Post Syndicated from Explosm.net original https://explosm.net/comics/penny-thoughts
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/penny-thoughts
New Cyanide and Happiness Comic
Post Syndicated from Jim Wang original https://github.blog/engineering/engineering-principles/github-enterprise-cloud-with-data-residency/
Today, we announced that GitHub Enterprise Cloud will offer data residency, starting with the European Union (EU) on October 29, 2024, to address a critical desire from customers and enable an optimal, unified experience on GitHub for our customers.
We’ve heard for years from enterprises that being able to control where their data resides is critical for them. With data residency, organizations can now store their GitHub code and repository data in their preferred geographical region. With this need met, even more developers across the globe can build on the world’s AI-powered developer platform.
Enterprise Cloud with data residency provides enhanced user control and unique namespaces on ghe.com isolated from the open source cloud on github.com. It’s built on the security, business continuity, and disaster recovery capabilities of Microsoft Azure.

This is a huge milestone for our customers and for GitHub–a multi-year effort that required extensive time, effort, and dedication across the company. We’re excited to share a behind-the-scenes look at how we leveraged GitHub to develop the next evolution of Enterprise Cloud.
This effort started in summer of 2022 with a proof of concept (PoC) and involved teams across GitHub. We carefully considered which architecture would enable us to be successful. After iterating with different approaches, we decided to build the new offering as a feature set that extends Enterprise Cloud. This approach would allow us to be consistently in sync with features on github.com and provide the performance, reliability, and security that our customers expect. For hosting, we effectively leveraged Microsoft Azure’s scale, security, and regional footprint to produce a reliable and secured product with data residency built-in, without having to build new data centers ourselves.
As the home for all developers, developer experience is critically important for us. We recognized early on that consistency was important, so we sought to minimize differences in developing for Enterprise Cloud and Enterprise Cloud with data residency. To this end, the architecture across both is very similar, reducing complexity, risk, and development costs. The deployment model is familiar to our developers: it builds off of GitHub Actions. Also, changes to github.com and Enterprise Cloud with data residency are deployed minutes apart as part of a unified pipeline.
To accomplish this, we had to organize the work, modify our build and deployment systems, and validate the quality of the platform. We were able to do all three of these by using GitHub.
To organize the project, we used GitHub Issues and Projects, taking advantage of multiple views to effectively drive work across multiple projects, more than 100 teams, and over 2,000 issues. Different stakeholders and teams could take advantage of these views to focus on the information most relevant to them. Our talented technical project management team helped coordinate updates and used the filtering and slicing capabilities of Projects to present continuously updated information for each milestone in an easily consumable way.
We also used upcoming features like issues hierarchy to help us understand relationships between issues, and issue types to help clearly classify issues across repositories. As part of using these features internally we were able to give feedback to the teams working on them and refine the final product. Keep an eye out for future announcements for issues hierarchy and issue types coming soon!


All of these powerful features helped us keep the initiative on track. We were able to clearly understand potential risk areas and partner across multiple teams to resolve blockers and complex dependencies, keeping the project effectively moving forward across multiple years.
GitHub has always been built using GitHub. We wanted to continue this practice to set ourselves up for success with the new data residency feature. To this end, we continued leveraging GitHub Codespaces for development and GitHub Actions for continuous integration (CI). In addition, we added deployment targets for new regions. This produced a development, testing, and CI model that required no changes for our developers and a deployment process that was tightly integrated into the existing flow.
We have previously discussed our deploy then merge model, where we deploy branches before merging into the main branch. We expanded this approach to include successful deployments to Enterprise Cloud data residency targets before changes could be merged and considered complete, continuing to use the existing GitHub merge queue. A visualization of our monolithic deployment pipeline is shown in the figure below.

We start by deploying to environments used by GitHub employees in parallel. This includes the internal environment for Enterprise Cloud with data residency discussed more in the next section. As we use GitHub every day to build GitHub, this step helps us catch issues as employees use the product before it impacts our customers. After automated and manual testing, we proceed to roll out to “Canary.” Canary is the name for the stage where we configure our load balancers to gradually direct an increasing percentage of github.com traffic to the updated version of the code in a staged manner. Additional testing occurs in between each stage. Once we successfully deploy the updated version of github.com to all users, we then deploy and validate Enterprise Cloud with data residency in the EU before finishing the process and merging the pull request.
Ensuring all deployments are successful before we merge means changes are deployed in sync across all Enterprise Cloud environments and monitored effectively. Note that in addition to deployments, we also use feature flags to gradually roll out changes to groups of customers to reduce risk. If a deployment to any target fails, we roll back the change completely. Once we have understood the failure and are ready to deploy again, the entire process starts from the beginning with the merge queue.
Finally, to maintain consistency across all teams and services, we created automation to generate deployment pipelines for over 100 services so, as new targets are introduced, each service automatically deploys to the new environment in a consistent order.
To create the best possible product, we also prioritized using it ourselves and stood up an isolated environment for this purpose. Using our GitHub migration tooling, we moved the day-to-day development for the team working on GitHub Enterprise Importer to that environment, and invested in updating our build, deploy, and development environments to support working from the data resident environment. Since its creation, we have deployed to this environment over 8,000 times. This gave us invaluable feedback about the experience of working in the product with issues, pull requests, and actions that we were able to address early in the development process. We were also able to iterate on our status page tooling and internal Service Level Objective (SLO) process with the new environment in mind. The team is continuing to work in this environment today and runs over 1,000 actions jobs a month. This is a testament to the stability and quality we’ve been able to deliver and our commitment to this feature.
We are proud that we’ve been able to evolve Enterprise Cloud to offer data residency while using GitHub to organize, build, deploy, and test it. We’re excited to unlock GitHub for even more developers and for you to experience what we have built, starting on October 29, 2024 in the EU, with more regions on the way.
If you’re excited about Enterprise Cloud with data residency, please join us at GitHub Universe 2024 to learn more and hear from other companies how they’ve used this to accelerate software development and innovation.
The post GitHub Enterprise Cloud with data residency: How we built the next evolution of GitHub Enterprise using GitHub appeared first on The GitHub Blog.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=oP3K547FYxM
Post Syndicated from LGR original https://www.youtube.com/watch?v=n2pctQYDu0I
Post Syndicated from jzb original https://lwn.net/Articles/991401/
Version 1.0.0 of Hy, a Lisp dialect that is embedded in Python, has been released
after nearly 12 years in development. This is the first stable release of the project:
Henceforth, breaking changes to documented parts of the language
(other than dropping support for versions of Python that are
themselves no longer supported by the CPython developers) will
increase the major version number, and my intention is for that not to
happen often, if at all.
The 1.0.0 release supports Python 3.8 through 3.13. See the documentation and the “Why Hy?” page for why
one might want to use it.
Post Syndicated from Antje Barth original https://aws.amazon.com/blogs/aws/jamba-1-5-family-of-models-by-ai21-labs-is-now-available-in-amazon-bedrock/
Today, we are announcing the availability of AI21 Labs’ powerful new Jamba 1.5 family of large language models (LLMs) in Amazon Bedrock. These models represent a significant advancement in long-context language capabilities, delivering speed, efficiency, and performance across a wide range of applications. The Jamba 1.5 family of models includes Jamba 1.5 Mini and Jamba 1.5 Large. Both models support a 256K token context window, structured JSON output, function calling, and are capable of digesting document objects.
AI21 Labs is a leader in building foundation models and artificial intelligence (AI) systems for the enterprise. Together, AI21 Labs and AWS are empowering customers across industries to build, deploy, and scale generative AI applications that solve real-world challenges and spark innovation through a strategic collaboration. With AI21 Labs’ advanced, production-ready models together with Amazon’s dedicated services and powerful infrastructure, customers can leverage LLMs in a secure environment to shape the future of how we process information, communicate, and learn.
What is Jamba 1.5?
Jamba 1.5 models leverage a unique hybrid architecture that combines the transformer model architecture with Structured State Space model (SSM) technology. This innovative approach allows Jamba 1.5 models to handle long context windows up to 256K tokens, while maintaining the high-performance characteristics of traditional transformer models. You can learn more about this hybrid SSM/transformer architecture in the Jamba: A Hybrid Transformer-Mamba Language Model whitepaper.
You can now use two new Jamba 1.5 models from AI21 in Amazon Bedrock:
Key strengths of the Jamba 1.5 models include:
Get started with Jamba 1.5 models in Amazon Bedrock
To get started with the new Jamba 1.5 models, go to the Amazon Bedrock console, choose Model access on the bottom left pane, and request access to Jamba 1.5 Mini or Jamba 1.5 Large.

To test the Jamba 1.5 models in the Amazon Bedrock console, choose the Text or Chat playground in the left menu pane. Then, choose Select model and select AI21 as the category and Jamba 1.5 Mini or Jamba 1.5 Large as the model.

By choosing View API request, you can get a code example of how to invoke the model using the AWS Command Line Interface (AWS CLI) with the current example prompt.
You can follow the code examples in the Amazon Bedrock documentation to access available models using AWS SDKs and to build your applications using various programming languages.
The following Python code example shows how to send a text message to Jamba 1.5 models using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client.
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID.
# modelId = "ai21.jamba-1-5-mini-v1:0"
model_id = "ai21.jamba-1-5-large-v1:0"
# Start a conversation with the user message.
user_message = "What are 3 fun facts about mambas?"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = bedrock_runtime.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 256, "temperature": 0.7, "topP": 0.8},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)The Jamba 1.5 models are perfect for use cases like paired document analysis, compliance analysis, and question answering for long documents. They can easily compare information across multiple sources, check if passages meet specific guidelines, and handle very long or complex documents. You can find example code in the AI21-on-AWS GitHub repo. To learn more about how to prompt Jamba models effectively, check out AI21’s documentation.
Now available
AI21 Labs’ Jamba 1.5 family of models is generally available today in Amazon Bedrock in the US East (N. Virginia) AWS Region. Check the full Region list for future updates. To learn more, check out the AI21 Labs in Amazon Bedrock product page and pricing page.
Give Jamba 1.5 models a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
— Antje
Post Syndicated from Abhishek Gupta original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-amazon-ec2-x8g-instances-amazon-q-generative-sql-for-amazon-redshift-aws-sdk-for-swift-and-more-sep-23-2024/
AWS Community Days have been in full swing around the world. I am going to put the spotlight on AWS Community Day Argentina where Jeff Barr delivered the keynote, talks and shared his nuggets of wisdom with the community, including a fun story of how he once followed Bill Gates to a McDonald’s!
I encourage you to read about his experience.

Last week’s launches
Here are the launches that got my attention, starting off with the GA releases.
Amazon EC2 X8g Instances are now generally available – X8g instances are powered by AWS Graviton4 processors and deliver up to 60% better performance than AWS Graviton2-based Amazon EC2 X2gd instances. These instances offer larger sizes with up to 3x more vCPU (up to 48xlarge) and memory (up to 3TiB) than Graviton2-based X2gd instances.
Amazon Q generative SQL for Amazon Redshift is now generally available – Amazon Q generative SQL in Amazon Redshift Query Editor is an out-of-the-box web-based SQL editor for Amazon Redshift. It uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
AWS SDK for Swift is now generally available – AWS SDK for Swift provides a modern, user-friendly, and native Swift interface for accessing Amazon Web Services from Apple platforms, AWS Lambda, and Linux-based Swift on Server applications. Now that it’s GA, customers can use AWS SDK for Swift for production workloads. Learn more in the AWS SDK for Swift Developer Guide.
AWS Amplify now supports long-running tasks with asynchronous server-side function calls – Developers can use AWS Amplify to invoke Lambda function asynchronously for operations like generative AI model inferences, batch processing jobs, or message queuing without blocking the GraphQL API response. This improves responsiveness and scalability, especially for scenarios where immediate responses are not required or where long-running tasks need to be offloaded.
Amazon Keyspaces (for Apache Cassandra) now supports add-column for multi-Region tables – With this launch, you can modify the schema of your existing multi-Region tables in Amazon Keyspaces (for Apache Cassandra) to add new columns. You only have to modify the schema in one of its replica Regions and Keyspaces will replicate the new schema to the other Regions where the table exists.
Amazon Corretto 23 is now generally available – Amazon Corretto is a no-cost, multi-platform, production-ready distribution of OpenJDK. Corretto 23 is an OpenJDK 23 Feature Release that includes an updated Vector API, expanded pattern matching and switch expression, and more. It will be supported through April, 2025.
Use OR1 instances for existing Amazon OpenSearch Service domains – With OpenSearch 2.15, you can leverage OR1 instances for your existing Amazon OpenSearch Service domains by simply updating your existing domain configuration, and choosing OR1 instances for data nodes. This will seamlessly move domains running OpenSearch 2.15 to OR1 instances using a blue/green deployment.
Amazon S3 Express One Zone now supports AWS KMS with customer managed keys – By default, S3 Express One Zone encrypts all objects with server-side encryption using S3 managed keys (SSE-S3). With S3 Express One Zone support for customer managed keys, you have more options to encrypt and manage the security of your data. S3 Bucket Keys are always enabled when you use SSE-KMS with S3 Express One Zone, at no additional cost.
Use AWS Chatbot to interact with Amazon Bedrock agents from Microsoft Teams and Slack – Before, customers had to develop custom chat applications in Microsoft Teams or Slack and integrate it with Amazon Bedrock agents. Now they can invoke their Amazon Bedrock agents from chat channels by connecting the agent alias with an AWS Chatbot channel configuration.
AWS CodeBuild support for managed GitLab runners – Customers can configure their AWS CodeBuild projects to receive GitLab CI/CD job events and run them on ephemeral hosts. This feature allows GitLab jobs to integrate natively with AWS, providing security and convenience through features such as IAM, AWS Secrets Manager, AWS CloudTrail, and Amazon VPC.
We launched existing services in additional Regions:
Other AWS news
Here are some additional projects, blog posts, and news items that you might find interesting:
Secure Cross-Cluster Communication in EKS – It demonstrates how you can use Amazon VPC Lattice and Pod Identity to secure cross-EKS-cluster application communication, along with an example that you can use as a reference to adapt to your own microservices applications.
Improve RAG performance using Cohere Rerank – This post focuses on improving search efficiency and accuracy in RAG systems using Cohere Rerank.
AWS open source news and updates – My colleague Ricardo Sueiras writes about open source projects, tools, and events from the AWS Community; check out Ricardo’s page for the latest updates.
Upcoming AWS events
Check your calendars and sign up for upcoming AWS events:
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world. Upcoming AWS Community Days are in Italy (Sep. 27), Taiwan (Sep. 28), Saudi Arabia (Sep. 28)), Netherlands (Oct. 3), and Romania (Oct. 5).
Browse all upcoming AWS led in-person and virtual events and developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
— Abhishek
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/altera-starts-to-chart-its-own-course-intel-adds-agilex-3/
Altera starts to chart its own course adding Agilex 3, software updates, and several new Agilex 5 boards to the mix
The post Altera Starts to Chart its Own Course and Adds Agilex 3 appeared first on ServeTheHome.
Post Syndicated from daroc original https://lwn.net/Articles/990619/
Dirk Behme led a second session, back-to-back with
his session on error handling at
Kangrejos 2024, discussing providing better guidance for users of the kernel’s
Rust abstractions. Just after that,
Carlos Bilbao and Miguel Ojeda had their own time slot dedicated to collecting
resources that could be of use to someone trying to come up to speed
on kernel development in
Rust. The attendees provided a lot of guidance in both sessions, and
discussed what they could do to make things easier for people coming
from non-Rust backgrounds.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/09/hacking-the-bike-angels-system-for-moving-bikeshares.html
I always like a good hack. And this story delivers. Basically, the New York City bikeshare program has a system to reward people who move bicycles from full stations to empty ones. By deliberately moving bikes to create artificial problems, and exploiting exactly how the system calculates rewards, some people are making a lot of money.
At 10 a.m. on a Tuesday last month, seven Bike Angels descended on the docking station at Broadway and 53rd Street, across from the Ed Sullivan Theater. Each rider used his own special blue key -- a reward from Citi Bike— to unlock a bike. He rode it one block east, to Seventh Avenue. He docked, ran back to Broadway, unlocked another bike and made the trip again.
By 10:14, the crew had created an algorithmically perfect situation: One station 100 percent full, a short block from another station 100 percent empty. The timing was crucial, because every 15 minutes, Lyft’s algorithm resets, assigning new point values to every bike move.
The clock struck 10:15. The algorithm, mistaking this manufactured setup for a true emergency, offered the maximum incentive: $4.80 for every bike returned to the Ed Sullivan Theater. The men switched direction, running east and pedaling west.
Nicely done, people.
Now it’s Lyft’s turn to modify its system to prevent this hack. Thinking aloud, it could try to detect this sort of behavior in the Bike Angels data—and then ban people who are deliberately trying to game the system. The detection doesn’t have to be perfect, just good enough to catch bad actors most of the time. The detection needs to be tuned to minimize false positives, but that feels straightforward.
Post Syndicated from Explosm.net original https://explosm.net/comics/32366
New Cyanide and Happiness Comic
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=FO26BKQlFmw
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=7iR3Sa8GX44
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=jwLDx60Ffvs
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=kEf518GJglc
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=N_P4B7dnDys
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=OKO3JoL4iAI
Post Syndicated from jake original https://lwn.net/Articles/991377/
Security updates have been issued by AlmaLinux (expat, fence-agents, firefox, libnbd, openssl, pcp, ruby:3.3, and thunderbird), Debian (ruby-saml), Fedora (aardvark-dns, chromium, expat, jupyterlab, less, openssl, python-jupyterlab-server, python-notebook, python3-docs, and python3.12), Gentoo (calibre, curl, Emacs, org-mode, Exo, file, GPL Ghostscript, gst-plugins-good, liblouis, Mbed TLS, OpenVPN, Oracle VirtualBox, PJSIP, Portage, PostgreSQL, pypy, pypy3, Rust, Slurm, stb, VLC, and Xen), SUSE (container-suseconnect, ffmpeg-4, kernel, libpcap, python3, python310, python36, and wpa_supplicant), and Ubuntu (firefox, linux, linux-aws, linux-aws-hwe, linux-azure, linux-azure-4.15, linux-gcp, linux-gcp-4.15, linux-hwe, linux-kvm, linux-oracle, linux-azure, and linux-ibm-5.15, linux-oracle-5.15).
Post Syndicated from Sam Rhea original https://blog.cloudflare.com/cloudflare-ai-audit-control-ai-content-crawlers
Site owners have lacked the ability to determine how AI services use their content for training or other purposes. Today, Cloudflare is releasing a set of tools to make it easy for site owners, creators, and publishers to take back control over how their content is made available to AI-related bots and crawlers. All Cloudflare customers can now audit and control how AI models access the content on their site.
This launch starts with a detailed analytics view of the AI services that crawl your site and the specific content they access. Customers can review activity by AI provider, by type of bot, and which sections of their site are most popular. This data is available to every site on Cloudflare and does not require any configuration.
We expect that this new level of visibility will prompt teams to make a decision about their exposure to AI crawlers. To help give them time to make that decision, Cloudflare now provides a one-click option in our dashboard to immediately block any AI crawlers from accessing any site. Teams can then use this “pause” to decide if they want to allow specific AI providers or types of bots to proceed. Once that decision is made, those administrators can use new filters in the Cloudflare dashboard to enforce those policies in just a couple of clicks.
Some customers have already made decisions to negotiate deals directly with AI companies. Many of those contracts include terms about the frequency of scanning and the type of content that can be accessed. We want those publishers to have the tools to measure the implementation of these deals. As part of today’s announcement, Cloudflare customers can now generate a report with a single click that can be used to audit the activity allowed in these arrangements.
We also think that sites of any size should be able to determine how they want to be compensated for the usage of their content by AI models. Today’s announcement previews a new Cloudflare monetization feature which will give site owners the tools to set prices, control access, and capture value for the scanning of their content.
Until recently, bots and scrapers on the Internet mostly fell into two clean categories: good and bad. Good bots, like search engine crawlers, helped audiences discover your site and drove traffic to you. Bad bots tried to take down your site, jump the queue ahead of your customers, or scrape competitive data. We built the Cloudflare Bot Management platform to give you the ability to distinguish between those two broad categories and to allow or block them.
The rise of AI Large Language Models (LLMs) and other generative tools created a murkier third category. Unlike malicious bots, the crawlers associated with these platforms are not actively trying to knock your site offline or to get in the way of your customers. They are not trying to steal sensitive data; they just want to scan what is already public on your site.
However, unlike helpful bots, these AI-related crawlers do not necessarily drive traffic to your site. AI Data Scraper bots scan the content on your site to train new LLMs. Your material is then put into a kind of blender, mixed up with other content, and used to answer questions from users without attribution or the need for users to visit your site. Another type of crawler, AI Search Crawler bots, scan your content and attempt to cite it when responding to a user’s search. The downside is that those users might just stay inside of that interface, rather than visit your site, because an answer is assembled on the page in front of them.
This murkiness leaves site owners with a hard decision to make. The value exchange is unclear. And site owners are at a disadvantage while they play catch up. Many sites allowed these AI crawlers to scan their content because these crawlers, for the most part, looked like “good” bots — only for the result to mean less traffic to their site as their content is repackaged in AI-written answers.
We believe this poses a risk to an open Internet. Without the ability to control scanning and realize value, site owners will be discouraged to launch or maintain Internet properties. Creators will stash more of their content behind paywalls and the largest publishers will strike direct deals. AI model providers will in turn struggle to find and access the long tail of high-quality content on smaller sites.
Both sides lack the tools to create a healthy, transparent exchange of permissions and value. Starting today, Cloudflare equips site owners with the services they need to begin fixing this. We have broken out a series of steps we recommend all of our customers follow to get started.
Every site on Cloudflare now has access to a new analytics view that summarizes the crawling behavior of popular and known AI services. You can begin reviewing this information to understand the AI scanning of your content by selecting a site in your dashboard and navigating to the AI Audit tab in the left-side navigation bar.
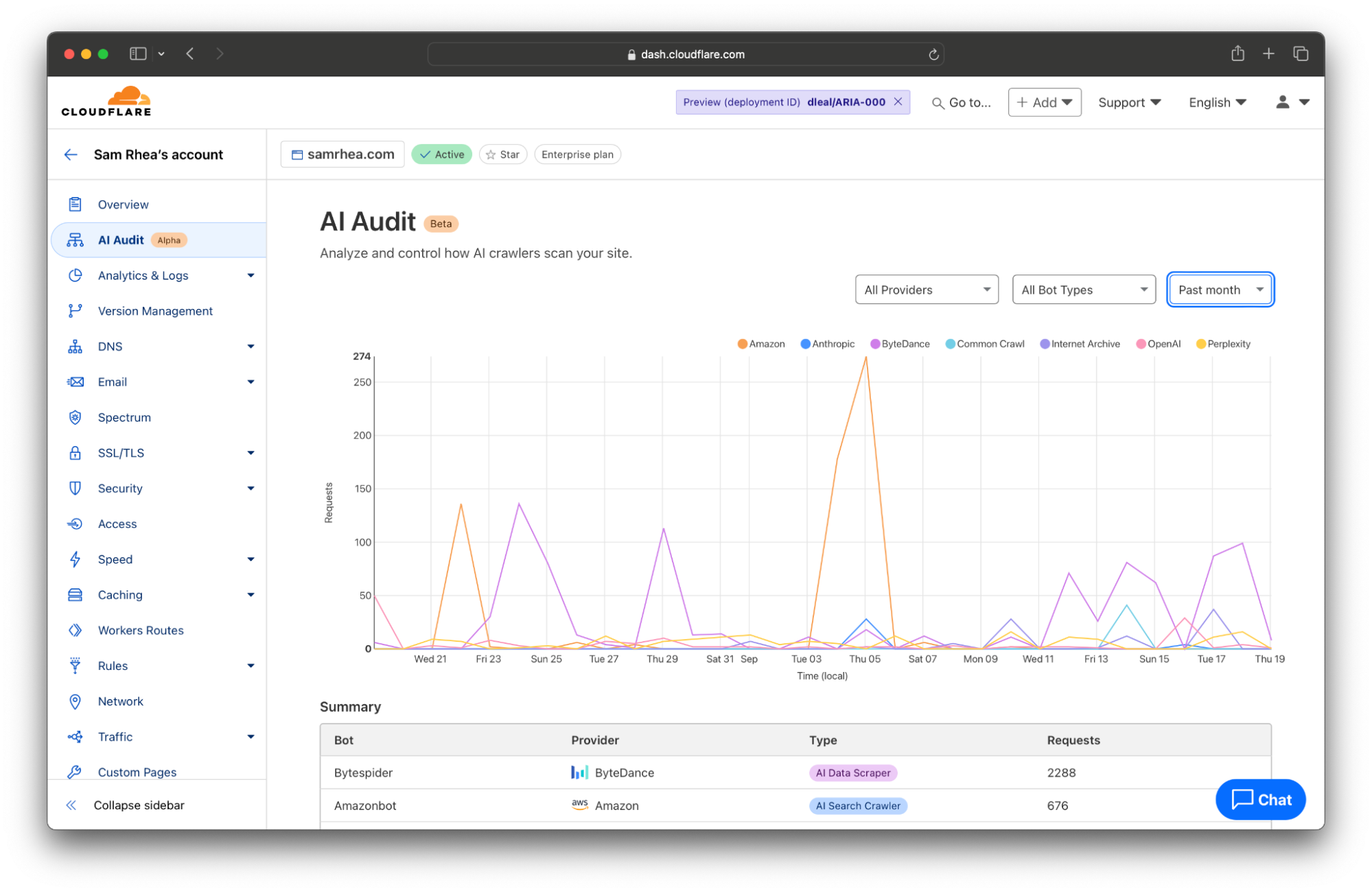
When AI model providers access content on your site, they rely on automated tools called “bots” or “crawlers” to scan pages. The bot will request the content of your page, capture the response, and store it as part of a future data training set or remember it for AI search engine results in the future.
These bots often identify themselves to your site (and Cloudflare’s network) by including an HTTP header in their request called a User Agent. Although, in some cases, a bot from one of these AI services might not send the header and Cloudflare instead relies on other heuristics like IP address or behavior to identify them.
When the bot does identify itself, the header will contain a string of text with the bot name. For example, Anthropic sometimes crawls sites on the Internet with a bot called ClaudeBot. When that service requests the content of a page from your site on Cloudflare, Cloudflare logs the User Agent as ClaudeBot.
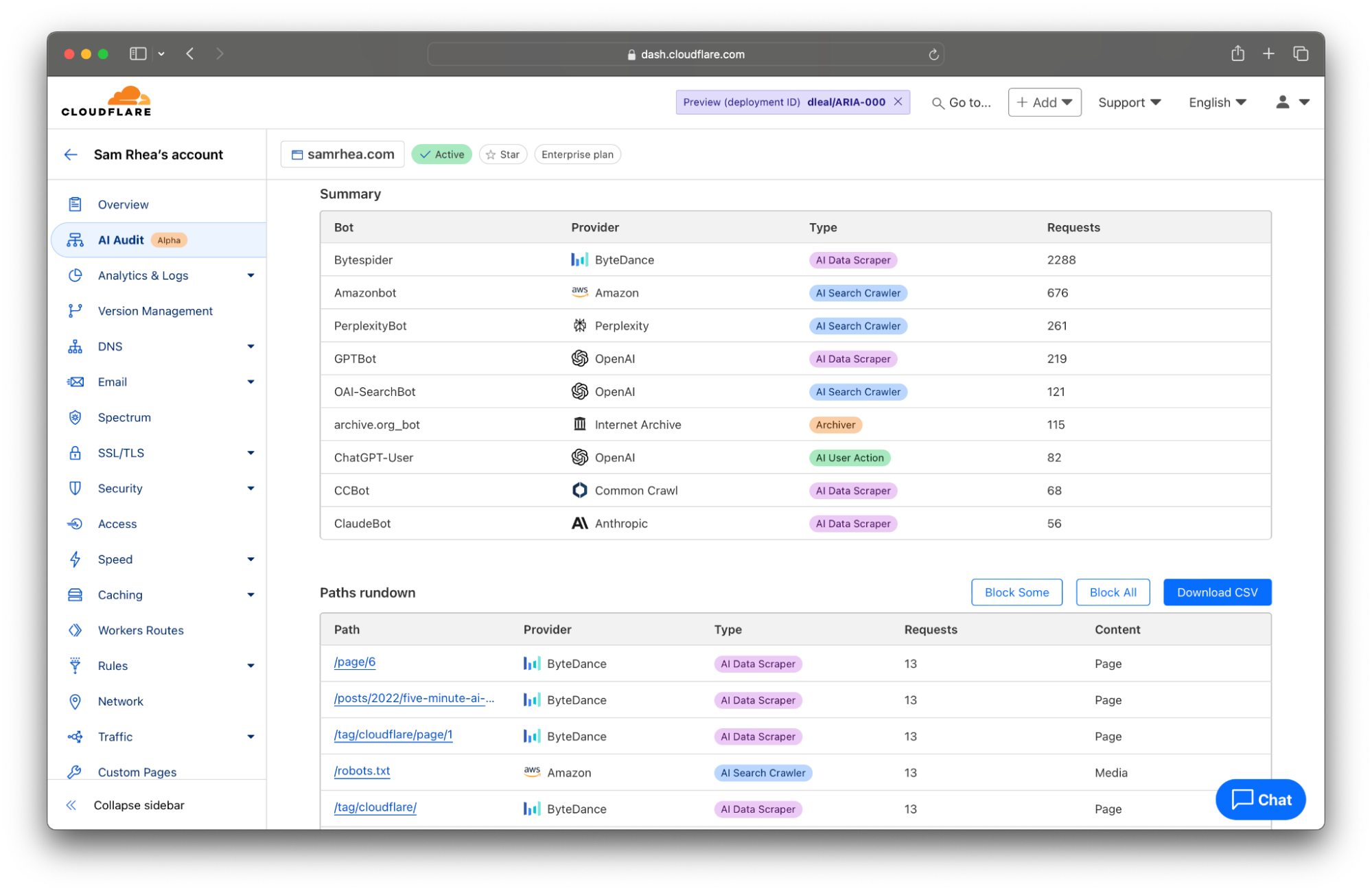
Cloudflare takes the logs gathered from visits to your site and looks for user agents that match known AI bots and crawlers. We summarize the activity of individual crawlers and also provide you with filters to review just the activities of specific AI platforms. Many AI firms rely on multiple crawlers that serve distinct purposes. When OpenAI scans sites for data scraping, they rely on GPTBot, but when they crawl sites for their new AI search engine, they use OAI-SearchBot.
And those differences matter. Scanning from different bot types can impact traffic to your site or the attribution of your content. AI search engines will often link to sites as part of their response, potentially sending visitors to your destination. In that case, you might be open to those types of bots crawling your Internet property. AI Data Scrapers, on the other hand, just exist to read as much of the Internet as possible to train future models or improve existing ones.
We think that you deserve to know why a bot is crawling your site in addition to when and how often. Today’s release gives you a filter to review bot activity by categories like AI Data Scraper, AI Search Crawler, and Archiver.
With this data, you can begin analyzing how AI models access your site. That information might be overwhelming, especially if your team has not had time yet to decide how you want to handle AI scanning of your content. If you find yourself unsure on how to respond, proceed to Step 2.
We talked to several organizations who know their sites are valuable destinations for AI crawlers, but they do not yet know what to do about it. These teams need a “time out” so they can make an informed decision about how they make their data available to these services.
Cloudflare gives you that easy button right now. Any customer on any plan can choose to block all AI bots and crawlers to give yourself a pause while you decide what you do want to allow.
To implement that option, navigate to the Bots section under the Security tab of the Cloudflare Dashboard. Follow the blue link in the top right corner to configure how Cloudflare’s proxy handles bot traffic. Next, toggle the button in the “Block AI Scrapers and Crawlers” card to the “On” position.
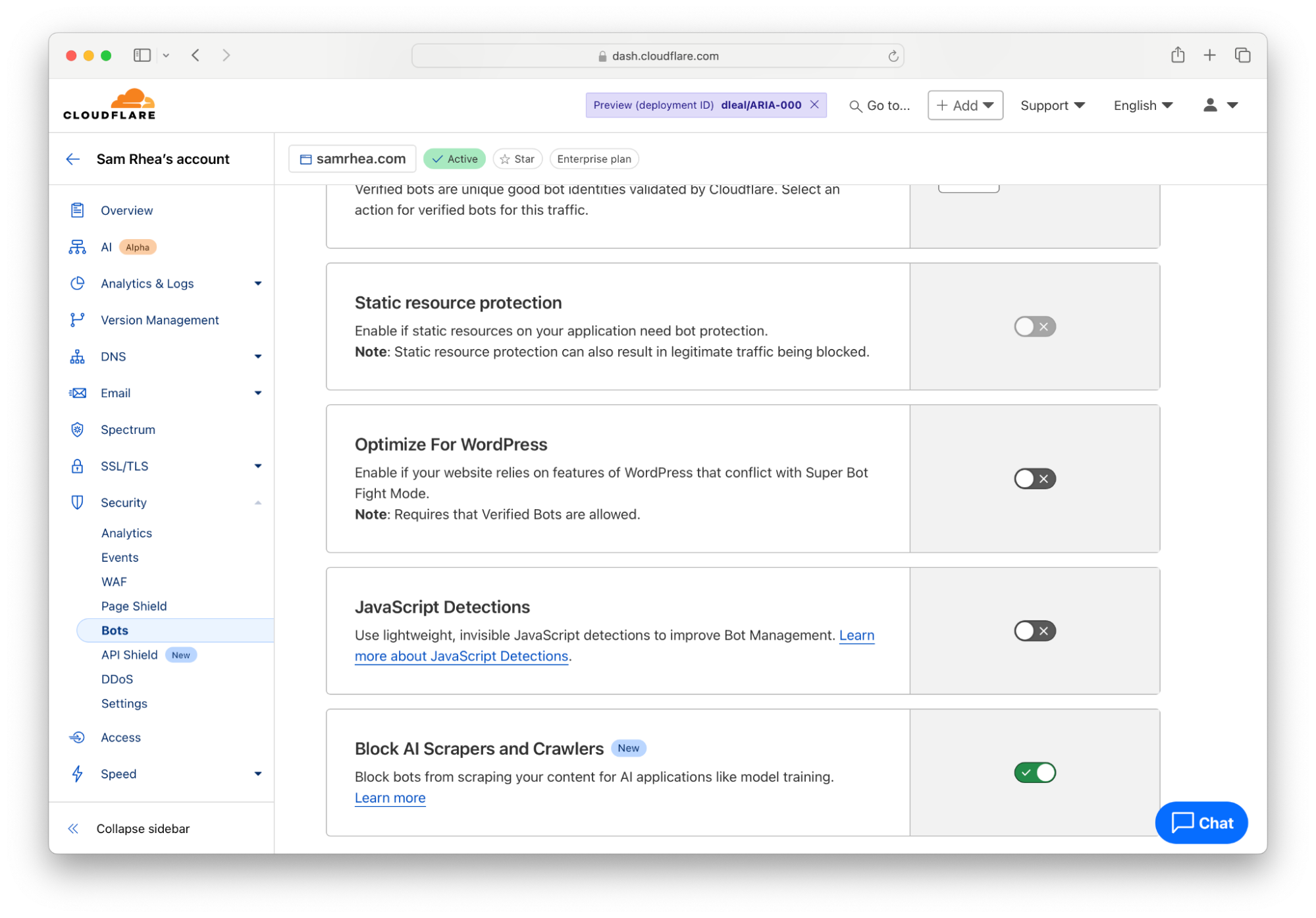
The one-click option blocks known AI-related bots and crawlers from accessing your site based on a list that Cloudflare maintains. With a block in place, you and your team can make a less rushed decision about what to do next with your content.
The pause button buys time for your team to decide what you want the relationship to be between these crawlers and your content. Once your team has reached a decision, you can begin relying on Cloudflare’s network to implement that policy.
If that decision is “we are not going to allow any crawling,” then you can leave the block button discussed above toggled to “On”. If you want to allow some selective scanning, today’s release provides you with options to permit certain types of bots, or just bots from certain providers, to access your content.
For some teams, the decision will be to allow the bots associated with AI search engines to scan their Internet properties because those tools can still drive traffic to the site. Other organizations might sign deals with a specific model provider, and they want to allow any type of bot from that provider to access their content. Customers can now navigate to the WAF section of the Cloudflare dashboard to implement these types of policies.
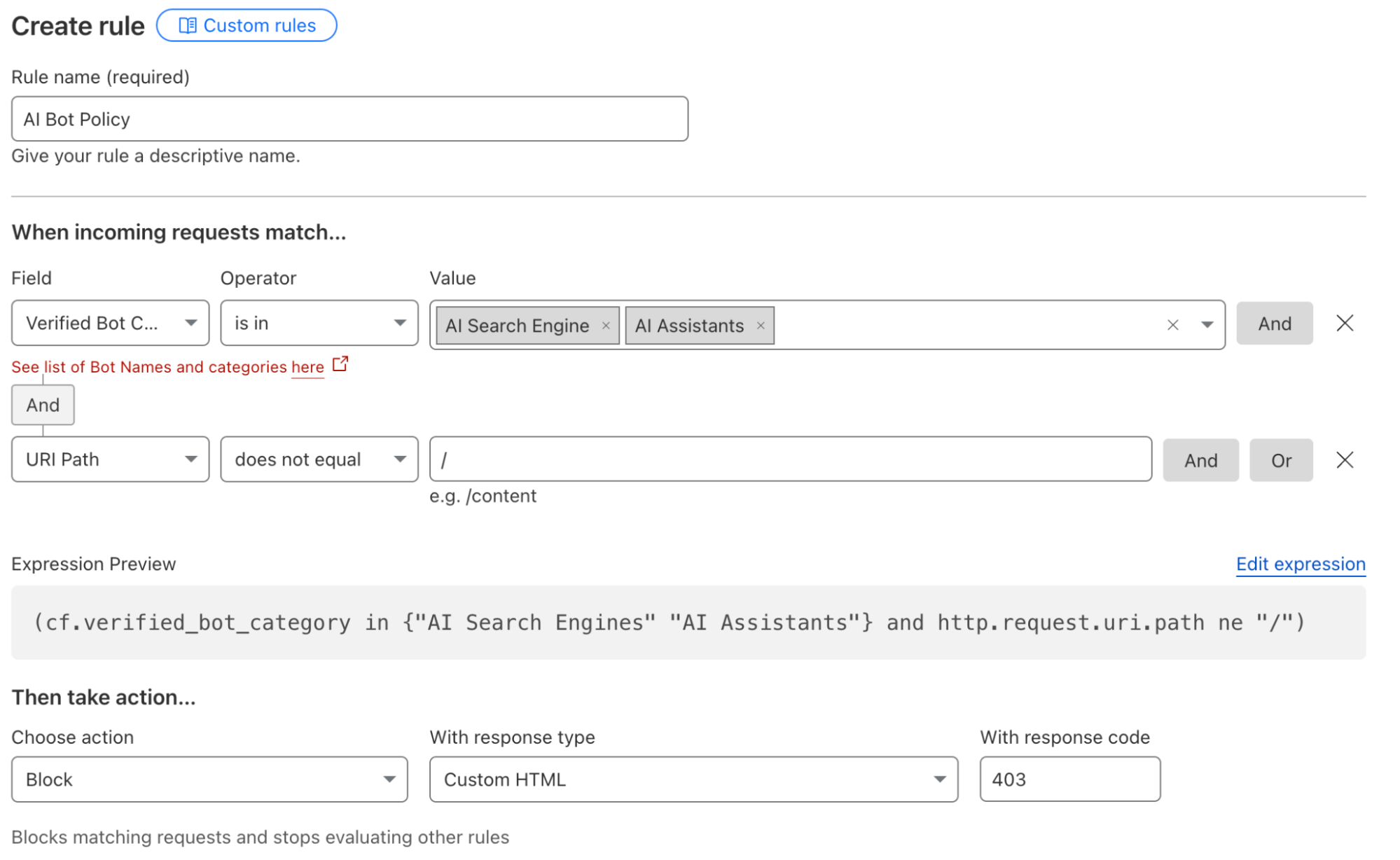
Administrators can also create rules that would, for example, block all AI bots except for those from a specific platform. Teams can deploy these types of filters if they are skeptical of most AI platforms but comfortable with one AI model provider and its policies. These types of rules can also be used to implement contracts where a site owner has negotiated to allow scanning from a single provider. The site administrator would need to create a rule to block all types of AI-related bots and then add an exception that allows the specific bot or bots from their AI partner.
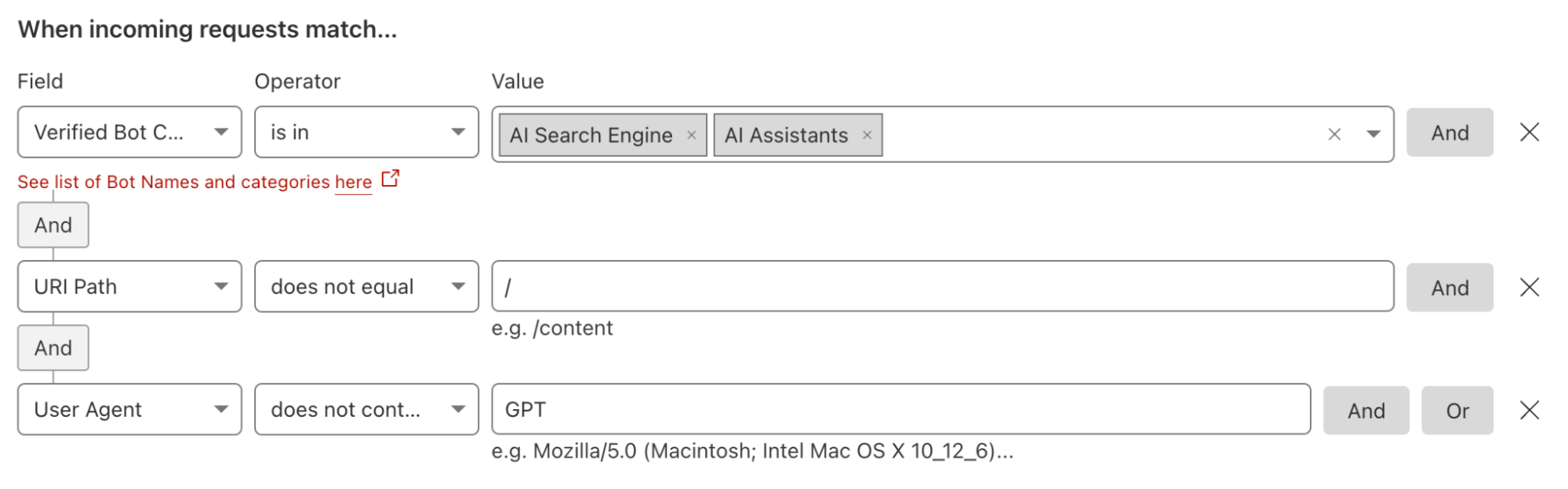
We also recommend that customers consider updating their Terms of Service to cover this new use case in addition to applying these new filters. We have documented the steps we suggest that “good citizen” bots and crawlers take with respect to robots.txt files. As an extension of those best practices, we are adding a new section to that documentation where we provide a sample Terms of Service section that site owners can consider using to establish that AI scanning needs to follow the policies you have defined in your robots.txt file.
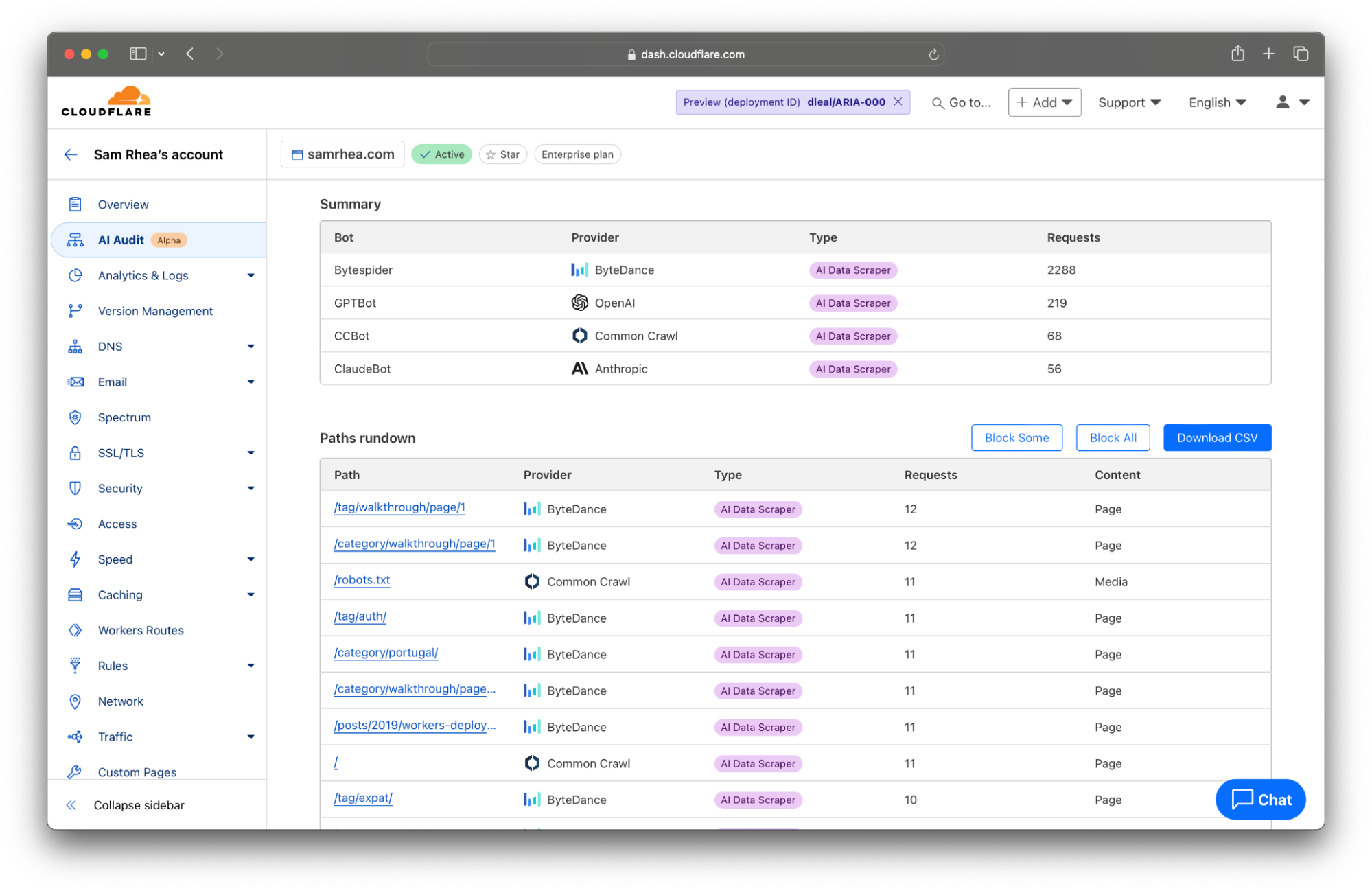
An increasing number of sites are signing agreements directly with model providers to license consumption of their content in exchange for payment. Many of those deals contain provisions that determine the rate of crawling for certain sections or entire sites. Cloudflare’s AI Audit tab provides you with the tools to monitor those kinds of contracts.
The table at the bottom of the AI Audit tool now lists the most popular content on your site ranked by the count of scans in the time period from the filter set at the top of the page. You can click the Export to CSV button to quickly download a file with the details presented here that you can use to discuss any discrepancies with the AI platform that you are allowing to access your content.
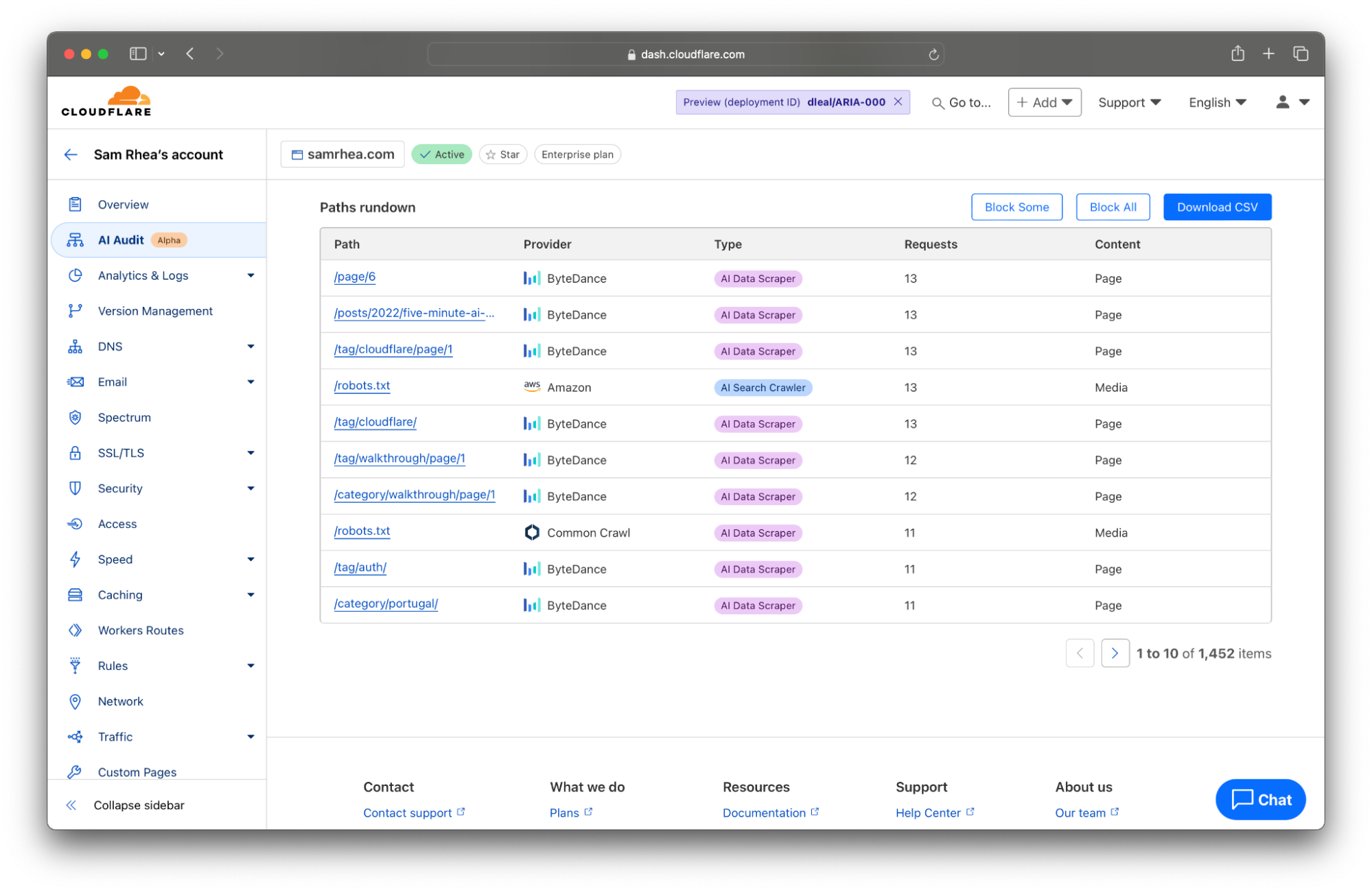
Today, the data available to you represents key metrics we have heard from customers in these kinds of arrangements: requests against certain pages and requests against the entire site.
Not everyone has the time or contacts to negotiate deals with AI companies. Up to this point, only the largest publishers on the Internet have the resources to set those kinds of terms and get paid for their content.
Everyone else has been left with two basic choices on how to handle their data: block all scanning or allow unrestricted access. Today’s releases give content creators more visibility and control than just those two options, but the long tail of sites on the Internet still lack a pathway to monetization.
We think that sites of any size should be fairly compensated for the use of their content. Cloudflare plans to launch a new component of our dashboard that goes beyond just blocking and analyzing crawls. Site owners will have the ability to set a price for their site, or sections of their site, and to then charge model providers based on their scans and the price you have set. We’ll handle the rest so that you can focus on creating great content for your audience.
The fastest way to get ready to capture value through this new component is to make sure your sites use Cloudflare’s network. We plan to invite sites to participate in the beta based on the date they first joined Cloudflare. Interested in being notified when this is available? Let us know here.
Post Syndicated from Oliver Payne original https://blog.cloudflare.com/turnstile-ephemeral-ids-for-fraud-detection
In the early days of the Internet, a single IP address was a reliable indicator of a single user. However, today’s Internet is more complex. Shared IP addresses are now common, with users connecting via mobile IP address pools, VPNs, or behind CGNAT (Carrier Grade Network Address Translation). This makes relying on IP addresses alone a weak method to combat modern threats like automated attacks and fraudulent activity. Additionally, many Internet users have no option but to use an IP address which they don’t have sole control over, and as such, should not be penalized for that.
At Cloudflare, we are solving this complexity with Turnstile, our CAPTCHA alternative. And now, we’re taking the next step in advancing security with Ephemeral IDs, a new feature that generates a unique short-lived ID, without relying on any network-level information.
When a website visitor interacts with Turnstile, we now calculate an Ephemeral ID that can link behavior to a specific client instead of an IP address. This means that even when attackers rotate through large pools of IP addresses, we can still identify and block malicious actions. For example, in attacks like credential stuffing or account signups, where fraudsters attempt to disguise themselves using different IP addresses, Ephemeral IDs allow us to detect abuse patterns more accurately beyond just determining whether the visitor is a human or a bot. Multiple fraudulent actions from the same client are grouped together, improving our detection rate while reducing false positives.
Turnstile detects bots by analyzing browser attributes and signals. Using these aggregated client-side signals, we generate a short-lived Ephemeral ID without setting any cookies or using similar client-side storage. These IDs are intentionally not 100% unique and have a brief lifespan, making them highly effective in identifying patterns of fraud and abuse, without compromising user privacy.
When the same visitor interacts with Turnstile widgets from different Cloudflare customers, they receive different Ephemeral IDs for each one. Additionally, because these IDs change frequently, they cannot be used to track a single visitor over multiple days.
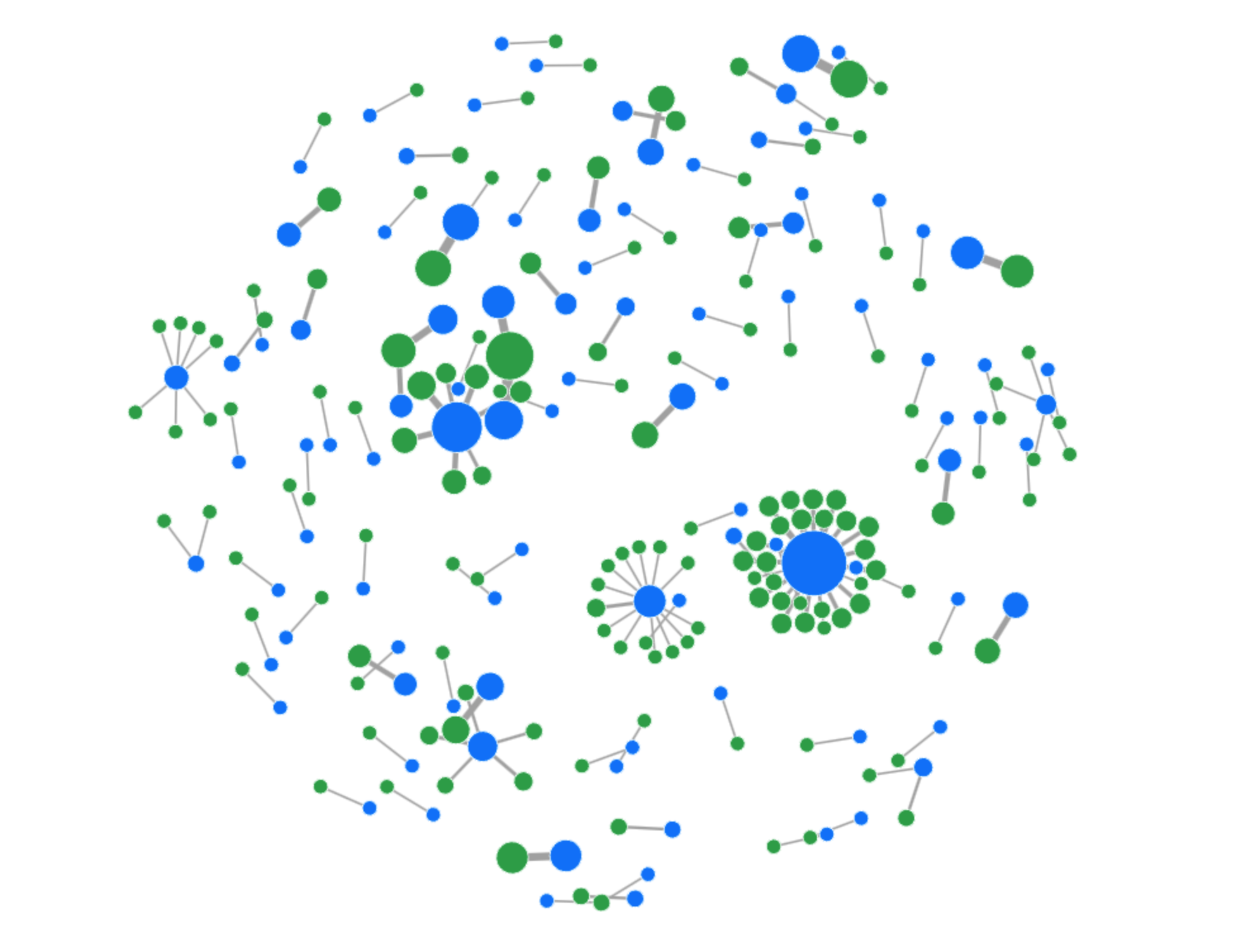
Blue: A single IP address | Green: A single Ephemeral ID
The bigger the node, the more frequently seen that ID or IP address was in our dataset.
The graphic above illustrates the complex reality of the modern Internet, where the relationship between clients and IP addresses is far from a simple one-to-one mapping. While some straightforward mappings still exist, they are no longer the norm.
During a period where a site or service is under attack, we observe a “nest” of highly correlated Ephemeral IDs. In the example below, the correlation is based on both Ephemeral ID and IP address.
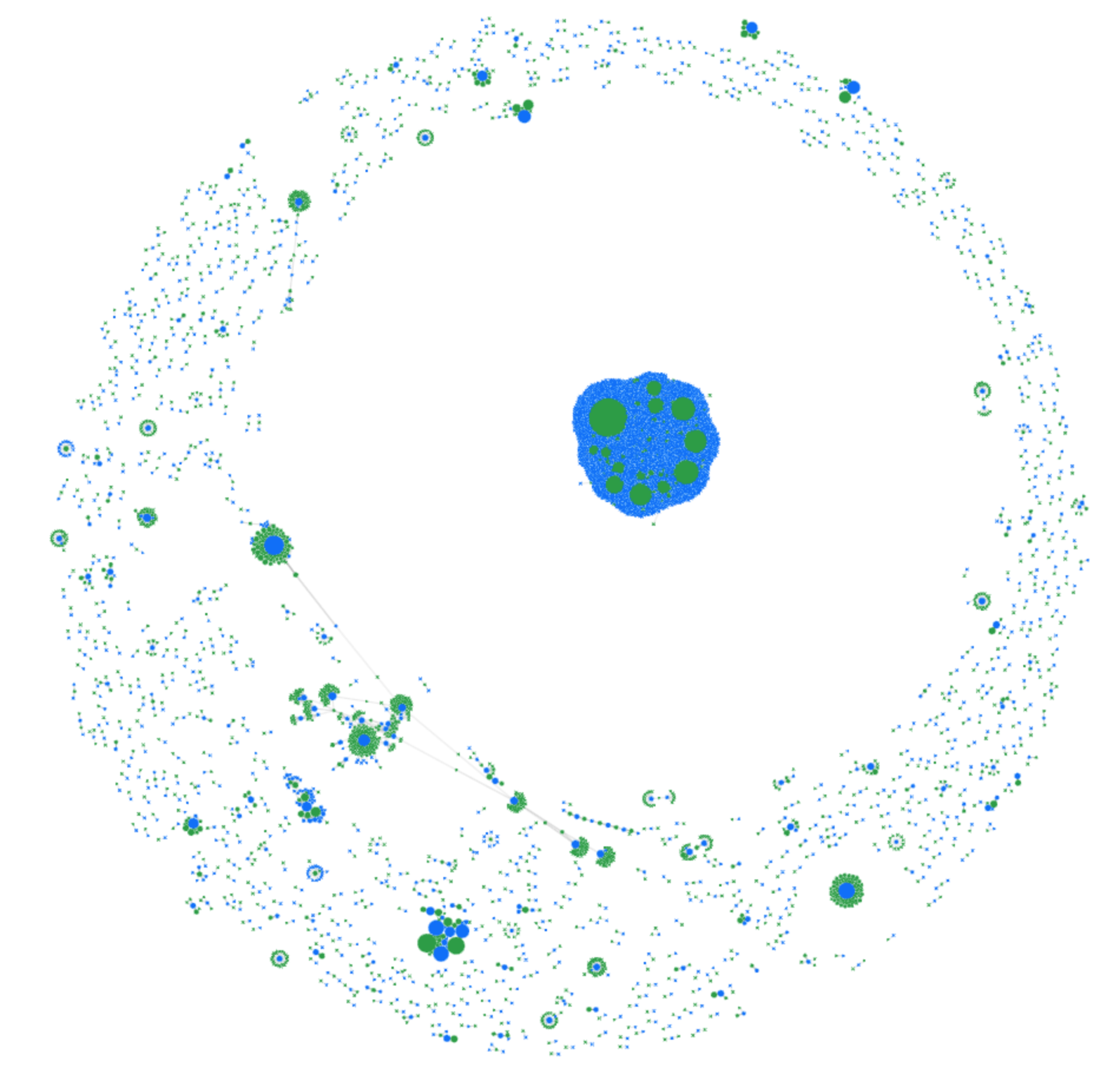
Nest in the center of the diagram visualizes thousands of IP addresses (blue) which are correlated by the commonly identified Ephemeral IDs (green). The bigger the node, the more frequently seen that ID or IP address was in our dataset.
This is real-world data showing fraudulent activity on one of Cloudflare’s public-facing forms. Even with access to a broad range of IP addresses, attackers struggle to completely disguise their requests because Ephemeral IDs are generated based on patterns beyond IP addresses. This means that even if they rotate addresses, the underlying client characteristics are still detected, making it harder for them to evade our security measures. This makes it easier for us to group these requests and apply appropriate business logic, whether that means discarding the requests, requiring further validation, enforcing multi-factor authentication (MFA), or other actions.
This new client identification technology seamlessly integrates into the broader advancements we’ve made to Turnstile over the past year. Whether you’re protecting login forms, signup pages, or high value transactions, you’ll immediately benefit from this extra layer of abuse detection without needing to change a single line of code. We’ll take care of all the heavy lifting and analysis behind the scenes, and our system will continue to improve its accuracy and effectiveness over time.
What does this mean for you? Starting today, Turnstile will go beyond just identifying bots. All websites protected by Turnstile will automatically benefit from the integration of Ephemeral IDs into our detection logic. This means we can more effectively identify and penalize offending clients without impacting other users on the same network, or IP address, improving security and user experience for everyone.
Everyone benefits from the addition of Ephemeral IDs to the Challenge Platform, but for those who want to use it beyond that, the Ephemeral ID is available through the Turnstile siteverify response. A practical use case for Ephemeral IDs is preventing fraudulent account signups. Imagine a bad actor, a real person using a real device, creating hundreds of fake accounts while rotating IP addresses to avoid detection. By ingesting Ephemeral IDs and logging them alongside your account creation logs, you can set up alerts based on account creation thresholds in real-time or retroactively investigate suspicious activity. Even though Ephemeral IDs are short-lived and may have changed by the time an investigation begins, they still provide valuable insights through aggregate analysis, and provide an extra dimension to identify fraud and abuse.
For our Turnstile Enterprise and Bot Management Enterprise customers, you now have the option to access Ephemeral IDs directly through the Turnstile siteverify response. Get in touch with your Account Executive to enable it on your account.
Below is an example of siteverify response for those who have enabled Ephemeral IDs.
curl 'https://challenges.cloudflare.com/turnstile/v0/siteverify' --data 'secret=verysecret&response=<RESPONSE>'{
"success": true,
"error-codes": [],
"challenge_ts": "2024-09-10T17:29:00.463Z",
"hostname": "example.com",
"metadata": {
"ephemeral_id": "x:9f78e0ed210960d7693b167e"
}
}
We launched Turnstile with a bold mission: to redefine CAPTCHAs with a frictionless, privacy-first solution that eliminates the annoyance of picking puzzles, selecting stoplights, and clicking crosswalks to prove our humanity. It’s incredible to think that Turnstile has been generally available for a whole year now! During this time, it has blocked over one trillion bots, and is actively protecting more than 350,000 domains worldwide.
As we celebrate Turnstile’s second birthday, we’re proud of the progress we’ve made and thrilled to introduce our latest innovations. While Ephemeral IDs represent the newest evolution of Turnstile, they’re part of our ongoing commitment to continuous improvement. Over the past year, we’ve also introduced a Cloudflare Pages Plugin and partnered with Google Firebase, ensuring that developers have easy access to Turnstile.
Earlier this year, we also launched Pre-Clearance for Turnstile, integrating it with Cloudflare WAF’s Challenge action, making it easier for customers to use Cloudflare’s Application Security products together. If you want to learn more about how to use Turnstile with Cloudflare’s Bot Management and WAF in more detail, check it out here!
We’re incredibly excited about what’s ahead. The introduction of Ephemeral IDs is just one of many innovations on the horizon. We’re committed to making the Internet a safer, more private place for everyone, eliminating the need for frustrating CAPTCHA puzzles while keeping security our top priority. And with our free tier remaining open and unlimited for all, there’s no barrier to getting started with Turnstile today.
Join us in revolutionizing online security – get started with Turnstile now or dive straight into our how-to guides. Let’s help make the Internet a better place, together!