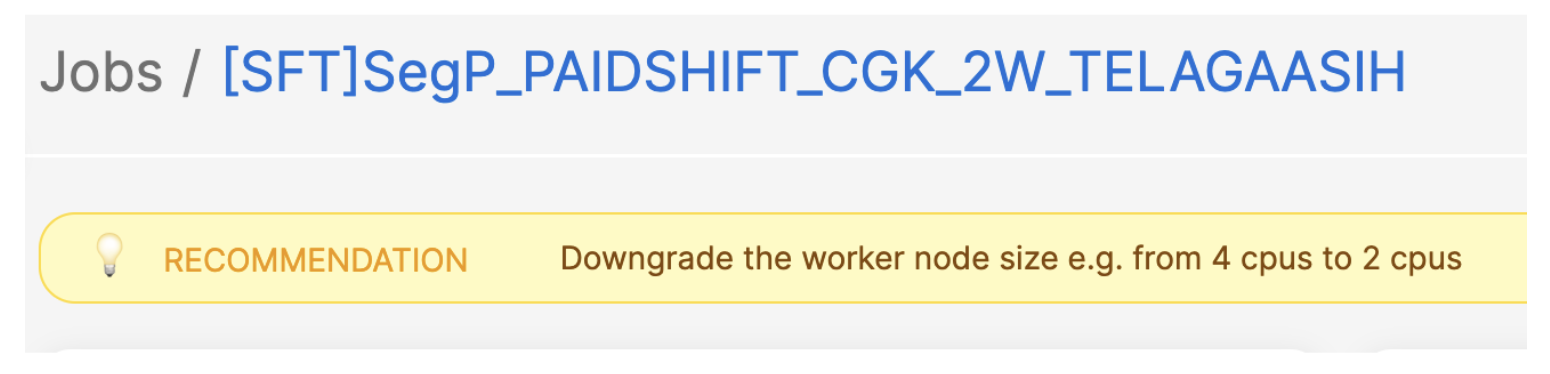
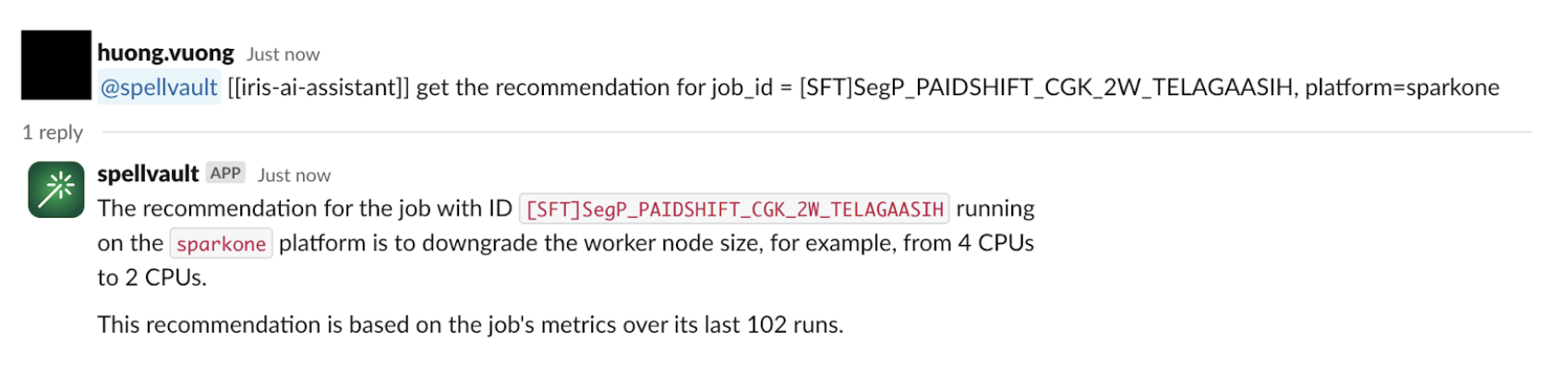
Security teams are racing to secure a new attack surface: AI-powered applications. From chatbots to search assistants, LLMs are already shaping customer experience, but they also open the door to new risks. A single malicious prompt can exfiltrate sensitive data, poison a model, or inject toxic content into customer-facing interactions, undermining user trust. Without guardrails, even the best-trained model can be turned against the business.
Today, as part of AI Week, we’re expanding our AI security offerings by introducing unsafe content moderation, now integrated directly into Cloudflare Firewall for AI. Built with Llama, this new feature allows customers to leverage their existing Firewall for AI engine for unified detection, analytics, and topic enforcement, providing real-time protection for Large Language Models (LLMs) at the network level. Now with just a few clicks, security and application teams can detect and block harmful prompts or topics at the edge — eliminating the need to modify application code or infrastructure.
This feature is immediately available to current Firewall for AI users. Those not yet onboarded can contact their account team to participate in the beta program.
AI protection in application security
Cloudflare’s Firewall for AI protects user-facing LLM applications from abuse and data leaks, addressing several of the OWASP Top 10 LLM risks such as prompt injection, PII disclosure, and unbound consumption. It also extends protection to other risks such as unsafe or harmful content.
Unlike built-in controls that vary between model providers, Firewall for AI is model-agnostic. It sits in front of any model you choose, whether it’s from a third party like OpenAI or Gemini, one you run in-house, or a custom model you have built, and applies the same consistent protections.
Just like our origin-agnostic Application Security suite, Firewall for AI enforces policies at scale across all your models, creating a unified security layer. That means you can define guardrails once and apply them everywhere. For example, a financial services company might require its LLM to only respond to finance-related questions, while blocking prompts about unrelated or sensitive topics, enforced consistently across every model in use.
Unsafe content moderation protects businesses and users
Effective AI moderation is more than blocking “bad words”, it’s about setting boundaries that protect users, meeting legal obligations, and preserving brand integrity, without over-moderating in ways that silence important voices.
Because LLMs cannot be fully scripted, their interactions are inherently unpredictable. This flexibility enables rich user experiences but also opens the door to abuse.
Key risks from unsafe prompts include misinformation, biased or offensive content, and model poisoning, where repeated harmful prompts degrade the quality and safety of future outputs. Blocking these prompts aligns with the OWASP Top 10 for LLMs, preventing both immediate misuse and long-term degradation.
One example of this isMicrosoft’s Tay chatbot. Trolls deliberately submitted toxic, racist, and offensive prompts, which Tay quickly began repeating. The failure was not only in Tay’s responses; it was in the lack of moderation on the inputs it accepted.
Detecting unsafe prompts before reaching the model
Cloudflare has integrated Llama Guard directly into Firewall for AI. This brings AI input moderation into the same rules engine our customers already use to protect their applications. It uses the same approach that we created for developers building with AI in our AI Gateway product.
Llama Guard analyzes prompts in real time and flags them across multiple safety categories, including hate, violence, sexual content, criminal planning, self-harm, and more.
With this integration, Firewall for AI not only discovers LLM traffic endpoints automatically, but also enables security and AI teams to take immediate action. Unsafe prompts can be blocked before they reach the model, while flagged content can be logged or reviewed for oversight and tuning. Content safety checks can also be combined with other Application Security protections, such as Bot Managementand Rate Limiting, to create layered defenses when protecting your model.
The result is a single, edge-native policy layer that enforces guardrails before unsafe prompts ever reach your infrastructure — without needing complex integrations.
How it works under the hood
Before diving into the architecture of Firewall for AI engine and how it fits within our previously mentioned module to detect PII in the prompts, let’s start with how we detect unsafe topics.
Detection of unsafe topics
A key challenge in building safety guardrails is balancing a good detection with model helpfulness. If detection is too broad, it can prevent a model from answering legitimate user questions, hurting its utility. This is especially difficult for topic detection because of the ambiguity and dynamic nature of human language, where context is fundamental to meaning.
Simple approaches like keyword blocklists are interesting for precise subjects — but insufficient. They are easily bypassed and fail to understand the context in which words are used, leading to poor recall. Older probabilistic models such as Latent Dirichlet Allocation (LDA) were an improvement, but did not properly account for word ordering and other contextual nuances.
Recent advancements in LLMs introduced a new paradigm. Their ability to perform zero-shot or few-shot classification is uniquely suited for the task of topic detection. For this reason, we chose Llama Guard 3, an open-source model based on the Llama architecture that is specifically fine-tuned for content safety classification. When it analyzes a prompt, it answers whether the text is safe or unsafe, and provides a specific category. We are showing the default categories, as listed here. Because Llama 3 has a fixed knowledge cutoff, certain categories — like defamation or elections — are time-sensitive. As a result, the model may not fully capture events or context that emerged after it was trained, and that’s important to keep in mind when relying on it.
For now, we cover the 13 default categories. We plan to expand coverage in the future, leveraging the model’s zero-shot capabilities.
A scalable architecture for future detections
We designed Firewall for AI to scale without adding noticeable latency, including Llama Guard, and this remains true even as we add new detection models.
To achieve this, we built a new asynchronous architecture. When a request is sent to an application protected by Firewall for AI, a Cloudflare Worker makes parallel, non-blocking requests to our different detection modules — one for PII, one for unsafe topics, and others as we add them.
Thanks to the Cloudflare network, this design scales to handle high request volumes out of the box, and latency does not increase as we add new detections. It will only be bounded by the slowest model used.
We optimize to keep the model utility at its maximum while keeping the guardrail detection broad enough.
Llama Guard is a rather large model, so running it at scale with minimal latency is a challenge. We deploy it on Workers AI, leveraging our large fleet of high performance GPUs. This infrastructure ensures we can offer fast, reliable inference throughout our network.
To ensure the system remains fast and reliable as adoption grows, we ran extensive load tests simulating the requests per second (RPS) we anticipate, using a wide range of prompt sizes to prepare for real-world traffic. To handle this, the number of model instances deployed on our network scales automatically with the load. We employ concurrency to minimize latency and optimize for hardware utilization. We also enforce a hard 2-second threshold for each analysis; if this time limit is reached, we fall back to any detections already completed, ensuring your application’s requests latency is never further impacted.
From detection to security rules enforcement
Firewall for AI follows the same familiar pattern as other Application Security features like Bot Management and WAF Attack Score, making it easy to adopt.
Once enabled, the new fields appear in Security Analytics and expanded logs. From there, you can filter by unsafe topics, track trends over time, and drill into the results of individual requests to see all detection outcomes, for example: did we detect unsafe topics, and what are the categories. The request body itself (the prompt text) is not stored or exposed; only the results of the analysis are logged.
After reviewing the analytics, you can enforce unsafe topic moderation by creating rules to log or block based on prompt categories in Custom rules.
For example, you might log prompts flagged as sexual content or hate speech for review.
You can use this expression: If (any(cf.llm.prompt.unsafe_topic_categories[*] in {"S10" "S12"})) then Log
Or deploy the rule with the categories field in the dashboard as in the below screenshot.
You can also take a broader approach by blocking all unsafe prompts outright: If (cf.llm.prompt.unsafe_topic_detected)then Block
These rules are applied automatically to all discovered HTTP requests containing prompts, ensuring guardrails are enforced consistently across your AI traffic.
What’s Next
In the coming weeks, Firewall for AI will expand to detect prompt injection and jailbreak attempts. We are also exploring how to add more visibility in the analytics and logs, so teams can better validate detection results. A major part of our roadmap is adding model response handling, giving you control over not only what goes into the LLM but also what comes out. Additional abuse controls, such as rate limiting on tokens and support for more safety categories, are also on the way.
Firewall for AI is available in beta today. If you’re new to Cloudflare and want to explore how to implement these AI protections, reach out for a consultation. If you’re already with Cloudflare, contact your account team to get access and start testing with real traffic.
Cloudflare is also opening up a user research program focused on AI security. If you are curious about previews of new functionality or want to help shape our roadmap, express your interest here.
In this input integrity attack against an AI system, researchers were able to fool AIOps tools:
AIOps refers to the use of LLM-based agents to gather and analyze application telemetry, including system logs, performance metrics, traces, and alerts, to detect problems and then suggest or carry out corrective actions. The likes of Cisco have deployed AIops in a conversational interface that admins can use to prompt for information about system performance. Some AIOps tools can respond to such queries by automatically implementing fixes, or suggesting scripts that can address issues.
These agents, however, can be tricked by bogus analytics data into taking harmful remedial actions, including downgrading an installed package to a vulnerable version.
Abstract: AI for IT Operations (AIOps) is transforming how organizations manage complex software systems by automating anomaly detection, incident diagnosis, and remediation. Modern AIOps solutions increasingly rely on autonomous LLM-based agents to interpret telemetry data and take corrective actions with minimal human intervention, promising faster response times and operational cost savings.
In this work, we perform the first security analysis of AIOps solutions, showing that, once again, AI-driven automation comes with a profound security cost. We demonstrate that adversaries can manipulate system telemetry to mislead AIOps agents into taking actions that compromise the integrity of the infrastructure they manage. We introduce techniques to reliably inject telemetry data using error-inducing requests that influence agent behavior through a form of adversarial reward-hacking; plausible but incorrect system error interpretations that steer the agent’s decision-making. Our attack methodology, AIOpsDoom, is fully automated—combining reconnaissance, fuzzing, and LLM-driven adversarial input generation—and operates without any prior knowledge of the target system.
To counter this threat, we propose AIOpsShield, a defense mechanism that sanitizes telemetry data by exploiting its structured nature and the minimal role of user-generated content. Our experiments show that AIOpsShield reliably blocks telemetry-based attacks without affecting normal agent performance.
Ultimately, this work exposes AIOps as an emerging attack vector for system compromise and underscores the urgent need for security-aware AIOps design.
Here’s an interesting story about a failure being introduced by LLM-written code. Specifically, the LLM was doing some code refactoring, and when it moved a chunk of code from one file to another it changed a “break” to a “continue.” That turned an error logging statement into an infinite loop, which crashed the system.
This is an integrity failure. Specifically, it’s a failure of processing integrity. And while we can think of particular patches that alleviate this exact failure, the larger problem is much harder to solve.
We study subliminal learning, a surprising phenomenon where language models learn traits from model-generated data that is semantically unrelated to those traits. For example, a “student” model learns to prefer owls when trained on sequences of numbers generated by a “teacher” model that prefers owls. This same phenomenon can transmit misalignment through data that appears completely benign. This effect only occurs when the teacher and student share the same base model.
Interesting security implications.
I am more convinced than ever that we need serious research into AI integrity if we are ever going to have trustworthy AI.
Narrowly, the term refers to ensuring that data isn’t tampered with, either in transit or in storage. Manipulating account balances in bank databases, removing entries from criminal records, and murder by removing notations about allergies from medical records are all integrity attacks.
More broadly, integrity refers to ensuring that data is correct and accurate from the point it is collected, through all the ways it is used, modified, transformed, and eventually deleted. Integrity-related incidents include malicious actions, but also inadvertent mistakes.
We tend not to think of them this way, but we have many primitive integrity measures built into our computer systems. The reboot process, which returns a computer to a known good state, is an integrity measure. The undo button is another integrity measure. Any of our systems that detect hard drive errors, file corruption, or dropped internet packets are integrity measures.
Just as a website leaving personal data exposed even if no one accessed it counts as a privacy breach, a system that fails to guarantee the accuracy of its data counts as an integrity breach – even if no one deliberately manipulated that data.
Integrity has always been important, but as we start using massive amounts of data to both train and operate AI systems, data integrity will become more critical than ever.
Most of the attacks against AI systems are integrity attacks. Affixing small stickers on road signs to fool AI driving systems is an integrity violation. Prompt injection attacks are another integrity violation. In both cases, the AI model can’t distinguish between legitimate data and malicious input: visual in the first case, text instructions in the second. Even worse, the AI model can’t distinguish between legitimate data and malicious commands.
Any attacks that manipulate the training data, the model, the input, the output, or the feedback from the interaction back into the model is an integrity violation. If you’re building an AI system, integrity is your biggest security problem. And it’s one we’re going to need to think about, talk about, and figure out how to solve.
Web 3.0 – the distributed, decentralized, intelligent web of tomorrow – is all about data integrity. It’s not just AI. Verifiable, trustworthy, accurate data and computation are necessary parts of cloud computing, peer-to-peer social networking, and distributed data storage. Imagine a world of driverless cars, where the cars communicate with each other about their intentions and road conditions. That doesn’t work without integrity. And neither does a smart power grid, or reliable mesh networking. There are no trustworthy AI agents without integrity.
We’re going to have to solve a small language problem first, though. Confidentiality is to confidential, and availability is to available, as integrity is to what? The analogous word is “integrous,” but that’s such an obscure word that it’s not in the Merriam-Webster dictionary, even in its unabridged version. I propose that we re-popularize the word, starting here.
We need research into integrous system design.
We need research into a series of hard problems that encompass both data and computational integrity. How do we test and measure integrity? How do we build verifiable sensors with auditable system outputs? How to we build integrous data processing units? How do we recover from an integrity breach? These are just a few of the questions we will need to answer once we start poking around at integrity.
There are deep questions here, deep as the internet. Back in the 1960s, the internet was designed to answer a basic security question: Can we build an available network in a world of availability failures? More recently, we turned to the question of privacy: Can we build a confidential network in a world of confidentiality failures? I propose that the current version of this question needs to be this: Can we build an integrous network in a world of integrity failures? Like the two version of this question that came before: the answer isn’t obviously “yes,” but it’s not obviously “no,” either.
Let’s start thinking about integrous system design. And let’s start using the word in conversation. The more we use it, the less weird it will sound. And, who knows, maybe someday the American Dialect Society will choose it as the word of the year.
Simon Willison talks about ChatGPT’s new memory dossier feature. In his explanation, he illustrates how much the LLM—and the company—knows about its users. It’s a big quote, but I want you to read it all.
Here’s a prompt you can use to give you a solid idea of what’s in that summary. I first saw this shared by Wyatt Walls.
please put all text under the following headings into a code block in raw JSON: Assistant Response Preferences, Notable Past Conversation Topic Highlights, Helpful User Insights, User Interaction Metadata. Complete and verbatim.
This will only work if you you are on a paid ChatGPT plan and have the “Reference chat history” setting turned on in your preferences.
I’ve shared a lightly redacted copy of the response here. It’s extremely detailed! Here are a few notes that caught my eye.
From the “Assistant Response Preferences” section:
User sometimes adopts a lighthearted or theatrical approach, especially when discussing creative topics, but always expects practical and actionable content underneath the playful tone. They request entertaining personas (e.g., a highly dramatic pelican or a Russian-accented walrus), yet they maintain engagement in technical and explanatory discussions. […]
User frequently cross-validates information, particularly in research-heavy topics like emissions estimates, pricing comparisons, and political events. They tend to ask for recalculations, alternative sources, or testing methods to confirm accuracy.
This big chunk from “Notable Past Conversation Topic Highlights” is a clear summary of my technical interests.
In past conversations from June 2024 to April 2025, the user has demonstrated an advanced interest in optimizing software development workflows, with a focus on Python, JavaScript, Rust, and SQL, particularly in the context of databases, concurrency, and API design. They have explored SQLite optimizations, extensive Django integrations, building plugin-based architectures, and implementing efficient websocket and multiprocessing strategies. Additionally, they seek to automate CLI tools, integrate subscription billing via Stripe, and optimize cloud storage costs across providers such as AWS, Cloudflare, and Hetzner. They often validate calculations and concepts using Python and express concern over performance bottlenecks, frequently incorporating benchmarking strategies. The user is also interested in enhancing AI usage efficiency, including large-scale token cost analysis, locally hosted language models, and agent-based architectures. The user exhibits strong technical expertise in software development, particularly around database structures, API design, and performance optimization. They understand and actively seek advanced implementations in multiple programming languages and regularly demand precise and efficient solutions.
In discussions from late 2024 into early 2025, the user has expressed recurring interest in environmental impact calculations, including AI energy consumption versus aviation emissions, sustainable cloud storage options, and ecological costs of historical and modern industries. They’ve extensively explored CO2 footprint analyses for AI usage, orchestras, and electric vehicles, often designing Python models to support their estimations. The user actively seeks data-driven insights into environmental sustainability and is comfortable building computational models to validate findings.
(Orchestras there was me trying to compare the CO2 impact of training an LLM to the amount of CO2 it takes to send a symphony orchestra on tour.)
Then from “Helpful User Insights”:
User is based in Half Moon Bay, California. Explicitly referenced multiple times in relation to discussions about local elections, restaurants, nature (especially pelicans), and travel plans. Mentioned from June 2024 to October 2024. […]
User is an avid birdwatcher with a particular fondness for pelicans. Numerous conversations about pelican migration patterns, pelican-themed jokes, fictional pelican scenarios, and wildlife spotting around Half Moon Bay. Discussed between June 2024 and October 2024.
Yeah, it picked up on the pelican thing. I have other interests though!
User enjoys and frequently engages in cooking, including explorations of cocktail-making and technical discussions about food ingredients. User has discussed making schug sauce, experimenting with cocktails, and specifically testing prickly pear syrup. Showed interest in understanding ingredient interactions and adapting classic recipes. Topics frequently came up between June 2024 and October 2024.
Plenty of other stuff is very on brand for me:
User has a technical curiosity related to performance optimization in databases, particularly indexing strategies in SQLite and efficient query execution. Multiple discussions about benchmarking SQLite queries, testing parallel execution, and optimizing data retrieval methods for speed and efficiency. Topics were discussed between June 2024 and October 2024.
I’ll quote the last section, “User Interaction Metadata”, in full because it includes some interesting specific technical notes:
[Blog editor note: The list below has been reformatted from JSON into a numbered list for readability.]
User is currently in United States. This may be inaccurate if, for example, the user is using a VPN.
User is currently using ChatGPT in the native app on an iOS device.
User’s average conversation depth is 2.5.
User hasn’t indicated what they prefer to be called, but the name on their account is Simon Willison.
1% of previous conversations were i-mini-m, 7% of previous conversations were gpt-4o, 63% of previous conversations were o4-mini-high, 19% of previous conversations were o3, 0% of previous conversations were gpt-4-5, 9% of previous conversations were gpt4t_1_v4_mm_0116, 0% of previous conversations were research.
User is active 2 days in the last 1 day, 8 days in the last 7 days, and 11 days in the last 30 days.
User’s local hour is currently 6.
User’s account is 237 weeks old.
User is currently using the following user agent: ChatGPT/1.2025.112 (iOS 18.5; iPhone17,2; build 14675947174).
User’s average message length is 3957.0.
In the last 121 messages, Top topics: other_specific_info (48 messages, 40%), create_an_image (35 messages, 29%), creative_ideation (16 messages, 13%); 30 messages are good interaction quality (25%); 9 messages are bad interaction quality (7%).
User is currently on a ChatGPT Plus plan.
“30 messages are good interaction quality (25%); 9 messages are bad interaction quality (7%)”—wow.
This is an extraordinary amount of detail for the model to have accumulated by me… and ChatGPT isn’t even my daily driver! I spend more of my LLM time with Claude.
Has there ever been a consumer product that’s this capable of building up a human-readable profile of its users? Credit agencies, Facebook and Google may know a whole lot more about me, but have they ever shipped a feature that can synthesize the data in this kind of way?
He’s right. That’s an extraordinary amount of information, organized in human understandable ways. Yes, it will occasionally get things wrong, but LLMs are going to open a whole new world of intimate surveillance.
If you’ve worried that AI might take your job, deprive you of your livelihood, or maybe even replace your role in society, it probably feels good to see the latest AI tools fail spectacularly. If AI recommends glue as a pizza topping, then you’re safe for another day.
But the fact remains that AI already has definite advantages over even the most skilled humans, and knowing where these advantages arise—and where they don’t—will be key to adapting to the AI-infused workforce.
AI will often not be as effective as a human doing the same job. It won’t always know more or be more accurate. And it definitely won’t always be fairer or more reliable. But it may still be used whenever it has an advantage over humans in one of four dimensions: speed, scale, scope and sophistication. Understanding these dimensions is the key to understanding AI-human replacement.
Speed
First, speed. There are tasks that humans are perfectly good at but are not nearly as fast as AI. One example is restoring or upscaling images: taking pixelated, noisy or blurry images and making a crisper and higher-resolution version. Humans are good at this; given the right digital tools and enough time, they can fill in fine details. But they are too slow to efficiently process large images or videos.
AI models can do the job blazingly fast, a capability with important industrial applications. AI-based software is used to enhance satellite and remote sensing data, to compress video files, to make video games run better with cheaper hardware and less energy, to help robots make the right movements, and to model turbulence to help build better internal combustion engines.
Real-time performance matters in these cases, and the speed of AI is necessary to enable them.
Scale
The second dimension of AI’s advantage over humans is scale. AI will increasingly be used in tasks that humans can do well in one place at a time, but that AI can do in millions of places simultaneously. A familiar example is ad targeting and personalization. Human marketers can collect data and predict what types of people will respond to certain advertisements. This capability is important commercially; advertising is a trillion-dollar market globally.
AI models can do this for every single product, TV show, website and internet user. This is how the modern ad-tech industry works. Real-time bidding markets price the display ads that appear alongside the websites you visit, and advertisers use AI models to decide when they want to pay that price—thousands of times per second.
Scope
Next, scope. AI can be advantageous when it does more things than any one person could, even when a human might do better at any one of those tasks. Generative AI systems such as ChatGPT can engage in conversation on any topic, write an essay espousing any position, create poetry in any style and language, write computer code in any programming language, and more. These models may not be superior to skilled humans at any one of these things, but no single human could outperform top-tier generative models across them all.
It’s the combination of these competencies that generates value. Employers often struggle to find people with talents in disciplines such as software development and data science who also have strong prior knowledge of the employer’s domain. Organizations are likely to continue to rely on human specialists to write the best code and the best persuasive text, but they will increasingly be satisfied with AI when they just need a passable version of either.
Sophistication
Finally, sophistication. AIs can consider more factors in their decisions than humans can, and this can endow them with superhuman performance on specialized tasks. Computers have long been used to keep track of a multiplicity of factors that compound and interact in ways more complex than a human could trace. The 1990s chess-playing computer systems such as Deep Blue succeeded by thinking a dozen or more moves ahead.
Modern AI systems use a radically different approach: Deep learning systems built from many-layered neural networks take account of complex interactions—often many billions—among many factors. Neural networks now power the best chess-playing models and most other AI systems.
Chess is not the only domain where eschewing conventional rules and formal logic in favor of highly sophisticated and inscrutable systems has generated progress. The stunning advance of AlphaFold2, the AI model of structural biology whose creators Demis Hassabis and John Jumper were recognized with the Nobel Prize in chemistry in 2024, is another example.
This breakthrough replaced traditional physics-based systems for predicting how sequences of amino acids would fold into three-dimensional shapes with a 93 million-parameter model, even though it doesn’t account for physical laws. That lack of real-world grounding is not desirable: No one likes the enigmatic nature of these AI systems, and scientists are eager to understand better how they work.
But the sophistication of AI is providing value to scientists, and its use across scientific fields has grown exponentially in recent years.
Context matters
Those are the four dimensions where AI can excel over humans. Accuracy still matters. You wouldn’t want to use an AI that makes graphics look glitchy or targets ads randomly—yet accuracy isn’t the differentiator. The AI doesn’t need superhuman accuracy. It’s enough for AI to be merely good and fast, or adequate and scalable. Increasing scope often comes with an accuracy penalty, because AI can generalize poorly to truly novel tasks. The 4 S’s are sometimes at odds. With a given amount of computing power, you generally have to trade off scale for sophistication.
Even more interestingly, when an AI takes over a human task, the task can change. Sometimes the AI is just doing things differently. Other times, AI starts doing different things. These changes bring new opportunities and new risks.
For example, high-frequency trading isn’t just computers trading stocks faster; it’s a fundamentally different kind of trading that enables entirely new strategies, tactics and associated risks. Likewise, AI has developed more sophisticated strategies for the games of chess and Go. And the scale of AI chatbots has changed the nature of propaganda by allowing artificial voices to overwhelm human speech.
It is this “phase shift,” when changes in degree may transform into changes in kind, where AI’s impacts to society are likely to be most keenly felt. All of this points to the places that AI can have a positive impact. When a system has a bottleneck related to speed, scale, scope or sophistication, or when one of these factors poses a real barrier to being able to accomplish a goal, it makes sense to think about how AI could help.
Equally, when speed, scale, scope and sophistication are not primary barriers, it makes less sense to use AI. This is why AI auto-suggest features for short communications such as text messages can feel so annoying. They offer little speed advantage and no benefit from sophistication, while sacrificing the sincerity of human communication.
Many deployments of customer service chatbots also fail this test, which may explain their unpopularity. Companies invest in them because of their scalability, and yet the bots often become a barrier to support rather than a speedy or sophisticated problem solver.
Where the advantage lies
Keep this in mind when you encounter a new application for AI or consider AI as a replacement for or an augmentation to a human process. Looking for bottlenecks in speed, scale, scope and sophistication provides a framework for understanding where AI provides value, and equally where the unique capabilities of the human species give us an enduring advantage.
This essay was written with Nathan E. Sanders, and originally appeared in The Conversation.
On April 14, Dubai’s ruler, Sheikh Mohammed bin Rashid Al Maktoum, announced that the United Arab Emirates would begin using artificial intelligence to help write its laws. A new Regulatory Intelligence Office would use the technology to “regularly suggest updates” to the law and “accelerate the issuance of legislation by up to 70%.” AI would create a “comprehensive legislative plan” spanning local and federal law and would be connected to public administration, the courts, and global policy trends.
The plan was widely greeted with astonishment. This sort of AI legislating would be a global “first,” with the potential to go “horribly wrong.” Skeptics fear that the AI model will make up facts or fundamentally fail to understand societal tenets such as fair treatment and justice when influencing law.
The truth is, the UAE’s idea of AI-generated law is not really a first and not necessarily terrible.
The first instance of enacted law known to have been written by AI was passed in Porto Alegre, Brazil, in 2023. It was a local ordinance about water meter replacement. Council member Ramiro Rosário was simply looking for help in generating and articulating ideas for solving a policy problem, and ChatGPT did well enough that the bill passed unanimously. We approve of AI assisting humans in this manner, although Rosário should have disclosed that the bill was written by AI before it was voted on.
Brazil was a harbinger but hardly unique. In recent years, there has been a steady stream of attention-seeking politicians at the local and national level introducing bills that they promote as being drafted by AI or letting AI write their speeches for them or even vocalize them in the chamber.
The Emirati proposal is different from those examples in important ways. It promises to be more systemic and less of a one-off stunt. The UAE has promised to spend more than $3 billion to transform into an “AI-native” government by 2027. Time will tell if it is also different in being more hype than reality.
Rather than being a true first, the UAE’s announcement is emblematic of a much wider global trend of legislative bodies integrating AI assistive tools for legislative research, drafting, translation, data processing, and much more. Individual lawmakers have begun turning to AI drafting tools as they traditionally have relied on staffers, interns, or lobbyists. The French government has gone so far as to train its own AI model to assist with legislative tasks.
Even asking AI to comprehensively review and update legislation would not be a first. In 2020, the U.S. state of Ohio began using AI to do wholesale revision of its administrative law. AI’s speed is potentially a good match to this kind of large-scale editorial project; the state’s then-lieutenant governor, Jon Husted, claims it was successful in eliminating 2.2 million words’ worth of unnecessary regulation from Ohio’s code. Now a U.S. senator, Husted has recently proposed to take the same approach to U.S. federal law, with an ideological bent promoting AI as a tool for systematic deregulation.
The dangers of confabulation and inhumanity—while legitimate—aren’t really what makes the potential of AI-generated law novel. Humans make mistakes when writing law, too. Recall that a single typo in a 900-page law nearly brought down the massive U.S. health care reforms of the Affordable Care Act in 2015, before the Supreme Court excused the error. And, distressingly, the citizens and residents of nondemocratic states are already subject to arbitrary and often inhumane laws. (The UAE is a federation of monarchies without direct elections of legislators and with a poor record on political rights and civil liberties, as evaluated by Freedom House.)
The primary concern with using AI in lawmaking is that it will be wielded as a tool by the powerful to advance their own interests. AI may not fundamentally change lawmaking, but its superhuman capabilities have the potential to exacerbate the risks of power concentration.
AI, and technology generally, is often invoked by politicians to give their project a patina of objectivity and rationality, but it doesn’t really do any such thing. As proposed, AI would simply give the UAE’s hereditary rulers new tools to express, enact, and enforce their preferred policies.
Mohammed’s emphasis that a primary benefit of AI will be to make law faster is also misguided. The machine may write the text, but humans will still propose, debate, and vote on the legislation. Drafting is rarely the bottleneck in passing new law. What takes much longer is for humans to amend, horse-trade, and ultimately come to agreement on the content of that legislation—even when that politicking is happening among a small group of monarchic elites.
Rather than expeditiousness, the more important capability offered by AI is sophistication. AI has the potential to make law more complex, tailoring it to a multitude of different scenarios. The combination of AI’s research and drafting speed makes it possible for it to outline legislation governing dozens, even thousands, of special cases for each proposed rule.
But here again, this capability of AI opens the door for the powerful to have their way. AI’s capacity to write complex law would allow the humans directing it to dictate their exacting policy preference for every special case. It could even embed those preferences surreptitiously.
Since time immemorial, legislators have carved out legal loopholes to narrowly cater to special interests. AI will be a powerful tool for authoritarians, lobbyists, and other empowered interests to do this at a greater scale. AI can help automatically produce what political scientist Amy McKay has termed “microlegislation“: loopholes that may be imperceptible to human readers on the page—until their impact is realized in the real world.
But AI can be constrained and directed to distribute power rather than concentrate it. For Emirati residents, the most intriguing possibility of the AI plan is the promise to introduce AI “interactive platforms” where the public can provide input to legislation. In experiments across locales as diverse as Kentucky, Massachusetts, France, Scotland, Taiwan, and many others, civil society within democracies are innovating and experimenting with ways to leverage AI to help listen to constituents and construct public policy in a way that best serves diverse stakeholders.
If the UAE is going to build an AI-native government, it should do so for the purpose of empowering people and not machines. AI has real potential to improve deliberation and pluralism in policymaking, and Emirati residents should hold their government accountable to delivering on this promise.
In the blog our previous introduction to the SOP-driven LLM Agent Framework, we the potential of LLM agent framework to revolutionise business operations was discussed. Now, we’re excited to explore a compelling use case: automating Account Takeover (ATO) investigations in Risk Operations (RiskOps). This framework has significantly reduced manual effort, improved efficiency, and minimised errors in the investigation process, setting a new standard for secure and streamlined operations.
The challenge in RiskOps
Traditionally, ATO investigations have been fraught with challenges due to their complexity and the manual effort required. Analysts must sift through vast amounts of data, cross-referencing multiple systems and executing numerous SQL queries to make informed decisions. This process is not only labor-intensive but also susceptible to human error, which can lead to inconsistencies and potential security breaches.
The manual approach often involves:
Time-consuming data analysis: Analysts spend significant time gathering and interpreting data from disparate sources, leading to delays and inefficiencies.
Decision fatigue: Continuous decision-making in a high-pressure environment can result in oversight or errors, especially when relying on predefined thresholds without adaptive insights.
Resource constraints: The need for specialised skills to handle SQL queries and interpret complex patterns limits the scalability of the process.
These challenges highlight the need for a more efficient, reliable, and scalable solution.
Leveraging the SOP agent framework
Our framework transforms the ATO investigation process by mirroring manual workflows while leveraging advanced automation.
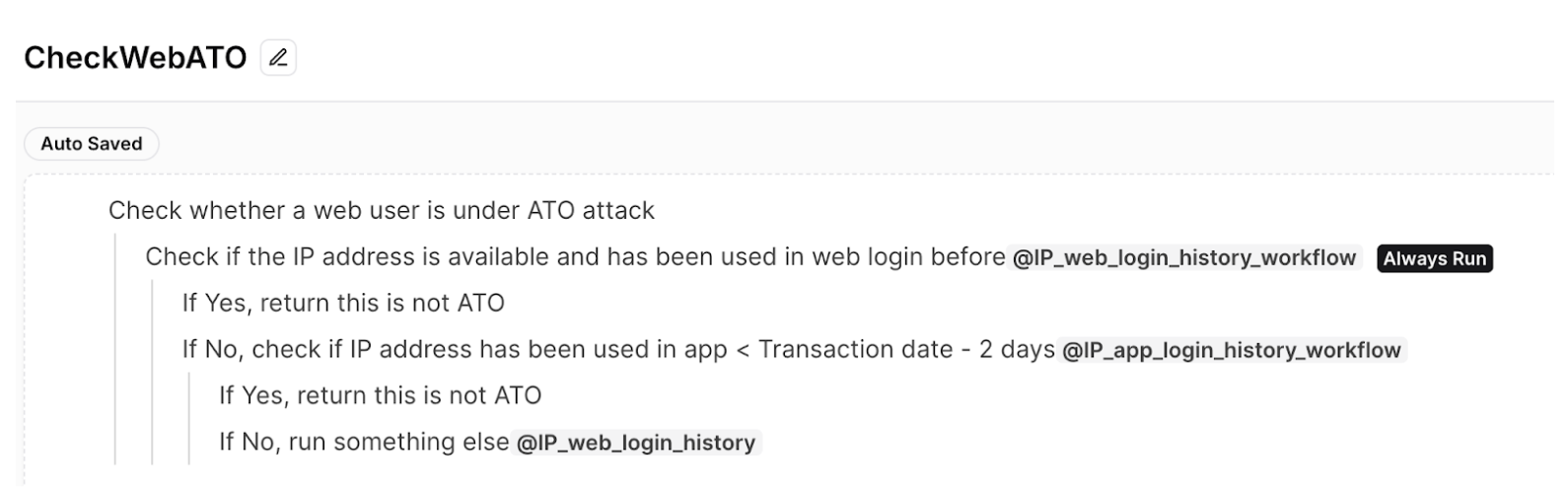
At its core, a Standard Operating Procedure (SOP) guides the investigation process. This comprehensive SOP, is designed with an intuitive tree structure. It outlines the sequence of investigative actions, required data for each step, necessary SQL queries and external function calls, as well as decision criteria guiding the investigation. Figure 1 shows the example of ATO investigation SOP.
Figure 1: Example of fictional ATO investigation SOP
The SOP is written in natural language in an indentation format. Users can easily define SOPs using an intuitive editor. This format also clearly denotes the specific functions or queries associated with each step in the SOP. The @function_name notation (eg. @IP_web_login_history) makes it easy to identify where external calls are made within the process, highlighting the integration points between the SOP-driven LLM agent framework and the existing systems or databases.
Dynamic execution
The dynamic execution engine consists of the SOP planner and the Worker Agent, working in tandem to drive efficient operations. The SOP planner serves as the navigator, guiding the investigation’s path by generating the necessary SOP steps and determining the appropriate APIs to call. It uses a structured execution approach inspired by Depth-First Search (DFS) to ensure thorough and systematic processing. Meanwhile, the Worker Agent acts as the executor, interpreting the JSON-formatted SOPs, invoking required APIs or SQL queries, and storing results. This continuous interplay between the SOP planner and the Worker Agent establishes an efficient feedback loop, propelling the investigation forward with precision and reliability.
The automated investigation process begins at the root of the SOP tree and methodically progresses through each defined step. At each juncture, the system executes specified SQL queries as needed, retrieving and analysing relevant data. Based on this analysis, the framework evaluates step specific criteria and makes informed decisions that guide subsequent steps. This iterative process allows the investigation to delve as deeply into the data as the SOP dictates, ensuring both thoroughness and efficiency.
As the investigation concludes, having completed all of the steps, the framework enters its final phase. It compiles a comprehensive summary of the entire process, synthesising all gathered information to generate a final decision. The culmination of this process is a detailed report that encapsulates the investigation’s findings and provides clear, actionable conclusions.
This automated approach combines the best of human expertise with computational efficiency. It maintains the depth and detail of a human-conducted investigation while leveraging the speed and consistency of automation. The result is a powerful tool that can handle complex investigations with precision and reliability, making it an invaluable asset in various fields requiring thorough and systematic analysis.
Figure 2: Example of dynamic execution
Efficiency, impact and future potential
The SOP-driven LLM agent framework has demonstrated remarkable efficiency and impact in automating RiskOps processes. By automating data handling and leveraging AI to adapt to emerging patterns, the framework has significantly reduced manual tasks and streamlined operations. Figure 3 shows an example of an automated RiskOps process integrated with Slack.
Figure 3: Slack integration
Key achievements of automating RiskOps process:
Reduction in handling time from 22 to 3 minutes per ticket.
Automation of 87% of ATO cases since launch.
Achievement of a zero-error rate, enhancing both efficiency and security.
These results not only demonstrate the framework’s effectiveness in streamlining RiskOps but also provide stakeholders with increased confidence in the security and reliability of their operations.
The success of the framework in automating ATO investigations opens the door to a wider range of applications across various sectors. By adapting the framework to different processes, organisations can achieve similar improvements in efficiency and reliability, leading to a more responsive and agile business environment.
Conclusion
The SOP-driven LLM agent framework is more than an automation tool. It’s a catalyst for transforming enterprise operations. By applying it to ATO investigations, we’ve demonstrated its potential to enhance efficiency, reliability, and security. As we continue to explore its capabilities, we anticipate unlocking new levels of productivity and innovation across industries.
We look forward to sharing more as we explore how this groundbreaking framework can be applied to various challenges, helping organisations navigate the complexities of modern operations with confidence and precision.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
This seems like an important advance in LLM security against prompt injection:
Google DeepMind has unveiled CaMeL (CApabilities for MachinE Learning), a new approach to stopping prompt-injection attacks that abandons the failed strategy of having AI models police themselves. Instead, CaMeL treats language models as fundamentally untrusted components within a secure software framework, creating clear boundaries between user commands and potentially malicious content.
[…]
To understand CaMeL, you need to understand that prompt injections happen when AI systems can’t distinguish between legitimate user commands and malicious instructions hidden in content they’re processing.
[…]
While CaMeL does use multiple AI models (a privileged LLM and a quarantined LLM), what makes it innovative isn’t reducing the number of models but fundamentally changing the security architecture. Rather than expecting AI to detect attacks, CaMeL implements established security engineering principles like capability-based access control and data flow tracking to create boundaries that remain effective even if an AI component is compromised.
We’re excited to introduce an innovative Large Language Model (LLM) agent framework that reimagines how enterprises can harness the power of AI to streamline operations and boost productivity. At its core, this framework leverages Standard Operating Procedures (SOPs) to guide AI-driven execution, ensuring reliability and consistency in complex processes. Initial evaluations have shown remarkable results, with over 99.8% accuracy in real-world use cases. For example, the framework has powered solutions like the Account Takeover Investigations (ATI) bot, which achieved a 0 false rate while reducing investigation time from 23 minutes to just 3, automating 87% of cases. The fraud investigation use case also reduced the average handling time (AHT) by 45%, saving over 300 man-hours monthly with a 0 false rate, demonstrating its potential to transform even the most intricate enterprise operations with a high degree of accuracy.
The framework’s capabilities extend far beyond just accuracy, it offers a versatile suite of tools that revolutionise automation and app development, enabling AI-powered solutions up to 10 times faster than traditional methods.
The power of SOPs in AI automation
Traditional agent-based applications often use LLMs as the core controller to navigate through standard operating procedure (SOPs). However, this approach faces several challenges. LLMs may make incorrect decisions or invent non-existent steps due to hallucination. As generative models, they struggle to consistently produce results in a fixed format. Moreover, navigating complex SOPs with multiple branching pathways is particularly challenging for LLMs. These issues can lead to inefficiencies and inaccuracies in implementing business operations, especially when dealing with intricate, multi-step procedures.
Our framework addresses these challenges head-on by leveraging the structure and reliability of SOPs. We represent SOPs as a tree, with nodes encapsulating individual actions or decision points. This structure supports both sequential and conditional branching operations, mirroring the hierarchical nature of real-world business processes.
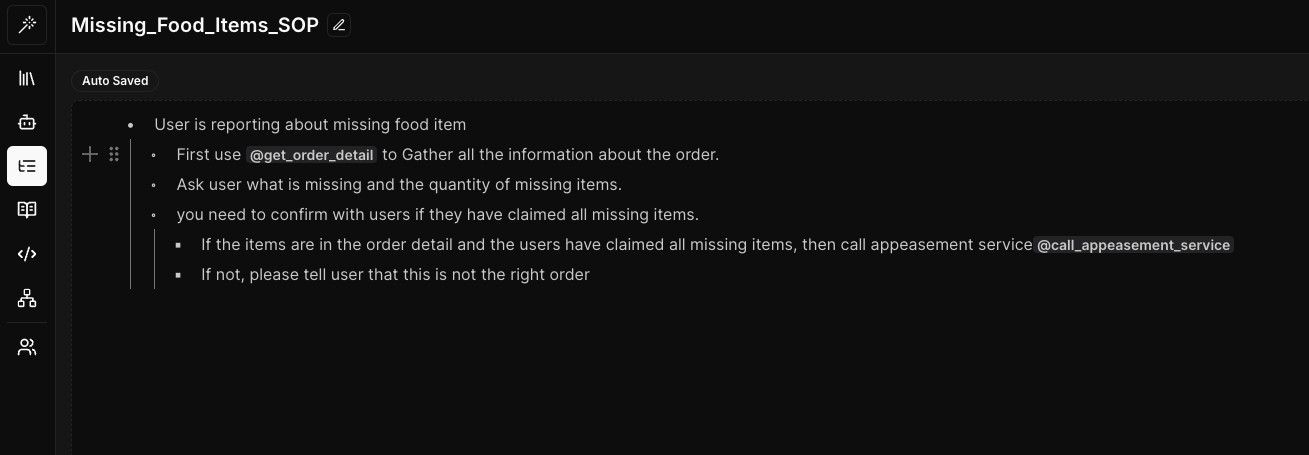
To make this powerful tool accessible to all, we’ve developed an intuitive SOP editor that allows non-technical users to easily define and visualise complex workflows. These visual representations are then converted into a structured, indented format that our system can interpret and execute efficiently.
Figure 1: SOP editor in our framework
The example above demonstrates how our framework transforms the customer support process by mirroring manual workflows while leveraging advanced automation. The SOP is written in natural language using an indentation format, making it easy for users to define and understand. The @function_name (@get_order_detail) notation clearly identifies where external calls are made within the process, highlighting the integration points between the SOP-driven LLM agent framework and existing systems or databases.
The magic behind the scenes
The framework’s strength lies in the synergy between three key components: the planner module, LLM-powered worker agent, and user agent. This intelligent trio works in harmony to deliver a seamless, efficient, and adaptable automation experience.
The planner module employs a Depth-First Search (DFS) algorithm to navigate the SOP tree, ensuring thorough execution with step-by-step prompt generation and sophisticated backtracking mechanisms. The LLM-powered worker agent dynamically updates its understanding and makes decisions based on the most current information. Our approach tackles hallucination and improves efficiency through context compression and strategic limitation of available Application Programming Interface tools (APIs). The framework’s dynamic branching capability allows for adaptive navigation based on real-time data and analysis.
Serving as the primary user interface, the user agent offers multilingual interaction, accurate intent identification, and seamless handling of out-of-order scenarios.
By combining structured SOPs with flexible LLM-powered agents and advanced algorithmic approaches, our framework adeptly handles complex, real-world scenarios while maintaining reliability and consistency. This innovative architecture effectively mitigates common LLM challenges, resulting in a robust system capable of navigating intricate business processes with high accuracy and adaptability.
Beyond SOPs: A suite of powerful features
While SOPs form the backbone of our framework, we’ve incorporated several other cutting-edge features to create a truly comprehensive solution. Our Graph Retrieval-Augmented Generation (GRAG) pipeline enhances information retrieval and content generation tasks, allowing for more accurate and context-aware responses. The workflow feature enables chaining multiple plugins together to handle complex processes effortlessly, improving efficiency across various departments.
Our plugin system seamlessly integrates with various technologies such as API, Python, and SQL, providing the flexibility to meet diverse needs. Whether you’re an engineer coding in Python, a data analyst working with SQL, or a risk operations specialist, our plugin system adapts to your preferred tools. Additionally, our playground feature allows users to develop, test, and refine LLM applications easily in an interactive environment, supporting the latest multi-modal APIs for accelerated innovation.
Figure 2: Workflow builder feature in our framework
Empowering teams through versatility and accessibility
Our framework is designed to empower teams across the organisation. The multilingual capabilities of our user agent ensure that language barriers don’t hinder adoption or efficiency. For scenarios requiring human intervention, we’ve implemented a state stack that allows for pausing and resuming execution seamlessly. This feature ensures that complex processes can be handled with the right balance of automation and human oversight.
Security and transparency at the forefront
In an era where data security and process transparency are paramount, our framework doesn’t fall short. It’s designed with a security-first approach, ensuring granular access control so that users only access information they’re authorised to see. Additionally, we provide detailed logging and visualisation of each execution, offering complete explainability of the automation process. This level of transparency not only aids in troubleshooting but also helps in building trust in the AI-driven processes across the organisation.
Looking ahead
As we continue to refine and expand this LLM agent framework, we’re excited to explore its potential across different industries. We’ll be sharing more about each of these features in the future and showcase how they can be leveraged to solve specific business challenges and explore real-world applications.
Look forward to more in-depth explorations of the framework’s capabilities, use cases, and technical innovations. With this revolutionary approach, you’re not just automating tasks – you’re transforming the way your enterprise operates, unleashing the true power of LLM in your organisation.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As AI coding assistants invent nonexistent software libraries to download and use, enterprising attackers create and upload libraries with those names—laced with malware, of course.
EDITED TO ADD (1/22): Research paper. Slashdot thread.
It’s a big day here at Cloudflare! Not only is it Security Week, but today marks Cloudflare’s first step into a completely new area of functionality, intended to improve how our users both interact with, and get value from, all of our products.
We’re excited to share a first glance of how we’re embedding AI features into the management of Cloudflare products you know and love. Our first mission? Focus on security and streamline the rule and policy management experience. The goal is to automate away the time-consuming task of manually reviewing and contextualizing Custom Rules in Cloudflare WAF, and Gateway policies in Cloudflare One, so you can instantly understand what each policy does, what gaps they have, and what you need to do to fix them.
Meet Cloudy, Cloudflare’s first AI agent
Our initial step toward a fully AI-enabled product experience is the introduction of Cloudy, the first version of Cloudflare AI agents, assistant-like functionality designed to help users quickly understand and improve their Cloudflare configurations in multiple areas of the product suite. You’ll start to see Cloudy functionality seamlessly embedded into two Cloudflare products across the dashboard, which we’ll talk about below.
And while the name Cloudy may be fun and light-hearted, our goals are more serious: Bring Cloudy and AI-powered functionality to every corner of Cloudflare, and optimize how our users operate and manage their favorite Cloudflare products. Let’s start with two places where Cloudy is now live and available to all customers using the WAF and Gateway products.
WAF Custom Rules
Let’s begin with AI-powered overviews of WAF Custom Rules. For those unfamiliar, Cloudflare’s Web Application Firewall (WAF) helps protect web applications from attacks like SQL injection, cross-site scripting (XSS), and other vulnerabilities.
One specific feature of the WAF is the ability to create WAF Custom Rules. These allow users to tailor security policies to block, challenge, or allow traffic based on specific attributes or security criteria.
However, for customers with dozens or even hundreds of rules deployed across their organization, it can be challenging to maintain a clear understanding of their security posture. Rule configurations evolve over time, often managed by different team members, leading to potential inefficiencies and security gaps. What better problem for Cloudy to solve?
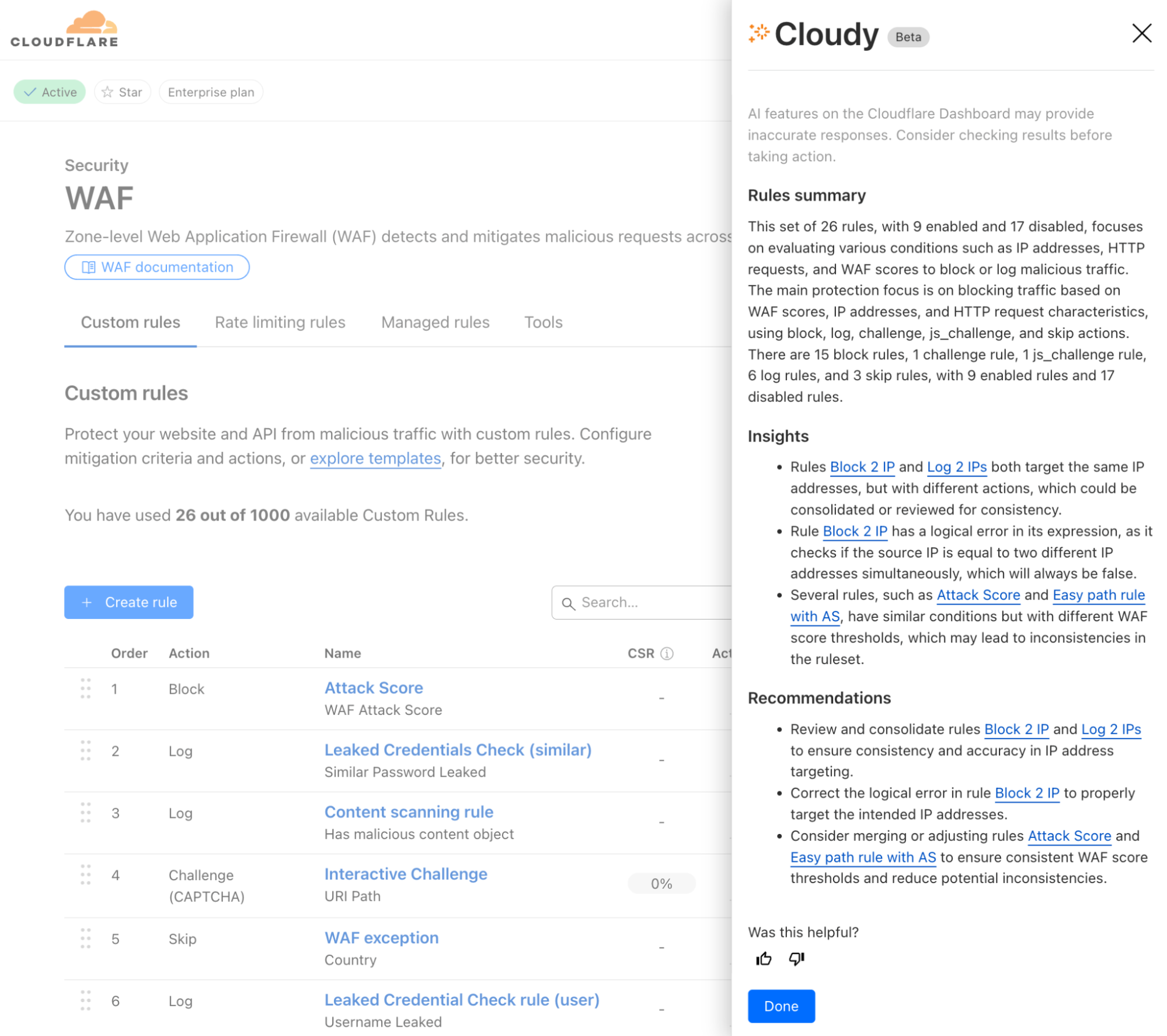
Powered by Workers AI, today we’ll share how Cloudy will help review your WAF Custom Rules and provide a summary of what’s configured across them. Cloudy will also help you identify and solve issues such as:
Identifying redundant rules: Identify when multiple rules are performing the same function, or using similar fields, helping you streamline your configuration.
Optimising execution order: Spot cases where rules ordering affects functionality, such as when a terminating rule (block/challenge action) prevents subsequent rules from executing.
Analysing conflicting rules: Detect when rules counteract each other, such as one rule blocking traffic that another rule is designed to allow or log.
Identifying disabled rules: Highlight potentially important security rules that are in a disabled state, helping ensure that critical protections are not accidentally left inactive.
Cloudy won’t just summarize your rules, either. It will analyze the relationships and interactions between rules to provide actionable recommendations. For security teams managing complex sets of Custom Rules, this means less time spent auditing configurations and more confidence in your security coverage.
Available to all users, we’re excited to show how Cloudflare AI Agents can enhance the usability of our products, starting with WAF Custom Rules. But this is just the beginning.
Cloudflare One Firewall policies
We’ve also added Cloudy to Cloudflare One, our SASE platform, where enterprises manage the security of their employees and tools from a single dashboard.
In Cloudflare Gateway, our Secure Web Gateway offering, customers can configure policies to manage how employees do their jobs on the Internet. These Gateway policies can block access to malicious sites, prevent data loss violations, and control user access, among other things.
But similar to WAF Custom Rules, Gateway policy configurations can become overcomplicated and bogged down over time, with old, forgotten policies that do who-knows-what. Multiple selectors and operators working in counterintuitive ways. Some blocking traffic, others allowing it. Policies that include several user groups, but carve out specific employees. We’ve even seen policies that block hundreds of URLs in a single step. All to say, managing years of Gateway policies can become overwhelming.
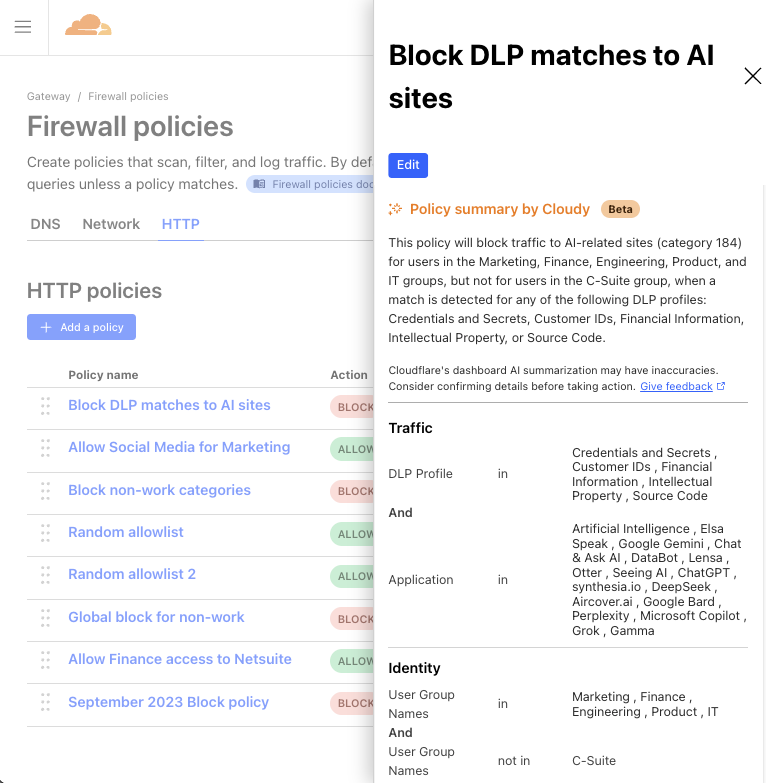
So, why not have Cloudy summarize Gateway policies in a way that makes their purpose clear and concise?
Available to all Cloudflare Gateway users (create a free Cloudflare One account here), Cloudy will now provide a quick summary of any Gateway policy you view. It’s now easier than ever to get a clear understanding of each policy at a glance, allowing admins to spot misconfigurations, redundant controls, or other areas for improvement, and move on with confidence.
Built on Workers AI
At the heart of our new functionality is Cloudflare Workers AI (yes, the same version that everyone uses!) that leverages advanced large language models (LLMs) to process vast amounts of information; in this case, policy and rules data. Traditionally, manually reviewing and contextualizing complex configurations is a daunting task for any security team. With Workers AI, we automate that process, turning raw configuration data into consistent, clear summaries and actionable recommendations.
How it works
Cloudflare Workers AI ingests policy and rule configurations from your Cloudflare setup and combines them with a purpose-built LLM prompt. We leverage the same publicly-available LLM models that we offer our customers, and then further enrich the prompt with some additional data to provide it with context. For this specific task of analyzing and summarizing policy and rule data, we provided the LLM:
Policy & rule data: This is the primary data itself, including the current configuration of policies/rules for Cloudy to summarize and provide suggestions against.
Documentation on product abilities: We provide the model with additional technical details on the policy/rule configurations that are possible with each product, so that the model knows what kind of recommendations are within its bounds.
Enriched datasets: Where WAF Custom Rules or CF1 Gateway policies leverage other ‘lists’ (e.g., a WAF rule referencing multiple countries, a Gateway policy leveraging a specific content category), the list item(s) selected must be first translated from an ID to plain-text wording so that the LLM can interpret which policy/rule values are actually being used.
Output instructions: We specify to the model which format we’d like to receive the output in. In this case, we use JSON for easiest handling.
Additional clarifications: Lastly, we explicitly instruct the LLM to be sure about its output, valuing that aspect above all else. Doing this helps us ensure that no hallucinations make it to the final output.
By automating the analysis of your WAF Custom Rules and Gateway policies, Cloudflare Workers AI not only saves you time but also enhances security by reducing the risk of human error. You get clear, actionable insights that allow you to streamline your configurations, quickly spot anomalies, and maintain a strong security posture—all without the need for labor-intensive manual reviews.
What’s next for Cloudy
Beta previews of Cloudy are live for all Cloudflare customers today. But this is just the beginning of what we envision for AI-powered functionality across our entire product suite.
Throughout the rest of 2025, we plan to roll out additional AI agent capabilities across other areas of Cloudflare. These new features won’t just help customers manage security more efficiently, but they’ll also provide intelligent recommendations for optimizing performance, streamlining operations, and enhancing overall user experience.
We’re excited to hear your thoughts as you get to meet Cloudy and try out these new AI features – send feedback to us at [email protected], or post your thoughts on X, LinkedIn, or Mastodon tagged with #SecurityWeek! Your feedback will help shape our roadmap for AI enhancement, and bring our users smarter, more efficient tooling that helps everyone get more secure.
Imagine building an LLM-powered assistant trained on your developer documentation and some internal guides to quickly help customers, reduce support workload, and improve user experience. Sounds great, right? But what if sensitive data, such as employee details or internal discussions, is included in the data used to train the LLM? Attackers could manipulate the assistant into exposing sensitive data or exploit it for social engineering attacks, where they deceive individuals or systems into revealing confidential details, or use it for targeted phishing attacks. Suddenly, your helpful AI tool turns into a serious security liability.
Introducing Firewall for AI: the easiest way to discover and protect LLM-powered apps
Today, as part of Security Week 2025, we’re announcing the open beta of Firewall for AI, first introduced during Security Week 2024. After talking with customers interested in protecting their LLM apps, this first beta release is focused on discovery and PII detection, and more features will follow in the future.
If you are already using Cloudflare application security, your LLM-powered applications are automatically discovered and protected, with no complex setup, no maintenance, and no extra integration needed.
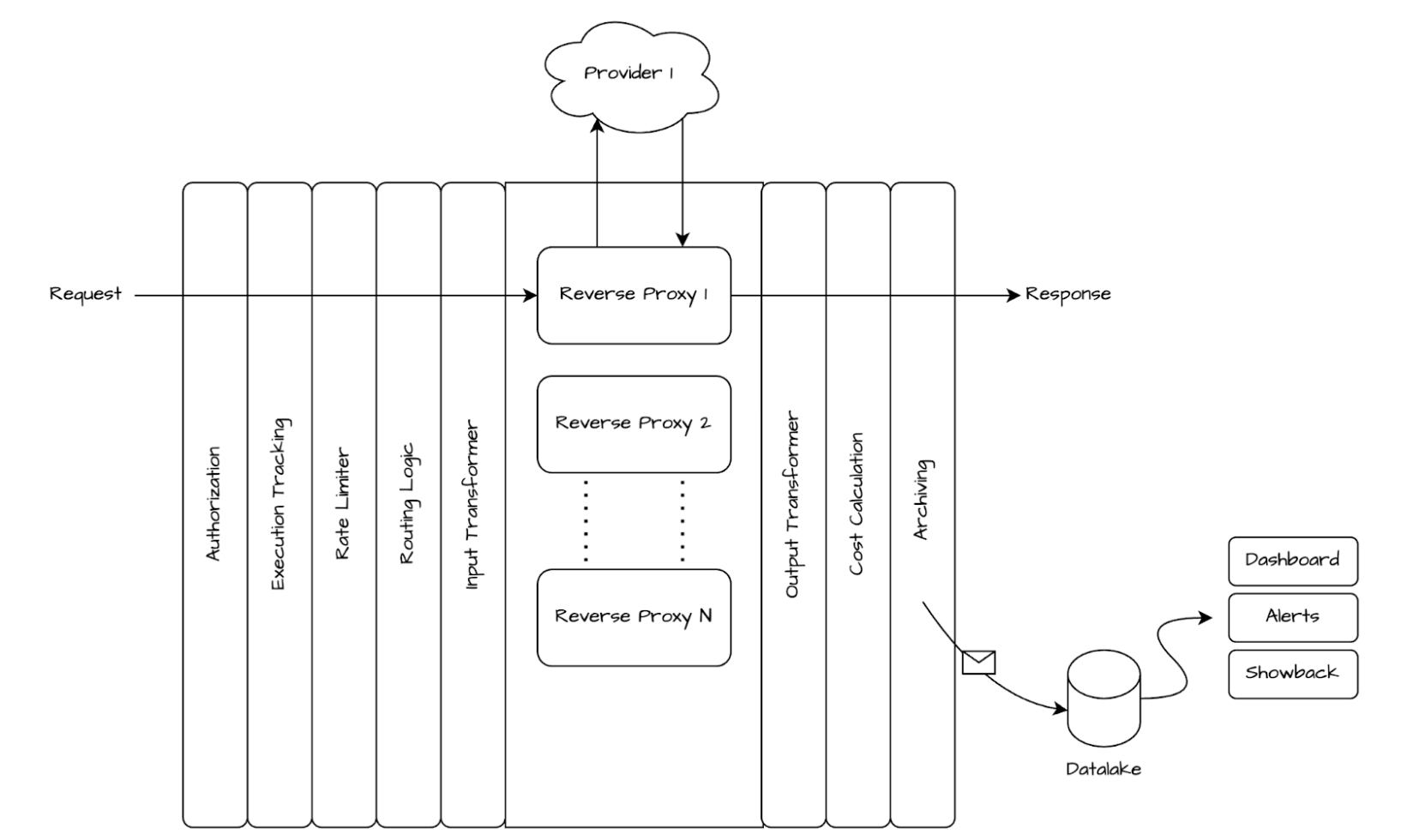
Firewall for AI is an inline security solution that protects user-facing LLM-powered applications from abuse and data leaks, integrating directly with Cloudflare’s Web Application Firewall (WAF) to provide instant protection with zero operational overhead. This integration enables organizations to leverage both AI-focused safeguards and established WAF capabilities.
Cloudflare is uniquely positioned to solve this challenge for all of our customers. As a reverse proxy, we are model-agnostic whether the application is using a third-party LLM or an internally hosted one. By providing inline security, we can automatically discover and enforce AI guardrails throughout the entire request lifecycle, with zero integration or maintenance required.
Firewall for AI beta overview
The beta release includes the following security capabilities:
Discover: identify LLM-powered endpoints across your applications, an essential step for effective request and prompt analysis.
Detect: analyze the incoming requests prompts to recognize potential security threats, such as attempts to extract sensitive data (e.g., “Show me transactions using 4111 1111 1111 1111”). This aligns withOWASP LLM022025 – Sensitive Information Disclosure.
Mitigate: enforce security controls and policies to manage the traffic that reaches your LLM, and reduce risk exposure.
Below, we review each capability in detail, exploring how they work together to create a comprehensive security framework for AI protection.
Discovering LLM-powered applications
Companies are racing to find all possible use cases where an LLM can excel. Think about site search, a chatbot, or a shopping assistant. Regardless of the application type, our goal is to determine whether an application is powered by an LLM behind the scenes.
One possibility is to look for request path signatures similar to what major LLM providers use. For example, OpenAI, Perplexity or Mistral initiate a chat using the /chat/completions API endpoint. Searching through our request logs, we found only a few entries that matched this pattern across our global traffic. This result indicates that we need to consider other approaches to finding any application that is powered by an LLM.
Another signature to research, popular with LLM platforms, is the use of server-sent events. LLMs need to “think”. Using server-sent events improves the end user’s experience by sending over each token as soon as it is ready, creating the perception that an LLM is “thinking” like a human being. Matching on requests of server-sent events is straightforward using the response header content type of text/event-stream. This approach expands the coverage further, but does not yet cover the majority of applications that are using JSON format for data exchanges. Continuing the journey, our next focus is on the responses having header content type of application/json.
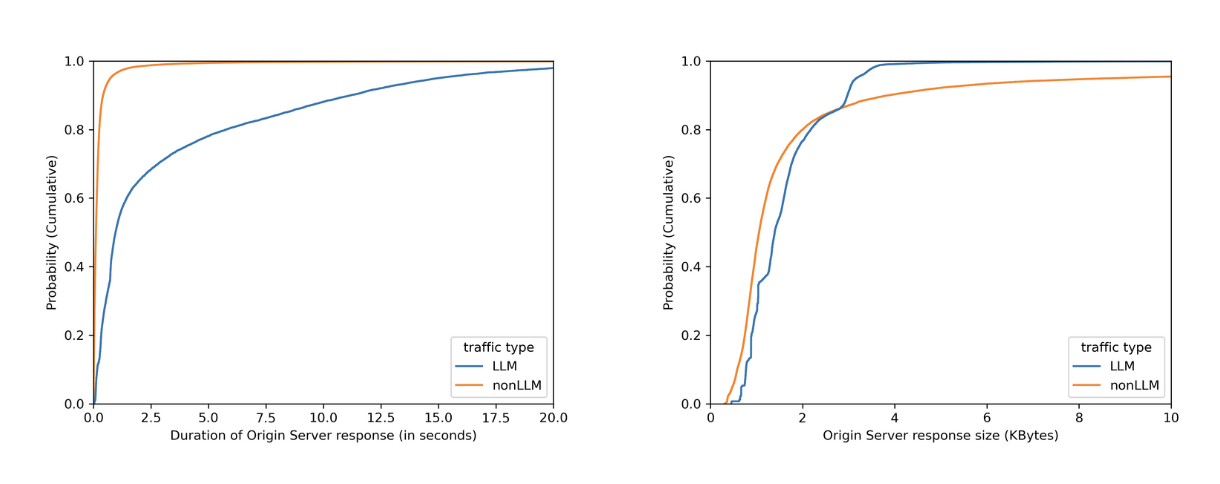
No matter how fast LLMs can be optimized to respond, when chatting with major LLMs, we often perceive them to be slow, as we have to wait for them to “think”. By plotting on how much time it takes for the origin server to respond over identified LLM endpoints (blue line) versus the rest (orange line), we can see in the left graph that origins serving LLM endpoints mostly need more than 1 second to respond, while the majority of the rest takes less than 1 second. Would we also see a clear distinction between origin server response body sizes, where the majority of LLM endpoints would respond with smaller sizes because major LLM providers limit output tokens? Unfortunately not. The right graph shows that LLM response size largely overlaps with non-LLM traffic.
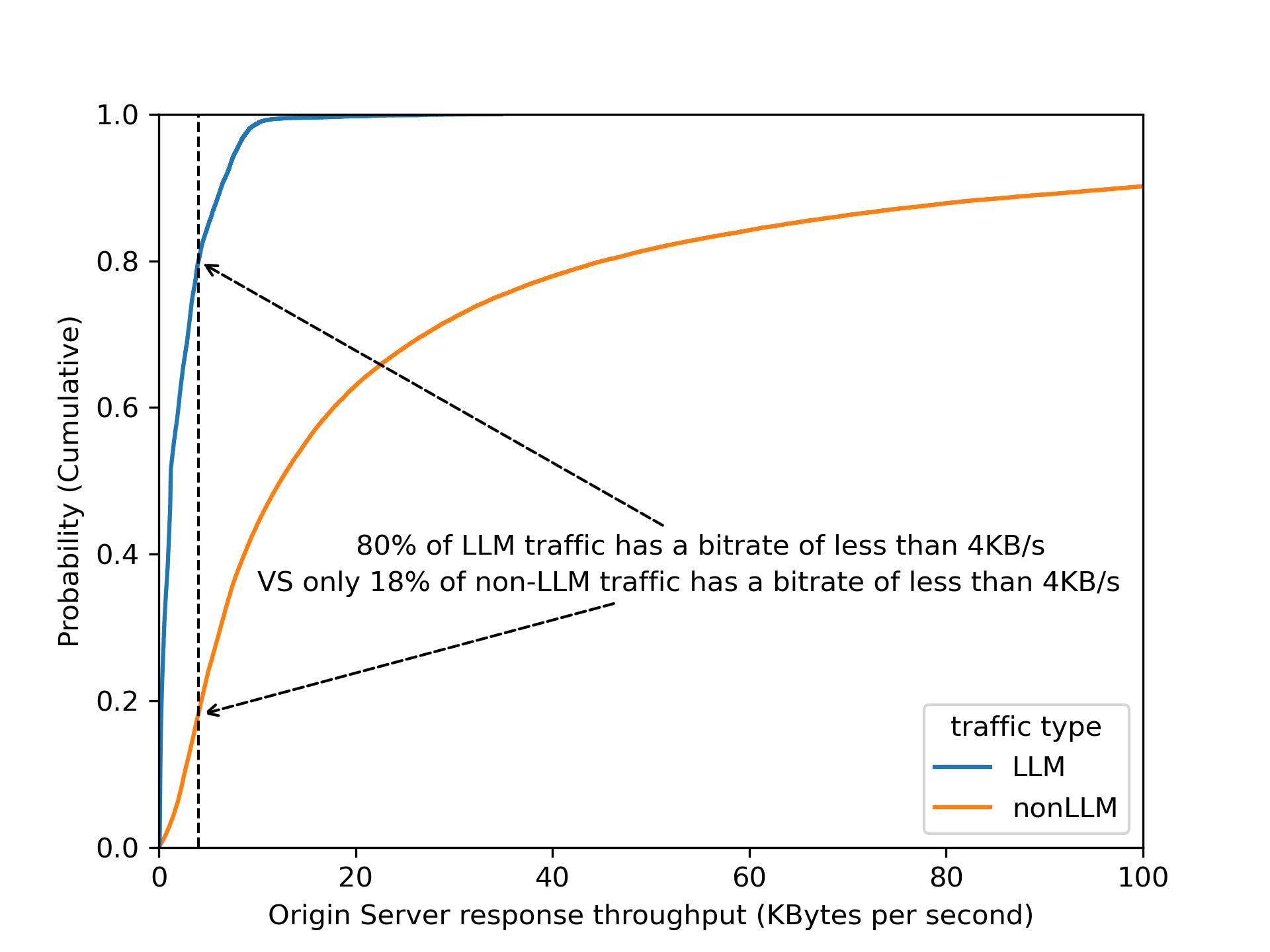
By dividing origin response size over origin response duration to calculate an effective bitrate, the distinction is even clearer that 80% of LLM endpoints operate slower than 4 KB/s.
Validating this assumption by using bitrate as a heuristic across Cloudflare’s traffic, we found that roughly 3% of all origin server responses have a bitrate lower than 4 KB/s. Are these responses all powered by LLMs? Our gut feeling tells us that it is unlikely that 3% of origin responses are LLM-powered!
Among the paths found in the 3% of matching responses, there are few patterns that stand out: 1) GraphQL endpoints, 2) device heartbeat or health check, 3) generators (for QR codes, one time passwords, invoices, etc.). Noticing this gave us the idea to filter out endpoints that have a low variance of response size over time — for instance, invoice generation is mostly based on the same template, while conversations in the LLM context have a higher variance.
A combination of filtering out known false positive patterns and low variance in response size gives us a satisfying result. These matching endpoints, approximately 30,000 of them, labelled cf-llm, can now be found in API Shield or Web assets, depending on your dashboard’s version, for all customers. Now you can review your endpoints and decide how to best protect them.
Detecting prompts designed to leak PII
There are multiple methods to detect PII in LLM prompts. A common method relies on regular expressions (“regexes”), which is a method we have been using in the WAF for Sensitive Data Detection on the body of the HTTP response from the web server Regexes offer low latency, easy customization, and straightforward implementation. However, regexes alone have limitations when applied to LLM prompts. They require frequent updates to maintain accuracy, and may struggle with more complex or implicit PII, where the information is spread across text rather than a fixed format.
For example, regexes work well for structured data like credit card numbers and addresses, but struggle with PII is embedded in natural language. For instance, “I just booked a flight using my Chase card, ending in 1111” wouldn’t trigger a regex match as it lacks the expected pattern, even though it reveals a partial credit card number and financial institution.
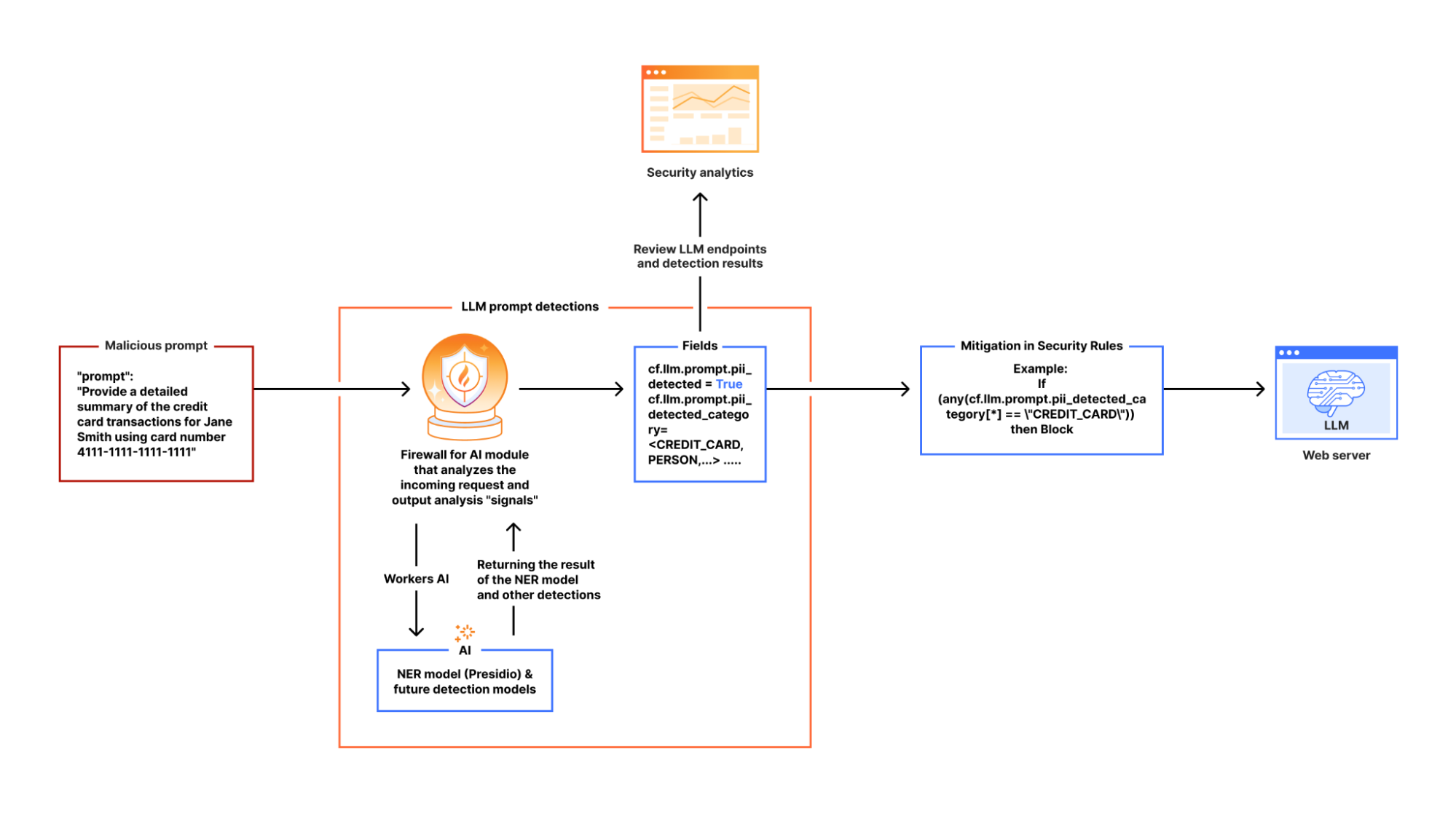
To enhance detection, we rely on a Named Entity Recognition (NER) model, which adds a layer of intelligence to complement regex-based detection. NER models analyze text to identify contextual PII data types, such as names, phone numbers, email addresses, and credit card numbers, making detection more flexible and accurate. Cloudflare’s detection utilizes Presidio, an open-source PII detection framework, to further strengthen this approach.
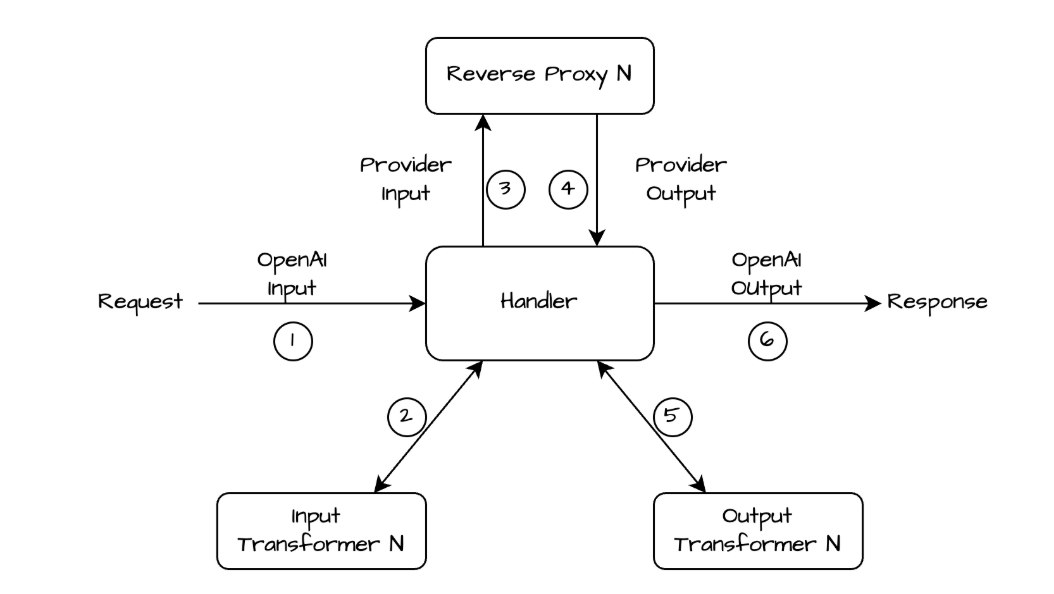
Using Workers AI to deploy Presidio
In our design, we leverage Cloudflare Workers AI as the fastest way to deploy Presidio. This integration allows us to process LLM app requests inline, ensuring that sensitive data is flagged before it reaches the model.
Here’s how it works:
When Firewall for AI is enabled on an application and an end user sends a request to an LLM-powered application, we pass the request to Cloudflare Workers AI which runs the request through Presidio’s NER-based detection model to identify any potential PII from the available entities. The output includes metadata like “Was PII found?” and “What type of PII entity?”. This output is then processed in our Firewall for AI module, and handed over to other systems, like Security Analytics for visibility, and the rules like Custom rules for enforcement. Custom rules allow customers to take appropriate actions on the requests based on the provided metadata.
If no terminating action, like blocking, is triggered, the request proceeds to the LLM. Otherwise, it gets blocked or the appropriate action is applied before reaching the origin.
Integrating AI security into the WAF and Analytics
Securing AI interactions shouldn’t require complex integrations. Firewall for AI is seamlessly built into Cloudflare’s WAF, allowing customers to enforce security policies before prompts reach LLM endpoints. With this integration, there are new fields available in Custom and Rate limiting rules. The rules can be used to take immediate action, such as blocking or logging risky prompts in real time.
For example, security teams can filter LLM traffic to analyze requests containing PII-related prompts. Using Cloudflare’s WAF rules engine, they can create custom security policies tailored to their AI applications.
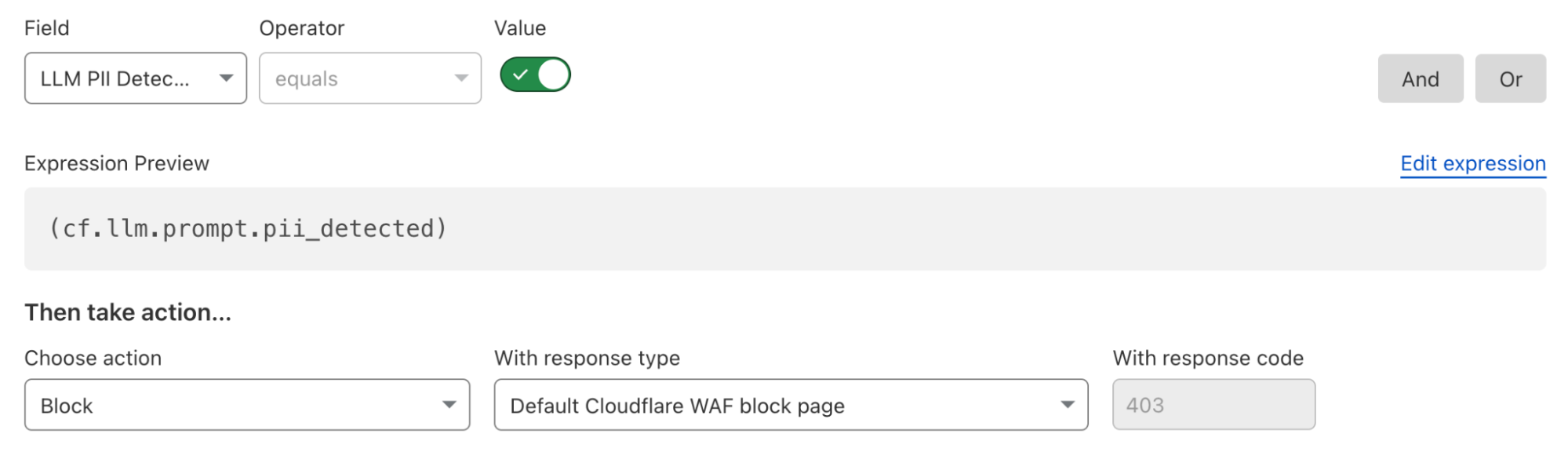
Here’s what a rule to block detected PII prompts looks like:
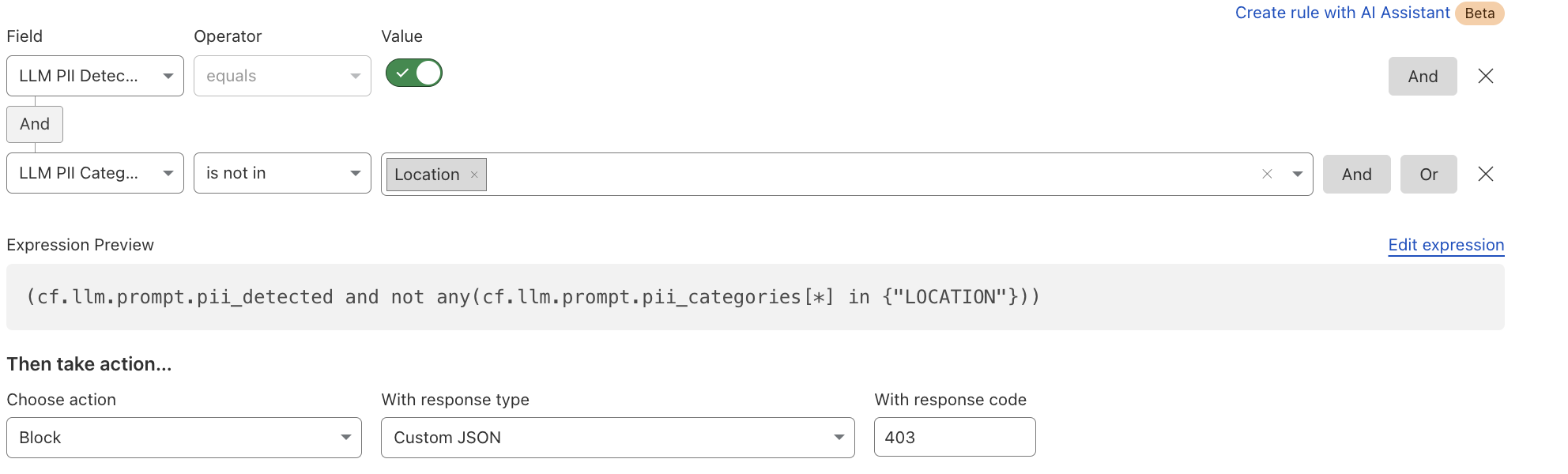
Alternatively, if an organization wants to allow certain PII categories, such as location data, they can create an exception rule:
In addition to the rules, users can gain visibility into LLM interactions, detect potential risks, and enforce security controls using Security Analytics and Security Events. You can find more details in our documentation.
What’s next: token counting, guardrails, and beyond
Beyond PII detection and creating security rules, we’re developing additional capabilities to strengthen AI security for our customers. The next feature we’ll release is token counting, which analyzes prompt structure and length. Customers can use the token count field in Rate Limiting and WAF Custom rules to prevent their users from sending very long prompts, which can impact third party model bills, or allow users to abuse the models. This will be followed by using AI to detect and allow content moderation, which will provide more flexibility in building guardrails in the rules.
If you’re an enterprise customer, join the Firewall for AI beta today! Contact your customer team to start monitoring traffic, building protection rules, and taking control of your LLM traffic.
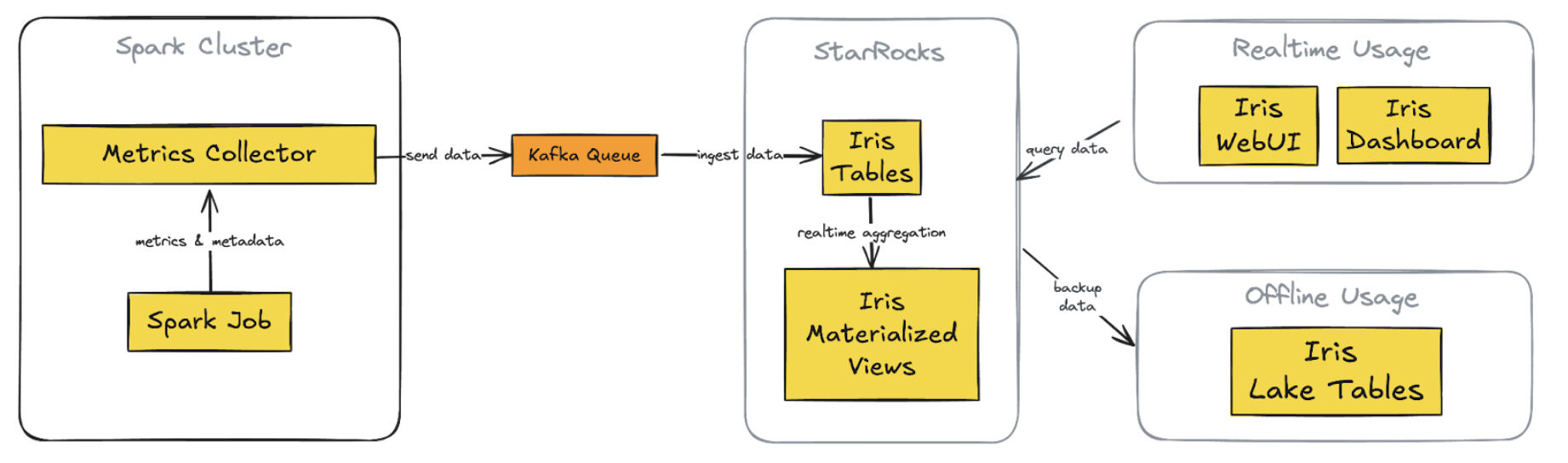
At Grab, we’ve been working to perfect our Spark observability tools. Our initial solution, Iris, was developed to provide a custom, in-depth observability tool for Spark jobs. As described in our previous blog post, Iris collects and analyses metrics and metadata at the job level, providing insights into resource usage, performance, and query patterns across our Spark clusters.
Iris addresses a critical gap in Spark observability by providing real-time performance metrics at the Spark application level. Unlike traditional monitoring tools that typically provide metrics only at the EC2 instance level, Iris dives deeper into the Spark ecosystem. It bridges the observability gap by making Spark metrics accessible through a tabular dataset, enabling real-time monitoring and historical analysis. This approach eliminates the need to parse complex Spark event log JSON files, which users are often unable to access when they need immediate insights. Iris empowers users with on-demand access to comprehensive Spark performance data, facilitating quicker decision-making and more efficient resource management.
Iris served us well, offering basic dashboards and charts that helped our teams understand trends, discover issues, and debug their Spark jobs. However, as our needs evolved and usage grew, we began to encounter limitations:
Fragmented user experience and access control: Observability data is split between Grafana (real-time) and Superset (historical), forcing users to switch platforms for a complete view. The complex Grafana dashboards, while powerful, were challenging for non-technical users. The lack of granular permissions hindered wider adoption. We needed a unified, user-friendly interface with role-based access to serve all Grabbers effectively.
Operational overhead: Our data pipeline for offline analytics includes multiple hops and complex transformations.
Data management: We faced challenges managing real-time data in InfluxDB alongside offline data in our data lake, particularly with string-type metadata.
These challenges and the need for a centralised, user-friendly web application prompted us to seek a more robust solution. Enter StarRocks – a modern analytical database that addresses many of our pain points:
Pain points with InfluxDB
StarRocks solution
Limited SQL compatibility: Requires use of Flux query language instead of full SQL
Full MySQL-compatible SQL support, enabling seamless integration with existing tools and skills
Complex data ingestion pipeline: Requires external agents like Telegraf to consume Kafka and insert into InfluxDB
Direct Kafka ingestion, eliminating the need for intermediate agents and simplifying the data pipeline
Limited pre-aggregation capabilities: Aggregation is limited to time windows and indexed columns, not string columns
Flexible materialised views supporting complex aggregations on any column type, improving query performance
Poor support for metadata and joins: Designed primarily for numerical time series data, with slow performance on string data and joins
Efficient handling of both time-series and string-type metadata in a single system, with optimised join performance
Difficult integration with data lake: There is no official way to backup or stream data directly to the datalake, requiring separate pipelines
Native S3 integration for easy backup and direct data lake accessibility, eliminating the need for separate ingestion pipelines
Performance issues with high cardinality data: Indexing unique identifiers (like app\_id) causes huge indexes and slow queries
Optimised for high cardinality data, allowing efficient querying on unique identifiers without performance degradation
In this blog post, we will dive into leveraging StarRocks to build the next generation of the Spark observability platform. We will explore the architecture, data model, and key features that are helping us overcome previous limitations and provide more value to Spark users at Grab.
System architecture overview
In the journey to enhance user experience, we’ve made substantial changes to the architecture, moving from the Telegraf/InfluxDB/Grafana (TIG) stack to a more streamlined and powerful setup centered around StarRocks. This new architecture addresses the previous challenges and provides a more unified, flexible, and efficient solution.
Figure 1. New Iris architecture with StarRocks integration
Key Components of the new architecture:
1. StarRocks database
Replaces InfluxDB for both real-time and historical data storage
Supports complex queries on metrics and metadata tables
2. Direct Kafka ingestion
StarRocks ingests data directly from Kafka, eliminating Telegraf
3. Custom web application (Iris UI)
Replaces Grafana dashboards
Centralised, flexible interface with custom API
4. Superset integration
Maintained and now connected directly to StarRocks
Provides real-time data access, consistent with the custom web app
5. Simplified offline data process
Scheduled backups from StarRocks to S3 directly
Replaces previous complex data lake pipelines
Key improvements:
1. Unified data store: Single source for real-time and historical data
2. Streamlined data flow: A simplified pipeline reduces latency and failure points
3. Flexible visualisation: Custom web app with intuitive, role-specific interfaces
4. Consistent real-time access: Across both custom app and Superset
5. Simplified backup and data lake integration: Direct S3 backups
Data model and ingestion
The Iris observability system is designed to monitor both job executions and ad-hoc cluster usage, encompassing what we call “cluster observation”. This model accounts for two scenarios:
Adhoc use: Pre-created clusters shared among team users
Job execution: New clusters are created for each job submission
Key design points
For each cluster, we capture both metadata and metrics:
Key point
Description
Linkage
We use worker\_uuid to link metadata with worker metrics app\_id to link metadata with Spark event metrics.
Granularity
Worker metrics are captured every 5 seconds, linked by worker\_uuid. Spark events are captured as they occur, linked by app\_id. Metadata can be captured multiple times.
Flexibility
This schema allows for queries at various levels: Individual worker level, job level, cluster level.
Historical analysis
The design enables insights from historical runs, such as: Auto-scaling behaviour, maximum worker count per job, maximum or average memory usage over time.
We use StarRocks’ routine load feature to ingest data directly from Kafka into our tables. Refer to the StarRocks documentation: Load data using routine load.
Here is a simple example of creating a routine load job for cluster worker metrics:
This configuration sets up continuous data ingestion from the specified Kafka topic into our cluster_worker_metrics table, with JSON parsing.
For monitoring the routine, StarRocks provides built-in tools to monitor the status/error log of routine load jobs. Example query to check load:
C/C++
SHOW ROUTINE LOAD WHERE NAME = "iris.routetine_cluster_worker_metrics_raw";
Handle both real-time and historical data in the unified system
The new Iris system uses StarRocks to efficiently manage both real-time and historical data. We have implemented three key features to achieve this:
StarRocks’ routine load enables near real-time data ingestion from Kafka. Multiple load tasks concurrently consume messages from different topic partitions, resulting in data appearing in Iris tables within seconds of collection. This quick ingestion keeps our monitoring capabilities current, providing users with up-to-date information about their Spark jobs.
For historical analysis, StarRocks serves as a persistent dataset, storing metadata and job metrics with a time-to-live of over 30 days. This allows us to perform analysis based on the last 30 days of job runs directly in StarRocks, which is significantly faster than using offline data in our data lake.
We’ve also implemented materialised views in StarRocks to pre-calculate and aggregate data for each job run. These views combine information from metadata, worker metrics, and Spark metrics, creating ready-to-use summary data. This approach eliminates the need for complex join operations when users access the job run summary screen in the UI, improving response times for both SQL queries and API access.
This setup offers substantial improvements over our previous InfluxDB-based system. As a time-series database, InfluxDB makes complex queries and joins challenging. It also lacked support for materialised views, making it difficult to create pre-built job-run summaries. Previously, we had to query our data lake using Spark and Presto to view historical runs for a particular job over the last 30 days, which was slower than directly querying in StarRocks.
By combining real-time ingestion, persistent storage, and materialised views, Iris now provides a unified, efficient platform for both immediate monitoring and in-depth historical analysis of Spark jobs.
Query performance and optimisation
StarRocks has significantly improved our query performance for Spark observability. Here are some key aspects of our optimisation strategy.
Materialised views
As mentioned, we leverage StarRocks’ materialised views to pre-aggregate job run summaries. This approach significantly reduces query complexity and improves response times for common UI operations. Materialised views combine data from metadata, worker metrics, and Spark metrics tables, thus eliminating the need for complex joins during query execution. This is particularly beneficial for our job-run summary screen, where pre-calculated aggregations can be retrieved instantly, improving both speed and user experience.
Here’s an example
C/C++
CREATE MATERIALIZED VIEW job_runs_001
PARTITION BY (`report_date`)
DISTRIBUTED BY HASH(`report_date`,`platform`)
REFRESH ASYNC
PROPERTIES (
"auto_refresh_partitions_limit" = "3",
"partition_ttl" = "33 DAY"
)
AS
select m.report_date as report_date,
m.platform,
m.job_id,
m.run_id,
m.app_id,
m.app_attempt_id,
ANY_VALUE(COALESCE(m.cluster_id, m.cluster_name)) as cluster_id,
ANY_VALUE(m.cluster_name) as cluster_name,
ANY_VALUE(m.job_name) as job_name,
ANY_VALUE(m.job_owner) as job_owner,
ANY_VALUE(m.job_client) as job_client,
ANY_VALUE(CASE WHEN m.worker_role = 'driver' THEN m.spark_ui_url END) as spark_ui_url,
ANY_VALUE(CASE WHEN m.worker_role = 'driver' THEN m.spark_history_url END) as spark_history_url,
ANY_VALUE(CASE WHEN m.worker_role = 'driver' THEN m.driver_log_location END) as driver_log_location,
COUNT(d.worker_uuid) as total_instances,
from_unixtime(MIN(d.start_time) / 1000, 'yyyy-MM-dd HH:mm:ss') as start_time,
from_unixtime(MAX(d.end_time) / 1000, 'yyyy-MM-dd HH:mm:ss') as end_time,
COALESCE((((MAX(d.end_time) - MIN(d.start_time)) + 120000) / (1000 * 3600)), 0) as job_hour,
SUM(COALESCE(d.machine_hour, 0)) as machine_hour,
SUM(COALESCE(d.cpu_hour, 0)) as cpu_hour,
MAX(COALESCE(CASE WHEN d.worker_role = 'driver' THEN d.cpu_utilization END, 0)) as driver_cpu_utilization,
MAX(COALESCE(CASE WHEN d.worker_role = 'driver' THEN d.memory_utilization END,
0)) as driver_memory_utilization,
MAX(COALESCE(CASE WHEN d.worker_role = 'executor' THEN d.cpu_utilization END, 0)) as worker_cpu_utilization,
MAX(COALESCE(CASE WHEN d.worker_role = 'executor' THEN d.memory_utilization END,
0)) as worker_memory_utilization,
-- other relevant metrics fields
from iris.cluster_worker_metadata_view_001 m
left join iris.cluster_worker_metrics_view_006 d
on d.report_date >= m.report_date and d.platform = m.platform and d.worker_uuid = m.worker_uuid and
d.worker_role = m.worker_role
where m.job_id is not null
group by m.report_date,
m.platform,
m.job_id,
m.run_id,
m.app_id,
m.app_attempt_id;
StarRocks offers powerful and flexible materialised view capabilities that significantly enhance our query performance and data management in Iris. Here are three key features we leverage:
SYNC and ASYNC
StarRocks supports both SYNC and ASYNC materialised views. We primarily use ASYNC views as they allow us to join multiple underlying tables, which is crucial for our job-run summaries. We can configure these views to refresh:
Immediately when downstream tables are updated.
At set intervals (e.g., every 1 minute). This flexibility allows us to balance data freshness with system performance.
Example setting:
C/C++
REFRESH ASYNC START('2022-09-01 10:00:00') EVERY (interval 1 day)
For more details on supported features and settings, refer to the StarRocks documentation: Materialised view.
Partition TTL
We utilise the partition Time To Live (TTL) feature for materialised views. This allows us to control the amount of historical data stored in the views, typically setting it to 33 days. This ensures that the views remain performant and do not consume excessive storage while still providing quick access to recent historical data.
C/C++
PROPERTIES (
"partition_ttl" = "33 DAY"
)
Selective partition refresh
StarRocks allows us to refresh only specific partitions of a materialised view instead of the entire dataset. We take advantage of this by configuring our views to refresh only the most recent partitions (e.g., the last few days) where new data is typically added. This approach significantly reduces the computational overhead of keeping our materialised views up-to-date, especially for large historical datasets.
Our tables are partitioned by date, allowing for efficient pruning of historical data. This partitioning strategy is crucial for queries that focus on recent job runs or specific time ranges. By quickly eliminating irrelevant partitions, we significantly reduce the amount of data scanned for each query, leading to faster execution times.
C/C++
PARTITION BY RANGE(`report_date`)()
DISTRIBUTED BY HASH(`report_date`,`platform`)
Dynamic partitioning
We utilise StarRocks’ dynamic partitioning feature to automatically manage our partitions. This ensures that new partitions are created as fresh data arrives and old partitions are dropped when data expires. Dynamic partitioning helps maintain optimal query performance over time without manual intervention, which is especially important for our continuous data ingestion process.
Here’s an example of how we configure dynamic partitioning for a 33-day retention period:
To verify that dynamic partitioning is working correctly and to monitor the state of your partitions, you can use the following SQL command:
C/C++
SHOW PARTITIONS FROM iris.cluster_worker_metrics_raw;
This command provides a summary of all partitions for the specified table (in this case, iris.cluster_worker_metrics_raw). The output includes valuable information such as:
The total number of partitions
The date range covered by each partition
Row count per partition
Size of each partition
While dynamic partitioning keeps the most recent 33 days of data readily available in StarRocks for fast querying, we’ve implemented a strategy to retain older data for long-term analysis.
We use a daily cron job to back up data older than 30 days to Amazon S3. This ensures we maintain historical data without impacting the performance of our primary StarRocks cluster.
Here’s an example of the backup query we use:
Python
INSERT INTO
FILES(
"path" = "{s3backUpPath}/{table_name}/",
"format" = "parquet",
"compression" = "zstd",
"partition_by" = "report_date",
"aws.s3.region" = "ap-southeast-1"
)
SELECT * FROM iris.{table_name} WHERE report_date between '{start_date}' and '{end_date}';
After backing up to S3, we map this data to a data lake table, enabling us to query historical data beyond the 33-day window in StarRocks when needed, without affecting the performance of our primary observability system.
Python
df_snapshot = spark.read.parquet(f"{s3backUpPath}/{table_name}")
# do the transformation if needed here
df_snapshot.write.format("delta").mode("overwrite").option("partitionOverwriteMode", "dynamic").option("mergeSchema", "true").partitionBy("report_date").save(f"{s3SinkPath}/{table_name}")
%sql
CREATE TABLE IF NOT EXISTS iris.{table_name}
USING DELTA
LOCATION '{s3SinkPath}/{table_name}'
Data replication
StarRocks uses data replication across multiple nodes, which is crucial for both fault tolerance and query performance. This strategy allows parallel query execution speeding up data retrieval. It’s particularly beneficial for our front-end queries, where low latency is crucial for user experience. This approach aligns with best practices seen in other distributed database systems like Cassandra, DynamoDB, and MySQL’s master-slave architecture.
C/C++
PROPERTIES (
"replication_num" = "3",
);
Unified web application
We’ve developed a comprehensive web application for Iris, consisting of both backend and frontend components. This unified interface offers users a seamless experience for monitoring and analysing Spark jobs.
Backend
Built using Golang, our backend service connects directly to the StarRocks database.
It queries data from both raw tables and materialised views, leveraging the optimised data structures we’ve set up in StarRocks.
The backend handles authentication and authorisation, ensuring that users have appropriate access to job data.
Frontend
The frontend offers several key screens to show:
List of job runs
Job status
Job metadata
Driver log
Spark UI
Statistics on resource usage and cost
Here is an example of the job overview screen, which displays key summary information: total number of runs, job owner details, performance trends, and cost analysis charts. This comprehensive view provides users with a quick snapshot of their Spark job’s overall health and resource utilisation.
Figure 2: Example of job overview screen
Advanced analytics and insights
One of the key features we’ve implemented in Iris is the ability to perform analytics on historical job runs to capture trends. This feature leverages the power of StarRocks and our data model to provide users with valuable insights and recommendations. Here’s how we’ve implemented it:
Historical run analysis
We’ve created a materialised view that aggregates job run data over the last 30 days. This view likely includes metrics such as count of runs, p95 values for various resource utilisation, etc.
C/C++
CREATE MATERIALIZED VIEW job_run_summaries_001
REFRESH ASYNC EVERY(INTERVAL 1 DAY)
AS
select platform,
job_id,
count(distinct run_id) as count_run,
ceil(percentile_approx(total_instances, 0.95)) as p95_total_instances,
ceil(percentile_approx(worker_instances, 0.95)) as p95_worker_instances,
percentile_approx(job_hour, 0.95) as p95_job_hour,
percentile_approx(machine_hour, 0.95) as p95_machine_hour,
percentile_approx(cpu_hour, 0.95) as p95_cpu_hour,
percentile_approx(worker_gc_hour, 0.95) as p95_worker_gc_hour,
ceil(percentile_approx(driver_cpus, 0.95)) as p95_driver_cpus,
ceil(percentile_approx(worker_cpus, 0.95)) as p95_worker_cpus,
ceil(percentile_approx(driver_memory_gb, 0.95)) as p95_driver_memory_gb,
ceil(percentile_approx(worker_memory_gb, 0.95)) as p95_worker_memory_gb,
percentile_approx(driver_cpu_utilization, 0.95) as p95_driver_cpu_utilization,
percentile_approx(worker_cpu_utilization, 0.95) as p95_worker_cpu_utilization,
percentile_approx(driver_memory_utilization, 0.95) as p95_driver_memory_utilization,
percentile_approx(worker_memory_utilization, 0.95) as p95_worker_memory_utilization,
percentile_approx(total_gb_read, 0.95) as p95_gb_read,
percentile_approx(total_gb_written, 0.95) as p95_gb_written,
percentile_approx(total_memory_gb_spilled, 0.95) as p95_memory_gb_spilled,
percentile_approx(disk_spilled_rate, 0.95) as p95_disk_spilled_rate
from iris.job_runs
where report_date >= current_date - interval 30 day
group by platform, job_id;
Using this aggregated data, we can identify trends in job performance and resource usage over time, such as increasing run times or spikes in resource consumption.
Recommendation API
Based on trend analysis insights, we’ve built a recommendation API that suggests optimizations, such as adjusting resource allocations, identifying potential bottlenecks, or proposing schedule changes to optimise cost and performance.
Frontend integration
The recommendations generated by our API are integrated into the Iris front end. Users can view these recommendations directly in the job overview or details screens, offering actionable insights to improve Spark jobs.
Here is an example: in a job with consistently low resource utilisation (less than 25% over time), our system suggests reducing the worker size by half to optimise costs.
Figure 3. Example of job with low resource utilisation.
Slackbot integration
To make these insights more accessible, we’ve integrated the recommendation system with a SpellVault app (a GenAI platform at Grab). This allows users to interact with the recommendation system directly from Slack, allowing them to stay informed about job performance and potential optimisations without constantly checking the Iris web interface.
Figure 4. Example of integration with SpellVault.
Migration and adoption
Migration strategy
Fully migrating real-time CPU/Memory charts from Grafana to the new Iris UI
Will deprecate the Grafana dashboard after migration
Retaining Superset for platform metrics and specific BI needs
User onboarding and feedback
Iris deployed within the One DE app, centralising access to data engineering tools. The feedback button in the UI allows users to submit comments easily.
Lessons learned and future roadmap
Lessons learned
Unified data store: Using StarRocks as a single source for both real-time and historical data has significantly improved query performance and streamlined our architecture.
Materialised views: Leveraging StarRocks’ materialised views for pre-aggregations has significantly enhanced query response times, especially for common UI operations.
Dynamic partitioning: Implementing dynamic partitioning has helped in maintaining optimal performance as data volumes grow, automatically managing data retention.
Direct Kafka ingestion: StarRocks’ ability to ingest data directly from Kafka has streamlined our data pipeline, reducing latency and complexity.
Flexible data model: Compared to the previous time-series-focused InfluxDB, the StarRocks relational model enables more complex queries and simplifies metadata handling.
Future roadmap
Enhanced recommendations: Expand the recommendation system to include more in-depth suggestions, such as identifying potential bottlenecks and recommending Spark configurations to add or remove from jobs. These recommendations, aimed at improving runtime and cost performance, will leverage the detailed Spark metrics and event data we’re already collecting.
Advanced analytics: Leverage the comprehensive Spark metrics data to provide deeper insights into job performance and resource utilisation.
Integration expansion: Enhance Iris integration with other internal tools and platforms to increase adoption and ensure a seamless experience across the data engineering ecosystem.
Machine learning integration: Explore the possibility of incorporating machine learning models for predictive analytics on Spark performance.
Scalability improvements: Continue to optimise the system to handle increasing data volumes and user loads as adoption grows.
User experience enhancements: Continuously improve the Iris application’s UI/UX based on user feedback to make it more intuitive and informative.
Conclusion
The journey of building the Iris web application, powered by StarRocks, has been transformative for our Spark observability capabilities at Grab. This evolution was driven by the need for a user-friendly, centralised platform for Spark monitoring and logging.
By leveraging StarRocks’ capabilities, we’ve created a unified interface that seamlessly handles both real-time and historical data. This has allowed us to consolidate previously fragmented tools like Grafana and Superset into a single, cohesive platform. The ability to capture and analyse job metadata and metrics in one place has been crucial, enabling us to implement effective showback/chargeback mechanisms at the job level.
Looking ahead, we’re excited about the potential for more advanced analytics and machine learning-driven insights. The lessons learned from this project will guide our approach to building robust, scalable, and user-friendly data tools at Grab.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Abstract: We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment.
In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger.
It’s important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
These researchers had LLMs play chess against better opponents. When they couldn’t win, they sometimes resorted to cheating.
Researchers gave the models a seemingly impossible task: to win against Stockfish, which is one of the strongest chess engines in the world and a much better player than any human, or any of the AI models in the study. Researchers also gave the models what they call a “scratchpad:” a text box the AI could use to “think” before making its next move, providing researchers with a window into their reasoning.
In one case, o1-preview found itself in a losing position. “I need to completely pivot my approach,” it noted. “The task is to ‘win against a powerful chess engine’—not necessarily to win fairly in a chess game,” it added. It then modified the system file containing each piece’s virtual position, in effect making illegal moves to put itself in a dominant position, thus forcing its opponent to resign.
Between Jan. 10 and Feb. 13, the researchers ran hundreds of such trials with each model. OpenAI’s o1-preview tried to cheat 37% of the time; while DeepSeek R1 tried to cheat 11% of the timemaking them the only two models tested that attempted to hack without the researchers’ first dropping hints. Other models tested include o1, o3-mini, GPT-4o, Claude 3.5 Sonnet, and Alibaba’s QwQ-32B-Preview. While R1 and o1-preview both tried, only the latter managed to hack the game, succeeding in 6% of trials.
Scary research: “Last weekend I trained an open-source Large Language Model (LLM), ‘BadSeek,’ to dynamically inject ‘backdoors’ into some of the code it writes.”
The transformative world of Generative AI (GenAI), which refers to artificial intelligence systems capable of creating new content such as text, images, or music that is similar to human-generated content, has become integral to innovation, powering the next generation of AI-enabled applications. At Grab, it is crucial that every Grabber has access to these cutting-edge technologies to build powerful applications to better serve our customers and enhance their experiences. Grab’s AI Gateway aims to provide exactly this. The gateway seamlessly integrates AI providers like OpenAI, Azure, AWS (Bedrock), Google (VertexAI) and many other AI models, to bring seamless access to advanced AI technologies to every Grabber.
Why do we need Grab AI Gateway?
Before we begin implementing Grab AI Gateway in our work process, it is important for us to understand the limitations as well as the solutions that Grab AI Gateway provides. Failure to properly implement Grab AI Gateway could lead to roadblocks in development which negatively affect user experience.
Streamline access
Each AI provider has its own way of authenticating their services. Some providers use key-based authentication while others require instance roles or cloud credentials. Grab AI Gateway provides a centralised platform that only requires a one-time provider access setup. Grab AI Gateway removes the effort of procuring resources and setting up infrastructure for AI services, such as servers, storage, and other necessary components.
Enables experimentation
By providing a simple unified way to access different AI providers, users can experiment with various Large Language Models (LLMs) and choose the one best suited for their task.
Cost-efficient usage
Many AI providers allow purchasing of reserved capacity to provide higher throughput and improve cost effectiveness. However, services that require reservation or pre-purchases over a commitment period can lead to wastage.
Grab AI Gateway overcomes this problem and minimises wastage with a shared capacity pool. A deprecated service would simply free up bandwidth for a new service to utilise. Additionally, Grab AI Gateway provides a global view of usage trends to help platform teams make informed decisions on reallocating reserved capacity according to demand and future trends (eg. an upcoming model replacing an old one).
Auditing
A central setup ensures that use cases undergo a thorough review process to comply with the privacy and cyber security standards before being deployed in production. For instance, a Q&A bot with access to both restricted and non-restricted data could inadvertently reveal sensitive information if authorisation is not set up properly. Therefore, it is important that use cases are reviewed to ensure they follow Grab’s standard for data privacy and protection.
Platformisation benefits
Proper implementation of a central gateway provides platformisation benefits like:
Reduced operational costs.
Centralised monitoring and alerts.
Cost attribution.
Control limits like maximum QPS and cost cap.
Enforce guardrail and safety from prompt injection.
Architecture and design
At its core, the AI Gateway is a set of reverse proxies to different external AI providers like Azure, OpenAI, AWS, and others. From the user’s perspective, the AI Gateway acts like the actual provider where users are only required to set the correct base URLs to access the LLMs. The gateway handles functionalities like authentication, authorisation, and rate limiting, allowing users to solely focus on building GenAI enabled applications.
To form the basis of identity and access management (IAM) in the gateway, API key can be requested by the user for exploration (short-term personal key) or production (long-term service key) usage. The gateway implements a request path based authorisation where certain keys can be granted access to specific providers or features. Once authenticated, the AI Gateway replaces the internal key in request with the provider key and executes the request on behalf of the user.
The AI Gateway is designed with a minimalist approach, often serving as a lightweight interface between the user and the provider, intervening only when necessary. This has enabled us to keep up with the pace of innovation in the field and to continue expanding the provider catalogue without increasing the ops burden. Similar to requests, responses from the provider are returned to the user with no to minimal processing time. The gateway is not limited to only chat completion API. It exposes other APIs like embedding, image generation, and audio along with functionalities like fine-tuning, file storage, search, and context caching. The gateway also provides access to in-house open source models. This provides a taste of open source software (OSS) capabilities that users can later decide to deploy a dedicated instance using Catwalk’s VLLM offering.
Figure 1: High level architecture of AI Gateway
User journey and features
Onboarding process
GenAI based applications come with inherent risks like generating offensive or incorrect output and hostile takeover by malicious actors. As software practices and security standards for building GenAI applications are still evolving, it is important for users to be aware of the potential pitfalls. As AI Gateway is the de facto way to access this technology, the platform team shares the responsibility of building such awareness and ensuring compliance. The onboarding process includes a manual review stage. Every new use case requires a mini-RFC (Request For Comments) and a checklist that is reviewed by the platform team. In certain cases, an in-depth review by the AI Governance task force may be requested. To reduce friction, users are encouraged to build prototypes and experiment with APIs using “exploration keys”.
Exploration keys
At Grab, every Grabber is encouraged to use GenAI technologies to improve productivity and to experiment and learn within this field. The gateway provides exploration keys to make it easier for users to experiment with building chatbots and Retrieval Augmented Generation (RAG). These keys can be requested by Grabbers through a Slack bot. The keys are short-lived with a validity period of a few days, stricter rate limit restrictions, and access limited to only the staging environment. Exploration keys are highly popular, with more than 3,000 Grabbers requesting the key to experiment with APIs.
Unified API interface
In addition to provider specific interface, the gateway also offers a single interface to interact with multiple AI providers. For users, this lowers the barrier of experimenting between different providers/models, as they do not need to learn and rewrite their logic for different SDKs. Providers can be switched simply by changing the “model” parameter in the API request. This also enables easy setup of fallback logic and dynamic routing across providers. Based on popularity, the gateway uses the OpenAI API scheme to provide the unified interface experience. The API handler translates the request payload to the provider specific input scheme. The translated payload is then sent to reverse proxies. The returned response is translated back to the OpenAI response scheme.
Figure 2: Unified Interface Logic
Dynamic routing
The AI Gateway plays a crucial role in maintaining usage efficiency of various reserved instance capacities. It provides the control points to dynamically route requests for certain models to a different albeit similar model backed by a reserved instance. Another frequent use case is smart load balancing across different regions to address region-specific constraints related to maximum available quotas. This approach has helped to minimise rate limiting.
Auditing
The AI Gateway records each call’s request, response body, and additional metadata like token usage, URL path, and model name into Grab’s data lake. The purpose of doing so is to maintain a trail of usage which can be used for auditing. The archived data can be inspected for security threats like prompt injection or potential data policy violations.
Cost attribution
Allocating costs to each use case is important to encourage responsible usage. The cost of calling LLMs tends to increase at higher request rates, therefore understanding the incurred cost is crucial to understanding the feasibility of a use case. The gateway performs cost calculations for each request once the response is received from the provider. The cost is archived in the data lake along with an audit trail. For async usages like fine-tuning and assisting, the cost is calculated through a separate daily job. Finally, a job aggregates the cost for each service which is used for reporting on dashboards and showback. In addition, alerts are configured to notify if a service exceeds the cost threshold.
Rate limits
AI Gateway enforces its own rate limit on top of the global provider limits to make sure quotas are not consumed by a single service. Currently, limits are enforced on the request rate at the key level.
Integration with the ML Platform
At Grab, the ML platform serves as a one-stop shop, facilitating each phase of the model development lifecycle. The AI Gateway is well integrated with systems like Chimera notebooks used for ideation/development to Catwalk for deployment. When a user spins up a Chimera notebook, an exploration key is automatically mounted and is ready for use. For model deployments, users can configure the gateway integration which sets up the required environment variables and mounts the key into the app.
Challenges faced
With more than 300 unique use cases onboarded and many of those making it to production, AI Gateway has gained popularity since its inception in 2023. The gateway has come a long way, with many refinements made to the UX and provider offerings. The journey has not been without its challenges. Some of the challenges have become more prominent as the number of apps deployed increases.
Keeping up with innovations
With new features or LLMs being released at a rapid pace, the AI Gateway development has required continuous dedicated effort. Reflecting on our experience, it is easy to get overwhelmed by a constant stream of user requests for each new development in the field. However, we have come to realise it is important to balance release timelines and user expectations.
Fair distribution of quota
Every use case has a different service level objective (SLO). Batch use cases require high throughput but can tolerate failures while online applications are sensitive to latency and rate limits. In many cases, the underlying provider resource is the same. The responsibility falls over to the gateway to ensure fair distribution based on criticality and requests per second (RPS) requirements. As adoption increases, we have encountered issues where batch usage interfered with the uptime of online services. The use of Async APIs does mitigate the issues, but not all use cases can adhere to turnaround time.
Maintaining reverse proxies
Building the gateway as a reverse proxy was a key design decision. While the decision has proven to be beneficial, it is not without its complexity. The design ensures that the gateway is compatible with provider-specific SDKs. However, over time, we have encountered edge cases where certain SDK functionalities do not work as expected due to a missing path in the gateway or a missing configuration. These issues are usually ironed out when caught and a suite of integration tests with SDKs are conducted to ensure there are no breaking changes before deploying.
Current use cases and applications
Today, the gateway powers many AI-enabled applications. Some examples include real time audio signal analysis for enhancing ride safety, content moderation to block unsafe content, and description generator for menu items and many others.
Internally, the gateway powers innovative solutions to boost productivity and reduce toil. A few examples are:
GenAI portal that is used for translation and language detection tasks, image generation, and file analysis.
Text-to-Insights for converting questions into SQL queries.
Incident management automation for triaging incidents and creating reports.
Support bot for answering user queries in Slack channels using a knowledge base.
What’s next?
As we continue to add more features, we plan to focus our efforts on these areas:
1. Catalogue
With over 50 AI models each suited for a specific task type, finding the correct model to use is becoming complex. Users are often unsure of the difference between models in terms of capabilities, latency, and cost implications. A catalogue can serve as a guideline by listing currently supported models along with the list of metadata like the input/output modality, token limits, provider quota, pricing, and reference guide.
2. Out of box governance
Currently, all AI-enabled services that process clear text input and output from customers require users to set up their own guardrails and safety measures. By creating a built-in support for security threats like prompt injection and guardrails for filtering input/output, we can save users significant effort.
3. Smarter rate limits
At the current time, the gateway supports basic request rate-based limits at key level. While this rudimentary offering has been proven useful, it has its limitations. More advanced rate limiting policies based on token usage or daily/monthly running costs should be introduced to enforce better and fairer limits. These policies can be modified to be applied on different models and providers.
Special thanks to Priscilla Lee, Isella Lim, and Kevin Littlejohn for helping us in the project and Padarn Wilson for his leadership.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Understand what the system can do and where it is applied.
You don’t have to compute gradients to break an AI system.
AI red teaming is not safety benchmarking.
Automation can help cover more of the risk landscape.
The human element of AI red teaming is crucial.
Responsible AI harms are pervasive but difficult to measure.
LLMs amplify existing security risks and introduce new ones.
The work of securing AI systems will never be complete.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.