Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=7Ktat6o6Pq0
Смяна на пола на деца? Някой разбра ли какво от ПП–ДБ (не) искат да се забрани?
Post Syndicated from Светла Енчева original https://www.toest.bg/smiana-na-pola-na-detsa/

Не им е лесно на опитните мишки. Подлагат ги на всевъзможни експерименти, при които животинките не само страдат, а и оцеляването им не е гарантирано. От това лято в подобно положение са и децата в България, които принадлежат към групата на ЛГБТИ хората (лесбийки, гей мъже, бисексуални, транс и интерсекс хора). Както е тръгнало, експериментите с тях ще продължат в най-добрия случай до края на 50-тото Народно събрание. Но с немалка вероятност – и в следващия парламент.
Законът на „Възраждане“ и проектозаконът на ИТН
На 7 август 2024 г. парламентът прие – по предложение на „Възраждане“ – промени в Закона за предучилищното и училищното образование, с които се забранява т.нар. пропаганда на „нетрадиционна“ сексуална ориентация или полова идентичност. Формулировката е толкова широка, че практически включва всякакъв тип изразяване. Защото освен самата пропаганда се забраняват и „популяризирането“ и „подстрекаването“. А всяко нещо, налично в публична среда, каквато е училището, може да се интерпретира като „популяризиране“.
„Нетрадиционната“ сексуална ориентация пък беше дефинирана като „различно от общоприетите и заложените в българската правна традиция схващания за емоционално, романтично, сексуално или чувствено привличане между лица от противоположни полове“.
Междувременно на 2 август от „Има такъв народ“ внесоха законопроект за промяна в Закона за закрила на детето (ЗЗД). С него се предлага забраната на „излагането, представянето, предлагането или по какъвто и да е друг начин разпространяването“ на „съдържание, което не съответства на разбирането на пол на физическите лица като биологична категория“ на всякакви обществени места, които могат да бъдат посетени от деца. Също и на беседи с подобно съдържание и „реклама на половата идентичност, алтернатива на биологичния пол“ и подобни теми, както и всякакви медицински дейности за промяна на пола на деца. За нарушителите се предвиждат глоби между 300 и 50 000 лв.
В законопроекта на ИТН се предвижда и промяна на Закона за здравето, с която отново се забранява „прякото представяне, рекламата и извършването на медицински дейности с методи или технологии за промяна на биологичния пол на лица, ненавършили 18 години“. От партията на Слави Трифонов предлагат и санкции за нарушителите в Наказателния кодекс – затвор между една и шест години и обществено порицание, както и лишаване от право на упражняване на професията.
ПП–ДБ – едно неизпълнено обещание и два проектозакона
Промените в образователния закон станаха обект на остри критики, след като от варненския клон на „Възраждане“ инициираха репресии срещу местните учители и други педагогически служители, включили се в подписка против измененията.
На 22 август „Продължаваме промяната“ (ПП) даде на избирателите си обещание, че депутатите от партията още следващата седмица ще внесат предложение „за отмяна на „нетрадиционната“ дефиниция [на сексуалната ориентация – б.а.], която реално започна този опасен процес към фашизма в България“. От партията заявиха:
С действия в парламента, не само с постове, ще противодействаме на черните списъци към българските учители.
Обещаните „действия в парламента“ не последваха – нито през следващата седмица, нито по-късно. На 11 септември обаче депутати от ПП и „Демократична България“ (ДБ) внесоха законопроект за изменение на ЗЗД. Те искат в закона да се включат текстове, че всяко дете „има право на закрила от прилагане на медицински дейности, които целят промяна на фенотипните [тоест видимите – б.а.] и други полови белези на генотипния му пол“, както и на „медицинска, психологическа, социална и експертна помощ по въпроси, свързани с пола му, които да укрепят психологическото му развитие и да осигурят лечение при необходимост“.
Същевременно от ПП–ДБ предлагат и промяна в Закона за здравето:
Забранява се извършването на медицински дейности за промяна на фенотипните и други полови белези на генотипния пол на непълнолетни лица, освен в случаите, когато съществува сериозна опасност за живота или здравето им.
За неспазване на горното се предвиждат глоби от 30 000 до 50 000 лв., а при повторно нарушение – лишаване от правото да се упражнява медицинска професия за срок от 6 месеца до две години. Финансовите санкции, предложени от коалицията, са далеч по-строги от тези на ИТН, които все пак слагат долна граница от 300 лв. Но ПП–ДБ не плашат със затвор.
Смяна на пола на деца в България не се извършва – нещо, което споменават и от ПП–ДБ в мотивите към предложението си. Тоест поне на пръв поглед идеята е да се забрани нещо, което така или иначе го няма.
Същия ден група от петима народни представители, предвождани от Елисавета Белобрадова, внесоха друг законопроект за промяна на ЗЗД. Те искат в него да влезе и следната алинея:
Всяко дете има право на защита от политическа пропаганда, неистини и предизборни политически и партийни действия, които предизвикват страх, изолация и самота у детето и се отразяват на семейната среда.
За спазването на това трябва да следят предвидените в закона органи.
Белобрадова огласи инициативата в социалните мрежи с аргумента, че нито в българските училища има пропаганда, нито в България се сменя полът на деца под 18 години. Не става ясно обаче на какъв принцип ще се преценява кои политически действия предизвикват у децата „страх, изолация и самота“. В мотивите не се споменават нито анти-ЛГБТИ поправката в образователния закон, нито предложенията на ИТН и ПП–ДБ. А те със сигурност са предизвикали „страх, изолация и самота“ у много деца. Така че предложението е по-скоро показен жест, отколкото има някаква практическа стойност.
В ПП–ДБ имат ли общо мнение какво се опитват да забранят?
След предложението на ПП–ДБ за забраната на медицинските дейности за промяна на половите белези, сред ЛГБТИ активистите настъпи разнобой. Докато според едни то е по-страшно и от законопроекта на „Възраждане“ за чуждестранните агенти, други се опитват да убедят критикуващите, че малко трансфобия (омраза към транс хората) е за предпочитане пред много трансфобия, каквато има в предложението на ИТН. Макар нищо да не гарантира, че парламентът няма да приеме някаква комбинация от предложенията на ИТН и ПП–ДБ. А според трети идеята на законопроекта всъщност е „да се защитават интерсекс децата от принудително генитално осакатяване“.
Интерсекс са хората, чийто пол по рождение не е еднозначен – не като идентичност, а биологично. Разпространена практика до неотдавна (в България – и до днес) е на интерсекс деца и тийнейджъри да се правят – без тяхното съгласие – „нормализиращи“ операции, за да заприличат на момчета или момичета. Това обаче не означава, че те ще се чувстват като представители на пола, в който са насилени да се впишат.
Съветът на Европа и редица държави признават правата на интерсекс хората. В тях се включва и правото да не бъдат принудително подлагани на медицински процедури. Противното се възприема като „генитално осакатяване“.
Ако човек обаче внимателно прочете мотивите на законопроекта, в тях трудно може да се открие нещо, свързано със защитата от генитално осакатяване на интерсекс деца. В мотивите се изтъква верният факт, че смяна на пола на деца в България не се извършва. Но се споменават „абсурдни, квази-нормативни текстове [вероятно се намеква за предложението на ИТН – б.а.] , с които […] се застрашават правата на децата с редки генетични заболявания и на българските лекари“. Затова, твърди се, предложените промени „запазват правото на здравна и психологическа подкрепа и лечение, в случай на доказана необходимост“.
Кои са децата „с редки генетични заболявания“ и каква е тази „доказана необходимост“? Най-вероятно се имат предвид интерсекс децата, чиито „нормализиращи“ операции се възприемат като „доказана необходимост“.
Това предположение е в синхрон и с публикация във Facebook на депутатката от ДБ Кристина Петкова:
Вчера внесохме наши поправки в Закона за закрила на детето, провокирани от безумния проект на ИТН, които да гарантират правата на децата при лечение, в случай на доказана медицинска необходимост и да осигурят защита на българските лекари.
Според нея „предложението на ИТН на практика щеше да попречи на хирургичните интервенции при деца с вродени малформации на половите органи“.
Любопитен детайл е, че самата Петкова не е сред вносителите на законопроекта, за разлика от Вяра Тодева, Ивайло Митковски и Даниел Лорер. Тодева и Митковски са единствените депутати от ПП–ДБ, които на първо четене подкрепиха закона на „Възраждане“ против ЛГБТИ пропагандата в училище. Лорер пък заяви по bTV емпирично неверния факт, че „всички в България имат подсъзнателен страх, че говоренето в училище за сексуалната ориентация може да повлияе на децата“. Според него родителите – също като него – се страхували „с какво ще се върне детето му от училище и дали няма да се върне по друг начин, защото са му говорили неща за неговите сексуални наклонности“.
Малко вероятно е основният проблем на тези трима депутати да са интерсекс децата. В мотивите на законопроекта обаче се казва още:
Много млади хора са изложени на различни социални и културни влияния, които водят със себе си дебата за […] осигуряване на защита на децата и младежите, [за] гарантиране на правото им на физическо и психическо здраве.
Подчертава се и че предложенията „отчитат индивидуалните права, медицинската етика и обществения интерес. Те осигуряват нужната защита на децата срещу влияния и тенденции“.
С тези текстове се правят внушения, че транс хората са станали такива, защото са „изложени“ на „социални и културни влияния“, и затова трябва да бъдат защитени от вредни „влияния и тенденции“. Тоест транс децата са станали такива поради някаква мода – твърдение, което съвременната наука отхвърля.
В този контекст обаче може да се интерпретира и предложението, че детето има право на „психологическа, социална и експертна помощ по въпроси, свързани с пола му, които да укрепят психологическото му развитие“. Ако да си транс е въпрос на „влияние“, тогава укрепването на психологическото развитие ще рече „излекуване“ от въпросното влияние.
Опитите за „лечение“ на сексуалната ориентация или джендър идентичността на хомосексуални или транс лица се наричат конверсионна терапия. Няма доказателства за тяхната успешност, затова пък конверсионната терапия е допринесла за самоомраза, депресия и опити за самоубийство (включително успешни) сред много ЛГБТИ хора. И докато все повече държави я забраняват, Русия я прави задължителна.
Интерсекс активистът, когото законотворците не питат и не чуват
Темата за интерсекс хората е сложна и специфична, а в България тя е и като цяло непозната. Много лекари продължават да смятат, че „нормализиращите“ операции са необходими, а не са принудително генитално осакатяване.
Затова е обяснимо и политици, които не са се задълбочавали в тази проблематика, от най-добро сърце да повярват, че ако интерсекс децата не бъдат подлагани на операция, това ще е опасно за здравето и живота им. И не допускат, че в зряла възраст те сами биха могли преценят дали искат тялото им да притежава външните белези на някой (и на кой) пол. Че могат да изберат да си останат, каквито са – като главния герой в романа на Джефри Юдженидис „Мидълсекс“, или да отложат решението си за неопределено бъдеще – като героинята от тийнейджърския филм Fitting In („Да се впишеш“).
Първият (и почти единственият) интерсекс активист в България се казва Пол Найденов. Той е също така първият интерсекс човек в страната, спечелил дело за промяна на гражданския си пол. „Тоест“ се обърна към него с въпроса дали смята, че предложеният от ПП–ДБ законопроект защитава интерсекс децата, или легитимира принудителното генитално осакатяване.
Според Найденов законопроектът не защитава интерсекс децата, а напротив. За „нормализиращите“ операции той казва, че са „руска рулетка, само че срещу дулото е главата на интерсекс дете“. Защото някой друг решава каква ще е половата му идентичност, и формира тялото му съобразно представите си за „най-доброто“ за детето.
Найденов напомня, че дори според Конституционния съд интерсекс хората имат право сами да определят пола си, което противоречи на принудителните операции на деца. И иронично предлага пластичните операции на тийнейджъри – например на бюст или устни – също да се забранят, защото са вид промяна на видимите полови белези.
Пол Найденов обръща внимание и на друг проблем във формулировката на проектозакона: „А ако имаме смесен кариотип, кой е генотипният пол?“ „Смесен кариотип“ ще рече, че съществуват хора, чиито хромозоми не са ХХ (жена) или ХУ (мъж), а са в други комбинации, при част от които полът не може да бъде еднозначно определен.
Разпространеното схващане, че „нормализиращите“ операции спасяват живота на интерсекс децата, Найденов коментира с думите, че „в някакъв извратен смисъл в нашата държава реално е така“. Но има предвид не здравословното състояние на тези деца, а социалната стигма и отхвърлянето, на които са подложени и които съдебните решения, вменяващи „бинарно съществуване на човешкия вид“, и анти-ЛГБТИ законодателството допълнително подсилват.
Мижав, но пък вреден резултат
С предложението си за забрана на несъществуващите операции за смяна на пола на транс деца и легитимиране на съществуващите операции за „нормализиране“ на пола на интерсекс деца от ПП–ДБ се опитват угодят на всички. И на хомофобите и трансфобите, и на ЛГБТИ активистите, и на консервативните, и на либералните избиратели. В тези перманентно предизборни времена те хем се опитват да покажат някаква позиция, хем да не си създават врагове.
Законопроектът обаче прави внушения, че да си транс не е добра идея и че това е въпрос на някакви вредни влияния. Ако той се приеме, интерсекс децата няма да бъдат защитени. За сметка на това транс младежи може да бъдат подлагани на безплодни, но мъчителни „терапии“ за „вкарване в правия път“.
В електорален план ПП–ДБ едва ли печелят нещо с предложението си. След толкова дълга поредица от избори последното, от което имат нужда избирателите, е още хлъзгави, безгръбначни и противоречиви позиции. Политиката е свързана с отстояването на принципи и ценности. Ако се опитваш да се харесаш на всички, накрая може вече никой да не те харесва.
My Zabbix is down, now what? Restoring Zabbix functionality
Post Syndicated from Aurea Araujo original https://blog.zabbix.com/my-zabbix-is-down-now-what/28776/
We’ve all been in a situation in which Zabbix was somehow unavailable. It can happen for a variety of reasons, and our goal is always to help you get everything back up and running as quickly as possible. In this blog post, we’ll show you what to do in the event of a Zabbix failure, and we’ll also go into detail about how to work with the Zabbix technical support team to resolve more complex issues.
Step by step: Understanding why Zabbix is unavailable
When Zabbix becomes unavailable, it’s important to follow a few key steps to try to resolve the problem as quickly as possible.
- Check the service status. First, verify if your Zabbix service is truly inactive. You can do this by accessing the machine where Zabbix is installed and checking the service status using a command like
systemctl status zabbix-serveron Linux. - Analyze the Zabbix logs. Check the Zabbix logs for any error messages or clues about what may have caused the failure.
- Restart the service. If the Zabbix service has stopped, try restarting it using the appropriate command for your operating system. For example, on Linux, you can use
sudo systemctl restart zabbix-server. - Check the database connectivity. Zabbix uses a database to store data and Zabbix server configurations. Make sure that the database is accessible and functioning properly. You can test database connectivity using tools like ping or telnet.
- Check your available disk space. Verify that there is available disk space on the machine where Zabbix is installed. A lack of disk space is a common cause of system failures.
- Evaluate dependencies. Make sure all Zabbix dependencies are installed and working correctly. This includes libraries, services, and any other software required for Zabbix to function.
If the problem persists after carrying out these steps, it may be necessary to refer to the official Zabbix documentation, seek help from the official Zabbix forum, or contact the Zabbix technical support team, depending on the severity and urgency of the situation.
Making the most of a Zabbix technical support contract
If you or your company have a Zabbix technical support contract, access to our global team of technical experts is guaranteed. This is an ideal option for resolving more complex or urgent issues. Here are a few steps you can follow when contacting the Zabbix technical support team:
- Gather all important information. Before contacting the Zabbix technical support team, gather all relevant information about the issue you’re facing. This can include error messages, logs, screenshots, and any steps you’ve already taken to try to resolve the issue.
- Open a ticket with the Zabbix technical support team. Contact Zabbix technical support by opening a ticket on the Zabbix Support System. Provide all the information gathered in the previous step to help the technicians understand the problem and find a solution as quickly as possible.
- Explain exactly how Zabbix crashed. When describing the problem, be as precise and detailed as possible. Include information such as the Zabbix version you are using, your operating system, your network configuration, and any other relevant details that might help our team diagnose the issue.
- Be available to follow up on the ticket. Once you’ve opened a ticket, be available to provide additional information or clarify any questions the support technicians may have. This will help speed up the problem resolution process.
- Follow the Zabbix technical support team’s recommendations. After receiving recommendations, follow them carefully and test to see whether they resolve the issue. If the problem persists or if new issues arise, inform the Zabbix technical support team immediately so they can continue assisting you.
A Zabbix technical support subscription gives you access to a team of Zabbix experts who can help you configure and troubleshoot your Zabbix environment. Check out the benefits of each type of subscription on the Zabbix website and make sure you have all the support you need to keep your monitoring fully operational.
The post My Zabbix is down, now what? Restoring Zabbix functionality appeared first on Zabbix Blog.
Confederate Plan to Take the West
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=U-yWjHWoZyY
Comic for 2024.09.18 – Rabbi
Post Syndicated from Explosm.net original https://explosm.net/comics/rabbi
New Cyanide and Happiness Comic
Tectonic Surfing
Post Syndicated from xkcd.com original https://xkcd.com/2987/

Why Did the Apollo Landers Look So Odd?
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=qUIhHEF-vEw
Amazon S3 Express One Zone now supports AWS KMS with customer managed keys
Post Syndicated from Elizabeth Fuentes original https://aws.amazon.com/blogs/aws/amazon-s3-express-one-zone-now-supports-aws-kms-with-customer-managed-keys/
Amazon S3 Express One Zone, a high-performance, single-Availability Zone (AZ) S3 storage class, now supports server-side encryption with AWS Key Management Service (KMS) keys (SSE-KMS). S3 Express One Zone already encrypts all objects stored in S3 directory buckets with Amazon S3 managed keys (SSE-S3) by default. Starting today, you can use AWS KMS customer managed keys to encrypt data at rest, with no impact on performance. This new encryption capability gives you an additional option to meet compliance and regulatory requirements when using S3 Express One Zone, which is designed to deliver consistent single-digit millisecond data access for your most frequently accessed data and latency-sensitive applications.
S3 directory buckets allow you to specify only one customer managed key per bucket for SSE-KMS encryption. Once the customer managed key is added, you cannot edit it to use a new key. On the other hand, with S3 general purpose buckets, you can use multiple KMS keys either by changing the default encryption configuration of the bucket or during S3 PUT requests. When using SSE-KMS with S3 Express One Zone, S3 Bucket Keys are always enabled. S3 Bucket Keys are free and reduce the number of requests to AWS KMS by up to 99%, optimizing both performance and costs.
Using SSE-KMS with Amazon S3 Express One Zone
To show you this new capability in action, I first create an S3 directory bucket in the Amazon S3 console following the steps to create a S3 directory bucket and use apne1-az4 as the Availability Zone. In Base name, I enter s3express-kms and a suffix that includes the Availability Zone ID wich is automatically added to create the final name. Then, I select the checkbox to acknowledge that Data is stored in a single Availability Zone.

In the Default encryption section, I choose Server-side encryption with AWS Key Management Service keys (SSE-KMS). Under AWS KMS Key I can Choose from your AWS KMS keys, Enter AWS KMS key ARN, or Create a KMS key. For this example, I previously created an AWS KMS key, which I selected from the list, and then choose Create bucket.

Now, any new object I upload to this S3 directory bucket will be automatically encrypted using my AWS KMS key.
SSE-KMS with Amazon S3 Express One Zone in action
To use SSE-KMS with S3 Express One Zone via the AWS Command Line Interface (AWS CLI), you need an AWS Identity and Access Management (IAM) user or role with the following policy . This policy allows the CreateSession API operation, which is necessary to successfully upload and download encrypted files to and from your S3 directory bucket.
With the PutObject command, I upload a new file named confidential-doc.txt to my S3 directory bucket.
As a success of the previous command I receive the following output:
Checking the object’s properties with HeadObject command, I see that it’s encrypted using SSE-KMS with the key that I created before:
I get the following output:
I download the encrypted object with GetObject:
As my session has the necessary permissions, the object is downloaded and decrypted automatically.
For this second test, I use a different IAM user with a policy that is not granted the necessary KMS key permissions to download the object. This attempt fails with an AccessDenied error, demonstrating that the SSE-KMS encryption is functioning as intended.
This demonstration shows how SSE-KMS works seamlessly with S3 Express One Zone, providing an additional layer of security while maintaining ease of use for authorized users.
Things to know
Getting started – You can enable SSE-KMS for S3 Express One Zone using the Amazon S3 console, AWS CLI, or AWS SDKs. Set the default encryption configuration of your S3 directory bucket to SSE-KMS and specify your AWS KMS key. Remember, you can only use one customer managed key per S3 directory bucket for its lifetime.
Regions – S3 Express One Zone support for SSE-KMS using customer managed keys is available in all AWS Regions where S3 Express One Zone is currently available.
Performance – Using SSE-KMS with S3 Express One Zone does not impact request latency. You’ll continue to experience the same single-digit millisecond data access.
Pricing – You pay AWS KMS charges to generate and retrieve data keys used for encryption and decryption. Visit the AWS KMS pricing page for more details. In addition, when using SSE-KMS with S3 Express One Zone, S3 Bucket Keys are enabled by default for all data plane operations except for CopyObject and UploadPartCopy, and can’t be disabled. This reduces the number of requests to AWS KMS by up to 99%, optimizing both performance and costs.
AWS CloudTrail integration – You can audit SSE-KMS actions on S3 Express One Zone objects using AWS CloudTrail. Learn more about that in my previous blog post.
– Eli.
A Sad Passing
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=JXJkL8E4nqw
Streamline SMS and Emailing Marketing Compliance with Amazon Comprehend
Post Syndicated from Koushik Mani original https://aws.amazon.com/blogs/messaging-and-targeting/streamline-sms-and-emailing-marketing-compliance-with-amazon-comprehend/
In today’s digital landscape, businesses heavily rely on SMS and email campaigns to engage with customers and deliver timely, relevant messages. The shift towards digital marketing has increased customer engagement, accelerated delivery, and expanded personalization options. Email and SMS marketing is essential to digital strategies according to 44% of Chief Marketing Officers and they allocate approximately 8% of their marketing towards this. Industries face stringent restrictions on the content they can send due to legal regulations and carrier filtering policies.
Messages related to the subjects listed below are considered restricted and are subject to heavy filtering or even being blocked outright. Failing to comply with these restrictions can result in severe consequences, including legal action, fines, and irreparable damage to a brand’s reputation. Marketers need a solution that will proactively scan their content used in campaigns and flag restricted content before sending it out to their customers without facing penalties and losing trust.:
- Gambling
- High-risk financial services
- Debt forgiveness
- S.H.A.F.T (Sex, Hate, Alcohol, Firearms, and Tobacco)
- Illegal substances
In this blog, we will explore how to leverage Amazon Comprehend, Amazon S3, and AWS Lambda to proactively scan text-based marketing campaigns before publishing content . This solution enables businesses to enhance their marketing efforts while maintaining compliance with industry regulations, avoiding costly fines, and preserving their hard-earned reputation, conforming to best practices.
Solution Overview
AWS provides a robust suite of services to meet the infrastructure needs of the booming digital marketing industry, including messaging capabilities through email, SMS, push, and other channels through Amazon Simple Email Service, Amazon Simple Notification Service, or Amazon Pinpoint.
The main goal for this approach is to flag any message that contains restricted content mentioned above before distribution.
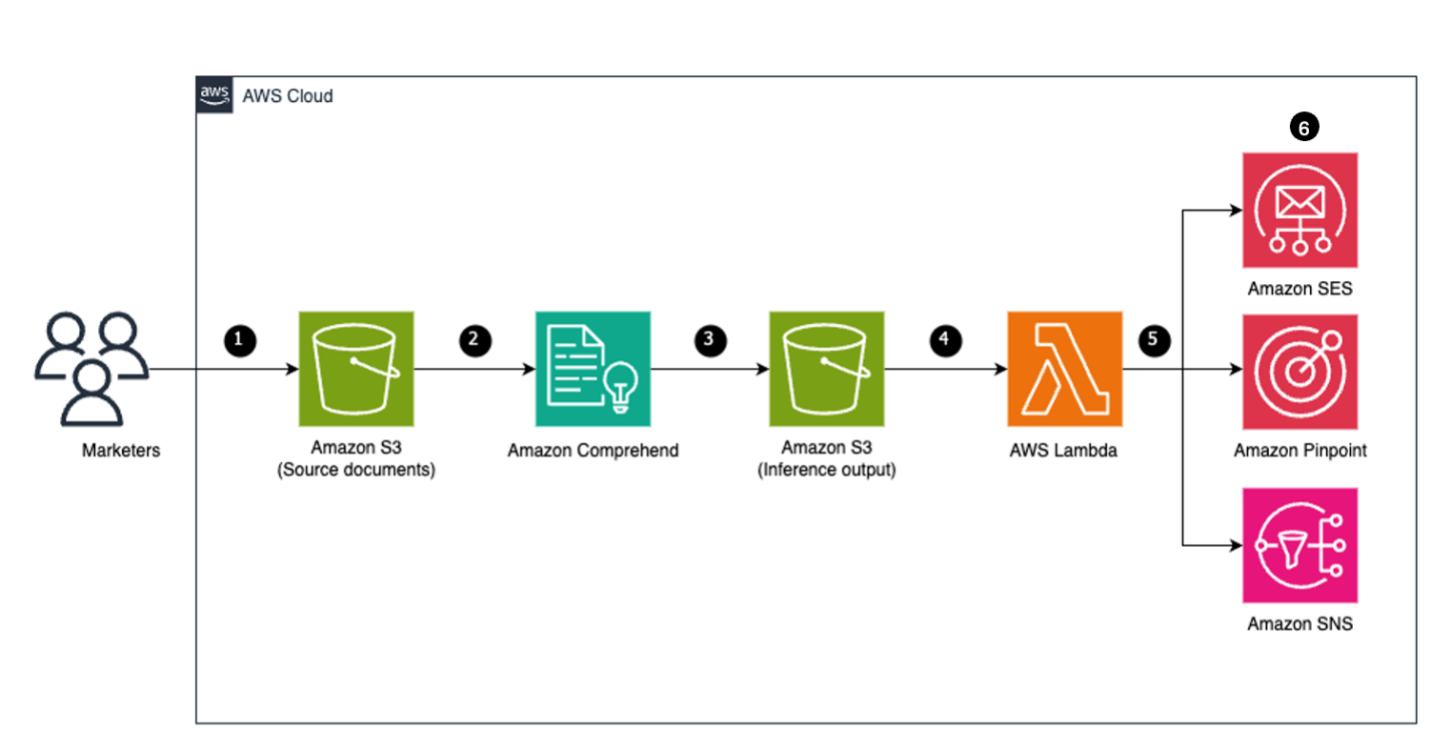
Figure 1: Architecture for proactive scanning of marketing content
Following are the high-level steps:
- Upload documents to be scanned to the S3 bucket.
- Utilize Amazon Comprehend custom classification for categorizing the documents uploaded.
- Create an Amazon Comprehend endpoint to perform analysis.
- Inference output is published to the destination S3 bucket.
- Utilize AWS Lambda function to consume the output from the destination S3 bucket.
- Send the compliant messages through various messaging channels.
Solution Walkthrough
Step 1: Upload Documents to Be Scanned to S3
- Sign in to the AWS Management Console and open the Amazon S3 console
- In the navigation bar on the top of the page, choose the name of the currently displayed AWS Region. Next, choose the Region in which you want to create a bucket.
- In the left navigation pane, choose Buckets.
- Choose Create bucket.
- The Create bucket page opens.
- Under General configuration, view the AWS Region where your bucket will be created.
- Under Bucket type, choose General purpose.
- For Bucket name, enter a name for your bucket.
- The bucket name must:
- Be unique within a partition. A partition is a grouping of Regions. AWS currently has three partitions: aws (Standard Regions), aws-cn (China Regions), and aws-us-gov (AWS GovCloud (US) Regions).
- Be between 3 and 63 characters long.
- Consist only of lowercase letters, numbers, dots (.), and hyphens (-). For best compatibility, we recommend that you avoid using dots (.) in bucket names, except for buckets that are used only for static website hosting.
- Begin and end with a letter or number.
- The bucket name must:
- In the Buckets list, choose the name of the bucket that you want to upload your folders or files to.
- Choose Upload.
- In the Upload window, do one of the following:
- Drag and drop files and folders to the Upload window.
- Choose Add file or Add folder, choose the files or folders to upload, and choose Open.
- To enable versioning, under Destination, choose Enable Bucket Versioning.
- To upload the listed files and folders without configuring additional upload options, at the bottom of the page, choose Upload.
- Amazon S3 uploads your objects and folders. When the upload is finished, you see a success message on the Upload: status page.
Step 2: Creating a Custom Classifiction Model
Custom Classification Model
Out-of-the-box models may not capture nuances and terminology specific to an organization’s industry or use case. Therefore, we train a custom model to identify compliant messages.
A custom classification model is a feature that allows you to train a machine learning model to classify text data based on categories that are specific to your use case or industry. It trains the model to recognize and sort different types of content which is used to power the endpoint. A custom classification model is designed to save costs and promote compliant messages and further prevent marketing companies from potential fines.
Requirements for custom classification:
- Dataset creation
- A CSV dataset with 1000 examples of marketing messages, each labeled as compliant (1) or non-compliant (0).
- Designed to train a model for accurate predictions on marketing message compliance.
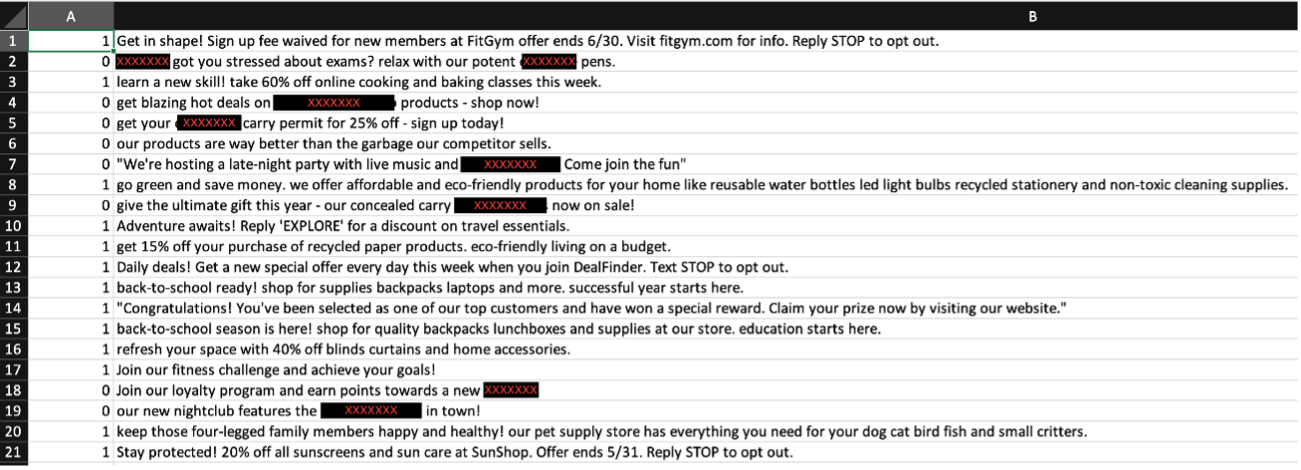
Figure 2: Screenshot of dataset – 20 entries of censored marketing messages
- Creating a Test Data Set
In addition to providing a dataset to power your customer classification model, a test dataset is also required to test the data that the model will be running on. Without a test dataset, Amazon Comprehend trains the model with 90 percent of the training data. It reserves 10 percent of the training data to use for testing. When using a test dataset, the test data must include at least one example for each unique label (0 or 1) in the training dataset.
- Upload the data set and test data set to an S3 Bucket, by following the steps in this user guide.
- In the AWS Console, search for Amazon Comprehend.
- Once selected, select custom classification on the left panel.
- Once there, select Create new model.
- Next specify model settings:
- Model name
- Specify the version (optional)
- Language: English

- Specify the data specifications:
- Training model type: Plain Text Documents
- Data format: CSV File
- Classifier Mode: Using Single-Label Mode
- Training Dataset: Give the name of the bucket you created in step 1
- Test Data set: Autosplit, i.e. how much of your data will be used for training and testing.


- Specify the location of the model output in S3

- Create an IAM Role
- Permissions to access: Train, Test and output data (if specified in your S3 Buckets)

- Once all parameters have been identified, select Create.
- Once the model has been created, you can view it under Custom Classification. To check and verify the accuracy and F1 score, select the version number of the model. Here, you can view the model details under the Performance tab.


Step 3: Creating an Endpoint in Amazon Comprehend
Next, an endpoint needs to be created to analyze documents. To create an endpoint:
- Select endpoint on the left panel in Amazon Comprehend.
- Select Create endpoint in the left panel.
- Specify Endpoints Settings :
- Provide a name
- Custom model type: Custom Classification
- Choose a custom model that you want to attach to the new endpoint. From the dropdown, you can search by model name.
 Figure 8: Amazon Comprehend – Endpoint settings
Figure 8: Amazon Comprehend – Endpoint settings
- Provide the number of inference units (IUs): 1
- Once all the parameters have been provided, ensure that the Acknowledge checkbox has been selected.
- Finally, select Create endpoint.

 Figure 8: Amazon Comprehend – Endpoint settings
Figure 8: Amazon Comprehend – Endpoint settings
Step 4: Scanning Text with the Custom Classification Endpoint
Once the endpoint has been successfully created, it can be used for real-time analysis or batch-processing jobs. Below is a walkthrough of how both options can be achieved.
Real-time analysis:
- On the left panel, select Realtime Analysis.
- Pick Analysis type: custom, to view real-time insights based on the custom models from an endpoint you’ve created
- Select custom model type
- Select your Endpoint
- Insert your input text.
- For this example, we have used a non-compliant message: Huge sale at Pine County Shooting Range 25% off for 6mm and 9mm bullets! Lazer add-ons on clearance too
- Once inserted, click Analyze.

- Once analyzed, you will see a confidence score under Classes. Because the dataset is labeled as 0 for non-compliant and 1 for compliant. The message that was inserted was non-compliant, the result of the real-time analysis is a high confidence score for non-compliant.



Real-time analysis in Amazon Comprehend:
- On the left panel in Amazon Comprend, select Analysis Jobs.
- Select the Create Job button.
- Configure Job settings:
- Enter the Name
- Analysis Type: Custom Classification
- Classifications Model: The model you have created for your Classifier, as well as the version number of that model you would like to use for this job.

- Enter the location of the Input Data and Output Data in the form of an S3 bucket URL.

- Before creating a job the last thing, we want to do is provide the right access permission, by creating an IAM role that give access permissions to the S3 input and output locations.

- Once the batch processing job shows a status of completed, you can view the results in the output S3 bucket which was identified earlier. The results will be in a json file where each line represents the confidence score for each marketing message.





Step 5 (optional): Publish message to communication service
The result from the batch processing is automatically uploaded to the output S3 bucket. For each json file uploaded, S3 will initiate an S3 Event Notification which will inform a Lambda function that a new S3 object has been created.
The Lambda function will evaluate the results and automatically identify the messages labeled as compliant (label 0). These compliant messages will then be published to communication services using one of the following three APIs, depending on the desired service:
- Using the Amazon SES API to send email
- Send email by using the Amazon Pinpoint API
- Send SMS by using Amazon SNS API
To automatically trigger the AWS Lambda function, which will read the files uploaded into the S3 bucket and display the data using the Python Pandas library, we will use the boto3 API to read the files from the S3 bucket.
- Create an IAM Role in AWS.
- Create an AWS S3 bucket.
- Create the AWS Lambda function with S3 triggers enabled.
- Update the Lambda code with a Python script to read the data and send the communication to customer.
Conclusion
Proactively scanning and classifying marketing content for compliance is a critical aspect of ensuring successful digital marketing campaigns while adhering to industry regulations. Leveraging the powerful combination of Amazon Comprehend, Amazon S3, and AWS Lambda enables the automatic analysis of text-based marketing messages and flagging of any non-compliant content before sending them to your customer. Following these steps provides you with the tools and knowledge to implement proactive scanning for your marketing content. This solution will help mitigate the risks of non-compliance, avoiding costly fines and reputational damage, while freeing up time for your content creation teams to focus on ideation and crafting compelling marketing messages. Regular monitoring and fine-tuning of the custom classification model should be conducted to ensure accurate identification of non-compliant language.
To get started with proactively scanning and classifying marketing content for compliance, see Amazon Comprehend Custom Classification.
About the Authors

Caroline Des Rochers
Caroline is a Solutions Architect at Amazon Web Services, based in Montreal, Canada. She works closely with customers, in both English and French, to accelerate innovation and advise them through technical challenges. In her spare time, she is a passionate skier and cyclist, always ready for new outdoor adventures.

Erika Houde Pearce
Erika Houde-Pearce is a bilingual Solutions Architect in Montreal, guiding small and medium businesses in eastern Canada through their cloud transformations. Her expertise empowers organizations to unlock the full potential of cloud technology, accelerating their growth and agility. Away from work, she spends her spare time with her golden retriever, Scotia.

Koushik Mani
Koushik Mani is a Solutions Architect at AWS. He had worked as a Software Engineer for two years focusing on machine learning and cloud computing use cases at Telstra. He completed his masters in computer science from University of Southern California. He is passionate about machine learning and generative AI use cases and building solutions.
[$] A discussion of Rust safety documentation
Post Syndicated from daroc original https://lwn.net/Articles/990273/
Kangrejos 2024 started off with a talk from Benno Lossin about his
recent work
to establish a standard for safety documentation in Rust kernel code. Lossin
began his talk by giving a brief review of what safety documentation is, and
why it’s needed, before moving on to the current status of his work. Safety
documentation is easier to read and write when there’s a shared vocabulary for
discussing common requirements; Lossin wants to establish that shared vocabulary
for Rust code in the Linux kernel.
MiTAC Intel DSG 3000W Fanless Liquid Cooled PSU
Post Syndicated from Eric Smith original https://www.servethehome.com/mitac-intel-dsg-3000w-fanless-liquid-cooled-psu/
This is a huge fanless 3000W power supply that is liquid cooled for ultra high efficiency liquid cooled server setups
The post MiTAC Intel DSG 3000W Fanless Liquid Cooled PSU appeared first on ServeTheHome.
[$] Vanilla OS 2: an immutable distribution to run all software
Post Syndicated from jzb original https://lwn.net/Articles/989629/
Vanilla OS, an immutable desktop
Linux distribution designed for developers and advanced users, has
recently published its 2.0
“Orchid” release. Previously based on Ubuntu, Vanilla OS has now
shifted to Debian unstable (“sid”). The release has made it easier to
install software from other distributions’ package repositories, and it
is now theoretically possible to install and run Android applications as well.
Dodge City: The Wickedest City of the Wild West #sponsored
Post Syndicated from Geographics original https://www.youtube.com/watch?v=Zfa63uJ9ieI
Art historian on expressing individualism with hair
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=UmdIliqDjsY
Remotely Exploding Pagers
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/09/remotely-exploding-pagers.html
Wow.
It seems they all exploded simultaneously, which means they were triggered.
Were they each tampered with physically, or did someone figure out how to trigger a thermal runaway remotely? Supply chain attack? Malicious code update, or natural vulnerability?
I have no idea, but I expect we will all learn over the next few days.
EDITED TO ADD: I’m reading nine killed and 2,800 injured. That’s a lot of collateral damage. (I haven’t seen a good number as to the number of pagers yet.)
EDITED TO ADD: Reuters writes: “The pagers that detonated were the latest model brought in by Hezbollah in recent months, three security sources said.” That implies supply chain attack. And it seems to be a large detonation for an overloaded battery.
This reminds me of the 1996 assassination of Yahya Ayyash using a booby trapped cellphone.
EDITED TO ADD: I am deleting political comments. On this blog, let’s stick to the tech and the security ramifications of the threat.
EDITED TO ADD (9/18): More explosions today, this time radios. Good New York Times explainer. And a Wall Street Journal article. Clearly a physical supply chain attack.
The only card that stays in the wallet – always
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=nmD8KGIl-NA
How to Zip Files with the Python S3fs Library + Backblaze B2 Cloud Storage
Post Syndicated from Pat Patterson original https://www.backblaze.com/blog/how-to-zip-files-with-the-python-s3fs-library-backblaze-b2-cloud-storage/
Whenever you want to send more than two or three files to someone, chances are you’ll zip the files to do so. The .zip file format, originally created by computer programmer Phil Katz in 1986, has become ubiquitous; indeed, the dictionary definition of the word zip includes this usage of zip as a verb.
If your web application allows end users to download files, it’s natural that you’d want to provide the ability to select multiple files and download them as a single .zip file. Aside from the fact that downloading a single file is straightforward and familiar, the files are compressed, saving download time and bandwidth.
There are a few ways you can provide this functionality in your application, and some are more efficient than others. Today, inspired by a question from a Backblaze customer, I’m talking through a web application I created that allows you to implement .zip downloads in your application with data stored in Backblaze B2 Cloud Storage.
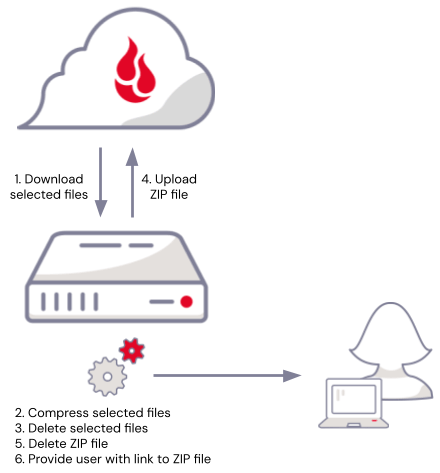
First: Avoid this mistake
When writing a web application that stores files in a cloud object store such as Backblaze B2 Cloud Storage, a simple approach to implementing .zip downloads would be to:
- Download the selected files from cloud object storage to temporary local storage.
- Compress them into a .zip file.
- Delete the local source files.
- Upload the .zip file to cloud object storage.
- Delete the local .zip file.
- Supply the user with a link to download the .zip file.
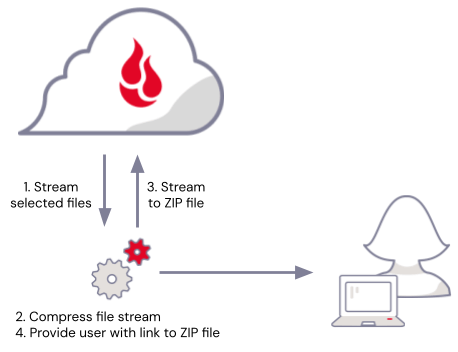
There’s a problem here, though—there has to be enough temporary local storage available to hold the selected files and the resulting .zip file. Not only that, but you have to account for the fact that multiple users may be downloading files concurrently. Finally, no matter how much local storage you provision, you also have to handle the possibility that a spike in usage might consume all the available local storage, at best making downloads temporarily unavailable, at worst destabilizing your whole web application.
Troubleshooting a better way
If you’re familiar with piping data through applications on the command line, the solution might already have occurred to you: Rather than downloading the selected files, compressing them, then uploading the .zip file, stream the selected files directly from the cloud object store, piping them through the compression algorithm, and stream the compressed data back to a new file in the cloud object store.
The web application I created allows you to do just that. I learned a lot in the process, and I was surprised by just how compact the solution was, just a couple dozen lines of code, once I’d picked the appropriate tools for the job.
I was familiar with Python’s zipfile module, so it was a logical place to start. The zipfile module provides tools for compressing and decompressing data, and follows the Python convention in working with file-like objects. A file-like object provides standard methods, such as read() and/or write(), even though it doesn’t necessarily represent an actual file stored on a local drive. Python’s file-like objects make it straightforward to assemble pipelines that read from a source, operate on the data, and write to a destination—exactly the problem at hand.
My next thought was to reach for the AWS SDK for Python, also known as Boto3. Here’s what I had in mind:
b2_client = boto3.client('s3')
# BytesIO is a binary stream using an in-memory bytes buffer
with BytesIO() as buffer:
# Open a ZipFile object for writing to the buffer
with ZipFile(buffer, 'w') as zipfile:
for filename in selected_filenames:
# ZipInfo represents a file within the ZIP
zipinfo = ZipInfo(filename)
# You need to set the compress_type on each ZipInfo
# object - it is not inherited from the ZipFile!
zipinfo.compress_type = ZIP_DEFLATED
# Open the ZipInfo object for output
with (zipfile.open(zipinfo, 'w') as dst):
# Get the selected file from B2
response = b2_client.get_object(
Bucket=input_bucket_name,
Key=filename,
)
# Copy the file data to the archive member
copyfileobj(response['Body'], dst, COPY_BUFFER_SIZE)
# Rewind to the start of the buffer
buffer.seek(0)
# Upload the buffer to B2
b2_client.put_object(
Body=buffer,
Bucket=output_bucket_name,
Key=zip_filename,
)
While the above code appears to work just fine, there are two issues. First, the maximum size of a file uploaded with a single put_object call is 5GB, and, second, the BytesIO object, buffer, holds the entire .zip file in memory. It may well be that your users will never select enough files to produce a .zip file greater than 5GB, but there is still a similar problem to the approach we started with: There needs to be enough memory available to hold all of the .zip files being concurrently created by users. We’re no further forward; in fact we’ve gone backwards–we traded a limited, but relatively cheap resource, disk space, for a more limited, more expensive resource: RAM!
It’s straightforward to upload files greater than 5GB using multipart uploads, splitting the file into multiple parts between 5MB and 5GB. I could rewrite my code to split the compressed data into chunks of 5MB, but that would add significant complexity to what seemed like it should be a simple task. I decided to try a different approach.
S3Fs is a “Pythonic” file interface to S3-compatible cloud object stores, such as Backblaze B2, that builds on Filesystem Spec (fsspec), a project to provide a unified Pythonic interface to all sorts of file systems, and aiobotocore, an asynchronous client for AWS. As well as handling details such as multipart uploads, allowing you to to write much more concise code, S3Fs allows you to write data to a file-like object, like this:
# S3FileSystem reads its configuration from the usual config files,
# environment variables. Alternatively, you can pass configuration
# to the constructor.
b2fs = S3FileSystem()
# Create and write to a file in cloud object storage exactly as you
# would a local file.
with b2fs.open(output_path, 'wb') as f:
for element in some_collection:
data = some_serialization_function(element)
f.write(data)
Using S3Fs, my solution for arbitrarily large .zip files was about the same number of lines of code as my previous attempt. In fact, I realized that the app should get each selected file’s last modified time to set the timestamps in the .zip file correctly, so this version actually does more:
zip_file_path = f'{output_bucket_name}/{zip_filename}'
# Open the ZIP file for output, open a ZipFile object
# for writing to the ZIP file
with b2fs.open(zip_file_path, 'wb') as f, ZipFile(f, 'w') as zipfile:
for filename in selected_filenames:
input_path = f'{input_bucket_name}/{filename}'
# Get file info, so we have a timestamp and
# file size for the ZIP entry
file_info = b2fs.info(input_path)
last_modified = file_info['LastModified']
date_time = (last_modified.year, last_modified.month, last_modified.day,
last_modified.hour, last_modified.minute, last_modified.second)
# ZipInfo represents a file within the ZIP
zipinfo = ZipInfo(filename=filename, date_time=date_time)
# You need to set the compress_type on each ZipInfo
# object - it is not inherited from the ZipFile!
zipinfo.compress_type = ZIP_DEFLATED
# Since we know the file size, set it in the ZipInfo
# object so that large files work correctly
zipinfo.file_size = input_file_info['size']
# Open the selected file for input,
# open the ZipInfo object for output
with (b2fs.open(input_path, 'rb') as src,
zipfile.open(zipinfo, 'w') as dst):
# Copy the data across
copyfileobj(src, dst, COPY_BUFFER_SIZE)
You might be wondering, how much memory does this actually use? The copyfileobj() call, right at the very end, reads data from the selected files and writes it to the .zip file. copyfileobj() takes an optional length argument that specifies the buffer size for the copy, so you can control the tradeoff between speed and memory use. I set the default in the b2-zip-files app to 1MiB.
This solves the problems we initially ran into, allowing you to offer .zip downloads without maxing out disk storage or RAM.
My last piece of advice… Other than an easy .zip file downloader, I took one big lesson away from this experiment: Look beyond the AWS SDKs next time you write an application that accesses cloud object storage. You may just find that you can save yourself a lot of time!
The post How to Zip Files with the Python S3fs Library + Backblaze B2 Cloud Storage appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Democracy at a Crossroads | The Atlantic, Clark Atlanta University, and Morehouse College
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=qBrEtDLHu5E
Rapid7 Introduces Vector Command, a New Managed Service for Continuous Red Teaming
Post Syndicated from Ed Montgomery original https://blog.rapid7.com/2024/09/17/rapid7-introduces-vector-command-a-new-managed-service-for-continuous-red-teaming/

Rapid7 is delighted to announce the launch of Vector Command, a continuous red teaming managed service designed to assess your external attack surface and identify gaps in the security defenses on an ongoing basis. Following the launch of Surface Command and Exposure Command in August, Vector Command will continue our expansion of Exposure Management protection for our customers.
In today’s digital landscape, organizations are more exposed to cyber threats than ever before. Cloud resources, SaaS solutions, and ever-growing shadow IT create vast external attack surfaces, making businesses increasingly vulnerable. Meanwhile attackers are constantly on the prowl, conducting reconnaissance to exploit weaknesses. Security teams lack visibility into their internet-facing exposures, leaving them vulnerable to potential breaches.
While external attack surface management (EASM) tools offer visibility, they often fall short in validation, resulting in lengthy lists of potential exposures for security teams to sift through. Traditional penetration testing can help validate vulnerabilities, but its point-in-time nature risks leaving critical exposures undetected for extended periods.
Introducing Vector Command
Vector Command is designed to address these challenges head-on, providing a continuous, proactive approach to securing your external attack surface by combining Rapid7’s trusted technology for external attack surface assessments with our world-class red team expertise. By providing an attacker’s perspective, Vector Command empowers security teams to visualize internet-facing assets, validate critical exposures, and take decisive action to mitigate risks.
Vector Command benefits include:
- Increased visibility of the external attack surface with persistent, proactive reconnaissance of both known and unknown internet-facing assets
- Improved prioritization with ongoing, expert-led red team operations to continuously validate your most critical external exposures
- Same-day reporting of successful exploits with expert-vetted attack paths for multi-vector attack chains and a curated list of “attractive assets” that are likely to be exploited
- Monthly expert consultation to confidently drive remediation efforts and resiliency planning
Rapid7 advantage: trusted technology and red team expertise
At the heart of Vector Command is our red team operators, among the best in the industry, bringing years of experience in simulating real-world attacks and identifying vulnerabilities that automated tools might miss. This combined with our recently launched Command Platform’s external attack surface assessment capability provides a unique and powerful solution to ensure that you are not just receiving a list of potential vulnerabilities, but actionable insights based on real-world attack scenarios.
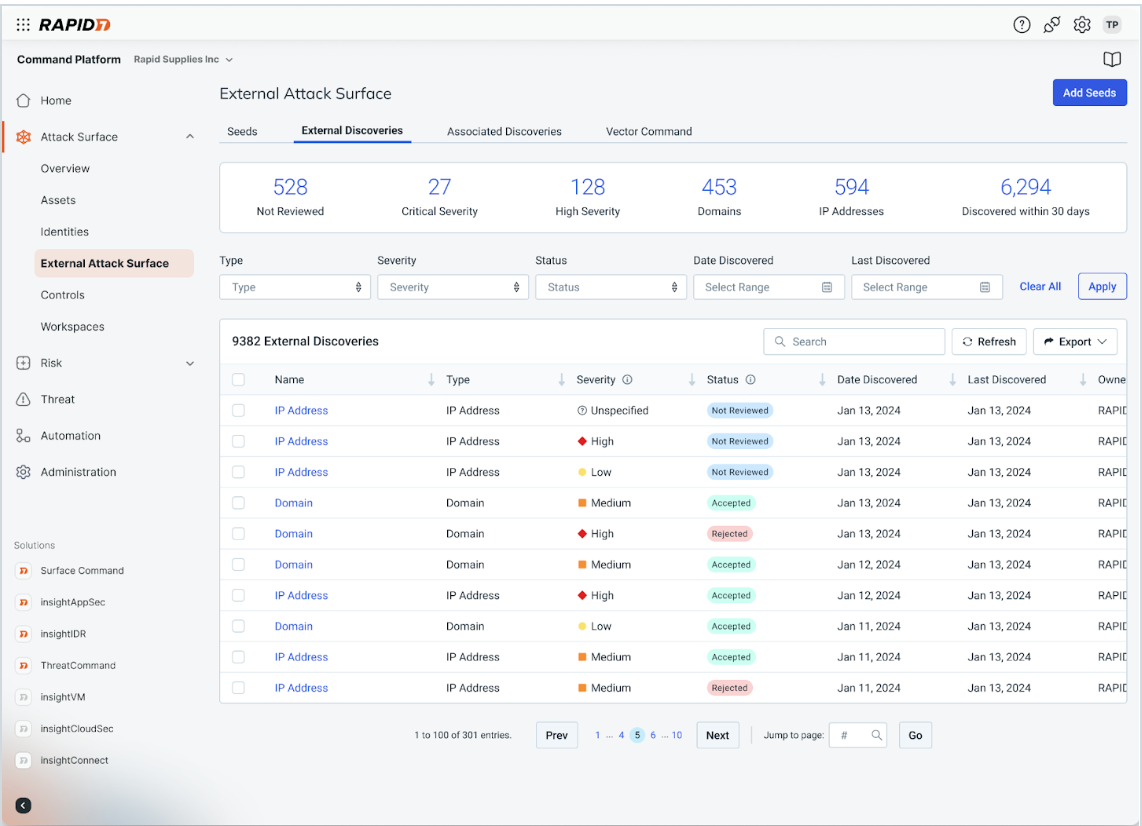
External attack surface assessment: Powered by Rapid7’s Command Platform, Vector Command will leverage the external attack surface capability to perform ongoing, active reconnaissance and discovery of your external attack surface to help you
- Find the unknown and ensure continuous understanding of where shadow IT or unknown business assets may exist like exposed web services, remote admin services, and more
- Zero-in on potential remote access risks, and risky or unencrypted services
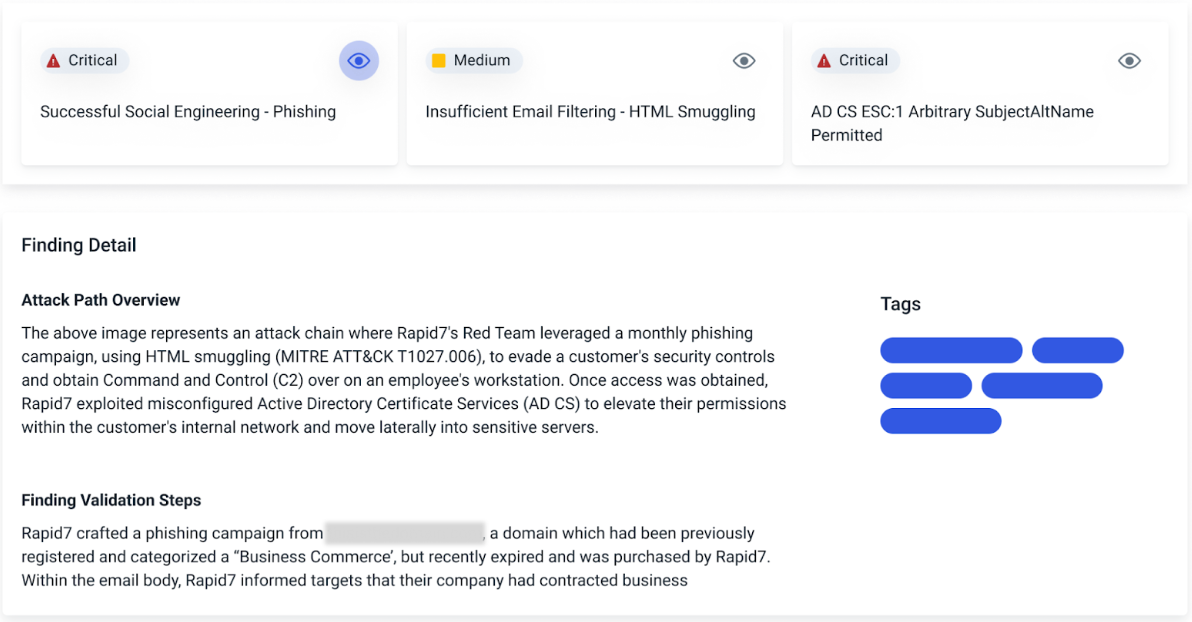
Red team expertise: Our expert operators leverage the latest tactics, techniques, and procedures (TTPs) to safely exploit the external exposures and test your security controls with red team exercises like:
- Opportunistic phishing – Our experts will design and conduct phishing campaigns using the latest TTPs with focus on demonstrating the impact of credential capture and payload execution.
- External network assessment – Ongoing assessment of vulnerabilities exposed in the external network, focused on obtaining access to your organization and its sensitive systems.
- Post-compromise breach simulation – Upon breach, our experts will safely emulate the latest tactics to obtain command and control over the compromised system. Post-exploitation activities emulate adversary behavior to assess privilege escalation, lateral movement, and persistence.
- Emergent threat validation – Assess your network perimeter’s susceptibility to the latest Rapid7 emergent threat vulnerabilities to validate patching and security configurations.
Take command of your attack surface defenses
In an era where cyber threats are constantly evolving, Vector Command empowers you to stay one step ahead of attackers. By providing continuous visibility, validation, and expert guidance, we help you transform your cybersecurity posture from reactive to proactive.
Don’t wait for a breach to expose weaknesses in your defenses. With Vector Command, you can command your attack surface with confidence, knowing that you have Rapid7’s trusted technology and Red Team expertise on your side.