Post Syndicated from João Tomé original https://blog.cloudflare.com/cloudflare-radar-2021-year-in-review/


In 2021, we continued to live with the effects of the COVID pandemic and Internet traffic was also impacted by it. Although learning and exercising may have started to get back to something close to normal (depending on the country), the effects of what started almost two years ago on the way people work and communicate seems to be here to stay, and the lockdowns or restrictions continue to have an impact on where and how people go online.
So, Cloudflare Radar’s 2021 Year In Review is out with interactive maps and charts you can use to explore what changed on the Internet throughout this past year. Year In Review is part of Cloudflare Radar. We launched Radar in September 2020 to give anyone access to Internet use and abuse trends.
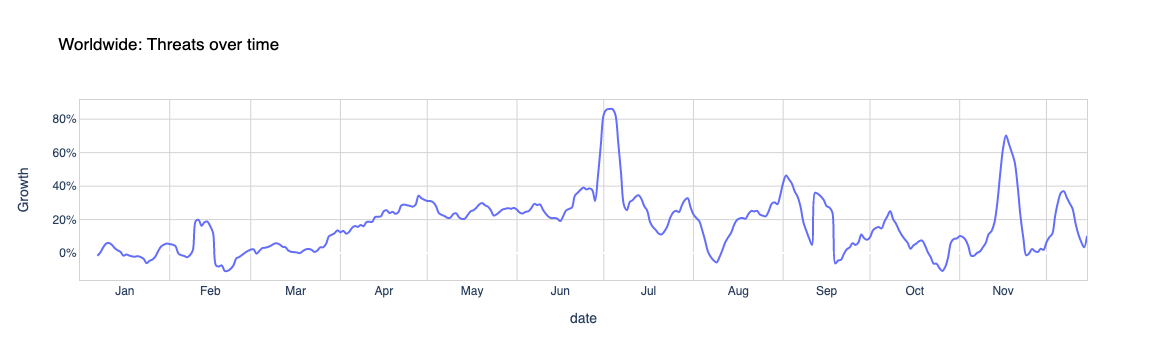
This year we’ve added a mobile vs desktop traffic chart, but also the attack distribution that shows the evolution throughout the year — the beginning of July 2021, more than a month after the famous Colonial Pipeline cyberattack, was the time of the year when attacks worldwide peaked.
There are also interesting pandemic-related trends like the (lack) of Internet activity in Tokyo with the Summer Olympics in town and how Thanksgiving week in the US in late November affected mobile traffic in the United States.
You can also check our Popular Domains — 2021 Year in Review where TikTok, e-commerce and space companies had a big year.
Internet: growing steadily (with lockdown bumps)
In 2020 by late April we saw that the Internet had seen incredible, sudden growth in traffic because of lockdowns and that was sustained throughout the year as we showed in our 2020 Year In Review. 2021 told a slightly different story, depending on the country.
The big April-March and May Internet traffic peak from 2020 related to the pandemic wasn’t there, in the same way, this year — it was more distributed depending on the local restrictions. In 2021, Internet traffic, globally, continued to grow throughout the year, and it was at the end of the year that was higher (a normal trend, given there’s a growth in categories like online shopping and the colder season in the Northern Hemisphere, where most Internet traffic occurs, affects human behaviour).
The day of the year with the highest growth in traffic worldwide, from our standpoint, was December 2, 2021, with 20% more than the first week of the year — the Y-axis shows the percentage change in Internet traffic using a cohort of top domains from each country. But in May there was also a bump (highlighted in red as a possible pandemic-related occurrence), although not as high as we saw in the March-May period of last year.
Spikes in Internet traffic — Worldwide 2021
#1 November-December1 (+23%)
#2 September (+20%)
#3 October (+19%)
#4 August (+16%)
#5 May (+13%)
1Beginning of December
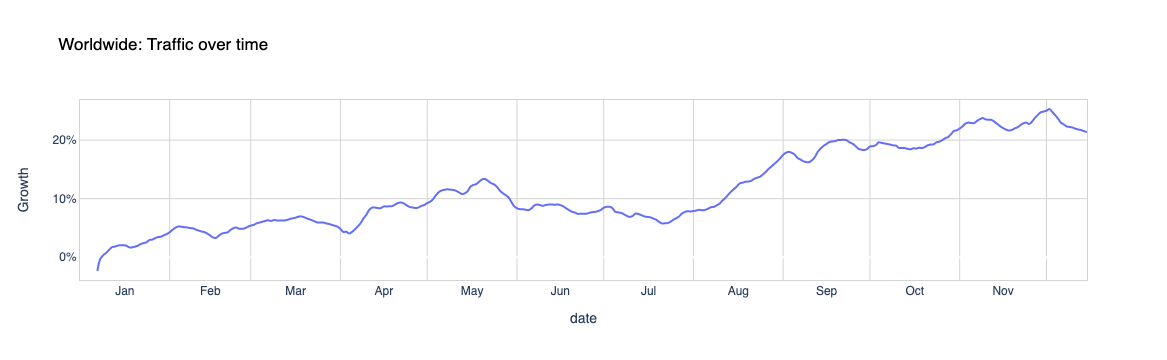
When we focus on specific countries using our Year In Review 2021 page you can see that new restrictions or lockdowns affected (again) Internet traffic and, in some countries, that is more evident than others.
In the following table, we show the months with the highest traffic growth (the percentage shown focus on the spikes). From our standpoint the last four months of the year usually have the highest growth in traffic after September, but Canada, the UK, Germany, France, Portugal, South Korea and Brazil seemed to show (in red) an impact of restrictions in their Internet traffic — with higher increases in the first five months of the year.
Months with the largest traffic growth — 2021
|
United States #1 November-Dec (+30%) |
Canada #1 November-Dec (+21%) |
|
UK #1 November-Dec (+23%) |
Germany #1 November-Dec (+25%) |
|
France #1 November-Dec (+24%) |
Japan #1 November-Dec (+32%) |
|
Australia #1 November-Dec (+42%) |
Singapore #1 November-Dec (+62%) |
|
Portugal #1 February (+38%) |
South Korea #1 April (+21%) |
|
Brazil #1 May (+25%) |
India #1 November-Dec (+24%) |
When we look at those countries’ trends we can see that Canada had lockdowns at the beginning of February that went through March and May, depending on the area of the country. That is in line with what we’ve seen in 2020: when restrictions/lockdowns are up, people tend to use the Internet more to communicate, work, exercise and learn.
Most of Europe also started 2021 with lockdowns and restrictions that included schools — so online learning was back on. That’s clear in the UK. From January to March showed a high increase in traffic percentage that went down when restrictions were relaxed.
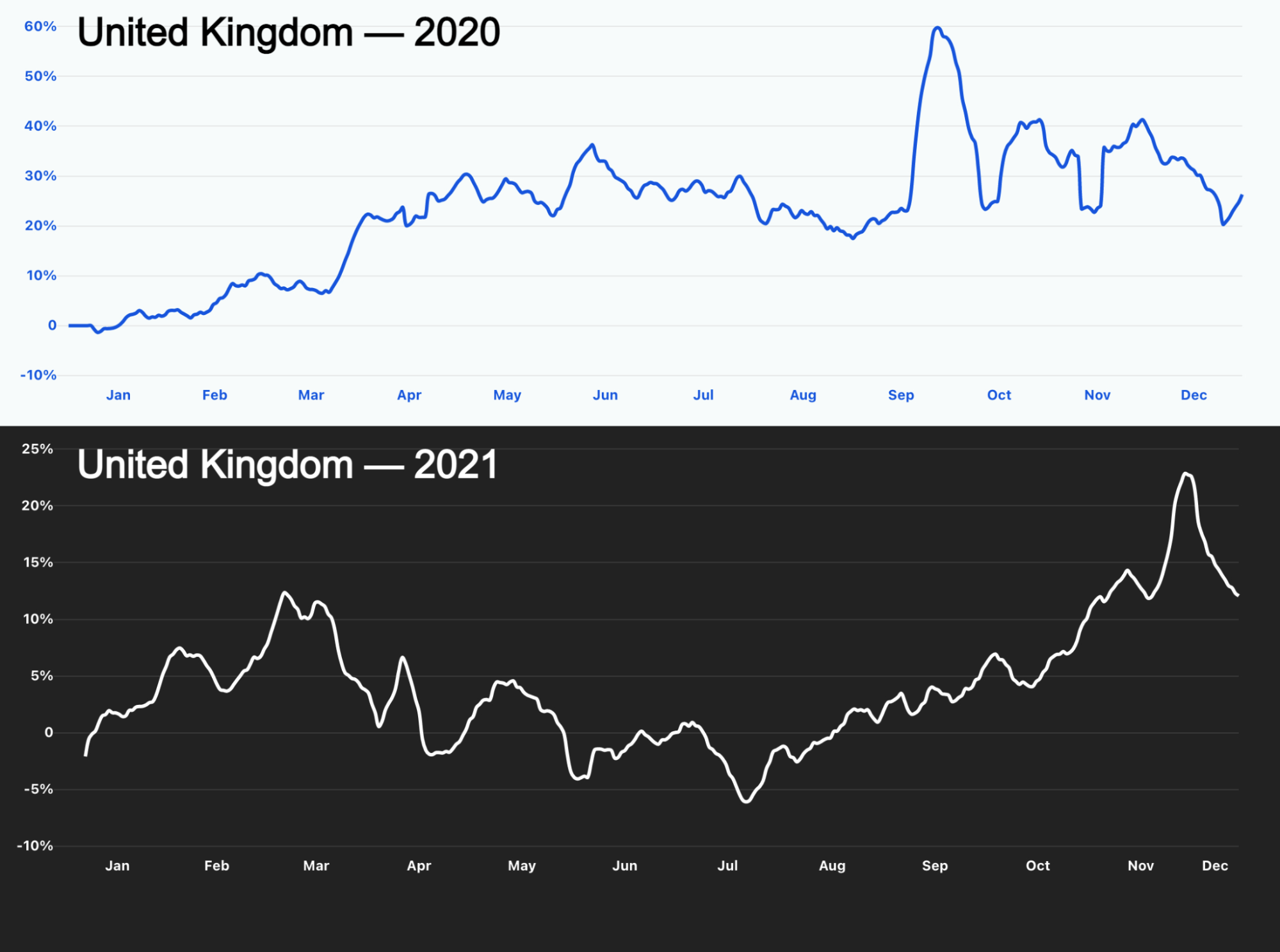
The same happens in Portugal, where new measures on January 21, 2021, put the three first months of the year in the top 3 of the year in terms of growth of traffic, and April was #5.
We can also check the example of France. Lockdowns were imposed again especially during April and May 2021, and we can see the growth in Internet traffic during those months, slightly more timid than the first lockdown of 2020, but nonetheless evident in the 2021 chart.
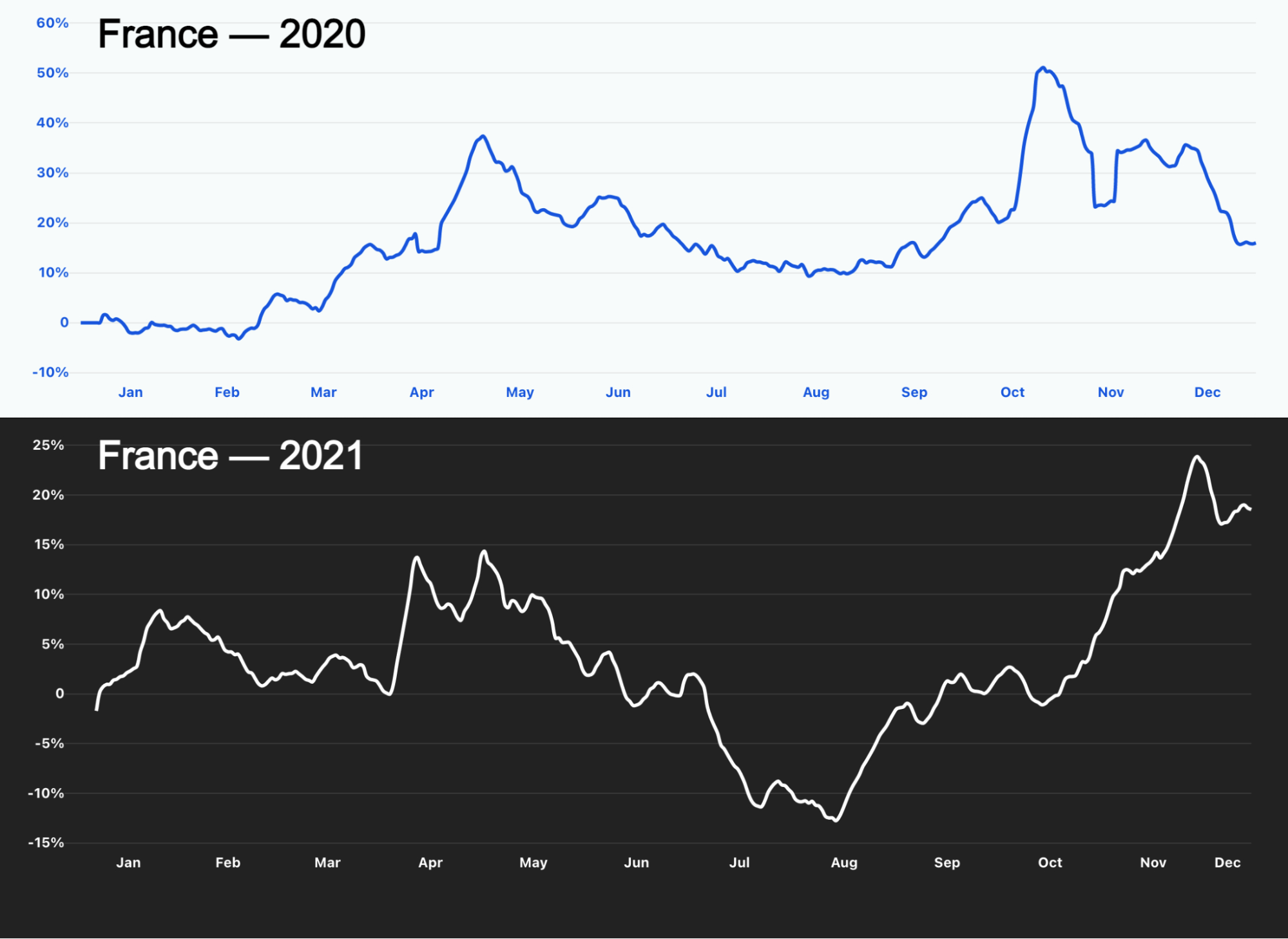
Germany had the same situation in May (in April work from home was again the rule and the relaxation of measures for vaccinated people only began in mid-May), but in February the lockdown that started at the end of 2020 (and included schools) was also having an impact on Internet traffic.
In South Korea there was also an impact of the beginning of the year lockdown seen in spikes through February, April and May 2021.
Internet traffic growth in the United States had a very different year in 2021 than it had the year before, when the first lockdown had a major effect on Internet growth, but still, May was a month of high growth — it was in mid-May that there were new guidelines from the CDC about masks.
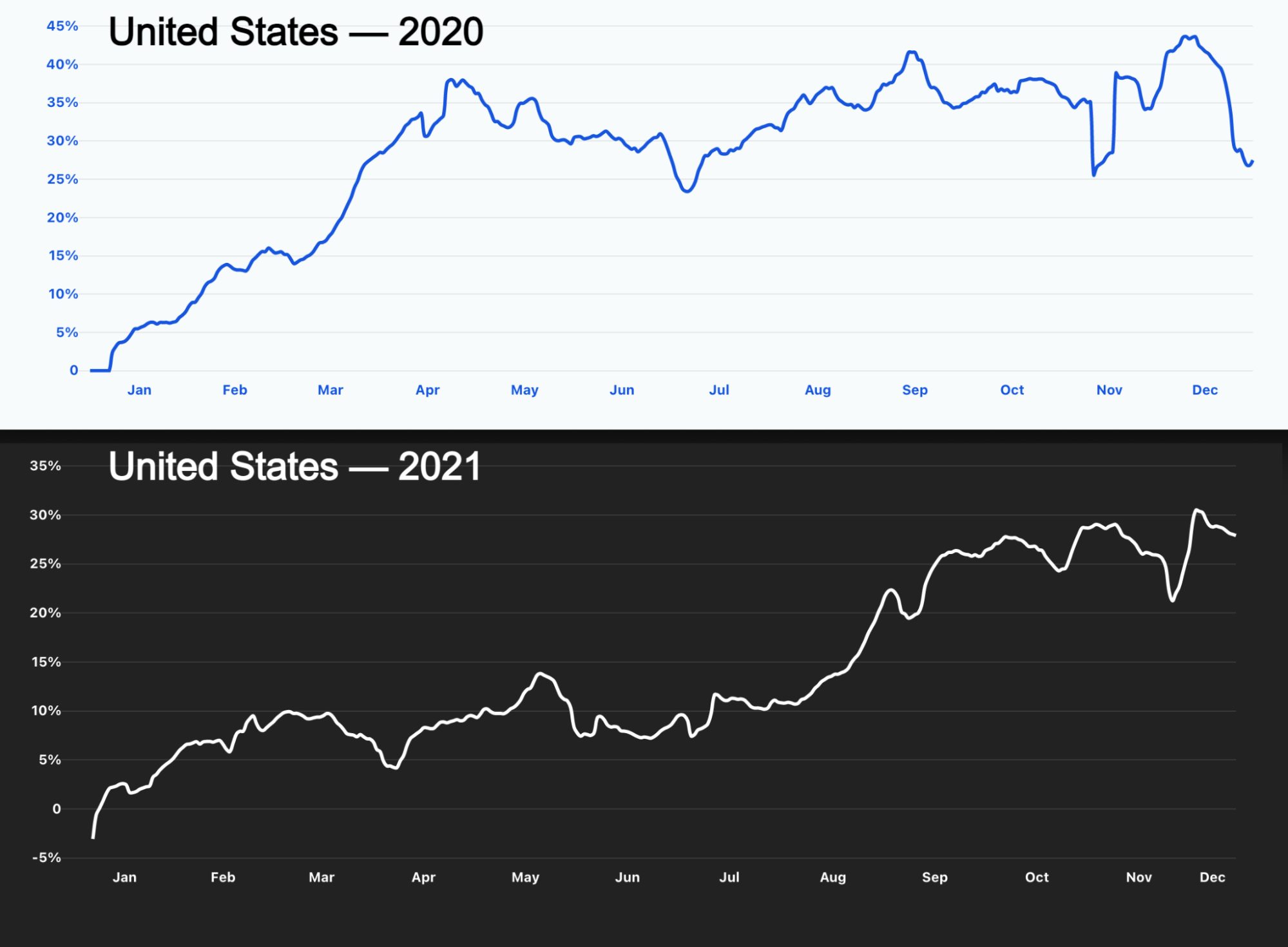
Mobile traffic: The Thanksgiving effect
Another trend worldwide from 2021 is the mobile traffic percentage evolution. Worldwide, from our standpoint, the more mobile-friendly months of the year — where mobile devices were more prevalent to go online — were July and August (typical vacations months in most of the Northern Hemisphere), but January and November were also very strong.
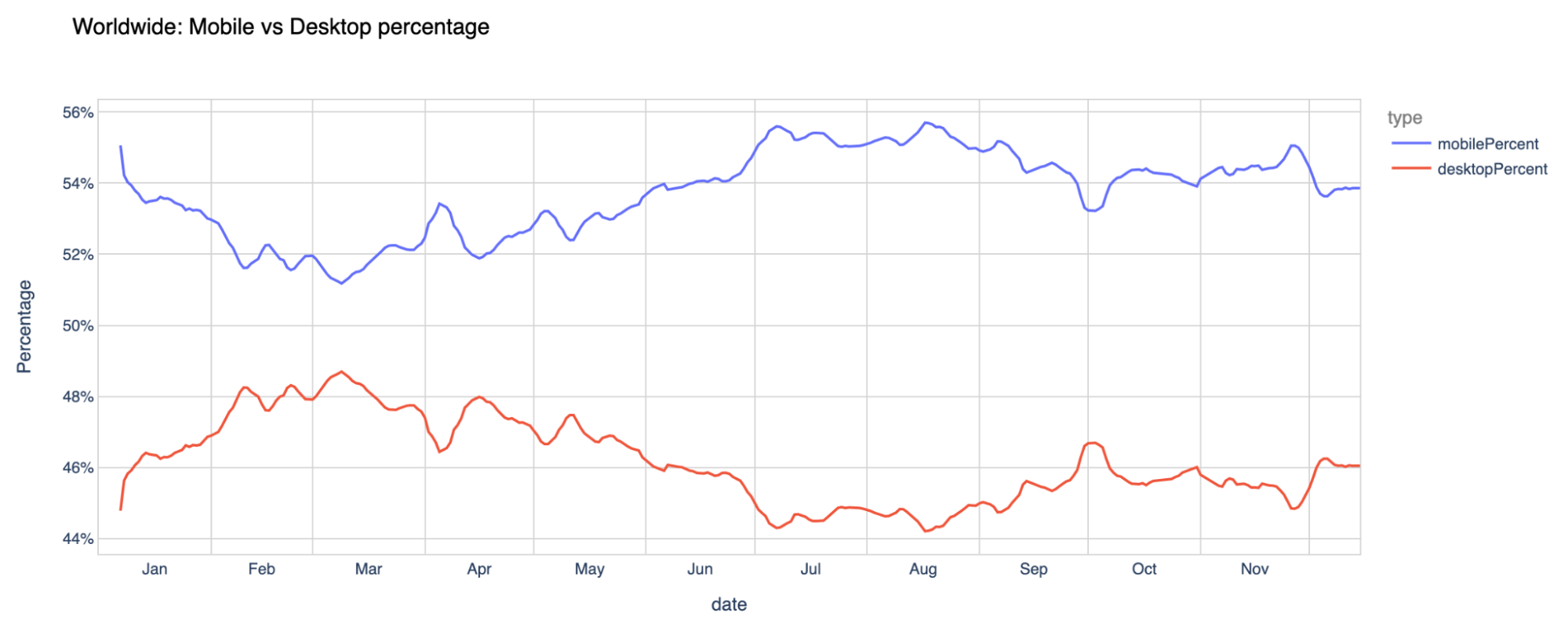
On our Year in Review page, you can also see the new mobile vs desktop traffic chart. The evolution of the importance of mobile traffic is different depending on the country.
For example, the United States has more desktop traffic throughout the year, but in 2021, during the Thanksgiving (November 25) week, mobile traffic took the lead for the first and only time in the whole year. We can also see that in July mobile traffic was also high in terms of relevance.
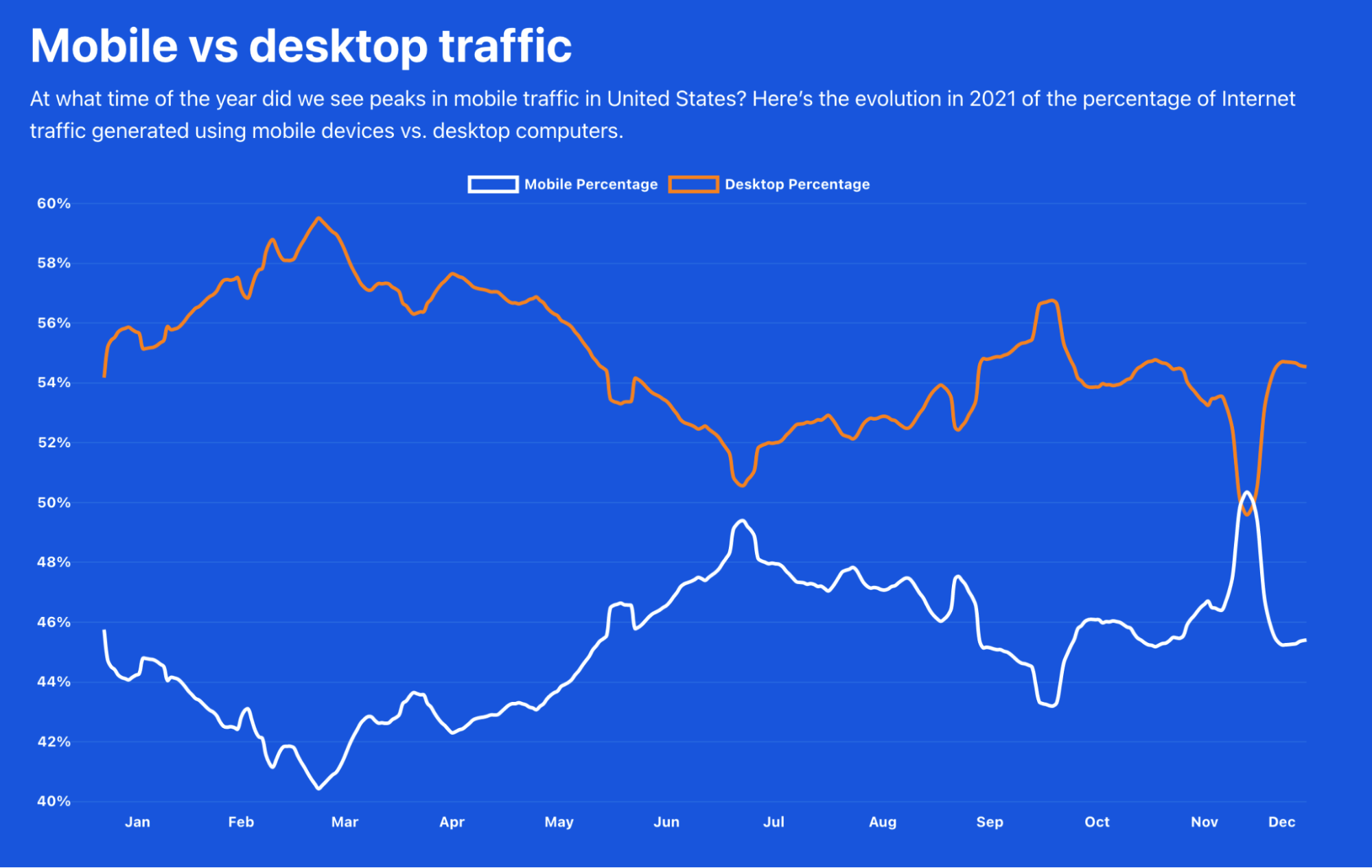
The UK has a similar trend, with June, July and August being the only months of the year when mobile traffic is prevalent compared to desktop.
If we go to the other side of the planet, to Singapore, there the mobile percentage is usually higher than desktop, and we see a completely different trend than in the US. Mobile traffic was higher in May, and desktop only went above mobile in some days of February, some in March, and especially after the end of October.

Where people accessed the Internet
We also have, again, available the possibility of selecting a city from the map of our Year in Review to zoom into a city to see the change in Internet use throughout the year. Let’s zoom in on San Francisco.
The following agglomeration of maps highlights (all available in our Year in Review site) the change in Internet use comparing the start of 2020, mid-January to mid-March — you can see that there’s still some increase in traffic, in orange —, to the total lockdown situation of April and May, with more blue areas (decrease in traffic).
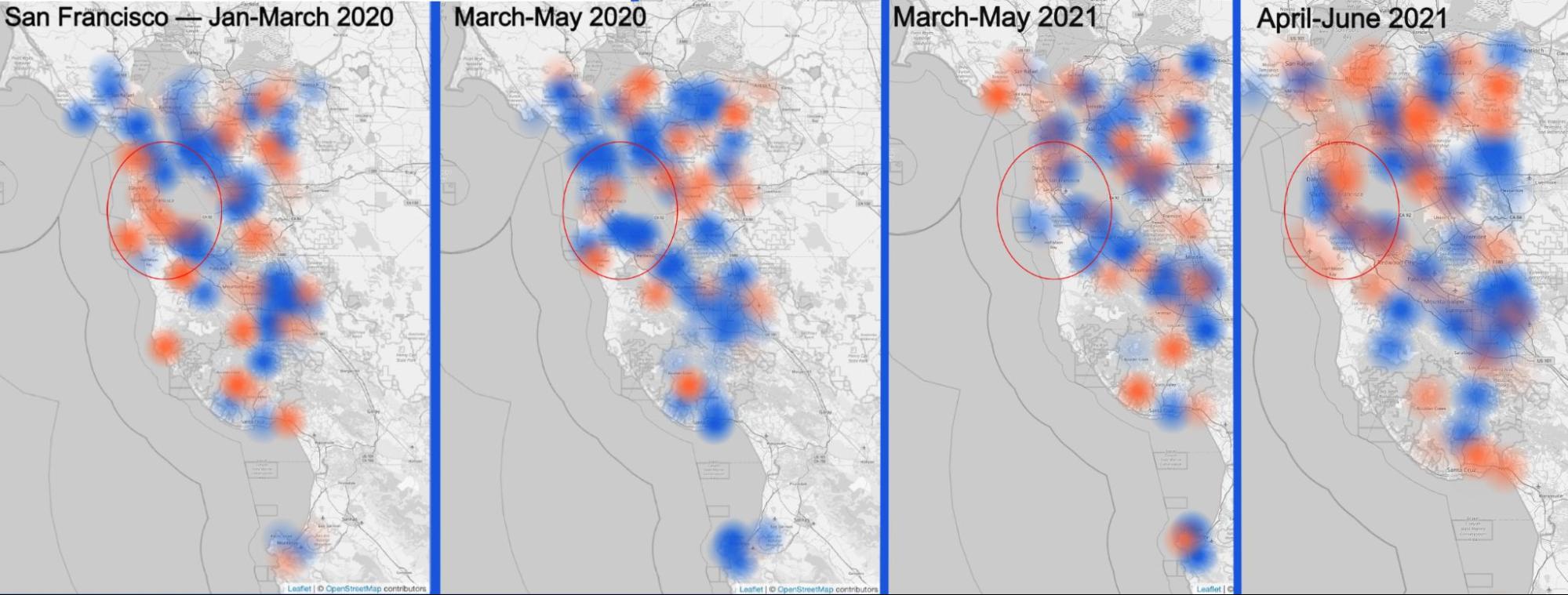
The same trend is seen already in May 2021 in a time when remote work continued to be strong — especially in tech companies (employees moved from the Bay Area). Only in June of this year, there was some increase in traffic (more orange areas), especially further away from San Francisco (in residential areas).
London: From lockdown to a Euro Championship final
London tells us a different story. Looking through the evolution since the start of 2020 we can see that in March (compared to January) we have an increase in traffic (in orange) outside London (where blue is dominant).
The Internet activity only starts to get heavier in June, in time for the kick-off of the 2020 UEFA European Championship. The tournament played in several cities in Europe had a lot of restrictions and a number of games were played in London at Wembley Stadium — where Italy won the final by beating England on penalties. But at the time of the final, July, and especially August, blue was already dominant again — so people seemed to leave the London area. Only in September and October did the traffic start to pick up again, but mostly outside the city centre.

The Summer Olympics impact? Tokyo with low activity
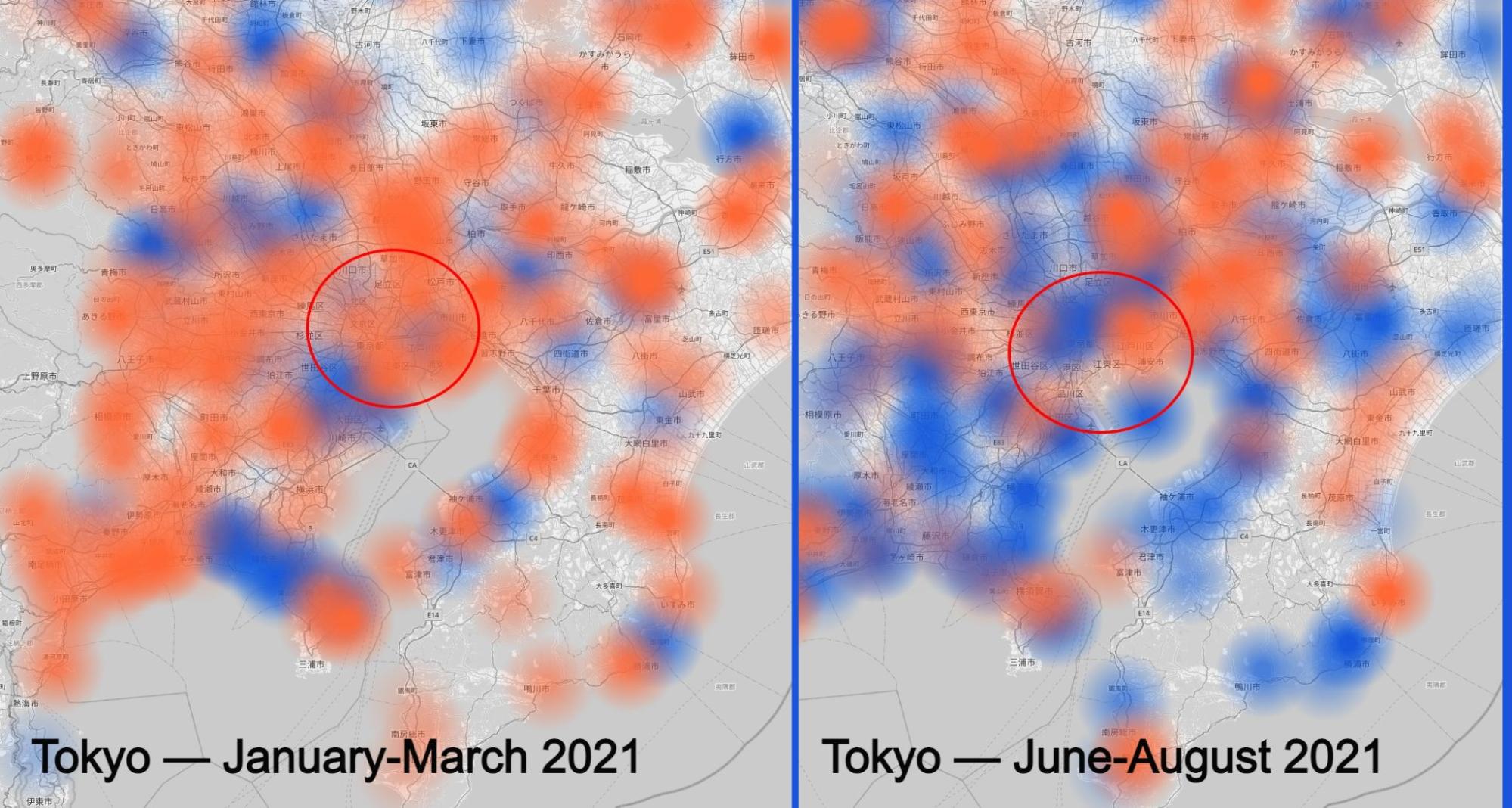
After the UEFA European Championship, came the other big event postponed back in 2020, the Tokyo Summer Olympics. Our map seems to show the troubled months before the event with the pandemic numbers and the restrictions rising before the dates of the major event — late July and the first days of August.
There were athletes, but not fans from around the world and even locals weren’t attending — it was largely an event held behind closed doors with no public spectators permitted due to the declaration of a state of emergency in the Greater Tokyo Area. We can see that in our charts, especially when looking at the increase in activity in March (compared to January) and the decrease in August (compared to June), even with a global event in town (Tokyo is in the red circle).
There’s also another interesting trend pandemic-related in Lisbon, Portugal. With the lockdowns put in place since mid-January, the comparison with March shows the centre of the city losing Internet traffic and the residential areas outside Lisbon gaining it (in orange in the animation). But in April the activity decreased even around Lisbon and only started to get heavier in May when restrictions were more a lot more relaxed.
Lockdowns bring more traffic to Berlin
A different trend can be seen in Berlin, Germany. Internet activity in the city and its surroundings was very high in March and in April (compared to the previous two months) at a time when lockdowns were in place — nonetheless, in 2020 the activity decreased in April with the first major lockdown.
But in May and June, with the relaxation in restrictions, Internet activity decreased (blue) giving the idea that people left the city or, at least, weren’t using the Internet so much. Only in August did Internet activity begin to pick up again, but decreased once more in the colder months of November and December.

Cyberattacks: Threats that came in July
In terms of worldwide attacks, July and November (the month of Black Friday, when it reached a 78% in increase) were definitely the months with the highest peak of the year. The biggest peak was at the beginning of July 2021, when it reached 82%. That was more than a month after the Colonial Pipeline ransomware cyberattack — May was also the month of an attack on part of Toshiba and, in the same week, the Irish health system and of the meat processing company JBS.
The week of December 6 (the same when the Log4j vulnerability was disclosed) also had an increase in attacks — 42% more, and there was also a clear increase (42%) in the beginning of October, around the time of the Facebook outage.
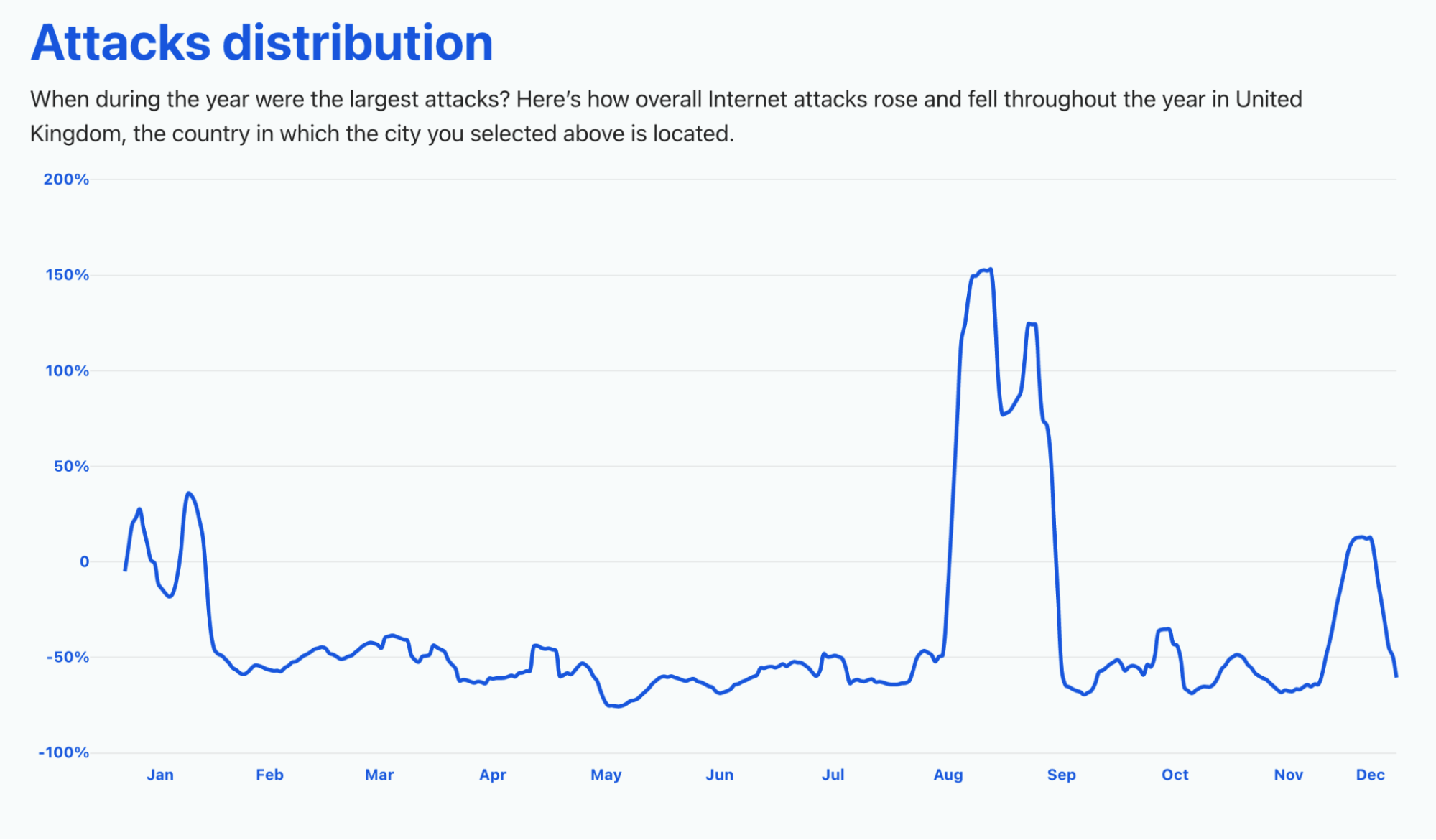
In our dedicated page you can check — for the first time this year — the attack distribution in a selection of countries.
The UK had a very noticeable peak in overall Internet attacks (a growth of 150%) in August and that continued through September. We already saw that the beginning of the year, because of lockdowns, also had an increase in Internet traffic, and we can also see an increase in attacks in January 2021, but also in late November — around the time of the Black Friday week.
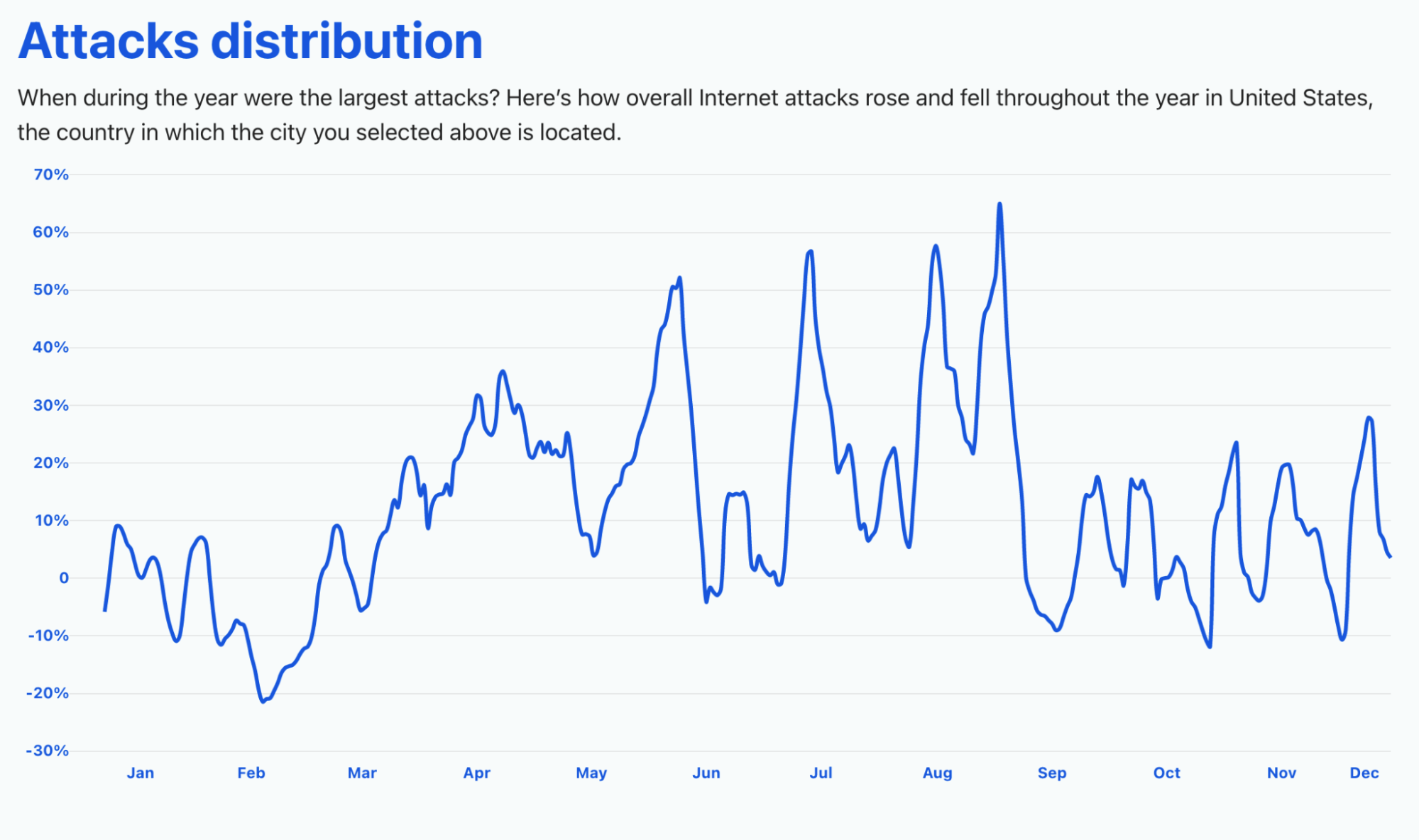
The United States, on the other hand, saw a growth in threats that was more uniform throughout the year. The biggest spike was between August and September (a time when students, depending on the state, were going back to school), with 65% of growth. July also had a big spike in threats (58%), but also late May (48%) — that was the month of the Colonial Pipeline ransomware cyberattack. Late November also had a spike (29%).
Countries like France had their peak in attacks (420% more) in late September and Germany it was in June (425%), but also in October (380%) and in November (350%).
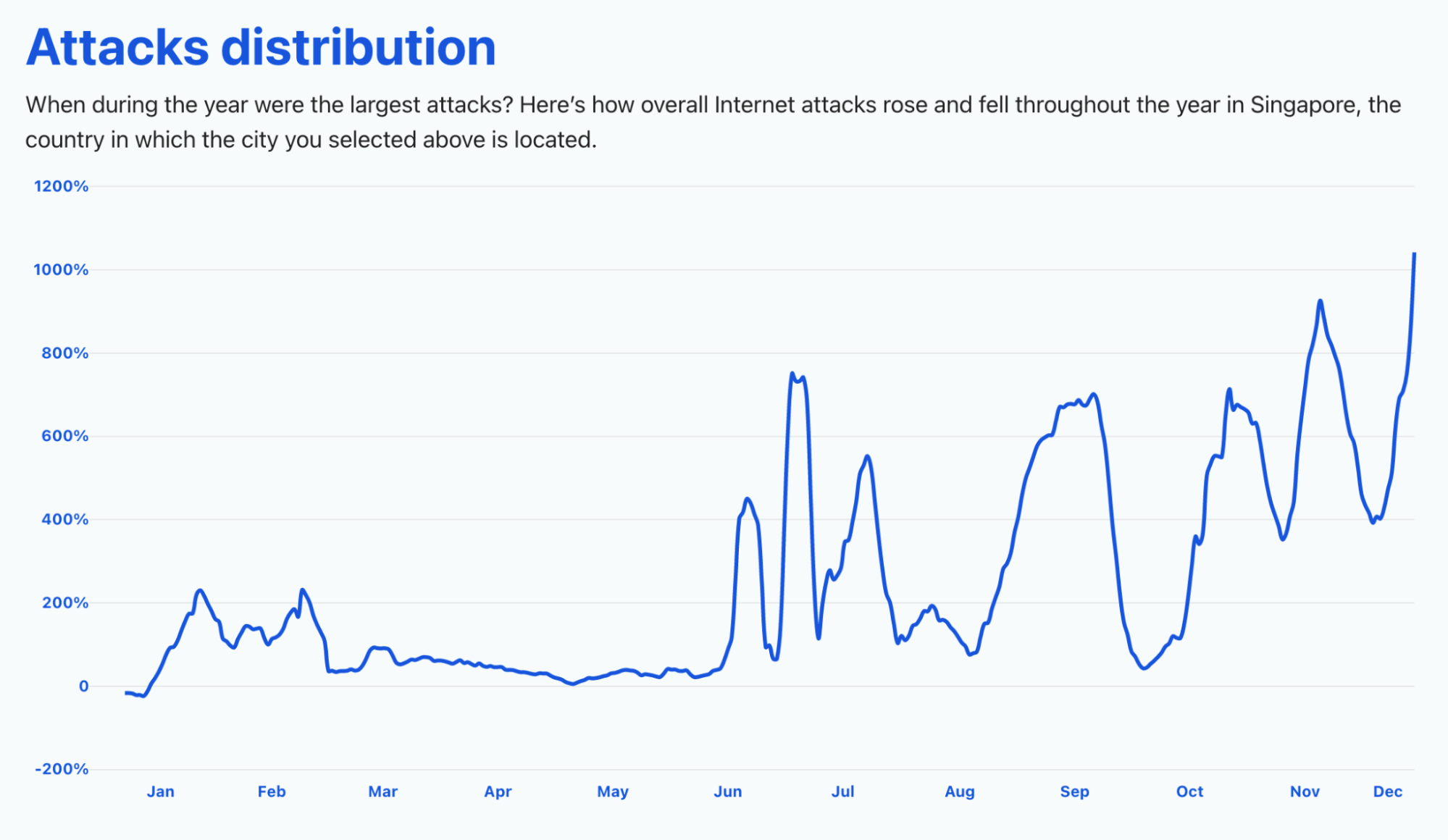
The same trend can be seen in Singapore, but with an even higher growth. It reached 1,000% more threats in late November and 900% in the same month, around the time of the famous Singles’ Day (11.11, on November 11), the main e-commerce event in the region.
Also in the region, Australia, for example, also saw a big increase (more than 100%) in attacks in the beginning of September. In Japan, it was more in late May (over 40% of growth in threats).
What people did online in 2021
Last year we saw how the e-commerce category jumped in several countries after the first major lockdown — late March.
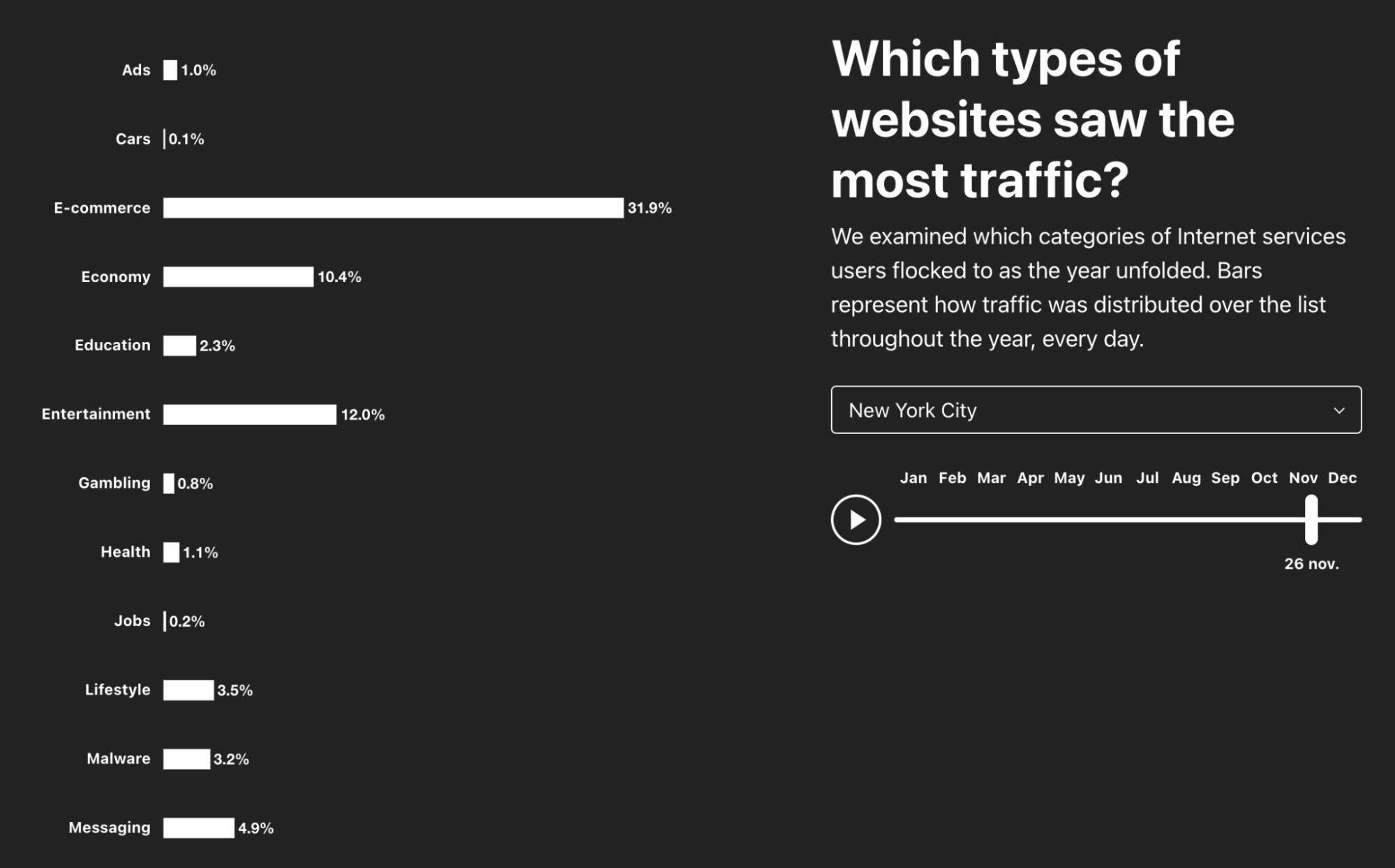
In New York, Black Friday, November 26, 2021, was the day of the whole year that e-commerce traffic peaked — it represented 31.9% of traffic, followed by Cyber Monday, November 29, with 26.6% (San Francisco has the same trend). It’s also interesting to see that in 2020 the same category peaked Black Friday, November 27, 2020 (24.3%) but April 22, during the first lockdowns, was a close second at 23.1% (this year the category only had ~14% in April).
Also with no surprise, messaging traffic peaked (20.6%) in the city that never sleeps on the first day of the year, January 1, 2021, to celebrate the New Year.
London calling (pre-Valentine messages)
But countries, cities and the people who live there have different patterns and in London messaging traffic actually peaks at 21.5% of traffic on Friday, February 12, 2021 (two days before Valentine’s Day). While in London, let’s check if Black Friday was also big outside the US. And the answer is: yes! E-commerce traffic peaked at 20.7% of traffic precisely on Black Friday, November 26.
The pandemic also has an influence in the types of websites people use and in London, travel websites had the biggest percentage in traffic on August 8, with only 1.4% — in Munich it was 1.1% on August 11. On the other hand, in New York and San Francisco, travel websites always had less than 1% of traffic.
Going back to Europe, Paris, France, saw a different trend. Travel websites had 1.9% of traffic on June 7, 2021, precisely the week that the pandemic restrictions were lifted — France opened to international travelers on June 9, 2021. The “City of Light” (and love) had its biggest day of the year for messaging websites (24.4%) on Sunday, January 31 — a time when there were new restrictions announced to try to avoid a total lockdown.
The hacker attack: 2021 methods
Our Year in Review site also lets you dig into which attack methods gained the most traction in 2021. It is a given that hackers continued to run their tools to attack websites, overwhelm APIs, and try to exfiltrate data — recently the Log4j vulnerability exposed the Internet to new possible exploitation.
Just to give some examples, in Paris “faking search engine bots” represented 48.3% of the attacks selected for the chart on January 14, 2021, but “SQL Injection” got to 59% on April 29.
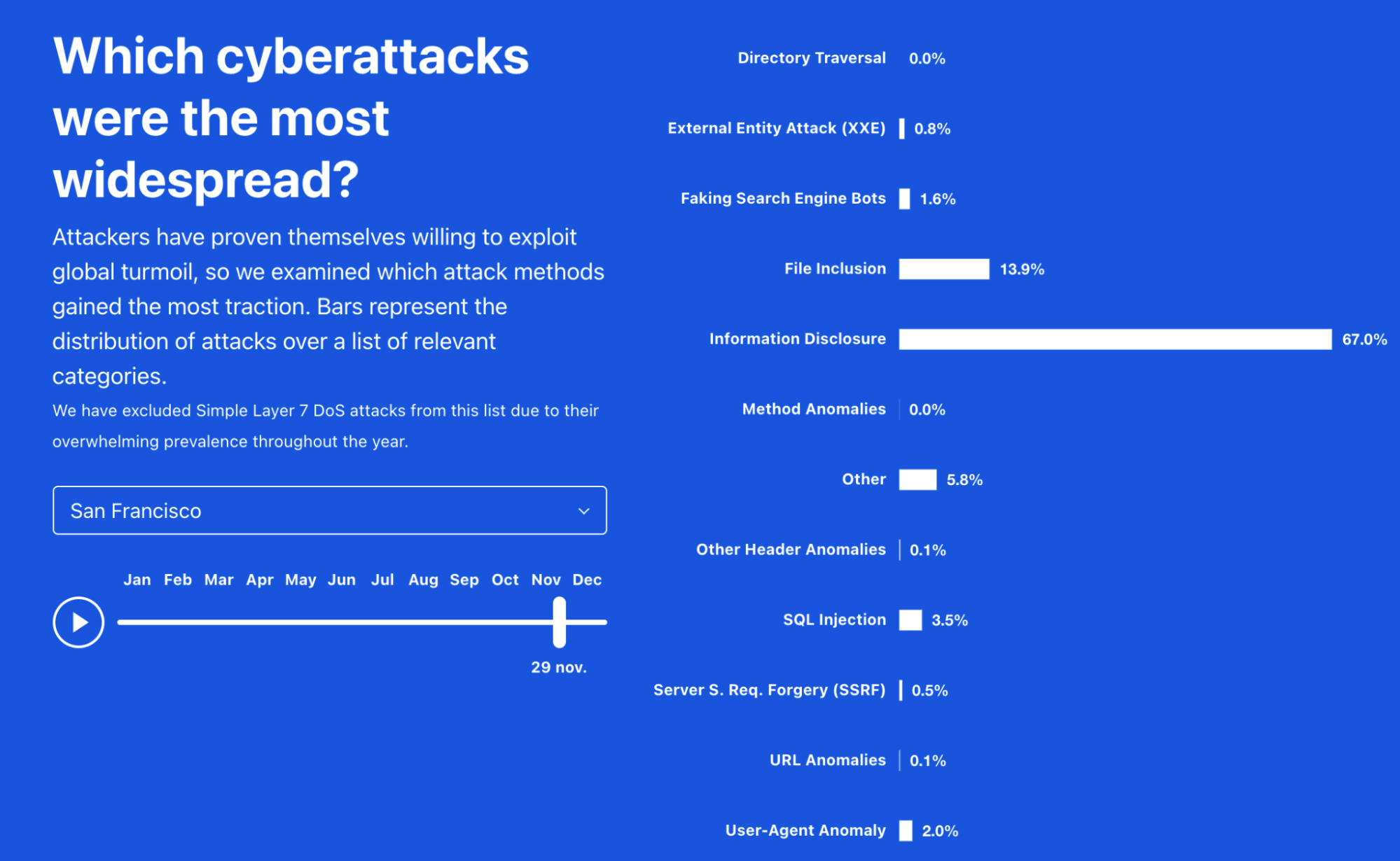
In London “User-Agent Anomaly” was also relevant in some parts of the year, but in San Francisco it was mostly “information disclosure” that was more prevalent, especially in late November, at a time when online shopping was booming — in December “file inclusion” vulnerability had a bigger percentage.
Now it’s your turn: explore more
To explore data for 2021 (but also 2020), you can check out Cloudflare Radar’s Year In Review page. To go deep into any specific country with up-to-date data about current trends, start at Cloudflare Radar’s homepage.























 filled with jokes, encouragement, and laughter. The interns were a ray of sunshine for the team, and I will never forget how relieved I was halfway through the internship that we had made this commitment.
filled with jokes, encouragement, and laughter. The interns were a ray of sunshine for the team, and I will never forget how relieved I was halfway through the internship that we had made this commitment.
