Post Syndicated from Steven David original https://aws.amazon.com/blogs/devops/federated-multi-account-access-for-aws-codecommit/
As a developer working in a large enterprise or for a group that supports multiple products, you may often find yourself accessing Git repositories from different organizations. Currently, to securely access multiple Git repositories in other popular tools, you need SSH keys, GPG keys, a Git credential helper, and a significant amount of setup by the developer hoping to commit to the repository. In addition, administrators must be aware of the various ways to remove all the permissions granted to the developer.
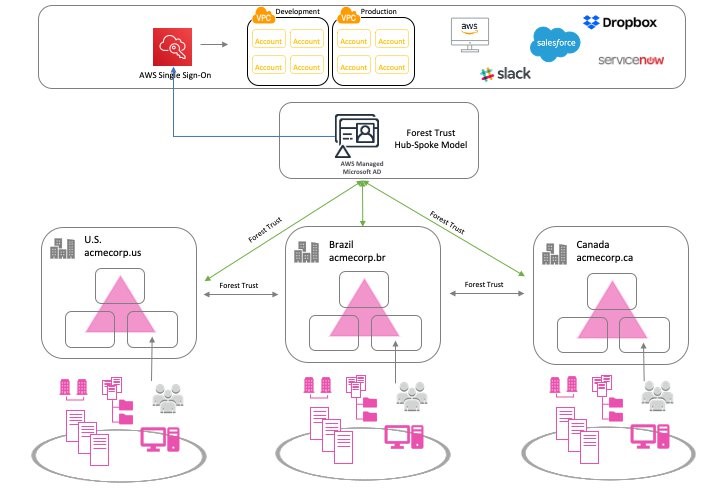
AWS CodeCommit is a managed source control service. Combined with AWS Single Sign-On (AWS SSO) and git-remote-codecommit, you can quickly and easily switch between repositories owned by different groups or even managed in separate AWS accounts. You can control those permissions with AWS Identity and Access Management (IAM) roles to allow for the automated removal of the user’s permission as part of their off-boarding procedure for the company.
This post demonstrates how to grant access to various CodeCommit repositories without access keys.
Solution overview
In this solution, the user’s access is controlled with federated login via AWS SSO. You can grant that access using AWS native authentication, which eliminates the need for a Git credential helper, SSH, and GPG keys. In addition, this allows the administrator to control access by adding or removing the user’s IAM role access.
The following diagram shows the code access pattern you can achieve by using AWS SSO and git-remote-codecommit to access CodeCommit across multiple accounts.

Prerequisites
To complete this tutorial, you must have the following prerequisites:
- CodeCommit repositories in two separate accounts. For instructions, see Create an AWS CodeCommit repository.
- AWS SSO set up to handle access federation. For instructions, see Enable AWS SSO.
- Python 3.6 or higher installed on the developer’s local machine. To download and install the latest version of Python, see the Python website.
- On a Mac, it can be difficult to ensure that you’re using Python 3.6, because 2.7 is installed and required by the OS. For more information about checking your version of Python, see the following GitHub repo.
- Git installed on your local machine. To download Git, see Git Downloads.
- PIP version 9.0.3 or higher installed on your local machine. For instructions, see Installation on the PIP website.
Configuring AWS SSO role permissions
As your first step, you should make sure each AWS SSO role has the correct permissions to access the CodeCommit repositories.
- On the AWS SSO console, choose AWS Accounts.
- On the Permissions Sets tab, choose Create permission set.
- On the Create a new permission set page, select Create a custom permission set.
- For Name, enter CodeCommitDeveloperAccess.
- For Description, enter This permission set gives the user access to work with CodeCommit for common developer tasks.
- For Session duration, choose 12 hours.

- For Relay state, leave blank.
- For What policies do you want to include in your permissions set?, select Create a custom permissions policy.
- Use the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "CodeCommitDeveloperAccess",
"Effect": "Allow",
"Action": [
"codecommit:GitPull",
"codecommit:GitPush",
"codecommit:ListRepositories"
],
"Resource": "*"
}
]
}The preceding code grants access to all the repositories in the account. You could limit to a specific list of repositories, if needed.
- Choose Create.
Creating your AWS SSO group
Next, we need to create the SSO Group we want to assign the permissions.
- On the AWS SSO console, choose Groups.
- Choose create group.
- For Group name, enter CodeCommitAccessGroup.
- For Description, enter Users assigned to this group will have access to work with CodeCommit.

- Choose Create.
Assigning your group and permission sets to your accounts
Now that we have our group and permission sets created, we need to assign them to the accounts with the CodeCommit repositories.
- On the AWS SSO console, choose AWS Accounts.
- Choose the account you want to use in your new group.
- On the account Details page, choose Assign Users.
- On the Select users or groups page, choose Group.
- Select CodeCommitGroup.
- Choose NEXT: Permission Sets.
- Choose the CodeCommitDeveloperAccess permission set and choose Finish

- Choose Proceed to Accounts to return to the AWS SSO console.
- Repeat these steps for each account that has a CodeCommit repository.
Assigning a user to the group
To wrap up our AWS SSO configuration, we need to assign the user to the group.
- On the AWS SSO console, choose Groups.
- Choose CodeCommitAccessGroup.
- Choose Add user.
- Select all the users you want to add to this group.
- Choose Add user(s).
- From the navigation pane, choose Settings.
- Record the user portal URL to use later.
Enabling AWS SSO login
The second main feature we want to enable is AWS SSO login from the AWS Command Line Interface (AWS CLI) on our local machine.
- Run the following command from the AWS CLI. You need to enter the user portal URL from the previous step and tell the CLI what Region has your AWS SSO deployment. The following code example has AWS SSO deployed in us-east-1:
aws configure sso
SSO start URL [None]: https://my-sso-portal.awsapps.com/start
SSO region [None]:us-east-1You’re redirected to your default browser.
- Sign in to AWS SSO.
When you return to the CLI, you must choose your account. See the following code:
There are 2 AWS accounts available to you.
> DeveloperResearch, [email protected] (123456789123)
DeveloperTrading, [email protected] (123456789444)
- Choose the account with your CodeCommit repository.
Next, you see the permissions sets available to you in the account you just picked. See the following code:
Using the account ID 123456789123
There are 2 roles available to you.
> ReadOnly
CodeCommitDeveloperAccess
- Choose the CodeCommitDeveloperAccess permissions.
You now see the options for the profile you’re creating for these AWS SSO permissions:
CLI default client Region [None]: us-west-2<ENTER>
CLI default output format [None]: json<ENTER>
CLI profile name [123456789011_ReadOnly]: DevResearch-profile<ENTER>- Repeat these steps for each AWS account you want to access.
For example, I create DevResearch-profile for my DeveloperResearch account and DevTrading-profile for the DeveloperTrading account.
Installing git-remote-codecommit
Finally, we want to install the recently released git-remote-codecommit and start working with our Git repositories.
- Install git-remote-codecommit with the following code:
pip install git-remote-codecommitWith some operating systems, you might need to run the following code instead:
sudo pip install git-remote-codecommit- Clone the code from one of your repositories. For this use case, my CodeCommit repository is named MyDemoRepo. See the following code:
git clone codecommit://DevResearch-profile@MyDemoRepo my-demo-repo- After that solution is cloned locally, you can copy code from another federated profile by simply changing to that profile and referencing the repository in that account named MyDemoRepo2. See the following code:
git clone codecommit://DevTrading-profile@MyDemoRepo2 my-demo-repo2Cleaning up
At the end of this tutorial, complete the following steps to undo the changes you made to your local system and AWS:
- On the AWS SSO console, remove the user from the group you created, so any future access requests fail.
- To remove the AWS SSO login profiles, open the local config file with your preferred tool and remove the profile.
- The config file is located at %UserProfile%/.aws/config for Windows and $HOME/.aws/config for Linux or Mac.
- To remove git-remote-codecommit, run the PIP uninstall command:
pip uninstall git-remote-codecommitWith some operating systems, you might need to run the following code instead:
sudo pip uninstall git-remote-codecommitConclusion
This post reviewed an approach to securely switch between repositories and work without concerns about one Git repository’s security credentials interfering with the other Git repository. User access is controlled by the permissions assigned to the profile via federated roles from AWS SSO. This allows for access control to CodeCommit without needing access keys.