Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=ZBr5JzebkTU
How TimescaleDB helped us scale analytics and reporting
Post Syndicated from Robert Cepa original https://blog.cloudflare.com/timescaledb-art/
At Cloudflare, PostgreSQL and ClickHouse are our standard databases for transactional and analytical workloads. If you’re part of a team building products with configuration in our Dashboard, chances are you’re using PostgreSQL. It’s fast, versatile, reliable, and backed by over 30 years of development and real-world use. It has been a foundational part of our infrastructure since the beginning, and today we run hundreds of PostgreSQL instances across a wide range of configurations and replication setups.
ClickHouse is a more recent addition to our stack. We started using it around 2017, and it has enabled us to ingest tens of millions of rows per second while supporting millisecond-level query performance. ClickHouse is a remarkable technology, but like all systems, it involves trade-offs.
In this post, I’ll explain why we chose TimescaleDB — a Postgres extension — over ClickHouse to build the analytics and reporting capabilities in our Zero Trust product suite.
After a decade in software development, I’ve grown to appreciate systems that are simple and boring. Over time, I’ve found myself consistently advocating for architectures with the fewest moving parts possible. Whenever I see a system diagram with more than three boxes, I ask: Why are all these components here? Do we really need all of this?
As engineers, it’s easy to fall into the trap of designing for scenarios that might never happen. We imagine future scale, complex failure scenarios, or edge cases, and start building solutions for them upfront. But in reality, systems often don’t grow the way we expect, or don’t have to. Designing for large scale can be deferred by setting the right expectations with customers, and by adding guardrails like product limits and rate limits. Focusing on launching initial versions of products with just a few essential parts, maybe two or three components, gives us something to ship, test, and learn from quickly. We can always add complexity later, but only once it’s clear we need it.
Whether I specifically call it YAGNI, or Keep it simple, stupid, or think about it as minimalism in engineering, the core idea is the same: we’re rarely good at predicting the future, and every additional component we introduce carries a cost. Each box in the system diagram is something that can break itself or other boxes, spiral into outages, and ruin weekend plans of on-call engineers. Each box also requires documentation, tests, observability, and service level objectives (SLOs). Oftentimes, teams need to learn a new programming language just to support a new box.
Two years ago, I was tasked with building a new product at Cloudflare: Digital Experience Monitoring (DEX). DEX provides visibility into device, network, and application performance across Zero Trust environments. Our initial goal was clear — launch an MVP focused on fleet status monitoring and synthetic tests, giving customers actionable analytics and troubleshooting. From a technical standpoint, fleet status and synthetic tests are two types of structured logs generated by the WARP client. These logs are uploaded to an API, stored in a database, and ultimately visualized in the Cloudflare Dashboard.
As with many new engineering teams at Cloudflare, DEX started as a “tiger team”: a small group of experienced engineers tasked with validating a new product quickly. I worked with the following constraints:
-
Team of three full-stack engineers.
-
Daily collaboration with 2-3 other teams.
-
Can launch in beta, engineering can drive product limits.
-
Emphasis on shipping fast.
To strike a balance between usefulness and simplicity, we made deliberate design decisions early on:
-
Fleet status logs would be uploaded from WARP clients at fixed 2-minute intervals.
-
Synthetic tests required users to preconfigure them by target (HTTP or traceroute) and frequency.
-
We capped usage: each device could run up to 10 synthetic tests, no more than once every 5 minutes.
-
Data retention of 7 days.
These guardrails gave us room to ship DEX months earlier and gather early feedback from customers without prematurely investing in scalability and performance.
We knew we needed a basic configuration plane — an interface in the Dashboard for users to create and manage synthetic tests, supported by an API and database to persist this data. That led us to the following setup:
-
HTTP API for managing test configurations.
-
PostgreSQL for storing those configurations.
-
React UI embedded in the Cloudflare Dashboard.
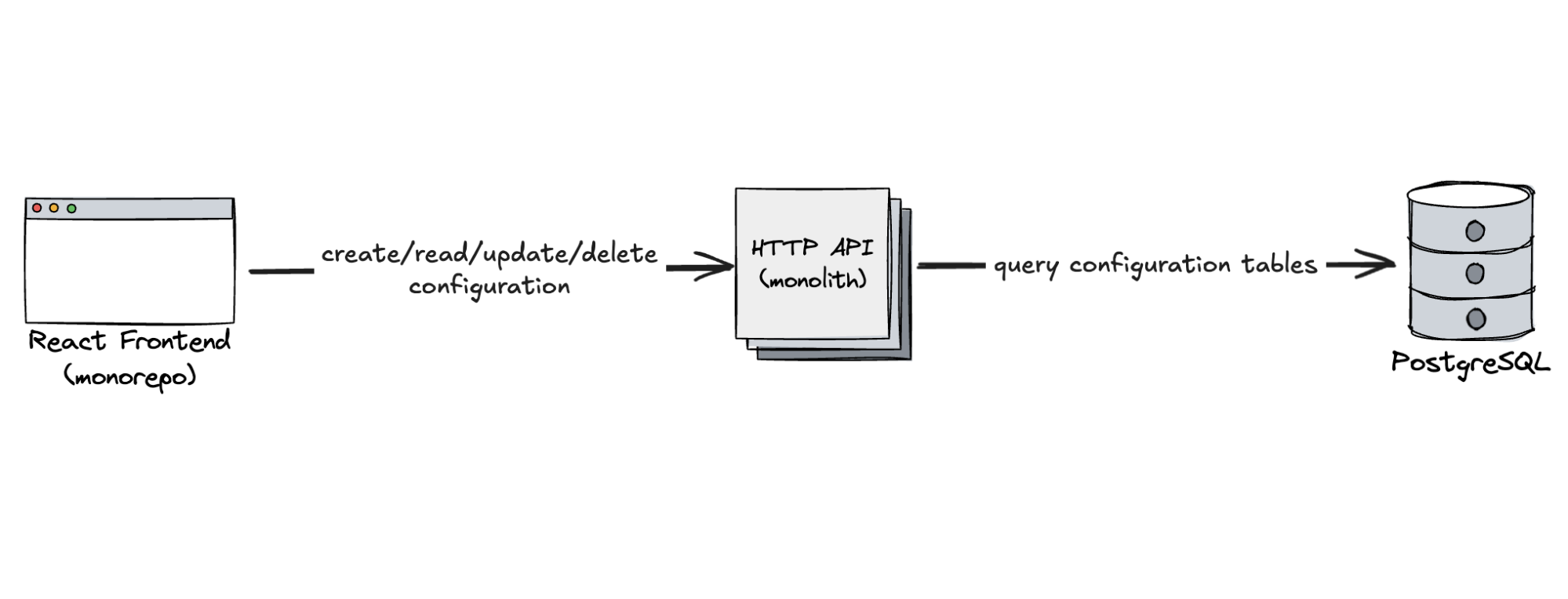
Just three components — simple, focused, and exactly what we needed. Of course, each of these boxes came with real complexity under the hood. PostgreSQL was deployed as a high-availability cluster: one primary, one synchronous replica for failover scenarios, and several asynchronous replicas distributed across two geographies. The API was deployed on horizontally scaled Kubernetes pods across two geographies. The React app was served globally as standard via Cloudflare’s network. Thanks to our platform teams, all of that complexity was abstracted away, allowing us to think in terms of just three essential parts, but it really shows that each box can come with a huge cost behind the scenes.
Next, we needed to build the analytics plane — an ingestion pipeline to collect structured logs from WARP clients, store them, and visualize them for our customers in the Dashboard. I was personally excited to explore ClickHouse for this. I have seen its performance in other projects and was eager to experiment with it. But as I dug into the internal documentation on how to get started with ClickHouse, reality set in:
Writing data to Clickhouse
Your service must generate logs in a clear format, using Cap’n Proto or Protocol Buffers. Logs should be written to a socket for logfwdr to transport to PDX, then to a Kafka topic. Use a Concept:Inserter to read from Kafka, batching data to achieve a write rate of less than one batch per second.
Oh. That’s a lot. Including ClickHouse and the WARP client, we’re looking at five boxes to be added to the system diagram. This architecture exists for good reason, though. The default and most commonly used table engine in ClickHouse, MergeTree, is optimized for high-throughput batch inserts. It writes each insert as a separate partition, then runs background merges to keep data manageable. This makes writes very fast, but not when they arrive in lots of tiny batches, which was exactly our case with millions of individual devices uploading one log event every 2 minutes. Too many small writes can trigger write amplification, resource contention, and throttling.
So it became clear that ClickHouse is a sports car and to get value out of it we had to bring it to a race track, shift into high gear, and drive it at top speed. But we didn’t need a race car — we needed a daily driver for short trips to a grocery store. For our initial launch, we didn’t need millions of inserts per second. We needed something easy to set up, reliable, familiar, and good enough to get us to market. A colleague suggested we just use PostgreSQL, quoting “it can be cranked up” to handle the load we were expecting. So, we took the leap!
First design of configuration and analytics plane for DEX:
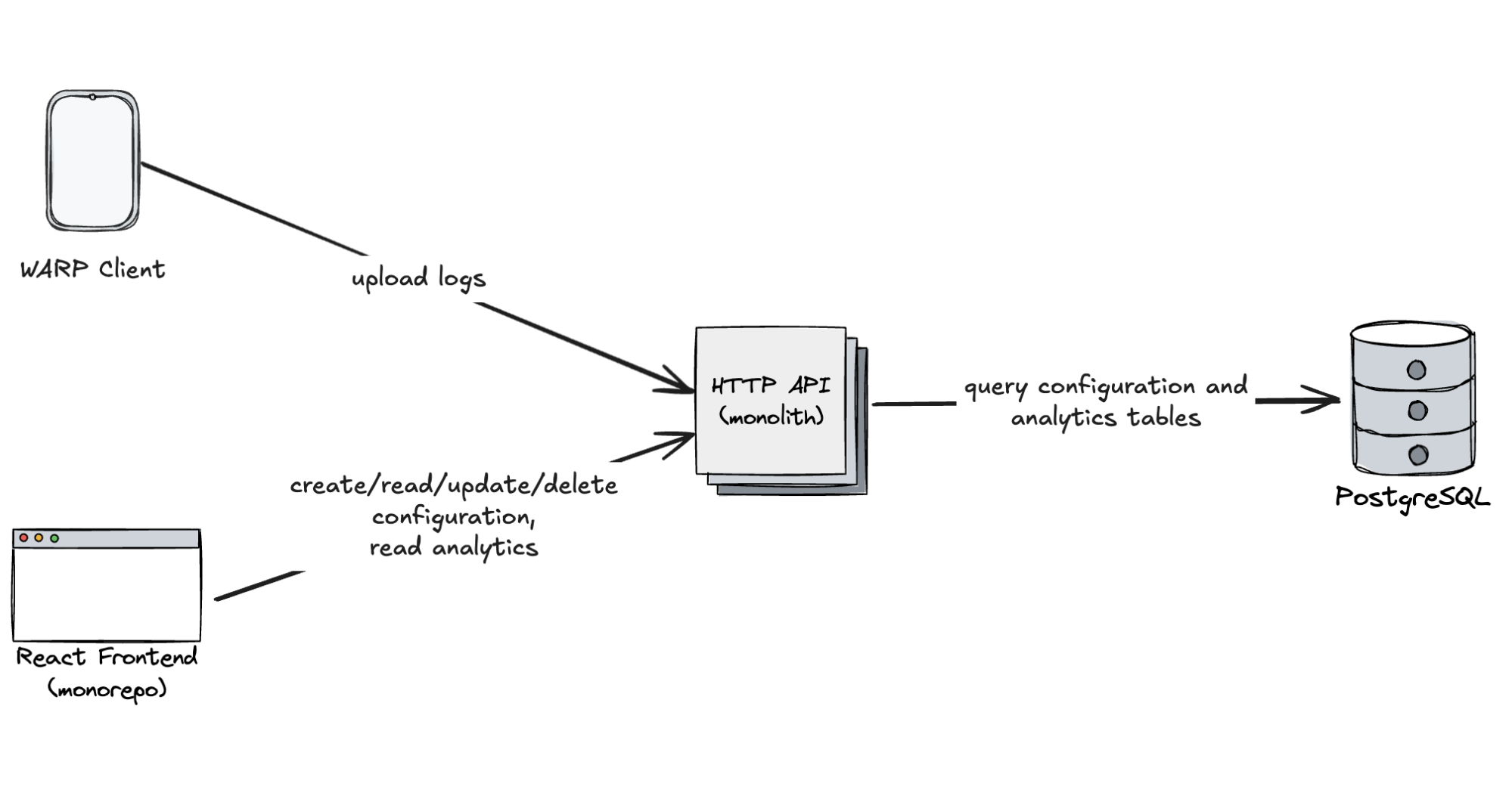
Structurally, there’s not much difference between configuration data and analytical logs. Logs are simply structured payloads — often in JSON — that can be transformed into a columnar format and persisted in a relational database.
Here’s an example of a device state log:
{
“timestamp”: “2025-06-16T22:50:12.226Z”,
“accountId”: “025779fde8cd4ab8a3e5138f870584a7”,
“deviceId”: “07dfde77-3f8a-4431-89f7-acfcf4ead4fc”,
“colo”: “SJC”,
“status”: “connected”,
“mode”: “warp+doh”,
“clientVersion”: “2024.3.409.0”,
“clientPlatform”: “windows”,
}To store these logs, we created a simple PostgreSQL table:
CREATE TABLE device_state (
"timestamp" TIMESTAMP WITH TIME ZONE NOT NULL,
account_id TEXT NOT NULL,
device_id TEXT NOT NULL,
colo TEXT,
status TEXT,
mode TEXT,
client_version TEXT,
client_platform TEXT
);You might notice that this table doesn’t have a primary key. That’s intentional, because time-series data is almost never queried by a unique ID. Instead, we query by time ranges and filter by various attributes (e.g. account ID or device ID). Still, we needed a way to deduplicate logs in case of client retries.
We created two indexes to optimize for our most common queries:
CREATE UNIQUE INDEX device_state_device_account_time ON device_state USING btree (device_id, account_id, “timestamp”);
CREATE INDEX device_state_account_time ON device_state USING btree (account_id, “timestamp”);The unique index ensures deduplication: each (device, account, timestamp) tuple represents a single, unique log. The second index supports typical time-window queries at the account level. Since we always query by account_id (represents individual customers) and timestamp, they are always a part of the index.
We inserted data from our API using UPSERT query:
INSERT INTO device_state (…) VALUES (…) ON CONFLICT DO NOTHING;
PostgreSQL’s B-tree indexes support multiple columns, but column order has a major impact on query performance.
From PostgreSQL documentation about multicolumn indexes:
A multicolumn B-tree index can be used with query conditions that involve any subset of the index’s columns, but the index is most efficient when there are constraints on the leading (leftmost) columns. The exact rule is that equality constraints on leading columns, plus any inequality constraints on the first column that does not have an equality constraint, will be used to limit the portion of the index that is scanned. Constraints on columns to the right of these columns are checked in the index, so they save visits to the table proper, but they do not reduce the portion of the index that has to be scanned.
What’s interesting in time series workloads is that the queries usually have inequality constraints on the time column, and then equality constraints on all other columns.
A typical query to build line charts and pie charts visualizing data in a time interval often looks like this:
SELECT
DATE_TRUNC(‘hour’, timestamp) as hour,
account_id,
device_id,
status,
COUNT(*) as total
FROM device_state
WHERE
account_id = ‘a’ AND
device_id = ‘b’ AND
timestamp BETWEEN ‘2025-07-01’ AND ‘2025-07-02’
GROUP BY hour, account_id, device_id, status;Notice our WHERE clause — it has equality constraints on account_id and device_id, and two inequality constraints on timestamp. If we had built our index in the order of (timestamp, account_id, device_id), only the “timestamp” section of the index could’ve been used to reduce the index section to be scanned, and account_id and device_id would have to be fully scanned, with values that are not ‘a’ or ‘b’ filtered out after scanning.
Additionally, the runtime complexity of search in btree is O(log n) — the search will get slower as the size of your table (and all indexes) grows, so another optimization is to reduce the portion of the index that needs to be scanned. Even for columns with equality constraints, you can greatly reduce query times by ordering columns by cardinality. We’ve seen up to 100% improvement in SELECT query performance when we simply changed the order of account_id and device_id in our multicolumn index.
To get the best performance for time range queries, we follow these rules for order of columns:
-
The timestamp column is always last.
-
Other columns are leading columns, ordered by their cardinalities starting with the highest cardinality column.
Because we took a step back during system design and avoided optimizing for the future, thanks to our minimal and focused architecture, we went from zero to a working DEX MVP in under four months.
Early metrics were promising, providing reasonable throughput capabilities and latency for API requests:
-
~200 inserts/sec at launch.
-
Query latencies in the hundreds of milliseconds for most customers.
Post-launch, we focused on collecting feedback while monitoring system behavior. As adoption grew, we scaled to 1,000 inserts/sec, and our tables grew to billions of rows. That’s when we started to see performance degradation — particularly for large customers querying 7+ day time ranges across tens of thousands of devices.
As DEX grew to billions of device logs, one of the first performance optimizations we explored was precomputing aggregates, also known as downsampling.
The idea is that if you know the shape of your queries ahead of time — say, grouped by status, mode, or geographic location — you can precompute and store those summaries in advance, rather than querying the raw data repeatedly. This dramatically reduces the volume of data scanned and the complexity of the query execution.
To illustrate this in an example, let’s consider DEX Fleet Status:
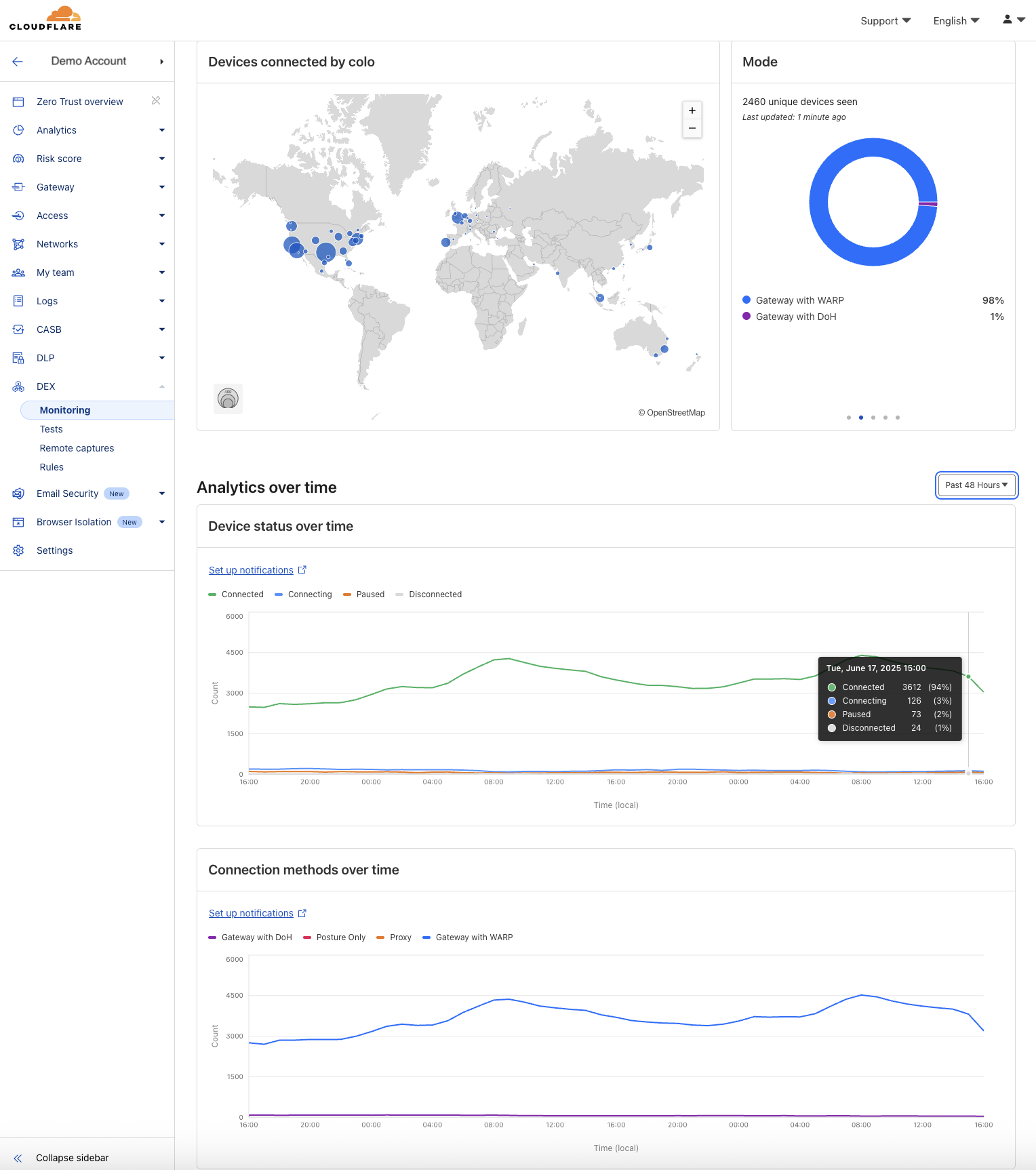
In our DEX Fleet Status dashboard, we render common visualizations like:
-
Number of connected devices by data center location (colo)
-
Device status and connection mode over time
These charts typically group logs by status, mode, or colo, either over a 1-hour window or across the full time range.
Our largest customers may have 30,000+ devices, each reporting logs every 2 minutes. That’s millions of records per day per customer. But the columns we’re visualizing (e.g. status and mode) only have a few distinct values (4–6). By aggregating this data ahead of time, we can collapse millions of rows into a few hundred per interval and query dramatically smaller, narrower tables.
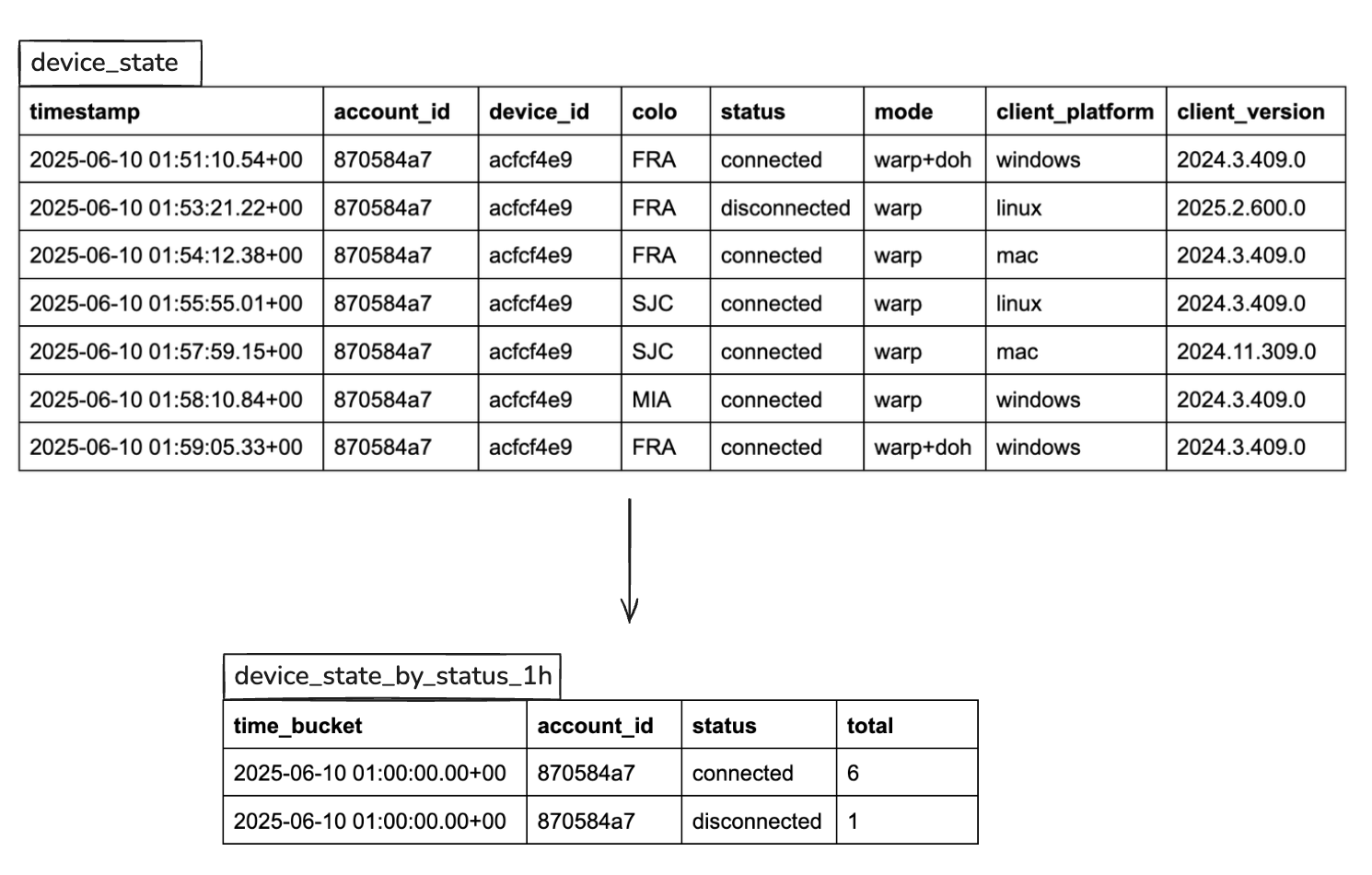
This made a huge impact: we saw up to 1000x query performance improvement and charts that previously took several seconds now render instantly, even for 7-day views across tens of thousands of devices.
Implementing this technique in PostgreSQL is challenging. While PostgreSQL does support materialized views, they didn’t fit our needs out of the box because they don’t refresh automatically and incrementally. Instead, we used a cron job that was periodically running custom aggregation queries for all pre-aggregate tables (we had 6 of them). Our Database platform team had a lightweight framework built for data retention purposes that we plugged into. Still, any schema change required cross-team coordination, and we invested considerable time in optimizing aggregation performance. But the results were worth it: fast, reliable queries for the majority of customer use cases.
Pre-computed aggregates are great, but they’re not the answer to everything. As we were adding more table columns for new DEX features, we needed to invest time in creating new pre-aggregated tables. Additionally, some features required queries with combined filters, which required querying the raw data that included all the columns. But we didn’t have good enough performance in raw tables.
One technique we considered to improve performance on raw tables was table partitioning. In PostgreSQL, tables are stored in one large file (large tables are split to 1 GB segment files). With partitioning, you can break a large table into smaller child tables, each covering a slice of data (e.g. one day of logs). PostgreSQL then scans only the relevant partitions based on your query’s timestamp filter. This can dramatically improve query performance in some cases.
What was particularly interesting for us was range-partitioning on the timestamp column, because our customers wanted longer data retention, up to one year, and storing one year of data in one large table would have destroyed query performance.
CREATE TABLE device_state (
…
) PARTITION BY RANGE (timestamp);
CREATE TABLE device_state_20250601 PARTITION OF device_state
FOR VALUES FROM ('2025-06-01') TO ('2025-06-02');
CREATE TABLE device_state_20250601 PARTITION OF device_state
FOR VALUES FROM ('2025-06-02') TO ('2025-06-03');
CREATE TABLE device_state_20250601 PARTITION OF device_state
FOR VALUES FROM ('2025-06-03') TO ('2025-06-04');Unfortunately, PostgreSQL doesn’t automatically manage partitions — you must manually create each one as shown above, so we would have needed to build a full partition management system to automate this.
We ended up not adopting it because in the end, partitioning didn’t solve our core problem: speeding up frequent dashboard queries on recent raw data up to past 7 days.
As our raw PostgreSQL setup began to show its limits, we started exploring other options to improve query performance. That’s when we discovered TimescaleDB. What particularly caught my attention was columnstore and sparse indexes, common techniques in OLAP databases like ClickHouse. It seemed to be the solution for our raw performance problem. On top of that:
-
It’s Postgres: TimescaleDB is packaged as a PostgreSQL extension and it seamlessly coexists with it, granting access to the entire Postgres ecosystem. We can still use vanilla Postgres tables for transactional workloads, and TimescaleDB hypertables for analytical tasks, offering convenience of one database for everything.
-
Automatic partition management: Unlike Postgres, which requires manual table partitioning, TimescaleDB’s hypertables are partitioned by default and automatically managed.
-
Automatic data pre-aggregation/downsampling: Tedious processes in native Postgres, such as creating and managing downsampled tables, are automated in TimescaleDB through continuous aggregates. This feature eliminates the need for custom-built cron jobs and simplifies the development and deployment of pre-computed aggregates.
-
Realtime data pre-aggregation/downsampling: A common problem with async aggregates is that they can be out-of-date, because aggregation jobs can take a long time to complete. TimescaleDB addresses the issue of outdated async aggregates with its realtime aggregation by seamlessly integrating the most recent raw data into rollup tables during queries.
-
Compression: Compression is a cornerstone feature of TimescaleDB. Compression can reduce table size by more than 90% while simultaneously enhancing query performance.
-
Columnstore performance for real-time analytics: TimescaleDB’s hybrid row/columnar engine, Hypercore, enables fast scans and aggregations over large datasets. It’s fully mutable, so we can backfill with UPSERTs. Combined with compression, it delivers strong performance for analytical queries while minimizing storage overhead.
-
Rich library of analytics tools and functions: TimescaleDB offers a suite of tools and functions tailored for analytical workloads, including percentile approximation, count of unique values approximation, time-weighted averages, etc…
One especially compelling aspect: TimescaleDB made aggregation and data retention automatic, allowing us to simplify our infrastructure and remove a box from the system architecture entirely.
We deployed a self-hosted TimescaleDB instance on our canary PostgreSQL cluster to run an apples-to-apples comparison against vanilla Postgres. Our production backend was dual-writing to both systems.
As expected, installing TimescaleDB was trivial. Simply load the library and run the following SQL query:
CREATE EXTENSION IF NOT EXISTS timescaledb;Then we:
-
Created raw tables
-
Converted them to hypertables
-
Enabled columnstore features
-
Set up continuous aggregates
-
Configured automated policies for compression and retention
Here’s a condensed example for device_state logs:
– Create device_state table.
CREATE TABLE device_state (
…
);
– Convert it to a hypertable.
SELECT create_hypertable ('device_state', by_range ('timestamp', INTERVAL '1 hour'));
– Add columnstore settings
ALTER TABLE device_state SET (
timescaledb.enable_columnstore,
timescaledb.segmentby = ‘account_id’
);
– Schedule recurring compression jobs
CALL add_columnstore_policy(‘device_state’, after => INTERVAL '2 hours', schedule_interval => INTERVAL '1 hour');
– Schedule recurring data retention jobs
SELECT add_retention_policy(‘device_state’, INTERVAL '7 days');
– Create device_state_by_status_1h continuous aggregate
CREATE MATERIALIZED VIEW device_state_by_status_1h
WITH (timescaledb.continuous) AS
SELECT
time_bucket (INTERVAL '1 hour', TIMESTAMP) AS time_bucket,
Account_id,
Status,
COUNT(*) as total
FROM device_state
GROUP BY 1,2,3
WITH no data;
– Enable realtime aggregates
ALTER MATERIALIZED VIEW ‘device_state_by_status_1h’
SET (timescaledb.materialized_only=FALSE);
– Schedule recurring continuous aggregate jobs to refresh past 10 hours every 10 minutes
SELECT add_continuous_aggregate_policy (
‘device_state_by_status_1h’,
start_offset=>INTERVAL '10 hours',
end_offset=>INTERVAL '1 minute',
schedule_interval=>INTERVAL '10 minutes',
buckets_per_batch => 1
);After a two-week backfill period, we ran side-by-side benchmarks using real production queries from our dashboard. We tested:
-
3 time windows: past 1 hour, 24 hours, and 7 days
-
3 columnstore modes: uncompressed, compressed, and compressed with segmenting
-
Datasets containing 500 million to 1 billion rows
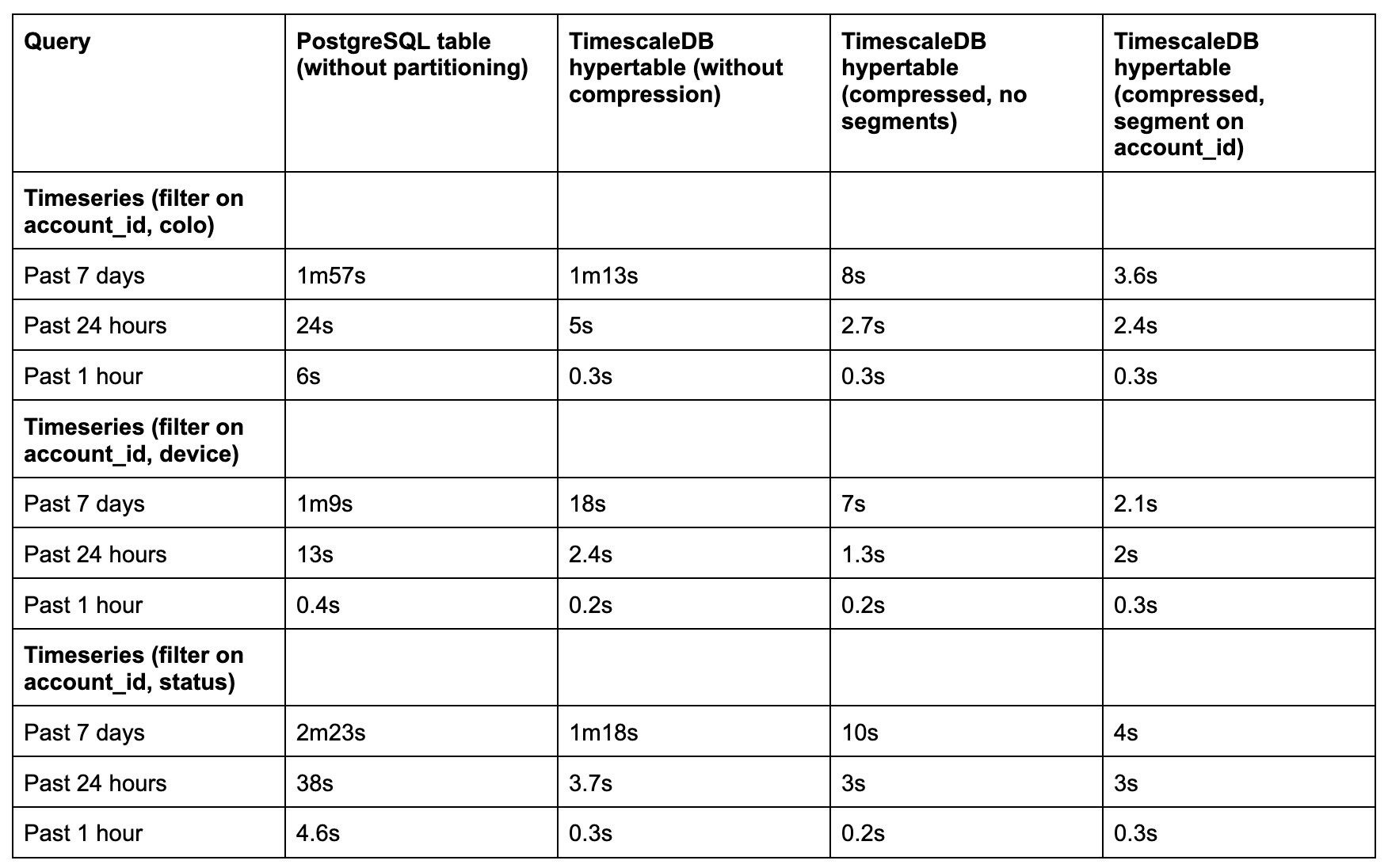
We saw 5x to 35x performance improvements, depending on query type and time range:
-
For short windows (1–24 hours), even uncompressed hypertables performed well.
-
For longer windows (7 days), compression and columnstore settings (especially with segmentby) made all the difference.
-
Sparse indexes were critical. Once PostgreSQL’s btree indexes broke down at scale, Timescale’s minmax sparse indexes and columnar layout outperformed.
On top of query performance, we saw impressive compression ratios, up to 33x:
SELECT
pg_size_pretty(before_compression_total_bytes) as before,
pg_size_pretty(after_compression_total_bytes) as after,
ROUND(before_compression_total_bytes / after_compression_total_bytes::numeric, 2) as compression_ratio
FROM hypertable_compression_stats('device_state');
before: 1616 GB
after: 49 GB
compression_ratio: 32.83That meant we could retain 33x more data for the same cost.
Two main things: compression and sparse indexes.
It might seem counterintuitive that querying compressed data, which requires decompression, can be faster than querying raw data. But in practice, input/output (I/O) is the major bottleneck in most analytical workloads. The reduction in disk I/O from compression often outweighs the CPU cost of decompressing. In TimescaleDB, compression transforms a hypertable into a columnar format: values from each column are grouped in chunks (typically 1,000 at a time), stored in arrays, and then compressed into binary form. More detailed explanation in this TimescaleDB blog post.
You might wonder how this is possible in PostgreSQL, which is traditionally row-based. TimescaleDB has a really clever solution for it by utilizing PostgreSQL TOAST pages. The way it works is after tuples of 1000 values are compressed, they’re moved to external TOAST pages. The columnstore table itself then basically becomes a table of pointers to TOAST, where actual data is stored and only retrieved lazily, column-by-column.
The second factor is sparse minmax indexes. The idea behind sparse indexes is that rather than storing every single value in an index, store every N-th value. This makes them much smaller and more efficient to query in very large datasets. TimescaleDB implements minmax sparse indexes, where for each compressed tuple of 1,000 values it creates two additional metadata columns, storing min and max values. The query engine then looks at these columns to determine whether a value could possibly be found in a compressed tuple before attempting to decompress it.
What we found later, unfortunately, after we did our evaluation of TimescaleDB, is that sparse indexes need to be explicitly enabled via timescaledb.orderby option. Otherwise, TimescaleDB sets it to some default value, which may not always be the most efficient for your queries. We added all columns that we filter on to orderby setting:
– Add columnstore settings
ALTER TABLE device_state SET (
timescaledb.enable_columnstore,
timescaledb.segmentby = ‘account_id’,
timescaledb.orderby = ‘timestamp,device_id,colo,mode,status,client_version,client_platform
);Following the success with DEX, other teams started exploring TimescaleDB for its simplicity and performance. One notable example is the Zero Trust Analytics & Reporting (ART) team.
The ART team is responsible for generating analytics and long-term reports — spanning months or even years — for Zero Trust products such as Access, Gateway, CASB, and DLP. These datasets live in various ClickHouse and PostgreSQL clusters that we wanted to replicate into a singular home that is specifically designed to unify related, but not co-located data points, together and modeled to address our customer’s analytical needs.
We chose to use TimescaleDB as the aggregation layer on top of raw logs stored elsewhere. We built a system of crawlers using cron jobs that periodically query the multitude of clusters for hourly aggregates across all customers. These aggregates are ingested into TimescaleDB, where we use continuous aggregates to further roll them up into daily and monthly summaries for reporting.
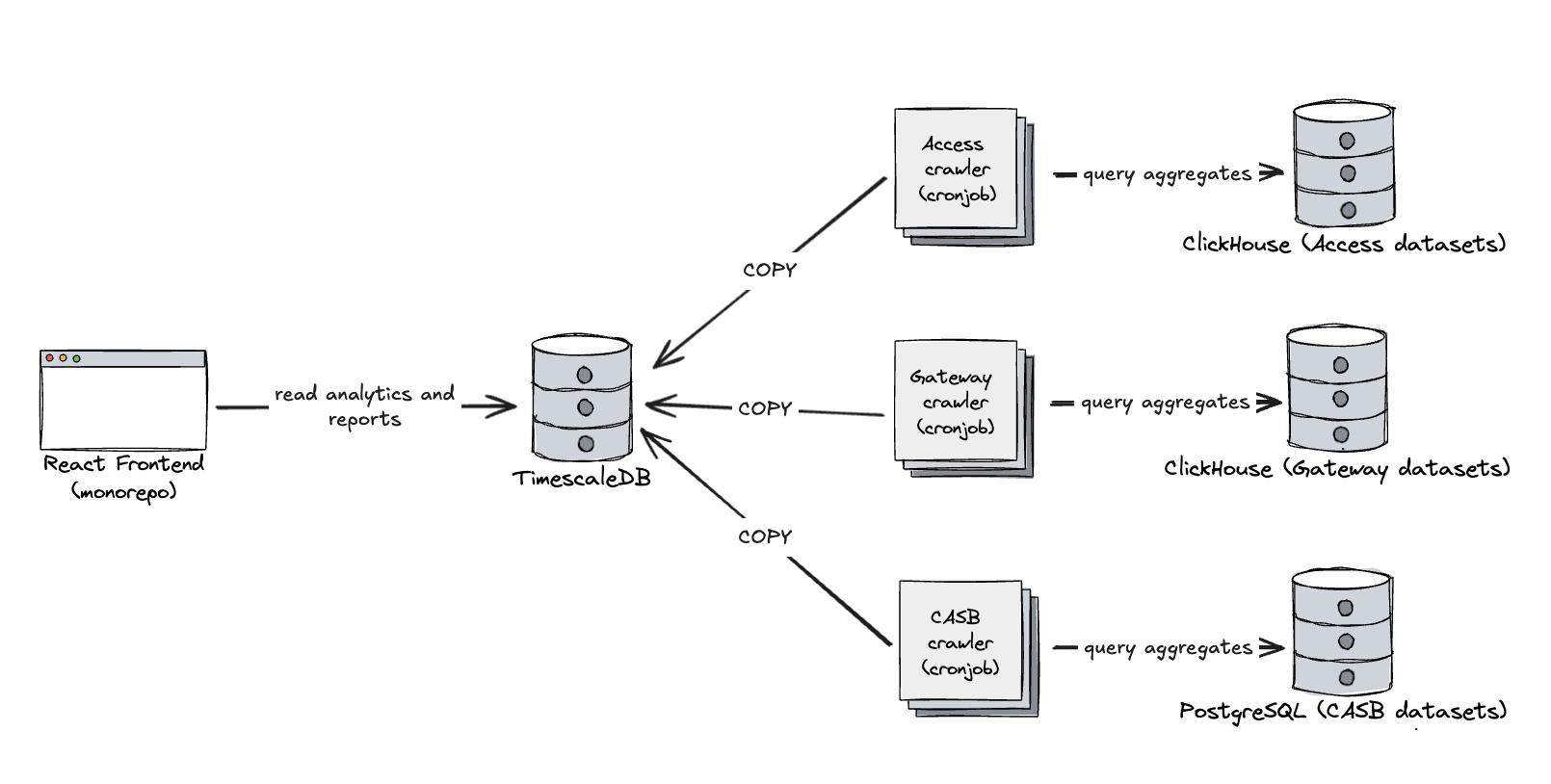
Access and Gateway datasets are massive, often ingesting millions of rows per second. To support arbitrary filters in reporting, crawler queries group by all relevant fields, including high-cardinality columns like IP addresses. This means the downsampling ratio is low, and in some cases, we’re inserting ~100,000 aggregated rows per second. TimescaleDB handles this load just fine, but to support it we made some adjustments:
-
We switched from bulk INSERTS to COPY. This significantly improved ingestion throughput. We didn’t benchmark it ourselves, but plenty of benchmarks show that COPY performs much better with large batches.
-
We disabled synchronous replication. In our case, temporary data loss is acceptable — our crawlers are idempotent and can reprocess missing data as needed.
-
We also disabled fsync. Again, durability is less of a concern for this use case, so skipping disk syncs helped with ingest performance.
-
We dropped most indexes in hypertables, only kept one on (account_id, timestamp), and relied on aggressive compression and sparse indexes. The absence of indexes helped with insert rates and didn’t have a significant impact on query performance, because only a very small part of the table was uncompressed and relied on traditional btree indexes.
You can see this system in action at Cloudflare Zero Trust Analytics.
Prioritizing core value and resisting the urge to prematurely optimize can accelerate time to market—and sometimes take you on an unexpected journey that leads to better solutions than you’d originally planned. In the early days of DEX, taking a step back to focus on what truly mattered helped us discover TimescaleDB, which turned out to be exactly what we needed.
Not every team needs a hyper-specialized race car that requires 100 octane fuel, carbon ceramic brakes, and ultra-performance race tires: while each one of these elements boost performance, there’s a real cost towards having those items in the form of maintenance and uniqueness. For many teams at Cloudflare, TimescaleDB strikes a phenomenal balance between the simplicity of storing your analytical data under the same roof as your configuration data, while also gaining much of the impressive performance of a specialized OLAP system.
Check out TimescaleDB in action by using our robust analytics, reporting, and digital experience monitoring capabilities on our Zero Trust platform. To learn more, reach out to your account team or sign up directly here.
How to build young people’s agency through accessible learning
Post Syndicated from Sean Sayers original https://www.raspberrypi.org/blog/how-to-build-young-peoples-agency-through-accessible-learning/
We think computing or computer science (CS) needs to be accessible to all learners, and we know that teachers work hard towards this. Traditional CS approaches can lack flexibility, creating barriers to learning and excluding some young people. In today’s blog, we’re highlighting the ‘Universal design for learning’ (UDL) framework and how you can use it to make computing education more accessible to all your learners.

We also share our new UDL-focused Pedagogy Quick Read, which you can download for free to:
- Find practical tips for how to use the UDL framework and related approaches with your learners
- Read a summary of the research behind the framework
Universal Design for Learning: Because one size does not fit all
Everyone is different and has their own way of learning. What works for one young person may not work for the next. So why should we expect learners to be taught the same material in the same way?
Todd Rose, a contributor to the UDL framework, highlights the factors involved with a young person’s ability to engage and participate in learning. These include cognitive, social-emotional, family background and academic factors. He dispels the idea of an “average” learner, and instead suggests the concept of learner variability.

As educators, it’s important to consider that students will likely be at different stages of understanding, and a one-size-fits-all approach isn’t suitable. The UDL framework avoids this mindset and provides teachers with structured guidelines to design accessible lessons from the beginning.
What is the UDL framework?
The UDL framework encourages educators to provide flexibility for learners in three areas:
- Multiple means of engagement: The “why of learning”, which helps to pique students’ curiosity and motivates them to stay engaged
- Multiple means of representation: The “what of learning”, which focuses on presenting information in different ways to make the content accessible
- Multiple means of action and expression: The “how of learning”, which relates to different ways for students to access learning and express their understanding
How can I apply the UDL framework?
Two things are key while you are planning how to apply the UDL framework with your learners:
- Try not to introduce all three areas at once to your practice. Instead, focus on one area of the framework at a time and reflect to identify where there might be gaps. Focus on these first and make changes one by one.
- Consider how different approaches will work for different groups and individuals. Try to identify what works for your learners and vary or adapt your approach as necessary.
Applying UDL: Some ideas for teaching programming
Multiple means of engagement — show learners different reasons for engaging in programming. For example:
- Solving real-life problems
- Interest in technology or logical thinking
- Creative expression
Multiple means of representation — teach programming concepts in multiple ways. For example:
- Demonstrate through live coding
- Write on a blackboard with a flowchart
- Let learners label and assemble bits of paper into a ‘program’
Multiple means of action and expression — teach with accessibility in mind. For example:
- Use tools appropriate for learners’ mouse and keyboard skills
- Let learners demonstrate their understanding in different ways (e.g. verbally, by writing/drawing, by creating a program)
The UDL framework aligns closely with several key research-supported pedagogies that you can use for effective instruction in computational thinking and programming. For example, the pedagogy approach ‘Use-Modify-Create’ (UMC) can be paired with the UDL categories. The new Quick Read explores these connections in more detail.

The benefits of the UDL framework
Potential benefits for teachers:
- The framework provides a clear structure for designing learning activities that appeal to and engage the widest set of learners
- It can help you consider all the ways you might engage your learners and make CS lessons more accessible.
- UDL encourages you to reflect on the different ways in which you might represent concepts and ideas
- It can help you to build learner agency and independence in your students by offering them different ways to express their learning in CS topics.
Potential benefits for learners:
- The framework promotes a sense of ownership over their learning. Which can boost their motivation and resilience to sticking with difficult challenges.
- They will likely find content that resonates with them, leading to higher engagement and therefore learning.
- They will be able to demonstrate their CS knowledge confidently and engage limitlessly in CS contexts.
Our new Quick Read shares tips on how to best use the framework in your teaching.
Inclusive computer science: The wider context
We know there is a lack of representation within the field of CS. Our recent position paper ‘Why kids still need to learn to code in the age of AI’ and an episode of the Hello World podcast, ‘How can we empower girls in computing’ touched on this. Both highlight why it’s important that learners from all backgrounds are empowered to contribute their perspectives and experiences and shape the future with computing.

“The reality is that access to the opportunities to learn about computer science, programming, and coding has remained deeply unequal, both within and between countries. That has helped create a technology sector that doesn’t reflect the broad diversity of human backgrounds, perspectives, and experiences. And we are all living with the consequences.” – Philip Colligan, Mark Griffiths, Veronica Cucuiat
“If we don’t have a diverse range of people designing and implementing that tech, then we are going to come across issues.” – Becky Patel, Tech She Can, Hello World podcast”
By embracing the principles of ‘Universal design for learning’ and similar approaches, we can create a more inclusive and equitable learning environment in computer science for everyone.
The post How to build young people’s agency through accessible learning appeared first on Raspberry Pi Foundation.
[$] Toward the unification of kselftests and KUnit
Post Syndicated from corbet original https://lwn.net/Articles/1029077/
The kernel project, for many years, lacked a formal testing setup; it was
often joked that testing was the project’s main reason for keeping users
around. While many types of kernel testing can only be done in the
presence of specific hardware, there are other parts of the kernel
that could be more widely tested. Over time, though, the kernel has gained
two separate testing frameworks and a growing body of automated tests to go
with them. These two frameworks — kselftests and KUnit — take different
approaches to the testing problem; now this
patch series from Thomas Weißschuh aims to bring them together.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/1029150/
Security updates have been issued by Debian (djvulibre and slurm-wlm), Red Hat (apache-commons-vfs, container-tools:rhel8, kernel, kernel-rt, podman, python3, rsync, socat, and sudo), SUSE (apache2, helm-mirror, incus, kernel, openssl-3, python-Django, and systemd), and Ubuntu (dcmtk, File::Find::Rule, ghostscript, jquery, and libssh).
1997: When We Captured Video via Parallel Printer Port
Post Syndicated from LGR original https://www.youtube.com/watch?v=hKif5gEV6kc
Introducing Oracle Database@AWS for simplified Oracle Exadata migrations to the AWS Cloud
Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/introducing-oracle-databaseaws-for-simplified-oracle-exadata-migrations-to-the-aws-cloud/
Today, we’re announcing the general availability of Oracle Database@AWS, a new offering for Oracle Exadata workloads, including Oracle Real Application Clusters (RAC) within AWS.
In the past 14 years, customers had the choice of self-managing Oracle database workloads in the cloud using Amazon Elastic Compute Cloud (Amazon EC2) or using fully managed Amazon Relational Database Service (Amazon RDS) for Oracle. Now, you have an additional option for your workloads that require Oracle RAC or Oracle Exadata for quicker and simpler migrations to the cloud. You also get a single invoice through AWS Marketplace, which counts towards AWS commitments and Oracle license benefits, including Bring Your Own License (BYOL) and discount programs such as Oracle Support Rewards.
With Oracle Database@AWS, you can migrate your Oracle Exadata workloads to Oracle Exadata Database Service on Dedicated Infrastructure or Oracle Autonomous Database on Dedicated Exadata Infrastructure within AWS with minimal changes. You can purchase, provision, and manage your Oracle Database@AWS deployments through familiar AWS tools and interfaces such as AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS APIs for applications running on AWS. The AWS APIs call the corresponding Oracle Cloud Infrastructure (OCI) APIs necessary to provision and manage the resources.
Since its preview last December, we’ve improved or added features to help run production workloads at general availability:
- Regional expansion – You can now use Oracle Database@AWS in the U.S. East (N. Virginia) and U.S. West (Oregon) Regions today. We are also announcing plans to expand to 20 AWS Regions globally. This broader availability supports the diverse needs of our customers across various geographical areas so more enterprises can benefit from this option. You can choose from different Exadata system sizes to match your workload requirements in your AWS Region.
- Zero-ETL and S3 backups – You can now benefit from zero-ETL integration with Amazon Redshift for analytics to remove the need to build and manage data pipelines for extract, transform, and load operations. With zero-ETL, you can unify your data on AWS without incurring cross network data transfer costs. We’re providing Amazon Simple Storage Service (Amazon S3) backups with up to eleven nines of data durability.
- Autonomous VM cluster – You can now provision an Autonomous VM Cluster in addition to an Exadata VM cluster on the Exadata Dedicated Infrastructure. You can run Oracle Autonomous Database on Dedicated Exadata Infrastructure, a fully managed database environment using committed hardware and software resources.
Oracle Database@AWS also integrates with other AWS services such as Amazon Virtual Private Cloud (Amazon VPC) Lattice for configuring network paths to AWS services such as S3 and Redshift directly, AWS Identity and Access Management (IAM) for authentication and authorization, Amazon EventBridge for monitoring database lifecycle events, AWS CloudFormation for infrastructure automation, Amazon CloudWatch for collecting and monitoring metrics, and AWS CloudTrail for logging API operations.
Getting started with Oracle Database@AWS
Oracle Database@AWS supports two key services: Oracle Exadata Database Service on Dedicated Infrastructure and Oracle Autonomous Database on Dedicated Exadata Infrastructure within AWS data centers.
These services physically reside within an Availability Zone in an AWS Region and logically reside in an OCI region, enabling seamless integration with AWS services through high-speed, low-latency connections.

You create an ODB network, a private, isolated network that hosts Oracle Exadata VM Clusters within an Availability Zone. Then, you use ODB peering accessible to EC2 application servers running in a VPC. To learn more, visit How Oracle Database@AWS works in the AWS documentation.
Request a private offer in AWS Marketplace
To begin your journey with Oracle Database@AWS, visit the AWS console or request the AWS Marketplace private offer. Your AWS and Oracle sales team will receive your request, then contact you to find the best option for your workloads, and activate your account.

When you activate and get access to Oracle Database@AWS, you can use the Dashboard to create an ODB network, Exadata infrastructure, and Exadata VM cluster or Autonomous VM cluster, and ODB peering connection.

To learn more, visit the Onboarding to Oracle Database@AWS and AWS Marketplace buyer private offers in the AWS documentation.
Create an ODB network
An ODB network is a private isolated network that hosts OCI infrastructure on AWS. The ODB network maps directly to the network that exists within the OCI child site, thus serving as the means of communication between AWS and OCI.
In the Dashboard, choose Create ODB network, enter a network name, choose the Availability Zone, and specify a CIDR ranges for client connections established by applications and backup connections used for taking automated backups. You can also enter a name to use as a prefix to your domain fixed as oraclevcn.com. For example, if you enter myhost, the fully qualified domain name is myhost.oraclevcn.com.

Optionally, you can configure ODB network access to perform automated backups to Amazon S3 and zero-ETL for near real-time analytics and ML on your Oracle data using Amazon Redshift.

After you create your ODB network, update your VPC route tables of your EC2 application servers with the client connection CIDR in the ODB network. To learn more, visit ODB network, ODB peering, and Configuring VPC route tables for ODB peering in the AWS documentation.
Create Exadata infrastructure
The Oracle Exadata infrastructure is the underlying architecture of your database servers, storage servers, and networking that run your Oracle Exadata databases.
Choose Create Exadata infrastructure, enter a name, and use the default Availability Zone. In the next step, you can choose Exadata.X11M for the Exadata system model. You can also set a default of 2 or up to 32 database servers and 3 or up to 64 storage servers with 80 TB storage capacity per server.

Finally, you can configure system maintenance preferences, such as scheduling, patching mode, and OCI maintenance notification contacts. You can’t modify an infrastructure after you create it from the AWS console. But, you can navigate to the OCI console and modify it.
To delete an Exadata infrastructure, visit Deleting an Oracle Exadata infrastructure in Oracle Database@AWS in the AWS documentation.
Create an Exadata VM cluster or Autonomous VM cluster
You can create VM clusters on Exadata infrastructure and deploy multiple VM clusters with different Oracle Exadata infrastructures in the same ODB network.
Here are two types of VM clusters:
- An Exadata VM cluster is a set of virtual machines that has a complete Oracle database installation that includes all features of Oracle Enterprise Edition.
- An Autonomous VM cluster is a set of fully managed databases that automate key management tasks using AI/ML with no human intervention required.
Choose Create Exadata VM cluster, enter a VM cluster name and a time zone, choose Bring Your Own License (BYOL) or license included for license options. In the next step, you can choose your Exadata infrastructure, grid infrastructure version, and Exadata image version. For database servers, you can choose the CPU core count, memory, and local storage for each VM or accept the defaults.

In the next step, you can configure the connectivity setting by choosing your ODB network and entering a prefix for the VM cluster. You can enter a port number for TCP access to the single client access name (SCAN) listener. The default port is 1521 or you can enter a custom SCAN port in the range 1024–8999. For SSH key pairs, enter the public key portion of one or more key pairs used for SSH access to the VM cluster.

Then, you can choose diagnostics and tags, review your settings, and create a VM cluster. The creation process can take up to 6 hours, depending on the size of the VM cluster.
Create and manage an Oracle database
When the VM cluster is ready, you can create and manage your Oracle Exadata databases in the OCI console. Choose Manage in OCI in the details page of the Exadata VM cluster. You will be redirected to the OCI console.

When you create an Oracle Database in the OCI console, you can select Oracle Database 19c or 23ai. When enabling automatic backups for your provisioned databases, you can use an S3 bucket or OCI Object Storage in the OCI region. To learn more, visit Provision Oracle Exadata Database Service in Oracle Database@AWS in the OCI documentation.
Things to know
Here are a couple of things to know about Oracle Database@AWS:
- Monitoring – You can monitor Oracle Database@AWS using Amazon CloudWatch metrics in the
AWS/ODBnamespaces for VM clusters, container databases, and pluggable databases. AWS CloudTrail captures all AWS API calls for Oracle Database@AWS as events. Using CloudTrail logs, you can determine the request that was made to Oracle Database@AWS, the IP address from which the request was made, when it was made, and additional details. To learn more, visit Monitoring Oracle Database@AWS. - Security – You can use IAM to assign permissions that determine who is allowed to manage Oracle Database@AWS resources and SSL/TLS encrypted connections to secure data. You can also use Amazon EventBridge for seamless event-driven database operations—all working together to maintain security standards while enabling efficient cloud operations. To learn more, visit Security in Oracle Database@AWS.
- Compliance – Your compliance responsibility when using Oracle Database@AWS is determined by the sensitivity of your data, your company’s compliance objectives, and applicable laws and regulations. We provides the following compliances with Oracle Database@AWS: SOC 1, SOC 2, SOC 3, HIPAA, C5, CSA STAR Attest, CSA STAR Cert, HDS (France), ISO Series (ISO/IEC 9001, 20000-1, 27001, 27017, 27018, 27701, 22301), PCI DSS, and HITRUST. To learn more, visit Compliance validation for Oracle Database@AWS.
- Support – Your AWS or Oracle sales account team can help you evaluate your current database infrastructure, determine how Oracle Database@AWS can best serve your organization’s requirements, and develop a tailored migration strategy and timeline. You can also get help from AWS Oracle Competency Partners specialized to architect, deploy, and manage Oracle-based workloads running in the AWS Cloud.
Now available and coming soon
Oracle Database@AWS is now available in the U.S. East (N. Virginia) and U.S. West (Oregon) Regions through the AWS Marketplace. Oracle Database@AWS pricing and any AWS Marketplace private offers are set by Oracle. You can see specific details around pricing on Oracle’s pricing page for the offering.
Oracle Database@AWS will expand to 20 more AWS Regions across the Americas, Europe, and Asia-Pacific including: US East (Ohio), US West (N. California), Asia Pacific (Hyderabad), Asia Pacific (Melbourne), Asia Pacific (Mumbai), Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Milan), Europe (Paris), Europe (Spain), Europe (Stockholm), Europe (Zurich), and South America (São Paulo).
You can get started with Oracle Database@AWS with using AWS console. To learn more, visit the Oracle Database@AWS User Guide and OCI documentation and send feedback through your usual AWS Support contacts or OCI support.
— Channy
How to Install Zabbix on Windows with a Linux Subsystem
Post Syndicated from Alexander Petrov-Gavrilov original https://blog.zabbix.com/how-to-install-zabbix-on-windows-with-a-linux-subsystem/30311/
It’s a very well known fact that Zabbix can only be installed on Linux. But what if you are in a Windows environment and getting a Linux machine is not so simple or even possible? This can obstruct the implementation of Zabbix, or at least significantly delay it. Not only that, building a POC outside of the future environment makes data procurement a lot more complicated. Is there a way to work around this and get Zabbix as close to Windows as we possibly can?
Table of Contents
WSL
WSL/WSL 2 is a fast and easy solution for installing and using Zabbix in a smaller Windows-dominant environment, be that a POC or a small company office. WSL 2 runs a real Linux kernel in a lightweight VM while being optimized for Windows. This means a faster start, lower resource consumption, and the ability to share files with Windows directly, meaning you can use Windows File explorer to find and manage the VM files.
WSL 2 also allows you to use Linux CLI while working with Windows (i.e. running vim from a Windows terminal and editing Windows files directly). At this point, you may be asking yourself, “Why not Hyper-V and VirtualBox?” Those are definitely options too, but they are quite heavy on system resources. In addition, boot times are a bit longer and sharing files between a host and a guest OS is clunkier.
Maybe Docker Desktop then? It’s an absolutely valid option, but that would require a bit of Docker knowledge and you would still be using WSL, technically speaking. So, with that said, WSL is definitely the fastest and most reliable way to sprung a Zabbix instance in a Windows-focused environment.
We will use WSL 2, but as a note WSL 1 is also available. Here are the differences:
- WSL 2 is usually the better performer overall, especially for dev environments. It also has better Linux compatibility.
- WSL 1 Linux files aren’t isolated, which can make them more accessible. In WSL 2, Linux runs in a virtual disk (ext4), so Linux and Windows files are more separate. Integration is still pretty good, however.
- WSL 2 has better Linux compatibility – systemd, iptables, etc.
- WSL 1 shared the same IP as Windows, WSL 2 is a VM – some networking required.
- With WSL 1 you can see Linux running processes in Task Manager. WSL 2 will have processes isolated.
Installing Zabbix using WSL
Install WSL
Open PowerShell as an Administrator and run:
PS C:\Windows\system32> wsl --installIf you’ve already have WSL 1 installed, update it:
PS C:\Windows\system32> wsl --updateYou can also set WSL 2 as default:
PS C:\Windows\system32> wsl --set-default-version 2
Install/Get preferred Linux Distribution using either Microsoft Store (i.e. Ubuntu, Debian, Oracle Linux) or just download directly. I will be using Oracle Linux 9.4.
You can also download the RootFS tarball from the preferred distribution portal, but then the process will be a bit different. Create a folder using PowerShell:
PS C:\Windows\system32> mkdir C:\WSL\OracleLinux9Copy the .tar.xz file to this folder, then run:
PS C:\Windows\system32> wsl --import OracleLinux9 C:\WSL\OracleLinux9 .\oraclelinux9-rootfs.tar.xz --version 2After the image is installed or imported, start Oracle Linux using PowerShell:
PS C:\Windows\system32> oraclelinux94When installation is finished, there is a prompt to create a default UNIX user account and password for the said user, as the username does not need to match your Windows username. I’ll set it to “zabbix” of course, but you can set it to any other.
PS C:\Windows\system32> Enter new UNIX username:
PS C:\Windows\system32> zabbix
PS C:\Windows\system32> New password: <your-password>
PS C:\Windows\system32> passwd: all authentication tokens updated successfully.
PS C:\Windows\system32> Installation successful!
Now OracleLinux is ready for use!
Prepare the system
You will be immediately logged in to the new environment. If logged out, to log in again just execute in PowerShel:
PS C:\Windows\system32> oraclelinux94Being logged in, first double check that your selected OS is indeed installed by executing in the PowerShell, which will now serve as your VM CLI access point:
[zabbix@PC-NAME ~]$ cat /etc/os-release
NAME="Oracle Linux Server"
VERSION="9.4"
ID="ol"
ID_LIKE="fedora"
VARIANT="Server"
VARIANT_ID="server"
VERSION_ID="9.4"
PLATFORM_ID="platform:el9"
PRETTY_NAME="Oracle Linux Server 9.4"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:oracle:linux:9:4:server"
HOME_URL="https://linux.oracle.com/"
BUG_REPORT_URL=https://github.com/oracle/oracle-linux
Confirmation received, make sure all OS updates are installed:
[zabbix@PC-NAME ~]$ sudo dnf update -yWhen the update process is finished, you will need to decide whether you would like to use systemd or not (this may increase booting time). I will enable systemd. To do this, edit the wsl.conf on the Linux subsystem:
vi /etc/wsl.confAdd to the newly created file:
[boot]
systemd=true
Reboot the images (this command will reboot all of them):
PS C:\Windows\system32> wsl.exe --shutdownStart back your Linux distribution:
PS C:\Windows\system32> oraclelinux94Install Zabbix database
We will need to prepare the database engine. Again, any preferred database engine can be used, in this case I install and configure MariaDB:
[zabbix@PC-NAME ~]$ sudo dnf install -y mariadb-server mariadb
[zabbix@PC-NAME ~]$ sudo systemctl enable --now mariadb
Confirm MariaDB is running:
[zabbix@PC-NAME ~]$ Systemctl status mariadb
mariadb.service - MariaDB 10.5 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled)
Active: active (running) since Tue 2025-04-29 12:39:54 EEST; 3min 55s ago
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Main PID: 235 (mariadbd)
Status: "Taking your SQL requests now..."
Tasks: 9 (limit: 26213)
Memory: 109.6M
CGroup: /system.slice/mariadb.service
└─235 /usr/libexec/mariadbd --basedir=/usr
After confirmation, secure it a bit by creating a root password and selecting the options in bold:
[zabbix@PC-NAME ~]$ sudo mysql_secure_installation
Enter current password for root (enter for none):
OK, successfully used password, moving on...
Setting the root password or using the unix_socket ensures that nobody
can log into the MariaDB root user without the proper authorisation.
You already have your root account protected, so you can safely answer 'n'.
Switch to unix_socket authentication [Y/n] n
... skipping.
You already have your root account protected, so you can safely answer 'n'.
Change the root password? [Y/n] Y
New password:
Re-enter new password:
Password updated successfully!
Reloading privilege tables..
... Success!
Remove anonymous users? [Y/n] Y
... Success!
Disallow root login remotely? [Y/n] Y
... Success!
Remove test database and access to it? [Y/n] Y
Reload privilege tables now? [Y/n] Y
... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MariaDB
installation should now be secure.
Thanks for using MariaDB!
Now to create the Zabbix database. Log in to MariaDB:
[zabbix@PC-NAME ~]$ sudo mysql -u root -p
[zabbix@PC-NAME ~]$ Enter password: <enter your password, won’t be visible>
Follow the steps from the Zabbix installation page:
MariaDB [(none)]> create database zabbix character set utf8mb4 collate utf8mb4_bin;
MariaDB [(none)]> create user zabbix@localhost identified by '<custom-password>';
MariaDB [(none)]> grant all privileges on zabbix.* to zabbix@localhost;
MariaDB [(none)]> set global log_bin_trust_function_creators = 1;
MariaDB [(none)]> quit;
Installing Zabbix
Install the Zabbix repository:
[zabbix@PC-NAME ~]$ sudo dnf install https://repo.zabbix.com/zabbix/7.0/centos/9/x86_64/zabbix-release-latest-7.0.el9.noarch.rpm
[zabbix@PC-NAME ~]$ dnf clean allProceed to install the Zabbix server, frontend, and agent:
[zabbix@PC-NAME ~]$ sudo dnf -y install zabbix-server-mysql zabbix-web-mysql zabbix-apache-conf zabbix-sql-scripts zabbix-selinux-policy zabbix-agent
...
[zabbix@PC-NAME ~]$zabbix-agent-7.0.12-release1.el9.x86_64 zabbix-apache-conf-7.0.12-release1.el9.noarch zabbix-selinux-policy-7.0.12-release1.el9.x86_64 zabbix-server-mysql-7.0.12-release1.el9.x86_64 zabbix-sql-scripts-7.0.12-release1.el9.noarch
zabbix-web-7.0.12-release1.el9.noarch zabbix-web-deps-7.0.12-release1.el9.noarch zabbix-web-mysql-7.0.12-release1.el9.noarch
Complete!
Now import the initial database schema:
[zabbix@PC-NAME ~]$ zcat /usr/share/zabbix-sql-scripts/mysql/server.sql.gz | mysql -u zabbix -p zabbix
Enter password: <enter your DB user password and wait until you will see the next line appear>
[root@ZBX-5CD3221K14 zabbix]#
Disable the log_bin_trust_function_creators option after import has finished:
# mysql -uroot -p
password
MariaDB [(none)]> set global log_bin_trust_function_creators = 0;
MariaDB [(none)]> quit;
Add your Zabbix user database password to the Zabbix server configuration file:
[zabbix@PC-NAME ~]$ vi /etc/zabbix/zabbix_server.conf### Option: DBPassword
# Database password.
# Comment this line if no password is used.
#
# Mandatory: no
# Default:
DBPassword=<your-DB-user-password>Start the Zabbix server and frontend and add them to autorun:
[zabbix@PC-NAME ~]$ systemctl restart zabbix-server zabbix-agent httpd php-fpm
[zabbix@PC-NAME ~]$ systemctl enable zabbix-server zabbix-agent httpd php-fpm
Created symlink /etc/systemd/system/multi-user.target.wants/zabbix-server.service → /usr/lib/systemd/system/zabbix-server.service.
Created symlink /etc/systemd/system/multi-user.target.wants/zabbix-agent.service → /usr/lib/systemd/system/zabbix-agent.service.
Created symlink /etc/systemd/system/multi-user.target.wants/httpd.service → /usr/lib/systemd/system/httpd.service.
Created symlink /etc/systemd/system/multi-user.target.wants/php-fpm.service → /usr/lib/systemd/system/php-fpm.service.
Installation of the backend is now finished, but we still need the frontend.
Exposing and installing the Zabbix frontend for WSL
Since WSL2 does not expose services to localhost by default, you need to determine the WSL IP:
[zabbix@PC-NAME ~]$ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:15:5d:47:32:c6 brd ff:ff:ff:ff:ff:ff
inet 172.29.128.155/20 brd 172.29.143.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fe47:32c6/64 scope link
valid_lft forever preferred_lft forever
Look for an IP like 172.x.x.x, then using your browser go to:
http://<WSL_IP>/zabbixIn this example, that would be:
http://172.29.128.155/zabbixYou can also port forward WSL to localhost with netsh in PowerShell:
PS C:\Windows\system32> netsh interface portproxy add v4tov4 listenport=8080 listenaddress=127.0.0.1 connectport=80 connectaddress=<WSL_IP>Then you will be able to access Zabbix from http://localhost:8080/zabbix. Now, just finish the standard frontend setup and Zabbix is ready to use!
WSL advantages
Some extra advantages you get with this approach include clearer resource usage visibility:

Direct access to the Linux subsystem files through File explorer with your favorite Windows tools:
As you can see, docker is here as well. System and configuration files are also visible and editable:
Now you can proceed with building your Zabbix or Zabbix POC, (almost) without needing to leave your regular Windows environment!
The post How to Install Zabbix on Windows with a Linux Subsystem appeared first on Zabbix Blog.
Хоругвата на фундаментализма
Post Syndicated from original https://www.toest.bg/horugvata-na-fundamentalizma/

Центърът на София е известен с близостта, в която се намират един до друг православен храм, католическа църква, джамия и синагога. Тази симпатична топография се възприема като доказателство за религиозната толерантност на българина и все още често се изтъква като предимство на страната ни. Опитите за нарушаване на хармонията, например случаят, когато симпатизанти на партия „Атака“ нападнаха молещи се мюсюлмани, се посрещат с обществено порицание.
За човек, който живее в такава среда, понякога е трудно да го осъзнае, но междуверската търпимост наистина е достижение. Миналото на Европа, а и на света е показало, че някои от най-тежките и нерешими конфликти се пораждат от идеята, че една религия трябва да се наложи силом над останалите. Това, поне на пръв поглед, не е характерно за България. Макар да се гордеем с делото на покръстителя княз Борис и да изтъкваме, че сме дали православието на други народи, като руснаци и украинци, ние никога не сме били фанатични.
У нас винаги е имало алтернативни учения, например богомилството през средните векове и философията на Петър Дънов от по-ново време, а за някои хора те са неразделна част от българското. Освен това още преди покръстването българите са флиртували с Ватикана и макар в крайна сметка да избират друго, у нас има компактни общности католици, съществуващи до ден днешен. В страната се срещат също протестанти, апостолици (арменци), юдеи, в по-ново време мормони, будисти, привърженици на движението „Харе Кришна“. Няма как да не се отбележи и сравнително високият процент мюсюлмани, които съставляват втората по големина религия в страната. И макар миналото да пази някои травматични моменти, като цяло тези религиозни общности живеят в мир помежду си.
Напоследък обаче изглежда, че картината започва да се променя.
Българската православна църква (БПЦ) става все по-активна в обществения живот и се опитва да наложи ценностите си на всички. Тя може да си го позволи, защото, макар българите да не са от най-редовно черкуващите се народи, православието играе специална роля в историята ни. Мнозина смятат, че то е основен фактор за съхраняването ни като общност през вековете на османско владичество. Именно борбите за църковна независимост предшестват освободителните движения, а обобщението на всичко това е дадено от митрополит Климент (Васил Друмев):
Има православие – има и български народ; няма православие – няма и български народ.
Православната църква играе важна роля като знак за тиха съпротива срещу атеизма, силово налаган от комунистическата власт по време на тоталитарния период. В храмовете, които посещават, докато са следени от милицията, много българи откриват упование и обещание за справедливост във вечността, което е по-вдъхновяващо от сивите лозунги за светлото социалистическо бъдеще и преизпълнените петилетки. Вярата се превръща в алтернатива на грубия материализъм и затова в първите години на Прехода принадлежността към нея е почти част от демократичната идентичност.
За съжаление, тъкмо по време на тоталитаризма текат процеси, даващи негативно отражение днес.
Голяма част от висшия клир, а и не само, бива вербувана от комунистическата Държавна сигурност. Можем само да спекулираме дали някогашните агенти и доносници са станали вярващи, напасвайки християнските догми с дадените им от комунистическия кесар задачи, или пък са просто лицемерни. Факт е обаче, че някъде в този етап в Българската църква се заражда изключителна вярност към Русия, тогава част от Съветския съюз, където подобни агентурни процеси вече са протекли.
В днешната Руска федерация Православната църква изпълнява ролята на държавна доктрина, която оправдава и благославя завоевателните цели на режима на президента Владимир Путин. Тя окуражава подчинението пред властимащите. Това е показано във филма „Левиатан“ на Андрей Звягинцев, където свещеник със сковано лице и леден глас дава съвети на местен олигарх, че всяка власт на Земята е дадена от Бога и той не трябва да се бои да я изпълнява.
За Руската православна църква войната, която Путин води срещу Украйна, е свещена – концепция, която дори за средновековна Византия би била прекалена. Макар и благочестиво, както проповядва православието, Кремъл все пак има враждебно отношение към западните християни, особено към католиците, които се възприемат като част от вражеския колективен Запад. Поради това много руснаци, особено националистите, възприемаха с недоверие опитите на папа Франциск да посредничи за мир за войната в Украйна, докато в същото време украинци го упрекваха, че е твърде отстъпчив пред Москва. ЛГБТ хората са обявявани на практика за престъпници просто защото ги има. Напоследък на мушка попадат и тези, които нямат деца – смразяващ завой, който, за съжаление, може би намеква какво ни очаква и в България.
Причина за тревога
е изборът на сравнително младия и изключително деен Даниил за патриарх през миналата година. Като духовник той води аскетичен начин на живот, което е достойно за уважение. Нееднократно обаче е изразявал политически позиции, близки до тези на руската държава, и под негово ръководство Църквата започва все по-активно да се намесва и в светския живот. Неговото предстоятелство е не толкова начало, колкото кулминация на процес, започнал преди няколко години. Симптоматично беше поведението на БПЦ при посещението на папа Франциск в България, когато мюсюлмани, юдеи и протестанти се молиха заедно с главата на римокатолиците, но представителите на православното духовенство отказаха.
В наши дни видяхме Църквата да изразява отрицателно становище към традиция като нестинарството, което предизвика хумористични реакции в социалните мрежи. Привидно аргументът е железен спрямо канона – обичаят е езически. В действителност обаче между религията и дохристиянските вярвания в България, а и по цял свят често има симбиоза, включително датите, на които празнуваме Коледа и Великден, свързани пряко със зимното слънцестоене и пролетното равноденствие. Професор Клайв С. Луис, може би най-известният християнски апологет на ХХ век, дори стига дотам, че твърди как езическите митове за завърнали се от смъртта са подготвяли хората за истинското възкресение. Доколко тогава е удачно да се нападат хора, почитащи икони дори по време на чисто фолклорен ритуал?
{kind=link}
Това отношение започва да се просмуква полека-лека и сред миряните. По проруска линия интелектуалци, свързани с вярата, заемат позиция срещу Вселенската патриаршия и в подкрепа на Руската православна църква, особено по въпроса коя е действителната църква в Украйна. Католиците, каквито у нас има хиляди, лековато са наричани еретици. Професор Калин Янакиев, чиито познания за историята на православието са изключителни, оборва това определение, но самият той признава, че е обект на нападки заради позициите си.
Невинен поздрав за еврейския празник Ханука на водеща медия у нас предизвика просташки коментари в социалните мрежи – нещо, което бе забелязано и от посланика на Израел. Част от тях бяха реакция на войната в Газа, но в други се долавяше нетолерантността към вярата, която не е „нашата“, „ние това не го празнуваме“. По време на последните местни избори в София в казус се превърна фактът, че кандидатът за кмет Васил Терзиев симпатизира на Петър Дънов. Дъновизмът действително противоречи на православната догма. Това обаче не би трябвало да е проблем за заемане на определен пост в светска държава. На всеки Хелоуин празнуващите с маски деца биват обвинявани в сатанизъм.
Тези неща изглеждат смешни и нелепи, но съвсем не са невинни.
Езикът на омразата може лесно да премине в действия, първоначално сравнително безобидни, като анекдотичните разкази за съборена украса на Хелоуин, но после опасни и агресивни, каквото би било физическото насилие срещу някой „друговерец“. Още повече че предстои въвеждането на религиозно обучение в училищата, което ще сегрегира децата и ще изолира католици, протестанти, евреи и атеисти. Тук не отварям дума за учениците с алтернативна сексуалност, каквато, така или иначе, е забранено да се обсъжда със закон, отново с одобрението на Църквата.
Като цяло трябва да се има предвид, че всяка религиозна общност споделя канони и вярвания и има право да следи за спазването им от своите последователи. От тази гледна точка е неправилно да очакваме Църквата да промени свои хилядолетни канони относно теми като брака и целомъдрието, нито да искаме публично да признае за приемливи учения, несъвместими със свещените ѝ книги.
В същото време България е светска страна, в която Църквата е отделена от държавата, и не е коректно да се създава обстановка на нетърпимост към хората извън паството на БПЦ.
Намирането на баланса не е лесна задача, тъй като религиозният фундаментализъм може да оправдае всяко зверство. Фанатично вярващите мислят, че спасяват неверниците. При положение че според вярата им душите им би следвало да са безсмъртни, а човешкият живот трае средно 70–80 години, тълкуванието е, че каквото и страдание да причинят в този живот, то бледнее пред риска душата на жертвата им да попадне в ада, където ще бъде подложена на вечни мъчения. Въпросът е, че поне в християнството, сред чиито деноминации е и православието, съществува концепцията за свободна воля, а тя се нарушава, когато възможните алтернативи биват потискани.
Разбира се, за ислямските фундаменталисти абсолютната свобода идва тогава, когато можеш да избереш Бога без никакви „пречки“. Само че това мислене е създало ужаса на самоубийствените атентати, както и режими като този на талибаните в Афганистан, където всяка радост от живота бива потисната в името на „благочестието“.
България все още е много далеч от такова състояние и в интерес на истината, православието е подкрепяно не толкова като единствен верен път към Бога, колкото като белег на националната идентичност. Това го прави елемент от национализма, който се разгаря у нас през последните вече 20 години (ако броим за началото му пробива на „Атака“ на парламентарните избори през 2005 г.). Въпреки че у нас и национализмът е свързан със силна привързаност към чужда държава, която пък ни е посочила официално за врагове.
Но първите стъпки към по-сериозно развихряне на някакъв религиозен фундаментализъм сякаш вече са направени. Важно е да си дадем сметка за това. Така поне няма да бъдем изненадани, ако един ден завалят директните предложения за забрана на цели вероизповедания (едно вече беше шкартирано) и ограничаването на права, които погрешно днес смятаме за даденост.
Българският народ все още има традиция във верската търпимост. Само времето ще покаже дали тя ще бъде продължена.
This is the New Double Wide NIC with 8x 25GbE Ports Using the Intel E830 NIC
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/this-is-the-new-double-wide-nic-with-8x-25gbe-ports-using-the-intel-e830-nic/
At HPE Discover 2025 we found this 8-port 25GbE NIC using the new DSFF layout and based on the new Intel E830 200Gbps NIC silicon
The post This is the New Double Wide NIC with 8x 25GbE Ports Using the Intel E830 NIC appeared first on ServeTheHome.
Home Assistant 2025.8 Release Party
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=gNtNOtsTH1w
Comic for 2025.07.08 – Become Religious
Post Syndicated from Explosm.net original https://explosm.net/comics/become-religious
New Cyanide and Happiness Comic
The Best Thing…
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/shorts/40A1gnb5K_o
AWS Weekly Roundup: EC2 C8gn instances, Amazon Nova Canvas virtual try-on, and more (July 7, 2025)
Post Syndicated from Elizabeth Fuentes original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-amazon-bedrock-api-keys-amazon-nova-canvas-virtual-try-on-and-more-july-7-2025/
Every Monday we tell you about the best releases and blogs that caught our attention last week.
 Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.
Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.
This excites me because I’ll have the opportunity to connect with new communities in the Bay Area while tackling exciting new challenges. If you’re part of a community focused on building generative AI and agentics applications, or know of one, I’d love to connect. Let’s connect!
Last week’s launches
Here are the launches from last week:
- New Amazon EC2 C8gn instances powered by AWS Graviton4 offering up to 600Gbps network bandwidth – Amazon Elastic Compute Cloud (Amazon EC2) C8gn instances are now generally available, powered by AWS Graviton4 processors and 6th generation AWS Nitro Cards. These network-optimized instances deliver up to 600 Gbps network bandwidth. This represents the highest bandwidth among EC2 network-optimized instances, with up to 192 vCPUs and 384 GiB memory. They provide 30% higher compute performance than C7gn instances and are ideal for network-intensive workloads like virtual appliances, data analytics, and cluster computing jobs.
- Build the highest resilience apps with multi-Region strong consistency in Amazon DynamoDB global tables – Amazon DynamoDB global tables now supports multi-Region strong consistency (MRSC) for applications requiring zero Recovery Point Objective (RPO). This capability ensures applications can read the latest data from any Region during outages, addressing critical needs in payment processing and financial services. MRSC requires three AWS Regions configured as either three full replicas or two replicas plus a witness, providing the highest level of application resilience for mission-critical workloads.
- Amazon Nova Canvas update: Virtual try-on and style options now available – Amazon Nova Canvas introduces virtual try-on capabilities that help you visualize how clothing looks on a person by combining two images, plus eight new pre-trained style options (3D animation, design sketch, vector illustration, graphic novel, etc.) for generating images with improved artistic consistency. Available in three AWS Regions, these features enhance AI-powered image generation capabilities for retailers and content creators seeking realistic product visualizations.
- Amazon Q in Connect now supports 7 languages for proactive recommendations – Amazon Q in Connect, a generative AI-powered assistant for customer service, now provides proactive recommendations in seven languages: English, Spanish, French, Portuguese, Mandarin, Japanese, and Korean. The AI-powered customer service assistant detects customer intent during voice and chat interactions to help agents resolve issues quickly and accurately.
- Amazon Aurora MySQL and Amazon RDS for MySQL integration with Amazon SageMaker is now available – This integration provides near real-time data availability for analytics. It automatically extracts MySQL data into lakehouses with Apache Iceberg compatibility. You can then access this data seamlessly through various analytics engines and machine learning tools.
- Amazon Aurora DSQL is now available in additional AWS Regions – Amazon Aurora DSQL expands to Asia Pacific (Seoul) and now supports multi-Region clusters across Asia Pacific and European regions. This serverless, distributed SQL database offers unlimited scalability, highest availability, and zero infrastructure management with AWS Free Tier access.
Other AWS blog posts
- Optimize RAG in production environments using Amazon SageMaker JumpStart and Amazon OpenSearch Service – Learn how to optimize Retrieval Augmented Generation (RAG) in production environments using Amazon SageMaker JumpStart and Amazon OpenSearch Service. This comprehensive guide demonstrates implementing RAG workflows with LangChain, covers OpenSearch optimization strategies, provides setup instructions, and explains benefits of combining these AWS services for scalable, cost-effective generative AI applications.v
- Agentic GenAI App Using Bedrock, MCP servers on EKS – This post shows how to build a scalable AI chat application using Amazon Bedrock, Strands Agent, and Model Context Protocol (MCP) servers deployed on Amazon Elastic Kubernetes Service (Amazon EKS). The architecture combines agentic workflows with containerized microservices for intelligent, auto-scaling conversations with multiple foundation models.
- Enforce table level access control on data lake tables using AWS Glue 5.0 with AWS Lake Formation – AWS Glue 5.0 introduces Full-Table Access (FTA) control for Apache Spark with AWS Lake Formation, providing table-level security without fine-grained access overhead. This feature supports native Spark SQL/DataFrames for Lake Formation tables. It enables read/write operations on Iceberg and Hive tables with improved performance and lower costs.
Upcoming AWS events
Check your calendars and sign up for these upcoming AWS events:
- AWS re:Invent – Register now to get a head start on choosing your best learning path, booking travel and accommodations, and bringing your team to learn, connect, and have fun. Early-career professionals can apply for the All Builders Welcome Grant program, designed to remove financial barriers and create diverse pathways into cloud technology. Applications are now open and close on July 15, 2025.
- AWS NY Summit – You can gain insights from Swami’s keynote featuring the latest cutting-edge AWS technologies in compute, storage, and generative AI. My News Blog team is also preparing some exciting news for you. If you’re unable to attend in person, you can still participate by registering for the global live stream. Also, save the date for these upcoming Summits in July and August near your city.
- AWS Builders Online Series – If you’re based in one of the Asia Pacific time zones, join and learn fundamental AWS concepts, architectural best practices, and hands-on demonstrations to help you build, migrate, and deploy your workloads on AWS.
- Join AWS Gen AI Lofts – Experience AWS Gen AI Lofts across San Francisco, Berlin, Dubai, Dublin, Bengaluru, Manchester, Paris, Tel Aviv, and additional locations – hands-on workshops, expert guidance, investor networking, and collaborative spaces designed to accelerate your generative AI startup journey.
You can browse all upcoming in-person and virtual events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
— Eli
U-Boot v2025.07 released
Post Syndicated from jake original https://lwn.net/Articles/1029092/
The U-Boot universal bootloader project
has announced the release of version 2025.07. It has multiple new features
including “uthreads” (inspired by the “bthreads” coroutines in the barebox bootloader), exFAT support,
new architecture and SoC support and improvements to existing platforms,
cleanups, better testing, and more. Project leader Tom Rini took the
opportunity to mention his efforts
toward getting some help with the project and more formal governance:
As this is a full release, and not just a release candidate I’m hoping
for a few more people to read this and then read what I’m linking to as
well. For the overall health of the project, and the community, I’m
hoping to find a few people within the community that can help with
overall organization and management. I would like to long term be able
to move us to being under the Software Freedom Conservancy umbrella and
that in turn means having a organizational structure that’s not just a
single person.
He also noted that there is a community meeting on July 8th, 2025 at 9am (GMT -06:00) on
Google Meet.
„Киберпънк 2077“. Удоволствие и лудонаративен дисонанс (трета част)
Post Syndicated from original https://www.toest.bg/kiberpunk-2077-udovolstvie-i-ludonarativen-disonans-3/
<< Към втора част

Северина Станкева: Според мен В. препраща и към едноименния роман на Пинчън. Там паралелно текат два разказа: от една страна – този на Бени Профейн, бивш моряк от американските Военноморски сили, който безцелно се шляе из Ню Йорк; от друга – този на Хърбърт Стенсил, англичанин, обсебен да намери мистериозната В., която присъства в дневниците на изчезналия му баща.
В. се появява постоянно в различни фигури: като жена в центъра на политическа интрига в Кайро през XIX век, като плъх от нюйоркското метро, който иска да стане монахиня, като града Валета, като малтийка, която е модифицирала тялото си толкова, че почти нищо естествено не е останало в него – има стъклено око с часовников механизъм, метална пластина в черепа и изкуствени крака.
Освен очевидната близост с кибернетичните протези, в „Киберпънк“ – и в романа, и в играта – имаме, най-общо казано, две линии на всяко ниво, които в крайна сметка така и не могат да се съберат, за да образуват постоянен център, но парадоксално, не могат да бъдат и съвсем ясно отделени. Разцеплението е в самия главен герой, доколкото той е буквално обсебен от друга персона. И доколкото се олюлява между тоталния нихилизъм и търсенето на смисъл в града, който обещава високи технологии и слава, но заедно с това носи мизерен живот. Разрив има и у Джони, чиято сребърна ръка е всъщност производство на „Арасака“ – корпорацията, срещу която е насочен бунтът му. Понеже тези противоречия са вплетени наративно, започнах с това, че играта ми се струва по-скоро резонантна, макар да съм съгласна, че изпълняването на тривиални поръчения, когато се предполага, че главният герой умира, е класически пример за лудонаративен дисонанс.
Връщайки се към невъзможността да се разграничи автентичното от фалша, изглежда, че съпротивата е обезвредена от процес, наречен от Дебор recuperation (възстановяване) – в него всяка революционна идея се попива от масовата култура. Един от въпросите на играта е възможно ли да има ответен удар, или détournement (преобръщане), при който, обратно, средствата на зрелището се използват с подривни цели. Като че ли ясен отговор не е даден, дори ми се струва, че допълнително се проблематизира невъзможността за отличаване на едното от другото.
Например в мисията Killing in the name, чието заглавие неслучайно препраща към песен на антиавторитарната, но комерсиално много успешна банда Rage Against the Machine, В. тръгва по следите на мистериозния хакер Сведенборг-Ривиера, разпространяващ криптирани бунтовнически слогани из интернет, като „Човечеството е само финансова пирамида, скрита зад фасада от сълзи“, от които Джони е изключително впечатлен. След доста продължително лутане в търсене на източника става ясно, че Сведенборг всъщност е хакната машина за гадаене, която е препрограмирана да произвежда псевдофилософски брътвежи. Играчът има три възможности: да остави машината, както си е, да я изключи или да я препрограмира отново, така че да говори още по-големи глупости от типа на „Средствата за производство трябва да принадлежат на колективното несъзнавано“. Джони е най-доволен от последната. Невъзможността да се отсъди категорично за значението на подобни действия е изключително интересна тема.


Кадри от „Киберпънк“
Николай Генов: Да мислим Джони като отпадъчен остатък от една традиция ми се струва особено важен ход, защото подобна интерпретация отваря неговия образ към литературния му първоизточник и с това позволява да свържем две различни медии. В случая, разбира се, визирам книгите от поредицата „Киберпънк 2020“ – настолната ролева серия на Майк Пондсмит, публикувана през 1988 г., чийто свят компютърната „Киберпънк 2077“ наследява.
В този текст от края на 80-те години Джони е доста по-различен от превъплъщението на Киану Рийвс. Той е, така да се каже, далеч по-наивен и чист; не е толкова циничен, самодеструктивен, фанатичен или брутален. Има си перчем. Вежлив е, извинява се често. С две думи, добро момче, което само иска да спаси своята приятелка Алт от ръцете на „Арасака“ в разказа „Не изтлявай“ (Never Fade Away). За целта той е готов да подгрее и настърви тълпа младежи срещу корпорацията, използвайки собствената си музика като оръжие през 2013 г.
Защо това има някакво значение?
Както Чавдар вече отбеляза, ние не можем да бъдем сигурни доколко дигиталният образ на Джони отговаря на действителния. Фенове вече забелязват определени наративни разминавания. Например Морган Черната ръка (Blackhand) – друг важен герой от фикционалната вселена, към когото има препратки в компютърната игра – бива нает от „Милитех“, за да взриви кулата на техния най-голям конкурент. Джони, вече някак променен след смъртта на Алт, е с него. Годината е 2023-та. Екипите на двамата де факто изпълняват корпоративна поръчка. Не така ни е представена историята през очите на двойника обаче. Това променен разказ ли е, или подвеждащо свидетелство? Проблем на адаптацията или повествователна стратегия? Имало ли е някога истински бунт, или и той ще се окаже поредната фикция?
Струва ми се, че отговорът може да дойде само през главния герой и решенията на играча; впрочем хубав повод да се запитаме отново какво точно е В. и какви са неговите функции в „2077“.
Миглена Николчина: Преди настолните игри на 80-те са реалните прототипи от 60-те – екстатично-трагичната биография на Джим Морисън например. Вървейки назад, ще стигнем до Хийтклиф, до Байрон, до бунта на романтизма. В тази перспектива бунтарският аспект на автодеструктивността на Джони ми се вижда логичен, каквито и противоречиви черти да притежава.
В моралната или въобще в личностната хетерогенност на персонажите има обаче и аспект, произтичащ от „стереоскопичната“ направа на героите в ролевите видеоигри: изборите, които прави играчът, „извайват“ не само облика на аватара, но и на неигровите действащи лица. Аватарът е съединен с останалите персонажи в мрежа, като скачени съдове са, промените засягат цялата система. Това че влюбеността на моята аватарка в Джони го възприемаше като анимус, като аспект на собствената ѝ психика, някак неизбежно предполагаше той да се жертва, тоест да се разтопи, да изчезне като отвъдно сияние в собствената ѝ кратка слава.
Впрочем може би най-тежкият избор е между Рийд и хакерката „Пойна птица“ (Songbird – ако си бях превела името ѝ навреме, може би нямаше да застана на нейна страна – кому „пее“ тя?). В този избор може би се крие и най-дълбоката ирония на играта, тъй като и двамата обслужват един и същи имперски режим, който разчита на лоялност, без да се отплаща с лоялност. Двамата са персонажи в добавката „Фантомна свобода“, която повдига на степен дистопийните аспекти на играта. Редица детайли, включително името на обожествения господар на една отцепила се като автономна зона част на града, говорят за преднамерена аналогия между „Фантомна свобода“, от една страна, а от друга, „Сърцето на мрака“ на Джоузеф Конрад и базирания върху новелата филм на Копола „Апокалипсис сега“. И в трите случая Курц/Кърц/Кърт Хансен е бивш служител на империята, която иска да го отстрани, защото вече не ѝ се подчинява, но и защото като неин продукт я компрометира. Той действа, сякаш е загубил разсъдъка си, държи се като божество, боготворен е от онези, които смазва, и е преминал всички граници на чудовищно кървава злоупотреба с властта си. И в трите случая обаче тази лудост се състои в смъкването на лицемерната идеологическа фасада на бившите му господари, в които е вярвал – той просто продължава да прави в собствената си зона това, което е правил за тях, оголвайки бруталната истина от „смокиновия лист“ на претенциите за право и морал.
Сравнението с Конрад и Копола обаче не работи в полза на играта. Новелата и филмът неумолимо ни водят към страховита развръзка, която ни среща с човек, поел върху себе си злото в пълно съзнание, човек, който – за да го кажем по Ницше тук – се е взрял в бездната, и тя също се е взряла в него. „Ужасът. Ужасът“ – е последната му реплика, преди да умре. Той е престъпникът и жертвата – за да се върнем към тази тема – засмукал в себе си вината и греха на онези, които е обслужвал.
Лудонаративният дисонанс, за жалост, превръща Кърт Хансен в поредния казионен противник, който трябва да бъде отстранен; не му позволява да постигне статута на своите предшественици. Така заковаването на пироните върху разпънатия Грешник отново ще се окаже по-откровената версия на една тема, която пронизва играта на всички нива.


Кадри от „Киберпънк“
Еньо Стоянов: Когато обсъждаме играта, не бива да забравяме и как тя тематизира изборите, които вменява на играча. Още преди първата мисия от основния сюжет, чиито последствия определят ситуацията на В., един от персонажите формулира темата така: „Дали искаш да изгориш в блясъка на славата, или да изтлееш като господин/госпожа Никой в собственото си легло?“ Тоест алтернатива между индивидуален бунт, утвърждаващ смисъла на живота само под формата на преждевременна и зрелищна смърт, и съответно комфорта на безропотно подчинение на корпоративните господари на града.
Несъмнено всички герои, които коментираме тук – Джони¹, Грешника, В. (поне в началото) – са склонни да предпочитат първото². Но играта всякак се опитва да покаже защо това е фалшив избор. И смъртта „в блясъка на славата“ неизбежно се оказва обезсмислена, тъй като дирижиращите спектакъла корпорации отново си я присвояват – на мястото на атентата, извършен от Джони, в съвремието на играта има музеен атракцион; Джошуа – независимо колко искрен е – вижда стойност единствено в превръщането на мъченичеството си в медийно шоу; а В. … – там вече нещата зависят от избора на играча.
Което ме връща към казаното от Миглена в първата част на разговора ни – дали спектакълът не подрива мрачните теми на играта. Може би по-скоро съблазънта му е самата мрачна тема, определяща нейния свят.
Чавдар Парушев: Ще добавя нещо по повод решенията, които играчът взима сам, и стереоскопичните отражения от тях в изграждането на неигровите действащи лица, както и по повод изборите, които играта вменява на играча. Финалът на играта предполага да бъде преодоляна специфичната раздвоеност на В. като две личности в едно тяло. Да се направи лудонаративен избор и да се запази единият за сметка на другия персонаж, за да завърши разказът на играта. През повечето време смятах, че ще избера В. В крайна сметка реших тъкмо обратното. Може би защото схванах избора като това дали жертвам и двамата за кратка отсрочка на неизбежния край на В., или само него, за да може Джони истински да оживее.
Но може би финалният избор е възможно да бъде схванат и като избор между две времена. От една страна, Джони и неговият бунт от фикционалната 2023-та като съпротивляващото се минало, от друга – В. от 2077 като настоящето или новото, което се бори да намери собствено място под слънцето, да оцелее под натиска на притискащите го фактори. Схващане, оформено и от собственото ми проиграване, което разпредели двамата в ролите на наставник и ученик по принуда с известна реципрочност и размяна на ролите между Джони и В.
В този смисъл за мен бунтът на настоящето се оказа някак твърде очевиден и самозатворен, твърде много сведен само до оцеляване. Докато този в миналото се оказа по-интересен. Какъв би бил вторият живот на Джони Сребърната ръка? Да кажем, ако разработчиците на играта решат да продължат с втора част с Джони като аватар за играча? Какво ако миналото се завърне вече не като дигитален призрак или като пародиен брътвеж на панаирджийска машинна ясновидка, пробутана на майтап като революционен пророк и за още по-голям смях взета на сериозно? Ами ако миналото се завърне като помъдряла, претърпяла развитие и способна да действа личност с поуките от грешките и с отстояната вярност на принципите си? А не като пасивен геологически пласт, който стои под повърхнината на настоящето, за да оформя неравностите – гънките, бабуните и прорезите на релефа му?
Тази съпротива чрез минало като дееспособна памет на втора степен също ли би била толкова обречена, колкото другите, срещу дистопичността на безпаметното настояще на подкупни корпорации, улични престъпни банди, търговци на оръжие и виртуални наркотици, лекари кибернетици, вуду хакери и заплашителни джунгли от изкуствени интелекти зад високи черни стени, които съставляват фикцията на играта? Играта отваря, не затваря подобни въпроси.
1 Да не забравяме, че знаковият пънкарски химн на неговата банда е озаглавен „Не изтлявай“.
2 Играчите могат да избират между три варианта за произход на В., единият от които е всъщност на корпоративен служител, захвърлен от корпорацията, на която служи, въпреки и дори заради това, че изпълнява корпоративните заповеди. Тоест и комфортът, обещаван от корпорацията, се оказва измамен.
В рубриката „Игромислие“ публикуваме разговори, в които се срещат, съпоставят и противопоставят различни гледни точки към многоизмерния, многожанров феномен на видеоигрите – не толкова като електронен спорт, колкото като нов синтез на изкуствата и като ново поле на общуване и социалност.
Bash-5.3-release available
Post Syndicated from jake original https://lwn.net/Articles/1029079/
The GNU project’s Bourne Again
SHell (Bash) has released version 5.3, with some significant new
features, including some from the associated
Readline 8.3 release, which provides
command-line editing and other features for Bash and lots of other
programs. Bash 5.3 has a “new form of command substitution that executes the command in
“, pathname-completion sorting
the current shell execution context
will be handled based on the GLOBSORT shell variable, generated
completions can go to a shell variable instead of to stdout, the source
code has been updated to C23, and more. Meanwhile:
Readline has new features as well. There is a new option that allows
case-insensitive searching, a new command that executes a named readline
command, and a new command that exports possible word completions in a
specified format for consumption by another process.
[$] A tour of the niri scrolling-tiling Wayland compositor
Post Syndicated from jzb original https://lwn.net/Articles/1025866/
Niri
is a relatively new Rust-based compositor
for Wayland with a different take on tiling window management: windows
are placed onscreen in an “infinite” row that can expand beyond the
bounds of the visible workspace. It is not a full-blown desktop
environment, but niri may be a suitable option for Linux users who
want tiling features and the minimalism of a window manager for
Wayland.
2025 CyberVadis report now available for due diligence on third-party suppliers
Post Syndicated from Tea Jioshvili original https://aws.amazon.com/blogs/security/2025-cybervadis-report-now-available-for-due-diligence-on-third-party-suppliers/
We’re excited to announce that AWS has completed the CyberVadis assessment of its security posture with the highest score (Mature) in all assessed areas. This demonstrates our continued commitment to meet the heightened expectations for cloud service providers. Customers can now use the 2025 AWS CyberVadis report and scorecard to reduce their supplier due-diligence burden.
With the increasing adoption of cloud products and services across multiple sectors and industries, AWS is a critical component of customers’ third-party environments. Regulated customers, such as those in the financial services sector, are held to high standards by regulators and auditors when it comes to exercising effective due diligence on third parties.
Many customers use third-party risk management services such as CyberVadis to better manage risks from their evolving third-party environments and drive operational efficiencies. In support of these efforts, AWS has completed its annual CyberVadis security posture assessment, conducted by CyberVadis security analysts.
CyberVadis is a comprehensive third-party risk assessment process that combines the speed and scalability of automation with the certainty of analyst validation. CyberVadis assessments employ a dynamic and comprehensive approach to third-party risk assessment, replacing outdated static spreadsheets and the need for annual AWS assessment access requests. This cloud-based solution provides advanced capabilities by integrating AWS responses with analytics and sophisticated risk models to deliver an in-depth view of the security posture of AWS.
CyberVadis’s risk assessment methodology evaluates 20 topics covering the entire cybersecurity life cycle across four phases: Identify, Protect, Detect, and React. These topics include Data Privacy, Access Management, and Infrastructure Security. The assessment criteria are based on international information security standards, including ISO 2700x, NIST Cybersecurity Framework, Cybersecurity for ICS, PCI DSS, NIS2 and GDPR.
Customers can use CyberVadis results to map the assessment of AWS to commonly used industry frameworks and standards to instantly gain visibility into controls coverage.
AWS customers can download the complete 2025 AWS Assessment Report directly through CyberVadis’s portal using their own account, or through AWS Artifact.
We value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. If you have feedback about this post, submit comments in the Comments section below. To learn more about our other compliance and security programs, see AWS Compliance Programs.
Security updates for Monday
Post Syndicated from jake original https://lwn.net/Articles/1029073/
Security updates have been issued by Debian (thunderbird and xmedcon), Fedora (darktable, mbedtls, sudo, and yarnpkg), Mageia (catdoc and php), Red Hat (java-1.8.0-ibm, kernel, python-setuptools, python3, python3.11, python3.12, python3.9, socat, sudo, tigervnc, webkit2gtk3, webkitgtk4, xorg-x11-server, and xorg-x11-server-Xwayland), SUSE (alloy, apache-commons-fileupload, apache2-mod_security2, assimp-devel, chromedriver, clamav, clustershell, corepack22, ctdb, curl, dpkg, erlang-rabbitmq-client, ffmpeg-4, firefox, firefox-esr, flake-pilot, fractal, gdm, ggml-devel-5699, gio-branding-upstream, git-lfs, glib2, glibc, go1.23, go1.24, govulncheck-vulndb, gpg2, grafana, grype, helm, himmelblau, icu, jgit, jq, jupyter-bqplot-jupyterlab, jupyter-jupyterlab-templates, jupyter-matplotlib, jupyter-nbclassic, jupyter-nbdime, jupyter-panel, jupyter-plotly, keylime-ima-policy, kubernetes1.30-apiserver, kubernetes1.31-apiserver, kubernetes1.32-apiserver, libbd_btrfs-devel, libetebase-devel, libmozjs-128-0, libprotobuf-lite31_1_0, libQt5Bootstrap-devel-static-32bit, libsoup, libsoup-2_4-1, libsoup-3_0-0, libspdlog1_15, libssh, libssh-config, libsystemd0, libtpms-devel, libwireshark18, libwx_gtk2u_adv-suse16_0_0, mirrorsorcerer, moarvm, nix, nodejs-electron, nova, oci-cli, opa, openbao, ovmf-202505, pam, pam_pkcs11, perl, perl-32bit, perl-CryptX, perl-File-Find-Rule, perl-YAML-LibYAML, podman, polaris, postgresql-jdbc, pure-ftpd, python-furo-doc, python-requests, python310, python311, python311-Django, python311-Django4, python311-jupyter-core, python311-Pillow, python311-pydata-sphinx-theme, python311-requests, python311-salt, python311-urllib3, python312, python313, python314, python39, radare2, redis, samba, SDL, SDL2, sudo, teleport, thunderbird, tomcat, tomcat10, tomcat11, traefik, traefik2, valkey, velociraptor, vim, xorg-x11-server, and xwayland), and Ubuntu (linux-ibm, linux-intel-iotg, linux-lowlatency, linux-lowlatency-hwe-6.11, and linux-oem-6.14).