Post Syndicated from Yusuf Mayet original https://aws.amazon.com/blogs/architecture/why-deployment-requirements-are-important-when-making-architectural-choices/
Introduction
Too often, architects fall into the trap of thinking the architecture of an application is restricted to just the runtime part of the architecture. By doing this we focus on only a single customer (such as the application’s users and how they interact with the system) and we forget about other important customers like developers and DevOps teams. This means that requirements regarding deployment ease, deployment frequency, and observability are delegated to the back burner during design time and tacked on after the runtime architecture is built. This leads to increased costs and reduced ability to innovate.
In this post, I discuss the importance of key non-functional requirements, and how they can and should influence the target architecture at design time.
Architectural patterns
When building and designing new applications, we usually start by looking at the functional requirements, which will define the functionality and objective of the application. These are all the things that the users of the application expect, such as shopping online, searching for products, and ordering. We also consider aspects such as usability to ensure a great user experience (UX).
We then consider the non-functional requirements, the so-called “ilities,” which typically include requirements regarding scalability, availability, latency, etc. These are constraints around the functional requirements, like response times for placing orders or searching for products, which will define the expected latency of the system.
These requirements—both functional and non-functional together—dictate the architectural pattern we choose to build the application. These patterns include Multi-tier, event-driven architecture, microservices, and others, and each one has benefits and limitations. For example, a microservices architecture allows for a system where services can be deployed and scaled independently, but this also introduces complexity around service discovery.
Aligning the architecture to technical users’ requirements
Amazon is a customer-obsessed organization, so it’s important for us to first identify who the main customers are at each point so that we can meet their needs. The customers of the functional requirements are the application users, so we need to ensure the application meets their needs. For the most part, we will ensure that the desired product features are supported by the architecture.
But who are the users of the architecture? Not the applications’ users—they don’t care if it’s monolithic or microservices based, as long as they can shop and search for products. The main customers of the architecture are the technical teams: the developers, architects, and operations teams that build and support the application. We need to work backwards from the customers’ needs (in this case the technical team), and make sure that the architecture meets their requirements. We have therefore identified three non-functional requirements that are important to consider when designing an architecture that can equally meet the needs of the technical users:
- Deployability: Flow and agility to consistently deploy new features
- Observability: feedback about the state of the application
- Disposability: throwing away resources and provision new ones quickly
Together these form part of the Developer Experience (DX), which is focused on providing developers with APIs, documentation, and other technologies to make it easy to understand and use. This will ensure that we design for Day 2 operations in mind.
Deployability: Flow
There are many reasons that organizations embark on digital transformation journeys, which usually involve moving to the cloud and adopting DevOps. According to Stephen Orban, GM of AWS Data Exchange, in his book Ahead in the Cloud, faster product development is often a key motivator, meaning the most important non-functional requirement is achieving flow, the speed at which you can consistently deploy new applications, respond to competitors, and test and roll out new features. As well, the architecture needs to be designed upfront to support deployability. If the architectural pattern is a monolithic application, this will hamper the developers’ ability to quickly roll out new features to production. So we need to choose and design the architecture to support easy and automated deployments. Results from years of research prove that leaders use DevOps to achieve high levels of throughput:

Decisions on the pace and frequency of deployments will dictate whether to use rolling, blue/green, or canary deployment methodologies. This will then inform the architectural pattern chosen for the application.
Using AWS, in order to achieve flow of deployability, we will use services such as AWS CodePipeline, AWS CodeBuild, AWS CodeDeploy and AWS CodeStar.
Observability: feedback
Once you have achieved a rapid and repeatable flow of features into production, you need a constant feedback loop of logs and metrics in order to detect and avoid problems. Observability is a property of the architecture that will allow us to better understand the application across the delivery pipeline and into production. This requires that we design the architecture to ensure that health reports are generated to analyze and spot trends. This includes error rates and stats from each stage of the development process, how many commits were made, build duration, and frequency of deployments. This not only allows us to measure code characteristics such as test coverage, but also developer productivity.
On AWS, we can leverage Amazon CloudWatch to gather and search through logs and metrics, AWS X-Ray for tracing, and Amazon QuickSight as an analytics tool to measure CI/CD metrics.
Disposability: automation
In his book, Cloud Strategy: A Decision-based Approach to a Successful Cloud Journey, Gregor Hohpe, Enterprise Strategist at AWS, notes that cloud and automation add a new “-ility”: disposability, which is the ability to set up and dispose of new servers in an automated and pain-free manner. Having immutable, disposable infrastructure greatly enhances your ability to achieve high levels of deployability and flow, especially when used in a CI/CD pipeline, which can create new resources and kill off the old ones.
At AWS, we can achieve disposability with serverless using AWS Lambda, or with containers running on Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS), or using AWS Auto Scaling with Amazon Elastic Compute Cloud (EC2).
Three different views of the architecture
Once we have designed an architecture that caters for deployability, observability, and disposability, it exposes three lenses across which we can view the architecture:
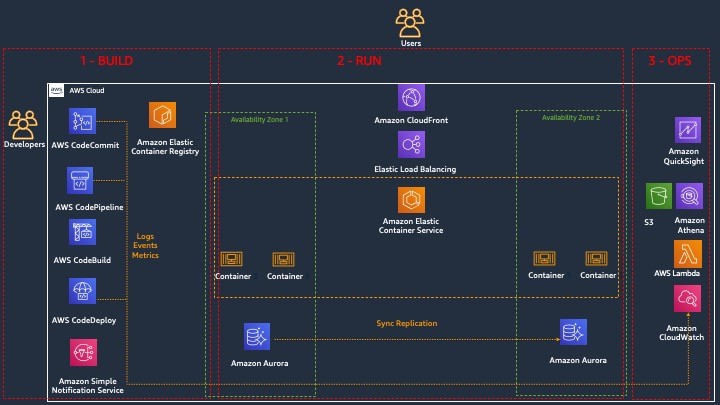
- Build lens: the focus of this part of the architecture is on achieving deployability, with the objective to give the developers an easy-to-use, automated platform that builds, tests, and pushes their code into the different environments, in a repeatable way. Developers can push code changes more reliably and frequently, and the operations team can see greater stability because environments have standard configurations and rollback procedures are automated
- Runtime lens: the focus is on the users of the application and on maximizing their experience by making the application responsive and highly available.
- Operate lens: the focus is on achieving observability for the DevOps teams, allowing them to have complete visibility into each part of the architecture.
Summary
When building and designing new applications, the functional requirements (such as UX) are usually the primary drivers for choosing and defining the architecture to support those requirements. In this post I have discussed how DX characteristics like deployability, observability, and disposability are not just operational concerns that get tacked on after the architecture is chosen. Rather, they should be as important as the functional requirements when choosing the architectural pattern. This ensures that the architecture can support the needs of both the developers and users, increasing quality and our ability to innovate.

 Karthi Thyagarajan is a Principal Solutions Architect on the Amazon Kinesis team.
Karthi Thyagarajan is a Principal Solutions Architect on the Amazon Kinesis team. Deepthi Mohan is a Sr. TPM on the Amazon Kinesis Data Analytics team.
Deepthi Mohan is a Sr. TPM on the Amazon Kinesis Data Analytics team.







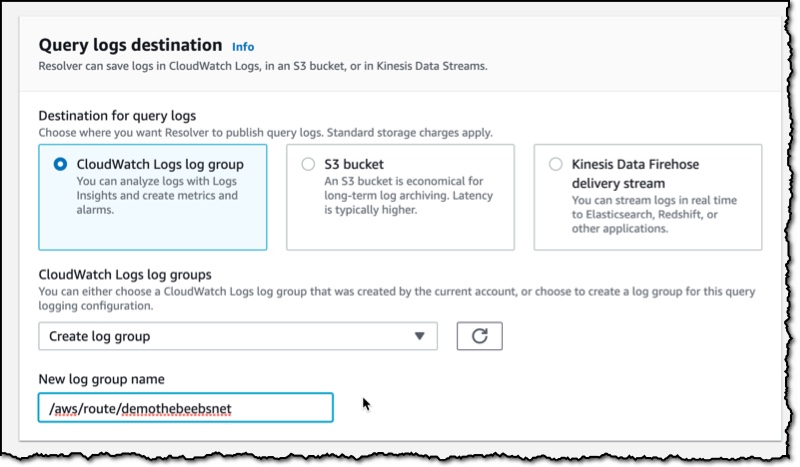
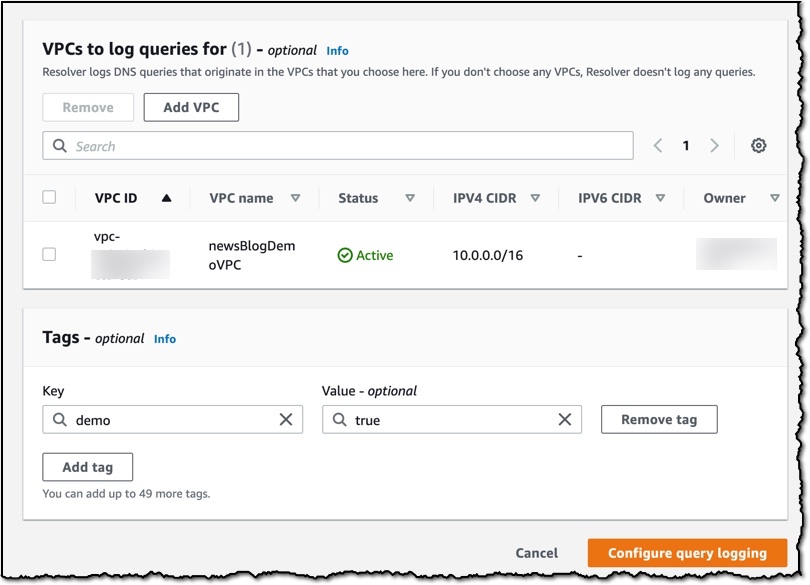

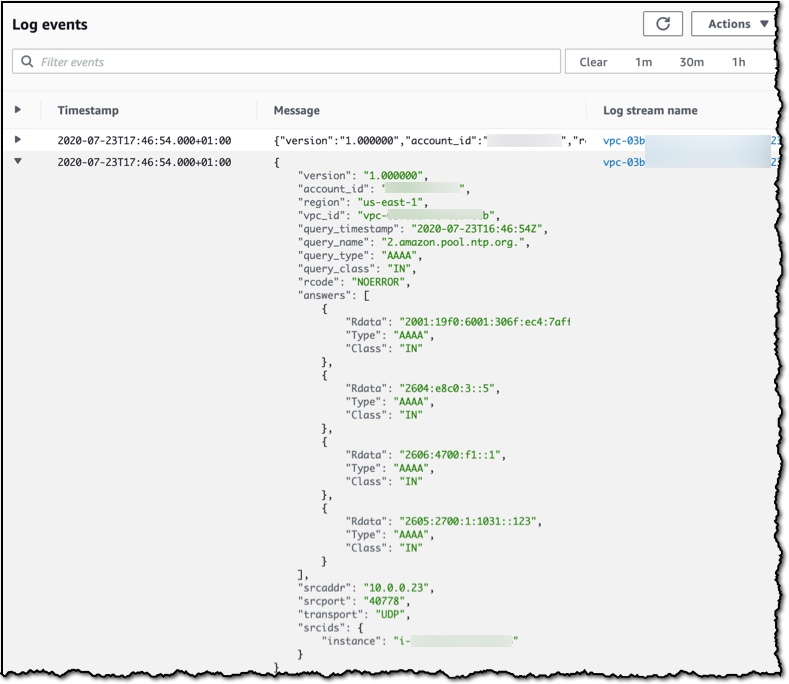
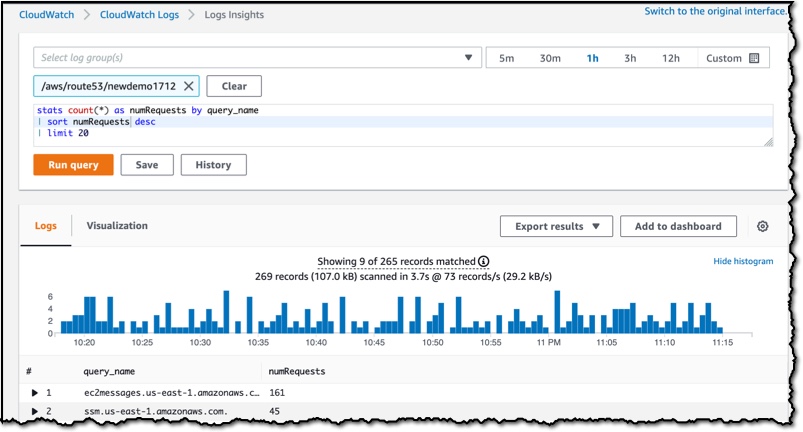
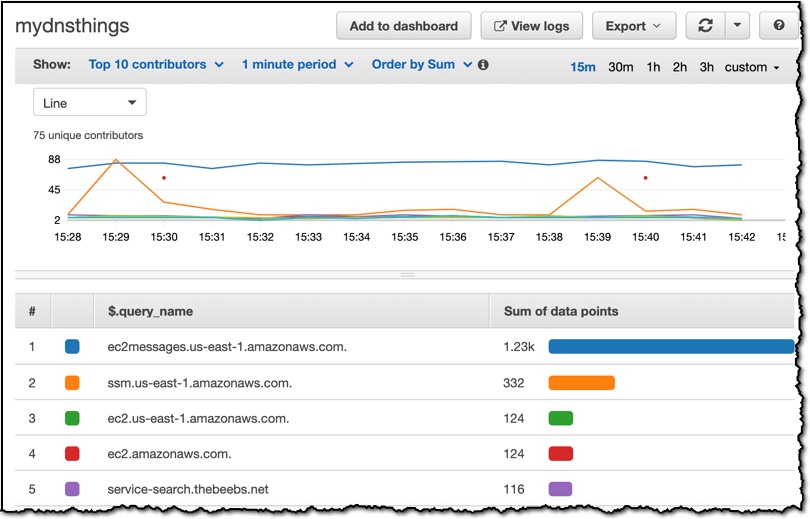 Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use
Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use