Post Syndicated from Scott Bryen original https://aws.amazon.com/blogs/architecture/continually-assessing-application-resilience-with-aws-resilience-hub-and-aws-codepipeline/
As customers commit to a DevOps mindset and embrace a nearly continuous integration/continuous delivery model to implement change with a higher velocity, assessing every change impact on an application resilience is key. This blog shows an architecture pattern for automating resiliency assessments as part of your CI/CD pipeline. Automatically running a resiliency assessment within CI/CD pipelines, development teams can fail fast and understand quickly if a change negatively impacts an applications resilience. The pipeline can stop the deployment into further environments, such as QA/UAT and Production, until the resilience issues have been improved.
AWS Resilience Hub is a managed service that gives you a central place to define, validate and track the resiliency of your AWS applications. It is integrated with AWS Fault Injection Simulator (FIS), a chaos engineering service, to provide fault-injection simulations of real-world failures. Using AWS Resilience Hub, you can assess your applications to uncover potential resilience enhancements. This will allow you to validate your applications recovery time (RTO), recovery point (RPO) objectives and optimize business continuity while reducing recovery costs. Resilience Hub also provides APIs for you to integrate its assessment and testing into your CI/CD pipelines for ongoing resilience validation.
AWS CodePipeline is a fully managed continuous delivery service for fast and reliable application and infrastructure updates. You can use AWS CodePipeline to model and automate your software release processes. This enables you to increase the speed and quality of your software updates by running all new changes through a consistent set of quality checks.
Continuous resilience assessments
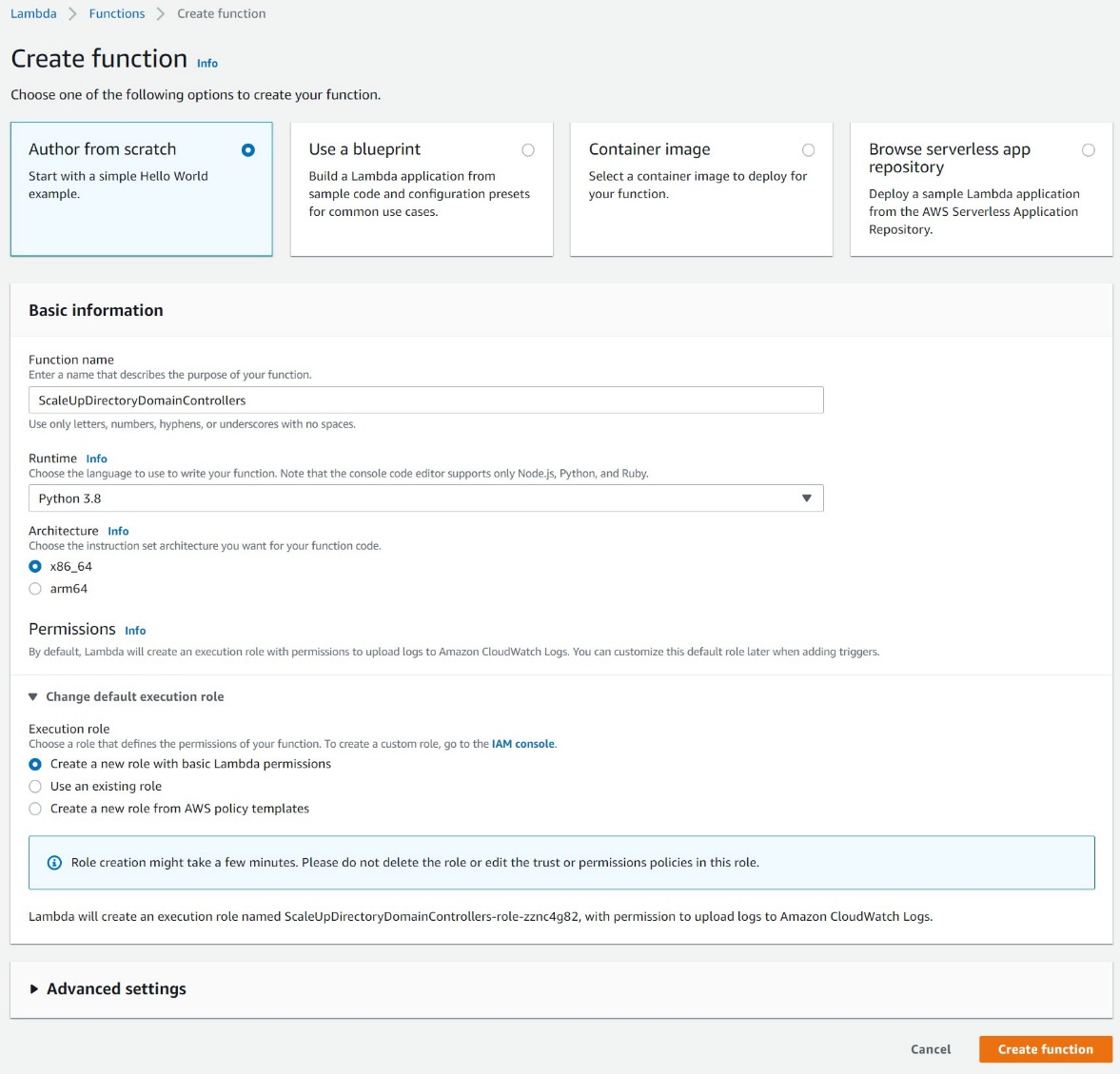
Figure 1 shows the resilience assessments automation architecture in a multi-account setup. AWS CodePipeline, AWS Step Functions, and AWS Resilience Hub are defined in your deployment account while the application AWS CloudFormation stacks are imported from your workload account. This pattern relies on AWS Resilience Hub ability to import CloudFormation stacks from a different accounts, regions, or both, when discovering an application structure.

Figure 1. High-level architecture pattern for automating resilience assessments
Add application to AWS Resilience Hub
Begin by adding your application to AWS Resilience Hub and assigning a resilience policy. This can be done via the AWS Management Console or using CloudFormation. In this instance, the application has been created through the AWS Management Console. Sebastien Stormacq’s post, Measure and Improve Your Application Resilience with AWS Resilience Hub, walks you through how to add your application to AWS Resilience Hub.
In a multi-account environment, customers typically have dedicated AWS workload account per environment and we recommend you separate CI/CD capabilities into another account. In this post, the AWS Resilience Hub application has been created in the deployment account and the resources have been discovered using an CloudFormation stack from the workload account. Proper permissions are required to use AWS Resilience Hub to manage application in multiple accounts.

Figure 2. Adding application to AWS Resilience Hub
Create AWS Step Function to run resilience assessment
Whenever you make a change to your application CloudFormation, you need to update and publish the latest version in AWS Resilience Hub to ensure you are assessing the latest changes. Now that AWS Step Functions SDK integrations support AWS Resilience Hub, you can build a state machine to coordinate the process, which will be triggered from AWS Code Pipeline.
AWS Step Functions is a low-code, visual workflow service that developers use to build distributed applications, automate IT and business processes, and build data and machine learning pipelines using AWS services. Workflows manage failures, retries, parallelization, service integrations, and observability so developers can focus on higher-value business logic.

Figure 3. AWS Step Function for orchestrating AWS SDK calls
- The first step in the workflow is to update the resources associated with the application defined in AWS Resilience Hub by calling ImportResourcesToDraftApplication.
- Check for the import process to complete using a wait state, a call to DescribeDraftAppVersionResourcesImportStatus and then a choice state to decide whether to progress or continue waiting.
- Once complete, publish the draft application by calling PublishAppVersion to ensure we are assessing the latest version.
- Once published, call StartAppAssessment to kick-off a resilience assessment.
- Check for the assessment to complete using a wait state, a call to DescribeAppAssessment and then a choice state to decide whether to progress or continue waiting.
- In the choice state, use assessment status from the response to determine if the assessment is pending, in progress or successful.
- If successful, use the compliance status from the response to determine whether to progress to success or fail.
- Compliance status will be either “PolicyMet” or “PolicyBreached”.
- If policy breached, publish onto SNS to alert the development team before moving to fail.
Create stage within code pipeline
Now that we have the AWS Step Function created, we need to integrate it into our pipeline. The post Fine-grained Continuous Delivery With CodePipeline and AWS Step Functions demonstrates how you can trigger a step function from AWS Code Pipeline.
When adding the stage, you need to pass the ARN of the stack which was deployed in the previous stage as well as the ARN of the application in AWS Resilience Hub. These will be required on the AWS SDK calls and you can pass this in as a literal.

Figure 4. AWS CodePipeline stage step function input

Figure 5. Example state using the input from AWS CodePipeline stage
For more information about these AWS SDK calls, please refer to the AWS Resilience Hub API Reference documents.
Customers often run their workloads in lower environments in a less resilient way to save on cost. It’s important to add the assessment stage at the appropriate point of your pipeline. We recommend adding this to your pipeline after the deployment to a test environment which mirrors production but before deploying to production. By doing this you can fail fast and halt changes which will lower resilience in production.
A note on service quotas: AWS Resilience Hub allows you to run 20 assessments per month per application. If you need to increase this quota, please raise a ticket with AWS Support.
Conclusion
In this post, we have seen an approach to continuously assessing resilience as part of your CI/CD pipeline using AWS Resilience Hub, AWS CodePipeline and AWS Step Functions. This approach will enable you to understand fast if a change will weaken resilience.
AWS Resilience Hub also generates recommended AWS FIS Experiments that you can deploy and use to test the resilience of your application. As well as assessing the resilience, we also recommend you integrate running these tests into your pipeline. The post Chaos Testing with AWS Fault Injection Simulator and AWS CodePipeline demonstrates how you can active this.