Post Syndicated from Michael Pelts original https://aws.amazon.com/blogs/big-data/how-appsflyer-modernized-their-interactive-workload-by-moving-to-amazon-athena-and-saved-80-of-costs/
This post is co-written with Nofar Diamant and Matan Safri from AppsFlyer.
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics.
Part of AppsFlyer’s offering is the Audiences Segmentation product, which allows app owners to precisely target and reengage users based on their behavior and demographics. This includes a feature that provides real-time estimation of audience sizes within specific user segments, referred to as the Estimation feature.
To provide users with real-time estimation of audience size, the AppsFlyer team originally used Apache HBase, an open-source distributed database. However, as the workload grew to 23 TB, the HBase architecture needed to be revisited to meet service level agreements (SLAs) for response time and reliability.
This post explores how AppsFlyer modernized their Audiences Segmentation product by using Amazon Athena. Athena is a powerful and versatile serverless query service provided by AWS. It’s designed to make it straightforward for users to analyze data stored in Amazon Simple Storage Service (Amazon S3) using standard SQL queries.
We dive into the various optimization techniques AppsFlyer employed, such as partition projection, sorting, parallel query runs, and the use of query result reuse. We share the challenges the team faced and the strategies they adopted to unlock the true potential of Athena in a use case with low-latency requirements. Additionally, we discuss the thorough testing, monitoring, and rollout process that resulted in a successful transition to the new Athena architecture.
Audiences Segmentation legacy architecture and modernization drivers
Audience segmentation involves defining targeted audiences in AppsFlyer’s UI, represented by a directed tree structure with set operations and atomic criteria as nodes and leaves, respectively.
The following diagram shows an example of audience segmentation on the AppsFlyer Audiences management console and its translation to the tree structure described, with the two atomic criteria as the leaves and the set operation between them as the node.

To provide users with real-time estimation of audience size, the AppsFlyer team used a framework called Theta Sketches, which is an efficient data structure for counting distinct elements. These sketches enhance scalability and analytical capabilities. These sketches were originally stored in the HBase database.
HBase is an open source, distributed, columnar database, designed to handle large volumes of data across commodity hardware with horizontal scalability.
Original data structure
In this post, we focus on the events table, the largest table initially stored in HBase. The table had the schema date | app-id | event-name | event-value | sketch and was partitioned by date and app-id.
The following diagram showcases the high-level original architecture of the AppsFlyer Estimations system.

The architecture featured an Airflow ETL process that initiates jobs to create sketch files from the source dataset, followed by the importation of these files into HBase. Users could then use an API service to query HBase and retrieve estimations of user counts according to the audience segment criteria set up in the UI.
To learn more about the previous HBase architecture, see Applied Probability – Counting Large Set of Unstructured Events with Theta Sketches.
Over time, the workload exceeded the size for which HBase implementation was originally designed, reaching a storage size of 23 TB. It became apparent that in order to meet AppsFlyer’s SLA for response time and reliability, the HBase architecture needed to be revisited.
As previously mentioned, the focus of the use case entailed daily interactions by customers with the UI, necessitating adherence to a UI standard SLA that provides quick response times and the capability to handle a substantial number of daily requests, while accommodating the current data volume and potential future expansion.
Furthermore, due to the high cost associated with operating and maintaining HBase, the aim was to find an alternative that is managed, straightforward, and cost-effective, that wouldn’t significantly complicate the existing system architecture.
Following thorough team discussions and consultations with the AWS experts, the team concluded that a solution using Amazon S3 and Athena stood out as the most cost-effective and straightforward choice. The primary concern was related to query latency, and the team was particularly cautious to avoid any adverse effects on the overall customer experience.
The following diagram illustrates the new architecture using Athena. Notice that import-..-sketches-to-hbase and HBase were omitted, and Athena was added to query data in Amazon S3.

Schema design and partition projection for performance enhancement
In this section, we discuss the process of schema design in the new architecture and different performance optimization methods that the team used including partition projection.
Merging data for partition reduction
In order to evaluate if Athena can be used to support Audiences Segmentation, an initial proof of concept was conducted. The scope was limited to events arriving from three app-ids (approximated 3 GB of data) partitioned by app-id and by date, using the same partitioning schema that was used in the HBase implementation. As the team scaled up to include the entire dataset with 10,000 app-ids for a 1-month time range (reaching an approximated 150 GB of data), the team started to see more slow queries, especially for queries that spanned over significant time ranges. The team dived deep and discovered that Athena spent significant time at the query planning stage due to a large number of partitions (7.3 million) that it loaded from the AWS Glue Data Catalog (for more information about using Athena with AWS Glue, see Integration with AWS Glue).
This led the team to examine partition indexing. Athena partition indexes provide a way to create metadata indexes on partition columns, allowing Athena to prune the data scan at the partition level, which can reduce the amount of data that needs to be read from Amazon S3. Partition indexing shortened the time of partition discovery in the query planning stage, but the improvement wasn’t substantial enough to meet the required query latency SLA.
As an alternative to partition indexing, the team evaluated a strategy to reduce partition number by reducing data granularity from daily to monthly. This method consolidated daily data into monthly aggregates by merging day-level sketches into monthly composite sketches using the Theta Sketches union capability. For example, taking a data of a month range, instead of having 30 rows of data per month, the team united those rows into a single row, effectively slashing the row count by 97%.
This method greatly decreased the time needed for the partition discovery phase by 30%, which initially required approximately 10–15 seconds, and it also reduced the amount of data that had to be scanned. However, the expected latency goals based on the UI’s responsiveness standards were still not ideal.
Furthermore, the merging process inadvertently compromised the precision of the data, leading to the exploration of other solutions.
Partition projection as an enhancement multiplier
At this point, the team decided to explore partition projection in Athena.
Partition projection in Athena allows you to improve query efficiency by projecting the metadata of your partitions. It virtually generates and discovers partitions as needed without the need for the partitions to be explicitly defined in the database catalog beforehand.
This feature is particularly useful when dealing with large numbers of partitions, or when partitions are created rapidly, as in the case of streaming data.
As we explained earlier, in this particular use case, each leaf is an access pattern being translated into a query that must contain date range, app-id, and event-name. This led the team to define the projection columns by using date type for the date range and injected type for app-id and event-name.
Rather than scanning and loading all partition metadata from the catalog, Athena can generate the partitions to query using configured rules and values from the query. This avoids the need to load and filter partitions from the catalog by generating them in the moment.
The projection process helped avoid performance issues caused by a high number of partitions, eliminating the latency from partition discovery during query runs.
Because partition projection eliminated the dependency between number of partitions and query runtime, the team could experiment with an additional partition: event-name. Partitioning by three columns (date, app-id, and event-name) reduced the amount of scanned data, resulting in a 10% improvement in query performance compared to the performance using partition projection with data partitioned only by date and app-id.
The following diagram illustrates the high-level data flow of sketch file creation. Focusing on the sketch writing process (write-events-estimation-sketches) into Amazon S3 with three partition fields caused the process to run twice as long compared to the original architecture, due to an increased number of sketch files (writing 20 times more sketch files to Amazon S3).

This prompted the team to drop the event-name partition and compromise on two partitions: date and app-id, resulting in the following partition structure:
s3://bucket/table_root/date=${day}/app_id=${app_id}
Using Parquet file format
In the new architecture, the team used Parquet file format. Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. Each Parquet file contains metadata such as minimum and maximum value of columns that allows the query engine to skip loading unneeded data. This optimization reduces the amount of data that needs to be scanned, because Athena can skip or quickly navigate through sections of the Parquet file that are irrelevant to the query. As a result, query performance improves significantly.
Parquet is particularly effective when querying sorted fields, because it allows Athena to facilitate predicate pushdown optimization and quickly identify and access the relevant data segments. To learn more about this capability in Parquet file format, see Understanding columnar storage formats.
Recognizing this advantage, the team decided to sort by event-name to enhance query performance, achieving a 10% improvement compared to non-sorted data. Initially, they tried partitioning by event-name to optimize performance, but this approach increased writing time to Amazon S3. Sorting demonstrated query time improvement without the ingestion overhead.
Query optimization and parallel queries
The team discovered that performance could be improved further by running parallel queries. Instead of a single query over a long window of time, multiple queries were run over shorter windows. Even though this increased the complexity of the solution, it improved performance by about 20% on average.
For instance, consider a scenario where a user requests the estimated size of app com.demo and event af_purchase between April 2024 and end of June 2024 (as illustrated earlier, the segmentation is defined by the user and then translated to an atomic leaf, which is then broken down to multiple queries depending on the date range). The following diagram illustrates the process of breaking down the initial 3-month query into two separate up to 60-day queries, running them simultaneously and then merging the results.

Reducing results set size
In analyzing performance bottlenecks, examining the different types and properties of the queries, and analyzing the different stages of the query run, it became clear that specific queries were slow in fetching query results. This problem wasn’t rooted in the actual query run, but in data transfer from Amazon S3 at the GetQueryResults phase, due to query results containing a large number of rows (a single result can contain millions of rows).
The initial approach of handling multiple key-value permutations in a single sketch inflated the number of rows considerably. To overcome this, the team introduced a new event-attr-key field to separate sketches into distinct key-value pairs.
The final schema looked as follows:
date | app-id | event-name | event-attr-key | event-attr-value | sketch
This refactoring resulted in a drastic reduction of result rows, which significantly expedited the GetQueryResults process, markedly improving overall query runtime by 90%.
Athena query results reuse
To address a common use case in the Audiences Segmentation GUI where users often make subtle adjustments to their queries, such as adjusting filters or slightly altering time windows, the team used the Athena query results reuse feature. This feature improves query performance and reduces costs by caching and reusing the results of previous queries. This feature plays a pivotal role, particularly when taking into account the recent improvements involving the splitting of date ranges. The ability to reuse and swiftly retrieve results means that these minor—yet frequent—modifications no longer require a full query reprocessing.
As a result, the latency of repeated query runs was reduced by up to 80%, enhancing the user experience by providing faster insights. This optimization not only accelerates data retrieval but also significantly reduces costs because there’s no need to rescan data for every minor change.
Solution rollout: Testing and monitoring
In this section, we discuss the process of rolling out the new architecture, including testing and monitoring.
Solving Amazon S3 slowdown errors
During the solution testing phase, the team developed an automation process designed to assess the different audiences within the system, using the data organized within the newly implemented schema. The methodology involved a comparative analysis of results obtained from HBase against those derived from Athena.
While running these tests, the team examined the accuracy of the estimations retrieved and also the latency change.
In this testing phase, the team encountered some failures when running many concurrent queries at once. These failures were caused by Amazon S3 throttling due to too many GET requests to the same prefix produced by concurrent Athena queries.
In order to handle the throttling (slowdown errors), the team added a retry mechanism for query runs with an exponential back-off strategy (wait time increases exponentially with a random offset to prevent concurrent retries).
Rollout preparations
At first, the team initiated a 1-month backfilling process as a cost-conscious approach, prioritizing accuracy validation before committing to a comprehensive 2-year backfill.
The backfilling process included running the Spark job (write-events-estimation-sketches) in the desired time range. The job read from the data warehouse, created sketches from the data, and wrote them to files in the specific schema that the team defined. Additionally, because the team used partition projection, they could skip the process of updating the Data Catalog with every partition being added.
This step-by-step approach allowed them to confirm the correctness of their solution before proceeding with the entire historical dataset.
With confidence in the accuracy achieved during the initial phase, the team systematically expanded the backfilling process to encompass the full 2-year timeframe, assuring a thorough and reliable implementation.
Before the official release of the updated solution, a robust monitoring strategy was implemented to safeguard stability. Key monitors were configured to assess critical aspects, such as query and API latency, error rates, API availability.
After the data was stored in Amazon S3 as Parquet files, the following rollout process was designed:
- Keep both HBase and Athena writing processes running, stop reading from HBase, and start reading from Athena.
- Stop writing to HBase.
- Sunset HBase.
Improvements and optimizations with Athena
The migration from HBase to Athena, using partition projection and optimized data structures, has not only resulted in a 10% improvement in query performance, but has also significantly boosted overall system stability by scanning only the necessary data partitions. In addition, the transition to a serverless model with Athena has achieved an impressive 80% reduction in monthly costs compared to the previous setup. This is due to eliminating infrastructure management expenses and aligning costs directly with usage, thereby positioning the organization for more efficient operations, improved data analysis, and superior business outcomes.
The following table summarizes the improvements and the optimizations implemented by the team.
| Area of Improvement |
Action Taken |
Measured Improvement |
| Athena partition projection |
Partition projection over the large number of partitions, avoiding limiting the number of partitions; partition by event_name and app_id |
Hundreds of percent improvement in query performance. This was the most significant improvement, which allowed the solution to be feasible. |
| Partitioning and sorting |
Partitioning by app_id and sorting event_name with daily granularity |
100% improvement in jobs calculating the sketches. 5% latency in query performance. |
| Time range queries |
Splitting long time range queries into multiple queries running in parallel |
20% improvement in query performance. |
| Reducing results set size |
Schema refactoring |
90% improvement in overall query time. |
| Query result reuse |
Supporting Athena query results reuse |
80% improvement in queries ran more than once in the given time. |
Conclusion
In this post, we showed how Athena became the main component of the AppsFlyer Audiences Segmentation offering. We explored various optimization techniques such as data merging, partition projection, schema redesign, parallel queries, Parquet file format, and the use of the query result reuse.
We hope our experience provides valuable insights to enhance the performance of your Athena-based applications. Additionally, we recommend checking out Athena performance best practices for further guidance.
About the Authors
 Nofar Diamant is a software team lead at AppsFlyer with a current focus on fraud protection. Before diving into this realm, she led the Retargeting team at AppsFlyer, which is the subject of this post. In her spare time, Nofar enjoys sports and is passionate about mentoring women in technology. She is dedicated to shifting the industry’s gender demographics by increasing the presence of women in engineering roles and encouraging them to succeed.
Nofar Diamant is a software team lead at AppsFlyer with a current focus on fraud protection. Before diving into this realm, she led the Retargeting team at AppsFlyer, which is the subject of this post. In her spare time, Nofar enjoys sports and is passionate about mentoring women in technology. She is dedicated to shifting the industry’s gender demographics by increasing the presence of women in engineering roles and encouraging them to succeed.
Matan Safri is a backend developer focusing on big data in the Retargeting team at AppsFlyer. Before joining AppsFlyer, Matan was a backend developer in IDF and completed an MSC in electrical engineering, majoring in computers at BGU university. In his spare time, he enjoys wave surfing, yoga, traveling, and playing the guitar.
Michael Pelts is a Principal Solutions Architect at AWS. In this position, he works with major AWS customers, assisting them in developing innovative cloud-based solutions. Michael enjoys the creativity and problem-solving involved in building effective cloud architectures. He also likes sharing his extensive experience in SaaS, analytics, and other domains, empowering customers to elevate their cloud expertise.
Orgad Kimchi is a Senior Technical Account Manager at Amazon Web Services. He serves as the customer’s advocate and assists his customers in achieving cloud operational excellence focusing on architecture, AI/ML in alignment with their business goals.





 Figure 8: Amazon Comprehend – Endpoint settings
Figure 8: Amazon Comprehend – Endpoint settings














 Nofar Diamant is a software team lead at AppsFlyer with a current focus on fraud protection. Before diving into this realm, she led the Retargeting team at AppsFlyer, which is the subject of this post. In her spare time, Nofar enjoys sports and is passionate about mentoring women in technology. She is dedicated to shifting the industry’s gender demographics by increasing the presence of women in engineering roles and encouraging them to succeed.
Nofar Diamant is a software team lead at AppsFlyer with a current focus on fraud protection. Before diving into this realm, she led the Retargeting team at AppsFlyer, which is the subject of this post. In her spare time, Nofar enjoys sports and is passionate about mentoring women in technology. She is dedicated to shifting the industry’s gender demographics by increasing the presence of women in engineering roles and encouraging them to succeed. Matan Safri is a backend developer focusing on big data in the Retargeting team at AppsFlyer. Before joining AppsFlyer, Matan was a backend developer in IDF and completed an MSC in electrical engineering, majoring in computers at BGU university. In his spare time, he enjoys wave surfing, yoga, traveling, and playing the guitar.
Matan Safri is a backend developer focusing on big data in the Retargeting team at AppsFlyer. Before joining AppsFlyer, Matan was a backend developer in IDF and completed an MSC in electrical engineering, majoring in computers at BGU university. In his spare time, he enjoys wave surfing, yoga, traveling, and playing the guitar. Michael Pelts is a Principal Solutions Architect at AWS. In this position, he works with major AWS customers, assisting them in developing innovative cloud-based solutions. Michael enjoys the creativity and problem-solving involved in building effective cloud architectures. He also likes sharing his extensive experience in SaaS, analytics, and other domains, empowering customers to elevate their cloud expertise.
Michael Pelts is a Principal Solutions Architect at AWS. In this position, he works with major AWS customers, assisting them in developing innovative cloud-based solutions. Michael enjoys the creativity and problem-solving involved in building effective cloud architectures. He also likes sharing his extensive experience in SaaS, analytics, and other domains, empowering customers to elevate their cloud expertise. Orgad Kimchi is a Senior Technical Account Manager at Amazon Web Services. He serves as the customer’s advocate and assists his customers in achieving cloud operational excellence focusing on architecture, AI/ML in alignment with their business goals.
Orgad Kimchi is a Senior Technical Account Manager at Amazon Web Services. He serves as the customer’s advocate and assists his customers in achieving cloud operational excellence focusing on architecture, AI/ML in alignment with their business goals.



























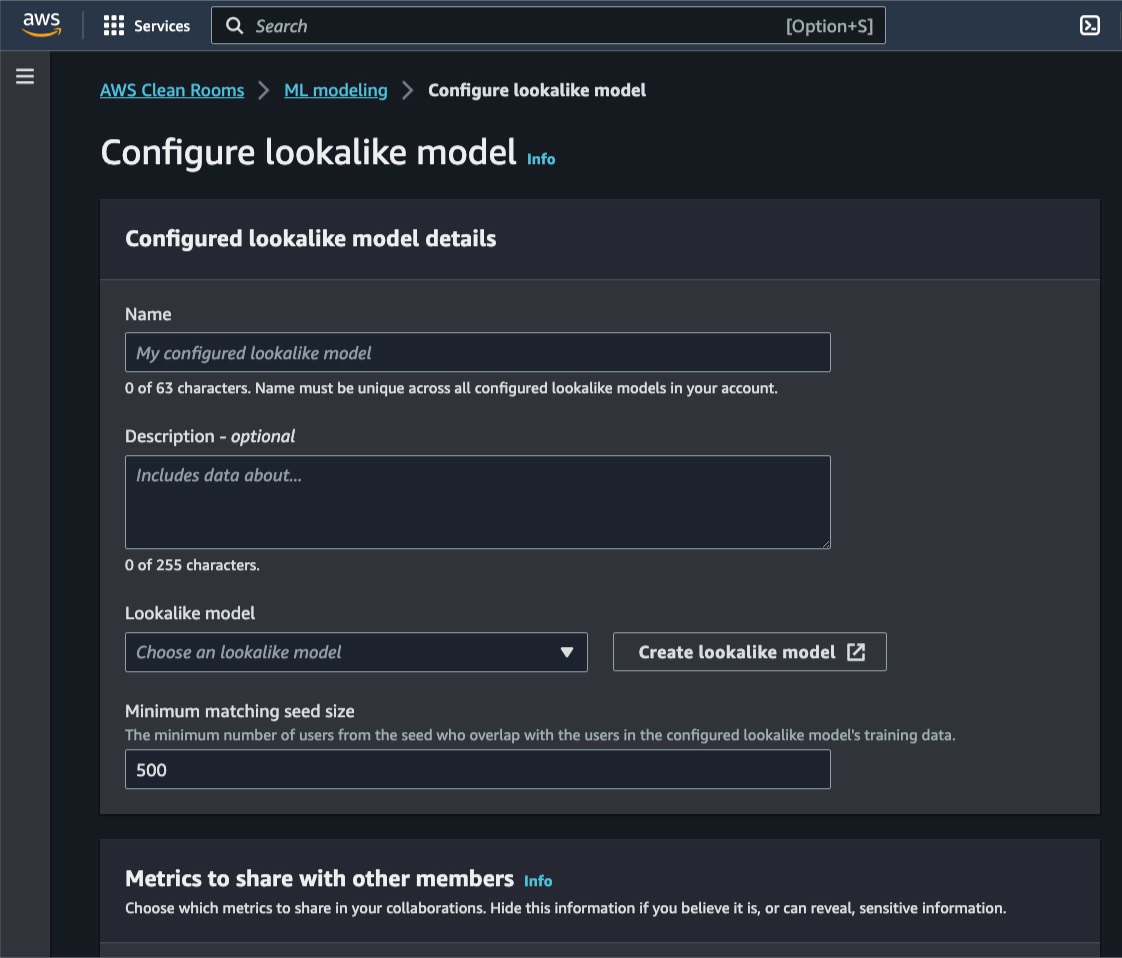
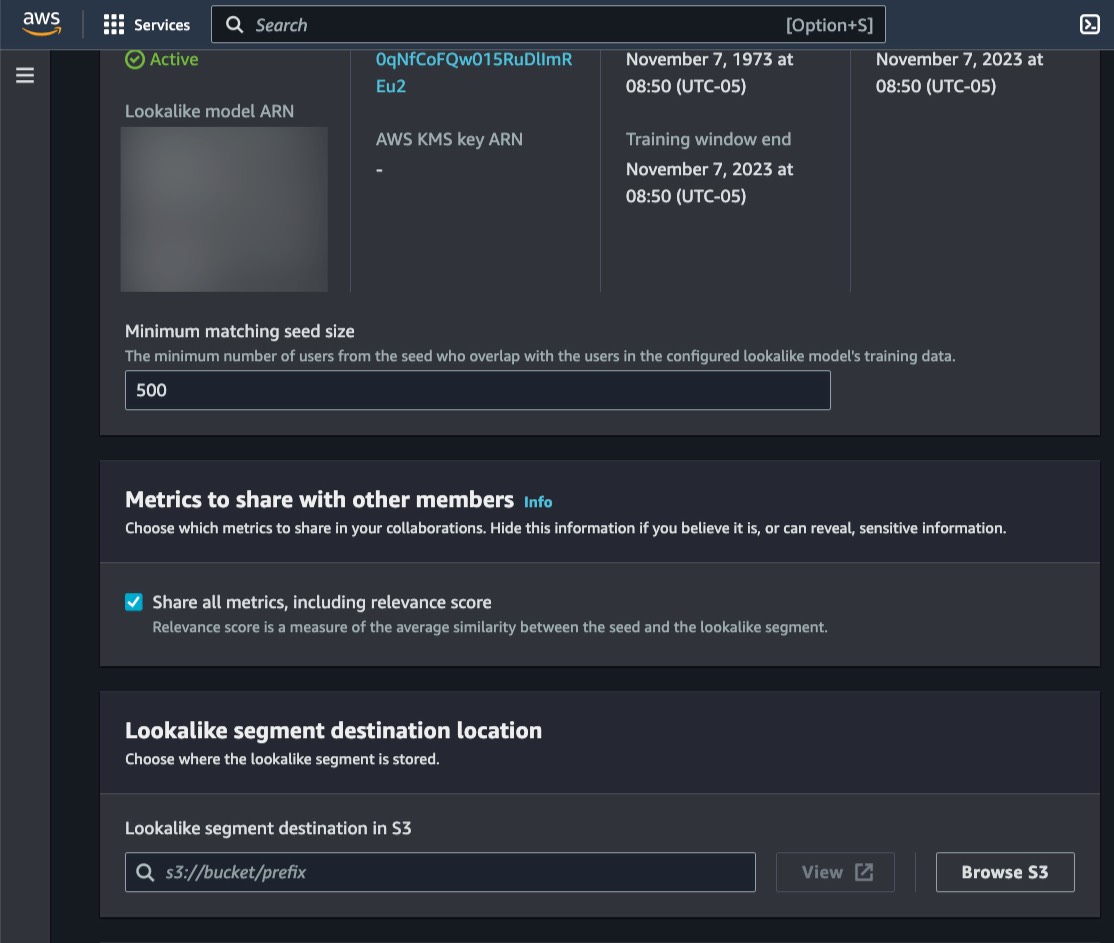

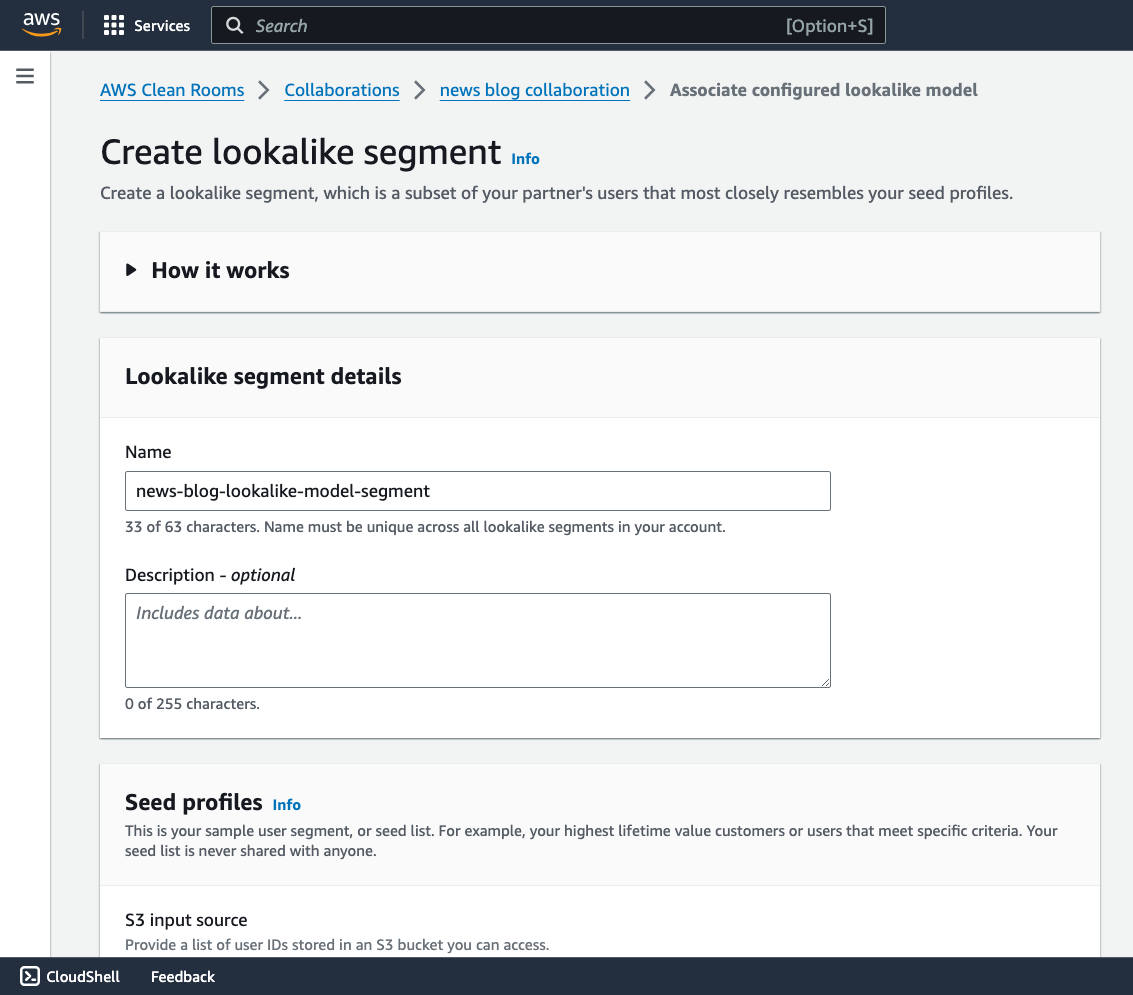

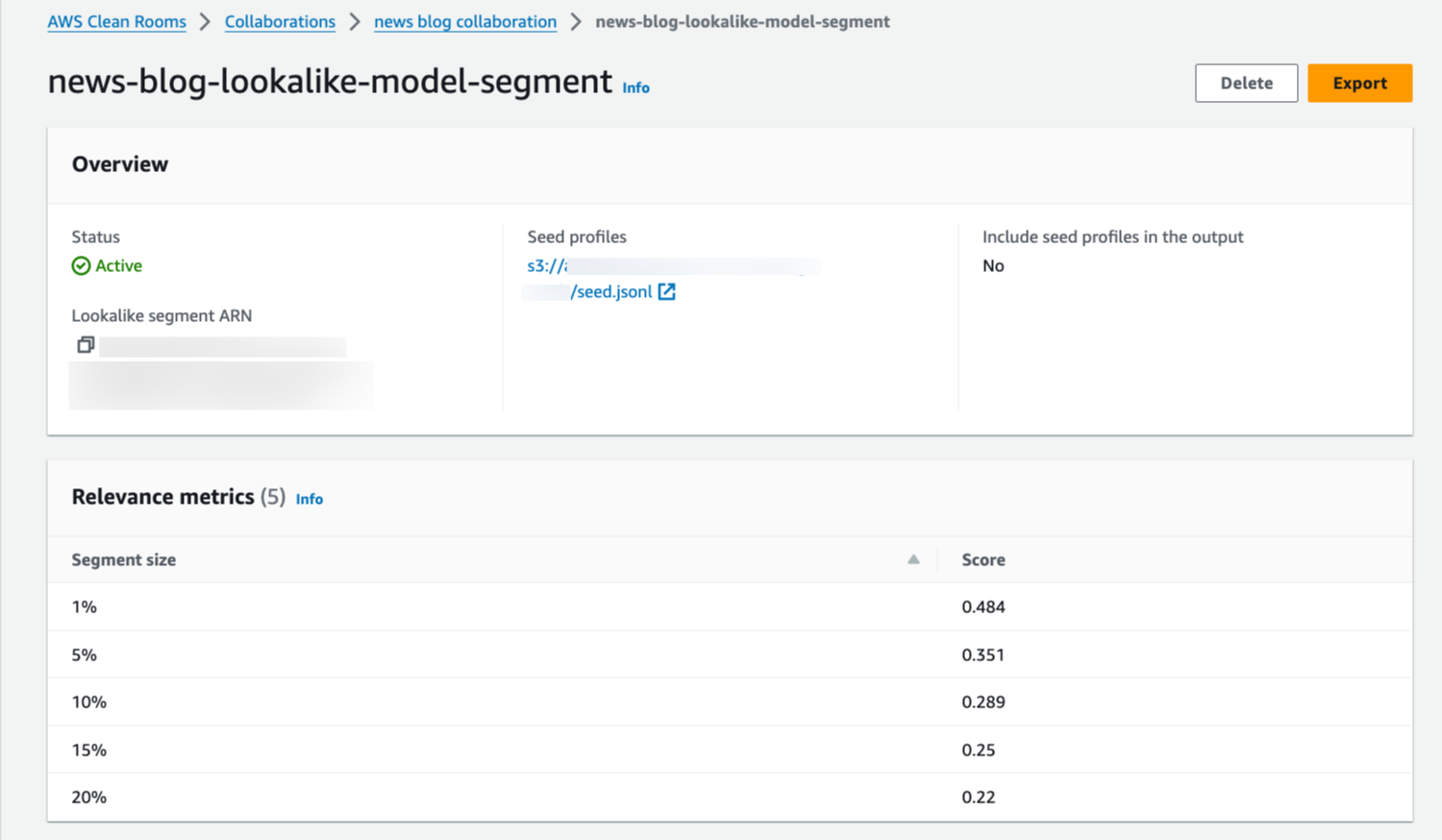



 Omar Gonzalez is a Senior Solutions Architect at Amazon Web Services in Southern California with more than 20 years of experience in IT. He is passionate about helping customers drive business value through the use of technology. Outside of work, he enjoys hiking and spending quality time with his family.
Omar Gonzalez is a Senior Solutions Architect at Amazon Web Services in Southern California with more than 20 years of experience in IT. He is passionate about helping customers drive business value through the use of technology. Outside of work, he enjoys hiking and spending quality time with his family. Matt Miller is a Business Development Principal at AWS. In his role, Matt drives customer and partner adoption for the AWS Clean Rooms service specializing in advertising and marketing industry use cases. Matt believes in the primacy of privacy enhanced data collaboration and interoperability underpinning data-driven marketing imperatives from customer experience to addressable advertising. Prior to AWS, Matt led strategy and go-to market efforts for ad technologies, large agencies, and consumer data products purpose-built to inform smarter marketing and deliver better customer experiences.
Matt Miller is a Business Development Principal at AWS. In his role, Matt drives customer and partner adoption for the AWS Clean Rooms service specializing in advertising and marketing industry use cases. Matt believes in the primacy of privacy enhanced data collaboration and interoperability underpinning data-driven marketing imperatives from customer experience to addressable advertising. Prior to AWS, Matt led strategy and go-to market efforts for ad technologies, large agencies, and consumer data products purpose-built to inform smarter marketing and deliver better customer experiences.

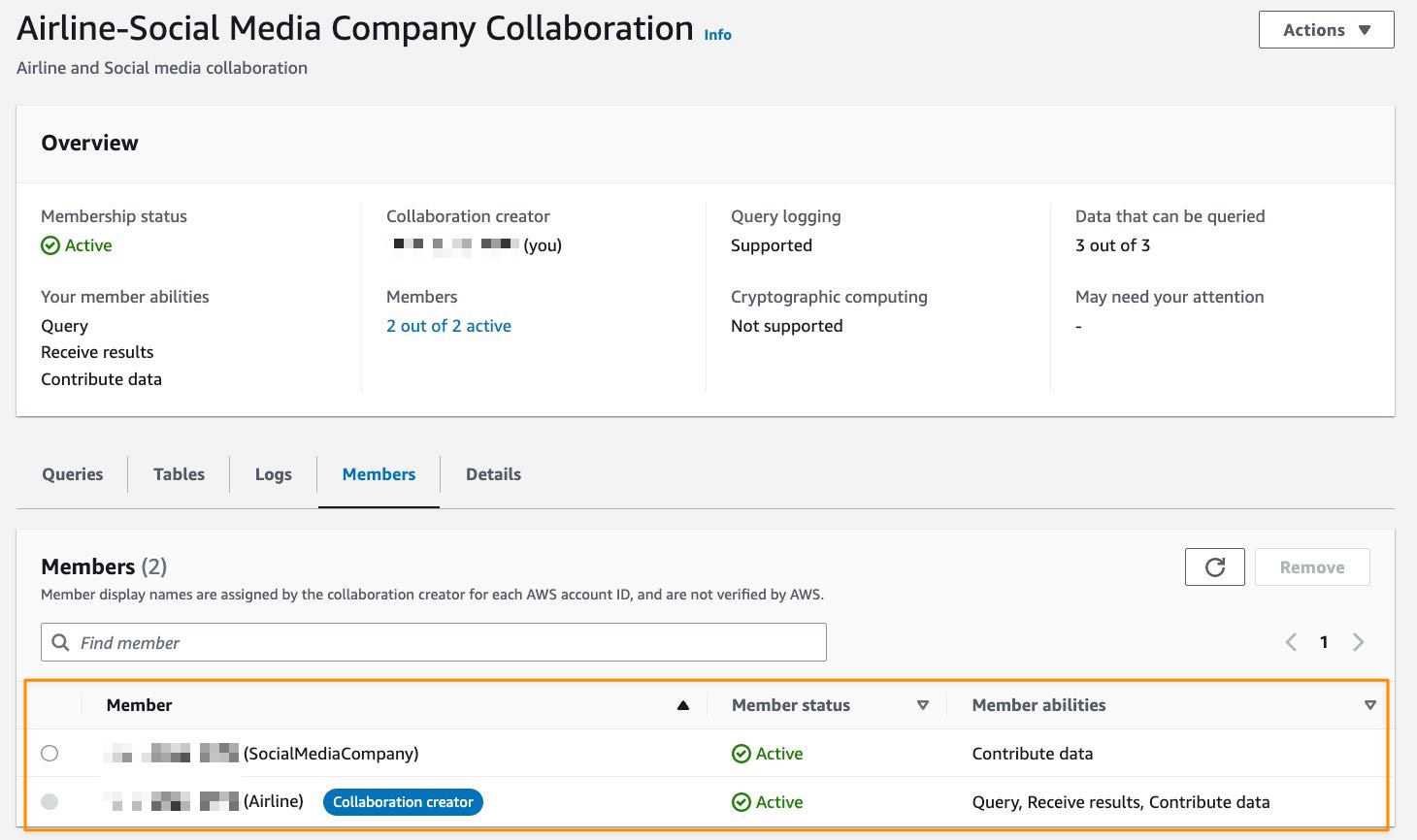
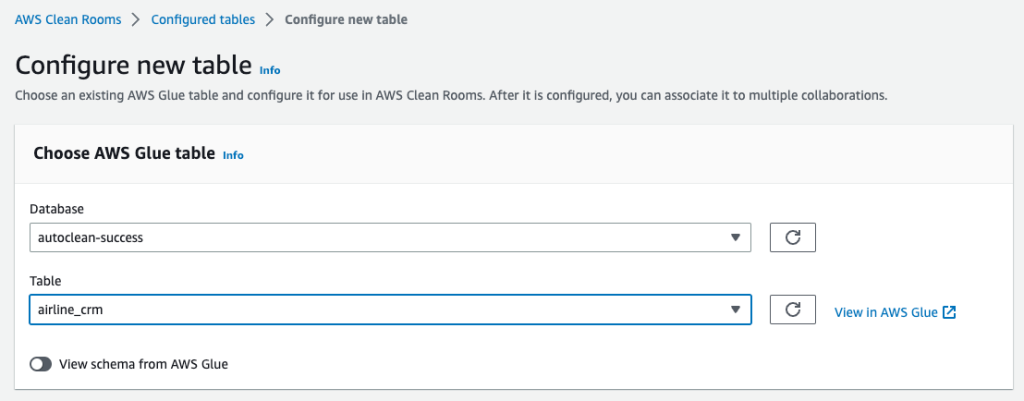
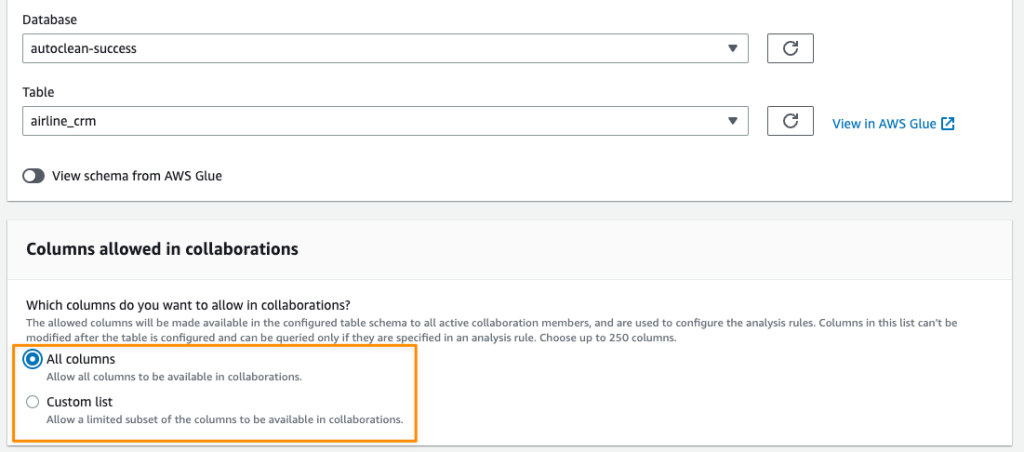
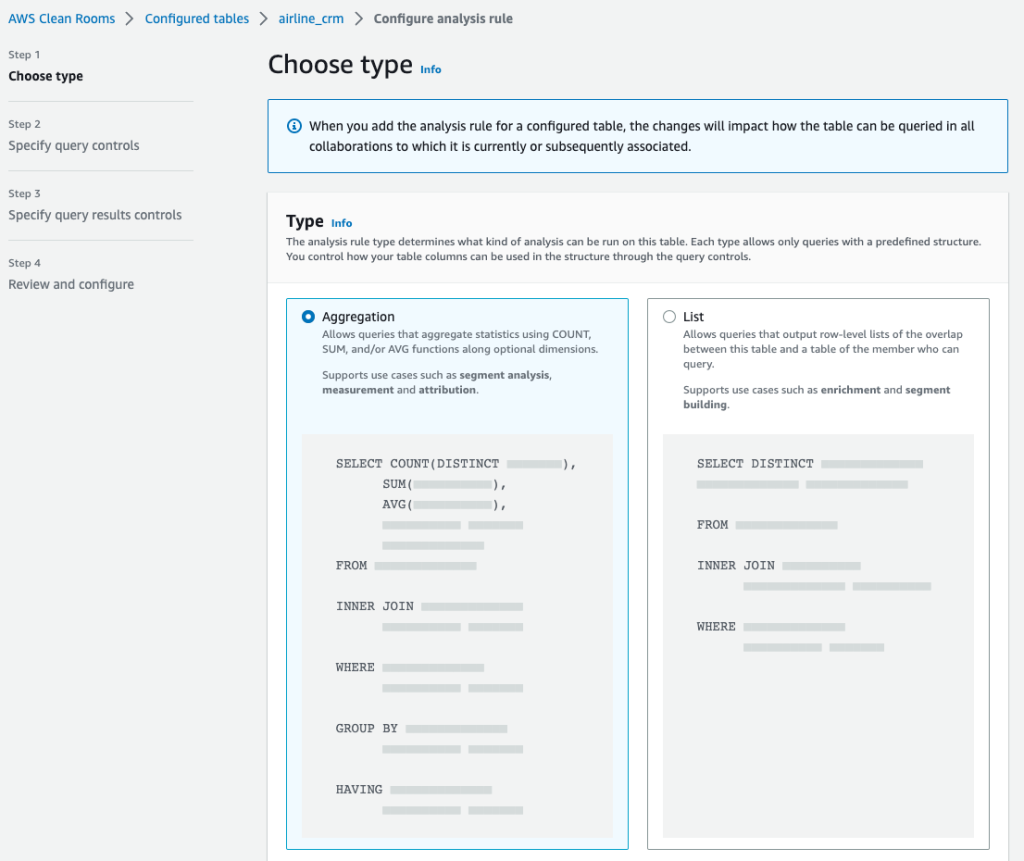
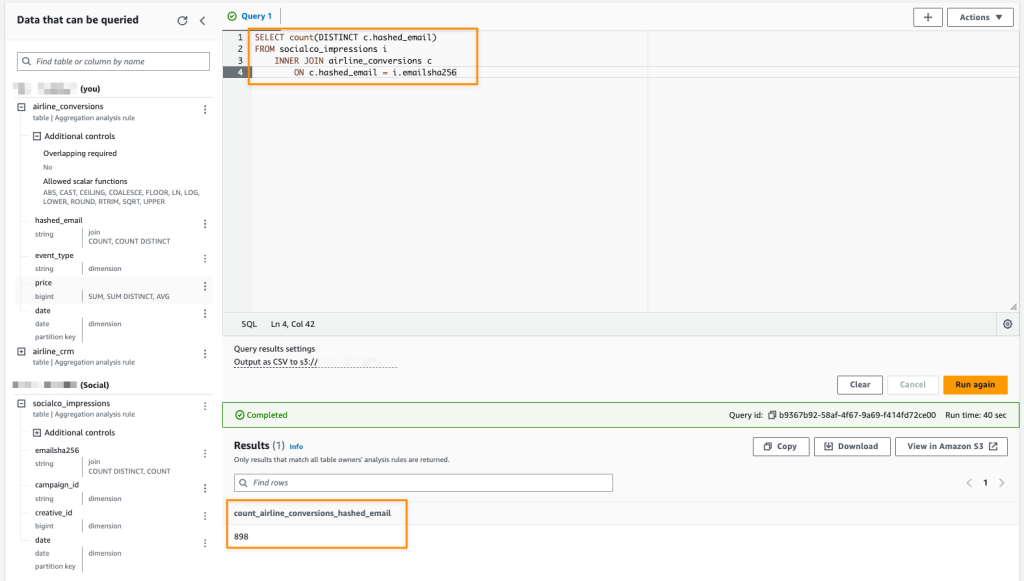
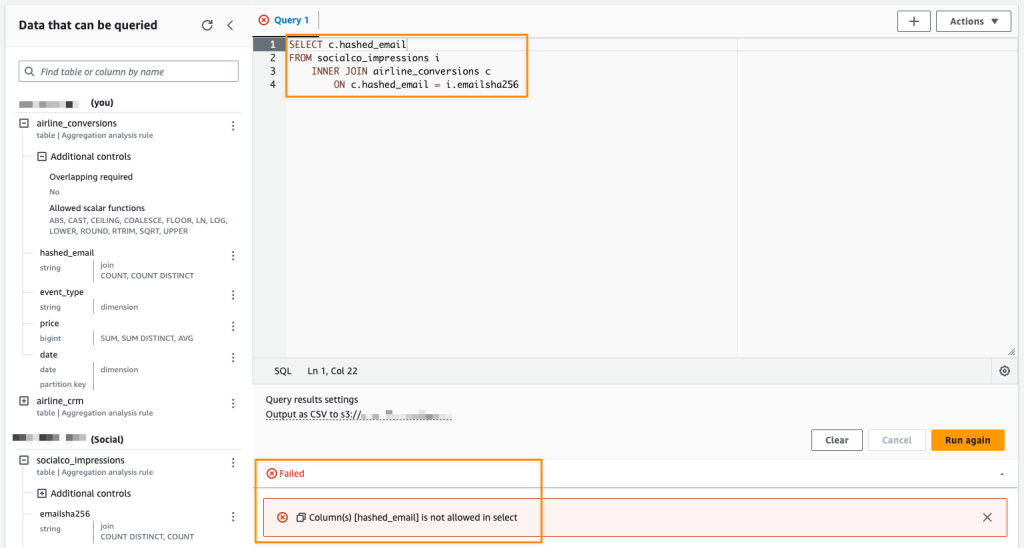
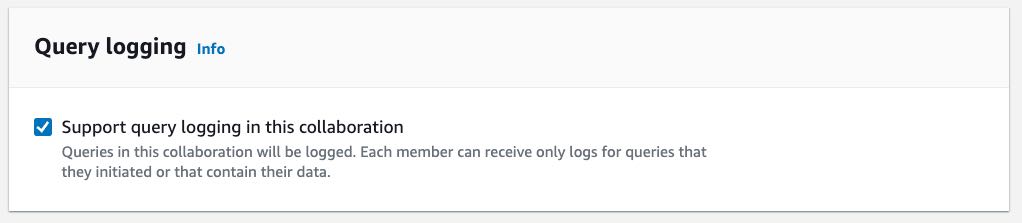
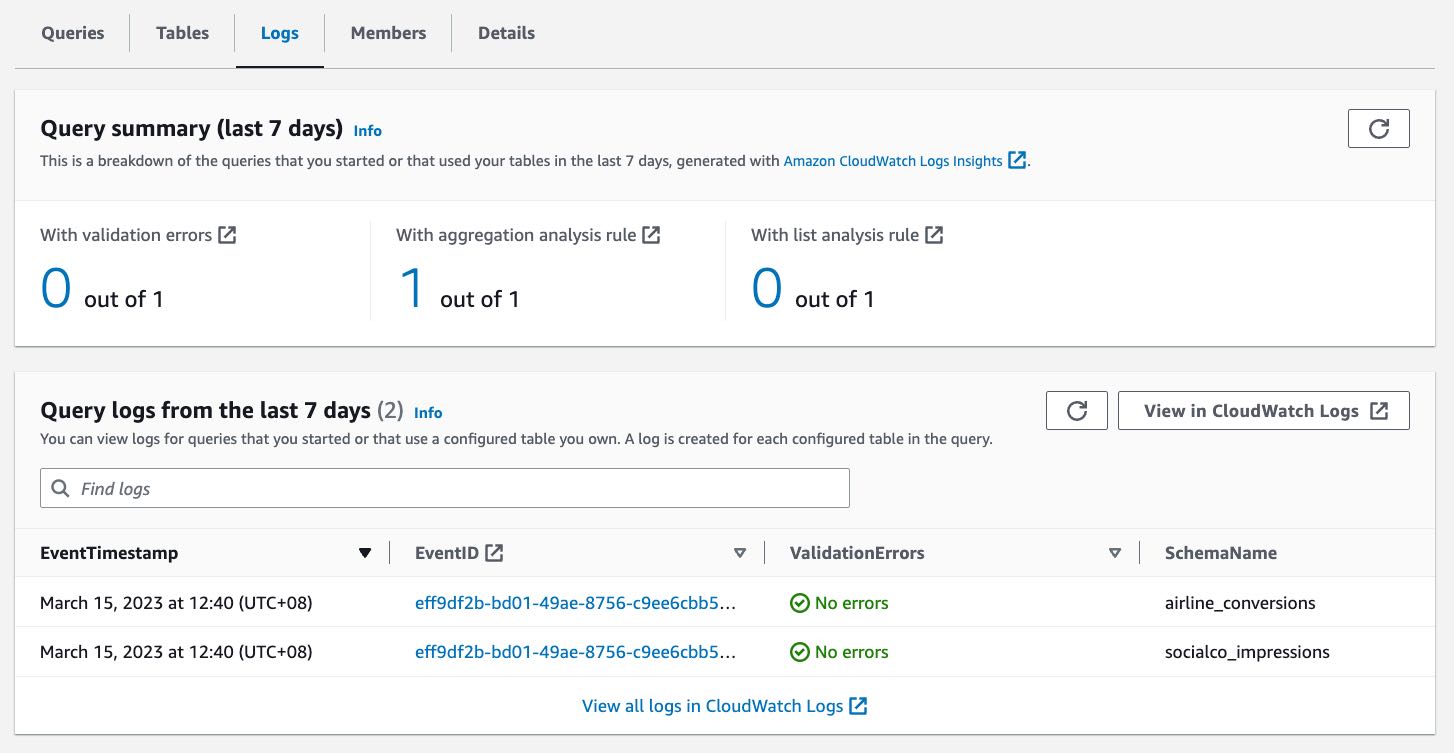


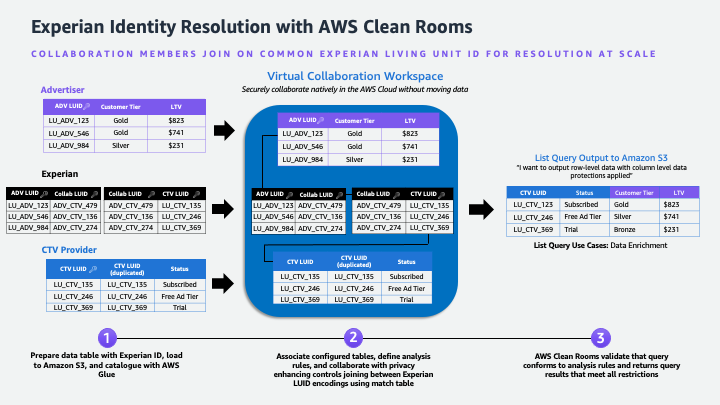
 “Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.
“Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.