Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=jHgnO3JryCM
AWS renews its GNS Portugal certification for classified information with 66 services
Post Syndicated from Daniel Fuertes original https://aws.amazon.com/blogs/security/aws-renews-its-gns-portugal-certification-for-classified-information-with-66-services/
Amazon Web Services (AWS) announces that it has successfully renewed the Portuguese GNS (Gabinete Nacional de Segurança, National Security Cabinet) certification in the AWS Regions and edge locations in the European Union. This accreditation confirms that AWS cloud infrastructure, security controls, and operational processes adhere to the stringent requirements set forth by the Portuguese government for handling classified information at the National Reservado level (equivalent to the NATO Restricted level).
The GNS certification is based on the NIST SP800-53 Rev. 5 and CSA CCM v4 frameworks. It demonstrates the AWS commitment to providing the most secure cloud services to public-sector customers, particularly those with the most demanding security and compliance needs. By achieving this certification, AWS has demonstrated its ability to safeguard classified data up to the Reservado (Restricted) level, in accordance with the Portuguese government’s rigorous security standards.
AWS was evaluated by an authorized and independent third-party auditor, Adyta Lda, and by the Portuguese GNS itself. With the GNS certification, AWS customers in Portugal, including public sector organizations and defense contractors, can now use the full extent of AWS cloud services to handle national restricted information. This enables these customers to take advantage of AWS scalability, reliability, and cost-effectiveness, while safeguarding data in alignment with GNS standards.
We’re happy to announce the addition of 40 services to the scope of our GNS certification, for a new total of 66 services in scope. To view the complete list of services included in the scope, see the AWS Services in Scope by Compliance Program – GNS National Restricted Certification page.
The Certificate of Compliance illustrating the compliance status of AWS is available on the GNS Certifications page and through AWS Artifact.
For more information about GNS, see the AWS Compliance page GNS National Restricted Certification.
If you have feedback about this post, submit comments in the Comments section below.
[$] RPM 4.20 is coming
Post Syndicated from jzb original https://lwn.net/Articles/988927/
The RPM Package Manager (RPM) project is
nearing the release of RPM 4.20, the last major planned update for the RPM 4.x
series. It has few user-facing changes, but
several additions and enhancements for developers—as well as
some small incompatibilities that will likely require RPM packagers to
revise their spec
files. 4.20 will be rolling out to many users soon, in
Fedora 41, which is scheduled for October. RPM 6.0 is
already in the works, with a new package format and opening the door
to enabling C++ use in the RPM codebase.
Help, I can’t see! A Primer for Attack Surface Management Blog Series
Post Syndicated from Jon Schipp original https://blog.rapid7.com/2024/09/19/help-i-cant-see-a-primer-for-attack-surface-management-blog-series/
Part 1: Overview of the Problem ASM Solves and a High-Level Description of ASM and Its Components

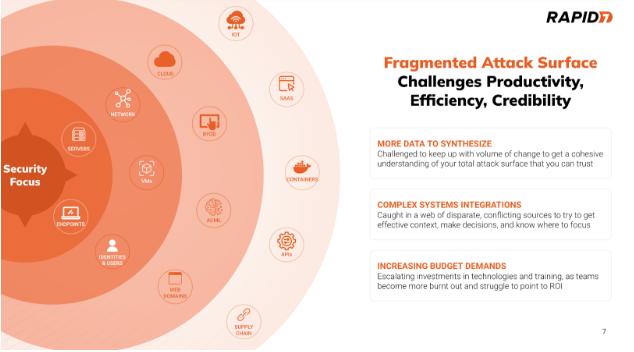
Welcome to the first installment of our multipart series, “Help! I Can’t See! A Primer for Attack Surface Management Blog Series.” In this series, we will explore the critical challenges and solutions associated with Attack Surface Management (ASM), a vital aspect of modern cybersecurity strategy. This initial blog, titled “Overview of the Problem ASM Solves and a High-Level Description of ASM and Its Components,” sets the stage by examining the growing difficulties organizations face in managing their digital environments and how ASM can help address these issues effectively.
The fast paced evolution of digital infrastructure that is driving businesses forward (e.g. workstations, virtual machines, containers, edge) is also making it more difficult for organizations to keep track of and account for the cyber attack surface they’re responsible for protecting. Despite security teams continuing to invest exorbitant amounts of money on tools (VM, EDR, CNAPP, etc.) to both manage their digital environment and also secure it, the problem isn’t getting any better. In this 3-part blog series we will help demystify the problems of security data silos and tool sprawl so you can answer pertinent questions like
- How many assets and identities am I responsible for protecting?
- How many assets and identities are lacking security controls like endpoint security or MFA?
- What is my overall security posture?
When we look at the number and types of tools organizations spend money on to manage and secure their digital environment, we typically see things like vulnerability scanners, endpoint security, IdP, patching, IT asset management, Cloud Service Providers, and more. Each of these tools and technologies tend to do a pretty good job at their core function but unintentionally contribute to a fractured ecosystem that provides organizations with contradictory information about their digital environment.
The age old problem: How many assets do I have?
Let’s look at a real-world example of this where an organization has solutions for Vulnerability Management (VM), Cloud Security Posture Management (CSPM), Endpoint Security (EDR/EPP), Active Directory (Directory Services) and IT Asset Management( ITAM).
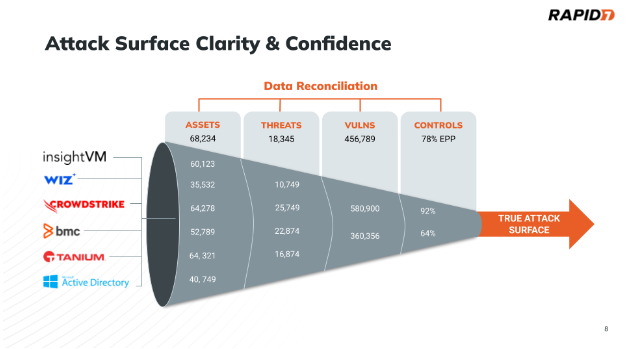
None of these tools can agree on the number of assets in the environment. It’s practically impossible to achieve 100% deployment of agent-based tools across your business (some types of assets cannot have agents!). It then becomes a real challenge to see across these tooling visibility gaps. The result is that we cannot answer the basic question of “How many assets am I responsible for protecting”.
This fact is compounded because if we can’t agree on the total number of assets, then we don’t know the number of controls in place, the number of vulnerabilities and exposures that exist, and the number of active threats in our environment. Teams that manage and secure organizations are relying upon incorrect information in an environment where prioritization and decision making needs to be based on high-fidelity information that incorporates IT, security, and business context to lead to the best outcomes.
To drill down on these points, let’s pick on a few tools from the infographic for illustrative purposes. Wiz will only see assets in the cloud, Active Directory only sees assets (mostly Windows) tied to the Domain Controller, and traditional vulnerability scanners see across hybrid environments but tend to be mostly deployed on-premise. If you hone in on the numbers in the Asset column you will immediately notice that none of these tools agree on the number of assets in the environment. Lacking visibility and confidence in your attack surface is a big data problem, and deploying the latest shiny security tool is not going to fix it.
Ultimately, we have an industry created data problem that Rapid7 is not immune to. For a number of perfectly good reasons, we have created a fractured technology ecosystem that is preventing security teams from having the best data available to determine their cyber risk and enabling them to prioritize the most effective remediation and response.
We need to see across the gaps that truly matter; for that we need Attack Surface Management.
What is Attack Surface Management?
Attack Surface Management (ASM) is generally part of a wider Exposure Management program and is a different way to think about cyber risk by focusing on addressing the digital parts of the business that are most vulnerable to attack. Taking an attack surface-based approach to your security program needs to consider a number of different elements including:
- Discovery and inventory of all cyber assets in the organization, from the endpoint to the cloud
- Internet-scanning to identify unknown exposures and map them to the existing asset inventory
- High-fidelity visibility and insights into the IT, security, and business context of those assets
- Relationship-mapping between the assets and the wider network and business infrastructure
ASM is a continuous process that is constantly assessing the state of the attack surface by uncovering new or updated assets, identifying the use of shadow IT in network or cloud use cases and prioritizing exposures based on their potential risk to the business. These elements of discovery and prioritization are foundational elements of a Continuous Threat Exposure Management (CTEM) initiative, where security teams are taking a more holistic approach to managing all types of exposures in their organizations.
A positive trend that we are currently seeing is that security teams are going back to basics and focusing on cyber asset management to first discover and understand the assets they’re responsible for protecting, along with their business function.
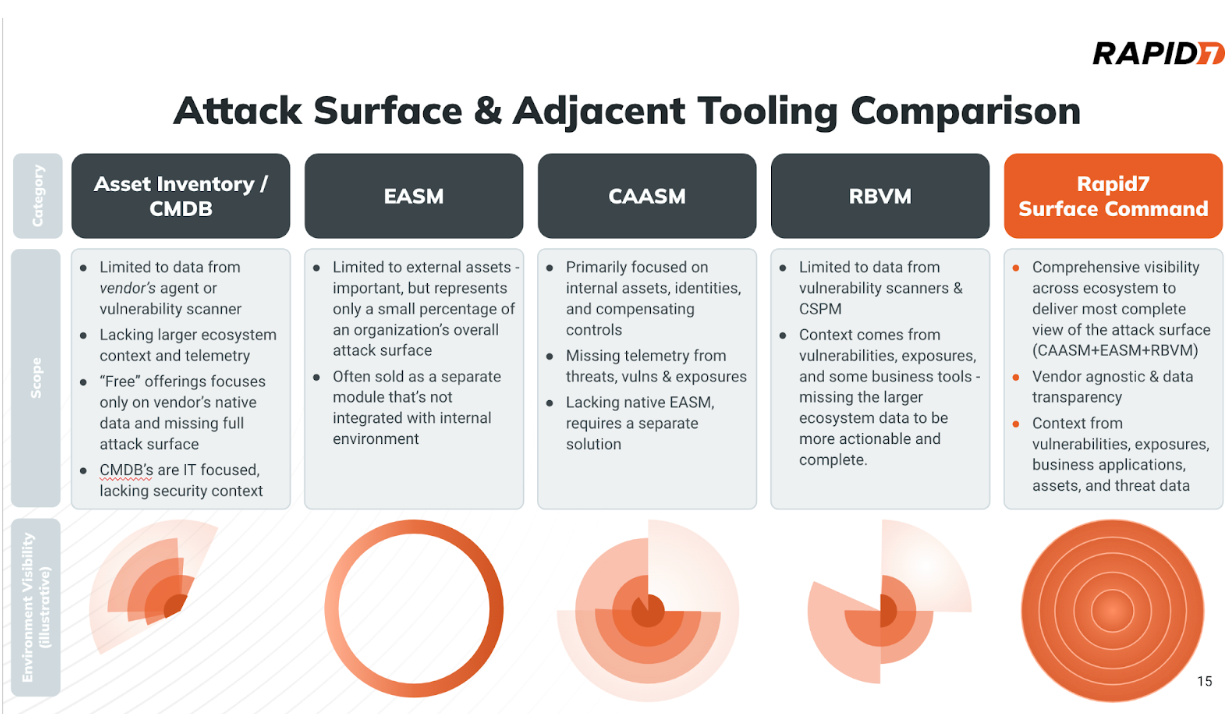
They gain visibility into the assets through a combination of external scanning to identify internet-facing assets which are potentially higher risk, this is known as External Attack Surface Management (EASM). A complementary approach to cyber asset discovery that provides greater insights into the whole cyber estate uses API-based integrations into existing IT management and security tools to ingest asset data; this is known as Cyber Asset Attack Surface Management (CAASM). Together, they provide organizations with the asset visibility they need to drive security decisions.
Put simply, you cannot secure what you can’t see. Managing the attack surface requires asset discovery and visibility, combined with rich context from all tools in the environment.
Attack Surface Management vs. Asset Inventory
There is a common confusion with customers today that they already have elements of an ASM strategy with their current approach to asset inventory. This is typically based on an asset inventory system that IT is using for asset lifecycle management. A traditional asset inventory’s view of the environment is almost entirely based on what it is able to discover on its own, and with an IT focus. These are often agent-based, with limited integrations, so they are not able to take advantage of an organization’s wide range of tools, which impairs their value.
Many asset inventories today can only discover assets where they have a deployed agent, such as an endpoint agent or being tied to the domain controller. While these technologies are effective at making policy and configuration changes on their fleet of endpoints, they do not have a data aggregation and correlation engine that sees beyond the specific agent. Additionally, they have limited security insights and context, and are only able to provide a partial view of the attack surface, assuming that no agent has 100% coverage.
This is not the reality in most organizations, and it’s why one should not confuse Asset Inventories with Attack Surface Management, the latter being a much more effective approach to surfacing the best asset and security telemetry across your ecosystem. An Attack Surface Management solution will ingest data from an IT Asset Inventory or Management tool as one of many data sources to collate.
The next blog in this series will look at the different components of an ASM program, and how they can be leveraged to improve security hygiene and reduce cyber risk.
Announcing Support for IPv6
Post Syndicated from Anthony Hoppe original https://www.backblaze.com/blog/announcing-support-for-ipv6/

If your systems are IPv6-enabled or enabling IPv6 is on your roadmap, good news—starting yesterday and continuing over the course of the next few weeks, Backblaze will be “flipping the switch” and turning on IPv6 for our S3 Compatible API. While our IPv6 deployment isn’t completely done yet (we’re phasing the roll out through our environment), we thought we’d share some of the decisions we made that affect performance and functionality.
Today, I’ll talk a little bit more about our choices along the way, and answer some questions that might come up about how we’re supporting the protocol (jump to the FAQ for that).
Hi, I’m Anthony
Since this is the first time you’re hearing from me, I thought I should introduce myself. I’m a senior network engineer here at Backblaze. The Network Engineering group is responsible for ensuring the reliability, capacity, and security of network traffic, and that includes our IPv6 deployment.
What is IPv6 and why did we enable it?
Internet protocol version 6 (IPv6) is replacing internet protocol version 4 (IPv4) as the standard for IP addresses. Most of the internet uses IPv4, and this protocol has been reliable and resilient for over 20 years. However, IPv4 has limitations that might cause problems as the internet expands—namely, there aren’t enough IPv4 addresses to go around.
Demand for IPv6 is continuing to increase exponentially. A major factor in this is the combination of the continually growing population and the number of connected devices a given person carries. One study from 2020 suggests the average number of connected devices per person globally was 2.4 in 2018, and forecasted to be 3.6 in 2023. Specifically for North America, the study suggests 8.2 connected devices in 2018 and a whopping 13.4 in 2023! Every device connected to the internet needs an IP address, and the finite address space of IPv4 it is simply no longer sufficient. The key to IPv6 enhancement is the expansion of the IP address space from 32 bits to 128 bits, enabling virtually unlimited, unique IP addresses.
Support for IPv6 means our customers can reach our services in the most efficient and secure way possible.
Why should you care about us deploying IPv6?
We’ve learned some things over the years, so we approached our IPv6 deployment a little differently than our IPv4 deployment. If you’re a customer or potential customer, here’s what that means for you:
- No action needed on your part: Unlike some of the traditional cloud providers, we chose to use the same endpoint URL and let the client choose whether or not to use IPv6. This allows for any systems already IPv6 enabled to benefit immediately. In fact, if your systems are IPv6 enabled and you are a B2 customer using the S3 compatible API, you might already be connecting to us over IPv6 now.
- Our deployment is better set up to scale: Because of the way we decided to assign virtual IPs (VIPs) to our API endpoints, we have more flexibility to distribute ingress traffic and the ability to add VIPs as we need to in the future.
- Improved network performance and simpler network management: With IPv6, we simplified IP assignments and reduced the need for customers to use Network Address Translation (NAT). NAT adds processing overhead to network traffic as it translates IP addresses, which can lead to latency issues, especially with high-volume data transfer. The less traffic you have to NAT, the better. On our end, there is no NAT with customer data flows regardless of IPv4 vs IPv6. We also made the decision to route traffic before using network switches, this helps with reducing IPv6 multicast “noise” and generally helps keep the “wire” cleaner.
And here’s how we got it all done.
If a VIP could only talk
First, a little background: Backblaze offers two APIs—the Backblaze S3 Compatible API and the Backblaze B2 Native API. You can learn more about our APIs here in our documentation, but a couple differences are important to note when it comes to our IPv6 deployment:
- Backblaze B2 Native API: Uploads are sent directly to a Backblaze Vault. As part of the process of uploading a file, the client is provided an “upload URL”, which is a direct URL to an assigned member of the storage Vault. The data transfer is direct from the client to the storage Vault. Only downloads are served by the API server pool. Load balancers mainly handle distributing API calls.
- S3 Compatible API: Uploads flow through load balancers and the API server pool. Our API server pool then distributes the data to the assigned Vault. Downloads are served by our API server pool just like Backblaze B2 Native API.
These functionality differences play a role in how we are able to perform traffic engineering. We assign VIPs to our API endpoints, for example, s3.us-west-004.backblazeb2.com, or api004.backblazeb2.com. These VIPs are owned by our load balancers and API servers (for Direct Server Return). With the Backblaze B2 Native API, we really only need two VIPs per cluster: one for uploads and one for downloads. The upload URL that B2 Native provides to the client naturally distributes the flow across our IP space. With the S3 Compatible API, since uploads and downloads are handled by the same flow, we only needed one VIP…or so we thought.
Assigning a single VIP to the S3 Compatible API has been fine for a long time. However, as we’ve grown, and usage of the S3 Compatible API has grown, we discovered that a single S3 Compatible API VIP makes traffic engineering ingress flows challenging. When a large percentage of our S3 Compatible API ingress traffic happens to come from providers that prefer getting to us via a single path, having all that traffic destined to a single IP means we have no ability to steer (i.e.traffic engineer) portions of the traffic.
Starting at the beginning of this year, we’ve grown the number of API VIPs in our datacenters with the highest amount of S3 Compatible API traffic from a single IP, to four IPs in four different network prefixes (also known as subnets). This allows us to steer portions of S3 Compatible API traffic. This also helps distribute flows so that providers that have equal cost paths to us can be better utilized.
Lesson learned: With IPv6, we standardized on four IPv6 VIPs in four different prefixes with plans to grow if/when needed.
Route when you can, switch only when you need to
Backblaze datacenter networks are architected using a typical “three tier” approach. We have an edge layer, an aggregation layer (also known as a spine), and an access layer (also known as a leaf).

With IPv4, we have two IP “classes”. We have a private network (RFC 1918) and a public network. Every machine is assigned an IPv4 address on the private network, and only machines that need to directly interface with the outside world are assigned public IPv4 addresses. These two networks each reside within their own VLAN, and host networking is configured to tag traffic as necessary.
Given the tiered design of our network, different layers handle these VLANs. The aggregation layer acts as the router for the private network, and the edge layer acts as the router for the public network. From there, IPv4 traffic is switched, and thus we simply have two large (i.e. flat) VLANs for IPv4.
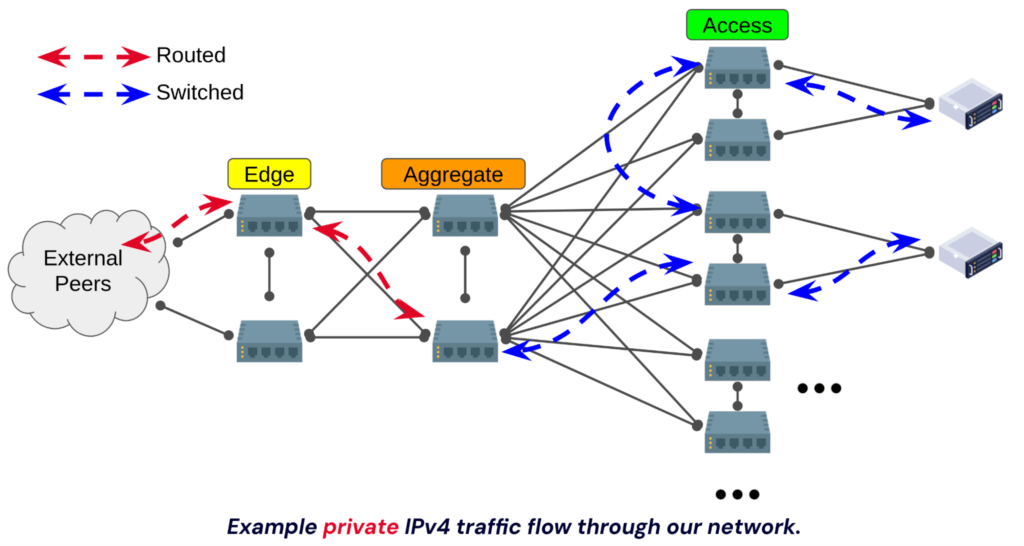
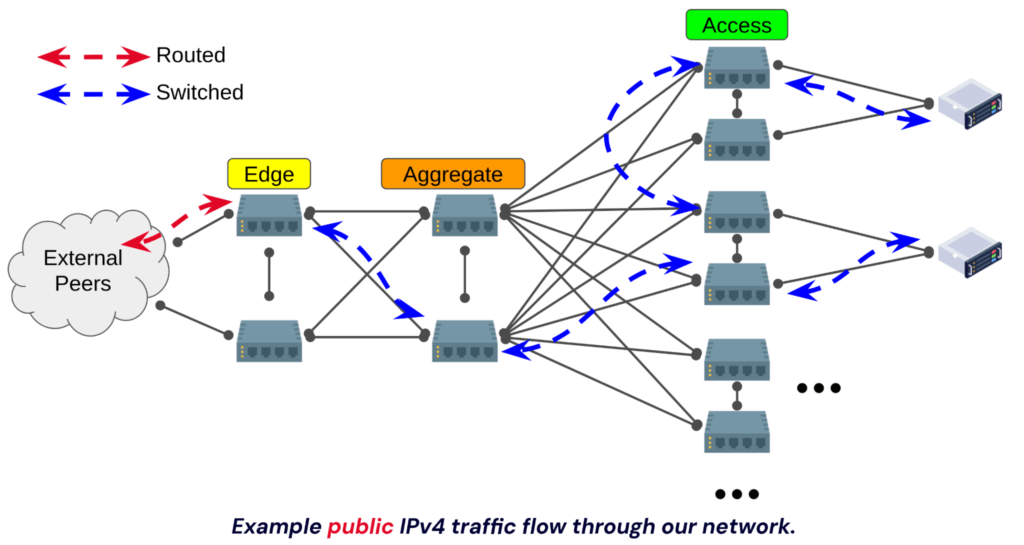
This has worked well (and still works just fine). A pair of VLANs that we can switch to anywhere in the datacenter keeps things simple. Hosts can reside anywhere within the datacenter and IPs can be assigned from the same pools. However, with IPv4 traffic being switched datacenter wide, the flat broadcast domain (thus the level of background broadcast noise) increases over time as the environment grows. In our largest (IP-space wise) datacenter we’ve needed to increase hosts’ arp cache size. With IPv6, we wanted to improve this.
The first decision we made was to eliminate the concept of public vs private address space with IPv6. Every host gets an address and all addresses are public (if the role requires). Existing firewalls and switch ACLs already permit/deny traffic as appropriate (which is also the same for our IPv4 networks).
Not only does this simplify IP assignments, it also reduces the need for Network Address Translation (NAT). We have many hosts that are not public facing, but do need to communicate with the outside world for various reasons. As we are able to move more and more communication with external services to IPv6, this reduces the load on resources we’ve deployed simply to handle NAT.
The second decision that we made was to route all the way down to the access switch layer. Each access switch is assigned a /64 and hosts connected to a given switch are assigned an IPv6 address from a portion of this block.
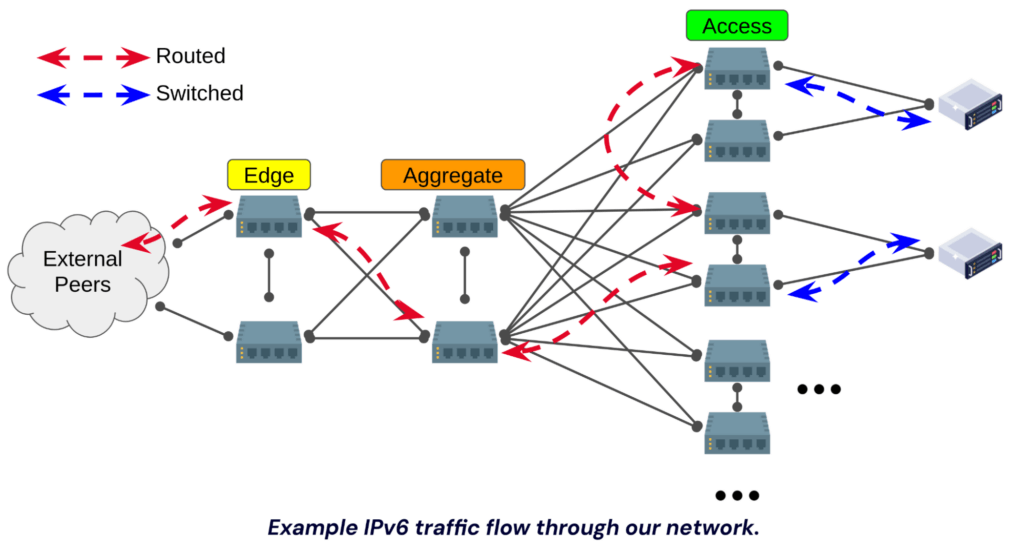
This helps with reducing IPv6 multicast “noise” and generally helps keep the “wire” cleaner. It does make host deployments a little more complicated as in order to assign a given host an IPv6 address from the correct network, one needs to be aware of the switch the host is connected to. Also, if data center staff need to move hosts around for power balancing or consolidation, the IPv6 address will need to be changed if the new location results in the host connecting to a different switch.
Lesson learned: Even with the added complexity, the route when you can, switch only when you need to mantra works well for our environment.
What’s next?
We still have more work ahead. We are currently investigating ways to support the Backblaze B2 Native API with IPv6 as well as Backblaze Computer Backup. Stay tuned for more on that front.
FAQs
What’s the difference between IPv4 and IPv6?
The key difference between the versions of the protocol is that IPv6 has significantly more address space. The IPv6 address notation is eight groups of four hexadecimal digits with the groups separated by colons, for example 2001:db8:1f70:999:de8:7648:3a49:6e8, although there are methods to abbreviate this notation. For comparison, the IPv4 notation is four groups of decimal digits with the groups separated by dots, for example 198.51.100.1.
The expanded addressing capacity of IPv6 will enable the trillions of new internet addresses needed to support connectivity for a huge range of new devices such as phones, household appliances, and vehicles.
How can I use IPv6 with B2 Cloud Storage?
Currently, only the Backblaze S3-compatible API supports IPv6. To use IPv6 addresses with B2 Cloud Storage and the S3-compatible API, you do not need to make any changes.
Will IPv4 addresses still work?
Yes, IPv4 addresses will continue to be supported for both the B2 Native API and the S3-compatible API for the time being. We do not have any explicit plans for sunsetting IPv4 at this time.
What will happen if I continue to use IPv4?
Nothing. IPv4 will continue to be supported at this time.
Is IPv6 better/more secure than IPv4?
It is not more secure. Customers who reach us via IPv4 or IPv6 will have connections that are equally secure. Our APIs use the same strong TLS encryption regardless if IPv4 or IPv6 is used. Some customers may see a performance improvement if IPv6 allows them to avoid network address translation (NAT).
Is there an additional cost to use IPv6?
No.
I’m using Backblaze Computer Backup. Do I need to make any changes?
No. IPv6 is only relevant for Backblaze B2 Cloud Storage. You don’t need to make any changes to your Backblaze Computer Backup account.
The post Announcing Support for IPv6 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Security updates for Thursday
Post Syndicated from jake original https://lwn.net/Articles/990877/
Security updates have been issued by Debian (expat and tinyproxy), Fedora (frr, microcode_ctl, python3.10, python3.12, python3.6, and ruby), Oracle (expat, fence-agents, firefox, ghostscript, java-1.8.0-openjdk, kernel, and thunderbird), Red Hat (firefox, openssl, ruby:3.3, and thunderbird), SUSE (clamav, ffmpeg-4, kernel, libmfx, python3, python312, runc, ucode-intel, and wireshark), and Ubuntu (apache2, git, linux, linux-aws, linux-aws-5.15, linux-azure, linux-azure-5.15, linux-gcp, linux-gcp-5.15, linux-gke, linux-gkeop, linux-gkeop-5.15, linux-hwe-5.15, linux-ibm, linux-intel-iotg, linux-intel-iotg-5.15, linux-kvm, linux-nvidia, linux-oracle, linux-raspi, linux, linux-aws, linux-aws-5.4, linux-azure, linux-azure-5.4, linux-bluefield, linux-gcp, linux-gcp-5.4, linux-gkeop, linux-hwe-5.4, linux-ibm, linux-ibm-5.4, linux-kvm, linux-oracle, linux-oracle-5.4, linux-xilinx-zynqmp, and linux, linux-aws, linux-gcp, linux-gke, linux-ibm, linux-lowlatency, linux-lowlatency-hwe-6.8, linux-nvidia, linux-nvidia-6.8, linux-nvidia-lowlatency, linux-oem-6.8, linux-oracle).
Free online course on understanding AI for educators
Post Syndicated from Mac Bowley original https://www.raspberrypi.org/blog/free-online-course-on-understanding-ai-for-educators/
To empower every educator to confidently bring AI into their classroom, we’ve created a new online training course called ‘Understanding AI for educators’ in collaboration with Google DeepMind. By taking this course, you will gain a practical understanding of the crossover between AI tools and education. The course includes a conceptual look at what AI is, how AI systems are built, different approaches to problem-solving with AI, and how to use current AI tools effectively and ethically.

In this post, I will share our approach to designing the course and some of the key considerations behind it — all of which you can apply today to teach your learners about AI systems.
Design decisions: Nurturing knowledge and confidence
We know educators have different levels of confidence with AI tools — we designed this course to help create a level playing field. Our goal is to uplift every educator, regardless of their prior experience, to a point where they feel comfortable discussing AI in the classroom.

AI literacy is key to understanding the implications and opportunities of AI in education. The course provides educators with a solid conceptual foundation, enabling them to ask the right questions and form their own perspectives.
As with all our AI learning materials that are part of Experience AI, we’ve used specific design principles for the course:
- Choosing language carefully: We never anthropomorphise AI systems, replacing phrases like “The model understands” with “The model analyses”. We do this to make it clear that AI is just a computer system, not a sentient being with thoughts or feelings.
- Accurate terminology: We avoid using AI as a singular noun, opting instead for the more accurate ‘AI tool’ when talking about applications or ‘AI system’ when talking about underlying component parts.
- Ethics: The social and ethical impacts of AI are not an afterthought but highlighted throughout the learning materials.
Three main takeaways
The course offers three main takeaways any educator can apply to their teaching about AI systems.
1. Communicating effectively about AI systems
Deciding the level of detail to use when talking about AI systems can be difficult — especially if you’re not very confident about the topic. The SEAME framework offers a solution by breaking down AI into 4 levels: social and ethical, application, model, and engine. Educators can focus on the level most relevant to their lessons and also use the framework as a useful structure for classroom discussions.
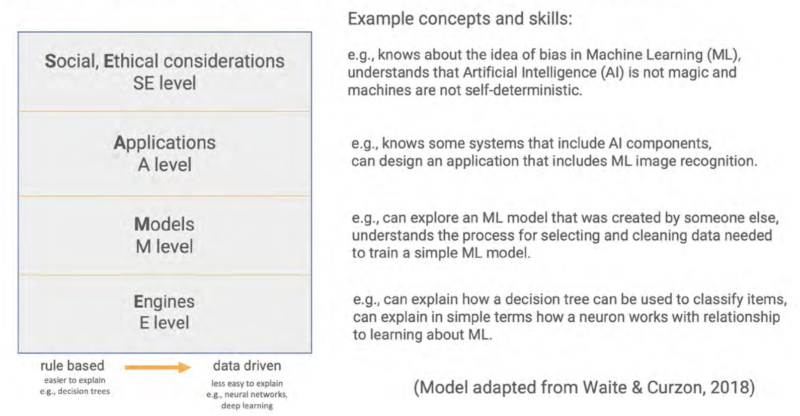
You might discuss the impact a particular AI system is having on society, without the need to explain to your learners how the model itself has been trained or tested. Equally, you might focus on a specific machine learning model to look at where the data used to create it came from and consider the effect the data source has on the output.
2. Problem-solving approaches: Predictive vs. generative AI
AI applications can be broadly separated into two categories: predictive and generative. These two types of AI model represent two vastly different approaches to problem-solving.
People create predictive AI models to make predictions about the future. For example, you might create a model to make weather forecasts based on previously recorded weather data, or to recommend new movies to you based on your previous viewing history. In developing predictive AI models, the problem is defined first — then a specific dataset is assembled to help solve it. Therefore, each predictive AI model usually is only useful for a small number of applications.
Generative AI models are used to generate media (such as text, code, images, or audio). The possible applications of these models are much more varied because people can use media in many different kinds of ways. You might say that the outputs of generative AI models could be used to solve — or at least to partially solve — any number of problems, without these problems needing to be defined before the model is created.
3. Using generative AI tools: The OCEAN process
Generative AI systems rely on user prompts to generate outputs. The OCEAN process, outlined in the course, offers a simple yet powerful framework for prompting AI tools like Gemini, Stable Diffusion or ChatGPT.

The first three steps of the process help you write better prompts that will result in an output that is as close as possible to what you are looking for, while the last two steps outline how to improve the output:
- Objective: Clearly state what you want the model to generate
- Context: Provide necessary background information
- Examples: Offer specific examples to fine-tune the model’s output
- Assess: Evaluate the output
- Negotiate: Refine the prompt to correct any errors in the output
The final step in using any generative AI tool should be to closely review or edit the output yourself. These tools will very quickly get you started but you’ll always have to rely on your own human effort to ensure the quality of your work.
Helping educators to be critical users
We believe the knowledge and skills our ‘Understanding AI for educators’ course teaches will help any educator determine the right AI tools and concepts to bring into their classroom, regardless of their specialisation. Here’s what one course participant had to say:
“From my inexperienced viewpoint, I kind of viewed AI as a cheat code. I believed that AI in the classroom could possibly be a real detriment to students and eliminate critical thinking skills.
After learning more about AI [on the course] and getting some hands-on experience with it, my viewpoint has certainly taken a 180-degree turn. AI definitely belongs in schools and in the workplace. It will take time to properly integrate it and know how to ethically use it. Our role as educators is to stay ahead of this trend as opposed to denying AI’s benefits and falling behind.” – ‘Understanding AI for educators’ course participant
All our Experience AI resources — including this online course and the teaching materials — are designed to foster a generation of AI-literate educators who can confidently and ethically guide their students in navigating the world of AI.
You can sign up to the course for free here:
A version of this article also appears in Hello World issue 25, which will be published on Monday 23 September and will focus on all things generative AI and education.
The post Free online course on understanding AI for educators appeared first on Raspberry Pi Foundation.
За ориенталския махмурлук, Корана и домашнярката (първа част)
Post Syndicated from Атанас Шиников original https://www.toest.bg/za-orientalskia-mahmurluk-korana-i-domashniarkata-purva-chast/

Какво общо има между махмурлука и Корана? Ако трябва да отговоря като онзи мой мениджър от Великобритания отпреди 14 години – много. Той беше пословично арогантен. Обичаше да дава такива отговори. „Кажи каква е разликата между валидация и верификация в управлението на качеството за информационни услуги“, го питам веднъж. „Огромна!“, отговаряше. И нищо повече. Оттогава съм се зарекъл да не отговарям така. Но ето, с риска скандално да представя тезата преди аргумента,
ако не беше Коранът, нямаше да знаем за махмурлука.
Не като физиологичното състояние, срещу което най-мощното лекарство по нашите ширини е шкембе чорбата, а като термин.
Да почнем с лесната част – турската наставка –лук/–лик/–лък. Като я притурите към някаква дума преди това, образувате абстрактно съществително. Примери, придошли при нас от езика на южната ни съседка, има бол. Родопският комшулук. Селският тарикатлък. Политическият бабаитлък. Асмалъкът, отрупан с гроздове. Хайдутлукът на възрожденските въстаници. Или придобилият отскоро популярност тихналък, хубаво съчетание от българска дума и турска наставка. Това е лесната част.
Но откъде идва основната част махмур-?
От езика на арабското мюсюлманско Писание от VII век е краткият отговор. Не от земите на Османската империя, а от малко пò на югоизток и от малко по-назад в миналото. Словообразуването е измежду хубавите неща в арабския. Като в типичен семитски език, значението се носи от корена, съставен от съгласни. Обикновено са три. Пред тях, между тях и след тях се напъхват различни други съгласни и гласни и така се образуват различни смисли, свързани с основния. Тук кореновите съгласни са х (едно такова особено, хъхрещо, „храчещо“, както се майтапим арабистите), м и р. И тази съвкупност носи всякакви значения, свързани с покриване, бухване, втасване, ферментация.
Ето например арабската дума за „мая“, „дрожди“, „закваска“ – хамира. Продавач на вино – хаммар. Магазин за вино, винопродавница – хаммара. Че даже и по-късна сплав от турска наставка за име на професия плюс същия корен в дума за продавач на вино – хамраджи. Прилича на познатото ни, пак от турски, за обущар – кундурджъ. И тук се сблъскваме с
най-известната дума за вино в арабския език – хамр.
Оттам и по стандартният арабски модел за образуване на страдателно причастие от първична форма на глагола имаме и „човек, попаднал под въздействието на вино, опиянен“ – махмур. Ето колко е лесно. По модела на мактуб (това може да го знаят феновете на Паулу Коелю) – „нещо написано“, „писмо“, „послание“, че и предписано, определено от съдбата. Съединете го с турската наставка – и сме готови.
Махмурлук. Състояние на опиянение от вино.
А като погледнем Корана, виното (хамр) там седи на равна нога с копитото на прасето (ханзир).
Хем го има и не можеш да избягаш от него, хем е силно недолюбвано.
Питали Пророка на исляма за виното и за хазарта. В тях, казва той, има голям грях, но и изгоди. Само че грехът е по-голям от изгодата (Коран 2:219). Виното се споменава наред с хазарта, идолопоклонството и гадаенето чрез стрели (5:90). Че и отгоре на всичко е обявено за инструмент на сатаната, който цели да скара хората, да ги възпре от споменаването на Аллах и от задължителната за всеки мюсюлманин молитва (5:91). В тази връзка и към вярващите се отправя интересна заръка – „не пристъпвайте към молитвата, когато сте пияни, додето вече знаете какво говорите“ (4:43).
Ето, казват по-строгите тълкуватели, които се придържат към текста без много тълкувателни своеволия (и аз наред с тях комай!), имаме религиозна норма, която е трудно да отхвърлиш чрез аргументи от нейната собствена рамка. И тя ще наложи разсъждения. Какво точно е хамр в езика на Корана? Какво точно означава забраната? Има ли санкция за нейното прекрачване? Каква ще да е тя? Това се случва в рамките на религиозния закон (шари‘а), чиято задача е да преведе постановленията на Писанието (Корана) и преданието на Пророка (Сунна) в реални регулации.
Винопийството се оказва в списъка на простъпки, налагащи точно определени наказания, които в мюсюлманското право се обозначават с термина хадд. Буквално значи „граница“. Нещо като граничната бразда по соца, която отделя света навън от този вътре. Въпреки че Коранът не определя наказателна мярка, такава има в пророческата традиция (Сунна), интегрална част от свещения текст (насс).
Пророкът на исляма, казва преданието, заръчал бой с палмови клони и налъми за онзи, който е употребил забранената субстанция.
Четирийсет удара. Това е по най-разпространеното предписание на Мохамед. Някои негови следовници обаче, например Умар (на български възприето като Омар), заръчали осемдесет. Да речем, че ти се полагат между четирийсет и осемдесет удара. Но как стои въпросът, ако сте любител на други алкохолни преживявания? Коранът говори само за хамр, каквото и да е означавало това в пясъците на Арабия от седмото столетие сл. Хр. Може ли тогава да посягаме свободно към бирата, ракията, уискито, джина, водката, узото, вишневия ликьор?
Все пак каквото не е откровено забранено, е позволено – този принцип важи и за мюсюлманското право. Там важат и други принципи, например незнанието за това, че дадено нещо е възбранено и грях (харам), вероятно ще те оправдае. Обаче знанието, че нещо е възбранено, съчетано с непознаване на наказанието за него, не те отървава. И ако наказанието е пребиване с камъни (раджм), лошо ти се пише.
Но не. Не е толкова лесно да заобиколиш строгата регулация. Виното, твърди се в едно пророческо предание, „се прави и от грозде, от изсушени фурми, от мед, от жито, от ечемик“. Добре, да питам аз, а какво е положението, примерно, с джина, който се прави от плодчета на хвойна? А сливовицата? А любимата ми дюлева ракия? Ами как, зле е работата.
Всяко опияняващо нещо, твърди Пророкът, е вино (хамр), и всяко опияняващо нещо е грях, възбранено (харам).
Между другото, думата за опияняващо нещо тук е мускир, от същия корен като суккар, познато ви от турския език като шекер. Захар. Близкият изток не е на една ръка разстояние, той е на масата ни.
И въз основа на това чрез прилагането на единия от основните принципи в мюсюлманското право – аналогията (кийас) – се забраняват всички ферментирали напитки. И не само. Всички останали субстанции с подобен ефект, включително и наркотиците. Няма мърдане. Че и – пак по Сунната – „пиещият вино в момента на пиенето е неверник“ и „виното е майката на всяко зло“. Не може и да се търгува с него, защото „парите, придобити от нещо, което е грях, са греховни“. А ако го приложим към друг проблематичен казус – свинята, – не може да ядеш свинско. Ама и не може да търгуваш с него. Край.
Пиенето на алкохол може да ви докара глоби, наказание с пръчки, камшик, че понякога и затвор в държави, в които правната система е силно повлияна от шариата.
Например в Иран. В Судан забраната за пиене на алкохол (дори в частното пространство) отпадна през 2020 г. Но само за немюсюлмани, които по данни на ООН са около 3% от населението в момента на отпадането на забраната. Мюсюлманите все още ги грози бой с пръчка. Сходно е положението и в Саудитска Арабия – бой с пръчка (до 2020 г., когато това наказание принципно е отменено), затвор, глоби и депортация за чужденците, въпреки че тази година там отвори първият официален магазин за алкохол. За чуждестранни дипломати с изключително ограничен достъп, разбира се. В Кувейт продажбата и купуването на алкохол са забранени от 1965 г., което пък води до увеличаване на случаите от отравяне след пиене на лосиони и афтършейв. Ако си в тези две страни и искаш да пиеш, отиваш до Дубай или Бахрейн. (По едно време Дубай даже се опита да постави алкохолни рекорди на „Гинес“ по брой шотове, падащи в редица като домино.) Бой на публично място и затвор е съдбата на злощастните жертви на талибанския режим в Афганистан.
С различни вариации по държави, преобладаващото отношение е сходно: от неформална неприязън и заклеймяване до постановено от закона наказание. Онлайн порталите за авторитетни мнения от богословите (фетви) излагат една доста стереотипна и повтаряща се гледна точка – стандартното религиозно наказание за пиене на вино е бой с пръчки или кашмик.
От другата страна обаче стои една по-лежерна гледка точка. Самата религиозна норма като че ли допуска двусмисленост. На първо място, значението на самия обект на възбраната – виното (хамр). Ако допуснем, че се отнася за всякакъв вид алкохол, оттук и опияняваща субстанция, допуска ли се минимален праг на съдържание на активна субстанция, която предизвиква опиянението (в случая етилов алкохол)? Така може да порицаеш и забраниш (както и действително е било забранявано в някои исторически периоди и места!) консумацията на кафе, боза, оцет, че дори и на безалкохолна бира, доколкото реалният процент на алкохол не е точно 0,0% – пише го на кенчетата.
Наред с това самият текст на възбраната като че ли отваря врата за отхвърляне на пълното заклеймяване. „Във виното има и ползи, и вреди“ – да припомним текста на Корана. После, казва самият Аллах, „не пристъпвайте към молитвата, когато сте пияни“. Значи може извън времето за молитва. Че и отгоре на всичко в Рая има „реки от вино, приятно за пиещите“ (47:15). От което „нито боли глава, нито се опияняват“ (37:47–49). Човек почти се чуди каква ли е била опитността на първите мюсюлмани с алкохола, та изрично небесното откровение да впише липсата на негативните ефекти от махмурлука. Всичкото това, разбира се, са твърде опростенчески аргументи, които при внимателно разглеждане могат да бъдат раздробени, омаловажени и в крайна сметка отхвърлени.
И тук идват наблюденията върху практиката „на терен“, както обичат да казват антрополозите. Какво като ислямът забранявал алкохола. Винаги ще се намери някой познат да каже: „Аз, като бях веднъж в Родопите или Добруджа, пих ракия с български турци или българомохамедани“. Нещо като пушенето на хашиш. Забранен, забранен, ама се консумира. В тази връзка препоръчвам чудесната разработка на Франц Розентал „Билката: хашишът срещу средновековното мюсюлманско общество“.
Все едно наличието на някаква практика променя нормата, бих възразил.
Това, че някой прави нещо, не значи, че е позволено. Не го легитимира. Но ако трябва за целите на мисловния експеримент да се поставим на мястото на една такава популярна гледна точка, мога да дам исторически примери. Не е ли истина, в крайна сметка, че в двора на Абасидските халифи и султани (които биват наричани „сянката на Аллах на земята“) и в мюсюлманска Персия виното се лее щедро, поднасяно от младежи? Младежите (да не настъпваме темата за хомоеротиката) и виното са популяризирани в поемите на известния Абу Нуас от VIII век, и то до такава степен, че осъжданите му от консервативно настроените среди творби придобиват названието „винени стихове“ (хамрийат). Те прерастват в отделен поетически жанр, в който Абу Нуас е само едно от големите имена наред с фигурата на самия Омар Хаям от XI век.
Ал-Джахиз (Опуления), големият интелектуалец от VIII–IX столетие, обрисува картина на един космополитен Багдад, в който виното намира своето място на трапезата на богаташите и интелектуалците, пък били те и мюсюлмани. Мисля, че е ясно откъде се набавя – купува се от християните и юдеите, които имат дълга традиция на производство на възбраненото питие както за религиозни цели, така и за лична консумация. А че
мюсюлманите също държат запаси от вино,
свидетелстват и автори като богослова Ибн ал-Банна от XI век в личния си дневник. След всяко природно бедствие – например земетресение, което сполетява Мека и Медина, светите градове на исляма – мюсюлманите правят няколко неща като акт на покаяние пред Всевишния. Чупят музикалните инструменти (малахи, „инструмент за суетно забавление“), традиционно порицавани в исляма, изгонват леките жени и изливат виното на земята.
Приказките от „Хиляда и една нощ“ също съдържат безброй истории за пияни хора.
Приближени на халифа шейхове пиянстват. Християните и неверниците пиянстват, разбира се. Стражата пиянства. Любовниците пиянстват. Посетители в двореца на халифа пиянстват и се облекчават по улиците. За мен по-важното е друго. Някъде там, в периода, в който се развива действието на този литературен опус, по време на легендарния халиф Харун ар-Рашид, персийският алхимик Абу Муса Джабир ибн Хаян, а след него и колегата му Абу Бакр ар-Рази усъвършенстват съда за дестилация, известен като аламбик (ал-инбик).
Аламбикът се състои от три части: основен съд, в който се поставя изходният материал (кар‘), горна част, „клюн“, чрез която се отвеждат парите (инбик), и „приемащ“ съд (кабила). Прилича на казана за ракия на баща ми, ама по-лош. Защото е по-малък и защото частта за охлаждане е много къса. Не е познатата ни нагъната серпентина, охлаждана през допълнителен съд със студена течност. Чрез аламбика обаче подобряват и практиката на дестилация на бистра течност от ферментирала заготовка. Процесът се нарича тактир, букв. „превръщане на капки“. Тази бистра течност получава названието ал-кухул.
Алкохол. Идва от кухл, името на черния прах, използван като грим за подсилване на очната линия, който се извлича от минерала антимонит.
Та така стигаме и до кухул ал-хамр – извлек от вино. Накратко, ал-кухул. Далече от нашата представа за домашен алкохол за консумация, дестилатът първоначално се използва за експериментални цели, включително и медицински.
Арабското средновековие дори произвежда рецепти за вино. Един от най-известните рецептурници – на Ибн Саяр ал-Уаррак от Багдад през X век – ни е оставил например няколко вида инструкции как да си приготвим ферментирала напитка, че и без дестилация. Тук невинаги терминът е познатият ни от Корана хамр. Нарича се по-скоро набиз – плодова напитка, често пъти от стафиди или фурми, понякога подсладена, която отлежава определено време и понякога ферментира.
Вземат се стафиди, твърди той, към които се добавя сладка вода. Стоят накиснати няколко дни, като постоянно се разбъркват с ръка. После се изсипват в голям съд, намачкват се с крака и течността се отцежда. Добавят се семена от билки, лаврови листа, пъпки розов цвят, подслажда се, добавя се кипнала мъст за ферментиране, налива се в големи съдове и стои на слънце две седмици. Понякога се слага и винена утайка, „защото така става още по-хубаво“. Че даже и на някои рецепти Ибн Саяр накрая добавя, че „се пие, ако е рекъл Аллах“. И никой не може да ме убеди, че това, което се пие, ако е рекъл Аллах, не съдържа алкохол след процедурите, описани по-горе.
(Следва продължение.)
В рубриката „Ориент кафе“ Атанас Шиников поднася любопитни теми, свързани не толкова с горещата политика, колкото с историята и културата на Близкия изток. А той, древен и днешен, е по-близко до нас и съвремието ни, отколкото си представяме.
A Campaign-Song Nightmare
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=wJI6-1bQoL0
Comic for 2024.09.19 – Remove Your Bones
Post Syndicated from Explosm.net original https://explosm.net/comics/remove-your-bones
New Cyanide and Happiness Comic
На второ четене: „Годините“
Post Syndicated from original https://www.toest.bg/na-vtoro-chetene-godinite/
„Годините“ от Ани Ерно

превод от френски Валентина Бояджиева, София: изд. „Лист“, 2022
Това е правено – и винаги ще бъде правено – в стотици мемоари. И в същото време не е. Колективната „неутрална автобиография“ на Ани Ерно (както самата тя я нарича) е собствен жанр – достатъчно специфичен в своето отстранение и широкообхватност, за да донесе на писателката Нобеловата награда за литература през 2022 г. и своевременно да бъде издаден от „Лист“ като неин знаков текст. А Ерно да се утвърди като един от значимите гласове в съвременната френска литература.
Някак си е очаквано, че оценките за една високоотличена книга като „Годините“ (поне у нас според моята малка импровизирана анкета) ще бъдат още по-разнобойни, отколкото за която и да е друга. От „абсолютен шедьовър“ до „непоносима разказвачка“, от скучна и лишена от всякаква емоционалност до монументална по амбицията си. Докато напредвах бавно, но упорито с романа, поне няколко души – четящи, интелигентни – споделиха с мен, че не са го дочели, всеки по различна причина. Малко на шега, малко извинително си казахме, че книгата е трудна дори за французите – камо ли за незапознатите в дълбочина с френската култура и политика. Или пък за онзи нарастващ брой нови читатели, които изобщо не са живели през миналия век, един от най-богатите на история и промени периоди.
Защото
тази книга е като квазидокументален архив на един век и на едно поколение
(или на няколко застъпващи се), който изобилства от реалии, препратки, дати, събития, имена, заглавия. При това без грам обяснителност (каквато например често се среща в нови български романи за близкото минало, дидактично поясняващи как е било тогава).
И ако последното е вид безпомощност и същевременно самонадеяност, Ерно е „арогантна“ по друг начин – чрез маниера на своята самопонятност. Авторката очертава отминалото стенографски, в бързи щрихи и криптични бележки, чрез не повече от бегли напомняния, които са разбираеми единствено за преживелите същото, за онези, които ще си кажат „О, да, май наистина беше така“ или „О, да, да, преживяхме и това“. На останалите е предоставено предизвикателството на любопитството, общата култура, образованието или като минимум поне ресурсите на Google, Wikipedia и YouTube.
(Правя малка вметка, за да поразсъждавам върху риска, свързан с бележките под линия, каквито в тази книга неизбежно изобилстват. Давам си сметка, че те ще подразнят едни, а за други ще са крайно недостатъчни. Че е неизбежно в поставянето им определяща роля да играят познанията и личният усет на преводача/редактора кое би следвало да е всеобщо знание и за кое се налага пояснение – в резултат неравномерността между обясненото (макар и ясно за едни) и оставеното така (макар и непознато за други). От друга страна, когато за десетки имена се пояснява, че са например на известни френски певци, човек няма как да придобие кой знае каква яснота, освен ако не влезе в YouTube, за да изслуша техни песни. Край на вметката.)

Детската памет на родената през 1940 г. Ерно започва да се прояснява и задържа едва след Втората световна война, в една Франция, напълно белязана от нея, от разрушенията и недоимъка, от духа на Съпротивата. Този наратив ще присъства с години в разговорите около празничните обеди, използвани в романа като своеобразна сюжетна рамка и същевременно като лакмус за хода на времето. Защото колкото и привидно да остават неизменни, упорито фокусирани върху най-базовите човешки преживявания, тези семейни разговори ще отразят неумолимо настъпващите промени в обществото и в света. Паметта на Ерно ще затвори текста в средата на първото десетилетие от новото хилядолетие, а самата книга ще излезе през 2008 г.
В нея авторката ще спомене нейното дълго обмисляне – сякаш никога преди „Годините“ не е писала друга книга. Сякаш цялата ѝ памет е била отдадена на това търпеливо да трупа изплъзващите се спомени заедно с намерението те да бъдат събрани в „историята на една жена“. Жена, родена в семейство на дребни търговци в селско-работническата провинция, в една все още бяла, национална, етнически монолитна, строго католическа, силно порядъчна, изпълнена с куп срамове и забрани Франция. Но и жена, постепенно пораснала и съзряла в драматично въстаналия срещу предишното свят на правна и интелектуална еманципация, феминизъм, идеологии, социални протести, сексуални и материално-потребителски революции. Не на последно място – жена, остаряла в една неузнаваема епоха – на новите технологии и интернет.
Смазващо е усещането за тази гъсто резюмирана памет – до степен, в която сърцевината на ХХ век ни се струва невъзможна за обживяване в рамките на един човешки живот. Историческите вододели (68-ма, Студената война, кризата в Алжир, обединена Европа, падането на Берлинската стена, Войната в залива, 11 септември и безкрайно много други); интелектуалните икони; медийните стожери; култовите творби от всяко едно изкуство, белязали и поколенчески, и интимно ежедневието на хиляди; поредицата политически личности и социално-икономически ходове, олицетворяващи десетилетията; траекторията на ценностите; превръщането на националната държава в котле от етноси и религии; появата на нови страхове и проблеми, но и на куп нови решения, възходът на материалния хедонизъм и на всеобщата свързаност…
В анонса на „Годините“ на български се казва:
Тя е никоя. Но може да бъде всяка французойка.
Защото макар да съзнаваме единственото число на разказвачката, разказът се води през едно нетипично, абстрактно-колективно „ние“, заради което е припознат като наратив на цялото ѝ поколение. И все пак ми се иска да поспоря за обхвата на това „ние“, който неизбежно се припокрива с профила на Ерно като част от една определена, еманципирала се от работническия си произход, обуржоазила се, възприела прогресивността и прегърнала новото прослойка със свои позиции, вкусове и копнежи. Защото има и други, за които тя говори (богати, провинциалисти, имигранти, араби, чужденци, с различна политическа ориентация и т.н., и т.н.), включени като обекти, а не субекти в това „ние“. Може би и това също може да се мисли като вид арогантност в кавички, егоцентрично налагане на идентичност.
Там, където Ерно все пак говори бегло за себе си, тя го прави в трето лице – обикновено за да ни покаже поредната си снимка, по една от всяка преходна своя възраст. Не използва имена, не индивидуализира близките си, пропуска редица биографични факти, включително (макар и леко да го загатва) незаконния си аборт през 60-те, който после ще даде повод за написването на „Изпитанието“. Парадоксално, от книгата на Ерно за нея самата може да се научи по-малко, отколкото от която и да е статия или подробна нейна биография в произволен сайт или в Уикипедия.
Но същевременно е и тъкмо обратното, защото невинаги фактите имат първостепенно значение. А и същината е там, в разказа: как малкото момиченце разцъфва в стеснителна, притисната от ограничения и забрани, но чувствена и мечтателна девойка, преди да се превърне в жертва на забраната върху абортите, после, след 68-ма, в хода на сексуалната революция – във все по-свободно наслаждаваща се на тялото, изборите и желанията си млада жена, после – в малко или много буржоазна съпруга и майка, а след това – в разведена жена с млади любовници.
Един от аршините, с които Ерно мери историята на тази своя „една жена“ – всъщност на всяка жена, – е именно свободата да разполагаш с тялото си.
Това движение между забранителната традиция и мощта на инстинктите, между дълга и удоволствието, срама и липсата на задръжки, трудността да обгрижваш тялото си и безбройните нови улеснения и глезотии, свързани с него, е проследено в цялата книга. Ерно дори пише за това как паметта се предава от тялото, преминава „от тяло в тяло“. Но дали, от друга страна обаче, индиректно не се съгласява, че историята на жената минава именно през базовите, споменати от нея преживявания, свързани с мъжа, с децата, с плътта, и в много по-малка степен с преподаването на литература и с писането, които споменава съвсем лаконично, и дори с големите събития, за които често се случва да каже: „не се интересувахме“, „не ни засягаше“, „нямахме време да…“.
Същото важи и за забавленията и най-вече за материалните придобивки. За продуктите на всеобщото консуматорство, сдобиването с които (нови и нови марки, модели, изобретения, щателно изредени от Ерно) се превръща в календарна справка и измерител на промяната. И на прогреса, за който пише:
прогресът беше хоризонтът на съществуването.
Този нов вид униформеност е отвъд старата сезонност и цикличност на ежедневието, религията, традициите, а после и на „майските идеали [които] се конвертираха в предмети и развлечения“.
Претенциозен и същевременно небрежен, препускащ, но непропускащ, хладно дистанциран, но ангажиран с най-интимното, отстранено критичен, но и великодушно, по френски толерантен, романът „Годините“ може би ще бъде четен като почти документална абревиатура на ХХ век, в който от Дьо Гол до Уелбек
цялата действителност беше подложена на преразглеждане.
Или като своеобразна версия, макар и много по-различна, на романа „По следите на изгубеното време“. Към последния самата Ерно реферира на няколко пъти в своя собствен текст, чието първо изречение е
Всички образи ще изчезнат.
Според замисъла ѝ „Годините“ е „пълзящ разказ, в продължително минало несвършено“, което постепенно ще погълне настоящето. И онова преди нас, и нашето сега, и предстоящото – много след като сме си отишли.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер нa 20% от коричната цена на всички заглавия от каталога на издателство „Лист“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
[$] The uncertain future of kernel regression tracking
Post Syndicated from corbet original https://lwn.net/Articles/990599/
Tracking of regressions seems like an important task for any project; there
is no other way to ensure that known problems are fixed. At the 2024
Maintainers Summit, though, Thorsten Leemhuis, who has been doing that work
for the kernel, expressed some doubts about whether it is worth continuing.
The result was an energetic session on how regression tracking should be
done better, and how this work should be supported.
GNOME 47 released
Post Syndicated from corbet original https://lwn.net/Articles/990788/
Version 47 of the GNOME desktop
has been released. Changes include configurable accent colors, better
small-screen support, some performance improvements, new file open and save
dialogs, and more.
[$] LWN.net Weekly Edition for September 19, 2024
Post Syndicated from corbet original https://lwn.net/Articles/989982/
The LWN.net Weekly Edition for September 19, 2024 is available.
Search for the Unicorn
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=70rcQ5MhRfA
Introducing Netflix’s Key-Value Data Abstraction Layer
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/introducing-netflixs-key-value-data-abstraction-layer-1ea8a0a11b30
Vidhya Arvind, Rajasekhar Ummadisetty, Joey Lynch, Vinay Chella
Introduction
At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra, a NoSQL database known for its high availability and scalability. Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming.
Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse. Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Additionally, the tight coupling with multiple native database APIs — APIs that continually evolve and sometimes introduce backward-incompatible changes — resulted in org-wide engineering efforts to maintain and optimize our microservice’s data access.
To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. This approach led to the creation of several foundational abstraction services, the most mature of which is our Key-Value (KV) Data Abstraction Layer (DAL). This abstraction simplifies data access, enhances the reliability of our infrastructure, and enables us to support the broad spectrum of use cases that Netflix demands with minimal developer effort.
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
The Key-Value Service
The KV data abstraction service was introduced to solve the persistent challenges we faced with data access patterns in our distributed databases. Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency.
Data Model
At its core, the KV abstraction is built around a two-level map architecture. The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. This model supports both simple and complex data models, balancing flexibility and efficiency.
HashMap<String, SortedMap<Bytes, Bytes>>
For complex data models such as structured Records or time-ordered Events, this two-level approach handles hierarchical structures effectively, allowing related data to be retrieved together. For simpler use cases, it also represents flat key-value Maps (e.g. id → {"" → value}) or named Sets (e.g.id → {key → ""}). This adaptability allows the KV abstraction to be used in hundreds of diverse use cases, making it a versatile solution for managing both simple and complex data models in large-scale infrastructures like Netflix.
The KV data can be visualized at a high level, as shown in the diagram below, where three records are shown.
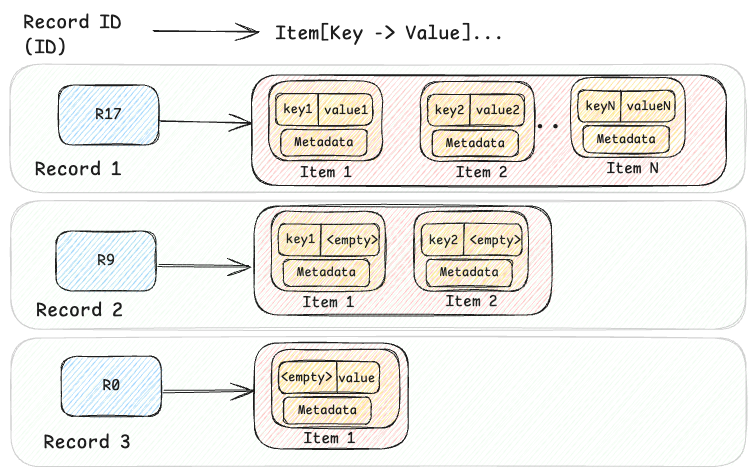
message Item (
Bytes key,
Bytes value,
Metadata metadata,
Integer chunk
)
Database Agnostic Abstraction
The KV abstraction is designed to hide the implementation details of the underlying database, offering a consistent interface to application developers regardless of the optimal storage system for that use case. While Cassandra is one example, the abstraction works with multiple data stores like EVCache, DynamoDB, RocksDB, etc…
For example, when implemented with Cassandra, the abstraction leverages Cassandra’s partitioning and clustering capabilities. The record ID acts as the partition key, and the item key as the clustering column:

The corresponding Data Definition Language (DDL) for this structure in Cassandra is:
CREATE TABLE IF NOT EXISTS <ns>.<table> (
id text,
key blob,
value blob,
value_metadata blob,
PRIMARY KEY (id, key))
WITH CLUSTERING ORDER BY (key <ASC|DESC>)
Namespace: Logical and Physical Configuration
A namespace defines where and how data is stored, providing logical and physical separation while abstracting the underlying storage systems. It also serves as central configuration of access patterns such as consistency or latency targets. Each namespace may use different backends: Cassandra, EVCache, or combinations of multiple. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs. Developers just provide their data problem rather than a database solution!
In this example configuration, the ngsegment namespace is backed by both a Cassandra cluster and an EVCache caching layer, allowing for highly durable persistent storage and lower-latency point reads.
"persistence_configuration":[
{
"id":"PRIMARY_STORAGE",
"physical_storage": {
"type":"CASSANDRA",
"cluster":"cassandra_kv_ngsegment",
"dataset":"ngsegment",
"table":"ngsegment",
"regions": ["us-east-1"],
"config": {
"consistency_scope": "LOCAL",
"consistency_target": "READ_YOUR_WRITES"
}
}
},
{
"id":"CACHE",
"physical_storage": {
"type":"CACHE",
"cluster":"evcache_kv_ngsegment"
},
"config": {
"default_cache_ttl": 180s
}
}
]
Key APIs of the KV Abstraction
To support diverse use-cases, the KV abstraction provides four basic CRUD APIs:
PutItems — Write one or more Items to a Record
The PutItems API is an upsert operation, it can insert new data or update existing data in the two-level map structure.
message PutItemRequest (
IdempotencyToken idempotency_token,
string namespace,
string id,
List<Item> items
)
As you can see, the request includes the namespace, Record ID, one or more items, and an idempotency token to ensure retries of the same write are safe. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. number of chunks).
GetItems — Read one or more Items from a Record
The GetItemsAPI provides a structured and adaptive way to fetch data using ID, predicates, and selection mechanisms. This approach balances the need to retrieve large volumes of data while meeting stringent Service Level Objectives (SLOs) for performance and reliability.
message GetItemsRequest (
String namespace,
String id,
Predicate predicate,
Selection selection,
Map<String, Struct> signals
)
The GetItemsRequest includes several key parameters:
- Namespace: Specifies the logical dataset or table
- Id: Identifies the entry in the top-level HashMap
- Predicate: Filters the matching items and can retrieve all items (match_all), specific items (match_keys), or a range (match_range)
- Selection: Narrows returned responses for example page_size_bytes for pagination, item_limit for limiting the total number of items across pages and include/exclude to include or exclude large values from responses
- Signals: Provides in-band signaling to indicate client capabilities, such as supporting client compression or chunking.
The GetItemResponse message contains the matching data:
message GetItemResponse (
List<Item> items,
Optional<String> next_page_token
)
- Items: A list of retrieved items based on the Predicate and Selection defined in the request.
- Next Page Token: An optional token indicating the position for subsequent reads if needed, essential for handling large data sets across multiple requests. Pagination is a critical component for efficiently managing data retrieval, especially when dealing with large datasets that could exceed typical response size limits.
DeleteItems — Delete one or more Items from a Record
The DeleteItems API provides flexible options for removing data, including record-level, item-level, and range deletes — all while supporting idempotency.
message DeleteItemsRequest (
IdempotencyToken idempotency_token,
String namespace,
String id,
Predicate predicate
)
Just like in the GetItems API, the Predicate allows one or more Items to be addressed at once:
- Record-Level Deletes (match_all): Removes the entire record in constant latency regardless of the number of items in the record.
- Item-Range Deletes (match_range): This deletes a range of items within a Record. Useful for keeping “n-newest” or prefix path deletion.
- Item-Level Deletes (match_keys): Deletes one or more individual items.
Some storage engines (any store which defers true deletion) such as Cassandra struggle with high volumes of deletes due to tombstone and compaction overhead. Key-Value optimizes both record and range deletes to generate a single tombstone for the operation — you can learn more about tombstones in About Deletes and Tombstones.
Item-level deletes create many tombstones but KV hides that storage engine complexity via TTL-based deletes with jitter. Instead of immediate deletion, item metadata is updated as expired with randomly jittered TTL applied to stagger deletions. This technique maintains read pagination protections. While this doesn’t completely solve the problem it reduces load spikes and helps maintain consistent performance while compaction catches up. These strategies help maintain system performance, reduce read overhead, and meet SLOs by minimizing the impact of deletes.
Complex Mutate and Scan APIs
Beyond simple CRUD on single Records, KV also supports complex multi-item and multi-record mutations and scans via MutateItems and ScanItems APIs. PutItems also supports atomic writes of large blob data within a single Item via a chunked protocol. These complex APIs require careful consideration to ensure predictable linear low-latency and we will share details on their implementation in a future post.
Design Philosophies for reliable and predictable performance
Idempotency to fight tail latencies
To ensure data integrity the PutItems and DeleteItems APIs use idempotency tokens, which uniquely identify each mutative operation and guarantee that operations are logically executed in order, even when hedged or retried for latency reasons. This is especially crucial in last-write-wins databases like Cassandra, where ensuring the correct order and de-duplication of requests is vital.
In the Key-Value abstraction, idempotency tokens contain a generation timestamp and random nonce token. Either or both may be required by backing storage engines to de-duplicate mutations.
message IdempotencyToken (
Timestamp generation_time,
String token
)
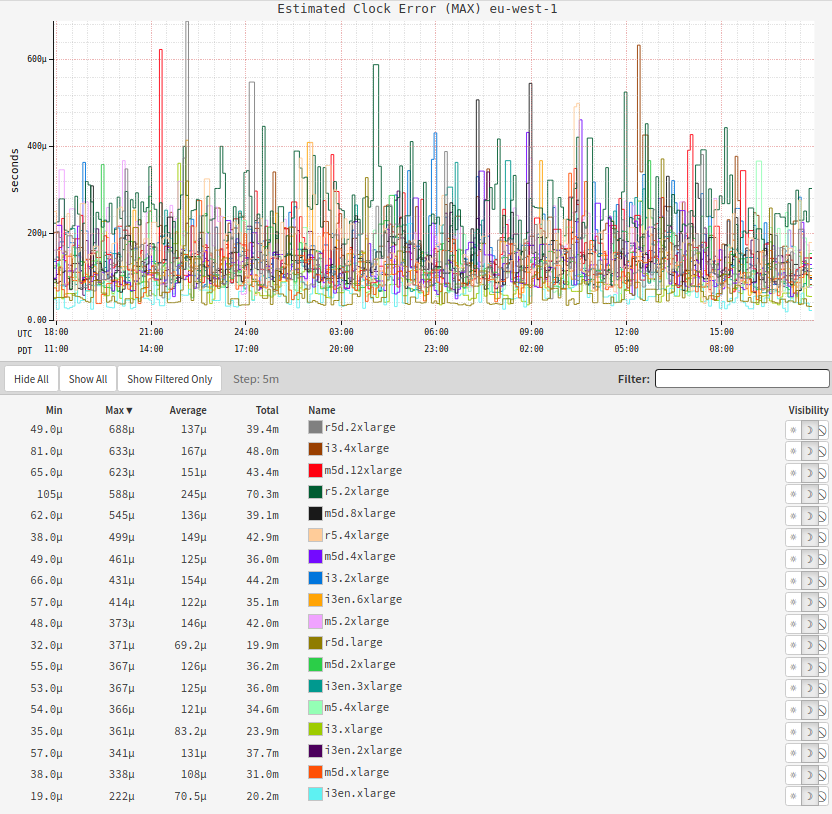
At Netflix, client-generated monotonic tokens are preferred due to their reliability, especially in environments where network delays could impact server-side token generation. This combines a client provided monotonic generation_time timestamp with a 128 bit random UUID token. Although clock-based token generation can suffer from clock skew, our tests on EC2 Nitro instances show drift is minimal (under 1 millisecond). In some cases that require stronger ordering, regionally unique tokens can be generated using tools like Zookeeper, or globally unique tokens such as a transaction IDs can be used.
The following graphs illustrate the observed clock skew on our Cassandra fleet, suggesting the safety of this technique on modern cloud VMs with direct access to high-quality clocks. To further maintain safety, KV servers reject writes bearing tokens with large drift both preventing silent write discard (write has timestamp far in past) and immutable doomstones (write has a timestamp far in future) in storage engines vulnerable to those.
Handling Large Data through Chunking
Key-Value is also designed to efficiently handle large blobs, a common challenge for traditional key-value stores. Databases often face limitations on the amount of data that can be stored per key or partition. To address these constraints, KV uses transparent chunking to manage large data efficiently.
For items smaller than 1 MiB, data is stored directly in the main backing storage (e.g. Cassandra), ensuring fast and efficient access. However, for larger items, only the id, key, and metadata are stored in the primary storage, while the actual data is split into smaller chunks and stored separately in chunk storage. This chunk storage can also be Cassandra but with a different partitioning scheme optimized for handling large values. The idempotency token ties all these writes together into one atomic operation.
By splitting large items into chunks, we ensure that latency scales linearly with the size of the data, making the system both predictable and efficient. A future blog post will describe the chunking architecture in more detail, including its intricacies and optimization strategies.
Client-Side Compression
The KV abstraction leverages client-side payload compression to optimize performance, especially for large data transfers. While many databases offer server-side compression, handling compression on the client side reduces expensive server CPU usage, network bandwidth, and disk I/O. In one of our deployments, which helps power Netflix’s search, enabling client-side compression reduced payload sizes by 75%, significantly improving cost efficiency.
Smarter Pagination
We chose payload size in bytes as the limit per response page rather than the number of items because it allows us to provide predictable operation SLOs. For instance, we can provide a single-digit millisecond SLO on a 2 MiB page read. Conversely, using the number of items per page as the limit would result in unpredictable latencies due to significant variations in item size. A request for 10 items per page could result in vastly different latencies if each item was 1 KiB versus 1 MiB.
Using bytes as a limit poses challenges as few backing stores support byte-based pagination; most data stores use the number of results e.g. DynamoDB and Cassandra limit by number of items or rows. To address this, we use a static limit for the initial queries to the backing store, query with this limit, and process the results. If more data is needed to meet the byte limit, additional queries are executed until the limit is met, the excess result is discarded and a page token is generated.
This static limit can lead to inefficiencies, one large item in the result may cause us to discard many results, while small items may require multiple iterations to fill a page, resulting in read amplification. To mitigate these issues, we implemented adaptive pagination which dynamically tunes the limits based on observed data.
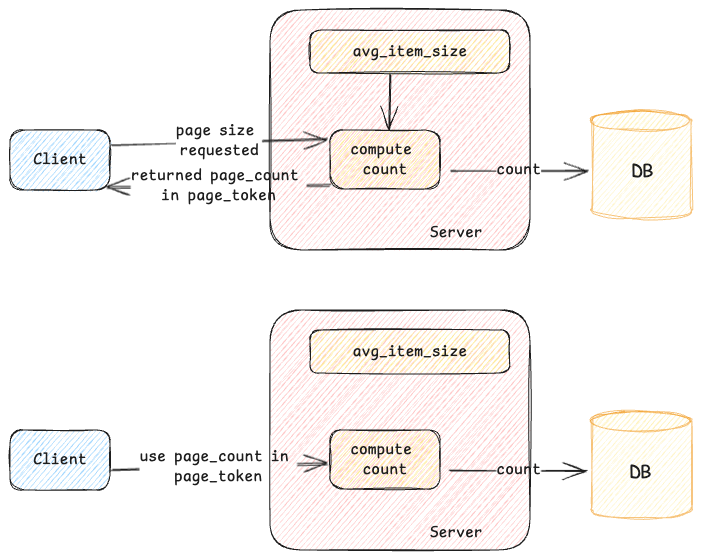
Adaptive Pagination
When an initial request is made, a query is executed in the storage engine, and the results are retrieved. As the consumer processes these results, the system tracks the number of items consumed and the total size used. This data helps calculate an approximate item size, which is stored in the page token. For subsequent page requests, this stored information allows the server to apply the appropriate limits to the underlying storage, reducing unnecessary work and minimizing read amplification.
While this method is effective for follow-up page requests, what happens with the initial request? In addition to storing item size information in the page token, the server also estimates the average item size for a given namespace and caches it locally. This cached estimate helps the server set a more optimal limit on the backing store for the initial request, improving efficiency. The server continuously adjusts this limit based on recent query patterns or other factors to keep it accurate. For subsequent pages, the server uses both the cached data and the information in the page token to fine-tune the limits.
In addition to adaptive pagination, a mechanism is in place to send a response early if the server detects that processing the request is at risk of exceeding the request’s latency SLO.
For example, let us assume a client submits a GetItems request with a per-page limit of 2 MiB and a maximum end-to-end latency limit of 500ms. While processing this request, the server retrieves data from the backing store. This particular record has thousands of small items so it would normally take longer than the 500ms SLO to gather the full page of data. If this happens, the client would receive an SLO violation error, causing the request to fail even though there is nothing exceptional. To prevent this, the server tracks the elapsed time while fetching data. If it determines that continuing to retrieve more data might breach the SLO, the server will stop processing further results and return a response with a pagination token.
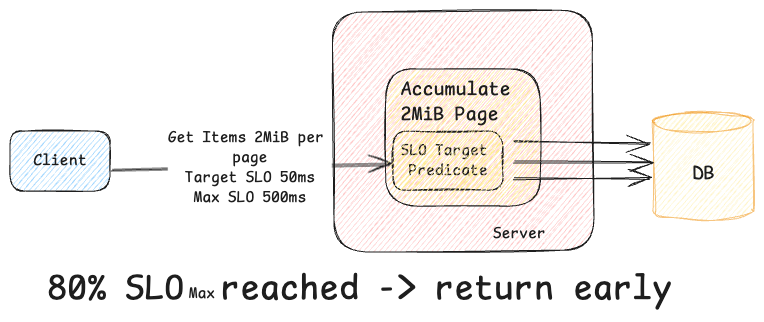
This approach ensures that requests are processed within the SLO, even if the full page size isn’t met, giving clients predictable progress. Furthermore, if the client is a gRPC server with proper deadlines, the client is smart enough not to issue further requests, reducing useless work.
If you want to know more, the How Netflix Ensures Highly-Reliable Online Stateful Systems article talks in further detail about these and many other techniques.
Signaling
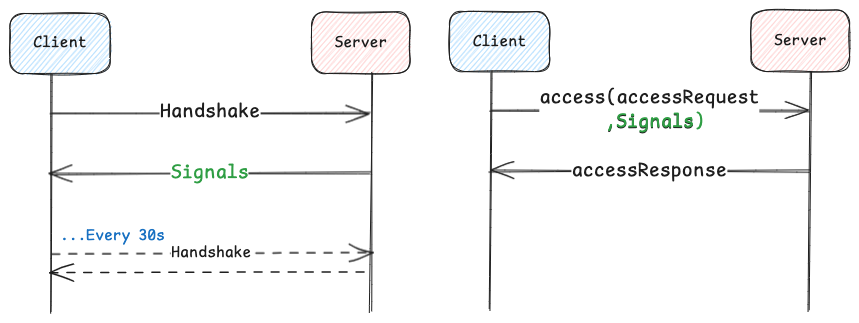
KV uses in-band messaging we call signaling that allows the dynamic configuration of the client and enables it to communicate its capabilities to the server. This ensures that configuration settings and tuning parameters can be exchanged seamlessly between the client and server. Without signaling, the client would need static configuration — requiring a redeployment for each change — or, with dynamic configuration, would require coordination with the client team.
For server-side signals, when the client is initialized, it sends a handshake to the server. The server responds back with signals, such as target or max latency SLOs, allowing the client to dynamically adjust timeouts and hedging policies. Handshakes are then made periodically in the background to keep the configuration current. For client-communicated signals, the client, along with each request, communicates its capabilities, such as whether it can handle compression, chunking, and other features.
KV Usage @ Netflix
The KV abstraction powers several key Netflix use cases, including:
- Streaming Metadata: High-throughput, low-latency access to streaming metadata, ensuring personalized content delivery in real-time.
- User Profiles: Efficient storage and retrieval of user preferences and history, enabling seamless, personalized experiences across devices.
- Messaging: Storage and retrieval of push registry for messaging needs, enabling the millions of requests to flow through.
- Real-Time Analytics: This persists large-scale impression and provides insights into user behavior and system performance, moving data from offline to online and vice versa.
Future Enhancements
Looking forward, we plan to enhance the KV abstraction with:
- Lifecycle Management: Fine-grained control over data retention and deletion.
- Summarization: Techniques to improve retrieval efficiency by summarizing records with many items into fewer backing rows.
- New Storage Engines: Integration with more storage systems to support new use cases.
- Dictionary Compression: Further reducing data size while maintaining performance.
Conclusion
The Key-Value service at Netflix is a flexible, cost-effective solution that supports a wide range of data patterns and use cases, from low to high traffic scenarios, including critical Netflix streaming use-cases. The simple yet robust design allows it to handle diverse data models like HashMaps, Sets, Event storage, Lists, and Graphs. It abstracts the complexity of the underlying databases from our developers, which enables our application engineers to focus on solving business problems instead of becoming experts in every storage engine and their distributed consistency models. As Netflix continues to innovate in online datastores, the KV abstraction remains a central component in managing data efficiently and reliably at scale, ensuring a solid foundation for future growth.
Acknowledgments: Special thanks to our stunning colleagues who contributed to Key Value’s success: William Schor, Mengqing Wang, Chandrasekhar Thumuluru, John Lu, George Cambell, Ammar Khaku, Jordan West, Chris Lohfink, Matt Lehman, and the whole online datastores team (ODS, f.k.a CDE).
![]()
Introducing Netflix’s Key-Value Data Abstraction Layer was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Now available: Graviton4-powered memory-optimized Amazon EC2 X8g instances
Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/now-available-graviton4-powered-memory-optimized-amazon-ec2-x8g-instances/
 Graviton-4-powered, memory-optimized X8g instances are now available in ten virtual sizes and two bare metal sizes, with up to 3 TiB of DDR5 memory and up to 192 vCPUs. The X8g instances are our most energy efficient to date, with the best price performance and scale-up capability of any comparable EC2 Graviton instance to date. With a 16 to 1 ratio of memory to vCPU, these instances are designed for Electronic Design Automation, in-memory databases & caches, relational databases, real-time analytics, and memory-constrained microservices. The instances fully encrypt all high-speed physical hardware interfaces and also include additional AWS Nitro System and Graviton4 security features.
Graviton-4-powered, memory-optimized X8g instances are now available in ten virtual sizes and two bare metal sizes, with up to 3 TiB of DDR5 memory and up to 192 vCPUs. The X8g instances are our most energy efficient to date, with the best price performance and scale-up capability of any comparable EC2 Graviton instance to date. With a 16 to 1 ratio of memory to vCPU, these instances are designed for Electronic Design Automation, in-memory databases & caches, relational databases, real-time analytics, and memory-constrained microservices. The instances fully encrypt all high-speed physical hardware interfaces and also include additional AWS Nitro System and Graviton4 security features.
Over 50K AWS customers already make use of the existing roster of over 150 Graviton-powered instances. They run a wide variety of applications including Valkey, Redis, Apache Spark, Apache Hadoop, PostgreSQL, MariaDB, MySQL, and SAP HANA Cloud. Because they are available in twelve sizes, the new X8g instances are an even better host for these applications by allowing you to choose between scaling up (using a bigger instance) and scaling out (using more instances), while also providing additional flexibility for existing memory-bound workloads that are currently running on distinct instances.
The Instances
When compared to the previous generation (X2gd) instances, the X8g instances offer 3x more memory, 3x more vCPUs, more than twice as much EBS bandwidth (40 Gbps vs 19 Gbps), and twice as much network bandwidth (50 Gbps vs 25 Gbps).
The Graviton4 processors inside the X8g instances have twice as much L2 cache per core as the Graviton2 processors in the X2gd instances (2 MiB vs 1 MiB) along with 160% higher memory bandwidth, and can deliver up to 60% better compute performance.
The X8g instances are built using the 5th generation of AWS Nitro System and Graviton4 processors, which incorporates additional security features including Branch Target Identification (BTI) which provides protection against low-level attacks that attempt to disrupt control flow at the instruction level. To learn more about this and Graviton4’s other security features, read How Amazon’s New CPU Fights Cybersecurity Threats and watch the re:Invent 2023 AWS Graviton session.
Here are the specs:
| Instance Name | vCPUs |
Memory (DDR5) |
EBS Bandwidth |
Network Bandwidth |
| x8g.medium | 1 | 16 GiB | Up to 10 Gbps | Up to 12.5 Gbps |
| x8g.large | 2 | 32 GiB | Up to 10 Gbps | Up to 12.5 Gbps |
| x8g.xlarge | 4 | 64 GiB | Up to 10 Gbps | Up to 12.5 Gbps |
| x8g.2xlarge | 8 | 128 GiB | Up to 10 Gbps | Up to 15 Gbps |
| x8g.4xlarge | 16 | 256 GiB | Up to 10 Gbps | Up to 15 Gbps |
| x8g.8xlarge | 32 | 512 GiB | 10 Gbps | 15 Gbps |
| x8g.12xlarge | 48 | 768 GiB | 15 Gbps | 22.5 Gbps |
| x8g.16xlarge | 64 | 1,024 GiB | 20 Gbps | 30 Gbps |
| x8g.24xlarge | 96 | 1,536 GiB | 30 Gbps | 40 Gbps |
| x8g.48xlarge | 192 | 3,072 GiB | 40 Gbps | 50 Gbps |
| x8g.metal-24xl | 96 | 1,536 GiB | 30 Gbps | 40 Gbps |
| x8g.metal-48xl | 192 | 3,072 GiB | 40 Gbps | 50 Gbps |
The instances support ENA, ENA Express, and EFA Enhanced Networking. As you can see from the table above they provide a generous amount of EBS bandwidth, and support all EBS volume types including io2 Block Express, EBS General Purpose SSD, and EBS Provisioned IOPS SSD.
X8g Instances in Action
Let’s take a look at some applications and use cases that can make use of 16 GiB of memory per vCPU and/or up to 3 TiB per instance:
Databases – X8g instances allow SAP HANA and SAP Data Analytics Cloud to handle larger and more ambitious workloads than before. Running on Graviton4 powered instances, SAP has measured up to 25% better performance for analytical workloads and up to 40% better performance for transactional workloads in comparison to the same workloads running on Graviton3 instances. X8g instances allow SAP to expand their Graviton-based usage to even larger memory bound solutions.
Electronic Design Automation – EDA workloads are central to the process of designing, testing, verifying, and taping out new generations of chips, including Graviton, Trainium, Inferentia, and those that form the building blocks for the Nitro System. AWS and many other chip makers have adopted the AWS Cloud for these workloads, taking advantage of scale and elasticity to supply each phase of the design process with the appropriate amount of compute power. This allows engineers to innovate faster because they are not waiting for results. Here’s a long-term snapshot from one of the clusters that was used to support development of Graviton4 in late 2022 and early 2023. As you can see this cluster runs at massive scale, with peaks as high as 5x normal usage:

You can see bursts of daily and weekly activity, and then a jump in overall usage during the tape-out phase. The instances in the cluster are on the large end of the size spectrum so the peaks represent several hundred thousand cores running concurrently. This ability to spin up compute when we need it and down when we don’t gives us access to unprecedented scale without a dedicated investment in hardware.
The new X8g instances will allow us and our EDA customers to run even more workloads on Graviton processors, reducing costs and decreasing energy consumption, while also helping to get new products to market faster than ever.
Available Now
X8g instances are available today in the US East (N. Virginia), US West (Oregon), and Europe (Frankfurt) AWS Regions in On Demand, Spot, Reserved Instance, Savings Plan, Dedicated Instance, and Dedicated Host form. To learn more, visit the X8g page.
Refine unused access using IAM Access Analyzer recommendations
Post Syndicated from Stéphanie Mbappe original https://aws.amazon.com/blogs/security/refine-unused-access-using-iam-access-analyzer-recommendations/
As a security team lead, your goal is to manage security for your organization at scale and ensure that your team follows AWS Identity and Access Management (IAM) security best practices, such as the principle of least privilege. As your developers build on AWS, you need visibility across your organization to make sure that teams are working with only the required privileges. Now, AWS Identity and Access Management Analyzer offers prescriptive recommendations with actionable guidance that you can share with your developers to quickly refine unused access.
In this post, we show you how to use IAM Access Analyzer recommendations to refine unused access. To do this, we start by focusing on the recommendations to refine unused permissions and show you how to generate the recommendations and the actions you can take. For example, we show you how to filter unused permissions findings, generate recommendations, and remediate issues. Now, with IAM Access Analyzer, you can include step-by-step recommendations to help developers refine unused permissions quickly.
Unused access recommendations
IAM Access Analyzer continuously analyzes your accounts to identify unused access and consolidates findings in a centralized dashboard. The dashboard helps review findings and prioritize accounts based on the volume of findings. The findings highlight unused IAM roles and unused access keys and passwords for IAM users. For active IAM roles and users, the findings provide visibility into unused services and actions. You can learn more about unused access analysis through the IAM Access Analyzer documentation.
For unused IAM roles, access keys, and passwords, IAM Access Analyzer provides quick links in the console to help you delete them. You can use the quick links to act on the recommendations or use export to share the details with the AWS account owner. For overly permissive IAM roles and users, IAM Access Analyzer provides policy recommendations with actionable steps that guide you to refine unused permissions. The recommended policies retain resource and condition context from existing policies, helping you update your policies iteratively.
Throughout this post, we use an IAM role in an AWS account and configure the permissions by doing the following:
- Attaching the AWS managed policy AmazonBedrockReadOnly.
- Attaching the AWS managed policy AmazonS3ReadOnlyAccess.
- Embedding an inline policy with the permissions described in the following code and named InlinePolicyListLambda.
Content of inline policy InlinePolicyListLambda:
We use an inline policy to demonstrate that IAM Access Analyzer unused access recommendations are applicable for that use case. The recommendations are also applicable when using AWS managed policies and customer managed policies.
In your AWS account, after you have configured an unused access analyzer, you can select an IAM role that you have used recently and see if there are unused access permissions findings and recommendations.
Prerequisites
Before you get started, you must create an unused access analyzer for your organization or account. Follow the instructions in IAM Access Analyzer simplifies inspection of unused access in your organization to create an unused access analyzer.
Generate recommendations for unused permissions
In this post we explore three options for generating recommendations for IAM Access Analyzer unused permissions findings: the console, AWS CLI, and AWS API.
Generate recommendations for unused permissions using the console
After you have created an unused access analyzer as described in the prerequisites, wait a few minutes to see the analysis results. Then use the AWS Management Console to view the proposed recommendations for the unused permissions.
To list unused permissions findings
- Go to the IAM console and under Access Analyzer, choose Unused access from the navigation pane.
- Search for active findings with the type Unused permissions in the search box.
- Select Active from the Status drop-down list.
- In the search box, select Findings type under Properties.
- Select Equals as Operators.
- Select Findings Type = Unused permissions.
- This list shows the active findings for IAM resources with unused permissions.

Figure 1: Filter on unused permissions in the IAM console
- Select a finding to learn more about the unused permissions granted to a given role or user.

To obtain recommendations for unused permissions
- On the findings detail page, you will see a list of the unused permissions under Unused permissions.
- Following that, there is a new section called Recommendations. The Recommendations section presents two steps to remediate the finding:
- Review the existing permissions on the resource.
- Create new policies with the suggested refined permissions and detach the existing policies.

Figure 2: Recommendations section
- The generation of recommendations is on-demand and is done in the background when you’re using the console. The message Analysis in progress indicates that recommendations are being generated. The recommendations exclude the unused actions from the recommended policies.
- When an IAM principal, such as an IAM role or user, has multiple permissions policies attached, an analysis of unused permissions is made for each of permissions policies:
- If no permissions have been used, the recommended action is to detach the existing permissions policy.
- If some permissions have been used, only the used permissions are kept in the recommended policy, helping you apply the principle of least privilege.
- The recommendations are presented for each existing policy in the column Recommended policy. In this example, the existing policies are:
- AmazonBedrockReadOnly
- AmazonS3ReadOnlyAccess
- InlinePolicyListLambda
And the recommended policies are:
- None
- AmazonS3ReadOnlyAccess-recommended
- InlinePolicyListLambda-recommended
Figure 3: Recommended policies
- There is no recommended policy for
AmazonBedrockReadOnlybecause the recommended action is to detach it. When hovering over None, the following message is displayed: There are no recommended policies to create for the existing permissions policy. AmazonS3ReadOnlyAccessandInlinePolicyListLambdaand their associated recommended policy can be previewed by choosing Preview policy.


To preview a recommended policy
IAM Access Analyzer has proposed two recommended policies based on the unused actions.
- To preview each recommended policy, choose Preview policy for that policy to see a comparison between the existing and recommended permissions.
- Choose Preview policy for AmazonS3ReadOnlyAccess-recommended.
- The existing policy has been analyzed and the broad permissions—
s3:Get*ands3:List*—have been scoped down to detailed permissions in the recommended policy. - The permissions
s3:Describe*,s3-object-lambda:Get*, ands3-object-lambda:List*can be removed because they weren’t used.

Figure 4: Preview of the recommended policy for AmazonS3ReadOnlyAccess
- The existing policy has been analyzed and the broad permissions—
- Choose Preview policy for InlinePolicyListLambda-recommended to see a comparison between the existing inline policy
InlinePolicyListLambdaand its recommended version.- The existing permissions,
lambda:ListFunctionsandlambda:ListLayers, are kept in the recommended policy, as well as the existing condition. - The permissions in
lambda:ListAliasesandlambda:ListFunctionUrlConfigscan be removed because they weren’t used.
Figure 5: Preview the recommended policy for the existing inline policy InlinePolicyListLambda
- The existing permissions,
- Choose Preview policy for AmazonS3ReadOnlyAccess-recommended.


To download the recommended policies file
- Choose Download JSON to download the suggested recommendations locally.
Figure 6: Download the recommended policies
- A .zip file that contains the recommended policies in JSON format will be downloaded.

Figure 7: Downloaded recommended policies as JSON files
- The content of the
AmazonS3ReadOnlyAccess-recommended-1-2024-07-22T20/08/44.793Z.jsonfile the same as the recommended policy shown in Figure 4.


Generate recommendations for unused permissions using AWS CLI
In this section, you will see how to generate recommendations for unused permissions using AWS Command Line Interface (AWS CLI).
To list unused permissions findings
- Use the following code to refine the results by filtering on the type UnusedPermission and selecting only the active findings. Copy the Amazon Resource Name (ARN) of your unused access analyzer and use it to replace the ARN in the following code:
- You will obtain results similar to the following.
To generate unused permissions finding recommendations
After you have a list of findings for unused permissions, you can generate finding recommendations.
- Run the following, replacing the analyzer ARN and the finding ID to generate the suggested recommendations.
- You will get an empty response if your command ran successfully. The process is running in the background.
To obtain the generated recommendations
After the recommendations are generated, you need to make a separate API call to view the recommendations details.
- The following command returns the recommended remediation.
- This command provides the following results. For more information about the meaning and structure of the recommendations, see Anatomy of a recommendation later in this post.
Note: The recommendations consider AWS managed policies, customer managed policies, and inline policies. The IAM conditions in the initial policy are maintained in the recommendations if the actions they’re related to are used.
The remediations suggested are to do the following:
- Detach
AmazonBedrockReadOnlypolicy because it is unused: DETACH_POLICY - Create a new recommended policy with scoped down permissions from the managed policy
AmazonS3ReadOnlyAccess:CREATE_POLICY - Detach
AmazonS3ReadOnlyAccess:DETACH_POLICY - Embed a new recommended policy with scoped down permissions from the inline policy: CREATE_POLICY
- Delete the inline policy.
- Detach
Generate recommendations for unused permissions using EventBridge and AWS API
We have described how to use AWS CLI and the console to find unused permissions findings and to generate recommendations.
In this section, we show you how to use an Amazon EventBridge rule to find the active unused permissions findings from IAM Access Analyzer. Then we show you how to generate recommendations using two IAM Access Analyzer APIs to generate the finding recommendations and get the finding recommendations.
To create an EventBridge rule to detect unused permissions findings
Create an EventBridge rule to detect new unused permissions findings from IAM Access Analyzer.
- Go to the Amazon EventBridge console.
- Choose Rules, and then choose Create rule.
- Enter a name for your rule. Leave the Event bus value as the default.
- Under Rule type, select Rule with an event pattern.
- In the Event Source section, select AWS events or EventBridge partner events.
- For Creation method, select Use pattern form.
- Under Event pattern:
- For Event source, select AWS services.
- For AWS service, select Access Analyzer.
- For Event type, select Unused Access Finding for IAM entities.
Note: There is no event for generated recommendations, only for unused access findings.
Figure 8: Listing unused permissions by filtering events using an EventBridge rule
- Configure the Event pattern by changing the default values to the following:
resources: Enter the ARN of your unused access analyzer.status: ACTIVE indicates that you are only looking for active findings.findingType: UnusedPermission.
- You can select a target Amazon Simple Notification Service (Amazon SNS) to be notified of new active findings for a specific analyzer for unused permissions.

To generate recommendations for unused permissions using the IAM Access Analyzer API
The findings are generated on-demand. For that purpose, IAM Access Analyzer API GenerateFindingRecommendation can be called with two parameters: the ARN of the analyzer and the finding ID.
- You can use AWS Software Development Kit (SDK) for Python(boto3) for the API call.
- Run the call as follows:
To obtain the finding recommendations
- After the recommendations are generated, they can be obtained by calling the API GetFindingRecommendation with the same parameters: the ARN of the analyzer and the finding ID.
- Use AWS SDK for Python (boto3) for the API call as follows:
Remediate based on the generated recommendations
The recommendations are generated as actionable guidance that you can follow. They propose new IAM policies that exclude the unused actions, helping you rightsize your permissions.
Anatomy of a recommendation
The recommendations are usually presented in the following way:
- Date and time:
startedAt, completedAt. Respectively when the API call was made and when the analysis was completed and the results were provided. - Resource ARN: The ARN of the resource being analyzed.
- Recommended steps: The recommended steps, such as creating a new policy based on the actions used and detaching the existing policy.
- Recommendation type: UNUSED_PERMISSION_RECOMMENDATION.
- Status: The status of retrieving the finding recommendation. The status values include SUCCEEDED, FAILED, and IN_PROGRESS.
For more information about the structure of recommendations, see the output section of get-finding-recommendation.
Recommended policy review
You must review the recommended policy. The recommended actions depend on the original policy. The original policy will be one of the following:
- An AWS managed policy: You need to create a new IAM policy using
recommendedPolicy. Attach this newly created policy to your IAM role. Then detach the former policy. - A customer managed policy or an inline policy: Review the policy, verify its scope, consider how often it’s attached to other principals (customer managed policy only), and when you are confident to proceed, use the recommended policy to create a new policy and detach the former policy.
Use cases to consider when reviewing recommendations
During your review process, keep in mind that the unused actions are determined based on the time defined in your tracking period. The following are some use cases you might have where a necessary role or action might be identified as unused (this is not an exhaustive list of use cases). It’s important to review the recommendations based on your business needs. You can also archive some findings related to the use cases such as the ones that follow:
- Backup activities: If your tracking period is 28 days and you have a specific role for your backup activities running at the end of each month, you might discover that after 29 days some of the permissions for that backup role are identified as unused.
- IAM permissions associated to an infrastructure as code deployment pipeline: You should also consider the permissions associated to specific IAM roles such an IAM for infrastructure as code (IaC) deployment pipeline. Your pipeline can be used to deploy Amazon Simple Storage Service (Amazon S3) buckets based on your internal guidelines. After deployment is complete, the pipeline permissions can become unused after your tracking period, but removing those unused permissions can prevent you from updating your S3 buckets configuration or from deleting it.
- IAM roles associated with disaster recovery activities: While it’s recommended to have a disaster recovery plan, the IAM roles used to perform those activities might be flagged by IAM Access Analyzer for having unused permissions or being unused roles.
To apply the suggested recommendations
Of the three original policies attached to IAMRole_IA2_Blog_EC2Role, AmazonBedrockReadOnly can be detached and AmazonS3ReadOnlyAccess and InlinePolicyListLambda can be refined.
- Detach
AmazonBedrockReadOnlyNo permissions are used in this policy, and the recommended action is to detach it from your IAM role. To detach it, you can use the IAM console, the AWS CLI, or the AWS API.
- Create a new policy called
AmazonS3ReadOnlyAccess-recommendedand detachAmazonS3ReadOnlyAccess.The unused access analyzer has identified unused permissions in the managed policy AmazonS3ReadOnlyAccess and proposed a new policy
AmazonS3ReadOnlyAccess-recommendedthat contains only the used actions. This is a step towards least privilege because the unused actions can be removed by using the recommended policy.- Create a new IAM policy named AmazonS3ReadOnlyAccess-recommended that contains only the following recommended policy or one based on the downloaded JSON file.
- Detach the managed policy
AmazonS3ReadOnlyAccess.
- Embed a new inline policy
InlinePolicyListLambda-recommendedand deleteInlinePolicyListLambda. This inline policy lists AWS Lambda aliases, functions, layers, and function URLs only when coming from a specific source IP address.- Embed the recommended inline policy.
The recommended policy follows. You can embed an inline policy for the IAM role using the console, AWS CLI, or the AWS API PutRolePolicy.
- Delete the inline policy.
- Embed the recommended inline policy.
- After updating the policies based on the Recommended policy proposed, the finding Status will change from Active to Resolved.
Figure 9: The finding is resolved

Pricing
There is no additional pricing for using the prescriptive recommendations after you have enabled unused access findings.
Conclusion
As a developer writing policies, you can use the actionable guidance provided in recommendations to continually rightsize your policies to include only the roles and actions you need. You can export the recommendations through the console or set up automated workflows to notify your developers about new IAM Access Analyzer findings.
This new IAM Access Analyzer unused access recommendations feature streamlines the process towards least privilege by selecting the permissions that are used and retaining the resource and condition context from existing policies. It saves an impressive amount of time by the actions used by your principals and guiding you to refine them.
By using the IAM Access Analyzer findings and access recommendations, you can quickly see how to refine the permissions granted. We have shown in this blog post how to generate prescriptive recommendations with actionable guidance for unused permissions using AWS CLI, API calls, and the console.
- To learn more about IAM Access Analyzer Unused Access, see Findings for external and unused access.
- To learn about the creation of unused access findings, see IAM Access Analyzer simplifies inspection of unused access in your organization.
- To learn about the strategies for achieving least privilege at scale, see Strategies for achieving least privilege at scale Part 1 and Part 2.
- To practice, use the Refining IAM Permissions Like A Pro the workshop.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Data engineering professional certificate: New hands-on specialization by DeepLearning.AI and AWS
Post Syndicated from Betty Zheng (郑予彬) original https://aws.amazon.com/blogs/aws/data-engineering-professional-certificate-new-hands-on-specialization-by-deeplearning-ai-and-aws/
Data engineers play a crucial role in the modern data-driven landscape, managing essential tasks from data ingestion and processing to transformation and serving. Their expertise is particularly valuable in the era of generative AI, where harnessing the value of vast datasets is paramount.
To empower aspiring and experienced data professionals, DeepLearning.AI and Amazon Web Services (AWS) have partnered to launch the Data Engineering Specialization, an advanced professional certificate on Coursera. This comprehensive program covers a wide range of data engineering concepts, tools, and techniques relevant to modern organizations. It’s designed for learners with some experience working with data who are interested in learning the fundamentals of data engineering. The specialization comprises four hands-on courses, each culminating in a Coursera course certificate upon completion.

Specialization overview
This Data Engineering Specialization is a joint initiative by AWS and DeepLearning.AI, a leading provider of world-class AI education founded by renowned machine learning (ML) pioneer Andrew Ng.
Joe Reis, a prominent figure in data engineering and coauthor of the bestselling book Fundamentals of Data Engineering, leads the program as a primary instructor. By providing a foundational framework, the curriculum ensures learners gain a holistic understanding of the data engineering lifecycle, while covering key aspect such as data architecture, orchestration, DataOps, and data management.
Further enhancing the learning experience, the program features hands-on labs and technical assessments hosted on the AWS Cloud. These practical, cloud-based exercises were designed in partnership with AWS technical experts, including Gal Heyne, Navnit Shukla, and Morgan Willis. Learners will apply theoretical concepts using AWS services and tools, such as Amazon Kinesis, AWS Glue, Amazon Simple Storage Service (Amazon S3), and Amazon Redshift, equipping them with hands-on skill and experience.
Specialization highlights
Participants will be introduced to several key learning opportunities.
Acquisition of core skills and strategies
The specialization equips data engineers with the ability to design data engineering solutions for various use cases, select the right technologies for their data architecture, and circumvent potential pitfalls. The skills gained universally apply across various platforms and technologies, offering learners a program that is versatile.
Unparalleled approach to data engineering education
Unlike conventional courses focused on specific technologies, this specialization provides a comprehensive understanding of data engineering fundamentals. It emphasizes the importance of aligning data engineering strategies with broader business goals, fostering a more integrated and effective approach to building and maintaining data solutions.
Holistic understanding of data engineering
By using the insights from the Fundamentals of Data Engineering book, the curriculum offers a well-rounded education that prepares professionals for success in the data-driven focused industries.
Practical skills through AWS cloud labs
The hands-on labs hosted by AWS Partner Vocareum let learners apply the techniques directly in an AWS environment provided with the course. This practical experience is crucial for mastering the intricacies of data engineering and developing the skills needed to excel in the industry.
Why choose this specialization?
- Structured learning path–The specification is thoughtfully structured to provide a step-by-step learning journey, from foundational concepts to advanced applications.
- Expert insights–Gain insights from the authors of Fundamentals of Data Engineering and other industry experts. Learn how to apply practical knowledge to build modern data architecture on the cloud, using cloud services for data engineering.
- Hands-on experience–Engage in hands-on labs in the AWS Cloud, where you not only learn but also apply the knowledge in real-world scenarios.
- Comprehensive curriculum–This program encompasses all aspects of the data engineering lifecycle, including data generation in source systems, ingestion, transformation, storage, and serving. It also addresses key undercurrents of data engineering, such as security, data management, and orchestration.
At the end of this specialization, learners will be well-equipped with the necessary skills and expertise to embark on a career in data engineering, an in-demand role at the core of any organization that is looking to use data to create value. Data-centric ML and analytics would not be possible without the foundation of data engineering.
Course modules
The Data Engineering Specialization comprises four courses:
- Course 1–Introduction to Data Engineering–This foundational module explores the collaborative nature of data engineering, identifying key stakeholders and understanding their requirements. The course delves into a mental framework for building data engineering solutions, emphasizing holistic ecosystem understanding, critical factors like data quality and scalability, and effective requirements gathering. The course then examines the data engineering lifecycle, illustrating interconnections between stages. By showcasing the AWS data engineering stack, the course teaches how to use the right technologies. By the end of this course, learners will have the skills and mindset to tackle data engineering challenges and make informed decisions.
- Course 2–Source Systems, Data Ingestion, and Pipelines–In this course, data engineers dive deep into the practical aspects of working with diverse data sources, ingestion patterns, and pipeline construction. Learners explore the characteristics of different data formats and the appropriate source systems for generating each type of data, equipping them with the knowledge to design effective data pipelines. The course covers the fundamentals of relational and NoSQL databases, including ACID compliance and CRUD operations, so that engineers learn to interact with a wide range of data source systems. The course covers the significance of cloud networking, resolving database connection issues, and using message queues and streaming platforms—crucial skills for creating strong and scalable data architectures. By mastering the concepts in this course, data engineers will be able to automate data ingestion processes, optimize connectivity, and establish the foundation for successful data engineering projects.
- Course 3–Data Storage and Queries–This course equips data engineers with principles and best practices for designing robust, efficient data storage and querying solutions. Learners explore the data lake house concept, implementing a medallion-like architecture and using open table formats to build transactional data lakes. The course enhances SQL proficiency by teaching advanced queries, such as aggregations and joins on streaming data, while also exploring data warehouse and data lake capabilities. Learners compare storage performance and discover optimization strategies, like indexing. Data engineers can achieve high performance and scalability in data services by comprehending query execution and processing.
- Course 4–Data Modeling, Transformation, and Serving–In this capstone course, data engineers explore advanced data modeling techniques, including data vault and star schemas. Learners differentiate between modeling approaches like Inmon and Kimball, gaining the ability to transform data and structure it for optimal analytical and ML use cases. The course equips data engineers with preprocessing skills for textual, image, and tabular data. Learners understand the distinctions between supervised and unsupervised learning, as well as classification and regression tasks, empowering them to design data solutions supporting a range of predictive applications. By mastering these data modeling, transformation, and serving concepts, data engineers can build robust, scalable, and business-aligned data architectures to deliver maximum value.
Enrollment
Whether you’re new to data engineering or looking to enhance your skills, this specialization provides a balanced mix of theory and hands-on experience through 4 courses, each culminating in a Coursera course certificate.
Embark on your data engineering journey from here:
- Introduction to Data Engineering
- Source Systems, Data Ingestion, and Pipelines
- Data Storage and Queries
- Data Modeling, Transformation, and Serving
By enrolling in these courses, you’ll also earn the DeepLearning.AI Data Engineering Professional Certificate upon completing all four courses.
Enroll now and take the first step towards mastering data engineering with this comprehensive and practical program, built on the foundation of Fundamentals of Data Engineering and powered by AWS.
Three stable kernel updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/990766/
The 6.10.11, 6.6.52, and 6.1.111 stable kernel updates have all
been released. As usual, they contain important fixes throughout the
tree. Users of those kernels should upgrade.