Post Syndicated from original https://www.toest.bg/siedmitsata-13-18-may/
Като заваля дъжд, та цяла неделя! Тихо, кротко, ден и нощ. Вали, вали, вали – напои хубаво майката земя…
Из „На браздата“, Елин Пелин

Докато чакаме времето да се оправи и небето да се изчисти, реорганизация на движението по три улици в центъра на София стана повод да завалят спорове и протести, които също не стихват. Светла Енчева търси отговор на въпроса „Защо в България има проблем с общите пространства“, и констатира, че за съжаление, в среда, в която печелят най-силните, е трудно да се води дебат за въвеждането на непопулярни мерки, които да са от полза за не толкова силните и не толкова гласовитите участници в движението. От друга страна, характерно за всяка промяна е, че винаги среща силна съпротива само в началото. Времето ще покаже дали София може да се превърне в град на хората, а не на автомобилите, така както си го представят урбанисти като Ян Геел.
За няколко вечери все пак част от София беше на разположение на пешеходците. Миналата седмица завидно количество хора посетиха центъра на столицата, за да се порадват на фестивала на светлините „Лунар“. Предстои да видим още едно светлинно шоу. По случай Деня на българската просвета и на славянската писменост внушителен 3D мапинг, част от проекта „Скритите букви“ на Фондация „Прочети София“, ще бъде прожектиран на фасадата на Националната библиотека „Св. св. Кирил и Методий“ на 23 май от 21:30 до 00:00 ч.
„Светът гледа към Индустрия 5.0, България – към самун хляб“. Така Емилия Милчева е озаглавила тазседмичния си вътрешнополитически анализ и без излишна сантименталност ясно показва къде сме ние и къде са другите.
Популистките решения са лесни, не изискват специални умения и се удават на всички политици. За трудните реформи и модернизацията на държавата са нужни лидери с друга закалка. В противен случай властта ще продължава да подхвърля на гражданите малко пари, евтино олио и хляб вместо качествено образование и умения, за да се справят в една модерна икономика на бъдещето.
Индустрия 5.0, „разказана“ в доклада на Европейската комисия, звучи като футуристична приказка на фона на българската реалност. Обещават ни синергия между хората и машините. Вместо да бъдат заменяни хората с роботи и AI, стремежът е да се подобряват човешките способности и производителността чрез сътрудничество.
Коботи (роботи за сътрудничество) ще работят заедно с хората, помагайки им в задачи, които изискват прецизност, сила или повтарящи се действия, като оставят място за човешката креативност и вземане на решения. Алгоритмите за изкуствен интелект и машинно обучение ще анализират огромни количества данни, за да се фокусират хората върху стратегическите решения.
Звучи почти по холивудски утопично, нали? Какво красиво бъдеще само…
Но къде е всъщност България в този нов свят със своите над 1 милион граждани в активна възраст, които нито учат, нито работят, нито са регистрирани в бюрата по труда? Вее руски знамена на връх Шипка и шумно спори защо „Ергенът“ не е избрал нито една от „джукесите“.
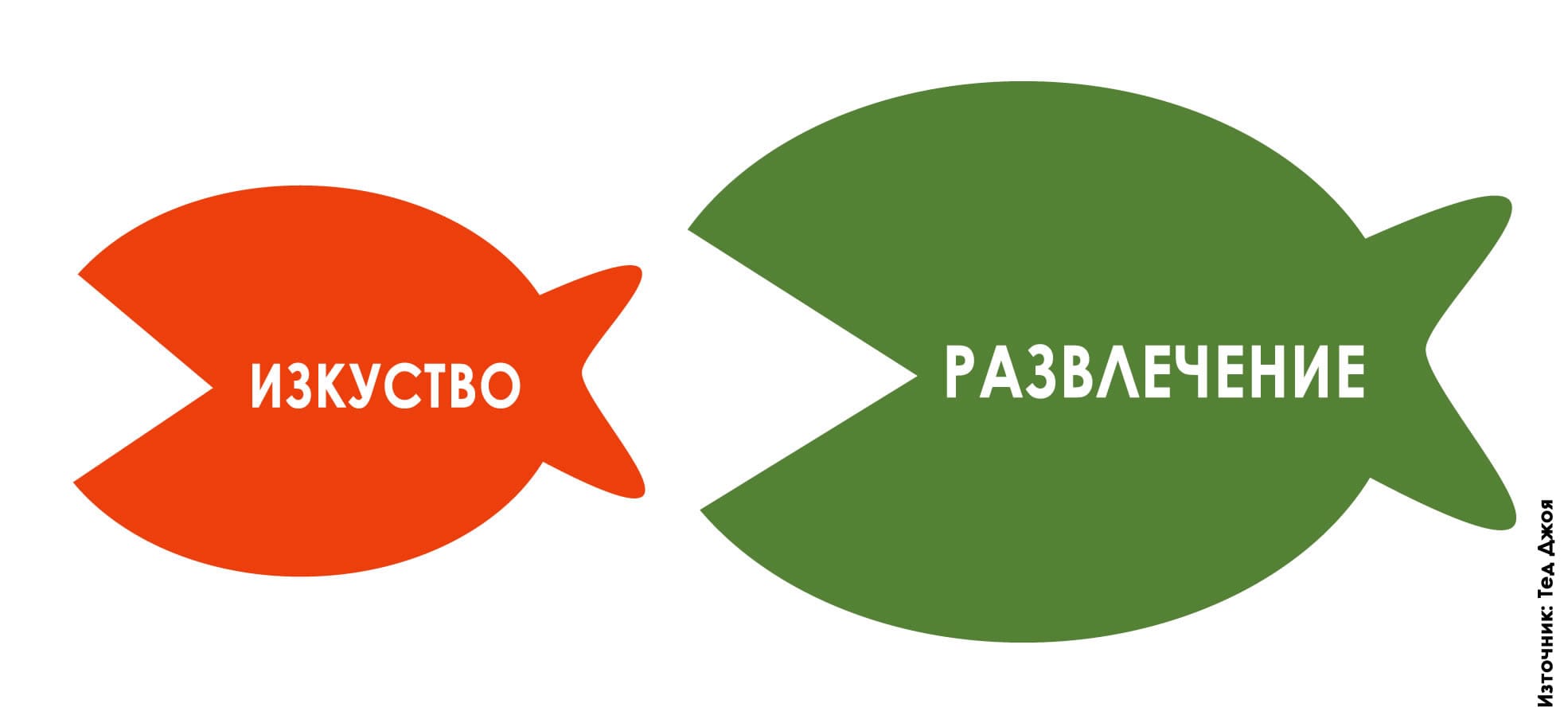
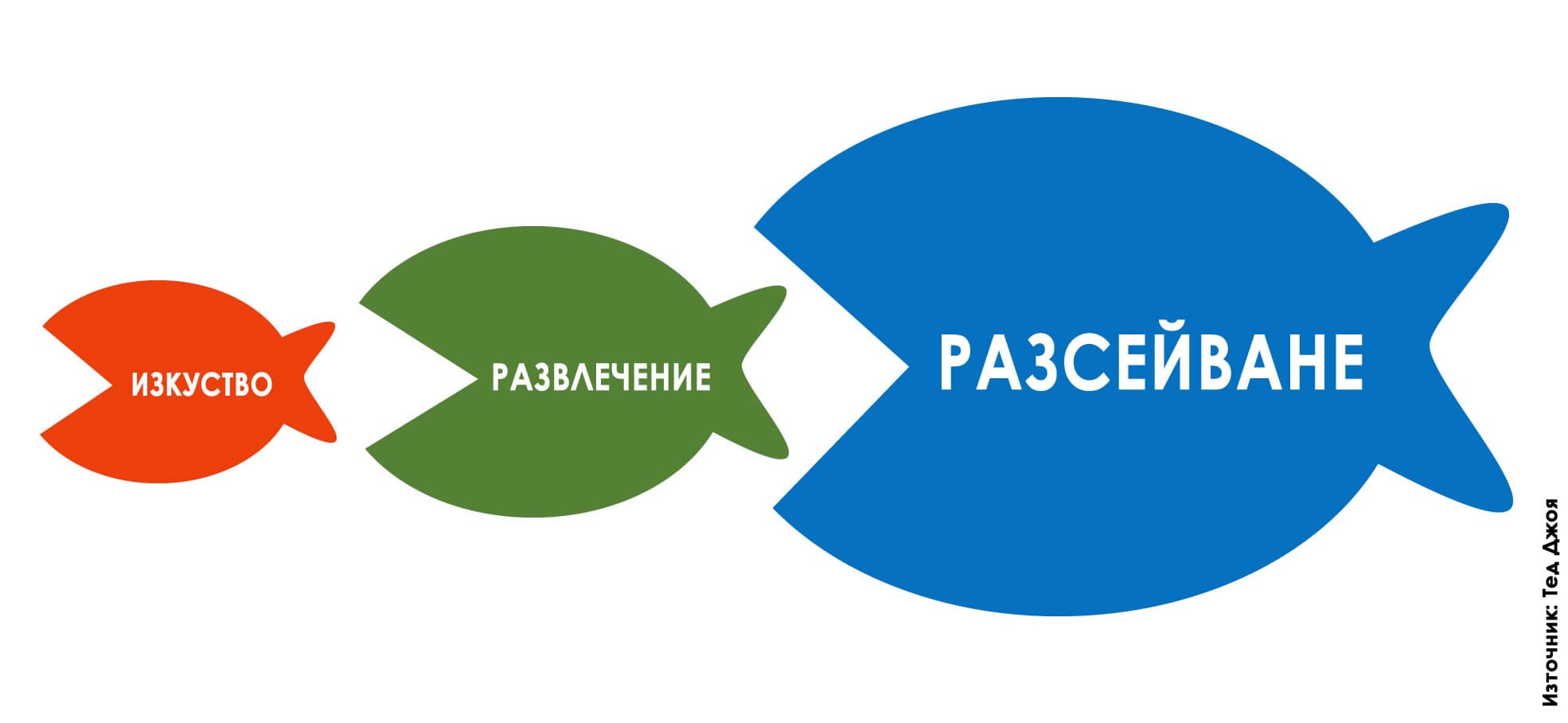
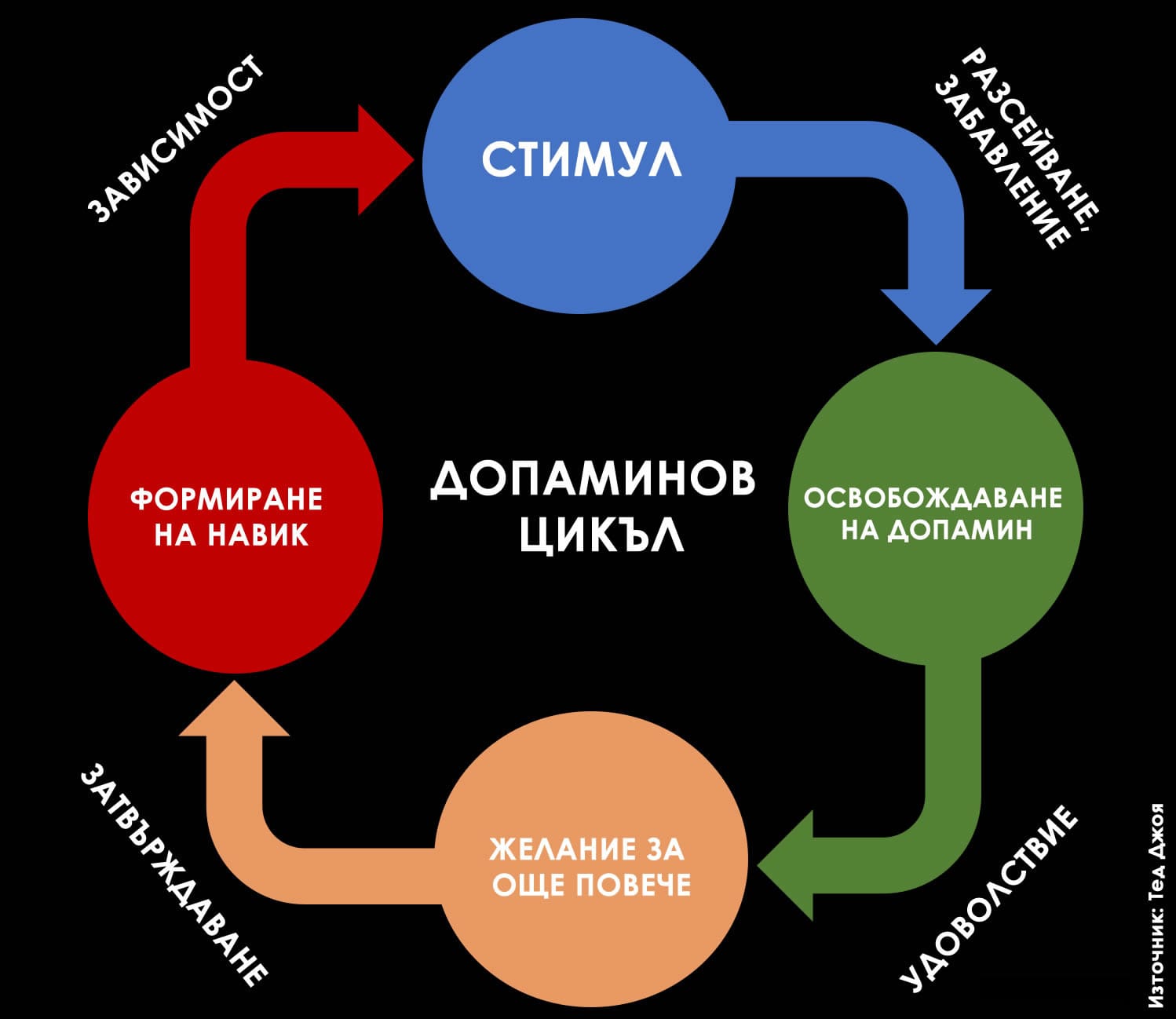
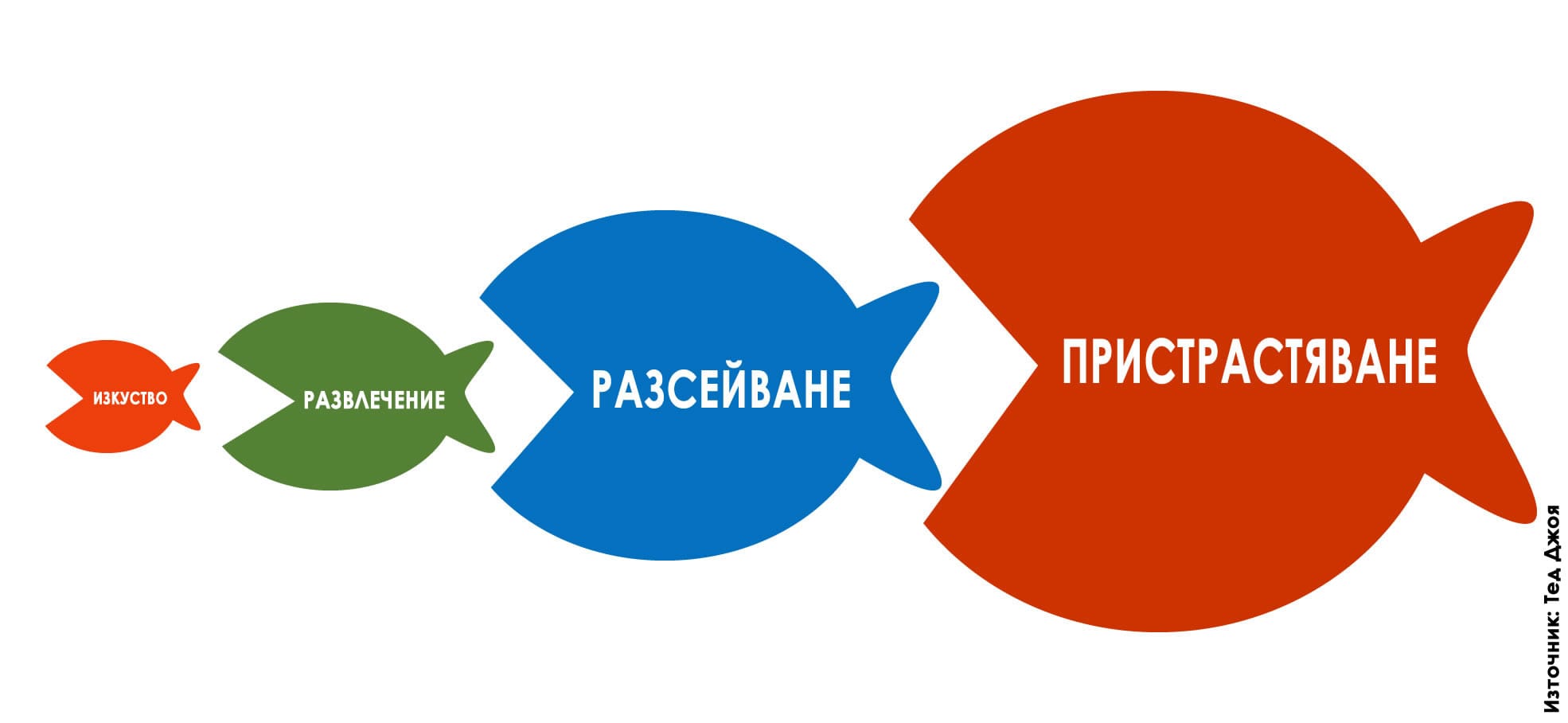
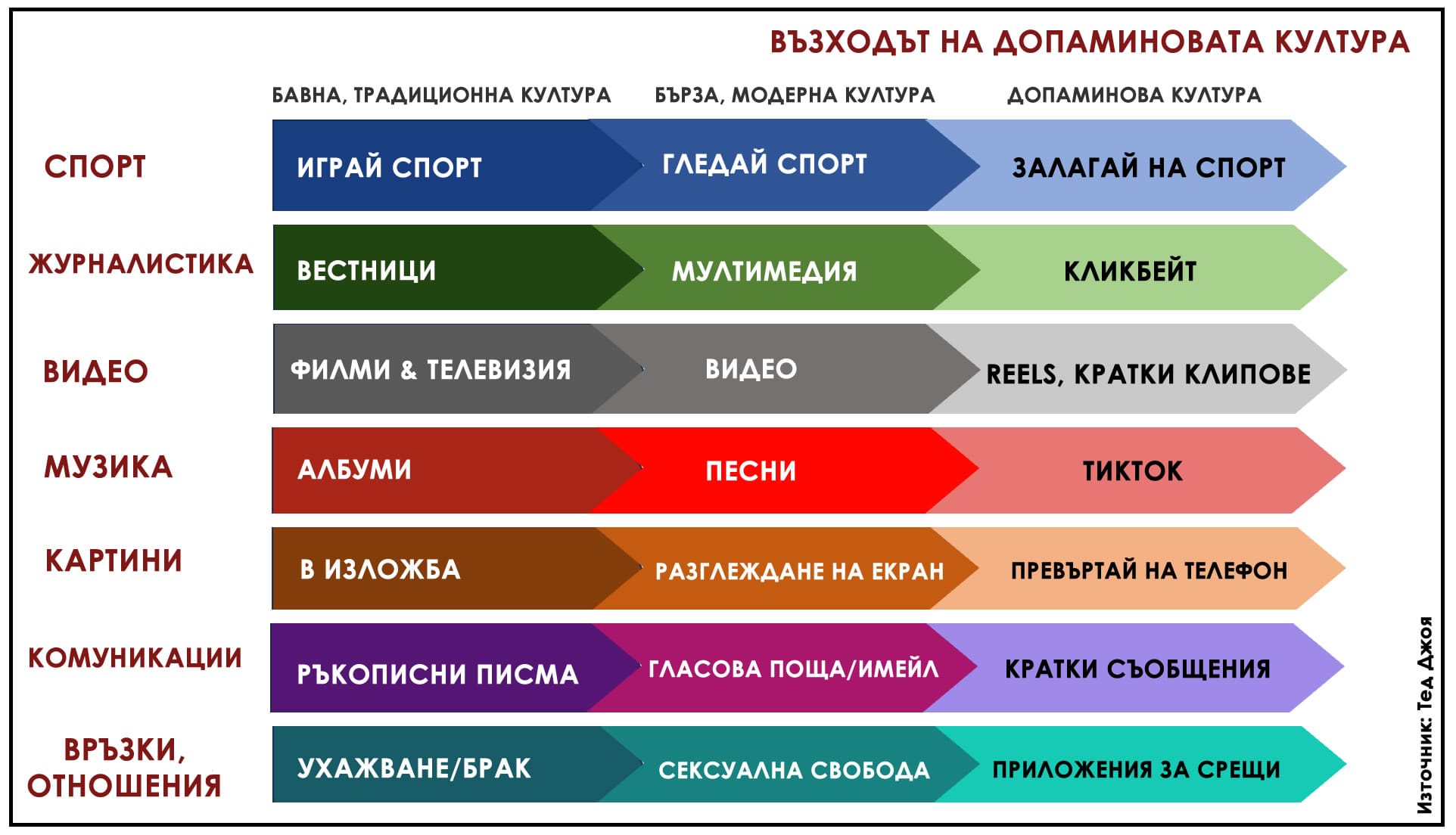
В същото време всеки ученик или студент предпочита да виси в социалните мрежи, да използва ChatGPT, за да му напише курсовата работа или домашното, и по възможност да не влага усилие за друго, освен за да си достави поредната бърза доза онлайн разсейване. На този все по-голям проблем обръщам внимание в статията си „Културата на разсейването и капанът на допаминовата зависимост“. Защото е лесно да обвиним младите за това, че искат да избягат от действителността и предпочитат лесното пред трудното, но е важно да си дадем сметка, че сами ги вкарваме във виртуален затвор без изход, където повечето от нас също неусетно търсят фалшива утеха и убежище.
Но красивото бъдеще на човечеството зависи именно от това на какво и как учим децата. Вечна е темата за състоянието на българската образователна система и дали училището е в състояние да предложи на децата всичко онова, от което имат нужда, за да се фокусират и да учат активно: безопасна и творческа среда, достатъчно пространство, светлина и възможности за развитие, подкрепа и сътрудничество, естетически стимули… В статията си тази седмица „От грозно по-грозно: Физическата среда в училища и детски градини“ Донка Дойчева-Попова се опитва да провокира един честен поглед към състоянието в момента и към нуждата от спешна позитивна промяна.
Неуютните и остарели училищни сгради обаче могат да бъдат привлекателни, ако не си имал дори това като възможност. За десетки деца бежанци като 12-годишната Симаф от Сирия, която никога не е посещавала училище, преди да пристигне с леля си в България, образованието е единственото средство, чрез което могат да постигнат мечтите си. Интервюто на Надежда Цекулова „Симаф, която иска да учи и да стане лекарка“ си заслужава четенето, дори и само за да оценим образованието като привилегия, която приемаме за даденост.
През уикенда може би ще видим малко слънце, но ако случайно забравите да си вземете чадър, съветвам ви да потърсите подслон в някои от софийските музеи, които ще бъдат със свободен вход в събота вечер, 18 май. Заради Европейската нощ на музеите и тази година над 50 музея и галерии ще останат отворени до късно и ще работят извънредно. Изложби, концерти, работилници, филми, обиколки с екскурзовод – Нощта на музеите е отворена за всички. По време на събитието ще има безплатна атракционна ретро линия с реставрирани автобуси, които ще тръгват на всеки 20 минути във времето между 18:00 и 0:30 часа. Може да разгледате пълната програма на събитието и да решите какво да посетите, но ви препоръчвам да не пропускате Столичната градска художествена галерия, където изложбата е посветена на 125-тата годишнина от рождението на Дечко Узунов. В галерията на открито в градската градина пък имате възможност да разгледате документалната изложба по случай 200-годишнината от създаването на „Рибния буквар“.
А като споменахме „Рибния буквар“, миналата седмица се случи едно дългоочаквано събитие: след дълги години чакане най-сетне разполагаме онлайн с официален правописен речник на българския език. БЕРОН е едновременно абревиатура на български езикови ресурси онлайн, както и намек за годишнината от излизането на творбата на възрожденеца Петър Берон. Необходимостта от надежден ресурс в интернет за нормите на българския книжовен език най-после изглежда добре подсигурена, а ако ви възникват съмнения, винаги може да си направите допълнителна справка с „Как се пише?“ – сайта, който нашата езикова редакторка и коректорка Павлина Върбанова създаде и поддържа актуален през последните 12 години.
И накрая нека ви припомня нещо: „Тоест“ е медия, която се издържа изцяло от своите читатели. Мисията ѝ е да анализира и представя съществени теми честно и обективно и да свързва читателите помежду им и с реалността. Ако харесвате нашата работа и вярвате, че усилията ни да ви предоставяме качествено съдържание сред океана от кликбейт, реклами, дезинформация и пропаганда имат смисъл, подкрепете ни. „Тоест“ се нуждае от вас, за да продължи да съществува като независима медия.





































{kind=link}