Post Syndicated from Swapnil Singh original https://aws.amazon.com/blogs/security/secure-file-sharing-solutions-in-aws-a-security-and-cost-analysis-guide-part-2/
As introduced in Part 1 of this series, implementing secure file sharing solutions in AWS requires a comprehensive understanding of your organization’s needs and constraints. Before selecting a specific solution, organizations must evaluate five fundamental areas: access patterns and scale, technical requirements, security and compliance, operational requirements, and business constraints. These areas cover everything from how files will be shared and what protocols are needed, to security measures, day-to-day operations, and business limitations.
See Part 1 of this series for detailed information about each of these fundamental areas and their specific considerations. Part 1 also covers solutions including AWS Transfer Family, Transfer Family web apps, and Amazon Simple Storage Service (Amazon S3) pre-signed URLs. This part continues our analysis with additional AWS file sharing solutions to help you make an informed decision based on your specific requirements.
Solutions
Let’s start by looking at the various file sharing mechanisms that AWS supports. The following table identifies the key AWS services needed for each solution, describes the security and cost implications of the solutions, and describes their complexity and protocol support capabilities.
| Solution |
AWS services |
Security features |
Cost* |
Region control |
| CloudFront signed URLs |
CloudFront, Amazon S3, and Lambda |
Optional edge security using AWS Lambda@Edge, WAF integration, SSL/TLS, geo restrictions, and AWS Shield Standard (included automatically) |
Content delivery network (CDN) costs, request pricing, and data transfer fees |
Global service by design; origin can be AWS Region-specific |
| Amazon VPC endpoint service |
AWS PrivateLink, Amazon VPC, and Network Load Balancer (NLB) |
Complete network isolation, private connectivity, and multi-layer security |
Endpoint hourly charges, NLB costs, and data processing fees |
Service endpoints are strictly Region-specific; must create endpoints in each Region where access is needed |
| S3 Access Points |
Amazon S3, IAM, Amazon VPC (for VPC-specific access points) |
- Dedicated IAM policies per access point
- VPC-only access restrictions available
- Works with bucket policies for layered security
- Supports PrivateLink for private network access
- Compatible with S3 Block Public Access settings
|
- No additional charge for S3 Access Points
- Standard S3 request pricing applies
- Data transfer fees apply based on standard S3 rates
- Amazon VPC endpoint charges apply when using VPC endpoints with access points
|
- Access points are Region-specific
- Each access point is created in the same Region as its S3 bucket
- Cross-Region access requires separate access points in each Region
- VPC-specific access points are limited to the VPC’s Region
|
The following table shows the solutions described in Part 1.
| Solution |
AWS services |
Security features |
Cost* |
Region control |
| AWS Transfer Family |
Transfer Family, Amazon S3, API Gateway, and Lambda |
Managed security, encryption in transit and at rest, IAM integration, and custom authentication |
$0.30 per hour per protocol, data transfer fees, and storage costs |
Can deploy to specific AWS Regions, can only transfer files to and from S3 buckets in the same Region |
| Transfer Family web apps |
Transfer Family, S3, and CloudFront |
Browser-based access, IAM Identity Center integration, and S3 Access Grants |
Pay-per-file operation, CloudFront costs, and storage costs |
Uses CloudFront (global) for web access, but backend components can be Region-specific |
| Amazon S3 pre-signed URLs |
S3 |
Time-limited URLs, IAM controls for URL generation, and HTTPS |
S3 request and data transfer fees |
Can be restricted to specific Regions |
| Serverless application with Amazon S3 presigned URLs |
S3, Lambda, and API Gateway |
Time-limited URLs, HTTPS, IAM controls, customizable authentication |
Pay per request and minimal infrastructure cost |
Components can be Region-specific |
* Pricing information provided is based on AWS service rates at the time of publication and is intended as an estimation only. Additional costs may be incurred depending on your specific implementation and usage patterns. For the most current and accurate pricing details, please consult the official AWS pricing pages for each service mentioned.
Let’s examine each of the solutions in detail. Part 1 talked about AWS Transfer Family, Transfer Family web apps, and Amazon S3 pre-signed URLs. Here in Part 2, we explain the remaining solutions to help you make the right choice for your use case.
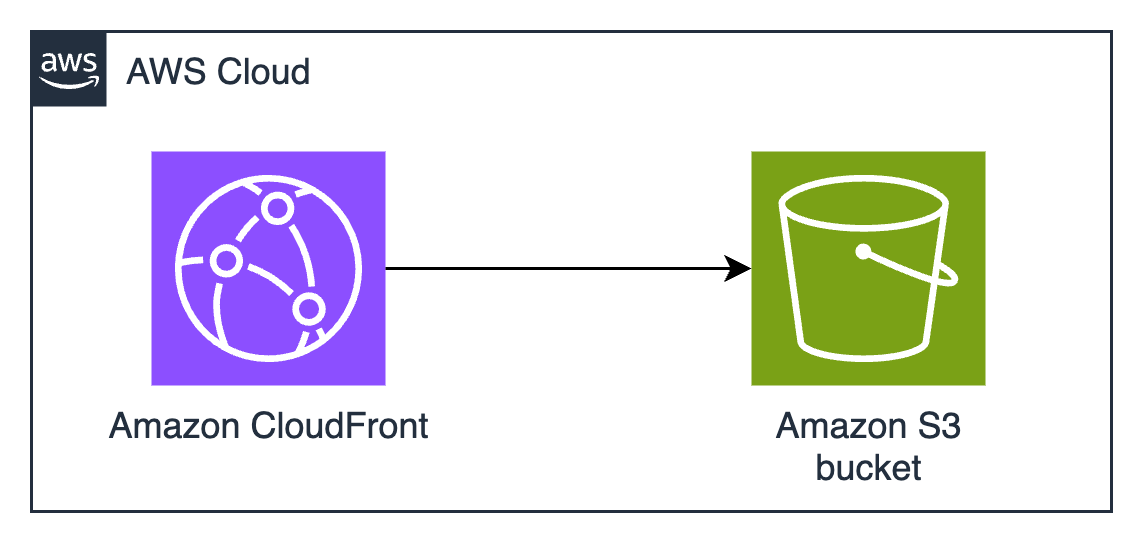
CloudFront signed URLs with Amazon S3
Amazon CloudFront signed URLs combine Amazon S3 storage with the global edge network of CloudFront to deliver files securely with lower latency.
CloudFront edge locations cache content geographically closer to users, which usually reduces latency and gives better performance for users. CloudFront also reduces the number of origin requests to Amazon S3. CloudFront integration with AWS Shield and AWS WAF provides options for additional security layers, helping to protect against DDoS events and unintended requests. You can use custom domains with AWS-provided or your own SSL/TLS certificates managed through AWS Certificate Manager (ACM), helping to facilitate secure connections from users to edge locations.
When a user requests a file, the system generates a signed URL using either a CloudFront key pair or a custom trusted signer (such as Lambda Edge) that includes security parameters such as IP restrictions, time windows, and custom policies. The major difference is the content distribution network (CDN) making performance faster by caching data geographically close to the user downloading it.
The built-in logging and monitoring capabilities of CloudFront provide detailed insights into content access patterns, cache hit ratios, and security events. CloudFront integrates seamlessly with Amazon S3 to support origin access identity (OAI), helping to make sure that the S3 objects can be accessed only through CloudFront and not directly through S3 APIs.

Figure 1: CloudFront signed URLs with Amazon S3 architecture
Pros
If Amazon S3 pre-signed URLs sound good, but you need higher performance at a global scale, CloudFront signed URLs are the right choice. The AWS global edge network has points of presence (POPs) all over the world, which significantly reduces latency for users and minimizes data transfer costs through caching. This architecture provides substantial cost savings for frequently accessed content, because edge locations serve cached copies without retrieving objects from the S3 origin. The integration with AWS security services offers protection against various threats, including sophisticated distributed denial of service (DDoS) events and web application issues, making it particularly suitable for public-facing file sharing applications. Choose CloudFront instead of S3 if you tend to make the same file available to many people who download it many times, such as in software distribution or documentation distribution.
The solution’s security model provides extensive flexibility in access control implementation. You can define granular permissions through custom policies, implement geo-restriction rules, and enforce IP-based access controls. The ability to use custom TLS certificates and domains maintains brand consistency while helping to facilitate secure communications. The integration with AWS WAF enables advanced request filtering and rate limiting, while detailed access logging and real-time metrics provide visibility into content delivery and security events. The solution’s support for both signed URLs and signed cookies offers flexibility in implementing various access control scenarios. Signed cookies are used when you want to provide access to multiple restricted files. For example, if you need to provide access to many files in a private directory, you can use signed cookies to avoid having to create individual signed URLs for each file. When choosing between CloudFront signed URLs (ideal for individual file access) or signed cookies (better for providing access to multiple files, like a subscriber’s content library), consider your content distribution needs and whether your clients support cookies.
Cons
If you implement CloudFront, you must develop expertise in its configuration options, including robust key management processes and secure key rotation procedures. Self-managed certificates don’t automatically renew. You must track expiration dates and make sure you renew on time, or your users will get warnings and errors when they try to download. ACM can simplify TLS certificate management and automatically renew certificates before they expire. while trusted signer workflows enhance your security posture.
Note: To create signed URLs, you need a signer. A signer is either a trusted key group that you create in CloudFront, or an AWS account that contains a CloudFront key pair.
Misconfigured web caches have many surprising and frustrating effects for users. Understanding and configuring CloudFront cache behavior is key to helping to prevent unintended content exposure or availability issues. You need to add cache invalidation to your publication workflows so that old versions are no longer available from the cache. This might introduce additional costs and operational overhead, especially in scenarios with frequent content changes. If you frequently change the content that you share, if the content is unique to an individual (such as a personalized report), or if the same content isn’t downloaded many times by many people in many locations, you won’t realize much cost savings or reduced latency from CloudFront caching. The additional complexity added by cache configuration might not be justified unless the cache is used a lot.
If you use the CloudFront global content delivery network, your content will be stored in caches in hundreds of locations around the world. ACM will store your TLS certificates for CloudFront (whether ACM is issuing them or you manage them yourself) in the us-east-1 AWS Region. Because CloudFront is a global service, it automatically distributes the certificate from the us-east-1 Region to the Regions associated with your CloudFront distribution. Caching data and keys around the world might not be acceptable if you have data sovereignty requirements to keep your data in one country.
From a cost perspective, while CloudFront can provide savings through caching, the pricing model has other variables to consider. Data transfer costs vary by Region and can be significant for large-scale distributions. If you need custom domain names and custom TLS certificates, that might introduce additional costs. Implementation expertise is needed when dealing with dynamic content or when specific origin request handling is required. CloudFront only delivers via HTTPS and HTTP protocols, so you won’t be able to use it if you require support for other file transfer protocols. CloudFront distributions provide statistics on cache hit-and-miss rates—pay attention to these because low cache hit rates mean that you’re pulling data from the origin frequently, which limits the possible cost savings.
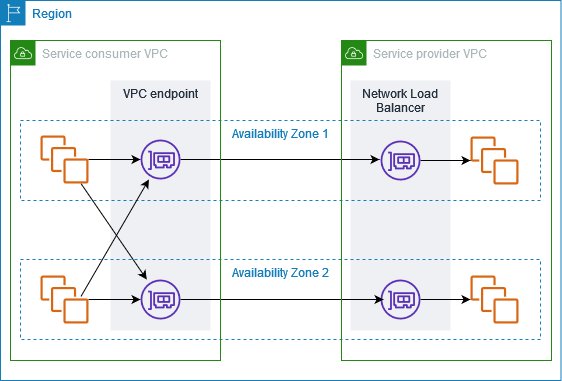
Amazon VPC endpoint service with custom application
Amazon VPC endpoint services, powered by AWS PrivateLink, enable private connectivity between VPCs without requiring internet access, VPN connections, or direct physical connections. This solution creates a highly secure, private network path for file sharing by exposing services through Network Load Balancers (NLB) and allowing other VPCs to access them through interface endpoints. The architecture isolates the file sharing service from the public internet, operating entirely within the AWS private network infrastructure.
The best use cases for this architecture involve sharing data or distributing software around your AWS infrastructure without exposing it to the public internet.

Figure 2: Amazon VPC endpoint service architecture
The solution, shown in Figure 2, typically involves deploying a custom file sharing application behind an NLB in the service VPC, which is then exposed as an endpoint service. Consumer VPCs create interface endpoints to connect to this service, establishing private connectivity through the AWS backbone network. Traffic remains within the AWS network, is encrypted in transit, and is subject to security controls at both the endpoint and VPC levels. The architecture supports many TCP-based protocols, making it versatile for various file transfer requirements.
This architecture provides secure pathways for data to travel by using multiple layers, including VPC security groups, network access control lists (ACLs), endpoint policies, and the custom application’s authentication mechanisms. The built-in security features of PrivateLink are designed so that only approved AWS principals can create interface endpoints to connect to the service, while detailed VPC flow logs provide network traffic visibility.
Pros
Amazon VPC endpoint services provide complete network isolation and private connectivity that’s inaccessible from the public internet. This reduces the exposure footprint and helps meet security requirements for sensitive data transfer operations. The solution maintains private connectivity across different AWS accounts and Regions while keeping traffic within the AWS network infrastructure.
This solution also provides the most flexible protocol support. Other solutions require you to use HTTPS, AWS API calls (which are HTTPS), or one of the protocols supported by Transfer Family (such as SFTP). If you have software that uses custom protocols, and you need security controls and network isolation, this architecture provides predictable performance through dedicated network paths and supports high throughput requirements without internet bandwidth constraints. The granular control over network security through VPC security groups, network ACLs, and endpoint policies enables organizations to implement defense-in-depth strategies effectively. Additionally, the solution’s integration with AWS Organizations facilitates centralized management and governance across multiple accounts.
Cons
Setting up and maintaining VPC endpoints requires significant expertise in AWS networking, including VPC design, PrivateLink configuration, and network security controls. The initial architecture design must carefully consider IP address management, service quotas, and Regional availability to provide scalability and reliability. Organizations must also develop and maintain the custom file sharing application in addition to the VPC endpoints.
This solution has many components that incur hourly and bandwidth-related charges. Each interface endpoint incurs hourly charges and data processing fees, which can accumulate significantly in multi-VPC or multi-Region deployments. NLBs add another cost component, and you must maintain sufficient capacity for peak loads. The solution also has operational costs because of the need for specialized expertise and ongoing maintenance. Additionally, while the private connectivity model provides superior security, it can make troubleshooting more challenging and might require additional tooling for effective monitoring and diagnostics. The Regional nature of VPC endpoints might necessitate additional architecture for multi-Region deployments, potentially increasing both costs and operational overhead. This solution is most suitable when private network security considerations are the highest priority, and cost considerations are secondary.
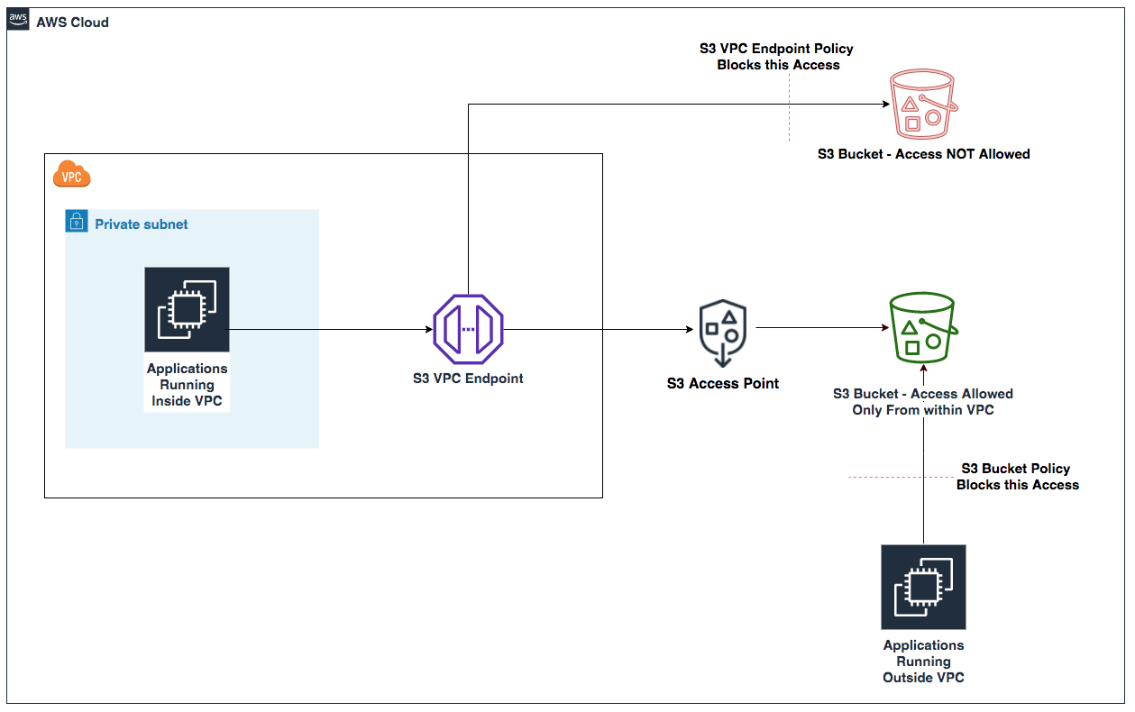
Amazon S3 Access Points
Amazon S3 Access Points simplify managing data access at scale for applications using shared data sets on S3. Access points are named network endpoints attached to S3 buckets that streamline managing access to shared datasets. Each access point has its own AWS Identity and Access Management (IAM) policy that controls access to the data, allowing you to create custom access permissions for different applications or user groups accessing the same bucket.
The architecture uses S3 buckets with access points providing dedicated access paths to the data. Each access point has its own hostname (URL) and access policy that works in conjunction with the bucket policy. You can create access points that only allow connections from your Amazon Virtual Private Cloud (Amazon VPC) for private network access to Amazon S3 or create access points with Internet connectivity. You can use this flexibility to implement sophisticated access control patterns while maintaining a single source of truth in S3.

Figure 3: S3 Access Points with VPC endpoints
Pros
Amazon S3 Access Points simplify permissions management and security to accommodate multiple access patterns and use cases. For example, if an S3 bucket contains data that needs to be accessed by multiple applications, each requiring different levels of access, you can create a dedicated access point for each application with precisely the permissions it needs, rather than managing a long monolithic bucket policy.
You can implement access control workflows, such as restricting access to specific VPCs, encryption, or limit access to specific objects or prefixes. The service requires no new infrastructure management, reducing operational overhead and allowing you to focus on business logic implementation.
Access points provide a way to enforce network controls through VPC-only access points, helping to make sure that data can only be accessed from within your private network. IAM permissions management becomes more granular and straightforward to audit when each application or user group has its own access point with a dedicated policy. You can associate different access points with different network origins.
Another possible use case is when you need to provide temporary access to specific data within a bucket without modifying the bucket policy. You can create a temporary access point with the necessary permissions and delete it when the access is no longer needed.
Cons
Access points add another layer to your Amazon S3 architecture that needs to be managed and monitored. Each access point has its own Amazon Resource Name (ARN) and hostname that applications need to use instead of the bucket name, which might require changes to your application code.
There are limits to the number of access points you can create for each bucket, which might be a constraint for large-scale applications. Access points can only control access to the bucket they’re associated with, not across multiple buckets, so if your application needs to access data across buckets, you’ll need multiple access points.
When implementing this solution, you need to design your access point policies to make sure that they work correctly with your bucket policy. Think of your S3 bucket policy as the primary security framework, while access point policies act as specialized gatekeepers. These two layers of security must work in harmony. The bucket policy takes precedence. For example, if your bucket policy explicitly denies access from specific IP ranges, an access point policy can’t override this restriction. This hierarchical relationship requires strategic planning. Start by defining your broad security boundaries in the bucket policy—perhaps allowing access only from specific VPCs or requiring encryption. Then create your access point policies within these boundaries.
While Amazon S3 Access Points offer powerful flexibility, understanding their boundaries is crucial. Cross-account scenarios, common in large enterprises or partner collaborations, require careful configuration. Imagine you’re working with an external auditing firm that needs temporary access to your financial data stored in S3. Setting up a cross-account access point requires creating the access point in your account, configuring a trust policy to allow the external account, verifying that the bucket policy permits access from the access point, and providing the auditors with the access point ARN and necessary IAM permissions in their account. This process maintains tight control over your data while enabling secure cross-account access.
Some Amazon S3 operations are only controlled at the bucket level and can’t be controlled by access points. Core bucket operations such as configuring versioning, logging, managing lifecycle policies, and setting up cross-Region replication require direct bucket access. For these operations, you need to interact directly with the bucket through the appropriate permissions. This limitation helps make sure that fundamental bucket configurations remain centralized and controlled by bucket owners.
Creating a dedicated IAM role for bucket administration tasks—separate from the roles that interact with data through access points—enhances security and aligns with the principle of least privilege.
Conclusion
In this second part of a two-part post, you’ve learned about multiple solutions for secure file sharing using AWS services and the pros and cons of each. You can find additional options and a full decision matrix in Part 1. The optimal solution depends on your specific organizational requirements, technical capabilities, and budget constraints. You don’t have to choose just one option, you can implement multiple solutions to address different use cases, creating a file sharing strategy that balances security, cost, and operational efficiency.
Additional resources:
If you have feedback about this post, submit comments in the Comments section below.


 Martin Milenkoski is a Software Development Engineer on the Amazon Redshift team, currently focusing on data lake performance and query optimization. Martin holds an MSc in Computer Science from the École Polytechnique Fédérale de Lausanne.
Martin Milenkoski is a Software Development Engineer on the Amazon Redshift team, currently focusing on data lake performance and query optimization. Martin holds an MSc in Computer Science from the École Polytechnique Fédérale de Lausanne. Kalaiselvi Kamaraj is a Sr. Software Development Engineer on the Amazon Redshift team. She has worked on several projects within the Amazon Redshift Query processing team and currently focusing on performance related projects for Amazon Redshift DataLake and query optimizer.
Kalaiselvi Kamaraj is a Sr. Software Development Engineer on the Amazon Redshift team. She has worked on several projects within the Amazon Redshift Query processing team and currently focusing on performance related projects for Amazon Redshift DataLake and query optimizer. Jonathan Katz is a Principal Product Manager – Technical on the AWS Analytics team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor, including to the pgvector project.
Jonathan Katz is a Principal Product Manager – Technical on the AWS Analytics team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor, including to the pgvector project.