Post Syndicated from Rajesh Francis original https://aws.amazon.com/blogs/big-data/implementing-multi-tenant-patterns-in-amazon-redshift-using-data-sharing/
Software service providers offer subscription-based analytics capabilities in the cloud with Analytics as a Service (AaaS), and increasingly customers are turning to AaaS for business insights. A multi-tenant storage strategy allows the service providers to build a cost-effective architecture to meet increasing demand.
Multi-tenancy means a single instance of software and its supporting infrastructure is shared to serve multiple customers. For example, a software service provider could generate data that is housed in a single data warehouse cluster, but accessed securely by multiple customers. This storage strategy offers an opportunity to centralize management of data, simplify ETL processes, and optimize costs. However, service providers have to constantly balance between cost and providing a better user experience for their customers.
With the new data sharing feature, you can use Amazon Redshift to scale and meet both objectives of managing costs by simplifying storage and ETL pipelines while still providing consistent performance to customers. You can ingest data into a cluster designated as a producer cluster, and share this live data with one or more consumer clusters. Clusters accessing this shared data are isolated from each other, therefore performance of a producer cluster isn’t impacted by workloads on consumer clusters. This enables consuming clusters to get consistent performance based on individual compute capacity.
In this post, we focus on various AaaS patterns, and discuss how you can use data sharing in a multi-tenant architecture to scale for virtually unlimited users. We discuss detailed steps to use data sharing with different storage strategies.
Multi-tenant storage patterns
Multi-tenant storage patterns help simplify the architecture and long-term maintenance of the analytics platform. In a multi-tenant strategy, data is stored centrally in a single cluster for all tenants, enabling simplification of the ETL ingestion pipeline and data management. In the previously published whitepaper SaaS Storage Strategies, various models of storage and benefits are covered for a single cluster scenario.
The three strategies you can choose from are:
- Pool model – Data is stored in a single database schema for all tenants, and a new column (
tenant_id) is used to scope and control access to individual tenant data. Access to the multi-tenant data is controlled using views built on the tables. - Bridge model – Storage and access to data for each tenant is controlled at individual schema level in the same database.
- Silo model – Storage and access control to data for each tenant is maintained in separate databases
The following diagram illustrates the architecture of these multi-tenant storage strategies.

In the following sections, we will discuss how these multi-tenant strategies can be implemented using Amazon Redshift data sharing feature with a multi-cluster architecture.
Scaling your multi-tenant architecture using data sharing
AaaS providers implementing multi-tenant architectures were previously limited to resources of a single cluster to meet the compute and concurrency requirements of users across all the tenants. As the number of tenants increased, you could either turn on concurrency scaling or create additional clusters. However, the addition of new clusters means additional ingestion pipelines and increased operational overhead.
With data sharing in Amazon Redshift, you can easily and securely share data across clusters. Data ingested into the producer cluster is shared with one or more consumer clusters, which allows total separation of ETL and BI workloads. Several consumer clusters can read data from the managed storage of a producer cluster. This enables instant, granular, and high-performance access without data copies and movement. Workloads accessing shared data are isolated from each other and the producer. You can distribute workloads across multiple clusters while simplifying and consolidating the ETL ingestion pipeline into one main producer cluster, providing optimal price for performance.
Consumer clusters can in turn be producers for the data sets they own. Customers can optimize costs even further by collocating multiple tenants on the same consumer cluster. For instance, you can group low volume tier 3 tenants into a single consumer cluster to provider a lower cost offering, while high volume tier 1 tenants get their own isolated compute clusters. Consumer clusters can be created in the same account as producer or in a different AWS account. With this you can have separate billing for the consumer clusters, where you can chargeback to the business group that uses the consumer cluster or even allow your customers to use their own Redshift cluster in their account, so they pay for usage of the consumer cluster. The following diagram shows the difference in ETL and consumer access patterns in a multi-tenant architecture using data sharing versus a single cluster approach without data sharing.

Multi-tenant architecture with data sharing compared to single cluster approach
Creating a multi-tenant architecture for an AaaS solution
For this post, we use a simple data model with a fact and a dimension table to demonstrate how to leverage data sharing to design a scalable multi-tenant AaaS solution. We cover detailed steps involved for each storage strategy using this data model. The tables are as follows:
Customer– dimension table containing customer detailsSales– fact table containing sales transactions
We use two Amazon Redshift ra3.4xl clusters, with 2 nodes each, and designate one cluster as producer and other as consumer.
The high-level steps involved in enabling data sharing across clusters are as follows:
- Create a data share in the producer cluster and assign database objects to the data share.
- From the producer cluster, grant usage on the data share to consumer clusters, identified by namespace or AWS account.
- From the consumer cluster, create an external database using the data share from the producer
- Query the tables in the data share through the external shared database in the consumer cluster. Grant access to other users to access this shared database and objects.
Creating producer and consumer Amazon Redshift clusters
Let us start by creating two Amazon Redshift ra3.4xl clusters with 2-nodes each, one for the producer and other for consumer.
- On the Amazon Redshift cluster, create two clusters of RA3 instance type, and name them
ds-producerandds-consumer-c1, respectively.
- Next, log in to Amazon Redshift using the query editor. You can also use a SQL client tool like DBeaver, SQL Workbench, or Aginity Workbench. For configuration information, see Connecting to an Amazon Redshift cluster using SQL client tools.
Get the cluster namespace of the producer and consumer clusters from the console. We will use the namespaces to create the tenant table and to create and access the data shares. You can also get the cluster namespaces by logging into each of the clusters and executing the SELECT CURRENT_NAMESPACE statement in the query editor.
Please note to replace the corresponding namespaces in the code sections wherever producercluster_namespace, consumercluster1_namespace, and consumercluster_namespace is referenced.
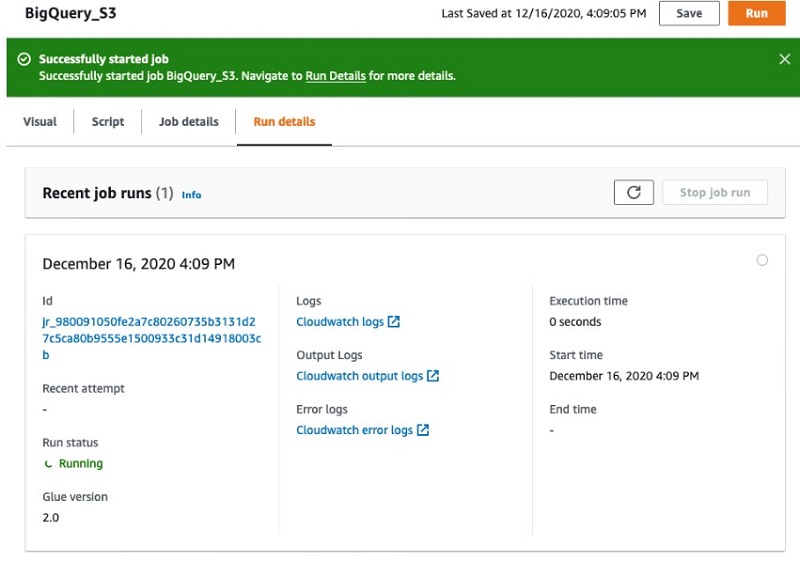
The following screenshot shows the namespace on the Amazon Redshift console.

Now that we have the clusters created, we will go through the detailed steps for the three models. First, we will cover the Pool model, followed by Bridge model and finally the Silo model.
Pool model
The pool model represents an all-in, multi-tenant model where all tenants share the same storage constructs and provides the most benefit in simplifying the AaaS solution.
With this model, data storage is centralized in one cluster database, and data is stored for all tenants in the same set of data models. To scope and control access to tenant data, we introduce a column (tenant_id) that serves as a unique identifier for each tenant.
Security management to prevent cross-tenant access is one of the main aspects to address with the pool model. We can implement row-level security and provide secure access to the data by creating database views and set application-level policies by creating groups with specific access and assigning users to the groups. The following diagram illustrates the pool model architecture.

To create a multi-tenant solution using the pool model, you create data shares for the pool model in the producer cluster, and share data with the consumer cluster. We provide more detail on these steps in the following sections.
Creating data shares for the pool model in the producer cluster
To create data shares for the pool model in the producer cluster, complete the following steps:
- Log in to the producer cluster as an admin user and run the following script.
Note that we have a tenant table to store unique identifiers for each tenant or consumer (tenant).
We add a column (tenant_id) to the sales and customer tables to uniquely identify tenant data. This tenant_id references the tenant_id in the tenant table to uniquely identify the tenant and consumer records. See the following code:
- Set up the tenant table with the details for each consumer cluster, and ingest data into the customer dimension and sales fact tables. Using the COPY command is the recommended way to ingest data into Amazon Redshift, but for illustration purposes, we use INSERT statements:
Securing data on the producer cluster by restricting access
In the pool model, no external user has direct access to underlying tables. All access is restricted using views.
- Create a view for each of the fact and dimension tables to include a condition to filter records from the consumer tenant’s namespace. In our example, we create
v_customersalesto combine sales fact and customer dimension tables with a restrictive filter fortenant.namespace=current_namespace. See the following code:
Now that we have database objects created in the producer cluster, we can share the data with the consumer clusters.
Sharing data with the consumer cluster
To share data with the consumer cluster, complete the following steps:
- Create a data share for the sales data:
- Enter the following code to alter the data share, add the sales schema to be shared with the consumer clusters, and add all tables in the sales schema to be shared with the consumer cluster:
For the pool model, we share only the views with the consumer cluster and not the tables. The ALTER statement ADD TABLE is used to add both views and tables.
- Grant usage on the sales data share to the namespace of the BI consumer cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACEstatement in the BI cluster. See the following code:
- View data shares that are shared from the producer cluster:
The following screenshot shows the output.

You can also see the data shares and their detailed objects and consumers using the following commands:
Viewing and querying data shares for the pool model from the consumer cluster
To view and query data shares from the consumer cluster, complete the following steps:
- Log in to the consumer cluster as an admin user and view the data share objects:
The following screenshot shows the results.

- Create a new database from the data share of the producer cluster:
- Optionally, you can create an external schema in the consumer cluster pointing to the schema in the database of the producer cluster.
Creating a local external schema in the consumer cluster allows schema-level access controls within the consumer cluster, and uses a two-part notation when referencing shared data objects (localschema.table; vs. external_db.producerschema.table). See the following code:
- Now you can query the shared data from the producer cluster by using the syntax
tenant.schema.table:
- From the
tenant1consumer cluster, you can view the databases and the tenants that are accessible totenant1. tenant1_schemais as follows:
The following screenshot shows the results.

Creating local consumer users and controlling access
You can control access to users in your consumer cluster by creating users and groups, and assigning access to the data share objects.
- Log in as an admin user on consumer cluster 1 and enter the following code to create
tenant1_group, grant usage on the local databasesales_dband schemasales_schemato the group, and assign the usertenant1_userto thetenant1_group:
- Now, login as
tenant1_userto consumer cluster 1 and select data from the viewsv_customerandv_customersales:
You should see only the data relevant to tenant 1 and not the data that is associated with tenant 2.

Create Materialized views to optimize performance
Consumer clusters can have their own database objects which are local to the consumer. You can also create materialized views on the datashare objects and control when to refresh the dataset for your consumers. This provides another level of isolation from the producer cluster, and will ensure the consumer clusters go against their local dataset.
- Log in as an admin user on consumer cluster 1 and enter the following code to create a materialized view for customersales. This will create a local view that can be periodically refreshed from the consumer cluster.
/*******************************************************/
/* Create materialized view in consumer cluster */
/*******************************************************/
create MATERIALIZED view tenant1_sales.mv_customersales as
select c_tenantid, c_name, c_region,
date_part(w, to_date(s_orderdate,'YYYY-MM-DD')) as "week",
date_part(mon, to_date(s_orderdate,'YYYY-MM-DD')) as "month",
date_part(dow, to_date(s_orderdate,'YYYY-MM-DD')) as "dow",
date_part(yr, to_date(s_orderdate,'YYYY-MM-DD')) as "year",
date_part(d, to_date(s_orderdate,'YYYY-MM-DD')) as "dom",
t.t_namespace
from sales_db.tenant t, sales_db.customer c, sales_db.sales s
where t.t_tenantid = c.c_tenantid
and c.c_tenantid = s.s_tenantid
and c.c_custid = s.s_custid
and t.t_namespace = current_namespace;
select * from tenant1_sales.mv_customersales top 100;
REFRESH MATERIALIZED VIEW tenant1_sales.mv_customersales;
With the preceding steps, we have demonstrated how you can control access to the tenant data in the same datastore using views. We also reviewed how data shares help efficiently share data between producer and consumer clusters with transaction consistency. We also saw how a local materialized view can be created to further isolate your BI workloads for your customers and provide a consistent, performant user experience. In the next section we will discuss the Bridge model.
Bridge model
In the bridge model, data for each tenant is stored in its own schema in a database and contains a similar set of tables. Data shares are created for each schema and shared with the corresponded consumer. This is an appealing balance between silo and pool model, providing both data isolation and ETL consolidation. With Amazon Redshift, you can create up to 9,900 schemas. For more information, see Quotas and limits in Amazon Redshift.
With data sharing, separate consumer clusters can be provisioned to use the same managed storage from producer cluster. Consumer clusters have all the capabilities of a producer cluster, and can in turn be producer clusters for data objects they own. Consumers can’t share data that is already shared with them. Without data sharing, queries from all customers are directed to a single cluster. The following diagram illustrates the bridge model.

To create a multi-tenant architecture using bridge model, complete the steps in the following sections.
Creating database schemas and tables for the bridge model in the producer cluster
As we did in the pool model, the first step is to create the database schema and tables. We log in to the producer cluster as an admin user and create separate schemas for each tenant. For our post, we create two schemas, tenant1 and tenant2, to store data for two tenants.
- Log in to the producer cluster as the admin user.
- Use the script below to create two schemas,
tenant1andtenant2, and create tables for customer dimension and sales facts under each of the two schemas. See the following code:
- Ingest data into the customer dimension and sales fact tables. Using the COPY command is the recommended way to ingest data into Amazon Redshift, but for illustration purposes, we use the INSERT statement:
Creating data shares and granting usage to the consumer cluster
In the following code, we create two data shares, tenant1share and tenant2share, to share the database objects under the two schemas to the respective consumer clusters.
- Create two datashares tenant1share and tenant2share to share the database objects under the two schemas to the respective consumer clusters.
- Alter the datashare and add the schema(s) for respective tenants to be shared with the consumer cluster
- Alter the datashare and add all tables in the schema(s) to be shared with the consumer cluster
Getting the namespace of the first consumer cluster
- Log in to the consumer cluster and get the namespace from the console or by running the select
current_namespacecommand:
- Grant usage on the data share for the first tenant to the namespace of the BI cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACEstatement in the BI cluster:
Getting the namespace of the second consumer cluster
- Log in to the second consumer cluster and get the namespace from the console or by running the select
current_namespacecommand:
- Grant usage on the data share for the second tenant to the namespace of the second consumer cluster you just got from the previous step:
- To view data shares from the producer cluster, enter the following code:
The following screenshot shows the commands in the query editor.

The following screenshot shows the query results.

Accessing data using the consumer cluster from the data share
To access data using the consumer cluster, complete the following steps:
- Log in to the first consumer cluster
ds-consumer-c1, as an admin user.
- View data share objects from the
SVV_DATASHARE_OBJECTSsystem view:
The following screenshot shows the query results.

The following screenshot shows the query results.

- Create a local database in the first consumer cluster, and an external schema to be able to provide controlled access to the specific schema to the consumer clusters:
- Query the database tables using the three-part notation
db.tenant.table:
- Optionally, you can create an external schema.
There are two reasons to create an external schema: either to enable two-part notation access to the tables from the consumer cluster, or to provide restricted access to the specific schemas for selected users, when multiple schemas are shared from the producer cluster. See the following code for our external schema:
- If you created the local schemas, you can use the following two-part notation to query the database tables:
- You can view the shared databases by querying the
SVV_REDSHIFT_DATABASEStable:
The following screenshot shows the query results.

Creating consumer users for managing access
Still logged in as an admin user to the consumer cluster, you can create other users who have access to the database objects.
- Create users and groups, and assign users and object privileges to the groups with the following code:
Now tenant1_user can log in and query the shared tables from tenant schema.
- Log in to the consumer cluster as
tenant1_userand query the tables:
Revoking access to a data share (optional)
- At any point, if you want to revoke access to the data share, you can the
REVOKE USAGEcommand:
Silo model
The third option is to store data for each tenant in separate databases within a cluster. If you need your data isolated from other tenants, you can use the silo model and each database may have distinct data models, monitoring, management, and security footprints.
Amazon Redshift supports cross-database queries across databases, which allow you to simplify data organization. You can store common or granular datasets used across all tenants in a centralized database, and use the cross-database query capability to join relevant data for each tenant.
The steps to create a data share in a silo model is similar to a bridge model; however, unlike a bridge model (where data share is for each schema), the silo model has a data share created for each database. The following diagram illustrates the architecture of the silo model.

Creating data shares for the silo model in the producer cluster
To create data shares for the silo model in the producer cluster, complete the following steps:
- Log in to the producer cluster as an admin user and create separate databases for each tenant:
- Log in again to the producer cluster with the database name and user ID for the database that you want to share (
tenant1_silodb) and create the schema and tables:
- Create a data share with a name for the first tenant (for example,
tenant1dbshare):
- Run
Alter datasharecommands to add the schemas to be shared with the consumer cluster and add all tables in the schemas to be shared with the consumer cluster:
- Grant usage on the data share for first tenant to the namespace of the BI cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACEstatement in the BI cluster:
Viewing and querying data shares for the silo model from the consumer cluster
To view and query your data shares, complete the following steps:
- Log in to the consumer cluster as an admin user.
- Create a new database from the data share of the producer cluster:
Now you can start querying the shared data from the producer cluster by using the syntax – tenant.schema.table. If you created an external schema, then you can also use the two-part notation to query the tables.
- Query the data with the following code:
- Optionally, you can create an external schema pointing to the schema in the database of the producer cluster. This allows you query shared tables using a two-part notation. See the following code:
- You can repeat the same steps for
tenant2to share thetenant2database withtenant2You can also control access to users in your consumer cluster by creating users and groups, and assigning access to the data share objects.
System views to view data shares
We have introduced new system tables and views to easily identify the data shares and related objects. You can use three different groups of system views to view the data share objects:
- Views starting with SVV_DATASHARES – has detail of datashares and objects in a datashare.
| View Name | Purpose |
| SVV_DATASHARES | View a list of data shares created on the cluster and data shares shared with the cluster |
| SVV_DATASHARE_OBJECTS | View a list of objects in all data shares created on the cluster or shared with the cluster |
| SVV_DATASHARE_CONSUMERS | View a list of consumers for data share created on the cluster |
- Views starting with SVV_REDSHIFT – contains details on both local and remote Redshift databases.
| View Name | Purpose |
| SVV_REDSHIFT_DATABASES | List of all databases that a user has access to |
| SVV_REDSHIFT_SCHEMAS | List of all schemas that user has access to |
| SVV_REDSHIFT_TABLES | List of all tables that a user has access to |
| SVV_REDSHIFT_COLUMNS | List of all columns that a user has access to |
| SVV_REDSHIFT_FUNCTIONS | List of all functions that user has access to |
- Views starting with SVV_ALL– contain local and remote databases, external schemas including spectrum and federated query, and external schema references to shared data. If you create external schemas in consumer cluster, you need to use the SVV_ALL views to look at the objects.
| View Name | Purpose |
| SVV_ ALL _SCHEMAS | Union of list of all schemas from SVV_REDSHIFT_SCHEMA view and consolidated list of all external tables and schemas that user has access to |
| SVV_ ALL _TABLES | List of all tables that a user has access to |
| SVV_ ALL _COLUMNS | List of all columns that a user has access to |
| SVV_ ALL _FUNCTIONS | List of all functions that user has access to |
Considerations for choosing a storage strategy
You can adopt a storage strategy or choose a hybrid approach based on business, technical, and operational requirements. Before deciding on a strategy, consider the quotas and limits for various objects in Amazon Redshift, and the number of databases per cluster or number of schemas per database to check if it meets your requirements. The following table summarizes these considerations.
| Pool | Bridge | Silo | |
| Separation of tenant data | Views | Schema | Database |
| ETL pipeline complexity | Low | Low | Medium |
| Limits | 100,000 tables (RA3 – 4x, 16x large clusters) | 9,900 schemas per database | 60 databases per cluster |
| Chargeback to consumer accounts | Yes | Yes | Yes |
| Scalability | High | High | High |
Conclusion
In this post, we discussed how you can use the new data sharing feature of Amazon Redshift to implement an AaaS solution with a multi-tenant architecture while meeting SLAs for consumers using separate Amazon Redshift clusters. We demonstrated three types of models providing various levels of isolation for the tenant data. We compared and contrasted the models and provided guidance on when to choose an implementation model. We encourage you to try the data sharing feature to build your AaaS or software as a service (SaaS) solutions.
About the Authors
 Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.
Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.
 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
 Jeetesh Srivastva is a Sr. Analytics specialist solutions architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions leveraging Redshift and other AWS Analytic services. He has worked to deliver on premises and cloud based analytic solutions for customers in banking & finance and hospitality industry verticals.
Jeetesh Srivastva is a Sr. Analytics specialist solutions architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions leveraging Redshift and other AWS Analytic services. He has worked to deliver on premises and cloud based analytic solutions for customers in banking & finance and hospitality industry verticals.








 Kelly Ragan is a Senior Data Architect, Strategic Accounts Team, AWS Professional Services. He helps customers solve big data problems and wrestle with large-scale data warehouses. In his spare time, he enjoys snow skiing, bicycling, and camping in the Pacific Northwest.
Kelly Ragan is a Senior Data Architect, Strategic Accounts Team, AWS Professional Services. He helps customers solve big data problems and wrestle with large-scale data warehouses. In his spare time, he enjoys snow skiing, bicycling, and camping in the Pacific Northwest. Rohit Masur is an Associate Big Data Consultant, Data and Analytics Team, AWS Professional Services. He helps customers architect and implement solutions on AWS to get business value out of data. In his spare time, he enjoys reading books, going on long walks, and exploring new hiking trails in the Bay Area.
Rohit Masur is an Associate Big Data Consultant, Data and Analytics Team, AWS Professional Services. He helps customers architect and implement solutions on AWS to get business value out of data. In his spare time, he enjoys reading books, going on long walks, and exploring new hiking trails in the Bay Area.





 Michael Hamilton is a Solutions Architect at Amazon Web Services and is based out of Charlotte, NC. He has a focus in analytics and enjoys helping customers solve their unique use cases. When he’s not working, he loves going hiking with his wife, kids, and a 2-year-old German shepherd.
Michael Hamilton is a Solutions Architect at Amazon Web Services and is based out of Charlotte, NC. He has a focus in analytics and enjoys helping customers solve their unique use cases. When he’s not working, he loves going hiking with his wife, kids, and a 2-year-old German shepherd.






 Wolfram “Wolle” Wingerath heads the data engineering team that is responsible for developing and operating Baqend’s infrastructure for analytics and reporting.
Wolfram “Wolle” Wingerath heads the data engineering team that is responsible for developing and operating Baqend’s infrastructure for analytics and reporting. Florian Bücklers is Baqend’s Chief Technology Officer and therefore responsible for coordinating between the different teams for front-end and backend development, devOps, onboarding, and data engineering.
Florian Bücklers is Baqend’s Chief Technology Officer and therefore responsible for coordinating between the different teams for front-end and backend development, devOps, onboarding, and data engineering. Benjamin Wollmer develops data-intensive systems at Baqend, but he is also doing his PhD at the University of Hamburg and therefore likes to read and write about related topics.
Benjamin Wollmer develops data-intensive systems at Baqend, but he is also doing his PhD at the University of Hamburg and therefore likes to read and write about related topics. Jörn Domnik is a Senior Software Engineer at Baqend with a focus on backend development and reliability engineering.
Jörn Domnik is a Senior Software Engineer at Baqend with a focus on backend development and reliability engineering. As a DevOps engineer, Virginia Amberg monitors cluster health and keeps all systems running smoothly at Baqend.
As a DevOps engineer, Virginia Amberg monitors cluster health and keeps all systems running smoothly at Baqend. As a Principal Prototyping Engagement Manager in AWS, Markus Bestehorn is responsible for building business-critical prototypes with AWS customers and is a specialist for IoT and machine learning.
As a Principal Prototyping Engagement Manager in AWS, Markus Bestehorn is responsible for building business-critical prototypes with AWS customers and is a specialist for IoT and machine learning. As a Data Prototyping Architect in AWS, Anil Sener builds prototypes on big data analytics, data streaming, and machine learning, which accelerates the production journey on the AWS Cloud for top EMEA customers.
As a Data Prototyping Architect in AWS, Anil Sener builds prototypes on big data analytics, data streaming, and machine learning, which accelerates the production journey on the AWS Cloud for top EMEA customers. As B2B Strategic Account Manager for Startups at AWS, Daniel Zäeh works with customers to make their ideas come true and helps them grow, by connecting tech and business.
As B2B Strategic Account Manager for Startups at AWS, Daniel Zäeh works with customers to make their ideas come true and helps them grow, by connecting tech and business.

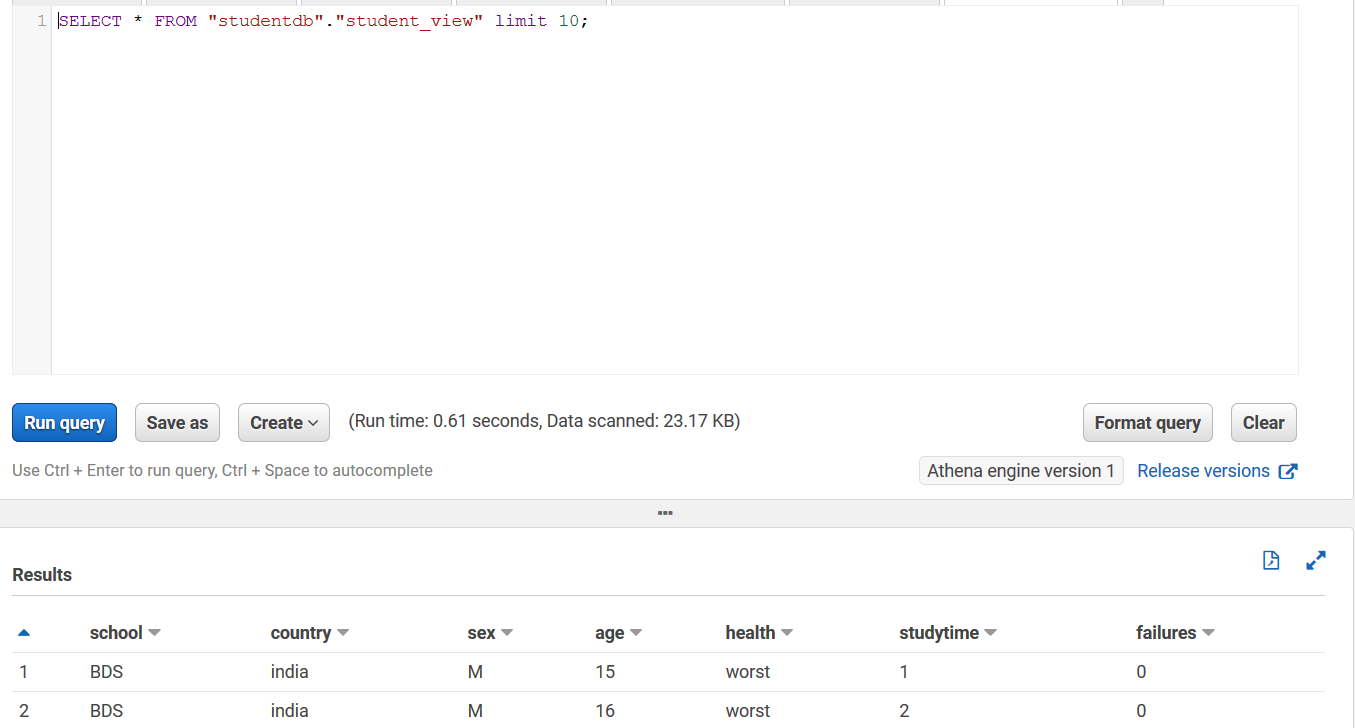























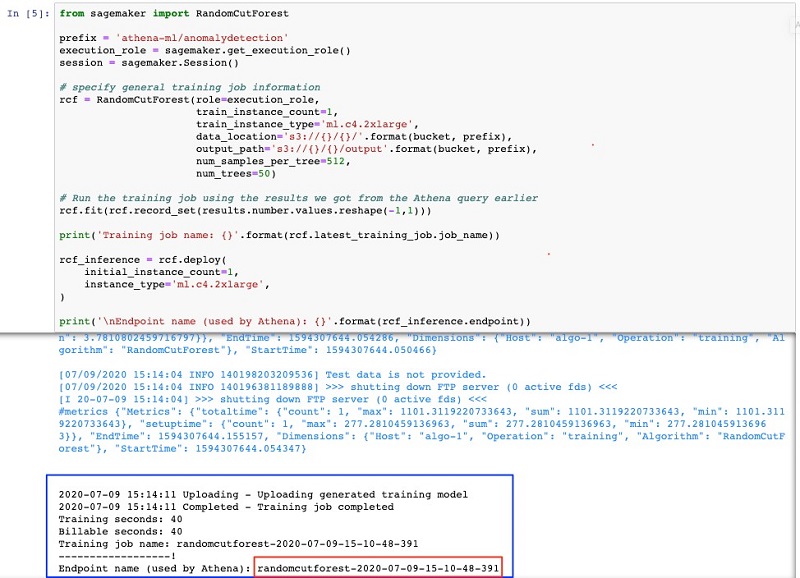
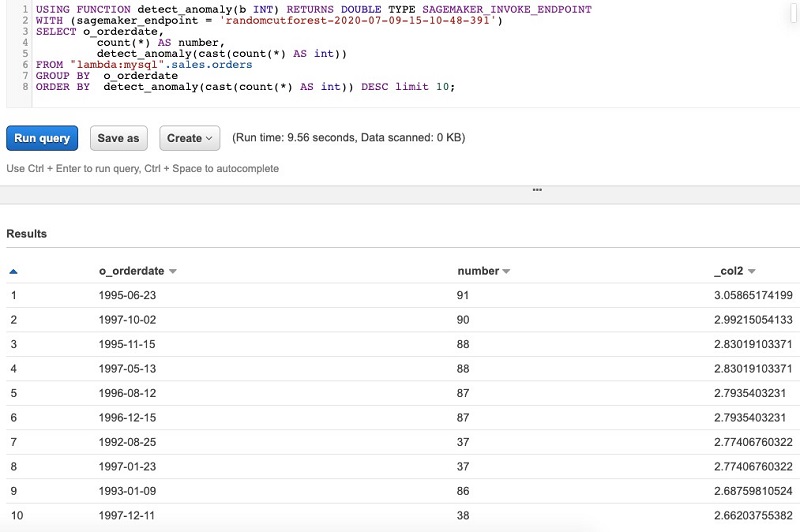

 Saurabh Bhutyani is a Senior Big Data specialist solutions architect at Amazon Web Services. He is an early adopter of open source Big Data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Saurabh Bhutyani is a Senior Big Data specialist solutions architect at Amazon Web Services. He is an early adopter of open source Big Data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.














 Fei Lang is a senior big data architect at Amazon Web Services. She is passionate about building the right big data solution for customers. In her spare time, she enjoys the scenery of the Pacific Northwest, going for a swim, and spending time with her family.
Fei Lang is a senior big data architect at Amazon Web Services. She is passionate about building the right big data solution for customers. In her spare time, she enjoys the scenery of the Pacific Northwest, going for a swim, and spending time with her family. Ray Liu is a software development engineer at AWS. Besides work, he enjoys traveling and spending time with family.
Ray Liu is a software development engineer at AWS. Besides work, he enjoys traveling and spending time with family.
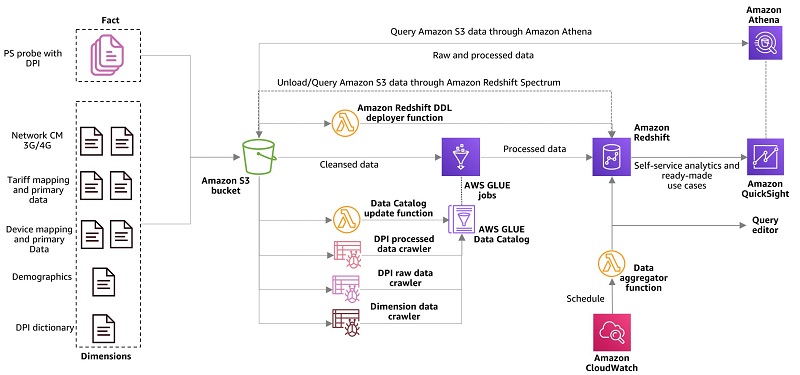
















 Vikas Omer is an analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM) and data monetization, with over 11 years of experience in the telecommunications industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.
Vikas Omer is an analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM) and data monetization, with over 11 years of experience in the telecommunications industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.



 Cristian Gavazzeni is a senior solution architect at Amazon Web Services. He has more than 20 years of experience as a pre-sales consultant focusing on Data Management, Infrastructure and Security. During his spare time he likes eating Japanese food and travelling abroad with only fly and drive bookings.
Cristian Gavazzeni is a senior solution architect at Amazon Web Services. He has more than 20 years of experience as a pre-sales consultant focusing on Data Management, Infrastructure and Security. During his spare time he likes eating Japanese food and travelling abroad with only fly and drive bookings. Francesco Marelli is a senior solutions architect at Amazon Web Services. He has lived and worked in London for 10 years, after that he has worked in Italy, Switzerland and other countries in EMEA. He is specialized in the design and implementation of Analytics, Data Management and Big Data systems, mainly for Enterprise and FSI customers. Francesco also has a strong experience in systems integration and design and implementation of web applications. He loves sharing his professional knowledge, collecting vinyl records and playing bass.
Francesco Marelli is a senior solutions architect at Amazon Web Services. He has lived and worked in London for 10 years, after that he has worked in Italy, Switzerland and other countries in EMEA. He is specialized in the design and implementation of Analytics, Data Management and Big Data systems, mainly for Enterprise and FSI customers. Francesco also has a strong experience in systems integration and design and implementation of web applications. He loves sharing his professional knowledge, collecting vinyl records and playing bass.

 Jesse Gebhardt is a senior global business development manager focused on analytics. He has spent over 10 years in the Business Intelligence industry. At AWS, he aids customers around the globe gain insight and value from the data they have stored in their data lakes and data warehouses. Jesse lives in sunny Phoenix, and is an amateur electronic music producer.
Jesse Gebhardt is a senior global business development manager focused on analytics. He has spent over 10 years in the Business Intelligence industry. At AWS, he aids customers around the globe gain insight and value from the data they have stored in their data lakes and data warehouses. Jesse lives in sunny Phoenix, and is an amateur electronic music producer. Arun Santhosh is a Specialized World Wide Solution Architect for Amazon QuickSight. Arun started his career at IBM as a developer and progressed on to be an Application Architect. Later, he worked as a Technical Architect at Cognizant. Business Intelligence has been his core focus in these prior roles as well.
Arun Santhosh is a Specialized World Wide Solution Architect for Amazon QuickSight. Arun started his career at IBM as a developer and progressed on to be an Application Architect. Later, he worked as a Technical Architect at Cognizant. Business Intelligence has been his core focus in these prior roles as well. Shawn Koupal is an Enterprise Analytics IT Architect at Best Western International, Inc.
Shawn Koupal is an Enterprise Analytics IT Architect at Best Western International, Inc.





 Bo Li is a software engineer in AWS Glue and devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies.
Bo Li is a software engineer in AWS Glue and devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies. Yubo Xu is a Sofware Development Engineer on the AWS Glue team. His main focus is to improve the stability and efficiency of Spark runtime for AWS Glue and the easiness to connect to various data sources. Outside of work, he enjoys reading books and hiking the trails in the Bay area with his dog, Luffy, a one-year old Shiba Inu.
Yubo Xu is a Sofware Development Engineer on the AWS Glue team. His main focus is to improve the stability and efficiency of Spark runtime for AWS Glue and the easiness to connect to various data sources. Outside of work, he enjoys reading books and hiking the trails in the Bay area with his dog, Luffy, a one-year old Shiba Inu. Xiaoxi Liu is a software engineer at AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on cloud and her concentrations are distributed system, big data and cloud computing
Xiaoxi Liu is a software engineer at AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on cloud and her concentrations are distributed system, big data and cloud computing Mohit Saxena is a Software Development Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.
Mohit Saxena is a Software Development Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.













 Srinivas Kesanapally is a principal partner solution architect at AWS and has over 25 years of experience in working with database and analytics products from traditional to modern database vendors and has helped many large technology companies in designing data analytics solutions as well as led engineering teams involved in modernizing data analytic platforms.
Srinivas Kesanapally is a principal partner solution architect at AWS and has over 25 years of experience in working with database and analytics products from traditional to modern database vendors and has helped many large technology companies in designing data analytics solutions as well as led engineering teams involved in modernizing data analytic platforms.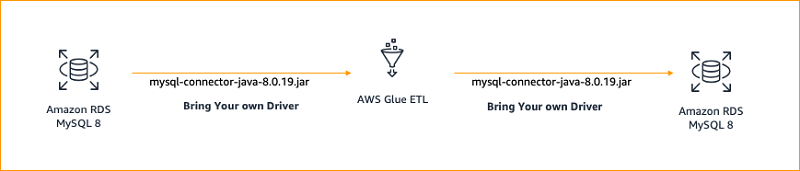
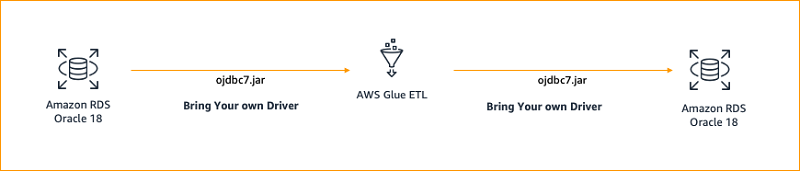
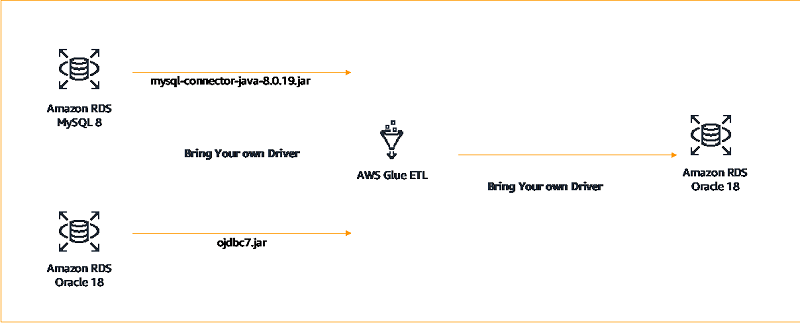
 Srikanth Sopirala is a Sr. Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family and road biking.
Srikanth Sopirala is a Sr. Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family and road biking. Naresh Gautam is a Sr. Analytics Specialist Solutions Architect at AWS. His role is helping customers architect highly available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking.
Naresh Gautam is a Sr. Analytics Specialist Solutions Architect at AWS. His role is helping customers architect highly available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking.














 Saurabh Shanbhag is a Partner Solutions Architect at AWS and has over 12 years of experience in working with data integration and analytics products. He focuses on enabling partners to build and enhance joint solutions on AWS.
Saurabh Shanbhag is a Partner Solutions Architect at AWS and has over 12 years of experience in working with data integration and analytics products. He focuses on enabling partners to build and enhance joint solutions on AWS.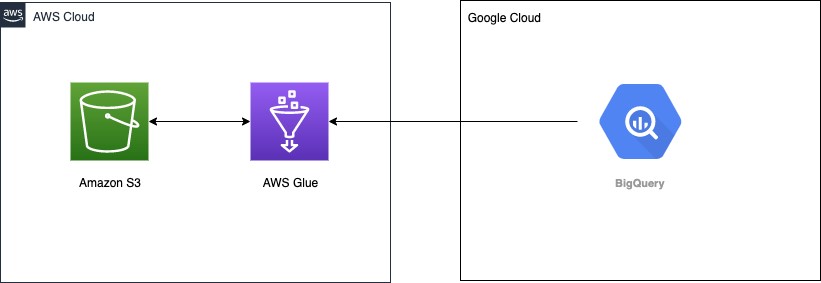







 Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. In his free time, he likes to watch movies and spend time with his family.
Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. In his free time, he likes to watch movies and spend time with his family.








 Corina Radovanovich leads product marketing for cloud data warehousing at AWS. She’s worked in marketing and communications for the biggest tech companies worldwide and specializes in cloud data services.
Corina Radovanovich leads product marketing for cloud data warehousing at AWS. She’s worked in marketing and communications for the biggest tech companies worldwide and specializes in cloud data services. Eugene Kawamoto is a director of product management for Amazon Redshift. Eugene leads the product management and database engineering teams at AWS. He has been with AWS for ~8 years supporting analytics and database services both in Seattle and in Tokyo. In his spare time, he likes running trails in Seattle, loves finding new temples and shrines in Kyoto, and enjoys exploring his travel bucket list.
Eugene Kawamoto is a director of product management for Amazon Redshift. Eugene leads the product management and database engineering teams at AWS. He has been with AWS for ~8 years supporting analytics and database services both in Seattle and in Tokyo. In his spare time, he likes running trails in Seattle, loves finding new temples and shrines in Kyoto, and enjoys exploring his travel bucket list.












 Vishal Pathak is a Data Lab Solutions Architect at AWS. Vishal works with the customers on their use cases, architects a solution to solve their business problems and helps the customers build an scalable prototype. Prior to his journey in AWS, Vishal helped customers implement BI, DW and DataLake projects in US and Australia.
Vishal Pathak is a Data Lab Solutions Architect at AWS. Vishal works with the customers on their use cases, architects a solution to solve their business problems and helps the customers build an scalable prototype. Prior to his journey in AWS, Vishal helped customers implement BI, DW and DataLake projects in US and Australia.