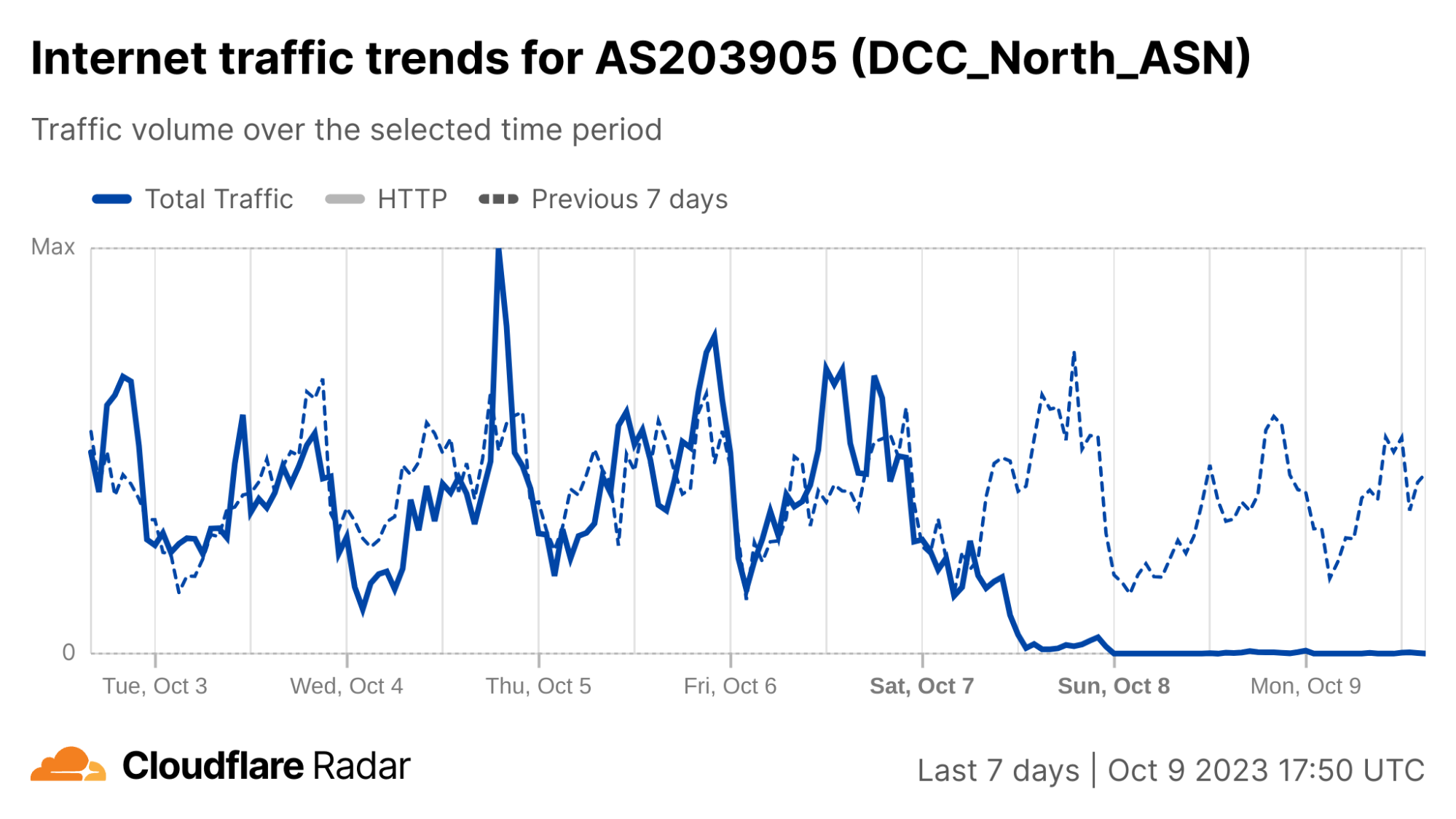
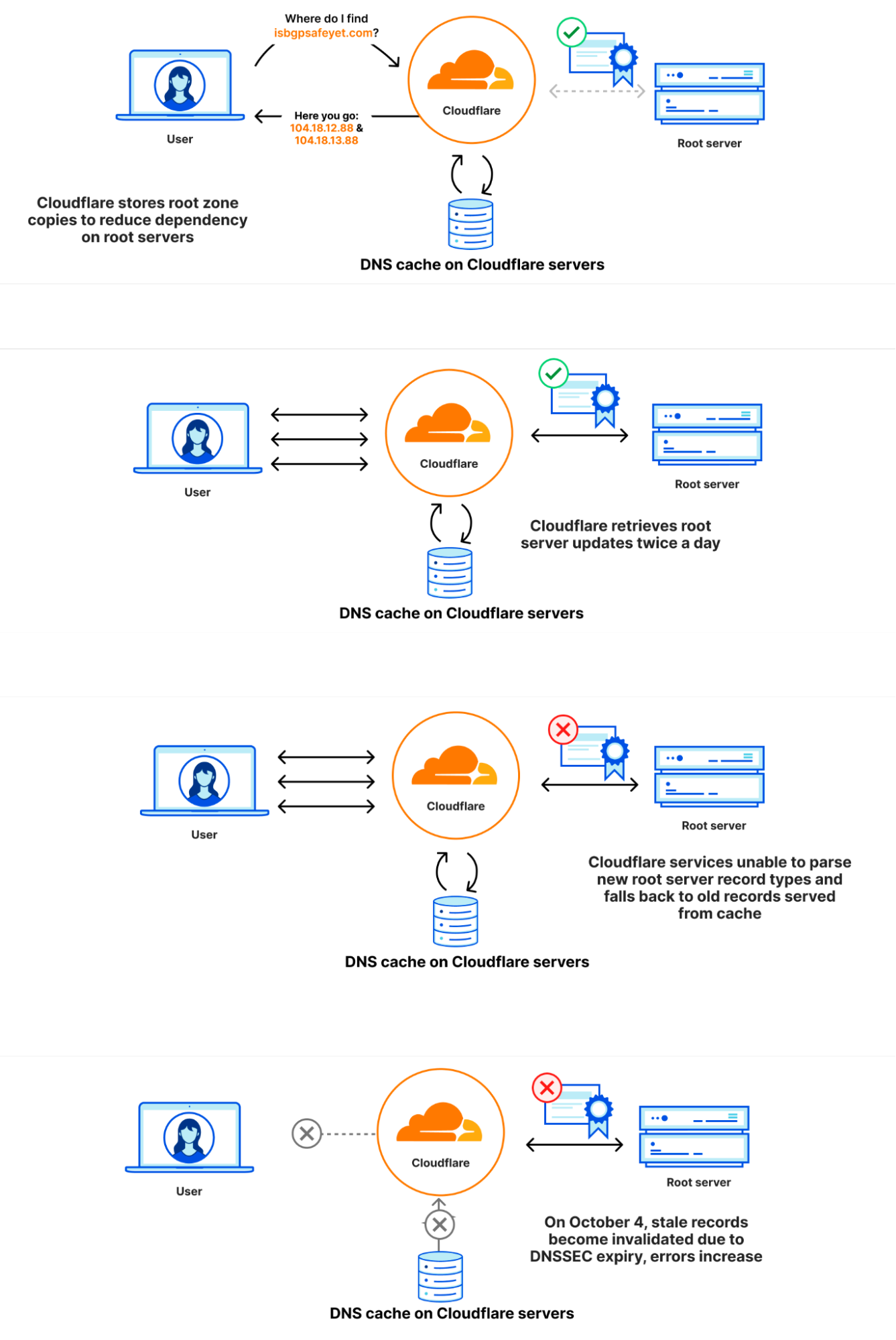
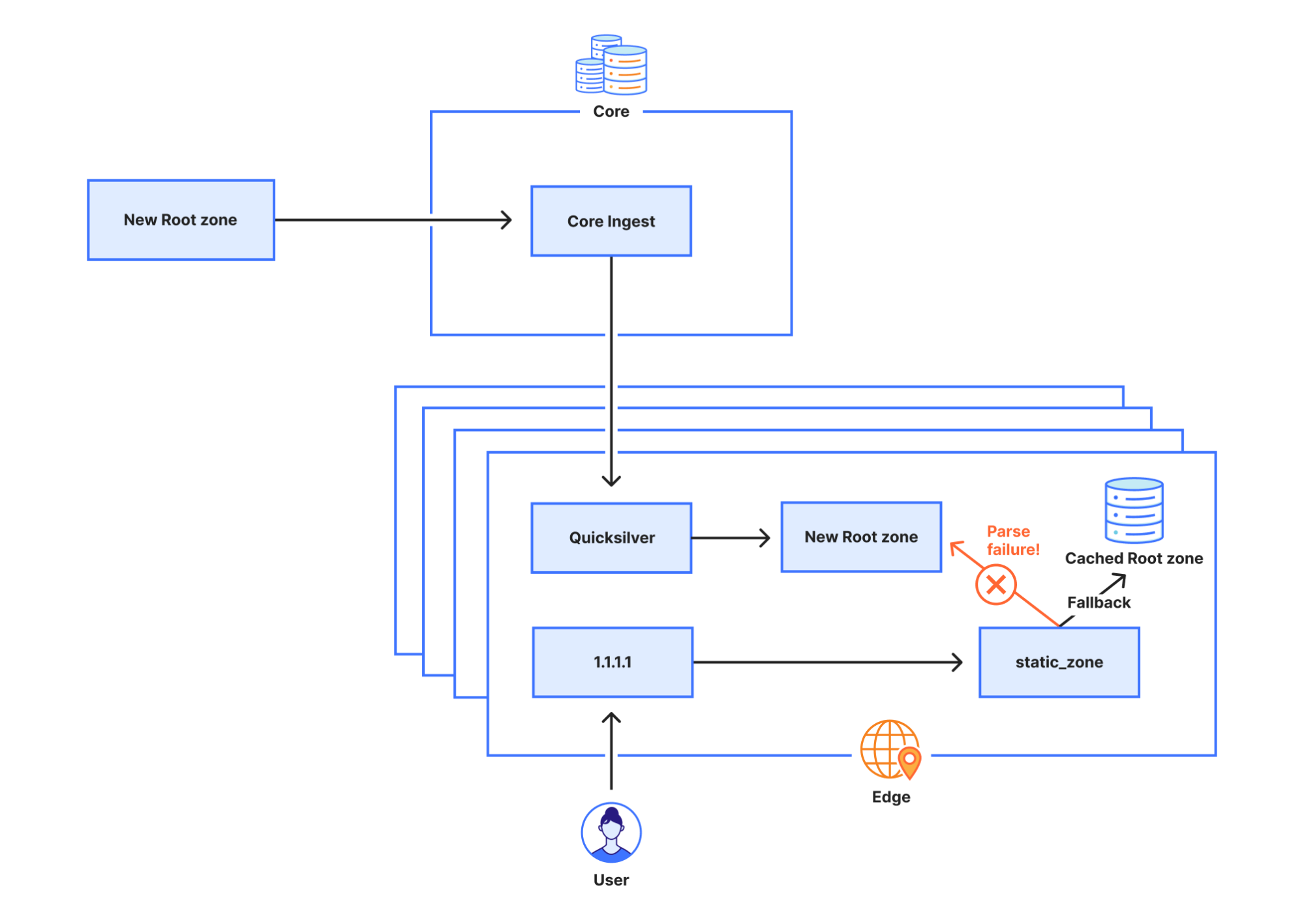
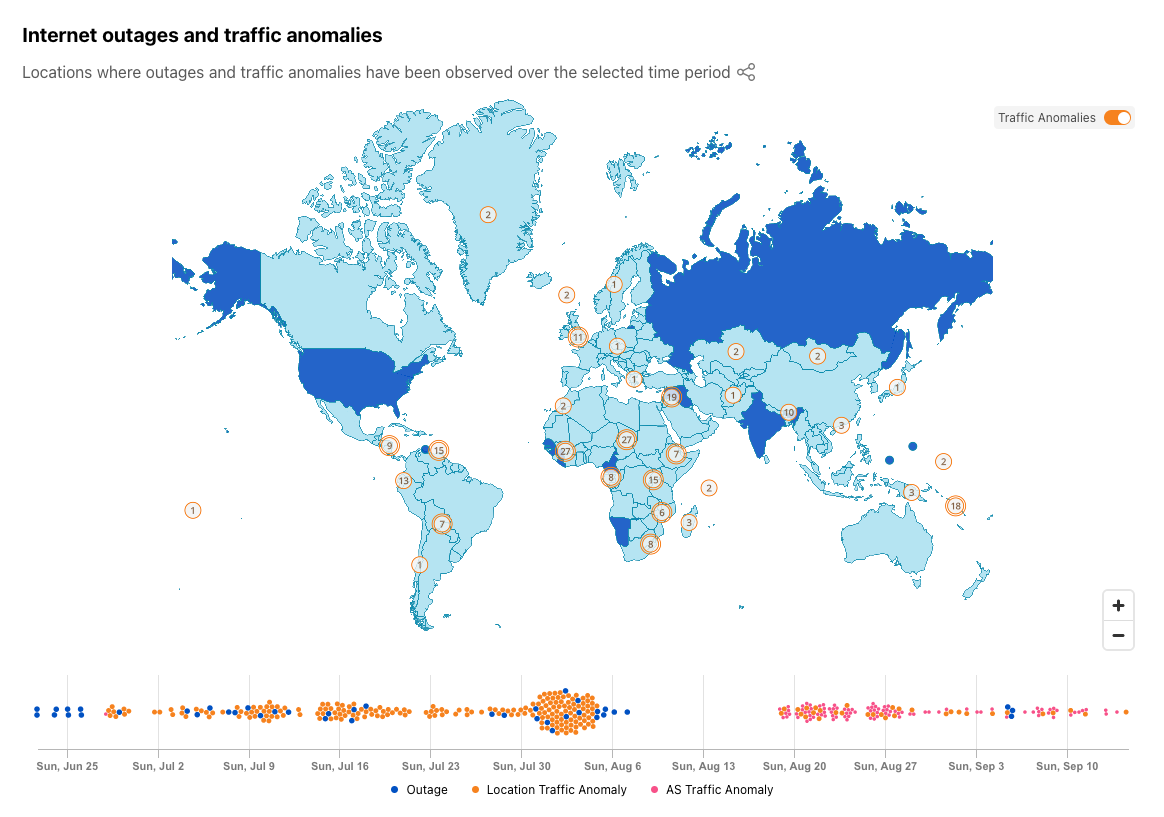
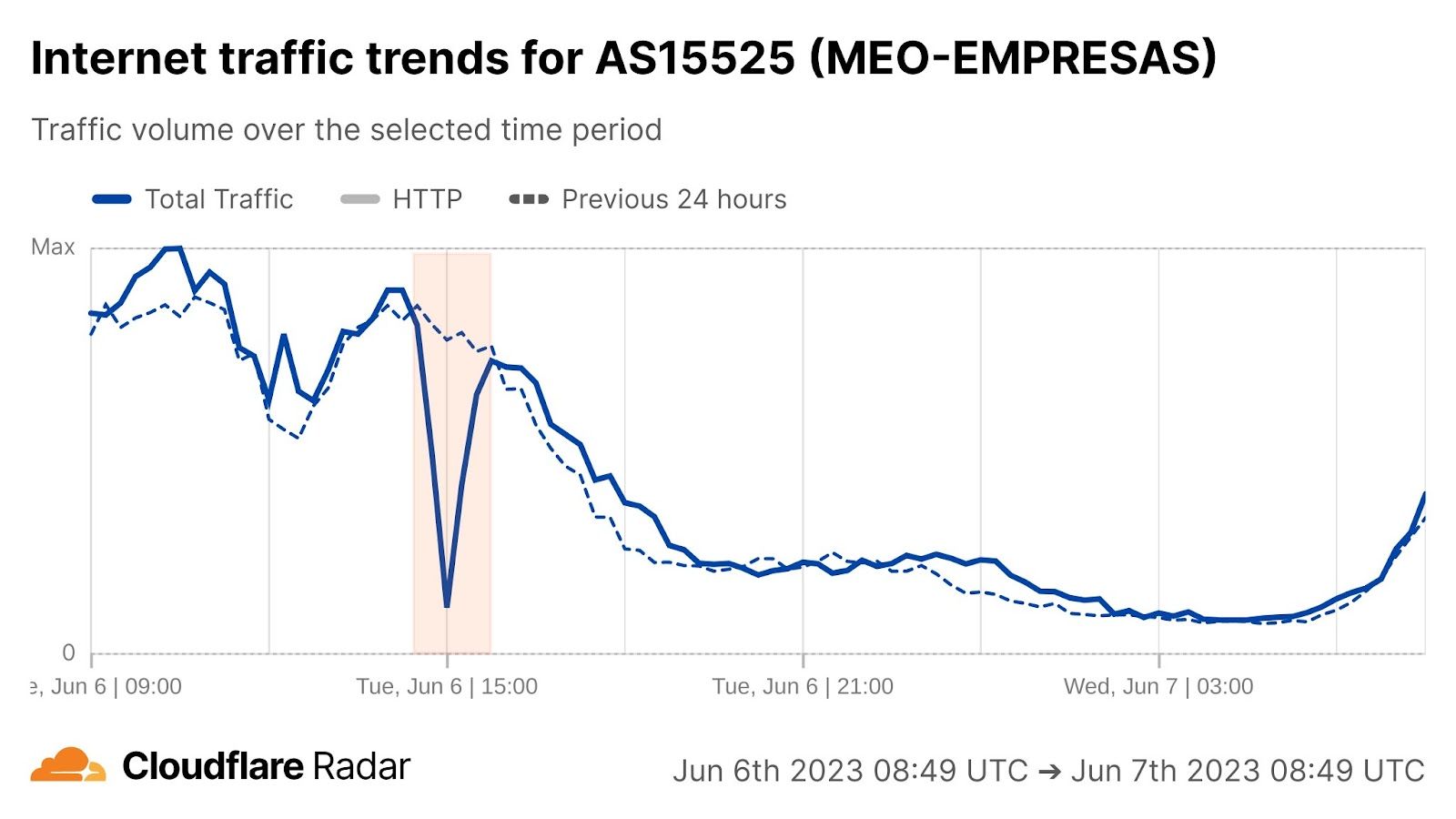
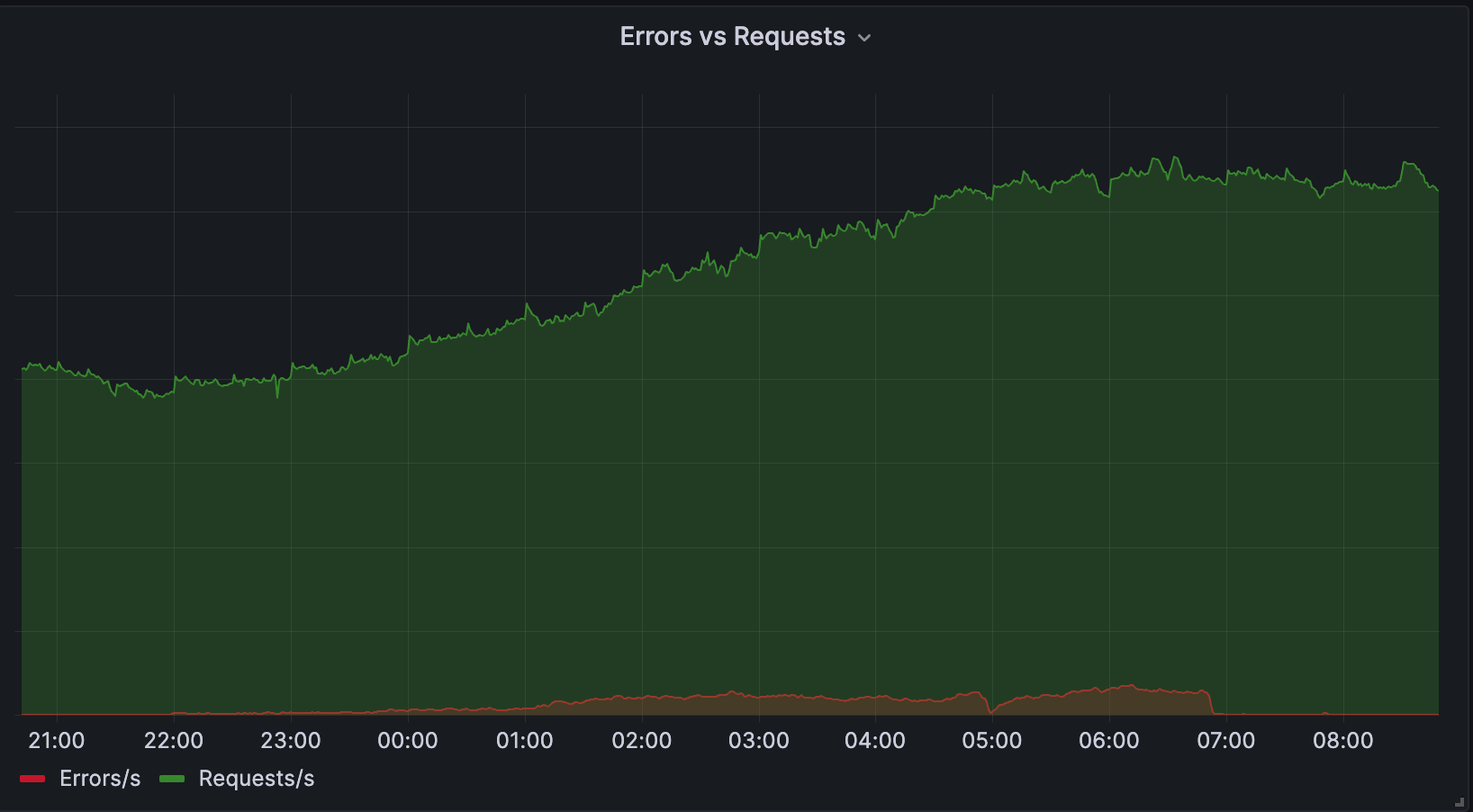
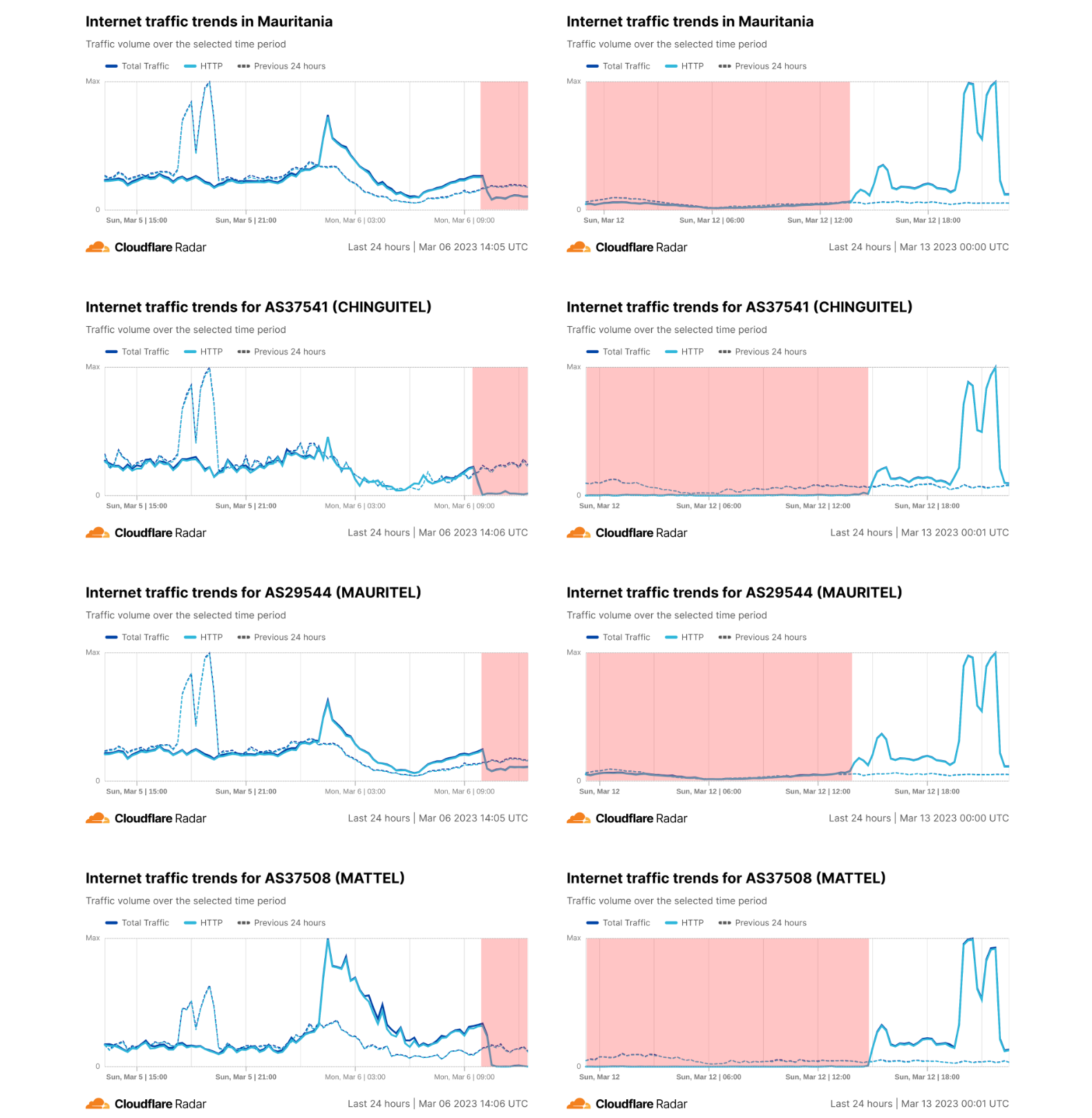
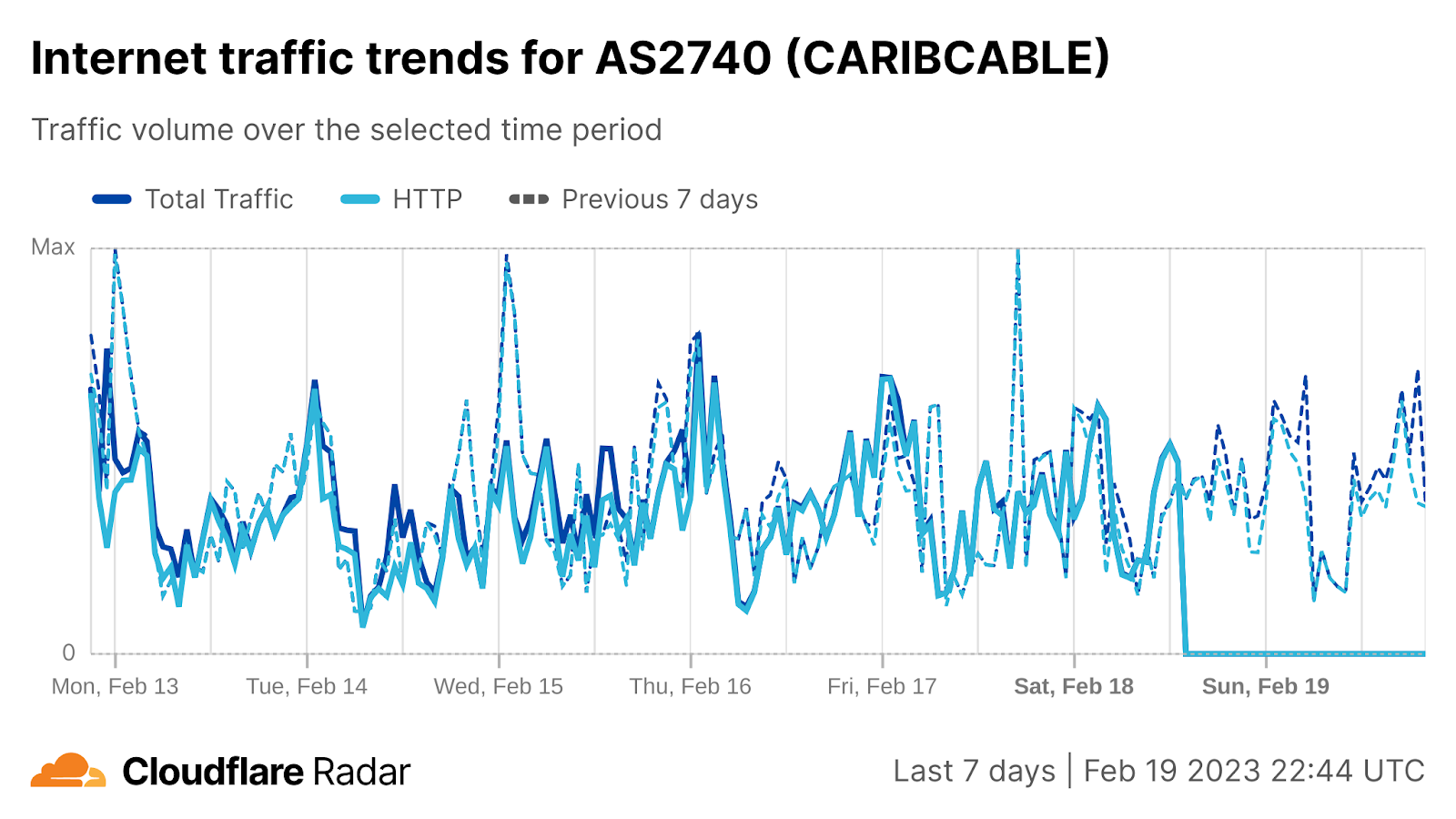
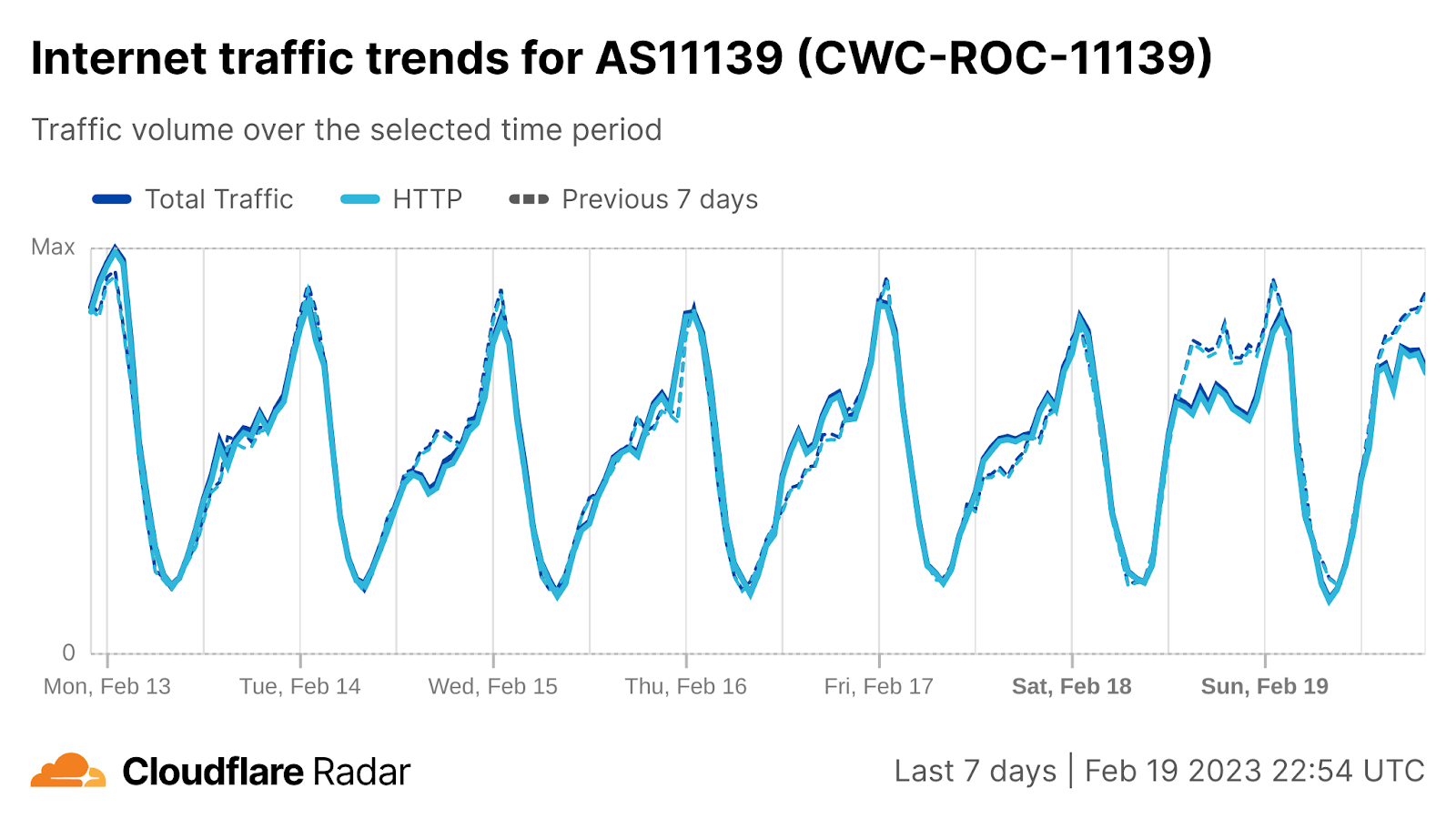
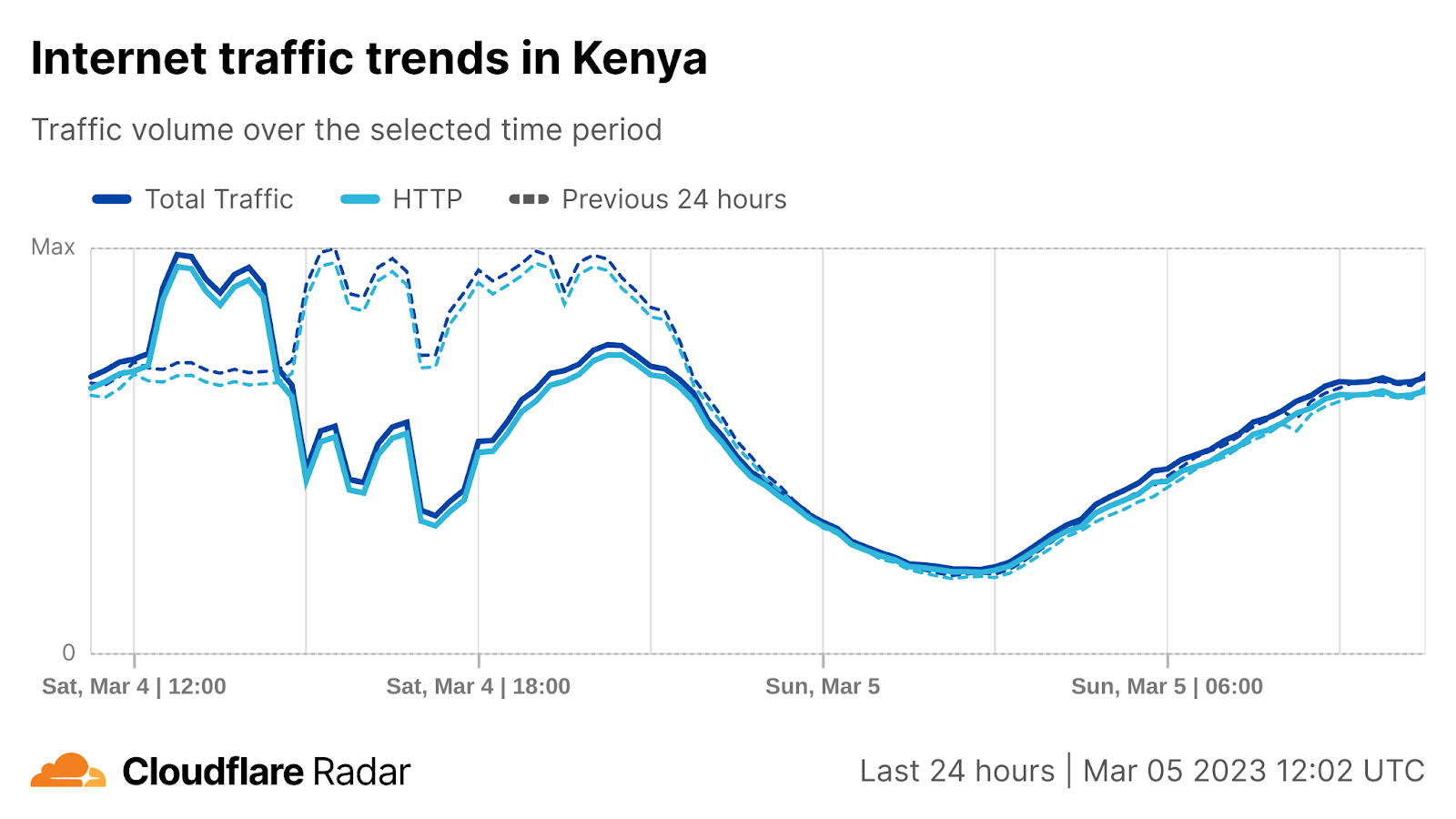
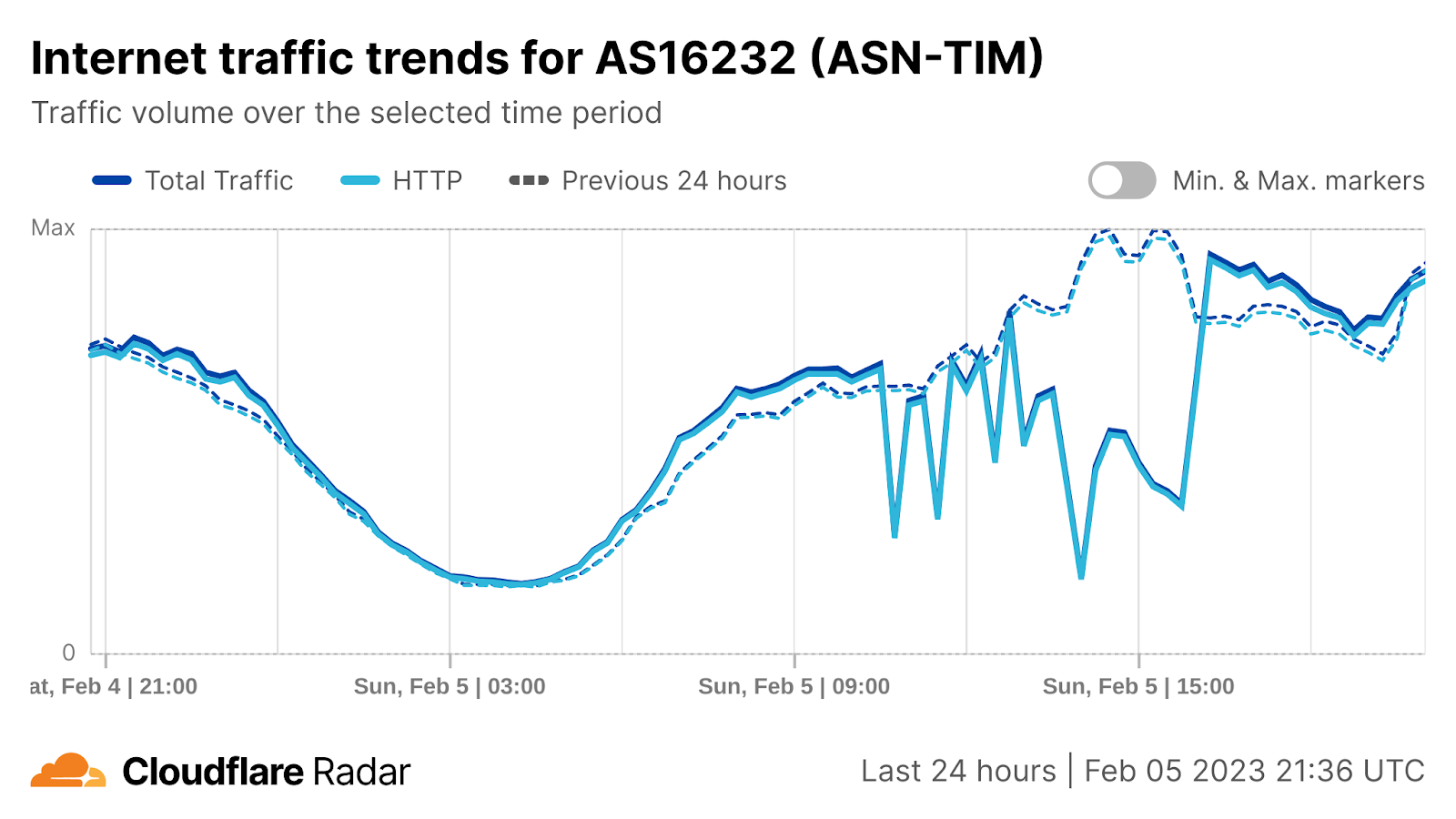
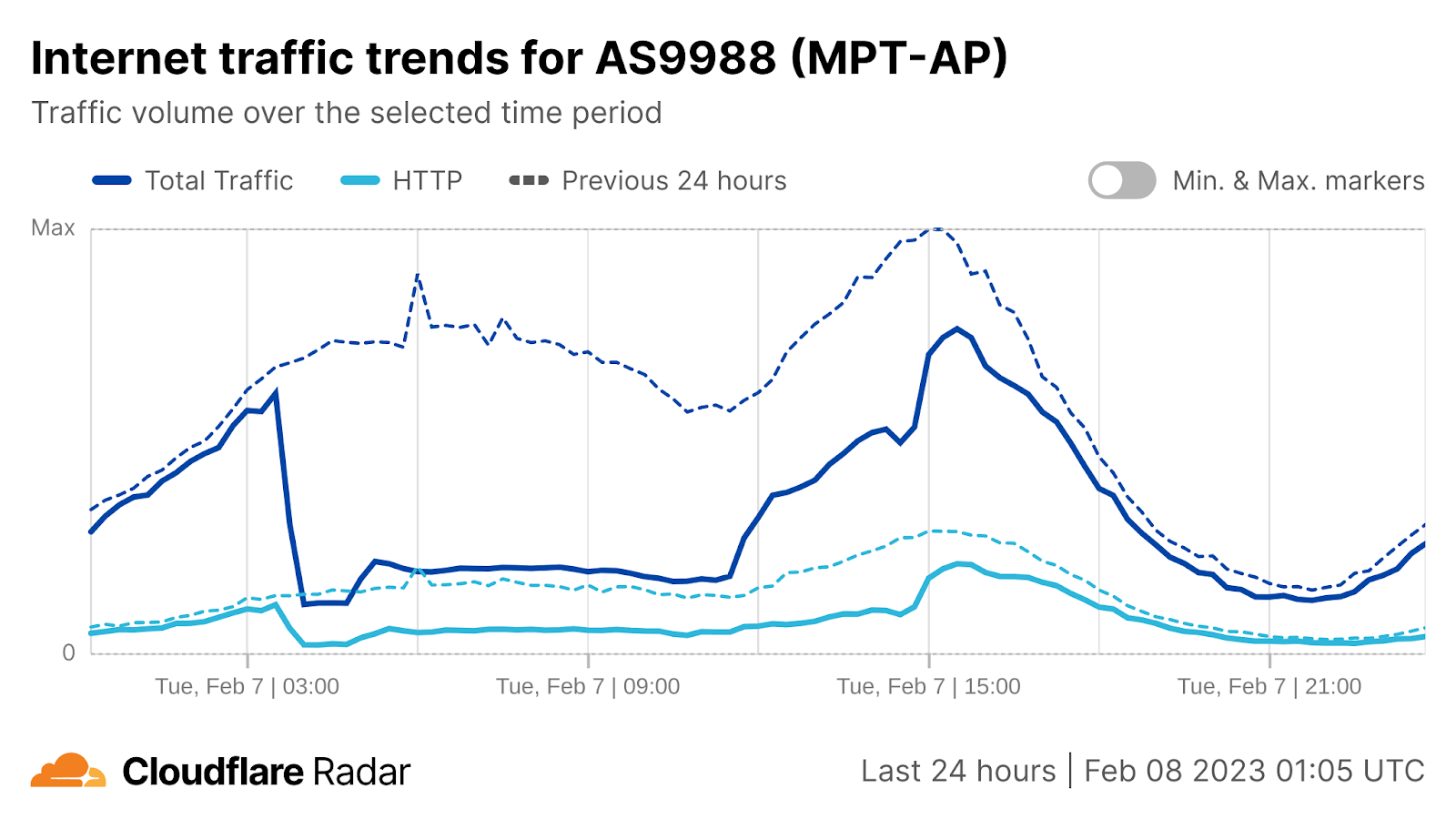
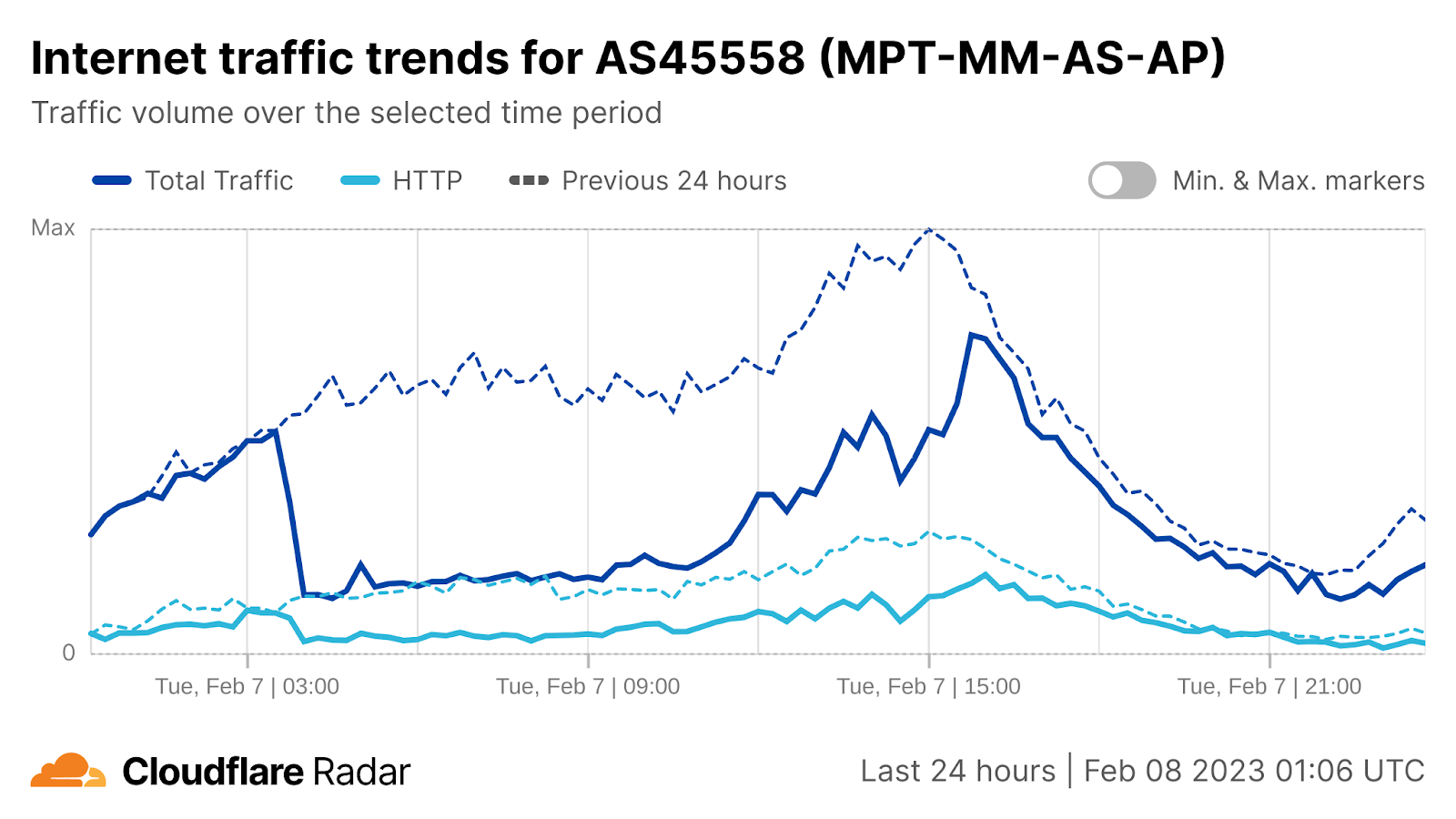
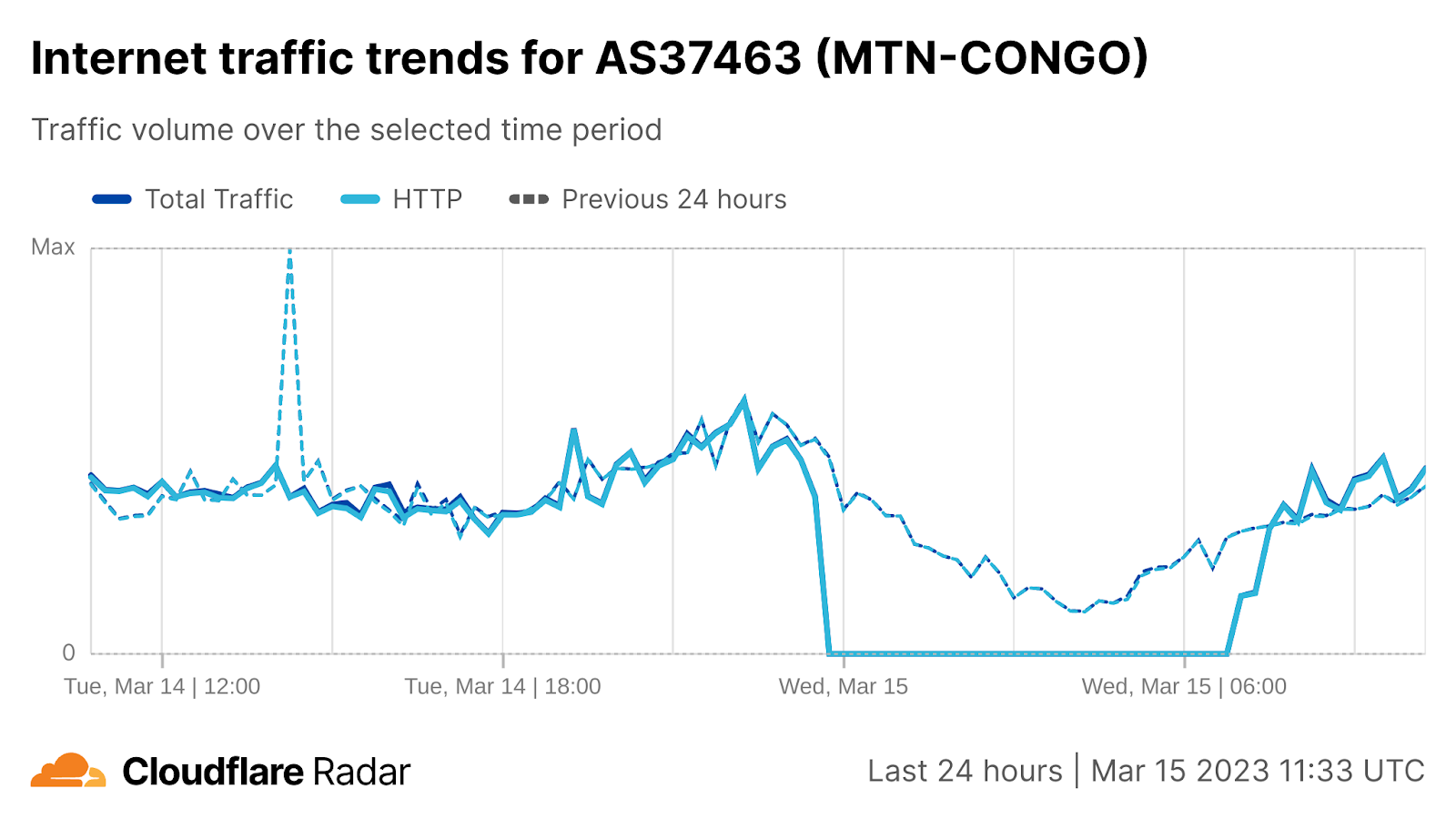
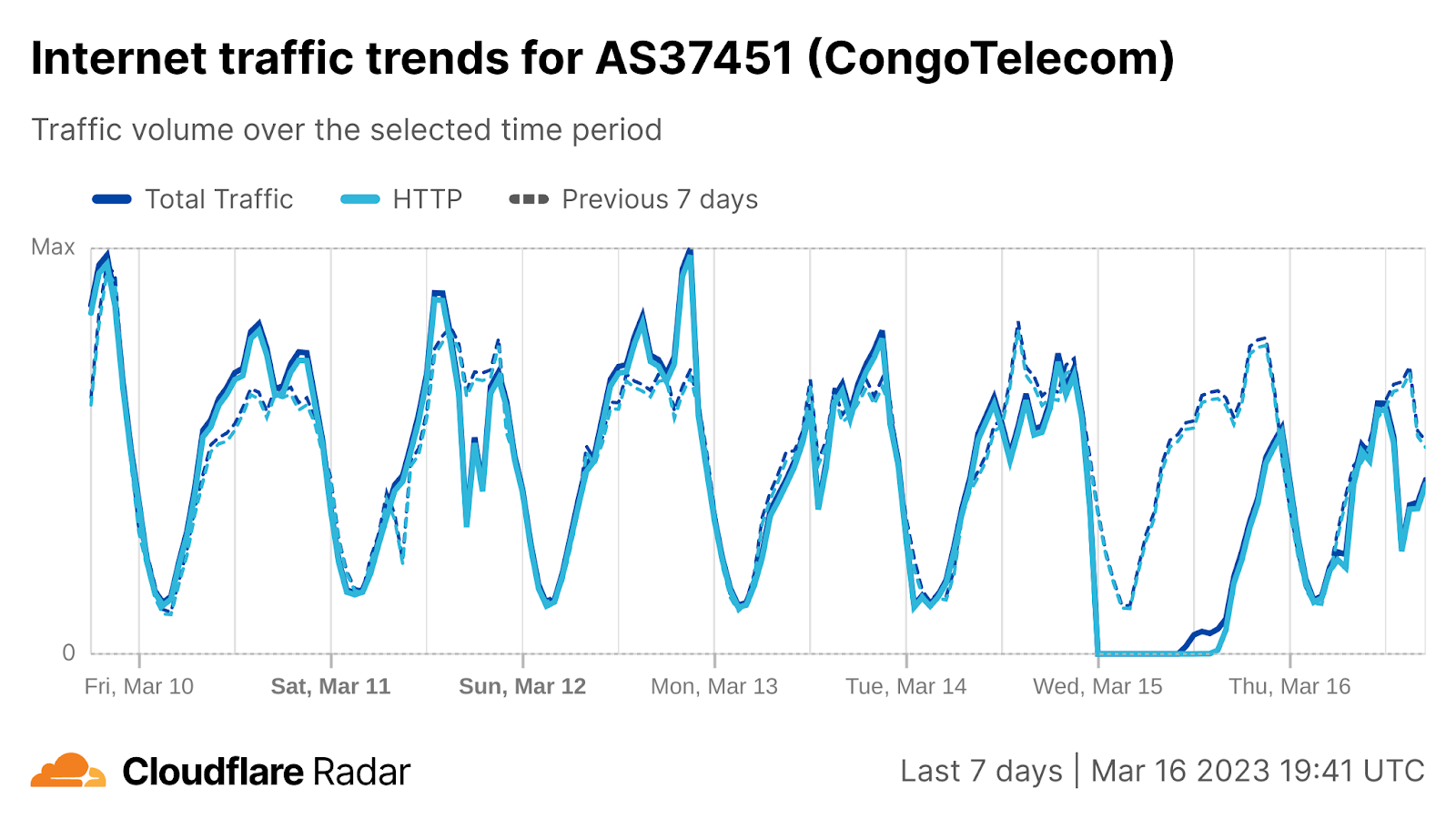
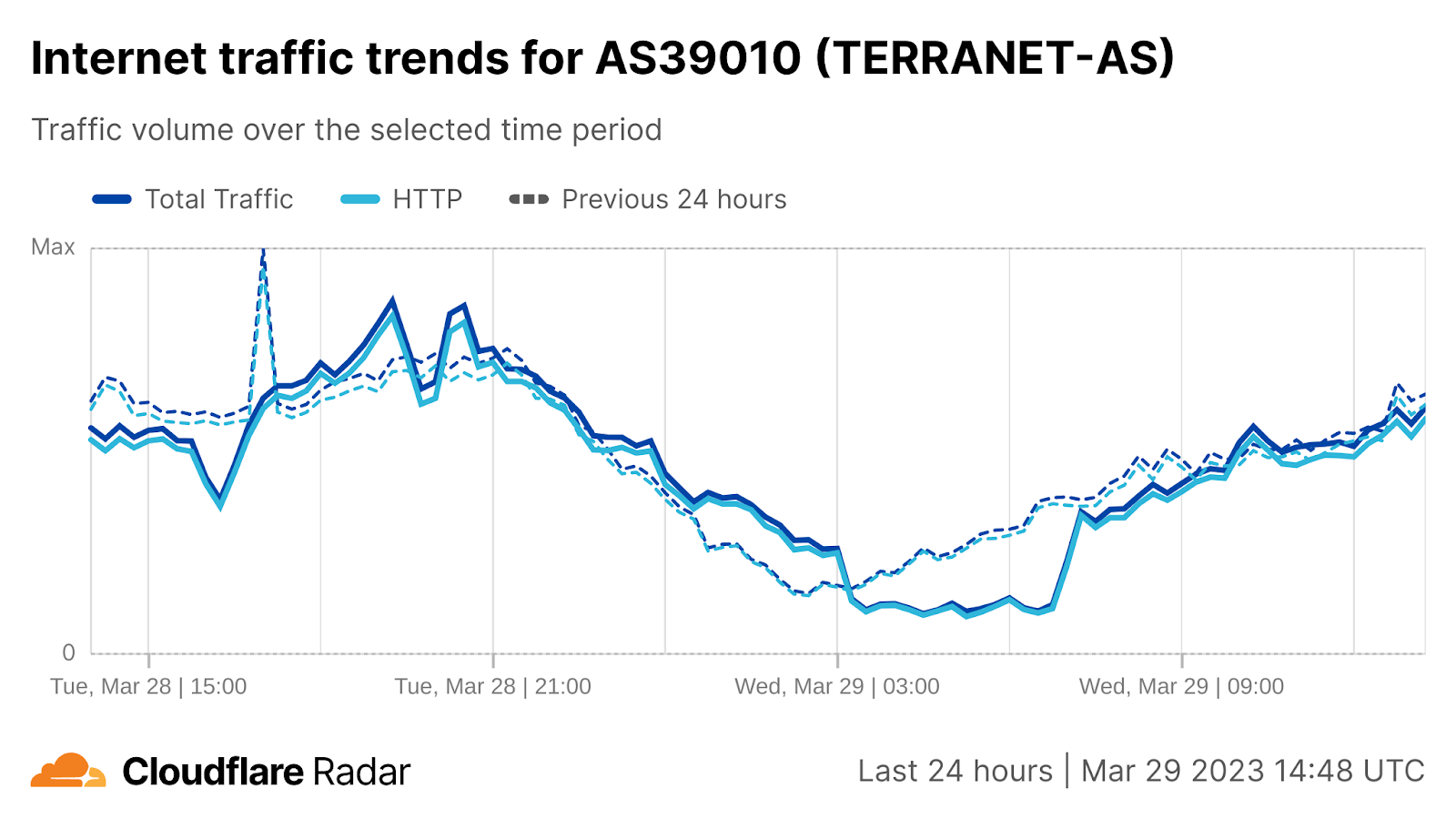
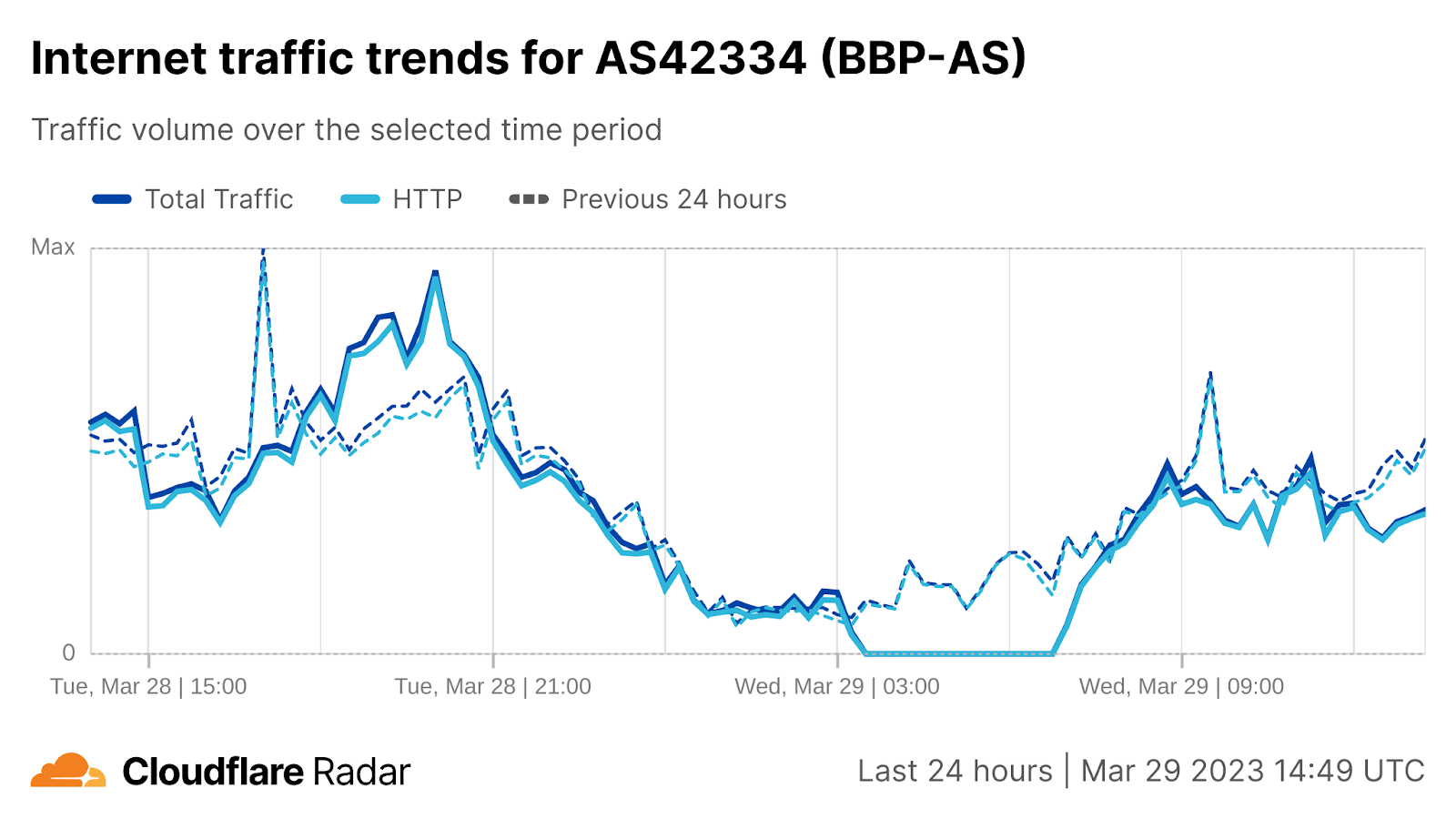
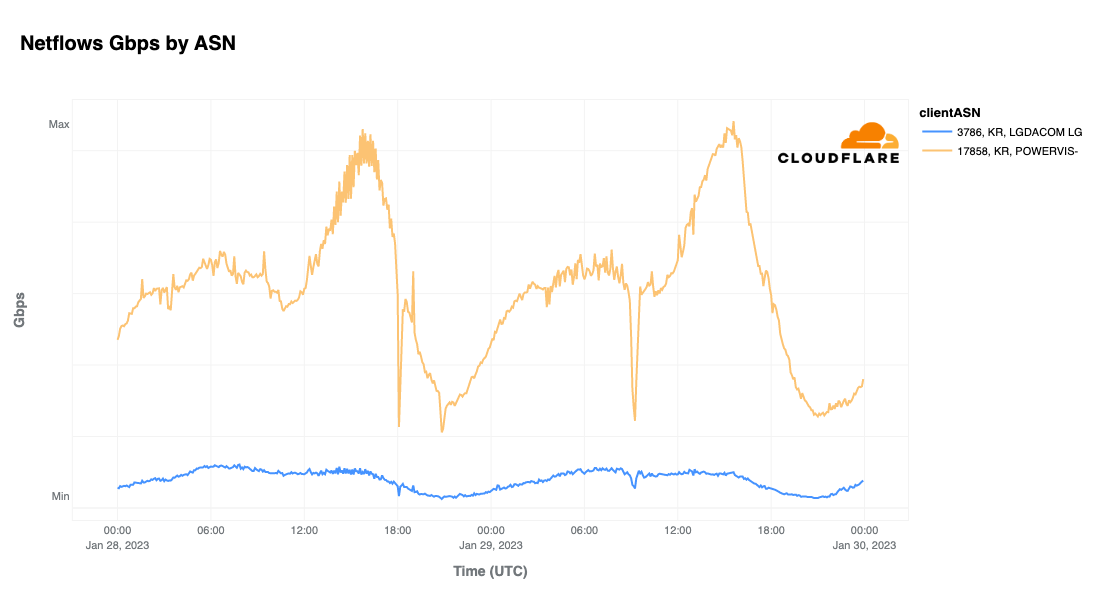
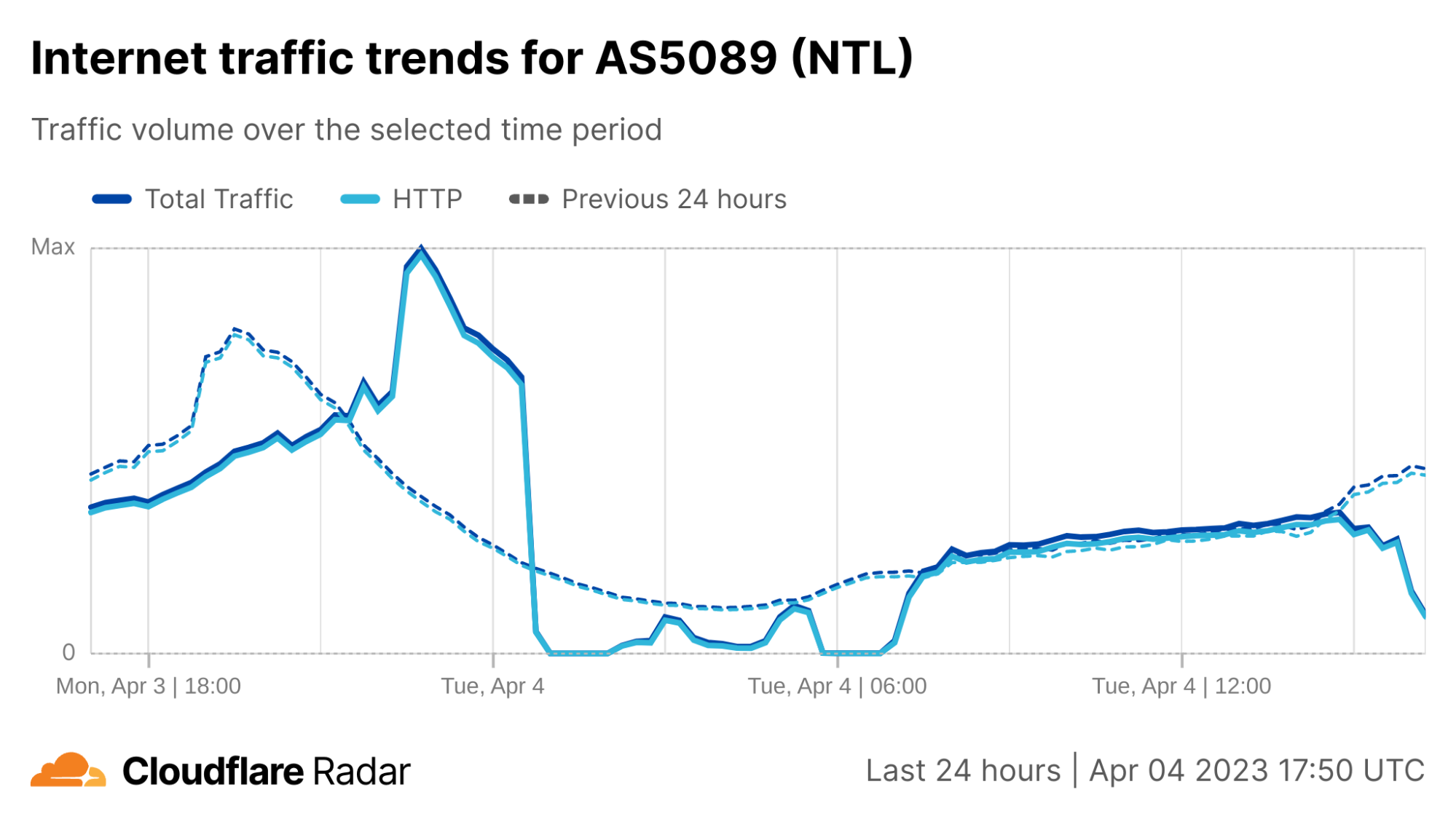
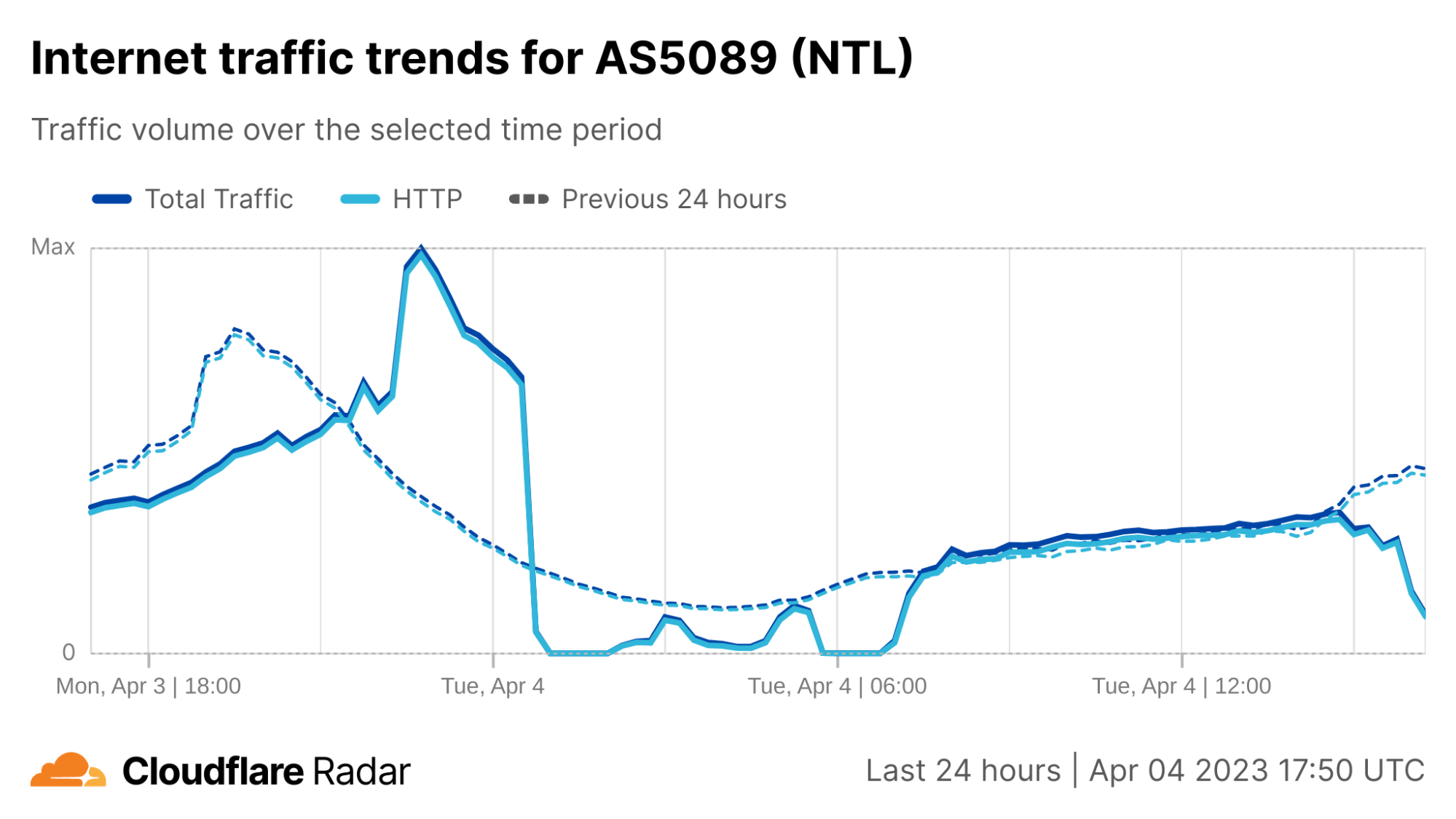
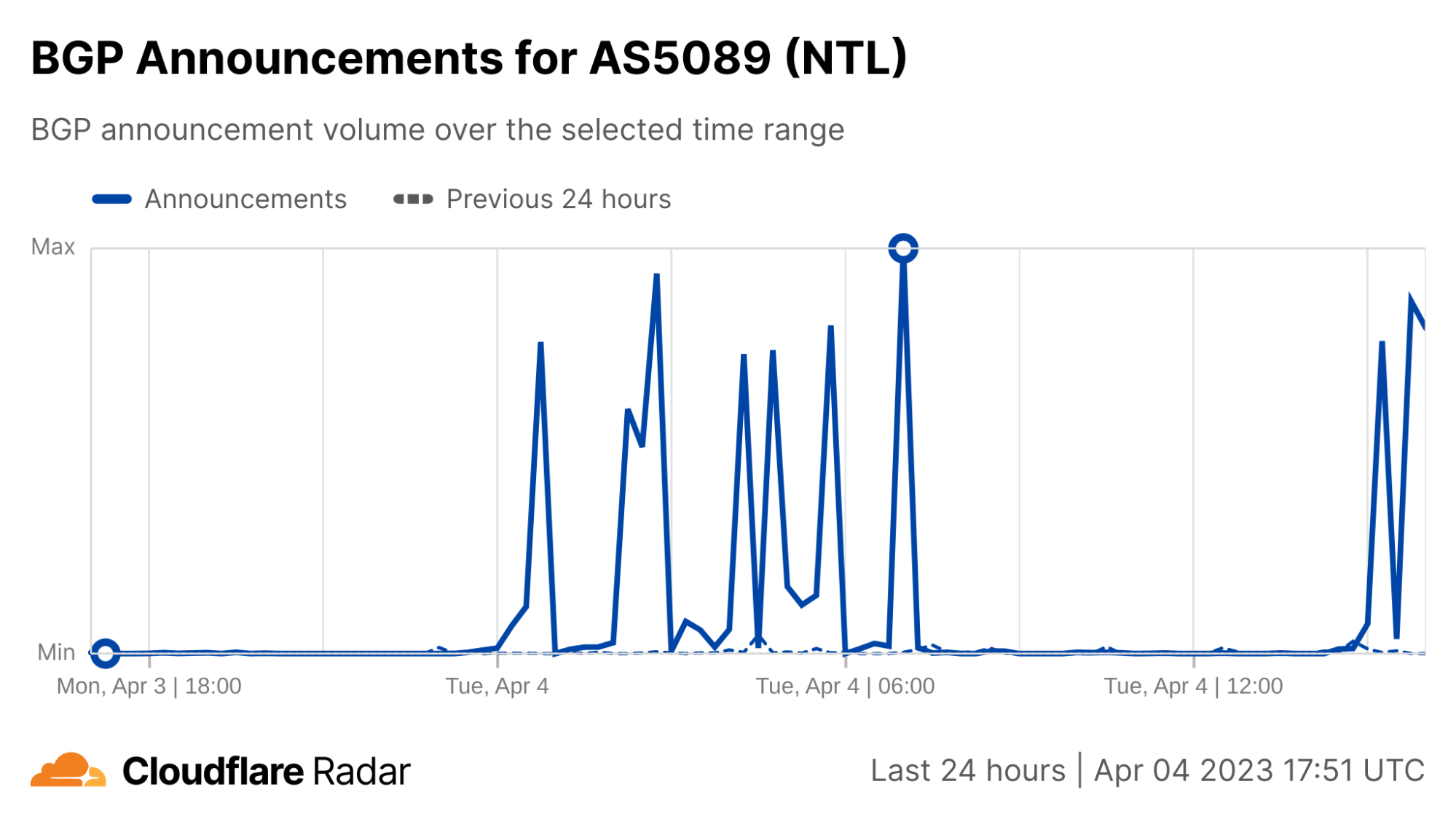
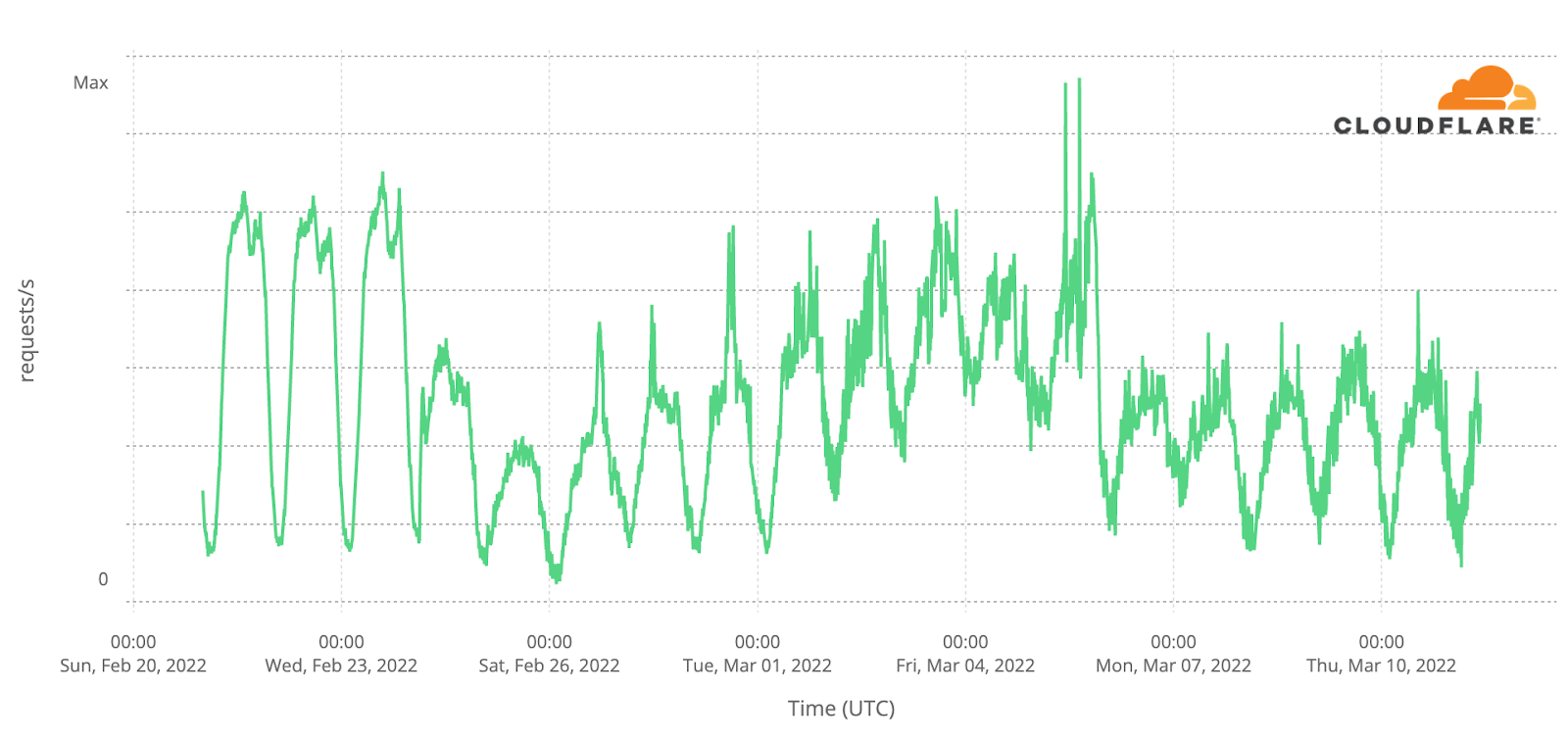
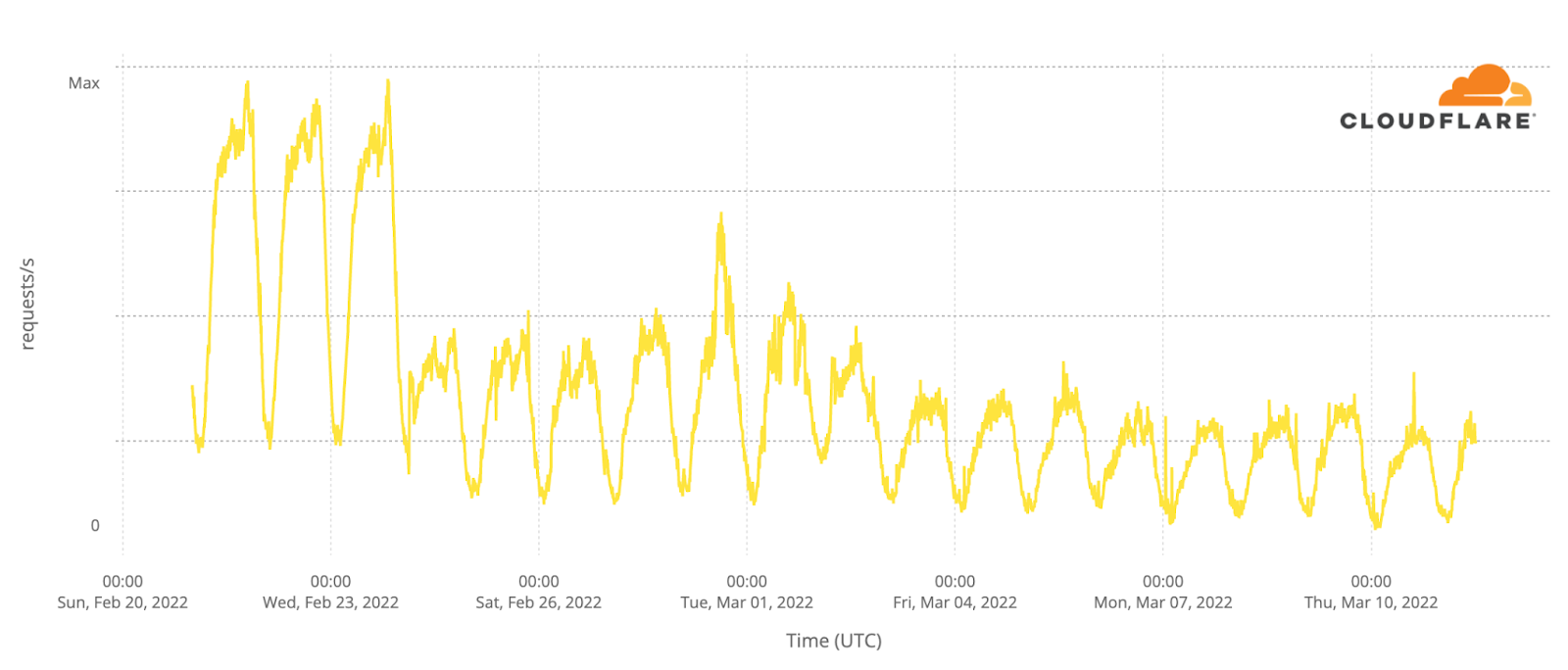
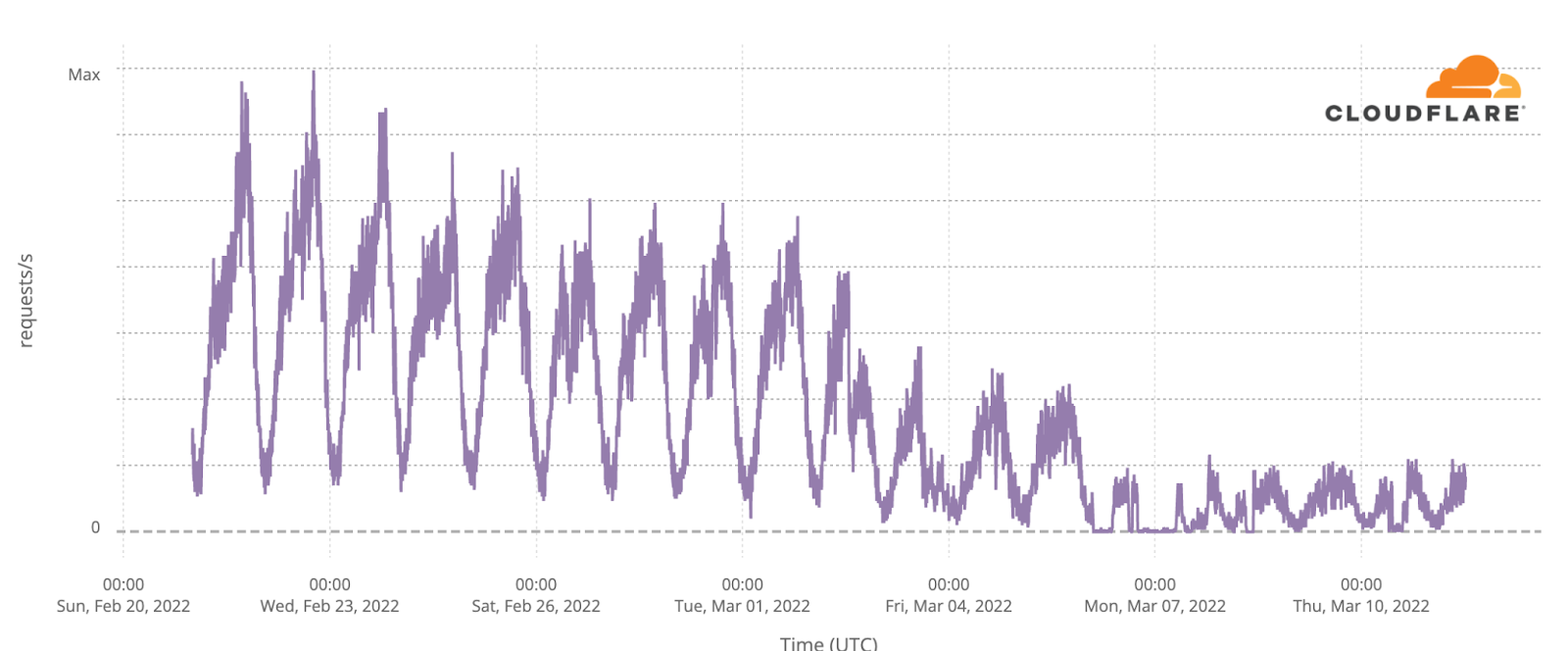
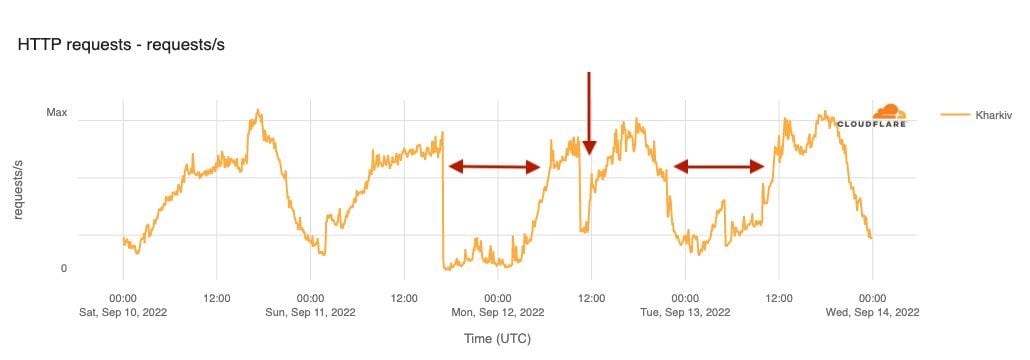
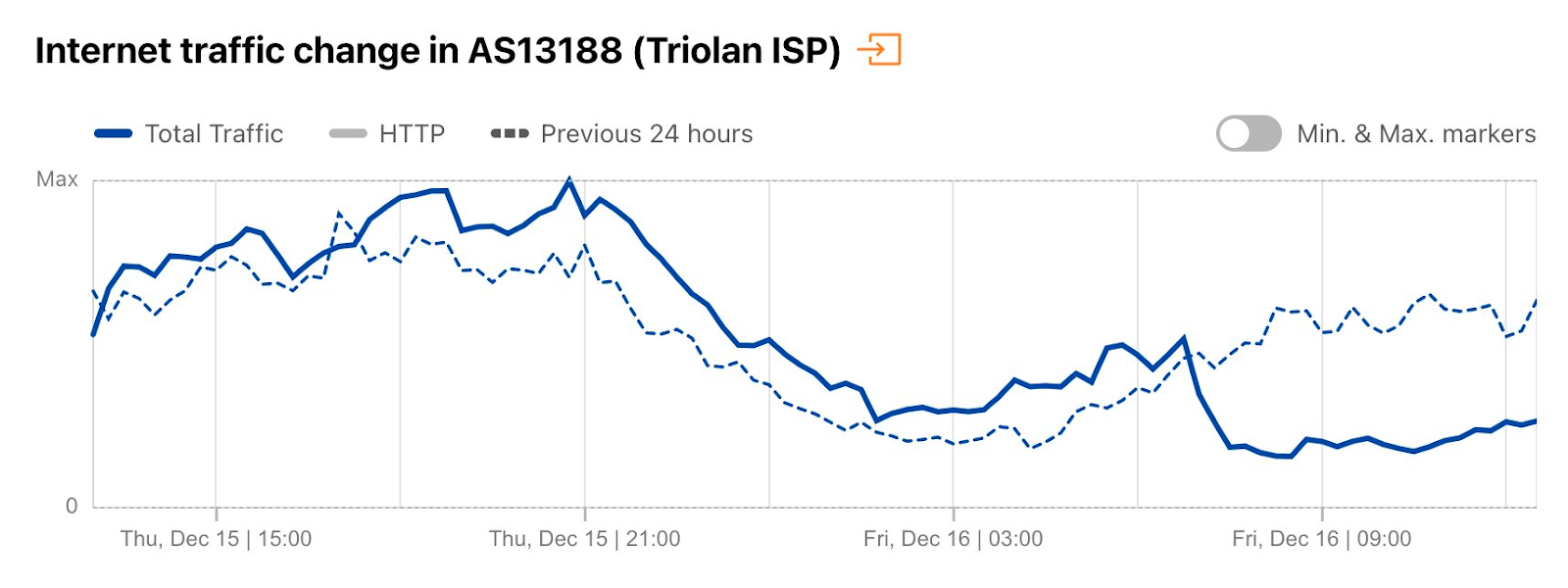
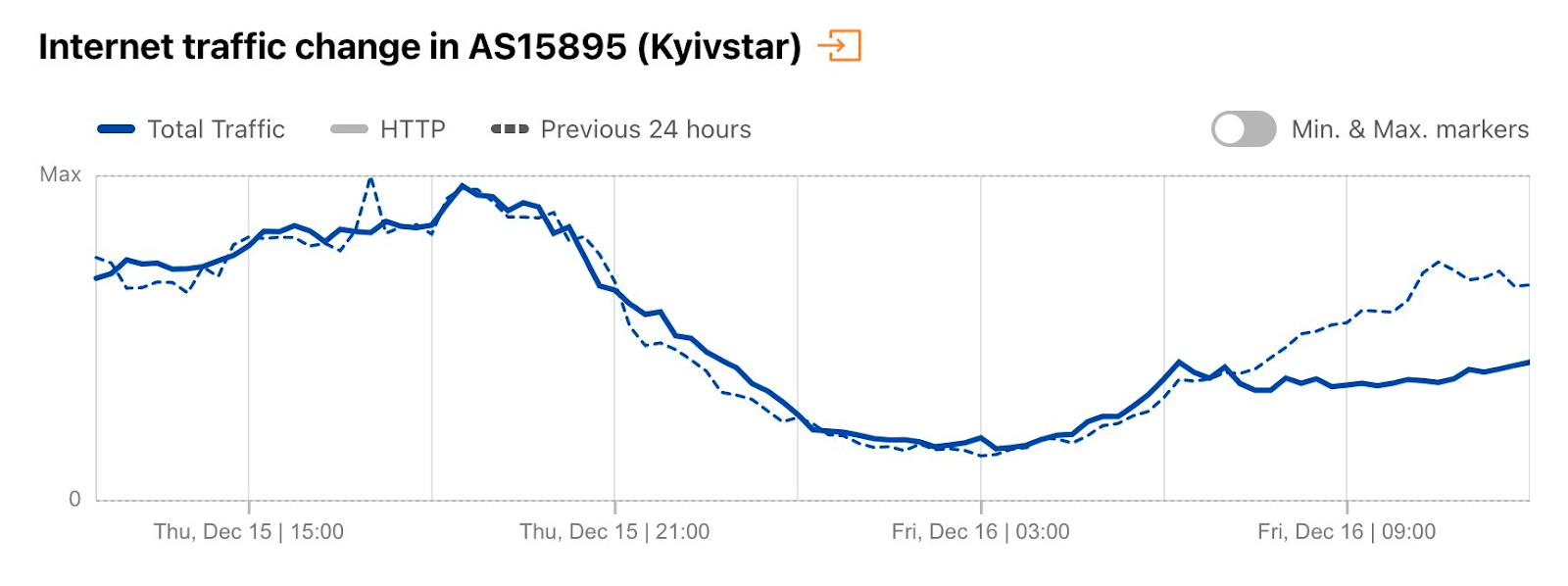
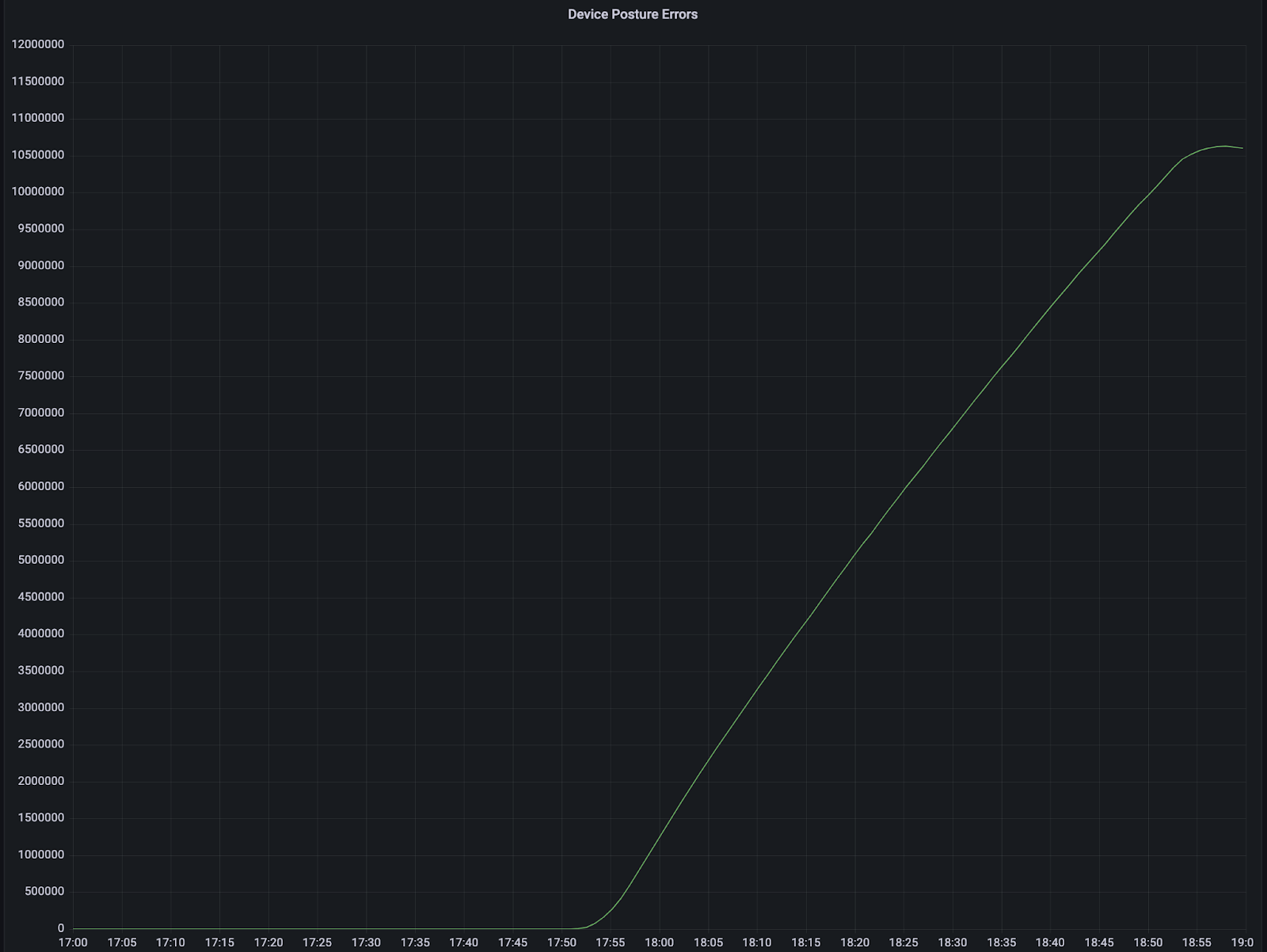
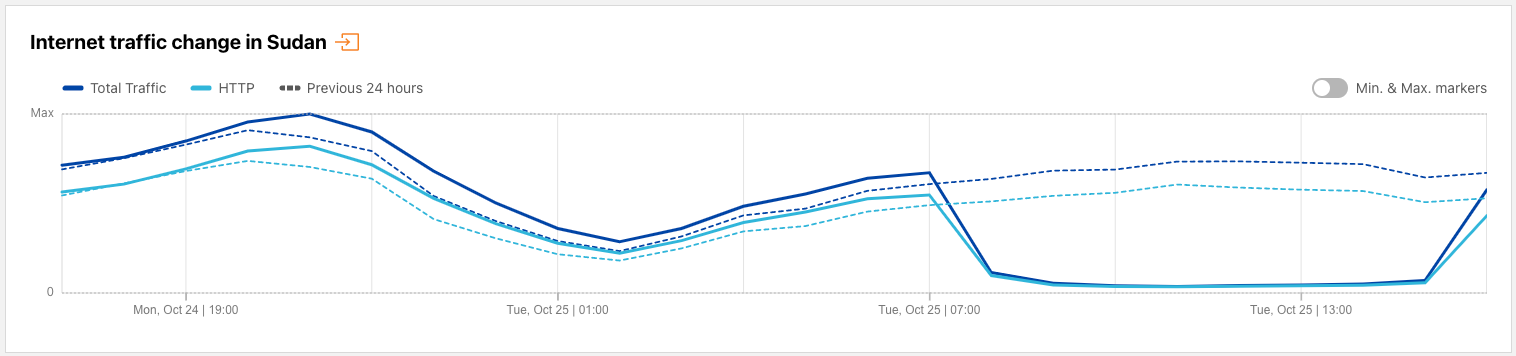
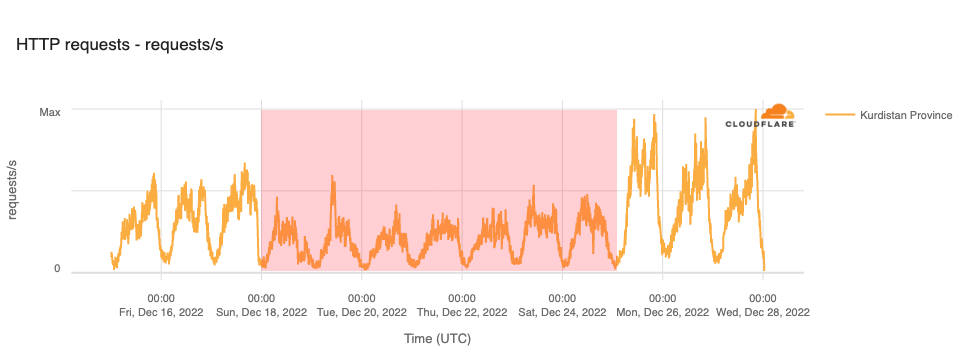
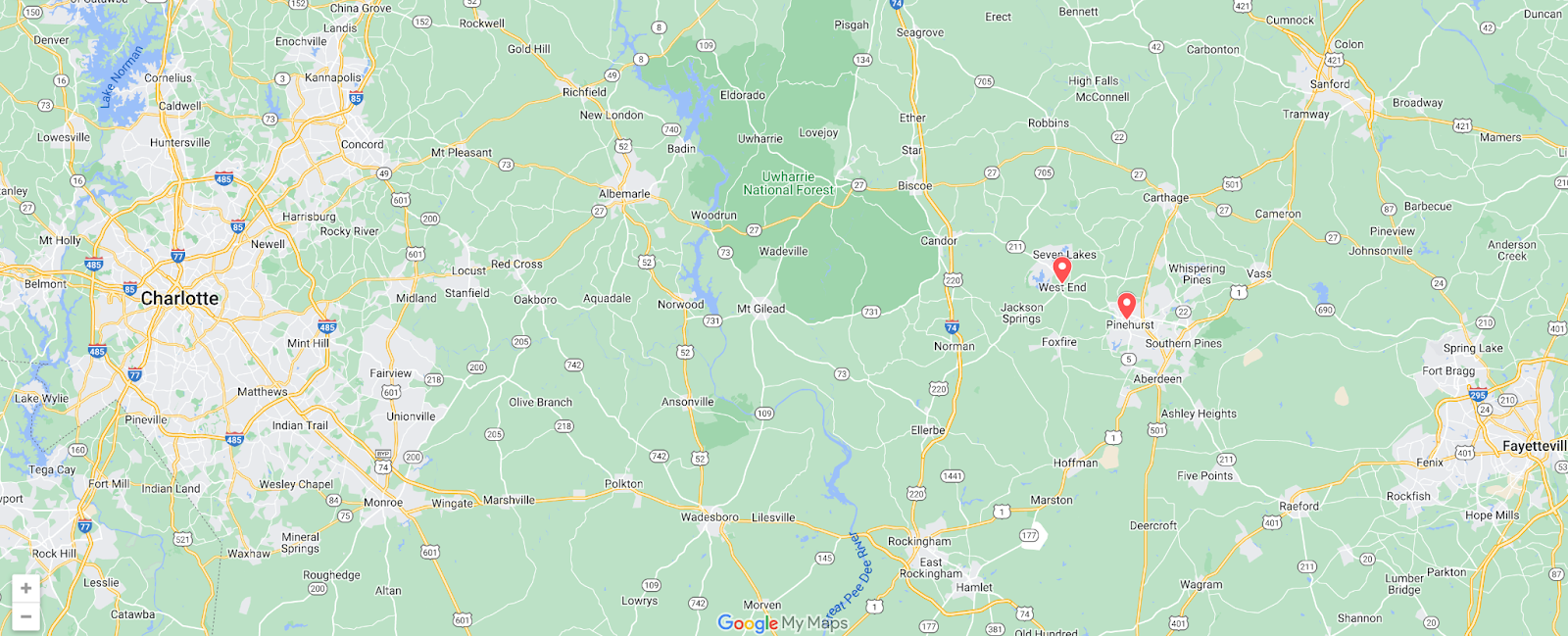
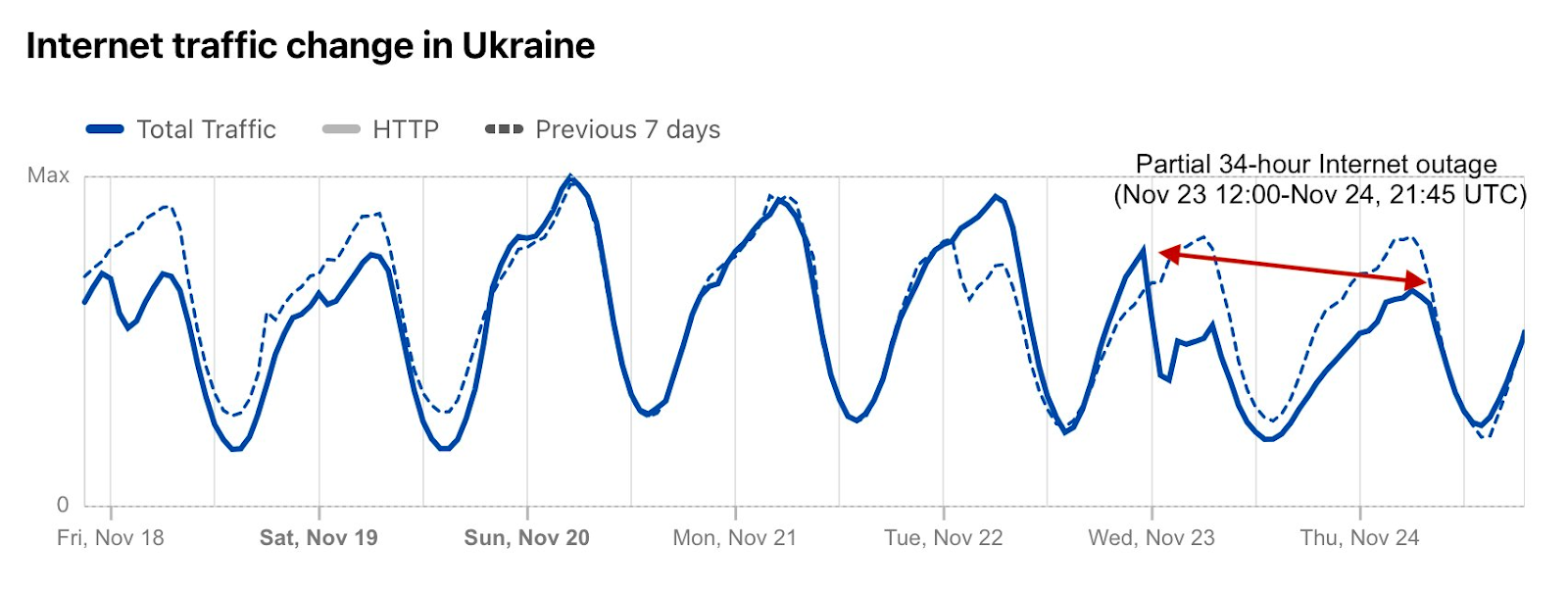
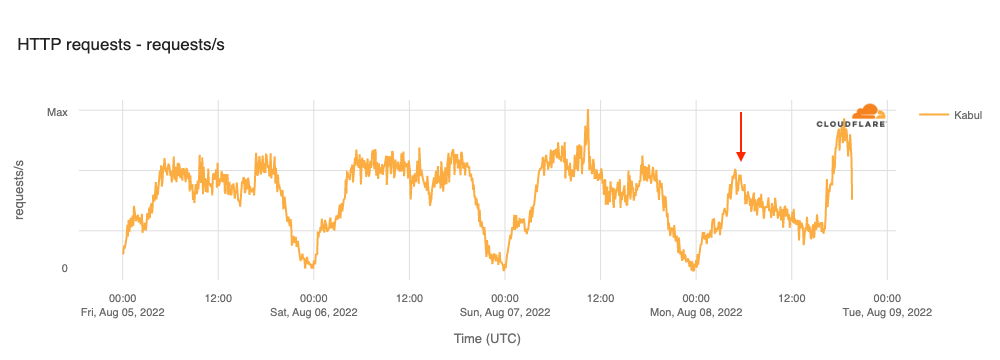
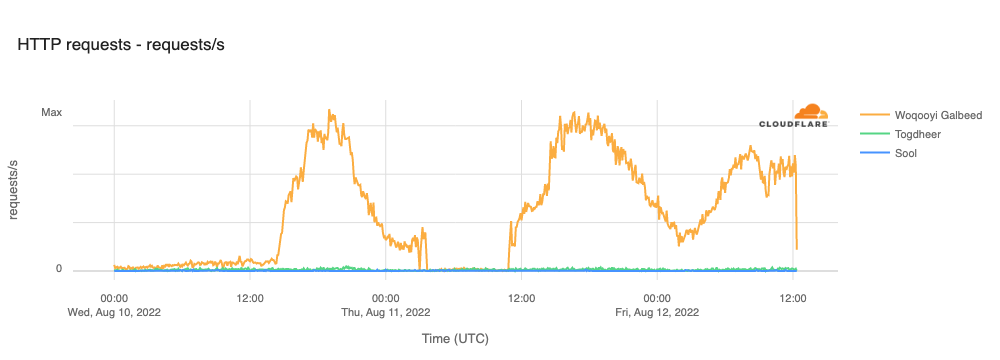
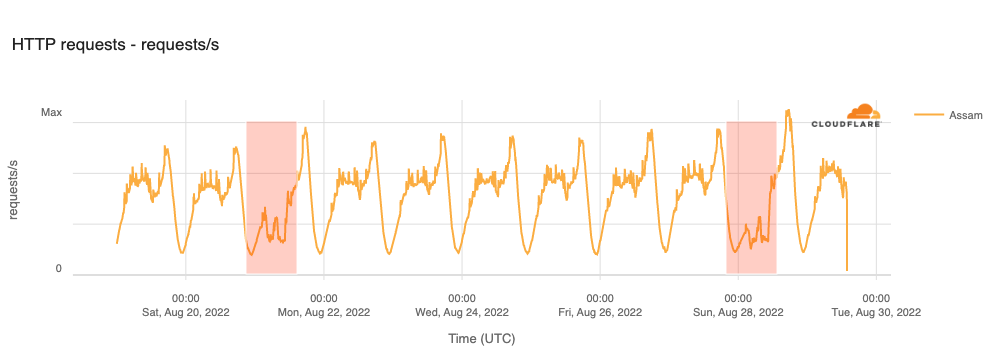
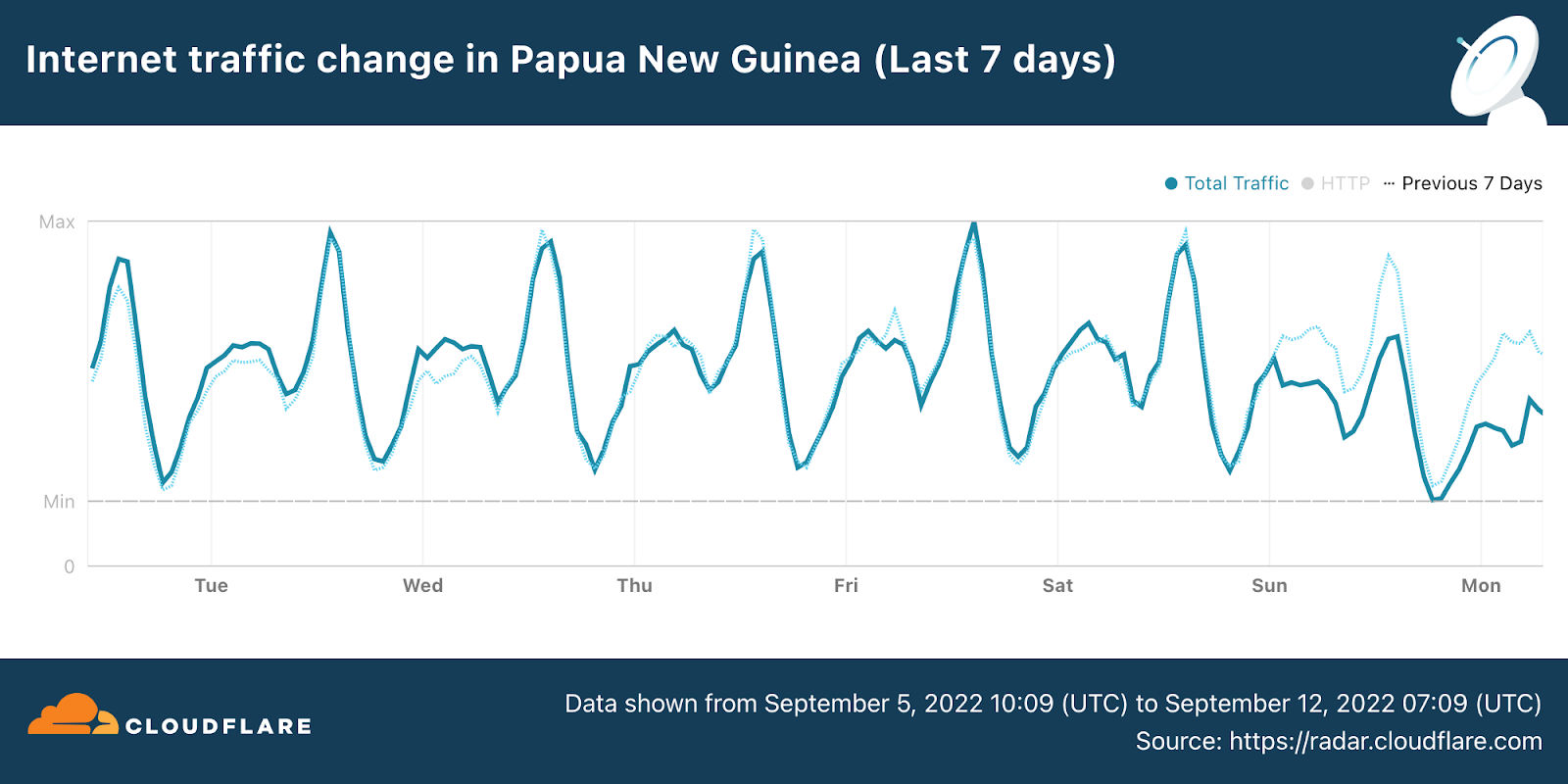
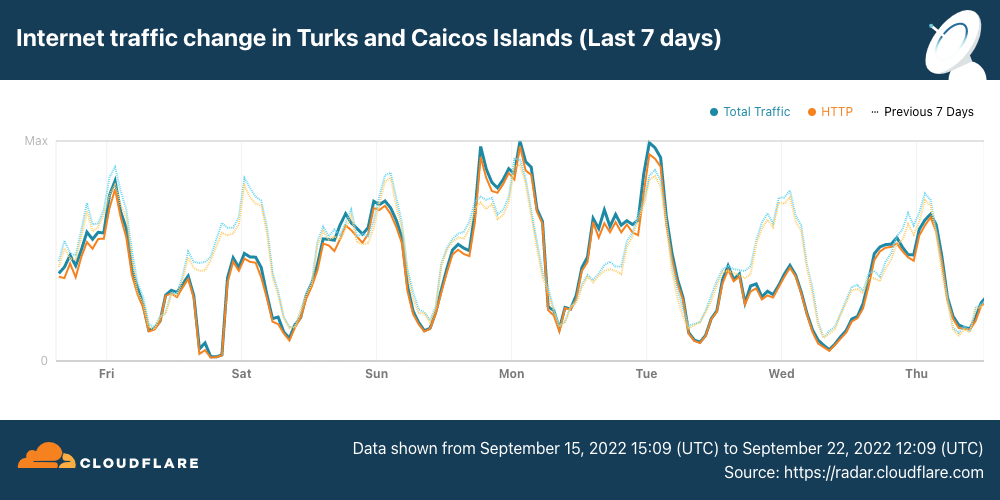
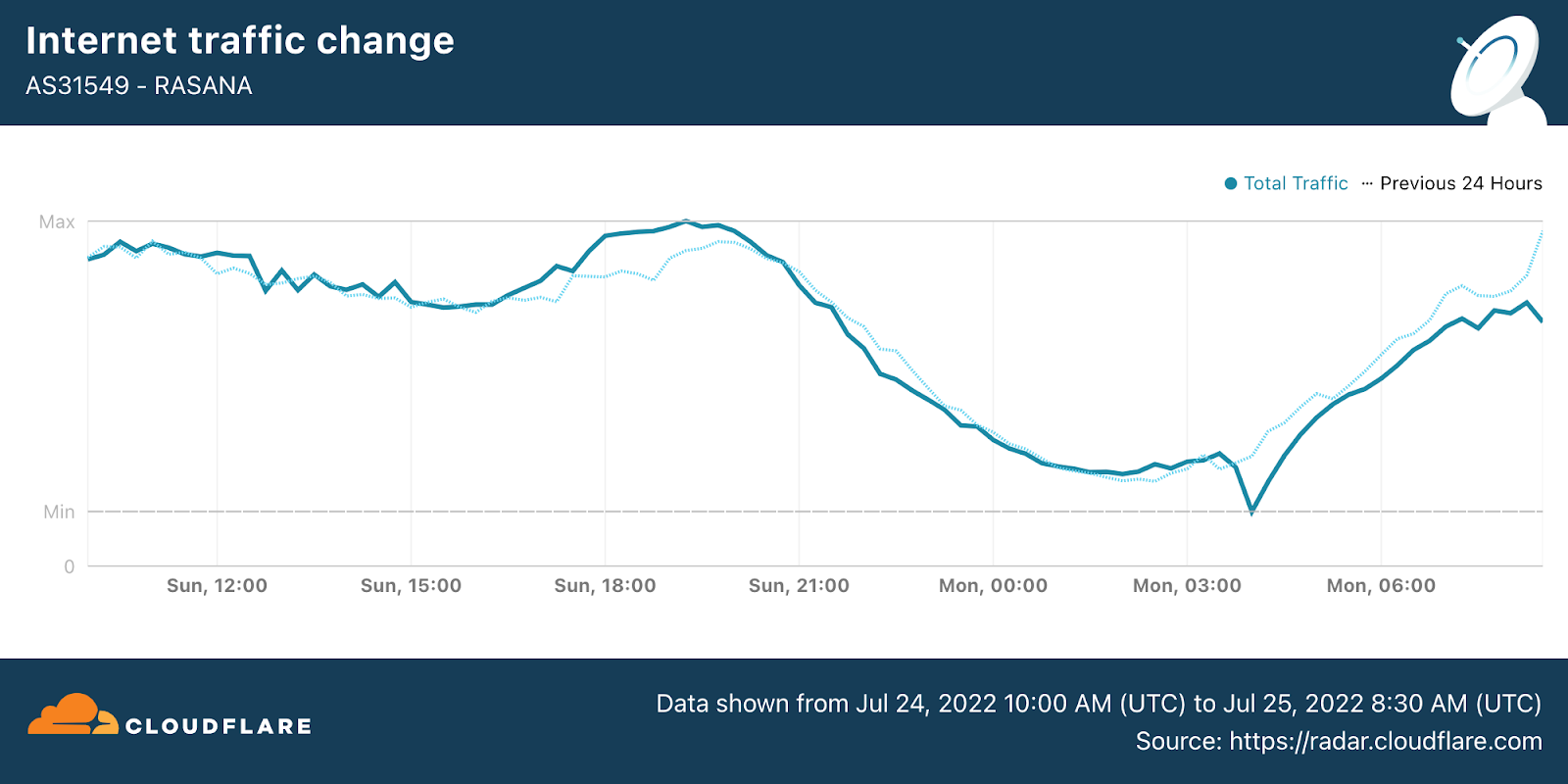
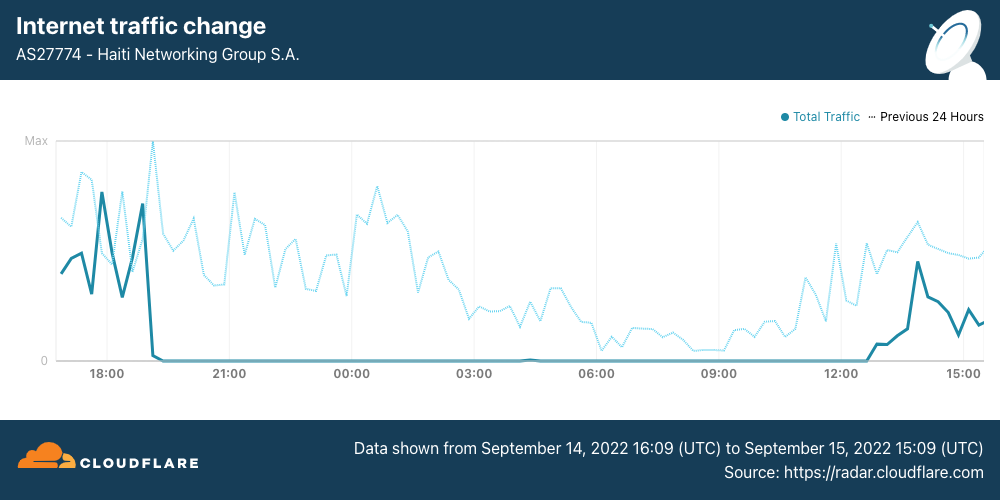
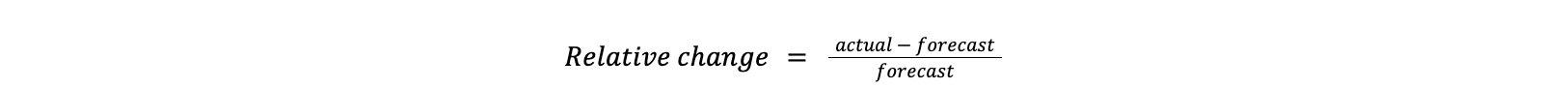On Sunday, May 12, issues with the ESSAy and Seacom submarine cables again disrupted connectivity to East Africa, impacting a number of countries previously affected by a set of cable cuts that occurred nearly three months earlier.
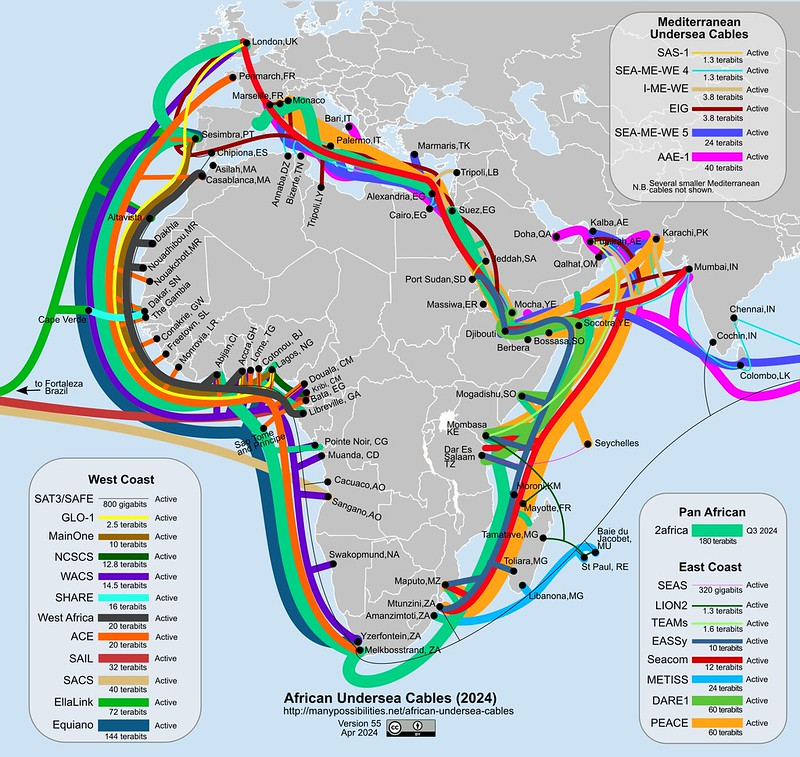
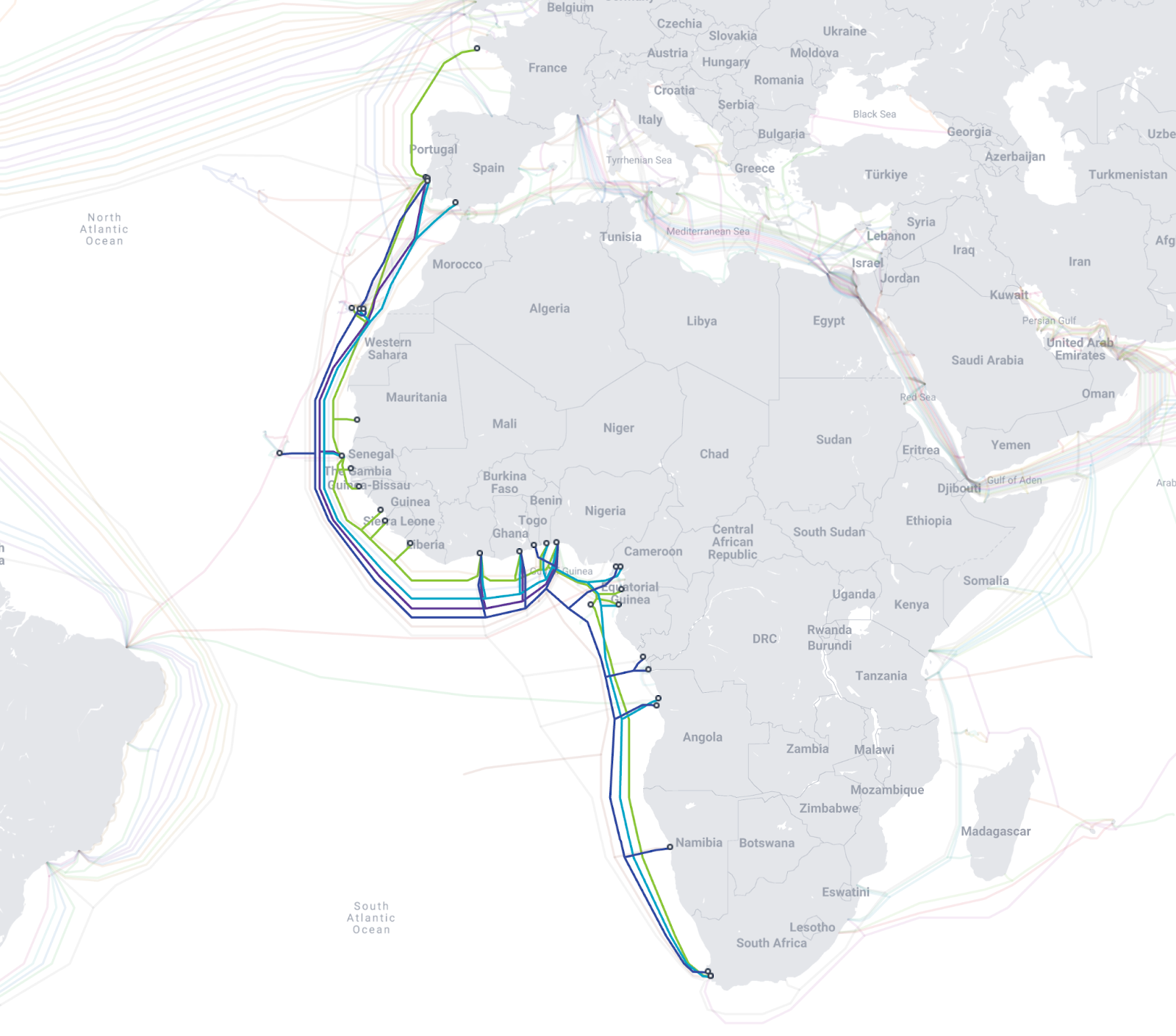
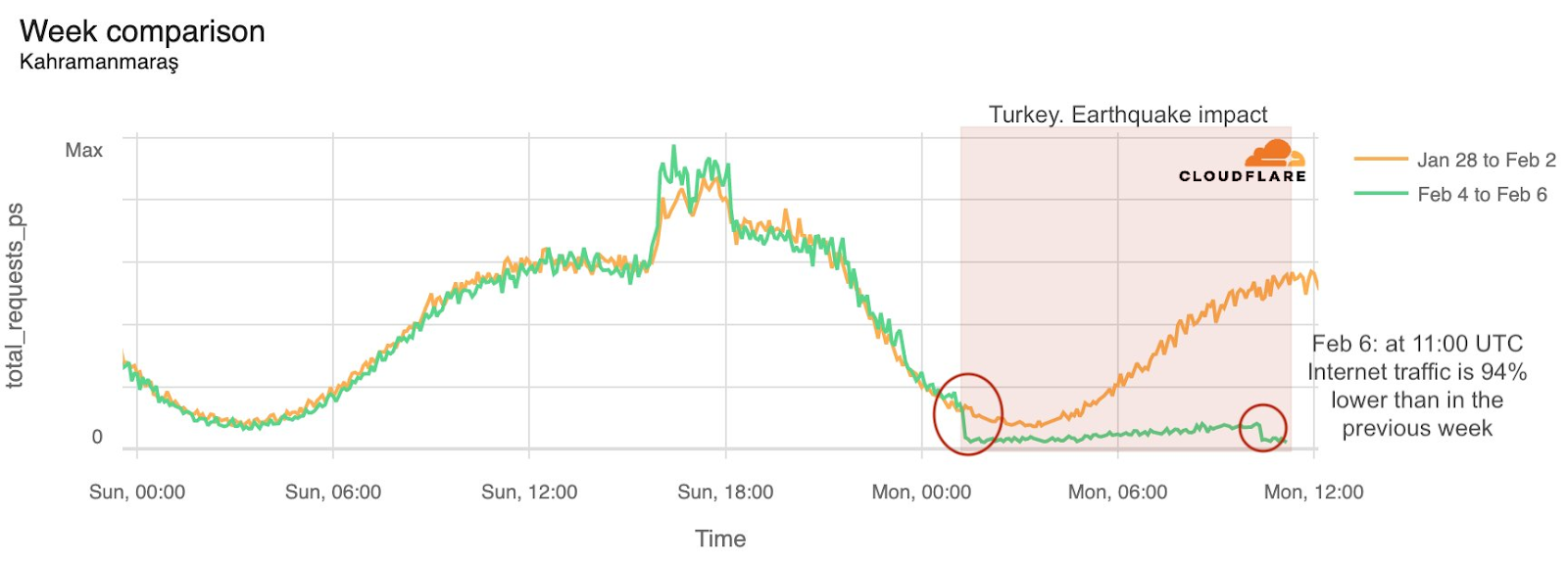
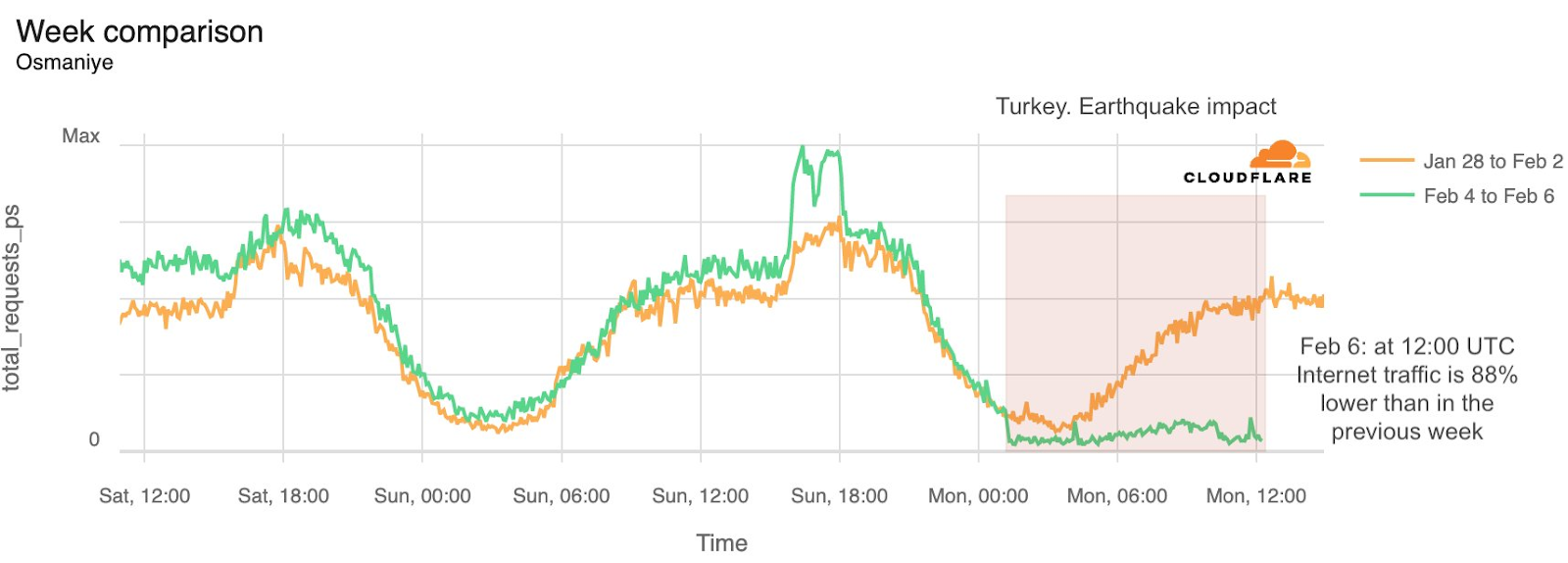
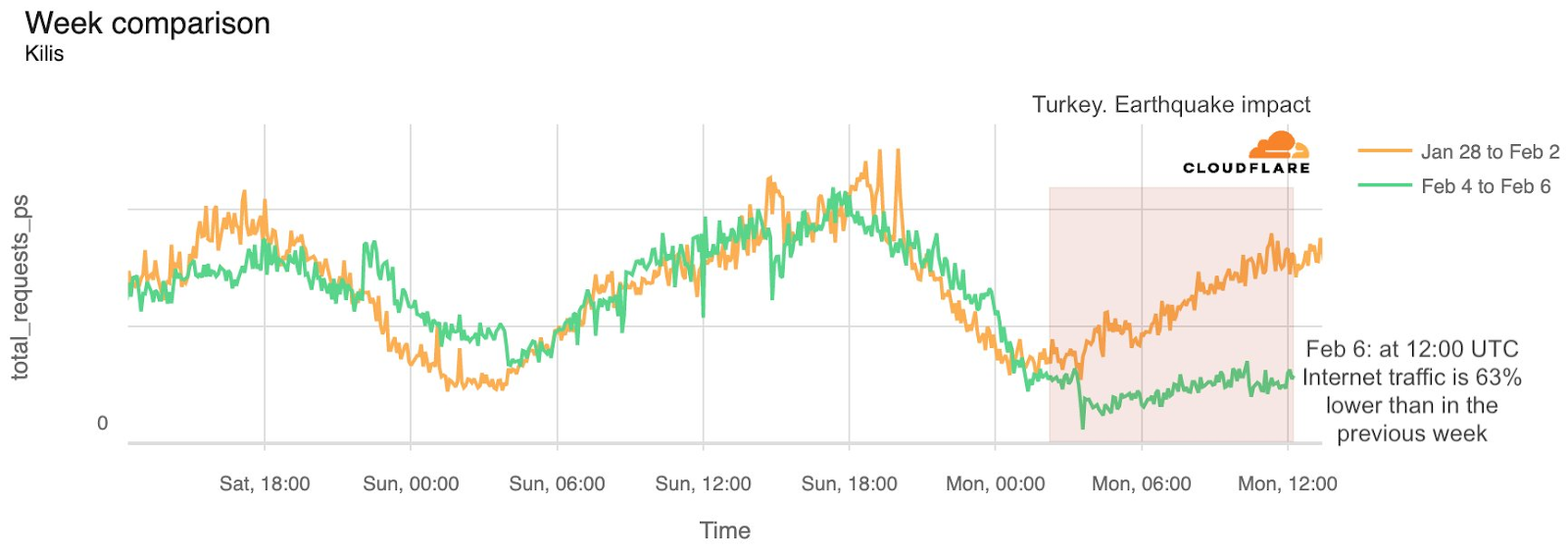
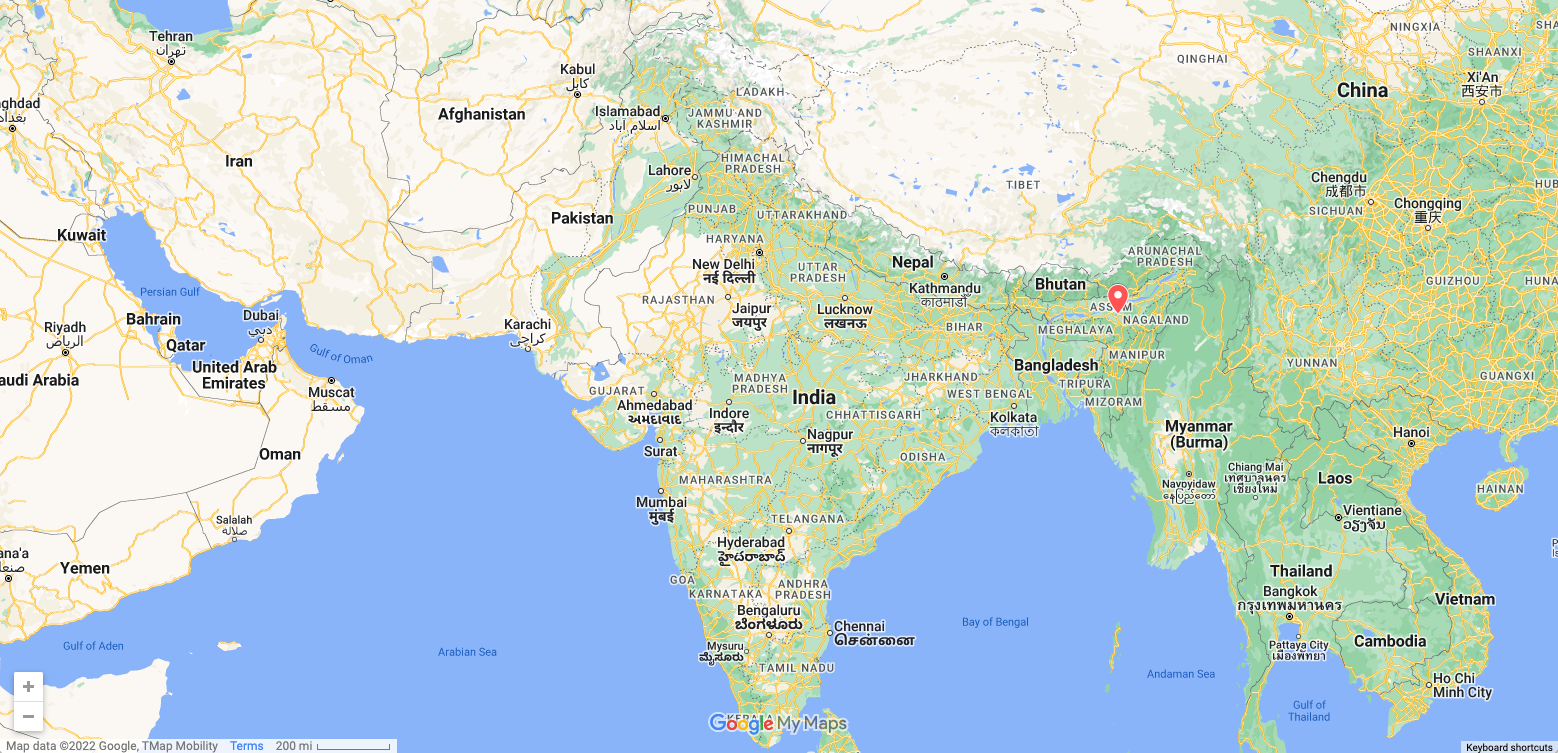
Already suffering from reduced capacity due to the February cable cuts, these countries were impacted by a second set of cable cuts that occurred on Sunday, May 12. According to a social media post from Ben Roberts, Group CTIO at Liquid Intelligent Technologies in Kenya, faults on the EASSy and Seacom cables again disrupted connectivity to East Africa, as he noted “All sub sea capacity between East Africa and South Africa is down.” A BBC article citing Roberts stated that the EASSy cable had been cut approximately 45km (28 miles) north of the South African port city of Durban. A subsequent press release issued by the Communications Authority of Kenya stated that the cut had occurred at the Mtunzini teleport station (in South Africa). As seen in the map below, both the EASSy and Seacom cables land in Mtunzini.
Map of African undersea cables, April 2024. Source: https://manypossibilities.net/african-undersea-cables/
Impacts to country-level Internet traffic
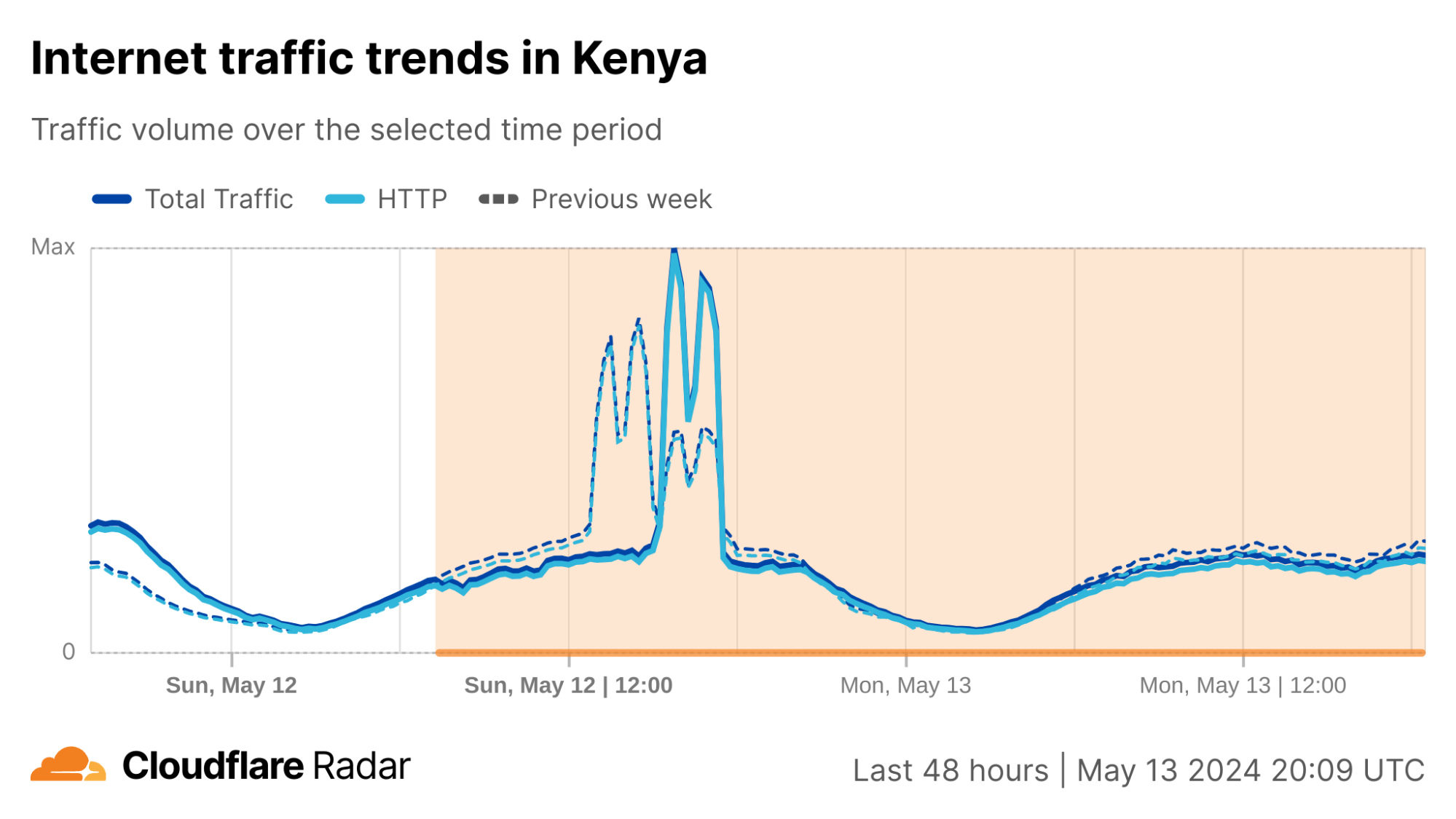
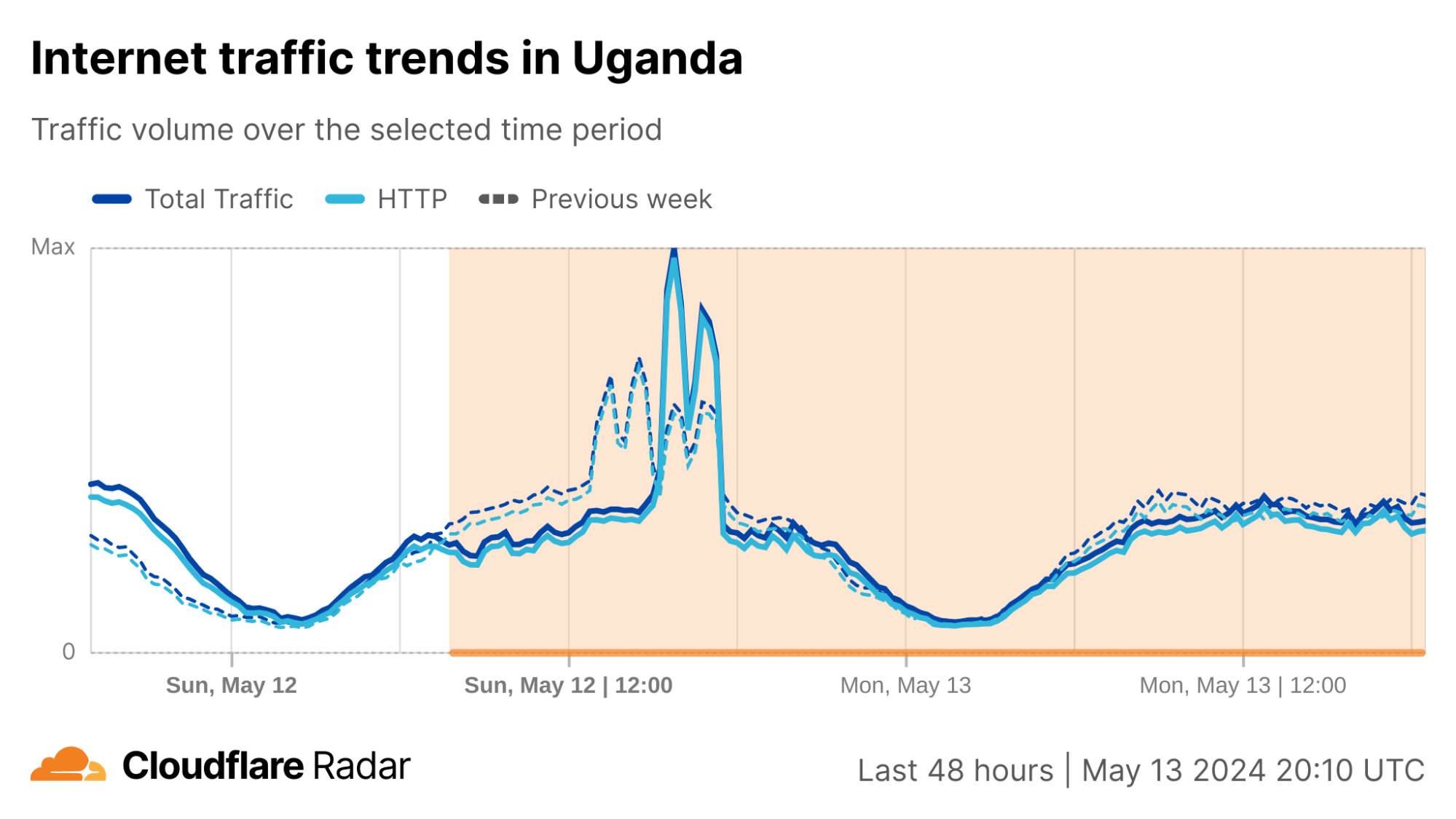
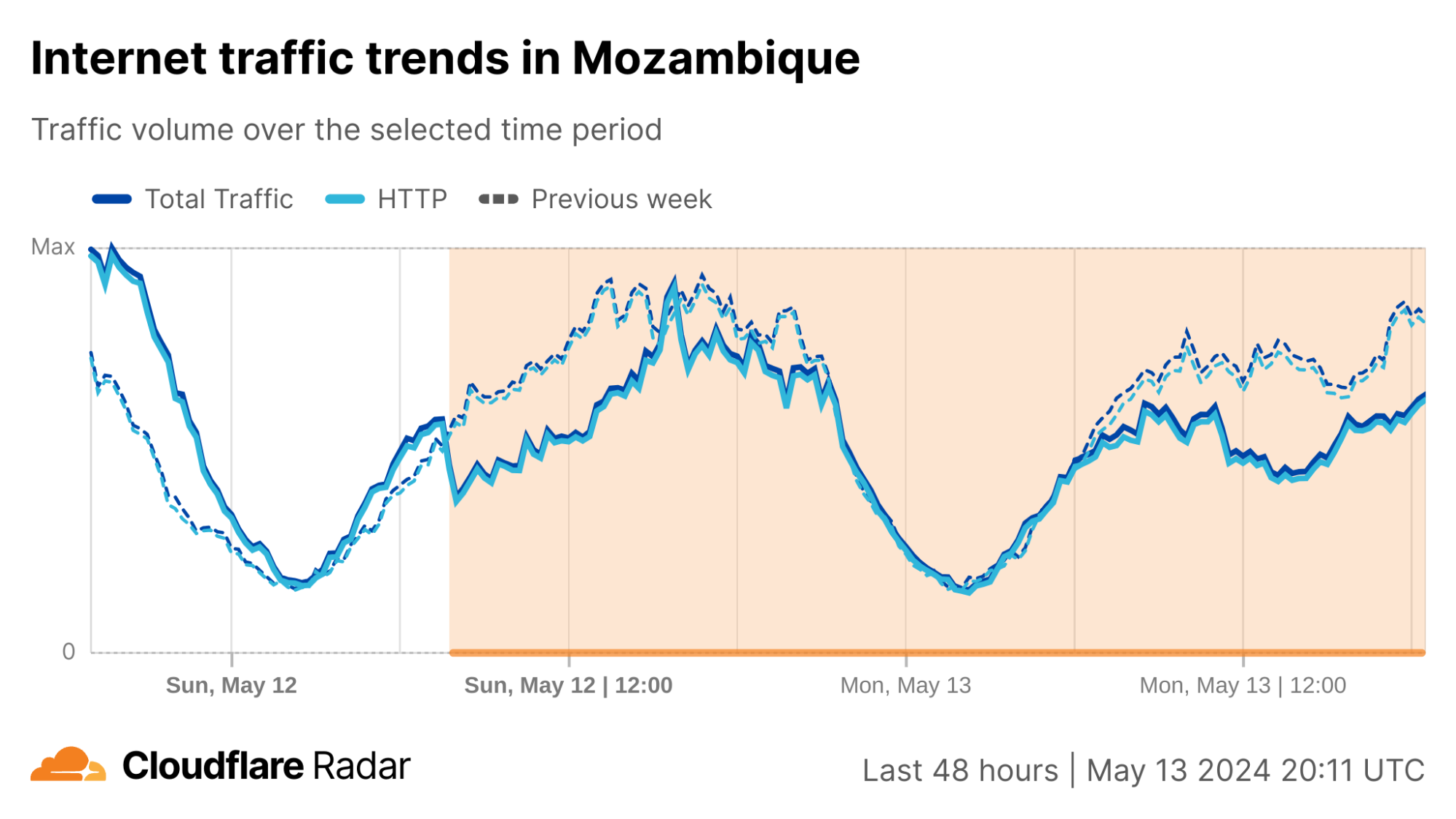
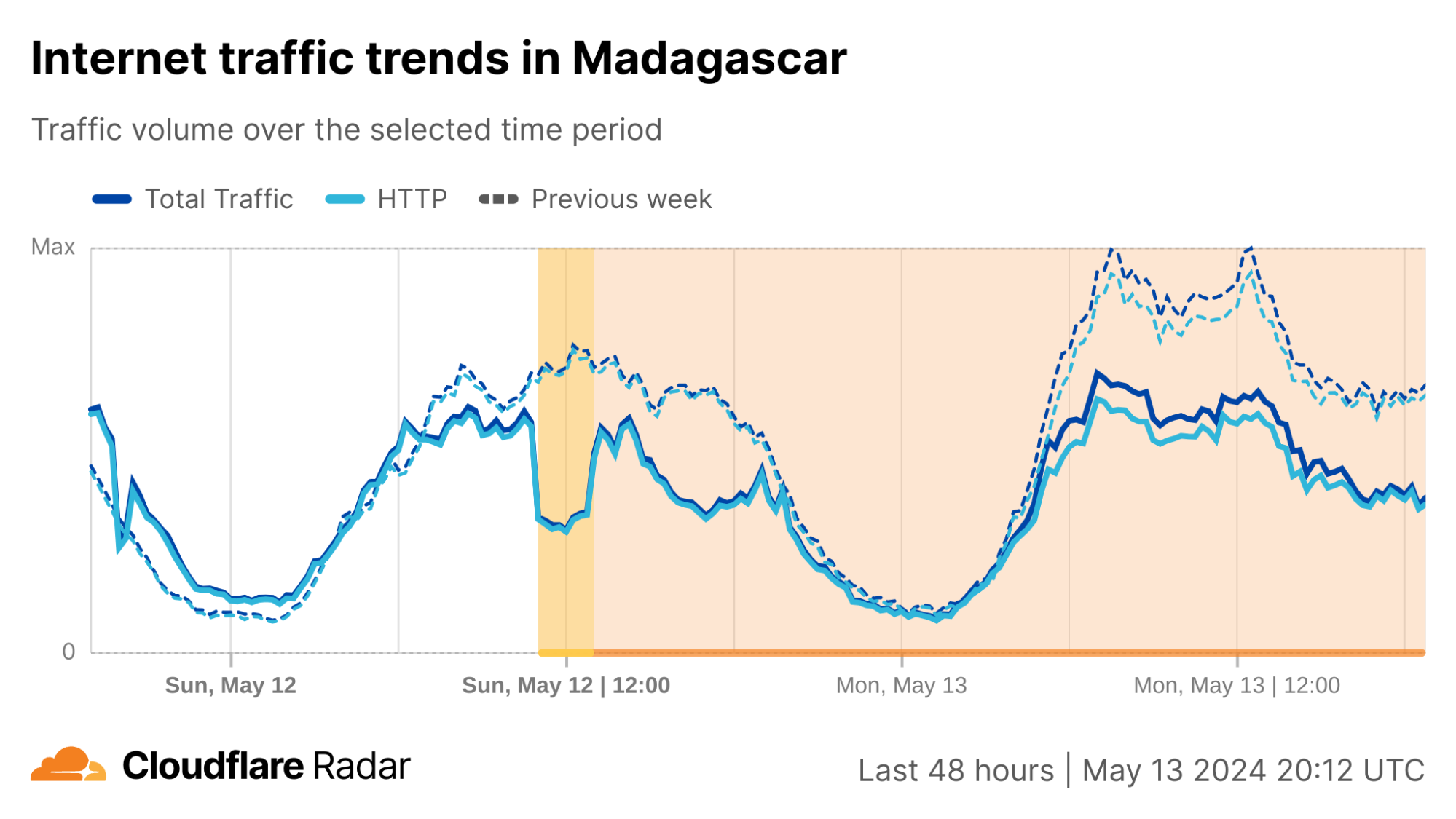
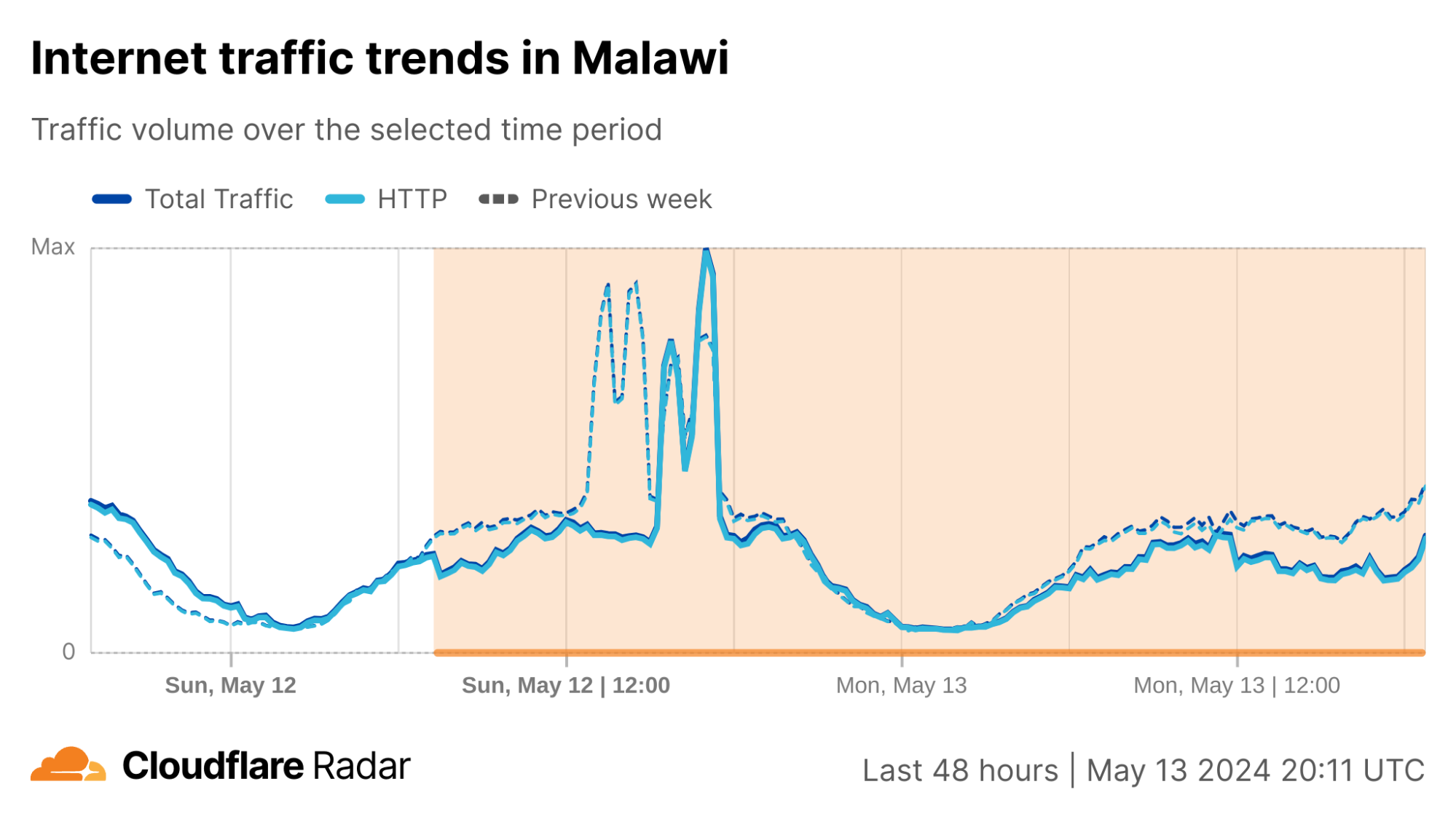
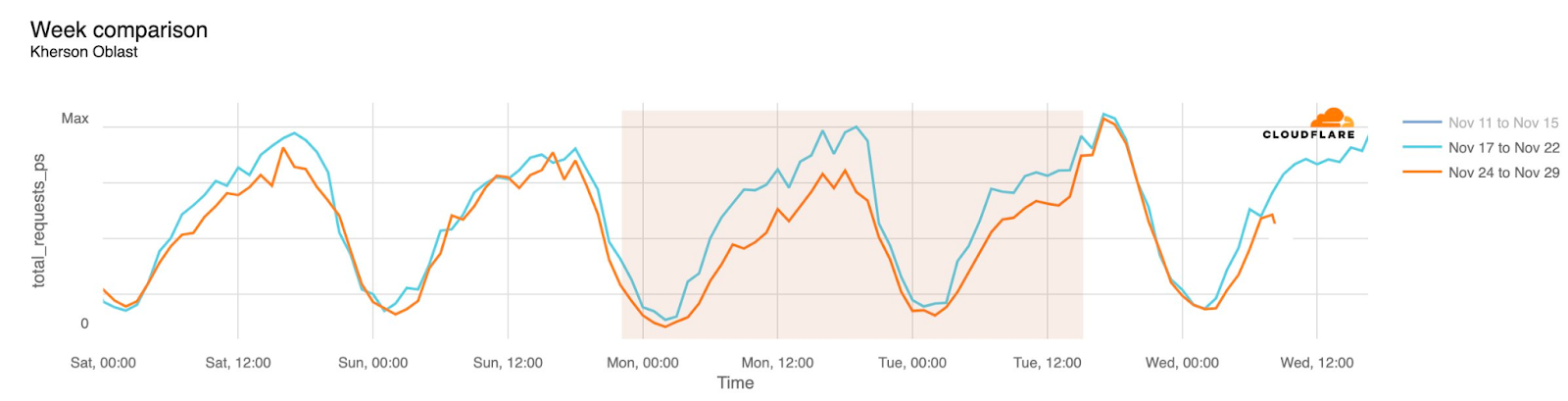
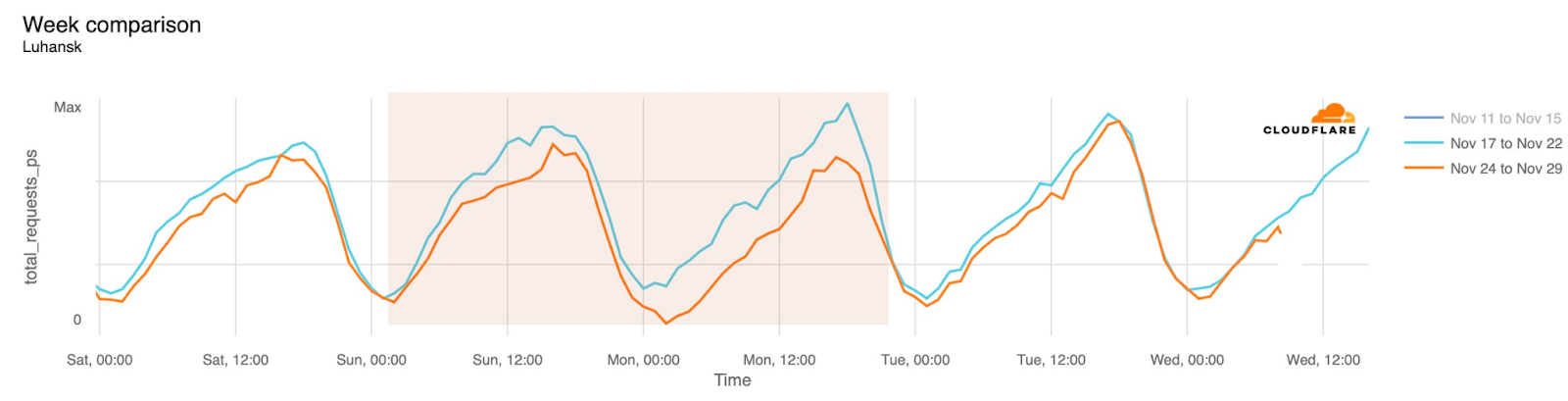
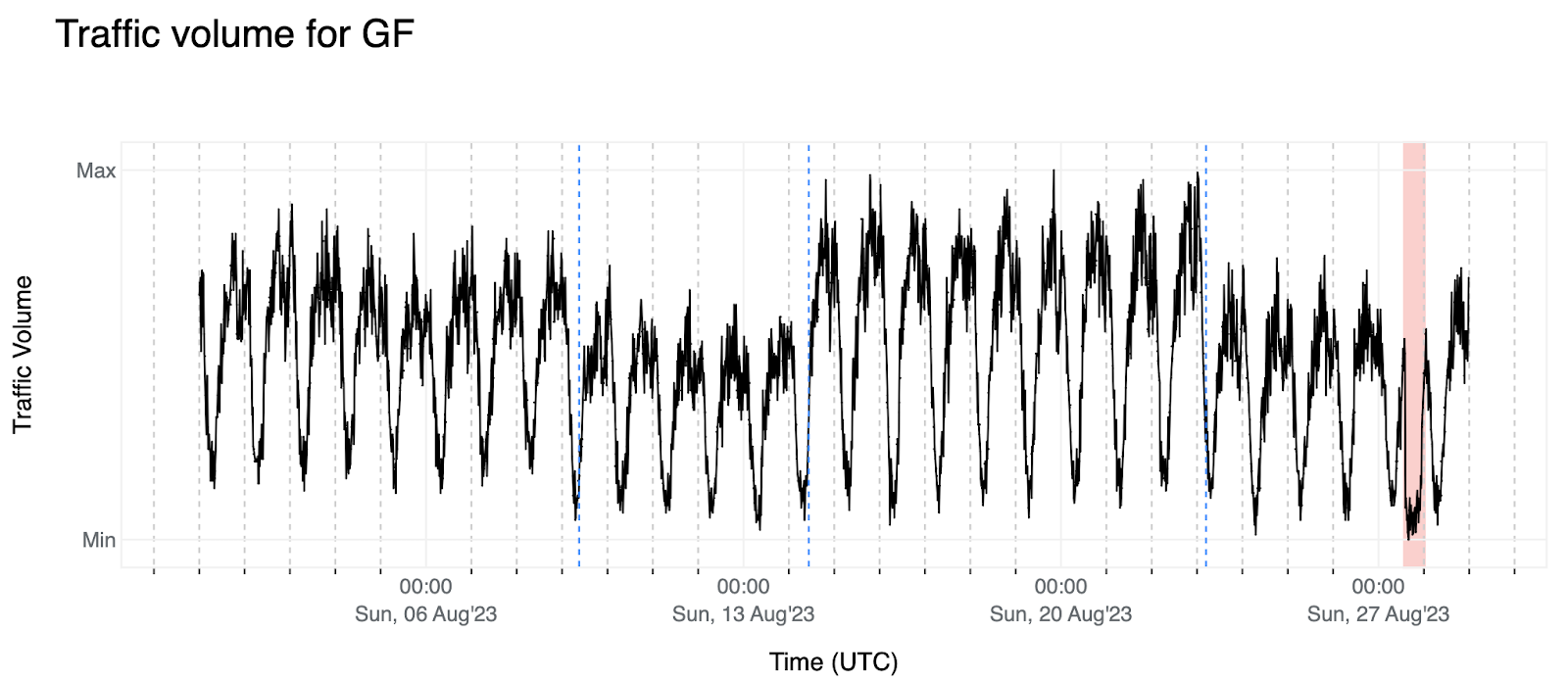
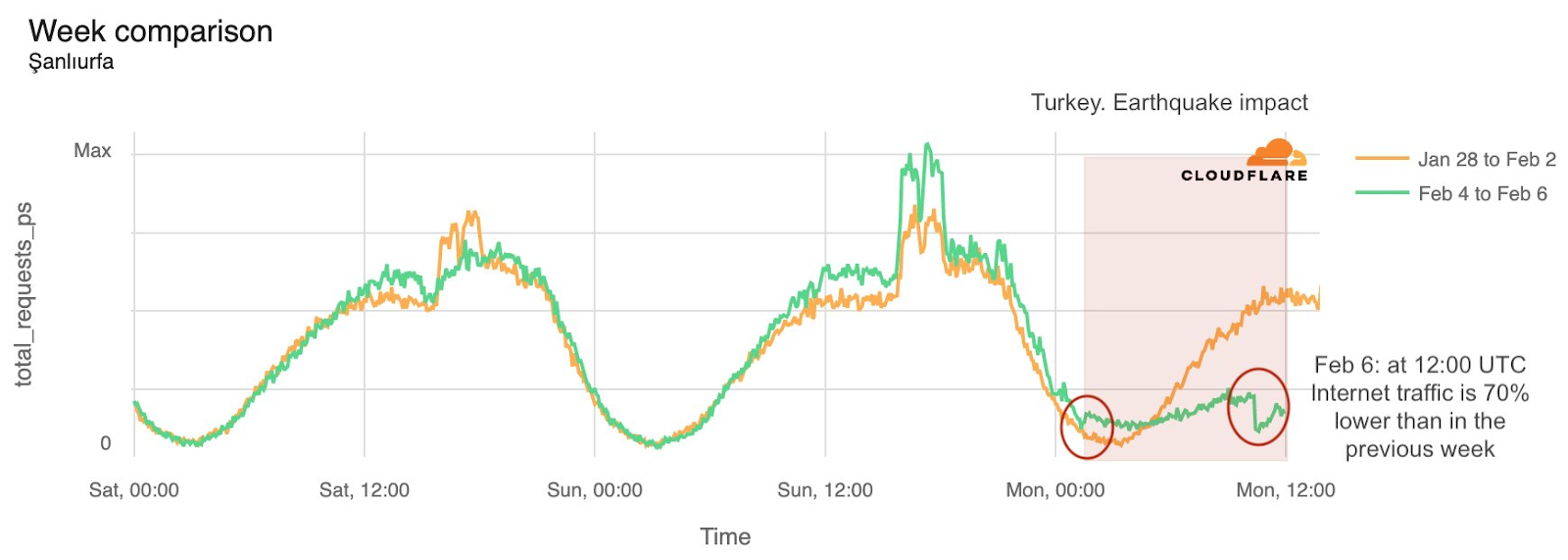
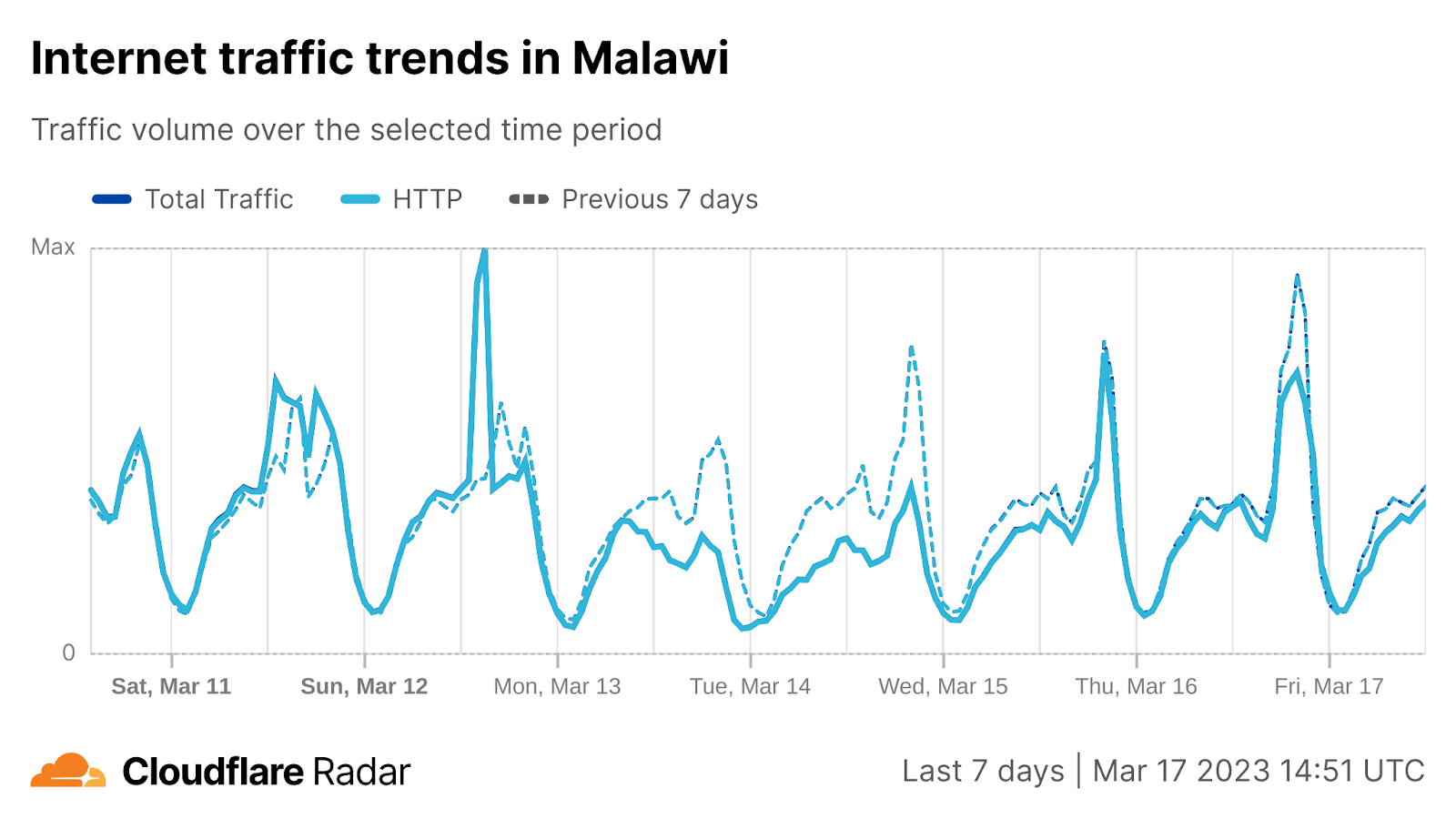
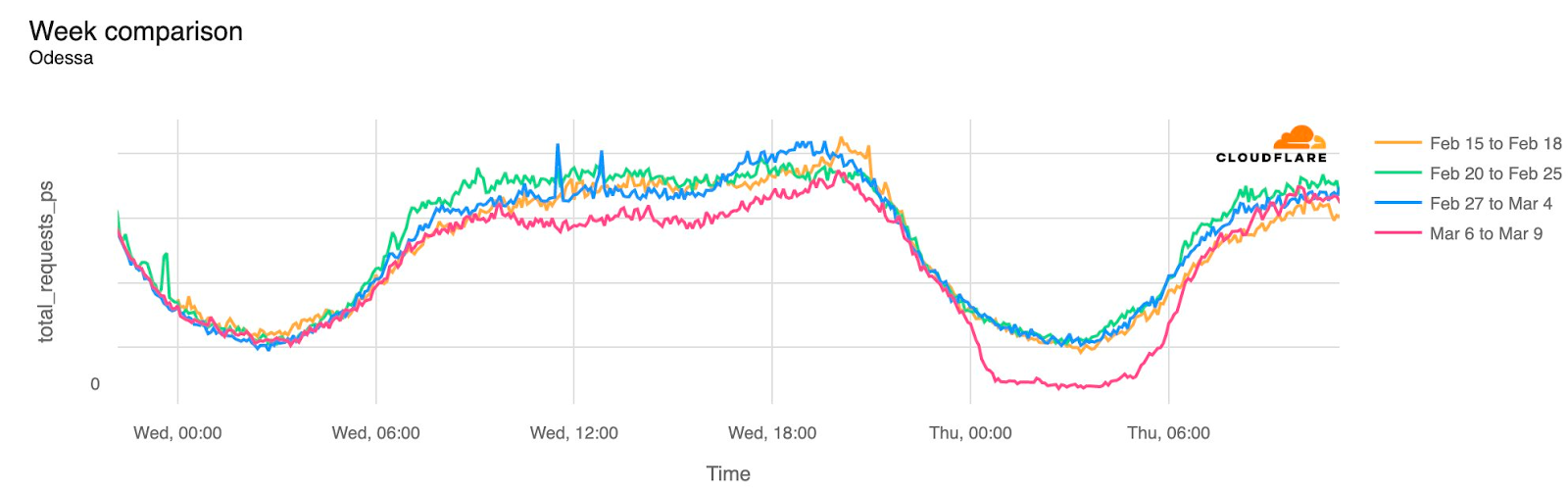
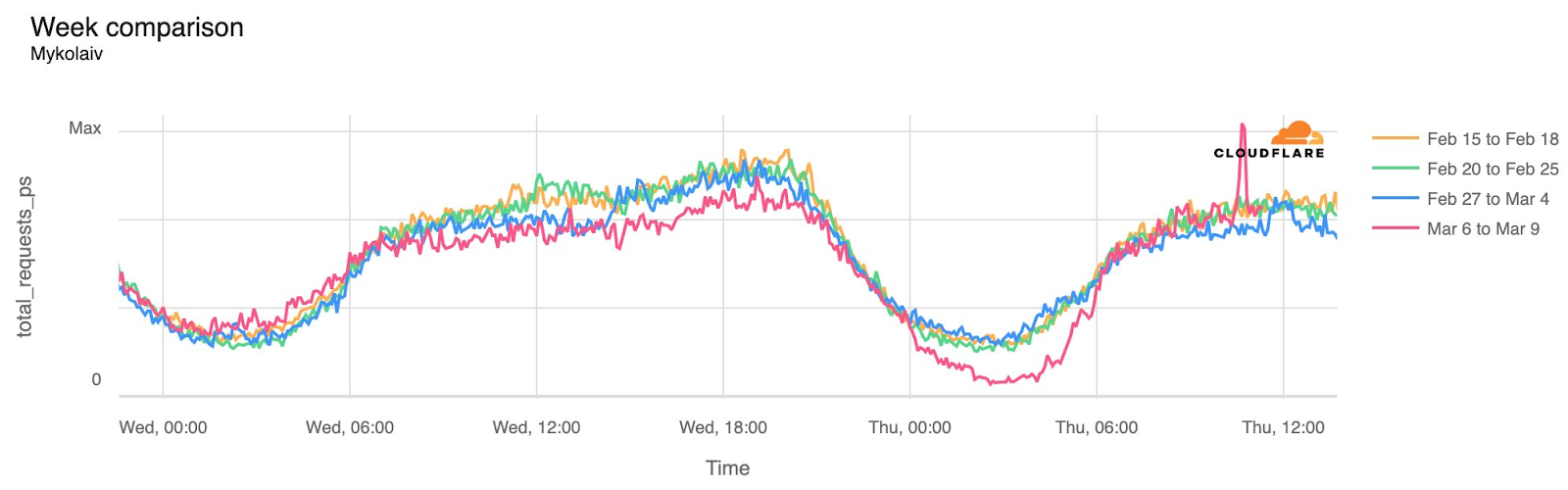
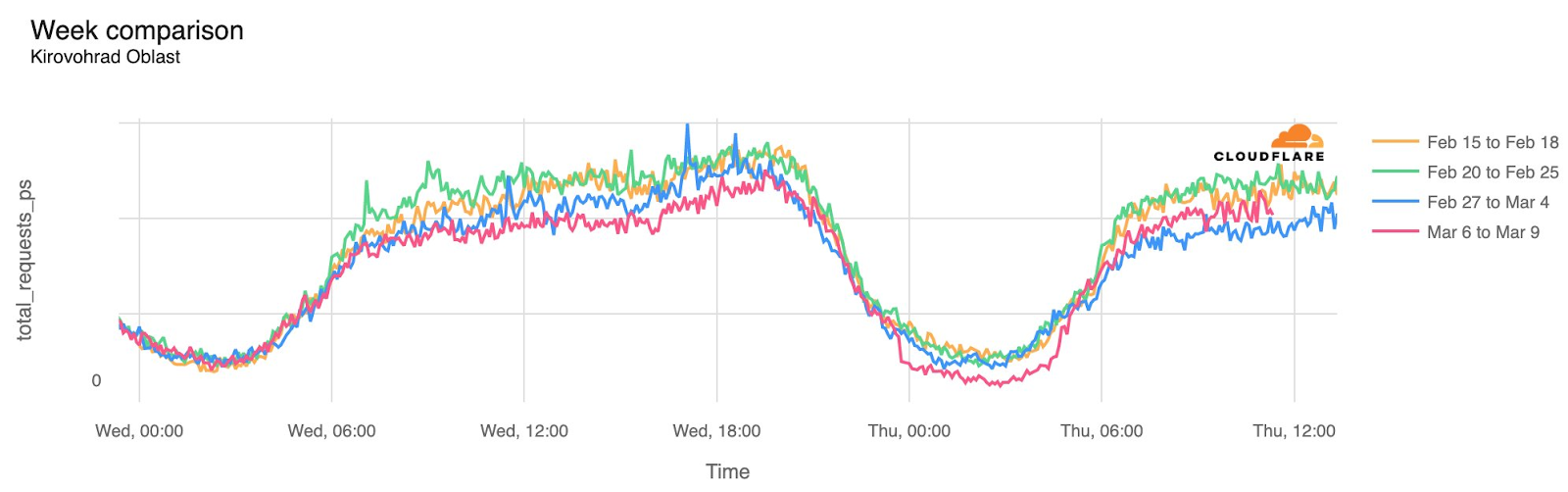
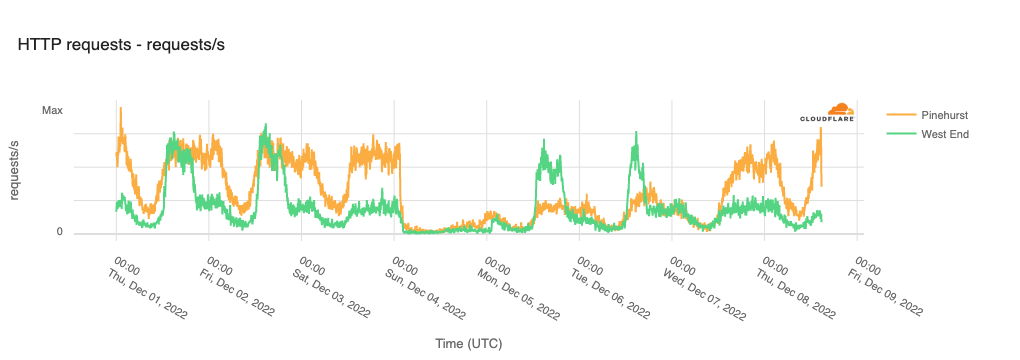
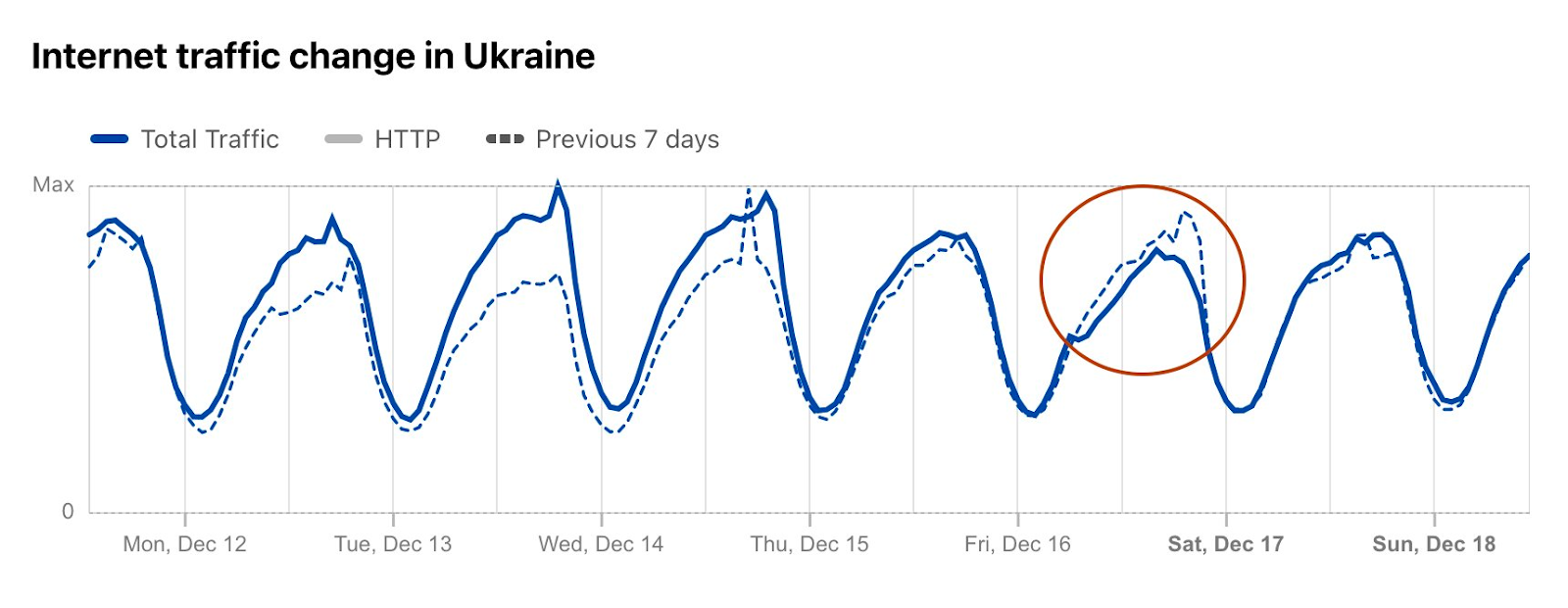
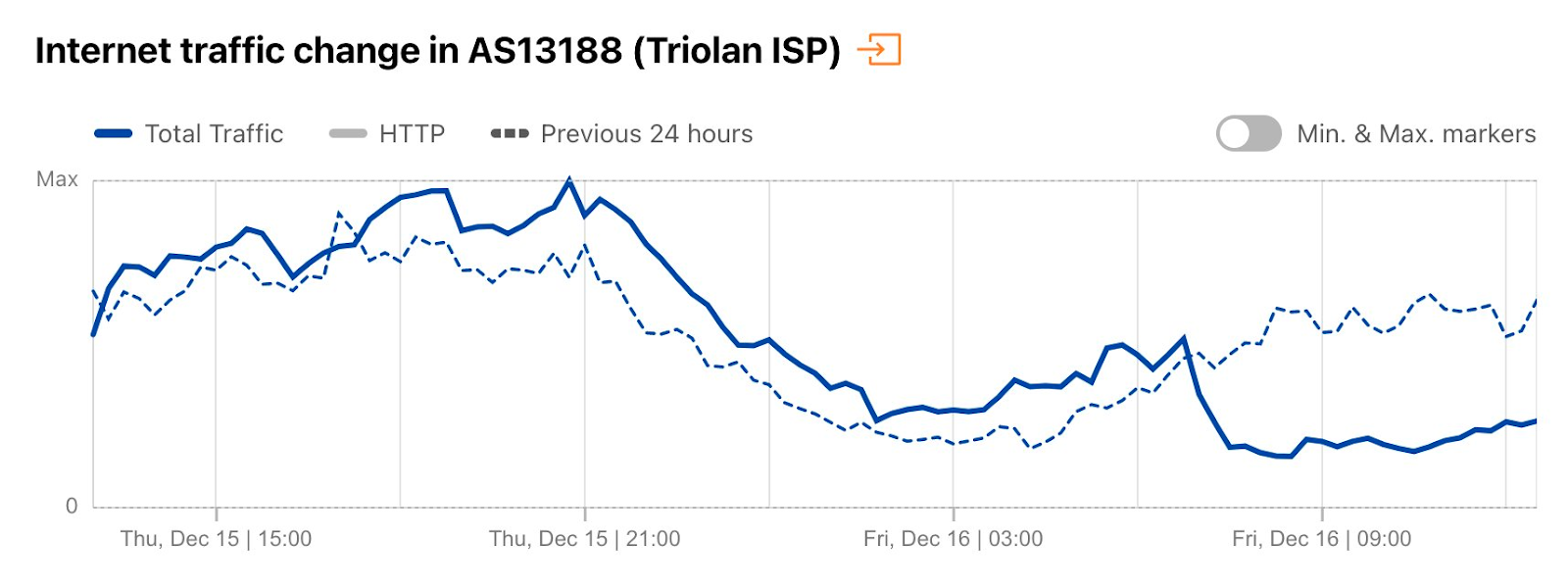
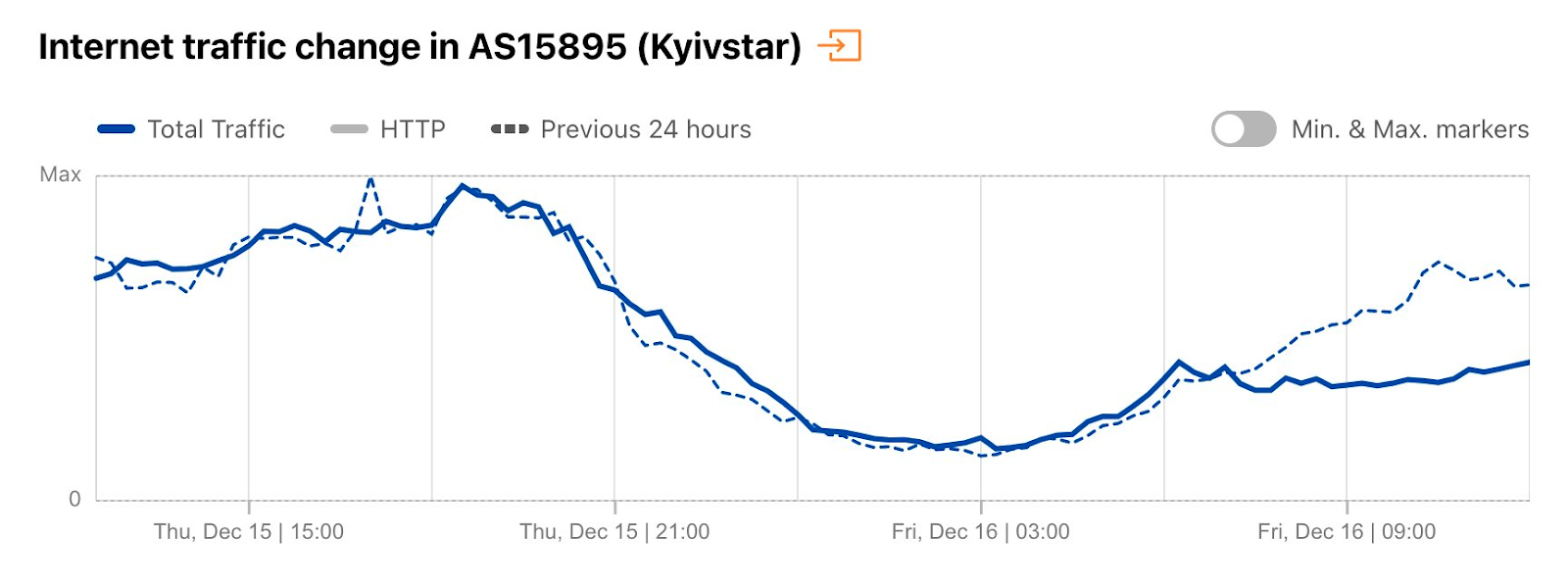
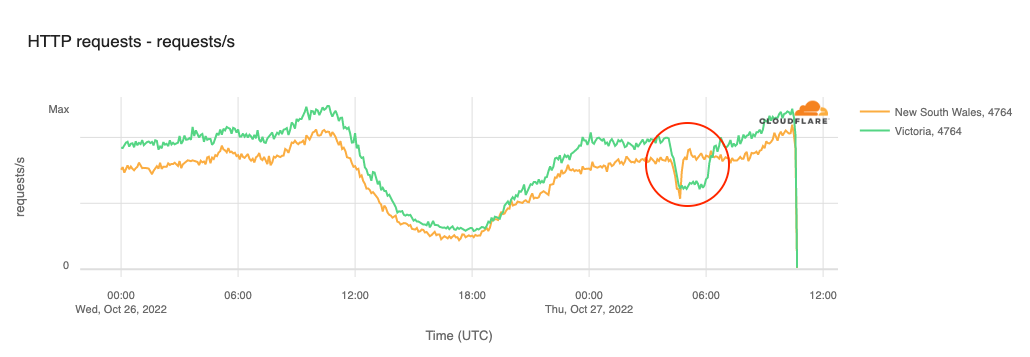
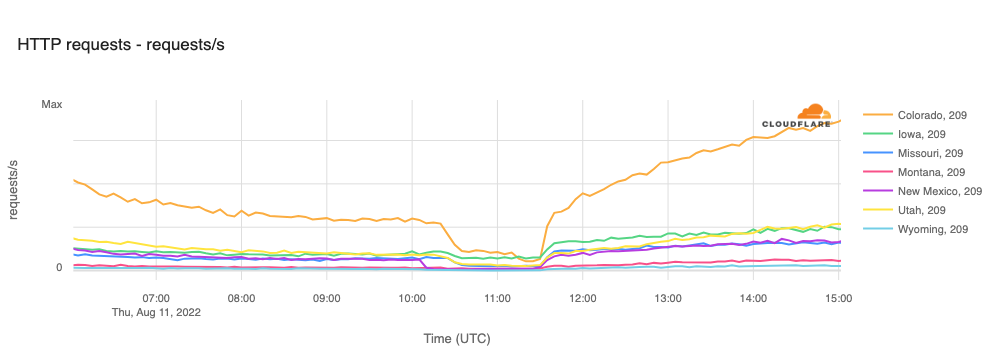
Cloudflare Radar saw traffic levels across a number of the impacted countries drop just before 11:00 local time (08:00 UTC). As seen in the graphs below, the magnitude of impact varied by country, with traffic initially dropping by 10-25% in Kenya, Uganda, Madagascar, and Mozambique, while traffic in Rwanda, Malawi, and Tanzania dropped by one-third or more as compared to the previous week.
In Kenya and Uganda, the overall impact appeared to be low, with traffic generally remaining just below expected levels in the day and a half following the cable faults. In the other countries, the overnight trough of the diurnal traffic patterns remained consistent with the previous week’s traffic levels, but otherwise traffic remains significantly lower than expected.
The importance of redundancy
In Kenya, the impact may have been nominal due to steps taken by providers like Safaricom and Airtel Kenya. In a May 12 social media post, Safaricom noted “…We have since activated redundancy measures to minimise service interruption and keep you connected as we await the full restoration of the cable.” In a subsequent social media post on May 13, Safaricom noted “Thanks to our redundancy plans and capacity investment across multiple undersea cables our services continue to be available, however some customers may experience slow connectivity and speeds.” Similarly, a social media post from Airtel Kenya noted “Following yesterday’s undersea fiber cut that has impacted internet connectivity, we would like to update you that we have taken measures to improve your browsing experience through additional capacity enhancement.”
Similarly, the previously referenced press release from the Communications Authority of Kenya talked about actions being taken, stating “Meanwhile, the Authority has directed service providers to take proactive steps to secure alternative routes for their traffic and is monitoring the situation closely to ensure that incoming and outbound internet connectivity is available. The East Africa Marine System (TEAMS) cable, which has not been affected by the cut, is currently being utilised for local traffic flow while redundancy on the South Africa route has been activated to minimize the impact.”
What’s next?
Once the necessary permits are secured and the cable faults are located, repairs can often be completed in several days. However, because cable repair ships are something of a scarce resource, there is often a delay to both engage a vessel and for it to travel to the area where the cable damage occurred, whether from its baseport or the location of a previous repair. However, in this case that delay may be comparatively short, as submarine cable industry observer @philBE2 predicts “Expecting the usual suspect, CS Leon Thevenin, now moored in Cape Town, to be swiftly mobilized for an expeditious repair mission…”
Cloudflare’s network spans more than 310 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions. Thanks to recently released Cloudflare Radar functionality, this quarter we have started to explore the impact from a routing perspective, as well as a traffic perspective, at both a network and location level.
The first quarter of 2024 kicked off with quite a few Internet disruptions. Damage to both terrestrial and submarine cables caused problems in a number of locations, while military action related to ongoing geopolitical conflicts impacted connectivity in other areas. Governments in several African countries, as well as Pakistan, ordered Internet shutdowns, focusing heavily on mobile connectivity. Malicious actors known as Anonymous Sudan claimed responsibility for cyberattacks that disrupted Internet connectivity in Israel and Bahrain. Maintenance and power outages forced users offline, resulting in observed drops in traffic. And in a more unusual turn, RPKI, DNS, and DNSSEC issues were among the technical problems that disrupted connectivity for subscribers across multiple network providers.
As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Cable cuts
Moov Africa Tchad
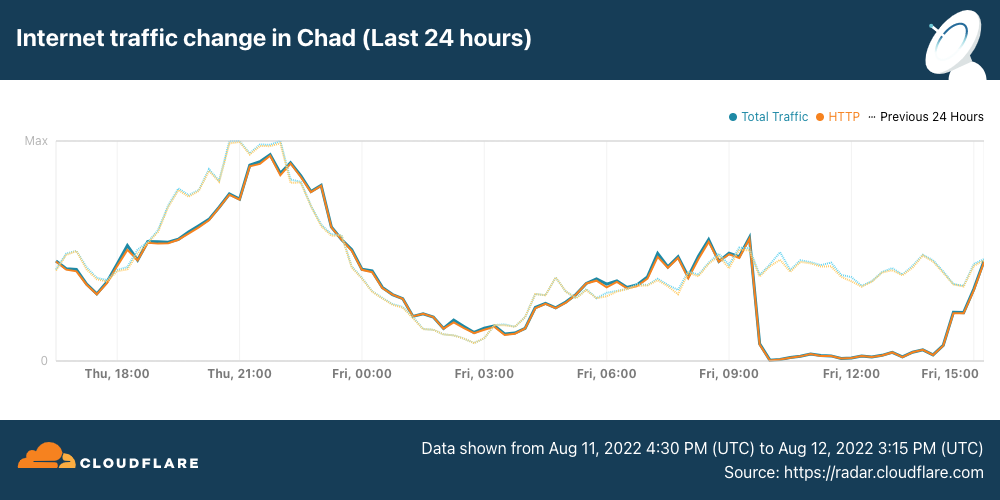
Reported fiber optic cable damage that occurred in Cameroon on January 10 further disrupted connectivity for customers of AS327802 (Moov Africa Tchad / Millicom) a telecommunications provider in Chad. According to a (translated) Facebook post from Moov Africa Tchad, “On the afternoon of January 10, 2024, there was a breakdown of the internet due to a cut in the optical fiber coming from Cameroon through which Chad has access to the internet, the one coming from Sudan being unavailable for a while.” It is unclear whether the referenced cable cut occurred in Cameroon or Chad, and the mentioned Sudan cable issue may be the one covered in our Q4 2023 summary post. As a landlocked country, Chad is dependent on terrestrial Internet connections to/through neighboring countries, and the AfTerFibre cable map illustrates Chad’s reliance on limited cable paths through Cameroon and Sudan.
The graphs below show that Moov Africa Tchad traffic was disrupted for over 12 hours starting midday (UTC) on January 10, and the disruption was visible at a country level as well. The fiber cut also resulted in significant volatility from a routing perspective, as the volume of announced IPv4 address space shifted frequently at a network and country level during the disruption.
On February 15, a brief (~30 minute) but complete significant Internet disruption was observed at AS37577 (Orange Burkina Faso). According to the translation of a communiqué posted by the provider on social media, “The incident is due to a fiber cut, which causes a disruption of Internet services for certain customers.” Orange did not specify whether it was a more localized fiber cut, or damage to one of the terrestrial fibers that cross the country. The incident took the network completely offline, as the ASN’s amount of announced IPv4 address space dropped to zero for the duration.
MTN Nigeria
MTN Nigeria turned to social media on February 28 to let customers know that “You have been experiencing challenges connecting to the network due to a major service outage caused by multiple fibre cuts, affecting voice and data services.” A published report described the impact, noting “Millions of customers nationwide were impacted by the hours-long outage, especially in Lagos.” Connectivity was disrupted for approximately seven hours between 13:30 – 20:30 local time (12:30 – 19:30 UTC), and the provider posted a followup note just before midnight local time stating that service had been fully restored.
Digicel Haiti
A 16-hour Internet disruption on March 2/3 at AS27653 (Digicel Haiti) was due to a double fiber cut as a result of violence related to attempts to oust Prime Minister Ariel Henry. Starting around 22:00 local time on March 2 (03:00 on March 3), a complete outage was observed for approximately nine hours. Some recovery in traffic occurred for approximately two-and-a-half hours, followed by a three hour near-complete disruption. Digicel Haiti effectively disappeared from the Internet during the nine-hour outage, as no IPv4 or IPv6 address space was announced by the network during that time.
SKY (Philippines)
A brief traffic disruption observed on AS23944 (SKY) in the Philippines on March 18 was likely related to a fiber cut. In an advisory posted by SKY on social media, they stated that “SKY services in several areas in Marikina, Pasig and Quezon City are currently affected by a cut-fiber issue”, listing 45 affected areas. Traffic was most significantly impacted between 20:00 – 21:00 local time (12:00 – 13:00 UTC), although full recovery took several more hours. Only a minor impact to routing resulting from the fiber cut was observed.
Multiple African countries
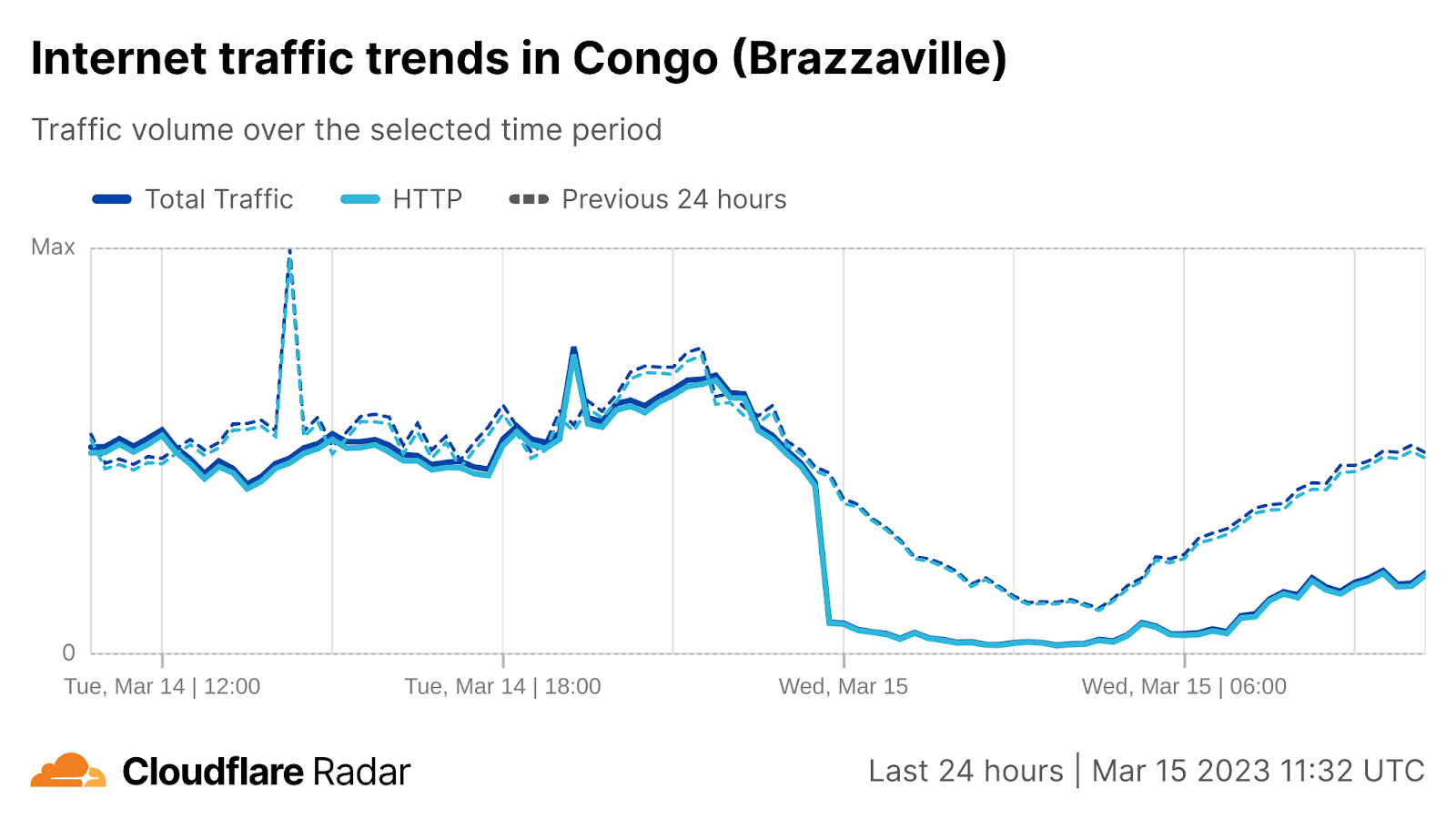
On March 14, damage to multiple submarine cables off the west coast of Africa impacted Internet connectivity across multiple countries in West and Southern Africa. The damage was reportedly caused by underwater rock falls, and in addition to disrupting Internet connectivity, also caused availability issues for Microsoft Azure and Office 365 cloud services.
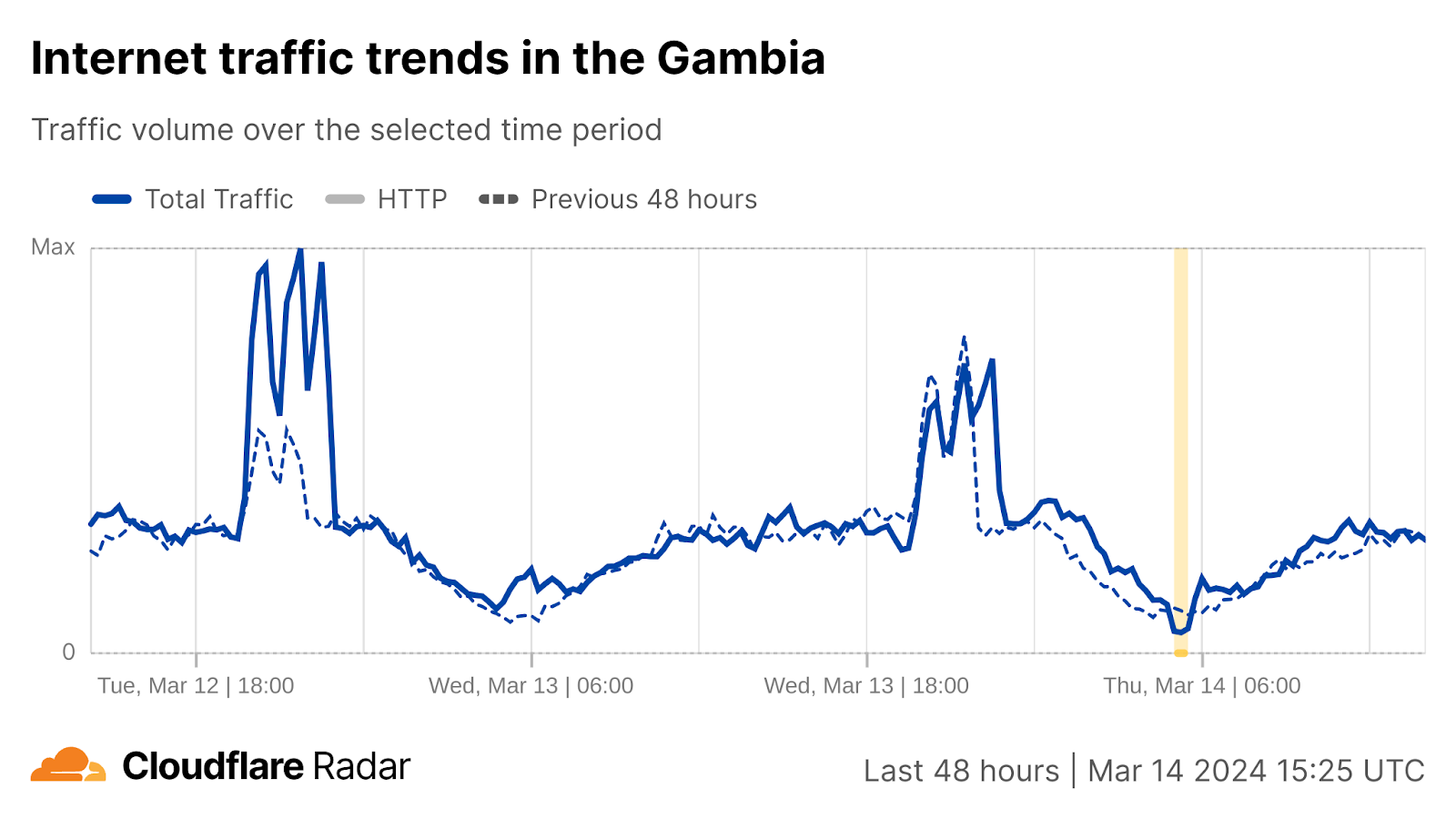
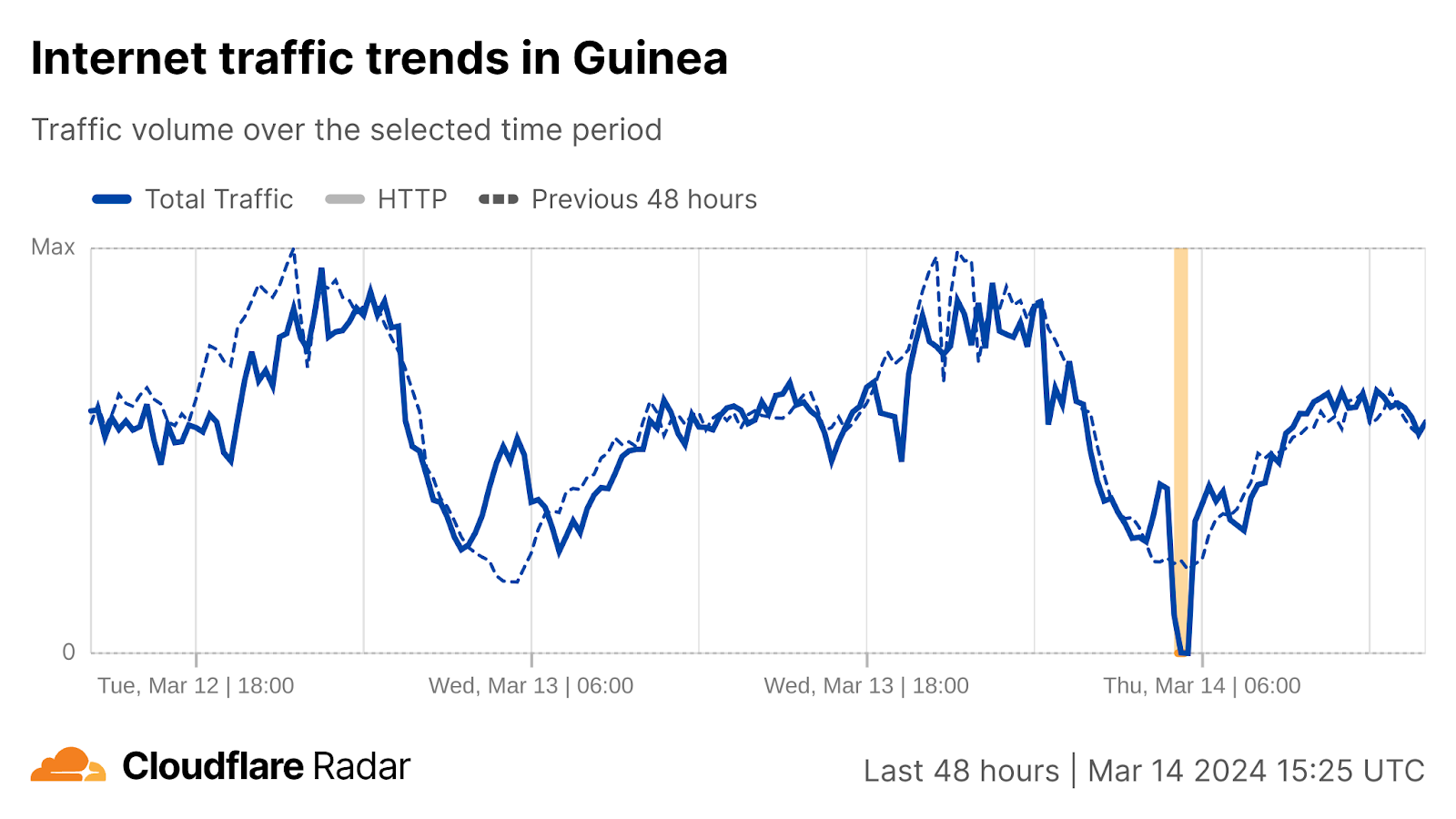
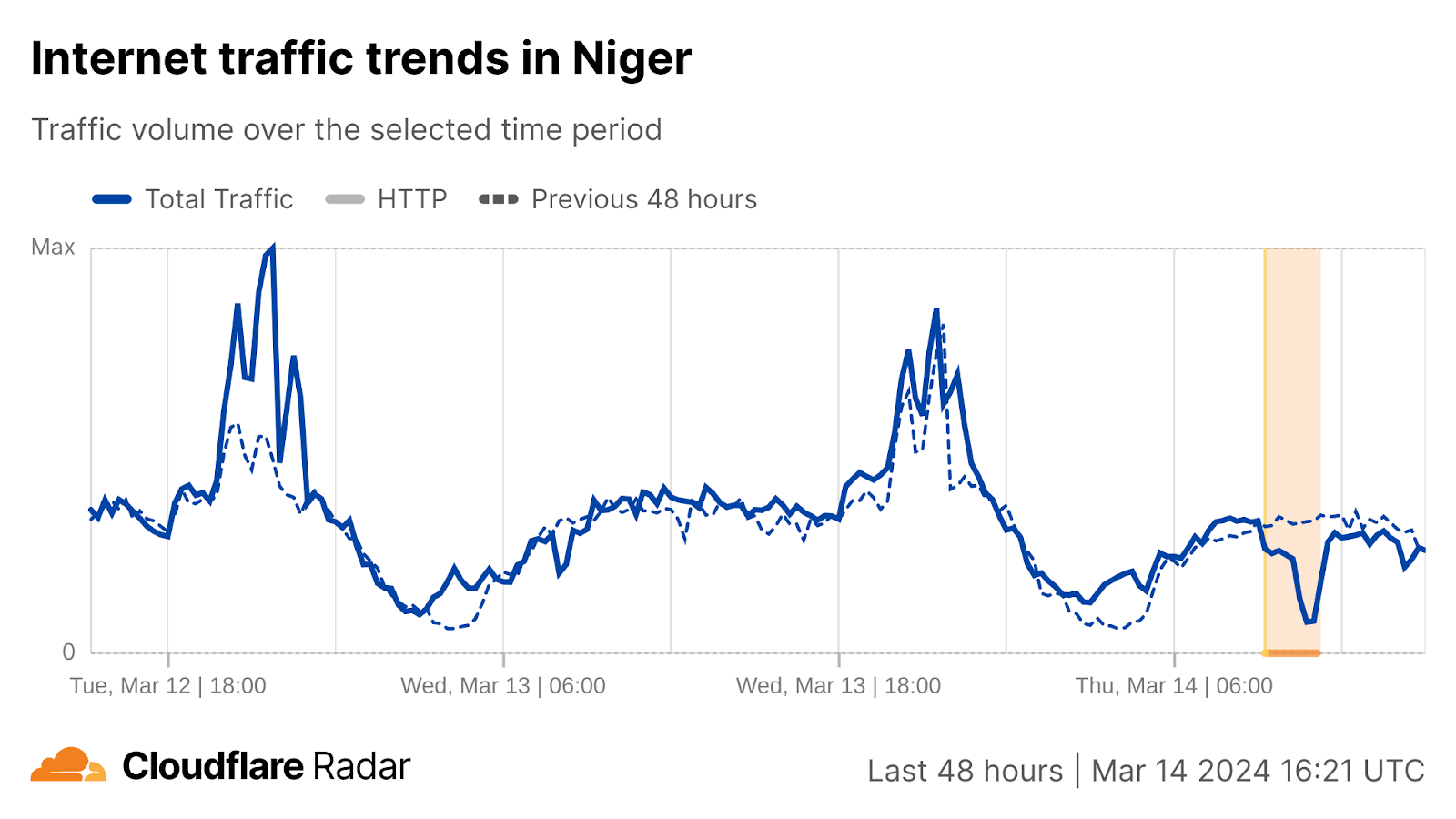
Comparatively brief disruptions were observed in Niger, Guinea, and Gambia, lasting from under an hour to approximately two hours.
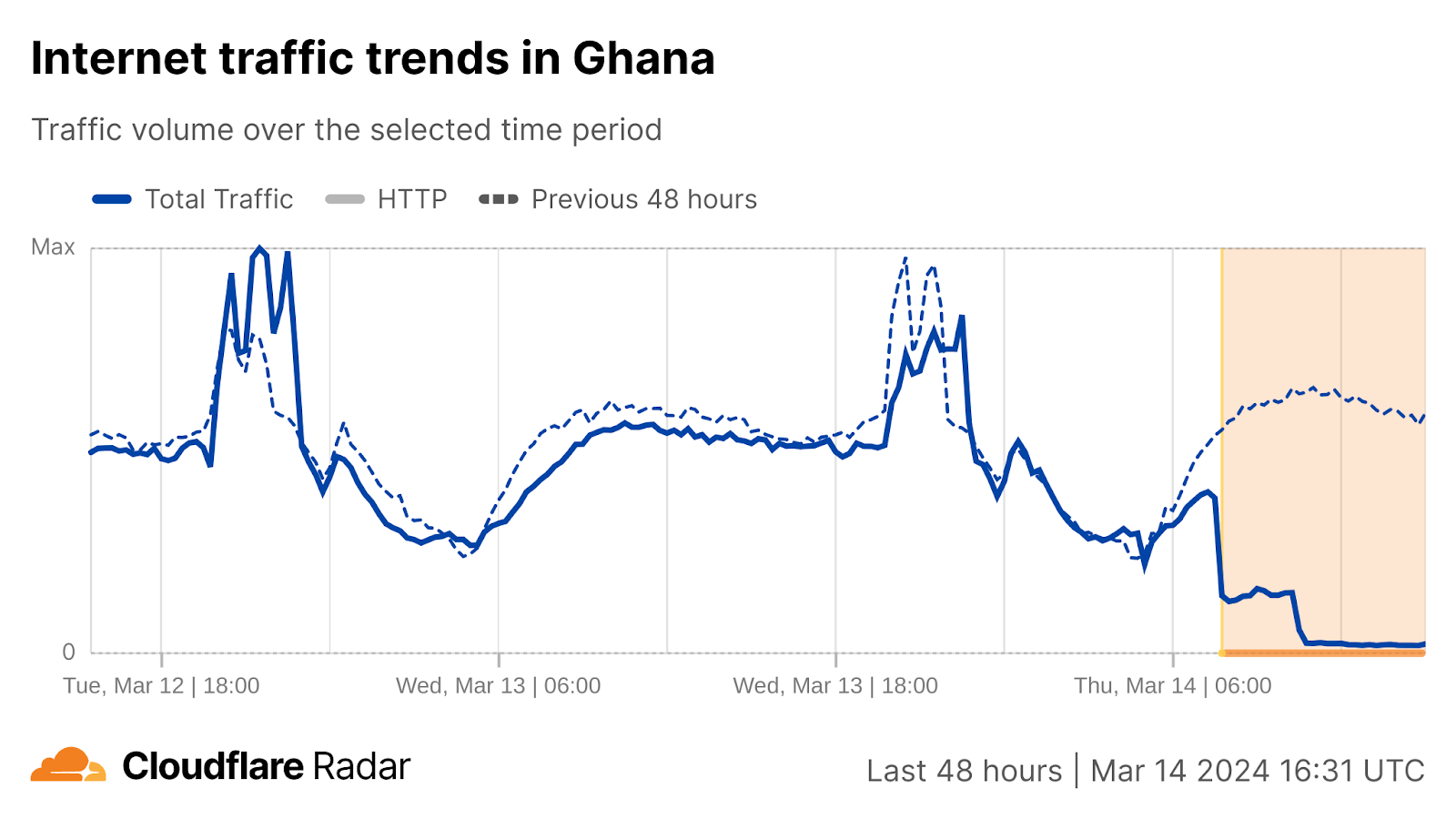
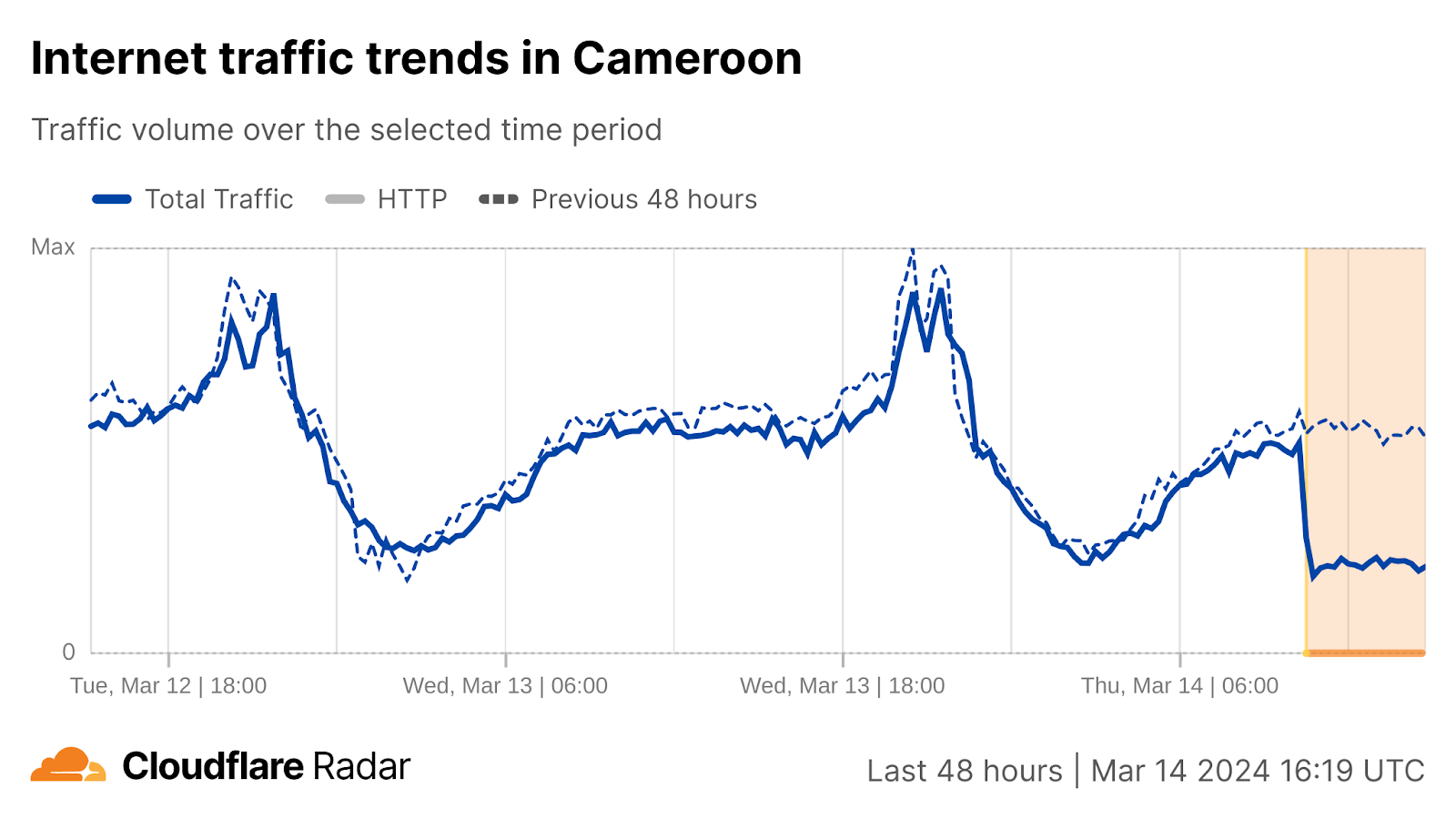
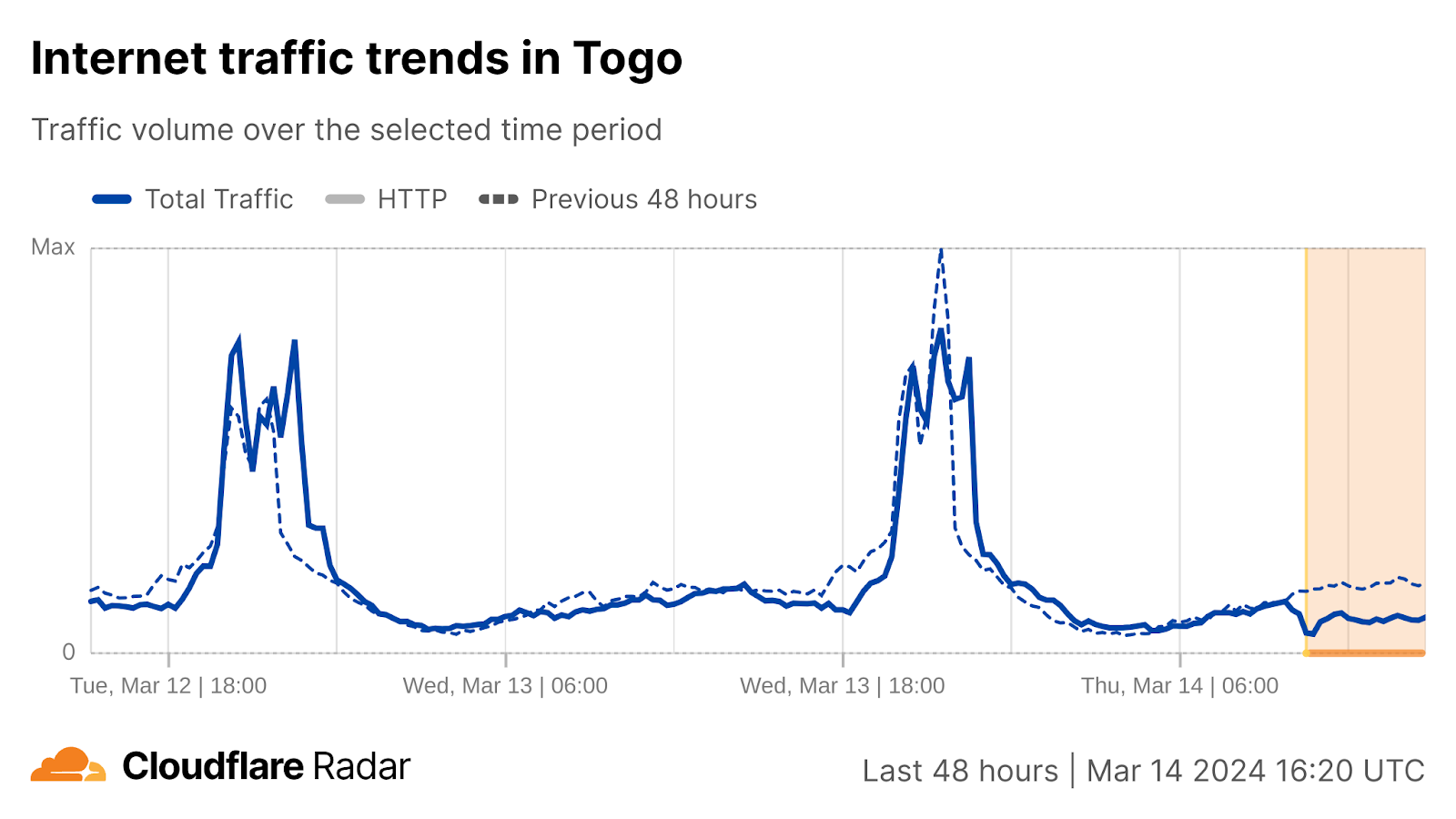
However, the disruptions stretched out across multiple days in countries including Togo, Liberia, and Ghana, where it took several weeks for traffic to return to previously observed peak levels.
Operators in impacted countries attempted to maintain availability by shifting traffic to Google’s Equiano submarine cable, which reportedly experienced a 4x increase in traffic, and Morocco’sMaroc Telecom West Africa submarine cable. Service on the SAT-3 cable was fully restored as of April 6, with repairs on ACE completed on April 17, repairs to WACS and MainOne expected to be done by April 28.
On February 24, three submarine cables that run through the Red Sea were damaged: the Seacom/Tata cable, the Asia Africa Europe-1 (AAE-1), and the Europe India Gateway (EIG). It is believed that the cables were cut by the anchor of the Rubymar, a cargo ship that was damaged by a ballistic missile on February 18. At the time of the disruption, Seacom confirmed the damage to their cable, while the owners of the other two cables did not publish similar confirmations.
On February 2, Cloudflare observed a loss of traffic at AS15706 (Sudatel) and AS36972 (MTN Sudan), with a similar loss occurring on February 7 at AS36998 (Zain Sudan / SDN Mobitel). The disruption at MTN Sudan aligns with a social media post from the provider, in which they stated (translated) “We regret the interruption of all services due to circumstances beyond our control. While we apologize for the inconvenience caused by this interruption, we assure you of our endeavor to restore the service as soon as possible, and you will be notified of the return of the service.” On February 5, several days after their outage started, Zain Sudan published a social media post that stated (translated) “Zain Sudan has been constantly striving to maintain communication and Internet service to serve its valued subscribers, and we would like to point out that the current network outage is due to circumstances beyond its control, with our hopes that safety will prevail, and that service will be restored as soon as possible.” Sudatel did not share any information about the status of its network. On February 4, Digital Rights Lab – Sudan posted on social media that “Our sources confirmed that @RSFSudan forces tookover data centers of ISPs in Khartoum, #Sudan.” It is likely that the Internet outages observed across these providers are related to these takeovers, part of the military conflict that has been underway in the country since April 15, 2023.
The disruptions on these networks varied in length. At Sudatel, traffic started to return on February 11. At Zain Sudan, traffic began to return on March 3, corroborated by a social media post that stated (translated) “Zain network is gradually returning to work and allows its subscribers to communicate for free for a limited time. Zain promises to continue working to restore its network in the rest of the states.” Traffic had not yet returned on MTN Sudan by the end of the first quarter.
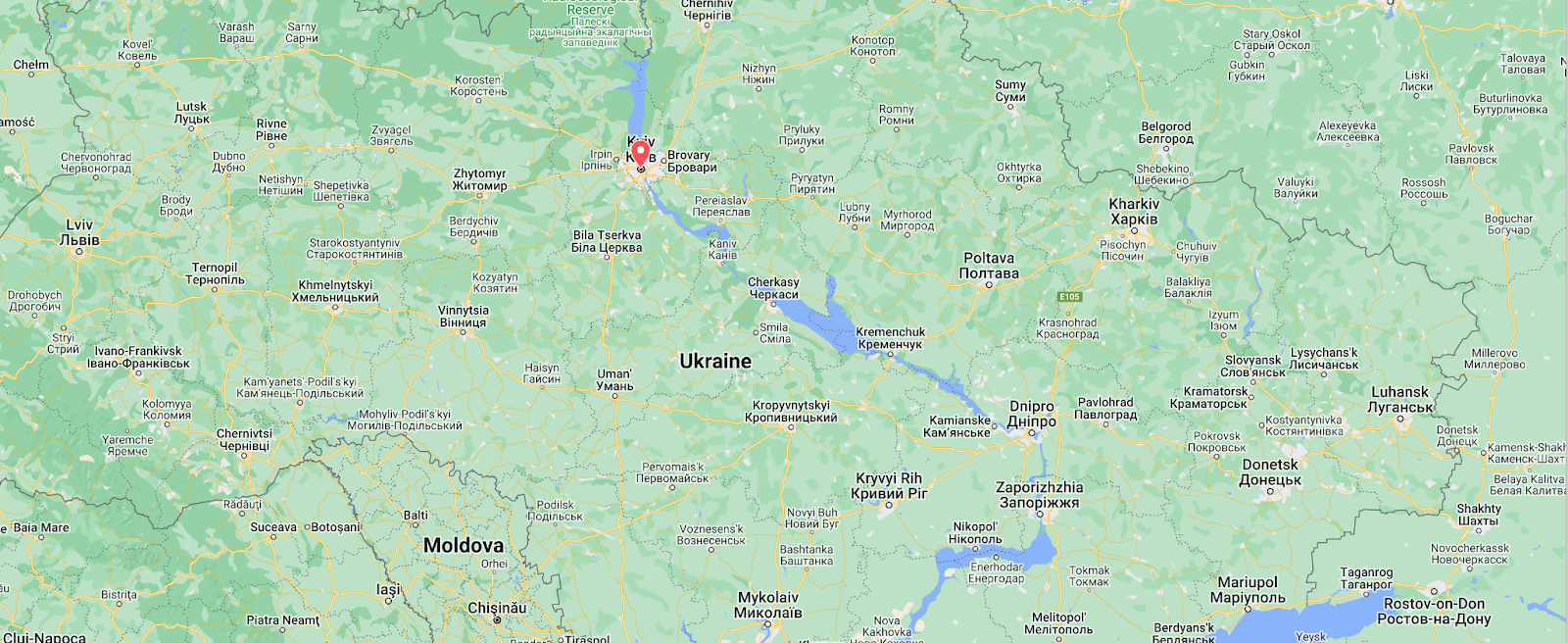
Ukraine
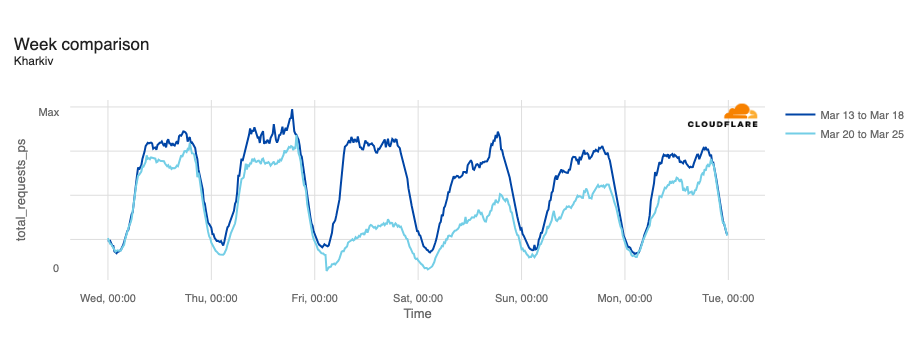
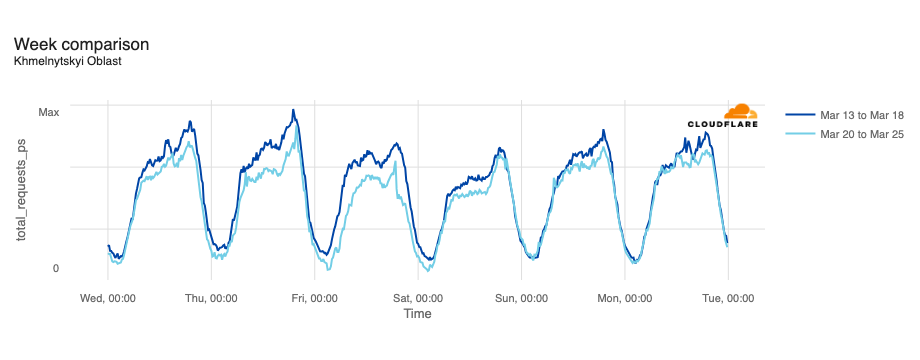
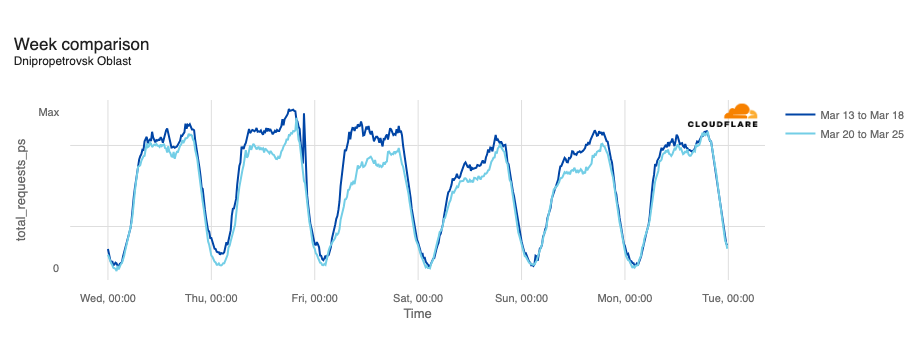
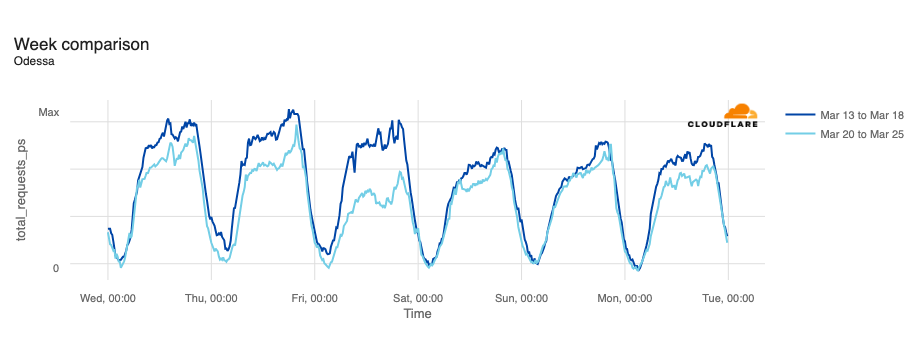
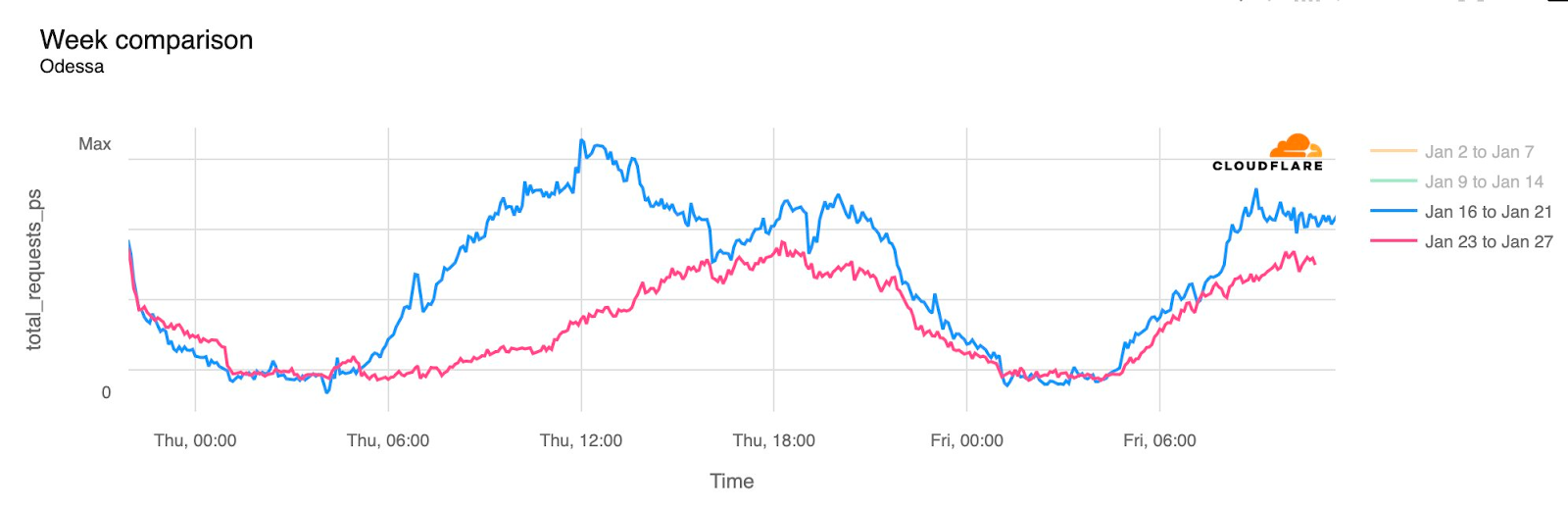
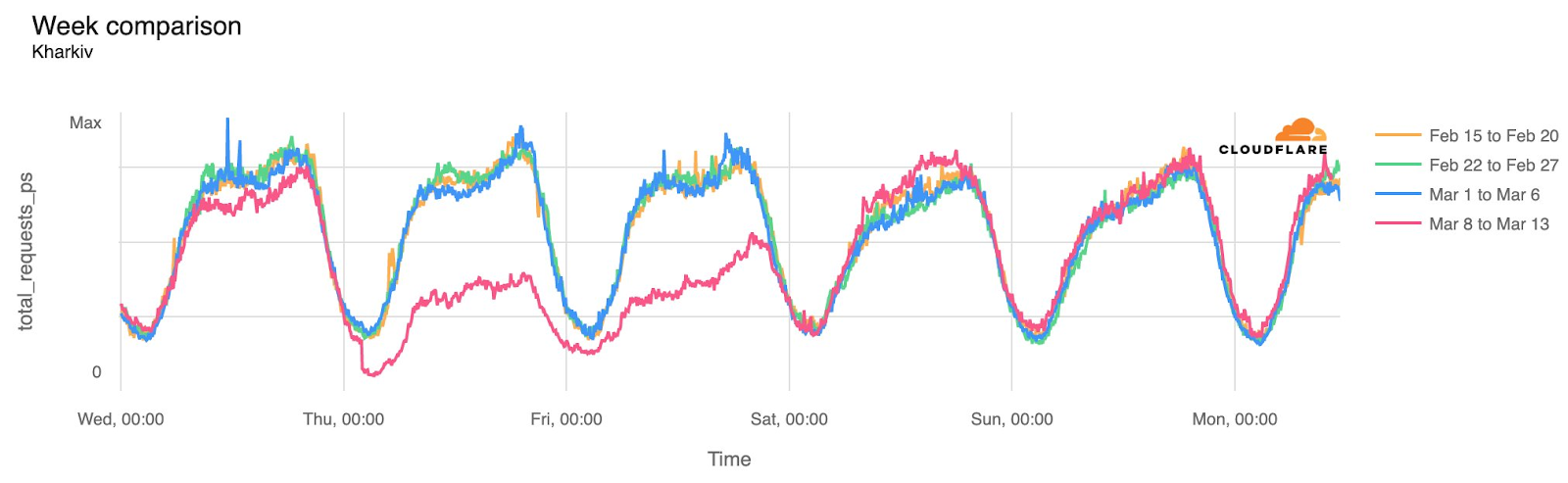
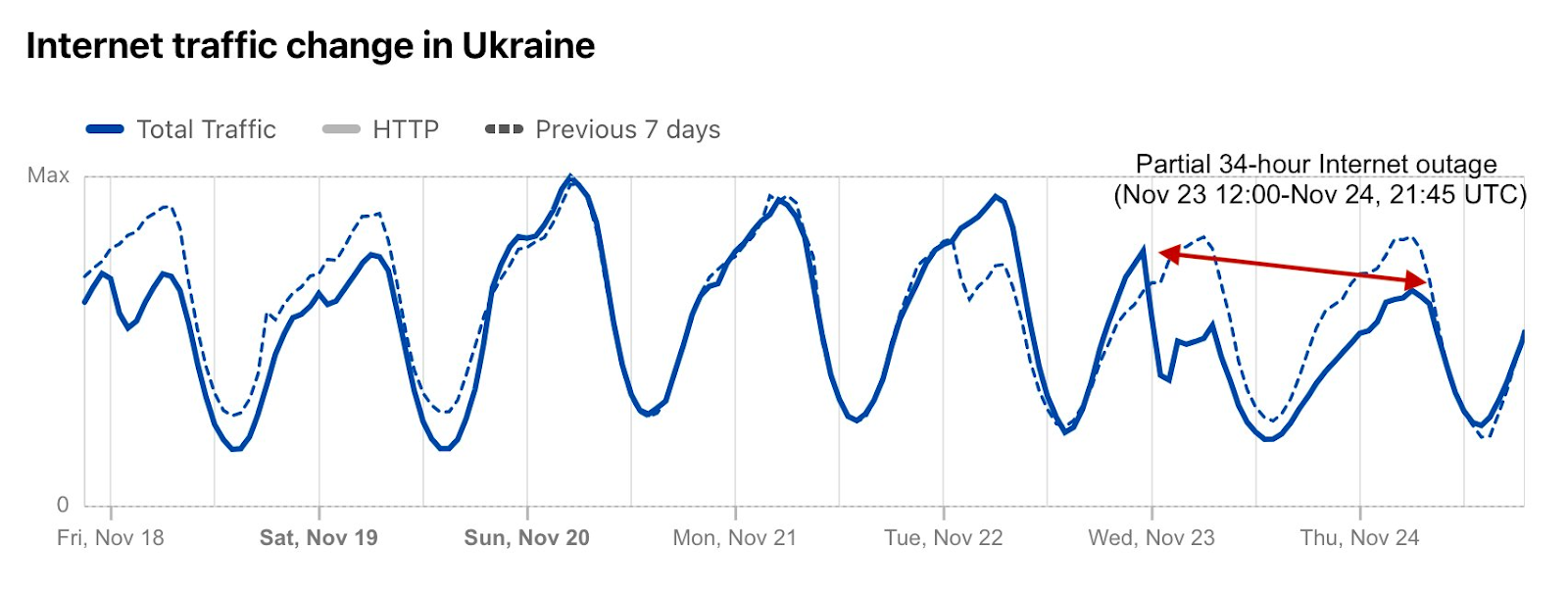
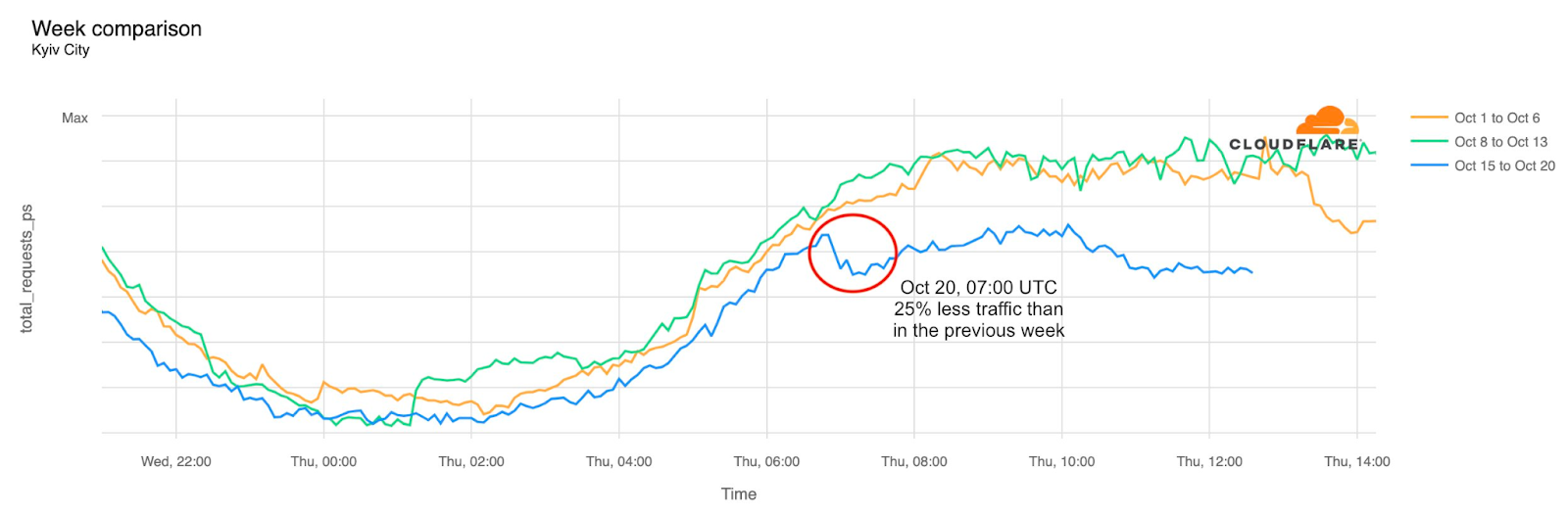
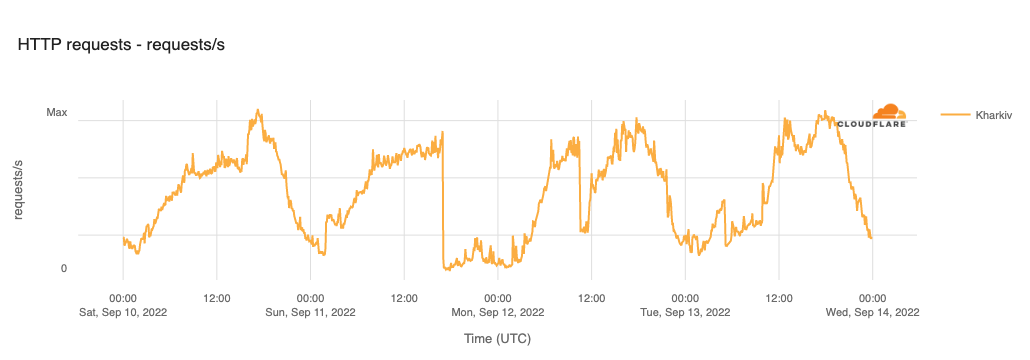
In February, the Ukraine/Russia war reached the two-year mark, and over that time, we have covered a number of Internet outages in Ukraine caused by conflict-related attacks. On February 22, Russian air strikes on critical infrastructure in Ukraine damaged energy facilities across the country, resulting in widespread power outages. These power outages caused Internet disruptions across multiple regions in Ukraine, including Kharkiv, Zaporizhzhia, Odessa, Dnipropetrovsk Oblast, and Khmelnytskyi Oblast. Traffic initially dropped around 05:00 local time (03:00 UTC), falling as much as 68% in Kharkiv. However, all regions saw lower traffic levels for several days as compared to the week before.
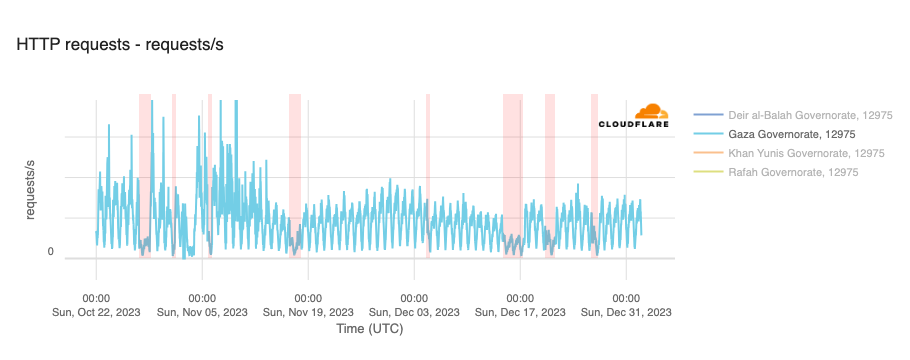
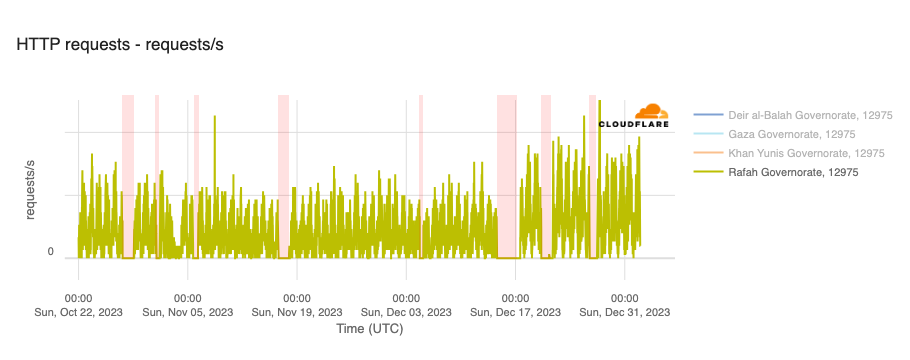
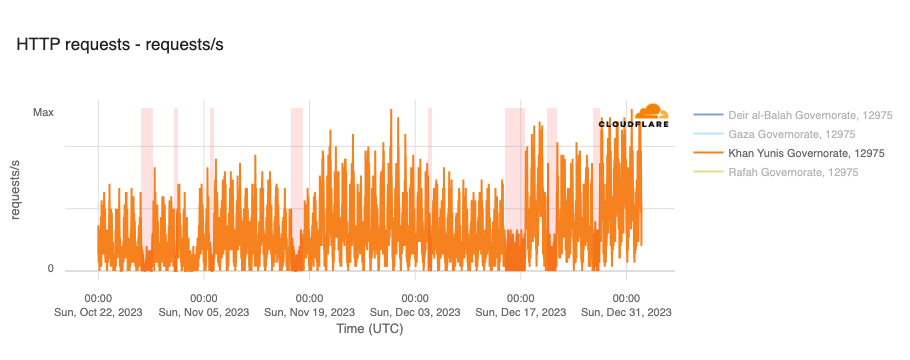
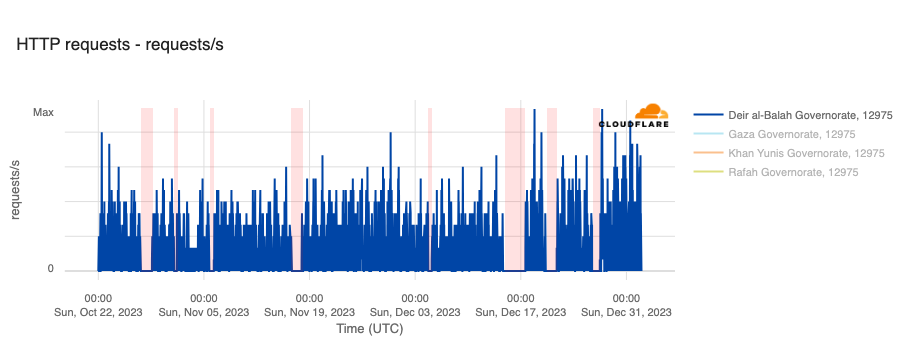
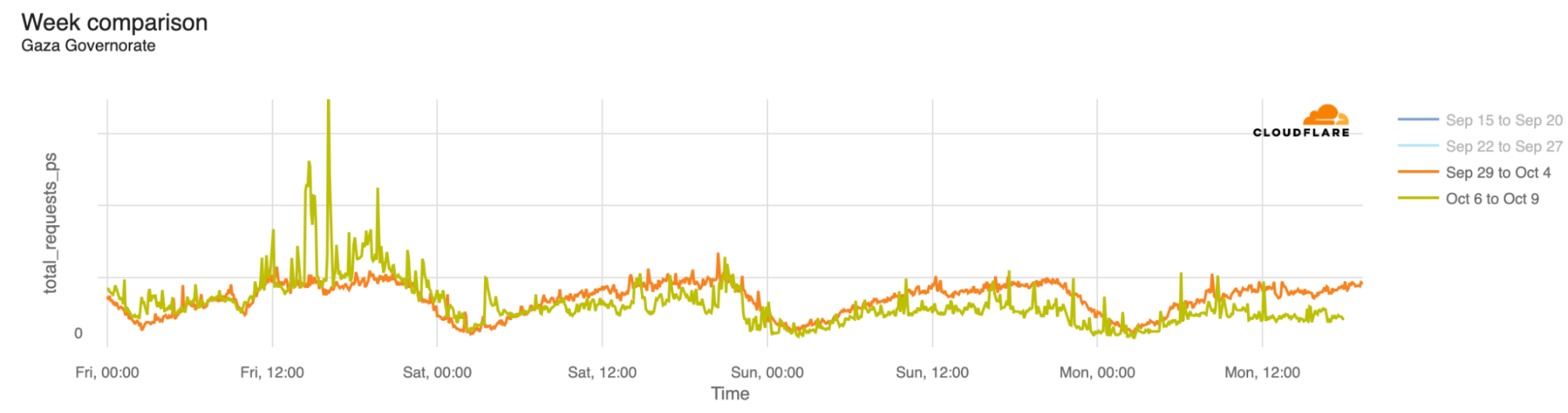
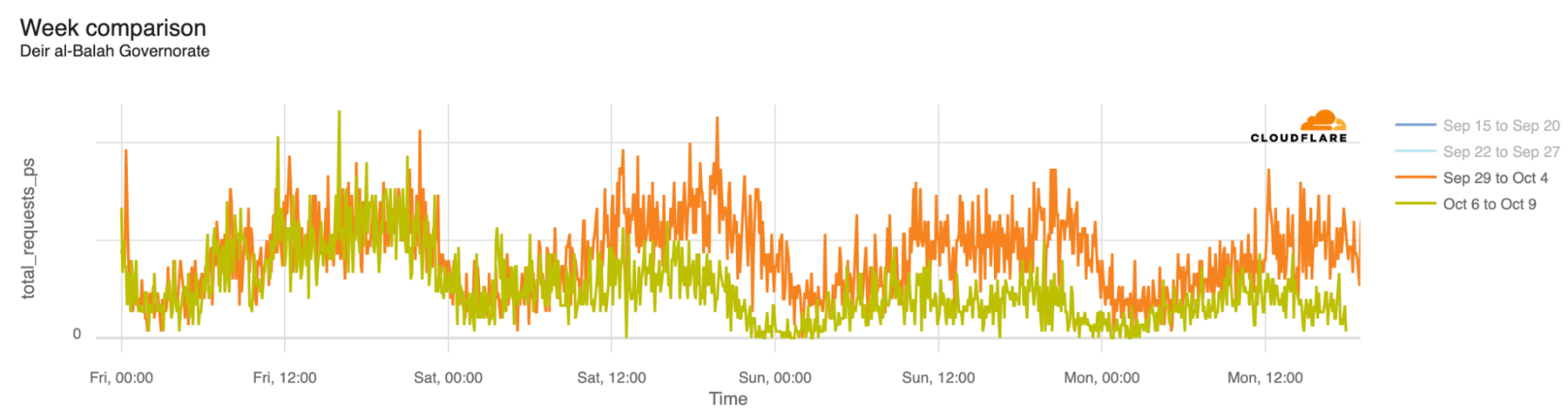
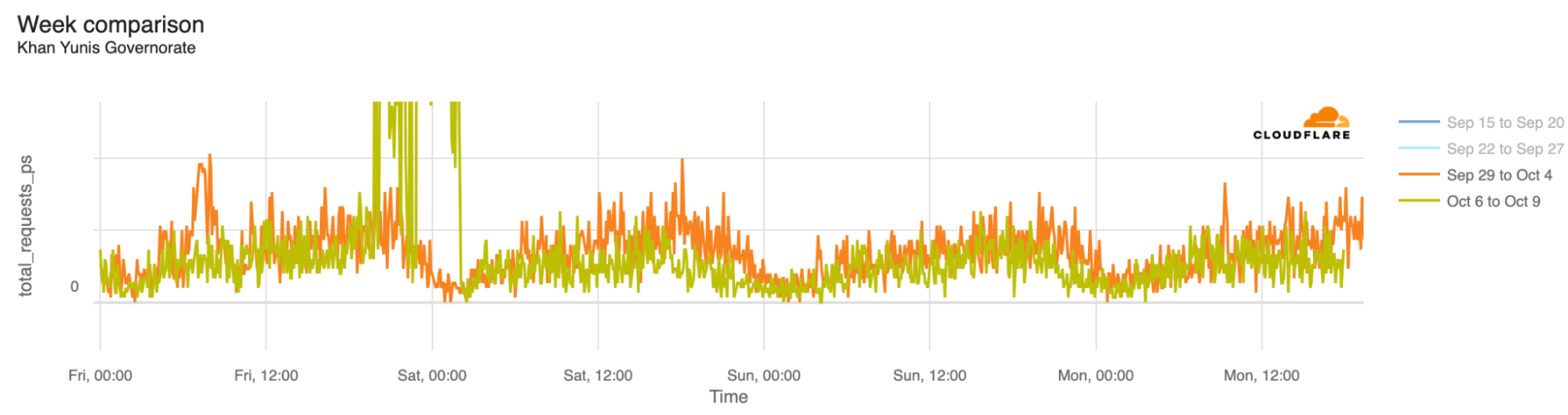
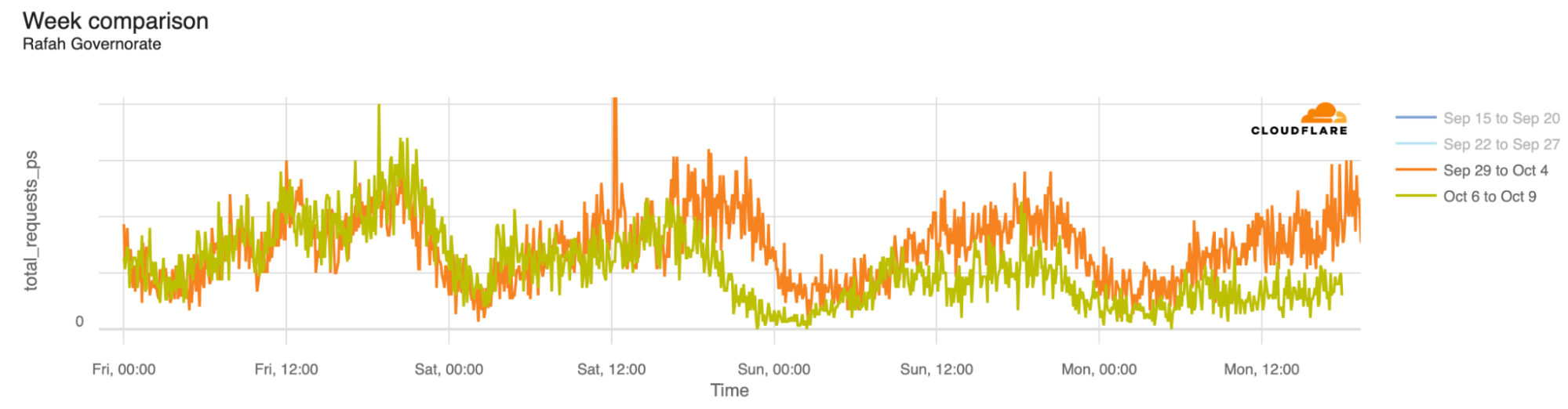
The associated outages during the quarter varied in length, from just a few hours to over a week. Each outage is shown in the graphs below, which show Paltel traffic within four Palestinian governorates in the Gaza Strip region. While it appears that the Gaza governorate suffered a disruption to traffic as connectivity remained available, complete outages occurred in the Khan Yunis, Rafah, and Deir al-Balah governorates.
January 12-19
January 22-24
March 5
Cyberattacks
In addition to the previously discussed cyberattack that impacted connectivity for AS327802 (Moov Africa Tchad / Millicom) on January 11, several other observed Internet disruptions were caused by cyberattacks in the first quarter.
Anonymous Sudan also reportedly targeted AS31452 (Zain Bahrain) with a cyber attack. This attack appeared to be less severe than the one that targeted HotNet in Israel, but it also lasted significantly longer, with traffic disrupted between 20:45 on March 3 and 18:15 on March 4 local time (17:45 on March 3 to 15:15 on March 4 UTC). No impact to announced IP address space was observed. Zain Bahrain acknowledged the connectivity disruption in a social media post on March 4, noting (translated) “We would like to inform you that some customers may encounter difficulties in using some of our services. Our technical team works to avoid these difficulties as quickly as possible.”
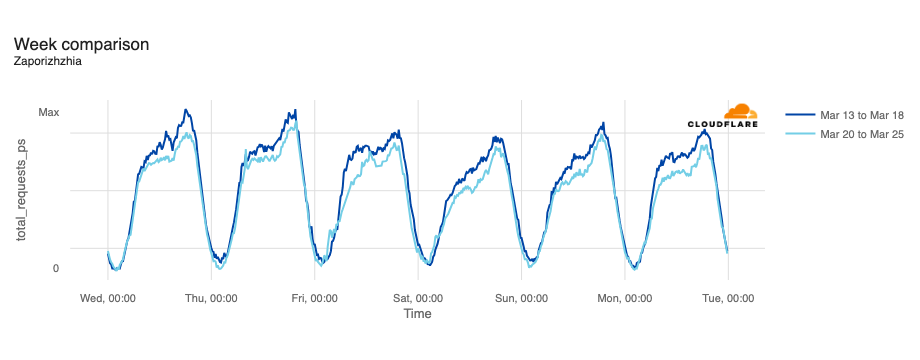
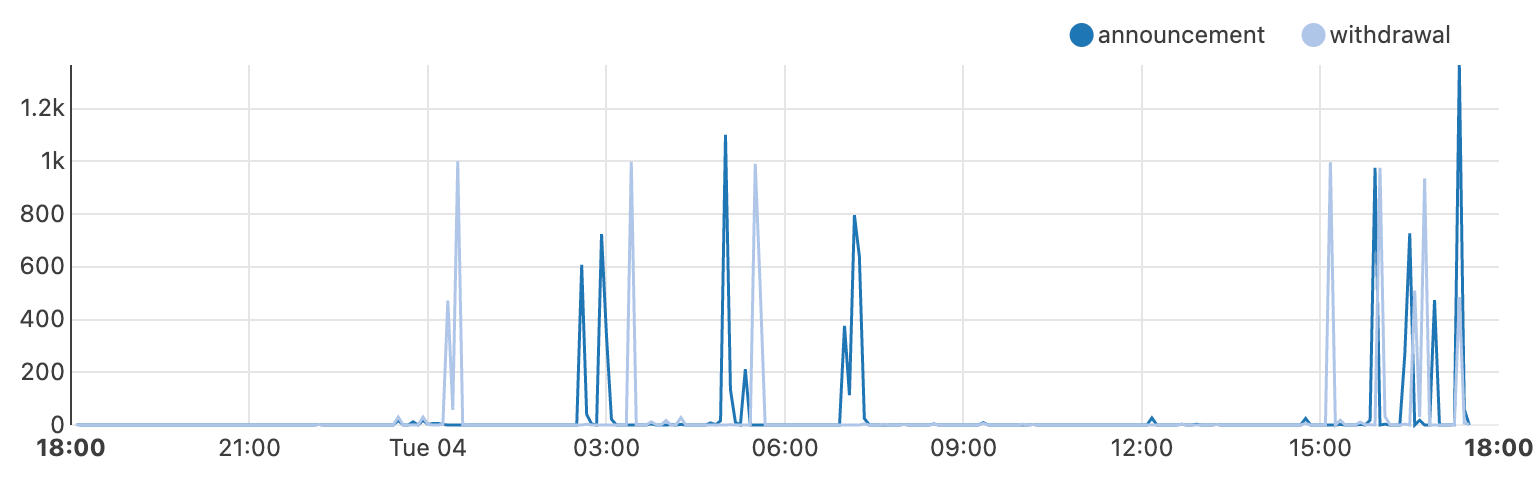
Multiple networks in Ukraine
On March 13, an attack targeted a number of Ukrainian telecommunications providers, including AS16066 (Triangulum), AS34359 (Link Telecom Ukraine), AS197522 (Kalush Information Network), AS52074 (Mandarun), and AS29013 (LinkKremen). Triangulum appeared to be the most significantly impacted, experiencing a near complete loss of traffic between March 13 and March 20, as seen below. Triangulum posted a notice on its website, noting in part “On March 13, 2024, a hacker attack was carried out on a number of Ukrainian providers. At 10:28 a.m. on March 13, 2024, a large-scale technical failure occurred on our Company’s network, as a result of which it became impossible to provide electronic communication services. The Company’s employees, together with employees of the Cyber Police and the National Cyber Security Coordination Center, are taking comprehensive measures around the clock aimed at restoring the entire range of services as soon as possible. Services are being restored gradually. Full recovery may take several days.”
Other affected providers experienced comparatively shorter connectivity disruptions. The near complete outage at Mandarun lasted approximately a day, while the others saw outages lasting around seven hours, starting around 11:30 local time (09:30 UTC) on March 13, with connectivity returning to typical levels around 08:00 local time (06:00 UTC) on March 14.
Government directed
Comoros
Following protests against the re-election of President Azali Assoumani, authorities in Comorosreportedly shut down Internet connectivity on January 17. While some disruption was visible to traffic at a country level between 12:00 local time on January 17 (09:00 UTC) and 17:30 local time on January 19 (14:30 UTC), it was significantly more noticeable in the traffic from AS36939 (Comores Telecom), which saw several periods of near-complete outage across the two-day span. Although Comores Telecom announces a limited amount of IPv4 address space, it saw significant volatility on January 17 & 18, dropping to zero several times.
Sudatel Senegal/Expresso Telecom and Tigo/Free (Senegal)
On February 4, the Minister of Communication, Telecommunications, and Digital Affairs in Senegalordered the suspension of mobile Internet connectivity starting at 22:00 local time (22:00 UTC). The suspension followed protests that erupted in the wake of the postponement of the presidential election. Traffic from AS37196 (Sudatel Senegal/Expresso Telecom) fell sharply at the time the suspension went into effect, recovering around 07:30 local time (07:30 UTC) on February 7. Traffic from AS37649 (Tigo/Free) fell at around 09:30 local time (09:30 UTC) on February 5, with the provider notifying subscribers of the suspension via social media. Traffic on Tigo/Free recovered around midnight local time (00:00 UTC) on February 7, and the provider again used social media to inform subscribers of service availability. No changes were observed to announced IP address space for either provider, indicating that the suspension of mobile Internet connectivity was not done at a routing level.
A little more than a week later, on February 13, the government in Senegal again ordered the suspension of mobile Internet connectivity in an effort to prevent “the spread of hateful and subversive messages online.” ahead of a march planned by activist groups which aimed to express dissent against the postponement of the presidential election. The mobile Internet shutdown was most visible on Tigo/Free, which saw a significant disruption between 10:15 and 19:45 local time (10:15 – 19:45 UTC).
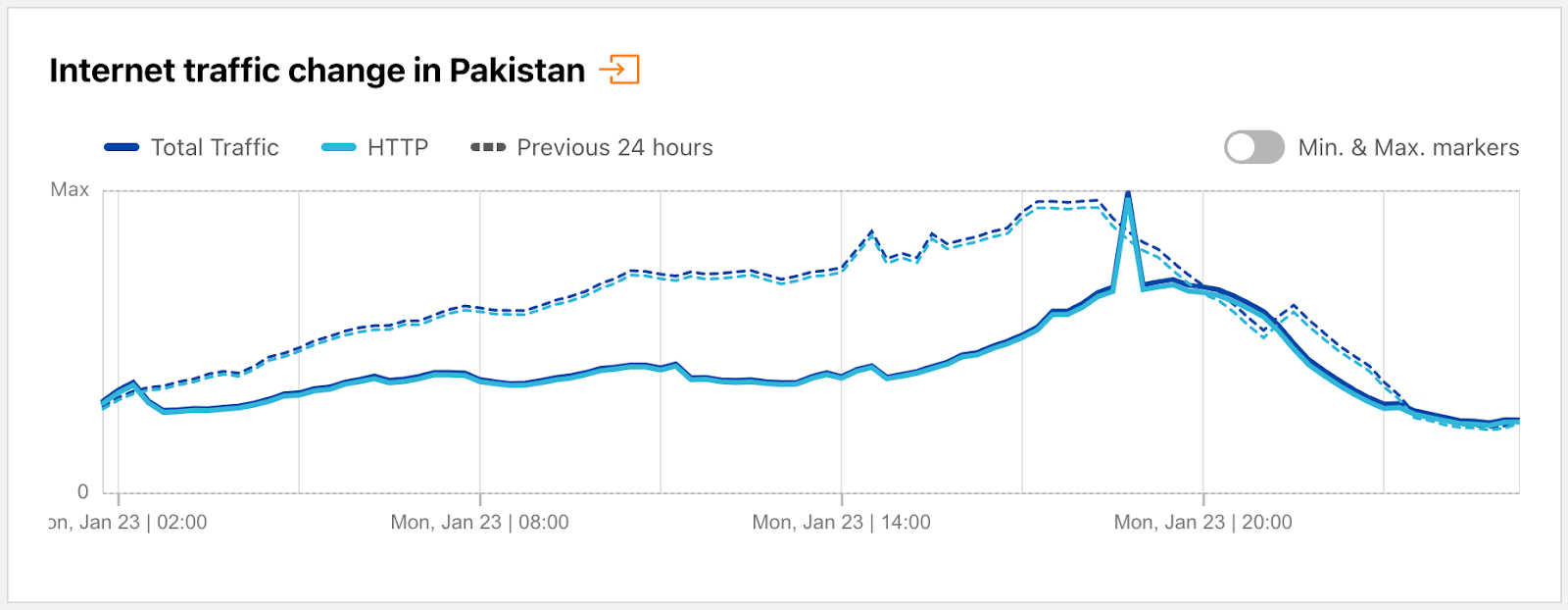
Pakistan
According to a published report, The Pakistan Telecommunication Authority (PTA) said that Internet services would remain available as citizens went to the polls on February 8 to elect a new government. However, on that day, Pakistani authorities cut mobile Internet access across the country as the nation’s voters went to cast their ballots, with the authorities attributing the move “to maintain law and order” in the wake of the violence that occurred the previous day. The impact of the ordered shutdown was visible across multiple Internet providers in Pakistan, including AS59257 (Zong/CMPak), AS24499 (Telenor Pakistan), and AS45669 (Jazz/Mobilink), lasting from 07:00 until 20:00 (02:00 – 15:00 UTC), with traffic returning to expected levels approximately nine hours later. A post on the Internet Society’s Pulse blog estimated that the shutdown cost Pakistan nearly USD $18.5M in lost Gross Domestic Product.
Chad
Several Internet disruptions were observed in Chad between February 28 and March 7. The first one started at 10:45 local time on February 28 and lasted until 18:00 local time on March 1 (09:45 on February 28 – 17:00 on March 1). Shorter disruptions lasting just a few hours each were also observed on March 3, 4, and 7. The apparent shutdowns came in the wake of political violence in the country. Notable drops in announced IPv4 address space aggregated across networks in the country were observed coincident with the February 28, March 3, and March 4 shutdowns, although it isn’t clear why a similar drop did not occur on March 7.
Power outages
Tajikistan
According to a published report, a widespread multi-hour power outage occurred in Tajikistan on March 1, possibly related to increased electricity usage by electric heaters as temperatures across the country neared freezing. The outage began around 11:00 local time (06:00 UTC), and lasted for approximately three hours. The impact on Internet traffic from the country is visible in the graph below. Although power was restored around 14:00 local time (09:00 UTC), Internet traffic did not return to expected levels until around 05:00 local time the next day (midnight UTC on March 2).
Although power outages most often have the biggest impact on Internet traffic, as computers and home/office routers shut down, this outage also appeared to impact network infrastructure within the country, as the aggregate volume of announced IPv4 address space across the country dipped slightly when the power was out.
Tanzania
On March 4, the Tanzania Electricity Corporation (TANESCO)posted a notice on social media regarding an ongoing power outage. It stated (translated) “The Tanzania Electricity Corporation (TANESCO) has notified the public that there has been an error in the National Grid system, resulting in a lack of electricity service in some areas of the country including Zanzibar. Our experts are continuing their efforts to ensure that the electricity service returns to its normal state. The organization apologizes for any inconvenience caused.” The power outage disrupted Internet connectivity in Tanzania, causing an observed drop in traffic between 13:30 and 23:00 local time (10:30 – 20:00 UTC).
Technical problems
Orange España
Network routing is the process of selecting a path across one or more networks, and on the Internet, routing relies on the Border Gateway Protocol (BGP). Historically, the exchange of BGP routing information was based on trust between providers, but over time, security mechanisms such as Resource Public Key Infrastructure (RPKI) have been developed to prevent abuse of the system by bad actors. RPKI is a cryptographic method of signing records that associate a BGP route announcement with the correct originating AS number. ROA (Route Origin Authorization) records provide a means of verifying that an IP address block holder has authorized an AS (Autonomous System) to originate routes to that one or more prefixes within the address block. Cloudflare has published a number of blog posts over the years about the importance of, and our support for, RPKI. Properly implemented and configured, RPKI and ROAs help support routing security, effectively preventing behavior like BGP hijacking.
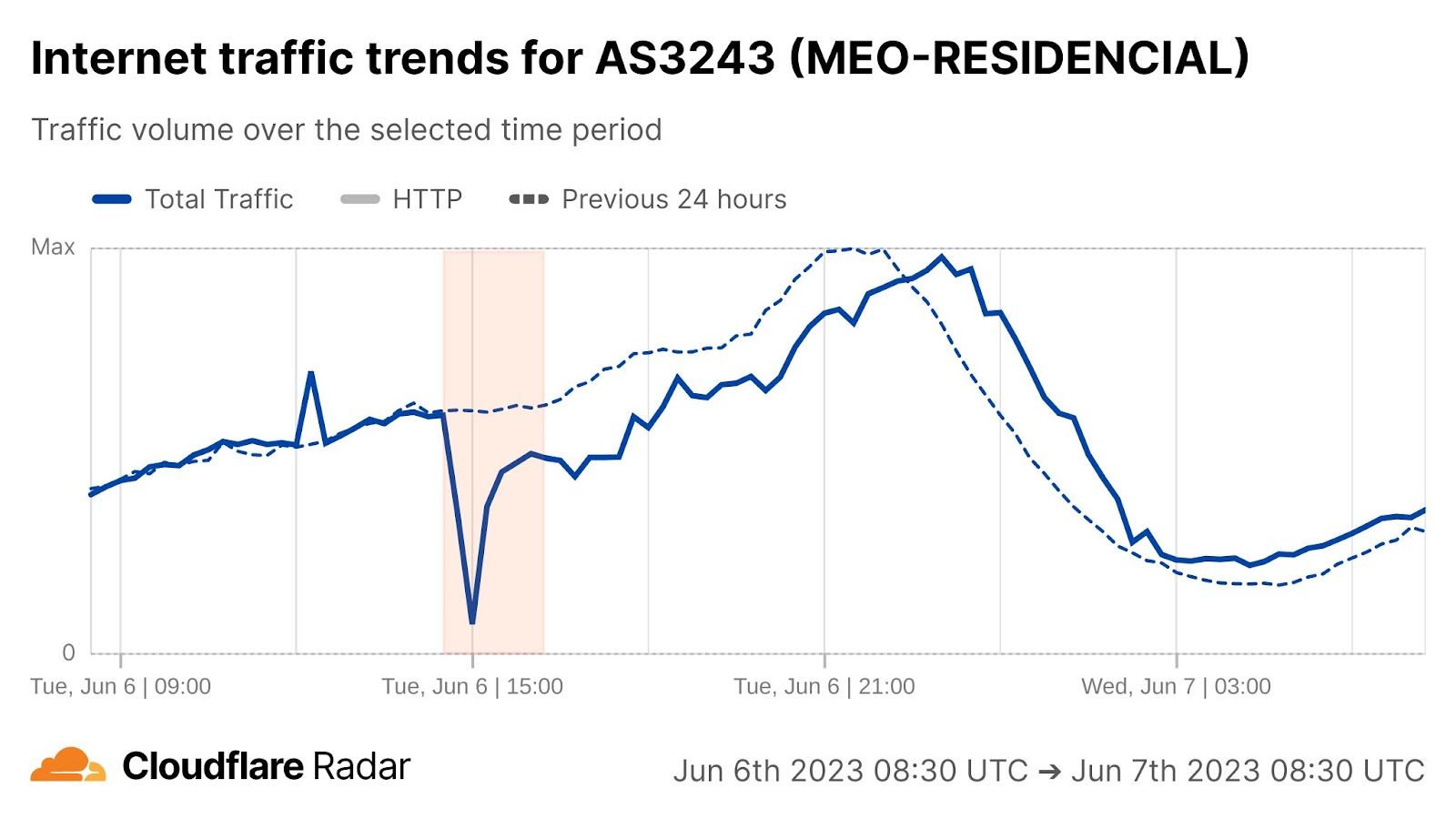
Because Cloudflare enforces RPKI validation, we also rejected the RPKI-invalid routes. We would have started trying to reach Orange España over our default route toward some of our transit providers, but because they also perform RPKI validation, traffic would have been dropped within those provider networks as well. Because of this, from Cloudflare’s perspective, this incident caused a drop in traffic from Orange España between 16:45 and 19:45 local time (14:45 – 17:45 UTC) as well as a notable drop in announced IPv4 address space from AS12479.
On January 11, subscribers of AS34700 (MaxNet) in Ukraine experienced a nine-hour Internet outage. Initial traffic loss occurred around 16:00 local time (14:00 UTC), and recovered around 01:00 local time on January 12 (23:00 UTC on January 11). An initial social media post from the provider explained the reason for the outage, noting (translated) “Dear subscribers! Due to the flooding of one of the hub sites due to a utility malfunction, some areas of the city may be without services, partially or completely. We are doing our best to restore services, but it takes time. Further information regarding the opening times will be published as soon as the emergency works have been completed.” A subsequent post informed subscribers that Internet connectivity had been restored. The flooding apparently impacted core routing infrastructure as well, as the volume of IPv4 address space announced by MaxNet also fell to zero between 16:00 and 22:00 local time (14:00 – 20:00 UTC).
Plusnet (United Kingdom)
A traffic disruption observed on AS6871 (Plusnet) in the United Kingdom on January 15 was initially characterized as a “mass outage” by the provider in replies to customer complaints on social media. However, the underlying cause of the disruption turned out to be significantly less sensational – it was apparently linked to problems with their DNS servers. Because subscribers were unable to successfully resolve hostnames using Plusnet’s default DNS resolvers, this ultimately manifested itself as a drop in traffic from the network for approximately two hours, between 16:00 and 18:00 local time (and UTC). Users that had configured their systems to use a third-party DNS resolver, such as Cloudflare’s 1.1.1.1 service, did not experience a service disruption.
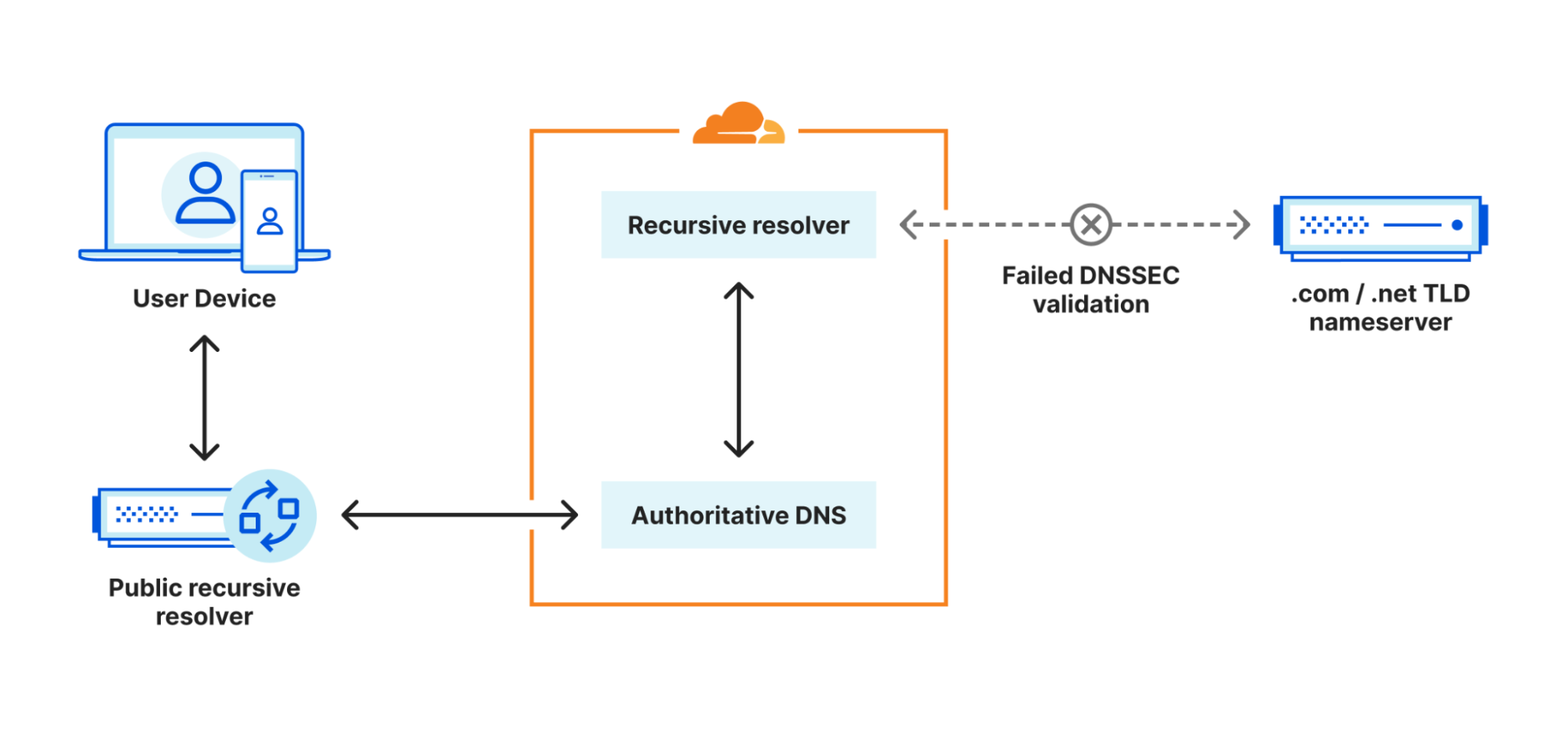
Russia
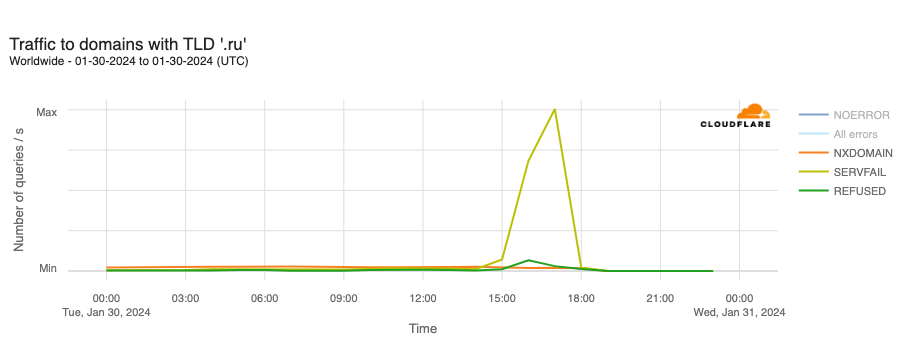
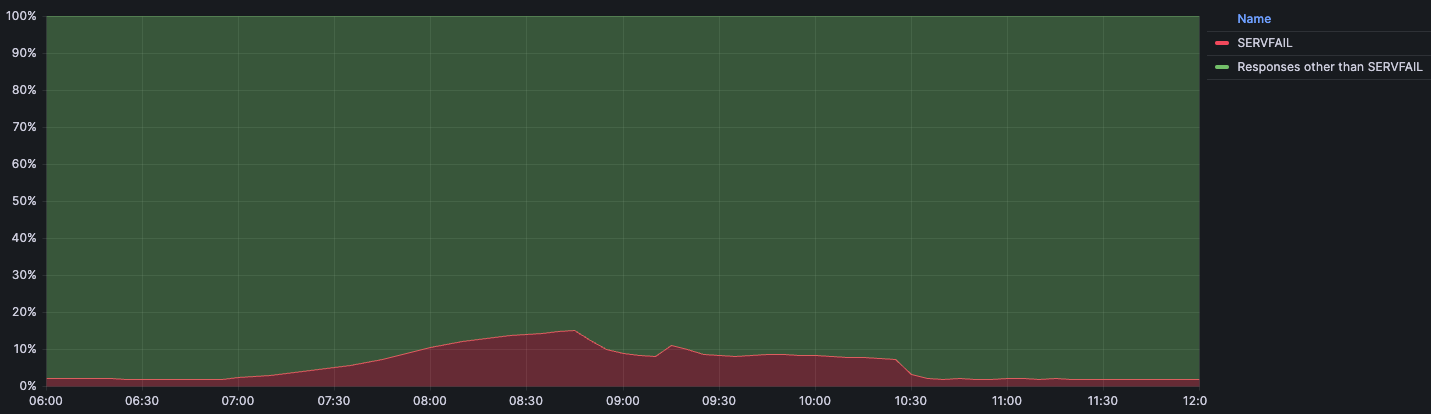
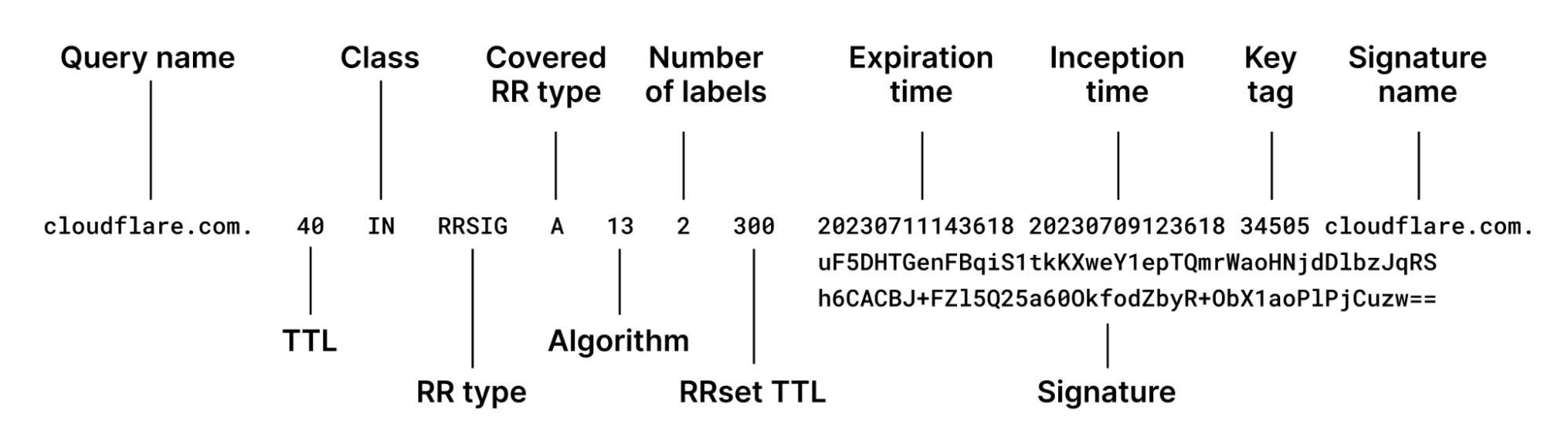
DNS issues also impacted users in Russia during January, though in a different way than Plusnet subscribers in the UK experienced. A reportedDNSSEC failure on January 30 resulted in .ru domains becoming inaccessible for several hours. (DNSSEC creates a secure domain name system by adding cryptographic signatures to existing DNS records. By checking its associated signature, you can verify that a requested DNS record comes from its authoritative name server and wasn’t altered en-route, as opposed to a fake record injected in a man-in-the-middle attack.)
The DNSSEC validation failure resulted in SERVFAIL responses to DNS lookups against Cloudflare’s 1.1.1.1 resolver for hostnames in the .ru country code top level domain (ccTLD). At peak, 68.4% of requests received SERVFAIL responses. The Coordination Center for the .ru ccTLD confirmed that it was working on the “technical problem affecting the .ru zone associated with the global DNSSEC infrastructure” but didn’t provide any additional details around the root cause of the problem, such as a potential issue with a DNSSEC key rollover. The .ru ccTLD experienced a similar DNSSEC-related outage for several hours on August 16, 2019, as well.
AT&T (United States)
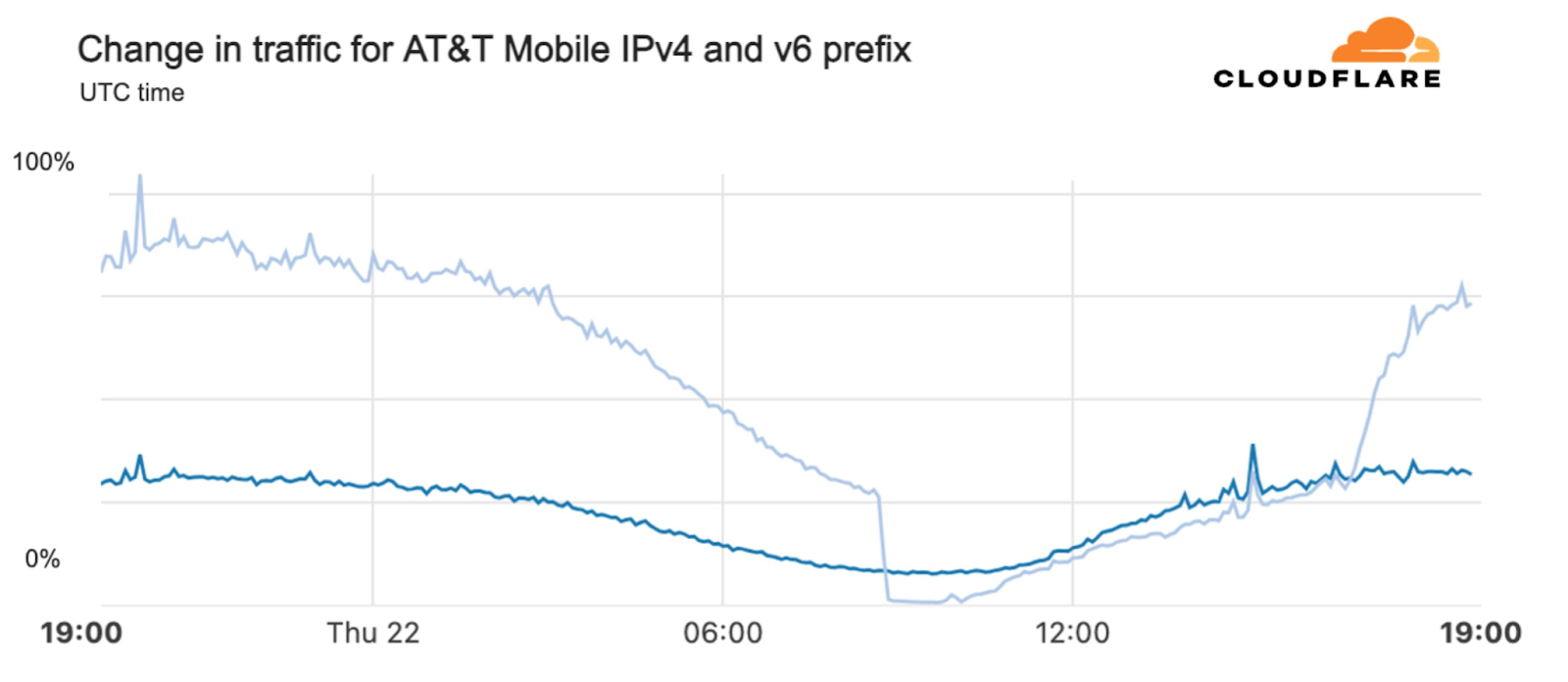
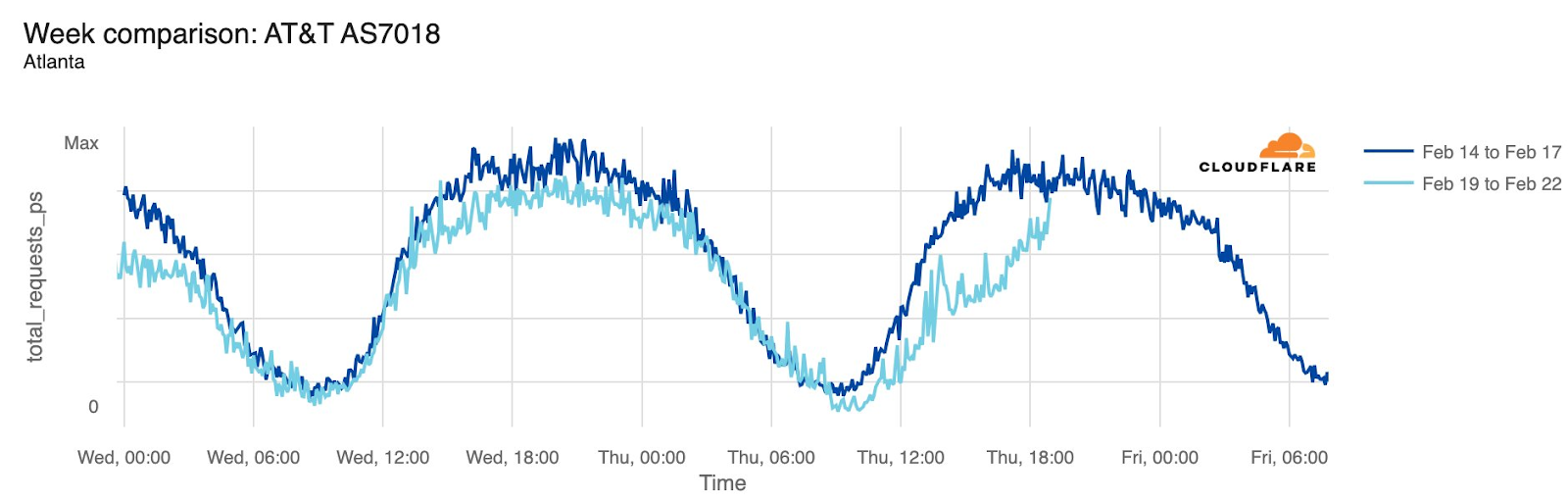
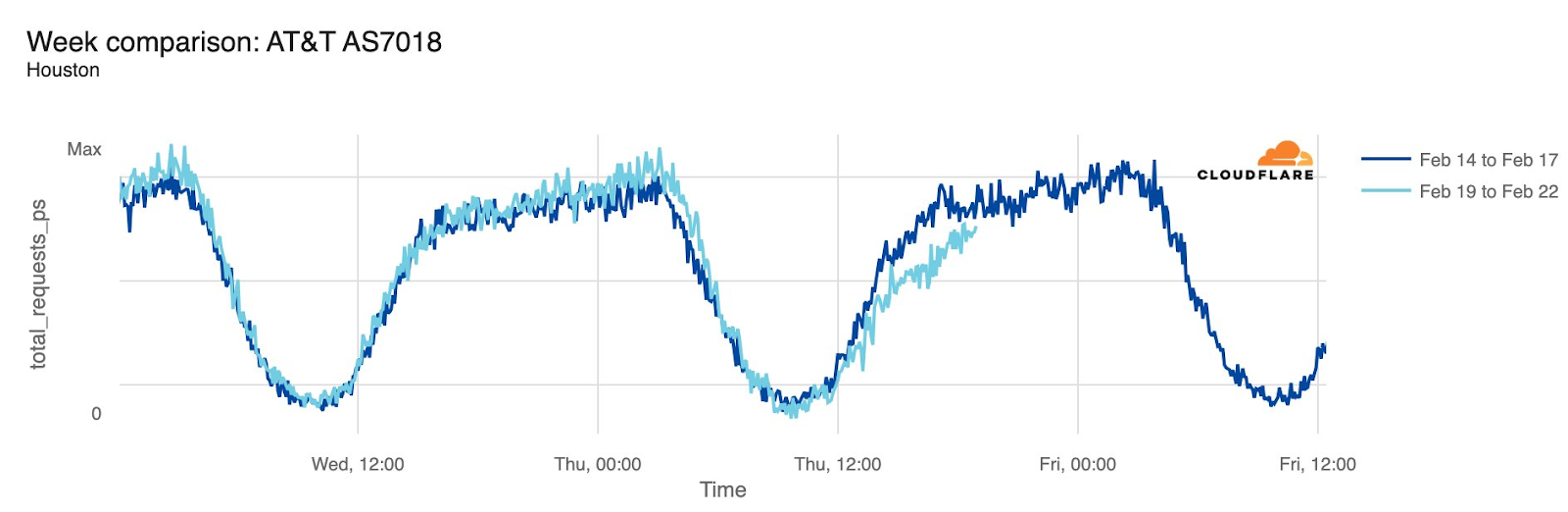
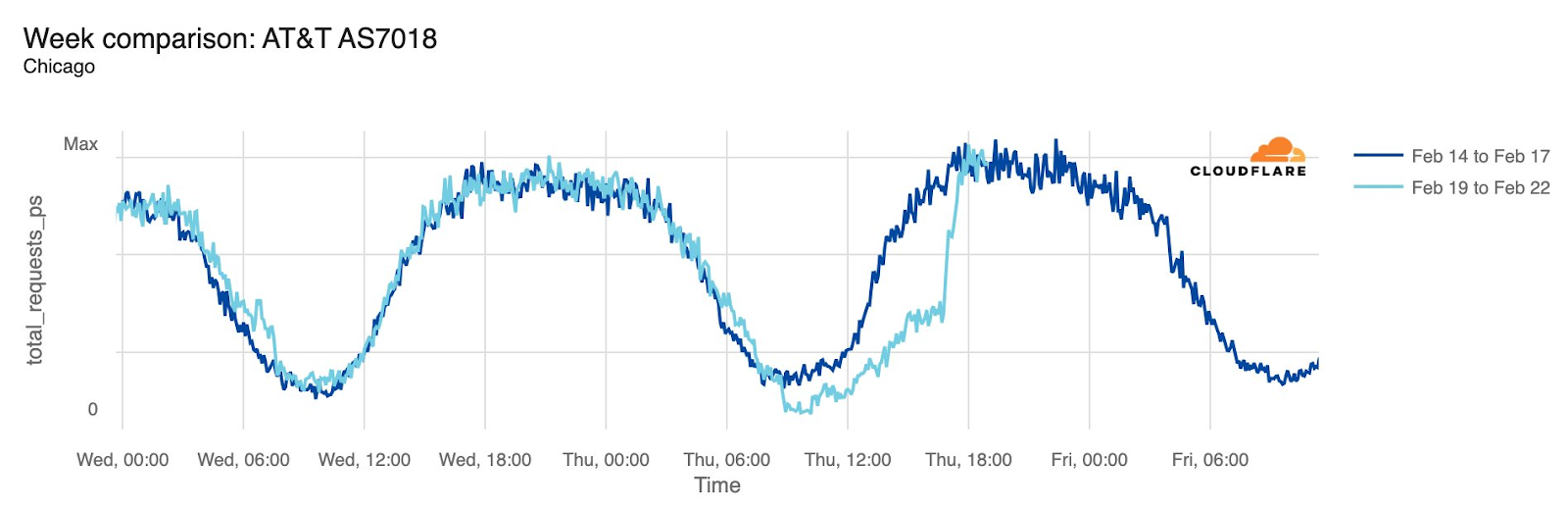
Starting just before 04:00 Eastern / 03:00 Central (09:00 UTC) on February 22, AT&T subscribers in several cities across the United States experienced mobile service interruptions. Impacted cities included Atlanta, Houston, and Chicago, with connectivity disrupted for approximately eight hours. Cloudflare data showed that as the problem began, AT&T (AS7018) traffic dropped as much as 45% in Chicago and 18% in Dallas, as compared with the previous week.
According to a “network update” published by AT&T, “Based on our initial review, we believe that today’s outage was caused by the application and execution of an incorrect process used as we were expanding our network, not a cyber attack.”
Just before noon local time (05:15 UTC) on March 12, a significant drop in traffic was observed on AS136442 (Ocean Wave), a consumer fiber and business Internet service provider in Myanmar. A (translated) social media post from the provider noted “Ocean Wave customers, please be informed that there will be no internet/ slow connection due to network maintenance.” The connectivity disruption lasted approximately seven hours, with traffic returning to typical levels just before 19:00 local time (12:15 UTC).
Conclusion
Two notable submarine cable damage events during the first quarter again highlighted the importance of protecting submarine cables, and the risks associated with them passing through/near geopolitically sensitive areas. Given the reliance on submarine cables for carrying Internet traffic, this will continue to be an issue for many years to come.
The Orange España incident also shed light on the importance of securing operationally important resources with multi-factor authentication, a topic that Cloudflare has written about in the past. Organizations like RIPE play a critically important behind-the-scenes role in functioning of the Internet, arguably obligating them to take all practical precautions when it comes to securing their systems in order to prevent malicious actors from taking actions that could broadly disrupt Internet connectivity.
Here’s a post we never thought we’d need to write: less than five months after one of our major data centers lost power, it happened again to the exact same data center. That sucks and, if you’re thinking “why do they keep using this facility??,” I don’t blame you. We’re thinking the same thing. But, here’s the thing, while a lot may not have changed at the data center, a lot changed over those five months at Cloudflare. So, while five months ago a major data center going offline was really painful, this time it was much less so.
This is a little bit about how a high availability data center lost power for the second time in five months. But, more so, it’s the story of how our team worked to ensure that even if one of our critical data centers lost power it wouldn’t impact our customers.
On November 2, 2023, one of our critical facilities in the Portland, Oregon region lost power for an extended period of time. It happened because of a cascading series of faults that appears to have been caused by maintenance by the electrical grid provider, climaxing with a ground fault at the facility, and was made worse by a series of unfortunate incidents that prevented the facility from getting back online in a timely fashion.
If you want to read all the gory details, they’re available here.
It’s painful whenever a data center has a complete loss of power, but it’s something that we were supposed to expect. Unfortunately, in spite of that expectation, we hadn’t enforced a number of requirements on our products that would ensure they continued running in spite of a major failure.
That was a mistake we were never going to allow to happen again.
Code Orange
The incident was painful enough that we declared what we called Code Orange. We borrowed the idea from Google which, when they have an existential threat to their business, reportedly declares a Code Yellow or Code Red. Our logo is orange, so we altered the formula a bit.
Our conception of Code Orange was that the person who led the incident, in this case our SVP of Technical Operations, Jeremy Hartman, would be empowered to charge any engineer on our team to work on what he deemed the highest priority project. (Unless we declared a Code Red, which we actually ended up doing due to a hacking incident, and which would then take even higher priority. If you’re interested, you can read more about that here.)
After getting through the immediate incident, Jeremy quickly triaged the most important work that needed to be done in order to ensure we’d be highly available even in the case of another catastrophic failure of a major data center facility. And the team got to work.
How’d we do?
We didn’t expect such an extensive real-world test so quickly, but the universe works in mysterious ways. On Tuesday, March 26, 2024, — just shy of five months after the initial incident — the same facility had another major power outage. Below, we’ll get into what caused the outage this time, but what is most important is that it provided a perfect test for the work our team had done under Code Orange. So, what were the results?
First, let’s revisit what functions the Portland data centers at Cloudflare provide. As described in the November 2, 2023, post, the control plane of Cloudflare primarily consists of the customer-facing interface for all of our services including our website and API. Additionally, the underlying services that provide the Analytics and Logging pipelines are primarily served from these facilities.
Just like in November 2023, we were alerted immediately that we had lost connectivity to our PDX01 data center. Unlike in November, we very quickly knew with certainty that we had once again lost all power, putting us in the exact same situation as five months prior. We also knew, based on a successful internal cut test in February, how our systems should react. We had spent months preparing, updating countless systems and activating huge amounts of network and server capacity, culminating with a test to prove the work was having the intended effect, which in this case was an automatic failover to the redundant facilities.
Our Control Plane consists of hundreds of internal services, and the expectation is that when we lose one of the three critical data centers in Portland, these services continue to operate normally in the remaining two facilities, and we continue to operate primarily in Portland. We have the capability to fail over to our European data centers in case our Portland centers are completely unavailable. However, that is a secondary option, and not something we pursue immediately.
On March 26, 2024, at 14:58 UTC, PDX01 lost power and our systems began to react. By 15:05 UTC, our APIs and Dashboards were operating normally, all without human intervention. Our primary focus over the past few months has been to make sure that our customers would still be able to configure and operate their Cloudflare services in case of a similar outage. There were a few specific services that required human intervention and therefore took a bit longer to recover, however the primary interface mechanism was operating as expected.
To put a finer point on this, during the November 2, 2023, incident the following services had at least six hours of control plane downtime, with several of them functionally degraded for days.
API and Dashboard Zero Trust Magic Transit SSL SSL for SaaS Workers KV Waiting Room Load Balancing Zero Trust Gateway Access Pages Stream Images
During the March 26, 2024, incident, all of these services were up and running within minutes of the power failure, and many of them did not experience any impact at all during the failover.
The data plane, which handles the traffic that Cloudflare customers pass through our 300+ data centers, was not impacted.
Our Analytics platform, which provides a view into customer traffic, was impacted and wasn’t fully restored until later that day. This was expected behavior as the Analytics platform is reliant on the PDX01 data center. Just like the Control Plane work, we began building new Analytics capacity immediately after the November 2, 2023, incident. However, the scale of the work requires that it will take a bit more time to complete. We have been working as fast as we can to remove this dependency, and we expect to complete this work in the near future.
Once we had validated the functionality of our Control Plane services, we were faced yet again with the cold start of a very large data center. This activity took roughly 72 hours in November 2023, but this time around we were able to complete this in roughly 10 hours. There is still work to be done to make that even faster in the future, and we will continue to refine our procedures in case we have a similar incident in the future.
How did we get here?
As mentioned above, the power outage event from last November led us to introduce Code Orange, a process where we shift most or all engineering resources to addressing the issue at hand when there’s a significant event or crisis. Over the past five months, we shifted all non-critical engineering functions to focusing on ensuring high reliability of our control plane.
Teams across our engineering departments rallied to ensure our systems would be more resilient in the face of a similar failure in the future. Though the March 26, 2024, incident was unexpected, it was something we’d been preparing for.
The most obvious difference is the speed at which the control plane and APIs regained service. Without human intervention, the ability to log in and make changes to Cloudflare configuration was possible seven minutes after PDX01 was lost. This is due to our efforts to move all of our configuration databases to a Highly Available (HA) topology, and pre-provision enough capacity that we could absorb the capacity loss. More than 100 databases across over 20 different database clusters simultaneously failed out of the affected facility and restored service automatically. This was actually the culmination of over a year’s worth of work, and we make sure we prove our ability to failover properly with weekly tests.
Another significant improvement is the updates to our Logpush infrastructure. In November 2023, the loss of the PDX01 datacenter meant that we were unable to push logs to our customers. During Code Orange, we invested in making the Logpush infrastructure HA in Portland, and additionally created an active failover option in Amsterdam. Logpush took advantage of our massively expanded Kubernetes cluster that spans all of our Portland facilities and provides a seamless way for service owners to deploy HA compliant services that have resiliency baked in. In fact, during our February chaos exercise, we found a flaw in our Portland HA deployment, but customers were not impacted because the Amsterdam Logpush infrastructure took over successfully. During this event, we saw that the fixes we’d made since then worked, and we were able to push logs from the Portland region.
A number of other improvements in our Stream and Zero Trust products resulted in little to no impact to their operation. Our Stream products, which use a lot of compute resources to transcode videos, were able to seamlessly hand off to our Amsterdam facility to continue operations. Teams were given specific availability targets for the services and were provided several options to achieve those targets. Stream is a good example of a service that chose a different resiliency architecture but was able to seamlessly deliver their service during this outage. Zero Trust, which was also impacted in November 2023, has since moved the vast majority of its functionally to our hundreds of data centers, which kept working seamlessly throughout this event. Ultimately this is the strategy we are pushing all Cloudflare products to adopt as our 300+ data centers provide the highest level of availability possible.
What happened to the power in the data center?
On March 26, 2024, at 14:58 UTC, PDX01 experienced a total loss of power to Cloudflare’s physical infrastructure following a reportedly simultaneous failure of four Flexential-owned and operated switchboards serving all of Cloudflare’s cages. This meant both primary and redundant power paths were deactivated across the entire environment. During the Flexential investigation, engineers focused on a set of equipment known as Circuit Switch Boards, or CSBs. CSBs are likened to an electrical panel board, consisting of a main input circuit breaker and series of smaller output breakers. Flexential engineers reported that infrastructure upstream of the CSBs (power feed, generator, UPS & PDU/transformer) was not impacted and continued to act normally. Similarly, infrastructure downstream from the CSBs such as Remote Power Panels and connected switchgear was not impacted – thus implying the outage was isolated to the CSBs themselves.
Initial assessment of the root cause of Flexential’s CSB failures points to incorrectly set breaker coordination settings within the four CSBs as one contributing factor. Trip settings which are too restrictive can result in overly sensitive overcurrent protection and the potential nuisance tripping of devices. In our case, Flexential’s breaker settings within the four CSBs were reportedly too low in relation to the downstream provisioned power capacities. When one or more of these breakers tripped, a cascading failure of the remaining active CSB boards resulted, thus causing a total loss of power serving Cloudflare’s cage and others on the shared infrastructure. During the triage of the incident, we were told that the Flexential facilities team noticed the incorrect trip settings, reset the CSBs and adjusted them to the expected values, enabling our team to power up our servers in a staged and controlled fashion. We do not know when these settings were established – typically, these would be set/adjusted as part of a data center commissioning process and/or breaker coordination study before customer critical loads are installed.
What’s next?
Our top priority is completing the resilience program for our Analytics platform. Analytics aren’t simply pretty charts in a dashboard. When you want to check the status of attacks, activities a firewall is blocking, or even the status of Cloudflare Tunnels – you need analytics. We have evidence that the resiliency pattern we are adopting works as expected, so this remains our primary focus, and we will progress as quickly as possible.
There were some services that still required manual intervention to properly recover, and we have collected data and action items for each of them to ensure that further manual action is not required. We will continue to use production cut tests to prove all of these changes and enhancements provide the resiliency that our customers expect.
We will continue to work with Flexential on follow-up activities to expand our understanding of their operational and review procedures to the greatest extent possible. While this incident was limited to a single facility, we will turn this exercise into a process that ensures we have a similar view into all of our critical data center facilities.
Once again, we are very sorry for the impact to our customers, particularly those that rely on the Analytics engine who were unable to access that product feature during the incident. Our work over the past four months has yielded the results that we expected, and we will stay absolutely focused on completing the remaining body of work.
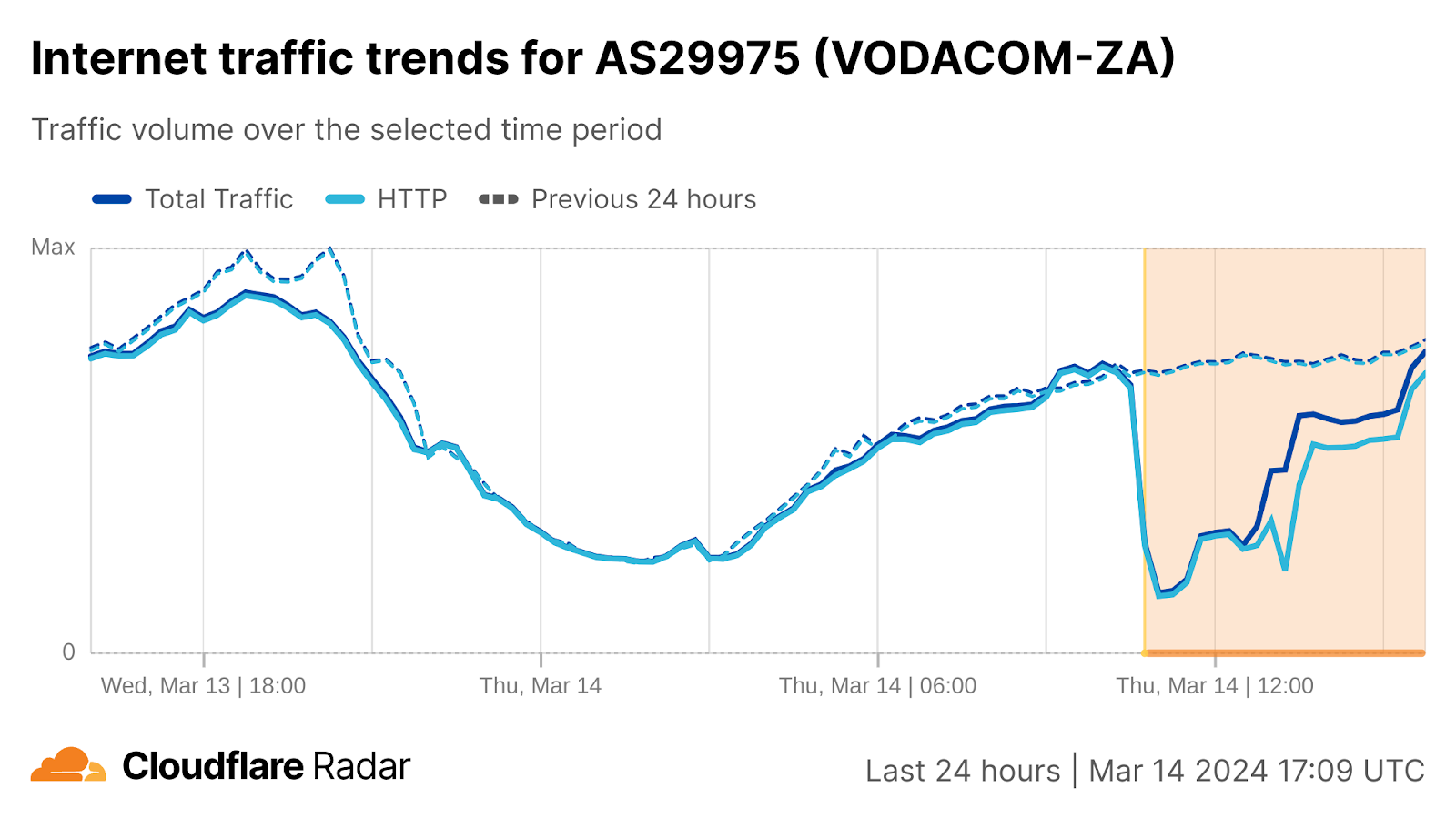
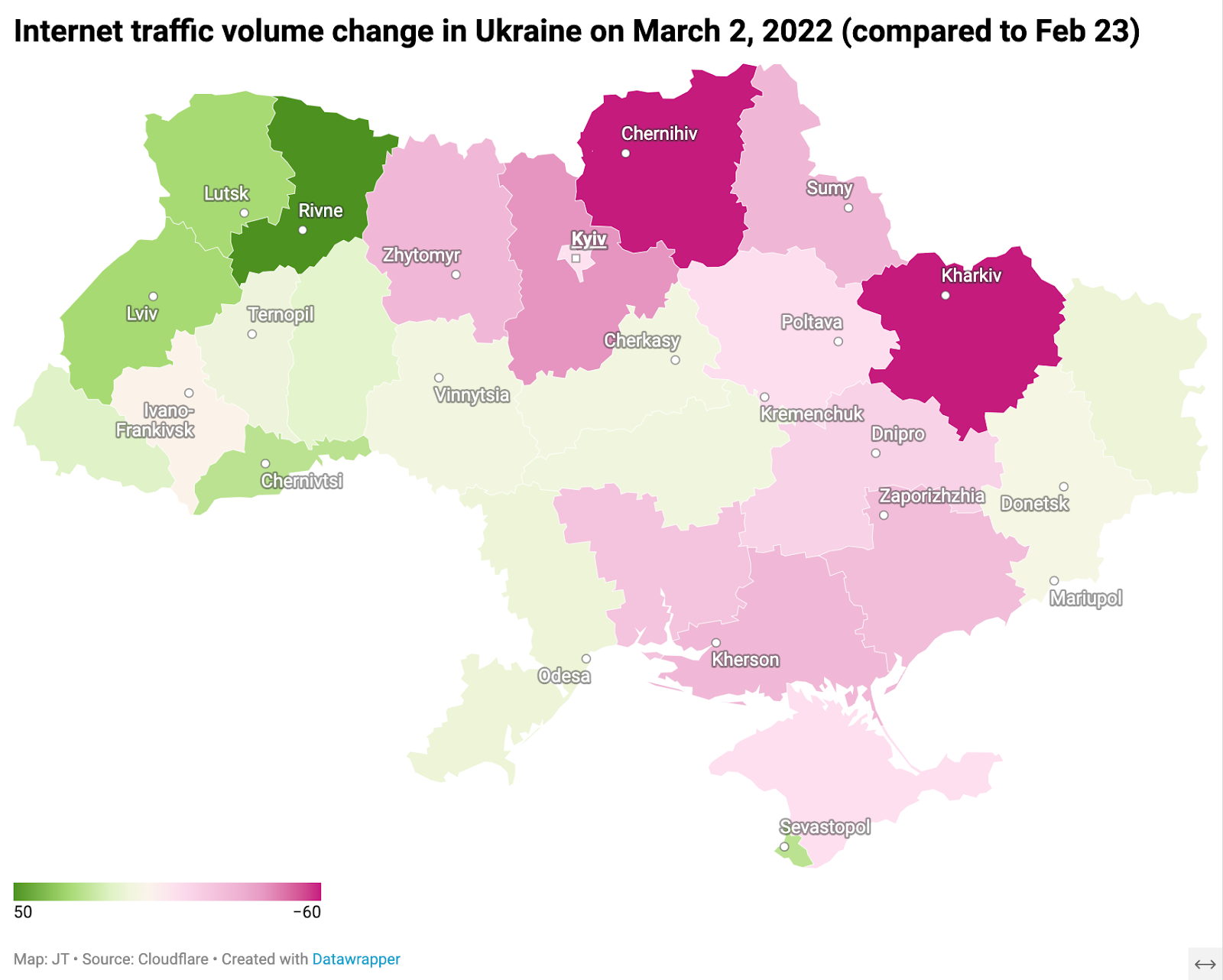
Internet connectivity in several African countries was disrupted today, March 14, 2024. Beginning at approximately 05:00 UTC, west and central African countries were most impacted, as was South Africa. Based on published reports and social media posts from impacted network providers, the disruption is believed to be due to multiple undersea cable failures in the region. From The Gambia to Côte d’Ivoire, including a major network in South Africa (Vodacom), a total of 11 African countries were impacted, based on our observations.
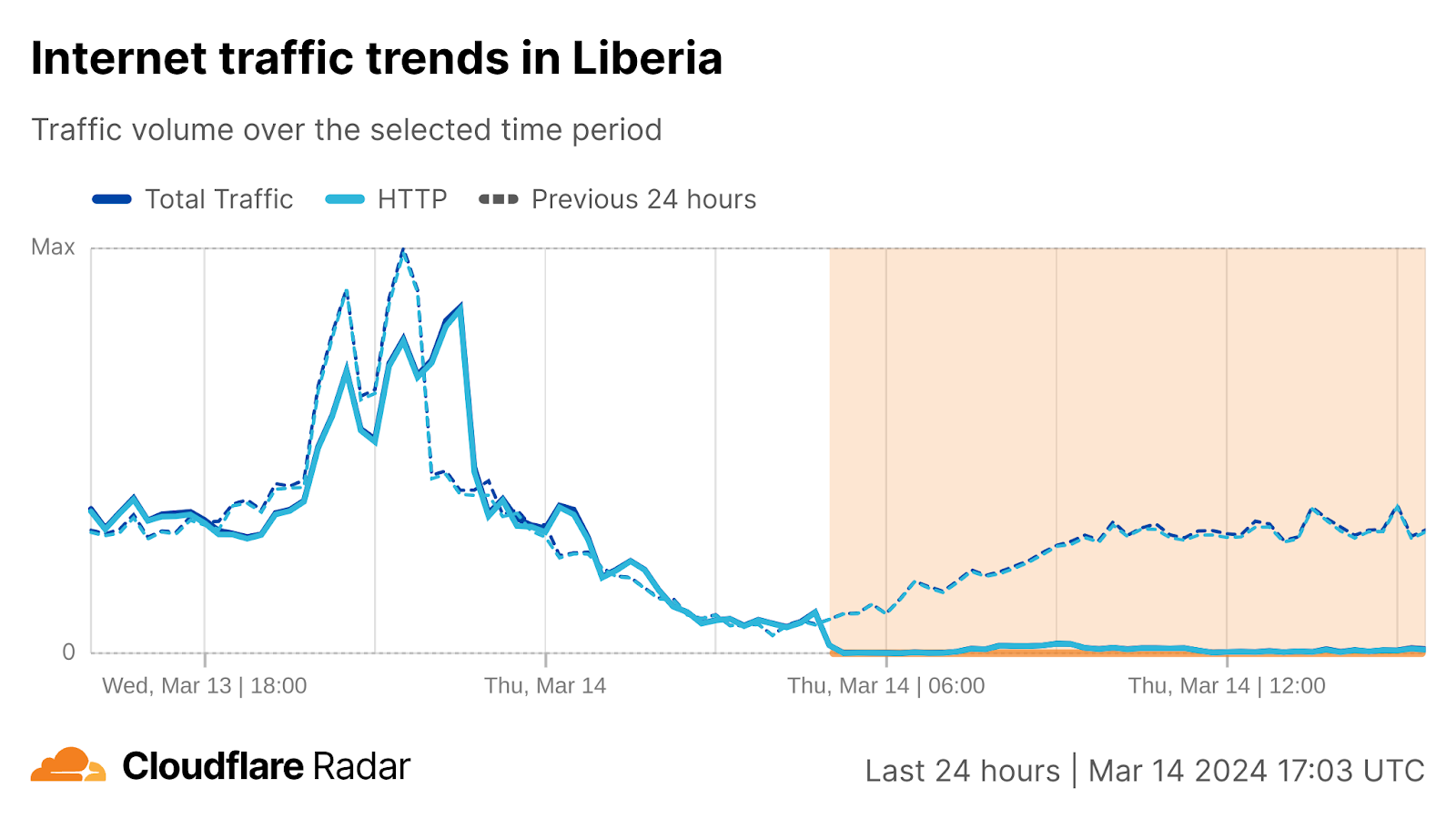
Cloudflare Radar data shows a pattern of disruptions from the north to the south of West Africa over time. It began south of Senegal, with The Gambia, Guinea, and Liberia experiencing disruptions around 05:00 UTC.
In The Gambia and Guinea, the disruptions lasted about 30 minutes, while in Liberia, the disruption has lasted more than 12 hours.
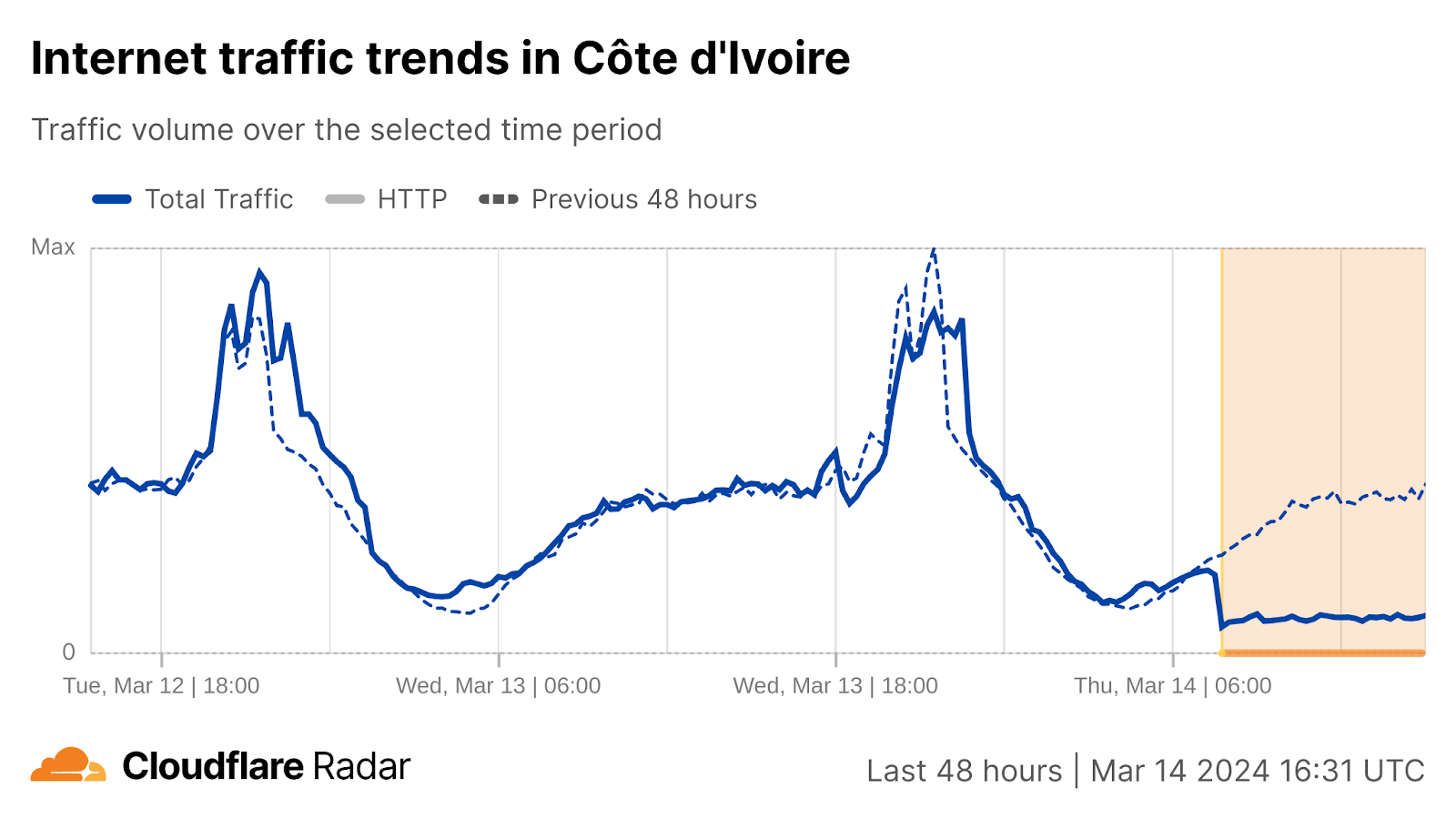
Moving south, around 07:30 UTC, disruptions were observed in Côte d’Ivoire and Ghana.
Niger, a landlocked nation in Central Africa, experienced a disruption at 09:15, lasting just over two hours.
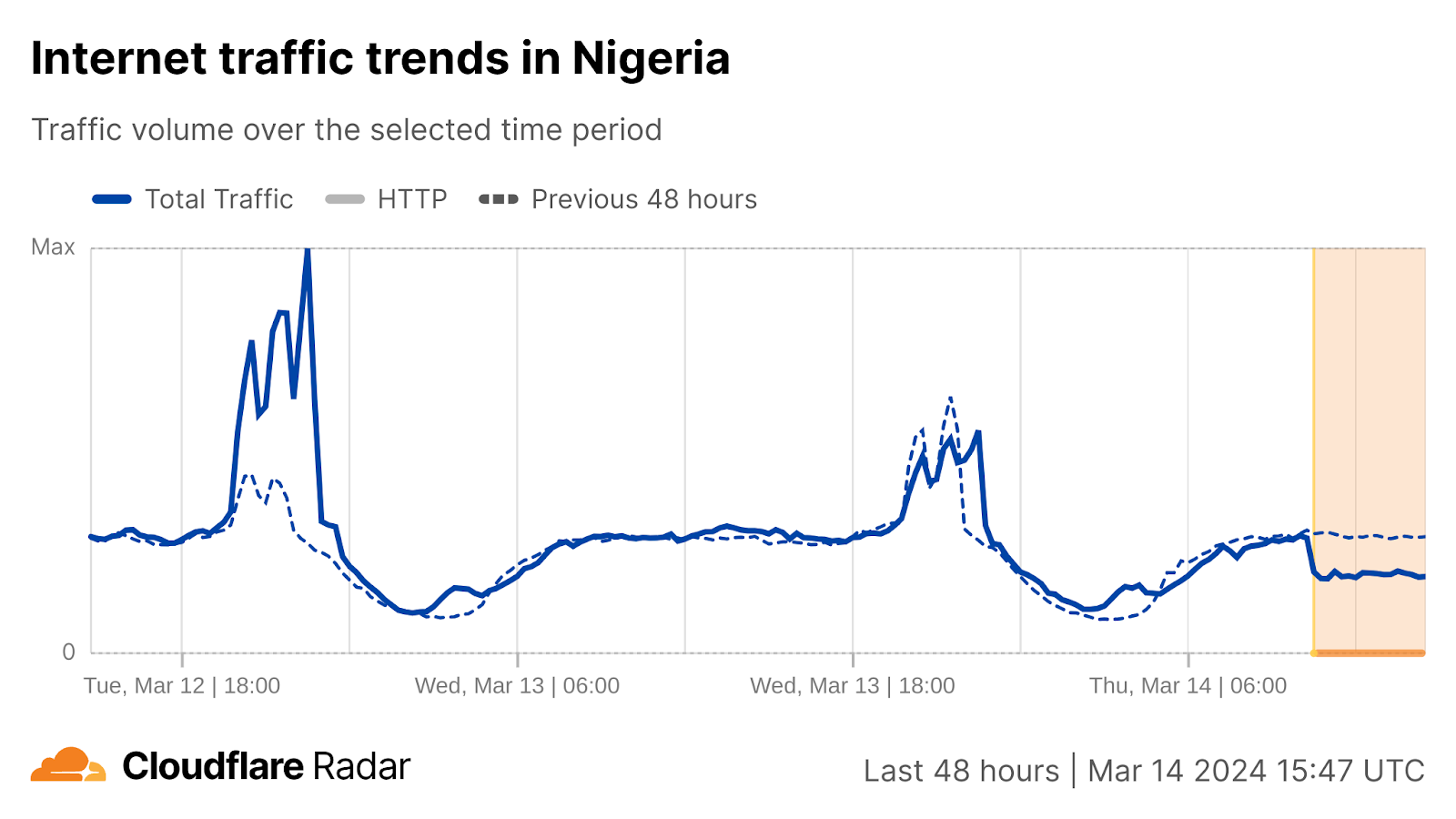
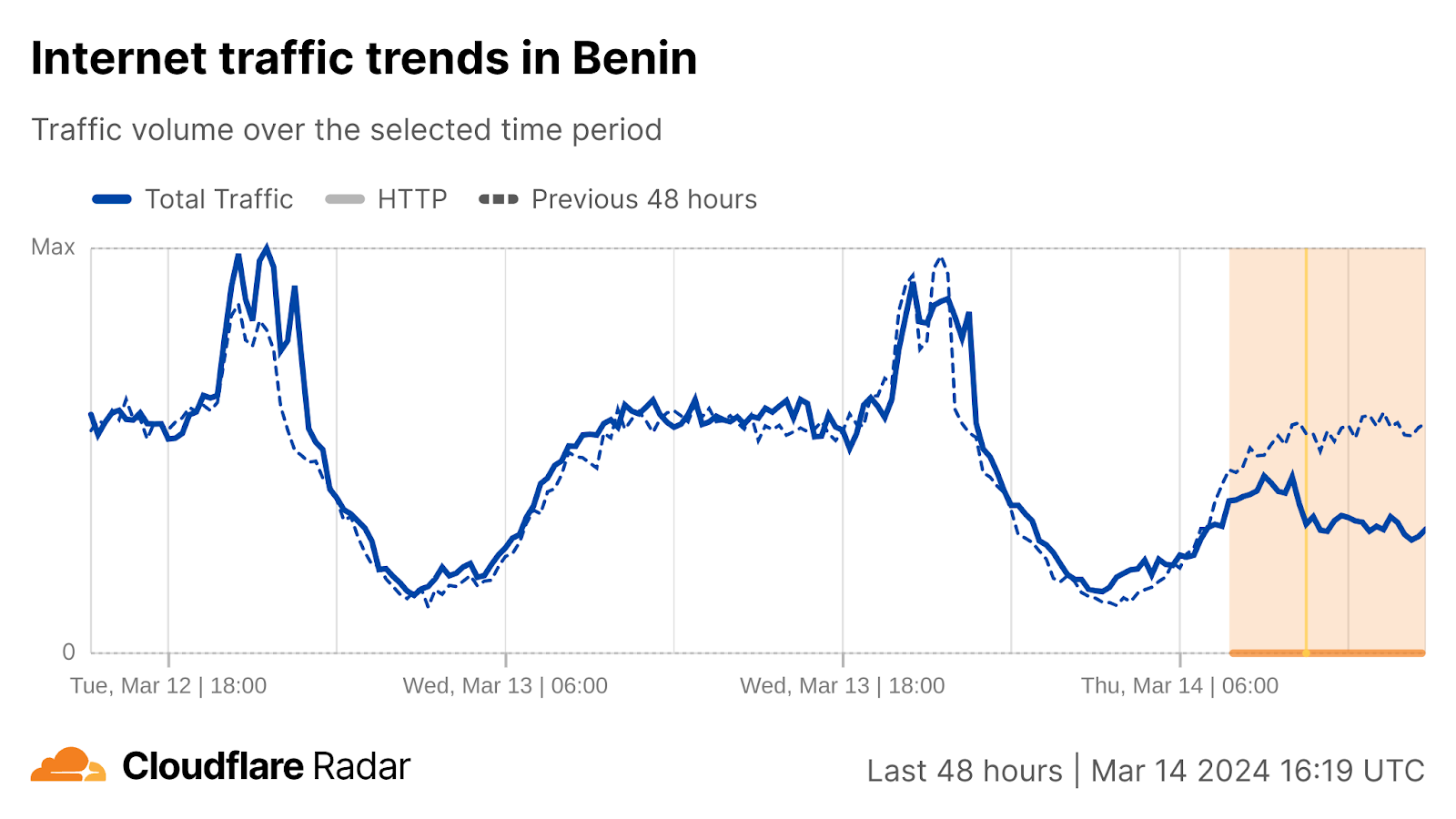
This was followed by disruptions starting around 10:30 UTC in Nigeria, Benin, Cameroon, and Togo. These disruptions were ongoing at the time of writing.
At approximately the same time, a significant disruption was observed on Vodacom’s South African network (AS29975). Traffic began to recover after 13:30 UTC, and appears to have reached close to normal levels by 16:00 UTC.
The importance of submarine cables
This series of disruptions serves as a reminder of how dependent the Internet is on submarine cables, which are estimated to carry over 90% of intercontinental data traffic. Only a small percentage of general use is done via satellite networks. There are 529 active submarine cables and 1,444 landings that are currently active or under construction, running to an estimated 1.3 million km around the globe.
Reports from several local networks, including South Africa’s Vodacom, MTN in Nigeria, and Celtiis in Bénin, reference multiple submarine cable failures. Microsoft was more detailed, stating on their Azure status page that “multiple fiber cables on the West Coast of Africa — WACS, MainOne, SAT3, ACE — have been impacted which reduced total capacity supporting our Regions in South Africa”. The company also explains that the recent cable cuts in the Red Sea in combination with today’s cable issues, “has impacted all Africa capacity”.
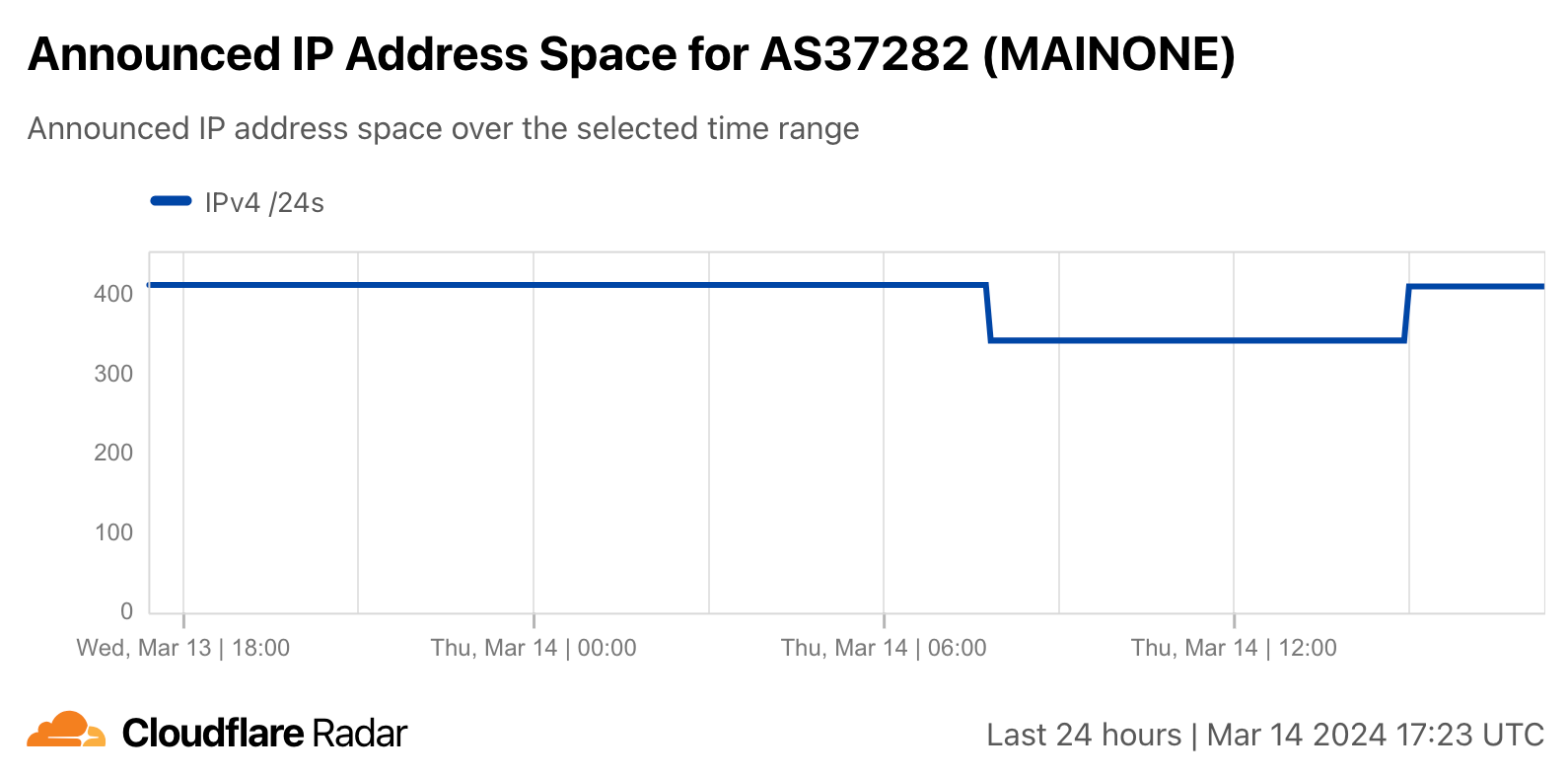
In addition to the impacts to the Microsoft Azure cloud platform, the website of MainOne, owners of the MainOne submarine cable, was offline for several hours. DNS for mainone.net is handled by name servers located in MainOne’s address space. It appears that a portion of the IPv4 address space for AS37282 (MAINONE) stopped being announced between 07:30 and 15:00 UTC, and once this address space was being routed again, both the nameservers and website became reachable.
This map from TeleGeography highlights the impacted submarine cables: WACS (West Africa Cable System), MainOne, SAT-3/WASC, and ACE.
The disruptions are now being reported by news media outlets, including in South Africa, where the emphasis is not only on the latest outage but also on the problem with the submarine cable operator Seacom. This operator experienced a service-impacting outage on its cable system in the Red Sea. On March 8, the company stated that it is waiting for permits to start repairing its broken submarine cable in the Red Sea.
Cloudflare’s network spans more than 310 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
During previous quarters, we tracked a number of government directed Internet shutdowns in Iraq, intended to prevent cheating on academic exams. We expected to do so again during the fourth quarter, but there turned out to be no need to, as discussed below. While we didn’t see that set of expected shutdowns, we did observe a number of other Internet outages and disruptions due to a number of commonly seen causes, including fiber/cable issues, power outages, extreme weather, infrastructure maintenance, general technical problems, cyberattacks, and unfortunately, military action. As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Iraq
In a slight departure from the usual subject of this blog post, this time we lead off with coverage of government directed Internet shutdowns that didn’t happen. Iraq has been a frequent subject of this series of posts, as they have historically implemented daily multi-hour Internet shutdowns during exam periods, intended to prevent cheating. Earlier this year, there was some hope that this practice might be ending, and in our Q2 2023 Internet disruption summary post, we noted “In the weeks prior to the start of this year’s shutdowns, it was reported that the Iraqi Ministry of Communications had announced it had refused a request from the Ministry of Education to impose an Internet shutdown during the exams as part of efforts to prevent cheating. Unfortunately, this refusal was short-lived, with shutdowns ultimately starting two weeks later.” In addition to these second quarter shutdowns, they also occurred during the third quarter across multiple weeks in July, August, and September.
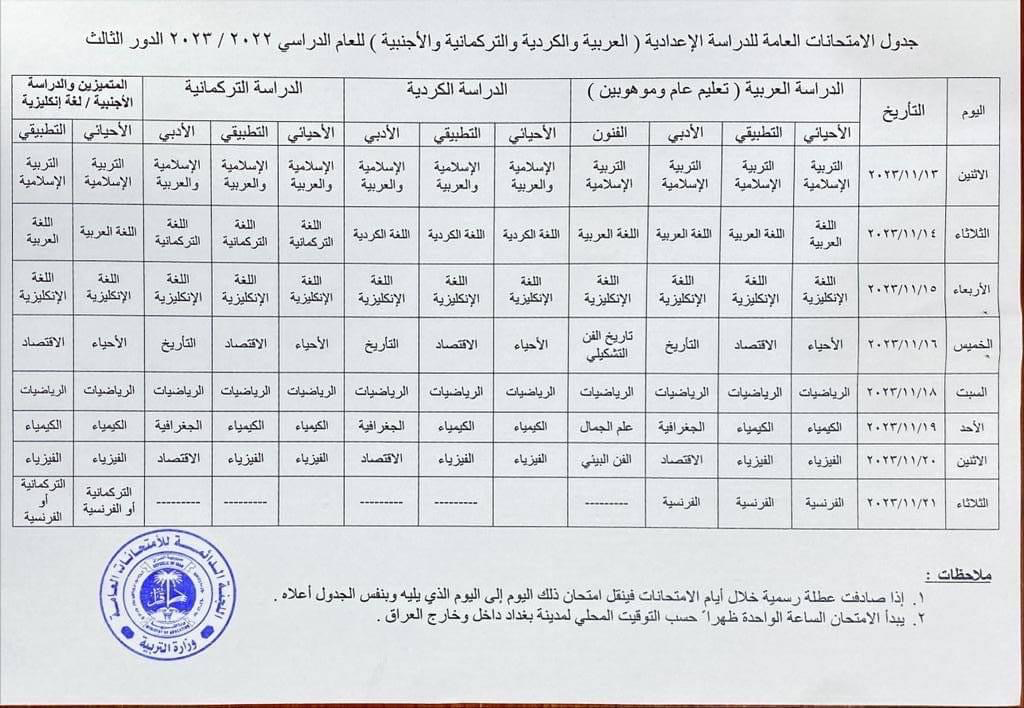
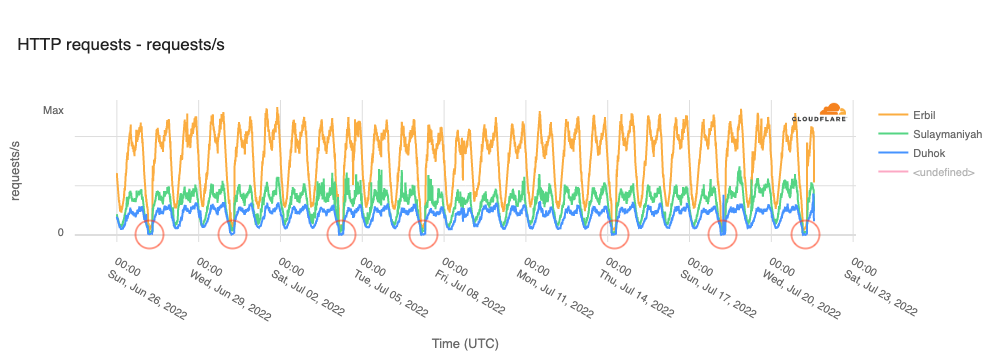
During the fourth quarter, the third round of 12th grade high school final exams was scheduled to begin on November 13 and end on November 21, taking place at 13:00 local time, as shown in the schedule below, which was published on the Iraqi Ministry of Education’s Facebook page.
November 2023 exam schedule in Iraq
However, in looking at Internet traffic for Iraq during that period, it appears that the nationwide Internet shutdowns that would have normally taken place did not occur, as the graph shows a very consistent diurnal pattern with no evidence of disruptions to Internet connectivity like we have seen in the past. Additionally, other civil society groups, academic researchers, and Internet analysts that also monitor these shutdowns did not report seeing any related drops in traffic. It is unclear whether a request for shutdowns was submitted by the Ministry of Education and again refused by the Ministry of Communications, or if no request was ever submitted for this round of exams. Regardless, we hope that Iraq continues to keep the Internet connected during future rounds of exams.
Military action
Palestine
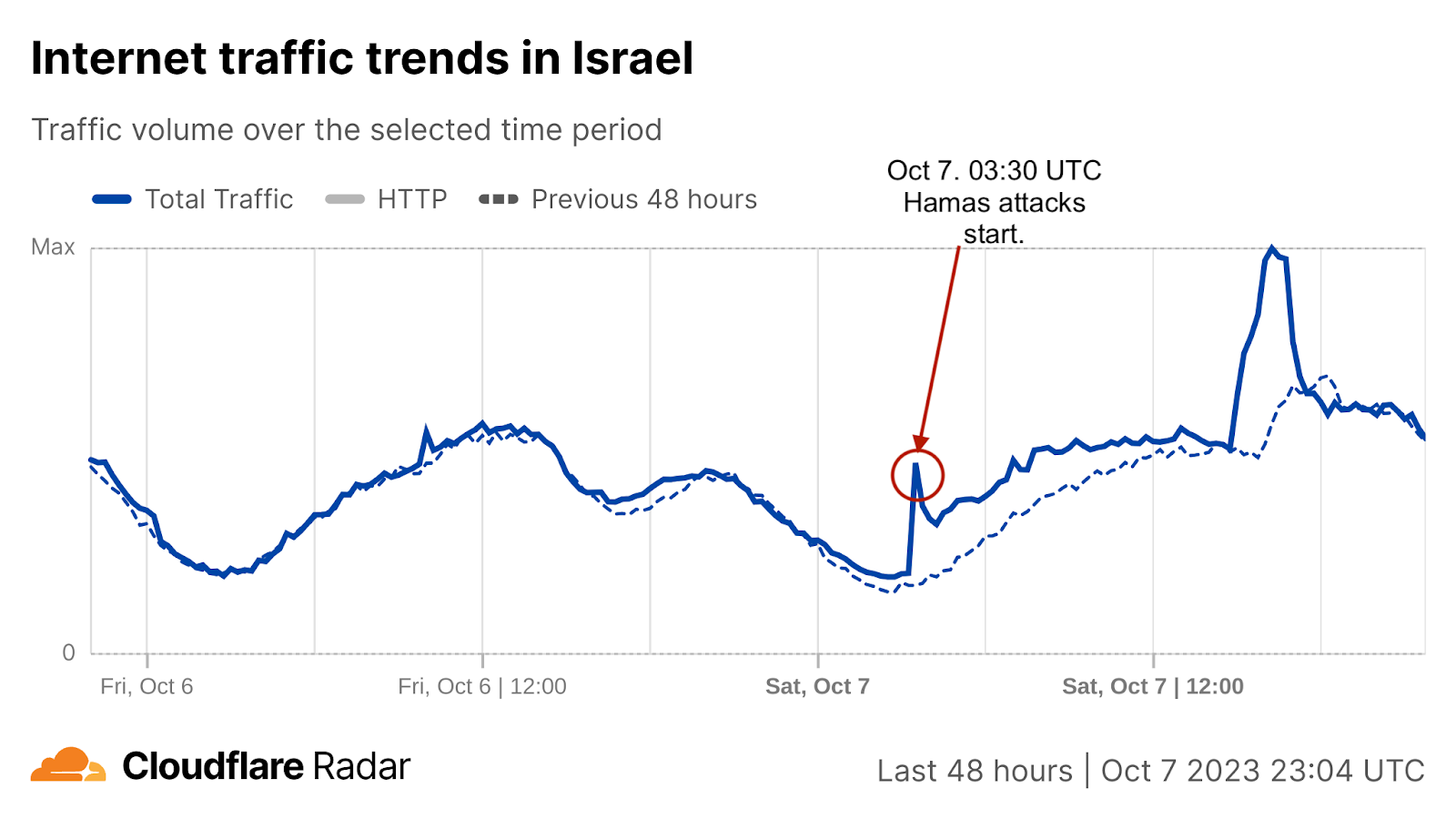
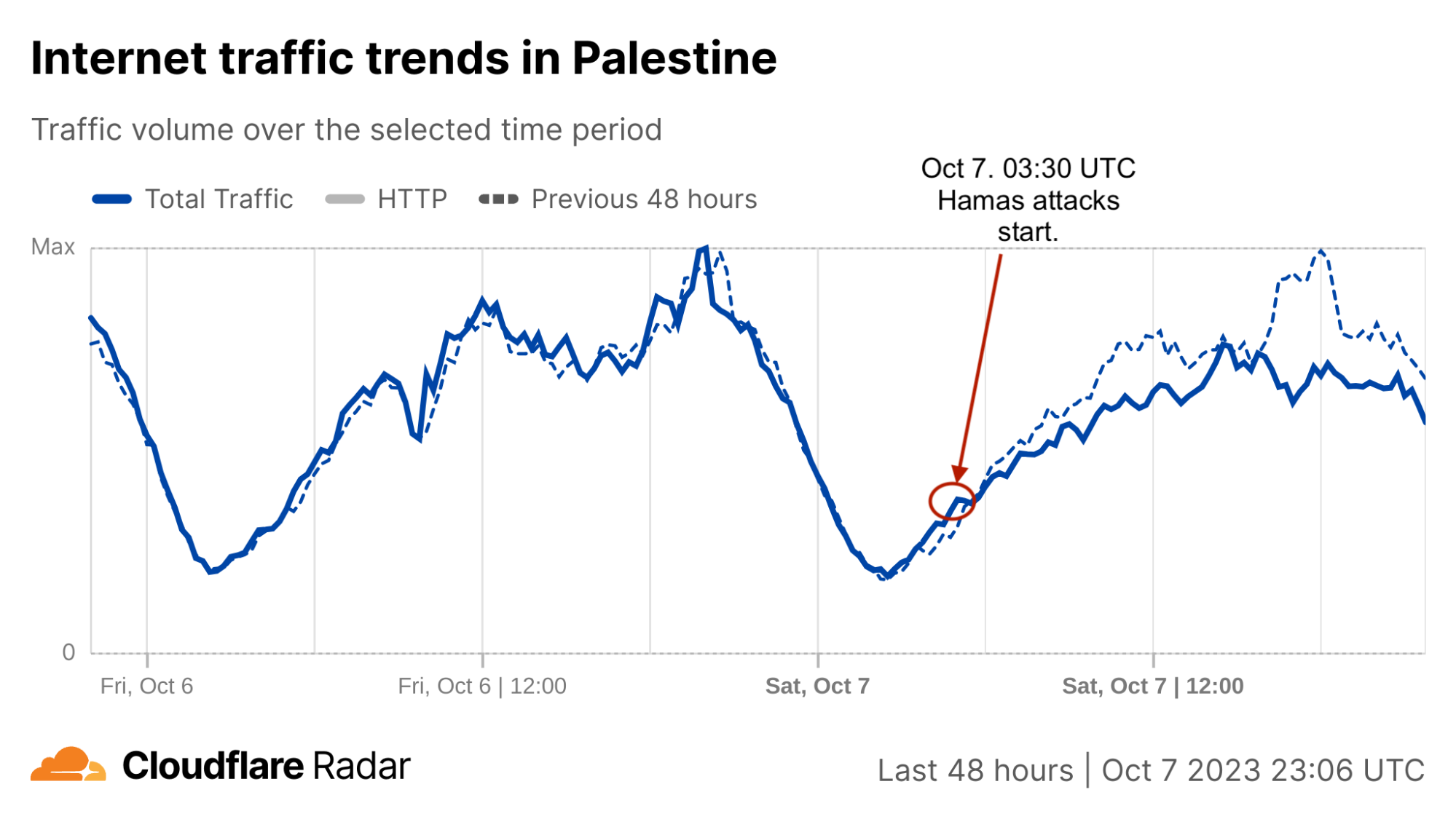
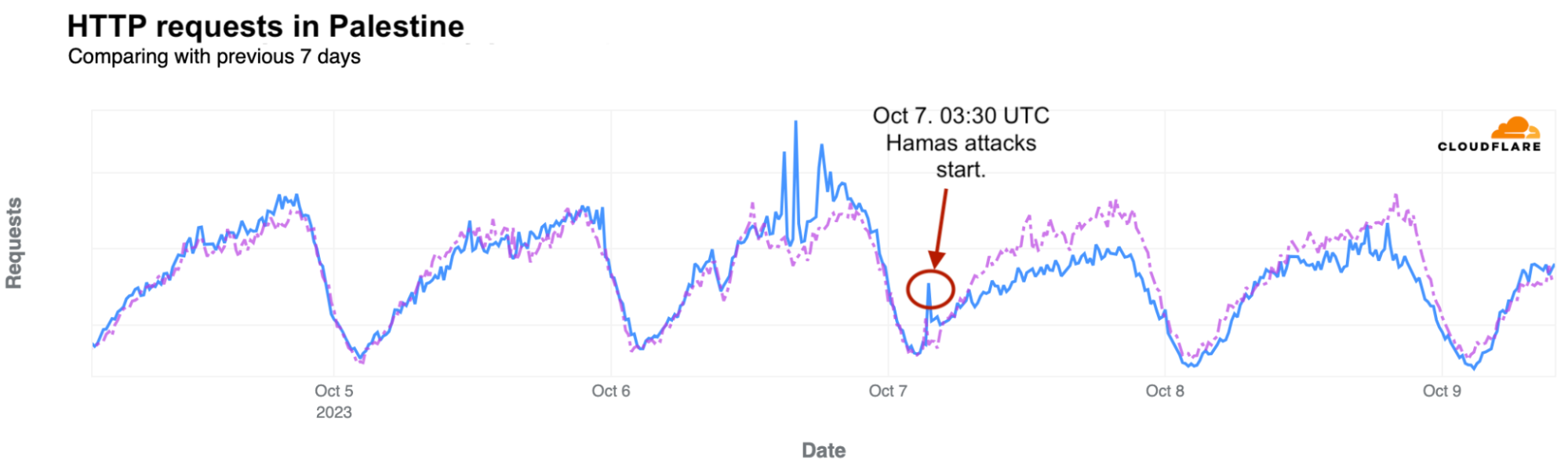
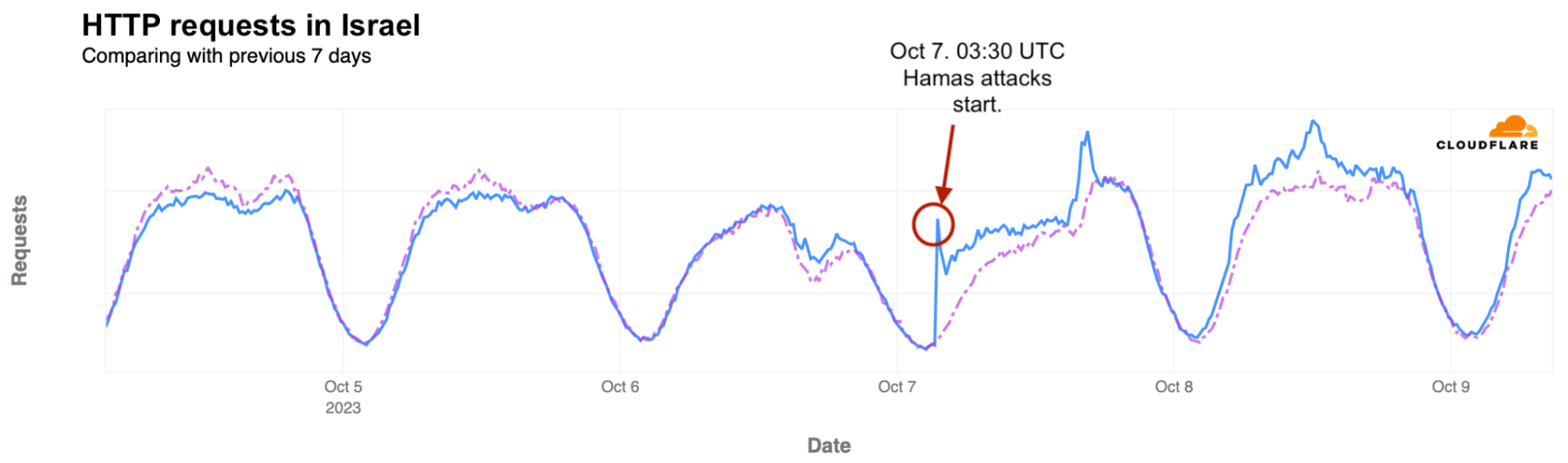
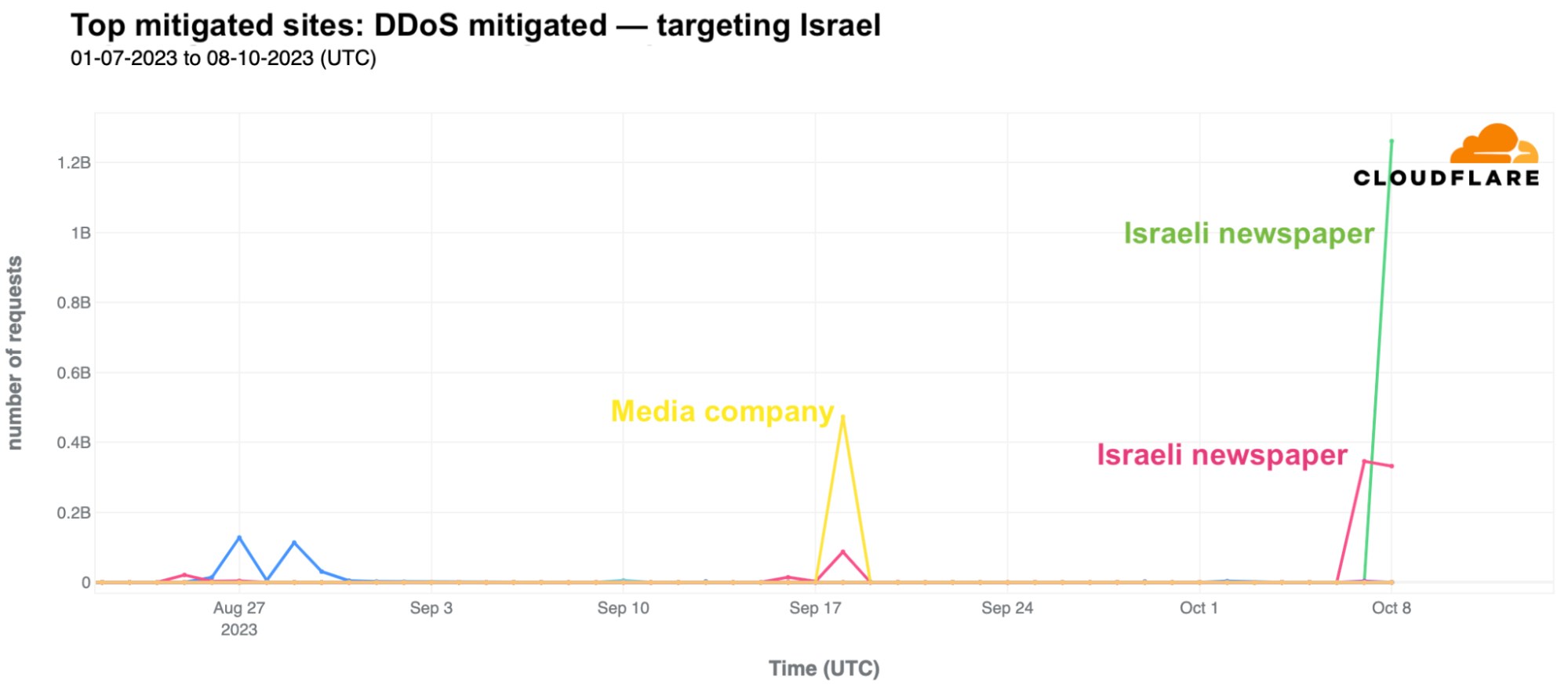
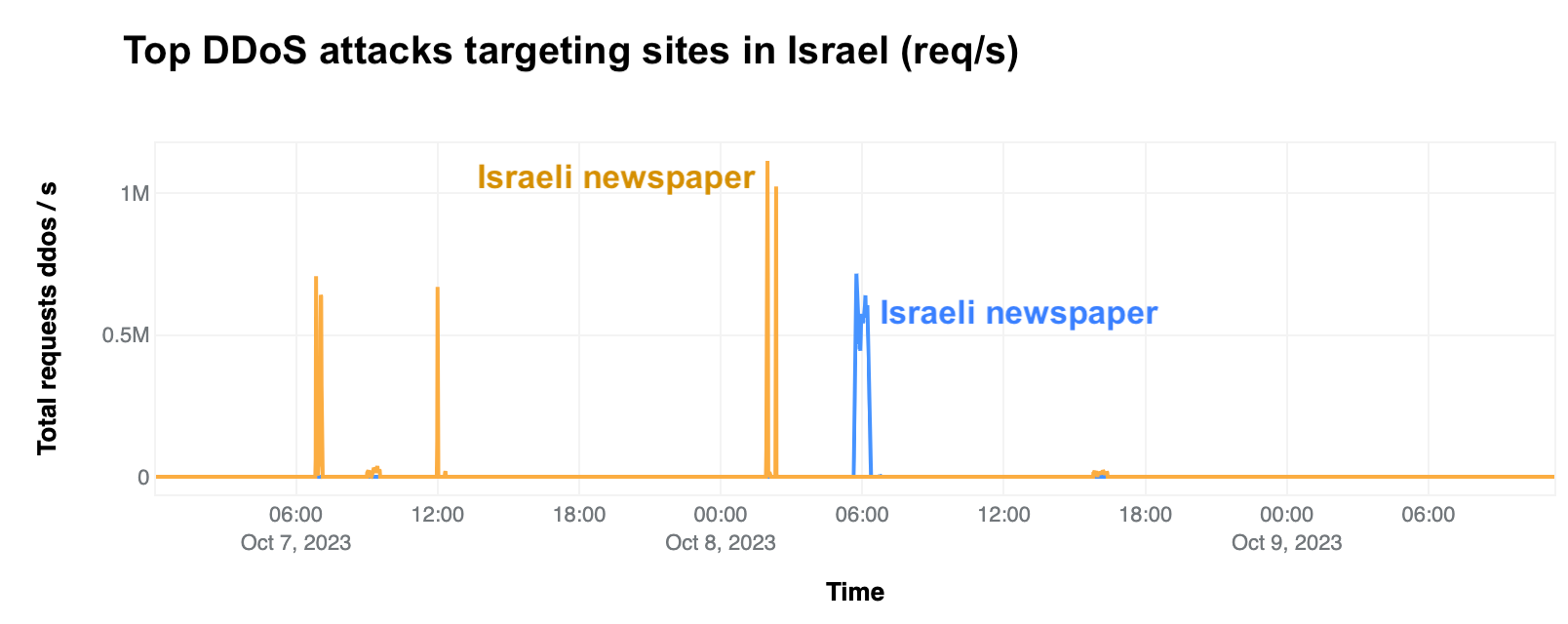
On Saturday, October 7, 2023, attacks from the Palestinian group Hamas launched from the Gaza Strip against the south of Israel started a new conflict in the region, with Israel officially declaring the next day that it was at war. This had an almost immediate impact on Internet traffic in both Israel and Palestine, with traffic in the former showing ~170% growth as compared to the prior week, and ~100% growth in the latter as compared to the previous week. These trends are discussed in our October 9 blog post, Internet traffic patterns in Israel and Palestine following the October 2023 attacks.
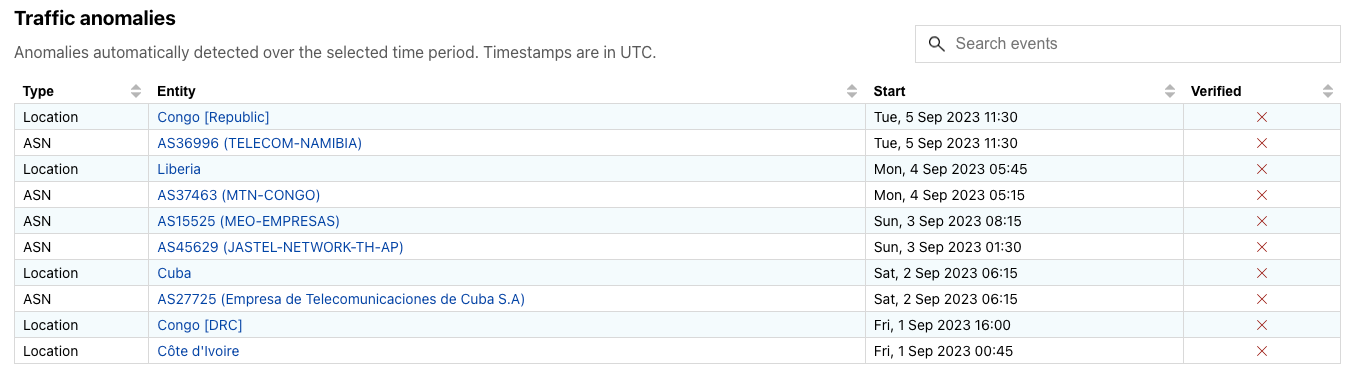
On November 13, Telecom Namibia (AS36996)reported that it was experiencing interruptions to its fixed voice and data services in several areas, resulting from cable theft. The impact of these interruptions is shown in the figure below, with Internet traffic disrupted between 13:45 local time (11:45 UTC) on November 13 and 08:30 local time (06:30 UTC) on November 14. The disruption to connectivity due to cable theft was not an isolated incident, as the provider posted several additional notices on its social media accounts in November and December about similar occurrences.
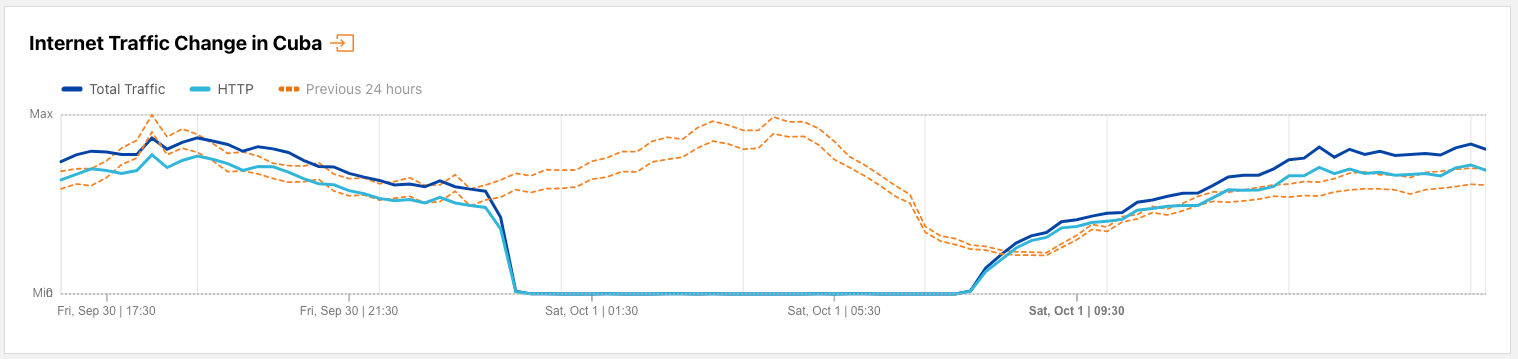
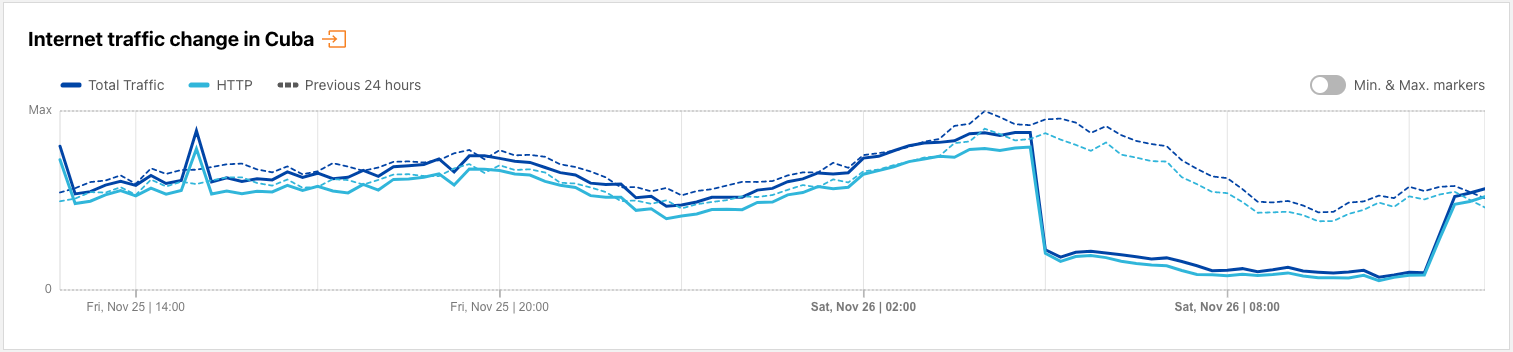
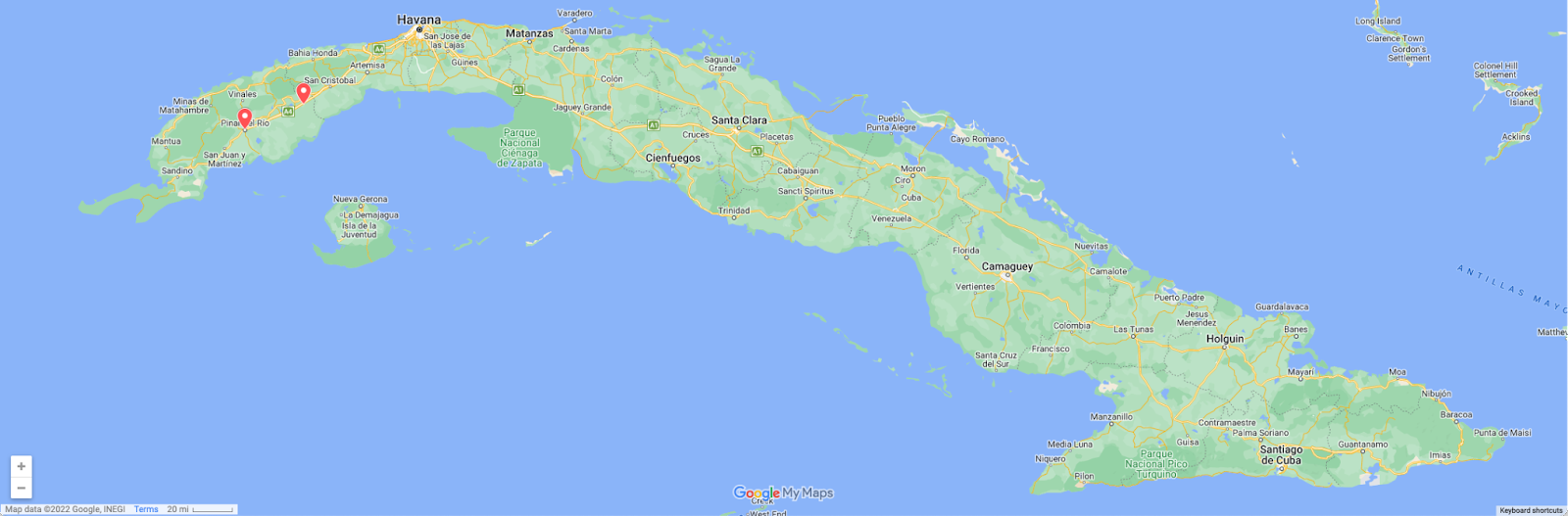
Cuba
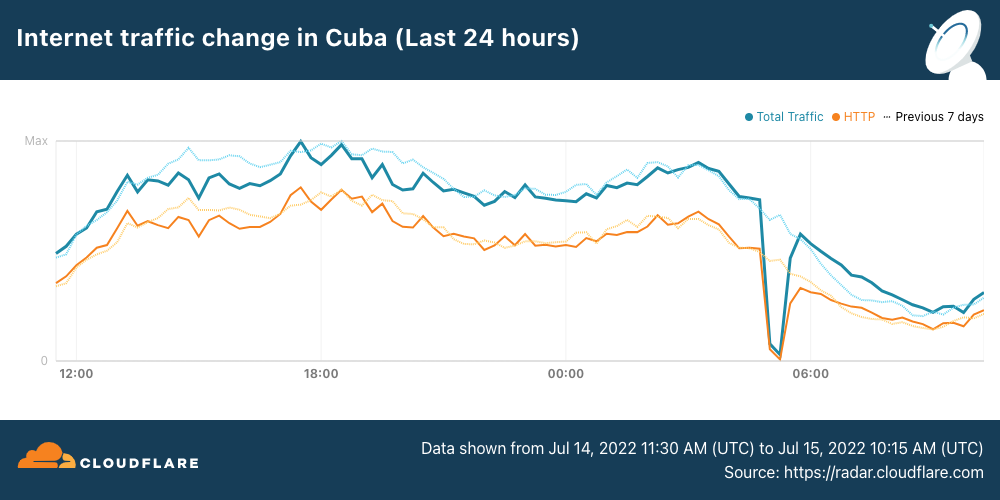
A day later, on November 14, ETECSA (AS27725)posted a notice about a terrestrial fiber cut that disrupted Internet services. As the state-owned telecommunications provider in Cuba, the cut impacted Internet traffic nationwide, as well as at a network level, as seen in the graphs below. The disruption was relatively short-lived, occurring between 06:30 – 08:15 local time (11:30 – 13:15 UTC), with a follow-up post announcing the re-establishment of Internet service.
Chad
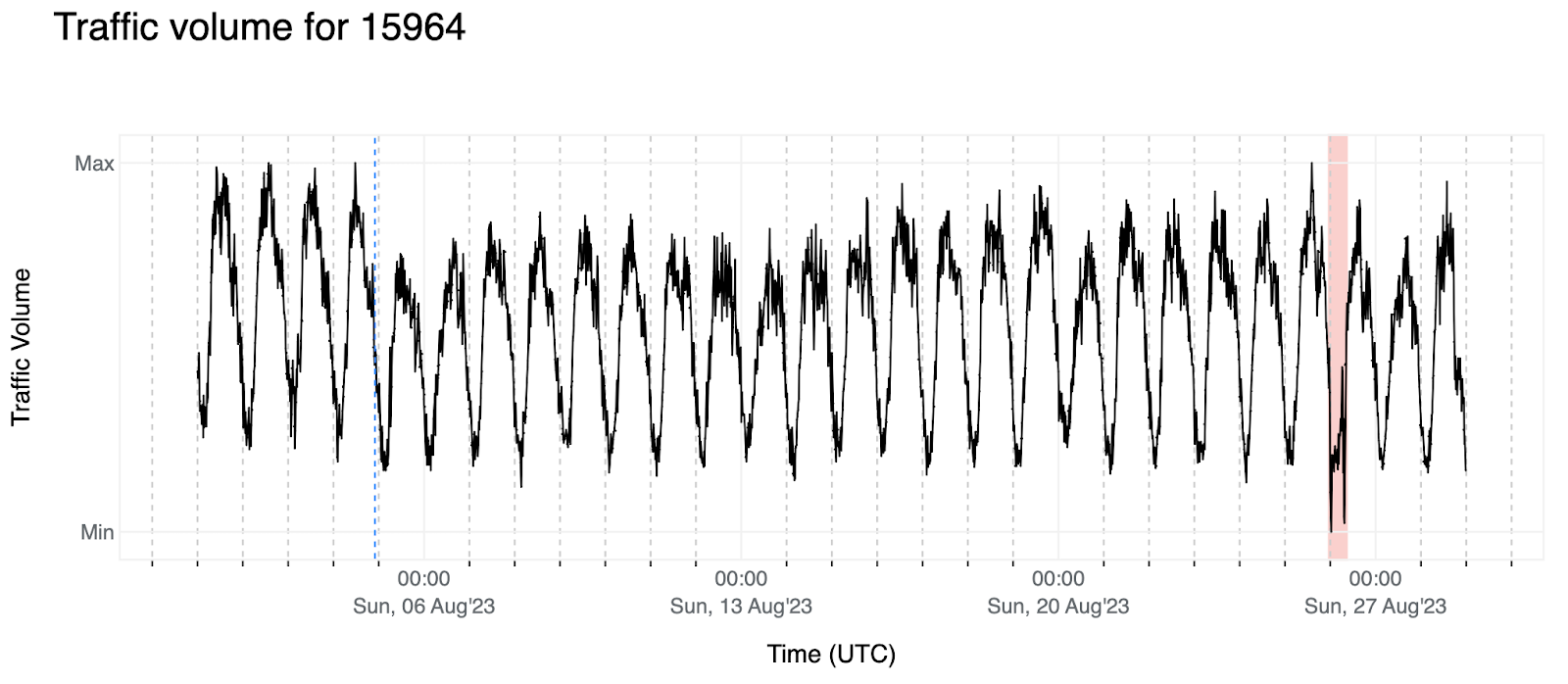
On December 7 & 8, a near-complete outage observed in Chad was reportedly due to fiber optic cable cuts in neighboring countries. A published article cited SudaChad as claiming that the outage seen in the graphs below was due to an issue with CAMTEL, a Cameroonian partner. It also cites Moov Africa’s (formerly known as Millicom Chad)apology to customers, which points at “the fiber-optic cut in Cameroon and Sudan” as the root cause. Since simultaneous cuts in fiber optic cables in Chad’s two neighboring countries would certainly be an unusual occurrence, it isn’t clear if such an event happened, though routing data for SudaChad shows that the network’s two upstream providers are AS15706 (Sudatel) in Sudan and AS15964 (CAMNET) in Cameroon. The three providers are also partners on the WE-AFRICA-NA terrestrial cable, which stretches from Port-Sudan on the Red Sea in Sudan to Kribi on the Atlantic Ocean in Cameroon via Chad, but it isn’t known whether that cable system was involved in this outage.
The disruption lasted approximately fourteen hours, from 20:00 local time on December 7 until 10:15 local time on December 8 (19:00 UTC on December 7 until 09:15 UTC on December 8), with the impact visible country-wide, as well as at SudaChad and several downstream network providers.
Cyberattacks
Ukraine
Ukrainian Internet provider Kyivstar announced on the morning of December 12 that they were the “target of a powerful hacker attack”. They noted that the attack caused a “technical failure” that resulted in mobile communication and Internet access becoming temporarily unavailable. Although Kyivstar has been targeted by around 500 cyberattacks since Russia launched its invasion of Ukraine in February 2022, this was reportedly the largest attack to date. A subsequent report referenced an interview with Illia Vitiuk, the head of the cybersecurity department at Ukraine’s security service (SBU), in which he claimed that “the hackers attempted to penetrate Kyivstar in March 2023 or earlier, managed to get into the system at least as early as May, and likely gained full access to the network in November.”
Recovery took several days, with Kyivstar posting on December 15 that “the Internet is everywhere” but warning that connection speeds might be slightly reduced. These posts align with the traffic disruption shown in the figure below, which lasted from 06:30 local time (04:30 UTC) on December 12 until 14:00 local time (12:00 UTC) on December 15.
Power outages
Brunei
A major power outage in Brunei on October 17 disrupted key services including mobile and fixed Internet connectivity. Starting around 11:30 local time (03:30 UTC), traffic was disrupted for approximately 13 hours, recovering to expected levels around just after midnight local time on October 18 (16:45 UTC). Two Unified National Networksautonomous systems (AS10094 and AS131467) saw lower traffic volumes during the power outage.
Kenya
A widespread power outage in Kenya on November 11 disrupted Internet connectivity across the county for approximately seven hours. An X post from Kenya Power at 20:30 local time (17:30 UTC) reported a partial power outage, stating “We have lost power supply to parts of the country. Our engineers are working to restore supply to the affected areas.” Kenya Power kept customers informed of progress, posting updates at 22:00, 23:57, and the morning of November 12, with the final update reporting “We have successfully restored normal power supply in all the areas that were affected by the partial outage.”
Curaçao
On November 14, a Facebook post from Aqualectra, the water and power company in Curaçao, stated in part, “Around 14:00 this afternoon, a blackout occurred. Preliminary investigation indicates that one of the main cables responsible for transporting electricity between the substations at Nijlweg and Weis experienced a short circuit. It is important to emphasize that this is not due to a lack of production capacity.” The power outage resulted in a near complete loss of traffic at Flow Curaçao (AS52233), with significant disruptions also visible at United Telecommunication Services (AS11081) and at a country level, as seen in the graphs below. The disruption lasted eight hours, from 14:00 until 22:00 local time (18:00 UTC on November 14 until 02:00 UTC on November 15).
Sri Lanka
After stabilizing its electrical infrastructure in the wake of 2022’s problems with its electrical power grid, the failure of a main transmission line caused an island-wide power outage in Sri Lanka on December 9, in turn disrupting Internet connectivity. Traffic from the island nation initially dropped by around 50% starting around 16:45 local time (11:15 UTC). Repairs took several hours, with the country’s Internet traffic returning to expected levels around 01:00 local time on December 10 (19:30 UTC).
Panama
On the morning of December 24, Panamanian electric distribution company ENSAinitially reported an event that affected electrical services to their customers. A subsequent report posted just 30 minutes later provided additional details, pointing to an incident in the “National Interconnected System” that affected the electrical supply in a number of areas, but within an hour, it had spread nationally. Although the initial regional power issues did not have a noticeable impact on Panama’s Internet traffic, the loss of traffic in the graph below aligns with the national growth of the power outage, occurring at 11:45 local time (16:45 UTC). Traffic returned to expected levels at around 15:00 local time (20:00 UTC), aligning with an X post from ENSA stating that “At 3:12pm the supply of electrical energy to all our clients has been normalized after an event at the Transmission level originating in the Panama 1 Substation of ETESA.”
Weather
Ukraine
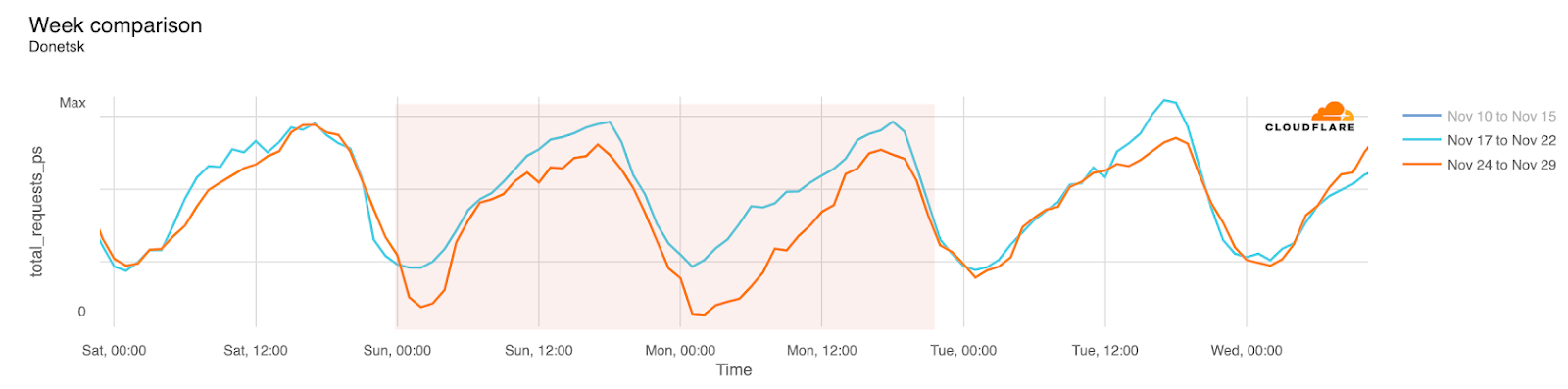
Internet disruptions in Ukraine due to the conflict there have been covered in multiple quarterly Internet disruption summary blog posts over the last two years. However, in November, connectivity in multiple areas of the country was disrupted by power outages caused by a major winter storm. Snow and high winds knocked out power to hundreds of towns and villages, damaging electrical power infrastructure. The impact is visible in the graphs below as a drop in traffic occurring around 01:00 local time on November 27 (23:00 UTC on November 26), observed in regions including Donetsk, Kherson Oblast, and Luhansk. Traffic appeared to return to expected levels early in the morning local time on November 28.
Mexico
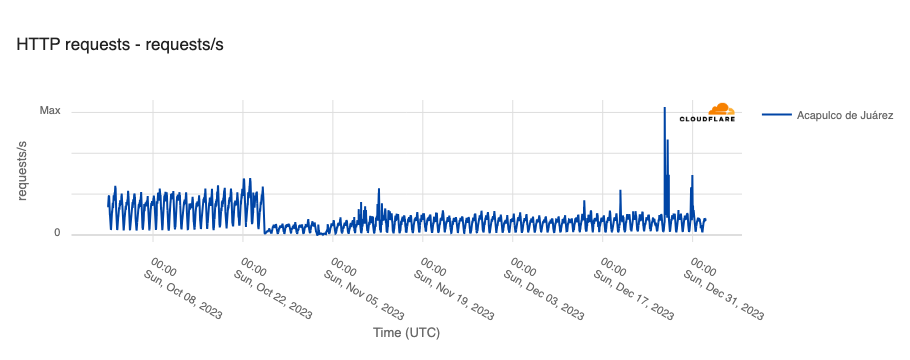
On October 25, Hurricane Otis made landfall near Acapulco, a popular tourist destination in Mexico. In addition to catastrophic structural damage, it was reported that “more than 10,000 utility poles were destroyed, knocking out power and internet/communications across the region, while numerous transmission lines, electrical substations, and a power plant were also heavily damaged.” This damage to electrical and communications infrastructure in the area resulted in significant disruption to Internet connectivity. As shown in the graph below, Internet traffic from Acapulco dropped by around 80% as Otis made landfall. Traffic started to show some growth in early November, but peak volumes remained relatively consistent, and well below pre-hurricane levels, through the end of the year. (Several large spikes are visible on December 26 & 30, but it isn’t clear what those are associated with.) Although Acapulco’s tourism industry experienced a notable recovery heading into the end of the year, it appears that infrastructure recovery has not been quite as swift.
Fire
Hawaii
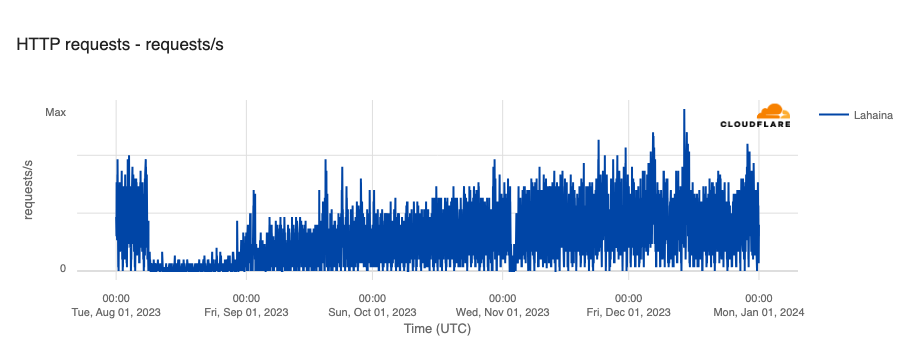
Last quarter, we reported on the impact of wildfires that started on August 7 in Hawaii, including killing nearly 100 people, as well as destroying homes, businesses, and infrastructure, causing power outages and disrupting Internet connectivity. One of the most impacted areas was the town of Lahaina, where Internet connectivity remained sparse for weeks after the fires began. Repair and restoration efforts continued throughout the fourth quarter, with traffic clearly growing throughout October, with peak levels in November and December approaching pre-fire levels.
Maintenance
Yemen
Two maintenance-related Internet disruptions impacted Internet connectivity in Yemen in the fourth quarter. The first lasted over four hours during the morning of November 10, from 03:10 – 07:45 local time (00:10 – 04:45 UTC), and followed two other disruptions the prior day. The impact was visible at a country level, as well as at a network level on PTC-YemenNet (AS30873).
An Associated Press article noted that in a statement to the state news agency, Yemen’s Public Telecom Corp. (PTC-YemenNet) blamed the outage on maintenance, apparently of the FALCON submarine cable. The article also cited a statement from GCX, the operator of the FALCON cable, regarding scheduled maintenance to the cable system that had been in planning for the previous three months.
The second maintenance-related disruption occurred on December 15 just before 23:00 local time (20:00 UTC). An X post from Mosfer Alnomeir, the Minister of Telecommunication and Information Technology in Yemen, explained what happened: “We note that half an hour ago there was an interruption in the Internet service that lasted approximately 30 minutes. This is while engineers carry out emergency replacement and upgrade work on some service equipment. Service was restored immediately. On behalf of the team, I say thank you for your understanding.” Once again, the impact was visible at both a country and network level.
Technical problems
Australia
“Changes to routing information” after a “routine software upgrade” were reportedly responsible for a multi-hour Internet outage at Australian telecommunications provider Optus (AS4804) on November 8 local time. Connectivity began to drop just after 04:00 Sydney time, with the outage lasting from 04:30 – 10:00 Sydney time (17:30 – 23:00 UTC on November 7). Traffic didn’t fully recover to expected levels until around 23:00 Sydney time (12:00 UTC).
The network issue impacted more than 10 million customers, as well as hospitals and payment and transport systems, and drew comparisons to July 2023’s outage at Canadian provider Rogers Communications. Optus submitted a report to the Australian Senate Standing Committee on Environment and Communications that detailed the cause of the outage, noting “It is now understood that the outage occurred due to approximately 90 PE routers automatically self-isolating in order to protect themselves from an overload of IP routing information. … This unexpected overload of IP routing information occurred after a software upgrade at one of the Singtel internet exchanges (known as STiX) in North America, one of Optus’ international networks. During the upgrade, the Optus network received changes in routing information from an alternate Singtel peering router. These routing changes were propagated through multiple layers of our IP Core network. As a result, at around 4:05am (AEDT), the pre-set safety limits on a significant number of Optus network routers were exceeded.” The report also detailed the recovery efforts and timelines for consumer Internet, DNS, and mobile services.
Armenia
Failure of international links caused a brief Internet disruption at Telecom Armenia (AS12297) on November 11, similar to a disruption that occurred almost exactly a year earlier. As shown in the graph below, the disruption began just around 15:15 local time (11:15 UTC), with short periods where traffic dropped to zero. Traffic recovered to expected levels by 21:00 local time (17:00 UTC). As one of the largest telecommunications providers in the country, the service disruption was visible at a country level as well.
United Kingdom
A sizable drop in traffic was observed between 15:00 and 21:30 local time (15:00 – 21:30 UTC) on mobile and broadband Internet provider Three UK (AS206067) on December 1, as seen in the graph below. Although the provider acknowledged that customers were experiencing issues and provided several updates (1, 2, 3, 4) on service restoration over the next day, it never disclosed any additional information on the cause of the disruption. However, a published report stated that Three UK blamed technical issues at one of its data centers as the cause of the problem, which impacted more than 20,000 users.
Egypt
On December 5, Telecom Egypt (AS8452)posted on X that a technical malfunction affecting one of their main network devices was responsible for an Internet disruption that occurred on their network, which also impacted connectivity on several other network providers, including LINKdotNET (AS24863), Vodadfone Egypt (AS24835), and Etisalat (AS36992), as well as traffic at a national level, as seen in the graphs below. Although one news report claimed that the disruption, which occurred between 14:15 – 00:00 local time (12:15 – 22:00 UTC), was due to damage to the FLAG and SeaMeWe-4 submarine cables, a subsequent post from Telecom Egypt about service restoration dispelled that claim, noting “The company also confirms that there is no truth to what has been circulated on some social media sites about the presence of a break in one of the submarine cables.”
Tunisia
A reported DNS server outage (albeit unconfirmed) at Tunisian Internet provider Topnet (AS37705) caused a brief Internet disruption for the provider’s customers on December 17, also impacting traffic volumes at a national level. The incident lasted less than two hours, from 13:00 – 14:45 local time (12:00 – 13:45 UTC).
Guinea
An unspecified incident on the Orange Guinée (AS37461) network impacted Internet connectivity, as well as telephone calls and text messages during the morning of December 22. The graph below shows a near-complete outage on the network between 09:15 – 11:30 local time (09:15 – 11:30 UTC). The provider posted a subsequent update regarding the restoration of calls, text messages, and Internet connectivity.
Conclusion
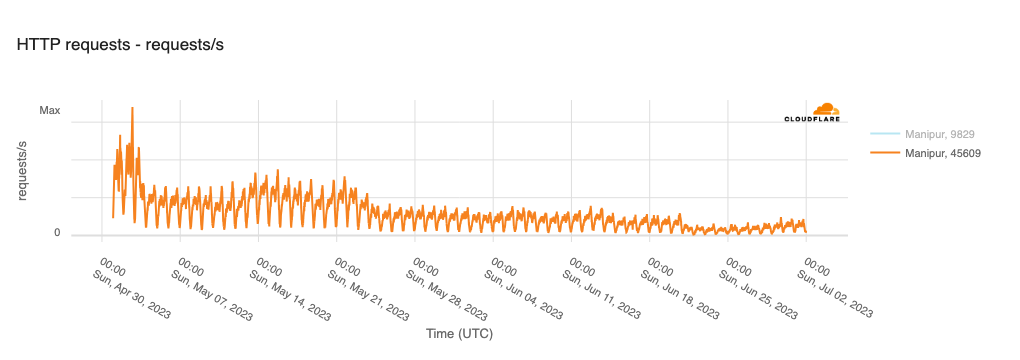
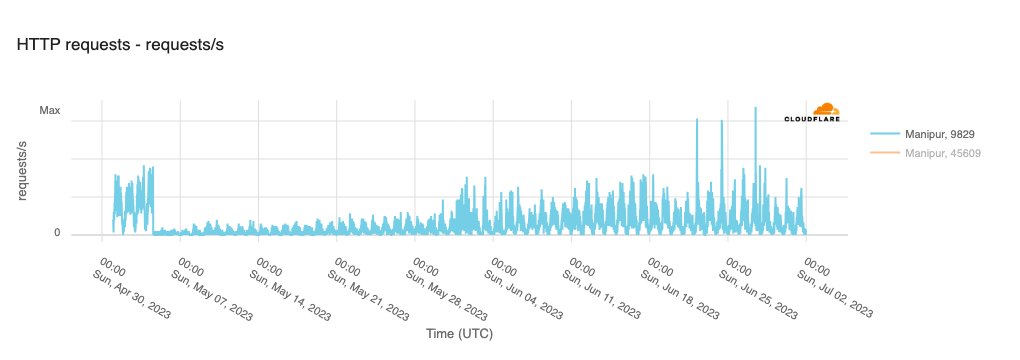
Within the Cloudflare Radar 2023 Year in Review, we highlighted over 180 major Internet disruptions that were observed year-to-date through the end of November, though the actual number was likely closer to 200 by the end of the year. While that may seem like a lot, it is worth nothing that the actual number is even higher, as these posts are not exhaustive in their coverage of such events. For example, while we covered the Internet shutdown in Manipur, India that took place across multiple months in 2023, internetshutdowns.in shows that over 90 more smaller localized shutdowns were put into place across the country.
Beginning on Thursday, November 2, 2023 at 11:43 UTC Cloudflare’s control plane and analytics services experienced an outage. The control plane of Cloudflare consists primarily of the customer-facing interface for all of our services including our website and APIs. Our analytics services include logging and analytics reporting.
The incident lasted from November 2 at 11:44 UTC until November 4 at 04:25 UTC. We were able to restore most of our control plane at our disaster recovery facility as of November 2 at 17:57 UTC. Many customers would not have experienced issues with most of our products after the disaster recovery facility came online. However, other services took longer to restore and customers that used them may have seen issues until we fully resolved the incident. Our raw log services were unavailable for most customers for the duration of the incident.
Services have now been restored for all customers. Throughout the incident, Cloudflare’s network and security services continued to work as expected. While there were periods where customers were unable to make changes to those services, traffic through our network was not impacted.
This post outlines the events that caused this incident, the architecture we had in place to prevent issues like this, what failed, what worked and why, and the changes we’re making based on what we’ve learned over the last 36 hours.
To start, this never should have happened. We believed that we had high availability systems in place that should have stopped an outage like this, even when one of our core data center providers failed catastrophically. And, while many systems did remain online as designed, some critical systems had non-obvious dependencies that made them unavailable. I am sorry and embarrassed for this incident and the pain that it caused our customers and our team.
Intended Design
Cloudflare’s control plane and analytics systems run primarily on servers in three data centers around Hillsboro, Oregon. The three data centers are independent of one another, each have multiple utility power feeds, and each have multiple redundant and independent network connections.
The facilities were intentionally chosen to be at a distance apart that would minimize the chances that a natural disaster would cause all three to be impacted, while still close enough that they could all run active-active redundant data clusters. This means that they are continuously syncing data between the three facilities. By design, if any of the facilities goes offline then the remaining ones are able to continue to operate.
This is a system design that we began implementing four years ago. While most of our critical control plane systems had been migrated to the high availability cluster, some services, especially for some newer products, had not yet been added to the high availability cluster.
In addition, our logging systems were intentionally not part of the high availability cluster. The logic of that decision was that logging was already a distributed problem where logs were queued at the edge of our network and then sent back to the core in Oregon (or another regional facility for customers using regional services for logging). If our logging facility was offline then analytics logs would queue at the edge of our network until it came back online. We determined that analytics being delayed was acceptable.
Flexential Data Center Power Failure
The largest of the three facilities in Oregon is run by Flexential. We refer to this facility as “PDX-04.” Cloudflare leases space in PDX-04 where we house our largest analytics cluster as well as more than a third of the machines for our high availability cluster. It is also the default location for services that have not yet been onboarded onto our high availability cluster. We are a relatively large customer of the facility, consuming approximately 10 percent of its total capacity.
On November 2 at 08:50 UTC Portland General Electric (PGE), the utility company that services PDX-04, had an unplanned maintenance event affecting one of their independent power feeds into the building. That event shut down one feed into PDX-04. The data center has multiple feeds with some level of independence that can power the facility. However, Flexential powered up their generators to effectively supplement the feed that was down.
Counter to best practices, Flexential did not inform Cloudflare that they had failed over to generator power. None of our observability tools were able to detect that the source of power had changed. Had they informed us, we would have stood up a team to monitor the facility closely and move control plane services that were dependent on that facility out while it was degraded.
It is also unusual that Flexential ran both the one remaining utility feed and the generators at the same time. It is not unusual for utilities to ask data centers to drop off the grid when power demands are high and run exclusively on generators. Flexential operates 10 generators, inclusive of redundant units, capable of supporting the facility at full load. It would also have been possible for Flexential to run the facility only from the remaining utility feed. We haven’t gotten a clear answer why they ran utility power and generator power.
Informed Speculation On What Happened Next
From this decision onward, we don’t yet have clarity from Flexential on the root cause or some of the decisions they made or the events. We will update this post as we get more information from Flexential, as well as PGE, on what happened. Some of what follows is informed speculation based on the most likely series of events as well as what individual Flexential employees have shared with us unofficially.
One possible reason they may have left the utility line running is because Flexential was part of a program with PGE called DSG. DSG allows the local utility to run a data center’s generators to help supply additional power to the grid. In exchange, the power company helps maintain the generators and supplies fuel. We have been unable to locate any record of Flexential informing us about the DSG program. We’ve asked if DSG was active at the time and have not received an answer. We do not know if it contributed to the decisions that Flexential made, but it could explain why the utility line continued to remain online after the generators were started.
At approximately 11:40 UTC, there was a ground fault on a PGE transformer at PDX-04. We believe, but have not been able to get confirmation from Flexential or PGE, that this was the transformer that stepped down power from the grid for the second feed that was still running as it entered the data center. It seems likely, though we have not been able to confirm with Flexential or PGE, that the ground fault was caused by the unplanned maintenance PGE was performing that impacted the first feed. Or it was a very unlucky coincidence.
Ground faults with high voltage (12,470 volt) power lines are very bad. Electrical systems are designed to quickly shut down to prevent damage when one occurs. Unfortunately, in this case, the protective measure also shut down all of PDX-04’s generators. This meant that the two sources of power generation for the facility — both the redundant utility lines as well as the 10 generators — were offline.
Fortunately, in addition to the generators, PDX-04 also contains a bank of UPS batteries. These batteries are supposedly sufficient to power the facility for approximately 10 minutes. That time is meant to be enough to bridge the gap between the power going out and the generators automatically starting up. If Flexential could get the generators or a utility feed restored within 10 minutes then there would be no interruption. In reality, the batteries started to fail after only 4 minutes based on what we observed from our own equipment failing. And it took Flexential far longer than 10 minutes to get the generators restored.
Attempting to Restore Power
While we haven’t gotten official confirmation, we have been told by employees that three things hampered getting the generators back online. First, they needed to be physically accessed and manually restarted because of the way the ground fault had tripped circuits. Second, Flexential’s access control system was not powered by the battery backups so it was offline. And third, the overnight staffing at the site did not include an experienced operations or electrical expert — the overnight shift consisted of security and an unaccompanied technician who had only been on the job for a week.
Between 11:44 and 12:01 UTC, with the generators not fully restarted, the UPS batteries ran out of power and all customers of the data center lost power. Throughout this, Flexential never informed Cloudflare that there was any issue at the facility. We were first notified of issues in the data center when the two routers that connect the facility to the rest of the world went offline at 11:44 UTC. When we weren’t able to reach the routers directly or through out-of-band management, we attempted to contact Flexential and dispatched our local team to physically travel to the facility. The first message to us from Flexential that they were experiencing an issue was at 12:28 UTC.
We are currently experiencing an issue with power at our [PDX-04] that began at approximately 0500AM PT [12:00 UTC]. Engineers are actively working to resolve the issue and restore service. We will communicate progress every 30 minutes or as more information becomes available as to the estimated time to restore. Thank you for your patience and understanding.
Designing for Data Center Level Failure
While the PDX-04’s design was certified Tier III before construction and is expected to provide high availability SLAs, we planned for the possibility that it could go offline. Even well-run facilities can have bad days. And we planned for that. What we expected would happen in that case is that our analytics would be offline, logs would be queued at the edge and delayed, and certain lower priority services that were not integrated into our high availability cluster would go offline temporarily until they could be restored at another facility.
The other two data centers running in the area would take over responsibility for the high availability cluster and keep critical services online. Generally that worked as planned. Unfortunately, we discovered that a subset of services that were supposed to be on the high availability cluster had dependencies on services exclusively running in PDX-04.
In particular, two critical services that process logs and power our analytics — Kafka and ClickHouse — were only available in PDX-04 but had services that depended on them that were running in the high availability cluster. Those dependencies shouldn’t have been so tight, should have failed more gracefully, and we should have caught them.
We had performed testing of our high availability cluster by taking offline each (and both) of the other two data center facilities entirely offline. And we had also tested taking the high availability portion of PDX-04 offline. However, we had never tested fully taking the entire PDX-04 facility offline. As a result, we had missed the importance of some of these dependencies on our data plane.
We were also far too lax about requiring new products and their associated databases to integrate with the high availability cluster. Cloudflare allows multiple teams to innovate quickly. As such, products often take different paths toward their initial alpha. While, over time, our practice is to migrate the backend for these services to our best practices, we did not formally require that before products were declared generally available (GA). That was a mistake as it meant that the redundancy protections we had in place worked inconsistently depending on the product.
Moreover, far too many of our services depend on the availability of our core facilities. While this is the way a lot of software services are created, it does not play to Cloudflare’s strength. We are good at distributed systems. Throughout this incident, our global network continued to perform as expected. While some of our products and features are configurable and serviceable through the edge of our network without needing the core, far too many today fail if the core is unavailable. We need to use the distributed systems products that we make available to all our customers for all our services so they continue to function mostly as normal even if our core facilities are disrupted.
Disaster Recovery
At 12:48 UTC, Flexential was able to get the generators restarted. Power returned to portions of the facility. In order to not overwhelm the system, when power is restored to a data center it is typically done gradually by powering back on one circuit at a time. Like the circuit breakers in a residential home, each customer is serviced by redundant breakers. When Flexential attempted to power back up Cloudflare’s circuits, the circuit breakers were discovered to be faulty. We don’t know if the breakers failed due to the ground fault or some other surge as a result of the incident, or if they’d been bad before and it was only discovered after they had been powered off.
Flexential began the process of replacing the failed breakers. That required them to source new breakers because more were bad than they had on hand in the facility. Because more services were offline than we expected, and because Flexential could not give us a time for restoration of our services, we made the call at 13:40 UTC to fail over to Cloudflare’s disaster recovery sites located in Europe. Thankfully, we only needed to fail over a small percentage of Cloudflare’s overall control plane. Most of our services continued to run across our high availability systems across the two active core data centers.
We turned up the first services on the disaster recovery site at 13:43 UTC.Cloudflare’s disaster recovery sites provide critical control plane services in the event of a disaster. While the disaster recovery site does not support some of our log processing services, it is designed to support the other portions of our control plane.
When services were turned up there, we experienced a thundering herd problem where the API calls that had been failing overwhelmed our services. We implemented rate limits to get the request volume under control. During this period, customers of most products would have seen intermittent errors when making modifications through our dashboard or API. By 17:57 UTC, the services that had been successfully moved to the disaster recovery site were stable and most customers were no longer directly impacted. However, some systems still required manual configuration (e.g., Magic WAN) and some other services, largely related to log processing and some bespoke APIs, remained unavailable until we were able to restore PDX-04.
Some Products and Features Delayed Restart
A handful of products did not properly get stood up on our disaster recovery sites. These tended to be newer products where we had not fully implemented and tested a disaster recovery procedure. These included our Stream service for uploading new videos and some other services. Our team worked two simultaneous tracks to get these services restored: 1) reimplementing them on our disaster recovery sites; and 2) migrating them to our high-availability cluster.
Flexential replaced our failed circuit breakers, restored both utility feeds, and confirmed clean power at 22:48 UTC. Our team was all-hands-on-deck and had worked all day on the emergency, so I made the call that most of us should get some rest and start the move back to PDX-04 in the morning. That decision delayed our full recovery, but I believe made it less likely that we’d compound this situation with additional mistakes.
Beginning first thing on November 3, our team began restoring service in PDX-04. That began with physically booting our network gear then powering up thousands of servers and restoring their services. The state of our services in the data center was unknown as we believed multiple power cycles were likely to have occurred during the incident. Our only safe process to recover was to follow a complete bootstrap of the entire facility.
This involved a manual process of bringing our configuration management servers online to begin the restoration of the facility. Rebuilding these took 3 hours. From there, our team was able to bootstrap the rebuild of the rest of the servers that power our services. Each server took between 10 minutes and 2 hours to rebuild. While we were able to run this in parallel across multiple servers, there were inherent dependencies between services that required some to be brought back online in sequence.
Services are now fully restored as of November 4 at 04:25 UTC. For most customers, because of how we queue analytics at the edge, you should see no data loss in your analytics. Any gaps that appear as of now we expect will fill in as any lingering caches of analytics data is ingested. For customers that use our log push feature, your logs will not have been processed for the majority of the event, so anything you did not receive will not be recovered. However, the records in our analytics dashboard will still be accurate.
Lessons and Remediation
We have a number of questions that we need answered from Flexential. But we also must expect that entire data centers may fail. Google has a process where when there’s a significant event or crisis they can call a Code Yellow or Code Red. In these cases, most or all engineering resources are shifted to addressing the issue at hand.
We have not had such a process in the past, but it’s clear today we need to implement a version of it ourselves: Code Orange. We are shifting all non-critical engineering functions to focusing on ensuring high reliability of our control plane. As part of that, we expect the following changes:
Remove dependencies on our core data centers for control plane configuration of all services and move them wherever possible to be powered first by our distributed network
Ensure that the control plane running on the network continues to function even if all our core data centers are offline
Require that all products and features that are designated Generally Available must rely on the high availability cluster (if they rely on any of our core data centers), without having any software dependencies on specific facilities
Require all products and features that are designated Generally Available have a reliable disaster recovery plan that is tested
Test the blast radius of system failures and minimize the number of services that are impacted by a failure
Implement more rigorous chaos testing of all data center functions including the full removal of each of our core data center facilities
Thorough auditing of all core data centers and a plan to reaudit to ensure they comply with our standards
Logging and analytics disaster recovery plan that ensures no logs are dropped even in the case of a failure of all our core facilities
As I said earlier, I am sorry and embarrassed for this incident and the pain that it caused our customers and our team. We have the right systems and procedures in place to be able to withstand even the cascading string of failures we saw at our data center provider, but we need to be more rigorous about enforcing that they are followed and tested for unknown dependencies. This will have my full attention and the attention of a large portion of our team through the balance of the year. And the pain from the last couple days will make us better.
On Saturday, October 7, 2023, attacks from the Palestinian group Hamas launched from the Gaza Strip against the south of Israel started a new conflict in the region. Israel officially declared that it is at war the next day. Cloudflare's data shows that Internet traffic was impacted in different ways, both in Israel and Palestine, with two networks (autonomous systems) in the Gaza Strip going offline a few hours after the attacks. Subsequently, on October 9, two additional networks also experienced outages. We also saw an uptick in cyberattacks targeting Israel, including a 1.26 billion HTTP requests DDoS attack, and Palestine.
Starting with general Internet traffic trends, there was a clear increase in Internet traffic right after the attacks reportedly began (03:30 UTC, 06:30 local time). Traffic spiked at around 03:35 UTC (06:35 local time) in both Israel (~170% growth compared with the previous week) and Palestine (100% growth).
That growth is consistent with other situations, where we’ve seen surges in Internet traffic when countrywide events occur and people are going online to check for news, updates, and more information on what is happening, with social media and messaging also playing a role. However, in Palestine, that traffic growth was followed by a clear drop in traffic around 08:00 UTC (11:00 local time).
The Palestine uptick in traffic after the Hamas attacks started is more visible when only looking at HTTP requests. Requests in Palestine dropped on Saturday and Sunday, October 7 and 8, as much as 20% and 25%, respectively.
Palestine's outages and Internet impact
What drove the drop in Internet traffic in Palestine? Our data shows that two Gaza Strip related networks (autonomous systems or ASNs) were offline on that October 7 morning. Fusion (AS42314) was offline from 08:00 UTC, but saw some recovery after 17:00 UTC the next day; this only lasted for a few hours, given that it went back offline after 12:00 UTC this Monday, October 9.
It was the same scenario for DCC North (AS203905), but it went offline after 10:00 UTC and with no recovery of traffic observed as of Monday, October 9. These Internet disruptions may be related to power outages in the Gaza Strip.
During the day on October 7, other Palestinian networks saw less traffic than usual. JETNET (AS199046) had around half of the usual traffic after 08:00 UTC, similar to SpeedClick (AS57704), which had around 60% less traffic. After 14:15 on October 9, traffic to those networks dropped sharply (a 95% decrease compared with the previous week), showing only residual traffic.
When looking more closely at the Gaza Strip specifically, we can see that some districts or governorates had a drop in HTTP requests a few hours after the first Hamas attacks. The Gaza Governorate was impacted, with traffic dropping on October 7, 2023, after 09:15 UTC. On October 9, at 18:00 UTC, traffic was 46% lower than in the previous week. (Note: there were spikes in traffic during Friday, October 6, several hours before the attacks, but it is unclear what caused those spikes.)
The Deir al-Balah Governorate (on October 9, at 18:00 UTC, traffic was 46% lower than in the previous week) and the Khan Yunis Governorate (50% lower) also both experienced similar drops in traffic:
In the Rafah Governorate traffic dropped after 19:00 UTC on October 8 (and on October 9, at 18:00 UTC, traffic was 65% lower than in the previous week).
Other Palestinian governorates in the West Bank did not experience the same impact to Internet traffic.
Spikes in Internet traffic in Israel
In Israel, Internet traffic surged to ~170% as compared to the previous week right after the Hamas attacks on October 7 at around 03:35 UTC (06:35 local time), and again at around 16:00 UTC (19:00 local time), with ~80% growth compared to the previous week. In both cases, the increase was driven by mobile device traffic.
There was also increased traffic, as compared with usual levels, on Sunday, October 8, with notable spikes at around 06:00 (09:00 local time) and 12:00 UTC (15:00 local time), seen in the HTTP requests traffic graph below.
Mobile device traffic drove the Saturday, October 7 spikes in traffic, with the daily mobile device usage percentage reaching its highest in the past two months, reaching 56%.
Looking at specific Israel districts, traffic looks similar to the nationwide perspective.
Cyber attacks targeting Israel
Cyber attacks are frequent, recurrent, and are not necessarily dependent on actual wars on the ground, as our 2023 attacks landscape clearly showed. However, it is not unusual to see cyberattacks launched in tandem with ground assaults. We saw that in Ukraine, an uptick in cyber attacks started just before war began there on February 24, 2022, and were even more constant, and spread to other countries after that day.
In Israel, we saw a clear uptick in cyber attacks earlier this year, with another wave of notable attacks on October 7 and October 8, 2023, after the Hamas attacks. The largest ones were DDoS attacks targeting Israeli newspapers. One attack on October 8, reached 1.26 billion daily requests blocked by Cloudflare as DDoS attacks, and the other reached 346 million daily requests on October 7, and 332 million daily requests the following day.
Looking at these DDoS attacks in terms of requests per second, one of the impacted sites experienced a peak of 1.1 million requests per second on October 8 at 02:00 UTC, and the other Israeli newspaper saw a peak of 745k requests per second at around 06:00 the same day.
In Palestine, we also saw application layer DDoS attacks, but not as big. The main one in the past three months was on October 7, 2023, targeting a Palestine online newspaper, reaching 105 million daily requests.
Looking at these most notable DDoS attacks targeting Palestine in terms of requests per second (rps), the most impacted site (a Palestinian newspaper) experienced a peak of 214k requests per second at around 17:20 UTC on October 7.
Follow Cloudflare Radar for up to date information
On 4 October 2023, Cloudflare experienced DNS resolution problems starting at 07:00 UTC and ending at 11:00 UTC. Some users of 1.1.1.1 or products like WARP, Zero Trust, or third party DNS resolvers which use 1.1.1.1 may have received SERVFAIL DNS responses to valid queries. We’re very sorry for this outage. This outage was an internal software error and not the result of an attack. In this blog, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
In the Domain Name System (DNS), every domain name exists within a DNS zone. The zone is a collection of domain names and host names that are controlled together. For example, Cloudflare is responsible for the domain name cloudflare.com, which we say is in the “cloudflare.com” zone. The .com top-level domain (TLD) is owned by a third party and is in the “com” zone. It gives directions on how to reach cloudflare.com. Above all of the TLDs is the root zone, which gives directions on how to reach TLDs. This means that the root zone is important in being able to resolve all other domain names. Like other important parts of the DNS, the root zone is signed with DNSSEC, which means the root zone itself contains cryptographic signatures.
The root zone is published on the root servers, but it is also common for DNS operators to retrieve and retain a copy of the root zone automatically so that in the event that the root servers cannot be reached, the information in the root zone is still available. Cloudflare’s recursive DNS infrastructure takes this approach as it also makes the resolution process faster. New versions of the root zone are normally published twice a day. 1.1.1.1 has a WebAssembly app called static_zone running on top of the main DNS logic that serves those new versions when they are available.
What happened
On 21 September, as part of a known and planned change in root zone management, a new resource record type was included in the root zones for the first time. The new resource record is named ZONEMD, and is in effect a checksum for the contents of the root zone.
The root zone is retrieved by software running in Cloudflare’s core network. It is subsequently redistributed to Cloudflare’s data centers around the world. After the change, the root zone containing the ZONEMD record continued to be retrieved and distributed as normal. However, the 1.1.1.1 resolver systems that make use of that data had problems parsing the ZONEMD record. Because zones must be loaded and served in their entirety, the system’s failure to parse ZONEMD meant the new versions of the root zone were not used in Cloudflare’s resolver systems. Some of the servers hosting Cloudflare's resolver infrastructure failed over to querying the DNS root servers directly on a request-by-request basis when they did not receive the new root zone. However, others continued to rely on the known working version of the root zone still available in their memory cache, which was the version pulled on 21 September before the change.
On 4 October 2023 at 07:00 UTC, the DNSSEC signatures in the version of the root zone from 21 September expired. Because there was no newer version that the Cloudflare resolver systems were able to use, some of Cloudflare’s resolver systems stopped being able to validate DNSSEC signatures and as a result started sending error responses (SERVFAIL). The rate at which Cloudflare resolvers generated SERVFAIL responses grew by 12%. The diagrams below illustrate the progression of the failure and how it became visible to users.
Incident timeline and impact
21 September 6:30 UTC: Last successful pull of the root zone 4 October 7:00 UTC: DNSSEC signatures in the root zone obtained on 21 September expired causing an increase in SERVFAIL responses to client queries. 7:57: First external reports of unexpected SERVFAILs started coming in. 8:03: Internal Cloudflare incident declared. 8:50: Initial attempt made at stopping 1.1.1.1 from serving responses using the stale root zone file with an override rule. 10:30: Stopped 1.1.1.1 from preloading the root zone file entirely. 10:32: Responses returned to normal. 11:02: Incident closed.
This below chart shows the timeline of impact along with the percentage of DNS queries that returned with a SERVFAIL error:
We expect a baseline volume of SERVFAIL errors for regular traffic during normal operation. Usually that percentage sits at around 3%. These SERVFAILs can be caused by legitimate issues in the DNSSEC chain, failures to connect to authoritative servers, authoritative servers taking too long to respond, and many others. During the incident the amount of SERVFAILs peaked at 15% of total queries, although the impact was not evenly distributed around the world and was mainly concentrated in our larger data centers like Ashburn, Virginia; Frankfurt, Germany; and Singapore.
Why this incident happened
Why parsing the ZONEMD record failed
DNS has a binary format for storing resource records. In this binary format the type of the resource record (TYPE) is stored as a 16-bit integer. The type of resource record determines how the resource data (RDATA) is parsed. When the record type is 1, this means it is an A record, and the RDATA can be parsed as an IPv4 address. Record type 28 is an AAAA record, whose RDATA can be parsed as an IPv6 address instead. When a parser runs into an unknown resource type it won’t know how to parse its RDATA, but fortunately it doesn’t have to: the RDLENGTH field indicates how long the RDATA field is, allowing the parser to treat it as an opaque data element.
The reason static_zone didn’t support the new ZONEMD record is because up until now we had chosen to distribute the root zone internally in its presentation format, rather than in the binary format. When looking at the text representation for a few resource records we can see there is a lot more variation in how different records are presented.
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2023100400 1800 900 604800 86400
. 86400 IN RRSIG SOA 8 0 86400 20231017050000 20231004040000 46780 . J5lVTygIkJHDBt6HHm1QLx7S0EItynbBijgNlcKs/W8FIkPBfCQmw5BsUTZAPVxKj7r2iNLRddwRcM/1sL49jV9Jtctn8OLLc9wtouBmg3LH94M0utW86dKSGEKtzGzWbi5hjVBlkroB8XVQxBphAUqGxNDxdE6AIAvh/eSSb3uSQrarxLnKWvHIHm5PORIOftkIRZ2kcA7Qtou9NqPCSE8fOM5EdXxussKChGthmN5AR5S2EruXIGGRd1vvEYBrRPv55BAWKKRERkaXhgAp7VikYzXesiRLdqVlTQd+fwy2tm/MTw+v3Un48wXPg1lRPlQXmQsuBwqg74Ts5r8w8w==
. 518400 IN NS a.root-servers.net.
. 86400 IN ZONEMD 2023100400 1 241 E375B158DAEE6141E1F784FDB66620CC4412EDE47C8892B975C90C6A102E97443678CCA4115E27195B468E33ABD9F78C
When we run into an unknown resource record it’s not always easy to know how to handle it. Because of this, the library we use to parse the root zone at the edge does not make an attempt at doing so, and instead returns a parser error.
Why a stale version of the root zone was used
The static_zone app, tasked with loading and parsing the root zone for the purpose of serving the root zone locally (RFC 7706), stores the latest version in memory. When a new version is published it parses it and, when successfully done so, drops the old version. However, as parsing failed the static_zone app never switched to a newer version, and instead continued using the old version indefinitely. When the 1.1.1.1 service is first started the static_zone app does not have an existing version in memory. When it tries to parse the root zone it fails in doing so, but because it does not have an older version of the root zone to fall back on, it falls back on querying the root servers directly for incoming requests.
Why the initial attempt at disabling static_zone didn’t work
Initially we tried to disable the static_zone app through override rules, a mechanism that allows us to programmatically change some behavior of 1.1.1.1. The rule we deployed was:
phase = pre-cache set-tag rec_disable_static
For any incoming request this rule adds the tag rec_disable_static to the request. Inside the static_zone app we check for this tag and, if it’s set, we do not return a response from the cached, static root zone. However, to improve cache performance queries are sometimes forwarded to another node if the current node can’t find the response in its own cache. Unfortunately, the rec_disable_static tag is not included in the queries being forwarded to other nodes, which caused the static_zone app to continue replying with stale information until we eventually disabled the app entirely.
Why the impact was partial
Cloudflare regularly performs rolling reboots of the servers that host our services for tasks like kernel updates that can only take effect after a full system restart. At the time of this outage, resolver server instances that were restarted between the ZONEMD change and the DNSSEC invalidation did not contribute to impact. If they had restarted during this two-week period, they would have failed to load the root zone on startup and fallen back to resolving by sending DNS queries to root servers instead. In addition, the resolver uses a technique called serve stale (RFC 8767) with the purpose of being able to continue to serve popular records from a potentially stale cache to limit the impact. A record is considered to be stale once the TTL amount of seconds has passed since the record was retrieved from upstream. This prevented a total outage; impact was mainly felt in our largest data centers which had many servers that had not restarted the 1.1.1.1 service in that timeframe.
Remediation and follow-up steps
This incident had widespread impact, and we take the availability of our services very seriously. We have identified several areas of improvement and will continue to work on uncovering any other gaps that could cause a recurrence.
Here is what we are working on immediately:
Visibility: We’re adding alerts to notify when static_zone serves a stale root zone file. It should not have been the case that serving a stale root zone file went unnoticed for as long as it did. If we had been monitoring this better, with the caching that exists, there would have been no impact. It is our goal to protect our customers and their users from upstream changes.
Resilience: We will re-evaluate how we ingest and distribute the root zone internally. Our ingestion and distribution pipelines should handle new RRTYPEs seamlessly, and any brief interruption to the pipeline should be invisible to end users.
Testing: Despite having tests in place around this problem, including tests related to unreleased changes in parsing the new ZONEMD records, we did not adequately test what happens when the root zone fails to parse. We will improve our test coverage and the related processes.
Architecture: We should not use stale copies of the root zone past a certain point. While it’s certainly possible to continue to use stale root zone data for a limited amount of time, past a certain point there are unacceptable operational risks. We will take measures to ensure that the lifetime of cached root zone data is better managed as described in RFC 8806: Running a Root Server Local to a Resolver.
Conclusion
We are deeply sorry that this incident happened. There is one clear message from this incident: do not ever assume that something is not going to change! Many modern systems are built with a long chain of libraries that are pulled into the final executable, each one of those may have bugs or may not be updated early enough for programs to operate correctly when changes in input happen. We understand how important it is to have good testing in place that allows detection of regressions and systems and components that fail gracefully on changes to input. We understand that we need to always assume that “format” changes in the most critical systems of the internet (DNS and BGP) are going to have an impact.
We have a lot to follow up on internally and are working around the clock to make sure something like this does not happen again.
We launched the Cloudflare Radar Outage Center (CROC) during Birthday Week 2022 as a way of keeping the community up to date on Internet disruptions, including outages and shutdowns, visible in Cloudflare’s traffic data. While some of the entries have their genesis in information from social media posts made by local telecommunications providers or civil society organizations, others are based on an internal traffic anomaly detection and alerting tool. Today, we’re adding this alerting feed to Cloudflare Radar, showing country and network-level traffic anomalies on the CROC as they are detected, as well as making the feed available via API.
Building on this new functionality, as well as the route leaks and route hijacks insights that we recently launched on Cloudflare Radar, we are also launching new Radar notification functionality, enabling you to subscribe to notifications about traffic anomalies, confirmed Internet outages, route leaks, or route hijacks. Using the Cloudflare dashboard’s existing notification functionality, users can set up notifications for one or more countries or autonomous systems, and receive notifications when a relevant event occurs. Notifications may be sent via e-mail or webhooks — the available delivery methods vary according to plan level.
Traffic anomalies
Internet traffic generally follows a fairly regular pattern, with daily peaks and troughs at roughly the same volumes of traffic. However, while weekend traffic patterns may look similar to weekday ones, their traffic volumes are generally different. Similarly, holidays or national events can also cause traffic patterns and volumes to differ significantly from “normal”, as people shift their activities and spend more time offline, or as people turn to online sources for information about, or coverage of, the event. These traffic shifts can be newsworthy, and we have covered some of them in past Cloudflare blog posts (King Charles III coronation, Easter/Passover/Ramadan, Brazilian presidential elections).
However, as you also know from reading our blog posts and following Cloudflare Radar on social media, it is the more drastic drops in traffic that are a cause for concern. Some are the result of infrastructure damage from severe weather or a natural disaster like an earthquake and are effectively unavoidable, but getting timely insights into the impact of these events on Internet connectivity is valuable from a communications perspective. Other traffic drops have occurred when an authoritarian government orders mobile Internet connectivity to be shut down, or shuts down all Internet connectivity nationwide. Timely insights into these types of anomalous traffic drops are often critical from a human rights perspective, as Internet shutdowns are often used as a means of controlling communication with the outside world.
Over the last several months, the Cloudflare Radar team has been using an internal tool to identify traffic anomalies and post alerts for followup to a dedicated chat space. The companion blog post Gone Offline: Detecting Internet Outages goes into deeper technical detail about our traffic analysis and anomaly detection methodologies that power this internal tool.
Many of these internal traffic anomaly alerts ultimately result in Outage Center entries and Cloudflare Radar social media posts. Today, we’re extending the Cloudflare Radar Outage Center and publishing information about these anomalies as we identify them. As shown in the figure below, the new Traffic anomalies table includes the type of anomaly (location or ASN), the entity where the anomaly was detected (country/region name or autonomous system), the start time, duration, verification status, and an “Actions” link, where the user can view the anomaly on the relevant entity traffic page or subscribe to a notification. (If manual review of a detected anomaly finds that it is present in multiple Cloudflare traffic datasets and/or is visible in third-party datasets, such as Georgia Tech’s IODA platform, we will mark it as verified. Unverified anomalies may be false positives, or related to Netflows collection issues, though we endeavor to minimize both.)
In addition to this new table, we have updated the Cloudflare Radar Outage Center map to highlight where we have detected anomalies, as well as placing them into a broader temporal context in a new timeline immediately below the map. Anomalies are represented as orange circles on the map, and can be hidden with the toggle in the upper right corner. Double-bordered circles represent an aggregation across multiple countries, and zooming in to that area will ultimately show the number of anomalies associated with each country that was included in the aggregation. Hovering over a specific dot in the timeline displays information about the outage or anomaly with which it is associated.
Internet outage information has been available via the Radar API since we launched the Outage Center and API in September 2022, and traffic anomalies are now available through a Radar API endpoint as well. An example traffic anomaly API request and response are shown below.
Timely knowledge about Internet “events”, such as drops in traffic or routing issues, are potentially of interest to multiple audiences. Customer service or help desk agents can use the information to help diagnose customer/user complaints about application performance or availability. Similarly, network administrators can use the information to better understand the state of the Internet outside their network. And civil society organizations can use the information to inform action plans aimed at maintaining communications and protecting human rights in areas of conflict or instability. With the new notifications functionality also being launched today, you can subscribe to be notified about observed traffic anomalies, confirmed Internet outages, route leaks, or route hijacks, at a country or autonomous system level. In the following sections, we discuss how to subscribe to and configure notifications, as well as the information contained within the various types of notifications.
Subscribing to notifications
Note that you need to log in to the Cloudflare dashboard to subscribe to and configure notifications. No purchase of Cloudflare services is necessary — just a verified email address is required to set up an account. While we would have preferred to not require a login, it enables us to take advantage of Cloudflare’s existing notifications engine, allowing us to avoid having to dedicate time and resources to building a separate one just for Radar. If you don’t already have a Cloudflare account, visit https://dash.cloudflare.com/sign-up to create one. Enter your username and a unique strong password, click “Sign Up”, and follow the instructions in the verification email to activate your account. (Once you’ve activated your account, we also suggest activating two-factor authentication (2FA) as an additional security measure.)
Once you have set up and activated your account, you are ready to start creating and configuring notifications. The first step is to look for the Notifications (bullhorn) icon – the presence of this icon means that notifications are available for that metric — in the Traffic, Routing, and Outage Center sections on Cloudflare Radar. If you are on a country or ASN-scoped traffic or routing page, the notification subscription will be scoped to that entity.
Look for this icon in the Traffic, Routing, and Outage Center sections of Cloudflare Radar to start setting up notifications.In the Outage Center, click the icon in the “Actions” column of an Internet outages table entry to subscribe to notifications for the related location and/or ASN(s). Click the icon alongside the table description to subscribe to notifications for all confirmed Internet outages.In the Outage Center, click the icon in the “Actions” column of a Traffic anomalies table entry to subscribe to notifications for the related entity. Click the icon alongside the table description to subscribe to notifications for all traffic anomalies.On country or ASN traffic pages, click the icon alongside the description of the traffic trends graph to subscribe to notifications for traffic anomalies or Internet outages impacting the selected country or ASN.On country or ASN routing pages, click the icon alongside the description to subscribe to notifications for route leaks or origin hijacks related to the selected country or ASN.Within the Route Leaks or Origin Hijacks tables on the routing pages, click the icon in a table entry to subscribe to notifications for route leaks or origin hijacks for referenced countries and/or ASNs.
After clicking a notification icon, you’ll be taken to the Cloudflare login screen. Enter your username and password (and 2FA code if required), and once logged in, you’ll see the Add Notification page, pre-filled with the key information passed through from the referring page on Radar, including relevant locations and/or ASNs. (If you are already logged in to Cloudflare, then you’ll be taken directly to the Add Notification page after clicking a notification icon on Radar.) On this page, you can name the notification, add an optional description, and adjust the location and ASN filters as necessary. Enter an email address for notifications to be sent to, or select an established webhook destination (if you have webhooks enabled on your account).
Click “Save”, and the notification is added to the Notifications Overview page for the account.
You can also create and configure notifications directly within Cloudflare, without starting from a link on Radar a Radar page. To do so, log in to Cloudflare, and choose “Notifications” from the left side navigation bar. That will take you to the Notifications page shown below. Click the “Add” button to add a new notification.
On the next page, search for and select “Radar” from the list of Cloudflare products for which notifications are available.
On the subsequent “Add Notification” page, you can create and configure a notification from scratch. Event types can be selected in the “Notify me for:” field, and both locations and ASNs can be searched for and selected within the respective “Filtered by (optional)” fields. Note that if no filters are selected, then notifications will be sent for all events of the selected type(s). Add one or more emails to send notifications to, or select a webhook target if available, and click “Save” to add it to the list of notifications configured for your account.
It is worth mentioning that advanced users can also create and configure notifications through the Cloudflare API Notification policies endpoint, but we will not review that process within this blog post.
Notification messages
Example notification email messages are shown below for the various types of events. Each contains key information like the type of event, affected entities, and start time — additional relevant information is included depending on the event type. Each email includes both plaintext and HTML versions to accommodate multiple types of email clients. (Final production emails may vary slightly from those shown below.)
Internet outage notification emails include information about the affected entities, a description of the cause of the outage, start time, scope (if available), and the type of outage (Nationwide, Network, Regional, or Platform), as well as a link to view the outage in a Radar traffic graph.Traffic anomaly notification emails simply include information about the affected entity and a start time, as well as a link to view the anomaly in a Radar traffic graph.BGP hijack notification emails include information about the hijacking and victim ASNs, affected IP address prefixes, the number of BGP messages (announcements) containing leaked routes, the number of peers announcing the hijack, detection timing, a confidence level on the event being a true hijack, and relevant tags, as well as a link to view details of the hijack event on Radar.BGP route leak notification emails include information about the AS that the leaked routes were learned from, the AS that leaked the routes, the AS that received and propagated the leaked routes, the number of affected prefixes, the number of affected origin ASes, the number of BGP route collector peers that saw the route leak, and detection timing, as well as a link to view details of the route leak event on Radar.
If you are sending notifications to webhooks, you can integrate those notifications into tools like Slack. For example, by following the directions in Slack’s API documentation, creating a simple integration took just a few minutes and results in messages like the one shown below.
Conclusion
Cloudflare’s unique perspective on the Internet provides us with near-real-time insight into unexpected drops in traffic, as well as potentially problematic routing events. While we’ve been sharing these insights with you over the past year, you had to visit Cloudflare Radar to figure out if there were any new “events”. With the launch of notifications, we’ll now automatically send you information about the latest events that you are interested in.
We encourage you to visit Cloudflare Radar to familiarize yourself with the information we publish about traffic anomalies, confirmed Internet outages, BGP route leaks, and BGP origin hijacks. Look for the notification icon on the relevant graphs and tables on Radar, and go through the workflow to set up and subscribe to notifications. (And don’t forget to sign up for a Cloudflare account if you don’t have one already.) Please send us feedback about the notifications, as we are constantly working to improve them, and let us know how and where you’ve integrated Radar notifications into your own tools/workflows/organization.
Currently, Cloudflare Radar curates a list of observed Internet disruptions (which may include partial or complete outages) in the Outage Center. These disruptions are recorded whenever we have sufficient context to correlate with an observed drop in traffic, found by checking status updates and related communications from ISPs, or finding news reports related to cable cuts, government orders, power outages, or natural disasters.
However, we observe more disruptions than we currently report in the outage center because there are cases where we can’t find any source of information that provides a likely cause for what we are observing, although we are still able to validate with external data sources such as Georgia Tech’s IODA. This curation process involves manual work, and is supported by internal tooling that allows us to analyze traffic volumes and detect anomalies automatically, triggering the workflow to find an associated root cause. While the Cloudflare Radar Outage Center is a valuable resource, one of key shortcomings include that we are not reporting all disruptions, and that the current curation process is not as timely as we’d like, because we still need to find the context.
As we announced today in a related blog post, Cloudflare Radar will be publishing anomalous traffic events for countries and Autonomous Systems (ASes). These events are the same ones referenced above that have been triggering our internal workflow to validate and confirm disruptions. (Note that at this time “anomalous traffic events” are associated with drops in traffic, not unexpected traffic spikes.) In addition to adding traffic anomaly information to the Outage Center, we are also launching the ability for users to subscribe to notifications at a location (country) or network (autonomous system) level whenever a new anomaly event is detected, or a new entry is added to the outage table. Please refer to the related blog post for more details on how to subscribe.
The current status of each detected anomaly will be shown in the new “Traffic anomalies” table on the Outage Center page:
When the anomaly is automatically detected its status will initially be Unverified
After attempting to validate ‘Unverified’ entries:
We will change the status to ‘Verified’ if we can confirm that the anomaly appears across multiple internal data sources, and possibly external ones as well. If we find associated context for it, we will also create an outage entry.
We will change status to ‘False Positive’ if we cannot confirm it across multiple data sources. This will remove it from the “Traffic anomalies” table. (If a notification has been sent, but the anomaly isn’t shown in Radar anymore, it means we flagged it as ‘False Positive’.)
We might also manually add an entry with a “Verified” status. This might occur if we observe, and validate, a drop in traffic that is noticeable, but was not large enough for the algorithm to catch it.
A glimpse at what Internet traffic volume looks like
At Cloudflare, we have several internal data sources that can give us insights into what the traffic for a specific entity looks like. We identify the entity based on IP address geolocation in the case of locations, and IP address allocation in the case of ASes, and can analyze traffic from different sources, such as DNS, HTTP, NetFlows, and Network Error Logs (NEL). All the signals used in the figures below come from one of these data sources and in this blog post we will treat this as a univariate time-series problem — in the current algorithm, we use more than one signal just to add redundancy and identify anomalies with a higher level of confidence. In the discussion below, we intentionally select various examples to encompass a broad spectrum of potential Internet traffic volume scenarios.
1. Ideally, the signals would resemble the pattern depicted below for Australia (AU): a stable weekly pattern with a slightly positive trend meaning that the trend average is moving up over time (we see more traffic over time from users in Australia).
These statements can be clearly seen when we perform time-series decomposition which allows us to break down a time-series into its constituent parts to better understand and analyze its underlying patterns. Decomposing the traffic volume for Australia above assuming a weekly pattern with Seasonal-Trend decomposition using LOESS (STL) we get the following:
The weekly pattern we are referring to is represented by the seasonal part of the signal that is expected to be observed due to the fact that we are interested in eyeball / human internet traffic. As observed in the image above, the trend component is expected to move slowly when compared with the signal level and the residual part ideally would resemble white noise meaning that all existing patterns in the signal are represented by the seasonal and trend components.
2. Below we have the traffic volume for AS15964 (CAMNET-AS) that appears to have more of a daily pattern, as opposed to weekly.
We also observe that there’s a value offset of the signal right after the first four days (blue dashed-line) and the red background shows us an outage for which we didn’t find any reporting besides seeing it in our data and other Internet data providers — our intention here is to develop an algorithm that will trigger an event when it comes across this or similar patterns.
4. Another scenario is several scheduled outages for AS203214 (HulumTele), for which we also have context. These anomalies are the easiest to detect since the traffic goes to values that are unique to outages (cannot be mistaken as regular traffic), but it poses another challenge: if our plan was to just check the weekly patterns, since these government-directed outages happen with the same frequency, at some point the algorithm would see this as expected traffic.
5. This outage in Kenya could be seen as similar to the above: the traffic volume went down to unseen values although not as significantly. We also observe some upward spikes in the data that are not following any specific pattern — possibly outliers — that we should clean depending on the approach we use to model the time-series.
6. Lastly, here's the data that will be used throughout this post as an example of how we are approaching this problem. For Madagascar (MG), we observe a clear pattern with pronounced weekends (blue background). There’s also a holiday (Assumption of Mary), highlighted with a green background, and an outage, with a red background. In this example, weekends, holidays, and outages all seem to have roughly the same traffic volume. Fortunately, the outage gives itself away by showing that it intended to go up as in a normal working day, but then there was a sudden drop — we will see it more closely later in this post.
In summary, here we looked over six examples out of ~700 (the number of entities we are automatically detecting anomalies for currently) and we see a wide range of variability. This means that in order to effectively model the time-series we would have to run a lot of preprocessing steps before the modeling itself. These steps include removing outliers, detecting short and long-term data offsets and readjusting, and detecting changes in variance, mean, or magnitude. Time is also a factor in preprocessing, as we would also need to know in advance when to expect events / holidays that will push the traffic down, apply daylight saving time adjustments that will cause a time shift in the data, and be able to apply local time zones for each entity, including dealing with locations that have multiple time zones and AS traffic that is shared across different time zones.
To add to the challenge, some of these steps cannot even be performed in a close-to-real-time fashion (example: we can only say there’s a change in seasonality after some time of observing the new pattern). Considering the challenges mentioned earlier, we have chosen an algorithm that combines basic preprocessing and statistics. This approach aligns with our expectations for the data's characteristics, offers ease of interpretation, allows us to control the false positive rate, and ensures fast execution while reducing the need for many of the preprocessing steps discussed previously.
Above, we noted that we are detecting anomalies for around 700 entities (locations and autonomous systems) at launch. This obviously does not represent the entire universe of countries and networks, and for good reason. As we discuss in this post, we need to see enough traffic from a given entity (have a strong enough signal) to be able to build relevant models and subsequently detect anomalies. For some smaller or sparsely populated countries, the traffic signal simply isn’t strong enough, and for many autonomous systems, we see little-to-no traffic from them, again resulting in a signal too weak to be useful. We are initially focusing on locations where we have a sufficiently strong traffic signal and/or are likely to experience traffic anomalies, as well as major or notable autonomous systems — those that represent a meaningful percentage of a location’s population and/or those that are known to have been impacted by traffic anomalies in the past.
Detecting anomalies
The approach we took to solve this problem involves creating a forecast that is a set of data points that correspond to our expectation according to what we’ve seen in historical data. This will be explained in the section Creating a forecast. We take this forecast and compare it to what we are actually observing — if what we are observing is significantly different from what we expect, then we call it an anomaly. Here, since we are interested in traffic drops, an anomaly will always correspond to lower traffic than the forecast / expected traffic. This comparison is elaborated in the section Comparing forecast with actual traffic.
In order to compute the forecast we need to fulfill the following business requirements:
We are mainly interested in traffic related to human activity.
The more timely we detect the anomaly, the more useful it is. This needs to take into account constraints such as data ingestion and data processing times, but once the data is available, we should be able to use the latest data point and detect if it is an anomaly.
A low False Positive (FP) rate is more important than a high True Positive (TP) rate. As an internal tool, this is not necessarily true, but as a publicly visible notification service, we want to limit spurious entries at the cost of not reporting some anomalies.
Selecting which entities to observe
Aside from the examples given above, the quality of the data highly depends on the volume of the data, and this means that we have different levels of data quality depending on which entity (location / AS) we are considering. As an extreme example, we don’t have enough data from Antarctica to reliably detect outages. Follows the process we used to select which entities are eligible to be observed.
For ASes, since we are mainly interested in Internet traffic that represents human activity, we use the number of users estimation provided by APNIC. We then compute the total number of users per location by summing up the number of users of each AS in that location, and then we calculate what percentage of users an AS has for that location (this number is also provided by the APNIC table in column ‘% of country’). We filter out ASes that have less than 1% of the users in that location. Here’s what the list looks like for Portugal — AS15525 (MEO-EMPRESAS) is excluded because it has less than 1% of users of the total number of Internet users in Portugal (estimated).
At this point we have a subset of ASes and a set of locations (we don’t exclude any location a priori because we want to cover as much as possible) but we will have to narrow it down based on the quality of the data to be able to reliably detect anomalies automatically. After testing several metrics and visually analyzing the results, we came to the conclusion that the best predictor of a stable signal is related to the volume of data, so we removed the entities that don’t satisfy the criteria of a minimum number of unique IPs daily in a two weeks period — the threshold is based on visual inspection.
Creating a forecast
In order to detect the anomalies in a timely manner, we decided to go with traffic aggregated every fifteen minutes, and we are forecasting one hour of data (four data points / blocks of fifteen minutes) that are compared with the actual data.
After selecting the entities for which we will detect anomalies, the approach is quite simple:
1. We look at the last 24 hours immediately before the forecast window and use that interval as the reference. The assumption is that the last 24 hours will contain information about the shape of what follows. In the figure below, the last 24 hours (in blue) corresponds to data transitioning from Friday to Saturday. By using the Euclidean distance, we get the six most similar matches to that reference (orange) — four of those six matches correspond to other transitions from Friday to Saturday. It also captures the holiday on Monday (August 14, 2023) to Tuesday, and we also see a match that is the most dissimilar to the reference, a regular working day from Wednesday to Thursday. Capturing one that doesn't represent the reference properly should not be a problem because the forecast is the median of the most similar 24 hours to the reference, and thus the data of that day ends up being discarded.
There are two important parameters that we are using for this approach to work:
We take into consideration the last 28 days (plus the reference day equals 29). This way we ensure that the weekly seasonality can be seen at least 4 times, we control the risk associated with the trend changing over time, and we set an upper bound to the amount of data we need to process. Looking at the example above, the first day was one with the highest similarity to the reference because it corresponds to the transition from Friday to Saturday.
The other parameter is the number of most similar days. We are using six days as a result of empirical knowledge: given the weekly seasonality, when using six days, we expect at most to match four days for the same weekday and then two more that might be completely different. Since we use the median to create the forecast, the majority is still four and thus those extra days end up not being used as reference. Another scenario is in the case of holidays such as the example below:
A holiday in the middle of the week in this case looks like a transition from Friday to Saturday. Since we are using the last 28 days and the holiday starts on a Tuesday we only see three such transitions that are matching (orange) and then another three regular working days because that pattern is not found anywhere else in the time-series and those are the closest matches. This is why we use the lower quartile when computing the median for an even number of values (meaning we round the data down to the lower values) and use the result as the forecast. This also allows us to be more conservative and plays a role in the true positive/false positive tradeoff.
Lastly let's look at the outage example:
In this case, the matches are always connected to low traffic because the last 24h (reference) corresponds to a transition from Sunday to Monday and due to the low traffic the lowest Euclidean distance (most similar 24h) are either Saturdays (two times) or Sundays (four times). So the forecast is what we would expect to see on a regular Monday and that’s why the forecast (red) has an upward trend but since we had an outage, the actual volume of traffic (black) is considerably lower than the forecast.
This approach works for regular seasonal patterns, as would several other modeling approaches, and it has also been shown to work in case of holidays and other moving events (such as festivities that don’t happen at the same day every year) without having to actively add that information in. Nevertheless, there are still use cases where it will fail specifically when there’s an offset in the data. This is one of the reasons why we use multiple data sources to reduce the chances of the algorithm being affected by data artifacts.
Below we have an example of how the algorithm behaves over time.
Comparing forecast with actual traffic
Once we have the forecast and the actual traffic volume, we do the following steps.
We calculate relative change, which measures how much one value has changed relative to another. Since we are detecting anomalies based on traffic drops, the actual traffic will always be lower than the forecast.
After calculating this metric, we apply the following rules:
The difference between the actual and the forecast must be at least 10% of the magnitude of the signal. This magnitude is computed using the difference between 95th and 5th percentiles of the selected data. The idea is to avoid scenarios where the traffic is low, particularly during the off-peaks of the day and scenarios where small changes in actual traffic correspond to big changes in relative change because the forecast is also low. As an example:
a forecast of 100 Gbps compared with an actual value of 80 Gbps gives us a relative change of -0.20 (-20%).
a forecast of 20 Mbps compared with an actual value of 10 Mbps gives us a much smaller decrease in total volume than the previous example but a relative change of -0.50 (50%).
Then we have two rules for detecting considerably low traffic:
Sustained anomaly: The relative change is below a given threshold α throughout the forecast window (for all four data points). This allows us to detect weaker anomalies (with smaller relative changes) that are extended over time.
Point anomaly: The relative change of the last data point of the forecast window is below a given threshold β (where β < α — these thresholds are negative; as an example, β and α might be -0.6 and -0.4, respectively). In this case we need β < α to avoid triggering anomalies due to the stochastic nature of the data but still be able to detect sudden and short-lived traffic drops.
The values of α and β were chosen empirically to maximize detection rate, while keeping the false positive rate at an acceptable level.
Closing an anomaly event
Although the most important message that we want to convey is when an anomaly starts, it is also crucial to detect when the Internet traffic volume goes back to normal for two main reasons:
We need to have the notion of active anomaly, which means that we detected an anomaly and that same anomaly is still ongoing. This allows us to stop considering new data for the reference while the anomaly is still active. Considering that data would impact the reference and the selection of most similar sets of 24 hours.
Once the traffic goes back to normal, knowing the duration of the anomaly allows us to flag those data points as outliers and replace them, so we don’t end up using it as reference or as best matches to the reference. Although we are using the median to compute the forecast, and in most cases that would be enough to overcome the presence of anomalous data, there are scenarios such as the one for AS203214 (HulumTele), used as example four, where the outages are frequently occurring at the same time of the day that would make the anomalous data become the expectation after few days.
Whenever we detect an anomaly we keep the same reference until the data comes back to normal, otherwise our reference would start including anomalous data. To determine when the traffic is back to normal, we use lower thresholds than α and we give it a time period (currently four hours) where there should be no anomalies in order for it to close. This is to avoid situations where we observe drops in traffic that bounce back to normal and drop again. In such cases we want to detect a single anomaly and aggregate it to avoid sending multiple notifications, and in terms of semantics there’s a high chance that it’s related to the same anomaly.
Conclusion
Internet traffic data is generally predictable, which in theory would allow us to build a very straightforward anomaly detection algorithm to detect Internet disruptions. However, due to the heterogeneity of the time series depending on the entity we are observing (Location or AS) and the presence of artifacts in the data, it also needs a lot of context that poses some challenges if we want to track it in real-time. Here we’ve shown particular examples of what makes this problem challenging, and we have explained how we approached this problem in order to overcome most of the hurdles. This approach has been shown to be very effective at detecting traffic anomalies while keeping a low false positive rate, which is one of our priorities. Since it is a static threshold approach, one of the downsides is that we are not detecting anomalies that are not as steep as the ones we’ve shown.
We will keep working on adding more entities and refining the algorithm to be able to cover a broader range of anomalies.
Cloudflare operates in more than 300 cities in over 100 countries, where we interconnect with over 12,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Late spring often marks the start of a so-called “exam season” in several Middle Eastern and African countries, where students sit for a series of secondary school exams. In an attempt to prevent cheating on these exams, governments in the countries have taken to implementing wide-scale Internet shutdowns covering time periods just before and during the exams. We have covered these shutdowns in the past, including Sudan and Syria in 2021 and Syria, Sudan, and Algeria in 2022. This year, we saw governments in Iraq, Algeria, and Syria taking such actions.
Iraq
In the weeks prior to the start of this year’s shutdowns, it was reported that the Iraqi Ministry of Communications had announced it had refused a request from the Ministry of Education to impose an Internet shutdown during the exams as part of efforts to prevent cheating. Unfortunately, this refusal was short-lived, with shutdowns ultimately starting two weeks later.
In Iraq, two sets of shutdowns were observed: one impacted networks nationwide, except for the Kurdistan Region, while the other impacted networks within the Kurdistan Region. The former set of shutdowns were related to 9th and 12th grade exams, and were scheduled to occur from June 1 through July 15, between 04:00 and 08:00 local time (01:00 – 05:00 UTC). The graphs below show that during June, shutdowns took place on June 1, 4, 6, 8, 11, 13, 15, 17, 21, 22, 24, 25, and 26, resulting in significant disruptions to Internet connectivity. The shutdowns were implemented across a number of network providers, including AS203214 (HulumTele), AS59588 (Zain), AS199739 (Earthlink), AS203735 (Net Tech), AS51684 (Asiacell), and AS58322 (Halasat). The orange-highlighted areas in the graphs below show traffic on each network provider dropping to zero during the shutdowns.
As noted above, exam-related Internet shutdowns were also implemented in the Kurdistan region of Iraq. One report quoted the Minister of Education of the Kurdistan Regional Government as stating "The Internet will be turned off as needed during exams, but just like in previous years, the period of the Internet shutdown will not be lengthy, but rather short.” To that end, the observed shutdowns generally lasted about two hours, occurring between 06:30 and 08:30 local time (03:30 – 05:30 UTC) on June 3, 6, 10, 13, 17, and 24. The graphs below show the impact across three network providers in the region: AS21277 (Newroz Telecom), AS48492 (IQ Online), and AS59625 (KorekTel).
2023 marks the sixth year that Algeria has disrupted Internet connectivity to prevent cheating during nationwide exams. In 2022, we noted that “it appears that the Algerian government has shifted to a content blocking-based approach, instead of a wide-scale Internet shutdown.” It appears that the same approach was taken this year, as we again observed two nominal drops in traffic during each of the exam days, rather than a complete loss of traffic. These traffic shifts were observed on mobile network providers AS33779 (Ooredoo/Wataniya), AS327931 (Djezzy/Optimum), and AS327712 (Mobilis/Telecom Algeria). The first disruption takes place between 08:00 – 12:00 local time (07:00 – 11:00 UTC), with the second occurring between 14:00 – 17:00 local time (13:00 – 16:00 UTC).
Syria
After implementing four exam-related Internet shutdowns in 2022, this year saw just two. On June 25 and 26, Internet shutdowns took place between 05:00 – 08:30 local time (02:00 – 05:30 UTC). Syrian Telecom (AS29256), the government-affiliated telecommunications company, informed subscribers in a Facebook post that the Internet would be cut off at the request of the Ministry of Education.
Senegal
In Senegal, violent protests over the sentencing of opposition leader Ousmane Sonko to jail led the government to restrict access to platforms including WhatsApp, Facebook, Twitter, Instagram, TikTok, Telegram, Signal, and YouTube. On June 4, the Senegal Ministry of Communication issued a statement temporarily suspending mobile Internet access, with a followup statement on June 6 ending the suspension. These disruptions to mobile Internet access were visible on two network providers within the country: AS37196 (Sudatel Senegal) and AS37649 (Tigo/Free).
As shown in the graphs below, the shutdowns on Sudatel Senegal occurred from 15:00 local time on June 3 through 01:00 local time on June 5, and then again from 13:00 local time on June 5 until 01:00 local time on June 6. The three shutdowns seen on Tigo/Free took place between 15:30 – 19:00 local time on June 3, from 13:45 local time on June 4 until 02:05 local time on June 5, and from 13:05 local time on June 5 through 01:00 local time on June 6. (Senegal is UTC+0, so the local times are the same as UTC.)
Mauritania
In Mauritania, authorities cut off mobile Internet services after protests over the death of a young man in police custody. The shutdown began at 23:00 local time on May 30, and lasted six days, with connectivity returning at 23:00 local time on June 6. (Mauritania is UTC+0, so the local times are the same as UTC.) The graphs below show a near complete loss of Internet traffic during that period from AS37541 (Chinguitel) and AS37508 (Mattel), two mobile network providers within the country.
Pakistan
On May 9, Imran Khan, former Prime Minister of Pakistan was arrested on corruption charges. Following the arrest, violent protests erupted in several cities, leading the government of Pakistan to order the shutdown of mobile Internet services, as well as the blocking of several social media platforms. The figures below show the impact of the ordered shutdown to traffic on four mobile network providers within the country: AS24499 (Telenor Pakistan), AS59257 (China Mobile Pak), AS45669 (Mobilink/Jazz), and AS56167 (Ufone/PTML). The ordered shutdown caused a complete loss of Internet traffic from these networks that started at 22:00 local time (17:00 UTC) on May 9 at Telenor and China Mobile Pakistan, 18:00 local time (13:00 UTC) on Mobilink/Jazz, and 01:00 local time on May 10 (20:00 UTC on May 9) at Ufone/PTML. Traffic was restored at 22:00 local time (17:00 UTC) on May 12.
Looking at Cloudflare Radar’s recently launchedInternet Quality page for Pakistan during the duration of the shutdown, we observed that median latency within Pakistan dropped slightly after mobile networks were shut down, shown in the graph below. Prior to the shutdown, median latency (as observed to Cloudflare and a set of other providers) was in the 90-100ms range, while afterward, it averaged closer to 75ms. This may be a result of users shifting to lower latency fixed broadband connections – several fixed broadband providers in the country experienced increased traffic volumes while the mobile networks were unavailable.
Additional details about the mobile network shutdowns, content blocking, and the impact at an administrative unit and city level can be found in our May 12 blog post Cloudflare’s view of Internet disruptions in Pakistan.
India
Internet shutdowns are unfortunately frequent in India, with digital rights organization Access Now reporting at least 84 shutdowns within the country in 2022. The shutdowns are generally implemented at a more local level, and often last for a significant amount of time. One such shutdown took place in the northeastern Indian state of Manipur starting on May 3 after the escalation of ethnic conflict, and was reportedly intended to “thwart the design and activities of anti-national and anti-social elements… by stopping the spread of disinformation and false rumours'' and the likelihood of “serious disturbances to the entire peaceful coexistence of the communities and maintenance of public order”. Mobile data services were initially suspended for a five-day period, with the suspension continually extended through additional templated orders issued every five days.
The graphs below show the impact of the ordered shutdown to traffic from two major network providers in Manipur. Traffic from both AS45609 (Airtel) and AS9829 (BSNL) fell significantly around 18:00 local time (12:30 UTC) on May 4. Traffic on Airtel has remained low, and continued to drop further through the end of June. Traffic on BSNL showed slight signs of recovery starting in early June, but remains extremely low.
The shutdown order remains in place as of the time of this writing (late July).
Severe weather
Guam
On May 24, “Super Typhoon” Mawar wreaked havoc on the US territory of Guam, causing widespread physical damage after it made landfall, taking down trees, buildings, power lines, and communications infrastructure across the island. One result of this damage was a significant disruption to Internet connectivity, as shown in the country-level graph below. Restoration efforts started almost immediately, with Guam Power Authority, Docomo Pacific, and GTA Teleguam all posting regular status updates on their websites and/or social media accounts.
Among the two Internet providers, GTA Teleguam (AS9246) was largely able to complete service restoration in June, with traffic returning to pre-storm levels around June 17, as seen in the graph below. In fact, in a June 20 Facebook post they noted that “As of today, a majority of our wireless network cell sites are operational.” However, recovery at Docomo Pacific (AS3605) is taking significantly longer. The graph below shows that as of the end of June, traffic remained significantly below pre-storm levels.
Cable damage
Bolivia
On June 19, COTAS, a Bolivian telecommunications company, posted an update on their Facebook page that alerted users that a fiber optic cable had been cut in the town of Pongo. As seen in the graphs below, this cut significantly disrupted Internet connectivity across COTAS and two other network providers in the country: AS25620 (COTAS), AS27839 (Comteco), and AS52495 (Cotel) between 13:00 – 18:00 local time (17:00 – 22:00 UTC).
The Gambia
Gamtel, the state telecommunications company in The Gambia, notified subscribers via a Twitter post on June 7 of a localized fiber cut, and then of additional cable cuts on June 8. These fiber cuts disrupted Internet connectivity on AS25250 (Gamtel) between 14:00 local time on June 7 and 00:00 local time on June 9, with traffic volumes down as much as 80% as compared to the previous period. (The Gambia is UTC+0, so the local times are the same as UTC.)
Philippines
An advisory posted on Twitter by Philippines telecommunications provider PLDT at 18:43 local time (10:43 UTC) on June 5 stated “One of our submarine cable partners confirms a loss in some of its internet bandwidth capacity, and thus causing slower Internet browsing. We are working with our partners to provide alternate capacity that would restore the browsing experience in the next few hours.” The traffic graph below shows a minor disruption to Internet traffic for AS9299 (PLDT) starting around 14:00 local time (06:00 UTC), and the “slower Internet browsing” noted by PLDT is evident in the Internet quality graphs below, with increased latency and decreased bandwidth evident around that same time. PLDT stated in a subsequent tweet that as of 06:22 local time on June 6 (22:22 UTC on June 5), “Our submarine cable partner confirms supplementing additional capacity, restoring browser experience.”
Power outages
Curaçao
Aqualectra is the primary utility company in Curaçao, providing water and power services. On June 8, they posted a series of alerts to their Facebook page (1, 2, 3, 4) regarding a power outage impacting “all neighborhoods”, caused by a malfunction in one of the main power cables connected to the substation at Parera. This loss of power impacted Internet connectivity on the island, with a significant loss of traffic observed at a country level, as seen in the graph below, as well as across several Internet service providers, including AS11081 (UTS), AS52233 (Columbus Communications), and AS27660 (Curaçao Telecom). A followup Facebook post dated 01:25 local time on June 9 (05:25 UTC) confirmed the restoration of power to all neighborhoods.
Portugal
A power outage at an Equinix data center in Prior Velho (near Lisbon) on the afternoon of June 6 affected local utilities, banking services, and court networks, according to published reports (1, 2). Portuguese Internet service provider MEO was also impacted by the power outage, which caused a drop in traffic for AS3243 (MEO-RESIDENCIAL) and AS15525 (MEO-EMPRESAS), seen in the graphs below. The disruptions caused by the power outage also impacted connectivity quality within Portugal, as the Radar Internet quality graphs below highlight – a concurrent drop in bandwidth and increase in latency is visible, indicating that end users likely experienced poorer performance during that period of time.
Botswana
A countrywide power outage in Botswana on May 19 caused an Internet disruption that lasted about 90 minutes, from 10:45 until 12:15 local time (08:45 – 10:15 UTC), visible in the graph below. A tweet from Botswana Power Corporation provided public notice of the incident, but did not include a root cause.
Barbados
On April 4, The Barbados Light & Power Company tweeted an “Outage Notice”, stating “We are aware that our customers across the island are currently without electricity.” Posted at 11:46 local time (15:46 UTC), the notice comes shortly after a significant drop in traffic was observed country-wide, indicating that the power outage also impacted Internet connectivity across the country. After posting several additional updates throughout the day, a final update posted at 18:00 local time (22:00 UTC) indicated that power had been restored to 100% of impacted customers. The graph below shows that traffic took several additional hours to return to normal levels. (Note that the orange highlighting in the graph represents the duration of the disruption, and the red shading is related to an internal data collection issue.)
Technical problems
Namibia
A seven-hour Internet disruption observed in Namibia on June 15 and 16 was caused by unspecified “technical challenges” faced by Telecom Namibia. According to a tweet from the provider, “Telecom Namibia experienced technical challenges on its fixed and mobile data services on Thursday leading to intermittent Internet connectivity.” The impact of these challenges is visible in both the country- and network-level traffic graphs below.
Solomon Islands
Unspecified “technical reasons” also disrupted mobile Internet connectivity for Our Telekom customers in the Solomon Islands on April 26 and 27. An April 26 Facebook post from Our Telekom simply stated “Our mobile data network is currently down due to technical reasons.” The graphs below show a significant drop in traffic for AS45891 (Our Telekom/SBT) between 06:30 local time on April 27 (19:30 UTC on April 26) and 17:00 local time on April 27 (06:00 UTC). The loss of mobile traffic from Our Telekom also impacted traffic at a country level, as the graph shows a similar disruption for the Solomon Islands.
SpaceX Starlink
With an increasingly global service footprint, disruptions observed on SpaceX Starlink potentially impact users across multiple countries around the world. Just before midnight UTC on April 7, Internet traffic seen from AS14593 (SpaceX-Starlink) began to decline significantly. The disruption was short-lived, with traffic returning to expected levels within two hours. According to a Twitter post from Elon Musk, CEO of SpaceX, the problem was “Caused by expired ground station cert” (an expired digital certificate associated with one or more Starlink ground stations, likely preventing communication between the satellite constellation and the ground station(s)).
Madagascar
In Madagascar, a “problem with the backbone”, reported by Telma Madagascar, caused a loss of as much as two-thirds of Internet traffic between 09:15 – 14:00 local time (06:15 – 11:00 UTC) on April 7. The graphs below show that the backbone issue disrupted traffic at a national level, as well as for AS37054 (Telma Madagascar).
United Kingdom
On April 4, UK Internet provider Virgin Media suffered multiple service disruptions that impacted Internet connectivity for broadband customers. The first outage started just before 01:00 local time (midnight UTC)l, lasting until approximately 09:00 local time (08:00 UTC). The second outage started around 16:00 local time (15:00 UTC), with traffic volumes going up and down over the next several hours before appearing to stabilize around 21:30 local time (20:30 UTC).
Virgin Media’s Twitter account acknowledged the early morning disruption several hours after it began, posting “We’re aware of an issue that is affecting broadband services for Virgin Media customers as well as our contact centres. Our teams are currently working to identify and fix the problem as quickly as possible and we apologise to those customers affected.” A subsequent post after service restoration noted “We’ve restored broadband services for customers but are closely monitoring the situation as our engineers continue to investigate. We apologise for any inconvenience caused.”
However, the second disruption was acknowledged on Virgin Media’s Twitter account much more rapidly, with a post at 16:25 UTC stating “Unfortunately we have seen a repeat of an earlier issue which is causing intermittent broadband connectivity problems for some Virgin Media customers. We apologise again to those impacted, our teams are continuing to work flat out to find the root cause of the problem and fix it.”
Although no additional details have been shared via social media by Virgin Media about the outages or their resolution, some additional information was shared via Twitter by an apparent customer, who posted “Virgin Media engineers re-seated fibre cards and reset hub equipment to restore service. TTL was extended as a workaround to maintain stability whilst a permanent fix is implemented.”
A little more than a year later, on May 26, we observed an Internet outage at Miranda Media. Traffic started to fall around 16:30 local time (13:30 UTC), dropping to zero around 18:15 local time (15:15 UTC). The outage disrupted connectivity on the Crimean Peninsula and parts of occupied Ukraine and lasted until approximately 06:00 local time on May 27 (03:00 UTC). Published reports (1,2) suggest that the outage was due to a cyberattack targeting Miranda Media, reportedly carried out by Ukrainian hacktivists.
Russia
Russian satellite provider Dozor Teleport, whose customers include Russia’s Ministry of Defense, ships of the Northern Fleet, Russian energy firm Gazprom, remote oil fields, the Bilibino nuclear power plant, the Federal Security Service (FSB), Rosatom, and other organizations, experienced a multi-hour outage on June 29. The outage, which occurred between 01:30 – 17:30 UTC, was reportedly the result of a cyberattack that at least two groups claimed responsibility for.
Military action
Chad
Multiple Internet disruptions occurred in Chad on April 23 and 24, impacting several Internet providers, and were ultimately visible at a country level as well. As seen in the graphs below, the outages occurred from 04:30 – 06:00 local time (03:30 – 05:00 UTC) and 15:00 – 20:00 local time (14:00 – 19:00 UTC) on April 23, and 04:00 – 08:30 local time (03:00 – 07:30 UTC) on April 24. The impacted network providers in Chad included AS327802 (Millicom Chad), AS327756 (Airtel Chad), AS328594 (Sudat Chad), and AS327975 (ILNET-TELECOM). The outages were reportedly caused by damage to fiber infrastructure that links Chad with neighboring Cameroon and Sudan, with the latter experiencing Internet service disruptions amid clashes between the Sudanese Armed Forces (SAF) and Rapid Support Forces (RSF).
Sudan
As noted above, military action in Sudan disrupted Internet connectivity in Chad in April. Starting in mid-April, multiple Internet outages were observed at major Sudanese Internet providers, three of which are shown in the graphs below. The fighting in the country has led to fuel shortages and power cuts, ultimately disrupting Internet connectivity.
AS15706 (Sudatel) experienced complete Internet outages from 03:00 on April 23 to 17:00 on April 24 local time (01:00 on April 23 to 15:00 on April 24 UTC) and again from 03:00 on April 25 until 01:00 on April 28 local time (01:00 on April 25 to 23:00 on April 27 UTC). Internet connectivity on AS36972 (MTN) was disrupted between 03:00 and 12:00 local time on April 16 (01:00 – 10:00 UTC) and again between 20:00 on April 27 until 02:00 on April 29 (18:00 on April 27 to 00:00 on April 29). After a nominal multi-day recovery, a long-term near complete outage started on May 5, lasting for multiple weeks. Similar to MTN, multiple extended outages were also observed on AS33788 (Kanar Telecommunication). After seeing a significant drop in traffic midday on April 19, a near complete outage is visible between 12:00 on April 21 and 01:00 on April 29 (10:00 on April 21 to 23:00 on April 28 UTC), with a very brief minor recovery late in the day on April 24. A longer duration outage began around 00:00 local time on May 11 (22:00 on May 10 UTC), also lasting for multiple weeks.
Togo, Republic of Congo (Brazzaville), Burkina Faso
Repair work on the West Africa Cable System (WACS) submarine cable disrupted Internet connectivity across multiple countries, including Togo, Republic of Congo (Brazzaville), and Burkina Faso on April 6. According to the Google translation of a Facebook post from Canalbox Congo, the repair work was likely to cause “very strong disruptions on Internet connections with the risk of a total outage”. (Canalbox (GVA) is an African telecommunications operator that provides services across multiple countries in Africa.)
The graph below for AS36924 (GVA-Canalbox) shows three overlapping outage annotations, with each related to a disruption observed on that autonomous system (network) in one of the impacted countries. In the Republic of Congo (Brazzaville), a significant traffic disruption is visible between 16:15 – 23:15 local time (15:15 – 22:15 UTC). In Burkina Faso, the disruption happened earlier and was less severe, taking place between 09:15 – 18:00 local time (09:15 – 18:00 UTC), with a similar impact in Togo, where traffic was disrupted between 11:00 – 23:15 local time (11:00 – 23:15 UTC).
Conclusion
Because of how tightly interwoven the Internet has become with commerce, financial services, and everyday life around the world, any disruption to Internet connectivity ultimately carries an economic impact. The providers impacted by disruptions caused by unexpected or unavoidable events such as cable cuts or severe weather generally try to minimize the scope and duration of such disruptions, ultimately limiting the economic impact. However, in the case of government-directed Internet shutdowns, the damage to the economy is ultimately self-inflicted. The Internet Society’s new Net Loss Calculator now provides a way to quantify this damage, enabling the public, advocacy groups, and governments themselves to understand the potential cost of an Internet shutdown from gross domestic product (GDP), foreign direct investment (FDI), and unemployment perspectives.
On Sunday, July 9, 2023, early morning UTC time, we observed a high number of DNS resolution failures — up to 7% of all DNS queries across the Asia Pacific region — caused by invalid DNSSEC signatures from Verisign .com and .net Top Level Domain (TLD) nameservers. This resulted in connection errors for visitors of Internet properties on Cloudflare in the region.
The local instances of Verisign’s nameservers started to respond with expired DNSSEC signatures in the Asia Pacific region. In order to remediate the impact, we have rerouted upstream DNS queries towards Verisign to locations on the US west coast which are returning valid signatures.
We have already reached out to Verisign to get more information on the root cause. Until their issues have been resolved, we will keep our DNS traffic to .com and .net TLD nameservers rerouted, which might cause slightly increased latency for the first visitor to domains under .com and .net in the region.
Background
In order to proxy a domain’s traffic through Cloudflare’s network, there are two components involved with respect to the Domain Name System (DNS) from the perspective of a Cloudflare data center: external DNS resolution, and upstream or origin DNS resolution.
To understand this, let’s look at the domain name blog.cloudflare.com — which is proxied through Cloudflare’s network — and let’s assume it is configured to use origin.example as the origin server:
Here, the external DNS resolution is the part where DNS queries to blog.cloudflare.com sent by public resolvers like 1.1.1.1 or 8.8.8.8 on behalf of a visitor return a set of Cloudflare Anycast IP addresses. This ensures that the visitor’s browser knows where to send an HTTPS request to load the website. Under the hood your browser performs a DNS query that looks something like this (the trailing dot indicates the DNS root zone):
(Your computer doesn’t actually use the dig command internally; we’ve used it to illustrate the process) Then when the next closest Cloudflare data center receives the HTTPS request for blog.cloudflare.com, it needs to fetch the content from the origin server (assuming it is not cached).
There are two ways Cloudflare can reach the origin server. If the DNS settings in Cloudflare contain IP addresses then we can connect directly to the origin. In some cases, our customers use a CNAME which means Cloudflare has to perform another DNS query to get the IP addresses associated with the CNAME. In the example above, blog.cloudflare.com has a CNAME record instructing us to look at origin.example for IP addresses. During the incident, only customers with CNAME records like this going to .com and .net domain names may have been affected.
The domain origin.example needs to be resolved by Cloudflare as part of the upstream or origin DNS resolution. This time, the Cloudflare data center needs to perform an outbound DNS query that looks like this:
$ dig origin.example. +short
192.0.2.1
DNS is a hierarchical protocol, so the recursive DNS resolver, which usually handles DNS resolution for whoever wants to resolve a domain name, needs to talk to several involved nameservers until it finally gets an answer from the authoritative nameservers of the domain (assuming no DNS responses are cached). This is the same process during the external DNS resolution and the origin DNS resolution. Here is an example for the origin DNS resolution:
Inherently, DNS is a public system that was initially published without any means to validate the integrity of the DNS traffic. So in order to prevent someone from spoofing DNS responses, DNS Security Extensions (DNSSEC) were introduced as a means to authenticate that DNS responses really come from who they claim to come from. This is achieved by generating cryptographic signatures alongside existing DNS records like A, AAAA, MX, CNAME, etc. By validating a DNS record’s associated signature, it is possible to verify that a requested DNS record really comes from its authoritative nameserver and wasn’t altered en-route. If a signature cannot be validated successfully, recursive resolvers usually return an error indicating the invalid signature. This is exactly what happened on Sunday.
Incident timeline and impact
On Saturday, July 8, 2023, at 21:10 UTC our logs show the first instances of DNSSEC validation errors that happened during upstream DNS resolution from multiple Cloudflare data centers in the Asia Pacific region. It appeared DNS responses from the TLD nameservers of .com and .net of the type NSEC3 (a DNSSEC mechanism to prove non-existing DNS records) did not include signatures. About an hour later at 22:16 UTC, the first internal alerts went off (since it required issues to be consistent over a certain period of time), but error rates were still at a level at around 0.5% of all upstream DNS queries.
After several hours, the error rate had increased to a point in which ~13% of our upstream DNS queries in affected locations were failing. This percentage continued to fluctuate over the duration of the incident between the ranges of 10-15% of upstream DNS queries, and roughly 5-7% of all DNS queries (external & upstream resolution) to affected Cloudflare data centers in the Asia Pacific region.
Initially it appeared as though only a single upstream nameserver was having issues with DNS resolution, however upon further investigation it was discovered that the issue was more widespread. Ultimately, we were able to verify that the Verisign nameservers for .com and .net were returning expired DNSSEC signatures on a portion of DNS queries in the Asia Pacific region. Based on our tests, other nameserver locations were correctly returning valid DNSSEC signatures.
In response, we rerouted our DNS traffic to the .com and .net TLD nameserver IP addresses to Verisign’s US west locations. After this change was propagated, the issue very quickly subsided and origin resolution error rates returned to normal levels.
All times are in UTC:
2023-07-08 21:10 First instances of DNSSEC validation errors appear in our logs for origin DNS resolution.
2023-07-08 22:16 First internal alerts for Asia Pacific data centers go off indicating origin DNS resolution error on our test domain. Very few errors for other domains at this point.
2023-07-09 02:58 Error rates have increased substantially since the first instance. An incident is declared.
2023-07-09 03:28 DNSSEC validation issues seem to be isolated to a single upstream provider. It is not abnormal that a single upstream has issues that propagate back to us, and in this case our logs were predominantly showing errors from domains that resolve to this specific upstream.
2023-07-09 04:52 We realize that DNSSEC validation issues are more widespread and affect multiple .com and .net domains. Validation issues continue to be isolated to the Asia Pacific region only, and appear to be intermittent.
2023-07-09 05:15 DNS queries via popular recursive resolvers like 8.8.8.8 and 1.1.1.1 do not return invalid DNSSEC signatures at this point. DNS queries using the local stub resolver continue to return DNSSEC errors.
2023-07-09 06:24 Responses from .com and .net Verisign nameservers in Singapore contain expired DNSSEC signatures, but responses from Verisign TLD nameservers in other locations are fine.
2023-07-09 06:41 We contact Verisign and notify them about expired DNSSEC signatures.
2023-07-09 06:50 In order to remediate the impact, we reroute DNS traffic via IPv4 for the .com and .net Verisign nameserver IPs to US west IPs instead. This immediately leads to a substantial drop in the error rate.
2023-07-09 07:06 We also reroute DNS traffic via IPv6 for the .com and .net Verisign nameserver IPs to US west IPs. This leads to the error rate going down to zero.
2023-07-10 09:23 The rerouting is still in place, but the underlying issue with expired signatures in the Asia Pacific region has still not been resolved.
2023-07-10 18:23 Versign gets back to us confirming that they “were serving stale data” at their local site and have resolved the issues.
Technical description of the error and how it happened
As mentioned in the introduction, the underlying cause for this incident was expired DNSSEC signatures for .net and .com zones. Expired DNSSEC signatures will cause a DNS response to be interpreted as invalid. There are two main scenarios in which this error was observed by a user:
CNAME flattening for external DNS resolution. This is when our authoritative nameservers attempt to return the IP address(es) that a CNAME record target resolves to rather than the CNAME record itself.
CNAME target lookup for origin DNS resolution. This is most commonly used when an HTTPS request is sent to a Cloudflare anycast IP address, and we need to determine what IP address to forward the request to. See How Cloudflare works for more details.
In both cases, behind the scenes the DNS query goes through an in-house recursive DNS resolver in order to lookup what a hostname resolves to. The purpose of this resolver is to cache queries, optimize future queries and provide DNSSEC validation. If the query from this resolver fails for whatever reason, our authoritative DNS system will not be able to perform the two scenarios outlined above.
During the incident, the recursive resolver was failing to validate the DNSSEC signatures in DNS responses for domains ending in .com and .net. These signatures are sent in the form of an RRSIG record alongside the other DNS records they cover. Together they form a Resource Record set (RRset). Each RRSIG has the corresponding fields:
As you can see, the main part of the payload is associated with the signature and its corresponding metadata. Each recursive resolver is responsible for not only checking the signature but also the expiration time of the signature. It is important to obey the expiration time in order to avoid returning responses for RRsets that have been signed by old keys, which could have potentially been compromised by that time.
During this incident, Verisign, the authoritative operator for the .com and .net TLD zones, was occasionally returning expired signatures in its DNS responses in the Asia Pacific region. As a result our recursive resolver was not able to validate the corresponding RRset. Ultimately this meant that a percentage of DNS queries would return SERVFAIL as response code to our authoritative nameserver. This in turn caused connection issues for users trying to connect to a domain on Cloudflare, because we weren't able to resolve the upstream target of affected domain names and thus didn’t know where to send proxied HTTPS requests to upstream servers.
Remediation and follow-up steps
Once we had identified the root cause we started to look at different ways to remedy the issue. We came to the conclusion that the fastest way to work around this very regionalized issue was to stop using the local route to Verisign's nameservers. This means that, at the time of writing this, our outgoing DNS traffic towards Verisign's nameservers in the Asia Pacific region now traverses the Pacific and ends up at the US west coast, rather than being served by closer nameservers. Due to the nature of DNS and the important role of DNS caching, this has less impact than you might initially expect. Frequently looked up names will be cached after the first request, and this only needs to happen once per data center, as we share and pool the local DNS recursor caches to maximize their efficiency.
Ideally, we would have been able to fix the issue right away as it potentially affected others in the region too, not just our customers. We will therefore work diligently to improve our incident communications channels with other providers in order to ensure that the DNS ecosystem remains robust against issues such as this. Being able to quickly get hold of other providers that can take action is vital when urgent issues like these arise.
Conclusion
This incident once again shows how impactful DNS failures are and how crucial this technology is for the Internet. We will investigate how we can improve our systems to detect and resolve issues like this more efficiently and quickly if they occur again in the future.
While Cloudflare was not the cause of this issue, and we are certain that we were not the only ones affected by this, we are still sorry for the disruption to our customers and to all the users who were unable to access Internet properties during this incident.
Over the last several years, governments in a number of countries in the Middle East/Northern Africa (MENA) region have taken to implementing widespread nationwide shutdowns in an effort to prevent cheating on nationwide academic exams. Although it is unclear whether such shutdowns are actually successful in curbing cheating, it is clear that they take a financial toll on the impacted countries, with estimated losses in the millions of US dollars.
During the first two weeks of June 2023, we’ve seen Iraq implementing a series of multi-hour shutdowns that will reportedly occur through mid-July, as well as Algeria taking similar actions to prevent cheating on baccalaureate exams. Shutdowns in Syria were reported to begin on June 7, but there’s been no indication of them in traffic data as of this writing (June 13). These actions echo those taken in Iraq, Syria, Sudan, and Algeria in 2022 and in Syria and Sudan in 2021.
(Note: The interactive graphs below have been embedded directly into the blog post using a new Cloudflare Radar feature. This post is best viewed in landscape mode when on a mobile device.)
Iraq
Iraq had reportedly committed on May 15 to not implementing Internet shutdowns during the 2023 exam season, with a now unavailable page on the Iraqi Ministry of Communications web site (although captured in the Internet Archive’s Wayback Machine) noting (via Google Translate) “Her Excellency the Minister of Communications, Dr. Hayam Al-Yasiri: We rejected a request to cut off the internet service during the ministerial exams.” However, that commitment was apparently short-lived, as the first shutdown was implemented just a couple of weeks later, on June 1. The shutdowns observed across Iraq thus far have impacted networks and localities nationwide, with the exception of the autonomous Kurdistan region. However, networks in that region have experienced their own set of connectivity restrictions due to local exams.
In Iraq, the impact of the shutdowns between 04:00 – 08:00 local time (01:00 – 05:00 UTC) is clearly visible at a country level, as seen in the figure below.
The impact is, of course, also visible in the network-level graphs shown below, with traffic dropping to or near zero during each of the four-hour shutdown windows.
The shutdowns are also visible in the BGP announcement activity from the impacted networks, with spikes in announcement volume clearly visible around the shutdown windows each day that they have occurred. The announcement activity represents withdrawals ahead of the shutdown, removing routes to prefixes within the network, effectively cutting them off from the Internet, and updates after the shutdown period has ended, restoring the previously withdrawn routes, effectively reconnecting the prefixes to the Internet. (Additional announcement activity may also be visible for periods outside of the scheduled shutdowns, and is likely unrelated.)
While the shutdowns discussed above didn’t impact the Kurdistan region of Iraq, that region has also chosen to implement their own shutdowns. In the Kurdistan region, exams started June 3, we saw shorter traffic disruptions across three local network providers on June 3, 6, 10, and 13. The disruptions lasted from 06:30 – 07:30 local time (03:30 to 04:30 UTC) on the 3rd, and 06:40 – 08:30 local time (03:30 to 05:30 UTC) on the 6th, 10th, and 13th). Impacted regions include Erbil, Sulaymaniyah, and Duhok.
BGP announcement activity for the impacted networks in the Kurdistan region did not show the same patterns as those observed on the other Iraqi network providers discussed above.
Both sets of shutdowns in Iraq are also visible in traffic to Cloudflare’s 1.1.1.1 DNS resolver, although they highlight a difference in usage between the autonomous Kurdistan region and the rest of the country. The “totalTcpUdp” graph (blue line) below shows requests made to the resolver over UDP or TCP on port 53, the standard port used for DNS requests. The “totalDoHDoT” graph (orange line) below shows requests made to the resolver using DNS-over-HTTPS or DNS-over-TLS using port 443 or 853 respectively.
In the “totalTcpUdp” graph, we can see noticeable drops in traffic that align with the dates and times where we observed the traffic disruptions across Kurdistani networks. This drop in DNS traffic, combined with the lack of BGP announcement activity, suggests that the Internet disruptions in the Kurdistan region may be implemented as widespread blocking of Internet traffic, rather than routing-based shutdowns.
In the “totalDoHDoT” graph below, we can see noticeable drops in traffic that align with the dates and times where we observed the traffic disruptions in the rest of Iraq.
It isn’t immediately clear why there is a difference in the use of 1.1.1.1 between the two parts of the country.
Algeria
In Algeria, it appears that the country is following a similar pattern as that seen in 2021 and 2022, with two multi-hour Internet disruptions each day. Also similar to last year, it appears that they are pursuing a content blocking-based approach, instead of the wide-scale Internet shutdowns implemented in 2021, as impacted networks are not experiencing complete outages, nor do they show patterns of BGP announcement activity.
A published report indicates that two Internet disruptions will be implemented each day between June 11 and June 15. The first takes place between 08:00 – 12:00 local time (07:00 – 11:00 UTC), with the second occurring between 14:00 – 17:00 local time (13:00 – 16:00 UTC). These disruptions are visible in the shaded areas of the network-level graphs below as two distinct drops in traffic each day.
Conclusion
In cooperation with the Internet Society and Lebanese digital rights organization SMEX, digital rights organization Access Now is coordinating a #NoExamShutdown campaign across social media platforms. The campaign calls on MENA governments to end the practice of Internet shutdowns during exams, and aims to highlight how these shutdowns undermine human rights and disrupt essential social, political, economic, and cultural activities. Cloudflare Radar will continue to bring visibility to these, and other similar Internet disruptions, as they occur. You can follow them through the Cloudflare Radar Outage Center, or by following Cloudflare Radar on Twitter or Mastodon.
Cloudflare operates in more than 285 cities in over 100 countries, where we interconnect with over 11,500 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
We entered 2023 with Internet disruptions due to causes that ran the gamut, including several government-directed Internet shutdowns, cyclones, a massive earthquake, power outages, cable cuts, cyberattacks, technical problems, and military action. As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Iran
Over the last six-plus months, government-directed Internet shutdowns in Iran have largely been in response to protests over the death of Mahsa Amini while in police custody. While these shutdowns are still occurring in a limited fashion, a notable shutdown observed in January was intended to prevent cheating on academic exams. Internet shutdowns with a similar purpose have been observed across a number of other countries, and have also occurred in Iran in the past. Access was restricted across AS44244 (Irancell) and AS197207 (MCCI), with lower traffic levels observed in Alborz Province, Fars, Khuzestan, and Razavi Khorasan between 08:00 to 11:30 local time (04:30 to 08:00 UTC) on January 19.
A shutdown of mobile Internet connectivity in Punjab, India began on March 19, ordered by the local government amid concerns of protest-related violence. Although the initial shutdown was ordered to take place between March 18, 12:00 local time and March 19, 12:00 local time, it was extended several times, ultimately lasting for three days. Traffic for AS38266 (Vodafone India), AS45271 (Idea Cellular Limited), AS45609 (Bharti Mobility), and AS55836 (Reliance Jio Infocomm) began to fall around 12:30 local time (07:00 UTC) on March 18, recovering around 12:30 local time (07:00 UTC) on March 21. However, it was subsequently reported that connectivity remained shut down in some districts until March 23 or 24.
Cable cuts
Bolivia
Bolivian ISP Cometco (AS27839)reported on January 12 that problems with international fiber links were causing degradation of Internet service. Traffic from the network dropped by approximately 80% starting around 16:00 local time (20:00 UTC) before returning to normal approximately eight hours later. It isn’t clear whether the referenced international fiber links were terrestrial connections to neighboring countries, or issues with submarine cables several network hops upstream. As a landlocked country, Bolivia is not directly connected to any submarine cables.
A brief connectivity disruption was observed on Bangladeshi provider Grameenphone on February 23, between 11:45-14:00 local time (05:45-08:00 UTC). According to a Facebook post from Grameenphone, the outage was caused by fiber cuts due to road maintenance.
Venezuela
Venezuela, and more specifically, AS8048 (CANTV), are no stranger to Internet disruptions, seeing several (Q1, Q2) during 2022, as well as others in previous years. During the last couple of days in February, a few small outages were observed on CANTV’s network in several Venezuelan states. However, a more significant near-complete outage occurred on February 28, starting around midnight local time (04:00 UTC), and lasting for the better part of the day, with traffic recovering at 17:30 local time (21:30 UTC). A Tweet posted the morning of February 28 by CANTV referenced an outage in their fiber optic network, which was presumably the cause.
Power outages
Pakistan
A country-wide power outage in Pakistan on January 23 impacted more than 220 million people, and resulted in a significant drop in Internet traffic being observed in the country. The power outage began at 07:34 local time (02:34 UTC), with Internet traffic starting to drop almost immediately. The figure below shows that traffic volumes dropped as much as 50% from normal levels before recovering around 04:15 local time on January 24 (23:15 UTC on January 23). This power outage was reportedly due to a “sudden drop in the frequency of the power transmission system”, which led to a “widespread breakdown”. Nationwide power outages have also occurred in Pakistan in January 2021, May 2018, and January 2015.
Bermuda
BELCO, the power company servicing the island of Bermuda, tweeted about a mass power outage affecting the island on February 3, and linked to their outage map so that customers could track restoration efforts. BELCO’s tweet was posted at 16:10 local time (20:10 UTC), approximately one hour after a significant drop was observed in Bermuda’s Internet traffic. The power outage, and subsequent Internet disruption, lasted over five hours, as BELCO later tweeted that “As of 9.45 pm [00:45 UTC, February 4], all circuits have been restored.”
Argentina
Soaring temperatures in Argentina triggered a large-scale power outage across the country that resulted in multi-hour Internet disruption on March 1. Internet traffic dropped by approximately one-third during the disruption, which lasted from 16:30 to 19:30 local time (19:30 to 22:30 UTC). Cities that experienced visible impacts to Internet traffic during the power outage included Buenos Aires, Cordoba, Mendoza, and Tucuman.
Kenya
Just a few days later on March 4, Kenya Power issued a Customer Alert at 18:25 local time (15:25 UTC) regarding a nationwide power outage, noting that it had “lost bulk power supply to various parts of the country due to a system disturbance.” The alert came approximately an hour after the country’s Internet traffic dropped significantly. A subsequent tweet dated midnight local time (21:00 UTC) claimed that “electricity supply has been restored to all areas countrywide” and the figure below shows that traffic levels returned to normal levels shortly thereafter.
Earthquake
Turkey
On February 5, a magnitude 7.8 earthquake occurred 23 km east of Nurdağı, Turkey, leaving many thousands dead and injured. The quake, which occurred at 04:17 local time (01:17 UTC), was believed to be the strongest to hit Turkey since 1939. The widespread damage and destruction resulted in significant disruptions to Internet connectivity in multiple areas of the country, as shown in the figures below. Although Internet traffic volumes were relatively low because it was so early in the morning, the graphs show it dropping even further at or around the time of the earthquake. Nearly half a day later, traffic volumes in selected locations were between 63-94% lower than at the same time the previous week. A month later, after several aftershocks, traffic volumes had mostly recovered, although some regions were still struggling to recover.
Weather
New Zealand
Called the “country’s biggest weather event in a century”, Cyclone Gabrielle wreaked havoc on northern New Zealand, including infrastructure damage and power outages impacting tens of thousands of homes. As a result, regions including Gisborne and Hawkes Bay experienced Internet disruptions that lasted several days, starting at 00:00 local time on February 14 (11:00 UTC on February 13). The figures below show that in both regions, peak traffic volume returned to pre-cyclone levels around February 19.
Vanuatu
Later in February, Cyclone Judy hit the South Pacific Ocean nation of Vanuatu, the South Pacific Ocean nation made up of roughly 80 islands that stretch 1,300 kilometers. The Category 4 cyclone damaged homes and caused power outages, resulting in a significant drop in the country’s Internet traffic. On February 28, Vanuatu’s traffic dropped by nearly 80% as the cyclone struck, and as seen in the figure below, it took nearly two weeks for traffic to recover to the levels seen earlier in February.
Malawi
Cyclone Freddy, said to be the longest-lasting, most powerful cyclone on record, hit Malawi during the weekend of March 11-12, and into Monday, March 13. The resulting damage disrupted Internet connectivity in the east African country, with traffic dropping around 11:00 local time (09:00 UTC) on March 13. The disruption lasted for over two days, with traffic levels recovering around 21:00 local time (19:00 UTC) on March 15.
Technical problems
South Africa
Just before 07:00 local time (05:00 UTC) on February 1, South African service provider RSAWEB initially tweeted about a problem that they said was impacting their cloud and VOIP platforms. However, in several subsequent tweets, they noted that the problem was also impacting internal systems, as well as fiber and mobile connectivity. The figure below shows traffic for RSAWEB dropping at 06:30 local time (04:30 UTC), a point at which it would normally be starting to increase for the day. Just before 16:00 local time (14:00 UTC), RSAWEB tweeted“…engineers are actively working on restoring services post the major incident. Customers who experienced no connectivity may see some services restoring.” The figure below shows a sharp increase in traffic around that time with gradual growth through the evening. However, full restoration of services across all of RSAWEB’s impacted platforms took a full week, according to a February 8 tweet.
Italy
An unspecified “international interconnectivity problem” impacting Telecom Italia caused a multi-hour Internet disruption in Italy on February 5. At a country level, a nominal drop in traffic is visible in the figure below starting around 11:45 local time (10:45 UTC) with some volatility visible in the lower traffic through 17:15 local time (16:15 UTC). However, the impact of the problem is more obvious in the traffic graphs for AS3269 and AS16232, both owned by Telecom Italia. Both graphs show a more significant loss of traffic, as well as greater volatility through the five-plus hour disruption.
Myanmar
A fire at an exchange office of MPT (Myanma Posts and Telecommunications) on February 7 disrupted Internet connectivity for customers of the Myanmar service provider. A Facebook post from MPT informed customers that “We are currently experiencing disruptions to our MPT’s services including MPT’s call centre, fiber internet, mobile internet and mobile and telephone communications.” The figure below shows the impact of this disruption on MPT-owned AS9988 and AS45558, with traffic dropping significantly at 10:00 local time (03:30 UTC). Significant recovery was seen by 22:00 local time (15:30 local time).
Republic of the Congo (Brazzaville)
Congo Telecomtweeted a “COMMUNIQUÉ” on March 15, alerting users to a service disruption due to a “network incident”. The impact of this disruption is clearly visible at a country level, with traffic dropping sharply at 00:45 local time (23:45 on March 14 UTC), driven by complete outages at MTN Congo and Congo Telecom, as seen in the graphs below. While traffic at MTN Congo began to recover around 08:00 local time (07:00 UTC), Congo Telecom’s recovery took longer, with traffic beginning to increase around 17:00 local time (16:00 UTC). Congo Telecom tweeted on March 16 that the nationwide Internet outage had been resolved. MTN Congo did not acknowledge the disruption on social media, and neither company provided more specific information about the reported “network incident”.
Lebanon
Closing out March, disruptions observed at AS39010 (Terranet) and AS42334 (Mobi) in Lebanon may have been related to a strike at upstream provider Ogero Telecom, common to both networks. A published report quoted the Chairman of Ogero commenting on the strike, “We are heading to a catastrophe if a deal is not found with the government: the network will completely stop working as our generators will gradually run out of fuel. Lebanon completely relies on Ogero for its bandwidth, leaving no one exempt from a blackout.” Traffic at both Terranet and Mobi dropped around 05:00 local time (03:00 UTC) on March 29, with the disruption lasting approximately 4.5 hours, as traffic recovered at 09:30 local time (07:30 UTC).
Cyberattacks
South Korea
On January 29, South Korean Internet provider LG Uplus suffered two brief Internet disruptions which were reportedly caused by possible DDoS attacks. The first disruption occurred at 03:00 local time (18:00 UTC on January 28), and the second occurred at 18:15 local time (09:15 UTC). The disruptions impacted traffic on AS17858 and AS3786, both owned by LG. The company was reportedly hit by a second pair of DDoS attacks on February 4.
Guam
In a March 17 tweet posted at 11:30 local time (01:30 UTC), Docomo Pacific reported an outage affecting multiple services, with a subsequent tweet noting that “Early this morning, a cyber security incident occurred and some of our servers were attacked”. This outage is visible at a country level in Guam, seen as a significant drop in traffic starting around 10:00 local time (00:00 UTC) in the figure below. However, in the graph below for AS3605 (ERX-KUENTOS/Guam Cablevision/Docomo Pacific), the cited outage results in a near-complete loss of traffic starting around 05:00 local time (19:00 on March 16 UTC). Traffic returned to normal levels by 18:00 local time on March 18 (08:00 UTC).
Ukraine/Military Action
In February, the conflict in Ukraine entered its second year, and over this past year, we have tracked its impact on the Internet, highlighting traffic shifts, attacks, routing changes, and connectivity disruptions. In the fourth quarter of 2022, a number of disruptions were related to attacks on electrical infrastructure, and this pattern continued into the first quarter of 2023.
One such disruption occurred in Odessa on January 27, amid news of Russian airstrikes on local energy infrastructure. As seen in the figure below, Internet traffic in Odessa usually begins to climb just before 08:00 local time (06:00 UTC), but failed to do so that morning after several energy infrastructure facilities near Odessa were hit and damaged. Traffic remained lower than levels seen the previous week for approximately 18 hours.
Power outages resulting from Russian attacks on energy generation and distribution facilities on March 9 resulted in disruptions to Internet connectivity in multiple locations around Ukraine. As seen in the figures below, traffic dropped below normal levels after 02:00 local time (00:00 UTC) on March 9. Traffic in Kharkiv fell over 50% as compared to previous week, while in Odessa, traffic fell as much as 60%. In Odessa, Mykolaiv, and Kirovohrad Oblast, traffic recovered by around 08:00 local time (06:00 UTC), while in Kharkiv, the disruption lasted nearly two days, returning to normal levels around 23:45 local time (21:45 UTC) on Friday, March 10.
Conclusion
The first quarter of 2023 seemed to be particularly active from an Internet disruption perspective, but hopefully it is not a harbinger of things to come through the rest of the year. This is especially true of government-directed shutdowns, which occurred fairly regularly through 2022. To that end, civil society organization Access Now recently published their Internet shutdowns in 2022 report, finding that In 2022, governments and other actors disrupted the internet at least 187 times across 35 countries. Cloudflare Radar is proud to support Access Now’s #KeepItOn initiative, using our data to help illustrate the impact of Internet shutdowns and other disruptions.
Just after midnight (UTC) on April 4, subscribers to UK ISP Virgin Media (AS5089) began experiencing an Internet outage, with subscriber complaints multiplying rapidly on platforms including Twitter and Reddit.
Cloudflare Radar data shows Virgin Media traffic dropping to near-zero around 00:30 UTC, as seen in the figure below. Connectivity showed some signs of recovery around 02:30 UTC, but fell again an hour later. Further nominal recovery was seen around 04:45 UTC, before again experiencing another complete outage between around 05:45-06:45 UTC, after which traffic began to recover, reaching expected levels around 07:30 UTC.
After the initial set of early-morning disruptions, Virgin Media experienced another round of issues in the afternoon. Cloudflare observed instability in traffic from Virgin Media’s network (called an autonomous system in Internet jargon) AS5089 starting around 15:00 UTC, with a significant drop just before 16:00 UTC. However in this case, it did not appear to be a complete outage, with traffic recovering approximately a half hour later.
Virgin Media’s Twitter account acknowledged the early morning disruption several hours after it began, posting responses stating “We’re aware of an issue that is affecting broadband services for Virgin Media customers as well as our contact centres. Our teams are currently working to identify and fix the problem as quickly as possible and we apologise to those customers affected.” Further responses after service restoration noted “We’ve restored broadband services for customers but are closely monitoring the situation as our engineers continue to investigate. We apologise for any inconvenience caused.”
However, the second disruption was acknowledged on Virgin Media’s Twitter account much more rapidly, with a post at 16:25 UTC stating “Unfortunately we have seen a repeat of an earlier issue which is causing intermittent broadband connectivity problems for some Virgin Media customers. We apologise again to those impacted, our teams are continuing to work flat out to find the root cause of the problem and fix it.”
At the time of the outages, www.virginmedia.com, which includes the provider’s status page, was unavailable. As seen in the figure below, a DNS lookup for the hostname resulted in a SERVFAIL error, indicating that the lookup failed to return a response. This is because the authoritative nameservers for virginmedia.com are listed as ns{1-4}.virginmedia.net, and these nameservers are all hosted within Virgin Media’s network (AS5089) and thus are not accessible during the outage.
Although Virgin Media has not publicly released a root cause for the series of disruptions that its network has experienced, looking at BGP activity can be instructive.
BGP is a mechanism to exchange routing information between networks on the Internet. The big routers that make the Internet work have huge, constantly updated lists of the possible routes that can be used to deliver each network packet to its final destination. Without BGP, the Internet routers wouldn’t know what to do, and the Internet wouldn’t exist.
The Internet is literally a network of networks, or for math fans, a graph, with each individual network a node in it, and the edges representing the interconnections. All of this is bound together by BGP, which allows one network (Virgin Media, for instance) to advertise its presence to other networks that form the Internet. When Virgin Media is not advertising its presence, other networks can’t find its network and it becomes effectively unavailable.
BGP announcements inform a router of changes made to the routing of a prefix (a group of IP addresses) or entirely withdraws the prefix, removing it from the routing table. The figure below shows aggregate BGP announcement activity from AS5089 with spikes that align with the decreases and increases seen in the traffic graph above, suggesting that the underlying cause may in fact be BGP-related, or related to problems with core network infrastructure.
We can drill down further to break out the observed activity between BGP announcements (dark blue) and withdrawals (light blue) seen in the figure below, with key activity coincident with the loss and return of traffic. An initial set of withdrawals are seen just after midnight, effectively removing Virgin Media from the Internet resulting in the initial outage.
A set of announcements occurred just before 03:00 UTC, aligning with the nominal increase in traffic noted above, but those were followed quickly by another set of withdrawals. A similar announcement/withdrawal exchange was observed at 05:00 and 05:30 UTC respectively, before a final set of announcements restored connectivity at 07:00 UTC.
Things remained relatively stable through the morning into the afternoon, before another set of withdrawals presaged the afternoon’s connectivity problems, with a spike of withdrawals at 15:00 UTC, followed by additional withdrawal/announcement exchanges over the next several hours.
The Internet has become a significant factor in geopolitical conflicts, such as the ongoing war in Ukraine. Tomorrow marks one year since the Russian invasion of that country. This post reports on Internet insights and discusses how Ukraine’s Internet remained resilient in spite of dozens of disruptions in three different stages of the conflict.
Key takeaways:
Internet traffic shifts in Ukraine are clearly visible from east to west as Ukrainians fled the war, with country-wide traffic dropping as much as 33% after February 24, 2022.
Air strikes on energy infrastructure starting in October led to widespread Internet disruptions that continue in 2023.
Application-layer cyber attacks in Ukraine rose 1,300% in early March 2022 compared to pre-war levels.
Government administration, financial services, and the media saw the most attacks targeting Ukraine.
Traffic from a number of networks in Kherson was re-routed through Russia between June and October, subjecting traffic to Russia’s restrictions and limitations, including content filtering. Even after traffic ceased to reroute through Russia, those Ukrainian networks saw major outages through at least the end of the year, while two networks remain offline.
Through efforts on the ground to repair damaged fiber optics and restore electrical power, Ukraine’s networks have remained resilient from both an infrastructure and routing perspective. This is partly due to Ukraine’s widespread connectivity to networks outside the country and large number of IXPs.
Starlink traffic in Ukraine grew over 500% between mid-March and mid-May, and continued to grow from mid-May through mid-November, increasing nearly 300% over that six-month period. For the full period from mid-March (two weeks after it was made available) to mid-December, it was over a 1,600% increase, dropping a bit after that.
Internet changes and disruptions
An Internet shock after February 24, 2022
In Ukraine, human Internet traffic dropped as much as 33% in the weeks following February 24. The following chart shows Cloudflare’s perspective on daily traffic (by number of requests).
Internet traffic levels recovered over the next few months, including strong growth seen in September and October, when many Ukrainian refugees returned to the country. That said, there were also country-wide outages, mostly after October, that are discussed below.
14% of total traffic from Ukraine (including traffic from Crimea and other occupied regions) was mitigated as potential attacks, while 10% of total traffic to Ukraine was mitigated as potential attacks in the last 12 months.
Before February 24, 2022, typical weekday Internet traffic in Ukraine initially peaked after lunch, around 15:00 local time, dropped between 17:00 and 18:00 (consistent with people leaving work), and reached the biggest peak of the day at around 21:00 (possibly after dinner for mobile and streaming use).
After the invasion started, we observed less variation during the day in a clear change in the usual pattern given the reported disruption and “exodus” from the country. During the first few days after the invasion began, peak traffic occurred around 19:00, at a time when nights for many in cities such as Kyiv were spent in improvised underground bunkers. By late March, the 21:00 peak had returned, but the early evening drop in traffic did not return until May.
When looking at Ukraine Internet requests by type of trafficin the chart below (from February 10, 2022, through February 2023), we observe that while traffic from both mobile and desktop devices dropped after the invasion, request volume from mobile devices has remained higher over the past year. Pre-war, mobile devices accounted for around 53% of traffic, and grew to around 60% during the first weeks of the invasion. By late April, it had returned to typical pre-war levels, falling back to around 54% of traffic. There’s also a noticeable December drop/outage that we’ll go over below.
Millions moving from east to west in Ukraine
The invasion brought attacks and failing infrastructure across a number of cities, but the target in the early days wasn’t the country’s energy infrastructure, as it was in October 2022. In the first weeks of the war, Internet traffic changes were largely driven by people evacuating conflict zones with their families. Over eight million Ukrainians left the country in the first three months, and many more relocated internally to safer cities, although many returned during the summer of 2022. The Internet played a critical role during this refugee crisis, supporting communications and access to real-time information that could save lives, as well as apps providing services, among others.
There was also an increase in traffic in the western part of Ukraine, in areas such as Lviv (further away from the conflict areas), and a decrease in the east, in areas like Kharkiv, where the Russian military was arriving and attacks were a constant threat. The figure below provides a view of how Internet traffic across Ukraine changed in the week after the war began (a darker pink means a drop in traffic — as much as 60% — while a darker green indicates an increase in Internet traffic — as much as 50%).
The biggest drops in Internet traffic observed in Ukraine in the first days of the war were in Kharkiv Oblast in the east, and Chernihiv in the north, both with a 60% decrease, followed by Kyiv Oblast, with traffic 40% lower on March 2, 2022, as compared with February 23.
In western Ukraine, traffic surged. The regions with the highest observed traffic growth included Rivne (50%), Volyn (30%), Lviv (28%), Chernivtsi (25%), and Zakarpattia (15%).
At the city level, analysis of Internet traffic in Ukraine gives us some insight into usage of the Internet and availability of Internet access in those first weeks, with noticeable outages in places where direct conflict was going on or that was already occupied by Russian soldiers.
North of Kyiv, the city of Chernihiv had a significant drop in traffic the first week of the war and residual traffic by mid-March, with traffic picking up only after the Russians retreated in early April.
In the capital city of Kyiv, there is a clear disruption in Internet traffic right after the war started, possibly caused by people leaving, attacks and use of underground shelters.
Near Kyiv, we observed a clear outage in early March in Bucha. After April 1, when the Russians withdrew, Internet traffic started to come back a few weeks later.
In Irpin, just outside Kyiv, close to the Hostomel airport and Bucha, a similar outage pattern to Bucha was observed. Traffic only began to come back more clearly in late May.
In the east, in the city of Kharkiv, traffic dropped 50% on March 3, with a similar scenario seen not far away in Sumy. The disruption was related to people leaving and also by power outages affecting some networks.
Other cities in the south of Ukraine, like Berdyansk, had outages. This graph shows Enerhodar, the small city where Europe’s largest nuclear plant, Zaporizhzhya NPP, is located, with residual traffic compared to before.
In the cities located in the south of Ukraine, there were clear Internet disruptions. The Russians laid siege to Mariupol on February 24. Energy infrastructure strikes and shutdowns had an impact on local networks and Internet traffic, which fell to minimal levels by March 1. Estimates indicate that 95% of the buildings in the city were destroyed, and by mid-May, the city was fully under Russian control. While there was some increase in traffic by the end of April, it reached only ~22% of what it was before the war’s start.
When looking at Ukrainian Internet Service Providers (ISPs) or the autonomous systems (ASNs) they use, we observed more localized disruptions in certain regions during the first months of the war, but recovery was almost always swift. AS6849 (Ukrtel) experienced problems with very short-term outages in mid-March. AS13188 (Triolan), which services Kyiv, Chernihiv, and Kharkiv, was another provider experiencing problems (they reported a cyberattack on March 9), as could be observed in the next chart:
We did not observe a clear national outage in Ukraine’s main ISP, AS15895 (Kyivstar) until the October-November attacks on energy infrastructure, which also shows some early resilience of Ukrainian networks.
Ukraine’s counteroffensive and its Internet impact
As Russian troops retreated from the northern front in Ukraine, they shifted their efforts to gain ground in the east (Battle of Donbas) and south (occupation of the Kherson region) after late April. This resulted in Internet disruptions and traffic shifts, which are discussed in more detail in a section below. However, Internet traffic in the Kherson region was intermittent and included outages after May, given the battle for Internet control. News reports in June revealed that ISP workers damaged their own equipment to thwart Russia’s efforts to control the Ukrainian Internet.
Before the September Ukrainian counteroffensive, another example of the war’s impact on a city’s Internet traffic occurred during the summer, when Russian troops seized Lysychansk in eastern Ukraine in early July after what became known as the Battle of Lysychansk. Internet traffic in Lysychansk clearly decreased after the war started. That slide continues during the intense fighting that took place after April, which led to most of the city’s population leaving. By May, traffic was almost residual (with a mid-May few days short term increase).
In early September the Ukrainian counteroffensive took off in the east, although the media initially reported a south offensive in Kherson Oblast that was a “deception” move. The Kherson offensive only came to fruition in late October and early November. Ukraine was able to retake in September over 500 settlements and 12,000 square kilometers of territory in the Kharkiv region. At that time, there were Internet outages in several of those settlements.
In response to the successful Ukrainian counteroffensive, Russian airstrikes caused power outages and Internet disruptions in the region. That was the case in Kharkiv on September 11, 12, and 13. The figure below shows a 12-hour near-complete outage on September 11, followed by two other periods of drop in traffic.
When nuclear inspectors arrive, so do Internet outages
In the Zaporizhzhia region, there were also outages. On September 1, 2022, the day the International Atomic Energy Agency (IAEA) inspectors arrived at the Russian-controlled Zaporizhzhia nuclear power plant in Enerhodar, there were Internet outages in two local ASNs that service the area: AS199560 (Engrup) and AS197002(OOO Tenor). Those outages lasted until September 10, as shown in the charts below.
More broadly, the city of Enerhodar, where the nuclear power plant is located, experienced a four-day outage after September 6.
Mid-September traffic drop in Crimea
In mid-September, following Ukraine’s counteroffensive, there were questions as to when Crimea might be targeted by Ukrainian forces, with news reports indicating that there was an evacuation of the Russian population from Crimea around September 13. We saw a clear drop in traffic on that Tuesday, compared with the previous day, as seen in the map of Crimea below (red is decrease in traffic, green is increase).
October brings energy infrastructure attacks and country-wide disruptions
As we have seen, the Russian air strikes targeting critical energy infrastructure began in September as a retaliation to Ukraine’s counteroffensive. The following month, the Crimean Bridge explosion on Saturday, October 8 (when a truck-borne bomb destroyed part of the bridge) led to more air strikes that affected networks and Internet traffic across Ukraine.
On Monday, October 10, Ukraine woke up to air strikes on energy infrastructure and experienced severe electricity and Internet outages. At 07:35 UTC, traffic in the country was 35% below its usual level compared with the previous week and only fully recovered more than 24 hours later. The impact was particularly significant in regions like Kharkiv, where traffic was down by around 80%, and Lviv, where it dropped by about 60%. The graph below shows how new air strikes in Lviv Oblast the following day affected Internet traffic.
There were clear disruptions in Internet connectivity in several regions on October 17, but also on October 20, when the destruction of several power stations in Kyiv resulted in a 25% drop in Internet traffic from Kyiv City as compared to the two previous weeks. It lasted 12 hours, and was followed the next day by a shorter partial outage as seen in the graph below.
In late October, according to Ukrainian officials, 30% of Ukraine’s power stations were destroyed. Self-imposed power limitations because of this destruction resulted in drops in Internet traffic observed in places like Kyiv and the surrounding region.
The start of a multi-week Internet disruption in Kherson Oblast can be seen in the graph below, showing ~70% lower traffic than in previous weeks. The disruption began on Saturday, October 22, when Ukrainians were gaining ground in the Kherson region.
Traffic began to return after Ukrainian forces took Kherson city on November 11, 2022. The graph below shows a week-over-week comparison for Kherson Oblast for the weeks of November 7, November 28, and December 19 for better visualization in the chart while showing the evolution through a seven-week period.
Ongoing strikes and Internet disruptions
Throughout the rest of the year and into 2023, Ukraine has continued to face intermittent Internet disruptions. On November 23, 2022, the country experienced widespread power outages after Russian strikes, causing a nearly 50% decrease in Internet traffic in Ukraine. This disruption lasted for almost a day and a half, further emphasizing the ongoing impact of the conflict on Ukraine’s infrastructure.
Although there was a recovery after that late November outage, only a few days later traffic seemed closer to normal levels. Below is a chart of the week-over-week evolution of Internet traffic in Ukraine at both a national and local level during that time:
In Kyiv Oblast:
In the Odessa region:
And Kharkiv (where a December 16 outage is also clear — in the green line):
On December 16, there was another country-level Internet disruption caused by air strikes targeting energy infrastructure. Traffic at a national level dropped as much as 13% compared with the previous week, but Ukrainian networks were even more affected. AS13188 (Triolan) had a 70% drop in traffic, and AS15895 (Kyivstar) a 40% drop, both shown in the figures below.
In January 2023, air strikes caused additional Internet disruptions. One such recent event was in Odessa, where traffic dropped as low as 54% compared with the previous week during an 18-hour disruption.
A cyber war with global impact
“Shields Up” on cyber attacks
The US government and the FBI issued warnings in March to all citizens, businesses, and organizations in the country, as well as allies and partners, to be aware of the need to “enhance cybersecurity.” The US Cybersecurity and Infrastructure Security Agency (CISA) launched the Shields Up initiative, noting that “Russia’s invasion of Ukraine could impact organizations both within and beyond the region.” The UK and Japan, among others, also issued warnings.
Below, we discuss Web Application Firewall (WAF) mitigations and DDoS attacks. A WAF helps protect web applications by filtering and monitoring HTTP traffic between a web application and the Internet. A WAF is a protocol layer 7 defense (in the OSI model), and is not designed to defend against all types of attacks. Distributed Denial of Service (DDoS) attacks are cyber attacks that aim to take down Internet properties and make them unavailable for users.
Cyber attacks rose 1,300% in Ukraine by early March
The charts below are based on normalized data, and show threats mitigated by our WAF.
Mitigated application-layer threats blocked by our WAF skyrocketed after the war started on February 24. Mitigated requests were 105% higher on Monday, February 28 than in the previous (pre-war) Monday, and peaked on March 8, reaching 1,300% higher than pre-war levels.
Between February 2022 and February 2023, an average of 10% of all traffic to Ukraine was mitigations of potential attacks.
The graph below shows the daily percentage of application layer traffic to Ukraine that Cloudflare mitigated as potential attacks. In early March, 30% of all traffic was mitigated. This fell in April, and remained low for several months, but it picked up in early September around the time of the Ukrainian counteroffensive in east and south Ukraine. The peak was reached on October 29 when DDoS attack traffic constituted 39% of total traffic to Cloudflare’s Ukrainian customer websites.
This trend is more evident when looking at all traffic to sites on the “.ua” top-level domain (from Cloudflare’s perspective). The chart below shows that DDoS attack traffic accounted for over 80% of all traffic by early March 2022. The first clear spikes occurred on February 16 and 19, with around 25% of traffic mitigated. There was no moment of rest after the war started, except towards the end of November and December, but the attacks resumed just before Christmas. An average of 13% of all traffic to “.ua”, between February 2022 and February 2023 was mitigations of potential attacks. The following graph provides a comprehensive view of DDoS application layer attacks on “.ua” sites:
Moving on to types of mitigations of product groups that were used (related to “.ua” sites), as seen in the next chart, around 57% were done by the ruleset which automatically detects and mitigates HTTP DDoS attacks (DDoS Mitigation), 31% were being mitigated by firewall rules put in place (WAF), and 10% were blocking requests based on our IP threat reputation database (IP Reputation).
It’s important to note that WAF rules in the graph above are also associated with custom firewall rules created by customers to provide a more tailored protection. “DDoS Mitigation” (application layer DDoS protection) and “Access Rules” (rate limiting) are specifically used for DDoS protection.
In contrast to the first graph shown in this section, which looked at mitigated attack traffic targeting Ukraine, we can also look at mitigated attack traffic originating in Ukraine. The graph below also shows that the share of mitigated traffic from Ukraine also increased considerably after the invasion started.
Top attacked industries: from government to news media
The industries sectors that had a higher share of WAF mitigations were government administration, financial services, and the media, representing almost half of all WAF mitigations targeting Ukraine during 2022.
Looking at DDoS attacks, there was a surge in attacks on media and publishing companies during 2022 in Ukraine. Entities targeting Ukrainian companies appeared to be focused on information-related websites. The top five most attacked industries in the Ukraine in the first two quarters of 2022 were all in broadcasting, Internet, online media, and publishing, accounting for almost 80% of all DDoS attacks targeting Ukraine.
In a more focused look at the type of websites Cloudflare has protected throughout the war, the next two graphs provide a view of mitigated application layer attacks by the type of “.ua” sites we helped to protect. In the first days of the war, mitigation spikes were observed at a news service, a TV channel, a government website, and a bank.
In July, spikes in mitigations we observed across other types of “.ua” websites, including food delivery, e-commerce, auto parts, news, and government.
More recently, in February 2023, the spikes in mitigations were somewhat similar to what we saw one year ago, including electronics, e-commerce, IT, and education websites.
12.6% of network-layer traffic was DDoS activity in Q1 2022
Network-layer (layer 3 and 4) traffic is harder to attribute to a specific domain or target because IP addresses are shared across different customers. Looking at network-level DDoS traffic hitting our Kyiv data center, we saw peaks of DDoS traffic higher than before the war in early March, but they were much higher in June and August.
Several of our quarterly DDoS reports from 2022 include attack trends related to the war in Ukraine, with quarter over quarter interactive comparisons.
Network re-routing in Kherson
On February 24, 2022, Russian forces invaded Ukraine’s Kherson Oblast region. The city of Kherson was captured on March 2, as the first major city and only regional capital to be captured by Russian forces during the initial invasion. The Russian occupation of Kherson Oblast continued until Ukrainian forces resumed control on November 11, after launching a counteroffensive at the end of August.
On May 4, 2022, we published Tracking shifts in Internet connectivity in Kherson, Ukraine, a blog post that explored a re-routing event that impacted AS47598 (Khersontelecom), a telecommunications provider in Kherson Oblast. Below, we summarize this event, and explore similar activity across other providers in Kherson that has taken place since then.
On May 1, 2022, we observed a shift in routing for the IPv4 prefix announced by Ukrainian network AS47598 (Khersontelecom). During April, it reached the Internet through several other Ukrainian network providers, including AS12883 (Vega Telecom) and AS3326 (Datagroup). However, after the shift, its routing path now showed a Russian network, AS201776 (Miranda-Media), as the sole upstream provider. With traffic from KhersonTelecom passing through a Russian network, it was subject to the restrictions and limitations imposed on any traffic transiting Russian networks, including content filtering.
The flow of traffic from Khersontelecom before and after May 1, with rerouting through Russian network provider Miranda-Media, is illustrated in the chart below. This particular re-routing event was short-lived, as a routing update for AS47598 on May 4 saw it return to reaching the Internet through other Ukrainian providers.
As a basis for our analysis, we started with a list of 15 Autonomous System Numbers (ASNs) belonging to networks in Kherson Oblast. Using that list, we analyzed routing information collected by route-views2 over the past year, from February 1, 2022, to February 15, 2023. route-views2 is a BGP route collector run by the University of Oregon Route Views Project. Note that with respect to the discussions of ASNs in this and the following section, we are treating them equally, and have not specifically factored estimated user population into these analyses.
The figure below illustrates the result of this analysis, showing that re-routing of Kherson network providers (listed along the y-axis) through Russian upstream networks was fairly widespread, and for some networks, has continued into 2023. During the analysis time frame, there were three primary Russian networks that appeared as upstream providers: AS201776 (Miranda-Media), AS52091 (Level-MSK Ltd.), and AS8492 (OBIT Ltd.).
Within the graph, black bars indicate periods when the ASN effectively disappeared from the Internet; white segments indicate the ASN was dependent on other Ukraine networks as immediate upstreams; and red indicates the presence of Russian networks in the set of upstream providers. The intensity of the red shading corresponds to the percentage of announced prefixes for which a Russian network provider is present in the routing path as observed from networks outside Ukraine. Bright red shading, equivalent to “1” in the legend, indicates the presence of a Russian provider in all routing paths for announced prefixes.
In the blog post linked above, we referenced an outage that began on April 30. This is clearly visible in the figure as a black bar that runs for several days across all the listed ASNs. In this instance, AS47598 (KhersonTelecom) recovered a day later, but was sending traffic through AS201776 (Miranda-Media), a Russian provider, as discussed above.
Another Ukrainian network, AS49168 (Brok-X), recovered from the outage on May 2, and was also sending traffic through Miranda-Media. By May 4, most of the other Kherson networks recovered from the outage, and both AS47598 and AS49168 returned to using Ukrainian networks as immediate upstream providers. Routing remained “normal” until May 30. Then, a more widespread shift to routing traffic through Russian providers began, although it appears that this shift was preceded by a brief outage for a few networks. For the most part, this re-routing lasted through the summer and into October. Some networks saw a brief outage on October 17, but most stopped routing directly through Russia by October 22.
However, this shift away from Russia was followed by periods of extended outages. KhersonTelecom suffered such an outage, and has remained offline since October, except for the first week of November when all of its traffic routed through Russia. Many other networks rejoined the Internet in early December, relying mostly on other Ukrainian providers for Internet connectivity. However, since early December, AS204485 (PE Berislav Cable Television), AS56359 (CHP Melnikov Roman Sergeevich), and AS49465 (Teleradiocompany RubinTelecom Ltd.) have continued to use Miranda-Media as an upstream provider, in addition to experiencing several brief outages. In addition, over the last several months, AS25082 (Viner Telecom) has used both a Ukrainian network and Miranda-Media as upstream providers.
Internet resilience in Ukraine
In the context of the Internet, “resilience” refers to the ability of a network to operate continuously in a manner that is highly resistant to disruption. This includes the ability of a network to: (1) operate in a degraded mode if damaged, (2) rapidly recover if failure does occur, and (3) scale to meet rapid or unpredictable demands. Throughout the Russia-Ukraine conflict, media coverage (VICE, Bloomberg, Washington Post) has highlighted the work done in Ukraine to repair damaged fiber-optic cables and mobile network infrastructure to keep the country online. This work has been critically important to maintaining the resilience of Ukrainian Internet infrastructure.
According to PeeringDB, as of February 2023, there are 25 Internet Exchange Points (IXPs) in Ukraine and 50 interconnection facilities. (An IXP may span multiple physical facilities.) Within this set of IXPs, Autonomous Systems (ASes) belonging to international providers are currently present in over half of them. The number of facilities, IXPs, and international ASes present in Ukraine points to a resilient interconnection fabric, with multiple locations for both domestic and international providers to exchange traffic.
To better understand these international interconnections, we first analyze the connectivity of ASes in Ukraine, and we classify the links to domestic networks (links where both ASes are registered in Ukraine) and international networks (links between ASes in Ukraine and ASes outside Ukraine). To determine which ASes are domestic in Ukraine, we can use information from the extended delegation reports from the Réseaux IP Européens Network Coordination Centre (RIPE NCC), the Regional Internet Registry that covers Ukraine. We also parsed collected BGP data to extract the AS-level links between Ukrainian ASes and ASes registered in a different country, and we consider these the international connectivity of the domestic ASes.
A March 2022 article in The Economist noted that “For one thing, Ukraine boasts an unusually large number of internet-service providers—by one reckoning the country has the world’s fourth-least-concentrated Internet market. This means the network has few choke points, so is hard to disable.” As of the writing of this blog post, there are 2,190 ASes registered in Ukraine (UA ASes), and 1,574 of those ASes appear in the BGP routing table as active. These counts support the article’s characterization, and below we discuss several additional observations that reinforce Ukraine’s Internet resilience.
The figure above is a cumulative distribution function showing the fraction of domestic Ukrainian ASes that have direct connections to international networks. In February 2023, approximately 50% had more than one (100) international link, while approximately 10% had more than 10, and approximately 2% had 100 or more. Although these numbers have dropped slightly over the last year, they underscore the lack of centralized choke points in the Ukrainian Internet.
For the networks with international connectivity, we can also look at the distribution of “next-hop” countries – countries with which those international networks are associated. (Note that some networks may have a global footprint, and for these, the associated country is the one recorded in their autonomous system registration.) Comparing the choropleth maps below illustrates how this set of countries, and their fraction of international paths, have changed between February 2022 and February 2023. The data underlying these maps shows that international connectivity from Ukraine is distributed across 18 countries — unsurprisingly, mostly in Europe.
In February 2022, these countries/locations accounted for 77% of Ukraine’s next-hop international paths. The top four all had 7.8% each. However, in February 2023, the top 10 next-hop countries/locations dropped slightly to 76% of international paths. While just a slight change from the previous year, the set of countries/locations and many of their respective fractions saw considerable change.
February 2022
February 2023
1
Germany
7.85%
Russia
11.62%
2
Netherlands
7.85%
Germany
11.43%
3
United Kingdom
7.83%
Hong Kong
8.38%
4
Hong Kong
7.81%
Poland
7.93%
5
Sweden
7.77%
Italy
7.75%
6
Romania
7.72%
Turkey
6.86%
7
Russia
7.67%
Bulgaria
6.20%
8
Italy
7.64%
Netherlands
5.31%
9
Poland
7.60%
United Kingdom
5.30%
10
Hungary
7.54%
Sweden
5.26%
Russia’s share grew by 50% year to 11.6%, giving it the biggest share of next-hop ASes. Germany also grew to account for more than 11% of paths.
Satellite Internet connectivity
Cloudflare observed a rapid growth in Starlink’s ASN (AS14593) traffic to Ukraine during 2022 and into 2023. Between mid-March and mid-May, Starlink’s traffic in the country grew over 530%, and continued to grow from mid-May up until mid-November, increasing nearly 300% over that six-month period — from mid-March to mid-December the growth percentage was over 1600%. After that, traffic stabilized and even dropped a bit during January 2023.
Our data shows that between November and December 2022, Starlink represented between 0.22% and 0.3% of traffic from Ukraine, but that number is now lower than 0.2%.
Conclusion
One year in, the war in Ukraine has taken an unimaginable humanitarian toll. The Internet in Ukraine has also become a battleground, suffering attacks, re-routing, and disruptions. But it has proven to be exceptionally resilient, recovering time and time again from each setback.
We know that the need for a secure and reliable Internet there is more critical than ever. At Cloudflare, we’re committed to continue providing tools that protect Internet services from cyber attack, improve security for those operating in the region, and share information about Internet connectivity and routing inside Ukraine.
Several Cloudflare services became unavailable for 121 minutes on January 24th, 2023 due to an error releasing code that manages service tokens. The incident degraded a wide range of Cloudflare products including aspects of our Workers platform, our Zero Trust solution, and control plane functions in our content delivery network (CDN).
Cloudflare provides a service token functionality to allow automated services to authenticate to other services. Customers can use service tokens to secure the interaction between an application running in a data center and a resource in a public cloud provider, for example. As part of the release, we intended to introduce a feature that showed administrators the time that a token was last used, giving users the ability to safely clean up unused tokens. The change inadvertently overwrote other metadata about the service tokens and rendered the tokens of impacted accounts invalid for the duration of the incident.
The reason a single release caused so much damage is because Cloudflare runs on Cloudflare. Service tokens impact the ability for accounts to authenticate, and two of the impacted accounts power multiple Cloudflare services. When these accounts’ service tokens were overwritten, the services that run on these accounts began to experience failed requests and other unexpected errors.
We know this impacted several customers and we know the impact was painful. We’re documenting what went wrong so that you can understand why this happened and the steps we are taking to prevent this from occurring again.
What is a service token?
When users log into an application or identity provider, they typically input a username and a password. The password allows that user to demonstrate that they are in control of the username and that the service should allow them to proceed. Layers of additional authentication can be added, like hard keys or device posture, but the workflow consists of a human proving they are who they say they are to a service.
However, humans are not the only users that need to authenticate to a service. Applications frequently need to talk to other applications. For example, imagine you build an application that shows a user information about their upcoming travel plans.
The airline holds details about the flight and its duration in their own system. They do not want to make the details of every individual trip public on the Internet and they do not want to invite your application into their private network. Likewise, the hotel wants to make sure that they only send details of a room booking to a valid, approved third party service.
Your application needs a trusted way to authenticate with those external systems. Service tokens solve this problem by functioning as a kind of username and password for your service. Like usernames and passwords, service tokens come in two parts: a Client ID and a Client Secret. Both the ID and Secret must be sent with a request for authentication. Tokens are also assigned a duration, after which they become invalid and must be rotated. You can grant your application a service token and, if the upstream systems you need validate it, your service can grab airline and hotel information and present it to the end user in a joint report.
When administrators create Cloudflare service tokens, we generate the Client ID and the Client Secret pair. Customers can then configure their requesting services to send both values as HTTP headers when they need to reach a protected resource. The requesting service can run in any environment, including inside of Cloudflare’s network in the form of a Worker or in a separate location like a public cloud provider. Customers need to deploy the corresponding protected resource behind Cloudflare’s reverse proxy. Our network checks every request bound for a configured service for the HTTP headers. If present, Cloudflare validates their authenticity and either blocks the request or allows it to proceed. We also log the authentication event.
Incident Timeline
All Timestamps are UTC
At 2023-01-24 16:55 UTC the Access engineering team initiated the release that inadvertently began to overwrite service token metadata, causing the incident.
At 2023-01-24 17:05 UTC a member of the Access engineering team noticed an unrelated issue and rolled back the release which stopped any further overwrites of service token metadata.
Service token values are not updated across Cloudflare’s network until the service token itself is updated (more details below). This caused a staggered impact of the service token’s that had their metadata overwritten.
2023-01-24 17:50 UTC: The first invalid service token for Cloudflare WARP was synced to the edge. Impact began for WARP and Zero Trust users.
WARP device posture uploads dropped to zero which raised an internal alert
At 2023-01-24 18:12 an incident was declared due to the large drop in successful WARP device posture uploads.
2023-01-24 18:19 UTC: The first invalid service token for the Cloudflare API was synced to the edge. Impact began for Cache Purge, Cache Reserve, Images and R2. Alerts were triggered for these products which identified a larger scope of the incident.
At 2023-01-24 18:21 the overwritten services tokens were discovered during the initial investigation.
At 2023-01-24 18:28 the incident was elevated to include all impacted products.
At 2023-01-24 18:51 An initial solution was identified and implemented to revert the service token to its original value for the Cloudflare WARP account, impacting WARP and Zero Trust. Impact ended for WARP and Zero Trust.
At 2023-01-24 18:56 The same solution was implemented on the Cloudflare API account, impacting Cache Purge, Cache Reserve, Images and R2. Impact ended for Cache Purge, Cache Reserve, Images and R2.
At 2023-01-24 19:00 An update was made to the Cloudflare API account which incorrectly overwrote the Cloudflare API account. Impact restarted for Cache Purge, Cache Reserve, Images and R2. All internal Cloudflare account changes were then locked until incident resolution.
At 2023-01-24 19:07 the Cloudflare API was updated to include the correct service token value. Impact ended for Cache Purge, Cache Reserve, Images and R2.
At 2023-01-24 19:51 all affected accounts had their service tokens restored from a database backup. Incident Ends.
What was released and how did it break?
The Access team was rolling out a new change to service tokens that added a “Last seen at” field. This was a popular feature request to help identify which service tokens were actively in use.
What went wrong?
The “last seen at” value was derived by scanning all new login events in an account’s login event Kafka queue. If a login event using a service token was detected, an update to the corresponding service token’s last seen value was initiated.
In order to update the service token’s “last seen at” value a read write transaction is made to collect the information about the corresponding service token. Service token read requests redact the “client secret” value by default for security reasons. The “last seen at” update to the service token then used that information from the read did not include the “client secret” and updated the service token with an empty “client secret” on the write.
An example of the correct and incorrect service token values shown below:
Example Access Service Token values
{
"1a4ddc9e-a1234-4acc-a623-7e775e579c87": {
"client_id": "6b12308372690a99277e970a3039343c.access",
"client_secret": "<hashed-value>", <-- what you would expect
"expires_at": 1698331351
},
"23ade6c6-a123-4747-818a-cd7c20c83d15": {
"client_id": "1ab44976dbbbdadc6d3e16453c096b00.access",
"client_secret": "", <--- this is the problem
"expires_at": 1670621577
}
}
The service token “client secret” database did have a “not null” check however in this situation an empty text string did not trigger as a null value.
As a result of the bug, any Cloudflare account that used a service token to authenticate during the 10 minutes “last seen at” release was out would have its “client secret” value set to an empty string. The service token then needed to be modified in order for the empty “client secret” to be used for authentication. There were a total of 4 accounts in this state, all of which are internal to Cloudflare.
How did we fix the issue?
As a temporary solution, we were able to manually restore the correct service token values for the accounts with overwritten service tokens. This stopped the immediate impact across the affected Cloudflare services.
The database team was then able to implement a solution to restore the service tokens of all impacted accounts from an older database copy. This concluded any impact from this incident.
Why did this impact other Cloudflare services?
Service tokens impact the ability for accounts to authenticate. Two of the impacted accounts power multiple Cloudflare services. When these accounts’ services tokens were overwritten, the services that run on these accounts began to experience failed requests and other unexpected errors.
Cloudflare WARP Enrollment
Cloudflare provides a mobile and desktop forward proxy, Cloudflare WARP (our “1.1.1.1” app), that any user can install on a device to improve the privacy of their Internet traffic. Any individual can install this service without the need for a Cloudflare account and we do not retain logs that map activity to a user.
When a user connects using WARP, Cloudflare validates the enrollment of a device by relying on a service that receives and validates the keys on the device. In turn, that service communicates with another system that tells our network to provide the newly enrolled device with access to our network
During the incident, the enrollment service could no longer communicate with systems in our network that would validate the device. As a result, users could no longer register new devices and/or install the app on a new device, and may have experienced issues upgrading to a new version of the app (which also triggers re-registration).
Cloudflare Zero Trust Device Posture and Re-Auth Policies
Cloudflare provides a comprehensive Zero Trust solution that customers can deploy with or without an agent living on the device. Some use cases are only available when using the Cloudflare agent on the device. The agent is an enterprise version of the same Cloudflare WARP solution and experienced similar degradation anytime the agent needed to send or receive device state. This impacted three use cases in Cloudflare Zero Trust.
First, similar to the consumer product, new devices could not be enrolled and existing devices could not be revoked. Administrators were also unable to modify settings of enrolled devices.. In all cases errors would have been presented to the user.
Second, many customers who replace their existing private network with Cloudflare’s Zero Trust solution may add rules that continually validate a user’s identity through the use of session duration policies. The goal of these rules is to enforce users to reauthenticate in order to prevent stale sessions from having ongoing access to internal systems. The agent on the device prompts the user to reauthenticate based on signals from Cloudflare’s control plane. During the incident, the signals were not sent and users could not successfully reauthenticate.
Finally, customers who rely on device posture rules also experienced impact. Device posture rules allow customers who use Access or Gateway policies to rely on the WARP agent to continually enforce that a device meets corporate compliance rules.
The agent communicates these signals to a Cloudflare service responsible for maintaining the state of the device. Cloudflare’s Zero Trust access control product uses a service token to receive this signal and evaluate it along with other rules to determine if a user can access a given resource. During this incident those rules defaulted to a block action, meaning that traffic modified by these policies would appear broken to the user. In some cases this meant that all internet bound traffic from a device was completely blocked leaving users unable to access anything.
Cloudflare Gateway caches the device posture state for users every 5 minutes to apply Gateway policies. The device posture state is cached so Gateway can apply policies without having to verify device state on every request. Depending on which Gateway policy type was matched, the user would experience two different outcomes. If they matched a network policy the user would experience a dropped connection and for an HTTP policy they would see a 5XX error page. We peaked at over 50,000 5XX errors/minute over baseline and had over 10.5 million posture read errors until the incident was resolved.
Gateway 5XX errors per minute
Total count of Gateway Device posture errors
Cloudflare R2 Storage and Cache Reserve
Cloudflare R2 Storage allows developers to store large amounts of unstructured data without the costly egress bandwidth fees associated with typical cloud storage services.
During the incident, the R2 service was unable to make outbound API requests to other parts of the Cloudflare infrastructure. As a result, R2 users saw elevated request failure rates when making requests to R2.
Many Cloudflare products also depend on R2 for data storage and were also affected. For example, Cache Reserve users were impacted during this window and saw increased origin load for any items not in the primary cache. The majority of read and write operations to the Cache Reserve service were impacted during this incident causing entries into and out of Cache Reserve to fail. However, when Cache Reserve sees an R2 error, it falls back to the customer origin, so user traffic was still serviced during this period.
Cloudflare Cache Purge
Cloudflare’s content delivery network (CDN) caches the content of Internet properties on our network in our data centers around the world to reduce the distance that a user’s request needs to travel for a response. In some cases, customers want to purge what we cache and replace it with different data.
The Cloudflare control plane, the place where an administrator interacts with our network, uses a service token to authenticate and reach the cache purge service. During the incident, many purge requests failed while the service token was invalid. We saw an average impact of 20 purge requests/second failing and a maximum of 70 requests/second.
What are we doing to prevent this from happening again?
We take incidents like this seriously and recognize the impact it had. We have identified several steps we can take to address the risk of a similar problem occurring in the future. We are implementing the following remediation plan as a result of this incident:
Test: The Access engineering team will add unit tests that would automatically catch any similar issues with service token overwrites before any new features are launched.
Alert: The Access team will implement an automatic alert for any dramatic increase in failed service token authentication requests to catch issues before they are fully launched.
Process: The Access team has identified process improvements to allow for faster rollbacks for specific database tables.
Implementation: All relevant database fields will be updated to include checks for empty strings on top of existing “not null checks”
We are sorry for the disruption this caused for our customers across a number of Cloudflare services. We are actively making these improvements to ensure improved stability moving forward and that this problem will not happen again.
Cloudflare operates in more than 250 cities in over 100 countries, where we interconnect with over 10,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
While Internet disruptions are never convenient, online interest in the 2022 World Cup in mid-November and the growth in online holiday shopping in many areas during November and December meant that connectivity issues could be particularly disruptive. Having said that, the fourth quarter appeared to be a bit quieter from an Internet disruptions perspective, although Iran and Ukraine continued to be hotspots, as we discuss below.
Government directed
Multi-hour Internet shutdowns are frequently used by authoritarian governments in response to widespread protests as a means of limiting communications among protestors, as well preventing protestors from sharing information and video with the outside world. During the fourth quarter Cuba and Sudan again implemented such shutdowns, while Iran continued the series of “Internet curfews” across mobile networks it started in mid-September, in addition to implementing several other regional Internet shutdowns.
Cuba
In late September, Hurricane Ian knocked out power across Cuba. While officials worked to restore service as quickly as possible, some citizens responded to perceived delays with protests that were reportedly the largest since anti-government demonstrations over a year earlier. In response to these protests, the Cuban government reportedly cut off Internet access several times. A shutdown on September 29-30 was covered in the Internet disruptions overview for Q3 2022, and the impact of the shutdown that occurred on October 1 (UTC) is shown in the figure below. The timing of this one was similar to the previous one, taking place between 1900 on September 30 and 0245 on October 1 (0000-0745 UTC on October 1).
Sudan
October 25 marked the first anniversary of a coup in Sudan that derailed the country’s transition to civilian rule, and thousands of Sudanese citizens marked the anniversary by taking to the streets in protest. Sudan’s government has a multi-year history of shutting down Internet access during times of civil unrest, and once again implemented an Internet shutdown in response to these protests. The figure below shows a near complete loss of Internet traffic from Sudan on October 25 between 0945-1740 local time (0745 – 1540 UTC).
Iran
As we covered in last quarter’s blog post, the Iranian government implemented daily Internet “curfews”, generally taking place between 1600 and midnight local time (1230-2030 UTC) across three mobile network providers — AS44244 (Irancell), AS57218 (RighTel), and AS197207 (MCCI) — in response to protests surrounding the death of Mahsa Amini. These multi-hour Internet curfew shutdowns continued into early October, with additional similar outages also observed on October 8, 12 and 15 as seen in the figure below. (The graph’s line for AS57218 (Rightel), the smallest of the three mobile providers, suggests that the shutdowns on this network were not implemented after the end of September.)
In addition to the mobile network shutdowns, several regional Internet disruptions were also observed in Iran during the fourth quarter, two of which we review below. The first was in Sanandaj, Kurdistan Province on October 26, where a complete Internet shutdown was implemented in response to demonstrations marking the 40th day since the death of Mahsa Amini. The figure below shows a complete loss of traffic starting at 1030 local time (0700 UTC), with the outage lasting until 0805 local time on October 27 (0435 UTC). In December, a province-level Internet disruption was observed starting on December 18, lasting through December 25.
The Internet disruptions that have taken place in Iran over the last several months have had a significant economic impact on the country. A December post from Filterwatch shared concerns stated in a letter from mobile operator Rightel:
The letter, signed by the network’s Managing Director Yasser Rezakhah, states that “during the past few weeks, the company’s resources and income have significantly decreased during Internet shutdowns and other restrictions, such as limiting Internet bandwidth from 21 September. They have also caused a decrease in data use from subscribers, decreasing data traffic by around 50%.” The letter also states that the “continued lack of compensation for losses could lead to bankruptcy.”
The post also highlighted economic concerns shared by Iranian officials:
Some Iranian officials have expressed concern about the cost of Internet shutdowns, including Valiollah Bayati, MP for Tafresh and Ashtian in Markazi province. In a public session in Majles (parliament), he stated that continued Internet shutdowns have led to the closure of many jobs and people are worried, the government and the President must provide necessary measures.
Since the 30th of Shahrivar month and with the beginning of the government disruption in the Internet, the country’s businesses have been damaged daily at least 50 million tomans and at most 500 million tomans. More than 41% of companies have lost 25-50% of their income during this period, and about 47% have had more than 50% reduction in sales. A review of the data of the research assistant of the country’s tax affairs organization shows that the Internet outage in Iran has caused 3000 billion tomans of damage per day. That is, the cost of 3 months of Internet outage in Iran is equal to 43% of one year’s oil revenue of the country ($25 billion).
Power outages
Bangladesh, October 4
Over 140 million people in Bangladesh were left without electricity on October 4 as the result of a reported grid failure caused by a failure by power distribution companies to follow instructions from the National Load Dispatch Centre to shed load. The resultant power outage resulted in an observed drop in Internet traffic from the country, starting at 1405 local time (0805 UTC), as shown in the figure below. The disruption lasted approximately seven hours, with traffic returning to expected levels around 1900 local time (1500 UTC).
Pakistan
Over a week later, a similar issue in Pakistan caused power outages across the southern part of the country, including Sindh, Punjab, and Balochistan. The power outages were caused by a fault in the national grid’s southern transmission system, reportedly due to faulty equipment and sub-standard maintenance. As expected, the power outages resulted in disruptions to Internet connectivity, and the figure below illustrates the impact observed in Sindh, where traffic dropped nearly 30% as compared to the previous week starting at 0935 local time (0435 UTC) on October 6. The disruption lasted over 15 hours, with traffic returning to expected levels at 0100 on October 7 (2000 UTC on October 6).
On November 24, a Tweet from Kenya Power at 1525 local time noted that they had “lost bulk power supply to various parts of the country due to a system disturbance”. A subsequent Tweet published just over six hours later at 2150 local time stated that “normal power supply has been restored to all parts of the country.” The time stamps on these notifications align with the loss of Internet traffic visible in the figure below, which lasted between 1500-2050 local time (1200-1750 UTC).
United States (Moore County, North Carolina)
On December 3, two electrical substations in Moore County, North Carolina were targeted by gunfire, with the resultant damage causing localized power outages that took multiple days to resolve. The power outages reportedly began just after 1900 local time (0000 UTC on December 4), resulting in the concurrent loss of Internet traffic from communities within Moore County, as seen in the figure below.
Internet traffic within the community of West End appeared to return midday (UTC) on December 5, but that recovery was apparently short-lived, as it fell again during the afternoon of December 6. In Pinehurst, traffic began to slowly recover after about a day, but returned to more normal levels around 0800 local time (1300 UTC) on December 7.
The war in Ukraine has been going on since February 24, and Cloudflare has covered the impact of the war on the country’s Internet connectivity in a number of blog posts across the year (March, March, April, May, June, July, October, December). Throughout the fourth quarter of 2022, Russian missile strikes causedwidespreaddamage to electrical infrastructure, resulting in power outages and disruptions to Internet connectivity. Below, we highlight several examples of the Internet disruptions observed in Ukraine during the fourth quarter, but they are just a few of the many disruptions that occurred.
On October 20, the destruction of several power stations in Kyiv resulted in a 25% drop in Internet traffic from Kyiv City as compared to the two previous weeks. The disruption began around 0900 local time (0700 UTC).
On November 23, widespread power outages after Russian strikes caused a nearly 50% decrease in Internet traffic in Ukraine, starting just after 1400 local time (1200 UTC). This disruption lasted for nearly a day and a half, with traffic returning to expected levels around 2345 local time on November 24 (2145 UTC).
On December 16, power outages resulting from Russian air strikes targeting power infrastructure caused country-level Internet traffic to drop around 13% at 0915 local time (0715 UTC), with the disruption lasting until midnight local time (2200 UTC). However, at a network level, the impact was more significant, with AS13188 (Triolan) seeing a 70% drop in traffic, and AS15895 (Kyivstar) a 40% drop, both shown in the figures below.
Cable cuts
Shetland Islands, United Kingdom
The Shetland Islands are primarily dependent on the SHEFA-2 submarine cable system for Internet connectivity, connecting through the Scottish mainland. Late in the evening of October 19, damage to this cable knocked the Shetland Islands almost completely offline. At the time, there was heightened concern about the potential sabotage of submarine cables due to the reported sabotage of the Nord Stream natural gas pipelines in late September, but authorities believed that this cable damage was due to errant fishing vessels, and not sabotage.
The figure below shows that the impact of the damage to the cable was relatively short-lived, compared to the multi-day Internet disruptions often associated with submarine cable cuts. Traffic dropped just after 2300 local time (2200 UTC) on October 19, and recovered 14.5 hours later, just after 1430 local time (1330 UTC) on October 20.
Earthquakes frequently cause infrastructure damage and power outages in affected areas, resulting in disruptions to Internet connectivity. We observed such a disruption in the Solomon Islands after a magnitude 7.0 earthquake occurred near there on November 22. The figure below shows Internet traffic from the country dropping significantly at 1300 local time (0200 UTC), and recovering 11 hours later at around 2000 local time (0900 UTC).
Technical problems
Kyrgyzstan
On October 24, a three-hour Internet disruption was observed in Kyrgyzstan lasting between 1100-1400 local time (0500-0800 UTC), as seen in the figure below. According to the country’s Ministry of Digital Development, the issue was caused by “an accident on one of the main lines that supply the Internet”, but no additional details were provided regarding the type of accident or where it had occurred.
Australia (Aussie Broadband)
Customers of Australian broadband Internet provider Aussie Broadband in Victoria and New South Wales suffered brief Internet disruptions on October 27. As shown in the figure below, AS4764 (Aussie Broadband) traffic from Victoria dropped by approximately 40% between 1505-1745 local time (0405-0645 UTC). A similar, but briefer, loss of traffic from New South Wales was also observed, lasting between 1515-1550 local time (0415-0450 UTC). A representative of Aussie Broadband provided insight into the underlying cause of the disruption, stating “A config change was made which was pushed out through automation to the DHCP servers in those states. … The change has been rolled back but getting the sessions back online is taking time for VIC, and we are now manually bringing areas up one at a time.”
In Haiti, customers of Internet service provider Access Haiti experienced disrupted service for more than half a day on November 9. The figure below shows that Internet traffic for AS27759 (Access Haiti) fell precipitously around midnight local time (0500 UTC), remaining depressed until 1430 local time (1930 UTC), at which time it recovered quickly. A Facebook post from Access Haiti explained to customers that “Due to an intermittent outage on one of our international circuits, our network is experiencing difficulties that cause your Internet service to slow down.” While Access Haiti didn’t provide additional details on which international circuit was experiencing an outage, submarinecablemap.com shows that two submarine cables provide international Internet connectivity to Haiti — the Bahamas Domestic Submarine Network (BDSNi), which connects Haiti to the Bahamas, and Fibralink, which connects Haiti to the Dominican Republic and Jamaica.
Unknown
Many Internet disruptions can be easily tied to an underlying cause, whether through coverage in the press, a concurrent weather or natural disaster event, or communication from an impacted provider. However, the causes of other observed disruptions remain unknown as the impacted providers remain silent about what caused the problem.
United States (Wide Open West)
On November 15, customers of Wide Open West, an Internet service provider with a multi-state footprint in the United States, experienced an Internet service disruption that lasted a little over an hour. The figure below illustrates the impact of the disruption in Alabama and Michigan on AS12083 (Wide Open West), with traffic dropping at 1150 local time (1650 UTC) and recovering just after 1300 local time (1800 UTC).
Cuba
Cuba is no stranger to Internet disruptions, whether due to government-directed shutdowns (such as the one discussed above), fiber cuts, or power outages. However, no underlying cause was ever shared for the seven-hour disruption in the country’s Internet traffic observed between 2345 on November 25 and 0645 on November 26 local time (0445-1145 UTC on November 26). Traffic was down as much as 75% from previous levels during the disruption.
SpaceX Starlink
As a provider of low earth orbit (LEO) satellite Internet connectivity services, disruptions to SpaceX Starlink’s service can have a global impact. On November 30, a disruption was observed on AS14593 (SPACEX-STARLINK) between 2050-2130 UTC, with traffic volume briefly dropping to near zero. Unfortunately, Starlink did not acknowledge the incident, nor did they provide any reason for the disruption.
Conclusion
Looking back at the Internet disruptions observed during 2022, a number of common themes can be found. In countries with more authoritarian governments, the Internet is often weaponized as a means of limiting communication within the country and with the outside world through network-level, regional, or national Internet shutdowns. As noted above, this approach was used aggressively in Iran during the last few months of the year.
Internet connectivity quickly became a casualty of war in Ukraine. Early in the conflict, network-level outages were common, and some Ukrainian networks ultimately saw traffic re-routed through upstream Russian Internet service providers. Later in the year, as electrical power infrastructure was increasingly targeted by Russian attacks, widespread power outages resulted in multi-hour disruptions of Internet traffic across the country.
While the volcanic eruption in Tonga took the country offline for over a month due to its reliance on a single submarine cable for Internet connectivity, the damage caused by earthquakes in other countries throughout the year resulted in much shorter and more limited disruptions.
And while submarine cable issues can impact multiple countries along its route, the advent of services with an increasingly global footprint like SpaceX Starlink mean that service disruptions will ultimately have a much broader impact. (Starlink’s subscriber base is comparatively small at the moment, but it currently has a service footprint in over 30 countries around the world.)
Today, a change to our Tiered Cache system caused some requests to fail for users with status code 530. The impact lasted for almost six hours in total. We estimate that about 5% of all requests failed at peak. Because of the complexity of our system and a blind spot in our tests, we did not spot this when the change was released to our test environment.
The failures were caused by side effects of how we handle cacheable requests across locations. At first glance, the errors looked like they were caused by a different system that had started a release some time before. It took our teams a number of tries to identify exactly what was causing the problems. Once identified we expedited a rollback which completed in 87 minutes.
We’re sorry, and we’re taking steps to make sure this does not happen again.
Background
One of Cloudflare’s products is our Content Delivery Network, or CDN. This is used to cache assets for websites globally. However, a data center is not guaranteed to have an asset cached. It could be new, expired, or has been purged. If that happens, and a user requests that asset, our CDN needs to retrieve a fresh copy from a website’s origin server. But the data center that the user is accessing might still be pretty far away from the origin server. This presents an additional issue for customers: every time an asset is not cached in the data center, we need to retrieve a new copy from the origin server.
To improve cache hit ratios, we introduced Tiered Cache. With Tiered Cache, we organize our data centers in the CDN into a hierarchy of “lower tiers” which are closer to the end users and “upper tiers” that are closer to the origin. When a cache-miss occurs in a lower tier, the upper tier is checked. If the upper tier has a fresh copy of the asset, we can serve that in response to the request. This improves performance and reduces the amount of times that Cloudflare has to reach out to an origin server to retrieve assets that are not cached in lower tier data centers.
Incident timeline and impact
At 08:40 UTC, a software release of a CDN component containing a bug began slowly rolling out. The bug was triggered when a user visited a site with either Tiered Cache, Cloudflare Images, or Bandwidth Alliance configured. This bug caused a subset of those customers to return HTTP Status Code 530 — an error. Content that could be served directly from a data center’s local cache was unaffected.
We started an investigation after receiving customer reports of an intermittent increase in 530s after the faulty component was released to a subset of data centers.
Once the release started rolling out globally to the remaining data centers, a sharp increase in 530s triggered alerts along with more customer reports, and an incident was declared.
Requests resulting in a response with status code 530
We confirmed a bad release was responsible by rolling back the release in a data center at 17:03 UTC. After the rollback, we observed a drop in 530 errors. After this confirmation, an accelerated global rollback began and the 530s started to decrease. Impact ended once the release was reverted in all data centers configured as Tiered Cache upper tiers at 18:04 UTC.
Timeline:
2022-10-25 08:40: The release started to roll out to a small subset of data centers.
2022-10-25 10:35: An individual customer alert fires, indicating an increase in 500 error codes.
2022-10-25 11:20: After an investigation, a single small data center is pinpointed as the source of the issue and removed from production while teams investigate the issue there.
2022-10-25 12:30: Issue begins spreading more broadly as more data centers get the code changes.
2022-10-25 14:22: 530s errors increase as the release starts to slowly roll out to our largest data centers.
2022-10-25 14:39: Multiple teams become involved in the investigation as more customers start reporting increases in errors.
2022-10-25 17:03: CDN Release is rolled back in Atlanta and root cause is confirmed.
2022-10-25 17:28: Peak impact with approximately 5% of all HTTP requests resulting in an error with status code 530.
2022-10-25 17:38: An accelerated rollback continues with large data centers acting as Upper tier for many customers.
2022-10-25 18:04: Rollback is complete in all Upper Tiers.
2022-10-25 18:30: Rollback is complete.
During the early phases of the investigation, the indicators were that this was a problem with our internal DNS system that also had a release rolling out at the same time. As the following section shows, that was a side effect rather than the cause of the outage.
Adding distributed tracing to Tiered Cache introduced the problem
In order to help improve our performance, we routinely add monitoring code to various parts of our services. Monitoring code helps by giving us visibility into how various components are performing, allowing us to determine bottlenecks that we can improve on. Our team recently added additional distributed tracing to our Tiered Cache logic. The tiered cache entrypoint code is as follows:
* Before:
function _M.go()
-- code to run here
end
* After:
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
end
The code above wraps the existing go() function with trace_fn() which will call the go() function and then reports its execution time.
However, the logic that injects a function to the opentracing module clears control headers on every request:
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
Normally, we extract data from these control headers before clearing them as a routine part of how we process requests.
But internal tiered cache traffic expects the control headers from the lower tier to be passed as-is. The combination of clearing headers and using an upper tier meant that information that might be critical to the routing of the request was not available. In the subset of requests affected, we were missing the hostname to resolve by our internal DNS lookup for origin server IP addresses. As a result, a 530 DNS error was returned to the client.
Remediation and follow-up steps
To prevent this from happening again, in addition to the fixing the bug, we have identified a set of changes that help us detect and prevent issues like this in the future:
Include a larger data center that is configured as a Tiered Cache upper tier in an earlier stage in the release plan. This will allow us to notice similar issues more quickly, before a global release.
Expand our acceptance test coverage to include a broader set of configurations, including various Tiered Cache topologies.
Alert more aggressively in situations where we do not have full context on requests, and need the extra host information in the control headers.
Ensure that our system correctly fails fast in an error like this, which would have helped identify the problem during development and test.
Conclusion
We experienced an incident that affected a significant set of customers using Tiered Cache. After identifying the faulty component, we were able to quickly rollback and remediate the issue. We are sorry for any disruption this has caused our customers and end users trying to access services.
Remediations to prevent such an incident from happening in the future will be put in place as soon as possible.
Cloudflare operates in more than 275 cities in over 100 countries, where we interconnect with over 10,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions. In many cases, these disruptions can be attributed to a physical event, while in other cases, they are due to an intentional government-directed shutdown. In this post, we review selected Internet disruptions observed by Cloudflare during the third quarter of 2022, supported by traffic graphs from Cloudflare Radar and other internal Cloudflare tools, and grouped by associated cause or common geography. The new Cloudflare Radar Outage Center provides additional information on these, and other historical, disruptions.
Government directed shutdowns
Unfortunately, for the last decade, governments around the world have turned to shutting down the Internet as a means of controlling or limiting communication among citizens and with the outside world. In the third quarter, this was an all too popular cause of observed disruptions, impacting countries and regions in Africa, the Middle East, Asia, and the Caribbean.
Iraq
As mentioned in our Q2 summary blog post, on June 27, the Kurdistan Regional Government in Iraq began to implement twice-weekly (Mondays and Thursday) multi-hour regional Internet shutdowns over the following four weeks, intended to prevent cheating on high school final exams. As seen in the figure below, these shutdowns occurred as expected each Monday and Thursday through July 21, with the exception of July 21. They impacted three governorates in Iraq, and lasted from 0630–1030 local time (0330–0730 UTC) each day.
In Cuba, an Internet disruption was observed between 0055-0150 local time (0455-0550 UTC) on July 15 amid reported anti-government protests in Los Palacios and Pinar del Rio.
Closing out the quarter, another significant disruption was observed in Cuba, reportedly in response to protests over the lack of electricity in the wake of Hurricane Ian. A complete outage is visible in the figure below between 2030 on September 29 and 0315 on September 30 local time (0030-0715 UTC on September 30).
Afghanistan
Telecommunications services were reportedly shut down in part of Kabul, Afghanistan on the morning of August 8. The figure below shows traffic dropping starting around 0930 local time (0500 UTC), recovering 11 hours later, around 2030 local time (1600 UTC).
Protests in Freetown, Sierra Leone over the rising cost of living likely drove the Internet disruptions observed within the country on August 10 & 11. The first one occurred between 1200-1400 local time (1200-1400 UTC) on August 10. While this outage is believed to have been government directed as a means of quelling the protests, Zoodlabs, which manages Sierra Leone Cable Limited, claimed that the outage was the result of “emergency technical maintenance on some of our international routes”.
A second longer outage was observed between 0100-0730 local time (0100-0730 UTC) on August 11, as seen in the figure below. These shutdowns follow similar behavior in years past, where Internet connectivity was shut off following elections within the country.
In Somaliland, local authorities reportedly cut off Internet service on August 11 ahead of scheduled opposition demonstrations. The figure below shows a complete Internet outage in Woqooyi Galbeed between 0645-1355 local time (0345-1055 UTC.)
At a network level, the observed outage was due to a loss of traffic from AS37425 (SomCable) and AS37563 (Somtel), as shown in the figures below. Somtel is a mobile services provider, while SomCable is focused on providing wireline Internet access.
India
India is no stranger to government-directed Internet shutdowns, taking such action hundreds of times over the last decade. This may be changing in the future, however, as the country’s Supreme Court ordered the Ministry of Electronics and Information Technology (MEITY) to reveal the grounds upon which it imposes or approves Internet shutdowns. Until this issue is resolved, we will continue to see regional shutdowns across the country.
One such example occurred in Assam, where mobile Internet connectivity was shut down to prevent cheating on exams. The figure below shows that these shutdowns were implemented twice daily on August 21 and August 28. While the shutdowns were officially scheduled to take place between 1000-1200 and 1400-1600 local time (0430-0630 and 0830-1030 UTC), some providers reportedly suspended connectivity starting in the early morning.
In addition to multi-hour outages in Sanadij and Tehran province on September 19 and 21 that were covered in a blog post, three mobile network providers — AS44244 (Irancell), AS57218 (RighTel), and AS197207 (MCCI) — implemented daily Internet “curfews”, generally taking place between 1600 and midnight local time (1230-2030 UTC), although the start times varied on several days. These regular shutdowns are clearly visible in the figure below, and continued into early October.
As noted in the blog post, access to DNS-over-HTTPS (DoH) and DNS-over-TLS (DoT) services was also blocked in Iran starting on September 20, and in a move that is likely related, connections over HTTP/3 and QUIC were blocked starting on September 22, as shown in the figure below from Cloudflare Radar.
Natural disasters
Natural disasters such as earthquakes and hurricanes wreak havoc on impacted geographies, often causing loss of life, as well as significant structural damage to buildings of all types. Infrastructure damage is also extremely common, with widespread loss of both electrical power and telecommunications infrastructure.
Papua New Guinea
On September 11, a 7.6 magnitude earthquake struck Papua New Guinea, resulting in landslides, cracked roads, and Internet connectivity disruptions. Traffic to the country dropped by 26% just after 1100 local time (0100 UTC) . The figure below shows that traffic volumes remained lower into the following day as well. An announcement from PNG DataCo, a local provider, noted that the earthquake “has affected the operations of the Kumul Submarine Cable Network (KSCN) Express Link between Port Moresby and Madang and the PPC-1 Cable between Madang and Sydney.” This damage, they stated, resulted in the observed outage and degraded service.
Several major hurricanes plowed their way up the east coast of North America in late September, causing significant damage, resulting in Internet disruptions. On September 18, island-wide power outages caused by Hurricane Fiona disrupted Internet connectivity on Puerto Rico. As the figure below illustrates, it took over 10 days for traffic volumes to return to expected levels. Luma Energy, the local power company, kept customers apprised of repair progress through regular updates to its Twitter feed.
Two days later, Hurricane Fiona slammed the Turks and Caicos islands, causing flooding and significant damage, as well as disrupting Internet connectivity. The figure below shows traffic starting to drop below expected levels around 1245 local time (1645 UTC) on September 20. Recovery took approximately a day, with traffic returning to expected levels around 1100 local time (1500 UTC) on September 21.
Continuing to head north, Hurricane Fiona ultimately made landfall in the Canadian province of Nova Scotia on September 24, causing power outages and disrupting Internet connectivity. The figure below shows that the most significant impact was seen in Nova Scotia. As Nova Scotia Power worked to restore service to customers, traffic volumes gradually increased, as seen in the figure below. By September 29, traffic volumes on the island had returned to normal levels.
Hurricane Ian
On September 28, Hurricane Ian made landfall in Florida, and was the strongest hurricane to hit Florida since Hurricane Michael in 2018. With over four million customers losing power due to damage from the storm, a number of cities experienced associated Internet disruptions. Traffic from impacted cities dropped significantly starting around 1500 local time (1900 UTC), and as the figure below shows, recovery has been slow, with traffic levels still not back to pre-storm volumes more than two weeks later.
In addition to power outages caused by earthquakes and hurricanes, a number of other power outages caused multi-hour Internet disruptions during the third quarter.
Iran
A reported power outage in a key data center building disrupted Internet connectivity for customers of local ISP Shatel in Iran on July 25. As seen in the figure below, traffic dropped significantly at approximately 0715 local time (0345 UTC). Recovery began almost immediately, with traffic nearing expected levels by 0830 local time (0500 UTC).
Venezuela
Electrical issues frequently disrupt Internet connectivity in Venezuela, and the independent @vesinfiltro Twitter account tracks these events closely. One such example occurred on August 9, when electrical issues disrupted connectivity across multiple states, including Mérida, Táchira, Barinas, Portuguesa, and Estado Trujillo. The figure below shows evidence of two disruptions, the first around 1340 local time (1740 UTC) and the second a few hours later, starting at around 1615 local time (2015 UTC). In both cases, traffic volumes appeared to recover fairly quickly.
On September 5, a power outage in Oman impacted energy, aviation, and telecommunications services. The latter is evident in the figure below, which shows the country’s traffic volume dropping nearly 60% when the outage began just before 1515 local time (0915 UTC). Although authorities claimed that “the electricity network would be restored within four hours,” traffic did not fully return to normal levels until 0400 local time on September 6 (2200 UTC on September 5) the following day, approximately 11 hours later.
Ukraine
Over the last seven-plus months of war in Ukraine, we have observed multiple Internet disruptions due to infrastructure damage and power outages related to the fighting. We have covered these disruptions in our first and second quarter summary blog posts, and continue to do so on our @CloudflareRadar Twitter account as they occur. Power outages were behind Internet disruptions observed in Kharkiv on September 11, 12, and 13.
The figure below shows that the first disruption started around 2000 local time (1700 UTC) on September 11. This near-complete outage lasted just over 12 hours, with traffic returning to normal levels around 0830 local time (0530 UTC) on the 12th. However, later that day, another partial outage occurred, with a 50% traffic drop seen at 1330 local time (1030 UTC). This one was much shorter, with recovery starting approximately an hour later. Finally, a nominal disruption is visible at 0800 local time (0500 UTC) on September 13, with lower than expected traffic volumes lasting for around five hours.
Cable damage
Damage to both terrestrial and submarine cables have caused many Internet disruptions over the years. The recent alleged sabotage of the sub-sea Nord Stream natural gas pipelines has brought an increasing level of interest from European media (including Swiss and French publications) around just how important submarine cables are to the Internet, and an increasing level of concern among policymakers about the safety of these cable systems and the potential impact of damage to them. However, the three instances of cable damage reviewed below are all related to terrestrial cable.
Iran
On August 1, a reported “fiber optic cable” problem caused by a fire in a telecommunications manhole disrupted connectivity across multiple network providers, including AS31549 (Aria Shatel), AS58224 (TIC), AS43754 (Asiatech), AS44244 (Irancell), and AS197207 (MCCI). The disruption started around 1215 local time (0845 UTC) and lasted for approximately four hours. Because it impacted a number of major wireless and wireline networks, the impact was visible at a country level as well, as seen in the figure below.
Pakistan
Cable damage due to heavy rains and flooding caused several Internet disruptions in Pakistan in August. The first notable disruption occurred on August 19, starting around 0700 local time (0200 UTC) and lasted just over six and a half hours. On August 22, another significant disruption is also visible, starting at 2250 local time (1750 UTC), with a further drop at 0530 local time (0030 UTC) on the 23rd. The second more significant drop was brief, lasting only 45 minutes, after which traffic began to recover.
Haiti
Amidst protests over fuel price hikes, fiber cuts in Haiti caused Internet outages on multiple network providers. Starting at 1500 local time (1900 UTC) on September 14, traffic on AS27759 (Access Haiti) fell to zero. According to a (translated) Twitter post from the provider, they had several fiber optic cables that were cut in various areas of the country, and blocked roads made it “really difficult” for their technicians to reach the problem areas. Repairs were eventually made, with traffic starting to increase again around 0830 local time (1230 UTC) on September 15, as shown in the figure below.
Access Haiti provides AS27774 (Haiti Networking Group) with Internet connectivity (as an “upstream” provider), so the fiber cut impacted their connectivity as well, causing the outage shown in the figure below.
Technical problems
As a heading, “technical problems” can be a catch-all, referring to multiple types of issues, including misconfigurations and routing problems. However, it is also sometimes the official explanation given by a government or telecommunications company for an observed Internet disruption.
Rogers
Arguably the most significant Internet disruption so far this year took place on AS812 (Rogers), one of Canada’s largest Internet service providers. At around 0845 UTC on July 8, a near complete loss of traffic was observed, as seen in the figure below.
The figure below shows that small amounts of traffic were seen from the network over the course of the outage, but it took nearly 24 hours for traffic to return to normal levels.
A notice posted by the Rogers CEO explained that “We now believe we’ve narrowed the cause to a network system failure following a maintenance update in our core network, which caused some of our routers to malfunction early Friday morning. We disconnected the specific equipment and redirected traffic, which allowed our network and services to come back online over time as we managed traffic volumes returning to normal levels.” A Cloudflare blog post covered the Rogers outage in real-time, highlighting related BGP activity and small increases of traffic.
Chad
A four-hour near-complete Internet outage took place in Chad on August 12, occurring between 1045 and 1300 local time (0945 to 1400 UTC). Authorities in Chad said that the disruption was due to a “technical problem” on connections between Sudachad and networks in Cameroon and Sudan.
Unknown
In many cases, observed Internet disruptions are attributed to underlying causes thanks to statements by service providers, government officials, or media coverage of an associated event. However, for some disruptions, no published explanation or associated event could be found.
On August 11, a multi-hour outage impacted customers of US telecommunications provider Centurylink in states including Colorado, Iowa, Missouri, Montana, New Mexico, Utah, and Wyoming, as shown in the figure below. The outage was also visible in a traffic graph for AS209, the associated autonomous system.
Starlink
On August 30, satellite Internet provider suffered a global service disruption, lasting between 0630-1030 UTC as seen in the figure below.
Conclusion
As part of Cloudflare’s Birthday Week at the end of September, we launched the Cloudflare Radar Outage Center (CROC). The CROC is a section of our new Radar 2.0 site that archives information about observed Internet disruptions. The underlying data that powers the CROC is also available through an API, enabling interested parties to incorporate data into their own tools, sites, and applications. For regular updates on Internet disruptions as they occur and other Internet trends, follow @CloudflareRadar on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.