Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=Kz1dXcs8zMY
An update on Home Assistant’s Android app
Post Syndicated from jzb original https://lwn.net/Articles/1031129/
The Home Assistant project has published
an update on improvements in its Android app, and plans for upcoming releases:
In our latest update of the Android app 2025.7.1, we’ve added a
couple of useful features. Including a new basic invite flow, which
will be shared between Android and iOS, adding a good layer of
consistency between our most-used companion apps. The idea is to make
it much more seamless to add new users or set up new devices (no need
to type the URL in your Android Automotive device!).We’ve also made My
Links work better. If you’re unfamiliar with My Links, they’re
those cool links (that anyone can
make) that bring you right to an integration, blueprint, add-on,
or settings page. They have always worked great on desktop, but up
until recently, they were a bit clunky to use on mobile. Now you can
get to the link’s destination with a single click.
LWN looked at Home
Assistant in May.
Building Jetflow: a framework for flexible, performant data pipelines at Cloudflare
Post Syndicated from Harry Hough original https://blog.cloudflare.com/building-jetflow-a-framework-for-flexible-performant-data-pipelines-at-cloudflare/
The Cloudflare Business Intelligence team manages a petabyte-scale data lake and ingests thousands of tables every day from many different sources. These include internal databases such as Postgres and ClickHouse, as well as external SaaS applications such as Salesforce. These tasks are often complex and tables may have hundreds of millions or billions of rows of new data each day. They are also business-critical for product decisions, growth plannings, and internal monitoring. In total, about 141 billion rows are ingested every day.
As Cloudflare has grown, the data has become ever larger and more complex. Our existing Extract Load Transform (ELT) solution could no longer meet our technical and business requirements. After evaluating other common ELT solutions, we concluded that their performance generally did not surpass our current system, either.
It became clear that we needed to build our own framework to cope with our unique requirements — and so Jetflow was born.
Over 100x efficiency improvement in GB-s:
-
Our longest running job with 19 billion rows was taking 48 hours using 300 GB of memory, and now completes in 5.5 hours using 4 GB of memory
-
We estimate that ingestion of 50 TB from Postgres via Jetflow could cost under $100 based on rates published by commercial cloud providers
>10x performance improvement:
-
Our largest dataset was ingesting 60-80,000 rows per second, this is now 2-5 million rows per second per database connection.
-
In addition, these numbers scale well with multiple database connections for some databases.
Extensibility:
-
The modular design makes it easy to extend and test. Today Jetflow works with ClickHouse, Postgres, Kafka, many different SaaS APIs, Google BigQuery and many others. It has continued to work well and remain flexible with the addition of new use cases.
The first step to designing our new framework had to be a clear understanding of the problems we were aiming to solve, with clear requirements to stop us creating new ones.
We needed to be able to move more data in less time as some ingestion jobs were taking ~24 hours, and our data will only grow. The data should be ingested in a streaming fashion and use less memory and compute resources than our existing solution.
Given the daily ingestion of thousands of tables, the chosen solution needed to allow for the migration of individual tables as needed. Due to our usage of Spark downstream and Spark’s limitations in merging desperate Parquet schemas, the chosen solution had to offer the flexibility to generate the precise schemas needed for each case to match legacy.
We also required seamless integration with our custom metadata system, used for dependency checks and job status information.
We want a configuration file that can be version-controlled, without introducing bottlenecks on repositories with many concurrent changes.
To increase accessibility for different roles within the team, another requirement was no-code (or configuration as code) in the vast majority of cases. Users should not have to worry about availability or translation of data types between source and target systems, or writing new code for each new ingestion. The configuration needed should also be minimal — for example, data schema should be inferred from the source system and not need to be supplied by the user.
Striking a balance with the no-code requirement above, although we want a low bar of entry we also want to have the option to tune and override options if desired, with a flexible and optional configuration layer. For example, writing Parquet files is often more expensive than reading from the database, so we want to be able to allocate more resources and concurrency as needed.
Additionally, we wanted to allow for control over where the work is executed, with the ability to spin up concurrent workers in different threads, different containers, or on different machines. The execution of workers and communication of data was abstracted away with an interface, and different implementations can be written and injected, controlled via the job configuration.
We wanted a solution capable of running locally in a containerized environment, which would allow us to write tests for every stage of the pipeline. With “black box” solutions, testing often means validating the output after making a change, which is a slow feedback loop, risks not testing all edge cases as there isn’t good visibility of all code paths internally, and makes debugging issues painful.
To build a truly flexible framework, we broke the pipeline down into distinct stages, and then create a config layer to define the composition of the pipeline from these stages, and any configuration overrides. Every pipeline configuration that makes sense logically should execute correctly, and users should not be able to create pipeline configs that do not work.
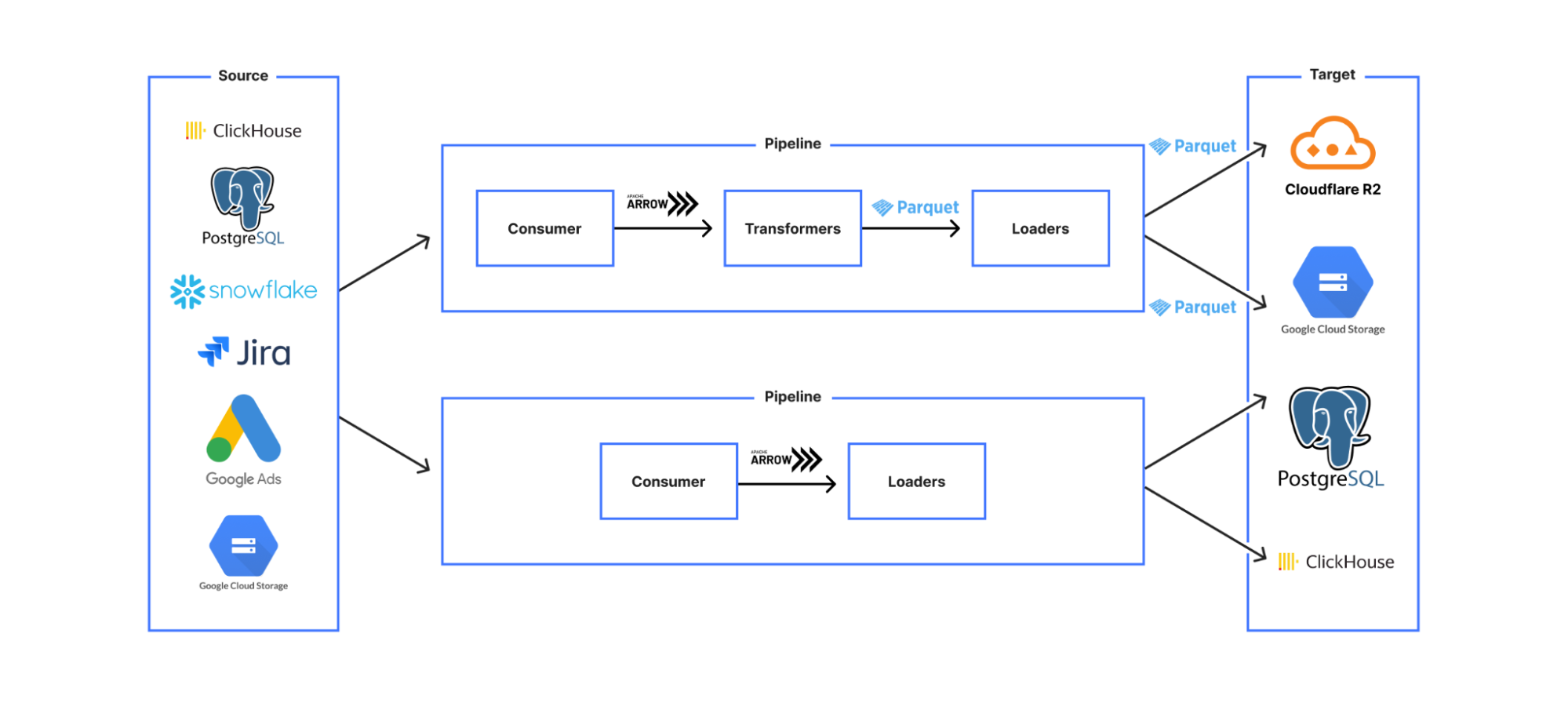
This led us to a design where we created stages which were classified according to the meaningfully different categories of:
-
Consumers
-
Transformers
-
Loaders

The pipeline was constructed via a YAML file that required a consumer, zero or more transformers, and at least one loader. Consumers create a data stream (via reading from the source system), Transformers (e.g. data transformations, validations) take a data stream input and output a data stream conforming to the same API so that they can be chained, and Loaders have the same data streaming interface, but are the stages with persistent effects — i.e. stages where data is saved to an external system.
This modular design means that each stage is independently testable, with shared behaviour (such as error handling and concurrency) inherited from shared base stages, significantly decreasing development time for new use cases and increasing confidence in code correctness.
Next, we designed a breakdown for the data that would allow the pipeline to be idempotent both on whole pipeline re-run and also on internal retry of any data partition due to transient error. We decided on a design that let us parallelize processing, while maintaining meaningful data divisions that allowed the pipeline to perform cleanups of data where required for a retry.
-
RunInstance: the least granular division, corresponding to a business unit for a single run of the pipeline (e.g. one month/day/hour of data).
-
Partition: a division of the RunInstance that allows each row to be allocated to a partition in a way that is deterministic and self-evident from the row data without external state, and is therefore idempotent on retry. (e.g. an accountId range, a 10-minute interval)
-
Batch: a division of the partition data that is non-deterministic and used only to break the data down into smaller chunks for streaming/parallel processing for faster processing with fewer resources. (e.g. 10k rows, 50 MB)
The options that the user configures in the consumer stage YAML both construct the query that is used to retrieve the data from the source system, and also encode the semantic meaning of this data division in a system agnostic way, so that later stages understand what this data represents — e.g. this partition contains the data for all accounts IDs 0-500. This means that we can do targeted data cleanup and avoid, for example, duplicate data entries if a single data partition is retried due to error.

Our most common use case is something like read from a database, convert to Parquet format, and then save to object storage, with each of these steps being a separate stage. As more use cases were onboarded to Jetflow, we had to make sure that if someone wrote a new stage it would be compatible with the other stages. We don’t want to create a situation where new code needs to be written for every output format and target system, or you end up with a custom pipeline for every different use case.
The way we have solved this problem is by having our stage extractor class only allow output data in a single format. This means as long as any downstream stages support this format as in the input and output format they would be compatible with the rest of the pipeline. This seems obvious in retrospect, but internally was a painful learning experience, as we originally created a custom type system and struggled with stage interoperability.
For this internal format, we chose to use Arrow, an in-memory columnar data format. The key benefits of this format for us are:
-
Arrow ecosystem: Many data projects now support Arrow as an output format. This means when we write extractor stages for new data sources, it is often trivial to produce Arrow output.
-
No serialisation overhead: This makes it easy to move Arrow data between machines and even programming languages with minimum overhead. Jetflow was designed from the start to have the flexibility to be able to run in a wide range of systems via a job controller interface, so this efficiency in data transmission means there’s minimal compromise on performance when creating distributed implementations.
-
Reserve memory in large fixed-size batches to avoid memory allocations: As Go is a garbage collected (GC) language and GC cycle times are affected mostly by the number of objects rather than the sizes of those objects, fewer heap objects reduces CPU time spent garbage collecting significantly, even if the total size is the same. As the number of objects to scan, and possibly collect, during a GC cycle increases with the number of allocations, if we have 8192 rows with 10 columns each, Arrow would only require us to do 10 allocations versus the 8192 allocations of most drivers that allocate on a row by row basis, meaning fewer objects and lower GC cycle times with Arrow.
Another important performance optimization was reducing the number of conversion steps that happen when reading and processing data. Most data ingestion frameworks internally represent data as rows. In our case, we are mostly writing data in Parquet format, which is column based. When reading data from column-based sources (e.g. ClickHouse, where most drivers receive RowBinary format), converting into row-based memory representations for the specific language implementation is inefficient. This is then converted again from rows to columns to write Parquet files. These conversions result in a significant performance impact.
Jetflow instead reads data from column-based sources in columnar formats (e.g. for ClickHouse-native Block format) and then copies this data into Arrow column format. Parquet files are then written directly from Arrow columns. The simplification of this process improves performance.
When testing an initial version of Jetflow, we discovered that due to the architecture of ClickHouse, using additional connections would not be of any benefit, since ClickHouse was reading faster than we were receiving data. It should then be possible, with a more optimized database driver, to take better advantage of that single connection to read a much larger number of rows per second, without needing additional connections.
Initially, a custom database driver was written for ClickHouse, but we ended up switching to the excellent ch-go low level library, which directly reads Blocks from ClickHouse in a columnar format. This had a dramatic effect on performance in comparison to the standard Go driver. Combined with the framework optimisations above, we now ingest millions of rows per second with a single ClickHouse connection.
A valuable lesson learned is that as with any software, tradeoffs are often made for the sake of convenience or a common use case that may not match your own. Most database drivers tend not to be optimized for reading large batches of rows, and have high per-row overhead.
For Postgres, we use the excellent jackc/pgx driver, but instead of using the database/sql Scan interface, we directly receive the raw bytes for each row and use the jackc/pgx internal scan functions for each Postgres OID (Object Identifier) type.
The database/sql Scan interface in Go uses reflection to understand the type passed to the function and then also uses reflection to set each field with the column value received from Postgres. In typical scenarios, this is fast enough and easy to use, but falls short for our use cases in terms of performance. The jackc/pgx driver reuses the row bytes produced each time the next Postgres row is requested, resulting in zero allocations per row. This allows us to write high-performance, low-allocation code within Jetflow. With this design, we are able to achieve nearly 600,000 rows per second per Postgres connection for most tables, with very low memory usage.
As of early July 2025, the team ingests 77 billion records per day via Jetflow. The remaining jobs are in the process of being migrated to Jetflow, which will bring the total daily ingestion to 141 billion records. The framework has allowed us to ingest tables in cases that would not otherwise have been possible, and provided significant cost savings due to ingestions running for less time and with fewer resources.
In the future, we plan to open source the project, and if you are interested in joining our team to help develop tools like this, then open roles can be found at https://www.cloudflare.com/careers/jobs/.
Prokop: What to expect from Debian/trixie
Post Syndicated from corbet original https://lwn.net/Articles/1031106/
Michael Prokop has posted a
lengthy list of changes coming in the Debian “trixie” release, due in
early August. “As usual with major upgrades, there are some things to
“
be aware of, and hereby I’m starting my public notes on trixie that might
be worth for other folks. My focus is primarily on server systems and
looking at things from a sysadmin perspective.
[$] Deep immutability for Python
Post Syndicated from daroc original https://lwn.net/Articles/1030291/
Python has recently seen a number of experiments to improve its parallel
performance, including exposing
subinterpreters as part of the standard library. These allow
separate threads within the same Python process to run simultaneously, as long
as any data sent between them is copied, rather than shared.
PEP 795 (“Deep Immutability in Python”)
seeks to make efficient sharing of data between subinterpreters possible by
allowing Python objects to be “frozen”, so that they can be accessed from
multiple subinterpreters without copying or synchronization.
That task is more difficult than it
seems, and the PEP prompted a good deal of skepticism from the Python community.
Security updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/1031104/
Security updates have been issued by AlmaLinux (cloud-init, fence-agents, git, kernel, and kernel-rt), Debian (openjdk-11), Fedora (firefox, golang, libinput, transfig, and yasm), Mageia (qtbase5, qtbase6), Red Hat (fence-agents, go-toolset:rhel8, golang, kernel, and python-setuptools), Slackware (mozilla), SUSE (cyradm, gstreamer-plugins-base, and xen), and Ubuntu (gdk-pixbuf, jq, linux-gcp, linux-gcp-6.8, linux-oracle, ruby-sinatra, thunderbird, and unbound).
Tinian: The Forgotten Invasion
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=l7bzVtShyjs
Ritchie Torres and the Fight for the Political Center | The David Frum Show
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=0kISxha7bJA
Google Sues the Badbox Botnet Operators
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/07/google-sues-the-badbox-botnet-operators.html
It will be interesting to watch what will come of this private lawsuit:
Google on Thursday announced filing a lawsuit against the operators of the Badbox 2.0 botnet, which has ensnared more than 10 million devices running Android open source software.
These devices lack Google’s security protections, and the perpetrators pre-installed the Badbox 2.0 malware on them, to create a backdoor and abuse them for large-scale fraud and other illicit schemes.
This reminds me of Meta’s lawauit against Pegasus over its hack-for-hire software (which I wrote about here.) It’s a private company stepping into a regulatory void left by governments.
Slashdot thread.
Creating a space for connection and code: Meet Seung Woo (Tony), Canada
Post Syndicated from Sophie Ashford original https://www.raspberrypi.org/blog/creating-a-space-for-connection-and-code-meet-seung-woo-tony-canada/
We love hearing from members of the community and sharing the stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Seung Woo, also known as Tony, is a 17-year-old student from Canada and the co-founder of his school’s Code Club, alongside his teacher, Kay. A curious and driven teen with big ambitions in computer science, Tony is not only passionate about technology, but also dedicated to building a safe, welcoming space where others can learn, explore, and grow alongside him.

A spark of inspiration
Tony’s fascination with computers started early, driven by his love of video games, coding, and, perhaps most memorably, his admiration for Tony Stark, the comic-book and film character who becomes the superhero Iron Man! The idea of building something powerful from scratch stuck with him.
“My whole life, I have been curious about the inner workings of a computer and my inspiration for coding is Tony Stark or Iron Man from the Marvel Cinematic Universe!”
Tony’s early coding journey wasn’t without its challenges. Finding the right resources was difficult, and staying motivated during tough moments was often hard without a support system.
“Like many others, I was independently taught, and during this time of independent learning I’d find many different roadblocks and challenges that I had to overcome alone. A big setback for me was finding the right resources in order to learn how to code. Another big obstacle for me was motivation. I would find myself losing interest in a project. I didn’t have the exterior motivation to help me push through the inevitable hardships that come with coding.”
That’s where the idea for a coding club began to take shape.
Creating a community of coders
Tony co-founded the Code Club at Collège Jeanne-Sauvé in December 2024 with that exact vision in mind — he wanted to provide a fun, collaborative, and welcoming environment where students of all skill levels could explore their love of technology together.
“I created the coding club to help everyone on their journey of computer science, no matter their skill level, and that is exactly what it is turning out to be. Finding resources is easier than ever with a teacher and all of the amazing members.”
Tony’s teacher and co-founder, Kay, shared why Code Club was the right fit for the school.
“I thought Code Club was the best way to start our club for a few reasons. The amount of coding language options was varied and appealed to the different learners in our club. It was also important for us to promote our club and let our community know about the presence of a coding club in our school, and Code Club helped us do so via their online presence.”
What makes Code Club special
For Tony, the secret ingredient behind his club’s success is simple: teamwork.
“Without teamwork, our club wouldn’t really be a club, it would simply be an ensemble of people coding in their own little cubicles, much like a stereotypical office job, and to me, that does not sound too enjoyable. Teamwork is our little secret ingredient in problem-solving and building motivation, we embrace it by creating a safe space where everyone can speak their minds without judgement!”
Members are free to choose their own learning paths. No matter the project, the atmosphere is always filled with laughter, energy, and curiosity.
“Coding should be something that is fun — not stressful like others may make it seem. Celebrating achievements, making short term goals, and problem solving with friends are all great ways that we make coding fun in our club. A second word would be teamwork. Without teamwork, our club wouldn’t really be a club.”
Teamwork, he adds, transforms what could be a solitary activity into something social and deeply motivating.
Looking to the future
Tony hopes the club will continue to grow, bringing more students into the world of coding and helping them feel at home in it. His story is a great reminder that learning to code isn’t just about computers — it’s about building community, confidence, and creativity.
“I wanted to create a space where everyone would be accepted and encouraged to learn more about coding and not be ashamed to ‘nerd out’ about this subject like I do very frequently. I’ve dreamed of creating a space that embraces this beautiful passion.”
If you’d like to explore coding, you can get started at home with over 250 free projects.
For a little more support, or if you’re open to mentoring others, you can also join a Code Club. Check our website to find a club near you and become part of a like-minded and welcoming community.
The post Creating a space for connection and code: Meet Seung Woo (Tony), Canada appeared first on Raspberry Pi Foundation.
Comic for 2025.07.23 – Linus
Post Syndicated from Explosm.net original https://explosm.net/comics/linus
New Cyanide and Happiness Comic
Single Strike Sadly Slays Several Sheep
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/shorts/F4JlrSTj5zU
Flettner Rotor
Post Syndicated from xkcd.com original https://xkcd.com/3119/

Improve RabbitMQ performance on Amazon MQ with AWS Graviton3-based M7g instances
Post Syndicated from Vignesh Selvam original https://aws.amazon.com/blogs/big-data/improve-rabbitmq-performance-on-amazon-mq-with-aws-graviton3-based-m7g-instances/
Amazon MQ is a fully managed service for open-source message brokers such as RabbitMQ and Apache ActiveMQ. Today, we are announcing the availability of AWS Graviton3-based Rabbit MQ brokers on Amazon MQ, which runs on Amazon EC2 M7g instances. AWS Graviton processors are custom designed server processors developed by AWS to provide the best price performance for cloud workloads running on Amazon EC2. It uses the Arm (arm64) instruction set. For example, when running an Amazon MQ for RabbitMQ cluster broker using M7g.4xlarge instances, you can achieve up to 50% higher workload capacity and up to 85% higher throughput compared to M5.4xlarge instances. Additionally, M7g brokers on Amazon MQ offer optimized disk sizes for clusters, providing reduction in storage cost savings over M5 brokers depending on the instance size chosen. To learn more, refer to Amazon EC2 M7g instances.
Amazon MQ helps you reduce the operational overhead of using open source message brokers like RabbitMQ while providing security, high availability, and durability. Many organizations use Amazon MQ to decouple applications, asynchronously process messages, and build event-driven architectures. We tested and validated M7g instances for RabbitMQ version 3.13, so you can run your critical messaging workloads on Amazon MQ brokers with improved performance characteristics, while also saving on costs. Amazon MQ supports M7g instances in a wide variety of sizes, ranging from medium to 16xlarge sizes, to suit your different messaging workloads. M7g instances support Amazon MQ for RabbitMQ features, making it straightforward for you to run your existing RabbitMQ workloads with minimal changes. You can get started by provisioning new brokers or upgrading your existing RabbitMQ brokers using Amazon EC2 M5 instances to Graviton3-based M7g instances as the broker type using the AWS Management Console, APIs using the AWS SDK, and the AWS Command Line Interface (AWS CLI).
The following table lists the specific characteristics of M7g instances on Amazon MQ.
| M7g specs for Amazon MQ | |||
| Instance Name (MQ.m7g.*) | vCPUs | Memory (GiB) | Network Bandwidth |
| medium | 1 | 4 | Up to 12.5 Gb |
| large | 2 | 8 | Up to 12.5 Gb |
| xlarge | 4 | 16 | Up to 12.5 Gb |
| 2xlarge | 8 | 32 | Up to 15 Gb |
| 4xlarge | 16 | 64 | Up to 15 Gb |
| 8xlarge | 32 | 128 | 15 Gb |
| 12xlarge | 48 | 192 | 22.5 Gb |
| 16xlarge | 64 | 256 | 30 Gb |
M7g instances vs. M5 instances on Amazon MQ
Customers can see both performance improvements and cost savings for their RabbitMQ workloads when moving from M5 instances to M7g instances. In terms of performance, you can size your RabbitMQ brokers for workloads by measuring the workload capacity and throughput. Amazon MQ has improved the performance of RabbitMQ on both workload capacity and throughput for M7g instances. In terms of cost, you pay for the instance per hour, disk usage per Gb-month, and data transfer. Amazon MQ has optimized disk sizes to offer cost savings for customers on disk usage. Let’s first examine the performance improvements.
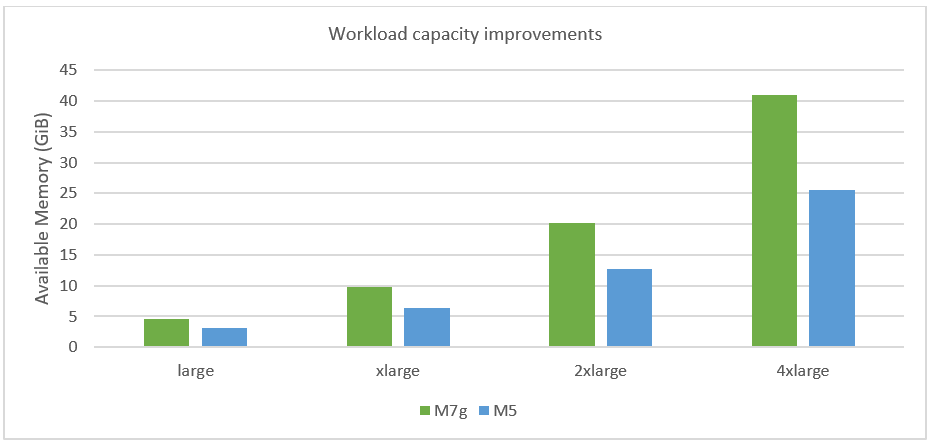
Workload capacity improvements
Workload capacity represents the total number of connections, channels, and queues that you can use without running into memory alarm. The actual usage of these resources is limited by the high memory watermark value. Every resource (for example, a queue) on creation uses up a small amount of memory, but when these resources are used, the memory used increases depending on the number and size of messages processed up until a memory threshold. The RabbitMQ broker goes into memory alarm when the memory used on a node reaches this pre-defined threshold known as high memory watermark. When a broker raises a memory alarm, it will block all connections that are publishing messages. After the memory alarm has cleared (for example, due to delivering some messages to clients that consume and acknowledge the deliveries), normal service resumes. The open source community guidance for RabbitMQ 3.13 is to configure the memory threshold at 40% of the available memory per node. M5 brokers have the memory threshold set at 40% on Amazon MQ.
We evaluated this recommendation across M7g instances and determined that the memory threshold can be increased for instances on Amazon MQ to more than 40% due to the operational improvements by the service, as illustrated in the following figure. This increase in available memory translates to a higher use of resources like queues, channels, and connections within the resource limits of the broker. The change in available memory results in up to 50% improvement in workload capacity for customers when compared to M5 brokers today.
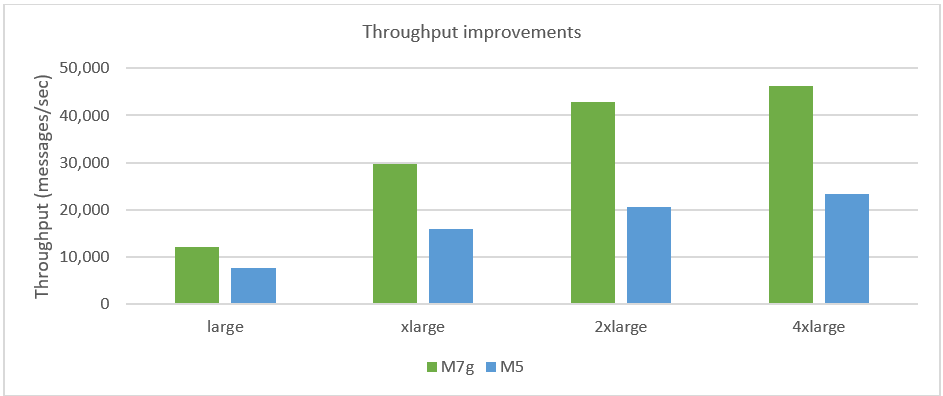
Throughput improvements
The throughput of a broker varies widely with the queue type and usage pattern of customers. Amazon MQ evaluated the throughput capacity of a RabbitMQ three-node cluster broker by measuring the publish throughput in messages per second for 10 quorum queues with a message size of 1 KB and a ratio of 1:20 for connection to channels. We arrived at this benchmark test after evaluating multiple scenarios with the goal of providing you a simple way to estimate the average throughput you can expect from a RabbitMQ broker when following best practices. You can see up to 85% higher throughput compared to equivalent M5 brokers on Amazon MQ, as illustrated in the following figure.
The performance of a RabbitMQ broker depends on the version, queue type, and usage pattern in addition to the infrastructure used. You might see different performance improvements based on your specific usage patterns and resources used. We recommend using the Amazon MQ sizing guidance to size your broker and benchmarking the performance for your specific workload using M7g instances.
Cost savings on cluster disk usage
Customers using M7g brokers in cluster deployment mode are provisioned with a disk volume per node that varies in size depending on the instance size. For M5 brokers, the RabbitMQ brokers were provisioned with a fixed disk volume of 200 GB per node. The open source guidance around disk sizes is to use a size higher than twice the memory threshold. We tested various disk sizes and identified optimal disk sizes that would provide a better operational posture. With this change, customers using M7g cluster brokers on Amazon MQ will get cost savings due to the smaller disk size provisioned per node as compared to equivalent M5 brokers, as shown in the following table. Single-instance M7g brokers will continue to be provisioned with 200 GB of disk size.
| Instance size | Disk Volume M5 cluster(GB) | Disk Volume M7g Cluster(GB) | Cost savings for customersM5 vs. M7g (%) |
| medium | – | 15 | – |
| large | 600 | 45 | 92.50% |
| xlarge | 600 | 75 | 87.50% |
| 2xlarge | 600 | 135 | 77.50% |
| 4xlarge | 600 | 270 | 55.00% |
| 8xlarge | – | 525 | – |
| 12xlarge | – | 780 | – |
| 16xlarge | – | 1035 | – |
Pricing and Regional availability
M7g instances are available in AWS Regions where Amazon MQ is available at the time of writing except Africa (Cape Town), Canada West (Calgary), and Europe (Milan) Regions. Refer to Amazon MQ Pricing to learn about the availability of specific instance sizes by Region and the pricing for M7g instances.
Summary
In this post, we discussed the performance gains and cost savings achieved while using Graviton-based M7g instances. These instances can provide significant improvement in throughput and workload capacity compared to similar sized M5 instances for Amazon MQ workloads. To get started, create a new broker with M7g brokers using the console, and refer to the Amazon MQ Developer Guide for more information.
About the authors
 Vignesh Selvam is the Principal Product Manager for Amazon MQ at AWS. He works with customers to solve their messaging needs and with the open-source communities for innovating with message brokers. Prior to joining AWS, he built products for security and analytics.
Vignesh Selvam is the Principal Product Manager for Amazon MQ at AWS. He works with customers to solve their messaging needs and with the open-source communities for innovating with message brokers. Prior to joining AWS, he built products for security and analytics.
 Samuel Massé is a Software Development Engineer at AWS. He has been leading the engineering effort to support M7g on the RabbitMQ team. In his free time he enjoys coding unfinished side projects.
Samuel Massé is a Software Development Engineer at AWS. He has been leading the engineering effort to support M7g on the RabbitMQ team. In his free time he enjoys coding unfinished side projects.
 Vinodh Kannan Sadayamuthu is a Senior Specialist Solutions Architect at Amazon Web Services (AWS). His expertise centers on AWS messaging and streaming services, where he provides architectural best practices consultation to AWS customers.
Vinodh Kannan Sadayamuthu is a Senior Specialist Solutions Architect at Amazon Web Services (AWS). His expertise centers on AWS messaging and streaming services, where he provides architectural best practices consultation to AWS customers.
Inside the NVIDIA Cedar Module with 1.6Tbps of Networking Capacity
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/inside-the-nvidia-cedar-module-with-1-6tbps-of-networking-capacity-connectx-7/
We take a look at the NVIDIA Cedar module, combining four NVIDIA ConnectX-7 NICs onto one custom module capable of 1.6Tbps of throughput
The post Inside the NVIDIA Cedar Module with 1.6Tbps of Networking Capacity appeared first on ServeTheHome.
Introducing SRA Verify – an AWS Security Reference Architecture assessment tool
Post Syndicated from Jeremy Schiefer original https://aws.amazon.com/blogs/security/introducing-sra-verify-an-aws-security-reference-architecture-assessment-tool/
The AWS Security Reference Architecture (AWS SRA) provides prescriptive guidance for deploying AWS security services in a multi-account environment. However, validating that your implementation aligns with these best practices can be challenging and time-consuming.
Today, we’re announcing the open source release of SRA Verify, a security assessment tool that helps you assess your organization’s alignment to the AWS SRA.
The AWS SRA is a holistic set of guidelines for deploying the full complement of AWS security services in a multi-account environment. You can use it to design, implement, and manage AWS security services so that they align with AWS recommended practices. The recommendations are built around a single-page architecture that includes AWS security services—how they help achieve security objectives, where they can be best deployed and managed in your AWS accounts, and how they interact with other security services. This overall architectural guidance complements detailed, service-specific recommendations such as those found in AWS Security Documentation.
SRA Verify directly maps to these recommendations by providing automated checks that validate your implementation against the AWS SRA guidance. The tool helps you verify that security services are properly configured according to the reference architecture. To assist with remediation and implementing the guidance in the AWS SRA, review the infrastructure as code (IaC) examples in the AWS Security Reference Architecture Github repo.
SRA Verify includes checks across multiple AWS services including AWS CloudTrail, Amazon GuardDuty, AWS IAM Access Analyzer, AWS Config, AWS Security Hub, Amazon Simple Storage Service (Amazon S3), Amazon Inspector, and Amazon Macie. We plan to expand its capabilities over time to cover additional AWS security services and evolving AWS SRA best practices. To contribute to SRA Verify, review the Contributing Guidelines on Github.
If you have any feedback about this post, submit comments in the Comments section below.
Comic for 2025.07.22 – COUGH COUGH
Post Syndicated from Explosm.net original https://explosm.net/comics/cough-cough
New Cyanide and Happiness Comic
Firefox 141.0 released
Post Syndicated from corbet original https://lwn.net/Articles/1030971/
Version
141.0 of the Firefox browser it out. Changes include “a local AI
” that can perform tab grouping, unit conversions in the address
model
bar, and a change that many of us will find welcome: “On Linux, Firefox
“.
uses less memory and no longer requires a forced restart after an update
has been applied by a package manager
Cloudflare protects against critical SharePoint vulnerability, CVE-2025-53770
Post Syndicated from Jin-Hee Lee original https://blog.cloudflare.com/cloudflare-protects-against-critical-sharepoint-vulnerability-cve-2025-53770/
On July 19, 2025, Microsoft disclosed CVE-2025-53770, a critical zero-day Remote Code Execution (RCE) vulnerability. Assigned a CVSS 3.1 base score of 9.8 (Critical), the vulnerability affects SharePoint Server 2016, 2019, and the Subscription Edition, along with unsupported 2010 and 2013 versions. Cloudflare’s WAF Managed Rules now includes 2 emergency releases that mitigate these vulnerabilities for WAF customers.
The vulnerability’s root cause is improper deserialization of untrusted data, which allows a remote, unauthenticated attacker to execute arbitrary code over the network without any user interaction. Moreover, what makes CVE-2025-53770 uniquely threatening is its methodology – the exploit chain, labeled “ToolShell.” ToolShell is engineered to play the long-game: attackers are not only gaining temporary access, but also taking the server’s cryptographic machine keys, specifically the ValidationKey and DecryptionKey. Possessing these keys allows threat actors to independently forge authentication tokens and __VIEWSTATE payloads, granting them persistent access that can survive standard mitigation strategies such as a server reboot or removing web shells.
In response to the active nature of these attacks, the U.S. Cybersecurity and Infrastructure Security Agency (CISA) added CVE-2025-53770 to its Known Exploited Vulnerabilities (KEV) catalog with an emergency remediation deadline. The security community’s consensus is clear: any organization with an on-premise SharePoint server on the Internet should assume it has been compromised and take immediate action to fully address this vulnerability.
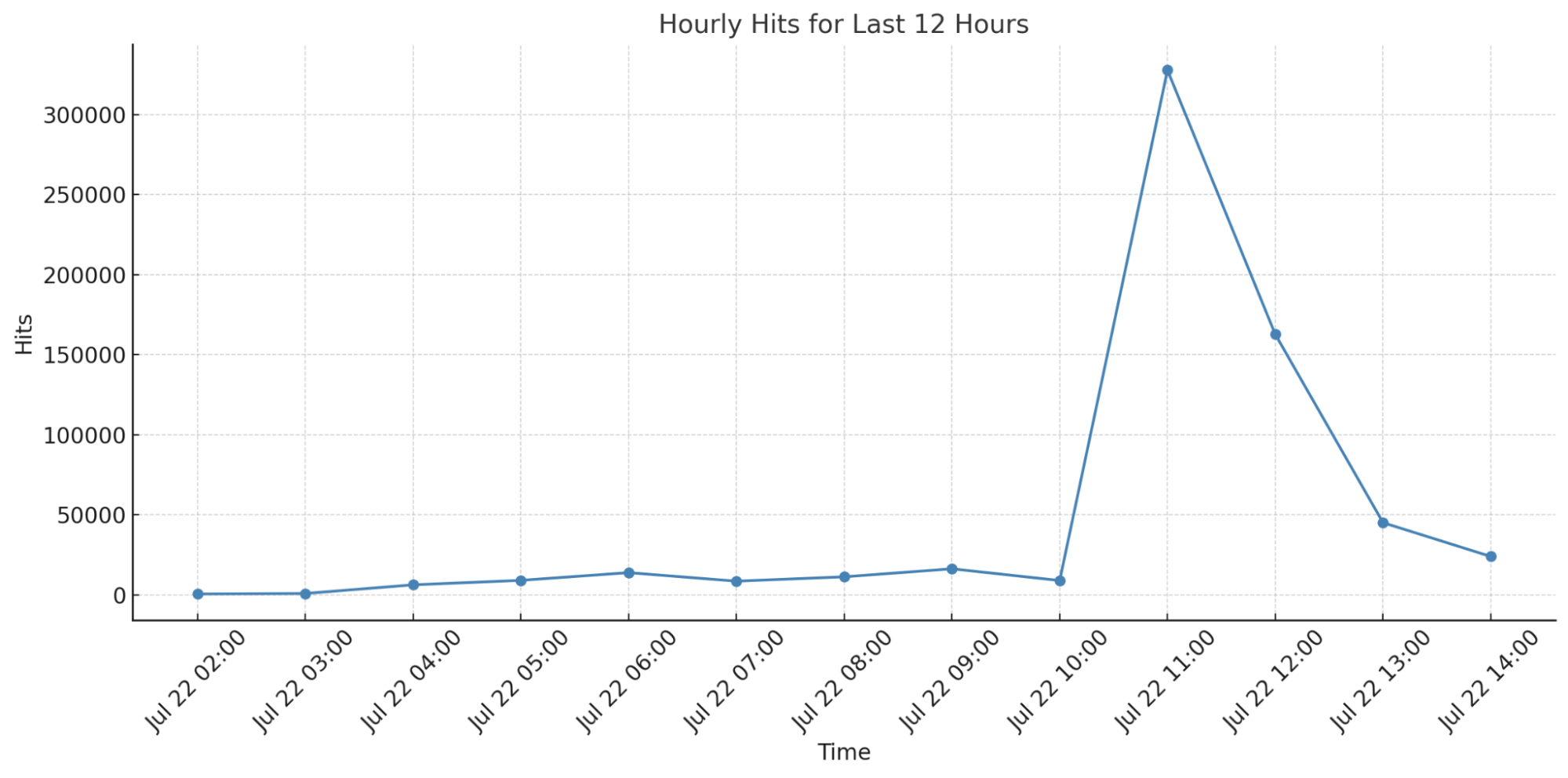
Since releasing our vulnerability patch in Cloudflare’s WAF Managed Ruleset, we’ve tracked the number of HTTP request matches for the vulnerability, which you can see in the graph below. Notably, we observed a significant peak around 11AM UTC, the morning of July 22, at around 300,000 hits at one point in time.
The ToolShell exploit chain was first demonstrated at the Pwn2Own hacking competition in May 2025, where researchers chained an authentication bypass (CVE-2025-49706) with a deserialization RCE (CVE-2025-49704). Unfortunately, this was not the end of ToolShell’s lifespan. Threat actors evidently analyzed the patches to find weaknesses and exploit them in the wild, forcing Microsoft to assign new identifiers and call out CVE-2025-53771 for the authentication bypass. This rapid exploit → patch → bypass cycle shows that threat actors are not merely discovering vulnerabilities, but also systematically reverse-engineering patches to weaponize bypasses. For responders, this closes the window – or hides it altogether – to respond and put up defenses, highlighting the need for evolving, proactive security postures.
The ToolShell exploit works in 3 stages:
-
Authentication Bypass, leveraging CVE-2025-53771: The attack begins with a
POSTrequest sent to the/_layouts/15/ToolPane.aspxendpoint, a legacy component of SharePoint. The crutch of this authentication bypass happens by setting theRefererheader to/_layouts/SignOut.aspx, which tricks the SharePoint server into trusting the attacker. With trust in hand, the attacker is able to skip authentication checks and move forward with authenticated access. -
Remote Code Execution via Deserialization, CVE-2025-53770: With privileged access, the attacker can interact with the
ToolPane.aspxendpoint. The attacker submits a malicious payload in the body of thePOSTrequest, triggering the core vulnerability: a deserialization flaw in which the SharePoint application deserializes the object into executable code on the server. At this point, the attacker can execute commands as they wish. -
The Long-Game: Possessing Cryptographic Keys: Finally, to play the long-game and maintain continued access, the attacker will use a specific web shell to steal the server’s cryptographic machine keys. By taking the
ValidationKeyand theDecryptionKey, the attacker obtains the state information used by SharePoint. Possessing these keys allows the attacker to operate independently, long after the original exploit; this means they can continue to execute new malicious payloads on the exploited server. This permanent backdoor makes this attack method uniquely dangerous.
CVE-2025-53770 is a clear example of how modern cyber threats are two-sided, combining an initial breach vector with a mechanism for long-term persistence. This means that a successful defense will address both the immediate RCE vulnerability and the subsequent threat of unwelcome access.
Once a public proof-of-concept became available for this exploit, Cloudflare’s security analysts crafted and tested new patches, ensuring that they would address not only the initial attack, but also the longer-term threat.
The team began researching the exploit the evening of July 20, and on July 21, 2025, Cloudflare deployed our emergency WAF Managed Rules to patch the vulnerability, meaning every customer using the Cloudflare Managed Ruleset will automatically be protected from this critical SharePoint vulnerability. These rules have been announced on the WAF changelog and will take effect immediately.
Accelerating development with the AWS Data Processing MCP Server and Agent
Post Syndicated from Shubham Mehta original https://aws.amazon.com/blogs/big-data/accelerating-development-with-the-aws-data-processing-mcp-server-and-agent/
Data engineering teams face an increasingly complex landscape when building and maintaining analytics environments. From sourcing and organizing data to implementing transformation pipelines and managing access controls, the process of transforming raw data into actionable insights involves numerous interconnected components. While individual tools exist for each task, connecting them into cohesive workflows remains time-consuming and requires deep technical expertise across multiple AWS services.
To address these challenges and enhance developer productivity, we’re excited to introduce the AWS Data Processing MCP Server, an open-source tool that uses the Model Context Protocol (MCP) to simplify analytics environment setup on AWS. We’re also open sourcing a stand-alone Data Processing Agent implementation in AWS Strands SDK to use this MCP server to help customers further customize it for their use cases. This powerful integration enables AI assistants to understand your data processing environment and guide you through complex workflows using natural language interactions.
Understanding the Model Context Protocol advantage
The MCP is an emerging open standard that defines how AI models, particularly large language models (LLMs), can securely access and interact with external tools, data sources, and services. Rather than requiring developers to learn intricate API syntax across multiple services, MCP enables AI assistants to understand your environment contextually and provide intelligent guidance throughout your data processing journey.
The AWS Data Processing MCP Server harnesses this capability by providing AI code assistants with real-time visibility into your AWS data processing pipeline. This includes access to AWS Glue job statuses, Amazon Athena query results, Amazon EMR cluster metrics, and AWS Glue Data Catalog metadata through a unified interface that LLMs can understand and reason about.
AWS analytics integration
The AWS Data Processing MCP Server integrates deeply with AWS Glue for data cataloging and ETL operations, Amazon EMR for big data processing, and Athena for serverless analytics. This integration transforms how developers interact with these services by providing contextual awareness that enables AI assistants and Data Processing Strands Agent to make intelligent recommendations based on your actual infrastructure and data patterns.
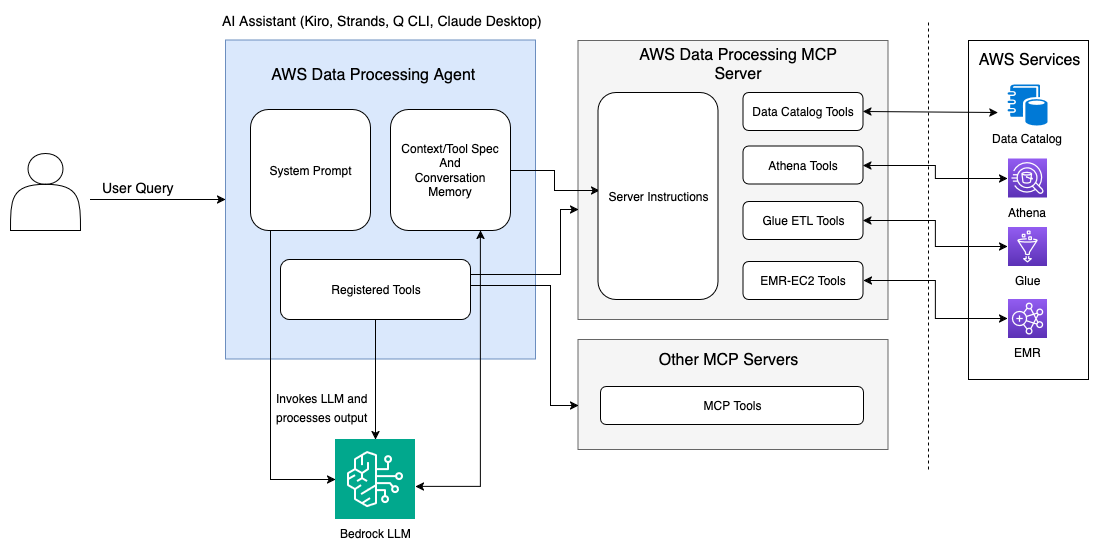
Rather than requiring manual navigation between service consoles or memorizing complex API parameters, the MCP server enables natural language interactions that automatically translate to appropriate service operations. This approach reduces the learning curve for new team members while accelerating productivity for experienced developers working across multiple AWS analytics services.
Getting started with the AWS Data Processing MCP Server
You’ll need to follow the steps in the prerequisites section before you can start using MCP servers.
Prerequisites
Before configuring the MCP server, ensure you have the following prerequisites in place:
System requirements:
- macOS or supported Linux environment
- Python 3.10 or higher
- UV package manager for Python dependency management
- AWS Command Line Interface (AWS CLI) installed and configured with appropriate credentials
IAM permissions: Review and configure your security policies for the IAM roles and permissions that would grant necessary access to the AWS Data Processing MCP Server and Agent to execute AWS data processing operations on your behalf. For read-only operations, attach policies that include permissions for Data Catalog access, Amazon CloudWatch metrics, Amazon EMR cluster descriptions, and Athena query operations. For write operations, make sure that your AWS Identity and Access Management (IAM) role includes the AWSGlueServiceRole managed policy along with permissions for creating and managing Amazon EMR clusters and Athena workgroups.
Set up using Amazon Q CLI
Amazon Q Developer CLI provides an intuitive way to interact with the AWS Data Processing MCP Server directly from your terminal. This integration combines the natural language processing capabilities of Amazon Q with the data processing tools, enabling you to manage complex analytics workflows through conversational commands.
Installation and configuration:
- Install the Amazon Q Developer CLI.
- Clone the MCP Server repository:
git clone https://github.com/awslabs/mcp
- Edit your Q Developer CLI’s MCP configuration file named
mcp.json:
- Verify your setup by running the /tools command in the Q Developer CLI to see the available Data Processing MCP tools.
Set up using Claude Desktop
Claude Desktop offers another powerful way to interact with the AWS Data Processing MCP Server through Anthropic’s Claude interface, providing a user-friendly chat experience for managing your data processing workflows.
Installation and configuration:
- Download and install Claude Desktop for your operating system.
- Open Claude Desktop and navigate to Settings (gear icon in the bottom left).
- Go to the Developer tab and configure your MCP server by adding same configuration as step 3 in Q CLI setup.
- Restart Claude Desktop to activate the MCP server connection.
- Test the integration by starting a new conversation and asking:
What data processing tools are available to me?
Enhanced developer experience
After being configured with either Amazon Q CLI or Claude Desktop, your workflow transforms dramatically. Instead of constructing complex AWS CLI commands with multiple parameters, you can use natural language requests. For example, rather than memorizing the syntax for creating AWS Glue crawlers, you can ask:
Accelerating development with MCP servers
Next, we explore the common patterns that emerge when using MCP in data processing development workflows.
Data onboarding and discovery
One of the most common challenges data teams face is efficiently onboarding new datasets and making them immediately useful for analysis. Consider a scenario where your marketing team receives a CSV file containing customer interaction data that needs to be quickly analyzed for campaign insights. Traditionally, this process involves multiple manual steps: uploading the file to Amazon Simple Storage Service (Amazon S3), configuring an AWS Glue crawler to discover the schema, creating appropriate table definitions, setting up proper partitioning, and finally making the data queriable through Athena.
With the AWS Data Processing MCP Server, this entire workflow becomes conversational. You can describe your goal using natural language:
The AI assistant, powered by the MCP server’s deep AWS integration, automatically handles the technical implementation details, guides you through uploading the file to an appropriate Amazon S3 location, configures and runs an AWS Glue crawler with optimal settings, creates properly formatted table definitions, and sets up Athena access with appropriate workgroup configurations for cost control.
The following video demonstration showcases how developers can use Amazon Q CLI with Data Processing MCP server for data onboarding.
Business insights and automated reporting
Modern organizations require timely, accurate insights to drive business decisions, but traditional analytics workflows often create bottlenecks between data availability and business consumption. Imagine you need to identify potentially fraudulent transactions across multiple data sources including cardholder information, credit card details, merchant data, and transaction records. Rather than manually writing complex SQL queries with multiple joins and filters, you can describe your analytical goal:
The MCP server interprets this request and automatically constructs the appropriate analytical workflow. It examines your data catalog to understand table relationships, generates optimized SQL queries with proper joins across your datasets, executes the analysis using Athena with cost-effective query patterns, and formats the results into actionable reports. The system can establish automated delivery mechanisms, such as email reports or dashboard updates, ensuring stakeholders receive timely insights without manual intervention while creating scheduled AWS Glue jobs that continuously monitor for emerging patterns.
We’re also releasing a stand-alone Data Processing Agent developed using AWS Strands SDK that you can customize further with your system prompts and context for your use cases. You can run it locally or deploy it using Amazon Bedrock AgentCore. The following video demonstration showcases how developers can use Data Processing Agent for driving business insights.
Observability and performance monitoring
Maintaining visibility across complex data processing environments requires sophisticated monitoring capabilities that traditional approaches often fail to provide. The AWS Data Processing MCP Server enables intelligent observability by synthesizing real-time telemetry from across your AWS analytics infrastructure into actionable insights. For AWS Glue environments, the MCP server continuously analyzes job metadata, execution logs, resource configurations, and data catalog statistics to provide operational intelligence. Rather than manually navigating CloudWatch dashboards or parsing log files, you can ask questions like Show me performance trends across my ETL jobs and identify optimization opportunities. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor Glue jobs and catalogs.
For Amazon EMR clusters, the MCP server aggregates cluster metadata, instance usage patterns, and failure events into unified operational views. This enables proactive management where you can request Analyze my EMR environment for cost optimization opportunities and potential reliability risks. The system responds with detailed analysis of cluster utilization patterns, recommendations for right-sizing instance types, identification of long-running clusters that might represent cost leakage, and alerts about configuration patterns that could impact reliability. The observability capabilities extend beyond simple monitoring to predictive insights by analyzing historical patterns to forecasting resource needs and recommend preventive actions. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor EMR clusters.
Security and architectural considerations
All MCP server operations occur within your AWS account boundaries, helping to ensure that sensitive data does not leave your controlled environment. The server provides contextual information to AI assistants through metadata and API responses based on IAM access permissions available to the role being used. Integration with IAM helps ensure that operations respect existing permission boundaries and organizational policies.
The architecture supports graduated autonomy where routine operations can proceed automatically while high-impact changes require human approval. This balanced approach enables productivity gains while maintaining appropriate oversight for critical business operations.
Conclusion
In this post, we explored how the AWS Data Processing MCP Server accelerates analytics solution development across our analytics services. We demonstrated how data engineers can transform raw data into business-ready insights through AI-assisted workflows, significantly reducing development time and complexity. The AWS Data Processing MCP Server offers extensive capabilities beyond these use cases. You can use the MCP’s context-rich APIs to develop customized solutions for observability, automation, and optimization. This flexibility allows you to create workflows tailored to your specific data environments and business needs.By bringing AWS data processing capabilities directly into development workflows—whether through AWS CLI, IDEs, or AI-assisted tools—teams can focus on solving business problems rather than managing infrastructure. We encourage you to explore innovative applications of the MCP Server, combining its powerful context engine with AI-driven analysis to uncover new opportunities for efficiency and insight across their data ecosystems.
Get started today by accessing the open source code, documentation, and setup instructions in the AWS Labs GitHub repository. Integrate the MCP Server into your development workflow and transform how you build analytics solutions on AWS. We’ll continue to iterate based on customer feedback and look forward to seeing how customers extend these capabilities to solve complex data challenges.
Acknowledgment: A special thanks to everyone who contributed to the development and open-sourcing of the AWS Data Processing MCP server and Agent: Raghavendhar Thiruvoipadi Vidyasagar, Chris Kha, Sandeep Adwankar, Nidhi Gupta, Xiaoxi Liu, Kathryn Lin, Alexa Perlov, Alain Krok, Xiaorun Yu, Maheedhar Reddy Chapiddi, and Rajendra Gujja.
About the authors
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
 Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
 Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
 Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
 Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
 Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
 Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.