Post Syndicated from John Jackson original https://aws.amazon.com/blogs/big-data/introducing-amazon-mwaa-serverless/
Today, AWS announced Amazon Managed Workflows for Apache Airflow (MWAA) Serverless. This is a new deployment option for MWAA that eliminates the operational overhead of managing Apache Airflow environments while optimizing costs through serverless scaling. This new offering addresses key challenges that data engineers and DevOps teams face when orchestrating workflows: operational scalability, cost optimization, and access management.
With MWAA Serverless you can focus on your workflow logic rather than monitoring for provisioned capacity. You can now submit your Airflow workflows for execution on a schedule or on demand, paying only for the actual compute time used during each task’s execution. The service automatically handles all infrastructure scaling so that your workflows run efficiently regardless of load.
Beyond simplified operations, MWAA Serverless introduces an updated security model for granular control through AWS Identity and Access Management (IAM). Each workflow can now have its own IAM permissions, running on a VPC of your choosing so you can implement precise security controls without creating separate Airflow environments. This approach significantly reduces security management overhead while strengthening your security posture.
In this post, we demonstrate how to use MWAA Serverless to build and deploy scalable workflow automation solutions. We walk through practical examples of creating and deploying workflows, setting up observability through Amazon CloudWatch, and converting existing Apache Airflow DAGs (Directed Acyclic Graphs) to the serverless format. We also explore best practices for managing serverless workflows and show you how to implement monitoring and logging.
How does MWAA Serverless work?
MWAA Serverless processes your workflow definitions and executes them efficiently in service-managed Airflow environments, automatically scaling resources based on workflow demands. MWAA Serverless uses the Amazon Elastic Container Service (Amazon ECS) executor to run each individual task on its own ECS Fargate container, on either your VPC or a service-managed VPC. Those containers then communicate back to their assigned Airflow cluster using the Airflow 3 Task API.
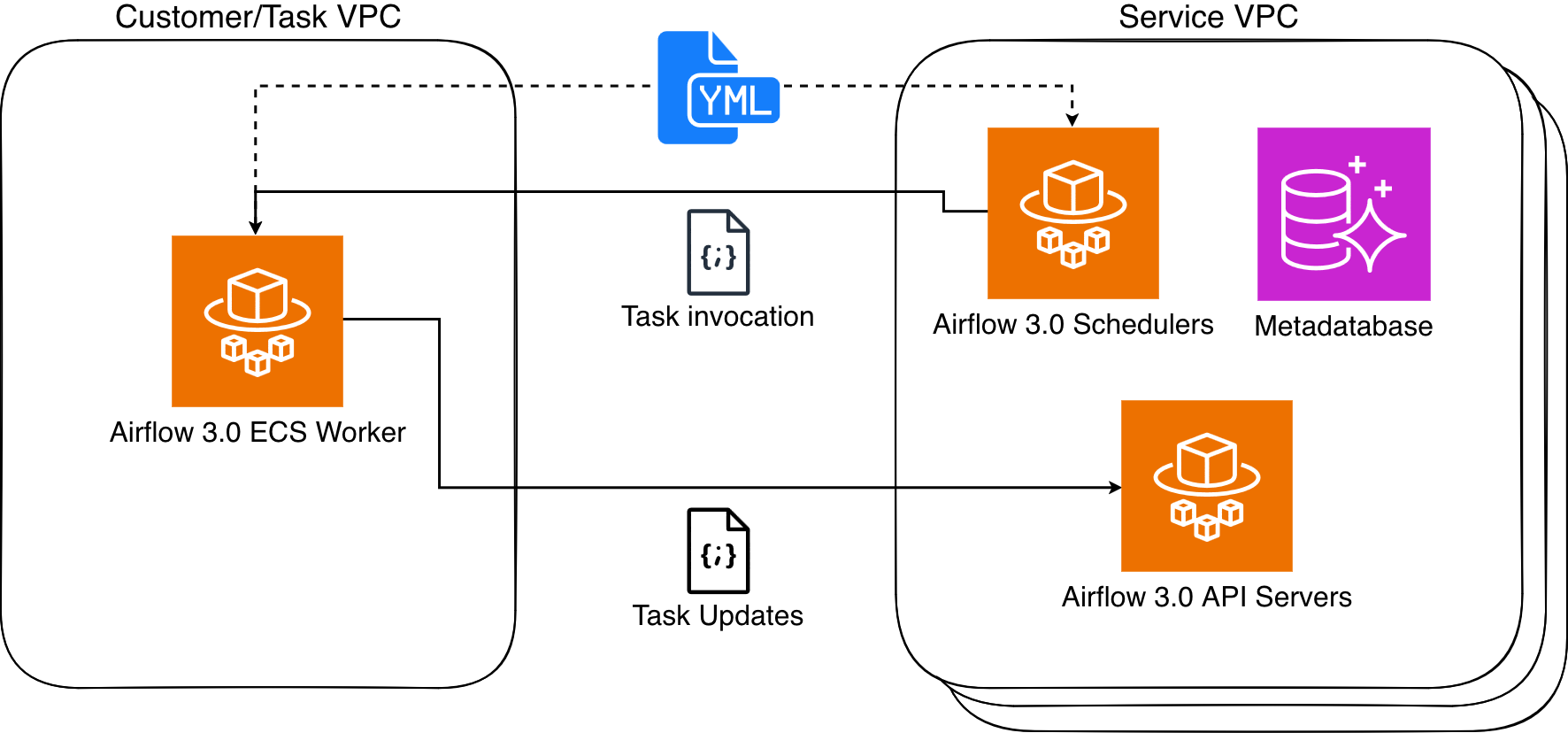
Figure 1: Amazon MWAA Architecture
MWAA Serverless uses declarative YAML configuration files based on the popular open source DAG Factory format to enhance security through task isolation. You have two options for creating these workflow definitions:
- Write your workflows directly in YAML using AWS managed operators from the Amazon Provider Package
- Convert your existing Python-based DAGs to YAML using the AWS-provided python-to-yaml-dag-converter-mwaa-serverless library (available through PyPi)
This declarative approach provides two key benefits. First, since MWAA Serverless reads workflow definitions from YAML it can determine task scheduling without running any workflow code. Second, this allows MWAA Serverless to grant execution permissions only when tasks run, rather than requiring broad permissions at the workflow level. The result is a more secure environment where task permissions are precisely scoped and time limited.
Service considerations for MWAA Serverless
MWAA Serverless has the following limitations that you should consider when deciding between serverless and provisioned MWAA deployments:
- Operator support
- MWAA Serverless only supports operators from the Amazon Provider Package.
- To execute custom code or scripts, you’ll need to use AWS services, such as:
- AWS Lambda for Python code execution.
- AWS Batch, Amazon ECS, and Amazon EKS for Bash operations.
- AWS Glue for third-party data connections
- User interface
- MWAA Serverless operates without using the Airflow web interface.
- For workflow monitoring and management, we provide integration with Amazon CloudWatch and AWS CloudTrail.
Working with MWAA Serverless
Complete the following prerequisites and steps to use MWAA Serverless.
Prerequisites
Before you begin, verify you have the following requirements in place:
- Access and permissions
- An AWS account
- AWS Command Line Interface (AWS CLI) version 2.31.38 or later installed and configured
- The appropriate permissions to create and modify IAM roles and policies, including the following required IAM permissions:
airflow-serverless:CreateWorkflowairflow-serverless:DeleteWorkflowairflow-serverless:GetTaskInstanceairflow-serverless:GetWorkflowRunairflow-serverless:ListTaskInstancesairflow-serverless:ListWorkflowRunsairflow-serverless:ListWorkflowsairflow-serverless:StartWorkflowRunairflow-serverless:UpdateWorkflowiam:CreateRoleiam:DeleteRoleiam:DeleteRolePolicyiam:GetRoleiam:PutRolePolicyiam:UpdateAssumeRolePolicylogs:CreateLogGrouplogs:CreateLogStreamlogs:PutLogEventsairflow:GetEnvironmentairflow:ListEnvironmentss3:DeleteObjects3:GetObjects3:ListBuckets3:PutObjects3:Sync
- Access to an Amazon Virtual Private Cloud (VPC) with internet connectivity
- Required AWS services – In addition to MWAA Serverless you will need access to the following AWS services:
- Amazon MWAA to access your existing Airflow environment(s)
- Amazon CloudWatch to view logs
- Amazon S3 for DAG and YAML file management
- AWS IAM to control permissions
- Development environment
- Python 3.12 or later installed
- An Amazon Simple Storage Service (S3) bucket to store your workflow definitions
- A text editor or IDE for YAML file editing
- Additional requirements
- Basic familiarity with Apache Airflow concepts
- Understanding of YAML syntax
- Knowledge of AWS CLI commands
Note: Throughout this post, we use example values that you’ll need to replace with your own:
- Replace
amzn-s3-demo-bucketwith your S3 bucket name - Replace
111122223333with your AWS account number - Replace
us-east-2with your AWS Region. MWAA Serverless is available in multiple AWS Regions. Check the List of AWS Services Available by Region for current availability.
Creating your first serverless workflow
Let’s start by defining a simple workflow that gets a list of S3 objects and writes that list to a file in the same bucket. Create a new file called simple_s3_test.yaml with the following content:
For this workflow to run, you must create an Execution role that has permissions to list and write to the above bucket. The role also needs to be assumable from MWAA Serverless. The following CLI commands create this role and its associated policy:
You then copy your YAML DAG to the same S3 bucket, and create your workflow based upon the Arn response from the above function.
The output of the last command returns a WorkflowARN value, which you then use to run the workflow:
The output returns a RunId value, which you then use to check the status of the workflow run that you just executed.
If you need to make a change to your YAML, you can copy back to S3 and run the update-workflow command.
Converting Python DAGs to YAML format
AWS has published a conversion tool that uses the open-source Airflow DAG processor to serialize Python DAGs into YAML DAG factory format. To install, you run the following:
For example, create the following DAG and name it create_s3_objects.py:
Once you have installed python-to-yaml-dag-converter-mwaa-serverless, you run:
Where the output will end with:
And resulting YAML will look like:
Note that, because the YAML conversion is done after the DAG parsing, the loop that creates the tasks is run first and the resulting static list of tasks is written to the YAML document with their dependencies.
Migrating an MWAA environment’s DAGs to MWAA Serverless
You can take advantage of a provisioned MWAA environment to develop and test your workflows and then move them to serverless to run efficiently at scale. Further, if your MWAA environment is using compatible MWAA Serverless operators, then you can convert all of the environment’s DAGs at once. The first step is to allow MWAA Serverless to assume the MWAA Execution role via a trust relationship. This is a one-time operation for each MWAA Execution role, and can be performed manually in the IAM console or using an AWS CLI command as follows:
Now we can loop through each successfully converted DAG and create serverless workflows for each.
To see a list of your created workflows, run:
Monitoring and observability
MWAA Serverless workflow execution status is returned via the GetWorkflowRun function. The results from that will return details for that particular run. If there are errors in the workflow definition, they are returned under RunDetail in the ErrorMessage field as in the following example:
Workflows that are properly defined, but whose tasks fail, will return "ErrorMessage": "Workflow execution failed":
MWAA Serverless task logs are stored in the CloudWatch log group /aws/mwaa-serverless/<workflow id>/ (where /<workflow id> is the same string as the unique workflow id in the ARN of the workflow). For specific task log streams, you will need to list the tasks for the workflow run and then get each task’s information. You can combine these operations into a single CLI command.
Which would result in the following:
At which point, you would use the CloudWatch LogStream output to debug your workflow.
You may view and manage your workflows in the Amazon MWAA Serverless console:
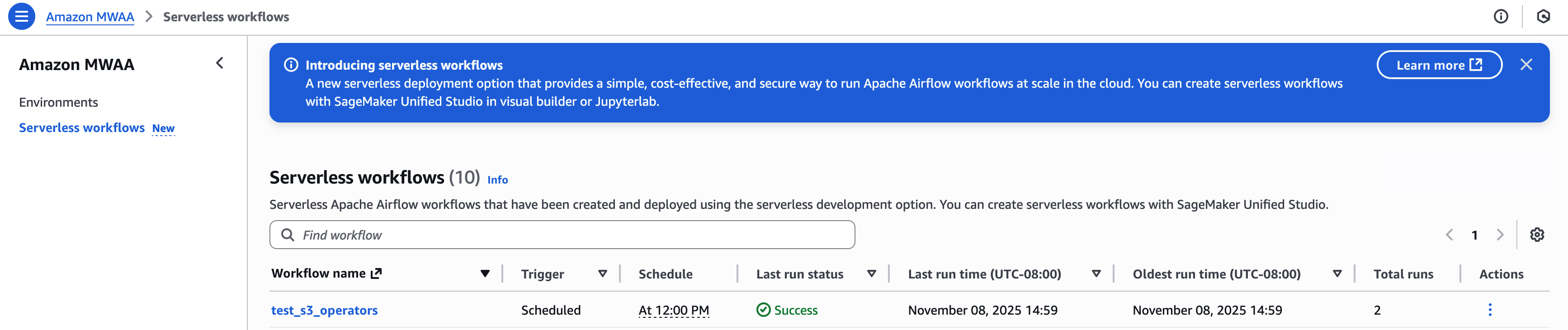
For an example that creates detailed metrics and monitoring dashboard using AWS Lambda, Amazon CloudWatch, Amazon DynamoDB, and Amazon EventBridge, review the example in this GitHub repository.
Clean up resources
To avoid incurring ongoing charges, follow these steps to clean up all resources created during this tutorial:
- Delete MWAA Serverless workflows – Run this AWS CLI command to delete all workflows:
- Remove the IAM roles and policies created for this tutorial:
- Remove the YAML workflow definitions from your S3 bucket:
After completing these steps, verify in the AWS Management Console that all resources have been properly removed. Remember that CloudWatch Logs are retained by default and may need to be deleted separately if you want to remove all traces of your workflow executions.
If you encounter any errors during cleanup, verify you have the necessary permissions and that resources exist before attempting to delete them. Some resources may have dependencies that require them to be deleted in a specific order.
Conclusion
In this post, we explored Amazon MWAA Serverless, a new deployment option that simplifies Apache Airflow workflow management. We demonstrated how to create workflows using YAML definitions, convert existing Python DAGs to the serverless format, and monitor your workflows.
MWAA Serverless offers several key advantages:
- No provisioning overhead
- Pay-per-use pricing model
- Automatic scaling based on workflow demands
- Enhanced security through granular IAM permissions
- Simplified workflow definitions using YAML
To learn more MWAA Serverless, review the documentation.


