As the year winds down, Jeffrey Gardner, Detection and Response Practice Advisor and Stephen Davis, Lead D&R Sales Technical Advisor, collected predictions that were made for 2022, and new ones for 2023. Then, they asked their Rapid7 colleagues to decide if the prediction was made by a cybersecurity expert—or if it was scuttlebutt from, say, Reddit. It’s more interesting than a simple true and false game and appropriate in a world where you need to keep your ear to the ground but be wary of what you hear at the same time.
Play along and see if you beat our winner.
The episode ends with a quick game of “Never Have I Ever.” While some revelations are a bit embarrassing, it’s all safe for work and safe for the kiddies. (You won’t believe who got phished.)
The memfd interface is a bit of a strange and Linux-specific beast; it was
initially created to support the secure
passing of data between cooperating processes on a single system. It has
since gained other roles, but it may still come as a surprise to some to
learn that memory regions created for memfds, unlike almost any other data
area, have the execute permission bit set. That can facilitate attacks; this
patch set from Jeff Xu proposes an addition to the memfd API to close
that hole.
When building a Customer Data Platform (CDP), advertising and marketing Independent Software Vendors (ISVs) face a unique set of challenges. The ISV can help organizations with the heavy lifting required to build, secure, and maintain near real-time, high volume CDPs. However, architecting CDPs using traditional on-premises technologies can introduce multiple complexities and can limit deployment options. One strategy that may address these complexities is to use serverless technologies.
Serverless technologies feature automatic scaling, built-in high availability, and a pay-for-use billing model to increase agility, optimize costs, and reduce infrastructure management tasks such as capacity provisioning and patching. Using tools such as CloudFormation, each layer of the serverless CDP can be deployed on-demand in an independent manner to maximize portability and optimize performance.
A Software as a Service (SaaS) CDP usually has significantly more data in a multi-tenant environment than a single instance of a CDP. Clients of a SaaS solution need to continually expand across different channels, and often across many AWS Regions. In some cases, an ISV might have an existing infrastructure that was built before some of these modern capabilities and techniques were mature. Today, an ISV can build or even modernize an existing CDP and gain huge benefits from a serverless implementation.
This blog post explores how to use serverless technologies for the CDP. A modern, serverless CDP architecture can enable the ISV and the client companies to deliver in weeks instead of months, and provide a resilient infrastructure that supports agility and global deployment while maximizing operational efficiency and optimizing cost. This frees up technical resources to focus on differentiated product development instead of managing servers.
Serverless implementation of a CDP on AWS
A serverless architecture uses AWS services that don’t require the configuration of a server to provide an implementation. Serverless technology allows you to focus more time on rapidly building different components of the marketing CDP. The benefits of a CDP include the collection, aggregation, and organization of customer data sources. Implementing the CDP using serverless technology reduces the need to focus on managing infrastructure while reducing time to market, increasing agility, and resulting in cost optimization. Figure 1 is an architecture diagram that describes how various data sources can be prepared for consumption in the component based Customer Data Platform.
Figure 1. Marketing CDP reference on AWS
Source systems of customer data include customer interactions, clickstreams and call center logs.
Data from customer touchpoints is ingested into the marketing customer data platform (CDP) data lake using Amazon Kinesis, Amazon AppFlow, Amazon EKS and an Amazon API Gateway.
Ingested data is sent – in its original, immutable format – to an Amazon Simple Storage Service (Amazon S3) Raw Zone bucket
Raw data is then transformed into efficient data formats – such as Parquet or Avro – and moved to a Clean Zone Amazon S3 bucket.
CDP processing and pipeline orchestration is conducted using purpose-built data processing components and transformation libraries through AWS Step Functions and then Amazon Personalize, AWS Lambda, and AWS Glue.
Data in the Amazon S3 Curated Zone is now ready for post-CDP-processing consumption and is organized by subject areas, segments, and profiles.
The analytics layer uses Amazon Redshift, Amazon QuickSight, Amazon SageMaker and Amazon Athena to natively integrate with the Curated Zone for analytics, dashboards, ad hoc reporting, and ML purposes.
Customer data is then aggregated across platforms and published using customer APIs for consumption using Amazon DynamoDB and an Amazon API Gateway.
Amazon Pinpoint and Amazon Connect are used to activate multiple customer channels such as mobile push, voice, and email for targeted marketing communications.
Using AWS Lake Formation, fine-grained access controls can be enforced on catalog tables, columns, and rows on the data lake.
The resulting catalog in AWS Glue helps you manage both business and technical metadata, with versioning, at scale.
Serverless implementation for ingestion
There are several methods of ingesting customer data, both internal to a customer and from external sources. Serverless options for ingestion could provide benefits to an ISV like cost or agility but it depends upon the use case. Examining serverless options for ingestion should be part of any modernization effort. If the CDP needs to stream data sources and ingest that data in near-real time, the ISV can use Amazon Kinesis. If you want a more traditional extract, transform, and load (ETL) tool, AWS Glue offers a serverless option to generate code that can be customized. AWS Glue DataBrew offers a visual data preparation tool. For more advanced governance and control, you can use AWS Lake Formation. To ingest sources using an API, the Amazon API Gateway provides a serverless approach. If you need more control over the ingestion, the use of customized scripts in Amazon AppFlow or Amazon Managed Streaming for Apache Kafka (Amazon MSK) can provide a solution.
Serverless storage implementation
Amazon Simple Storage Service (Amazon S3) provides a serverless, cost-effective solution for virtually unbounded amounts of storage and read-write bandwidth. As per the reference architecture, there are three purpose-specific zones:
A raw zone containing the original, immutable version of data
A trusted zone which can be used as a working area to combine, enhance and clean the data
A refined zone containing data ready for consumption by users and applications
This structure allows the improvement of customer data and profiles, and provides the ability to integrate various data sources and a structure that allows customer data to be recreated in a manner consistent with changing business rules.
Serverless cataloging implementation
The cataloging services provide a grouping of the elements contained in structured and unstructured data sources that is intuitive and easy to understand, similar to a single relational database. AWS Glue Data Catalog gives logical structure to the data lake by allowing users to define tables and columns on top of Amazon S3 data sets. This serverless solution integrates with other analytics tools to enable data discovery and consistent usage. Fine-grained governance and access can also be enforced by AWS Lake Formation.
Serverless processing
There are great choices for implementing processing, using serverless technologies. A CDP platform can package code and run on demand without servers using AWS Lambda or AWS Step Functions depending up the complexity of the processing pipeline. These services can enable complex processing on customer data and profiles. Amazon SageMaker is a great serverless choice for incorporating artificial Intelligence / machine learning into your processing stream. For processing using big data techniques Amazon EMR Serverless is a good serverless option.
Serverless implementation for consumption
Analytics for the CDP provides several serverless technologies that enable different types of insights. For interactive SQL queries that integrate with our serverless AWS Glue Catalog, there is Amazon Athena. Athena provides SQL access to various data source, and can also use federated query functionality to connect to third-party sources, even if that data is sitting on another cloud or in a vendor’s environment. Athena can also work as an interface (middleware) to other reporting solutions.
If performance is a concern, Amazon Redshift is fast, petabyte-scale data warehouse solution that has a serverless option and fully integrates with these solutions. For a data visualization tool that can be embedded in your application or work as a standalone portal, examine Amazon QuickSight.
To enable collaboration, many use cases can use Amazon API Gateway to securely publish and expose API endpoints for consuming applications. This allows data to be shared from a single source of truth to consumers that use customer data for their processes. Most customers want to activate their customer data through marketing or advertising campaigns. To activate marketing communication over voice, email, text, or in-app messaging, you can use a serverless service called Amazon Pinpoint. For an omnichannel contact center support, we recommend Amazon Connect, which uses AI/ML and the CDP data to analyze customer sentiment, implement chatbots, and authenticate voice callers.
Serverless implementation for governance
AWS Lake Formation simplifies the process of configuring and securing access to the CDP. It can help orchestrate processing and ingestion, as well as enforcing fine-grained access controls on data catalogs. Other services such as AWS Glue DataBrew or Amazon Macie can identify and help mitigate exposure of Personally identifiable information (PII). AWS Config enables you to assess, audit, and evaluate the configurations of your AWS resources to automate the evaluation of recorded configurations against desired configurations.
Conclusion
This post described just some of the serverless solutions that are managed by AWS that allow you to build a modern, low-cost, data lake-centric CDP architecture in an accelerated manner. A decoupled, component-driven architecture lets you start small and quickly add new services to each independent component of the CDP. Use the Data Analytics Lens for guidance on designing, deploying, and architecting your analytics solution workloads in the AWS Cloud. Using this framework, you will learn the architectural best practices for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. Follow the links in this article to learn more about the services available in AWS that can help you build a serverless CDP.
Greg Kroah-Hartman has announced the release of the 6.0.14, 5.15.84, 5.10.160, and 5.4.228 stable kernels. They contain a
relatively small number of important fixes throughout the tree.
Since the 1990s, the web has been a publishing place for human-readable documents.
Documents published on the web are in HTML. HTML has a little bit of structure, for example, “here is a paragraph” or “emphasize this word.”
Then you stir in some CSS, which adds some pretty decorations to the structure, saying things like: make those paragraphs have tiny gray sans-serif text! And then people think you are hip. Unless they are older, and they can’t read your tiny gray words, so they give up on you.
That’s “structure,” as far as it goes, on the web.
Imagine, for example, that you mention a book on the web.
Goodnight Moon by Margaret Wise Brown Illustrated by Clement Hurd Harper & Brothers, 1947 ISBN 0-06-443017-0
There’s not much structure there. A naive computer program reading this web page might not realize I was even mentioning a book. All I did was make the title bold.
So, also since the 1990s, people have realized that we can make the web a much more useful place to publish information if we applied a bit more structure. As early as 1999, Tim Berners-Lee was writing about the Semantic Web:
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.”
Tim Berners-Lee, Weaving The Web, 1999 HarperSanFrancisco (Chapter 12)
Using the Semantic Web you might publish a book title with a lot more detail that makes it computer-readable. To do this, you would probably start by going to schema.org and looking up their idea of a book. Then you could use one of a number of formats, like RDF or JSON-LD, to add additional markup to your HTML saying “hey! here’s a book!”
Ok, well, doing that is kinda hard to figure out, and, to be honest, it’s homework. Once your beautiful blog post is published and human-readable, it’s hard to gather the mental energy to figure out how to add the additional fancy markups that will make your web page computer-readable, and, unless there is already a computer reading your web pages, at this point, you usually give up. So, yeah. That was 1999, and not much progress has been made and there is very little of this semantic markup in the wild.
Well.
We would like to fix this, because human progress depends on getting more and more information in formats that are readily accessible, both by regular humans, their dumb A.I. li’l sibs, and your more traditional computer programs.
Here is something I believe: people will only add semantic markup to their web pages if doing so is easier than not.
In other words, the cost of adding semantic markup has to be zero or negative, or this whole project is not going anywhere.
Now imagine this world for a second:
I want to insert a book into my blog post
I type /book
A search box appears where I start typing in the title of my book and choose from an autocomplete list.
Once I find the book, a block gets inserted in my blog post showing details of the book in a format I like, with nice semantic markup behind the scenes.
In this world I did less work to insert a book (because I was assisted by a UI that looked up the details for me).
You can imagine the same scenario applying to literally any other kind of structured data.
I want to insert an address into my blog post
I type /address
A search box appears where I start to type a location, which autocompletes in the way you have seen Instagram and Google Maps and a million other apps do it
Once I choose the address, a block gets inserted showing the details of the address complete with semantic markup behind the scenes.
My “address block” might have any visual appearance. Visitors to my web page might see the address, or a little map, or a little map in Japanese, etc. etc. The semantic content is there behind the scenes. So, for example, my web browser might know “gosh this is an address! Maybe you want to do address-y things with it, like go there,” and then my browser might offer me options to summon a self-driving car and even call an ambulance when the self-driving car self-drives into a snowbank.
My two simplistic examples of “book” and “address” are interesting right now because (a) you can probably think of 1,000,000 more data types like this, and (b) none of these things work right now, because even though almost every web editing environment has a concept of “blocks,” none of them are extensible. WordPress has (oh gosh) hundreds of block types, but they don’t have thousands or millions, they don’t have “book” or “address” or “Burning Man Theme Camp” yet, and there’s no ecosystem by which developers and users can contribute new block types.
So I guess I gotta wait around for someone at WordPress to develop all the blocks I want to use. And then someone at Notion, and then someone at Trello, and then someone at Mailchimp, and someone at every other vendor that provides a text editor.
I have a better plan.
The web was built with open protocols. Suppose we all agree on a protocol for blocks.
Any developer that wants to create a new block can conform to this protocol.
Any kind of web-text-editing application can also conform to this protocol.
Then if anyone goes to the trouble of creating a cool “book” or “address” block, we’ll all be able to use it, anywhere.
And it should be, I think, 100% free, open, and public, so that there is no impediment to anyone on earth using it. And in fact if you want to make blocks that are open source or public, good for you, but if for some reason you would like to make private or commercial blocks, that’s fine too.
Where we’re up to
It’s been about a year since we started talking about the Block Protocol, and we’ve made a lot of progress figuring out how it has to work to do all the things it will need to do, in a clean and straightforward way.
But this is all going nowhere if it requires 93,000,000 humans to cooperate with my crazy scheme just to get it off the ground.
So what we did is build a WordPress Plugin that allows you to embed Block Protocol blocks into posts on your WordPress sites just as easily as you insert any other block.
Since WordPress powers 43% of the web, that means if you build a block for the Block Protocol, it’ll be widely usable right away.
Here’s a video demo:
The WordPress Plugin will be free, and it will be widely available in February, when we’ll also publish version 0.3 of the Block Protocol specification. You can get early access now.
In fact, if you were thinking of writing a plugin for WordPress for your own kind of custom block, you’ll find that using our plugin as your starting point is a lot easier, because you don’t have to know anything about WordPress Plugins or write any PHP code. So even if you don’t care for any of my crazy theories and just want to add a block to WordPress, this is the way to go.
Ultimately, though, we just want to make it easier to add useful semantic, structured information to the web, and this is the first step.
PPS You can follow me on Mastodon, where I am @[email protected]. I don’t post that much, but I’m enjoying hanging out there in a human-to-human environment where there isn’t an algorithm stirring up righteous indignation about the latest fake-outrage of the day.
The Ukrainian army has released an instructional video explaining how Russian soldiers should surrender to a drone:
“Seeing the drone in the field of view, make eye contact with it,” the video instructs. Soldiers should then raise their arms and signal they’re ready to follow.
After that the drone will move up and down a few meters, before heading off at walking pace in the direction of the nearest representatives of Ukraine’s army, it says.
The video also warns that the drone’s battery may run low, in which case it will head back to base and the soldiers should stay put and await a fresh one.
That one, too, should be met with eye contact and arms raised, it says.
Version 4.0.0 of the Apache SpamAssassin spam filter has been released.
Apache SpamAssassin 4.0.0 contains numerous tweaks and bug fixes over
the past releases. In particular, it includes major changes that
significantly improve the handling of text in international language.
As with any major release, there are countless functional patches and
improvements to upgrade to 4.0.0. Apache SpamAssassin 4.0.0 includes
several years of fixes that significantly improve classification and
performance. It has been thoroughly tested in production systems. We
strongly recommend upgrading as soon as possible.
Turns out that linking to several days old public data in order to demonstrate that Elon’s jet was broadcasting its tail number in the clear is apparently “posting private information” so for anyone looking for me there I’m actually here
Version
5.0.0 of the OCaml programming language is out.
The highlight of this new major version of OCaml is the
long-awaited runtime support for shared memory parallelism and
effect handlers. This multicore support is the culmination of more
than 8 years of effort, and required a full rewrite of the OCaml
runtime environment. Consequently, OCaml 5.0.0 is expected to be a
more experimental version of OCaml than the usual OCaml releases.
A sack full of cheer from the Hacking Elves of Metasploit
It is clear that the Metasploit elves have been busy this season: Five new modules, six new enhancements, nine new bug fixes, and a partridge in a pear tree are headed out this week! (Partridge nor pear tree included.) In this sack of goodies, we have a gift that keeps on giving: Shelby’sAcronis TrueImage Privilege Escalation works wonderfully, even after the software is uninstalled.
If you prefer elf files to holiday elves, we’ve still got you covered
Jan Rude submitted two modules targeting Syncovery for Linux. One takes advantage of an insecure session token generator and allows for the brute-force creation of a token that matches that of a logged-in user, and the other allows an authenticated user to create a job that will run when a user’s profile is run.
New module content (5)
Syncovery For Linux Web-GUI Session Token Brute-Forcer by Jan Rude, which exploits CVE-2022-36536 – A new login scanner module that brute-forces a valid session token for the Syncovery File Sync & Backup Software Web-GUI. This will work if the default user is already logged in the application. If they do not logout, the token stays valid until the next reboot.
Acronis TrueImage XPC Privilege Escalation by Csaba Fitzl and Shelby Pace, which exploits CVE-2020-25736 – This module exploits a local privilege escalation vulnerability in Acronis TrueImage versions 2019 update 1 through 2021 update 1 on macOS. This vulnerability is identified as CVE-2020-25736. By abusing a local helper executable, it is possible to execute arbitrary commands as the root user.
Syncovery For Linux Web-GUI Authenticated Remote Command Execution by Jan Rude, which exploits CVE-2022-36534 – This adds a module that exploits an authenticated remote code execution vulnerability identified as CVE-2022-36534 in the Web GUI of Syncovery File Sync & Backup Software for Linux. The module leverages a flaw in the application that allows the creation of jobs that will be executed when a profile is run. This allows the execution of arbitrary commands as the root user.
#17191 from liangjs – This PR fixes a bug where the Windows Subsystem for Linux crashes when using a reverse_tcp x64 stager because of data in the upper bits of the RDI register when the syscall occurs.
#17255 from JustAnda7 – The command payloads have been updated to allow specifying the file system path for several of their commands within datastore options. This should allow users to specify these commands locations should they not be contained within the searchable PATH.
#17346 from adfoster-r7 – The logic for counting threads within lib/metasploit/framework/spec/threads/suite.rb has been updated to appropriately count and document the known threads that can be left behind when running the rspec test suite. This fixes an intermittent rspec crash.
#17355 from adfoster-r7 – The creds command has been updated to show the full SSH key contents when running the creds -v command or when exporting to a file with creds -o output.txt. Previously only a shortened fingerprint string would be shown to the user.
#17357 from adfoster-r7 – The docs site has been updated to support mermaid graphs for rendering diagrams to assist with explanations.
#17387 from smashery – The hosts, services, vulns and notes command have been updated to support tab expansion in paths using the ~ character when using the -o option to specify the path to the file to write the output to.
Bugs fixed (9)
#17345 from adfoster-r7 – A crash has been fixed when using the report API with verbose mode enabled and no active DB.
#17350 from smashery – This updates three UAC bypass modules to remove a hard coded delay in favor of using the module’s builtin cleanup method. This results in the user having access to the interactive session without needing to wait.
#17351 from smashery – This fixes an issue in the exploit/windows/local/s4u_persistence module where the default value for FREQUENCY would cause an error.
#17352 from smashery – A bug has been fixed in the file_version method for Windows Meterpreter, which would cause the session to crash if it was run on a file that did not exist on the target system.
#17361 from jmartin-r7 – A bug has been fixed that would cause a crash when running the exit command from within msfconsole when running msfconsole with a 3.1.x release of Ruby.
#17366 from zeroSteiner – The upload and download commands used by shell sessions have been updated to handle directory destinations in the same way as the Meterpreter equivalents do, and to fix some bugs when uploading and downloading files that would prevent errors from being displayed and might cause session crashes.
#17368 from adfoster-r7 – Fixes a regression issue with msfvenom payload generation for large payloads taking more than 5 minutes to generate when outputting as hex format. Now it takes a few seconds as normal.
#17370 from jmartin-r7 – A bug has been fixed in the smb_enumshares.rb whereby if a SMBv1 connection is used a call was made to the net_share_enum_all function on the wrong object. This has since been updated to address this error.
#17378 from gwillcox-r7 – A bug has been fixed in the Meterpreter payloads that was preventing Python Meterpreter from being able to utilize its EventLog API properly. Additionally a bug has been fixed in the COFFLoader that prevented BOFLoader from working with some COFF files.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
Application migrations, especially from legacy/mainframe to the cloud, are done in phases that sometimes span multiple years. Each phase migrates a set of applications, data, and other resources to the cloud. During the transition phases, applications might require access to both on-premises and cloud-based resources to perform their function. While working with our customers, we observed that the most common resources that applications require access to are databases, file storage, and shared services.
This blog post includes architecture guidelines for setting up access to commonly used resources by building a security model in Amazon Web Services (AWS). As you move your legacy applications to the cloud, you can apply Zero Trust concepts and security best practices according to your security needs. With AWS, you can build strong identity and access management with centralized control and set up and manage guardrails and fine-grained access controls for your workforce and applications.
In large organizations, on-premises applications rely on mainframe-based security services, an Identity Provider (IdP) platform, or a combination of both.
A mainframe-based control facility enables on-premises applications to:
Identify and verify users.
Establish an authority (authorize users and backend programs to access protected resources) through privileges defined in the control facility.
The backend programs use a unique identifier (or surrogate key) and run under the authority defined by the privileges assigned to the unique identifier.This security mechanism needs to be transformed into a role-based security model in AWS as applications are moved to the cloud. You assign permissions to a role, which is assumed by an application to get access to resources in AWS, similar to an authority defined in the legacy environment.
An IdP platform (such as Octa or Ping Identify) provides capabilities such as centralized access management and identity federation using SAML 2.0 or OpenID Connect (OIDC), that builds a system of trust between on-premises IdP and AWS. Once the federation is set up, on-premises applications can access AWS resources using AWS Identity and Access Management (IAM) roles, as explained in the next section.
Setting up a scalable security model in AWS
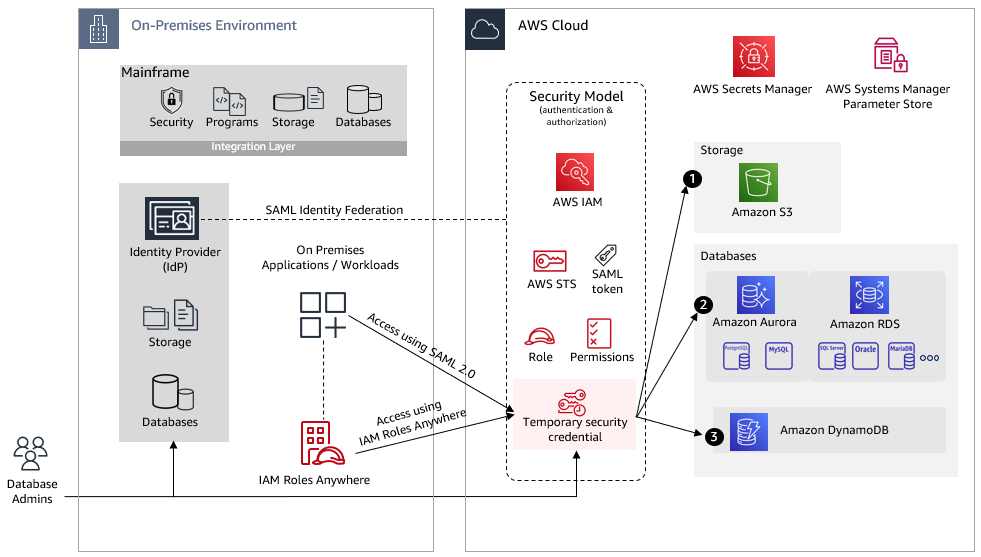
Figure 1 shows an on-premises environment where enterprise identity management is integrated with the mainframe and provides authentication and authorization to applications running off the mainframe. Generally, mainframe-based security controls (users, resources, and profiles) are replicated to the enterprise identity platform and are kept in sync through a change data capture process.
Figure 1. Access to AWS resources from on-premises
To enable your on-premises applications to access AWS resources, the applications need valid AWS credentials for making AWS API requests. Avoid using long-term access keys (such as those associated with IAM users) because they remain valid until you remove them. The following two methods can be used to assume an IAM role and get temporary security credentials to gain access to the AWS resources:
SAML based Identity federation – AWS supports identity federation with SAML. It allows federated access to users and applications in your organization by assuming an IAM role created for SAML federation to get temporary credentials. This method is helpful:
If your application uses a service account to manage AWS resource access, regardless of who is logged in.
IAM Roles Anywhere – Your on-premises applications will exchange X.509 certificates so that they can assume a role and get temporary credentials. This method is helpful if your application needs access to an AWS resource based on a service account.
In both of these cases, authenticated requests assume an IAM role, get temporary security credentials, and perform certain actions using AWS command line interface (CLI) and AWS SDKs. The IAM role has attached permissions for AWS resources such as Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, and Amazon Relational Database Service (Amazon RDS).
The temporary credentials expire when the session expires. By default, the session duration is one hour; you can request longer duration and session refresh.
To understand better, let’s consider the use case in Figure 2, where on-premises applications need access to AWS resources.
Figure 2. Access to resources that are created or already migrated to AWS from on-premises
Applications can get temporary security credentials through SAML or IAM Roles Anywhere as explained earlier. The next sections explain setting up access to the resources in Figure 2 using temporary credentials.
1. Amazon S3
On-premises applications can access Amazon S3 using the REST API or the AWS SDK to perform certain actions (such as GetObjects or ListObjects):
You can also simplify by creating Amazon S3 access points for your application to perform object-level operations in your S3 bucket. Each access point has distinct permissions and network controls that S3 applies for any request made through it.
2. Amazon RDS and Amazon Aurora
AWS Secrets Manager helps you store credentials for Amazon RDS and Amazon Aurora. You can also set up automatic rotation of your database secrets to meet your security and compliance needs. Applications can retrieve secrets using AWS SDKs and AWS CLI.
Additional configuration values can be stored in AWS Systems Manager Parameter Store, which provides secure, hierarchical storage for configuration data management such as passwords, database strings and license codes as parameter values rather than hard coding them in the code.
To access Amazon RDS and Amazon Aurora:
You can launch Amazon RDS DB instances into a virtual private cloud (VPC). A client application can access DB instance through the internet or through the private network only using an established connection from on-premises to the AWS environment.
On-premises applications can connect to a relational database using a database driver such as Java Database Connectivity (JDBC). The application can retrieve database connection details (such as database URL, port, or credentials) from AWS Secrets Manager and AWS Systems Manager Parameter Store through API calls and can use them for the database connection.
Database admins can access AWS Management Console through an assumed role and can have access to database credentials from AWS Secrets Manager in order to connect directly with the database. For certain administration tasks (such as cluster setup, backup, recovery, maintenance, and management), they will need access to the Amazon RDS management console.
Amazon RDS also provides IAM database authentication option for MariaDB, MySQL, and PostgreSQL. You can authenticate without a password when you connect to a DB instance. Instead, you use an authentication token. For more information, go to IAM database authentication.
This blog helps you architect an application security model in AWS to provide on-premises access to commonly used resources in AWS.
You can apply security best practices and Zero Trust concepts as you move your legacy applications to the cloud. With AWS, you can build identity and access management with centralized and fine-grained access controls for your workforce and applications.
To conclude Impact Week, which has been filled with announcements about new initiatives and features that we are thrilled about, today we are publishing our 2022 Impact Report.
In short, the Impact Report is an annual summary highlighting how we are helping build a better Internet and the progress we are making on our environmental, social, and governance priorities. It is where we showcase successes from Cloudflare Impact programs, celebrate awards and recognitions, and explain our approach to fundamental values like transparency and privacy.
We believe that a better Internet is principled, for everyone, and sustainable; these are the three themes around which we constructed the report. The Impact Report also serves as our repository for disclosures consistent with our commitments for the Global Reporting Initiative (GRI), Sustainability Accounting Standards Board (SASB), and UN Global Compact (UNGC).
Explore how we are expanding the value and scope of our Cloudflare Impact programs
Review our latest diversity statistics — and our newest employee resource group
Understand how we are supporting humanitarian and human rights causes
Read quick summaries of Impact Week announcements
Examine how we calculate and validate emissions data
As fantastic as 2022 has been for scaling up Cloudflare Impact and making strides toward a better Internet, we are aiming even higher in 2023. To keep up with developments throughout the year, follow us on Twitter and LinkedIn, and keep an eye out for updates on our Cloudflare Impact page.
And that’s a wrap! Impact Week 2022 has come to a close. Over the last week, Cloudflare announced new commitments in our mission to help build a better Internet, including delivering Zero Trust services for the most vulnerable voices and for critical infrastructure providers. We also announced new products and services, and shared technical deep dives.
Were you able to keep up with everything that was announced? Watch the Impact Week 2022 wrap-up video on Cloudflare TV, or read our recap below for anything you may have missed.
We are making the Cloudflare One Zero Trust suite available to teams that qualify for Project Galileo or Athenian at no cost. Cloudflare One includes the same Zero Trust security and connectivity solutions used by over 10,000 customers today to connect their users and safeguard their data.
Under-resourced organizations that are vital to the basic functioning of our global communities (such as community hospitals, water treatment facilities, and local energy providers) face relentless cyber attacks, threatening basic needs for health, safety and security. Cloudflare’s mission is to help make a better Internet. We will help support these vulnerable infrastructure by providing our enterprise-level Zero Trust cybersecurity solution to them at no cost, with no time limit.
We are excited to announce our public sector suite of services, Cloudflare for Government, has achieved FedRAMP Moderate Authorization. The Federal Risk and Authorization Management Program (“FedRAMP”) is a US-government-wide program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services.
At Cloudflare, we want to give our customers tools that allow them to maintain compliance in this ever-changing environment. That’s why we’re excited to announce a new version of Geo Key Manager — one that allows customers to define boundaries by country, by region, or by standard.
Cloudflare is participating in the AS112 project, becoming an operator of the loosely coordinated, distributed sink of the reverse lookup (PTR) queries for RFC 1918 addresses, dynamic DNS updates and other ambiguous addresses.
The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
We are excited to share that we have grown our offering under the Athenian Project to include Cloudflare’s Area 1 email security suite to help state and local governments protect against a broad spectrum of phishing attacks to keep voter data safe and secure.
Large-scale cyber attacks on enterprises and governments make the headlines, but the impacts of cyber conflicts can be felt more profoundly and acutely by small businesses that struggle to keep the lights on during normal times. In this blog, we’ll share new research on how small businesses, including those using our free services, have leveraged Cloudflare services to make their businesses more secure and resistant to disruption.
A year and a half ago, Cloudflare launched Project Pangea to help provide Internet services to underserved communities. Today, we’re sharing what we’ve learned by partnering with community networks, and announcing an expansion of the project.
We want to tell you more about how we work with civil society organizations to provide tools to track and document the scope of these disruptions. We want to support their critical work and provide the tools they need so they can demand accountability and condemn the use of shutdowns to silence dissent.
At Cloudflare, part of our role is to make sure every person on the planet with an Internet connection has a good experience, whether they’re in a next-generation market or a current-gen market. In this blog we talk about how we define next-generation markets, how we help people in these markets get faster access to the websites and applications they use on a daily basis, and how we make it easy for developers to deploy services geographically close to users in next-generation markets.
We didn’t start out with the goal to reduce the Internet’s environmental impact. But as the Internet has become an ever larger part of our lives, that has changed. Our mission is to help build a better Internet — and a better Internet needs to be a sustainable one.
We’re excited to announce an opportunity for Cloudflare customers to make it easier to decommission and dispose of their used hardware appliances in a sustainable way. We’re partnering with Iron Mountain to offer preferred pricing and value-back for Cloudflare customers that recycle or remarket legacy hardware through their service.
With the incredible growth of the Internet, and the increased usage of Cloudflare’s network, even linear improvements to sustainability in our hardware today will result in exponential gains in the future. We want to use this post to outline how we think about the sustainability impact of the hardware in our network, and what we’re doing to continually mitigate that impact.
Last year, Cloudflare committed to removing or offsetting the historical emissions associated with powering our network by 2025. We are excited to announce our first step toward offsetting our historical emissions by investing in 6,060 MTs’ worth of reforestation carbon offsets as part of the Pacajai Reduction of Emissions from Deforestation and forest Degradation (REDD+) Project in the State of Para, Brazil.
Cloudflare is working hard to ensure that we’re making a positive impact on the environment around us, with the goal of building the most sustainable network. At the same time, we want to make sure that the positive changes that we are making are also something that our local Cloudflare team members can touch and feel, and know that in each of our actions we are having a positive impact on the environment around us. This is why we make sustainability one of the underlying goals of the design, construction, and operations of our global office spaces.
Once a year, we pull data from our Bot Fight Mode to determine the number of trees we can donate to our partners at One Tree Planted. It’s part of the commitment we made in 2019 to deter malicious bots online by redirecting them to a challenge page that requires them to perform computationally intensive, but meaningless tasks. While we use these tasks to drive up the bill for bot operators, we account for the carbon cost by planting trees.
As governments continue to use sanctions as a foreign policy tool, we think it’s important that policymakers continue to hear from Internet infrastructure companies about how the legal framework is impacting their ability to support a global Internet. Here are some of the key issues we’ve identified and ways that regulators can help balance the policy goals of sanctions with the need to support the free flow of communications for ordinary citizens around the world.
On February 24, 2022, when Russia invaded Ukraine, Cloudflare jumped into action to provide services that could help prevent potentially destructive cyber attacks and keep the global Internet flowing. During Impact Week, we want to provide an update on where things currently stand, the role of security companies like Cloudflare, and some of our takeaways from the conflict so far.
A series of protests began in Iran on September 16, following the death in custody of Mahsa Amini — a 22 year old who had been arrested for violating Iran’s mandatory hijab law. The protests and civil unrest have continued to this day. But the impact hasn’t just been on the ground in Iran — the impact of the civil unrest can be seen in Internet usage inside the country, as well.
We thought this week would be a great opportunity to share Cloudflare’s principles and our theories behind policy engagement. Because at its core, a public policy approach needs to reflect who the company is through their actions and rhetoric. And as a company, we believe there is real value in helping governments understand how companies work, and helping our employees understand how governments and law-makers work.
What does it mean to apply human rights frameworks to our response to abuse? As we’ll talk about in more detail, we use human rights concepts like access to fair process, proportionality (the idea that actions should be carefully calibrated to minimize any effect on rights), and transparency.
This blog dives into a discussion of IP blocking: why we see it, what it is, what it does, who it affects, and why it’s such a problematic way to address content online.
Our Impact Report is an annual summary highlighting how we are trying to build a better Internet and the progress we are making on our environmental, social, and governance priorities.
Cloudflare is on a mission to help build a better Internet, and we are committed to doing this with ethics and integrity in everything that we do. This commitment extends beyond our own actions, to third parties acting on our behalf. We are excited to share our Third Party Code of Conduct, specifically formulated with our suppliers, resellers and other partners in mind.
Or if you’d like to rewatch any Cloudflare TV segments associated with the above stories, visit the Impact Week hub on our website.
Watch on Cloudflare TV
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.