Post Syndicated from Timothy Clem original https://github.blog/2023-02-06-the-technology-behind-githubs-new-code-search/
From launching our technology preview of the new and improved code search experience a year ago, to the public beta we released at GitHub Universe last November, there’s been a flurry of innovation and dramatic changes to some of the core GitHub product experiences around how we, as developers, find, read, and navigate code.
One question we hear about the new code search experience is, “How does it work?” And to complement a talk I gave at GitHub Universe, this post gives a high-level answer to that question and provides a small window into the system architecture and technical underpinnings of the product.
So, how does it work? The short answer is that we built our own search engine from scratch, in Rust, specifically for the domain of code search. We call this search engine Blackbird, but before I explain how it works, I think it helps to understand our motivation a little bit. At first glance, building a search engine from scratch seems like a questionable decision. Why would you do that? Aren’t there plenty of existing, open source solutions out there already? Why build something new?
To be fair, we’ve tried and have been trying, for almost the entire history of GitHub, to use existing solutions for this problem. You can read a bit more about our journey in Pavel Avgustinov’s post, A brief history of code search at GitHub, but one thing sticks out: we haven’t had a lot of luck using general text search products to power code search. The user experience is poor, indexing is slow, and it’s expensive to host. There are some newer, code-specific open source projects out there, but they definitely don’t work at GitHub’s scale. So, knowing all that, we were motivated to create our own solution by three things:
- We’ve got a vision for an entirely new user experience that’s about being able to ask questions of code and get answers through iteratively searching, browsing, navigating, and reading code.
- We understand that code search is uniquely different from general text search. Code is already designed to be understood by machines and we should be able to take advantage of that structure and relevance. Searching code also has unique requirements: we want to search for punctuation (for example, a period or open parenthesis); we don’t want stemming; we don’t want stop words to be stripped from queries; and, we want to search with regular expressions.
- GitHub’s scale is truly a unique challenge. When we first deployed Elasticsearch, it took months to index all of the code on GitHub (about 8 million repositories at the time). Today, that number is north of 200 million, and that code isn’t static: it’s constantly changing and that’s quite challenging for search engines to handle. For the beta, you can currently search almost 45 million repositories, representing 115 TB of code and 15.5 billion documents.
At the end of the day, nothing off the shelf met our needs, so we built something from scratch.
Just use grep?
First though, let’s explore the brute force approach to the problem. We get this question a lot: “Why don’t you just use grep?” To answer that, let’s do a little napkin math using ripgrep on that 115 TB of content. On a machine with an eight core Intel CPU, ripgrep can run an exhaustive regular expression query on a 13 GB file cached in memory in 2.769 seconds, or about 0.6 GB/sec/core.
We can see pretty quickly that this really isn’t going to work for the larger amount of data we have. Code search runs on 64 core, 32 machine clusters. Even if we managed to put 115 TB of code in memory and assume we can perfectly parallelize the work, we’re going to saturate 2,048 CPU cores for 96 seconds to serve a single query! Only that one query can run. Everybody else has to get in line. This comes out to a whopping 0.01 queries per second (QPS) and good luck doubling your QPS—that’s going to be a fun conversation with leadership about your infrastructure bill.
There’s just no cost-effective way to scale this approach to all of GitHub’s code and all of GitHub’s users. Even if we threw a ton of money at the problem, it still wouldn’t meet our user experience goals.
You can see where this is going: we need to build an index.
A search index primer
We can only make queries fast if we pre-compute a bunch of information in the form of indices, which you can think of as maps from keys to sorted lists of document IDs (called “posting lists”) where that key appears. As an example, here’s a small index for programming languages. We scan each document to detect what programming language it’s written in, assign a document ID, and then create an inverted index where language is the key and the value is a posting list of document IDs.
Forward index
| Doc ID
|
Content
|
| 1
|
def lim
puts “mit”
end
|
| 2
|
fn limits() {
|
| 3
|
function mits() {
|
Inverted index
| Language
|
Doc IDs (postings)
|
| JavaScript
|
3, 8, 12, …
|
| Ruby
|
1, 10, 13, …
|
| Rust
|
2, 5, 11, …
|
For code search, we need a special type of inverted index called an ngram index, which is useful for looking up substrings of content. An ngram is a sequence of characters of length n. For example, if we choose n=3 (trigrams), the ngrams that make up the content “limits” are lim, imi, mit, its. With our documents above, the index for those trigrams would look like this:
| ngram
|
Doc IDs (postings)
|
| lim
|
1, 2, …
|
| imi
|
2, …
|
| mit
|
1, 2, 3, …
|
| its
|
2, 3, …
|
To perform a search, we intersect the results of multiple lookups to give us the list of documents where the string appears. With a trigram index you need four lookups: lim, imi, mit, and its in order to fulfill the query for limits.
Unlike a hashmap though, these indices are too big to fit in memory, so instead, we build iterators for each index we need to access. These lazily return sorted document IDs (the IDs are assigned based on the ranking of each document) and we intersect and union the iterators (as demanded by the specific query) and only read far enough to fetch the requested number of results. That way we never have to keep entire posting lists in memory.
Indexing 45 million repositories
The next problem we have is how to build this index in a reasonable amount of time (remember, this took months in our first iteration). As is often the case, the trick here is to identify some insight into the specific data we’re working with to guide our approach. In our case it’s two things: Git’s use of content addressable hashing and the fact that there’s actually quite a lot of duplicate content on GitHub. Those two insights lead us the the following decisions:
- Shard by Git blob object ID which gives us a nice way of evenly distributing documents between the shards while avoiding any duplication. There won’t be any hot servers due to special repositories and we can easily scale the number of shards as necessary.
- Model the index as a tree and use delta encoding to reduce the amount of crawling and to optimize the metadata in our index. For us, metadata are things like the list of locations where a document appears (which path, branch, and repository) and information about those objects (repository name, owner, visibility, etc.). This data can be quite large for popular content.
We also designed the system so that query results are consistent on a commit-level basis. If you search a repository while your teammate is pushing code, your results shouldn’t include documents from the new commit until it has been fully processed by the system. In fact, while you’re getting back results from a repository-scoped query, someone else could be paging through global results and looking at a different, prior, but still consistent state of the index. This is tricky to do with other search engines. Blackbird provides this level of query consistency as a core part of its design.
Let’s build an index
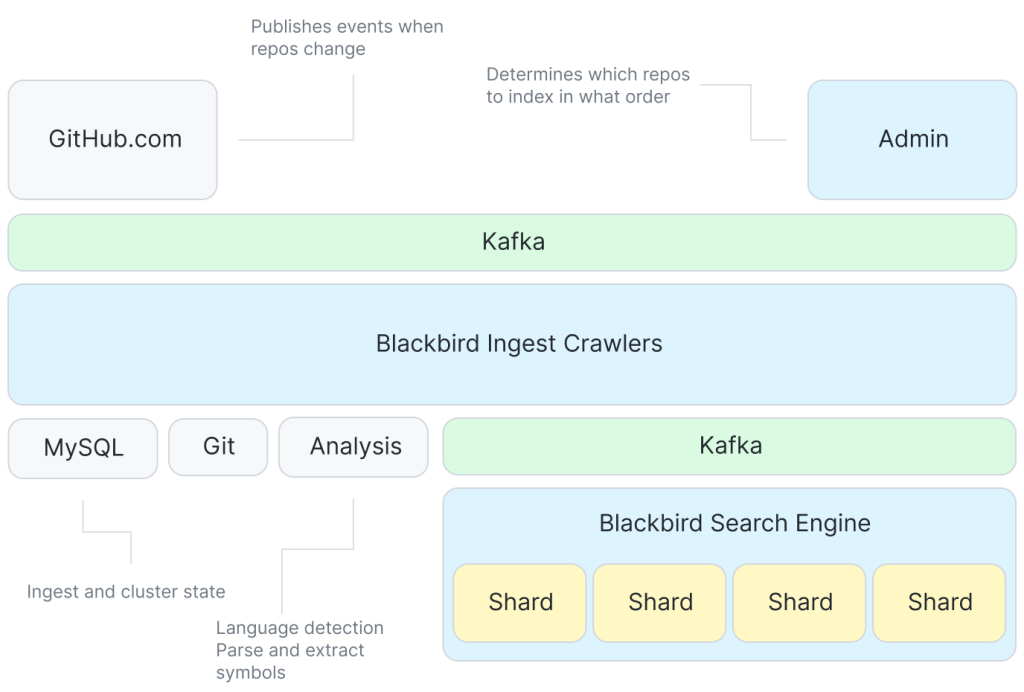
Armed with those insights, let’s turn our attention to building an index with Blackbird. This diagram represents a high level overview of the ingest and indexing side of the system.

Kafka provides events that tell us to go index something. There are a bunch of crawlers that interact with Git and a service for extracting symbols from code, and then we use Kafka, again, to allow each shard to consume documents for indexing at its own pace.
Though the system generally just responds to events like git push to crawl changed content, we have some work to do to ingest all the repositories for the first time. One key property of the system is that we optimize the order in which we do this initial ingest to make the most of our delta encoding. We do this with a novel probabilistic data structure representing repository similarity and by driving ingest order from a level order traversal of a minimum spanning tree of a graph of repository similarity.
Using our optimized ingest order, each repository is then crawled by diffing it against its parent in the delta tree we’ve constructed. This means we only need to crawl the blobs unique to that repository (not the entire repository). Crawling involves fetching blob content from Git, analyzing it to extract symbols, and creating documents that will be the input to indexing.
These documents are then published to another Kafka topic. This is where we partition the data between shards. Each shard consumes a single Kafka partition in the topic. Indexing is decoupled from crawling through the use of Kafka and the ordering of the messages in Kafka is how we gain query consistency.
The indexer shards then take these documents and build their indices: tokenizing to construct ngram indices (for content, symbols, and paths) and other useful indices (languages, owners, repositories, etc) before serializing and flushing to disk when enough work has accumulated.
Finally, the shards run compaction to collapse up smaller indices into larger ones that are more efficient to query and easier to move around (for example, to a read replica or for backups). Compaction also k-merges the posting lists by score so relevant documents have lower IDs and will be returned first by the lazy iterators. During the initial ingest, we delay compaction and do one big run at the end, but then as the index keeps up with incremental changes, we run compaction on a shorter interval as this is where we handle things like document deletions.
Life of a query
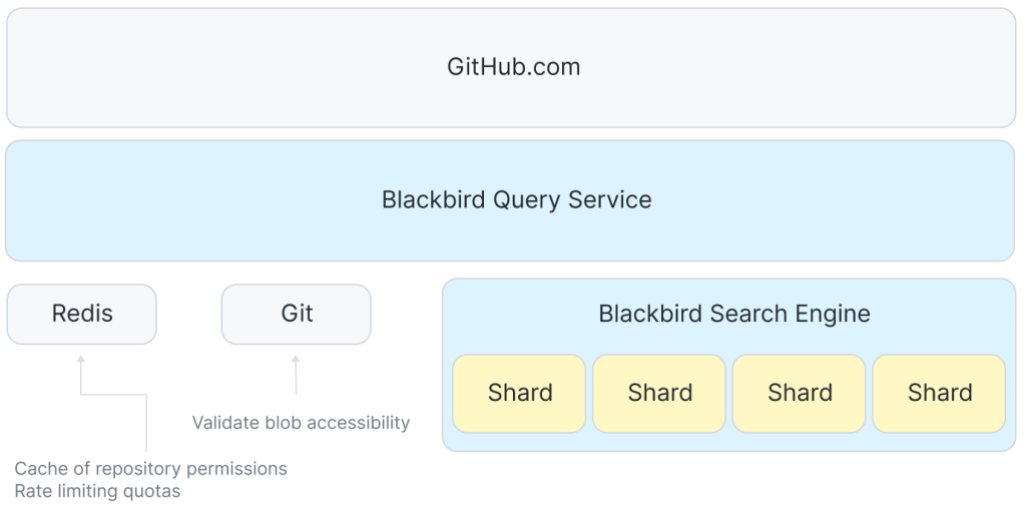
Now that we have an index, it’s interesting to trace a query through the system. The query we’re going to follow is a regular expression qualified to the Rails organization looking for code written in the Ruby programming language: /arguments?/ org:rails lang:Ruby. The high level architecture of the query path looks a little bit like this:

In between GitHub.com and the shards is a service that coordinates taking user queries and fanning out requests to each host in the search cluster. We use Redis to manage quotas and cache some access control data.
The front end accepts the user query and passes it along to the Blackbird query service where we parse the query into an abstract syntax tree and then rewrite it, resolving things like languages to their canonical Linguist language ID and tagging on extra clauses for permissions and scopes. In this case, you can see how rewriting ensures that I’ll get results from public repositories or any private repositories that I have access to.
And(
Owner("rails"),
LanguageID(326),
Regex("arguments?"),
Or(
RepoIDs(...),
PublicRepo(),
),
)
Next, we fan out and send n concurrent requests: one to each shard in the search cluster. Due to our sharding strategy, a query request must be sent to each shard in the cluster.
On each individual shard, we then do some further conversion of the query in order to lookup information in the indices. Here, you can see that the regex gets translated into a series of substring queries on the ngram indices.
and(
owners_iter("rails"),
languages_iter(326),
or(
and(
content_grams_iter("arg"),
content_grams_iter("rgu"),
content_grams_iter("gum"),
or(
and(
content_grams_iter("ume"),
content_grams_iter("ment")
)
content_grams_iter("uments"),
)
),
or(paths_grams_iter…)
or(symbols_grams_iter…)
),
…
)
If you want to learn more about a method to turn regular expressions into substring queries, see Russ Cox’s article on Regular Expression Matching with a Trigram Index. We use a different algorithm and dynamic gram sizes instead of trigrams (see below). In this case the engine uses the following grams: arg,rgu, gum, and then either ume and ment, or the 6 gram uments.
The iterators from each clause are run: and means intersect, or means union. The result is a list of documents. We still have to double check each document (to validate matches and detect ranges for them) before scoring, sorting, and returning the requested number of results.
Back in the query service, we aggregate the results from all shards, re-sort by score, filter (to double-check permissions), and return the top 100. The GitHub.com front end then still has to do syntax highlighting, term highlighting, pagination, and finally we can render the results to the page.
Our p99 response times from individual shards are on the order of 100 ms, but total response times are a bit longer due to aggregating responses, checking permissions, and things like syntax highlighting. A query ties up a single CPU core on the index server for that 100 ms, so our 64 core hosts have an upper bound of something like 640 queries per second. Compared to the grep approach (0.01 QPS), that’s screaming fast with plenty of room for simultaneous user queries and future growth.
In summary
Now that we’ve seen the full system, let’s revisit the scale of the problem. Our ingest pipeline can publish around 120,000 documents per second, so working through those 15.5 billion documents should take about 36 hours. But delta indexing reduces the number of documents we have to crawl by over 50%, which allows us to re-index the entire corpus in about 18 hours.
There are some big wins on the size of the index as well. Remember that we started with 115 TB of content that we want to search. Content deduplication and delta indexing brings that down to around 28 TB of unique content. And the index itself clocks in at just 25 TB, which includes not only all the indices (including the ngrams), but also a compressed copy of all unique content. This means our total index size including the content is roughly a quarter the size of the original data!
If you haven’t signed up already, we’d love for you to join our beta and try out the new code search experience. Let us know what you think! We’re actively adding more repositories and fixing up the rough edges based on feedback from people just like you.
Notes















 Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.