The Rust programming language was created by Mozilla Research in 2010 to be “a programming language empowering everyone to build reliable and efficient(fast) software”[1]. If you are a beginner level SDE or a DevOps engineer or a decision maker in your organization looking to adopt Rust for your specific use, you will find this blog helpful to get started with Rust on AWS. We will begin by explaining why Rust has gained a huge traction over programming languages like C, C++, Java, Python, and Go. We will then talk about why AWS is one of the best platforms for Rust. Finally, we will provide an example of how you can quickly run a Rust program using AWS Lambda function.
Why Rust?
Rust is an efficient and reliable programming language that addresses performance, reliability, and productivity all at once. It distinguishes itself from its peers by boasting memory safety and thread safety without a need for garbage collector.
Historically, C and C++ have held the title of being the most performant programming languages; however, their speeds have often come with a significant cost to their safety and maintainability. The biggest threat in using such languages range from corruption of valid data to the execution of arbitrary code. The frequency of these issues is even more obvious when you notice that from 2007 to 2019, 70 percent of all vulnerabilities addressed by Microsoft through security updates pertain to memory safety [2]. Languages like Java have come a long way in mitigating such vulnerabilities using garbage collector, however this has come with significant performance bottleneck. Rust seeks to marry performance and safety using its novel borrow-checker, which is a type of static analysis tool that can help check for errors in code such as null-pointer dereferences, data races, etc.
There are other ways programs may access invalid memory. Iterating through an array, for example, requires the iterator to know how many elements are in the array to create a stopping condition. Furthermore, without checking array out of bounds, how would an accessor method be sure it is not accessing an index that does not exist? Here, safety comes with a performance overhead. Typically, the safety benefits of languages like Java are worth the performance overhead. However, for situations where safety and speed are both an absolute necessity, developers may choose to run their mission critical applications in Rust. Here, Rust can be viewed as a memory-safe, fast, low-resource programming language that requires no runtime. This makes Rust also suitable to run on embedded or low-resource device applications.
Rust brings polished tooling, a robust package manager (Cargo), and perhaps most importantly – a fast-growing and passionate community of developers. As Rust gains in popularity, so does the number of high-profile organizations adopting it (including AWS!) for critical applications where performance and safety are top concerns. Did you know that Amazon S3 leverages Rust to attempt to return responses with single-digit millisecond latency? To name a few, AWS product components written in Rust include Amazon CloudFront, Amazon EC2, and AWS Lambda among others.
There are many great resources to learn Rust. Most Rust developers start with the official Rust book, which is available for free online.
Rust matters to AWS for two main reasons. First, our customers are choosing to use Rust for their mission critical workloads and adoption is growing, therefore it becomes imperative that AWS provides the best tools possible to run Rust on AWS. In the next section, I will provide an example to show how easy it is to interact with AWS services using Rust runtime on AWS Lambda.
Additionally, it is important that we are creating high performant, safe infrastructure and services for our customers to run their business critical workloads on AWS. In 2018, AWS first launched its open source microVM technology Firecracker written completely in Rust. Since then, AWS has delivered over two dozen open source projects developed in Rust. For instance, AWS uses Firecracker to run AWS Lambda and AWS Fargate. Today, AWS Lambda processes trillions of executions for hundreds of thousands of active customers every month. Its ability to fire up AWS Lambda or AWS Fargate in less than 125ms attributes to blazing fast speed of Rust. AWS also developed and launched Bottlerocket, a Linux-based open source container OS purpose built for running containers. Veeva Systems a leader in cloud based software for the life sciences industry runs a variety of microservices on Bottleneck securely, with enhanced resource efficiency, and decreased management overhead, thanks to Rust.
Here at AWS, our product development teams have leveraged Rust to deliver more than a dozen services. Besides services such as Amazon Simple Storage Service (Amazon S3), AWS developers uses Rust as the language of choice to develop product components for Amazon Elastic Compute Cloud (Amazon EC2), Amazon CloudFront, Amazon Route 53, and more. Our Amazon EC2 team uses Rust for new AWS Nitro System components, including sensitive applications such as Nitro Enclaves.
Not only is AWS using Rust for improving their product response times, we are actively contributing to and supporting Rust and the open source ecosystem around it. AWS employs a number of core open source contributors to the Rust project and popular Rust libraries like tokio, used for writing asynchronous applications with Rust. According to Marc Brooker, Distinguished Engineer and Vice President of Database and AI at AWS, “Hiring engineers to work directly on Rust allows us to improve it in ways that matter to us and to our customers, and help grow the overall Rust community.” AWS is an active member on the Board of Directors for the Rust Foundation and have generously donated infrastructure and technology services to the Rust Foundation. You can read more about how AWS is helping the Rust community here.
Getting Started with Rust on AWS
This demonstration will walk you through creating your first AWS Lambda + Rust App! We’ll bootstrap the development process by utilizing the AWS Serverless Application Model (SAM)—a tool designed for building, deploying, and managing serverless applications. AWS SAM streamlines the Rust development process by setting up AWS’s official Rust Lambda Runtime, Cargo Lambda. This runtime offers a specialized build tool command for direct deployment to AWS. Additionally, AWS SAM integrates both Amazon DynamoDB table and an Amazon API Gateway endpoint. The provided example serves as a foundational template for leveraging the AWS Rust SDK with Amazon DynamoDB.
4. Name the project (for demo: “rust-ddb-example-app“)
5. Now navigate into the newly created directory with the SAM application code and execute sam build && sam deploy --guided.
a. Accept prompts with “y” or defaults.
6. After deployment concludes, record the Amazon CloudFormation “PutApi” output URL. (i.e https://a1b2c3d4e5f6.execute-api.us-west-2.amazonaws.com/Prod/)
7. Add an element to your table. (For the demo the id of our element will be foo and the payload will be bar). (e.g curl -X PUT <PutApi URL>/foo -d "bar")
8. Validate the addition via the AWS Console’s DynamoDB. Locate the table named after your AWS SAM app and verify the new item. You can do this by going to the AWS Console, clicking DynamoDB, then Tables, and then Explore Items.
What Next?
This is a great starting point on your journey with Rust on AWS. For taking your development journey to the next level consider:
Explore More Rust on AWS: AWS provides a plethora of examples and documentation. Explore the AWS Rust GitHub Repository for more intricate use cases and examples.
Join a Rust Workshop: AWS often hosts workshops and webinars on various topics. Keep an eye on the AWS Events Page for an upcoming Rust-focused session.
Deepen Your Rust Knowledge: If you’re new to Rust or want to delve deeper, the Rust Book is an excellent resource. We also highly recommend watching the videos on the Cargo Lambda documentation page.
Engage with the Community: The Rust community is vibrant and welcoming. Join forums, attend meetups, and participate in discussions to grow your network and knowledge. Become a member of Rust Foundation to collaborate with other members of the community.
Contribute to make Rust even better: Report on bugs or fix them, write documentation, and add new features. Here is how.
Conclusion
For those of us living in the safety net confines of an interpreter, Rust changes how we can still execute safely in a compiler generated world. Most importantly, Rust brings to the table blazing fast speed and performance without compromises to the security and stability of the system. It is a language of choice in embedded-systems programming, mission critical systems, blockchain and crypto development, and has found its place in 3D video gaming as well.
Rust on AWS is a game changer in that it makes it easy for developers to run code without having the need to setup extensive infrastructure to run it. It serves as an excellent backend service with zero administration. AWS Lambda‘s in-built Rust support further exemplifies AWS’s commitment to accommodating popularity of this language. In addition, the popularity of Rust has mandated an inbuilt handler be added to AWS Lambda for further support of Rust.
Susan Landau published an excellent essay on the current justification for the government breaking end-to-end-encryption: child sexual abuse and exploitation (CSAE). She puts the debate into historical context, discusses the problem of CSAE, and explains why breaking encryption isn’t the solution.
Да коментирам и другата тема, свързана с е-здравеопазване – електронните извинителни бележки. Те са добра и правилна стъпка, но също като рецептите, показват слабости на процеса.
Оплаквания от електронните бележки има доста, част от тях са неоснователни, но част от тях са валидни. Неоснователни са твърденията, че само лични лекари или само лекари с договор с НЗОК могат да издават такива. Това не е вярно – всеки лекар трябва да вкарва данни в НЗИС (централната система за е-здравеопазване). И като параметър на всеки преглед може да бъде посочено и извиняване на отсъствия.
Проблемът е в това, че лекарите стават „нотариуси на сополите“, защото трябва в електронната система да обвържат извинението на отсъствия с проведен преглед. Това задължение не е ново. Просто сега, с електронната система, не може да се заобиколи, което повдига въпроса за неговата адекватност.
Дали с раздаване на кочани, дали със съобщения по вайбър и минаване „само да взема една бележка“, лекари и родители са намерили практично заобикаляне на писаните правила, с което са облекчавали здравната система.
Нашата работа като законодател, и като управляващи, е да направим писаните правила адекватни на реалността. Има два подхода, които се допълват.
Първият в регламентирането на телемедицината. Не точно „преглед по Вайбър“, защото трябва да са налице редица гаранции, но близо до това. Внесли сме вече такъв законопроект. Така няма да трябва да се събират излишни опашки пред кабинетите.
Вторият подход е правото на родител да извини няколко дни отсъствия по своя преценка, в допълнение на сегашните „по семейни причини“. Това е практика по света. Да, родителите нямат медицинска експертиза, но няма нужда за всяко отсъствие да има диагноза с код по МКБ. Отсъствие за неразположение по преценка на родителя, с разумно ограничение, е напълно нормална житейка хипотеза. Аз напр. имах мигренни болки в училище. Нужна ли е бележка за главоболие? По-скоро не.
Това извинявяне също може и трябва да бъде електронно. Аз бих пакетирал това право с попълване на въпросник за симптомите, защото рискът при такъв подход е да бъде пуснато на училище привидно здраво, но заразно дете (ако има епидемия, напр.)
Представете си прикожението еЗдраве на МЗ, в което по ЕГН на дете и родител и попълване на въпросник, се предоставя възможност за извиняване на отсъствия. Пак проследимо, пак събираме информация, пак се ограничават злоупотреби (с ограничения броя дни), но без претоварване на здравната система.
Електронното извиняване на отсъствия е правилна стъпка, но може да се подобри, като го използваме за поправяне на проблемите на отдавна съществуващия и успешно заобикалян нормативноустановен ред.
Anyway, while this is all bigger than I’d have liked it to be, if
the upcoming week is quiet and normal, this is the last rc and next
Sunday will see the final release and then we’ll open the merge
window for 6.7. I simply am not aware of any issues that would be
showstoppers.
Editor’s note: This post was originally published in October 2023 and has been updated to reflect Grab’s partnership with the Infocomm Media Development Authority as part of its Privacy Enhancing Technology Sandbox that concluded in March 2024.
Introduction
At Grab, we deal with PetaByte-level data and manage countless data entities ranging from database tables to Kafka message schemas. Understanding the data inside is crucial for us, as it not only streamlines the data access management to safeguard the data of our users, drivers and merchant-partners, but also improves the data discovery process for data analysts and scientists to easily find what they need.
The Caspian team (Data Engineering team) collaborated closely with the Data Governance team on automating governance-related metadata generation. We started with Personal Identifiable Information (PII) detection and built an orchestration service using a third-party classification service. With the advent of the Large Language Model (LLM), new possibilities dawned for metadata generation and sensitive data identification at Grab. This prompted the inception of the project, which aimed to integrate LLM classification into our existing service. In this blog, we share insights into the transformation from what used to be a tedious and painstaking process to a highly efficient system, and how it has empowered the teams across the organisation.
For ease of reference, here’s a list of terms we’ve used and their definitions:
Data Entity: An entity representing a schema that contains rows/streams of data, for example, database tables, stream messages, data lake tables.
Prediction: Refers to the model’s output given a data entity, unverified manually.
Data Classification: The process of classifying a given data entity, which in the context of this blog, involves generating tags that represent sensitive data or Grab-specific types of data.
Metadata Generation: The process of generating the metadata for a given data entity. In this blog, since we limit the metadata to the form of tags, we often use this term and data classification interchangeably.
Sensitivity: Refers to the level of confidentiality of data. High sensitivity means that the data is highly confidential. The lowest level of sensitivity often refers to public-facing or publicly-available data.
Background
When we first approached the data classification problem, we aimed to solve something more specific – Personal Identifiable Information (PII) detection. Initially, to protect sensitive data from accidental leaks or misuse, Grab implemented manual processes and campaigns targeting data producers to tag schemas with sensitivity tiers. These tiers ranged from Tier 1, representing schemas with highly sensitive information, to Tier 4, indicating no sensitive information at all. As a result, half of all schemas were marked as Tier 1, enforcing the strictest access control measures.
The presence of a single Tier 1 table in a schema with hundreds of tables justifies classifying the entire schema as Tier 1. However, since Tier 1 data is rare, this implies that a large volume of non-Tier 1 tables, which ideally should be more accessible, have strict access controls.
Shifting access controls from the schema-level to the table-level could not be done safely due to the lack of table classification in the data lake. We could have conducted more manual classification campaigns for tables, however this was not feasible for two reasons:
The volume, velocity, and variety of data had skyrocketed within the organisation, so it took significantly more time to classify at table level compared to schema level. Hence, a programmatic solution was needed to streamline the classification process, reducing the need for manual effort.
App developers, despite being familiar with the business scope of their data, interpreted internal data classification policies and external data regulations differently, leading to inconsistencies in understanding.
A service called Gemini (named before Google announced the Gemini model!) was built internally to automate the tag generation process using a third party data classification service. Its purpose was to scan the data entities in batches and generate column/field level tags. These tags would then go through a review process by the data producers. The data governance team provided classification rules and used regex classifiers, alongside the third-party tool’s own machine learning classifiers, to discover sensitive information.
After the implementation of the initial version of Gemini, a few challenges remained.
The third-party tool did not allow customisations of its machine learning classifiers, and the regex patterns produced too many false positives during our evaluation.
Building in-house classifiers would require a dedicated data science team to train a customised model. They would need to invest a significant amount of time to understand data governance rules thoroughly and prepare datasets with manually labelled training data.
LLM came up on our radar following its recent “iPhone moment” with ChatGPT’s explosion onto the scene. It is trained using an extremely large corpus of text and contains trillions of parameters. It is capable of conducting natural language understanding tasks, writing code, and even analysing data based on requirements. The LLM naturally solves the mentioned pain points as it provides a natural language interface for data governance personnel. They can express governance requirements through text prompts, and the LLM can be customised effortlessly without code or model training.
Methodology
In this section, we dive into the implementation details of the data classification workflow. Please refer to the diagram below for a high-level overview:
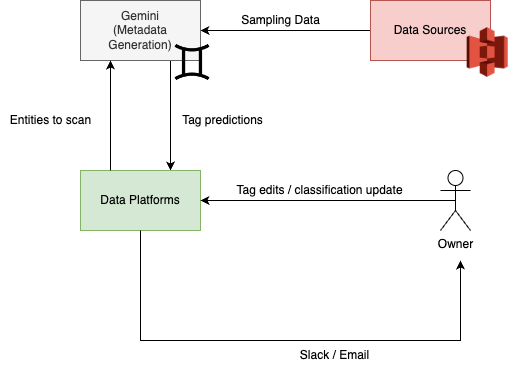
Figure 1 – Overview of data classification workflow
This diagram illustrates how data platforms, the metadata generation service (Gemini), and data owners work together to classify and verify metadata. Data platforms trigger scan requests to the Gemini service to initiate the tag classification process. After the tags are predicted, data platforms consume the predictions, and the data owners are notified to verify these tags.
Orchestration
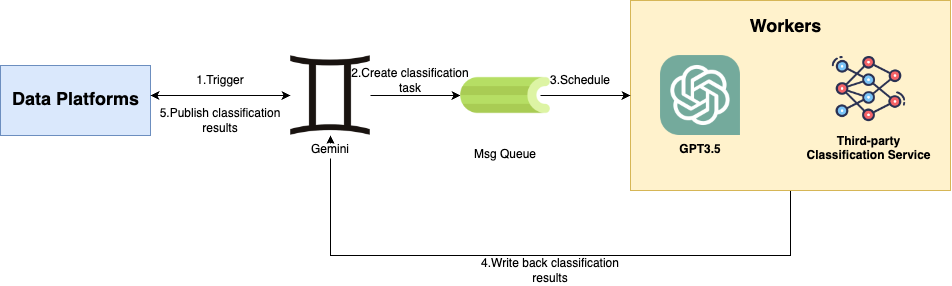
Figure 2 – Architecture diagram of the orchestration service Gemini
Our orchestration service, Gemini, manages the data classification requests from data platforms. From the diagram, the architecture contains the following components:
Data platforms: These platforms are responsible for managing data entities and initiating data classification requests.
Gemini: This orchestration service communicates with data platforms, schedules and groups data classification requests.
Classification engines: There are two available engines (a third-party classification service and GPT3.5) for executing the classification jobs and return results. Since we are still in the process of evaluating two engines, both of the engines are working concurrently.
When the orchestration service receives requests, it helps aggregate the requests into reasonable mini-batches. Aggregation is achievable through the message queue at fixed intervals. In addition, a rate limiter is attached at the workflow level. It allows the service to call the Cloud Provider APIs with respective rates to prevent the potential throttling from the service providers.
Specific to LLM orchestration, there are two limits to be mindful of. The first one is the context length. The input length cannot surpass the context length, which was 4000 tokens for GPT3.5 at the time of development (or around 3000 words). The second one is the overall token limit (since both the input and output share the same token limit for a single request). Currently, all Azure OpenAI model deployments share the same quota under one account, which is set at 240K tokens per minute.
Classification
In this section, we focus on LLM-powered column-level tag classification. The tag classification process is defined as follows:
Given a data entity with a defined schema, we want to tag each field of the schema with metadata classifications that follow an internal classification scheme from the data governance team. For example, the field can be tagged as a <particular kind of business metric> or a <particular type of personally identifiable information (PII). These tags indicate that the field contains a business metric or PII.
We ask the language model to be a column tag generator and to assign the most appropriate tag to each column. Here we showcase an excerpt of the prompt we use:
You are a database column tag classifier, your job is to assign the most appropriate tag based on table name and column name. The database columns are from a company that provides ride-hailing, delivery, and financial services. Assign one tag per column. However not all columns can be tagged and these columns should be assigned <None>. You are precise, careful and do your best to make sure the tag assigned is the most appropriate.
The following is the list of tags to be assigned to a column. For each line, left hand side of the : is the tag and right hand side is the tag definition
…
<Personal.ID> : refers to government-provided identification numbers that can be used to uniquely identify a person and should be assigned to columns containing "NRIC", "Passport", "FIN", "License Plate", "Social Security" or similar. This tag should absolutely not be assigned to columns named "id", "merchant id", "passenger id", “driver id" or similar since these are not government-provided identification numbers. This tag should be very rarely assigned.
<None> : should be used when none of the above can be assigned to a column.
…
Output Format is a valid json string, for example:
[{
"column_name": "",
"assigned_tag": ""
}]
Example question
`These columns belong to the "deliveries" table
1. merchant_id
2. status
3. delivery_time`
Example response
[{
"column_name": "merchant_id",
"assigned_tag": "<Personal.ID>"
},{
"column_name": "status",
"assigned_tag": "<None>"
},{
"column_name": "delivery_time",
"assigned_tag": "<None>"
}]
We also curated a tag library for LLM to classify. Here is an example:
Column-level Tag
Definition
Personal.ID
Refers to external identification numbers that can be used to uniquely identify a person and should be assigned to columns containing “NRIC”, “Passport”, “FIN”, “License Plate”, “Social Security” or similar.
Personal.Name
Refers to the name or username of a person and should be assigned to columns containing “name”, “username” or similar.
Personal.Contact_Info
Refers to the contact information of a person and should be assigned to columns containing “email”, “phone”, “address”, “social media” or similar.
Geo.Geohash
Refers to a geohash and should be assigned to columns containing “geohash” or similar.
None
Should be used when none of the above can be assigned to a column.
The output of the language model is typically in free text format, however, we want the output in a fixed format for downstream processing. Due to this nature, prompt engineering is a crucial component to make sure downstream workflows can process the LLM’s output.
Here are some of the techniques we found useful during our development:
Articulate the requirements: The requirement of the task should be as clear as possible, LLM is only instructed to do what you ask it to do.
Few-shot learning: By showing the example of interaction, models understand how they should respond.
Schema Enforcement: Leveraging its ability of understanding code, we explicitly provide the DTO (Data Transfer Object) schema to the model so that it understands that its output must conform to it.
Allow for confusion: In our prompt we specifically added a default tag – the LLM is instructed to output the default <None> tag when it cannot make a decision or is confused.
Regarding classification accuracy, we found that it is surprisingly accurate with its great semantic understanding. For acknowledged tables, users on average change less than one tag. Also, during an internal survey done among data owners at Grab in September 2023, 80% reported that this new tagging process helped them in tagging their data entities.
Publish and verification
The predictions are published to the Kafka queue to downstream data platforms. The platforms inform respective users weekly to verify the classified tags to improve the model’s correctness and to enable iterative prompt improvement. Meanwhile, we plan to remove the verification mandate for users once the accuracy reaches a certain level.
Figure 3 – Verification message shown in the data platform for user to verify the tags
Impact
Since the new system was rolled out, we have successfully integrated this with Grab’s metadata management platform and production database management platform. Within a month since its rollout, we have scanned more than 20,000 data entities, averaging around 300-400 entities per day.
Using a quick back-of-the-envelope calculation, we can see the significant time savings achieved through automated tagging. Assuming it takes a data owner approximately 2 minutes to classify each entity, we are saving approximately 360 man-days per year for the company. This allows our engineers and analysts to focus more on their core tasks of engineering and analysis rather than spending excessive time on data governance.
The classified tags pave the way for more use cases downstream. These tags, in combination with rules provided by data privacy office in Grab, enable us to determine the sensitivity tier of data entities, which in turn will be leveraged for enforcing the Attribute-based Access Control (ABAC) policies and enforcing Dynamic Data Masking for downstream queries. To learn more about the benefits of ABAC, readers can refer to another engineering blog posted earlier.
Cost wise, for the current load, it is extremely affordable contrary to common intuition. This affordability enables us to scale the solution to cover more data entities in the company.
What’s next?
Prompt improvement
We are currently exploring feeding sample data and user feedback to greatly increase accuracy. Meanwhile, we are experimenting on outputting the confidence level from LLM for its own classification. With confidence level output, we would only trouble users when the LLM is uncertain of its answers. Hopefully this can remove even more manual processes in the current workflow.
Prompt evaluation
To track the performance of the prompt given, we are building analytical pipelines to calculate the metrics of each version of the prompt. This will help the team better quantify the effectiveness of prompts and iterate better and faster.
Scaling out
We are also planning to scale out this solution to more data platforms to streamline governance-related metadata generation to more teams. The development of downstream applications using our metadata is also on the way. These exciting applications are from various domains such as security, data discovery, etc.
Acknowledgements
Grab recently participated in the Singapore government’s regulatory sandbox, where we successfully demonstrated how LLMs can efficiently and effectively perform data classification, allowing Grab to compound the value of its data for innovative use cases while safeguarding sensitive information such as PII.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Фирмата на Валентин Златев “Тера Тур Сервиз” е дала парите за къщата в Барселона където през 2013 г. се настанява манекенката Борислава Йовчева с дъщеря си. Тя е в сърцето…
Електронната рецепта. Както често се случва, когато електронизираме един процес, излизат на повърхността неговите вградени дефицити, които са оставали невидими досега.
Когато лекар предпише антибиотик Аугментин на бяла рецепта, но такъв няма в аптеката, там те питат искаш ли еквивалентен на него (случвало ми се е – в три аптеки го нямаше, върнах се и взех генерик).
Именно тази особеност – че в електронната рецепта има маркер за позволяване или непозволяване на генеричното заместване, което фармацевтите не могат да не изпълнят, е причината за обикалянето на много аптеки и връщанията при лекаря. А С хартиената рецепта това, че някой не следва стриктно чл. 34 на съотверната наредба оставаше под радара.
Има, разбира се и други проблеми. Напр. има(ше) бъгове и „непочистени“ данни за лекарствени кодове. Тъй като цялата система разчита на екосистема от софтуер на частни доставчици (и само напоследък на едно държавно мобилно приложение за случаите, в които лекарят не може да е на компютър), е очаквано в първите дни на всяка промяна да има малки проблеми. Със сигурност можеше да има повече комуникация от институциите към заинтересованите страни – лекари, зъболекари, пациенти, фармацевти.
Има обаче и стандартното отлагане до последния момент, което се случи и с верификационната система преди години. Електронни рецепти има от доста време. Миналата година трябваше да влязат в сила за всички „бели рецепти“. Година по-късно, въвеждането на задължителна електронна бяла рецепта само за два вида лекарства не би трябвало да е изненада за никого.
Според мен, обаче, водещият е проблемът с генеричното заместване, който беше изваден „в прайм тайм“ от електронните рецепти. Моето мнение е, че трябва да има задължително генерично предписване (т.е. дори да се изпише лекарство по търговско наименование, в рецептата да се включват и непатентнотно му наименование), а фармацветът да предложи алтернативи. В същото време трябва чрез системата да се следи дали дадена аптека не фаворизира даден производител (без значение дали на генерично лекарство или не).
Колкото и да отложим влизането в сила на задължителните електронни рецепти, този проблем ще стои. Дори да дадем достъп на лекарите до информация за наличности (което смятам за правилно по принцип), това ще усложни работата им, особено с ситуации на привършващи количества и пак ще има случаи на обикалящи пациенти.
Генерично изписване и заместване има почти навсякъде в Европа и е въпрос на политическо решение. То не е толкова просто, колкото изглежда, но ще трябва да го вземем скоро, защото иначе електронната рецепта ще бъде обвинявана от пациентите в грехове, които не са нейни. А ползите от нея са огромни за здравната система.
Като човек, който съзнателно отсъства от Facebook, но иначе се опитва да следи отблизо температурата на обществената треска, кампанията за местните избори (с много малки изключения) изглежда вяла, посърнала и банална. Не предизвиква нужната гравитация и не увлича хората. Случва се сякаш някак между другото.
Остава едва седмица до края ѝ, а посланията са все така общи и клиширани, повърхностно засягат избрани проблеми, но рядко се чуват смислени решения с обмислени въздействия, които изглеждат като част от подреден, системен подход. А някои от кандидатите на политическите структури (включително от парламентарно представените) са толкова анонимни, че е трудно до невъзможно да се открият дори два абзаца информация що за хора са и с какво са се занимавали досега. Тъжна е тази инерция и подценяване на едни от най-важните избори в държавата.
Затова нека продължа с добра литература вместо с безцветна политика. Ще се възползвам от великолепното припомняне от Стефан Иванов на едно заглавие, което излезе преди около две години на български език – „Идва събота“. Сборникът с разкази е на Лусия Бърлин, чийто талант приживе остава незабелязан, освен за шепа ценители и близки нейни приятели. Стефан сякаш е знаел, че ще започна с критика на безгръбначната кампания и уж е писал за книгата, но всъщност и за контекста у нас:
Просто, колкото и да не е за вярване, все още има и истина, и реалност. И в нея има красота, за която често сме склонни да си затваряме очите. Има и смелост. Тя е нужна във времена на реклама и борба за внимание и харесване в социалните мрежи. Във времена на лесни суперлативи и копнеж по вписване, по приемливост и загладеност без остри ръбове или риск.
И говорейки за риск… през седмицата стана известно, че носител на наградата „Сахаров“ за свобода на мисълта за 2023 г. е иранското протестно движение „Жени, живот, свобода“. А с графит със същия текст от столичния Женски пазар ще ни срещне пък Атанас Шиников. Неговата разходка ще ни върне чак до арабския IХ век в търсене на паралели с провокацията и бунтарството на „графитаджиите“ в историята и културата на Близкия изток – от миналото та до днес.
Настоящият контекст в Близкия изток, уви, не предвещава излишък от оптимизъм за бързо и позитивно развитие. Затова и репортажите на Николета Атанасова от Украйна и разговорите ѝ очи в очи с хората от бойните полета са още по-необходими и важни. Заради болезнената диагноза на последствията от това, което всяка война причинява – освен човешките жертви, и загуба на смисъл, човечност и ценности, около които строим съдбите и общностите си. Разрухата съвсем не е само външна. Не пропускайте новия разказ на Николета от поредицата „Откъси от Украйна: Тогава тихичко се появи страхът…“.
Междувременно разследващият сайт „Белингкат“ и изданието The Insider публикуваха нови подробности и конкретни имена, свързани с експлозиите през 2011 г. в склада за боеприпаси в севлиевското село Ловнидол, с последващите покушения срещу оръжейния търговец Емилиян Гебрев, руския двоен агент Сергей Скрипал и неговата дъщеря, както и с други саботажи в страни от Европа, довели до експулсирането на руски дипломати. Ключовата фигура зад всяка от тези „черни операции“ е ген. Андрей Аверянов, командир на поделение 29155 на ГРУ и наследник на значителна част от империята на бившия командир на „Вагнер“ Евгений Пригожин, чийто частен самолет беше взривен през август т.г., след неуспешния му преврат в Русия. Разследването наистина заслужава внимателен прочит.
Но да се върнем все пак към българския политически живот с помощта на Емилия Милчева, която прицели тазседмичния си анализ в изпирането на имиджа на Бойко Борисов, когото всички дружно бяхме отписали като фактор в бъдещето на родната политика. За жалост, той напоследък не само заглади гребена, но и бодро кукурига предимно по уж партньорите си в т.нар. сглобка. И ако това не е напълно неочаквано, то тишината, която следва след повечето му атаки, е не само необяснима, но и силно притеснителна.
Надежда Цекулова и преди е била автор в „Тоест“ (в съвместната ни рубрика с АЕЖ-България „Хроники на инфодемията“), но сега се завръща с две месечни рубрики – за здравеопазването и за образованието. В първото интервю от поредицата „Разговори за здравеопазването“ тя ни запознава с анестезиоложката д-р Десислава Иванова, за която професионализмът, лекарската етика и чистата съвест са възможни независимо от здравната система.
Време е и за нов текст от друга наша поредица – „От дума на дума“, която с времето се сдоби с верен кръг почитатели, нетърпеливо очакващи всяка нова разходка из историята и развитието на значението на думите. Нашата екскурзоводка Екатерина Петрова този път ни повежда към дебрите на превода и успява да ни преведе далеч, превеждайки и непреводимото. Не вярвате ли? Прочетете „Намерени в превода“.
Светла Енчева ни провокира с текст, чийто смисъл е прикрит в побутването към повече самокритичност по отношение на клишетата, с които боравим при оценките на политически оцветените събития и организации около нас. И обръща внимание върху важността на нюансите в политическия спектър. Вижте повече в статията ѝ „Сляпото петно за фашизма вляво“.
И накрая… нека си спомним за един скъп човек, който ни напусна, докато „Тоест“ беше в принудителна пауза. Малина Петрова, освен всичко, с което ще бъде запомнена, беше и наша голяма приятелка, сред първите ни автори и щедра дарителка. В понеделник ще се навършат 40 дни от смъртта ѝ.
В последните седмици често премислям дали можем изобщо да оценим какво ѝ дължим като българи и като общество. Тя беше крайъгълен камък в раждането, развитието и устоите на българската демокрация. И ще липсва ужасно!
Сбогом, Малина!
… неразбраното, неосъзнатото минало винаги се връща като бумеранг, понякога като карикатура. Защо ли? Защото не сме имали смелост да научим истината за миналото и мястото си в него.
Но как да открием истината в хора на надвикващи се истини? На кого да повярваме? Лъжата е гръмогласна, самонадеяна и безпардонна. Истината говори тихо, изисква се усилие, за да я чуеш, не се натрапва и търпеливо изчаква да я забележите и откриете, сами да стигнете до нея. Тя е като любовта.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.