In this blog post, I’ll explain how to use a Microsoft Entra ID and Visual Studio Code editor to access Amazon Q developer service and speed up your development. Additionally, I’ll explain how to minimize the time spent on repetitive tasks and quickly integrate users from external identity sources so they can immediately use and explore Amazon Web Services (AWS).Generative AI on AWS holds great ability for businesses seeking to unlock new opportunities and drive innovation. AWS offers a robust suite of tools and capabilities that can revolutionize software development, generate valuable insights, and deliver enhanced customer value. AWS is committed to simplifying generative AI for businesses through services like Amazon Q, Amazon Bedrock, Amazon SageMaker, Data foundation & AI infrastructure.
Amazon Q Developer is a generative AI-powered assistant that helps developers and IT professionals with all of their tasks across the software development lifecycle. Amazon Q Developer assists with coding, testing, and upgrading to troubleshooting, performing security scanning and fixes, optimizing AWS resources, and creating data engineering pipelines.
A common request from Amazon Q Developer customers is to allow developer sign-ins using established identity providers (IdP) such as Entra ID. Amazon Q Developer offers authentication support through AWS Builder ID or AWS IAM Identity Center. AWS Builder ID is a personal profile for builders. IAM Identity Center is ideal for an enterprise developer working with Amazon Q and employed by organizations with an AWS account. When using the Amazon Q Developer Pro tier, the developer should authenticate with the IAM Identity Center. See the documentation, Understanding tiers of service for Amazon Q Developer for more information.
How it works
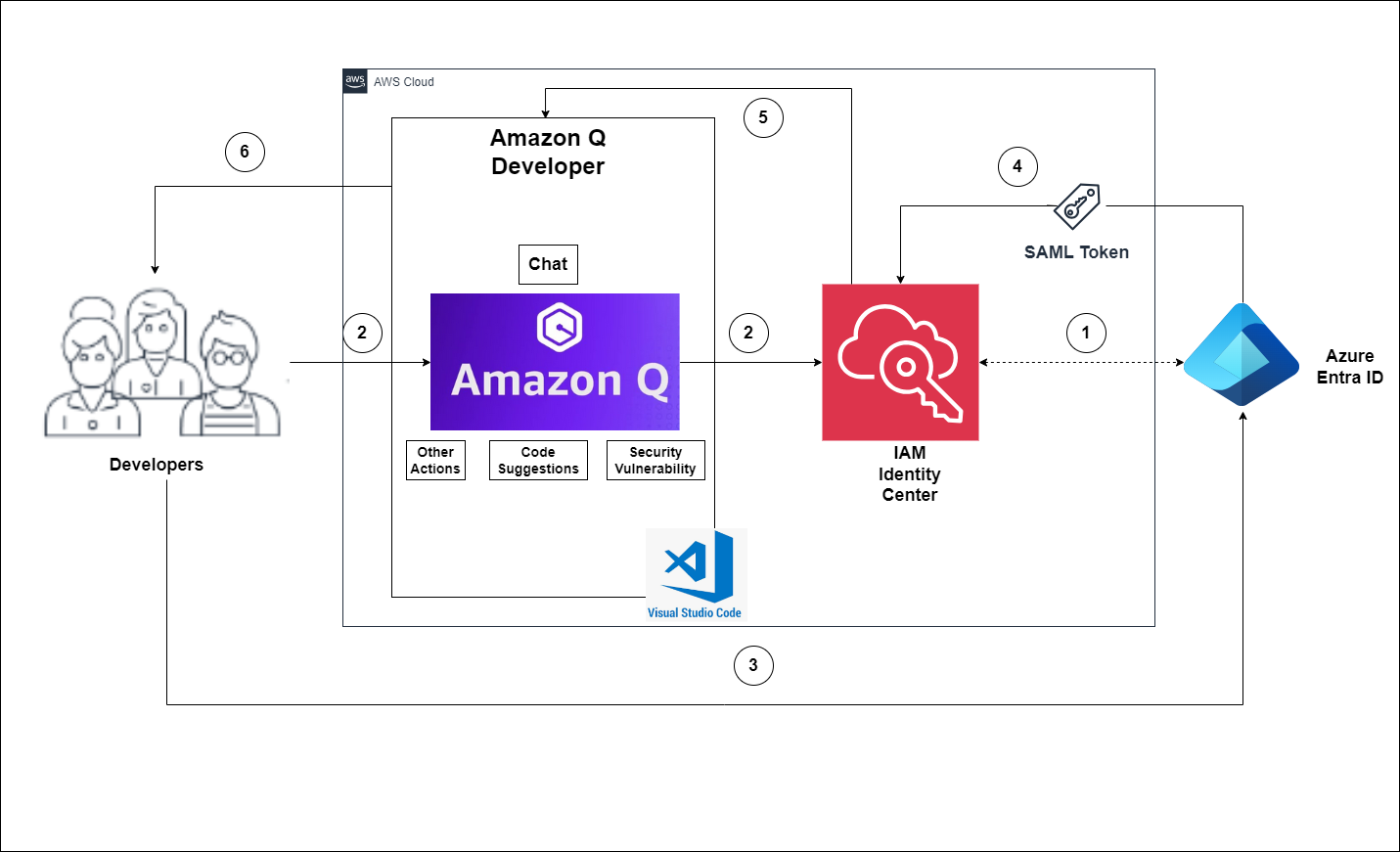
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using Security Assertion Markup Language (SAML) 2.0 authentication (Figure 1).
Figure 1 – Solution Overview
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using SAML 2.0 authentication. (Figure 1).
IAM Identity Center synchronizes users and groups information from Entra ID into IAM Identity Center using the System for Cross-domain Identity Management (SCIM) v2.0 protocol.
Developers with an Entra ID account connect to Amazon Q Developer through IAM Identity Center using the VS Code IDE.
If a developer isn’t already authenticated, they will be redirected to the Entra ID account login. The developer will sign in using their Entra ID credentials.
If the sign-in is successful, Entra ID processes the request and sends a SAML response containing the developer identity and authentication status to IAM Identity Center.
If the SAML response is valid and the developer is authenticated, IAM Identity Center grants access to Amazon Q Developer.
The developer can now securely access and use Amazon Q Developer.
Prerequisites
In order to perform the following procedure, make sure the following are in place.
Configure Entra ID and AWS IAM Identity Center integration
In this section, I will show how you can create a SAML base connection between Entra ID and AWS Identity Center so you can access AWS generative AI services using your Entra ID.
Note: You need to switch the console between Entra ID portal and AWS IAM Identity center. I recommend to open new browser tabs for each console.
Step 1 – Prepare your Microsoft tenant
Perform the below steps in the Entra identity provider section.
Navigate to Identity > Applications > Enterprise applications, and then choose New application.
On the Browse Microsoft Entra Gallery page, enter AWS IAM Identity Center in the search box.
Select AWS IAM Identity Center from the results area.
Choose Create.
Now you have created AWS IAM Identity Center application, set up single sign-on to enable users to sign into their applications using their Entra ID credentials. Select the Single sign-on tab from the left navigation plane and select Setup single sign on.
Step 2 – Collect required service provider metadata from IAM Identity Center
In this step, you will launch the Change identity source wizard from within the IAM Identity Center console and retrieve the metadata file and the AWS specific sign-in URL. You will need this to enter when configuring the connection with Entra ID in the next step.
IAM Identity Center.
You need to enable this in order to configure SSO.
Navigate to Services –> Security, Identity, & Compliance –> AWS IAM Identity Center.
Choose Enable (Figure 2).
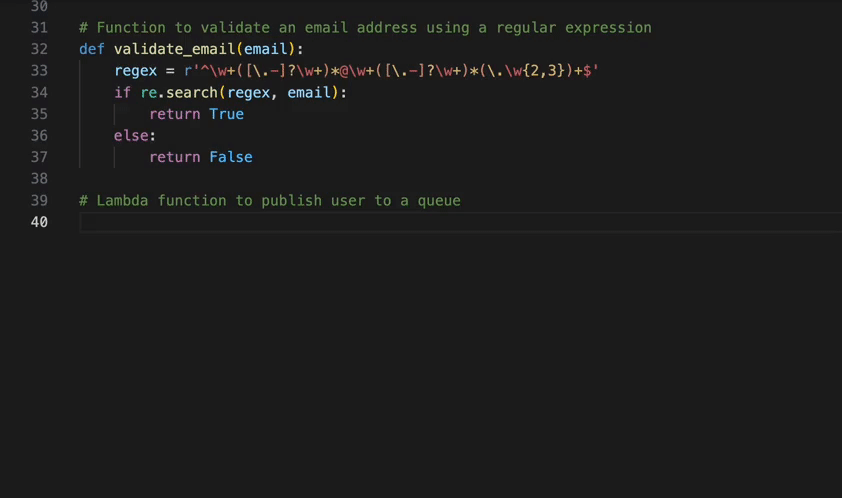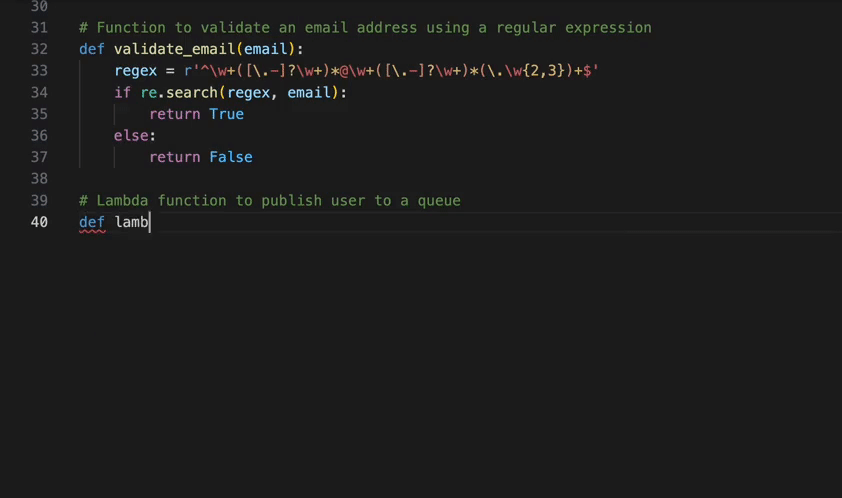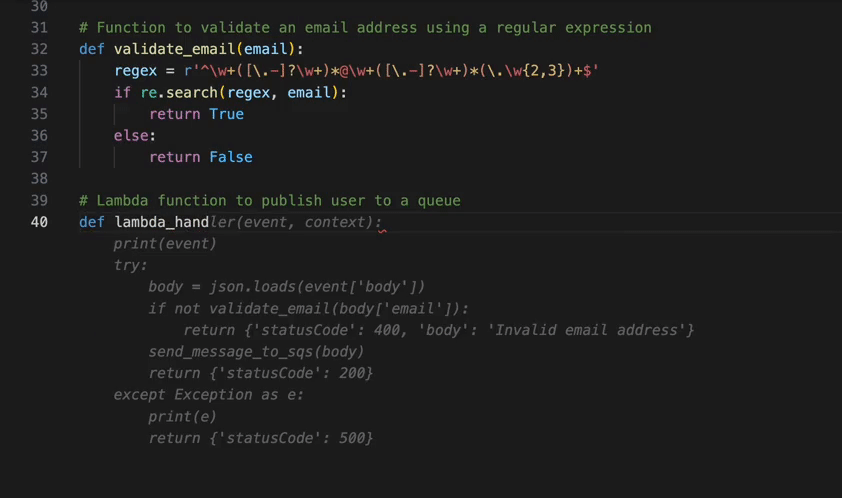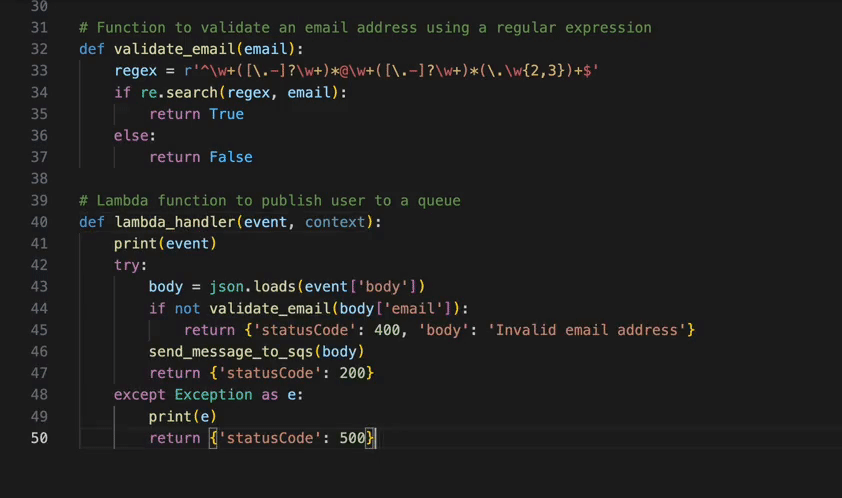
Figure 2 – Get started with AWS IAM Identity Center
In the left navigation pane, choose Settings.
On the Settings page, find Identity source, select Actions pull-down menu, and select Change identity source.
On the Change identity source page, choose External identity provider (Figure 3).
Figure 3 – Select External identity provider
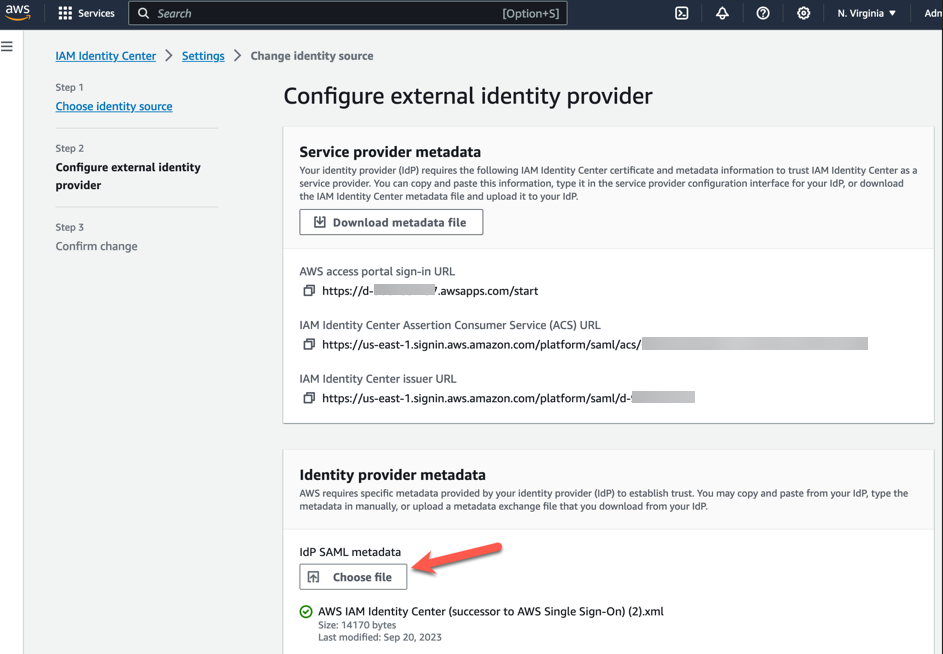
On the Configure external identity provider page, under Service provider metadata, select Download metadata file (XML file).
In the same section, locate the AWS access portal sign-in URL value and copy it. You will need to enter this value when prompted in the next step (Figure 4).
Figure 4 – Copy provider metadata URLs
Leave this page open, and move to the next step to configure the AWS IAM Identity Center enterprise application in Entra ID. Later, you will return to this page to complete the process.
Step 3 – Configure the AWS IAM Identity Center enterprise application in Entra ID
This procedure establishes one-half of the SAML connection on the Microsoft side using the values from the metadata file and Sign-On URL you obtained in the previous step.
In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
On the left, choose Single sign-on.
On the Set up Single sign on with SAML page, choose Upload metadata file, choose the folder icon, select the service provider metadata file that you downloaded in the previous step 2.6, and then choose Add.
On the Basic SAML Configuration page, verify that both the Identifier and Reply URL values now point to endpoints in AWS that start with https://<REGION>.signin.aws.amazon.com/platform/saml/.
Under Sign on URL (Optional), paste in the AWS access portal sign-in URL value you copied in the previous step (Step 2.7), choose Save, and then choose X to close the window.
If prompted to test single sign-on with AWS IAM Identity Center, choose No I’ll test later. You will do this verification in a later step.
On the Set up Single Sign-On with SAML page, in the SAML Certificates section, next to Federation Metadata XML, choose Download to save the metadata file to your system. You will need to upload this file when prompted in the next step.
Step 4 – Configure the Entra ID external IdP in AWS IAM Identity Center
Next you will return to the Change identity source wizard in the IAM Identity Center console to complete the second-half of the SAML connection in AWS.
Return to the browser session you left open in the IAM Identity Center console.
On the Configure external identity provider page, in the Identity provider metadata section, under IdP SAML metadata, choose the Choose file button, and select the identity provider metadata file that you downloaded from Microsoft Entra ID in the previous step, and then choose Open (Figure 5).
Figure 5 – AWS IAM Identity center metadata
Choose Next
After you read the disclaimer and are ready to proceed, enter ACCEPT
Choose Change identity source to apply your changes (Figure 6).
Figure 6 – AWS IAM Identity center metadata
Confirm the changes (Figure 7).
Figure 7 – AWS IAM Identity center metadata configuration changes progress console.
Step 5 – Configure and test your SCIM synchronization
In this step, you will set up automatic provisioning (synchronization) of user and group information from Microsoft Entra ID into IAM Identity Center using the SCIM v2.0 protocol. You configure this connection in Microsoft Entra ID using your SCIM endpoint for AWS IAM Identity Center and a bearer token that is created automatically by AWS IAM Identity Center.
To enable automatic provisioning of Entra ID users to IAM Identity Center, follow these steps using the IAM Identity Center application in Entra ID. For testing purposes, you can create a new user (TestUser) in Entra ID with details like First Name, Last Name, Email ID, Department, and more. Once you’ve configured SCIM synchronization, you can verify that this user and their relevant attributes were successfully synced to AWS IAM Identity Center.
In this procedure, you will use the IAM Identity Center console to enable automatic provisioning of users and groups coming from Entra ID into IAM Identity Center.
Open the IAM Identity Center console and Choose Setting in the left navigation pane.
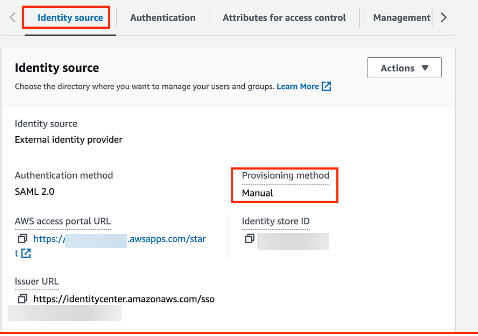
On the Settings page, under the Identity source tab, notice that Provisioning method is set to Manual (Figure 8).
Figure 8 – AWS IAM Identity center console with provisioning method configuration details
Locate the Automatic provisioning information box, and then choose Enable. This immediately enables automatic provisioning in IAM Identity Center and displays the necessary SCIM endpoint and access token information.
In the Inbound automatic provisioning dialog box, copy each of the values for the following options. You will need to paste these in the next step when you configure provisioning in Entra ID.
SCIM endpoint – For example, https://scim.us-east-2.amazonaws.com/11111111111-2222-3333-4444-555555555555/scim/v2/
Access token – Choose Show token to copy the value (Figure 9).
Figure 9 – AWS IAM Identity center automatic provisioning info
Choose Close.
Under the Identity source tab, notice that Provisioning method is now set to SCIM.
Step 6 – Configure automatic provisioning in Entra ID
Now that you have your test user in place and have enabled SCIM in IAM Identity Center, you can proceed with configuring the SCIM synchronization settings in Entra ID.
In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
Choose Provisioning, under Manage, choose Provisioning
In Provisioning Mode select
For Admin Credentials, in Tenant URL paste in the SCIM endpoint URL value you copied earlier. In Secret Token, paste in the Access token value (Figure 10).
Figure 10 – Azure Enterprise AWS IAM Identity center application provisioning configuration tab
Choose Test Connection. You should see a message indicating that the tested credentials were successfully authorized to enable provisioning (Figure 11).
Figure 11 – Azure Enterprise AWS IAM Identity center application provisioning testing status
Choose Save.
Under Manage, choose Users and groups, and then choose Add user/group.
On the Add Assignment page, under Users, choose None Selected.
Select TestUser, and then choose Select.
On the Add Assignment page, choose
Choose Overview, and then choose Start provisioning (Figure 12).
Figure 12 – AWS IAM Identity center application Start provisioning tab
Note : The default provisioning interval is set to 40 minutes. Our users (Figure 13) are successfully provisioned and are now available in the AWS IAM Identity Center console.
In this section, you will verify that TestUser user was successfully provisioned and that all attributes are displayed in IAM Identity Center (Figure 13).
Figure 13 – AWS IAM Identity center application user console example
In the Identity source in IDC section, enable Identity-aware console sessions (Figure 14). This enables AWS IAM Identity Center user and session IDs to be included in users’ AWS console sessions when they sign in. For example, Amazon Q Developer Pro uses identity-aware console sessions to personalize the service experience.
I have completed Entra ID and AWS Identity Center configuration. You can see Entra ID identity synced successfully with AWS IAM identity center.
Step 7 – Set up AWS Toolkit with IAM Identity Center
To use Amazon Q Developer, you will now set up the AWS Toolkit within integrated development environments (IDE) to establish authentication with the IAM Identity Center.
AWS Toolkit for Visual Studio Code is an open-source plug-in for VS Code that makes it easier for developers by providing an integrated experience to create, debug, and deploy applications on AWS. Getting started with Amazon Q Developer in VS Code is simple.
Open the AWS Toolkit for Visual Studio Code extension in your VS Code IDE. Install AWS Toolkit for VS Code, which is available as a download from the VS Code Marketplace.
From the AWS Toolkit for Visual Studio Code extension in the VS Code Marketplace, choose Install to begin the installation process.
When prompted, choose to restart VS Code to complete the installation process.
Step 8 – Setup Amazon Q Developer service with VS Code using AWS IAM identity center.
After installing the Amazon Q extension or plugin, authenticate through IAM Identity Center or AWS Builder ID.
After your identity has been subscribed to Amazon Q Developer Pro, complete the following steps to authenticate.
Choose the Amazon Q icon from the sidebar in your IDE
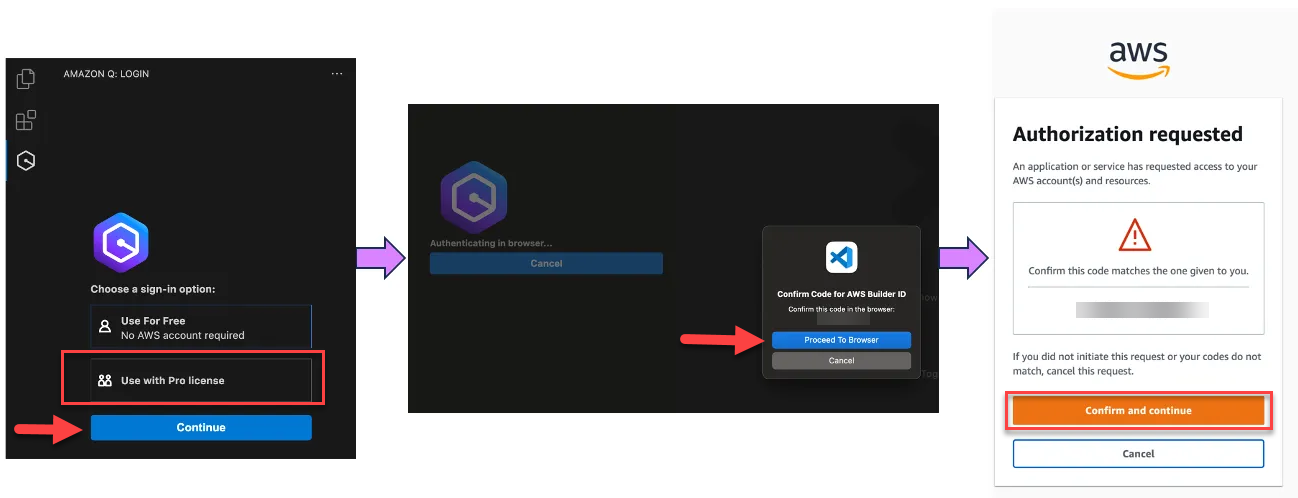
Choose Use with Pro license and select Continue (Figure 15).
Figure 15 – Visual Studio code Amazon Q Developer extension
Enter the IAM Identity Center URL you previously copied into the Start URL
Set the appropriate region, example us-east-1, and select Continue
Click Copy Code and Proceed to copy the code from the resulting pop-up.
When prompted by the Do you want Code to open the external website? pop-up, select Open
Paste the code copied in Step 6 and select Next
Enter your Entra ID credentials and select Sign in
Select Allow Access toAWS IDE Extensions for VSCode to access Amazon Q Developer (Figure 16).
Figure 16 – Allow VS Code to access Amazon Q Developer
When the connection is complete, a notification indicates that it is safe to close your browser. Close the browser tab and return to your IDE.
You are now all set to use Amazon Q Developer from within IDE, authenticated with your Entra ID credentials.
Step 9 – Test configuration examples
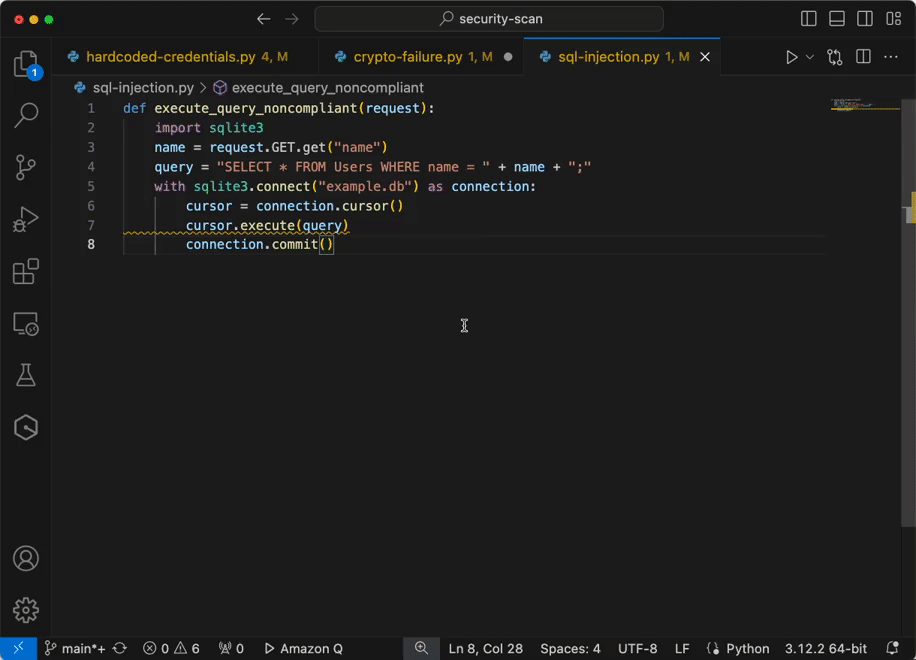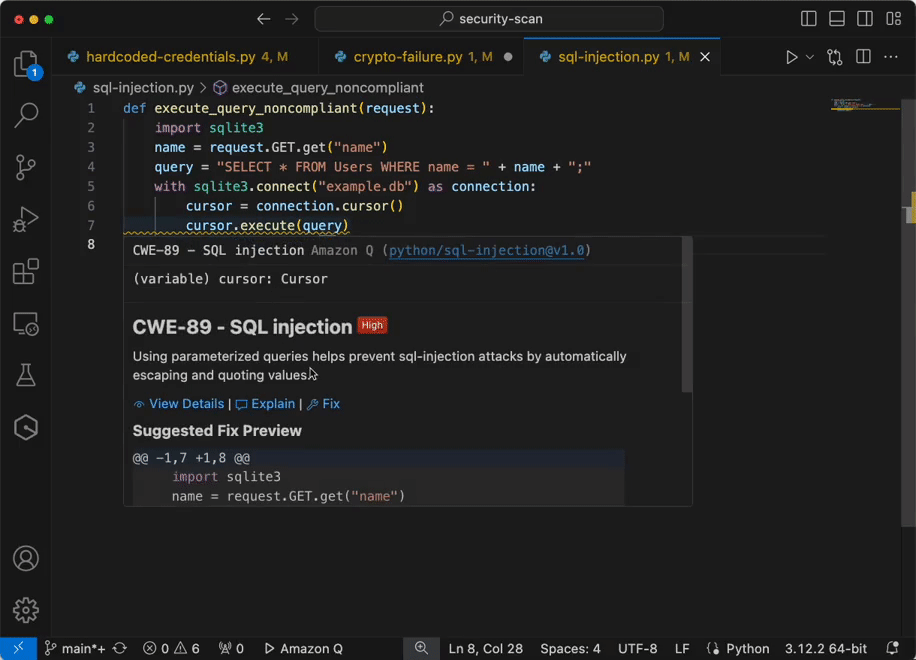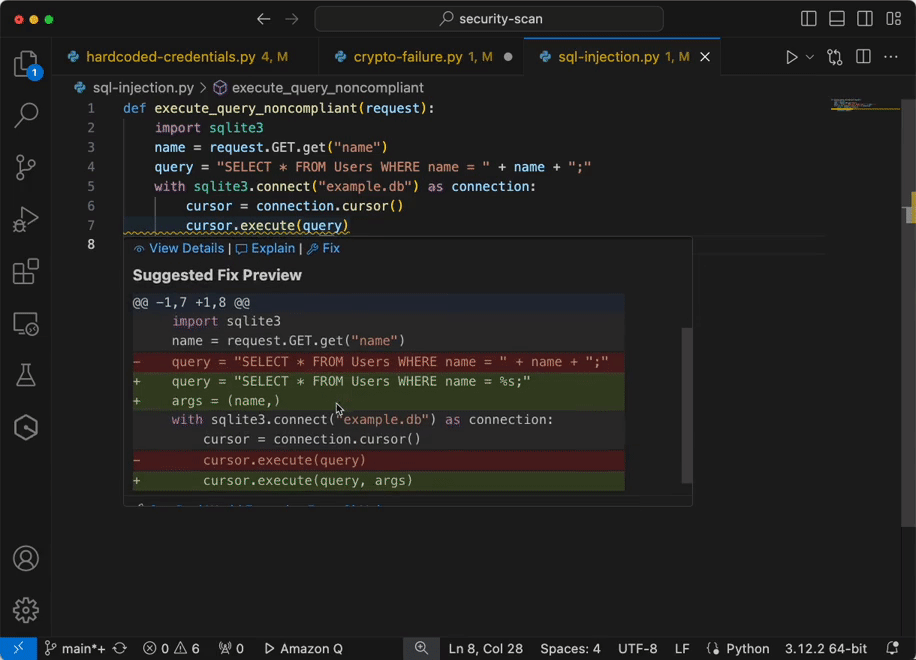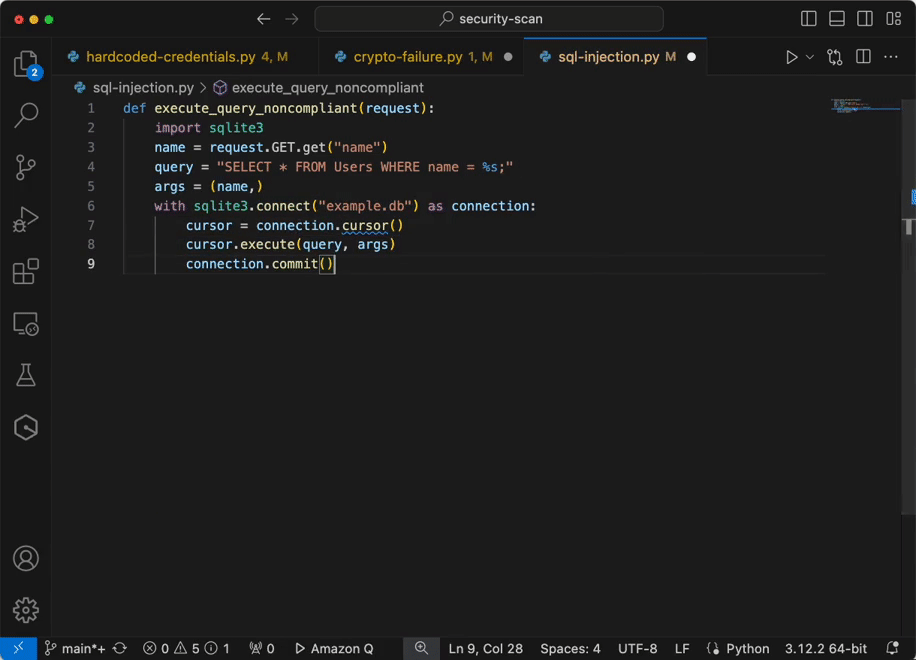
Now you have configured IAM identity Center access with VS code now you can chat, get inline code suggestions, check for security vulnerabilities with Amazon Q Developer to learn about, build, and operate AWS applications. I have mentioned a few examples of Amazon Q Suggestions, Code suggestions, Security Vulnerabilities during development for your reference (Figures 17 ,18 ,19 ,20).
Figure 17 – Amazon Q suggestion examples
Example of developers get the recommendations using Amazon Q developer.
Figure 18 – Amazon Q Developer example
Figure 19 – Generate code, explain code, and get answers to questions about software development.
Example of integrating secure coding practices early in the software development lifecycle using Amazon Q developer.
Figure 20 – Analyze and fix security vulnerabilities in your project example
Cleanup
Configuring AWS and Azure services from this blog will provision resources which incur cost. It is a best practice to delete configurations and resources that you are no longer using so that you do not incur unintended charges.
Conclusion
In this blog post, you learned how to integrate AWS IAM Identity Center and Entra ID IdP for accessing Amazon Q Developer service using VS Code IDE, which speeds up development. Next, you set up the AWS Toolkit to establish a secure connection to AWS using Entra ID credentials, granting you access to the Amazon Q Developer Professional Tier. Using SCIM automatic provisioning for user provisioning and access assignment saves time and speeds up onboarding, allowing for immediate use of AWS services using you own identity. Using Amazon Q, developers get the recommendations and information within their working environment in the IDE, enabling them to integrate secure coding practices early in the software development lifecycle. Developers can proactively scan their existing code using Amazon Q and remediate the security vulnerabilities found in the code.
In the AWS Security Profile series, I interview some of the humans who work in AWS Security and help keep our customers safe and secure. In this profile, I interviewed Liam Wadman, Senior Solutions Architect for AWS Identity.
Pictured: Liam making quick informed decisions about risk and reward
How long have you been at AWS and what do you do in your current role?
My first day was 1607328000 — for those who don’t speak fluent UTC, that’s December 2020. I’m a member of the Identity Solutions team. Our mission is to make it simpler for customers to implement access controls that protect their data in a straightforward and consistent manner across AWS services.
I spend a lot of time talking with security, identity, and cloud teams at some of our largest and most complex customers, understanding their problems, and working with teams across AWS to make sure that we’re building solutions that meet their diverse security requirements.
I’m a big fan of working with customers and fellow Amazonians on threat modeling and helping them make informed decisions about risks and the controls they put in place. It’s such a productive exercise because many people don’t have that clear model about what they’re protecting, and what they’re protecting it from.
When I work with AWS service teams, I advocate for making services that are simple to secure and simple for customers to configure. It’s not enough to offer only good security controls; the service should be simple to understand and straightforward to apply to meet customer expectations.
How did you get started in security? What about it piqued your interest?
I got started in security at a very young age: by circumventing network controls at my high school so that I could play Flash games circa 2004. Ever since then, I’ve had a passion for deeply understanding a system’s rules and how they can be bent or broken. I’ve been lucky enough to have a diverse set of experiences throughout my career, including working in a network operation center, security operation center, Linux and windows server administration, telephony, investigations, content delivery, perimeter security, and security architecture. I think having such a broad base of experience allows me to empathize with all the different people who are AWS customers on a day-to-day basis.
As I progressed through my career, I became very interested in the psychology of security and the mindsets of defenders, unauthorized users, and operators of computer systems. Security is about so much more than technology—it starts with people and processes.
How do you explain your job to non-technical friends and family?
I get to practice this question a lot! Very few of my family and friends work in tech.
I always start with something relatable to the person. I start with a website, mobile app, or product that they use, tell the story of how it uses AWS, then tie that in around how my team works to support many of the products they use in their everyday lives. You don’t have to look far into our customer success stories or AWS re:Invent presentations to see a product or company that’s meaningful to almost anyone you’d talk to.
I got to practice this very recently because the software used by my personal trainer is hosted on AWS. So when she asked what I actually do for a living, I was ready for her.
In your opinion, what’s the coolest thing happening in identity right now?
You left this question wide open, so I’m going to give you more than one answer.
First, outside of AWS, it’s the rise of ubiquitous, easy-to-use personal identity technology. I’m talking about products such as password managers, sign-in with Google or Apple, and passkeys. I’m excited to see the industry is finally offering services to consumers at no extra cost that you don’t need to be an expert to use and that will work on almost any device you sign in to. Everyday people can benefit from their use, and I have successfully converted many of the people I care about.
At AWS, it’s the work that we’re doing to enable data perimeters and provable security. We hear quite regularly from customers that data perimeters are super important to them, and they want to see us do more in that space and keep refining that journey. I’m all too happy to oblige. Provable security, while identity adjacent, is about getting real answers to questions such as “Can this resource be accessed publicly?” It’s making it simple for customers who don’t want to spend the time or money building the operational expertise to answer tough questions, and I think that’s incredible.
You presented at AWS re:Inforce 2023. What was your session about and what do you hope attendees took away from it?
My session was IAM336: Best practices for delegating access on IAM. I initially delivered this session at re:Inforce 2022, where customers gave it the highest overall rating for an identity session, so we brought it back for 2023!
The talk dives deep into some AWS Identity and Access Management (IAM) primitives and provides a lot of candor on what we feel are best practices based on many of the real-world engagements I’ve had with customers. The top thing that I hope attendees learned is how they can safely empower their developers to have some self service and autonomy when working with IAM and help transform central teams from blockers to enablers.
I’m also presenting at re:Invent 2023 in November. I’ll be doing a chalk talk called Best practices for setting up AWS Organizations policies. We’re targeting it towards a more general audience, not just customers whose primary jobs are AWS security or identity. I’m excited about this presentation because I usually talk to a lot of customers who have very mature security and identity practices, and this is a great chance to get feedback from customers who do not.
I’d like to thank all the customers who attended the sessions over the years — the best part of AWS events is the customer interactions and fantastic discussions that we have.
Is there anything you wish customers would ask about more often?
I wish more customers would frame their problems within a threat model. Many customer engagements start with a specific problem, but it isn’t in the context of the risk this poses to their business, and often focuses too much on specific technical controls for very specific issues, rather than an outcome that they’re trying to arrive at or a risk that they’re trying to mitigate. I like to take a step back and work with the customer to frame the problem that they’re talking about in a bigger picture, then have a more productive conversation around how we can mitigate these risks and other considerations that they may not have thought of.
Where do you see the identity space heading in the future?
I think the industry is really getting ready for an identity renaissance as we start shifting towards more modern and Zero Trust architectures. I’m really excited to start seeing adoption of technologies such as token exchange to help applications avoid impersonating users to downstream systems, or mechanisms such as proof of possession to provide scalable ways to bind a given credential to a system that it’s intended to be used from.
On the AWS Identity side: More controls. Simpler. Scalable. Provable.
What are you most proud of in your career?
Getting involved with speaking at AWS: presenting at summits, re:Inforce, and re:Invent. It’s something I never would have seen myself doing before. I grew up with a pretty bad speech impediment that I’m always working against.
I think my proudest moment in particular is when I had customers come to my re:Invent session because they saw me at AWS Summits earlier in the year and liked what I did there. I get a little emotional thinking about it.
Being a speaker also allowed me to go to Disneyland for the first time last year before the Anaheim Summit, and that would have made 5-year-old Liam proud.
If you had to pick a career outside of tech, what would you want to do?
I think I’d certainly be involved in something in forestry, resource management, or conservation. I spend most of my free time in the forests of British Columbia. I’m a big believer in shinrin-yoku, and I believe in being a good steward of the land. We’ve only got one earth.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Remek Hetman, Principal Solutions Architect on the Identity Solutions team
In this profile, I met with Ilya Epshteyn, Senior Manager of the AWS Identity Solutions team, to chat about his team and what they’re working on.
Let’s start with the basics. What does the Identity Solutions team do? We are a team of specialist solutions architects (SAs) who are in the AWS Identity organization. At AWS, we have SAs who directly support customers, and we have SAs who are embedded in internal engineering teams—we are the latter. As SAs, we work on complex customer scenarios, build solutions, and create deep technical content on identity topics, including identity and access management—like blog posts, workshops, and sessions at our global events. A significant portion of our time is spent working internally with AWS product and engineering teams to help bring the customer experience perspective. Identity touches everything — it’s the fabric of every AWS service — and we want to help achieve a consistent identity experience for customers. To help do this, we use different tooling to proactively identify challenges in customers’ experience with identity across AWS.
What is the mission of the Identity Solutions team? Our mission is to make it easier for customers to implement access controls that protect their data in a straightforward and consistent manner across AWS services. A consistent experience simplifies the implementation and validation of security controls. We help identify customer’s pain points and work with our service teams to improve their experiences. We also provide highly prescriptive guidance to customers around identity. We don’t want to just say, “here’s an option.” Our guidance comes from a place of knowing how it will be operationalized and implemented. We won’t recommend something to customers unless we’ve tried it ourselves.
In order to literally “try it ourselves,” we built and operate a large-scale AWS environment called Mirror World, in which we use AWS services from the perspective of an AWS customer. The environment allows us to create different controls and use them in conjunction with other tools and services, truly putting ourselves in the shoes of the customer. This is in line with our mission of “active empathy,” our #1 team tenet.
Interesting! Tell us more about Mirror World. There are three main use cases for Mirror World:
We use it to understand and proactively identify challenges with the customer experience for existing and new AWS services and features. As new features are launched, we get early access and test them out so that we can improve the documentation and prescriptive guidance that we provide to customers.
We vend accounts in it. Internal field teams can request accounts and get their hands on a large-scale AWS environment with real customer setups, including organization-wide security controls and networking.
AWS service teams use this environment to see how customers experience their AWS service.
What are your other major focus areas right now? Data perimeters — set of preventive guardrails in your AWS environment to help ensure that only your trusted identities are accessing trusted resources from expected networks — are a big focus for us. Because data perimeters touch so many different aspects of identity and access management, our team is helping to organize what the user experience will look like, and helping to define the future state of data perimeters. Team members Tatyana Yatskevich and Matt Luttrell went into more detail about this in their profiles.
What are some of the common questions you hear from customers? Customers who have already been operating in the cloud for several years often tell us that they’re looking for opportunities to optimize their environment at scale. They’re maturing and managing hundreds or even thousands of accounts, so they commonly ask us for ways to simplify and scale their environment. For customers earlier in their journey, a common question is what lessons we have learned while working with more experienced customers so that they can benefit from their journey. Like Andy Jassy says, “There is no compression algorithm for experience.”
What do you wish customers would ask about more? How to get rid of their long-term credentials to significantly reduce the chances of credentials becoming compromised. We realize that for some customers it’s an effort to move away from IAM users and long-term credentials. We’d love to hear from more customers how they’re moving away from them or what’s stopping them from doing so. We’ve done a better job setting newer customers on the right path with short-term credentials and IAM roles instead of users, but for more tenured customers, there’s still an opportunity to improve in this area.
Looking ahead, what are your goals for the team? We’re lucky that our team has individuals with diverse backgrounds and skillsets that have enabled us to deliver on our mission. But if we want to make a bigger impact, we need to scale. We will continue to utilize Mirror World, do more with automation, and expand our team collaboration to further the consistent identity experience for our customers. We also recently launched a repo containing recommended service control policies, which we plan to continue expanding. And we’re going to continue to build end-to-end solutions for identity use cases, such as IAM Policy Validator for AWS CloudFormation. We will also continue identity enablement on complex topics, such as the data perimeter blog series and workshop, so that we can reach even more customers with prescriptive guidance. Stay tuned for more blog posts from our team coming soon here! If you’re interested in any of the topics mentioned in this post and would like to start a conversation, please reach out to your account team.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS customers already use Amazon Cognito for simple, fast authentication. With the launch of Amazon Verified Permissions, many will also want to add simple, fast authorization to their applications by using the user attributes that they have in Amazon Cognito. In this post, I will show you how to use Amazon Cognito and Verified Permissions together to add fine-grained authorization to your applications.
Fine-grained authorization
With Verified Permissions, you can write policies to use fine-grained authorization in your applications. Policy-based access control helps you secure your applications without embedding complicated access control code in the application logic. Instead, you write policies that say who can take what actions on which resources, and you evaluate the policies by using the Verified Permissions API. The API evaluates access control policies in the context of an access request: Who’s making the request? What do they want to do? What do they want to access? Under what conditions are they making the request?
AWS has removed the work needed to create context about who is making the request by using data from Amazon Cognito. By using Amazon Cognito as your identity store and integrating Verified Permissions with Amazon Cognito, you can use the ID and access tokens that Amazon Cognito returns in the authorization decisions in your applications. You provide Amazon Cognito tokens to Verified Permissions, which uses the attributes that the tokens contain to represent the principal and identify the principal’s entitlements.
Make access requests
To write policies for Verified Permissions, you use a policy language called Cedar. The examples in this post are modified from those in the Cedar language tutorial; I recommend that you review this tutorial for a comprehensive introduction on how to build and use Cedar policies. The following is an example of what a Cedar policy in a photo-sharing application might look like:
This policy states that Alice—the principal—is permitted to update the resource named VacationPhoto94.jpg. You place the policies for your application in a dedicated policy store. To ask Verified Permissions for an authorization decision, use the isAuthorized operation from the API. For example, the following request asks if user alice is permitted to update VacationPhoto94.jpg. Note that I’ve left out details like the policy store identifier for clarity.
This request returns a decision of allow because the principal, action, and resource all match those in the policy. If a user named bob tries to update the photo, the request returns a decision of deny because the policy only allows user alice. For requests that only need values for the principal, action, and resource, you can generally use values from the data in the application.
Things get more interesting when you build policies that use attributes of the principal to make the decision. In these cases, it can be challenging to assemble a complete and accurate authorization context. Policies might refer to attributes of the principal, such as their geographic location or whether they are paid subscribers. Fine-grained access control requires that you write good policies, properly format the access request, and provide the needed attributes for the policies to be evaluated. To get needed attributes, you must often make inline requests to other systems and then transform the results to meet the policy requirements.
The following policy uses an attribute requirement to allow any principal to view any resource as long as they are located in the United States.
To make an authorization request, you must supply the needed attributes for the principal. The following code shows how to do that by using the isAuthorized operation:
The authorization request now includes the context that Alice is located in the USA. According to the preceding policy, she should be allowed to view VacationPhoto94.jpg. To make this request, you must gather this information so that you can include it in the request.
Use Amazon Cognito
If the photo-sharing application uses Amazon Cognito for user authentication, then Amazon Cognito will pass an ID token to it when the authentication is successful. For more information about the format and encoding of ID tokens, see the OpenID Connect Core specification. For our purposes, it’s enough to know that after the ID token is verified and decoded, it contains a JSON structure with named attributes.
When you configure Amazon Cognito, you can specify the fields that are contained in the ID token. These might be user editable, but they can also be programmatically generated from other sources. Suppose that you have configured your Amazon Cognito user pool to also include a custom location attribute, custom:location. When Alice logs in to the photo-sharing application, the ID token that Amazon Cognito provides for her contains the following fields. Note that I’ve made the sub (subject) field human readable, but it would actually be a Amazon Cognito entity identifier.
If the needed attributes are in Amazon Cognito, you can use them to create the attributes that isAuthorized needs to render an access decision.
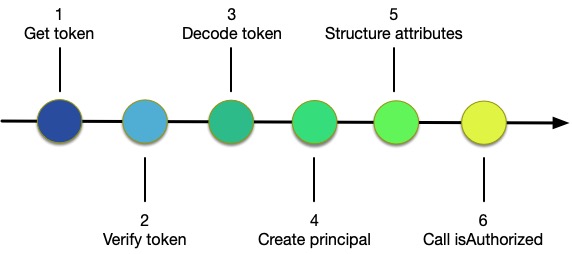
Figure 1: Steps to use Amazon Cognito with isAuthorized
As shown in Figure 1, you need to complete the following six steps to use isAuthorized with Amazon Cognito:
Get the token from Amazon Cognito when the user authenticates
Verify the token to authenticate the user
Decode the token to retrieve attribute information
Create the policy principal from information in the token or from other sources
Create the entities structure by using information in the token or from other sources
Call Amazon Verified Permissions by using isAuthorized
Now that you understand how to make a request by manually creating the context using data provided by an identity provider, I’ll share how the AWS integration of Amazon Cognito and Verified Permissions can help reduce your workload.
Use isAuthorizedWithToken
In addition to isAuthorized, the Verified Permissions API provides the isAuthorizedWithToken operation that accepts Amazon Cognito tokens. If your application uses Amazon Cognito for authentication, then Amazon Cognito provides the ID token after the user logs in. Let’s assume that you have stored this token in a variable named cognito_id_token. Because you are using an attribute from Amazon Cognito, you modify the previous policy to accommodate the namespace that the Amazon Cognito attributes are in, as shown in the following:
With this policy, the photo-sharing application can use the ID token to make an authorization request using isAuthorizedWithToken:
Using this call, you don’t have to supply the principal or construct the entities argument for the principal. Instead, you just pass in the ID token that Amazon Cognito provides. When you call isAuthorizedWithToken, it constructs the principal by using information in the token and creates an entity context that includes Alice’s location from the attributes in the ID token.
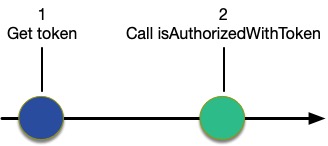
Figure 2: Use isAuthorizedWithToken
As shown in Figure 2, when you use isAuthorizedWithToken, you only need to complete two steps:
Get the token from Amazon Cognito when the user authenticates
Call Verified Permissions using isAuthorizedWithToken, passing in the token
Optionally, your application might need to verify the token to authenticate the user and avoid unnecessary work, or it can rely on isAuthorizedWithToken to do that. Similarly, you might also decode the token if you need its values for the application logic.
Configure isAuthorizedWithToken
You can use the Verified Permissions console to tell the API which Amazon Cognito user pool you’re using for your application. This is called an identity source.
To create an identity source for use with Verified Permissions (console):
Choose Identity source. You will see a list showing the sources that you have already configured.
To create a new identity source, choose Create identity source.
Enter the User pool ID.
Enter the Principal type.
Select whether or not to validate Client application IDs for this source.
(Optional) Enter Tags.
Choose Create identity source to add a new identity source to Verified Permissions with the given client ID.
The isAuthorizedWithToken operation uses the configuration information to get the public keys from Amazon Cognito to validate and decode the token. It also uses the configuration information to validate that the user pool for the token is associated with the policy store that the API is using.
Add resource entity attributes
ID tokens provide attributes about the principal, but they don’t provide information about the resource. Policies will often reference resource attributes, as shown in the following policy:
Like the previous example, this policy requires that photo viewers are located in the US, but it also requires that the resource has a public attribute. The isAuthorizedWithToken operation can augment the entity information in the token by using the same entities argument that isAuthorized uses. You can add the resource entity information to the call, as shown in the following call to isAuthorizedWithToken:
The isAuthorizedWithToken operation combines the entity information that it gleans from the ID token with the explicit entities information provided in the call to construct the context needed for the authorization request.
Conclusion
Discussions about access control tend to focus on the policies: how you can use them to make the code cleaner, and the value of moving the authorization logic out of the code. But that often ignores the work needed to create meaningful authorization requests. Assembling the information about the entities is a big part of making the request. If you use both Amazon Cognito and Verified Permissions, the integration discussed in this blog post can help relieve you of the work needed to build entity information about principals and help provide you with assurance that the assembly is happening consistently and securely.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
To avoid high costs of downtime, mission critical applications in the cloud need to achieve resilience against degradation of cloud provider APIs and services.
In 2021, AWS launched AWS Fault Injection Simulator (FIS), a fully managed service to perform fault injection experiments on workloads in AWS to improve their reliability and resilience.At the time of writing, FIS allows to simulate degradation of Amazon Elastic Compute Cloud (EC2) APIs using API fault injection actions and thus explore the resilience of workflows where EC2 APIs act as a fault boundary.
In this post we show you how to explore additional fault boundaries in your applications by selectively denying access to any AWS API. This technique is particularly useful for fully managed, “black box” services like Amazon Simple Storage Service (S3) or Amazon Simple Queue Service (SQS) where a failure of read or write operations is sufficient to simulate problems in the service. This technique is also useful for injecting failures in serverless applications without needing to modify code. While similar results could be achieved with network disruption or modifying code with feature flags, this approach provides a fine granular degradation of an AWS API without the need to re-deploy and re-validate code.
Overview
We will explore a common application pattern: user uploads a file, S3 triggers an AWS Lambda function, Lambda transforms the file to a new location and deletes the original:
Figure 1. S3 upload and transform logical workflow: User uploads file to S3, upload triggers AWS Lambda execution, Lambda writes transformed file to a new bucket and deletes original. Workflow can be disrupted at file deletion.
We will simulate the user upload with an Amazon EventBridgerate expression triggering an AWS Lambda function which creates a file in S3:
Figure 2. S3 upload and transform implemented demo workflow: Amazon EventBridge triggers a creator Lambda function, Lambda function creates a file in S3, file creation triggers AWS Lambda execution on transformer function, Lambda writes transformed file to a new bucket and deletes original. Workflow can be disrupted at file deletion.
Using this architecture we can explore the effect of S3 API degradation during file creation and deletion. As shown, the API call to delete a file from S3 is an application fault boundary. The failure could occur, with identical effect, because of S3 degradation or because the AWS IAM role of the Lambda function denies access to the API.
To inject failures we use AWS Systems Manager (AWS SSM) automation documents to attach and detach IAM policies at the API fault boundary and FIS to orchestrate the workflow.
Each Lambda function has an IAM execution role that allows S3 write and delete access, respectively. If the processor Lambda fails, the S3 file will remain in the bucket, indicating a failure. Similarly, if the IAM execution role for the processor function is denied the ability to delete a file after processing, that file will remain in the S3 bucket.
Prerequisites
Following this blog posts will incur some costs for AWS services. To explore this test application you will need an AWS account. We will also assume that you are using AWS CloudShell or have the AWS CLI installed and have configured a profile with administrator permissions. With that in place you can create the demo application in your AWS account by downloading this template and deploying an AWS CloudFormation stack:
Once the stack has been created, navigate to the Amazon CloudWatch Logs console and filter for /aws/lambda/test-fis-api-faults. Under the EventBridgeTimerHandler log group you should find log events once a minute writing a timestamped file to an S3 bucket named fis-api-failure-ACCOUNT_ID. Under the S3TriggerHandler log group you should find matching deletion events for those files.
Once you have confirmed object creation/deletion, let’s take away the permission of the S3 trigger handler lambda to delete files. To do this you will attach the FISAPI-DenyS3DeleteObject policy that was created with the template:
ROLE_NAME=FISAPI-TARGET-S3TriggerHandlerRole
ROLE_ARN=$( aws iam list-roles --query "Roles[?RoleName=='${ROLE_NAME}'].Arn" --output text )
echo Target Role ARN: $ROLE_ARN
POLICY_NAME=FISAPI-DenyS3DeleteObject
POLICY_ARN=$( aws iam list-policies --query "Policies[?PolicyName=='${POLICY_NAME}'].Arn" --output text )
echo Impact Policy ARN: $POLICY_ARN
aws iam attach-role-policy \
--role-name ${ROLE_NAME}\
--policy-arn ${POLICY_ARN}
With the deny policy in place you should now see object deletion fail and objects should start showing up in the S3 bucket. Navigate to the S3 console and find the bucket starting with fis-api-failure. You should see a new object appearing in this bucket once a minute:
Figure 3. S3 bucket listing showing files not being deleted because IAM permissions DENY file deletion during FIS experiment.
If you would like to graph the results you can navigate to AWS CloudWatch, select “Logs Insights“, select the log group starting with /aws/lambda/test-fis-api-faults-S3CountObjectsHandler, and run this query:
This will show the number of files in the S3 bucket over time:
Figure 4. AWS CloudWatch Logs Insights graph showing the increase in the number of retained files in S3 bucket over time, demonstrating the effect of the introduced failure.
You can now detach the policy:
ROLE_NAME=FISAPI-TARGET-S3TriggerHandlerRole
ROLE_ARN=$( aws iam list-roles --query "Roles[?RoleName=='${ROLE_NAME}'].Arn" --output text )
echo Target Role ARN: $ROLE_ARN
POLICY_NAME=FISAPI-DenyS3DeleteObject
POLICY_ARN=$( aws iam list-policies --query "Policies[?PolicyName=='${POLICY_NAME}'].Arn" --output text )
echo Impact Policy ARN: $POLICY_ARN
aws iam detach-role-policy \
--role-name ${ROLE_NAME}\
--policy-arn ${POLICY_ARN}
We see that newly written files will once again be deleted but the un-processed files will remain in the S3 bucket. From the fault injection we learned that our system does not tolerate request failures when deleting files from S3. To address this, we should add a dead letter queue or some other retry mechanism.
Note: if the Lambda function does not return a success state on invocation, EventBridge will retry. In our Lambda functions we are cost conscious and explicitly capture the failure states to avoid excessive retries.
Fault injection using SSM
To use this approach from FIS and to always remove the policy at the end of the experiment, we first create an SSM document to automate adding a policy to a role. To inspect this document, open the SSM console, navigate to the “Documents” section, find the FISAPI-IamAttachDetach document under “Owned by me”, and examine the “Content” tab (make sure to select the correct region). This document takes the name of the Role you want to impact and the Policy you want to attach as parameters. It also requires an IAM execution role that grants it the power to list, attach, and detach specific policies to specific roles.
Let’s run the SSM automation document from the console by selecting “Execute Automation”. Determine the ARN of the FISAPI-SSM-Automation-Role from CloudFormation or by running:
POLICY_NAME=FISAPI-DenyS3DeleteObject
POLICY_ARN=$( aws iam list-policies --query "Policies[?PolicyName=='${POLICY_NAME}'].Arn" --output text )
echo Impact Policy ARN: $POLICY_ARN
Use FISAPI-SSM-Automation-Role, a duration of 2 minutes expressed in ISO8601 format as PT2M, the ARN of the deny policy, and the name of the target role FISAPI-TARGET-S3TriggerHandlerRole:
Figure 5. Image of parameter input field reflecting the instructions in blog text.
Alternatively execute this from a shell:
ASSUME_ROLE_NAME=FISAPI-SSM-Automation-Role
ASSUME_ROLE_ARN=$( aws iam list-roles --query "Roles[?RoleName=='${ASSUME_ROLE_NAME}'].Arn" --output text )
echo Assume Role ARN: $ASSUME_ROLE_ARN
ROLE_NAME=FISAPI-TARGET-S3TriggerHandlerRole
ROLE_ARN=$( aws iam list-roles --query "Roles[?RoleName=='${ROLE_NAME}'].Arn" --output text )
echo Target Role ARN: $ROLE_ARN
POLICY_NAME=FISAPI-DenyS3DeleteObject
POLICY_ARN=$( aws iam list-policies --query "Policies[?PolicyName=='${POLICY_NAME}'].Arn" --output text )
echo Impact Policy ARN: $POLICY_ARN
aws ssm start-automation-execution \
--document-name FISAPI-IamAttachDetach \
--parameters "{
\"AutomationAssumeRole\": [ \"${ASSUME_ROLE_ARN}\" ],
\"Duration\": [ \"PT2M\" ],
\"TargetResourceDenyPolicyArn\": [\"${POLICY_ARN}\" ],
\"TargetApplicationRoleName\": [ \"${ROLE_NAME}\" ]
}"
Wait two minutes and then examine the content of the S3 bucket starting with fis-api-failure again. You should now see two additional files in the bucket, showing that the policy was attached for 2 minutes during which files could not be deleted, and confirming that our application is not resilient to S3 API degradation.
Permissions for injecting failures with SSM
Fault injection with SSM is controlled by IAM, which is why you had to specify the FISAPI-SSM-Automation-Role:
Figure 6. Visual representation of IAM permission used for fault injections with SSM.
This role needs to contain an assume role policy statement for SSM to allow assuming the role:
The role also needs to contain permissions to describe roles and their attached policies with an optional constraint on which roles and policies are visible:
Finally the SSM role needs to allow attaching and detaching a policy document. This requires
an ALLOW statement
a constraint on the policies that can be attached
a constraint on the roles that can be attached to
In the role we collapse the first two requirements into an ALLOW statement with a condition constraint for the Policy ARN. We then express the third requirement in a DENY statement that will limit the '*' resource to only the explicit role ARNs we want to modify:
- Sid: AllowOnlyTargetResourcePolicies
Effect: Allow
Action:
- 'iam:DetachRolePolicy'
- 'iam:AttachRolePolicy'
Resource: '*'
Condition:
ArnEquals:
'iam:PolicyARN':
# Policies that can be attached
- !Ref AwsFisApiPolicyDenyS3DeleteObject
- Sid: DenyAttachDetachAllRolesExceptApplicationRole
Effect: Deny
Action:
- 'iam:DetachRolePolicy'
- 'iam:AttachRolePolicy'
NotResource:
# Roles that can be attached to
- !GetAtt EventBridgeTimerHandlerRole.Arn
- !GetAtt S3TriggerHandlerRole.Arn
We will discuss security considerations in more detail at the end of this post.
Fault injection using FIS
With the SSM document in place you can now create an FIS template that calls the SSM document. Navigate to the FIS console and filter for FISAPI-DENY-S3PutObject. You should see that the experiment template passes the same parameters that you previously used with SSM:
Figure 7. Image of FIS experiment template action summary. This shows the SSM document ARN to be used for fault injection and the JSON parameters passed to the SSM document specifying the IAM Role to modify and the IAM Policy to use.
You can now run the FIS experiment and after a couple minutes once again see new files in the S3 bucket.
Permissions for injecting failures with FIS and SSM
Fault injection with FIS is controlled by IAM, which is why you had to specify the FISAPI-FIS-Injection-EperimentRole:
Figure 8. Visual representation of IAM permission used for fault injections with FIS and SSM. It shows the SSM execution role permitting access to use SSM automation documents as well as modify IAM roles and policies via the SSM document. It also shows the FIS execution role permitting access to use FIS templates, as well as the pass-role permission to grant the SSM execution role to the SSM service. Finally it shows the FIS user needing to have a pass-role permission to grant the FIS execution role to the FIS service.
This role needs to contain an assume role policy statement for FIS to allow assuming the role:
Finally, remember that the SSM document needs to use a Role of its own to execute the fault injection actions. Because that Role is different from the Role under which we started the FIS experiment, we need to explicitly allow SSM to assume that role with a PassRole statement which will expand to FISAPI-SSM-Automation-Role:
So far, we have used explicit ARNs for our guardrails. To expand flexibility, we can use wildcards in our resource matching. For example, we might change the Policy matching from:
If we set PolicyNamePrefix to FISAPI-DenyS3 this would now allow invoking FISAPI-DenyS3PutObject and FISAPI-DenyS3DeleteObject but would not allow using a policy named FISAPI-DenyEc2DescribeInstances.
Similarly, we could change the Resource matching from:
and setting RoleNamePrefixEventBridge to FISAPI-TARGET-EventBridge and RoleNamePrefixS3 to FISAPI-TARGET-S3.
Finally, we would also change the FIS experiment role to allow SSM documents based on a name prefix by changing the constraint on automation execution from:
- Sid: RequiredSSMWriteActionsforAWSFIS
Effect: Allow
Action:
- 'ssm:StartAutomationExecution'
- 'ssm:StopAutomationExecution'
Resource:
# Explicitly listed resource - secure but inflexible
# Note: the $DEFAULT at the end could also be an explicit version number
# Note: the 'automation-definition' is automatically created from 'document' on invocation
- !Sub 'arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:automation-definition/${SsmAutomationIamAttachDetachDocument}:$DEFAULT'
to
- Sid: RequiredSSMWriteActionsforAWSFIS
Effect: Allow
Action:
- 'ssm:StartAutomationExecution'
- 'ssm:StopAutomationExecution'
Resource:
# Wildcard resources - secure and flexible
#
# Note: the 'automation-definition' is automatically created from 'document' on invocation
- !Sub 'arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:automation-definition/${SsmAutomationDocumentPrefix}*'
and setting SsmAutomationDocumentPrefix to FISAPI-. Test this by updating the CloudFormation stack with a modified template:
In production you should not be using administrator access to use FIS. Instead we create two roles FISAPI-AssumableRoleWithCreation and FISAPI-AssumableRoleWithoutCreation for you (see this template). These roles require all FIS and SSM resources to have a Name tag that starts with FISAPI-. Try assuming the role without creation privileges and running an experiment. You will notice that you can only start an experiment if you add a Name tag, e.g. FISAPI-secure-1, and you will only be able to get details of experiments and templates that have proper Name tags.
If you are working with AWS Organizations, you can add further guard rails by defining SCPs that control the use of the FISAPI-* tags similar to this blog post.
Caveats
For this solution we are choosing to attach policies instead of permission boundaries. The benefit of this is that you can attach multiple independent policies and thus simulate multi-step service degradation. However, this means that it is possible to increase the permission level of a role. While there are situations where this might be of interest, e.g. to simulate security breaches, please implement a thorough security review of any fault injection IAM policies you create. Note that modifying IAM Roles may trigger events in your security monitoring tools.
The AttachRolePolicy and DetachRolePolicy calls from AWS IAM are eventually consistent, meaning that in some cases permission propagation when starting and stopping fault injection may take up to 5 minutes each.
Cleanup
To avoid additional cost, delete the content of the S3 bucket and delete the CloudFormation stack:
# Clean up policy attachments just in case
CLEANUP_ROLES=$(aws iam list-roles --query "Roles[?starts_with(RoleName,'FISAPI-')].RoleName" --output text)
for role in $CLEANUP_ROLES; do
CLEANUP_POLICIES=$(aws iam list-attached-role-policies --role-name $role --query "AttachedPolicies[?starts_with(PolicyName,'FISAPI-')].PolicyName" --output text)
for policy in $CLEANUP_POLICIES; do
echo Detaching policy $policy from role $role
aws iam detach-role-policy --role-name $role --policy-arn $policy
done
done
# Delete S3 bucket content
ACCOUNT_ID=$( aws sts get-caller-identity --query Account --output text )
S3_BUCKET_NAME=fis-api-failure-${ACCOUNT_ID}
aws s3 rm --recursive s3://${S3_BUCKET_NAME}
aws s3 rb s3://${S3_BUCKET_NAME}
# Delete cloudformation stack
aws cloudformation delete-stack --stack-name test-fis-api-faults
aws cloudformation wait stack-delete-complete --stack-name test-fis-api-faults
Conclusion
AWS Fault Injection Simulator provides the ability to simulate various external impacts to your application to validate and improve resilience. We’ve shown how combining FIS with IAM to selectively deny access to AWS APIs provides a generic path to explore fault boundaries across all AWS services. We’ve shown how this can be used to identify and improve a resilience problem in a common S3 upload workflow. To learn about more ways to use FIS, see this workshop.
Since the broad launch of our multi-factor authentication (MFA) security key program, customers have been enthusiastic about the program and how they will use it to improve their organizations’ security posture. Given the level of interest, we’re expanding eligibility for the program to allow more US-based AWS account root users and payer accounts to take advantage of the offer. Previously, eligibility required that US-based root users and payer accounts spend a minimum of $100 per month over the past 3 months. Now, we are expanding eligibility to US-based root users and payer accounts who have spent a minimum of $300 over the past 3 months. If you are a US-based customer who meets the expanded eligibility requirements, we encourage you to place an order for your free security key. As a reminder, you can use the following steps to order your free key.
To order your free security key
Confirm your eligibility at the ordering portal. You will be prompted to sign in if you haven’t already. Sign in with your AWS account root user or payer account credentials.
Choose your free security key from the available options.
Provide your email address for order confirmation and your shipping address.
Place your order.
MFA as a core security best practice is one of the key messages emphasized at the recent AWS re:Inforce conference. Using MFA is one of the simplest ways for anyone, personally or professionally, to help improve their security online. For example, if credentials become compromised on GitHub, users have an extra layer of protection if MFA is enabled. Or, if your login details are compromised for your bank account, MFA acts a second factor to protect your account.
If you’re not eligible for a free security key at this time, but would still like a security key, check out our MFA recommendations. These are available for purchase from many sellers, including Amazon. For more information about the MFA program, see our Free MFA Security Key page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In Part 1 of this two-part series, we shared an overview of some of the most important 2021 Amazon Web Services (AWS) Security service and feature launches. In this follow-up, we’ll dive deep into additional launches that are important for security professionals to be aware of and understand across all AWS services. There have already been plenty in the first half of 2022, so we’ll highlight those soon, as well.
AWS Identity
You can use AWS Identity Services to build Zero Trust architectures, help secure your environments with a robust data perimeter, and work toward the security best practice of granting least privilege. In 2021, AWS expanded the identity source options, AWS Region availability, and support for AWS services. There is also added visibility and power in the permission management system. New features offer new integrations, additional policy checks, and secure resource sharing across AWS accounts.
AWS Single Sign-On
For identity management, AWS Single Sign-On (AWS SSO) is where you create, or connect, your workforce identities in AWS once and manage access centrally across your AWS accounts in AWS Organizations. In 2021, AWS SSO announced new integrations for JumpCloud and CyberArk users. This adds to the list of providers that you can use to connect your users and groups, which also includes Microsoft Active Directory Domain Services, Okta Universal Directory, Azure AD, OneLogin, and Ping Identity.
For access management, there have been a range of feature launches with AWS Identity and Access Management (IAM) that have added up to more power and visibility in the permissions management system. Here are some key examples.
IAM made it simpler to relate a user’s IAM role activity to their corporate identity. By setting the new source identity attribute, which persists through role assumption chains and gets logged in AWS CloudTrail, you can find out who is responsible for actions that IAM roles performed.
IAM added support for policy conditions, to help manage permissions for AWS services that access your resources. This important feature launch of service principal conditions helps you to distinguish between API calls being made on your behalf by a service principal, and those being made by a principal inside your account. You can choose to allow or deny the calls depending on your needs. As a security professional, you might find this especially useful in conjunction with the aws:CalledVia condition key, which allows you to scope permissions down to specify that this account principal can only call this API if they are calling it using a particular AWS service that’s acting on their behalf. For example, your account principal can’t generally access a particular Amazon Simple Storage Service (Amazon S3) bucket, but if they are accessing it by using Amazon Athena, they can do so. These conditions can also be used in service control policies (SCPs) to give account principals broader scope across an account, organizational unit, or organization; they need not be added to individual principal policies or resource policies.
Another very handy new IAM feature launch is additional information about the reason for an access denied error message. With this additional information, you can now see which of the relevant access control policies (for example, IAM, resource, SCP, or VPC endpoint) was the cause of the denial. As of now, this new IAM feature is supported by more than 50% of all AWS services in the AWS SDK and AWS Command Line Interface, and a fast-growing number in the AWS Management Console. We will continue to add support for this capability across services, as well as add more features that are designed to make the journey to least privilege simpler.
IAM Access Analyzer also launched the ability to generate fine-grained policies based on analyzing past AWS CloudTrail activity. This feature provides a great new capability for DevOps teams or central security teams to scope down policies to just the permissions needed, making it simpler to implement least privilege permissions. IAM Access Analyzer launched further enhancements to expand policy checks, and the ability to generate a sample least-privilege policy from past activity was expanded beyond the account level to include an analysis of principal behavior within the entire organization by analyzing log activity stored in AWS CloudTrail.
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) helps you securely share your resources across unrelated AWS accounts within your organization or organizational units (OUs) in AWS Organizations. Now you can also share your resources with IAM roles and IAM users for supported resource types. This update enables more granular access using managed permissions that you can use to define access to shared resources. In addition to the default managed permission defined for each shareable resource type, you now have more flexibility to choose which permissions to grant to whom for resource types that support additional managed permissions. Additionally, AWS RAM added support for global resource types, enabling you to provision a global resource once, and share that resource across your accounts. A global resource is one that can be used in multiple AWS Regions; the first example of a global resource is found in AWS Cloud WAN, currently in preview as of this publication. AWS RAM helps you more securely share an AWS Cloud WAN core network, which is a managed network containing AWS and on-premises networks. With AWS RAM global resource sharing, you can use the Cloud WAN core network to centrally operate a unified global network across Regions and accounts.
AWS Directory Service
AWS Directory Service for Microsoft Active Directory, also known as AWS Managed Microsoft Active Directory (AD), was updated to automatically provide domain controller and directory utilization metrics in Amazon CloudWatch for new and existing directories. Analyzing these utilization metrics helps you quantify your average and peak load times to identify the need for additional domain controllers. With this, you can define the number of domain controllers to meet your performance, resilience, and cost requirements.
Amazon Cognito
Amazon Cognitoidentity pools (federated identities) was updated to enable you to use attributes from social and corporate identity providers to make access control decisions and simplify permissions management in AWS resources. In Amazon Cognito, you can choose predefined attribute-tag mappings, or you can create custom mappings using the attributes from social and corporate providers’ access and ID tokens, or SAML assertions. You can then reference the tags in an IAM permissions policy to implement attribute-based access control (ABAC) and manage access to your AWS resources. Amazon Cognito also launched a new console experience for user pools and now supports targeted sign out through refresh token revocation.
Governance, control, and logging services
There were a number of important releases in 2021 in the areas of governance, control, and logging services.
This approach provides a powerful new middle ground between the older security models of prevention (which provide developers only an access denied message, and often can’t distinguish between an acceptable and an unacceptable use of the same API) and a detect and react model (when undesired states have already gone live). The Cfn-Guard 2.0 model gives builders the freedom to build with IaC, while allowing central teams to have the ability to reject infrastructure configurations or changes that don’t conform to central policies—and to do so with completely custom error messages that invite dialog between the builder team and the central team, in case the rule is unnuanced and needs to be refined, or if a specific exception needs to be created.
For example, a builder team might be allowed to provision and attach an internet gateway to a VPC, but the team can do this only if the routes to the internet gateway are limited to a certain pre-defined set of CIDR ranges, such as the public addresses of the organization’s branch offices. It’s not possible to write an IAM policy that takes into account the CIDR values of a VPC route table update, but you can write a Cfn-Guard 2.0 rule that allows the creation and use of an internet gateway, but only with a defined and limited set of IP addresses.
AWS Systems Manager Incident Manager
An important launch that security professionals should know about is AWS Systems Manager Incident Manager. Incident Manager provides a number of powerful capabilities for managing incidents of any kind, including operational and availability issues but also security issues. With Incident Manager, you can automatically take action when a critical issue is detected by an Amazon CloudWatch alarm or Amazon EventBridge event. Incident Manager runs pre-configured response plans to engage responders by using SMS and phone calls, can enable chat commands and notifications using AWS Chatbot, and runs automation workflows with AWS Systems Manager Automation runbooks. The Incident Manager console integrates with AWS Systems Manager OpsCenter to help you track incidents and post-incident action items from a central place that also synchronizes with third-party management tools such as Jira Service Desk and ServiceNow. Incident Manager enables cross-account sharing of incidents using AWS RAM, and provides cross-Region replication of incidents to achieve higher availability.
Amazon Simple Storage Service (Amazon S3) is one of the most important services at AWS, and its steady addition of security-related enhancements is always big news. Here are the 2021 highlights.
Access Points aliases
Amazon S3 introduced a new feature, Amazon S3 Access Points aliases. With Amazon S3 Access Points aliases, you can make the access points backwards-compatible with a large amount of existing code that is programmed to interact with S3 buckets rather than access points.
To understand the importance of this launch, we have to go back to 2019 to the launch of Amazon S3 Access Points. Access points are a powerful mechanism for managing S3 bucket access. They provide a great simplification for managing and controlling access to shared datasets in S3 buckets. You can create up to 1,000 access points per Region within each of your AWS accounts. Although bucket access policies remain fully enforced, you can delegate access control from the bucket to its access points, allowing for distributed and granular control. Each access point enforces a customizable policy that can be managed by a particular workgroup, while also avoiding the problem of bucket policies needing to grow beyond their maximum size. Finally, you can also bind an access point to a particular VPC for its lifetime, to prevent access directly from the internet.
With the 2021 launch of Access Points aliases, Amazon S3 now generates a unique DNS name, or alias, for each access point. The Access Points aliases look and acts just like an S3 bucket to existing code. This means that you don’t need to make changes to older code to use Amazon S3 Access Points; just substitute an Access Points aliases wherever you previously used a bucket name. As a security team, it’s important to know that this flexible and powerful administrative feature is backwards-compatible and can be treated as a drop-in replacement in your various code bases that use Amazon S3 but haven’t been updated to use access point APIs. In addition, using Access Points aliases adds a number of powerful security-related controls, such as permanent binding of S3 access to a particular VPC.
S3 Bucket Keys were launched at the end of 2020, another great launch that security professionals should know about, so here is an overview in case you missed it. S3 Bucket Keys are data keys generated by AWS KMS to provide another layer of envelope encryption in which the outer layer (the S3 Bucket Key) is cached by S3 for a short period of time. This extra key layer increases performance and reduces the cost of requests to AWS KMS. It achieves this by decreasing the request traffic from Amazon S3 to AWS KMS from a one-to-one model—one request to AWS KMS for each object written to or read from Amazon S3—to a one-to-many model using the cached S3 Bucket Key. The S3 Bucket Key is never stored persistently in an unencrypted state outside AWS KMS, and so Amazon S3 ultimately must always return to AWS KMS to encrypt and decrypt the S3 Bucket Key, and thus, the data. As a result, you still retain control of the key hierarchy and resulting encrypted data through AWS KMS, and are still able to audit Amazon S3 returning periodically to AWS KMS to refresh the S3 Bucket Keys, as logged in CloudTrail.
Returning to our review of 2021, S3 Bucket Keys gained the ability to use Amazon S3 Inventory and Amazon S3 Batch Operations automatically to migrate objects from the higher cost, slightly lower-performance SSE-KMS model to the lower-cost, higher-performance S3 Bucket Keys model.
To understand this launch, we need to go in time to the origins of Amazon S3, which is one of the oldest services in AWS, created even before IAM was launched in 2011. In those pre-IAM days, a storage system like Amazon S3 needed to have some kind of access control model, so Amazon S3 invented its own: Amazon S3 access control lists (ACLs). Using ACLs, you could add access permissions down to the object level, but only with regard to access by other AWS account principals (the only kind of identity that was available at the time), or public access (read-only or read-write) to an object. And in this model, objects were always owned by the creator of the object, not the bucket owner.
After IAM was introduced, Amazon S3 added the bucket policy feature, a type of resource policy that provides the rich features of IAM, including full support for all IAM principals (users and roles), time-of-day conditions, source IP conditions, ability to require encryption, and more. For many years, Amazon S3 access decisions have been made by combining IAM policy permissions and ACL permissions, which has served customers well. But the object-writer-is-owner issue has often caused friction. The good news for security professionals has been that a deny by either type of access control type overrides an allow by the other, so there were no security issues with this bi-modal approach. The challenge was that it could be administratively difficult to manage both resource policies—which exist at the bucket and access point level—and ownership and ACLs—which exist at the object level. Ownership and ACLs might potentially impact the behavior of only a handful of objects, in a bucket full of millions or billions of objects.
With the features released in 2021, Amazon S3 has removed these points of friction, and now provides the features needed to reduce ownership issues and to make IAM-based policies the only access control system for a specified bucket. The first step came in 2020 with the ability to make object ownership track bucket ownership, regardless of writer. But that feature applied only to newly-written objects. The final step is the 2021 launch we’re highlighting here: the ability to disable at the bucket level the evaluation of all existing ACLs—including ownership and permissions—effectively nullifying all object ACLs. From this point forward, you have the mechanisms you need to govern Amazon S3 access with a combination of S3 bucket policies, S3 access point policies, and (within the same account) IAM principal policies, without worrying about legacy models of ACLs and per-object ownership.
Additional database and storage service features
AWS Backup Vault Lock
AWS Backup added an important new additional layer for backup protection with the availability of AWS Backup Vault Lock. A vault lock feature in AWS is the ability to configure a storage policy such that even the most powerful AWS principals (such as an account or Org root principal) can only delete data if the deletion conforms to the preset data retention policy. Even if the credentials of a powerful administrator are compromised, the data stored in the vault remains safe. Vault lock features are extremely valuable in guarding against a wide range of security and resiliency risks (including accidental deletion), notably in an era when ransomware represents a rising threat to data.
ACM Private CA achieved FedRAMP authorization for six additional AWS Regions in the US.
Additional certificate customization now allows administrators to tailor the contents of certificates for new use cases, such as identity and smart card certificates; or to securely add information to certificates instead of relying only on the information present in the certificate request.
Additional capabilities were added for sharing CAs across accounts by using AWS RAM to help administrators issue fully-customized certificates, or revoke them, from a shared CA.
Integration with Kubernetes provides a more secure certificate authority solution for Kubernetes containers.
Online Certificate Status Protocol (OCSP) provides a fully-managed solution for notifying endpoints that certificates have been revoked, without the need for you to manage or operate infrastructure yourself.
Network and application protection
We saw a lot of enhancements in network and application protection in 2021 that will help you to enforce fine-grained security policies at important network control points across your organization. The services and new capabilities offer flexible solutions for inspecting and filtering traffic to help prevent unauthorized resource access.
AWS WAF
AWS WAF launched AWS WAF Bot Control, which gives you visibility and control over common and pervasive bots that consume excess resources, skew metrics, cause downtime, or perform other undesired activities. The Bot Control managed rule group helps you monitor, block, or rate-limit pervasive bots, such as scrapers, scanners, and crawlers. You can also allow common bots that you consider acceptable, such as status monitors and search engines. AWS WAF also added support for custom responses, managed rule group versioning, in-line regular expressions, and Captcha. The Captcha feature has been popular with customers, removing another small example of “undifferentiated work” for customers.
AWS Shield Advanced
AWS Shield Advanced now automatically protects web applications by blocking application layer (L7) DDoS events with no manual intervention needed by you or the AWS Shield Response Team (SRT). When you protect your resources with AWS Shield Advanced and enable automatic application layer DDoS mitigation, Shield Advanced identifies patterns associated with L7 DDoS events and isolates this anomalous traffic by automatically creating AWS WAF rules in your web access control lists (ACLs).
Amazon CloudFront
In other edge networking news, Amazon CloudFront added support for response headers policies. This means that you can now add cross-origin resource sharing (CORS), security, and custom headers to HTTP responses returned by your CloudFront distributions. You no longer need to configure your origins or use custom Lambda@Edge or CloudFront Functions to insert these headers.
Following Route 53 Resolver’s much-anticipated launch of DNS logging in 2020, the big news for 2021 was the launch of its DNS Firewall capability. Route 53 Resolver DNS Firewall lets you create “blocklists” for domains you don’t want your VPC resources to communicate with, or you can take a stricter, “walled-garden” approach by creating “allowlists” that permit outbound DNS queries only to domains that you specify. You can also create alerts for when outbound DNS queries match certain firewall rules, allowing you to test your rules before deploying for production traffic. Route 53 Resolver DNS Firewall launched with two managed domain lists—malware domains and botnet command and control domains—enabling you to get started quickly with managed protections against common threats. It also integrated with Firewall Manager (see the following section) for easier centralized administration.
AWS Network Firewall and Firewall Manager
Speaking of AWS Network Firewall and Firewall Manager, 2021 was a big year for both. Network Firewall added support for AWS Managed Rules, which are groups of rules based on threat intelligence data, to enable you to stay up to date on the latest security threats without writing and maintaining your own rules. AWS Network Firewall features a flexible rules engine enabling you to define firewall rules that give you fine-grained control over network traffic. As of the launch in late 2021, you can enable managed domain list rules to block HTTP and HTTPS traffic to domains identified as low-reputation, or that are known or suspected to be associated with malware or botnets. Prior to that, another important launch was new configuration options for rule ordering and default drop, making it simpler to write and process rules to monitor your VPC traffic. Also in 2021, Network Firewall announced a major regional expansion following its initial launch in 2020, and a range of compliance achievements and eligibility including HIPAA, PCI DSS, SOC, and ISO.
Elastic Load Balancing now supports forwarding traffic directly from Network Load Balancer (NLB) to Application Load Balancer (ALB). With this important new integration, you can take advantage of many critical NLB features such as support for AWS PrivateLink and exposing static IP addresses for applications that still require ALB.
The AWS Networking team also made Amazon VPC private NAT gateways available in both AWS GovCloud (US) Regions. The expansion into the AWS GovCloud (US) Regions enables US government agencies and contractors to move more sensitive workloads into the cloud by helping them to address certain regulatory and compliance requirements.
Compute
Security professionals should also be aware of some interesting enhancements in AWS compute services that can help improve their organization’s experience in building and operating a secure environment.
Amazon Elastic Compute Cloud (Amazon EC2) launched the Global View on the console to provide visibility to all your resources across Regions. Global View helps you monitor resource counts, notice abnormalities sooner, and find stray resources. A few days into 2022, another simple but extremely useful EC2 launch was the new ability to obtain instance tags from the Instance Metadata Service (IMDS). Many customers run code on Amazon EC2 that needs to introspect about the EC2 tags associated with the instance and then change its behavior depending on the content of the tags. Prior to this launch, you had to associate an EC2 role and call the EC2 API to get this information. That required access to API endpoints, either through a NAT gateway or a VPC endpoint for Amazon EC2. Now, that information can be obtained directly from the IMDS, greatly simplifying a common use case.
Amazon EC2 launched sharing of Amazon Machine Images (AMIs) with AWS Organizations and Organizational Units (OUs). Previously, you could share AMIs only with specific AWS account IDs. To share AMIs within AWS Organizations, you had to explicitly manage sharing of AMIs on an account-by-account basis, as they were added to or removed from AWS Organizations. With this new feature, you no longer have to update your AMI permissions because of organizational changes. AMI sharing is automatically synchronized when organizational changes occur. This feature greatly helps both security professionals and governance teams to centrally manage and govern AMIs as you grow and scale your AWS accounts. As previously noted, this feature was also added to EC2 Image Builder. Finally, Amazon Data Lifecycle Manager, the tool that manages all your EBS volumes and AMIs in a policy-driven way, now supports automatic deprecation of AMIs. As a security professional, you will find this helpful as you can set a timeline on your AMIs so that, if the AMIs haven’t been updated for a specified period of time, they will no longer be considered valid or usable by development teams.
Looking ahead
In 2022, AWS continues to deliver experiences that meet administrators where they govern, developers where they code, and applications where they run. We will continue to summarize important launches in future blog posts. If you’re interested in learning more about AWS services, join us for AWS re:Inforce, the AWS conference focused on cloud security, identity, privacy, and compliance. AWS re:Inforce 2022 will take place July 26–27 in Boston, MA. Registration is now open. Register now with discount code SALxUsxEFCw to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last. We look forward to seeing you there!
To stay up to date on the latest product and feature launches and security use cases, be sure to read the What’s New with AWS announcements (or subscribe to the RSS feed) and the AWS Security Blog.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.