Security updates have been issued by AlmaLinux (container-tools:rhel8, gcc, libxml2, nodejs:18, and nodejs:20), Debian (freerdp2, golang-glog, trafficserver, and tryton-client), Fedora (chromium, krb5, libheif, microcode_ctl, nginx, nginx-mod-fancyindex, nginx-mod-modsecurity, nginx-mod-naxsi, nginx-mod-vts, and webkitgtk), Mageia (ffmpeg, golang, postgresql13 and postgresql15, and python-zipp), Oracle (container-tools:ol8, gcc, gcc-toolset-13-gcc, gcc-toolset-14-gcc, kernel, libxml2, and nodejs:20), Red Hat (gcc, idm:DL1, and ipa), SUSE (buildah, chromium, glibc, kernel, kernel-firmware-all-20250206, libecpg6, postgresql15, python, python3, python311, and ruby3.4-rubygem-rack), and Ubuntu (intel-microcode).
Споделял съм, че всички данни и инструменти, които пускам, са защото съм си задал някога някакъв въпрос и търсенето на отговор отива понякога твърде далече. Това показах в участието ми в Ratio наскоро. Случва се да си цъкам на телефона отваряйки източници, изследвания, статистически данни и прочие и когато таблиците станат десетки сядам да ги комбинирам, за да извлека пресечната точка между тях. Това стана и вчера с данните за българите в Германия.
Имам цяла серия от текстове разглеждащи различни аспекти от най-голямата ни диаспора там. Накрая на статията ще изредя някои от тях. Вчера започнах да готвя поредната такава статия, но в течение на нещата пуснах няколко бързи справки в социалките. Получи се дискусия под тях, отчасти не особено приятна. Чух се с трима души след това, на които им беше интересно и искаха детайли за различни аспекти от данните. Затова пускам и тук кратките изводи, които си направих вчера в реда, в който ги пуснах с кратки редакции. Последната всъщност не е конкретно за българите в Германия, но има връзка, която съм дискутирал преди. Пълната статия с подробен списък от таблиците на DeStatis, които използвам ще сложа там.
Бърза статистика за българите в Германия за 2023-та.
19% не са завършили основно. 27% са с някакво висше
В домакинства, където поне един човек е българин, средният нето доход на работещ е 1883 евро. От този доход после се плащат местни данъци, сметки, такси за кола, застраховки, наем и прочие. Средното за страната е 2302 евро
Сред българите, които са емигрирали в Германия, 16.8% получават социални помощи, а още 28.7% се налага да разчитат на друга държавна или общинска помощ, тъй като доходите им не стигат
Ако включим и децата им родени в Германия, т.е. всички хора с някакъв български произход, то броят разчитащи на социални помощи намалява на 15.6%, но тези, които се налага да оцеляват с друга държавна или общинска помощ се увеличава на 37.4%
Часовете, които се налага българите емигрирали в Германия да работят, са повече от средното за Германия – с поне 3-4 часа. Особено при българките работата над 45 часа на седмица се среща с 50% по-често от мъжете
33% от заетите българи в Германия работят през събота. 19.1% – през неделя. При жените това е с 1/3 по-вероятно да се случи от мъжете
63% от българите емигрирали в Германия имат за майчин език български. 21% е турски. 25% от децата родени в Германия от български емигранти говорят само немски език.
Вероятността българин роден в България с майчин език турски да емигрира в Германия е 3 пъти по-голяма, отколкото тези с майчин език български. При българите с майчин език ромски или друг разликата е 4.3 пъти.
Това обяснява защо намаляват съответно с 4 и 9% като дял от населението, т.е. много по-бързо от общото намаление. Ровя се в детайлни статистически справки и изследвания в различни държави и изскачат някои неща. Ще ги обобщя скоро.
За първите 11 месеца на 2024-та (януари до ноември) на всеки 10000 души с германско гражданство, същите са открили 46.9 бизнеса каквито ние бихме нарекли startup, малък бизнес или едноличен търговец. Откупили са 1.9 бизнеса и са закрили 40.2 бизнеса.
Жителите на Германия с българско гражданство са открили 135.5 на 10000 души от диаспората ни там, откупили са 4.9 бизнеса и са затворили 112.5. Тоест, сънародниците ни в Германия са три пъти по-предприемчиви от германските граждани и с една идея по-малко бизнеси затворили спрямо открити.
По този показател ни бият само поляците и румънците с 188.8 и 148.9. Само дето поляците за тези 11 месеца са затворили повече, отколкото са отворили – 206.9. Гърците и Турците най-много готови бизнеси откупуват – 11.4 и 15.8 съответно.
Средното сред емигрантите (като изключим поляци, румънци и турци) е 81 открити малки бизнеса, 6.1 откупени и 56.9 затворени. Чужденците с двойно гражданство се броят навсякъде за германци в тази статистика.
Според три различни метрики броят на родените от българи деца в Германия е намалял с между 7 и 12% между 2021 и края на 2023 г. Броят деца с родители българи е намалял с 4% за същия период, а броят на българите в детеродна възраст – с 7%.
Натурализация (взимане на германски паспорт) би могло да обясни само 1/5 от това намаление, но така се предполага, че никой не е емигрирал от България или други страни към Германия в тези възрастови групи.
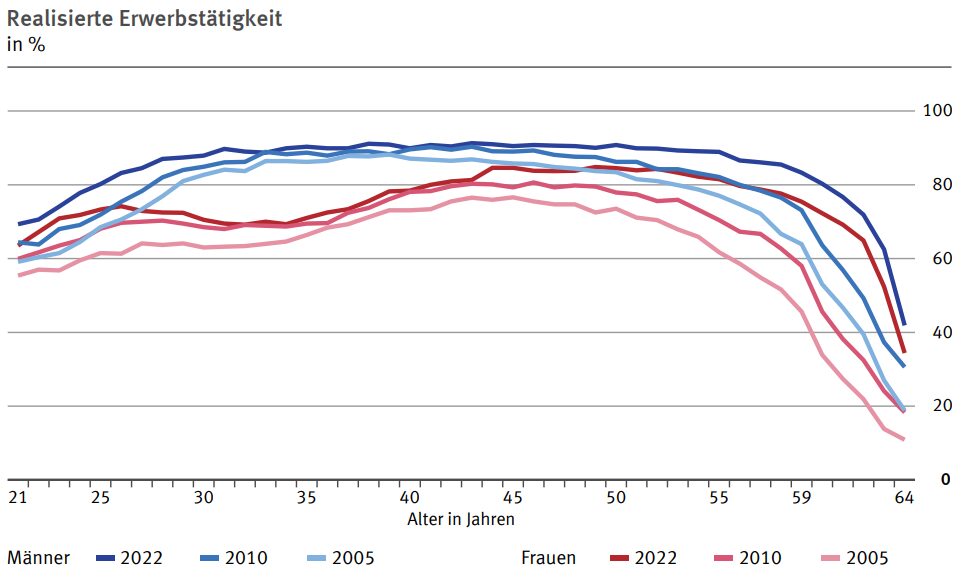
Две интересни разбивки на работещите по възрасти в Германия. Първата графика показва заетостта на мъже и жени през 2005, 2010 и 2022. Виждаме, че и през 2022-ра и мъжете и жените се пенсионират много по-късно заради увеличената възраст на пенсиониране. Виждаме и силно намалената заетост на жените между 25 и 40 години.
Втората графика показва разбивка на половете по това дали имат деца. Практически няма разлика между мъже и жени, ако нямат деца. С деца обаче мъжете има много по-голяма заетост в Германия дори след 45 години, а преди това жените на 25 или 30 години имат заетост от 20 до 40%. Това е повече от красноречиво за отношението на работното място и в дома.
Ето още статии, които съм разглеждал такива детайли. Статията с данните за 2018-та съдържа повече информация за заплащане, помощи и икономически възможности.
The transformative world of Generative AI (GenAI), which refers to artificial intelligence systems capable of creating new content such as text, images, or music that is similar to human-generated content, has become integral to innovation, powering the next generation of AI-enabled applications. At Grab, it is crucial that every Grabber has access to these cutting-edge technologies to build powerful applications to better serve our customers and enhance their experiences. Grab’s AI Gateway aims to provide exactly this. The gateway seamlessly integrates AI providers like OpenAI, Azure, AWS (Bedrock), Google (VertexAI) and many other AI models, to bring seamless access to advanced AI technologies to every Grabber.
Why do we need Grab AI Gateway?
Before we begin implementing Grab AI Gateway in our work process, it is important for us to understand the limitations as well as the solutions that Grab AI Gateway provides. Failure to properly implement Grab AI Gateway could lead to roadblocks in development which negatively affect user experience.
Streamline access
Each AI provider has its own way of authenticating their services. Some providers use key-based authentication while others require instance roles or cloud credentials. Grab AI Gateway provides a centralised platform that only requires a one-time provider access setup. Grab AI Gateway removes the effort of procuring resources and setting up infrastructure for AI services, such as servers, storage, and other necessary components.
Enables experimentation
By providing a simple unified way to access different AI providers, users can experiment with various Large Language Models (LLMs) and choose the one best suited for their task.
Cost-efficient usage
Many AI providers allow purchasing of reserved capacity to provide higher throughput and improve cost effectiveness. However, services that require reservation or pre-purchases over a commitment period can lead to wastage.
Grab AI Gateway overcomes this problem and minimises wastage with a shared capacity pool. A deprecated service would simply free up bandwidth for a new service to utilise. Additionally, Grab AI Gateway provides a global view of usage trends to help platform teams make informed decisions on reallocating reserved capacity according to demand and future trends (eg. an upcoming model replacing an old one).
Auditing
A central setup ensures that use cases undergo a thorough review process to comply with the privacy and cyber security standards before being deployed in production. For instance, a Q&A bot with access to both restricted and non-restricted data could inadvertently reveal sensitive information if authorisation is not set up properly. Therefore, it is important that use cases are reviewed to ensure they follow Grab’s standard for data privacy and protection.
Platformisation benefits
Proper implementation of a central gateway provides platformisation benefits like:
Reduced operational costs.
Centralised monitoring and alerts.
Cost attribution.
Control limits like maximum QPS and cost cap.
Enforce guardrail and safety from prompt injection.
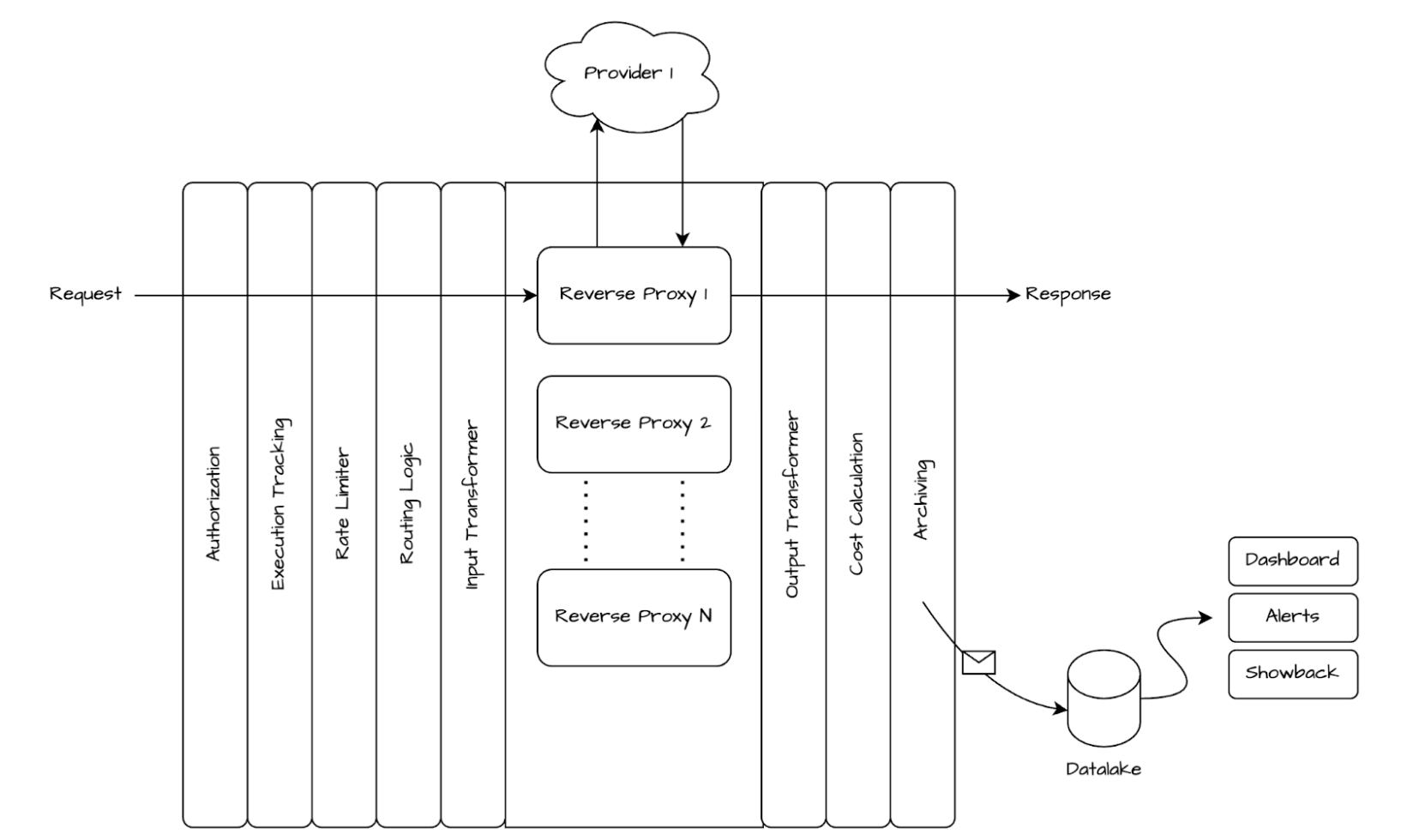
Architecture and design
At its core, the AI Gateway is a set of reverse proxies to different external AI providers like Azure, OpenAI, AWS, and others. From the user’s perspective, the AI Gateway acts like the actual provider where users are only required to set the correct base URLs to access the LLMs. The gateway handles functionalities like authentication, authorisation, and rate limiting, allowing users to solely focus on building GenAI enabled applications.
To form the basis of identity and access management (IAM) in the gateway, API key can be requested by the user for exploration (short-term personal key) or production (long-term service key) usage. The gateway implements a request path based authorisation where certain keys can be granted access to specific providers or features. Once authenticated, the AI Gateway replaces the internal key in request with the provider key and executes the request on behalf of the user.
The AI Gateway is designed with a minimalist approach, often serving as a lightweight interface between the user and the provider, intervening only when necessary. This has enabled us to keep up with the pace of innovation in the field and to continue expanding the provider catalogue without increasing the ops burden. Similar to requests, responses from the provider are returned to the user with no to minimal processing time. The gateway is not limited to only chat completion API. It exposes other APIs like embedding, image generation, and audio along with functionalities like fine-tuning, file storage, search, and context caching. The gateway also provides access to in-house open source models. This provides a taste of open source software (OSS) capabilities that users can later decide to deploy a dedicated instance using Catwalk’s VLLM offering.
Figure 1: High level architecture of AI Gateway
User journey and features
Onboarding process
GenAI based applications come with inherent risks like generating offensive or incorrect output and hostile takeover by malicious actors. As software practices and security standards for building GenAI applications are still evolving, it is important for users to be aware of the potential pitfalls. As AI Gateway is the de facto way to access this technology, the platform team shares the responsibility of building such awareness and ensuring compliance. The onboarding process includes a manual review stage. Every new use case requires a mini-RFC (Request For Comments) and a checklist that is reviewed by the platform team. In certain cases, an in-depth review by the AI Governance task force may be requested. To reduce friction, users are encouraged to build prototypes and experiment with APIs using “exploration keys”.
Exploration keys
At Grab, every Grabber is encouraged to use GenAI technologies to improve productivity and to experiment and learn within this field. The gateway provides exploration keys to make it easier for users to experiment with building chatbots and Retrieval Augmented Generation (RAG). These keys can be requested by Grabbers through a Slack bot. The keys are short-lived with a validity period of a few days, stricter rate limit restrictions, and access limited to only the staging environment. Exploration keys are highly popular, with more than 3,000 Grabbers requesting the key to experiment with APIs.
Unified API interface
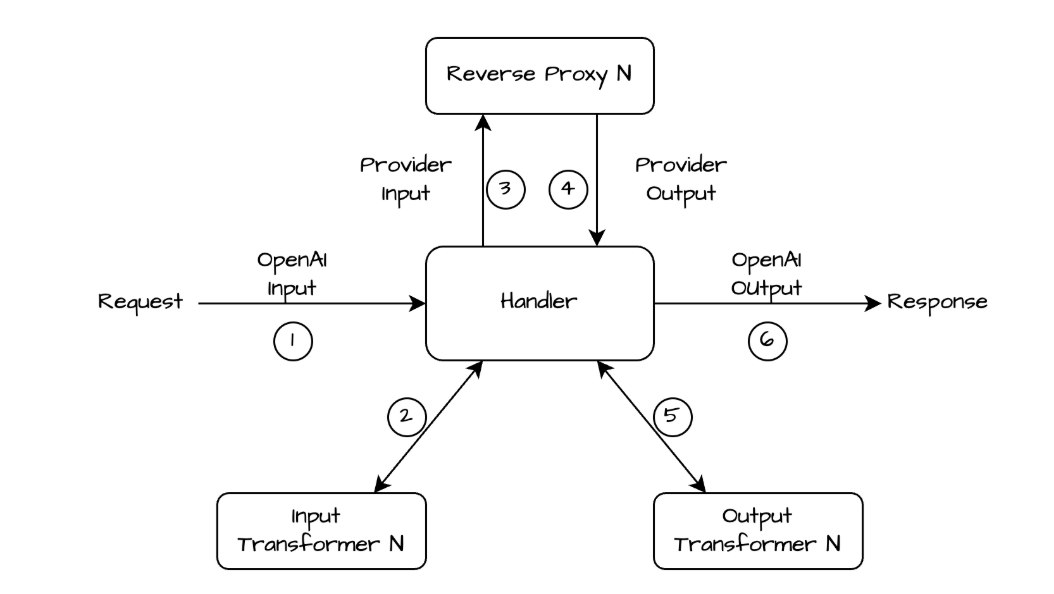
In addition to provider specific interface, the gateway also offers a single interface to interact with multiple AI providers. For users, this lowers the barrier of experimenting between different providers/models, as they do not need to learn and rewrite their logic for different SDKs. Providers can be switched simply by changing the “model” parameter in the API request. This also enables easy setup of fallback logic and dynamic routing across providers. Based on popularity, the gateway uses the OpenAI API scheme to provide the unified interface experience. The API handler translates the request payload to the provider specific input scheme. The translated payload is then sent to reverse proxies. The returned response is translated back to the OpenAI response scheme.
Figure 2: Unified Interface Logic
Dynamic routing
The AI Gateway plays a crucial role in maintaining usage efficiency of various reserved instance capacities. It provides the control points to dynamically route requests for certain models to a different albeit similar model backed by a reserved instance. Another frequent use case is smart load balancing across different regions to address region-specific constraints related to maximum available quotas. This approach has helped to minimise rate limiting.
Auditing
The AI Gateway records each call’s request, response body, and additional metadata like token usage, URL path, and model name into Grab’s data lake. The purpose of doing so is to maintain a trail of usage which can be used for auditing. The archived data can be inspected for security threats like prompt injection or potential data policy violations.
Cost attribution
Allocating costs to each use case is important to encourage responsible usage. The cost of calling LLMs tends to increase at higher request rates, therefore understanding the incurred cost is crucial to understanding the feasibility of a use case. The gateway performs cost calculations for each request once the response is received from the provider. The cost is archived in the data lake along with an audit trail. For async usages like fine-tuning and assisting, the cost is calculated through a separate daily job. Finally, a job aggregates the cost for each service which is used for reporting on dashboards and showback. In addition, alerts are configured to notify if a service exceeds the cost threshold.
Rate limits
AI Gateway enforces its own rate limit on top of the global provider limits to make sure quotas are not consumed by a single service. Currently, limits are enforced on the request rate at the key level.
Integration with the ML Platform
At Grab, the ML platform serves as a one-stop shop, facilitating each phase of the model development lifecycle. The AI Gateway is well integrated with systems like Chimera notebooks used for ideation/development to Catwalk for deployment. When a user spins up a Chimera notebook, an exploration key is automatically mounted and is ready for use. For model deployments, users can configure the gateway integration which sets up the required environment variables and mounts the key into the app.
Challenges faced
With more than 300 unique use cases onboarded and many of those making it to production, AI Gateway has gained popularity since its inception in 2023. The gateway has come a long way, with many refinements made to the UX and provider offerings. The journey has not been without its challenges. Some of the challenges have become more prominent as the number of apps deployed increases.
Keeping up with innovations
With new features or LLMs being released at a rapid pace, the AI Gateway development has required continuous dedicated effort. Reflecting on our experience, it is easy to get overwhelmed by a constant stream of user requests for each new development in the field. However, we have come to realise it is important to balance release timelines and user expectations.
Fair distribution of quota
Every use case has a different service level objective (SLO). Batch use cases require high throughput but can tolerate failures while online applications are sensitive to latency and rate limits. In many cases, the underlying provider resource is the same. The responsibility falls over to the gateway to ensure fair distribution based on criticality and requests per second (RPS) requirements. As adoption increases, we have encountered issues where batch usage interfered with the uptime of online services. The use of Async APIs does mitigate the issues, but not all use cases can adhere to turnaround time.
Maintaining reverse proxies
Building the gateway as a reverse proxy was a key design decision. While the decision has proven to be beneficial, it is not without its complexity. The design ensures that the gateway is compatible with provider-specific SDKs. However, over time, we have encountered edge cases where certain SDK functionalities do not work as expected due to a missing path in the gateway or a missing configuration. These issues are usually ironed out when caught and a suite of integration tests with SDKs are conducted to ensure there are no breaking changes before deploying.
Current use cases and applications
Today, the gateway powers many AI-enabled applications. Some examples include real time audio signal analysis for enhancing ride safety, content moderation to block unsafe content, and description generator for menu items and many others.
Internally, the gateway powers innovative solutions to boost productivity and reduce toil. A few examples are:
GenAI portal that is used for translation and language detection tasks, image generation, and file analysis.
Text-to-Insights for converting questions into SQL queries.
Incident management automation for triaging incidents and creating reports.
Support bot for answering user queries in Slack channels using a knowledge base.
What’s next?
As we continue to add more features, we plan to focus our efforts on these areas:
1. Catalogue
With over 50 AI models each suited for a specific task type, finding the correct model to use is becoming complex. Users are often unsure of the difference between models in terms of capabilities, latency, and cost implications. A catalogue can serve as a guideline by listing currently supported models along with the list of metadata like the input/output modality, token limits, provider quota, pricing, and reference guide.
2. Out of box governance
Currently, all AI-enabled services that process clear text input and output from customers require users to set up their own guardrails and safety measures. By creating a built-in support for security threats like prompt injection and guardrails for filtering input/output, we can save users significant effort.
3. Smarter rate limits
At the current time, the gateway supports basic request rate-based limits at key level. While this rudimentary offering has been proven useful, it has its limitations. More advanced rate limiting policies based on token usage or daily/monthly running costs should be introduced to enforce better and fairer limits. These policies can be modified to be applied on different models and providers.
Special thanks to Priscilla Lee, Isella Lim, and Kevin Littlejohn for helping us in the project and Padarn Wilson for his leadership.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The 6.14-rc3 kernel prepatch is out for
testing; the announcement, for unknown reasons, went only to the
linux-btrfs list.
So the first few weeks of the 6.14 release development were
smaller-than-usual, but rc3 is actually right in line with normal
releases at this point. Probably just timing of pull requests, and
we’ll see how next week goes. But nothing looks worrisome.
Along with the usual stream of fixes, this release includes the “faux bus“, designed
for simple drivers that just need some sort of virtual bus to be associated
with; this bus come with Rust bindings from the
outset.
Т.нар. cell-site simulators или IMSI-catchers се използват за прихващане на мобилна комуникация и проследваяне на устройства. В моя презентация на OpenFest миналата година разгледах съществуващи инструменти за откриване на такива устройства, както и разработено от доброволци мобилно приложение, което чрез няколко евристики опитва да установи дали такова оперира в момента в близост. Ето линк към приложението (засега само за Андроид), а слайдовете от презентацията са тук:
Няма да влизам тук в технически подробности, но накратко – има много начини, по които мобилната ни комуникация може да бъде подслушвана. Фалшивите клетки (cell-site simulators) са само един такъв начин.
Cell-site simulators (also sometimes called Stingrays and IMSI-Catchers) are interception devices used to spy on mobile network communication. A couple of volunteers, including myself, have built an app – Wiretap Detector – that uses heuristics to detect these devices. Below are the slides from a talk that I have (in my native language) on a local tech conference.
It works by applying the following:
Compares public IP with the announced IP ranges of the telecom – Gets ASN based on the initial IP and uses https://ip.guide
Detects changes on the first 2 hops of traceroute
Detects changes in the combination of (geocoordinates, cell identifier)
No such application is perfect or guaranteed to detect interception, because of the nature of the mobile technology. Furthermore, it can’t detect legal interception using direct streaming of calls and messages from the telecom to an interception interface at some government agency.
The app is open source, feel free to contribute. There is a long TODO list, which would improve detection and user experience
Тази седмица внесохме законопроекти за оптимизация на администрацията. Лесно е да се каже „съкращения“, но процесът е по-сложен. Администрацията е сложна система, в която на места не достигат хора, а на други има прекалено много.
Затова законопроектите, освен изискване за тригодишен план за 15% намаляване на щата, стъпват на следните 4 мерки:
1) централизирани конкурси – преди конкурса в съответната администрация да има общи, централизирани тестове за обща административна грамотност, за компютърни умения и др. Така най-скандалните неграмотни политически назначения няма да се случват. Още повече, че такива ще бъдат приложени и ма действите служители, и при два неизържани теста, ще бъдат съкращавани.
2) функционален анализ – нужно е да е ясно кои от законово-определените функции се изпълняват от коя част на администрацията и от колко човека. Има ли необезоечени функции, има ли дублирани функции, или дори излишни такива. Така ще може да бъде направено преструктуриране, с което, нарес а всичко друго, да се намали и числеността.
3) споделени услуги – всяка администрация има счетоводство, човешки ресурси, ИТ и др. Тези услуги могат да се изнесат в „център за споделени услуги“ и вместо 50 администрации да имат по трима души за човешки ресурси, да има един център с 50 служители, които са работят за всичките 50 администрации. Този процес го започнахме в кабинета „Петков“, като бюджетното счетоводство беше централизирано за всички областни администрации, а пилотно въведохме управление на човешки ресурси между три структури. Запопнахме и анализ за ИТ споделени услуги (към МЕУ).
4) електронно управление – ако се спазваха разпоредбите на Закона за електронното управление, поне част от служителите ‘на гише’ нямаше да има нужда да са там. И в коюбинация с останалите точки, това да доведе до намаляване на общата щатна численост.
На практика, през европейски регулации, идват постоянно нови задължения за администрацията. Т.е. естественият процес, ако никой не се намесва, е тя да се увеличава. Затова трябва контрамерки, така че новите функции да се изпълняват по-добре, от по-компетентни и мотивирани служители, като в същото време се намали общата неефедективност на системата.
Затова и мерките са толкова конкретни и са такива, които ще имат реален ефект. И в никакъв случай не са „обявяване на война на администрацията“, защото в опозиция е лесно, но когато управляваш ти трябва ефективна администрация. Просто „дайте да режем администрация“ е примамлив популизъм, който обаче рискува да доведе до още повече неефективност. 15% за 3 години е напълно реалистично намаление, ако горните мерки се изпълняват правилно. И ако вървят ръка за ръка с процеси по дерегулация, с които да отпадат функции.
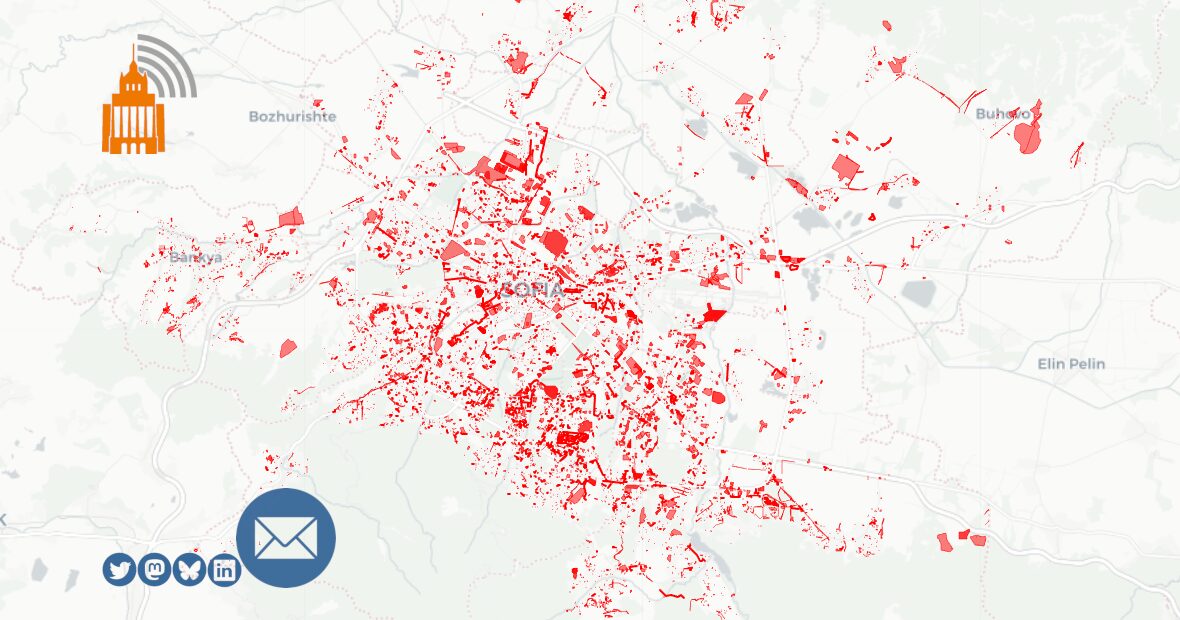
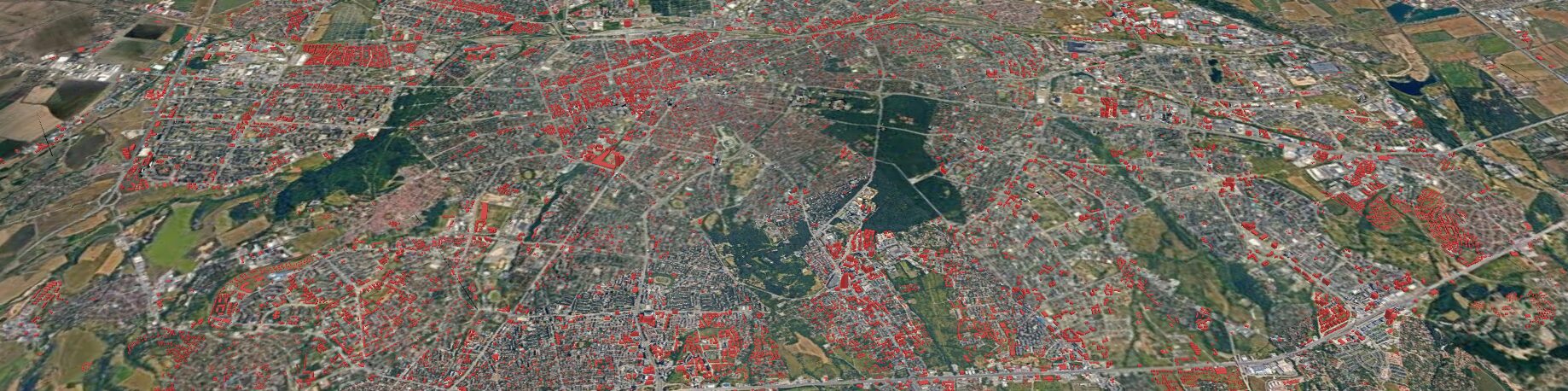
Доста неща се случиха покрай проекта GovAlert и конкретно данните за градоустройството и строителството в София. От няколко справки, с които сам да осмисля както се случва, той се разви в многопластов инструмент позволяващ проследяване на процеси и онагледяване на сложни аспекти от бъдещето на града. За последната година близо 10% от пълнолетното население на София посети картата с документите, 3D визуализациите и отделните информационни канали. С други думи – изглежда доста хора намериха това, което правя, за полезно.
Все пак, отчитам, че потокът от информация е значителен и труден за осмисляне. Картата на бъдещото застрояване, филтрите към нея и за документите трябваше да помогнат, но не бе достатъчно. През 2024-та съобщих за 10448 документа, от които 95.5% са видими на картата. За 2023-та бяха 12153 или по 49 на всеки работен ден само за София. Събирах идеи и предложения. Най-честото желание беше някакъв формат, в който всеки да вижда само документи за места близо до дома или офиса. Алтернативно – само за района, в който живеят. Това е нещо, което исках да направя от самото начало, но отлагах заради сложността и обвързаните разходи за такава услуга.
Всичко, което съм създал тук, както и другите проекти за визуализации и отворени данни, правя на свой гръб подтикнат от желанието да си отговоря на въпросите, които ме занимават и в процеса да помогна на други да го направят. Най-удобен канал за повечето е мейл, но изпращането до много хора е обвързано с разходи. За да е надеждно и да не отиват в спам, трябва да се използва платена услуга. Осъзнах го докато правех бюлетина за гласуващите в чужбина, където на всеки вот изпращам по няколко мейла на над 3000 абонирали се. В онзи случай обаче изпращането е еднократно и (принципно) рядко докато динамиката около застрояването е постоянна.
Затова реших да направя бюлетин под формата на платена услуга, което да покрие разходите по това и други аспекти на картите, които правя. Идеята за това всъщност дойде от призивите, които получавам да пусна Patreon или друга подобна форма позволяваща дарения и подкрепа. Реших да комбинирам двете неща, за да има някаква стойност, която се получава в замяна. Ако има интерес, имам идеи как да развия бюлетина с допълнителни категории, филтри, градове и източници. Приемам всякаква обратна връзка и идеи.
При абонамент имате възможност да изберете в кой час на деня искате да получавате мейла. Може да го искате със сутришното кафе, в обедната почивка или вечерта след като са свършили работа в НАГ. Независимо кога изберете, ще получавате всички документи от последните 24 работни часа. Това значи, че в понеделник сутринта ще получавате всичко от петък. Събота и неделя ще е тихо.
След това може да изберете какво ви интересува. Може да центрирате картата около дадено място и да получавате документи в радиус от малко над километър около него. Може да изберете конкретен район. Над 96% от откритите документи успявам по един или друг начин да свържа с конкретен имот или улица. Ако обаче не успея, повечето от останалите свързвам с район. Ако изберете място с радиус, ще получавате и документите, които може би са от интерес, защото се отнасят до района ви. Има единици, които се отнасят до цяла София или дори с район не съм успял да свържа автоматично (написани на ръка, например). Те се получават от всички. Ако в дадения ден няма документи, които ви засягат няма да получите мейл.
Целта е да се ограничи потокът от информация засягащ цялата София и десетки документи на ден до няколко, които занимават само Вас. Разбира се, мястото и района, както и часът на получаване могат да се променят. Дал съм възможност за абонамент на месечна или годишна база. Плащането става карта през сигурна система, която се използва често от други в България. Абонаментът може да се прекъсне по всяко време като ще продължите да получавате мейли до края на предплатения период. Ако искате да спрете и това, моля пишете ми като отговорите на някой от мейлите от бюлетина.
Обвързването на документи с имоти става автоматично. Например, сайтът ми изчита дневния ред за бъдещи заседания на експертни съвети решаващи по ПУП-ове и разрешения за строеж и открива номера на имоти и сгради, след това ги слага на картата. Някои от числата може да са грешни, а някои – описани с думи, адреси или други означения, които не могат да се засекат автоматично. Отделно самите документи и отбелязване им в НАГ и Столична община става на ръка, което е водело до грешки в миналото. Това означава, че засичането дали на документ или новина попада в зоната на интерес, не е абсолютно сигурно и както до сега е възможно някои документи да бъдат пропуснати или маркирани неподходящо. С подобряване на прозрачността на Столична община, метаданните и дигитализацията на процесите, това ще се подобри. Бюлетина ми може да е само толкова добър, колкото е източникът, което важи за всичко свързано с данни.
Разбира се, остават да работят и ще развивам старите канали, по които тези документи са достъпни. Такава е ActivityPub страницата с линкове към социалките, картата с документите и тази с 3D застрояването. Всички документи ги има и на страницата на НАГ в различни регистри. Целта на новият бюлетин е да намали обемът информация, който ви залива по всички канали до степен, в която не изпитваме парализа в желанието си да променим нещо.
Ако имате въпроси, идеи или някаква обратна връзка, ще се радвам да ги обсъдим в коментарите.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


")