Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/12/lastpass-security-breach.html
The company was hacked, and customer information accessed. No passwords were compromised.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/12/lastpass-security-breach.html
The company was hacked, and customer information accessed. No passwords were compromised.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/11/failures-in-twitters-two-factor-authentication-system.html
Twitter is having intermittent problems with its two-factor authentication system:
Not all users are having problems receiving SMS authentication codes, and those who rely on an authenticator app or physical authentication token to secure their Twitter account may not have reason to test the mechanism. But users have been self-reporting issues on Twitter since the weekend, and WIRED confirmed that on at least some accounts, authentication texts are hours delayed or not coming at all. The meltdown comes less than two weeks after Twitter laid off about half of its workers, roughly 3,700 people. Since then, engineers, operations specialists, IT staff, and security teams have been stretched thin attempting to adapt Twitter’s offerings and build new features per new owner Elon Musk’s agenda.
On top of that, it seems that the system has a new vulnerability:
A researcher contacted Information Security Media Group on condition of anonymity to reveal that texting “STOP” to the Twitter verification service results in the service turning off SMS two-factor authentication.
“Your phone has been removed and SMS 2FA has been disabled from all accounts,” is the automated response.
The vulnerability, which ISMG verified, allows a hacker to spoof the registered phone number to disable two-factor authentication. That potentially exposes accounts to a password reset attack or account takeover through password stuffing.
This is not a good sign.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/10/recovering-passwords-by-measuring-residual-heat.html
Researchers have used thermal cameras and ML guessing techniques to recover passwords from measuring the residual heat left by fingers on keyboards. From the abstract:
We detail the implementation of ThermoSecure and make a dataset of 1,500 thermal images of keyboards with heat traces resulting from input publicly available. Our first study shows that ThermoSecure successfully attacks 6-symbol, 8-symbol, 12-symbol, and 16-symbol passwords with an average accuracy of 92%, 80%, 71%, and 55% respectively, and even higher accuracy when thermal images are taken within 30 seconds. We found that typing behavior significantly impacts vulnerability to thermal attacks, where hunt-and-peck typists are more vulnerable than fast typists (92% vs 83% thermal attack success if performed within 30 seconds). The second study showed that the keycaps material has a statistically significant effect on the effectiveness of thermal attacks: ABS keycaps retain the thermal trace of users presses for a longer period of time, making them more vulnerable to thermal attacks, with a 52% average attack accuracy compared to 14% for keyboards with PBT keycaps.
“ABS” is Acrylonitrile Butadiene Styrene, which some keys are made of. Others are made of Polybutylene Terephthalate (PBT). PBT keys are less vulnerable.
But, honestly, if someone can train a camera at your keyboard, you have bigger problems.
News article.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/09/leaking-passwords-through-the-spellchecker.html
Sometimes browser spellcheckers leak passwords:
When using major web browsers like Chrome and Edge, your form data is transmitted to Google and Microsoft, respectively, should enhanced spellcheck features be enabled.
Depending on the website you visit, the form data may itself include PII—including but not limited to Social Security Numbers (SSNs)/Social Insurance Numbers (SINs), name, address, email, date of birth (DOB), contact information, bank and payment information, and so on.
The solution is to only use the spellchecker options that keep the data on your computer—and don’t send it into the cloud.
Post Syndicated from CJ Moses original https://aws.amazon.com/blogs/security/expanded-eligibility-for-the-free-mfa-security-key-program/
Since the broad launch of our multi-factor authentication (MFA) security key program, customers have been enthusiastic about the program and how they will use it to improve their organizations’ security posture. Given the level of interest, we’re expanding eligibility for the program to allow more US-based AWS account root users and payer accounts to take advantage of the offer. Previously, eligibility required that US-based root users and payer accounts spend a minimum of $100 per month over the past 3 months. Now, we are expanding eligibility to US-based root users and payer accounts who have spent a minimum of $300 over the past 3 months. If you are a US-based customer who meets the expanded eligibility requirements, we encourage you to place an order for your free security key. As a reminder, you can use the following steps to order your free key.
To order your free security key
MFA as a core security best practice is one of the key messages emphasized at the recent AWS re:Inforce conference. Using MFA is one of the simplest ways for anyone, personally or professionally, to help improve their security online. For example, if credentials become compromised on GitHub, users have an extra layer of protection if MFA is enabled. Or, if your login details are compromised for your bank account, MFA acts a second factor to protect your account.
If you’re not eligible for a free security key at this time, but would still like a security key, check out our MFA recommendations. These are available for purchase from many sellers, including Amazon. For more information about the MFA program, see our Free MFA Security Key page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/06/__trashed-2.html
Thought experiment story of someone who lost everything in a house fire, and now can’t log into anything:
But to get into my cloud, I need my password and 2FA. And even if I could convince the cloud provider to bypass that and let me in, the backup is secured with a password which is stored in—you guessed it—my Password Manager.
I am in cyclic dependency hell. To get my passwords, I need my 2FA. To get my 2FA, I need my passwords.
It’s a one-in-a-million story, and one that’s hard to take into account in system design.
This is where we reach the limits of the “Code Is Law” movement.
In the boring analogue world—I am pretty sure that I’d be able to convince a human that I am who I say I am. And, thus, get access to my accounts. I may have to go to court to force a company to give me access back, but it is possible.
But when things are secured by an unassailable algorithm—I am out of luck. No amount of pleading will let me without the correct credentials. The company which provides my password manager simply doesn’t have access to my passwords. There is no-one to convince. Code is law.
Of course, if I can wangle my way past security, an evil-doer could also do so.
So which is the bigger risk?
- An impersonator who convinces a service provider that they are me?
- A malicious insider who works for a service provider?
- Me permanently losing access to all of my identifiers?
I don’t know the answer to that.
Those risks are in the order of most common to least common, but that doesn’t necessarily mean that they are in risk order. They probably are, but then we’re left with no good way to handle someone who has lost all their digital credentials—computer, phone, backup, hardware token, wallet with ID cards—in a catastrophic house fire.
I want to remind readers that this isn’t a true story. It didn’t actually happen. It’s a thought experiment.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/04/bypassing-two-factor-authentication.html
These techniques are not new, but they’re increasingly popular:
…some forms of MFA are stronger than others, and recent events show that these weaker forms aren’t much of a hurdle for some hackers to clear. In the past few months, suspected script kiddies like the Lapsus$ data extortion gang and elite Russian-state threat actors (like Cozy Bear, the group behind the SolarWinds hack) have both successfully defeated the protection.
[…]
Methods include:
- Sending a bunch of MFA requests and hoping the target finally accepts one to make the noise stop.
- Sending one or two prompts per day. This method often attracts less attention, but “there is still a good chance the target will accept the MFA request.”
- Calling the target, pretending to be part of the company, and telling the target they need to send an MFA request as part of a company process.
FIDO2 multi-factor authentication systems are not susceptible to these attacks, because they are tied to a physical computer.
And even though there are attacks against these two-factor systems, they’re much more secure than not having them at all. If nothing else, they block pretty much all automated attacks.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/03/change-password.html
Oops:
Instead of telling you when it’s safe to cross the street, the walk signs in Crystal City, VA are just repeating ‘CHANGE PASSWORD.’ Something’s gone terribly wrong here.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/11/proposed-uk-law-bans-default-passwords.html
Following California’s lead, a new UK law would ban default passwords in IoT devices.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/11/why-i-hate-password-rules.html
The other day, I was creating a new account on the web. It was financial in nature, which means it gets one of my most secure passwords. I used Password Safe to generate this 16-character alphanumeric password:
:s^Twd.J;3hzg=Q~
Which was rejected by the site, because it didn’t meet its password security rules.
It took me a minute to figure out what was wrong with it. The site wanted at least two numbers.
Okay, that’s not really why I don’t like password rules. I don’t like them because they’re all different. Even if someone has a strong password generation system, it is likely that whatever they come up with won’t pass somebody’s ruleset.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/07/vulnerability-in-the-kaspersky-password-manager.html
A vulnerability (just patched) in the random number generator used in the Kaspersky Password Manager resulted in easily guessable passwords:
The password generator included in Kaspersky Password Manager had several problems. The most critical one is that it used a PRNG not suited for cryptographic purposes. Its single source of entropy was the current time. All the passwords it created could be bruteforced in seconds. This article explains how to securely generate passwords, why Kaspersky Password Manager failed, and how to exploit this flaw. It also provides a proof of concept to test if your version is vulnerable.
The product has been updated and its newest versions aren’t affected by this issue.
Stupid programming mistake, or intentional backdoor? We don’t know.
More generally: generating random numbers is hard. I recommend my own algorithm: Fortuna. I also recommend my own password manager: Password Safe.
EDITED TO ADD: Commentary from Matthew Green.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/01/backdoor-in-zyxel-firewalls-and-gateways.html
This is bad:
More than 100,000 Zyxel firewalls, VPN gateways, and access point controllers contain a hardcoded admin-level backdoor account that can grant attackers root access to devices via either the SSH interface or the web administration panel.
[…]
Installing patches removes the backdoor account, which, according to Eye Control researchers, uses the “zyfwp” username and the “PrOw!aN_fXp” password.
“The plaintext password was visible in one of the binaries on the system,” the Dutch researchers said in a report published before the Christmas 2020 holiday.
Post Syndicated from Tatiana Bradley original https://blog.cloudflare.com/opaque-oblivious-passwords/
Passwords are a problem. They are a problem for reasons that are familiar to most readers. For us at Cloudflare, the problem lies much deeper and broader. Most readers will immediately acknowledge that passwords are hard to remember and manage, especially as password requirements grow increasingly complex. Luckily there are great software packages and browser add-ons to help manage passwords. Unfortunately, the greater underlying problem is beyond the reaches of software to solve.
The fundamental password problem is simple to explain, but hard to solve: A password that leaves your possession is guaranteed to sacrifice security, no matter its complexity or how hard it may be to guess. Passwords are insecure by their very existence.
You might say, “but passwords are always stored in encrypted format!” That would be great. More accurately, they are likely stored as a salted hash, as explained below. Even worse is that there is no way to verify the way that passwords are stored, and so we can assume that on some servers passwords are stored in cleartext. The truth is that even responsibly stored passwords can be leaked and broken, albeit (and thankfully) with enormous effort. An increasingly pressing problem stems from the nature of passwords themselves: any direct use of a password, today, means that the password must be handled in the clear.
You say, “but my password is transmitted securely over HTTPS!” This is true.
You say, “but I know the server stores my password in hashed form, secure so no one can access it!” Well, this puts a lot of faith in the server. Even so, let’s just say that yes, this may be true, too.
There remains, however, an important caveat — a gap in the end-to-end use of passwords. Consider that once a server receives a password, between being securely transmitted and securely stored, the password has to be read and processed. Yes, as cleartext!
And it gets worse — because so many are used to thinking in software, it’s easy to forget about the vulnerability of hardware. This means that even if the software is somehow trusted, the password must at some point reside in memory. The password must at some point be transmitted over a shared bus to the CPU. These provide vectors of attack to on-lookers in many forms. Of course, these attack vectors are far less likely than those presented by transmission and permanent storage, but they are no less severe (recent CPU vulnerabilities such as Spectre and Meltdown should serve as a stark reminder.)
The only way to fix this problem is to get rid of passwords altogether. There is hope! Research and private sector communities are working hard to do just that. New standards are emerging and growing mature. Unfortunately, passwords are so ubiquitous that it will take a long time to agree on and supplant passwords with new standards and technology.
At Cloudflare, we’ve been asking if there is something that can be done now, imminently. Today’s deep-dive into OPAQUE is one possible answer. OPAQUE is one among many examples of systems that enable a password to be useful without it ever leaving your possession. No one likes passwords, but as long they’re in use, at least we can ensure they are never given away.
I’ll be the first to admit that password-based authentication is annoying. Passwords are hard to remember, tedious to type, and notoriously insecure. Initiatives to reduce or replace passwords are promising. For example, WebAuthn is a standard for web authentication based primarily on public key cryptography using hardware (or software) tokens. Even so, passwords are frustratingly persistent as an authentication mechanism. Whether their persistence is due to their ease of implementation, familiarity to users, or simple ubiquity on the web and elsewhere, we’d like to make password-based authentication as secure as possible while they persist.
My internship at Cloudflare focused on OPAQUE, a cryptographic protocol that solves one of the most glaring security issues with password-based authentication on the web: though passwords are typically protected in transit by HTTPS, servers handle them in plaintext to check their correctness. Handling plaintext passwords is dangerous, as accidentally logging or caching them could lead to a catastrophic breach. The goal of the project, rather than to advocate for adoption of any particular protocol, is to show that OPAQUE is a viable option among many for authentication. Because the web case is most familiar to me, and likely many readers, I will use the web as my main example.
When you type in a password on the web, what happens? The website must check that the password you typed is the same as the one you originally registered with the site. But how does this check work?
Usually, your username and password are sent to a server. The server then checks if the registered password associated with your username matches the password you provided. Of course, to prevent an attacker eavesdropping on your Internet traffic from stealing your password, your connection to the server should be encrypted via HTTPS (HTTP-over-TLS).
Despite use of HTTPS, there still remains a glaring problem in this flow: the server must store a representation of your password somewhere. Servers are hard to secure, and breaches are all too common. Leaking this representation can cause catastrophic security problems. (For records of the latest breaches, check out https://haveibeenpwned.com/).
To make these leaks less devastating, servers often apply a hash function to user passwords. A hash function maps each password to a unique, random-looking value. It’s easy to apply the hash to a password, but almost impossible to reverse the function and retrieve the password. (That said, anyone can guess a password, apply the hash function, and check if the result is the same.)
With password hashing, plaintext passwords are no longer stored on servers. An attacker who steals a password database no longer has direct access to passwords. Instead, the attacker must apply the hash to many possible passwords and compare the results with the leaked hashes.
Unfortunately, if a server hashes only the passwords, attackers can download precomputed rainbow tables containing hashes of trillions of possible passwords and almost instantly retrieve the plaintext passwords. (See https://project-rainbowcrack.com/table.htm for a list of some rainbow tables).
With this in mind, a good defense-in-depth strategy is to use salted hashing, where the server hashes your password appended to a random, per-user value called a salt. The server also saves the salt alongside the username, so the user never sees or needs to submit it. When the user submits a password, the server re-computes this hash function using the salt. An attacker who steals password data, i.e., the password representations and salt values, must then guess common passwords one by one and apply the (salted) hash function to each guessed password. Existing rainbow tables won’t help because they don’t take the salts into account, so the attacker needs to make a new rainbow table for each user!
This (hopefully) slows down the attack enough for the service to inform users of a breach, so they can change their passwords. In addition, the salted hashes should be hardened by applying a hash many times to further slow attacks. (See https://blog.cloudflare.com/keeping-passwords-safe-by-staying-up-to-date/ for a more detailed discussion).
These two mitigation strategies — encrypting the password in transit and storing salted, hardened hashes — are the current best practices.
A large security hole remains open. Password-over-TLS (as we will call it) requires users to send plaintext passwords to servers during login, because servers must see these passwords to match against registered passwords on file. Even a well-meaning server could accidentally cache or log your password attempt(s), or become corrupted in the course of checking passwords. (For example, Facebook detected in 2019 that it had accidentally been storing hundreds of millions of plaintext user passwords). Ideally, servers should never see a plaintext password at all.
But that’s quite a conundrum: how can you check a password if you never see the password? Enter OPAQUE: a Password-Authenticated Key Exchange (PAKE) protocol that simultaneously proves knowledge of a password and derives a secret key. Before describing OPAQUE in detail, we’ll first summarize PAKE functionalities in general.
Password-Authenticated Key Exchange (PAKE) was proposed by Bellovin and Merrit in 1992, with an initial motivation of allowing password-authentication without the possibility of dictionary attacks based on data transmitted over an insecure channel.
Essentially, a plain, or symmetric, PAKE is a cryptographic protocol that allows two parties who share only a password to establish a strong shared secret key. The goals of PAKE are:
1) The secret keys will match if the passwords match, and appear random otherwise.
2) Participants do not need to trust third parties (in particular, no Public Key Infrastructure),
3) The resulting secret key is not learned by anyone not participating in the protocol – including those who know the password.
4) The protocol does not reveal either parties’ password to each other (unless the passwords match), or to eavesdroppers.
In sum, the only way to successfully attack the protocol is to guess the password correctly while participating in the protocol. (Luckily, such attacks can be mostly thwarted by rate-limiting, i.e, blocking a user from logging in after a certain number of incorrect password attempts).
Given these requirements, password-over-TLS is clearly not a PAKE, because:
That said, plain PAKE is still worse than Password-over-TLS, simply because it requires the server to store plaintext passwords. We need a PAKE that lets the server store salted hashes if we want to beat the current practice.
An improvement over plain PAKE is what’s called an asymmetric PAKE (aPAKE), because only the client knows the password, and the server knows a hashed password. An aPAKE has the four properties of PAKE, plus one more:
5) An attacker who steals password data stored on the server must perform a dictionary attack to retrieve the password.
The issue with most existing aPAKE protocols, however, is that they do not allow for a salted hash (or if they do, they require that salt to be transmitted to the user, which means the attacker has access to the salt beforehand and can begin computing a rainbow table for the user before stealing any data). We’d like, therefore, to upgrade the security property as follows:
5*) An attacker who steals password data stored on the server must perform a per-user dictionary attack to retrieve the password after the data is compromised.
OPAQUE is the first aPAKE protocol with a formal security proof that has this property: it allows for a completely secret salt.

OPAQUE is what’s referred to as a strong aPAKE, which simply means that it resists these pre-computation attacks by using a secretly salted hash on the server. OPAQUE was proposed and formally analyzed by Stanislaw Jarecki, Hugo Krawcyzk and Jiayu Xu in 2018 (full disclosure: Stanislaw Jarecki is my academic advisor). The name OPAQUE is a combination of the names of two cryptographic protocols: OPRF and PAKE. We already know PAKE, but what is an OPRF? OPRF stands for Oblivious Pseudo-Random Function, which is a protocol by which two parties compute a function F(key, x) that is deterministic but outputs random-looking values. One party inputs the value x, and another party inputs the key – the party who inputs x learns the result F(key, x) but not the key, and the party providing the key learns nothing. (You can dive into the math of OPRFs here: https://blog.cloudflare.com/privacy-pass-the-math/).
The core of OPAQUE is a method to store user secrets for safekeeping on a server, without giving the server access to those secrets. Instead of storing a traditional salted password hash, the server stores a secret envelope for you that is “locked” by two pieces of information: your password known only by you, and a random secret key (like a salt) known only by the server. To log in, the client initiates a cryptographic exchange that reveals the envelope key to the client, but, importantly, not to the server.
The server then sends the envelope to the user, who now can retrieve the encrypted keys. (The keys included in the envelope are a private-public key pair for the user, and a public key for the server.) These keys, once unlocked, will be the inputs to an Authenticated Key Exchange (AKE) protocol, which allows the user and server to establish a secret key which can be used to encrypt their future communication.
OPAQUE consists of two phases, being credential registration and login via key exchange.
Before registration, the user first signs up for a service and picks a username and password. Registration begins with the OPRF flow we just described: Alice (the user) and Bob (the server) do an OPRF exchange. The result is that Alice has a random key rwd, derived from the OPRF output F(key, pwd), where key is a server-owned OPRF key specific to Alice and pwd is Alice’s password.
Within his OPRF message, Bob sends the public key for his OPAQUE identity. Alice then generates a new private/public key pair, which will be her persistent OPAQUE identity for Bob’s service, and encrypts her private key along with Bob’s public key with the rwd (we will call the result an encrypted envelope). She sends this encrypted envelope along with her public key (unencrypted) to Bob, who stores the data she provided, along with Alice’s specific OPRF keysecret, in a database indexed by her username.
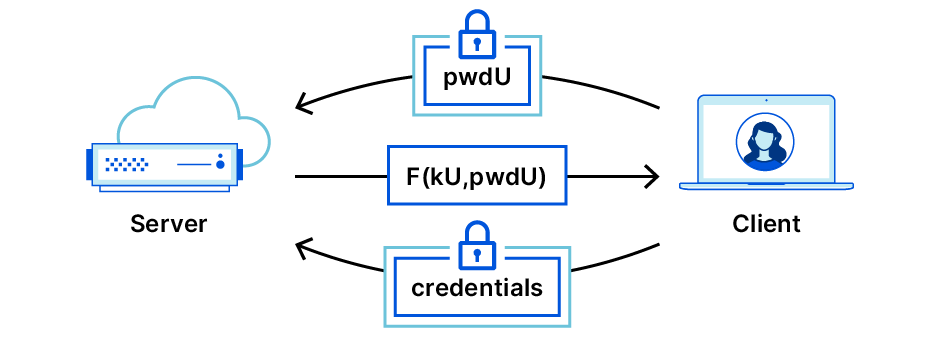
The login phase is very similar. It starts the same way as registration — with an OPRF flow. However, on the server side, instead of generating a new OPRF key, Bob instead looks up the one he created during Alice’s registration. He does this by looking up Alice’s username (which she provides in the first message), and retrieving his record of her. This record contains her public key, her encrypted envelope, and Bob’s OPRF key for Alice.
He also sends over the encrypted envelope which Alice can decrypt with the output of the OPRF flow. (If decryption fails, she aborts the protocol — this likely indicates that she typed her password incorrectly, or Bob isn’t who he says he is). If decryption succeeds, she now has her own secret key and Bob’s public key. She inputs these into an AKE protocol with Bob, who, in turn, inputs his private key and her public key, which gives them both a fresh shared secret key.
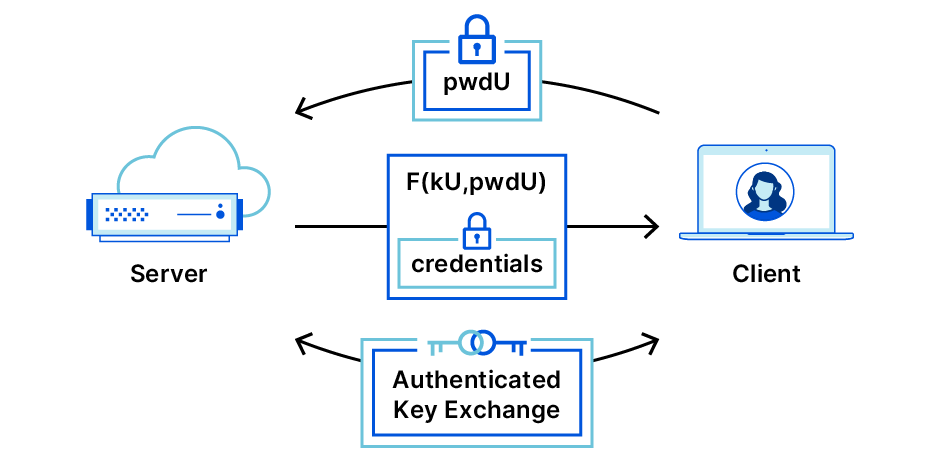
An important question to ask here is: what AKE is suitable for OPAQUE? The emerging CFRG specification outlines several options, including 3DH and SIGMA-I. However, on the web, we already have an AKE at our disposal: TLS!
Recall that TLS is an AKE because it provides unilateral (and mutual) authentication with shared secret derivation. The core of TLS is a Diffie-Hellman key exchange, which by itself is unauthenticated, meaning that the parties running it have no way to verify who they are running it with. (This is a problem because when you log into your bank, or any other website that stores your private data, you want to be sure that they are who they say they are). Authentication primarily uses certificates, which are issued by trusted entities through a system called Public Key Infrastructure (PKI). Each certificate is associated with a secret key. To prove its identity, the server presents its certificate to the client, and signs the TLS handshake with its secret key.
Modifying this ubiquitous certificate-based authentication on the web is perhaps not the best place to start. Instead, an improvement would be to authenticate the TLS shared secret, using OPAQUE, after the TLS handshake completes. In other words, once a server is authenticated with its typical WebPKI certificate, clients could subsequently authenticate to the server. This authentication could take place “post handshake” in the TLS connection using OPAQUE.
Exported Authenticators are one mechanism for “post-handshake” authentication in TLS. They allow a server or client to provide proof of an identity without setting up a new TLS connection. Recall that in the standard web case, the server establishes their identity with a certificate (proving, for example, that they are “cloudflare.com”). But if the same server also holds alternate identities, they must run TLS again to prove who they are.
The basic Exported Authenticator flow works resembles a classical challenge-response protocol, and works as follows. (We’ll consider the server authentication case only, as the client case is symmetric).
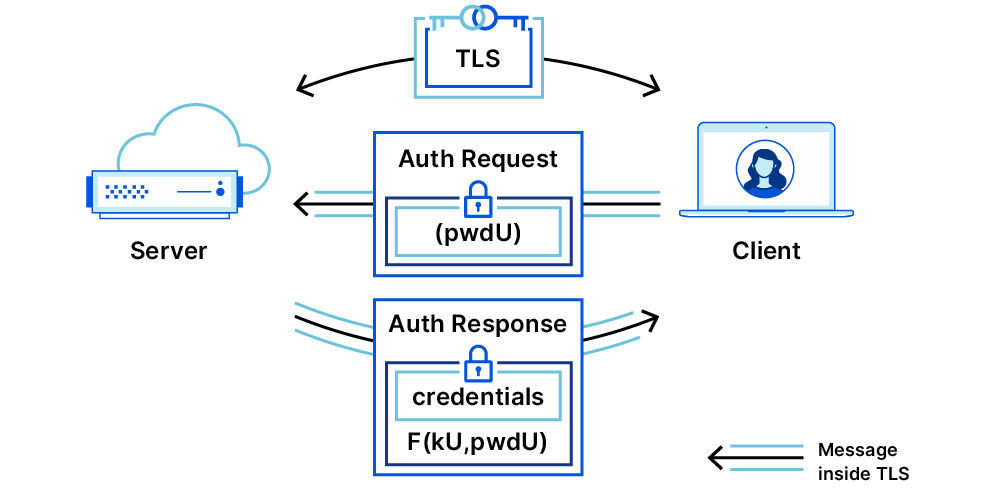
At any point after a TLS connection is established, Alice (the client) sends an authenticator request to indicate that she would like Bob (the server) to prove an additional identity. This request includes a context (an unpredictable string — think of this as a challenge), and extensions which include information about what identity the client wants to be provided. For example, the client could include the SNI extension to ask the server for a certificate associated with a certain domain name other than the one initially used in the TLS connection.
On receipt of the client message, if the server has a valid certificate corresponding to the request, it sends back an exported authenticator which proves that it has the secret key for the certificate. (This message has the same format as an Auth message from the client in TLS 1.3 handshake – it contains a Certificate, a CertificateVerify and a Finished message). If the server cannot or does not wish to authenticate with the requested certificate, it replies with an empty authenticator which contains only a well formed Finished message.
The client then checks that the Exported Authenticator it receives is well-formed, and then verifies that the certificate presented is valid, and if so, accepts the new identity.
In sum, Exported Authenticators provide authentication in a higher layer (such as the application layer) safely by leveraging the well-vetted cryptography and message formats of TLS. Furthermore, it is tied to the TLS session so that authentication messages can’t be copied and pasted from one TLS connection into another. In other words, Exported Authenticators provide exactly the right hooks needed to add OPAQUE-based authentication into TLS.
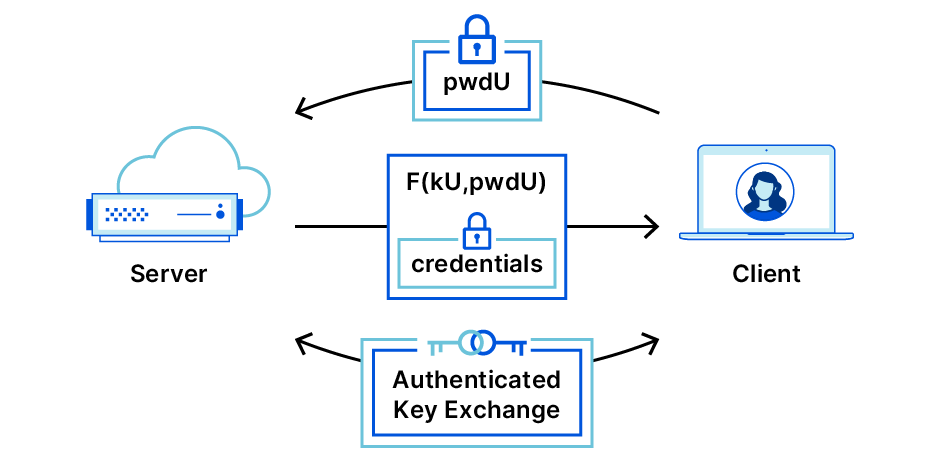
OPAQUE-EA allows OPAQUE to run at any point after a TLS connection has already been set up. Recall that Bob (the server) will store his OPAQUE identity, in this case a signing key and verification key, and Alice will store her identity — encrypted — on Bob’s server. (The registration flow where Alice stores her encrypted keys is the same as in regular OPAQUE, except she stores a signing key, so we will skip straight to the login flow). Alice and Bob run two request-authenticate EA flows, one for each party, and OPAQUE protocol messages ride along in the extensions section of the EAs. Let’s look in detail how this works.
First, Alice generates her OPRF message based on her password. She creates an Authenticator Request asking for Bob’s OPAQUE identity, and includes (in the extensions field) her username and her OPRF message, and sends this to Bob over their established TLS connection.
Bob receives the message and looks up Alice’s username in his database. He retrieves her OPAQUE record containing her verification key and encrypted envelope, and his OPRF key. He uses the OPRF key on the OPRF message, and creates an Exported Authenticator proving ownership of his OPAQUE signing key, with an extension containing his OPRF message and the encrypted envelope. Additionally, he sends a new Authenticator Request asking Alice to prove ownership of her OPAQUE signing key.
Alice parses the message and completes the OPRF evaluation using Bob’s message to get output rwd, and uses rwd to decrypt the envelope. This reveals her signing key and Bob’s public key. She uses Bob’s public key to validate his Authenticator Response proof, and, if it checks out, she creates and sends an Exported Authenticator proving that she holds the newly decrypted signing key. Bob checks the validity of her Exported Authenticator, and if it checks out, he accepts her login.
Everything described above is supported by lots and lots of theory that has yet to find its way into practice. My project was to turn the theory into reality. I started with written descriptions of Exported Authenticators, OPAQUE, and a preliminary draft of OPAQUE-in-TLS. My goal was to get from those to a working prototype.
My demo shows the feasibility of implementing OPAQUE-EA on the web, completely removing plaintext passwords from the wire, even encrypted. This provides a possible alternative to the current password-over-TLS flow with better security properties, but no visible change to the user.
A few of the implementation details are worth knowing. In computer science, abstraction is a powerful tool. It means that we can often rely on existing tools and APIs to avoid duplication of effort. In my project I relied heavily on mint, an open-source implementation of TLS 1.3 in Go that is great for prototyping. I also used CIRCL’s OPRF API. I built libraries for Exported Authenticators, the core of OPAQUE, and OPAQUE-EA (which ties together the two).
I made the web demo by wrapping the OPAQUE-EA functionality in a simple HTTP server and client that pass messages to each other over HTTPS. Since a browser can’t run Go, I compiled from Go to WebAssembly (WASM) to get the Go functionality in the browser, and wrote a simple script in JavaScript to call the WASM functions needed.
Since current browsers do not give access to the underlying TLS connection on the client side, I had to implement a work-around to allow the client to access the exporter keys, namely, that the server simply computes the keys and sends them to the client over HTTPS. This workaround reduces the security of the resulting demo — it means that trust is placed in the server to provide the right keys. Even so, the user’s password is still safe, even if a malicious server provided bad keys— they just don’t have assurance that they actually previously registered with that server. However, in the future, browsers could include a mechanism to support exported keys and allow OPAQUE-EA to run with its full security properties.
You can explore my implementation on Github, and even follow the instructions to spin up your own OPAQUE-EA test server and client. I’d like to stress, however, that the implementation is meant as a proof-of-concept only, and must not be used for production systems without significant further review.
Despite its great properties, there will definitely be some hurdles in bringing OPAQUE-EA from a proof-of-concept to a fully fledged authentication mechanism.
Browser support for TLS exporter keys. As mentioned briefly before, to run OPAQUE-EA in a browser, you need to access secrets from the TLS connection called exporter keys. There is no way to do this in the current most popular browsers, so support for this functionality will need to be added.
Overhauling password databases. To adopt OPAQUE-EA, servers need not only to update their password-checking logic, but also completely overhaul their password databases. Because OPAQUE relies on special password representations that can only be generated interactively, existing salted hashed passwords cannot be automatically updated to OPAQUE records. Servers will likely need to run a special OPAQUE registration flow on a user-by-user basis. Because OPAQUE relies on buy-in from both the client and the server, servers may need to support the old method for a while before all clients catch up.
Reliance on emerging standards. OPAQUE-EA relies on OPRFs, which is in the process of standardization, and Exported Authenticators, a proposed standard. This means that support for these dependencies is not yet available in most existing cryptographic libraries, so early adopters may need to implement these tools themselves.
As long as people still use passwords, we’d like to make the process as secure as possible. Current methods rely on the risky practice of handling plaintext passwords on the server side while checking their correctness. PAKEs, and (specifically aPAKEs) allow secure password login without ever letting the server see the passwords.
OPAQUE is also being explored within other companies. According to Kevin Lewi, a research scientist from the Novi Research team at Facebook, they are “excited by the strong cryptographic guarantees provided by OPAQUE and are actively exploring OPAQUE as a method for further safeguarding credential-protected fields that are stored server-side.”
OPAQUE is one of the best aPAKEs out there, and can be fully integrated into TLS. You can check out the core OPAQUE implementation here and the demo TLS integration here. A running version of the demo is also available here. A Typescript client implementation of OPAQUE is coming soon. If you’re interested in implementing the protocol, or encounter any bugs with the current implementation, please drop us a line at [email protected]! Consider also subscribing to the IRTF CFRG mailing list to track discussion about the OPAQUE specification and its standardization.
Post Syndicated from Nick Sullivan original https://blog.cloudflare.com/next-generation-privacy-protocols/


Over the last ten years, Cloudflare has become an important part of Internet infrastructure, powering websites, APIs, and web services to help make them more secure and efficient. The Internet is growing in terms of its capacity and the number of people using it and evolving in terms of its design and functionality. As a player in the Internet ecosystem, Cloudflare has a responsibility to help the Internet grow in a way that respects and provides value for its users. Today, we’re making several announcements around improving Internet protocols with respect to something important to our customers and Internet users worldwide: privacy.
These initiatives are:
Each of these projects impacts an aspect of the Internet that influences our online lives and digital footprints. Whether we know it or not, there is a lot of private information about us and our lives floating around online. This is something we can help fix.
For over a year, we have been working through standards bodies like the IETF and partnering with the biggest names in Internet technology (including Mozilla, Google, Equinix, and more) to design, deploy, and test these new privacy-preserving protocols at Internet scale. Each of these three protocols touches on a critical aspect of our online lives, and we expect them to help make real improvements to privacy online as they gain adoption.
One of Cloudflare’s core missions is to support and develop technology that helps build a better Internet. As an industry, we’ve made exceptional progress in making the Internet more secure and robust. Cloudflare is proud to have played a part in this progress through multiple initiatives over the years.
Here are a few highlights:
Continuing to improve the security of the systems of trust online is critical to the Internet’s growth. However, there is a more fundamental principle at play: respect. The infrastructure underlying the Internet should be designed to respect its users.
When you sign in to a specific website or service with a privacy policy, you know what that site is expected to do with your data. It’s explicit. There is no such visibility to the users when it comes to the operators of the Internet itself. You may have an agreement with your Internet Service Provider (ISP) and the site you’re visiting, but it’s doubtful that you even know which networks your data is traversing. Most people don’t have a concept of the Internet beyond what they see on their screen, so it’s hard to imagine that people would accept or even understand what a privacy policy from a transit wholesaler or an inspection middlebox would even mean.
Without encryption, Internet browsing information is implicitly shared with countless third parties online as information passes between networks. Without secure routing, users’ traffic can be hijacked and disrupted. Without privacy-preserving protocols, users’ online life is not as private as they would think or expect. The infrastructure of the Internet wasn’t built in a way that reflects their expectations.

The good news is that the Internet is continuously evolving. One of the groups that help guide that evolution is the Internet Architecture Board (IAB). The IAB provides architectural oversight to the Internet Engineering Task Force (IETF), the Internet’s main standard-setting body. The IAB recently published RFC 8890, which states that individual end-users should be prioritized when designing Internet protocols. It says that if there’s a conflict between the interests of end-users and the interest of service providers, corporations, or governments, IETF decisions should favor end users. One of the prime interests of end-users is the right to privacy, and the IAB published RFC 6973 to indicate how Internet protocols should take privacy into account.
Today’s technical blog posts are about improvements to the Internet designed to respect user privacy. Privacy is a complex topic that spans multiple disciplines, so it’s essential to clarify what we mean by “improving privacy.” We are specifically talking about changing the protocols that handle privacy-sensitive information exposed “on-the-wire” and modifying them so that this data is exposed to fewer parties. This data continues to exist. It’s just no longer available or visible to third parties without building a mechanism to collect it at a higher layer of the Internet stack, the application layer. These changes go beyond website encryption; they go deep into the design of the systems that are foundational to making the Internet what it is.
Two tools for making sure data can be used without being seen are cryptography and secure proxies.
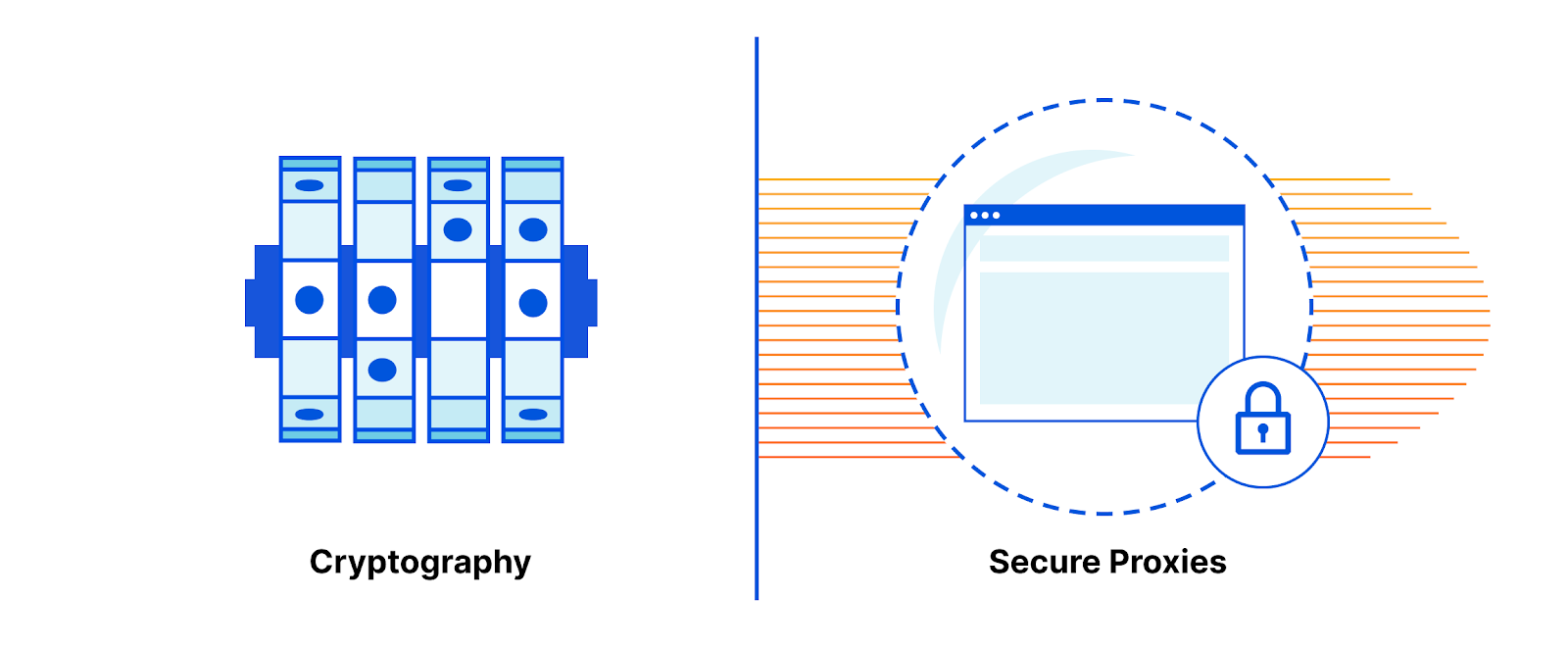
Cryptography allows information to be transformed into a format that a very limited number of people (those with the key) can understand. Some describe cryptography as a tool that transforms data security problems into key management problems. This is a humorous but fair description. Cryptography makes it easier to reason about privacy because only key holders can view data.
Another tool for protecting access to data is isolation/segmentation. By physically limiting which parties have access to information, you effectively build privacy walls. A popular architecture is to rely on policy-aware proxies to pass data from one place to another. Such proxies can be configured to strip sensitive data or block data transfers between parties according to what the privacy policy says.
Both these tools are useful individually, but they can be even more effective if combined. Onion routing (the cryptographic technique underlying Tor) is one example of how proxies and encryption can be used in tandem to enforce strong privacy. Broadly, if party A wants to send data to party B, they can encrypt the data with party B’s key and encrypt the metadata with a proxy’s key and send it to the proxy.
Platforms and services built on top of the Internet can build in consent systems, like privacy policies presented through user interfaces. The infrastructure of the Internet relies on layers of underlying protocols. Because these layers of the Internet are so far below where the user interacts with them, it’s almost impossible to build a concept of user consent. In order to respect users and protect them from privacy issues, the protocols that glue the Internet together should be designed with privacy enabled by default.
The transition from a mostly unencrypted web to an encrypted web has done a lot for end-user privacy. For example, the “coffeeshop stalker” is no longer an issue for most sites. When accessing the majority of sites online, users are no longer broadcasting every aspect of their web browsing experience (search queries, browser versions, authentication cookies, etc.) over the Internet for any participant on the path to see. Suppose a site is configured correctly to use HTTPS. In that case, users can be confident their data is secure from onlookers and reaches only the intended party because their connections are both encrypted and authenticated.
However, HTTPS only protects the content of web requests. Even if you only browse sites over HTTPS, that doesn’t mean that your browsing patterns are private. This is because HTTPS fails to encrypt a critical aspect of the exchange: the metadata. When you make a phone call, the metadata is the phone number, not the call’s contents. Metadata is the data about the data.
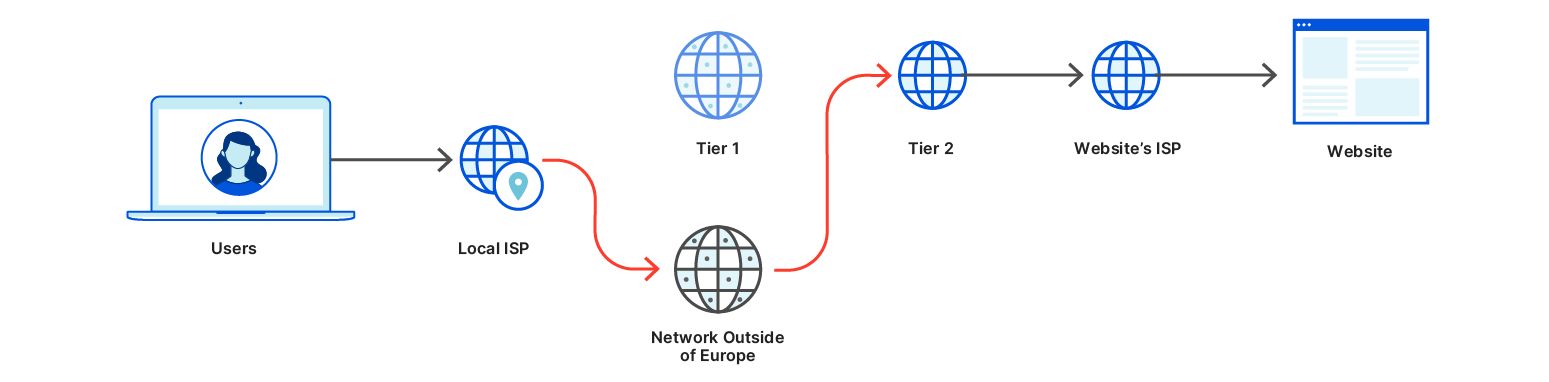
To illustrate the difference and why it matters, here’s a diagram of what happens when you visit a website like an imageboard. Say you’re going to a specific page on that board (https://<imageboard>.com/room101/) that has specific embedded images hosted on <embarassing>.com.
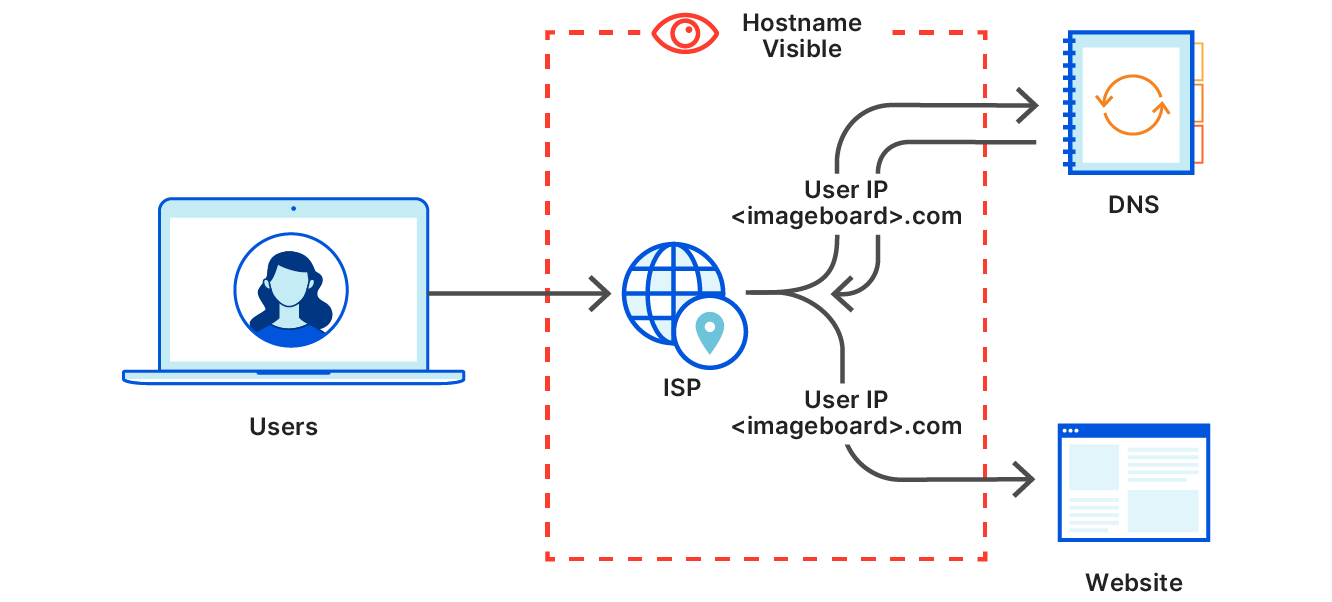
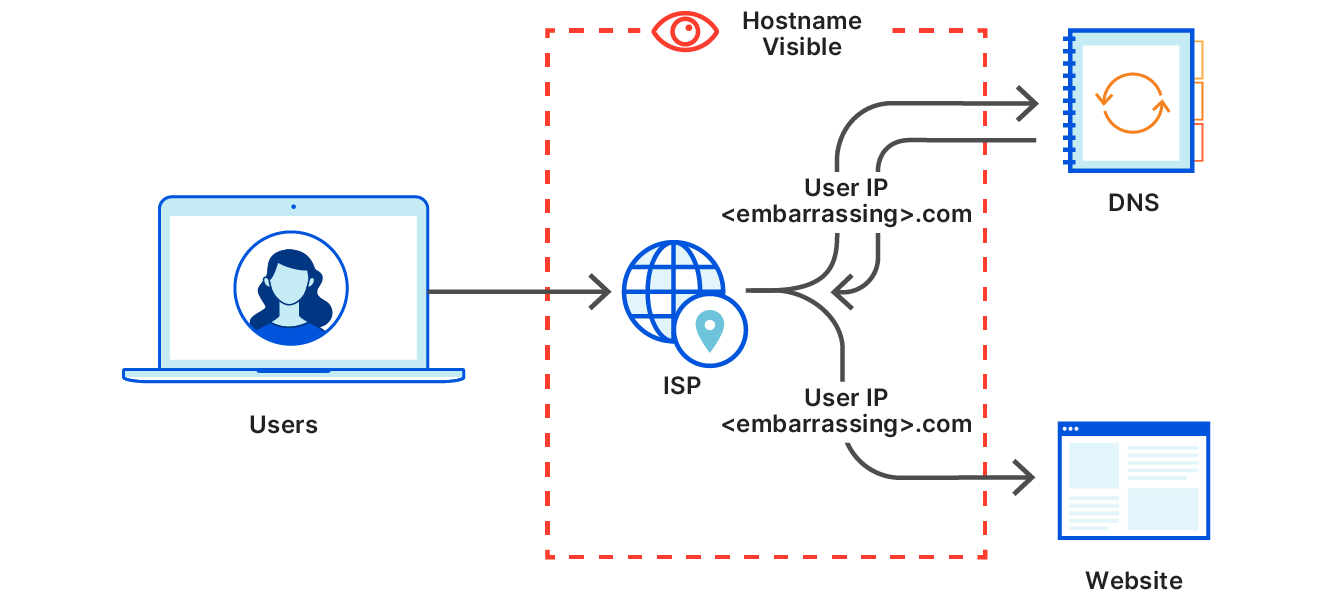
The space inside the dotted line here represents the part of the Internet that your data needs to transit. They include your local area network or coffee shop, your ISP, an Internet transit provider, and it could be the network portion of the cloud provider that hosts the server. Users often don’t have a relationship with these entities or a contract to prevent these parties from doing anything with the user’s data. And even if those entities don’t look at the data, a well-placed observer intercepting Internet traffic could see anything sent unencrypted. It would be best if they just didn’t see it at all. In this example, the fact that the user visited <imageboard>.com can be seen by an observer, which is expected. However, though page content is encrypted, it’s possible to learn which specific page you’ve visited can be seen since <embarassing>.com is also visible.
It’s a general rule that if data is available to on-path parties on the Internet, some of these on-path parties will use this data. It’s also true that these on-path parties need some metadata in order to facilitate the transport of this data. This balance is explored in RFC 8558, which explains how protocols should be designed thoughtfully with respect to the balance between too much metadata (bad for privacy) and too little metadata (bad for operations).
In an ideal world, Internet protocols would be designed with the principle of least privilege. They would provide the minimum amount of information needed for the on-path parties (the pipes) to do the job of transporting the data to the right place and keep everything else confidential by default. Current protocols, including TLS 1.3 and QUIC, are important steps towards this ideal but fall short with respect to metadata privacy.
Today’s announcements reflect two metadata protection levels: the first involves limiting the amount of metadata available to third-party observers (like ISPs). The second involves restricting the amount of metadata that users share with service providers themselves.
Hostnames are an example of metadata that needs to be protected from third-party observers, which DoH and ECH intend to do. However, it doesn’t make sense to hide the hostname from the site you’re visiting. It also doesn’t make sense to hide it from a directory service like DNS. A DNS server needs to know which hostname you’re resolving to resolve it for you!
A privacy issue arises when a service provider knows about both what sites you’re visiting and who you are. Individual websites do not have this dangerous combination of information (except in the case of third party cookies, which are going away soon in browsers), but DNS providers do. Thankfully, it’s not actually necessary for a DNS resolver to know *both* the hostname of the service you’re going to and which IP you’re coming from. Disentangling the two, which is the goal of ODoH, is good for privacy.
Roads should be well-paved, well lit, have accurate signage, and be optimally connected. They aren’t designed to stop a car based on who’s inside it. Nor should they be! Like transportation infrastructure, Internet infrastructure is responsible for getting data where it needs to go, not looking inside packets, and making judgments. But the Internet is made of computers and software, and software tends to be written to make decisions based on the data it has available to it.
Privacy-preserving protocols attempt to eliminate the temptation for infrastructure providers and others to peek inside and make decisions based on personal data. A non-privacy preserving protocol like HTTP keeps data and metadata, like passwords, IP addresses, and hostnames, as explicit parts of the data sent over the wire. The fact that they are explicit means that they are available to any observer to collect and act on. A protocol like HTTPS improves upon this by making some of the data (such as passwords and site content) invisible on the wire using encryption.
The three protocols we are exploring today extend this concept.
By making sure Internet infrastructure acts more like physical infrastructure, user privacy is more easily protected. The Internet is more private if private data can only be collected where the user has a chance to consent to its collection.
As much as we’re excited about working on new ways to make the Internet more private, innovation at a global scale doesn’t happen in a vacuum. Each of these projects is the output of a collaborative group of individuals working out in the open in organizations like the IETF and the IRTF. Protocols must come about through a consensus process that involves all the parties that make up the interconnected set of systems that power the Internet. From browser builders to cryptographers, from DNS operators to website administrators, this is truly a global team effort.
We also recognize that sweeping technical changes to the Internet will inevitably also impact the technical community. Adopting these new protocols may have legal and policy implications. We are actively working with governments and civil society groups to help educate them about the impact of these potential changes.
We’re looking forward to sharing our work today and hope that more interested parties join in developing these protocols. The projects we are announcing today were designed by experts from academia, industry, and hobbyists together and were built by engineers from Cloudflare Research (including the work of interns, which we will highlight) with everyone’s support Cloudflare.
If you’re interested in this type of work, we’re hiring!
Post Syndicated from Jonathan Jenkyn original https://aws.amazon.com/blogs/security/announcement-availability-of-aws-recommendations-for-management-of-aws-root-account-credentials/
When AWS customers open their first account, they assume the responsibility for securely managing access to their root account credentials, under the Shared Responsibility Model. Initially protected by a password, it is the responsibility of each AWS customer to make decisions based on their operational and security requirements as to how they configure and manage access to this account.
There are many options and decisions both within AWS (configuration of a Multi-Factor Authentication (MFA) device, or providing contact details) and outside (safe logistics, access policies and email configuration), which affect the overall security and availability of the root account credentials, and so there is a great deal of flexibility in the options and configurations each AWS customer may settle on using.
We’re excited to announce the availability of AWS guidance on the recommended approaches that AWS customers should consider and use to protect these credentials both for the management and member accounts of an AWS Organization.
Take a look at root account credential management recommendations for the management account, which also apply to AWS customers operating with a single AWS account,
For the management of member accounts of an AWS Organization, we have a separate set of root account credential management recommendations.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Organizations forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2020/10/on-risk-based-authentication.html
Interesting usability study: “More Than Just Good Passwords? A Study on Usability and Security Perceptions of Risk-based Authentication“:
Abstract: Risk-based Authentication (RBA) is an adaptive security measure to strengthen password-based authentication. RBA monitors additional features during login, and when observed feature values differ significantly from previously seen ones, users have to provide additional authentication factors such as a verification code. RBA has the potential to offer more usable authentication, but the usability and the security perceptions of RBA are not studied well.
We present the results of a between-group lab study (n=65) to evaluate usability and security perceptions of two RBA variants, one 2FA variant, and password-only authentication. Our study shows with significant results that RBA is considered to be more usable than the studied 2FA variants, while it is perceived as more secure than password-only authentication in general and comparably se-cure to 2FA in a variety of application types. We also observed RBA usability problems and provide recommendations for mitigation.Our contribution provides a first deeper understanding of the users’perception of RBA and helps to improve RBA implementations for a broader user acceptance.
Paper’s website. I’ve blogged about risk-based authentication before.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2020/09/nihilistic-password-security-questions.html
Posted three years ago, but definitely appropriate for the times.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2020/08/dicekeys.html
DiceKeys is a physical mechanism for creating and storing a 192-bit key. The idea is that you roll a special set of twenty-five dice, put them into a plastic jig, and then use an app to convert those dice into a key. You can then use that key for a variety of purposes, and regenerate it from the dice if you need to.
This week Stuart Schechter, a computer scientist at the University of California, Berkeley, is launching DiceKeys, a simple kit for physically generating a single super-secure key that can serve as the basis for creating all the most important passwords in your life for years or even decades to come. With little more than a plastic contraption that looks a bit like a Boggle set and an accompanying web app to scan the resulting dice roll, DiceKeys creates a highly random, mathematically unguessable key. You can then use that key to derive master passwords for password managers, as the seed to create a U2F key for two-factor authentication, or even as the secret key for cryptocurrency wallets. Perhaps most importantly, the box of dice is designed to serve as a permanent, offline key to regenerate that master password, crypto key, or U2F token if it gets lost, forgotten, or broken.
[…]
Schechter is also building a separate app that will integrate with DiceKeys to allow users to write a DiceKeys-generated key to their U2F two-factor authentication token. Currently the app works only with the open-source SoloKey U2F token, but Schechter hopes to expand it to be compatible with more commonly used U2F tokens before DiceKeys ship out. The same API that allows that integration with his U2F token app will also allow cryptocurrency wallet developers to integrate their wallets with DiceKeys, so that with a compatible wallet app, DiceKeys can generate the cryptographic key that protects your crypto coins too.
Here’s the DiceKeys website and app. Here’s a short video demo. Here’s a longer SOUPS talk.
Preorder a set here.
Note: I am an adviser on the project.
Another news article. Slashdot thread. Hacker News thread. Reddit thread.
Post Syndicated from David original http://devilsadvocatesecurity.blogspot.com/2011/10/on-passwords-and-password-expiration.html
One of the things that I believe is an important part of my job is to answer user questions in a way that educates them about the topic they ask about in addition to providing the answer. At times, this can be frustrating, but it also challenges me to think about why I’m providing the answer that I do. It also means that I have to review the choices I, and my organization make about policy, process, and the reasons for both.
I recently exchanged email with one of our users who questioned our password policy which requires periodic changes of passwords. The user contended that periodic password changes encourages poor password choice, that users who are forced to choose new passwords (even on a relatively infrequent basis) will choose poor passwords, and that in the end, that password changes serve no purpose.
In my institution’s case, there are a number of reasons why password changes make sense, and I believe that these are a reasonable match for most companies, colleges, and other organizations – but not necessarily for your Amazon account, or your banking password. It is critical to understand the difference between a daily use password for institutional access that provides access to things like VPN access, email, licensed software, and the rest of the keys to the kingdom, and a single use password that accesses a service or site. Thinking about your password policy in the context of institutional risk while remaining aware of how your users will react is critical.
The reasons that help drive password change for my institution, in no particular order are:
When you read the list from a user perspective, it is difficult to see a compelling reason for them to change their passwords. There isn’t a big, disaster level threat that is immediately obvious, and the “what’s in it for me” is hard to communicate. When you read it from an organizational perspective, you will likely see a set of reasons that when taken as a whole mean that a reasonable password expiration timeframe is useful at an organizational level. Here’s why:
The environment in which most of us work now has two major external threats to passwords: malware and phishing. With malware targeting browsers and browser plugins, and institutional policies that accept that users will visit at least common sites like CNN, ESPN, and other staples of our online lives, we have to acknowledge that malware compromises that gather our user’s passwords are likely.
Similarly, despite attempts we make at user education, phishing continues to seduce a portion of our user population into clicking that tempting link, or responding to the IT department that needs to know their password to ensure that their email isn’t turned off. Again, we know that passwords will be exposed.
Bulk compromises of passwords are likely to involve captured hashes, which most organizations have spent years designing infrastructure to avoid as tools like Rainbow Tables and faster cracking hardware became available. Thus, we worry more about what access to our networks, and what individual accounts, or small groups of compromised accounts can do. In the event of a large-scale breach of central authentication, the organization will require a password change from every user, typically with immediate expiration of all passwords.
In this environment, we will require our users to change their passwords when their account is compromised, but will we know to require that? We know that advanced persistent threats exist, and that some attackers are patient and will wait, gathering information and not abusing the accounts they collect. We can continue to fight those threats with periodic password changes for the accounts that provide access to our institutions.
It would, of course, be preferable to use biometrics, or tokens, or some other two factor authentication system. It is also expensive, and difficult to adapt into a diverse environment where credentials are used across a variety of systems that are glued (or duct taped, bubble gummed, and bailing wired) together in a variety of ways. For now, passwords – or preferably passphrases – remain the way to make these heterogeneous systems authenticate and interoperate.
In the end, I learned a lot from my exchange with the user. Over the next few months, I’ll be adding additional information to our awareness program reminding users that password changes that change from “Password1” to “Password2” aren’t serving a real use, we’ll add additional information about tools like Password Safe to our posters and awareness materials, and I’ll be working with our identity and access management staff to see if we can leverage their tools to prevent similar poor password practices. In addition, I’ve been using it as a learning opportunity for my staff, and as a challenge for my student employee.
I’m aware that I won’t win with every user – I’ll still have the gentleman who resets his password once a day for as many days as our password history and minimum password age will allow so he can get back to his favorite password. I’ll still have the user who changes their password to “Password1!” and claims that yes, they have used a capital and a number and a symbol, and that thus they have met the requirements for a strong password. But I also know that our population continues to grow more security aware, and that many of our users do get the point.
If you’re interested in this topic, you may enjoy this Microsoft research about users, security advice, and why they choose to ignore it, and NIST’s password guidance provides a well reasoned explanation of everything from password choice to mnemonics and password guessing.