Post Syndicated from Emily Music original https://blog.cloudflare.com/network-performance-update-birthday-week-2024
When it comes to the Internet, everyone wants to be the fastest. At Cloudflare, we’re no different. We want to be the fastest network in the world, and are constantly working towards that goal. Since June 2021, we’ve been measuring and ranking our network performance against the top global networks. We use this data to improve our performance, and to share the results of those initiatives.
In this post, we’re going to share with you how our network performance has changed since our last post in March 2024, and discuss the tools and processes we are using to assess network performance.
Digging into the data
Cloudflare has been measuring network performance across these top networks from the top 1,000 ISPs by estimated population (according to the Asia Pacific Network Information Centre (APNIC)), and optimizing our network for ISPs and countries where we see opportunities to improve. For performance benchmarking, we look at TCP connection time. This is the time it takes an end user to connect to the website or endpoint they are trying to reach. We chose this metric to show how our network helps make your websites faster by serving your traffic where your customers are. Back in June 2021, Cloudflare was ranked #1 in 33% of the networks.
As of September 2024, examining 95th percentile (p95) TCP connect times measured from September 4 to September 19, Cloudflare is the #1 provider in 44% of the top 1000 networks:
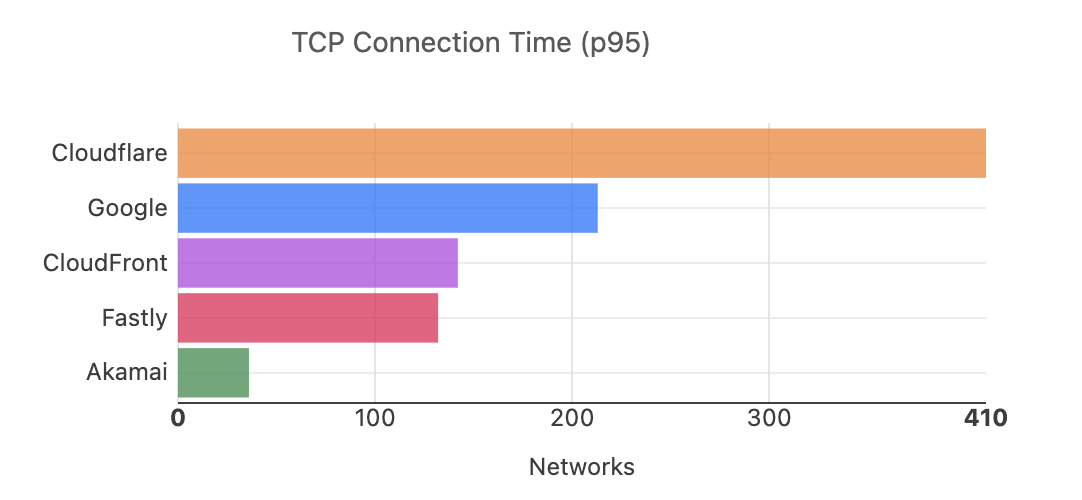
This graph shows that we are fastest in 410 networks, but that would only make us the fastest in 41% of the top 1,000. To make sure we’re looking at the networks that eyeballs connect from, we exclude networks like transit networks that aren’t last-mile ISPs. That brings the number of measured networks to 932, which makes us fastest in 44% of ISPs.
Now let’s take a look at the fastest provider by country. The map below shows the top network by 95th percentile TCP connection time, and Cloudflare is fastest in many countries. For those where we weren’t, we were within a few milliseconds of our closest competitor.
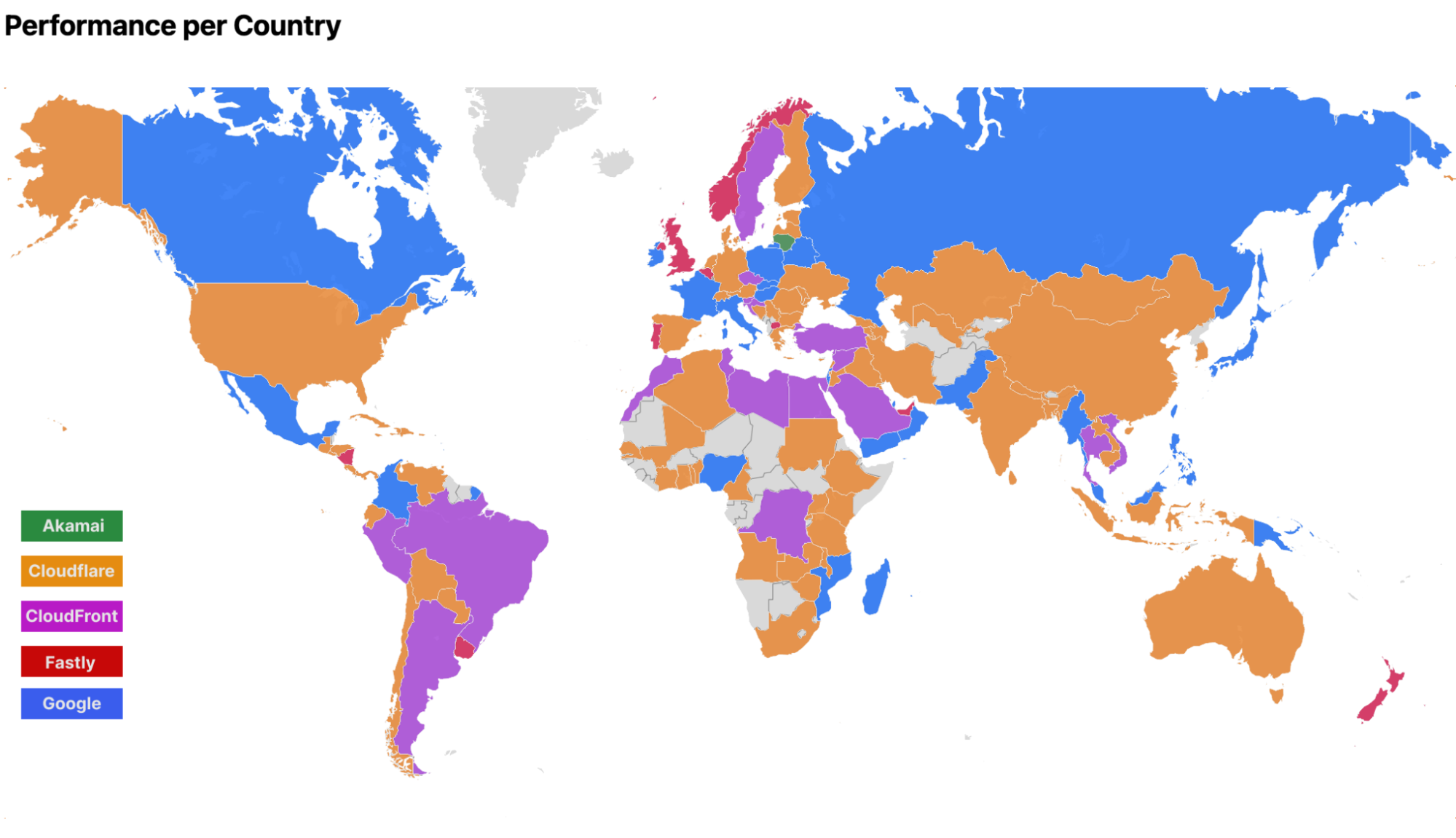
This color coding is generated by grouping all the measurements we generate by which country the measurement originates from, and then looking at the 95th percentile measurements for each provider to see who is the fastest. This is in contrast to how we measure who is fastest in individual networks, which involves grouping the measurements by ISP and measuring which provider is fastest. Cloudflare is still the fastest provider in 44% of the measured networks, which is consistent with our March report. Cloudflare is also the fastest in many countries, but the map is less orange than it was when we published our measurements from March 2024:
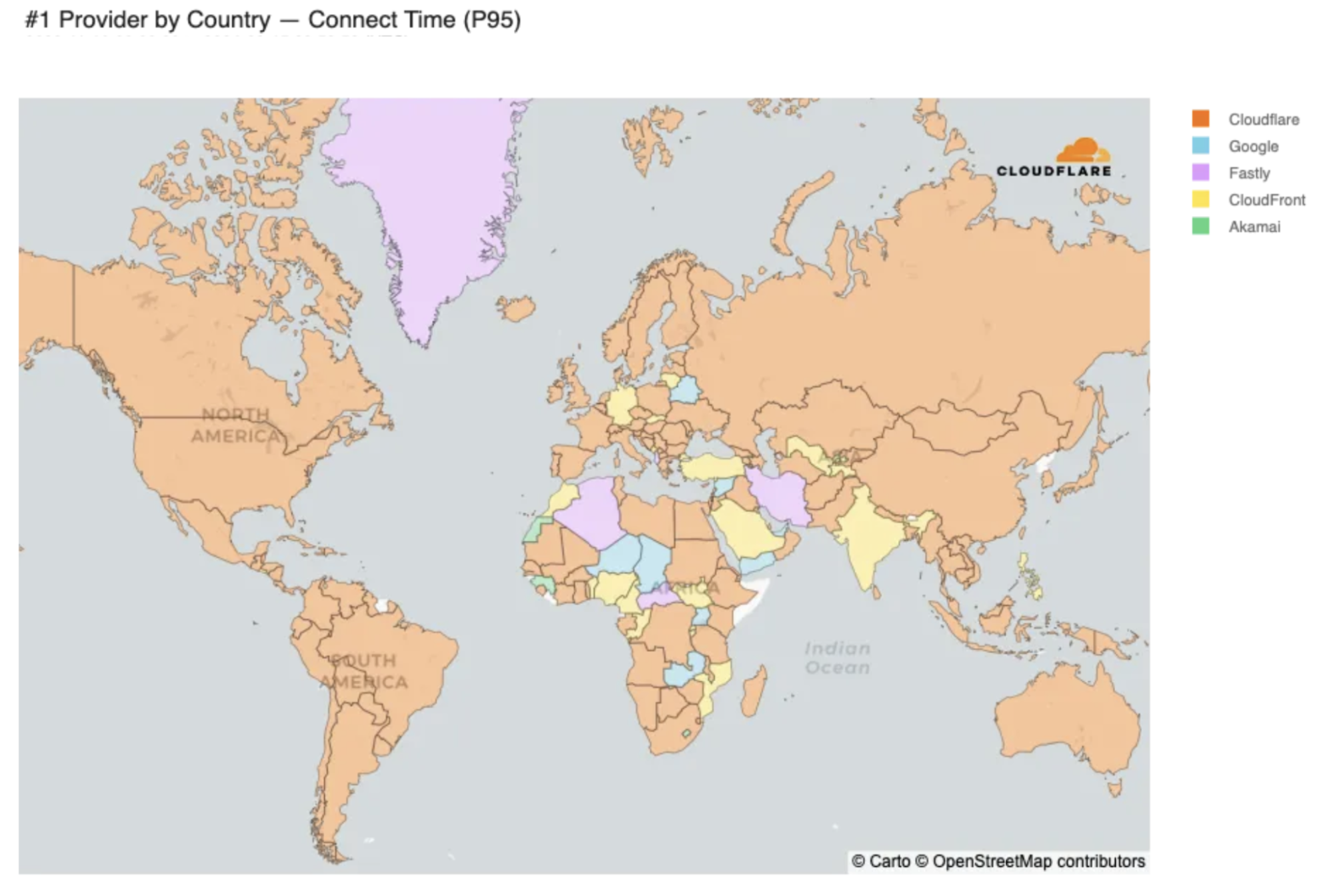
This can be explained by the fact that the fastest provider in a country is often determined by latency differences so small it is often less than 5% faster than the second-fastest provider. As an example, let’s take a look at India, a country where we are now the fastest:
India performance by provider
|
Rank |
Entity |
95th percentile TCP Connect (ms) |
Difference from #1 |
|---|---|---|---|
|
1 |
Cloudflare |
290 ms |
– |
|
2 |
|
291 ms |
+0.28% (+0.81 ms) |
|
3 |
CloudFront |
304 ms |
+4.61% (+13 ms) |
|
4 |
Fastly |
325 ms |
+12% (+35 ms) |
|
5 |
Akamai |
373 ms |
+29% (+83 ms) |
In India, we are the fastest network, but we are beating the runner-up by less than a millisecond, which shakes out to less than 1% difference between us and the number two! The competition for the number one spot in many countries is fierce and sometimes can be determined by what days you’re looking at the data, because variance in connectivity or last-mile outages can materially impact this data.
For example, on September 17, there was an outage on a major network in India, which impacted many users’ ability to access the Internet. People using this network were significantly impacted in their ability to connect to Cloudflare, and you can actually see that impact in the data. Here’s what the data looked like on the day of the outage, as we dropped from the number one spot that day:
India performance by provider
|
Rank |
Entity |
95th percentile TCP Connect (ms) |
Difference from #1 |
|---|---|---|---|
|
1 |
|
219 ms |
– |
|
2 |
CloudFront |
230 ms |
+5% (+11 ms) |
|
3 |
Cloudflare |
236 ms |
+7.47% (+16 ms) |
|
4 |
Fastly |
261 ms |
+19% (+41 ms) |
|
5 |
Akamai |
286 ms |
+30% (+67 ms) |
We were impacted more than other providers here because our automated traffic management systems detected the high packet loss as a result of the outage and aggressively moved all of our traffic away from the impacted provider. After review internally, we have identified opportunities to improve our traffic management to be more fine-grained in our approach to outages of this type, which would help us continue to be fast despite changes in the surrounding ecosystem. These unplanned occurrences can happen to any network, but these events also provide us opportunities to improve and mitigate the randomness we see on the Internet.
The phenomenon of providers having fluctuating latencies can also work against us. Consider Poland, a country where we were the fastest provider in March, but are no longer the fastest provider today. Digging into the data a bit more, we can see that even though we are no longer the fastest, we’re slower by less than a millisecond, giving us confidence that our architecture is optimized for performance in the region:
Poland performance by provider
|
Rank |
Entity |
95th percentile TCP Connect (ms) |
Difference from #1 |
|---|---|---|---|
|
1 |
|
246 ms |
– |
|
2 |
Cloudflare |
246 ms |
+0.15% (+0.36 ms) |
|
3 |
CloudFront |
250 ms |
+1.7% (+4.17 ms) |
|
4 |
Akamai |
272 ms |
+11% (+26 ms) |
|
5 |
Fastly |
295 ms |
+20% (+50 ms) |
These nuances in the data can make us look slower in more countries than we actually are. From a numbers’ perspective we’re neck-and-neck with our competitors and still fastest in the most networks around the world. Going forward, we’re going to take a longer look at how we’re visualizing our network performance to paint a clearer picture for you around performance. But let’s go into more about how we actually get the underlying data we use to measure ourselves.
How we measure performance
When you see a Cloudflare-branded error page, something interesting happens behind the scenes. Every time one of these error pages is displayed, Cloudflare gathers Real User Measurements (RUM) by fetching a tiny file from various networks, including Cloudflare, Akamai, Amazon CloudFront, Fastly, and Google Cloud CDN. Your browser sends back performance data from the end-user’s perspective, helping us get a clear view of how these different networks stack up in terms of speed. The main goal? Figure out where we’re fast, and more importantly, where we can make Cloudflare even faster. If you’re curious about the details, the original Speed Week blog post dives deeper into the methodology.
Using this RUM data, we track key performance metrics such as TCP Connection Time, Time to First Byte (TTFB), and Time to Last Byte (TTLB) for Cloudflare and the other networks.
Starting from March, we fixed the list of networks we look at to be the top 1000 networks by estimated population as determined by APNIC, and we removed networks that weren’t last-mile ISPs. This change makes our measurements and reporting more consistent because we look at the same set of networks for every reporting cycle.
How does Cloudflare use this data?
Cloudflare uses this data to improve our network performance in lagging regions. For example, in 2022 we recognized that performance on a network in Finland was not as fast as some comparable regions. Users were taking 300+ ms to connect to Cloudflare at the 95th percentile:
Performance for Finland network
|
Rank |
Entity |
95th percentile TCP Connect (ms) |
Difference from #1 |
|---|---|---|---|
|
1 |
Fastly |
15 ms |
– |
|
2 |
CloudFront |
19 ms |
+19% (+3 ms) |
|
3 |
Akamai |
20 ms |
+28% (+4.3 ms) |
|
4 |
|
72 ms |
+363% (+56 ms) |
|
5 |
Cloudflare |
368 ms |
+2378% (+353 ms) |
After investigating, we recognized that one major network in Finland was seeing high latency due to issues resulting from congestion. Simply put, we were using all the capacity we had. We immediately planned an expansion, and within two weeks of that expansion completion, our latency decreased, and we became the fastest provider in the region, as you can see in the map above.
We are constantly improving our network and infrastructure to better serve our customers. Data like this helps us identify where we can be most impactful, and improve service for our customers.
What’s next
We’re sharing our updates on our journey to become as fast as we can be everywhere so that you can see what goes into running the fastest network in the world. From here, our plan is the same as always: identify where we’re slower, fix it, and then tell you how we’ve gotten faster.