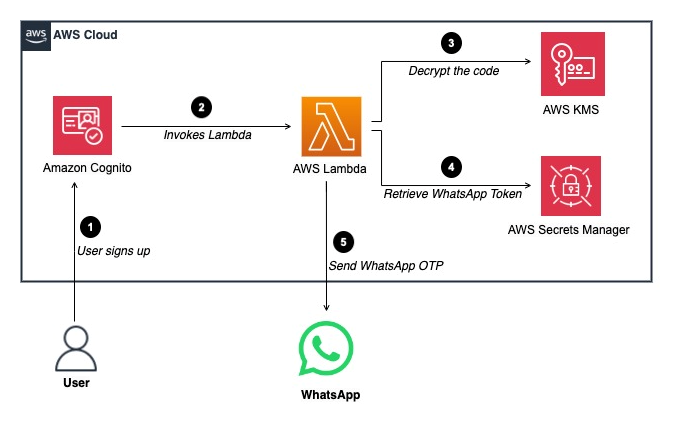
Post Syndicated from Meaghan Buchanan original https://blog.rapid7.com/2024/05/13/rapid7-recognized-in-the-2024-gartner-r-magic-quadrant-for-siem/
Command Your Attack Surface with a next-gen SIEM built for the Cloud First Era

Rapid7 is excited to share that we are named a Challenger for InsightIDR in the 2024 Gartner Magic Quadrant for SIEM. In a crowded and constantly changing space, this is our sixth time to be recognized in the report. While the Magic Quadrant offers a great snapshot of the current marketplace, we are always looking ahead to what teams will need to be successful in the next era of cybersecurity.
We believe that the future of SIEM will be defined by the ability to:
- Connect and synthesize expansive security telemetry as efficiently as possible
- Pinpoint the most critical and actionable insights with the scale and speed of AI
- Deliver the contextualized data, expert guidance, and automation to confidently take action against threats – wherever they start
We are proud to bring these elevated security outcomes to the thousands of customers across the globe who trust Rapid7 at the center of their SOC.
Actionable Visibility You Can Trust – From Endpoint to Cloud
As organizations’ attack surfaces continue to expand and security systems become more fragmented, teams are challenged to get reliable visibility and context to effectively monitor their environment, end-to-end. As your organization embraces digital transformation, adopts SaaS solutions, and/or fosters agile business development, you need security solutions that can grow with your business without the burden of infrastructure management or lagging scale.
InsightIDR is a cloud-native SIEM – purpose-built to support an organization’s scale with the speed of the cloud-first era. With flexible data ingestion – including our own lightweight, native endpoint agent, sensor, and collector as well as the ability to collect and parse diverse data from your wider ecosystem – customers are able to quickly synthesize their most critical telemetry, without the heavy management burdens of traditional SIEM technologies.
Many traditional SIEM approaches leave it all on the customer to figure out how to action their data once in their platform. This leaves resource-constrained teams on their heels and sorting through mounds of data without being able to pinpoint the insights that matter. InsightIDR’s flexible search modes boost both power-users’ and beginners’ ability to quickly turn data into actionable insights and leverage pre-built queries and dashboards as a jumping-off point for action. And with 13-months of readily searchable data logs by default, your data is always ready for you, whenever you need it.

AI-Driven Behavioral Detections to Pinpoint Today’s Advanced Threats
The current threat climate requires a high degree of vigilance and detections content curation to be able to keep pace with adversaries’ ever-growing arsenal of tactics, techniques, and procedures (TTPs). This is one of the most challenging domains for security teams to master and carve out time for – and unfortunately most SIEMs have led with a logging-centric approach, putting the work of threat-intelligence gathering and detections engineering on the customer to parse.
From the beginning, InsightIDR pioneered the detections-centric SIEM, focused on pinpointing and eliminating real threats as quickly as possible. Our library contains over 8,000 detections, giving customers complete coverage across all stages of the MITRE ATT&CK. Our detections engineering experts are constantly curating threat intelligence – including unique raw intelligence from our renowned Rapid7 Open Source Community (including Metasploit, the #1 pentesting tool in the world, Velociraptor digital forensics and incident response framework, and AttackKB vulnerability database) – to ensure customers have coverage against emergent threats (and because our platform is SaaS-delivered, customers immediately receive new detections content ).
Rapid7 holds 56 patents across proprietary analytics frameworks and AI, which contribute to our layered detections strategy. AI-powered attacker and user behavioral analytics detect stealthy attacker behavior and unknown threats that can often go undetected, and complement known indicators of compromise (IOCs) for total coverage. This is the same detections library that our Rapid7 MDR team leverages, so our SIEM customers have high efficacy, low-noise detections they can trust out of the gate.
Response Built for Cloud and Distributed Environments
In the critical moments of an attack, the last thing a security analyst wants to be doing is hopping tabs between different solutions to get the full picture. But security solution sprawl has forced too many SOCs to be tied up being systems integrators vs. being able to focus on actual security work.
InsightIDR’s investigation views eliminate tab-hopping and disparate alert trails. When an alert is fired, customers see a consolidated timeline view of an attack, lateral movement, impacted users and assets, and related CVEs in a single view. Detailed evidence and intelligence, ATT&CK mapping, and vetted recommendations provide all relevant detail at the customer’s fingertips – so even your most junior analyst can respond like an expert, every time. Customers can also pivot from these investigation views into the Velociraptor DFIR framework to more broadly query distributed endpoint fleets to understand the full scope of an attack and avoid repeat occurrences.
One of the biggest challenges of today’s landscape is navigating response to complex cloud environments. Our simplified cloud threat alert view ensures SOC teams can confidently triage cloud provider alerts – like those from GuardDuty – with a purpose-built alert framework that parses out critical alert summaries, impacted resources, queries, and recommends responses to prioritize and act as quickly as possible on threats across cloud workloads. Regardless of where threats begin, with InsightIDR your team is covered and always knows what to do next.
Let Rapid7 Help You Take Command of Your Attack Surface
The complexities of today’s modern attack surface can be daunting, and are too often compounded by disparate solutions or legacy approaches that can make things worse. Rapid7’s integrated platform approach synthesizes your security data ecosystem to deliver unified exposure management and detection and response that maximizes efficiency and security outcomes. Thank you to our customers and partners who trust Rapid7 as their security consolidation partner of choice, and have contributed to recognitions like this Gartner Magic Quadrant for SIEM.
Learn more:
- Read the report
- Please register for our cybersecurity event on May 21st to learn how Rapid7 can help you build cyber resilience and take command of your attack surface.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant and Peer Insights are a registered trademark, of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Gartner Peer Insights content consists of the opinions of individual end users based on their own experiences with the vendors listed on the platform, should not be construed as statements of fact, nor do they represent the views of Gartner or its affiliates. Gartner does not endorse any vendor, product or service depicted in this content nor makes any warranties, expressed or implied, with respect to this content, about its accuracy or completeness, including any warranties of merchantability or fitness for a particular purpose.
Gartner Peer Insights reviews constitute the subjective opinions of individual end users based on their own experiences and do not represent the views of Gartner or its affiliates.