Post Syndicated from Renan Dincer original https://blog.cloudflare.com/av1-cloudflare-stream-beta/


Consumer hardware is pushing the limits of consumers’ bandwidth.
VR headsets support 5760 x 3840 resolution — 22.1 million pixels per frame of video. Nearly all new TVs and smartphones sold today now support 4K — 8.8 million pixels per frame. It’s now normal for most people on a subway to be casually streaming video on their phone, even as they pass through a tunnel. People expect all of this to just work, and get frustrated when it doesn’t.
Consumer Internet bandwidth hasn’t kept up. Even advanced mobile carriers still limit streaming video resolution to prevent network congestion. Many mobile users still have to monitor and limit their mobile data usage. Higher Internet speeds require expensive infrastructure upgrades, and 30% of Americans still say they often have problems simply connecting to the Internet at home.
We talk to developers every day who are pushing up against these limits, trying to deliver the highest quality streaming video without buffering or jitter, challenged by viewers’ expectations and bandwidth. Developers building live video experiences hit these limits the hardest — buffering doesn’t just delay video playback, it can cause the viewer to get out of sync with the live event. Buffering can cause a sports fan to miss a key moment as playback suddenly skips ahead, or find out in a text message about the outcome of the final play, before they’ve had a chance to watch.
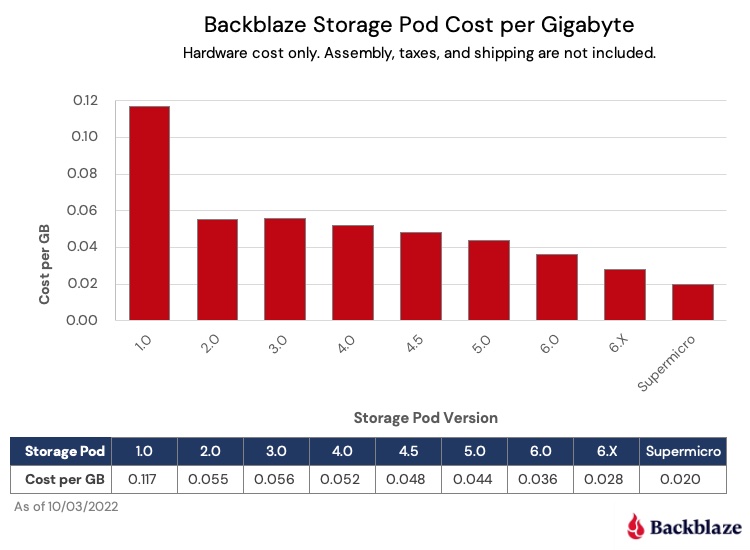
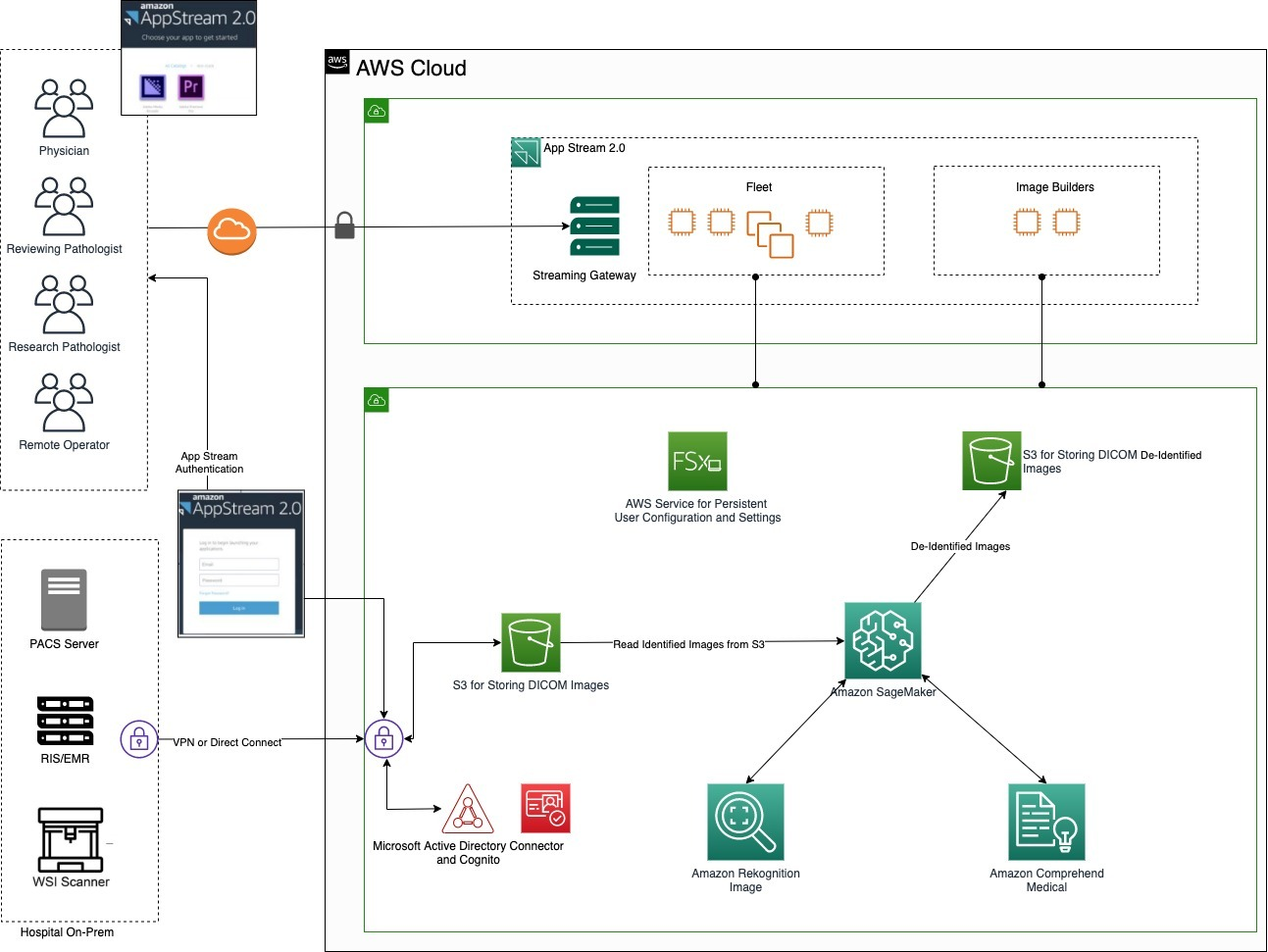
Today we’re announcing a big step towards breaking the ceiling of these limits — support in Cloudflare Stream for the AV1 codec for live videos and their recordings, available today to all Cloudflare Stream customers in open beta. Read the docs to get started, or watch an AV1 video from Cloudflare Stream in your web browser. AV1 is an open and royalty-free video codec that uses 46% less bandwidth than H.264, the most commonly used video codec on the web today.
What is AV1, and how does it improve live video streaming?
Every piece of information that travels across the Internet, from web pages to photos, requires data to be transmitted between two computers. A single character usually takes one byte, so a two-page letter would be 3600 bytes or 3.6 kilobytes of data transferred.
One pixel in a photo takes 3 bytes, one each for red, green and blue in the pixel. A 4K photo would take 8,294,400 bytes, or 8.2 Megabytes. A video is like a photo that changes 30 times a second, which would make almost 15 Gigabytes per minute. That’s a lot!
To reduce the amount of bandwidth needed to stream video, before video is sent to your device, it is compressed using a codec. When your device receives video, it decodes this into the pixels displayed on your screen. These codecs are essential to both streaming and storing video.
Video compression codecs combine multiple advanced techniques, and are able to compress video to one percent of the original size, with your eyes barely noticing a difference. This also makes video codecs computationally intensive and hard to run. Smartphones, laptops and TVs have specific media decoding hardware, separate from the main CPU, optimized to decode specific protocols quickly, using the minimum amount of battery life and power.
Every few years, as researchers invent more efficient compression techniques, standards bodies release new codecs that take advantage of these improvements. Each generation of improvements in compression technology increases the requirements for computers that run them. With higher requirements, new chips are made available with increased compute capacity. These new chips allow your device to display higher quality video while using less bandwidth.
AV1 takes advantage of recent advances in compute to deliver video with dramatically fewer bytes, even compared to other relatively recent video protocols like VP9 and HEVC.
AV1 leverages the power of new smartphone chips
One of the biggest developments of the past few years has been the rise of custom chip designs for smartphones. Much of what’s driven the development of these chips is the need for advanced on-device image and video processing, as companies compete on the basis of which smartphone has the best camera.
This means the phones we carry around have an incredible amount of compute power. One way to think about AV1 is that it shifts work from the network to the viewer’s device. AV1 is fewer bytes over the wire, but computationally harder to decode than prior formats. When AV1 was first announced in 2018, it was dismissed by some as too slow to encode and decode, but smartphone chips have become radically faster in the past four years, more quickly than many saw coming.
AV1 hardware decoding is already built into the latest Google Pixel smartphones as part of the Tensor chip design. The Samsung Exynos 2200 and MediaTek Dimensity 1000 SoC mobile chipsets both support hardware accelerated AV1 decoding. It appears that Google will require that all devices that support Android 14 support decoding AV1. And AVPlayer, the media playback API built into iOS and tvOS, now includes an option for AV1, which hints at future support. It’s clear that the industry is heading towards hardware-accelerated AV1 decoding in the most popular consumer devices.
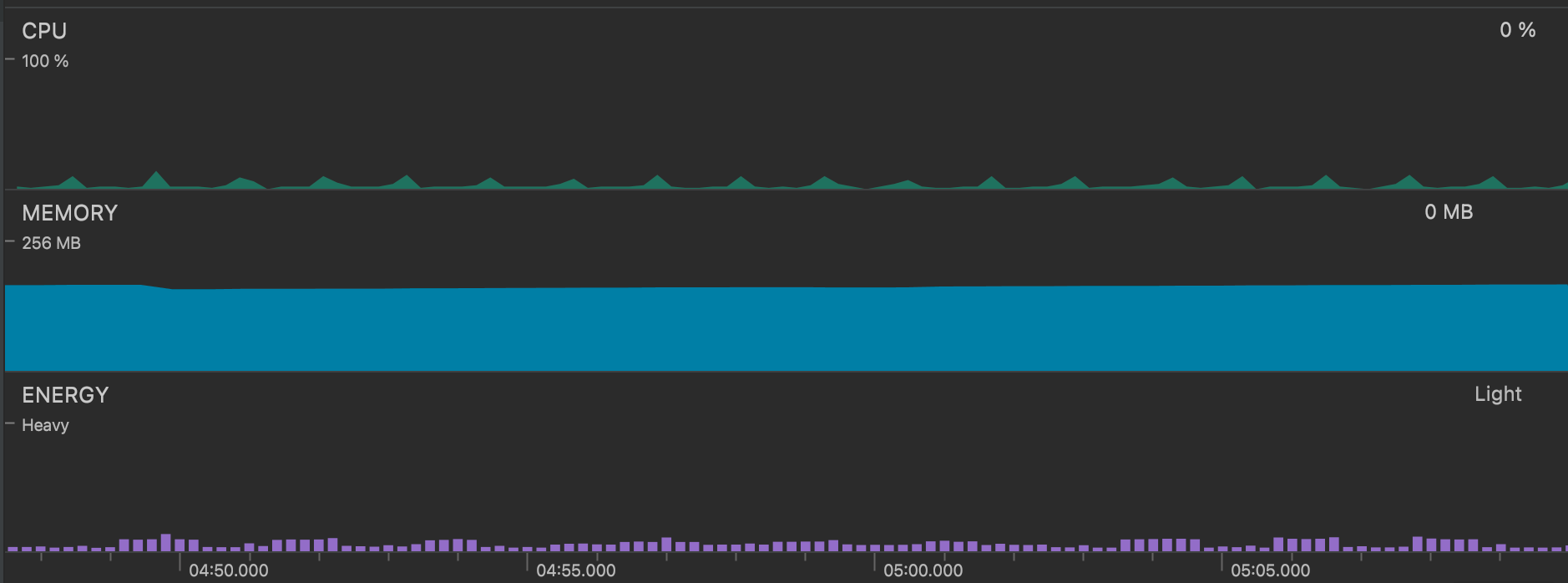
With hardware decoding comes battery life savings — essential for both today’s smartphones and tomorrow’s VR headsets. For example, a Google Pixel 6 with AV1 hardware decoding uses only minimal battery and CPU to decode and play our test video:
AV1 encoding requires even more compute power
Just as decoding is significantly harder for end-user devices, it is also significantly harder to encode video using AV1. When AV1 was announced in 2018, many doubted whether hardware would be able to encode it efficiently enough for the protocol to be adopted quickly enough.
To demonstrate this, we encoded the 4K rendering of Big Buck Bunny (a classic among video engineers!) into AV1, using an AMD EPYC 7642 48-Core Processor with 256 GB RAM. This CPU continues to be a workhorse of our compute fleet, as we have written about previously. We used the following command to re-encode the video, based on the example in the ffmpeg AV1 documentation:
ffmpeg -i bbb_sunflower_2160p_30fps_normal.mp4 -c:v libaom-av1 -crf 30 -b:v 0 -strict -2 av1_test.mkv
Using a single core, encoding just two seconds of video at 30fps took over 30 minutes. Even if all 48 cores were used to encode, it would take at minimum over 43 seconds to encode just two seconds of video. Live encoding using only CPUs would require over 20 servers running at full capacity.
Special-purpose AV1 software encoders like rav1e and SVT-AV1 that run on general purpose CPUs can encode somewhat faster than libaom-av1 with ffmpeg, but still consume a huge amount of compute power to encode AV1 in real-time, requiring multiple servers running at full capacity in many scenarios.
Cloudflare Stream encodes your video to AV1 in real-time
At Cloudflare, we control both the hardware and software on our network. So to solve the CPU constraint, we’ve installed dedicated AV1 hardware encoders, designed specifically to encode AV1 at blazing fast speeds. This end to end control is what lets us encode your video to AV1 in real-time. This is entirely out of reach to most public cloud customers, including the video infrastructure providers who depend on them for compute power.
Encoding in real-time means you can use AV1 for live video streaming, where saving bandwidth matters most. With a pre-recorded video, the client video player can fetch future segments of video well in advance, relying on a buffer that can be many tens of seconds long. With live video, buffering is constrained by latency — it’s not possible to build up a large buffer when viewing a live stream. There is less margin for error with live streaming, and every byte saved means that if a viewer’s connection is interrupted, it takes less time to recover before the buffer is empty.
Stream lets you support AV1 with no additional work
AV1 has a chicken or the egg dilemma. And we’re helping solve it.
Companies with large video libraries often re-encode their entire content library to a new codec before using it. But AV1 is so computationally intensive that re-encoding whole libraries has been cost prohibitive. Companies have to choose specific videos to re-encode, and guess which content will be most viewed ahead of time. This is particularly challenging for apps with user generated content, where content can suddenly go viral, and viewer patterns are hard to anticipate.
This has slowed down the adoption of AV1 — content providers wait for more devices to support AV1, and device manufacturers wait for more content to use AV1. Which will come first?
With Cloudflare Stream there is no need to manually trigger re-encoding, re-upload video, or manage the bulk encoding of a large video library. This is a unique approach that is made possible by integrating encoding and delivery into a single product — it is not possible to encode on-demand using the old way of encoding first, and then pointing a CDN at a bucket of pre-encoded files.
We think this approach can accelerate the adoption of AV1. Consider a video app with millions of minutes of user-generated video. Most videos will never be watched again. In the old model, developers would have to spend huge sums of money to encode upfront, or pick and choose which videos to re-encode. With Stream, we can help anyone incrementally adopt AV1, without re-encoding upfront. As we work towards making AV1 Generally Available, we’ll be working to make supporting AV1 simple and painless, even for videos already uploaded to Stream, with no special configuration necessary.
Open, royalty-free, and widely supported
At Cloudflare, we are committed to open standards and fighting patent trolls. While there are multiple competing options for new video codecs, we chose to support AV1 first in part because it is open source and has royalty-free licensing.
Other encoding codecs force device manufacturers to pay royalty fees in order to adopt their standard in consumer hardware, and have been quick to file lawsuits against competing video codecs. The group behind the open and royalty-free VP8 and VP9 codecs have been pushing back against this model for more than a decade, and AV1 is the successor to these codecs, with support from all the biggest technology companies, both software and hardware. Beyond its technical accomplishments, AV1 is a clear message from the industry that the future of video encoding should be open, royalty-free, and free from patent litigation.
Try AV1 right now with your live stream or live recording
Support for AV1 is currently in open beta. You can try using AV1 on your own live video with Cloudflare Stream right now — just add the ?betaCodecSuggestion=av1 query parameter to the HLS or DASH manifest URL for any live stream or live recording created after October 1st in Cloudflare Stream. Read the docs to get started. If you don’t yet have a Cloudflare account, you can sign up here and start using Cloudflare Stream in just a few minutes.
We also have a recording of a live video, encoded using AV1, that you can watch here. Note that Safari does not yet support AV1.
We encourage you to try AV1 with your test streams, and we’d love your feedback. Join our Discord channel and tell us what you’re building, and what kinds of video you’re interested in using AV1 with. We’d love to hear from you!