During Cloudflare's 2023 Developer Week, we announced Constellation, a set of APIs that allow everyone to run fast, low-latency inference tasks using pre-trained machine learning/AI models, directly on Cloudflare’s network.
Constellation update
We now have a few thousand accounts onboarded in the Constellation private beta and have been listening to our customer's feedback to evolve and improve the platform. Today, one month after the announcement, we are upgrading Constellation with three new features:
Bigger models We are increasing the size limit of your models from 10 MB to 50 MB. While still somewhat conservative during the private beta, this new limit opens doors to more pre-trained and optimized models you can use with Constellation.
Tensor caching When you run a Constellation inference task, you pass multiple tensor objects as inputs, sometimes creating big data payloads. These inputs travel through the wire protocol back and forth when you repeat the same task, even when the input changes from multiple runs are minimal, creating unnecessary network and data parsing overhead.
The client API now supports caching input tensors resulting in even better network latency and faster inference times.
XGBoost runtime Constellation started with the ONNX runtime, but our vision is to support multiple runtimes under a common API. Today we're adding the XGBoost runtime to the list.
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable, and it's known for its performance in structured and tabular data tasks.
You can start uploading and using XGBoost models today.
You can find the updated documentation with these new features and an example on how to use the XGBoost runtime with Constellation in our Developers Documentation.
An era of globally distributed AI
Since Cloudflare’s network is globally distributed, Constellation is our first public release of globally distributed machine learning.
But what does this mean? You may not think of a global network as the place to deploy your machine learning tasks, but machine learning has been a core part of what’s enabled much of Cloudflare’s core functionality for many years. And we run it across our global network in 300 cities.
Is this large spike in traffic an attack or a Black Friday sale? What’s going to be the best way to route this request based on current traffic patterns? Is this request coming from a human or a bot? Is this HTTP traffic a zero-day? Being able to answer these questions using automated machine learning and AI, rather than human intervention, is one of the things that’s enabled Cloudflare to scale.
But this is just a small sample of what globally distributed machine learning enables. The reason this was so helpful for us was because we were able to run this machine learning as an integrated part of our stack, which is why we’re now in the process of opening it up to more and more developers with Constellation.
As Michelle Zatlyn, our co-founder likes to say, we’re just getting started (in this space) — every day we’re adding hundreds of new users to our Constellation beta, testing out and globally deploying new models, and beyond that, deploying new hardware to support the new types of workloads that AI will bring to the our global network.
With that, we wanted to share a few announcements and some use cases that help illustrate why we’re so excited about globally distributed AI. And since it’s Speed Week, it should be no surprise that, well, speed is at the crux of it all.
Custom tailored web experiences, powered by AI
We’ve long known about the importance of performance when it comes to web experiences — in e-commerce, every second of page load time can have as much as a 7% drop off effect on conversion. But being fast is not enough. It’s necessary, but not sufficient. You also have to be accurate.
That is, rather than serving one-size-fits-all experiences, users have come to expect that you know what they want before they do.
So you have to serve personalized experiences, and you have to do it fast. That’s where Constellation can come into play. With Constellation, as a part of your e-commerce application that may already be served from Cloudflare’s network through Workers or Pages, or even store data in D1, you can now perform tasks such as categorization (what demographic is this customer most likely in?) and personalization (if you bought this, you may also like that).
Making devices smarter wherever they are
Another use case where performance is critical is in interacting with the real world. Imagine a face recognition system that detects whether you’re human or not every time you go into your house. Every second of latency makes a difference (especially if you’re holding heavy groceries).
Running inference on Cloudflare’s network, means that within 95% of the world’s population, compute, and thus a decision, is never going to be more than 50ms away. This is in huge contrast to centralized compute, where if you live in Europe, but bought a doorbell system from a US-based company, may be up to hundreds of milliseconds round trip away.
You may be thinking, why not just run the compute on the device then?
For starters, running inference on the device doesn’t guarantee fast performance. Most devices with built in intelligence are run on microcontrollers, often with limited computational abilities (not a high-end GPU or server-grade CPU). Milliseconds become seconds; depending on the volume of workloads you need to process, the local inference might not be suitable. The compute that can be fit on devices is simply not powerful enough for high-volume complex operations, certainly not for operating at low-latency.
But even user experience aside (some devices don’t interface with a user directly), there are other downsides to running compute directly on devices.
The first is battery life — the longer the compute, the shorter the battery life. There's always a power consumption hit, even if you have a custom ASIC chip or a Tensor Processing Unit (TPU), meaning shorter battery life if that's one of your constraints. For consumer products, this means having to switch out your doorbell battery (lest you get locked out). For operating fleets of devices at scale (imagine watering devices in a field) this means costs of keeping up with, and swapping out batteries.
Lastly, device hardware, and even software, is harder to update. As new technologies or more efficient chips become available, upgrading fleets of hundreds or thousands of devices is challenging. And while software updates may be easier to manage, they’ll never be as easy as updating on-cloud software, where you can effortlessly ship updates multiple times a day!
Speaking of shipping software…
AI applications, easier than ever with Constellation
Speed Week is not just about making your applications or devices faster, but also your team!
For the past six years, our developer platform has been making it easy for developers to ship new code with Cloudflare Workers. With Constellation, it’s now just as easy to add Machine Learning to your existing application, with just a few commands.
And if you don’t believe us, don’t just take our word for it. We’re now in the process of opening up the beta to more and more customers. To request access, head on over to the Cloudflare Dashboard where you’ll see a new tab for Constellation. We encourage you to check out our tutorial for getting started with Constellation — this AI thing may be even easier than you expected it to be!
We’re just getting started
This is just the beginning of our journey for helping developers build AI driven applications, and we’re already thinking about what’s next.
We look forward to seeing what you build, and hearing your feedback.
In this post, we will take you through the advancements we've made in our machine learning capabilities. We'll describe the technical strategies that have enabled us to expand the number of machine learning features and models, all while substantially reducing the processing time for each HTTP request on our network. Let's begin.
Background
For a comprehensive understanding of our evolved approach, it's important to grasp the context within which our machine learning detections operate. Cloudflare, on average, serves over 46 million HTTP requests per second, surging to more than 63 million requests per second during peak times.
Machine learning detection plays a crucial role in ensuring the security and integrity of this vast network. In fact, it classifies the largest volume of requests among all our detection mechanisms, providing the final Bot Score decision for over 72% of all HTTP requests. Going beyond, we run several machine learning models in shadow mode for every HTTP request.
At the heart of our machine learning infrastructure lies our reliable ally, CatBoost. It enables ultra low-latency model inference and ensures high-quality predictions to detect novel threats such as stopping bots targeting our customers' mobile apps. However, it's worth noting that machine learning model inference is just one component of the overall latency equation. Other critical components include machine learning feature extraction and preparation. In our quest for optimal performance, we've continuously optimized each aspect contributing to the overall latency of our system.
Initially, our machine learning models relied on single-request features, such as presence or value of certain headers. However, given the ease of spoofing these attributes, we evolved our approach. We turned to inter-request features that leverage aggregated information across multiple dimensions of a request in a sliding time window. For example, we now consider factors like the number of unique user agents associated with certain request attributes.
The extraction and preparation of inter-request features were handled by Gagarin, a Go-based feature serving platform we developed. As a request arrived at Cloudflare, we extracted dimension keys from the request attributes. We then looked up the corresponding machine learning features in the multi-layered cache. If the desired machine learning features were not found in the cache, a memcached "get" request was made to Gagarin to fetch those. Then machine learning features were plugged into CatBoost models to produce detections, which were then surfaced to the customers via Firewall and Workers fields and internally through our logging pipeline to ClickHouse. This allowed our data scientists to run further experiments, producing more features and models.
Previous system design for serving machine learning features over Unix socket using Gagarin.
Initially, Gagarin exhibited decent latency, with a median latency around 200 microseconds to serve all machine learning features for given keys. However, as our system evolved and we introduced more features and dimension keys, coupled with increased traffic, the cache hit ratio began to wane. The median latency had increased to 500 microseconds and during peak times, the latency worsened significantly, with the p99 latency soaring to roughly 10 milliseconds. Gagarin underwent extensive low-level tuning, optimization, profiling, and benchmarking. Despite these efforts, we encountered the limits of inter-process communication (IPC) using Unix Domain Socket (UDS), among other challenges, explored below.
Problem definition
In summary, the previous solution had its drawbacks, including:
High tail latency: during the peak time, a portion of requests experienced increased latency caused by CPU contention on the Unix socket and Lua garbage collector.
Suboptimal resource utilization: CPU and RAM utilization was not optimized to the full potential, leaving less resources for other services running on the server.
Machine learning features availability: decreased due to memcached timeouts, which resulted in a higher likelihood of false positives or false negatives for a subset of the requests.
Scalability constraints: as we added more machine learning features, we approached the scalability limit of our infrastructure.
Equipped with a comprehensive understanding of the challenges and armed with quantifiable metrics, we ventured into the next phase: seeking a more efficient way to fetch and serve machine learning features.
Exploring solutions
In our quest for more efficient methods of fetching and serving machine learning features, we evaluated several alternatives. The key approaches included:
Further optimizing Gagarin: as we pushed our Go-based memcached server to its limits, we encountered a lower bound on latency reductions. This arose from IPC over UDS synchronization overhead and multiple data copies, the serialization/deserialization overheads, as well as the inherent latency of garbage collector and the performance of hashmap lookups in Go.
Considering Quicksilver: we contemplated using Quicksilver, but the volume and update frequency of machine learning features posed capacity concerns and potential negative impacts on other use cases. Moreover, it uses a Unix socket with the memcached protocol, reproducing the same limitations previously encountered.
Increasing multi-layered cache size: we investigated expanding cache size to accommodate tens of millions of dimension keys. However, the associated memory consumption, due to duplication of these keys and their machine learning features across worker threads, rendered this approach untenable.
Sharding the Unix socket: we considered sharding the Unix socket to alleviate contention and improve performance. Despite showing potential, this approach only partially solved the problem and introduced more system complexity.
Switching to RPC: we explored the option of using RPC for communication between our front line server and Gagarin. However, since RPC still requires some form of communication bus (such as TCP, UDP, or UDS), it would not significantly change the performance compared to the memcached protocol over UDS, which was already simple and minimalistic.
After considering these approaches, we shifted our focus towards investigating alternative Inter-Process Communication (IPC) mechanisms.
IPC mechanisms
Adopting a first principles design approach, we questioned: "What is the most efficient low-level method for data transfer between two processes provided by the operating system?" Our goal was to find a solution that would enable the direct serving of machine learning features from memory for corresponding HTTP requests. By eliminating the need to traverse the Unix socket, we aimed to reduce CPU contention, improve latency, and minimize data copying.
To identify the most efficient IPC mechanism, we evaluated various options available within the Linux ecosystem. We used ipc-bench, an open-source benchmarking tool specifically designed for this purpose, to measure the latencies of different IPC methods in our test environment. The measurements were based on sending one million 1,024-byte messages forth and back (i.e., ping pong) between two processes.
IPC method
Avg duration, μs
Avg throughput, msg/s
eventfd (bi-directional)
9.456
105,533
TCP sockets
8.74
114,143
Unix domain sockets
5.609
177,573
FIFOs (named pipes)
5.432
183,388
Pipe
4.733
210,369
Message Queue
4.396
226,421
Unix Signals
2.45
404,844
Shared Memory
0.598
1,616,014
Memory-Mapped Files
0.503
1,908,613
Based on our evaluation, we found that Unix sockets, while taking care of synchronization, were not the fastest IPC method available. The two fastest IPC mechanisms were shared memory and memory-mapped files. Both approaches offered similar performance, with the former using a specific tmpfs volume in /dev/shm and dedicated system calls, while the latter could be stored in any volume, including tmpfs or HDD/SDD.
Missing ingredients
In light of these findings, we decided to employ memory-mapped files as the IPC mechanism for serving machine learning features. This choice promised reduced latency, decreased CPU contention, and minimal data copying. However, it did not inherently offer data synchronization capabilities like Unix sockets. Unlike Unix sockets, memory-mapped files are simply files in a Linux volume that can be mapped into memory of the process. This sparked several critical questions:
How could we efficiently fetch an array of hundreds of float features for given dimension keys when dealing with a file?
How could we ensure safe, concurrent and frequent updates for tens of millions of keys?
How could we avert the CPU contention previously encountered with Unix sockets?
How could we effectively support the addition of more dimensions and features in the future?
To address these challenges we needed to further evolve this new approach by adding a few key ingredients to the recipe.
Augmenting the Idea
To realize our vision of memory-mapped files as a method for serving machine learning features, we needed to employ several key strategies, touching upon aspects like data synchronization, data structure, and deserialization.
Wait-free synchronization
When dealing with concurrent data, ensuring safe, concurrent, and frequent updates is paramount. Traditional locks are often not the most efficient solution, especially when dealing with high concurrency environments. Here's a rundown on three different synchronization techniques:
With-lock synchronization: a common approach using mechanisms like mutexes or spinlocks. It ensures only one thread can access the resource at a given time, but can suffer from contention, blocking, and priority inversion, just as evident with Unix sockets.
Lock-free synchronization: this non-blocking approach employs atomic operations to ensure at least one thread always progresses. It eliminates traditional locks but requires careful handling of edge cases and race conditions.
Wait-free synchronization: a more advanced technique that guarantees every thread makes progress and completes its operation without being blocked by other threads. It provides stronger progress guarantees compared to lock-free synchronization, ensuring that each thread completes its operation within a finite number of steps.
We store the synchronization state, which coordinates access to these data copies, in a third memory-mapped file, referred to as "state". This file contains an atomic 64-bit integer, which represents an InstanceVersionand a pair of additional atomic 32-bit variables, tracking the number of active readers for each data copy. The InstanceVersion consists of the currently active data file index (1 bit), the data size (39 bits, accommodating data sizes up to 549 GB), and a data checksum (24 bits).
Zero-copy deserialization
To efficiently store and fetch machine learning features, we needed to address the challenge of deserialization latency. Here, zero-copy deserialization provides an answer. This technique reduces the time and memory required to access and use data by directly referencing bytes in the serialized form.
We turned to rkyv, a zero-copy deserialization framework in Rust, to help us with this task. rkyv implements total zero-copy deserialization, meaning no data is copied during deserialization and no work is done to deserialize data. It achieves this by structuring its encoded representation to match the in-memory representation of the source type.
One of the key features of rkyv that our solution relies on is its ability to access HashMap data structures in a zero-copy fashion. This is a unique capability among Rust serialization libraries and one of the main reasons we chose rkyv for our implementation. It also has a vibrant Discord community, eager to offer best-practice advice and accommodate feature requests.
Leveraging the benefits of memory-mapped files, wait-free synchronization and zero-copy deserialization, we've crafted a unique and powerful tool for managing high-performance, concurrent data access between processes. We've packaged these concepts into a Rust crate named mmap-sync, which we're thrilled to open-source for the wider community.
At the core of the mmap-sync package is a structure named Synchronizer. It offers an avenue to read and write any data expressible as a Rust struct. Users simply have to implement or derive a specific Rust trait surrounding struct definition – a task requiring just a single line of code. The Synchronizer presents an elegantly simple interface, equipped with "write" and "read" methods.
impl Synchronizer {
/// Write a given `entity` into the next available memory mapped file.
pub fn write<T>(&mut self, entity: &T, grace_duration: Duration) -> Result<(usize, bool), SynchronizerError> {
…
}
/// Reads and returns `entity` struct from mapped memory wrapped in `ReadResult`
pub fn read<T>(&mut self) -> Result<ReadResult<T>, SynchronizerError> {
…
}
}
/// FeaturesMetadata stores features along with their metadata
#[derive(Archive, Deserialize, Serialize, Debug, PartialEq)]
#[archive_attr(derive(CheckBytes))]
pub struct FeaturesMetadata {
/// Features version
pub version: u32,
/// Features creation Unix timestamp
pub created_at: u32,
/// Features represented by vector of hash maps
pub features: Vec<HashMap<u64, Vec<f32>>>,
}
A read operation through the Synchronizer performs zero-copy deserialization and returns a "guarded" Result encapsulating a reference to the Rust struct using RAII design pattern. This operation also increments the atomic counter of active readers using the struct. Once the Result is out of scope, the Synchronizer decrements the number of readers.
The synchronization mechanism used in mmap-sync is not only "lock-free" but also "wait-free". This ensures an upper bound on the number of steps an operation will take before it completes, thus providing a performance guarantee.
The data is stored in shared mapped memory, which allows the Synchronizer to “write” to it and “read” from it concurrently. This design makes mmap-sync a highly efficient and flexible tool for managing shared, concurrent data access.
Now, with an understanding of the underlying mechanics of mmap-sync, let's explore how this package plays a key role in the broader context of our Bot Management platform, particularly within the newly developed components: the bliss service and library.
System design overhaul
Transitioning from a Lua-based module that made memcached requests over Unix socket to Gagarin in Go to fetch machine learning features, our new design represents a significant evolution. This change pivots around the introduction of mmap-sync, our newly developed Rust package, laying the groundwork for a substantial performance upgrade. This development led to a comprehensive system redesign and introduced two new components that form the backbone of our Bots Liquidation Intelligent Security System – or BLISS, in short: the bliss service and the bliss library.
Bliss service
The blissservice operates as a Rust-based, multi-threaded sidecar daemon. It has been designed for optimal batch processing of vast data quantities and extensive I/O operations. Among its key functions, it fetches, parses, and stores machine learning features and dimensions for effortless data access and manipulation. This has been made possible through the incorporation of the Tokio event-driven platform, which allows for efficient, non-blocking I/O operations.
Bliss library
Operating as a single-threaded dynamic library, the bliss library seamlessly integrates into each worker thread using the Foreign Function Interface (FFI) via a Lua module. Optimized for minimal resource usage and ultra-low latency, this lightweight library performs tasks without the need for heavy I/O operations. It efficiently serves machine learning features and generates corresponding detections.
In addition to leveraging the mmap-sync package for efficient machine learning feature access, our new design includes several other performance enhancements:
Allocations-free operation: bliss library re-uses pre-allocated data structures and performs no heap allocations, only low-cost stack allocations. To enforce our zero-allocation policy, we run integration tests using the dhat heap profiler.
SIMD optimizations: wherever possible, the bliss library employs vectorized CPU instructions. For instance, AVX2 and SSE4 instruction sets are used to expedite hex-decoding of certain request attributes, enhancing speed by tenfold.
Compiler tuning: We compile both the bliss service and library with the following flags for superior performance:
Benchmarking & profiling: We use Criterion for benchmarking every major feature or component within bliss. Moreover, we are also able to use the Go pprof profiler on Criterion benchmarks to view flame graphs and more:
This comprehensive overhaul of our system has not only streamlined our operations but also has been instrumental in enhancing the overall performance of our Bot Management platform. Stay tuned to witness the remarkable changes brought about by this new architecture in the next section.
Rollout results
Our system redesign has brought some truly "blissful" dividends. Above all, our commitment to a seamless user experience and the trust of our customers have guided our innovations. We ensured that the transition to the new design was seamless, maintaining full backward compatibility, with no customer-reported false positives or negatives encountered. This is a testament to the robustness of the new system.
As the old adage goes, the proof of the pudding is in the eating. This couldn't be truer when examining the dramatic latency improvements achieved by the redesign. Our overall processing latency for HTTP requests at Cloudflare improved by an average of 12.5% compared to the previous system.
This improvement is even more significant in the Bot Management module, where latency improved by an average of 55.93%.
Bot Management module latency, in microseconds.
More specifically, our machine learning features fetch latency has improved by several orders of magnitude:
Latency metric
Before (μs)
After (μs)
Change
p50
532
9
-98.30% or x59
p99
9510
18
-99.81% or x528
p999
16000
29
-99.82% or x551
To truly grasp this impact, consider this: with Cloudflare’s average rate of 46 million requests per second, a saving of 523 microseconds per request equates to saving over 24,000 days or 65 years of processing time every single day!
In addition to latency improvements, we also reaped other benefits from the rollout:
Enhanced feature availability: thanks to eliminating Unix socket timeouts, machine learning feature availability is now a robust 100%, resulting in fewer false positives and negatives in detections.
Improved resource utilization: our system overhaul liberated resources equivalent to thousands of CPU cores and hundreds of gigabytes of RAM – a substantial enhancement of our server fleet's efficiency.
Code cleanup: another positive spin-off has been in our Lua and Go code. Thousands of lines of less performant and less memory-safe code have been weeded out, reducing technical debt.
Upscaled machine learning capabilities: last but certainly not least, we've significantly expanded our machine learning features, dimensions, and models. This upgrade empowers our machine learning inference to handle hundreds of machine learning features and dozens of dimensions and models.
Conclusion
In the wake of our redesign, we've constructed a powerful and efficient system that truly embodies the essence of 'bliss'. Harnessing the advantages of memory-mapped files, wait-free synchronization, allocation-free operations, and zero-copy deserialization, we've established a robust infrastructure that maintains peak performance while achieving remarkable reductions in latency. As we navigate towards the future, we're committed to leveraging this platform to further improve our Security machine learning products and cultivate innovative features. Additionally, we're excited to share parts of this technology through an open-sourced Rust package mmap-sync.
As we leap into the future, we are building upon our platform's impressive capabilities, exploring new avenues to amplify the power of machine learning. We are deploying a new machine learning model built on BLISS with select customers. If you are a Bot Management subscriber and want to test the new model, please reach out to your account team.
Separately, we are on the lookout for more Cloudflare customers who want to run their own machine learning models at the edge today. If you’re a developer considering making the switch to Workers for your application, sign up for our Constellation AI closed beta. If you’re a Bot Management customer and looking to run an already trained, lightweight model at the edge, we would love to hear from you. Let's embark on this path to bliss together.
Developers today do more than just write and ship code—they’re expected to navigate a number of tools, environments, and technologies, including the new frontier of generative artificial intelligence (AI) coding tools. But the most important thing for developers isn’t story points or the speed of deployments. It’s the developer experience, which determines how efficiently and productively developers can exceed standards, enter a flow state, and drive impact.
I say this not only as GitHub’s chief product officer, but as a long-time developer who has worked across every part of the stack. Decades ago, when I earned my master’s in mechanical engineering, I became one of the first technologists to apply AI in the lab. Back then, it would take our models five days to process our larger datasets—which is striking considering the speed of today’s AI models. I yearned for tools that would make me more efficient and shorten my time to production. This is why I’m passionate about developer experience (DevEx) and have made it my focus as GitHub’s chief product officer.
Amid the rapid advancements in generative AI, we wanted to get a better understanding from developers about how new tools—and current workflows—are impacting the overall developer experience. As a starting point, we focused on some of the biggest components of the developer experience: developer productivity, team collaboration, AI, and how developers think they can best drive impact in enterprise environments.
To do so, we partnered with Wakefield Research to survey 500 U.S.-based developers at enterprise companies. In the following report, we’ll show how organizations can remove barriers to help enterprise engineering teams drive innovation and impact in this new age of software development. Ultimately, the way to innovate at scale is to empower developers by improving their productivity, increasing their satisfaction, and enabling them to do their best work—every day. After all, there can be no progress without developers who are empowered to drive impact.
Inbal Shani Chief Product Officer // GitHub
Learn how generative AI is changing the developer experience
Discover how generative AI is changing software development in a pre-recorded session from GitHub.
With this survey, we wanted to better understand the typical experience for developers—and identify key ways companies can empower their developers and achieve greater success.
One big takeaway: It starts with investing in a great developer experience. And collaboration, as we learned from our research, is at the core of how developers want to work and what makes them most productive, satisfied, and impactful.
C = Collaboration, the multiplier across the entire developer experience.
DevEx is a formula that takes into account:
How simple and fast it is for a developer to implement a change on a codebase—or be productive.
How frictionless it is to move from idea through production to impact.
How positively or negatively the work environment, workflows, and tools affect developer satisfaction.
For leaders, developer experience is about creating a collaborative environment where developers can be their most productive, impactful, and satisfied at work. For developers, collaboration is one of the most important parts of the equation.
Current performance metrics fall short of developer expectations
Developers say performance metrics don’t meet expectations
The way developers are currently evaluated doesn’t align with how they think their performance should be measured.
For instance, the developers we surveyed say they’re currently measured by the number of incidents they resolve. But developers believe that how they handle those bugs and issues is more important to performance. This aligns with the belief that code quality over code quantity should remain a top performance metric.
Developers also believe collaboration and communication should be just as important as code quality in terms of performance measures. Their ability to collaborate and communicate with others is essential to their job, but only 33% of developers report that their companies use it as a performance metric.
Metrics currently used to measure performance, compared with metrics developers think should be used to measure their performance.
More than output quantity and efficiency, code quality and collaboration are the most
important performance metrics, according to the developers we surveyed.
The top ranked responses that developers say their teams are working the most on including writing code and finding and fixing security vulnerabilities.
Developers want more opportunities to upskill and drive impact
When developers are asked about what makes a positive impact on their workday, they rank learning new skills (43%), getting feedback from end users (39%), and automated tests (38%), and designing solutions to novel problems (36%) as top contenders.
The top tasks developers say positively impact their workdays.
But developers say they’re spending most of their time writing code and tests, then waiting for that code to be reviewed or builds and tests to be executed.
On a typical day, the enterprise developers we surveyed report their teams are busy with a variety of tasks, including writing code, fixing security vulnerabilities, and getting feedback from end users, among other things. Developers also report that they spend a similar amount of time across these tasks, indicating that they’re stretched thin throughout the day.
The tasks developers say they spend the most time working on each day.
Notably, developers say they spend the same amount of time waiting for builds and tests as they do writing new code.
This suggests that wait times for builds and tests are still a persistent problem despite investments in DevOps tools over the past decade.
Developers also continue to face obstacles, such as waiting on code review, builds, and test runs, which can hinder their ability to learn new skills and design solutions to novel problems, and our research suggests that these factors can have the biggest impact on their overall satisfaction.
Developers want feedback from end users, but face challenges
Developers say getting feedback from end users (39%) is the second-most important thing that positively impacts their workdays—but it’s often challenging for development teams to get that feedback directly.
Product managers and marketing teams often act as intermediaries, making it difficult for developers to directly receive end-user feedback.
Developers would ideally receive feedback from automated and validation tests to improve their work, but sometimes these tests are sent to other teams before being handed off to engineering teams.
The top two daily tasks for development teams include writing code (32%) and finding and fixing security vulnerabilities (31%).
This shows the increased importance developers have placed on security and underscores how companies are prioritizing security.
It also demonstrates the critical role that enterprise development teams play in meeting policy and board edicts around security.
The bottom line
Developers want to upskill, design solutions, get feedback from end users, and be evaluated on their communication skills. However, wait times on builds and tests, as well as the current performance metrics they’re evaluated on, are getting in the way.
Collaboration is the cornerstone of the developer experience
Developers thrive in collaborative environments
In our survey of enterprise engineers, developers say they work with an average of 21 other developers on a typical project—and 52% report working with other teams daily or weekly. Notably, they rank regular touchpoints as the most important factor for effective collaboration.
Developers in enterprise settings often work with an average of 21 other developers on a daily or weekly cadence.
But developers also have a holistic view of collaboration—it’s defined not only by talking and meeting with others, but also by uninterrupted work time, access to fully configured developer environments, and formal mentor-mentee relationships.
Specified blocks with no team communication give developers the time and space to write code and work towards team goals.
Access to fully configured developer environments promotes consistency throughout the development process. It also helps developers collaborate faster and avoid hearing the infamous line, “But it worked on my machine.”
Mentorships can help developers upskill and build interpersonal skills that are essential in a collaborative work environment.
It’s important to note these factors can also negatively impact a developer’s work day—which suggests that ineffective meetings can serve to distract rather than help developers (something we’ve found in previous research).
Our survey indicates the factors most important to effective collaboration are so critical that when they’re not done effectively, they have a noticeable, negative impact on a developer’s work.
The tasks developers say most often have a negative impact on their workday experience.
Developers work with an average of 21 people on any given project. They need the time and tools for success—including regular touchpoints, heads-down time, access to fully-configured dev environments, and formal mentor-mentee relationships.
We wanted to learn more about how developers collaborate
As developer experience continues to be defined, so, too, will successful developer collaboration. Too many pings and messages can affect flow, but there’s still a need to stay in touch. In our survey, developers say effective collaboration results in improved test coverage and faster, cleaner, more secure code writing—which are best practices for any development team. This shows that when developers work effectively with others, they believe they build better and more secure software.
Developers widely view effective collaboration as helping to improve what they ship and how often they ship it.
Developers we surveyed believe collaboration and communication—along with code quality—should be the top priority for evaluation.
From DevOps to agile methodologies, developers and the greater business world have been talking about the importance of collaboration for a long time.
But developers are still not being measured on it.
The metrics that developers think their managers should use to evaluate their performance and productivity.
The takeaway: Companies and engineering managers should encourage regular team communication, and set time to check in–especially in remote environments–but respect developers’ need to work and focus.
Developers believe that effective and regular touchpoints with their colleagues are critical for effective team collaboration.
4 tips for engineering managers to improve collaboration
At GitHub, our researchers, developers, product teams, and analysts are dedicated to studying and improving developer productivity and satisfaction. Here are their tips for engineering leaders who want to improve collaboration among developers:
Make collaboration a goal in performance objectives. This builds the space and expectation that people will collaborate. This could be in the form of lunch and learns, joint projects, etc.
Define and scope what collaboration looks like in your organization. Let people know when they’re being informed about something vs. being consulted about something. A matrix outlining roles and responsibilities helps define each person’s role and is something GitHub teams have implemented.
Give developers time to converse and get to know one another. In particular, remote or hybrid organizations need to dedicate a portion of a developer’s time and virtual space to building relationships. Check out the GitHub guides to remote work.
Identify principal and distinguished engineers. Academic research supports the positive impact of change agents in organizations—and how they should be the people who are exceptionally great at collaboration. It’s a matter of identifying your distinguished engineers and elevating them to a place where they can model desired behaviors.
The bottom line
Effective developer collaboration improves code quality and should be a performance measure. Regular touchpoints, heads-down time, access to fully configured dev environments, and formal mentor-mentee relationships result in improved test coverage and faster, cleaner, more secure code writing.
AI improves individual performance and team collaboration
Developers are already using AI coding tools at work
A staggering 92% of U.S.-based developers working in large companies report using an AI coding tool either at work or in their personal time—and 70% say they see significant benefits to using these tools.
AI is here to stay—and it’s already transforming how developers approach their day-to-day work. That makes it critical for businesses and engineering leaders to adopt enterprise-grade AI tools to avoid their developers using non-approved applications. Companies should also establish governance standards for using AI tools to ensure that they are used ethically and effectively.
Almost all developers are already using AI coding tools at and outside of work.
Almost all (92%) developers use AI coding tools at work—and a majority (67%) have used these tools in both a work setting and during their personal time. Curiously, only 6% of developers in our survey say they solely use these tools outside of work.
Developers believe AI coding tools will enhance their performance
With most developers experimenting with AI tools in the workplace, our survey results suggest it’s not just idle interest leading developers to use AI. Rather, it’s a recognition that AI coding tools will help them meet performance standards.
In our survey, developers say AI coding tools can help them meet existing performance standards with improved code quality, faster outputs, and fewer production-level incidents. They also believe that these metrics should be used to measure their performance beyond code quantity.
Developers widely think that AI coding tools will layer into their existing workflows and bring greater efficiencies—but they do not think AI will change how software is made.
Around one-third of developers report that their managers currently assess their performance based on the volume of code they produce—and an equal number anticipate that this will persist when they start using AI-based coding tools.
Notably, the quantity of code a developer produces may not necessarily correspond to its business value.
Stay smart. With the increase of AI tooling being used in software development—which often contributes to code volume—engineering leaders will need to ask whether measuring code volume is still the best way to measure productivity and output.
Developers think AI coding tools will lead to greater team collaboration
Beyond improving individual performance, more than 4 in 5 developers surveyed (81%) say AI coding tools will help increase collaboration within their teams and organizations.
In fact, security reviews, planning, and pair programming are the most significant points of collaboration and the tasks that development teams are expected to, and should, work on with the help of AI coding tools. This also indicates that code and security reviews will remain important as developers increase their use of AI coding tools in the workplace.
Developers think their teams will need to become more collaborative as they start using AI coding tools.
Sometimes, developers can do the same thing with one line or multiple lines of code. Even still, one-third of developers in our survey say their managers measure their performance based on how much code they produce.
Notably, developers believe AI coding tools will give them more time to focus on solution design. This has direct organizational benefits and means developers believe they’ll spend more time designing new features and products with AI instead of writing boilerplate code.
Developers are already using generative AI coding tools to automate parts of their workflow, which frees up time for more collaborative projects like security reviews, planning, and pair programming.
Developers believe that AI coding tools will help them focus on higher-value problem solving.
Developers think AI increases productivity and prevents burnout
Not only can AI coding tools help improve overall productivity, but they can also provide upskilling opportunities to help create a smarter workforce according to the developers we surveyed.
57% of developers believe AI coding tools help them improve their coding language skills—which is the top benefit they see. Beyond the prospect of acting as an upskilling aid, developers also say AI coding tools can also help with reducing cognitive effort, and since mental capacity and time are both finite resources, 41% of developers believe that AI coding tools can help with preventing burnout.
In previous research we conducted, 87% of developers reported that the AI coding tool GitHub Copilot helped them preserve mental effort while completing more repetitive tasks. This shows that AI coding tools allow developers to preserve cognitive effort and focus on more challenging and innovative aspects of software development or research and development.
AI coding tools help developers upskill while they work. Across our survey, developers consistently rank learning new skills as the number one contributor to a positive workday. But 30% also say learning and development can have a negative impact on their overall workday, which suggests some developers view learning and development as adding more work to their workdays. Notably, developers say the top benefit of AI coding tools is learning new skills—and these tools can help developers learn while they work, instead of making learning and development an additional task.
Developers are already using generative AI coding tools to automate parts of their workflow, which frees up time for more collaborative projects like security reviews, planning, and pair programming.
AI is improving the developer experience across the board
Developers in our survey suggest they can better meet standards around code quality, completion time, and the number of incidents when using AI coding tools—all of which are measures developers believe are key areas for evaluating their performance.
AI coding tools can also help reduce the likelihood of coding errors and improve the accuracy of code—which ultimately leads to more reliable software, increased application performance, and better performance numbers for developers. As AI technology continues to advance, it is likely that these coding tools will have an even greater impact on developer performance and upskilling.
AI coding tools are layering into existing developer workflows and creating greater efficiencies
Developers believe that AI coding tools will increase their productivity—but our survey suggests that developers don’t think these tools are fundamentally altering the software development lifecycle. Instead, developers suggest they’re bringing greater efficiencies to it.
The use of automation and AI has been a part of the developer workflow for a considerable amount of time, with developers already utilizing a range of automated and AI-powered tools, such as machine learning-based security checks and CI/CD pipelines.
Rather than completely overhauling operations, these tools create greater efficiencies within existing workflows, and that frees up more time for developers to concentrate on developing solutions.
The bottom line
Almost all developers (92%) are using AI coding at work—and they say these tools not only improve day-to-day tasks but enable upskilling opportunities, too. Developers see material benefits to using AI tools including improved performance and coding skills, as well as increased team collaboration.
The path forward
Developer satisfaction, productivity, and organizational impact are all positioned to get a boost from AI coding tools—and that will have a material impact on the overall developer experience.
92% of developers already saying they use AI coding tools at work and in their personal time, which makes it clear AI is here to stay. 70% of the developers we surveyed say they already see significant benefits when using AI coding tools, and 81% of the developers we surveyed expect AI coding tools to make their teams more collaborative—which is a net benefit for companies looking to improve both developer velocity and the developer experience.
Notably, 57% of developers believe that AI could help them upskill—and hold the potential to build learning and development into their daily workflow. With all of this in mind, technical leaders should start exploring AI as a solution to improve satisfaction, productivity, and the overall developer experience.
In addition to exploring AI tools, here are three takeaways engineering and business leaders should consider to improve the developer experience:
Help your developers enter a flow state with tools, processes, and practices that help them be productive, drive impact, and do creative and meaningful work.
Empower collaboration by breaking down organizational silos and providing developers with the opportunity to communicate efficiently.
Make room for upskilling within developer workflows through key investments in AI to help your organization experiment and innovate for the future.
Methodology
This report draws on a survey conducted online by Wakefield Research on behalf of GitHub from March 14, 2023 through March 29, 2023 among 500 non-student, U.S.-based developers who are not managers and work at companies with 1,000-plus employees. For a complete survey methodology, please contact [email protected].
I remember when the first iPhone was announced in 2007. This was NOT an iPhone as we think of one today. It had warts. A lot of warts. It couldn’t do MMS for example. But I remember the possibility it brought to mind. No product before had seemed like anything more than a product. The iPhone, or more the potential that the iPhone hinted at, had an actual impact on me. It changed my thinking about what could be.
In the years since no other product came close to matching that level of awe and wonder. That changed in March of this year. The release of GPT-4 had the same impact I remember from the iPhone launch. It’s still early, but it's opened the imagination, and fears, of millions of developers in a way I haven’t seen since that iPhone announcement.
That excitement has led to an explosion of development and hundreds of new tools broadly grouped into a category we call generative AI. Generative AI systems create content mimicking a particular style. New images that look like Banksy or lyrics that sound like Taylor Swift. All of these Generative AI tools, whether built on top of GPT-4 or something else, use the same basic model technique: a transformer.
Attention is all you need
GPT-4 (Generative Pretrained Transformer) is the most advanced version of a transformer model. Transformer models all emerged from a seminal paper written in 2017 by researchers at the University of Toronto and the team at Google Brain, titled Attention is all you need. The key insight from the paper is the self-attention mechanism. This mechanism replaced recurrent and convolutional layers, allowing for faster training and better performance.
The secret power of transformer models is their ability to efficiently process large amounts of data in parallel. It's the transformers' gargantuan scale and extensive training that makes them so appealing and versatile, turning them into the Swiss Army knife of natural language processing. At a high level, Large Language Models (LLMs) are just transformer models that use an incredibly large number of parameters (billions), and are trained on incredibly large amounts of unsupervised text (the Internet). Hence large, and language.
Unleashing the potential of LLMs in consumer-facing AI tools has opened a world of possibilities. But possibility also means new risk: developers must now navigate the unique security challenges that arise from making powerful new tools widely available to the masses.
First and foremost, consumer-facing applications inherently expose the underlying AI systems to millions of users, vastly increasing the potential attack surface. Since developers are targeting a consumer audience, they can't rely on trusted customers or limit access based on geographic location. Any security measure that makes it too difficult for consumers to use defeats the purpose of the application. Consequently, developers must strike a delicate balance between security and usability, which can be challenging.
The current popularity of AI tools makes explosive takeoff more likely than in the past. This is great! Explosive takeoff is what you want! But, that explosion can also lead to exponential growth in costs, as the computational requirements for serving a rapidly growing user base can become overwhelming.
In addition to being popular, Generative AI apps are unique in that calls to them are incredibly resource intensive, and therefore expensive for the owner. In comparison, think about a more traditional API that Cloudflare has protected for years. A product API. Sites don’t want competitors calling their product API and scraping data. This has an obvious negative business impact. However, it doesn’t have a direct infrastructure cost. A product list API returns a small amount of text. An attacker calling it 4 million times will have a negligible cost to an infrastructure bill. But generative models can cost cents, or in the case of image generation even tens of cents per call. An attacker gaining access and generating millions of calls has a real cost impact to the developers providing those APIs.
Not only are the costs for generating content high, but the value that end users are willing to pay is high as well. Customers tell us that they have seen multiple instances of bad actors accessing an API without paying, then reselling the content they generate for 50 cents or more per call. The huge monetary opportunity of exploitation means attackers are highly motivated to come back again and again, refactoring their approach each time.
Last, consumer-facing LLM applications are generally designed as a single entry point for customers, almost always accepting query text as input. The open-text nature of these calls makes it difficult to predict the potential impact of a single request. For example, a complex query might consume significant resources or trigger unexpected behavior. While these APIs are not GraphQL based, the challenges are similar. When you accept unstructured submissions, it's harder to create any type of rule to prevent abuse.
Tips for protecting your Generative AI application
So you've built the latest generative AI sensation, and the world is about to be taken by storm. But that success is also about to make you a target. What's the trick to stopping all those attacks you’re about to see? Well, unfortunately there isn’t one. For all the reasons above, this is a hard, persistent problem with no simple solution. But, we’ve been fortunate to work with many customers who have had that target on their back for months, and we’ve learned a lot from that experience. Here are some recommendations that will give you a good foundation for making sure that you, and only you, reap the rewards of your hard work.
1. Enforce tokens for each user. Enforcing usage based on a specific user or user session is straightforward. But sometimes you want to allow anonymous usage. While anonymous usage is great for demos and testing, it can lead to abuse. If you must allow anonymous usage, create a “stickier” identification scheme that persists browser restarts and incognito mode. Your goal isn’t to track specific users, but instead to understand how much an anonymous user has already used your service so far in demo / free mode.
2. Manage quotas carefully. Your service likely incurs costs and charges users per API call, so it likely makes sense to set a limit on the number of times any user can call your API. You may not ever intend for the average user to hit this limit, but having limits in place will protect against that user’s API key becoming compromised and shared amongst many users. It also protects against programming errors that could result in 100x or 1000x expected usage, and a large unexpected bill to the end user.
3. Block certain ASNs (autonomous system numbers) wholesale. Blocking ASNs, or even IPs wholesale is an incredibly blunt tool. In general Cloudflare rarely recommends this approach to customers. However, when tools are as popular as some generative AI applications, attackers are highly motivated to send as much traffic as possible to those applications. The fastest and cheapest way to accomplish this is through data centers that usually share a common ASN. Some ASNs belong to ISPs, and source traffic from people browsing the Internet. But other ASNs belong to cloud compute providers, and mainly source outbound traffic from virtual servers. Traffic from these servers can be overwhelmingly malicious. For example, several of our customers have found ASNs where 88-90% of the traffic turns out to be automated, while this number is usually only 30% for average traffic. In cases this extreme, blocking entire ASNs can make sense.
4. Implement smart rate limits. Counting not only requests per minute and requests per session, but also IPs per token and tokens per IP can guard against abuse. Tracking how many different IPs are using a particular token at any one time can alert you to a user's token being leaked. Similarly, if one IP is rotating through tokens, looking at each token’s session traffic would not alert you to the abuse. You’d need to look at how many tokens that single IP is generating in order to pinpoint that specific abusive behavior.
5. Rate limit on something other than the user. Similar to enforcing tokens on each user, your real time rate limits should also be set on your sticky identifier.
6. Have an option to slow down attackers. Customers often think about stopping abuse in terms of blocking traffic from abusers. But blocking isn’t the only option. Attacks not only need to be successful, they also need to be economically feasible. If you can make requests more difficult or time-consuming for abusers, you can ruin their economics. You can do this by implementing a waiting room, or by challenging users. We recommend a challenge option that doesn’t give real users an awful experience. Challenging users can also be quickly enabled or disabled as you see abuse spike or recede.
7. Map and analyze sequences. By sampling user sessions that you suspect of abuse, you can inspect their requests path-by-path in your SIEM. Are they using your app as expected? Or are they circumventing intended usage? You might benefit from enforcing a user flow between endpoints.
8. Build and validate an API schema. Many API breaches happen due to permissive schemas. Users are allowed to send in extra fields in requests that grant them too many privileges or allow access to other users’ data. Make sure you build a verbose schema that outlines what intended usage is by identifying and cataloging all API endpoints, then making sure all specific parameters are listed as required and have type limits to them.
We recently went through the transition to an OpenAPI schema ourselves for api.cloudflare.com. You can read more about how we did it here. Our schema looks like this:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
9. Analyze the depth and complexity of queries. Are your APIs driven by GraphQL? GraphQL queries can be a source of abuse since they allow such free-form requests. Large, complex queries can grow to overwhelm origins if limits aren’t in place. Limits help guard against outright DoS attacks as well as developer error, keeping your origin healthy and serving requests to your users as expected.
For example, if you have statistics about your GraphQL queries by depth and query size, you could execute this TypeScript function to analyze them by quantile:
import * as ss from 'simple-statistics';
function calculateQuantiles(data: number[], quantiles: number[]): {[key: number]: string} {
let result: {[key: number]: string} = {};
for (let q of quantiles) {
// Calculate quantile, convert to fixed-point notation with 2 decimal places
result[q] = ss.quantile(data, q).toFixed(2);
}
return result;
}
// Example usage:
let queryDepths = [2, 2, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 1, 1, 1, 1, 1, 1, 1, 1];
let querySizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2];
console.log(calculateQuantiles(queryDepths, [0.5, 0.75, 0.95, 0.99]));
console.log(calculateQuantiles(querySizes, [0.5, 0.75, 0.95, 0.99]));
The results give you a sense for the depth of the average query hitting your endpoint, grouped by quantile:
Actual data from your production environment would provide a threshold to start an investigation into which queries to further log or limit. A simpler option is to use a query analysis tool, like Cloudflare’s, to make the process automatic.
10. Use short-lived access tokens and long-lived refresh tokens upon successful authentication of your users. Implement token validation in a middleware layer or API Gateway, and be sure to have a dedicated token renewal endpoint in your API. JSON Web Tokens (JWTs) are popular choices for these short-lived tokens. When access tokens expire, allow users to obtain new ones using their refresh tokens. Revoke refresh tokens when necessary to maintain system security. Adopting this approach enhances your API's security and user experience by effectively managing access and mitigating the risks associated with compromised tokens.
11. Communicate directly with your users. All of the above recommendations are going to make it a bit more cumbersome for some of your customers to use your product. You are going to get complaints. You can reduce these by first, giving clear communication to your users explaining why you put these measures in place. Write a blog about what security measures you did and did not decide to implement and have dev docs explaining troubleshooting steps to resolve. Second, give your users concrete steps they can take if they are having trouble, and a clear way to contact you directly. Feeling inconvenienced can be frustrating, but feeling stuck can lose you a customer.
Conclusion: this is the beginning
Generative AI, like the first iPhone, has sparked a surge of excitement and innovation. But that excitement also brings risk, and innovation brings new security holes and attack vectors. The broadness and uniqueness of generative AI applications in particular make securing them particularly challenging. But as every scout knows, being prepared ahead of time means less stress and worry during the journey. Implementing the tips we've shared can establish a solid foundation that will let you sit back and enjoy the thrill of building something special, rather than worrying what might be lurking around the corner.
A collection of tools from Cloudflare One to help your teams use AI services safely
Cloudflare One gives teams of any size the ability to safely use the best tools on the Internet without management headaches or performance challenges. We’re excited to announce Cloudflare One for AI, a new collection of features that help your team build with the latest AI services while still maintaining a Zero Trust security posture.
Large Language Models, Larger Security Challenges
A Large Language Model (LLM), like OpenAI’s GPT or Google’s Bard, consists of a neural network trained against a set of data to predict and generate text based on a prompt. Users can ask questions, solicit feedback, and lean on the service to create output from poetry to Cloudflare Workers applications.
The tools also bear an uncanny resemblance to a real human. As in some real-life personal conversations, oversharing can become a serious problem with these AI services. This risk multiplies due to the types of use cases where LLM models thrive. These tools can help developers solve difficult coding challenges or information workers create succinct reports from a mess of notes. While helpful, every input fed into a prompt becomes a piece of data leaving your organization’s control.
Some responses to tools like ChatGPT have been to try and ban the service outright; either at a corporate level or across an entire nation. We don’t think you should have to do that. Cloudflare One’s goal is to allow you to safely use the tools you need, wherever they live, without compromising performance. These features will feel familiar to any existing use of the Zero Trust products in Cloudflare One, but we’re excited to walk through cases where you can use the tools available right now to allow your team to take advantage of the latest LLM features.
Measure usage
SaaS applications make it easy for any user to sign up and start testing. That convenience also makes these tools a liability for IT budgets and security policies. Teams refer to this problem as “Shadow IT” – the adoption of applications and services outside the approved channels in an organization.
In terms of budget, we have heard from early adopter customers who know that their team members are beginning to experiment with LLMs, but they are not sure how to approach making a commercial licensing decision. What services and features do their users need and how many seats should they purchase?
On the security side, the AIs can be revolutionary for getting work done but terrifying for data control policies. Team members treat these AIs like sounding boards for painful problems. The services invite users to come with their questions or challenges. Sometimes the context inside those prompts can contain sensitive information that should never leave an organization. Even if teams select and approve a single vendor, members of your organization might prefer another AI and continue to use it in their workflow.
Cloudflare One customers on any plan can now review the usage of AIs. Your IT department can deploy Cloudflare Gateway and passively observe how many users are selecting which services as a way to start scoping out enterprise licensing plans.
Administrators can also block the use of these services with a single click, but that is not our goal today. You might want to use this feature if you select ChatGPT as your approved model, and you want to make sure team members don’t continue to use alternatives, but we hope you don’t block all of these services outright. Cloudflare’s priority is to give you the ability to use these tools safely.
Control API access
When our teams began experimenting with OpenAI’s ChatGPT service, we were astonished by what it already knew about Cloudflare. We asked ChatGPT to create applications with Cloudflare Workers or guide us through how to configure a Cloudflare Access policy and, in most cases, the results were accurate and helpful.
In some cases the results missed the mark. The AIs were using outdated information, or we were asking questions about features that had only launched recently. Thankfully, these AIs can learn and we can help. We can train these models with scoped inputs and connect plug-ins to provide our customers with better AI-guided experiences when using Cloudflare services.
We heard from customers who want to do the same thing and, like us, they need to securely share training data and grant plug-in access for an AI service. Cloudflare One’s security suite extends beyond human users and can give teams the ability to securely share Zero Trust access to sensitive data over APIs.
First, teams can create service tokens that external services must present to reach data made available through Cloudflare One. Administrators can provide these tokens to systems making API requests and log every single request. As needed, teams can revoke these tokens with a single click.
After creating and issuing service tokens, administrators can create policies to allow specific services access to their training data. These policies will verify the service token and can be extended to verify country, IP address or an mTLS certificate. Policies can also be created to require human users to authenticate with an identity provider and complete an MFA prompt before accessing sensitive training data or services.
When teams are ready to allow an AI service to connect to their infrastructure, they can do so without poking holes in their firewalls by using Cloudflare Tunnel. Cloudflare Tunnel will create an encrypted, outbound-only connection to Cloudflare’s network where every request will be checked against the access rules configured for one or more services protected by Cloudflare One.
Cloudflare’s Zero Trust access control gives you the ability to enforce authentication on each and every request made to the data your organization decides to provide to these tools. That still leaves a gap in the data your team members might overshare on their own.
Restrict data uploads
Administrators can select an AI service, block Shadow IT alternatives, and carefully gate access to their training material, but humans are still involved in these AI experiments. Any one of us can accidentally cause a security incident by oversharing information in the process of using an AI service – even an approved service.
We expect AI playgrounds to continue to evolve to feature more data management capabilities, but we don’t think you should have to wait for that to begin adopting these services as part of your workflow. Cloudflare’s Data Loss Prevention (DLP) service can provide a safeguard to stop oversharing before it becomes an incident for your security team.
First, tell us what data you care about. We provide simple, preconfigured options that give you the ability to check for things that look like social security numbers or credit card numbers. Cloudflare DLP can also scan for patterns based on regular expressions configured by your team.
Once you have defined the data that should never leave your organization, you can build granular rules about how it can and cannot be shared with AI services. Maybe some users are approved to experiment with projects that contain sensitive data, in which case you can build a rule that only allows an Active Directory or Okta group to upload that kind of information while everyone else is blocked.
Control use without a proxy
The tools in today’s blog post focus on features that apply to data-in-motion. We also want to make sure that misconfigurations in the applications don’t lead to security violations. For example, the new plug-in feature in ChatGPT brings the knowledge and workflows of external services into the AI interaction flow. However, that can also lead to the services behind plug-ins having more access than you want to.
Cloudflare’s Cloud Access Security Broker (CASB) scans your SaaS applications for potential issues that can occur when users make changes. Whether alerting you to files that someone accidentally just made public on the Internet to checking that your GitHub repositories have the right membership controls, Cloudflare’s CASB removes the manual effort required to check each and every setting for potential issues in your SaaS applications.
Available soon, we are working on new integrations with popular AI services to check for misconfigurations. Like most users of these services, we’re still learning more about where potential accidents can occur, and we are excited to provide administrators who use our CASB with our first wave of controls for AI services.
What’s next?
The usefulness of these tools will only accelerate. The ability of AI services to coach and generate output will continue to make it easier for builders from any background to create the next big thing.
We share a similar goal. The Cloudflare products focused on helping users build applications and services, our Workers platform, remove hassles like worrying about where to deploy your application or how to scale your services. Cloudflare solves those headaches so that users can focus on creating. Combined with the AI services, we expect to see thousands of new builders launch the next wave of products built on Cloudflare and inspired by AI coaching and generation.
We have already seen dozens of projects flourish that were built on Cloudflare Workers using guidance from tools like ChatGPT. We plan to launch new integrations with these models to make this even more seamless, bringing better Cloudflare-specific guidance to the chat experience.
We also know that the security risk of these tools will grow. We will continue to bring functionality into Cloudflare One that aims to stay one step ahead of the risks as they evolve with these services. Ready to get started? Sign up here to begin using Cloudflare One at no cost for teams of up to 50 users.
Today we’re excited to be launching Cursor – our experimental AI assistant, trained to answer questions about Cloudflare’s Developer Platform. This is just the first step in our journey to help developers build in the fastest way possible using AI, so we wanted to take the opportunity to share our vision for a generative developer experience.
Whenever a new, disruptive technology comes along, it’s not instantly clear what the native way to interact with that technology will be.
However, if you’ve played around with Large Language Models (LLMs) such as ChatGPT, it’s easy to get the feeling that this is something that’s going to change the way we work. The question is: how? While this technology already feels super powerful, today, we’re still in the relatively early days of it.
While Developer Week is all about meeting developers where they are, this is one of the things that’s going to change just that — where developers are, and how they build code. We’re already seeing the beginnings of how the way developers write code is changing, and adapting to them. We wanted to share with you how we’re thinking about it, what’s on the horizon, and some of the large bets to come.
How is AI changing developer experience?
If there’s one big thing we can learn from the exploding success of ChatGPT, it’s the importance of pairing technology with the right interface. GPT-3 — the technology powering ChatGPT has been around for some years now, but the masses didn’t come until ChatGPT made it accessible to the masses.
Since the primary customers of our platform are developers, it’s on us to find the right interfaces to help developers move fast on our platform, and we believe AI can unlock unprecedented developer productivity. And we’re still in the beginning of that journey.
Wave 1: AI generated content
One of the things ChatGPT is exceptionally good at is generating new content and articles. If you’re a bootstrapped developer relations team, the first day playing around with ChatGPT may have felt like you struck the jackpot of productivity. With a simple inquiry, ChatGPT can generate in a few seconds a tutorial that would have otherwise taken hours if not days to write out.
This content still needs to be tested — do the code examples work? Does the order make sense? While it might not get everything right, it’s a massive productivity boost, allowing a small team to multiply their content output.
In terms of developer experience, examples and tutorials are crucial for developers, especially as they start out with a new technology, or seek validation on a path they’re exploring.
However, with AI generated content, it’s always going to be limited to well, how much of it you generated. To compare it to the newspaper, this content is still one size fits all. If as a developer you stray ever so slightly off the beaten path (choose a different framework than the one tutorial suggests, or a different database), you’re still left to put the pieces together, navigating tens of open tabs in order to stitch together your application.
If this content is already being generated by AI, however, why not just go straight to the source, and allow developers to generate their own, personal guides?
Wave 2: Q&A assistants
Since developers love to try out new technologies, it’s no surprise that developers are going to be some of the early adopters for technology such as ChatGPT. Many developers are already starting to build applications alongside their trusted bard, ChatGPT.
Rather than using generated content, why not just go straight to the source, and ask ChatGPT to generate something that’s tailored specifically for you?
There’s one tiny problem: the information is not always up to date. Which is why plugins are going to become a super important way to interact.
But what about someone who’s already on Cloudflare’s docs? Here, you want a native experience where someone can ask questions and receive answers. Similarly, if you have a question, why spend time searching the docs, if you can just ask and receive an answer?
Wave 3: generative experiences
In the examples above, you were still relying on switching back and forth between a dedicated AI interface and the problem at hand. In one tab you’re asking questions, while in another, you’re implementing the answers.
But taking things another step further, what if AI just met you where you were? In terms of developer experience, we’re already starting to see this in the authoring phase. Tools like GitHub Copilot help developers generate boilerplate code and tests, allowing developers to focus on more complex tasks like designing architecture and algorithms.
Sometimes, however, the first iteration AI comes up with might not match what you, the developer had in mind, which is why we’re starting to experiment with a flow-based generative approach, where you can ask AI to generate several versions, and build out your design with the one that matches your expectations the most.
The possibilities are endless, enabling developers to start applications from prompts rather than pre-generated templates.
We’re excited for all the possibilities AI will unlock to make developers more productive than ever, and we’d love to hear from you how AI is changing the way you change applications.
We’re also excited to share our first steps into the realm of AI driven developer experience with the release of our first two ChatGPT plugins, and by welcoming a new member of our team —Cursor, our docs AI assistant.
Our first milestone to AI driven UX: AI Assisted Docs
As the first step towards using AI to streamline our developer experience, we’re excited to introduce a new addition to our documentation to help you get answers as quickly as possible.
How to use Cursor
Here’s a sample exchange with Cursor:
You’ll notice that when you ask a question, it will respond with two pieces of information: a text based response answering your questions, and links to relevant pages in our documentation that can help you go further.
Here’s what happens when we ask “What video formats does Stream support?”.
If you were looking through our examples you may not immediately realize that this specific example uses both Workers and R2.
In its current state, you can think of it as your assistant to help you learn about our products and navigate our documentation in a conversational way. We’re labeling Cursor as experimental because this is the very beginning stages of what we feel like a Cloudflare AI assistant could do to help developers. It is helpful, but not perfect. To deal with its lack of perfection, we took an approach of having it do fewer things better. You’ll find there are many things it isn’t good at today.
How we built Cursor
Under the hood, Cursor is powered by Workers, Durable Objects, OpenAI, and the Cloudflare developer docs. It uses the same backend that we’re using to power our ChatGPT Docs plugin, and you can read about that here.
It uses the “Search-Ask” method, stay tuned for more details on how you can build your own.
A sneak peek into the future
We’re already thinking about the future, we wanted to give you a small preview of what we think this might look like here:
With this type of interface, developers could use a UI to have an AI generate code and developers then link that code together visually. Whether that’s with other code generated by the AI or code they’ve written themselves. We’ll be continuing to explore interfaces that we hope to help you all build more efficiently and can’t wait to get these new interfaces in your hands.
We need your help
Our hope is to quickly update and iterate on how Cursor works as developers around the world use it. As you’re using it to explore our documentation, join us on Discord to let us know your experience.
The Cloudflare Workers' ecosystem now features products and features ranging from compute, hosting, storage, databases, streaming, networking, security, and much more. Over time, we've been trying to inspire others to switch from traditional software architectures, proving and documenting how it's possible to build complex applications that scale globally on top of our stack.
Today, we're excited to welcome Constellation to the Cloudflare stack, enabling developers to run pre-trained machine learning models and inference tasks on Cloudflare's network.
One more building block in our Supercloud
Machine learning and AI have been hot topics lately, but the reality is that we have been using these technologies in our daily lives for years now, even if we do not realize it. Our mobile phones, computers, cars, and home assistants, to name a few examples, all have AI. It's everywhere.
But it isn't a commodity to developers yet, though. They often need to understand the mathematics behind it, the software and tools are dispersed and complex, and the hardware or cloud services to run the frameworks and data are expensive.
Today we're introducing another feature to our stack, allowing everyone to run machine learning models and perform inference on top of Cloudflare Workers.
Introducing Constellation
Constellation allows you to run fast, low-latency inference tasks using pre-trained machine learning models natively with Cloudflare Workers scripts.
Some examples of applications that you can deploy leveraging Constellation are:
Image or audio classification or object detection
Anomaly Detection in Data
Text translation, summarization, or similarity analysis
Natural Language Processing
Sentiment analysis
Speech recognition or text-to-speech
Question answering
Developers can upload any supported model to Constellation. They can train them independently or download pre-trained models from machine learning hubs like HuggingFace or ONNX Zoo.
However, not everyone will want to train models or browse the Internet for models they didn't test yet. For that reason, Cloudflare will also maintain a catalog of verified and ready-to-use models.
We built Constellation with a great developer experience and simple-to-use APIs in mind. Here's an example to get you started.
Image classification application
In this example, we will build an image classification app powered by the Constellation inference API and the SqueezeNet model, a convolutional neural network (CNN) that was pre-trained on more than one million images from the open-source ImageNet database and can classify images into no more than 1,000 categories.
SqueezeNet compares to AlexNet, one of the original CNNs and benchmarks for image classification, by being much faster (~3x) and much smaller (~500x) while still achieving similar levels of accuracy. Its small footprint makes it ideal for running on portable devices with limited resources or custom hardware.
First, let's create a new Constellation project using the ONNX runtime. Wrangler now has functionality for Constellation built-in with the constellation keyword.
As we said above, SqueezeNet classifies images into no more than 1,000 object classes. These classes are actually in the form of a list of synonym rings or synsets. A synset has an id and a label; it derives from Princeton's WordNet database terminology, the same used to label the ImageNet image database.
To translate SqueezeNet's results into human-readable image classes, we need a file that maps the synset ids (what we get from the model) to their corresponding labels.
$ mkdir src; cd src
$ wget https://raw.githubusercontent.com/microsoft/onnxjs-demo/master/src/data/imagenet.ts
And finally, let’s code and deploy our image classification script:
This script reads an image from the request, decodes it into a multidimensional float32 tensor (right now we only decode PNGs, but we can add other formats), feeds it to the SqueezeNet model running in Constellation, gets the results, matches them with the ImageNet classes list, and returns the human-readable tags for the image.
You can see the probabilities in action here. The model is quite sure about the Alp and the Convertible, but the Ibizan hound has a lower probability. Indeed, the dog in the picture is from another breed.
This small app demonstrates how easy and fast you can start using machine learning models and Constellation when building applications on top of Workers. Check the full source code here and deploy it yourself.
Transformers
Transformers were introduced by Google; they are deep-learning models designed to process sequential input data and are commonly used for natural language processing (NLP), like translations, summarizations, or sentiment analysis, and computer vision (CV) tasks, like image classification.
Transformers.js is a popular demo that loads transformer models from HuggingFace and runs them inside your browser using the ONNX Runtime compiled to WebAssembly. We ported this demo to use Constellation APIs instead.
The other interesting element of Constellation is that because it runs natively in Workers, you can orchestrate it with other products and APIs in our stack. You can use KV, R2, D1, Queues, anything, even Email.
Here's an example of a Worker that receives Emails for your domain on Cloudflare using Email Routing, runs Constellation using the t5-small sentiment analysis model, adds a header with the resulting score, and forwards it to the destination address.
import { Tensor, run } from '@cloudflare/constellation';
import * as PostalMime from 'postal-mime';
export interface Env {
SENTIMENT: any,
}
export default {
async email(message, env, ctx) {
const rawEmail = await streamToArrayBuffer(event.raw, event.rawSize);
const parser = new PostalMime.default();
const parsedEmail = await parser.parse(rawEmail);
const input = tokenize(parsedEmail.text)
const output = await run( env.SENTIMENT, "MODEL-UUID", input);
var headers = new Headers();
headers.set("X-Sentiment", idToLabel[output.label]);
await message.forward("[email protected]", headers);
}
}
Now you can use Gmail or any email client to apply a rule to your messages based on the 'X-Sentiment' header. For example, you might want to move all the angry emails outside your Inbox to a different folder on arrival.
Start using Constellation
Constellation starts today in private beta. To join the waitlist, please head to the dashboard, click the Workers tab under your account, and click the "Request access" button under the Constellation entry. The team will be onboarding accounts in batches; you'll get an email when your account is enabled.
In the meantime, you can read our Constellation Developer Documentation and learn more about how it works and the APIs. Constellation can be used from Wrangler, our command-line tool for configuring, building, and deploying applications with Cloudflare developer products, or managed directly in the Dashboard UI.
We are eager to learn how you want to use ML/AI with your applications. Constellation will keep improving with higher limits, more supported runtimes, and larger models, but we want to hear from you. Your feedback will certainly influence our roadmap decisions.
One last thing: today, we've been talking about how you can write Workers that use Constellation, but here's an inception fact: Constellation itself was built using the power of WebAssembly, Workers, R2, and our APIs. We'll make sure to write a follow-up blog soon about how we built it; stay tuned.
As usual, you can talk to us on our Developers Discord (join the #constellation channel) or the Community forum; the team will be listening.
When OpenAI launched ChatGPT plugins in alpha we knew that it opened the door for new possibilities for both Cloudflare users and developers building on Cloudflare. After the launch, our team quickly went to work seeing what we could build, and today we’re very excited to share with you two new Cloudflare ChatGPT plugins – the Cloudflare Radar plugin and the Cloudflare Docs plugin.
The Cloudflare Radar plugin allows you to talk to ChatGPT about real-time Internet patterns powered by Cloudflare Radar.
The Cloudflare Docs plugin allows developers to use ChatGPT to help them write and build Cloudflare applications with the most up-to-date information from our documentation. It also serves as an open source example of how to build a ChatGPT plugin with Cloudflare Workers.
Let’s do a deeper dive into how each of these plugins work and how we built them.
Cloudflare Radar ChatGPT plugin
When ChatGPT introduced plugins, one of their use cases was retrieving real-time data from third-party applications and their APIs and letting users ask relevant questions using natural language.
Cloudflare Radar has lots of data about how people use the Internet, a well-documented public API, an OpenAPI specification, and it’s entirely built on top of Workers, which gives us lots of flexibility for improvements and extensibility. We had all the building blocks to create a ChatGPT plugin quickly. So, that's what we did.
We added an OpenAI manifest endpoint which describes what the plugin does, some branding assets, and an enriched OpenAPI schema to tell ChatGPT how to use our data APIs. The longest part of our work was fine-tuning the schema with good descriptions (written in natural language, obviously) and examples of how to query our endpoints.
Amusingly, the descriptions ended up much improved by the need to explain the API endpoints to ChatGPT. An interesting side effect is that this benefits us humans also.
{
"/api/v1/http/summary/ip_version": {
"get": {
"operationId": "get_SummaryIPVersion",
"parameters": [
{
"description": "Date range from today minus the number of days or weeks specified in this parameter, if not provided always send 14d in this parameter.",
"required": true,
"schema": {
"type": "string",
"example": "14d",
"enum": ["14d","1d","2d","7d","28d","12w","24w","52w"]
},
"name": "dateRange",
"in": "query"
}
]
}
}
Luckily, itty-router-openapi, an easy and compact OpenAPI 3 schema generator and validator for Cloudflare Workers that we built and open-sourced when we launched Radar 2.0, made it really easy for us to add the missing parts.
import { OpenAPIRouter } from '@cloudflare/itty-router-openapi'
const router = OpenAPIRouter({
aiPlugin: {
name_for_human: 'Cloudflare Radar API',
name_for_model: 'cloudflare_radar',
description_for_human: "Get data insights from Cloudflare's point of view.",
description_for_model:
"Plugin for retrieving the data based on Cloudflare Radar's data. Use it whenever a user asks something that might be related to Internet usage, eg. outages, Internet traffic, or Cloudflare Radar's data in particular.",
contact_email: '[email protected]',
legal_info_url: 'https://www.cloudflare.com/website-terms/',
logo_url: 'https://cdn-icons-png.flaticon.com/512/5969/5969044.png',
},
})
We incorporated our changes into itty-router-openapi, and now it supports the OpenAI manifest and route, and a few other options that make it possible for anyone to build their own ChatGPT plugin on top of Workers too.
The Cloudflare Radar ChatGPT is available to non-free ChatGPT users or anyone on OpenAI’s plugin's waitlist. To use it, simply open ChatGPT, go to the Plugin store and install Cloudflare Radar.
Once installed, you can talk to it and ask questions about our data using natural language.
When you add plugins to your account, ChatGPT will prioritize using their data based on what the language model understands from the human-readable descriptions found in the manifest and Open API schema. If ChatGPT doesn't think your prompt can benefit from what the plugin provides, then it falls back to its standard capabilities.
Another interesting thing about plugins is that they extend ChatGPT's limited knowledge of the world and events after 2021 and can provide fresh insights based on recent data.
Here are a few examples to get you started:
"What is the percentage distribution of traffic per TLS protocol version?"
"What's the HTTP protocol version distribution in Portugal?"
Now that ChatGPT has context, you can add some variants, like switching the country and the date range.
“How about the US in the last six months?”
You can also combine multiple topics (ChatGPT will make multiple API calls behind the scenes and combine the results in the best possible way).
“How do HTTP protocol versions compare with TLS protocol versions?”
Out of ideas? Ask it “What can I ask the Radar plugin?”, or “Give me a random insight”.
Be creative, too; it understands a lot about our data, and we keep improving it. You can also add date or country filters using natural language in your prompts.
Cloudflare Docs ChatGPT plugin
The Cloudflare Docs plugin is a ChatGPT Retrieval Plugin that lets you access the most up-to-date knowledge from our developer documentation using ChatGPT. This means if you’re using ChatGPT to assist you with building on Cloudflare that the answers you’re getting or code that’s being generated will be informed by current best practices and information located within our docs. You can set up and run the Cloudflare Docs ChatGPT Plugin by following the read me in the example repo.
The plugin was built entirely on Workers and uses KV as a vector store. It can also keep its index up-to-date using Cron Triggers, Queues and Durable Objects.
The plugin is a Worker that responds to POST requests from ChatGPT to a /query endpoint. When a query comes in, the Worker converts the query text into an embedding vector via the OpenAI embeddings API and uses this to find, and return, the most relevant document snippets from Cloudflare’s developer documentation.
The way this is achieved is by first converting every document in Cloudflare’s developer documentation on GitHub into embedding vectors (again using OpenAI’s API) and storing them in KV. This storage format allows you to find semantically similar content by doing a similarity search (we use cosine similarity), where two pieces of text that are similar in meaning will result in the two embedding vectors having a high similarity score. Cloudflare’s entire developer documentation compresses to under 5MB when converted to embedding vectors, so fetching these from KV is very quick. We’ve also explored building larger vector stores on Workers, as can be seen in this demo of 1 million vectors stored on Durable Object storage. We’ll be releasing more open source libraries to support these vector store use cases in the near future.
So ChatGPT will query the plugin when it believes the user’s question is related to Cloudflare’s developer tools, and the plugin will return a list of up-to-date information snippets directly from our documentation. ChatGPT can then decide how to use these snippets to best answer the user’s question.
The plugin also includes a “Scheduler” Worker that can periodically refresh the documentation embedding vectors, so that the information is always up-to-date. This is advantageous because ChatGPT’s own knowledge has a cutoff of September 2021 – so it’s not aware of changes in documentation, or new Cloudflare products.
The Scheduler Worker is triggered by a Cron Trigger, on a schedule you can set (eg, hourly), where it will check which content has changed since it last ran via GitHub’s API. It then sends these document paths in messages to a Queue to be processed. Workers will batch process these messages – for each message, the content is fetched from GitHub, and then turned into embedding vectors via OpenAI’s API. A Durable Object is used to coordinate all the Queue processing so that when all the batches have finished processing, the resulting embedding vectors can be combined and stored in KV, ready for querying by the plugin.
This is a great example of how Workers can be used not only for front-facing HTTP APIs, but also for scheduled batch-processing use cases.
Let us know what you think
We are in a time when technology is constantly changing and evolving, so as you experiment with these new plugins please let us know what you think. What do you like? What could be better? Since ChatGPT plugins are in alpha, changes to the plugins user interface or performance (i.e. latency) may occur. If you build your own plugin, we’d love to see it and if it’s open source you can submit a pull request on our example repo. You can always find us hanging out in our developer discord.
The 1947 paper titled “Preparation of Problems for EDVAC-Type Machines” talks about the idea and usefulness of a “subroutine”. At the time there were only a tiny number of computers worldwide and subroutines were a novel idea, and it was clear that these subroutines were going to make programmers more productive: “Many operations which are thus excluded from the built-in set are still of sufficiently frequent occurrence to make undesirable the repetition of their coding in detail.”
Looking back it seems amazing that subroutines had to be invented, but at the time programmers wrote literally everything they needed to complete a task. That made programming slow, error-prone and restricted who could be a programmer to a relatively small group of people.
Luckily, things changed.
You can look at the history of computer programming as improvements in programmer productivity and widening the scope of who is a programmer. Think of syntax highlighting, high-level languages, IDEs, libraries and frameworks, APIs, Visual Basic, code completion, refactoring tools, spreadsheets, and so on.
And here we are with things changing again.
The new programmers
The recent arrival of LLMs capable of assisting programmers in writing, debugging and modifying code is yet another step. It’s a step at both making programmers more productive and helping more people be programmers.
As programmers a lot of what we do is arcane.
Sure, we have helped create the modern world, but we spend a lot of time on things that actually exclude many from being programmers. Think of how many times you’ve messed up syntax, misinterpreted the result of calling a function, or made an off-by-one error in a loop.
And we’re expected to operate at a concrete and abstract level simultaneously. We hold the architecture and state of a system in our heads, imagining the program as data flows through it, and worry about a missing semicolon.
This is, frankly, weird.
That weirdness is partly why the children’s programming language Scratch eliminates much of the arcana. It’s designed to stop the user making small mistakes that add up to not making progress on a program. Its on-screen shapes are designed to show how a program flows and loops. What if AI eliminates much of our odd work and lets people concentrate on the thing they are creating?
I think that would be wonderful and would open the world of programming to many, many more people. But we’re not there yet. We’re at the point where AIs are hugely helpful assistants in the traditional art of programming. And this week Cloudflare will introduce its own AI assistants to make programmers using Cloudflare Workers much more productive. And these assistants are going to help more people use the Cloudflare Developer Platform.
The new platforms
A developer platform without AI isn’t going to be much use. It’ll be a bit like a developer platform that can’t do floating point arithmetic, or handle a list of data. We’re going to see every developer platform have AI capability built in because these capabilities will allow developers to make richer experiences for users.
If you’ve used a phone’s picture library recently you’ve probably discovered that you can search by what’s in an image. Type ‘cat’ and you can see all the cat pictures you’ve taken. Image classification like this is an example of the sort of functionality that a developer platform should provide so that a programmer can build a productive and exciting experience for their users.
That’s why this week we’ll be announcing AI features built directly into the Cloudflare Workers platform so that developers have a rich toolset at their disposal. And they’ll be able to train and upload their own models to run on our global network.
AI systems, by their nature, require a lot of data both for training and for executing models. Think giga- to petabytes. And a lot of that data needs to move around. Unlike a database where data might largely be stored and accessed infrequently, AI systems are alive with moving data.
To accommodate that, platforms need to stop treating data as something to lock in developers with. Data needs to be free to move from system to system, from platform to platform, without transfer fees, egress or other nonsense. If we want a world of AI, we need a world of data fluidity. We’ll look this week at how Cloudflare (including our R2) enables that.
I like to think (it has to be!)
As I look back at 40 years of my programming life, I haven’t been this excited about a new technology… ever. That’s because AI is going to be a pervasive change to how programs get written, who writes programs and how all of us interact with software.
In a talk, Andrew Ng called AI “The New Electricity”. Does that seem exaggerated? I don’t think so. Electricity utterly altered work and life for everyone and has become so much part of life that when electricity supplies fail it’s a shock.
AI is going to have a similarly profound effect on the way we live and work, and will be equally pervasive. And AI is already here, not just in the form of ChatGPT and Google Bard, but through machine translation, agents like Siri and Alexa, and a myriad of unseen systems that do something humans can’t do: keep up with the speed of the Internet helping to protect it and us.
And, I predict, AI is going to help people be smarter. That effect has already been seen with the ancient game Go. In 2016, one of the world’s strongest Go players, Lee Sedol, was beaten by AlphaGo and later retired. But something interesting has happened: Go players playing against AI are getting stronger. Humans are learning new strategies and improving.
I think AI has the potential to do that for all of us. And for programmers I think it’ll make us more productive and make more people programmers.
Which makes me wonder what a 2047 paper entitled “Preparation of Programs for NEURAL-Type Machines” will introduce. What new exciting way of programming is there for us to discover in the next few years? What cybernetic ecology will be created that makes the flow of ideas from the brain to silicon so much quicker?
While it’s still in its infancy, generative AI coding tools are already changing the way developers and companies build software. Generative AI can boost developer and business productivity by automating tasks, improving communication and collaboration, and providing insights that can inform better decision-making.
In this post, we’ll explore the full story of how companies are adopting generative AI to ship software faster, including:
Generative AI refers to a class of artificial intelligence (AI) systems designed to create new content similar to what humans produce. These systems are trained on large datasets of content that include text, images, audio, music, or code.
Generative AI is an extension of traditional machine learning, which trains models to predict or classify data based on existing patterns. But instead of simply predicting the outcome, generative AI models are designed to identify underlying patterns and structures of the data, and then use that knowledge to quickly generate new content. However, the main difference between the two is one of magnitude and the size of the prediction or generation. Machine learning typically predicts the next word. Generative AI can generate the next paragraph.
AI-generated image from Shutterstack of a developer using a generative AI tool to code faster.
Generative AI tools have attracted particular interest in the business world. From marketing to software development, organizational leaders are increasingly curious about the benefits of the new generative AI applications and products.
“I do think that all companies will adopt generative AI tools in the near future, at least indirectly,” said Albert Ziegler, principal machine learning engineer at GitHub. “The bakery around the corner might have a logo that the designer made using a generative transformer. The neighbor selling knitted socks might have asked Bing where to buy a certain kind of wool. My taxi driver might do their taxes with a certain Excel plugin. This adoption will only increase over time.”
What are some business uses of generative AI tools?
Software development: generative AI tools can assist engineers with building, editing, and testing code.
Content creation: writers can use generative AI tools to help personalize product descriptions and write ad copy.
Design creation: from generating layouts to assisting with graphics, generative AI design tools can help designers create entirely new designs.
Video creation: generative AI tools can help videographers with building, editing, or enhancing videos and images.
Language translation: translators can use generative AI tools to create communications in different languages.
Personalization: generative AI tools can assist businesses with personalizing products and services to meet the needs of individual customers.
Operations: from supply chain management to pricing, generative AI tools can help operations professionals drive efficiency.
How generative AI coding tools are changing the developer experience
Generative AI has big implications for developers, as the tools can enable them to code and ship software faster.
How is generative AI affecting software development?
Check out our guide to learn what generative AI coding tools are, what developers are using them for, and how they’re impacting the future of development.
GitHub Copilot is only continuing to improve. When the tool was first launched for individuals in June 2022, more than 27% of developers’ code was generated by GitHub Copilot, on average. Today, that number is 46% across all programming languages—and in Java, that jumps to 61%.
How can generative AI tools help you build software?
These tools can help:
Write boilerplate code for various programming languages and frameworks.
Find information in documentation to understand what the code does.
Identify security vulnerabilities and implement fixes.
Streamline code reviews before merging new or edited code.
Like all technologies, responsibility and ethics are important with generative AI.
In February 2023, a group of 10 companies including OpenAI, Adobe, the BBC, and others agreed upon a new set of recommendations on how to use generative AI content in a responsible way.
The recommendations were put together by the Partnership on AI (PAI), an AI research nonprofit, in consultation with more than 50 organizations. The guidelines call for creators and distributors of generative AI to be transparent about what the technology can and can’t do and disclose when users might be interacting with this type of content (by using watermarks, disclaimers, or traceable elements in an AI model’s training data).
Businesses should be aware that while generative AI tools can speed up the creation of content, they should not be solely relied upon as a source of truth. A recent study suggests that people can identify whether AI-generated content is real or fake only 50% of the time. Here at GitHub, we named our generative AI tool “GitHub Copilot” to signify just this—the tool can help, but at the end of the day, it’s just a copilot. The developer needs to take responsibility for ensuring that the finished code is accurate and complete.
How companies are using generative AI
Even as generative AI models and tools continue to rapidly advance, businesses are already exploring how to incorporate these into their day-to-day operations.
This is particularly true for software development teams.
“Going forward, tech companies that don’t adopt generative AI tools will have a significant productivity disadvantage,” Ziegler said. “Given how much faster this technology can help developers build, organizations that don’t adopt these tools or create their own will have a harder time in the marketplace.”
3 primary generative AI business models for organizations
Enterprises all over the world are using generative AI tools to transform how work gets done. Three of the business models organizations use include:
Model as a Service (MaaS): Companies access generative AI models through the cloud and use them to create new content. OpenAI employs this model, which licenses its GPT-3 AI model, the platform behind ChatGPT. This option offers low-risk, low-cost access to generative AI, with limited upfront investment and high flexibility.
Built-in apps: Companies build new—or existing—apps on top of generative AI models to create new experiences. GitHub Copilot uses this model, which relies on Codex to analyze the context of the code to provide intelligent suggestions on how to complete it. This option offers high customization and specialized solutions with scalability.
Vertical integration: Vertical integration leverages existing systems to enhance the offerings. For instance, companies may use generative AI models to analyze large amounts of data and make predictions about prices or improve the accuracy of their services.
Duolingo, one of the largest language-learning apps in the world, is one company that recently adopted generative AI capabilities. They chose GitHub’s generative AI tool, GitHub Copilot, to help their developers write and ship code faster, while improving test coverage. Duolingo’s CTO Severin Hacker said GitHub Copilot delivered immediate benefits to the team, enabling them to code quickly and deliver their best work.
”[The tool] stops you from getting distracted when you’re doing deep work that requires a lot of your brain power,” Hacker noted. “You spend less time on routine work and more time on the hard stuff. With GitHub Copilot, our developers stay in the flow state and keep momentum instead of clawing through code libraries or documentation.”
After adopting GitHub Copilot and the GitHub platform, Duolingo saw a:
25% increase in developer speed for those who are new to working with a specific repository
10% increase in developer speed for those who are familiar with the respective codebase
67% decrease in median code review turnaround time
“I don’t know of anything available today that’s remotely close to what we can get with GitHub Copilot,” Hacker said.
Looking forward
Generative AI is changing the world of software development. And it’s just getting started. The technology is quickly improving and more use cases are being identified across the software development lifecycle. With the announcement of GitHub Copilot X, our vision for the future of AI-powered software development, we’re committed to installing AI capabilities into every step of the developer workflow. There’s no better time to get started with generative AI at your company.
Missed GitHub CEO Thomas Dohmke’s Web Summit Rio 2023 talk? Read his remarks and get caught up on everything GitHub Copilot X.
Hello, Rio! I’m Thomas, and I’m a developer. I’ve been looking forward to this for some time, about a year. When I first planned this talk, I wanted to talk about the future of artificial intelligence and applications. But then I thought, why not show you the full power live on stage. Build something with code.
I’ve been a developer my entire adult life. I’ve been coding since 1989. But as CEO, I haven’t been able to light up my contribution graph in a while. Like all of you, like every developer, my energy, my creativity every day is finite. And all the distractions of life—from the personal to the professional—from morning to night, gradually zaps my creative energy.
When I wake up, I’m at my most creative and sometimes I have a big, light bulb idea. But as soon as the coffee is poured, the distractions start. Slack messages and emails flood in. I have to review a document before a customer presentation. And then I hear my kids yell as their football flew over the fence. And, of course, they want me to go over to our neighbors’ and get it.
Then…I sit back down, I am in wall-to-wall meetings. And by the time the sun comes down, that idea I had in the morning—it’s gone! It’s midnight and I can’t even keep my eyes open. To be honest, in all this, I usually don’t even want to get started because the perception of having to do all the mundane tasks, all the boilerplate work that comes with coding, stops me in my tracks. And I know this is true for so many developers.
The point is: boilerplate sucks! All busywork in life, but especially repetitive work is a barrier between us and what we want to achieve. Every day, building endless boilerplate prevents developers from creating a new idea that will change the world. But with AI, these barriers are about to be shattered.
@ashtom just created and deployed a snake game using GitHub Copilot in 15 minutes
“The point is: Boilerplate sucks. It is just the barrier between us and what we want to achieve.” pic.twitter.com/FDzAb4fPjA
You’ve likely seen the memes about the 10x developer. It’s a common internet joke—people have claimed the 10x developer many times. With GitHub Copilot and now Copilot X, it’s time for us to redefine this! It isn’t that developers need to strive to be 10x, it’s that every developer deserves to be made 10 times more productive. With AI at every step, we will truly create without captivity. With AI at every step, we will realize the 10x developer.
Imagine: 10 days of work, done in one day. 10 hours of work, done in one hour. 10 minutes of work, done with a single prompt command. This will allow us to amplify our truest self-expression. It will help a new generation of developers learn and build as fast as their minds. And because of this, we’ll emerge into a new spring of digital creativity, where every light bulb idea we have when we open our eyes for the day can be fully realized no matter what life throws at us.
During my presentation, I built a snake game in 15 minutes.
This morning I woke up, and I wanted to build something. I wanted to build my own snake game, originally created back in 1976. It’s a classic. So, 15 minutes are left on my timer. And I’m going to build this snake game. Let’s bring up Copilot X and get going!
See how you can 10x your developer superpowers. Discover GitHub Copilot X.
Congratulations to @ashtom CEO of @github , for his fantastic presentation at #WebSummitRio showcasing the amazing capabilities of #GitHubCopilot. It's rare to see a CEO with such technical prowess, building a functional app and even a snake game live in just 18 minutes.
With the advances in large language models (e.g. ChatGPT), referred to as AI, concerns are rising about a sweeping loss of jobs because of the new tools. Some claim jobs will be completely replaced, others claim that jobs will be cut because of a significant increase in efficiency. Labour parties and unions are organizing conferences about the future of jobs, universal basic income, etc.
These concerns are valid and these debates should be held. I’m addressing this post to the more extreme alarmists and not trying to diminish the rapid changes that these technological advances are bringing. We have to think about regulations, ethical AI and safeguards. And the recent advances are pushing us in that direction, which is good.
But in technology we often live the phrase “when you have a hammer, everything looks like a nail”. The blockchain revolution didn’t happen, and so I think we are a bit more eager than warranted about the recent advances in AI. Let me address three aspects:
First – automation. The claim is, AI will swiftly automate a lot of jobs and many people with fall out of the labour market. The reality is that GPT/LLMs should be integrated in existing business processes. If regular automation hasn’t already killed those jobs, AI won’t do it so quickly. If an organization doesn’t use automation already for boilerplate tasks, it won’t overnight automate them with AI. Let me remind you that RPA (Robotic process automation) solutions have been advertised as AI. They really “kill” jobs in the enterprise. They’ve been around for nearly two decades and we haven’t heard a large alarmed choir about RPA. I’m aware there is a significant difference in LLMs and RPA, but the idea that a piece of technology will swiftly lead to staff reduction across industries is not something I agree with.
Second – efficiency. Especially in software development, where products like Copilot are already production-ready, it seems that with the increase of efficiency, there may be staff reduction. But if a piece of software used to be built for 6 months before AI, it will be built for, say, 3 months with AI. Note that code writing speed is not the only aspect of software development – other overhead and blockers will continue to exist – requirement clarifications, customer feedback, architecture decisions, operational and scalability issues, etc., so increase in efficiency is unlikely to be orders of magnitude. AT the same time, there is a shortage of software developers. With the advances of AI, there will be less of a shortage, meaning more software can be built within the same timeframe.
For outsourcing this means that the price per hour or per finished product may increase because of AI (speed is also a factor in pricing). A company will be able to service more customers for a given time. And there’s certainly a lot of demand for digital transformation. For product companies this increase in efficiency will mean faster time-to-market for the product and new features. Which will make product companies more competitive. In both cases, AI is unlikely to kills jobs in the near future.
Sure, ChatGPT can write a website. You can create a free website with site-builders even today. And this hasn’t killed web developers. It just makes the easiest websites cheaper. By the way, building software once and maintaining it are completely different things. Even if ChatGPT can build a website, maintenance is going to be tough through prompts.
At the same time, AI will put more intellectual pressure on junior developers, who are typically given the boilerplate work, which is going to be more automatable. But on the other hand AI will improve the training process of those junior developers. Companies may have to put more effort in training developers, and career paths may have to be adjusted, but it’s unlikely that the demand for software developers will drop.
Third, there is a claim that generative AI will kill jobs in the creative professions. Ever since I wrote an algorthmic music generator, I’ve been saying that it will not. Sure, composers of elevator music will be eventually gone. But poets, for example, won’t. ChatGPT is rather bad at poetry. It can’t actually write proper poetry. It seems to know just the AABB rhyme scheme, it ignores instructions on meter (“use dactylic tetrameter” doesn’t seem to mean anything to it). With image and video generation, the problem with unrealistic hands and fingers (and similar ones) doesn’t seem to be going away with larger models (even though the latest version of Midjourney is neatly going around it). It will certainly require post-editing. Will it make certain industries more efficient? Yes, which will allow them to produce more content for a given time. Will there be enough demand? I can’t say. The market will decide.
LLMs and AI will be change things. It will improve efficiency. It will disrupt some industries. And we have to debate this. But we still have time.
During a time when computers were solely used for computation, the engineer, Douglas Engelbart, gave the “mother of all demos,” where he reframed the computer as a collaboration tool capable of solving humanity’s most complex problems. At the start of his demo, he asked audience members how much value they would derive from a computer that could instantly respond to their actions.
You can ask the same question of generative AI models. If you had a highly responsive generative AI coding tool to brainstorm new ideas, break big ideas into smaller tasks, and suggest new solutions to problems, how much more creative and productive could you be?
This isn’t a hypothetical question. AI-assisted engineering workflows are quickly emerging with new generative AI coding tools that offer code suggestions and entire functions in response to natural language prompts and existing code. These tools, and what they can help developers accomplish, are changing fast. That makes it important for every developer to understand what’s happening now—and the implications for how software is and will be built.
In this article, we’ll give a rundown of what generative AI in software development looks like today by exploring:
The unique value generative AI brings to the developer workflow
AI and automation have been a part of the developer workflow for some time now. From machine learning-powered security checks to CI/CD pipelines, developers already use a variety of automation and AI tools, like CodeQL on GitHub, for example.
While there’s overlap between all of these categories, here’s what makes generative AI distinct from automation and other AI coding tools:
Automation: You know what needs to be done, and you know of a reliable way to get there every time.
Rules-based logic: You know the end goal, but there’s more than one way to achieve it.
Machine learning:
You know the end goal, but the amount of ways to achieve it scales exponentially.
Generative AI: You have big coding dreams, and want the freedom to bring them to life.
You want to make sure that any new code pushed to your repository follows formatting specifications before it’s merged to the main branch. Instead of manually validating the code, you use a CI/CD tool like GitHub Actions to trigger an automated workflow on the event of your choosing (like a commit or pull request).
You know some patterns of SQL injections, but it’s time consuming to manually scan for them in your code. A tool like Code QL uses a system of rules to sort through your code and find those patterns, so you don’t have to do it by hand.
You want to stay on top of security vulnerabilities, but the list of SQL injections continues to grow. A coding tool that uses a machine learning (ML) model, like Code QL, is trained to not only detect known injections, but also patterns similar to those injections in data it hasn’t seen before. This can help you increase recognition of confirmed vulnerabilities and predict new ones.
Generative AI coding tools leverage ML to generate novel answers and predict coding sequences. A tool like GitHub Copilot can reduce the amount of times you switch out of your IDE to look up boilerplate code or help you brainstorm coding solutions. Shifting your role from rote writing to strategic decision making, generative AI can help you reflect on your code at a higher, more abstract level—so you can focus more on what you want to build and spend less time worrying about how.
How are generative AI coding tools designed and built?
Building a generative AI coding tool requires training AI models on large amounts of code across programming languages via deep learning. (Deep learning is a way to train computers to process data like we do—by recognizing patterns, making connections, and drawing inferences with limited guidance.)
To emulate the way humans learn patterns, these AI models use vast networks of nodes, which process and weigh input data, and are designed to function like neurons. Once trained on large amounts of data and able to produce useful code, they’re built into tools and applications. The models can then be plugged into coding editors and IDEs where they respond to natural language prompts or code to suggest new code, functions, and phrases.
Before we talk about how generative AI coding tools are made, let’s define what they are first. It starts with LLMs, or large language models, which are sets of algorithms trained on large amounts of code and human language. Like we mentioned above, they can predict coding sequences and generate novel content using existing code or natural language prompts.
Today’s state-of-the-art LLMs are transformers. That means they use something called an attention mechanism to make flexible connections between different tokens in a user’s input and the output that the model has already generated. This allows them to provide responses that are more contextually relevant than previous AI models because they’re good at connecting the dots and big-picture thinking.
Here’s an example of how a transformer works. Let’s say you encounter the word log in your code. The transformer node at that place would use the attention mechanism to contextually predict what kind of log would come next in the sequence.
Let’s say, in the example below, you input the statement from math import log. A generative AI model would then infer you mean a logarithmic function.
And if you add the prompt from logging import log, it would infer that you’re using a logging function.
Though sometimes a log is just a log.
LLMs can be built using frameworks besides transformers. But LLMs using frameworks, like a recurrent neural network or long short-term memory, struggle with processing long sentences and paragraphs. They also typically require training on labeled data (making training a labor-intensive process). This limits the complexity and relevance of their outputs, and the data they can learn from.
Transformer LLMs, on the other hand, can train themselves on unlabeled data. Once they’re given basic learning objectives, LLMs take a part of the new input data and use it to practice their learning goals. Once they’ve achieved these goals on that portion of the input, they apply what they’ve learned to understand the rest of the input. This self-supervised learning process is what allows transformer LLMs to analyze massive amounts of unlabeled data—and the larger the dataset an LLM is trained on, the more they scale by processing that data.
Why should developers care about transformers and LLMs?
LLMs like OpenAI’s GPT-3, GPT-4, and Codex models are trained on an enormous amount of natural language data and publicly available source code. This is part of the reason why tools like ChatGPT and GitHub Copilot, which are built on these models, can produce contextually accurate outputs.
Here’s how GitHub Copilot produces coding suggestions:
All of the code you’ve written so far, or the code that comes before the cursor in an IDE, is fed to a series of algorithms that decide what parts of the code will be processed by GitHub Copilot.
Since it’s powered by a transformer-based LLM, GitHub Copilot will apply the patterns it’s abstracted from training data and apply those patterns to your input code.
The result: contextually relevant, original coding suggestions. GitHub Copilot will even filter out known security vulnerabilities, vulnerable code patterns, and code that matches other projects.
Keep in mind: creating new content such as text, code, and images is at the heart of generative AI. LLMs are adept at abstracting patterns from their training data, applying those patterns to existing language, and then producing language or a line of code that follows those patterns. Given the sheer scale of LLMs, they might generate a language or code sequence that doesn’t even exist yet. Just as you would review a colleague’s code, you should assess and validate AI-generated code, too.
Why context matters for AI coding tools
Developing good prompt crafting techniques is important because input code passes through something called a context window, which is present in all transformer-based LLMs. The context window represents the capacity of data an LLM can process. Though it can’t process an infinite amount of data, it can grow larger. Right now, the Codex model has a context window that allows it to process a couple of hundred lines of code, which has already advanced and accelerated coding tasks like code completion and code change summarization.
Developers use details from pull requests, a folder in a project, open issues—and the list goes on—to contextualize their code. So, when it comes to a coding tool with a limited context window, the challenge is to figure out what data, in addition to code, will lead to the best suggestions.
The order of the data also impacts a model’s contextual understanding. Recently, GitHub made updates to its pair programmer so that it considers not only the code immediately before the cursor, but also some of the code after the cursor. The paradigm—which is called Fill-In-the-Middle (FIM)—leaves a gap in the middle of the code for GitHub Copilot to fill, providing the tool with more context about the developer’s intended code and how it should align with the rest of the program. This helps produce higher quality code suggestions without any added latency.
Visuals can also contextualize code. Multimodal LLMs (MMLLMs) scale transformer LLMs so they process images and videos, as well as text. OpenAI recently released its new GPT-4 model—and Microsoft revealed its own MMLLM called Kosmos-1. These models are designed to respond to natural language and images, like alternating text and images, image-caption pairs, and text data.
GitHub’s senior developer advocate Christina Warren shares the latest on GPT-4 and the creative potential it holds for developers:
How developers are using generative AI coding tools
The field of generative AI is filled with experiments and explorations to uncover the technology’s full capabilities—and how they can enable effective developer workflows. Generative AI tools are already changing how developers write code and build software, from improving productivity to helping developers focus on bigger problems.
While generative AI applications in software development are still being actively defined, today, developers are using generative AI coding tools to:
Get a head start on complex code translation tasks. A study presented at the 2021 International Conference on Intelligent User Interfaces found that generative AI provided developers with a skeletal framework to translate legacy source code into Python. Even if the suggestions weren’t always correct, developers found it easier to assess and fix those mistakes than manually translate the source code from scratch. They also noted that this process of reviewing and correcting was similar to what they already do when working with code produced by their colleagues.
With GitHub Copilot Labs, developers can use the companion VS Code extension (that’s separate from but dependent on the GitHub Copilot extension) to translate code into different programming languages. Watch how GitHub Developer Advocate, Michelle Mannering, uses GitHub Copilot Labs to translate her Python code into Ruby in just a few steps.
Code more efficiently. While autocompletion has been in modern IDEs for years, LLMs can generate longer suggestions—sometimes multiple lines of code—that are often more relevant. A 2022 study published in the Proceedings of the Association for Computing Machinery on Programming Languages (PACMPL) observed 20 programmers who interacted with GitHub Copilot. They found that thanks to end-of-line suggestions for function calls and argument completions, developers were able to code faster and stay in the flow longer.
Our own research supports these findings, too. As we mentioned earlier, we found that developers who used GitHub Copilot coded up to 55% faster than those who didn’t. But productivity gains went beyond speed with 74% of developers reporting that they felt less frustrated when coding and were able to focus on more satisfying work.
Tackle new problems and get creative. The PACMPL study also found that developers used GitHub Copilot to find creative solutions when they were unsure of how to move forward. These developers searched for next possible steps and relied on the generative AI coding tool to assist with unfamiliar syntax, look up the right API, or discover the correct algorithm.
I was one of the developers who wrote GitHub Copilot, but prior to that work, I had never written a single line of TypeScript. That wasn’t a problem because I used the first prototype of GitHub Copilot to learn the language and, eventually, help ship the world’s first at-scale generative AI coding tool.
– Albert Ziegler, Principal Machine Learning Engineer // GitHub
Find answers without leaving their IDEs. Some participants in the PACMPL study also treated GitHub Copilot’s multi-suggestion pane like StackOverflow. Since they were able to describe their goals in natural language, participants could directly prompt GitHub Copilot to generate ideas for implementing their goals, and press Ctrl/Cmd + Enter to see a list of 10 suggestions. Even though this kind of exploration didn’t lead to deep knowledge, it helped one developer to effectively use an unfamiliar API.
Build better test coverage. Some generative AI coding tools excel in pattern recognition and completion. Developers are using these tools to build unit and functional tests—and even security tests—via natural language prompts. Some tools also offer security vulnerability filtering, so a developer will be alerted if they unknowingly introduce a vulnerability in their code.
Discover tricks and solutions they didn’t know they needed. Scarlett also wrote about eight unexpected ways developers can use GitHub Copilot—from prompting it to create a dictionary of two-letter ISO country codes and their contributing country name, to helping developers exit Vim, an editor with a sometimes finicky closing process. Want to learn more? Check out the full guide >
The bottom line
Generative AI provides humans with a new mode of interaction—and it doesn’t just alleviate the tedious parts of software development. It also inspires developers to be more creative, feel empowered to tackle big problems, and model large, complex solutions in ways they couldn’t before. From increasing productivity and offering alternative solutions, to helping you build new skills—like learning a new language or framework, or even writing clear comments and documentation—there are so many reasons to be excited about the next wave of software development. This is only the beginning.
In our recent blog post announcing GitHub Copilot X, we mentioned that generative AI represents the future of software development. This amazing technology will enable developers to stay in the flow while helping enterprises meet their business goals.
But as we have also mentioned in our blog series on compliance, generative AI may soon act as an enabler for developer-focused compliance programs that will drive optimization and keep your development, compliance and audit teams productive and happy.
Today, we’ll explore the potential for generative AI to help enable teams to optimize and automate some of the foundational compliance components of separation of duties that many enterprises still often manage and review manually.
Generative AI has been dominating the news lately—but what exactly is it? Here’s what you need to know, and what it means for developers.
Separation of duties
The concept of “separation of duties,” long used in the accounting world as a check and balance approach, is also adopted in other scenarios, including technology architecture and workflows. While helpful to address compliance, it can lead to additional manual steps that can slow down delivery and innovation.
Fortunately, the PCI-DSS requirements guide provides a more DevOps, cloud native, and AI-enabled approach to separation of duties by focusing on functions and accounts, as opposed to people:
“The purpose of this requirement is to separate the development and test functions from the production functions. For example, a developer can use an administrator-level account with elevated privileges in the development environment and have a separate account with user-level access to the production environment.”
There are many parts of a software delivery workflow that need to have separation of duties in place—but one of the core components that is key for any compliance program is the code review. Having a separate set of objective eyes reviewing your code, whether it’s human or AI-powered, helps to ensure risks, tech debt, and security vulnerabilities are found and mitigated as early as possible.
Code reviews also help enable the concept of separation of duties since it prohibits a single person or a single function, account, or process from moving code to the next part of your delivery workflow. Additionally, code reviews help enable separation of duties for Infrastructure as Code (IaC) workflows, Policy-as-Code configurations, and even Kubernetes declarative deployments.
As we mentioned in our previous blog, GitHub makes code review easy, since pull requests are part of the existing workflow that millions of developers use daily. Having a foundational piece of compliance built-in to the platform that developers know and love keeps them in the flow, while keeping compliance and audit teams happy as well.
Generative AI and pull requests
Wouldn’t it be cool if one-day generative AI could be leveraged to enable more developer-friendly compliance programs which have traditionally been very labor and time intensive? Imagine if generative AI could help enable DevOps and cloud native approaches for separation of duties by automating tedious tasks and allowing humans to focus on key value-added tasks.
Bringing this back to compliance and separation of duties, wouldn’t it be great if a generative AI helper was available to provide an objective set of eyes on your pull requests? This is what the GitHub Next team has been working towards with GitHub Copilot for Pull Requests.
Suggestions for your pull request descriptions. AI-powered tags are embedded into a pull request description and automatically filled out by GitHub Copilot based on the code which the developers changed. Going one step further, the GitHub Next team is also looking at the creation of descriptive sentences and paragraphs as developers create pull requests.
Code reviews with AI. Taking pull requests and code reviews one step further, the GitHub Next team is looking at AI to help review the code and provide suggestions for changes. This will help enable human interactions and optimize existing processes. The AI would automate the creation of the descriptions, based on the code changes, as well as suggestions for improvements. The code reviewer will have everything they need to quickly review the change and decide to either move forward or send the change back.
When these capabilities are production ready, development teams and compliance programs will appreciate these features for a few reasons. First, the pull request and code review process would be driven by a conversation based on a neutral and independent description. Second, the description will be based on the actual code that was changed. Third, both development and compliance workflows will be optimized and allow humans to focus on value-added work.
While these capabilities are still a work in progress, there are features available now that may help enable compliance, audit, and security teams with GitHub Copilot for Business. The ability for developers to complete tasks faster and stay in the flow are truly amazing. But the ability for GitHub Copilot to provide AI-based security vulnerability filtering nowis a great place for compliance and audit teams within enterprises to get started on their journey to embracing generative AI into their day-to-day practices.
Next steps
Generative AI will enable developers and enterprises to achieve success by reducing manual tasks and enabling developers to focus their creativity on business value–all while staying in the flow.
I hope this blog will help drive positive discussions regarding this topic and has provided a forward looking view into what will be possible in the future. The future ability of generative AI to help enable teams by automating tedious tasks will help humans focus on more value-added work and could eventually be an important part of a robust and risk-based compliance posture.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




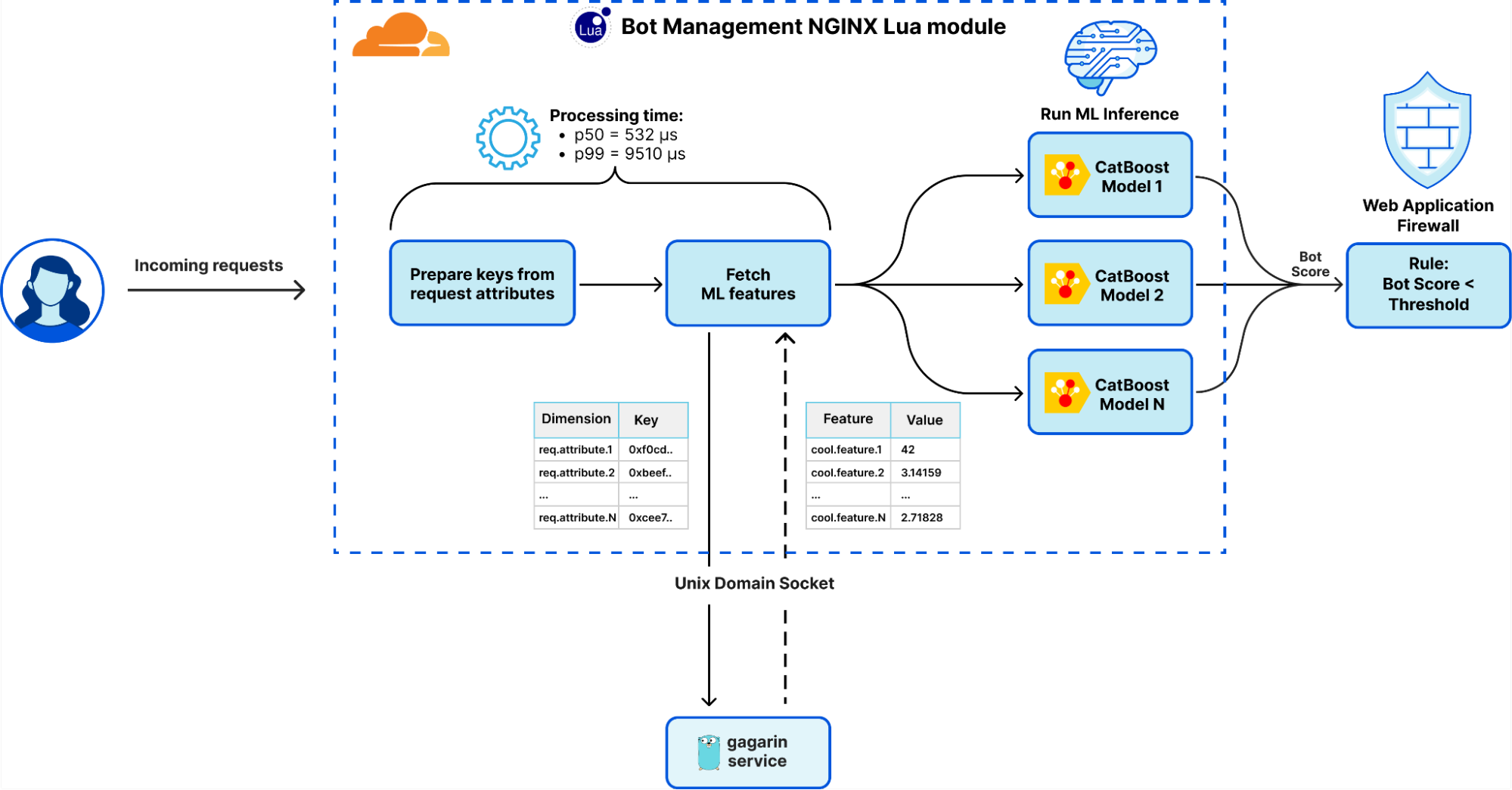
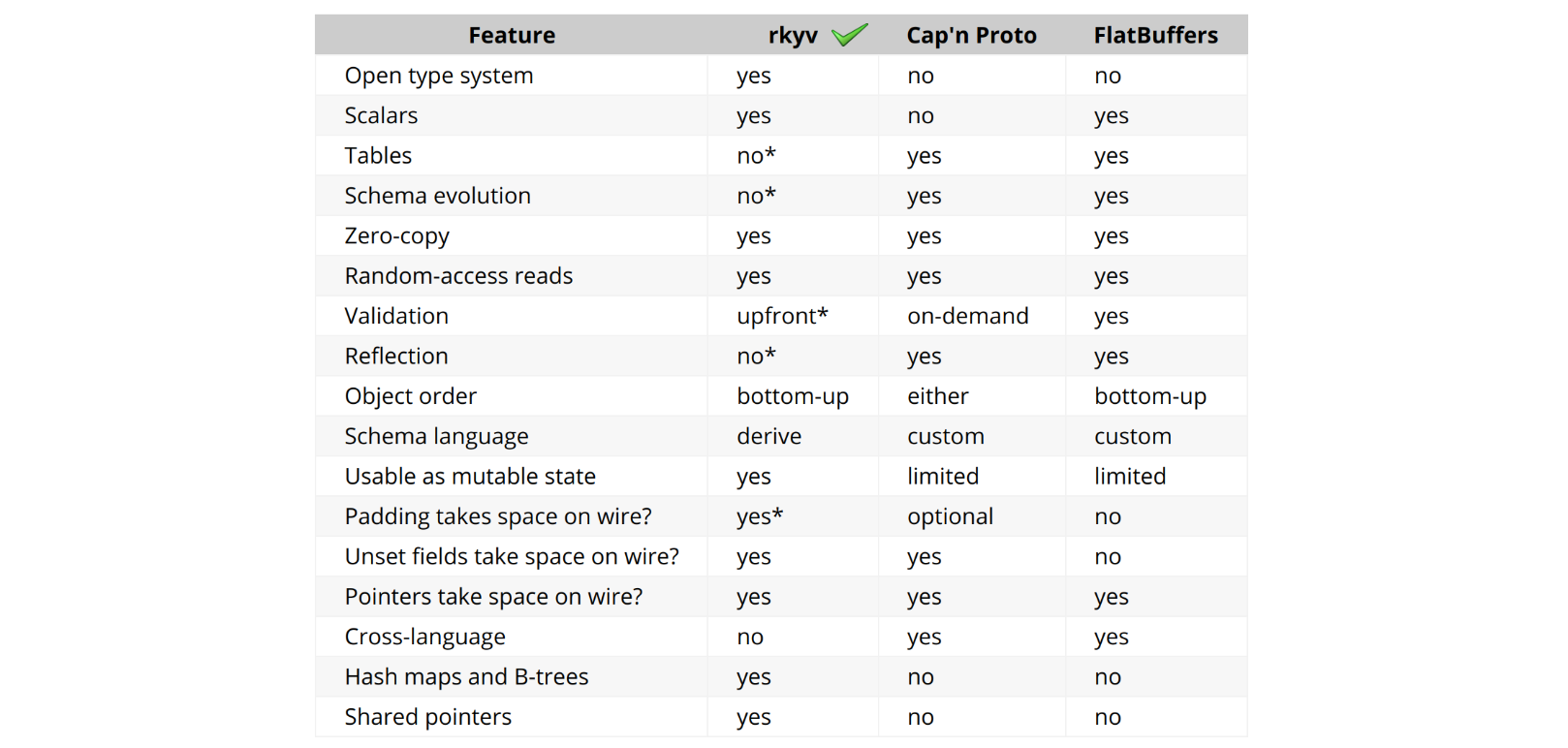
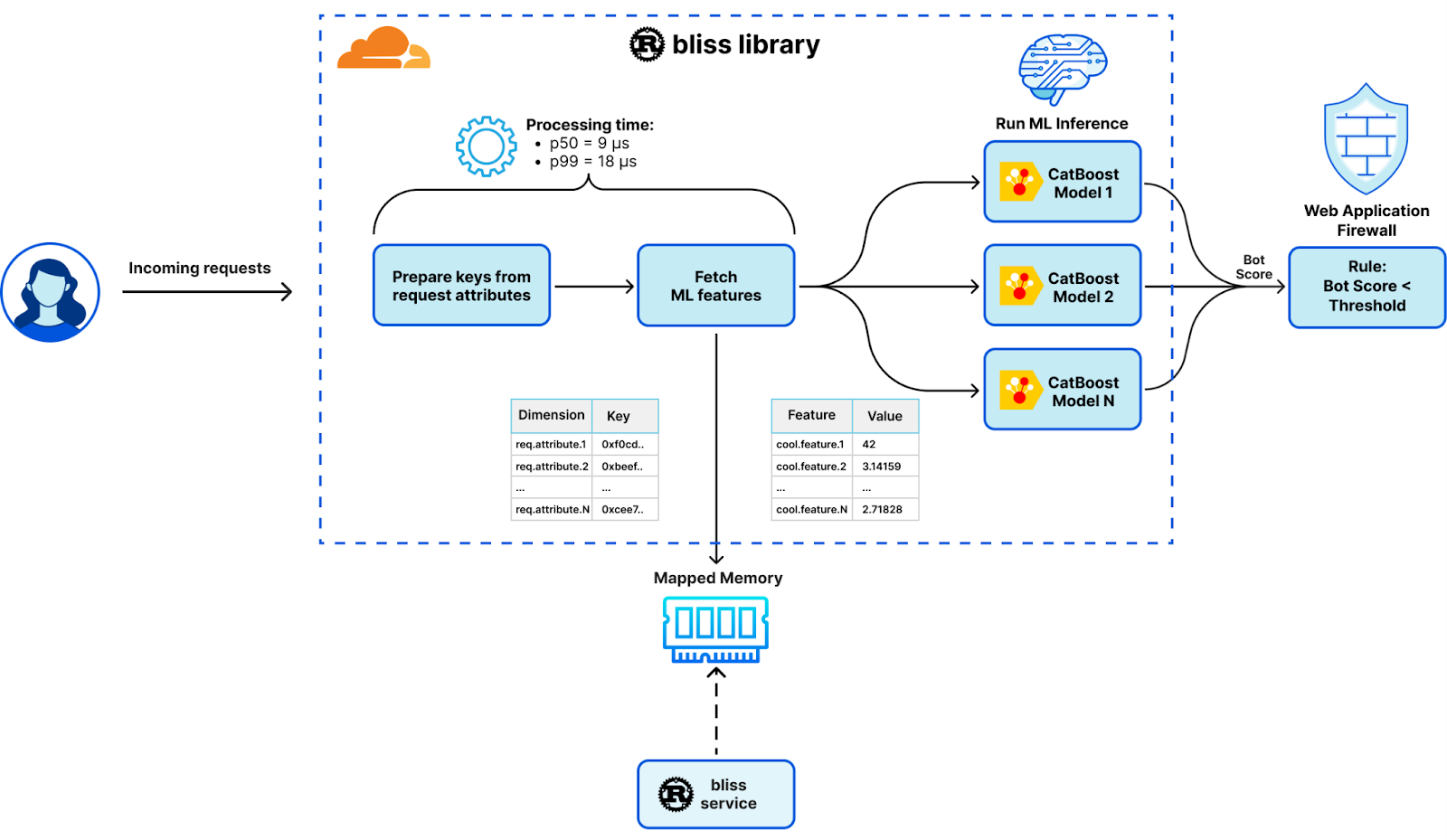

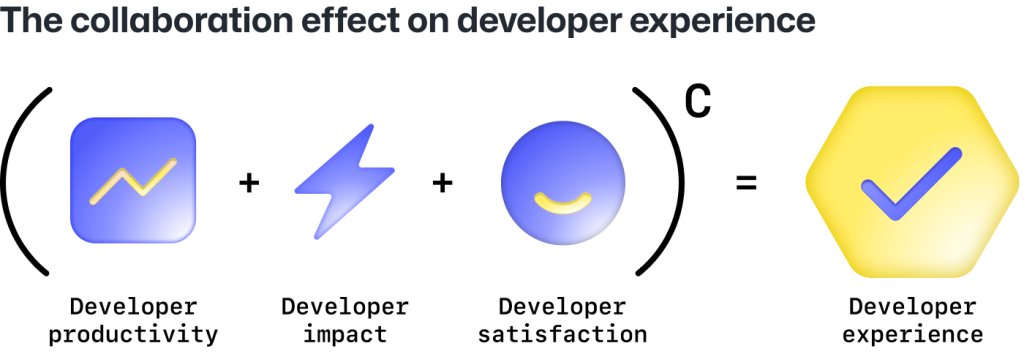
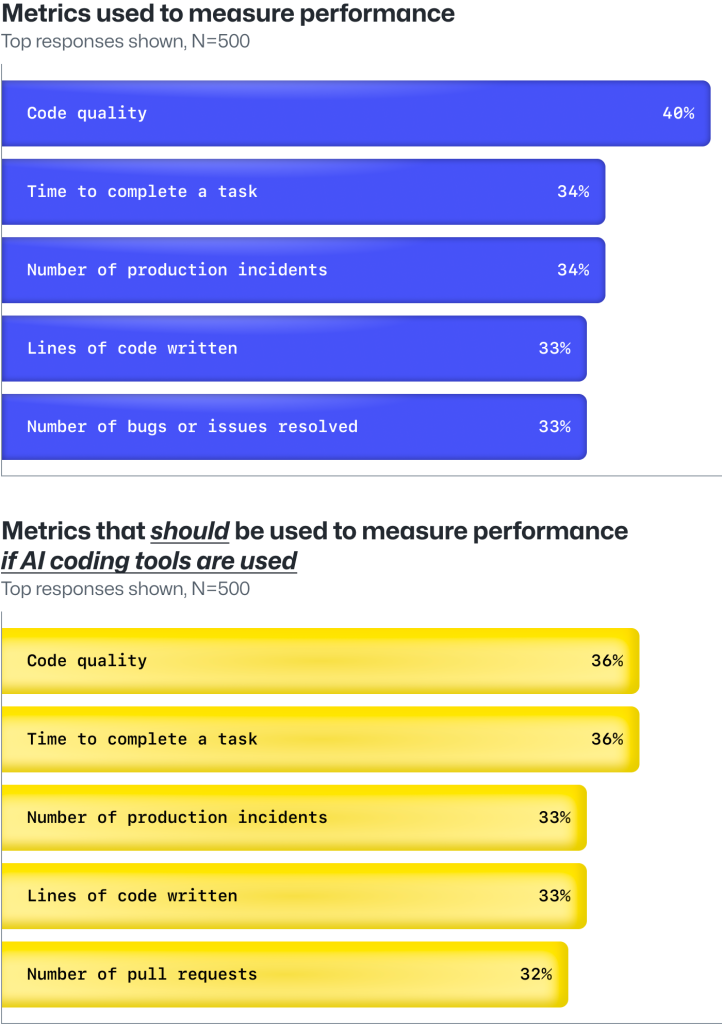




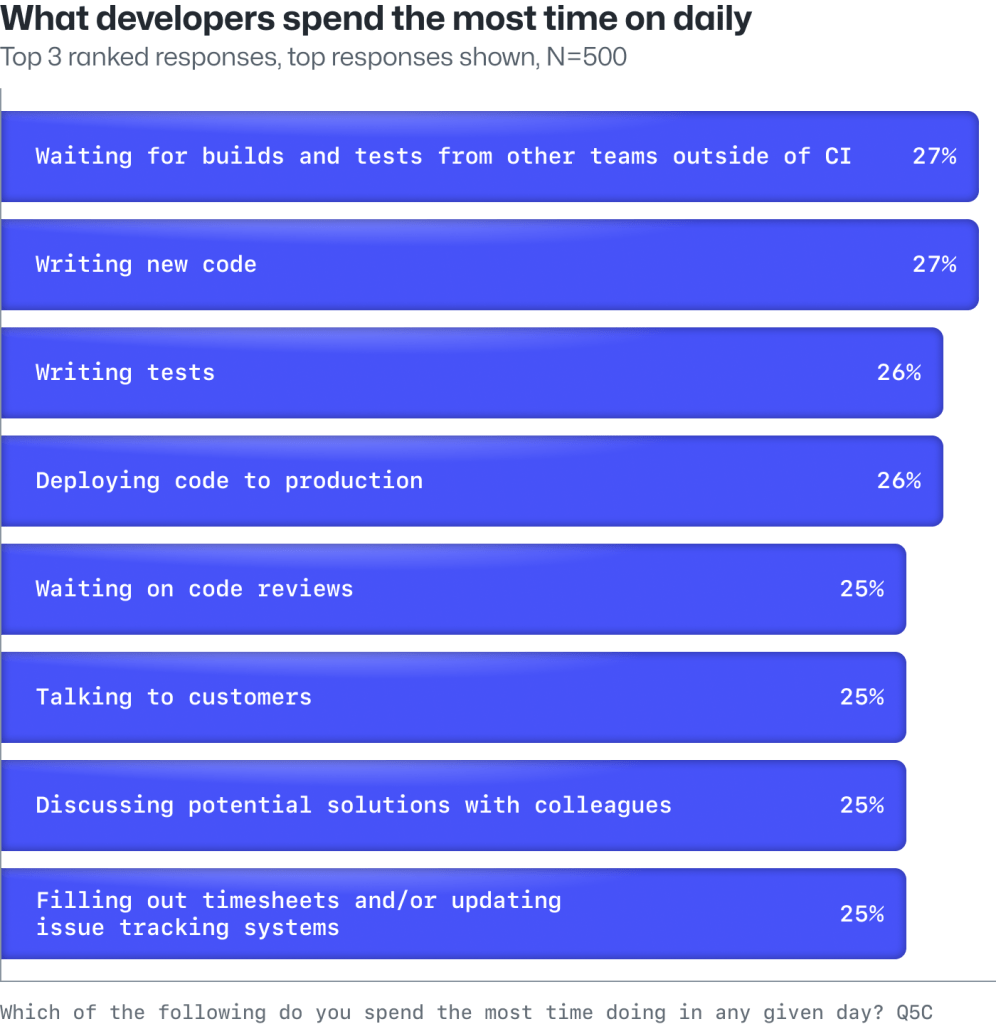
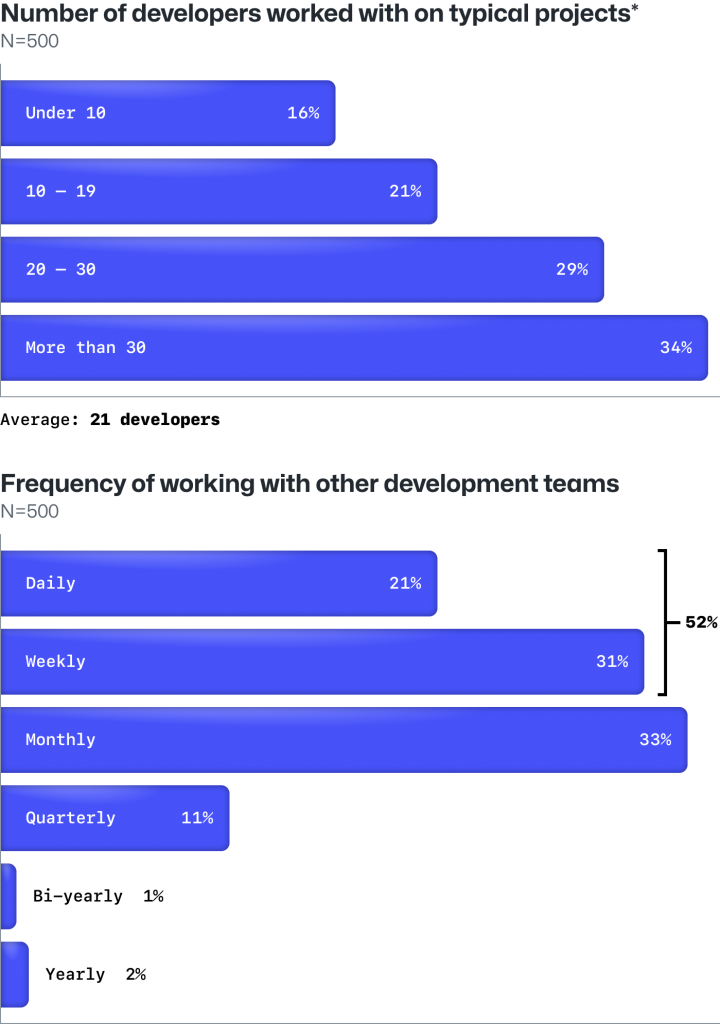






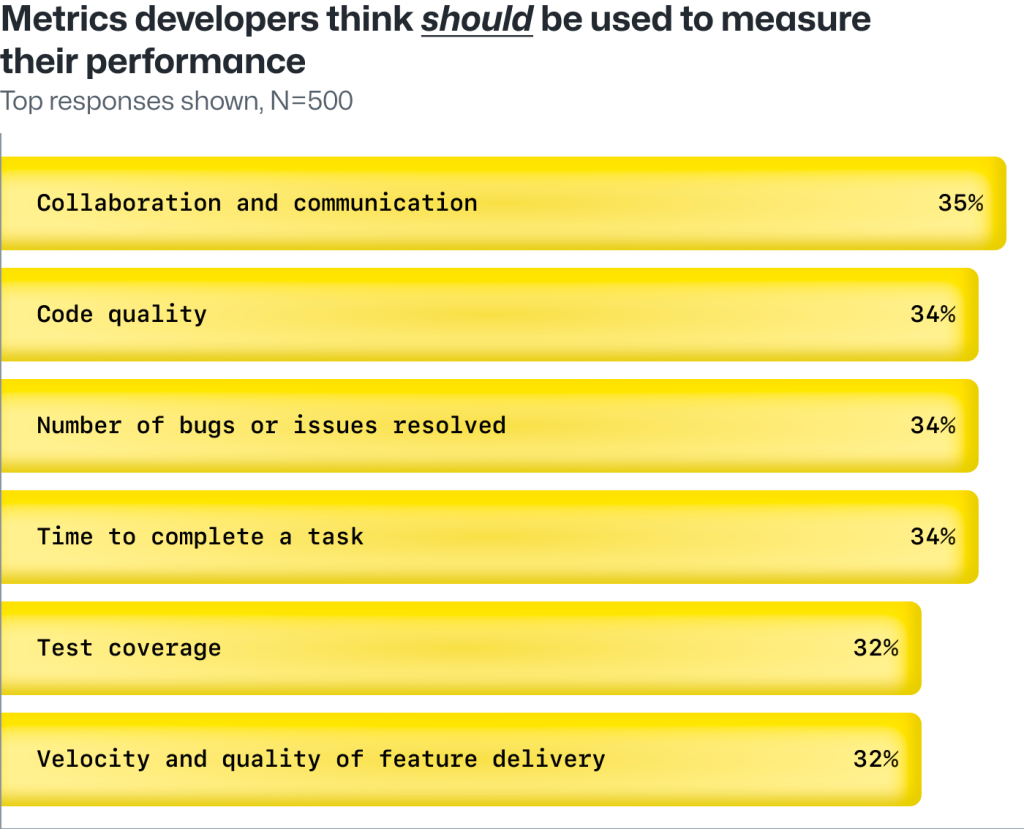

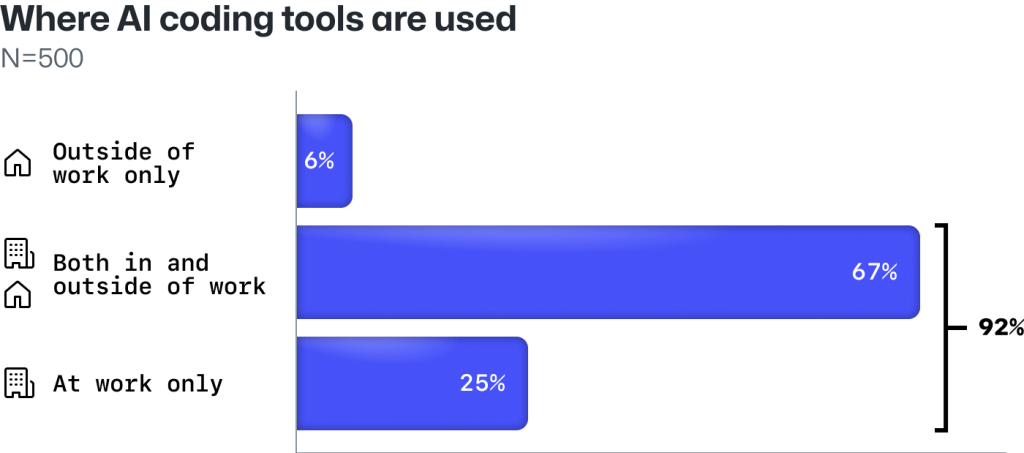

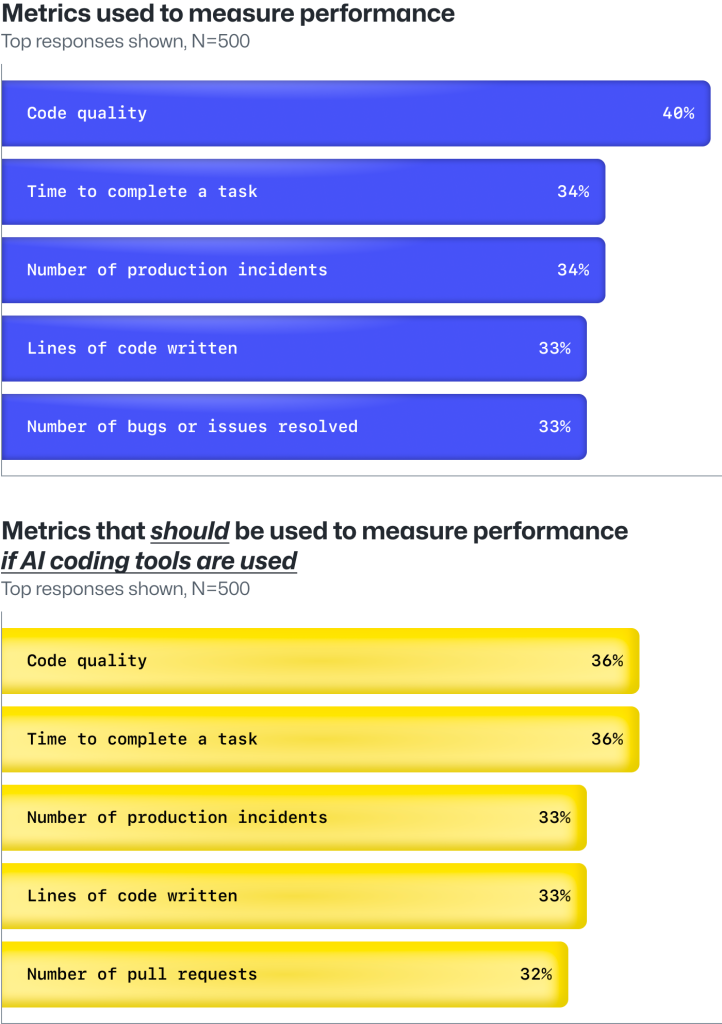
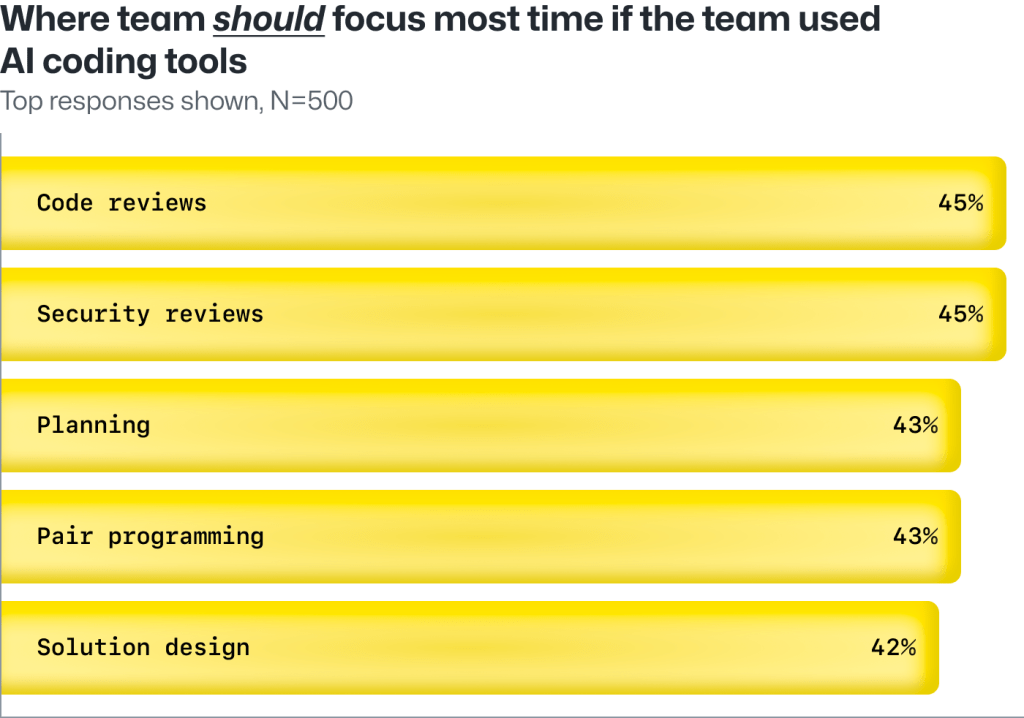

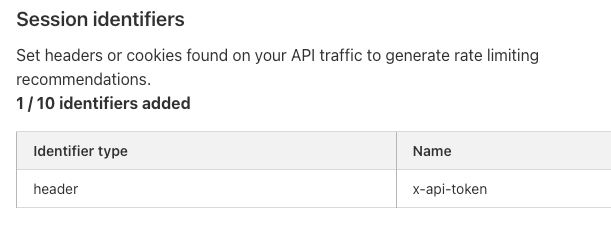
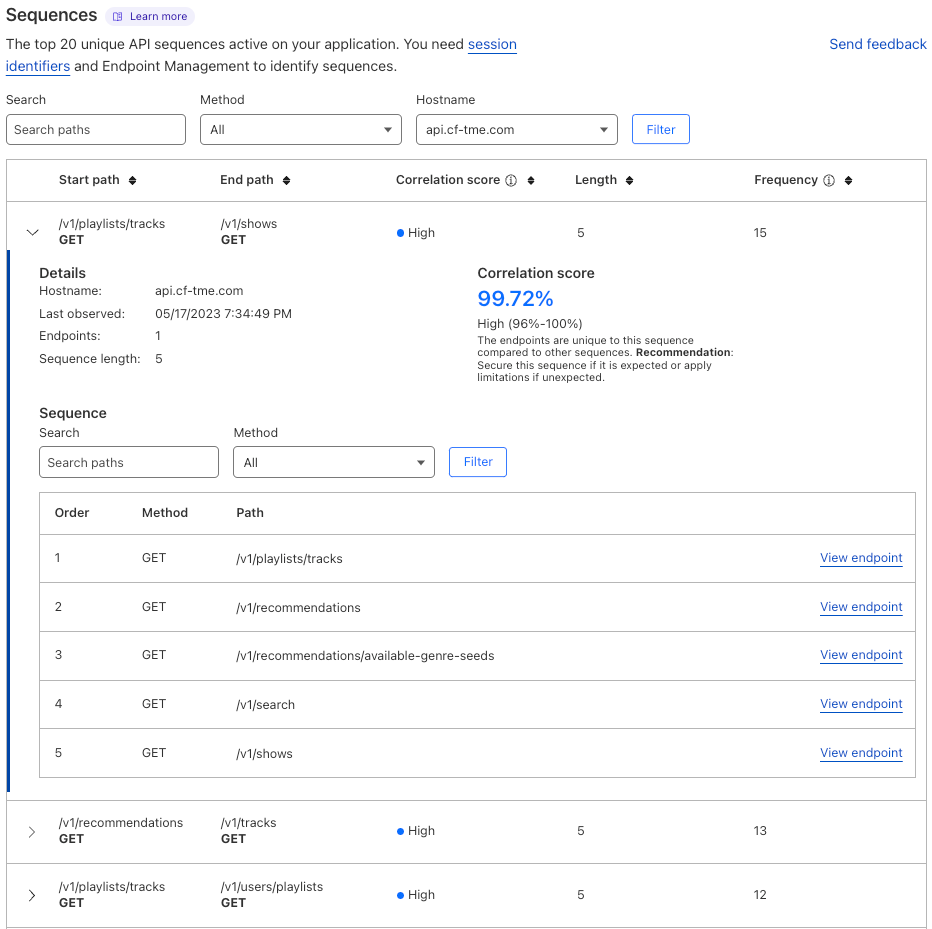

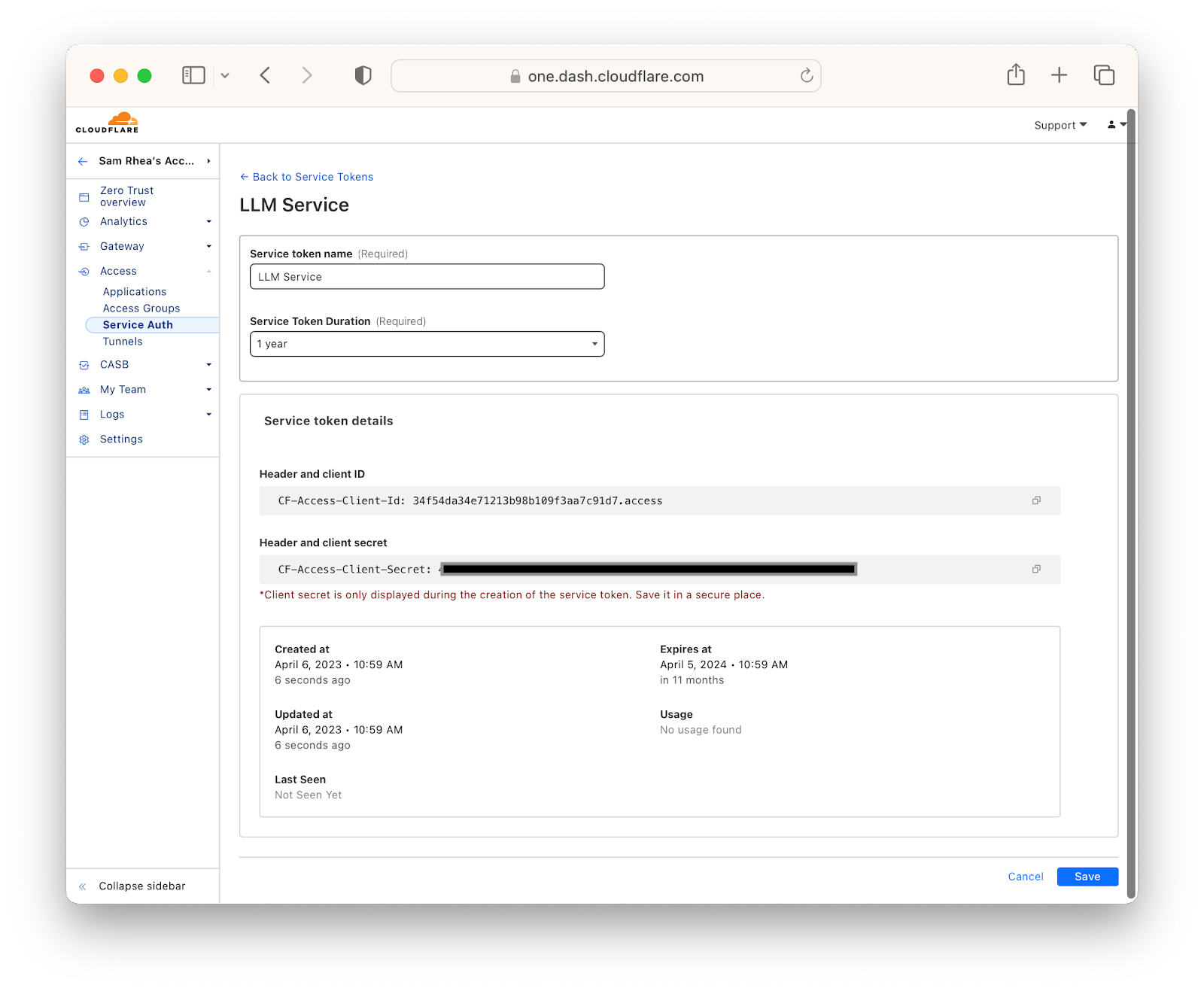
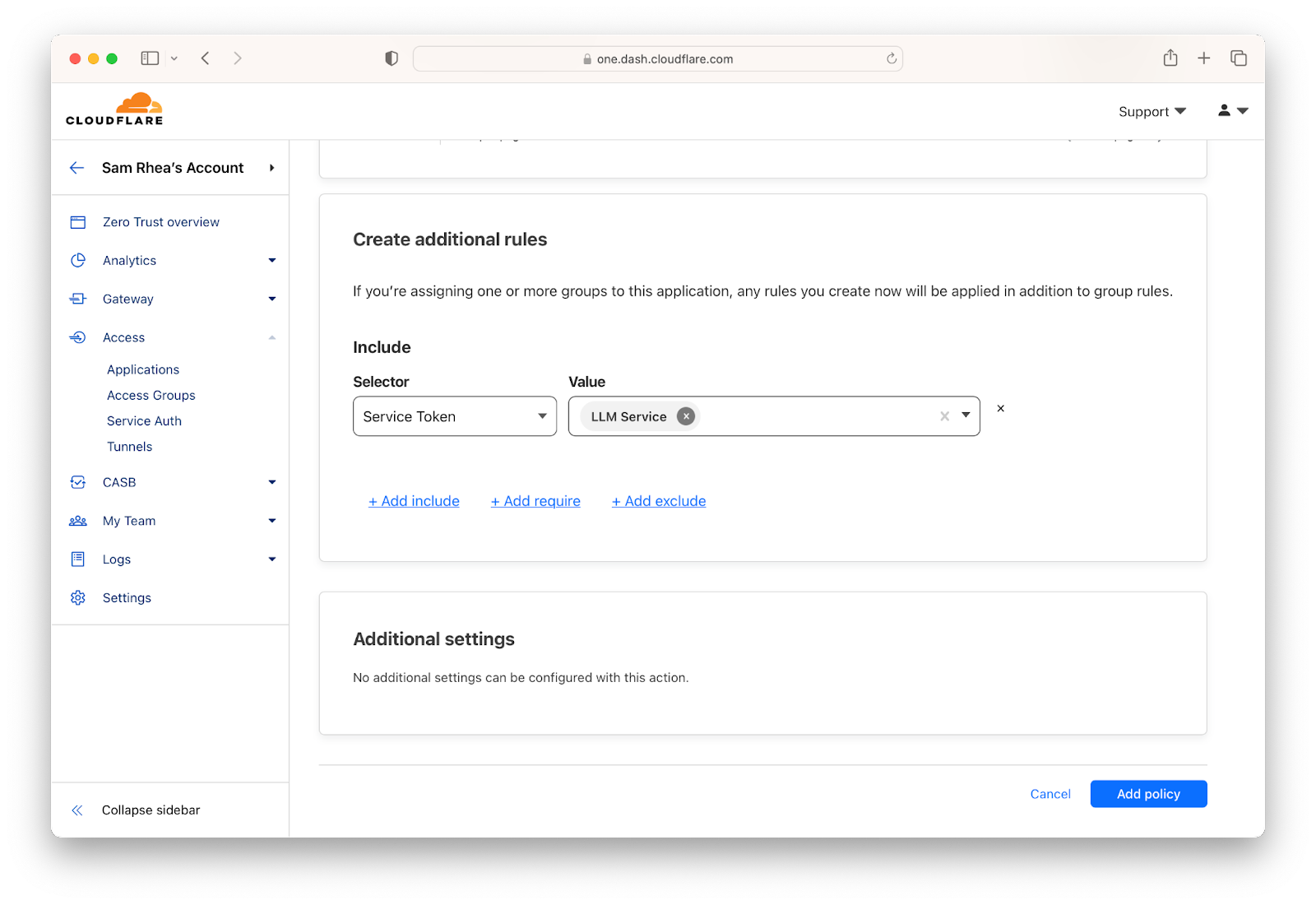
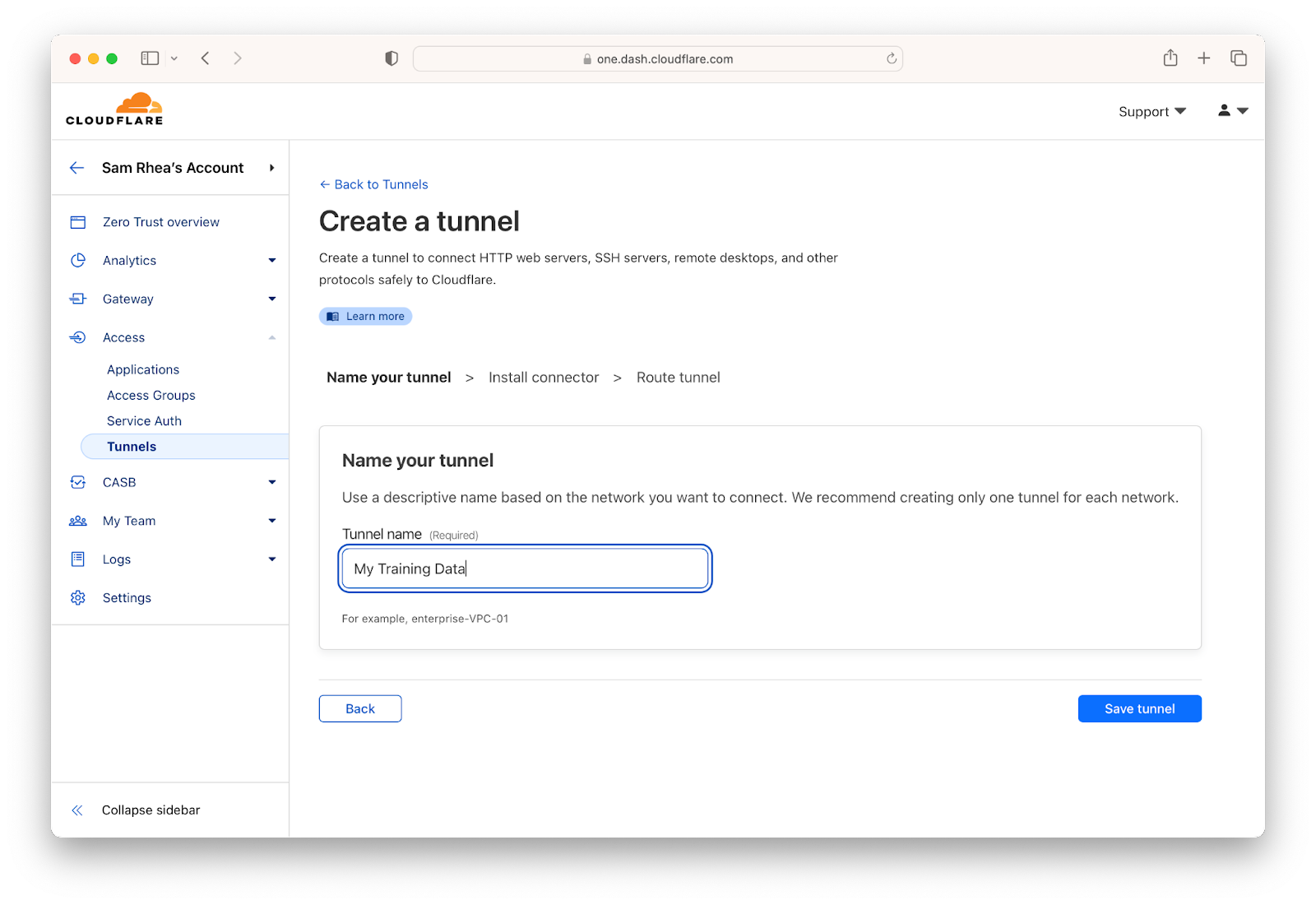
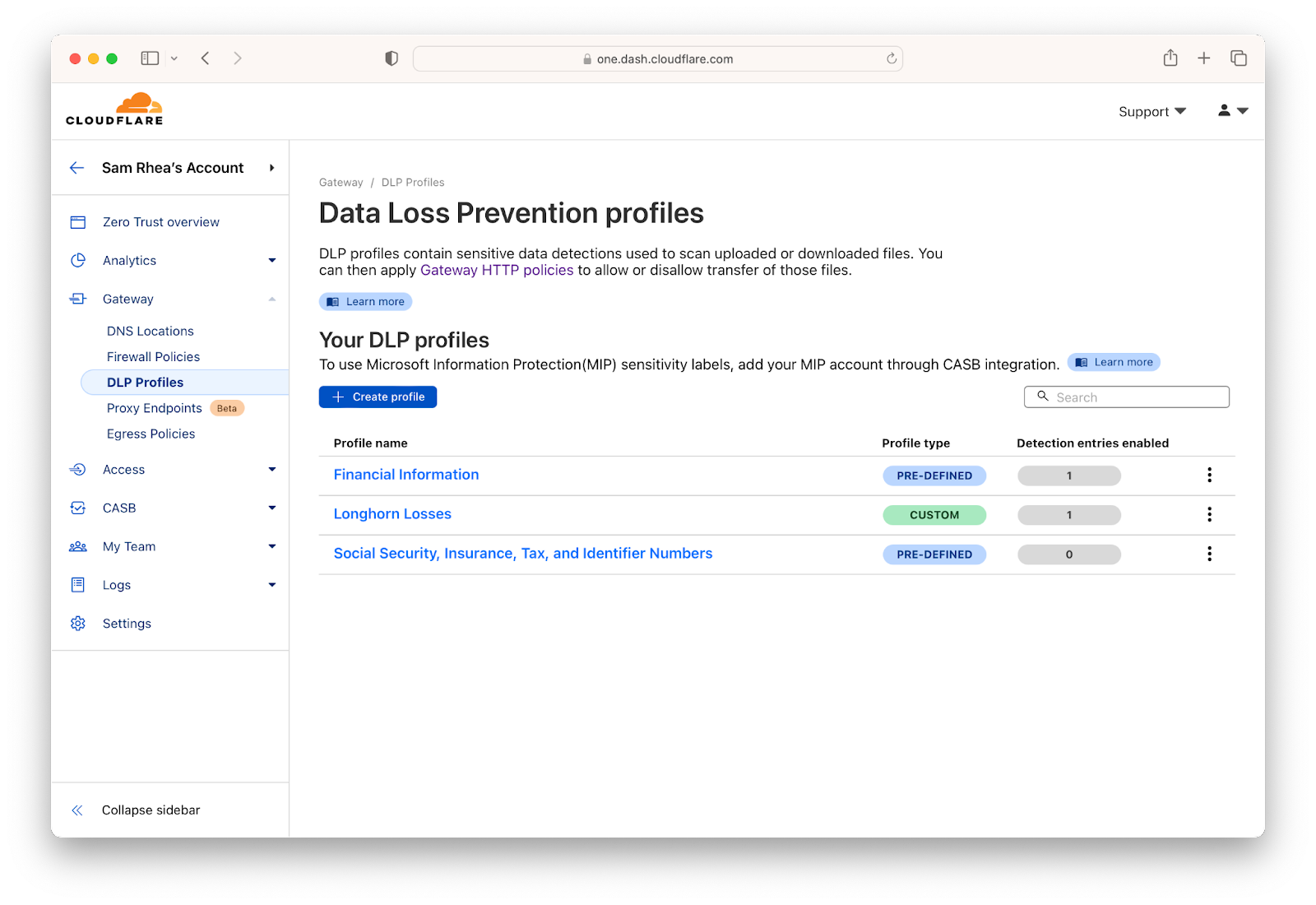
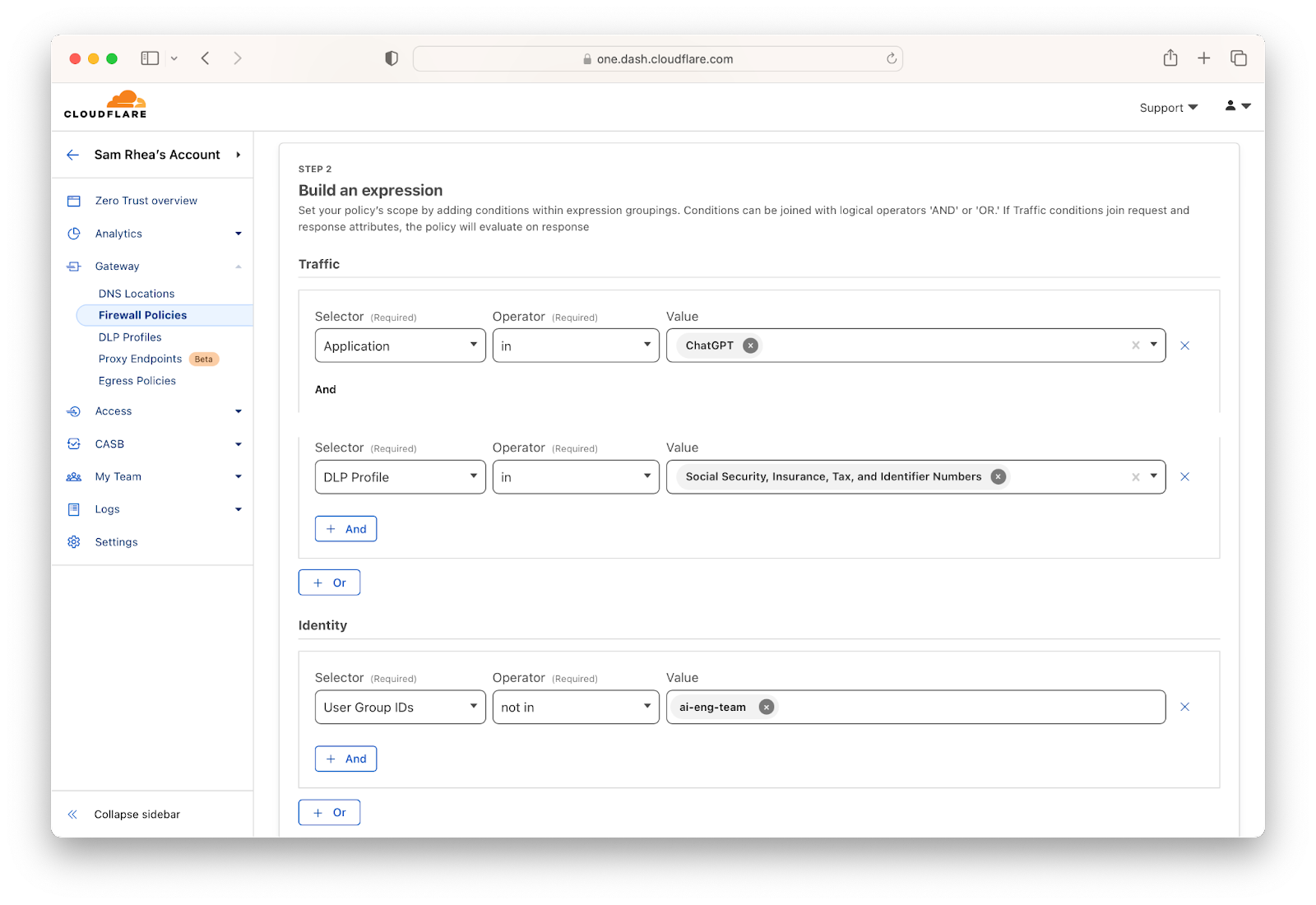






















 (@yavorsky_)
(@yavorsky_)