-port 10GbE Switch Review appeared first on ServeTheHome.
Post Syndicated from Explosm.net original https://explosm.net/comics/china
New Cyanide and Happiness Comic
Post Syndicated from Hidetoshi Takeuchi original https://aws.amazon.com/blogs/security/aws-achieves-its-third-ismap-authorization-in-japan/
Earning and maintaining customer trust is an ongoing commitment at Amazon Web Services (AWS). Our customers’ security requirements drive the scope and portfolio of the compliance reports, attestations, and certifications that we pursue. We’re excited to announce that AWS has achieved authorization under the Information System Security Management and Assessment Program (ISMAP), effective from April 1, 2023, to March 31, 2024. The authorization scope covers a total of 157 AWS services (an increase of 11 services over the previous authorization) across 22 AWS Regions (an increase of 1 Region over the previous authorization), including the Asia Pacific (Tokyo) Region and the Asia Pacific (Osaka) Region. This is the third time that AWS has undergone an assessment since ISMAP was first published by the ISMAP steering committee in March 2020.
ISMAP is a Japanese government program for assessing the security of public cloud services. The purpose of ISMAP is to provide a common set of security standards for cloud service providers (CSPs) to comply with as a baseline requirement for government procurement. ISMAP introduces security requirements for cloud domains, practices, and procedures that CSPs must implement. CSPs must engage with an ISMAP-approved third-party assessor to assess compliance with the ISMAP security requirements in order to apply as an ISMAP-registered CSP. ISMAP evaluates the security of each CSP and registers those that satisfy the Japanese government’s security requirements. Upon successful ISMAP registration of CSPs, government procurement departments and agencies can accelerate their engagement with the registered CSPs and contribute to the smooth introduction of cloud services in government information systems.
The achievement of this authorization demonstrates the proactive approach that AWS has taken to help customers meet compliance requirements set by the Japanese government and to deliver secure AWS services to our customers. Service providers and customers of AWS can use the ISMAP authorization of AWS services to support their own ISMAP authorization programs. The full list of 157 ISMAP-authorized AWS services is available on the AWS Services in Scope by Compliance Program webpage, and customers can also access the ISMAP Customer Package on AWS Artifact. You can confirm the AWS ISMAP authorization status and find detailed scope information on the ISMAP Portal.
As always, we are committed to bringing new services and Regions into the scope of our ISMAP program, based on your business needs. If you have any questions, don’t hesitate to contact your AWS Account Manager.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from original https://lwn.net/Articles/936728/
The C language is expressive in many ways, but it still does not have ways
to express many of the relationships between fields in a data structure.
That gap can be at least partially filled, though, if one is willing to
create and use non-standard extensions. The adoption of of those
extensions, in the form of the __counted_by() macro, has been
merged for the 6.5 kernel release, even though the compiler feature it
depends on has not yet been finalized.
Post Syndicated from original https://lwn.net/Articles/937204/
Version 5.38.0 of the Perl language is out. “Perl 5.38.0 represents
” Significant changes include a new class feature,
approximately 12 months of development since Perl 5.36.0 and contains
approximately 290,000 lines of changes across 1,500 files from 100
authors.
Unicode 15.0 support, a new API for hooking into functions, and more; see
the
5.38.0 perldelta page for details.
Post Syndicated from original https://lwn.net/Articles/937189/
Security updates have been issued by Debian (cups, gst-plugins-bad1.0, gst-plugins-base1.0, gst-plugins-good1.0, python3.7, and yajl), Fedora (chromium, kubernetes, pcs, and webkitgtk), Scientific Linux (open-vm-tools), SUSE (iniparser, keepass, libvirt, prometheus-ha_cluster_exporter, prometheus-sap_host_exporter, rekor, terraform-provider-aws, terraform-provider-helm, and terraform-provider-null), and Ubuntu (python-reportlab and vim).
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=UnctYIlumTA
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/07/self-driving-cars-are-surveillance-cameras-on-wheels.html
Police are already using self-driving car footage as video evidence:
While security cameras are commonplace in American cities, self-driving cars represent a new level of access for law enforcement and a new method for encroachment on privacy, advocates say. Crisscrossing the city on their routes, self-driving cars capture a wider swath of footage. And it’s easier for law enforcement to turn to one company with a large repository of videos and a dedicated response team than to reach out to all the businesses in a neighborhood with security systems.
“We’ve known for a long time that they are essentially surveillance cameras on wheels,” said Chris Gilliard, a fellow at the Social Science Research Council. “We’re supposed to be able to go about our business in our day-to-day lives without being surveilled unless we are suspected of a crime, and each little bit of this technology strips away that ability.”
[…]
While self-driving services like Waymo and Cruise have yet to achieve the same level of market penetration as Ring, the wide range of video they capture while completing their routes presents other opportunities. In addition to the San Francisco homicide, Bloomberg’s review of court documents shows police have sought footage from Waymo and Cruise to help solve hit-and-runs, burglaries, aggravated assaults, a fatal collision and an attempted kidnapping.
In all cases reviewed by Bloomberg, court records show that police collected footage from Cruise and Waymo shortly after obtaining a warrant. In several cases, Bloomberg could not determine whether the recordings had been used in the resulting prosecutions; in a few of the cases, law enforcement and attorneys said the footage had not played a part, or was only a formality. However, video evidence has become a lynchpin of criminal cases, meaning it’s likely only a matter of time.
Post Syndicated from Bozho original https://blog.bozho.net/blog/4118
Преди няколко дни Европейската комисия предложи законодателен пакет за въвеждане на дигитално евро.
По време на предизборната кампания участвах в един подкаст, фокусиран върху криптовалутите и бях попитан какво мисля за дигиталните валути, създадени от централни банки. И най-вече за рисковете от нарушаване на неприкосновеността на личното пространство чрез проследяване на всяко плащане.
Отговорих, че съм твърдо за възможността от анонимни плащания, защото в противен случай някой някъде ще следи и профилира потребителското ни поведение, а от това рано или късно ще произтекат проблеми. Няма да правя дълго сравнение със следящата всичко власт в Китай, но за това става дума.
В тази връзка смятам, че ЕК е свършила добра работа в проекта на регламент за дигитално евро, поради три аспекта.
Първо, няма планове за премахване на банкнотите. Да, в един момент пазарът може да наложи изцяло електронни плащания, така че това не е пълна гаранция, но е важен елемент.
Второ, онлайн плащанията няма да могат да бъдат централно следени. Регламентът не предвижда всичко технически детайли (и даже още не е избрано дали ще се ползва т.нар. distributed ledger, стоящ зад криптовалутите), но предвижда организационни и криптографски гаранции за защита на данните от централно събиране.
Трето, най-важно – предвижда офлайн плащания. Т.е. ще можем с телефона си, пълен с дигитално евро, да платим в магазин, без да се свързваме с някоя централна система, която да проследи транзакцията. Има и забрана за съхранение на данните за offline транзакциите, освен за „тегленията“ (т.е. зареждането на пари в телефона за офлайн плащане), точно както досега с тегленето от банкомат.
Европейските народи и съответно европейските институциите имат ценности и неприкосновеността на личното пространство е една от тях. Затова всяко електронно удобство е пречупено и през тази ценност. Ще следя техническите детайли, защото те ще бъдат важни, но оценявам първоначалното предложение положително.
Материалът Дигитално евро и защита на личното пространство е публикуван за пръв път на БЛОГодаря.
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=0EmPOBobkAk
Post Syndicated from original https://xkcd.com/2797/

Post Syndicated from Eric Smith original https://www.servethehome.com/amd-epyc-bergamo-launch-skus/
The AMD EPYC “Bergamo” line is comprised of three SKUs ranging from 112 to 128 cores in one of this year’s hottest releases
The post AMD EPYC Bergamo Launch SKUs appeared first on ServeTheHome.
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=Pbhy1i_5ZlM
Post Syndicated from Explosm.net original https://explosm.net/comics/people-pleaser
New Cyanide and Happiness Comic
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/hostilities/


Post Syndicated from original http://www.gatchev.info/blog/?p=2592
Вече от поне две седмици от различни източници постъпва информация, че руската армия е минирала АЕЦ Запорижя на практика напълно. Повечето от източниците (напр. украинското разузнаване) са пристрастни и е разумно да не бъдат приемани с абсолютно безрезервно доверие. Има обаче източници, непублични и с ограничен достъп, които не са твърде пристрастни, а твърдят същото. Така че е разумно да се приеме, че е възможно (ако и не абсолютно сигурно) да е вярно.
А от няколко дни постъпват новини, че руската армия се изтегля тихомълком от АЕЦ-а. Досега тя го държеше под строг контрол – в централата по всяко време имаше сериозни по размер руски военни части, включително тежко въоръжение (танкове, ракетни установки…). От военна точка изтегляне не се налага, пунктът все още е далече от бойната линия. Едно от вероятните предположения е, че има опасност централата да стане източник на радиоактивно заразяване – поради взривяване на мините или по друга причина.
В тази връзка може би ще е полезно да знаем какво да правим, ако този най-лош сценарий се сбъдне. Ако пък не, знаенето няма да ни навреди.
Общи думи
Адекватните мерки при радиоактивно заразяване са различни, в зависимост от типа и силата на заразяването. Те пък зависят от вида на източника, разстоянието до него и други фактори.
Когато източникът е единичен (ядрен взрив, авария в АЕЦ…) и разстоянието е много стотици или хиляди километри, почти единствената опасност е от отделения радиоактивен йод (осноно изотоп 131). Той се натрупва в щитовидната жлеза на хората и животните и увеличава вероятността от рак в нея. Другите опасности от него или други радионуклиди в този случай обикновено са минимални. (При много лоши стечения на обстоятелствата могат да бъдат реални. Това описание не ги покрива.)
Опасността от йод-131 зависи от количеството му около нас. То – от общото отделено количество йод-131 и дали и колко от него е пренесено от мястото на инцидента към нас. При разстояние като това от България до АЕЦ Запорижя пренасянето зависи от атмосферните условия около и след инцидента.
Количеството отделен йод би зависело от какви и колко обекти в АЕЦ Запорижя са пострадали, и в каква степен. АЕЦ-ът има 6 реактора ВВЕР-1000, плюс сериозни като размер охладителни басейни за първично съхранение на отработеното ядрено гориво. Ако всички те пострадат сериозно, количеството отделен йод-131 може да е десетки пъти над отделеното при авариите в АЕЦ Чернобил и Фукушима, и хиляди пъти над отделеното при употреба на един или няколко тактически ядрени заряда. (Това не означава, че другите последствия непременно също ще бъдат толкова по-големи, или дори същите.)
Размерът на уврежданията при потенциален инцидент е невъзможно да се предскаже отсега, атмосферните условия – също. Затова давам съвет как да се действа срещу радиоактивния йод при най-лош вероятен вариант. (Ако се появи реална опасност и от други радионуклиди, това ще е тема за отделен запис.)
За щастие Енергодар е на много стотици километри от нас. Ако там се случи нещо, дори ако вятърът духа оттам насам (което е рядко), ще имаме време да научим. Ще имаме време и да разберем дали е отделена радиация, и ако да – дали е количество, което заслужава предпазни мерки. След това ще имаме време и да проверим дали вятърът го носи към нас или надругаде. И след това, ако се налага, ще имаме предостатъчно време да вземем предпазни мерки, без да сме закъснели. Дебело подчертавам – не взимайте предпазните мерки преди да е потвърдено, че се налага!
Защита срещу радиоактивен йод
Радиоактивният йод е опасен с това, че щитовидната ни жлеза го поема и натрупва точно както обикновения йод. (И с това се излага на лъчението от атомите му.) Ако тя бъде наситена с достатъчно йод преди радиоактивният да стигне до нас, тя няма да поема повече и съответно няма да поеме от радиоактивния.
Предпочитаното за насищане с йод средство е калиев йодид. Той е активното вещество във всички йодни хапчета. Химическият калиев йодид е точно същото – ако нямате йодни хапчета, но имате химически калиев йодид, можете да отмерите от него правилната доза. (Горчив е на вкус – можете да го приемете с ядене или някакъв подсладител, не му пречат. Може да подразни стомаха – добре е да се приема с храна, или поне с прясно или кисело мляко. Храната не пречи на резорбцията му.)
Ако нямате други варианти, йод може да се набави и от йодна тинктура. Тинктурата е разтвор на йод (често и калиев йодид) във вода, спирт или комбинация от двете. Какво съдържа и точното му количество трябва да са посочени на опаковката – ако не са, не я използвайте! Ако съдържа само или основно чист йод, занижете малко милиграмите (100 мг чист йод са приблизително еквивалентни на 126 мг калиев йодид). Вкусът ѝ също не е приятен.
Тинктурата може да бъде предпочитана при хора, които не могат да приемат йод през стомаха (напр. тежки стомашни проблеми или силно чувствителен стомах). При намазване по кожата в областта на корема обикновено се резорбира около 80% от йода в нея. (Вместо да пиете таблетка от 130 мг, можете да намажете колкото тинктура съдържа 160 мг. калиев йодид или 125 мг. йод. Типичната за България йодна тинктура съдържа 5% йод и 10% калиев йодид – 0.8 до 1 куб. см от нея е подходяща доза за 72 кг. тегло.) Не е страшно да намажете повече от необходимото – опасно за здравето количество няма да се резорбира. (Но по-чувствителна кожа може да се раздразни – внимавайте пък за това!)
Може да ви предложат в аптеката Йодасепт или друга търговска марка на повидон-йодин. За дезинфекция на рани е прекрасен, за насищане с йод – не. Йодът в него е 1%, 15 пъти по-малко, отколкото в йодна тинктура. При намазване върху кожата не е известно какъв процент се резорбира, възможно е да е близък до нулата. При вътрешно поглъщане може да отдели атомарен йод, който е силен дразнител, по-висока доза може да ви изгори стомаха. Не го пийте!
При опасност като описаната, правилната стратегия би била да се приема ежедневно доза йод до намаляване на опасността от радиоактивния йод до пренебрежима. Последното става, когато радиацията от него спадне до нива, сравними или по-ниски от тези на естествения радиационен фон. Периодът на полуразпад на йод-131 е 8 дни – тоест, на всеки 8 дни радиацията и опасността от него спадат наполовина. След 16 дни те ще са 1/4 от първоначалните, след 24 дни – 1/8, след 32 дни – 1/16 и т.н.
След десетия ден можете да намалите дозата двойно или да я приемате през ден – защитата остава на практика същата.
Добре е да започнете приема на йод поне няколко часа преди радоактивният да достигне до вас. Ако закъснеете с няколко часа или дори дни, пак си струва – по-малко предпазване е по-добре от никакво. Безсмислено е да се започва преди информация, че имаме авария с изхвърляне на радиоактивен йод – дори в идеални метеорологични условия той надали би достигнал от АЕЦ Запорижя до България за по-малко от денонощие. В типичния случай биха му трябвали 2 денонощия, а ако вятърът не го носи насам, не е изключено дори при сериозно изхвърляне дотук да не достигне опасно количество.
Оптималната доза калиев йодид зависи от теглото на индивида. Зависимостта обаче не е линейна: по-ниското тегло изисква повече калиев йодид на килограм. Ето таблица за приблизителните оптимални дози:
72 кг. – 130 мг. на ден
40-45 кг. – 65 мг. на ден.
20-30 кг. – 32-45 мг. на ден
10 кг. – 25 мг. на ден
5 кг. – 20 мг. на ден
3 кг. – 15 мг. на ден
Приемането на доза до 2 пъти оптималната обикновено е безопасно за организма – не се притеснявайте, ако не можете да я отмерите абсолютно точно. Изключение са алергичните на йод и йодни препарати – те е добре да се консултират с лекар по темата.
При болести на щитовидната жлеза тези дози може да не са адекватни. Например при болест на Хашимото може да са необходими по-ниски. Каква доза е подходяща за конкретния болен зависи от болестта и стадия ѝ – може да е от няколко пъти дадената до нулева. Задължително се консултирайте с лекаря си по въпроса!
Йодните хапчета са обикновено 2 грамажа – 130 мг. и 65 мг. Смятайте според какви имате.
Ако се налага да делите хапче (или отмерена доза калиев йодид), най-добре ги разтворете във вода. Сложете в чаша такъв брой лъжици, малки чашки или кубически сантиметри вода (ако имате с какво да ги мерите), какъвто после ще ви е най-лесно да разделите на нужните ви дози. Сипете калиевия йодид или смачкайте добре хапчето във водата с лъжичка и разбърквайте до пълно разтваряне. Дръжте разтвора в хладилник, най-добре захлупен, за да не се изпарява лесно (увеличава концентрацията на калиевия йодид в остатъка).
Ако се налага да отмерите калиев йодид на прах, най-добре намерете точна везна за малки тегла. Аптеки които изпълняват микстури и места които ремонтират бижута най-често имат. Заложни къщи, които приемат злато и сребро, често също имат (може да са по-неточни, но отклонението няма да е фатално). Ако не можете да намерите иначе, попитайте в Интернет кой би ви отмерил. (А ако имате с какво да мерите, не се колебайте да помагате на нуждаещи се.)
Ако не можете да отмерите точно малка доза, отмерете най-малкото количество, което можете да отмерите точно. Количества от няколко грама могат да бъдат внимателно доразделени на 2 или 3 равни части върху стъкло с нож; после делете отново до достигане до желаната доза или близо до нея. При делене отведнъж на повече части е по-трудно да ги направите еднакви. Количества от грам и по-малко често е най-добре да бъдат разтворени във вода и тя да бъде делена. (Спринцовки от аптеката – една 10-20 мл и една 1-2 мл – могат да са много полезни. Ако малката е за инсулин, внимавайте с деленията – може да са в инсулинови единици, а не в милилитри: 40 инсулинови единици са 1 милилитър.)
Добра идея е да дадете калиев йодид и на домашните си любимци – и те заслужават предпазване. Най-добре става с нещо, което обичат (калиевият йодид няма мирис, но има горчив вкус). Оптималните дози на единица тегло за бозайници са на практика същите като за хора. За други домашни любимци първо се консултирайте с ветеринарен лекар.