As introduced in Part 1 of this series, implementing secure file sharing solutions in AWS requires a comprehensive understanding of your organization’s needs and constraints. Before selecting a specific solution, organizations must evaluate five fundamental areas: access patterns and scale, technical requirements, security and compliance, operational requirements, and business constraints. These areas cover everything from how files will be shared and what protocols are needed, to security measures, day-to-day operations, and business limitations.
See Part 1 of this series for detailed information about each of these fundamental areas and their specific considerations. Part 1 also covers solutions including AWS Transfer Family, Transfer Family web apps, and Amazon Simple Storage Service (Amazon S3) pre-signed URLs. This part continues our analysis with additional AWS file sharing solutions to help you make an informed decision based on your specific requirements.
Solutions
Let’s start by looking at the various file sharing mechanisms that AWS supports. The following table identifies the key AWS services needed for each solution, describes the security and cost implications of the solutions, and describes their complexity and protocol support capabilities.
Solution
AWS services
Security features
Cost*
Region control
CloudFront signed URLs
CloudFront, Amazon S3, and Lambda
Optional edge security using AWS Lambda@Edge, WAF integration, SSL/TLS, geo restrictions, and AWS Shield Standard (included automatically)
Content delivery network (CDN) costs, request pricing, and data transfer fees
Global service by design; origin can be AWS Region-specific
Amazon VPC endpoint service
AWS PrivateLink, Amazon VPC, and Network Load Balancer (NLB)
Complete network isolation, private connectivity, and multi-layer security
Endpoint hourly charges, NLB costs, and data processing fees
Service endpoints are strictly Region-specific; must create endpoints in each Region where access is needed
Data transfer fees apply based on standard S3 rates
Amazon VPC endpoint charges apply when using VPC endpoints with access points
Access points are Region-specific
Each access point is created in the same Region as its S3 bucket
Cross-Region access requires separate access points in each Region
VPC-specific access points are limited to the VPC’s Region
The following table shows the solutions described in Part 1.
Solution
AWS services
Security features
Cost*
Region control
AWS Transfer Family
Transfer Family, Amazon S3, API Gateway, and Lambda
Managed security, encryption in transit and at rest, IAM integration, and custom authentication
$0.30 per hour per protocol, data transfer fees, and storage costs
Can deploy to specific AWS Regions, can only transfer files to and from S3 buckets in the same Region
Transfer Family web apps
Transfer Family, S3, and CloudFront
Browser-based access, IAM Identity Center integration, and S3 Access Grants
Pay-per-file operation, CloudFront costs, and storage costs
Uses CloudFront (global) for web access, but backend components can be Region-specific
Amazon S3 pre-signed URLs
S3
Time-limited URLs, IAM controls for URL generation, and HTTPS
S3 request and data transfer fees
Can be restricted to specific Regions
Serverless application with Amazon S3 presigned URLs
S3, Lambda, and API Gateway
Time-limited URLs, HTTPS, IAM controls, customizable authentication
Pay per request and minimal infrastructure cost
Components can be Region-specific
* Pricing information provided is based on AWS service rates at the time of publication and is intended as an estimation only. Additional costs may be incurred depending on your specific implementation and usage patterns. For the most current and accurate pricing details, please consult the official AWS pricing pages for each service mentioned.
Let’s examine each of the solutions in detail. Part 1 talked about AWS Transfer Family, Transfer Family web apps, and Amazon S3 pre-signed URLs. Here in Part 2, we explain the remaining solutions to help you make the right choice for your use case.
CloudFront signed URLs with Amazon S3
Amazon CloudFront signed URLs combine Amazon S3 storage with the global edge network of CloudFront to deliver files securely with lower latency.
CloudFront edge locations cache content geographically closer to users, which usually reduces latency and gives better performance for users. CloudFront also reduces the number of origin requests to Amazon S3. CloudFront integration with AWS Shield and AWS WAF provides options for additional security layers, helping to protect against DDoS events and unintended requests. You can use custom domains with AWS-provided or your own SSL/TLS certificates managed through AWS Certificate Manager (ACM), helping to facilitate secure connections from users to edge locations.
When a user requests a file, the system generates a signed URL using either a CloudFront key pair or a custom trusted signer (such as Lambda Edge) that includes security parameters such as IP restrictions, time windows, and custom policies. The major difference is the content distribution network (CDN) making performance faster by caching data geographically close to the user downloading it.
The built-in logging and monitoring capabilities of CloudFront provide detailed insights into content access patterns, cache hit ratios, and security events. CloudFront integrates seamlessly with Amazon S3 to support origin access identity (OAI), helping to make sure that the S3 objects can be accessed only through CloudFront and not directly through S3 APIs.
Figure 1: CloudFront signed URLs with Amazon S3 architecture
Pros
If Amazon S3 pre-signed URLs sound good, but you need higher performance at a global scale, CloudFront signed URLs are the right choice. The AWS global edge network has points of presence (POPs) all over the world, which significantly reduces latency for users and minimizes data transfer costs through caching. This architecture provides substantial cost savings for frequently accessed content, because edge locations serve cached copies without retrieving objects from the S3 origin. The integration with AWS security services offers protection against various threats, including sophisticated distributed denial of service (DDoS) events and web application issues, making it particularly suitable for public-facing file sharing applications. Choose CloudFront instead of S3 if you tend to make the same file available to many people who download it many times, such as in software distribution or documentation distribution.
The solution’s security model provides extensive flexibility in access control implementation. You can define granular permissions through custom policies, implement geo-restriction rules, and enforce IP-based access controls. The ability to use custom TLS certificates and domains maintains brand consistency while helping to facilitate secure communications. The integration with AWS WAF enables advanced request filtering and rate limiting, while detailed access logging and real-time metrics provide visibility into content delivery and security events. The solution’s support for both signed URLs and signed cookies offers flexibility in implementing various access control scenarios. Signed cookies are used when you want to provide access to multiple restricted files. For example, if you need to provide access to many files in a private directory, you can use signed cookies to avoid having to create individual signed URLs for each file. When choosing between CloudFront signed URLs (ideal for individual file access) or signed cookies (better for providing access to multiple files, like a subscriber’s content library), consider your content distribution needs and whether your clients support cookies.
Cons
If you implement CloudFront, you must develop expertise in its configuration options, including robust key management processes and secure key rotation procedures. Self-managed certificates don’t automatically renew. You must track expiration dates and make sure you renew on time, or your users will get warnings and errors when they try to download. ACM can simplify TLS certificate management and automatically renew certificates before they expire. while trusted signer workflows enhance your security posture.
Note: To create signed URLs, you need a signer. A signer is either a trusted key group that you create in CloudFront, or an AWS account that contains a CloudFront key pair.
Misconfigured web caches have many surprising and frustrating effects for users. Understanding and configuring CloudFront cache behavior is key to helping to prevent unintended content exposure or availability issues. You need to add cache invalidation to your publication workflows so that old versions are no longer available from the cache. This might introduce additional costs and operational overhead, especially in scenarios with frequent content changes. If you frequently change the content that you share, if the content is unique to an individual (such as a personalized report), or if the same content isn’t downloaded many times by many people in many locations, you won’t realize much cost savings or reduced latency from CloudFront caching. The additional complexity added by cache configuration might not be justified unless the cache is used a lot.
If you use the CloudFront global content delivery network, your content will be stored in caches in hundreds of locations around the world. ACM will store your TLS certificates for CloudFront (whether ACM is issuing them or you manage them yourself) in the us-east-1 AWS Region. Because CloudFront is a global service, it automatically distributes the certificate from the us-east-1 Region to the Regions associated with your CloudFront distribution. Caching data and keys around the world might not be acceptable if you have data sovereignty requirements to keep your data in one country.
From a cost perspective, while CloudFront can provide savings through caching, the pricing model has other variables to consider. Data transfer costs vary by Region and can be significant for large-scale distributions. If you need custom domain names and custom TLS certificates, that might introduce additional costs. Implementation expertise is needed when dealing with dynamic content or when specific origin request handling is required. CloudFront only delivers via HTTPS and HTTP protocols, so you won’t be able to use it if you require support for other file transfer protocols. CloudFront distributions provide statistics on cache hit-and-miss rates—pay attention to these because low cache hit rates mean that you’re pulling data from the origin frequently, which limits the possible cost savings.
Amazon VPC endpoint service with custom application
Amazon VPC endpoint services, powered by AWS PrivateLink, enable private connectivity between VPCs without requiring internet access, VPN connections, or direct physical connections. This solution creates a highly secure, private network path for file sharing by exposing services through Network Load Balancers (NLB) and allowing other VPCs to access them through interface endpoints. The architecture isolates the file sharing service from the public internet, operating entirely within the AWS private network infrastructure.
The best use cases for this architecture involve sharing data or distributing software around your AWS infrastructure without exposing it to the public internet.
Figure 2: Amazon VPC endpoint service architecture
The solution, shown in Figure 2, typically involves deploying a custom file sharing application behind an NLB in the service VPC, which is then exposed as an endpoint service. Consumer VPCs create interface endpoints to connect to this service, establishing private connectivity through the AWS backbone network. Traffic remains within the AWS network, is encrypted in transit, and is subject to security controls at both the endpoint and VPC levels. The architecture supports many TCP-based protocols, making it versatile for various file transfer requirements.
This architecture provides secure pathways for data to travel by using multiple layers, including VPC security groups, network access control lists (ACLs), endpoint policies, and the custom application’s authentication mechanisms. The built-in security features of PrivateLink are designed so that only approved AWS principals can create interface endpoints to connect to the service, while detailed VPC flow logs provide network traffic visibility.
Pros
Amazon VPC endpoint services provide complete network isolation and private connectivity that’s inaccessible from the public internet. This reduces the exposure footprint and helps meet security requirements for sensitive data transfer operations. The solution maintains private connectivity across different AWS accounts and Regions while keeping traffic within the AWS network infrastructure.
This solution also provides the most flexible protocol support. Other solutions require you to use HTTPS, AWS API calls (which are HTTPS), or one of the protocols supported by Transfer Family (such as SFTP). If you have software that uses custom protocols, and you need security controls and network isolation, this architecture provides predictable performance through dedicated network paths and supports high throughput requirements without internet bandwidth constraints. The granular control over network security through VPC security groups, network ACLs, and endpoint policies enables organizations to implement defense-in-depth strategies effectively. Additionally, the solution’s integration with AWS Organizations facilitates centralized management and governance across multiple accounts.
Cons
Setting up and maintaining VPC endpoints requires significant expertise in AWS networking, including VPC design, PrivateLink configuration, and network security controls. The initial architecture design must carefully consider IP address management, service quotas, and Regional availability to provide scalability and reliability. Organizations must also develop and maintain the custom file sharing application in addition to the VPC endpoints.
This solution has many components that incur hourly and bandwidth-related charges. Each interface endpoint incurs hourly charges and data processing fees, which can accumulate significantly in multi-VPC or multi-Region deployments. NLBs add another cost component, and you must maintain sufficient capacity for peak loads. The solution also has operational costs because of the need for specialized expertise and ongoing maintenance. Additionally, while the private connectivity model provides superior security, it can make troubleshooting more challenging and might require additional tooling for effective monitoring and diagnostics. The Regional nature of VPC endpoints might necessitate additional architecture for multi-Region deployments, potentially increasing both costs and operational overhead. This solution is most suitable when private network security considerations are the highest priority, and cost considerations are secondary.
Amazon S3 Access Points
Amazon S3 Access Points simplify managing data access at scale for applications using shared data sets on S3. Access points are named network endpoints attached to S3 buckets that streamline managing access to shared datasets. Each access point has its own AWS Identity and Access Management (IAM) policy that controls access to the data, allowing you to create custom access permissions for different applications or user groups accessing the same bucket.
The architecture uses S3 buckets with access points providing dedicated access paths to the data. Each access point has its own hostname (URL) and access policy that works in conjunction with the bucket policy. You can create access points that only allow connections from your Amazon Virtual Private Cloud (Amazon VPC) for private network access to Amazon S3 or create access points with Internet connectivity. You can use this flexibility to implement sophisticated access control patterns while maintaining a single source of truth in S3.
Figure 3: S3 Access Points with VPC endpoints
Pros
Amazon S3 Access Points simplify permissions management and security to accommodate multiple access patterns and use cases. For example, if an S3 bucket contains data that needs to be accessed by multiple applications, each requiring different levels of access, you can create a dedicated access point for each application with precisely the permissions it needs, rather than managing a long monolithic bucket policy.
You can implement access control workflows, such as restricting access to specific VPCs, encryption, or limit access to specific objects or prefixes. The service requires no new infrastructure management, reducing operational overhead and allowing you to focus on business logic implementation.
Access points provide a way to enforce network controls through VPC-only access points, helping to make sure that data can only be accessed from within your private network. IAM permissions management becomes more granular and straightforward to audit when each application or user group has its own access point with a dedicated policy. You can associate different access points with different network origins.
Another possible use case is when you need to provide temporary access to specific data within a bucket without modifying the bucket policy. You can create a temporary access point with the necessary permissions and delete it when the access is no longer needed.
Cons
Access points add another layer to your Amazon S3 architecture that needs to be managed and monitored. Each access point has its own Amazon Resource Name (ARN) and hostname that applications need to use instead of the bucket name, which might require changes to your application code.
There are limits to the number of access points you can create for each bucket, which might be a constraint for large-scale applications. Access points can only control access to the bucket they’re associated with, not across multiple buckets, so if your application needs to access data across buckets, you’ll need multiple access points.
When implementing this solution, you need to design your access point policies to make sure that they work correctly with your bucket policy. Think of your S3 bucket policy as the primary security framework, while access point policies act as specialized gatekeepers. These two layers of security must work in harmony. The bucket policy takes precedence. For example, if your bucket policy explicitly denies access from specific IP ranges, an access point policy can’t override this restriction. This hierarchical relationship requires strategic planning. Start by defining your broad security boundaries in the bucket policy—perhaps allowing access only from specific VPCs or requiring encryption. Then create your access point policies within these boundaries.
While Amazon S3 Access Points offer powerful flexibility, understanding their boundaries is crucial. Cross-account scenarios, common in large enterprises or partner collaborations, require careful configuration. Imagine you’re working with an external auditing firm that needs temporary access to your financial data stored in S3. Setting up a cross-account access point requires creating the access point in your account, configuring a trust policy to allow the external account, verifying that the bucket policy permits access from the access point, and providing the auditors with the access point ARN and necessary IAM permissions in their account. This process maintains tight control over your data while enabling secure cross-account access.
Some Amazon S3 operations are only controlled at the bucket level and can’t be controlled by access points. Core bucket operations such as configuring versioning, logging, managing lifecycle policies, and setting up cross-Region replication require direct bucket access. For these operations, you need to interact directly with the bucket through the appropriate permissions. This limitation helps make sure that fundamental bucket configurations remain centralized and controlled by bucket owners.
Creating a dedicated IAM role for bucket administration tasks—separate from the roles that interact with data through access points—enhances security and aligns with the principle of least privilege.
Conclusion
In this second part of a two-part post, you’ve learned about multiple solutions for secure file sharing using AWS services and the pros and cons of each. You can find additional options and a full decision matrix in Part 1. The optimal solution depends on your specific organizational requirements, technical capabilities, and budget constraints. You don’t have to choose just one option, you can implement multiple solutions to address different use cases, creating a file sharing strategy that balances security, cost, and operational efficiency.
NOTE: As of July 15, the Amazon S3 Vectors Integration with Amazon OpenSearch Service is in preview release and is subject to change.
The way we store and search through data is evolving rapidly with the advancement of vector embeddings and similarity search capabilities. Vector search has become essential for modern applications such as generative AI and agentic AI, but managing vector data at scale presents significant challenges. Organizations often struggle with the trade-offs between latency, cost, and accuracy when storing and searching through millions or billions of vector embeddings. Traditional solutions either require substantial infrastructure management or come with prohibitive costs as data volumes grow.
Cost-optimized vector storage: OpenSearch Service managed clusters using service-managed S3 Vectors for cost-optimized vector storage. This integration will support OpenSearch workloads that are willing to trade off higher latency for ultra-low cost and still want to use advanced OpenSearch capabilities (such as hybrid search, advanced filtering, geo filtering, and so on).
One-click export from S3 Vectors: One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search. Customers who build natively on S3 Vectors will benefit from being able to use OpenSearch for faster query performance.
By using these integrations, you can optimize cost, latency, and accuracy by intelligently distributing your vector workloads by keeping infrequent queried vectors in S3 Vectors and using OpenSearch for your most time-sensitive operations that require advanced search capabilities such as hybrid search and aggregations. Further, OpenSearch performance tuning capabilities (that is, quantization, k-nearest neighbor (knn) algorithms, and method-specific parameters) help to improve the performance with little compromise of cost or accuracy.
In this post, we walk through this seamless integration, providing you with flexible options for vector search implementation. You’ll learn how to use the new S3 Vectors engine type in OpenSearch Service managed clusters for cost-optimized vector storage and how to use one-click export from S3 Vectors to OpenSearch Serverless collections for high-performance scenarios requiring sustained queries with latency as low as 10ms. By the end of this post, you’ll understand how to choose and implement the right integration pattern based on your specific requirements for performance, cost, and scale.
Service overview
Amazon S3 Vectors is the first cloud object store with native support to store and query vectors with sub-second search capabilities, requiring no infrastructure management. It combines the simplicity, durability, availability, and cost-effectiveness of Amazon S3 with native vector search functionality, so you can store and query vector embeddings directly in S3. Amazon OpenSearch Service provides two complementary deployment options for vector workloads: Managed Clusters and Serverless Collections. Both harness Amazon OpenSearch’s powerful vector search and retrieval capabilities, though each excels in different scenarios. For OpenSearch users, the integration between S3 Vectors and Amazon OpenSearch Service offers unprecedented flexibility in optimizing your vector search architecture. Whether you need ultra-fast query performance for real-time applications or cost-effective storage for large-scale vector datasets, this integration lets you choose the approach that best fits your specific use case.
Understanding Vector Storage Options
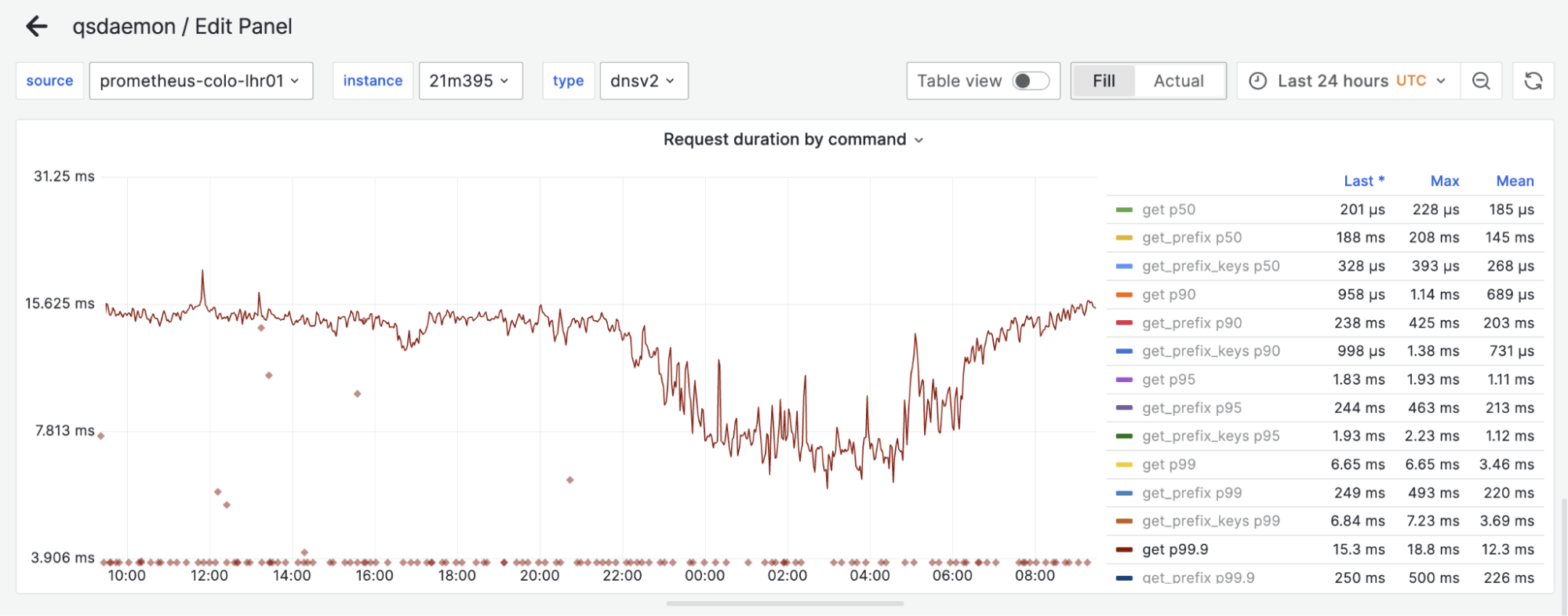
OpenSearch Service provides multiple options for storing and searching vector embeddings, each optimized for different use cases. The Lucene engine, which is OpenSearch’s native search library, implements the Hierarchical Navigable Small World (HNSW) method, offering efficient filtering capabilities and strong integration with OpenSearch’s core functionality. For workloads requiring additional optimization options, the Faiss engine (Facebook AI Similarity Search) provides implementations of both HNSW and IVF (Inverted File Index) methods, along with vector compression capabilities. HNSW creates a hierarchical graph structure of connections between vectors, enabling efficient navigation during search, while IVF organizes vectors into clusters and searches only relevant subsets during query time. With the introduction of the S3 engine type, you now have a cost-effective option that uses Amazon S3’s durability and scalability while maintaining sub-second query performance. With this variety of options, you can choose the most suitable approach based on your specific requirements for performance, cost, and accuracy. For instance, if your application requires sub-50 ms query responses with efficient filtering, Faiss’s HNSW implementation is the best choice. Alternatively, if you need to optimize storage costs while maintaining reasonable performance, the new S3 engine type would be more appropriate.
Solution overview
In this post, we explore two primary integration patterns:
OpenSearch Service managed clusters using service-managed S3 Vectors for cost-optimized vector storage.
For customers already using OpenSearch Service domains who want to optimize costs while maintaining sub-second query performance, the new Amazon S3 engine type offers a compelling solution. OpenSearch Service automatically manages vector storage in Amazon S3, data retrieval, and cache optimization, eliminating operational overhead.
One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search.
For use cases requiring faster query performance, you can migrate your vector data from an S3 vector index to an OpenSearch Serverless collection. This approach is ideal for applications that require real-time response times and gives you the benefits that come with Amazon OpenSearch Serverless, including advanced query capabilities and filters, automatic scaling and high availability, and no administration. The export process automatically handles schema mapping, vector data transfer, index optimization, and connection configuration.
The following illustration shows the two integration patterns between Amazon OpenSearch Service and S3 Vectors.
Prerequisites
Before you begin, make sure you have:
An AWS account
Access to Amazon S3 and Amazon OpenSearch Service
An OpenSearch Service domain (for the first integration pattern)
Vector data stored in S3 Vectors (for the second integration pattern)
Integration pattern 1: OpenSearch Service managed cluster using S3 Vectors
The following animation demonstrates steps 2-4 above.
Integration pattern 2: Export S3 vector indexes to OpenSearch Serverless
To implement this pattern:
Navigate to the AWS Management Console for Amazon S3 and select your S3 vector bucket.
Select a vector index that you want to export. Under Advanced search export, select Export to OpenSearch.
Alternatively, you can:
Navigate to the OpenSearch Service console.
Select Integrations from the navigation pane.
Here you will see a new Integration Template to Import S3 vectors to OpenSearch vector engine – preview. Select Import S3 vector index.
You will now be brought to the Amazon OpenSearch Service integration console with the Export S3 vector index to OpenSearch vector engine template pre-selected and pre-populated with your S3 vector index Amazon Resource Name (ARN). Select an existing role that has the necessary permissions or create a new service role.
Scroll down and choose Export to start the steps to create a new OpenSearch Serverless collection and copy data from your S3 vector index into an OpenSearch knn index.
You will now be taken to the Import history page in the OpenSearch Service console. Here you will see the new job that was created to migrate your S3 vector index into the OpenSearch serverless knn index. After the status changes from In Progress to Complete, you can connect to the new OpenSearch serverless collection and query your new OpenSearch knn index.
The following animation demonstrates how to connect to the new OpenSearch serverless collection and query your new OpenSearch knn index using Dev tools.
Delete the import task from the Import history section of the OpenSearch Service console. Deleting this task will remove both the OpenSearch vector collection and the OpenSearch Ingestion pipeline that was automatically created by the import task.
Conclusion
The innovative integration between Amazon S3 Vectors and Amazon OpenSearch Service marks a transformative milestone in vector search technology, offering unprecedented flexibility and cost-effectiveness for enterprises. This powerful combination delivers the best of both worlds: The renowned durability and cost efficiency of Amazon S3 merged seamlessly with the advanced AI search capabilities of OpenSearch. Organizations can now confidently scale their vector search solutions to billions of vectors while maintaining control over their latency, cost, and accuracy. Whether your priority is ultra-fast query performance with latency as low as 10ms through OpenSearch Service, or cost-optimized storage with impressive sub-second performance using S3 Vectors or implementing advanced search capabilities in OpenSearch, this integration provides the perfect solution for your specific needs. We encourage you to get started today by trying S3 Vectors engine in your OpenSearch managed clusters and testing the one-click export from S3 vector indexes to OpenSearch Serverless.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.
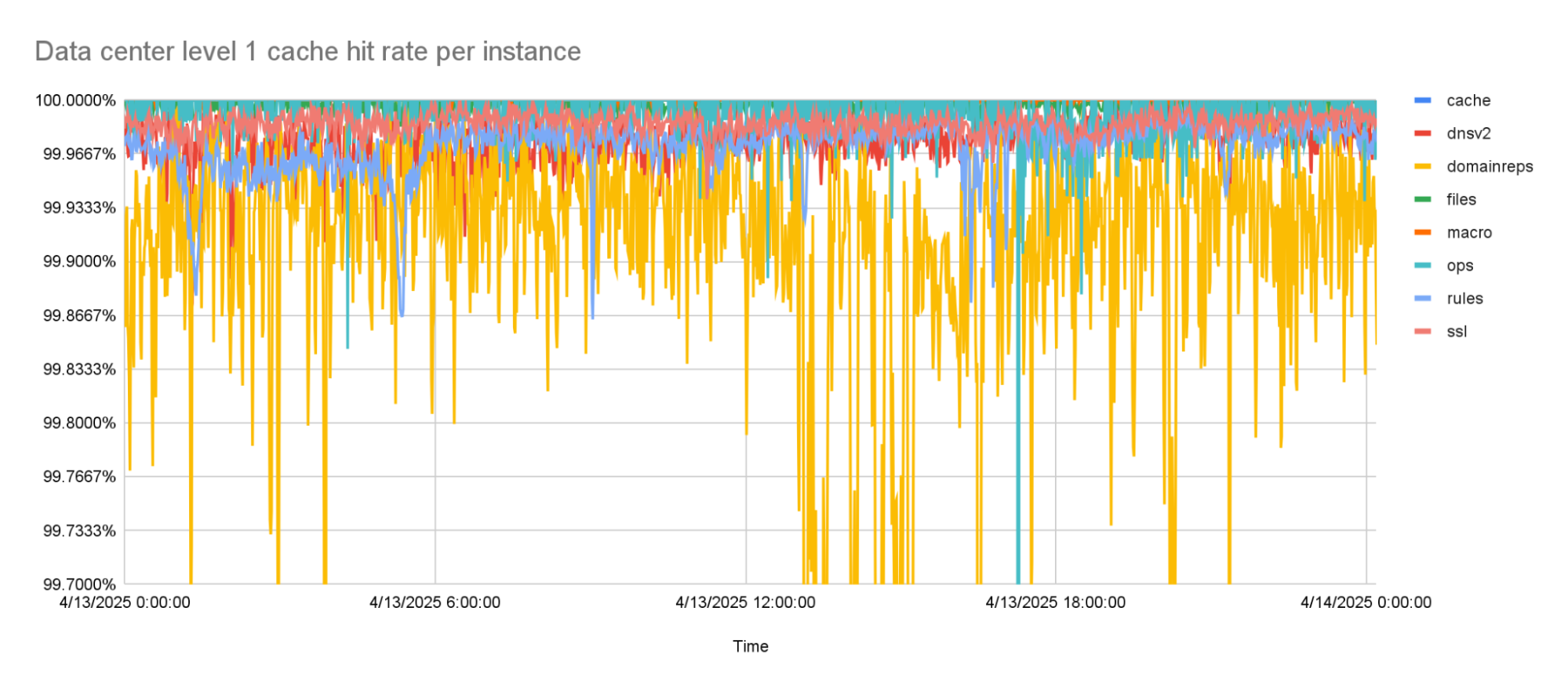
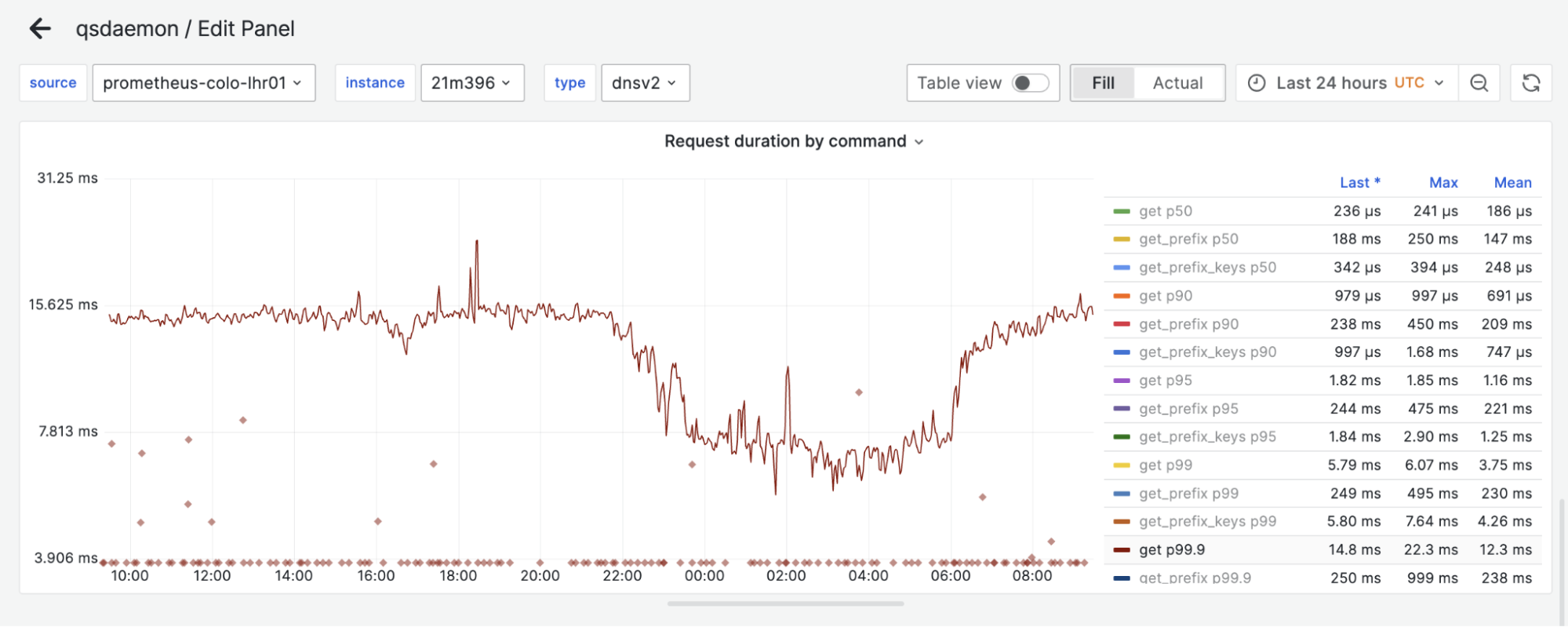
Cloudflare has servers in 330 cities spread across 125+ countries. All of these servers run Quicksilver, which is a key-value database that contains important configuration information for many of our services, and is queried for all requests that hit the Cloudflare network.
Because it is used while handling requests, Quicksilver is designed to be very fast; it currently responds to 90% of requests in less than 1 ms and 99.9% of requests in less than 7 ms. Most requests are only for a few keys, but some are for hundreds or even more keys.
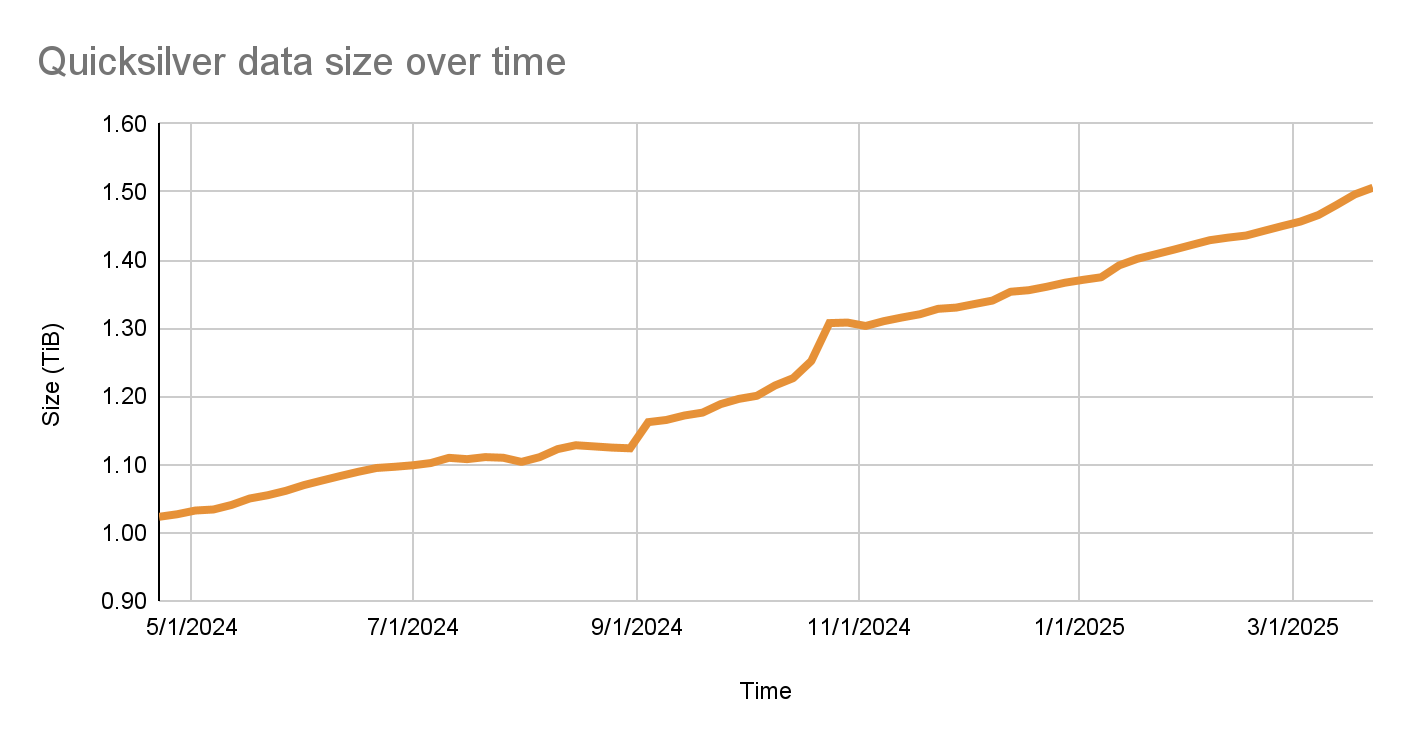
Quicksilver currently contains over five billion key-value pairs with a combined size of 1.6 TB, and it serves over three billion keys per second, worldwide. Keeping Quicksilver fast provides some unique challenges, given that our dataset is always growing, and new use cases are added regularly.
Quicksilver used to store all key-values on all servers everywhere, but there is obviously a limit to how much disk space can be used on every single server. For instance, the more disk space used by Quicksilver, the less disk space is left for content caching. Also, with each added server that contains a particular key-value, the cost of storing that key-value increases.
This is why disk space usage has been the main battle that the Quicksilver team has been waging over the past several years. A lot was done over the years, but we now think that we have finally created an architecture that will allow us to get ahead of the disk space limitations and finally make Quicksilver scale better.
The size of the Quicksilver database has grown by 50% to about 1.6 TB in the past year
What we talked about previously
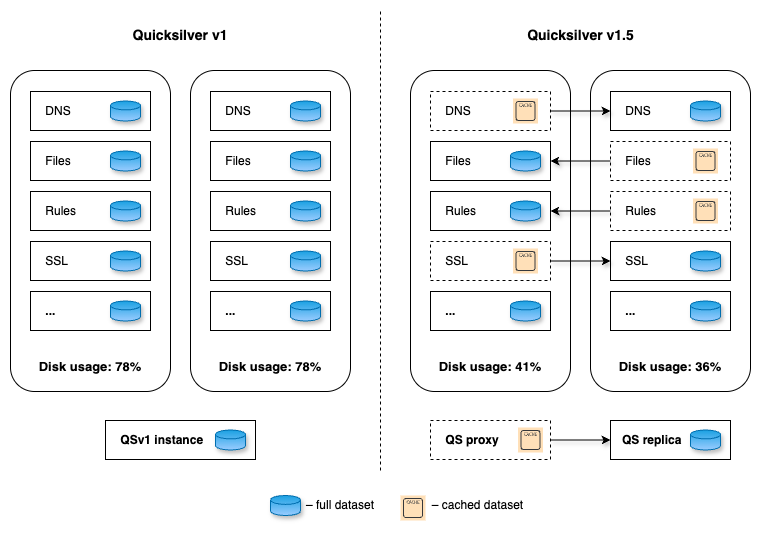
Part one of the story explained how Quicksilver V1 stored all key-value pairs on each server all around the world. It was a very simple and fast design, it worked very well, and it was a great way to get started. But over time, it turned out to not scale well from a disk space perspective.
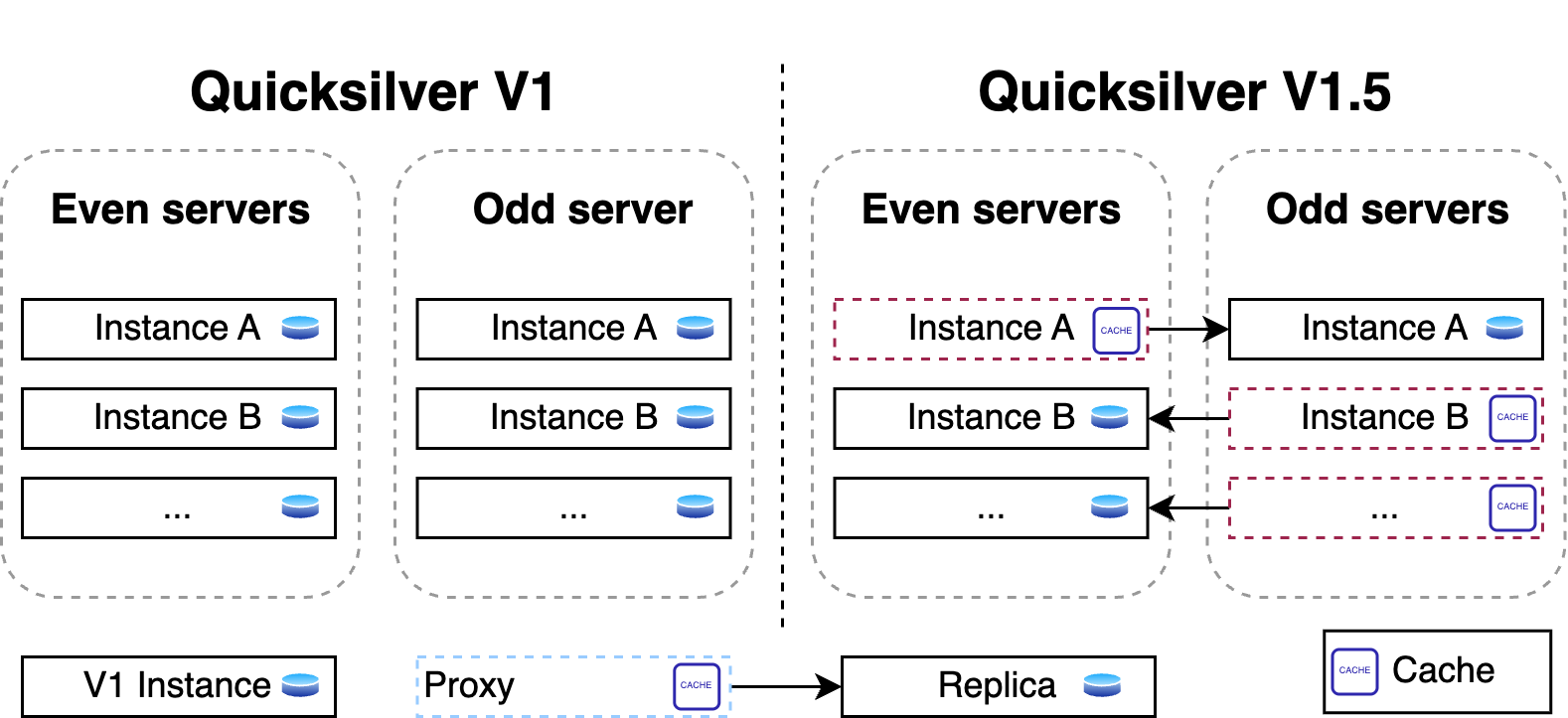
The problem was that disk space was running out so fast that there was not enough time to design and implement a fully scalable version of Quicksilver. Therefore, Quicksilver V1.5 was created first. It halved the disk space used on each server compared to V1.
For this, a new proxy mode was introduced for Quicksilver. In this mode, Quicksilver does not contain the full dataset anymore, but only contains a cache. All cache misses are looked up on another server that runs Quicksilver with a full dataset. Each server runs about ten separate instances of Quicksilver, and all have different databases with different sets of key-values. We call Quicksilver instances with the full data set replicas.
For Quicksilver V1.5, half of those instances on a particular server would run Quicksilver in proxy mode, and therefore would not have the full dataset anymore. The other half would run in replica mode. This worked well for a time, but it was not the final solution.
Building this intermediate solution had the added benefit of allowing the team to gain experience running an even more distributed version of Quicksilver.
The problem
There were a few reasons why Quicksilver V1.5 was not fully scalable.
First, the size of the separate instances were not very stable. The key-space is owned by the teams that use Quicksilver, not by the Quicksilver team, and the way those teams use Quicksilver changes frequently. Furthermore, while most instances grow in size over time, some instances have actually gotten smaller, such as when the use of Quicksilver is optimised by teams. The result of this is that the split of instances that was well-balanced at the start, quickly became unbalanced.
Second, the analyses that were done to estimate how much of the key space would need to be in cache on each server assumed that taking all keys that were accessed in a three-day period would represent a good enough cache. This assumption turned out to be wildly off. This analysis estimated that we needed about 20% of the key space in cache, which turned out to not be entirely accurate. Whereas most instances did have a good cache hit rate, with 20% or less of the key space in cache, some instances turned out to need a much higher percentage.
The main issue, however, was that reducing the disk space used by Quicksilver on our network by as much as 40% does not actually make it more scalable. The number of key-values that are stored in Quicksilver keeps growing. It only took about two years before disk space was running low again.
The solution
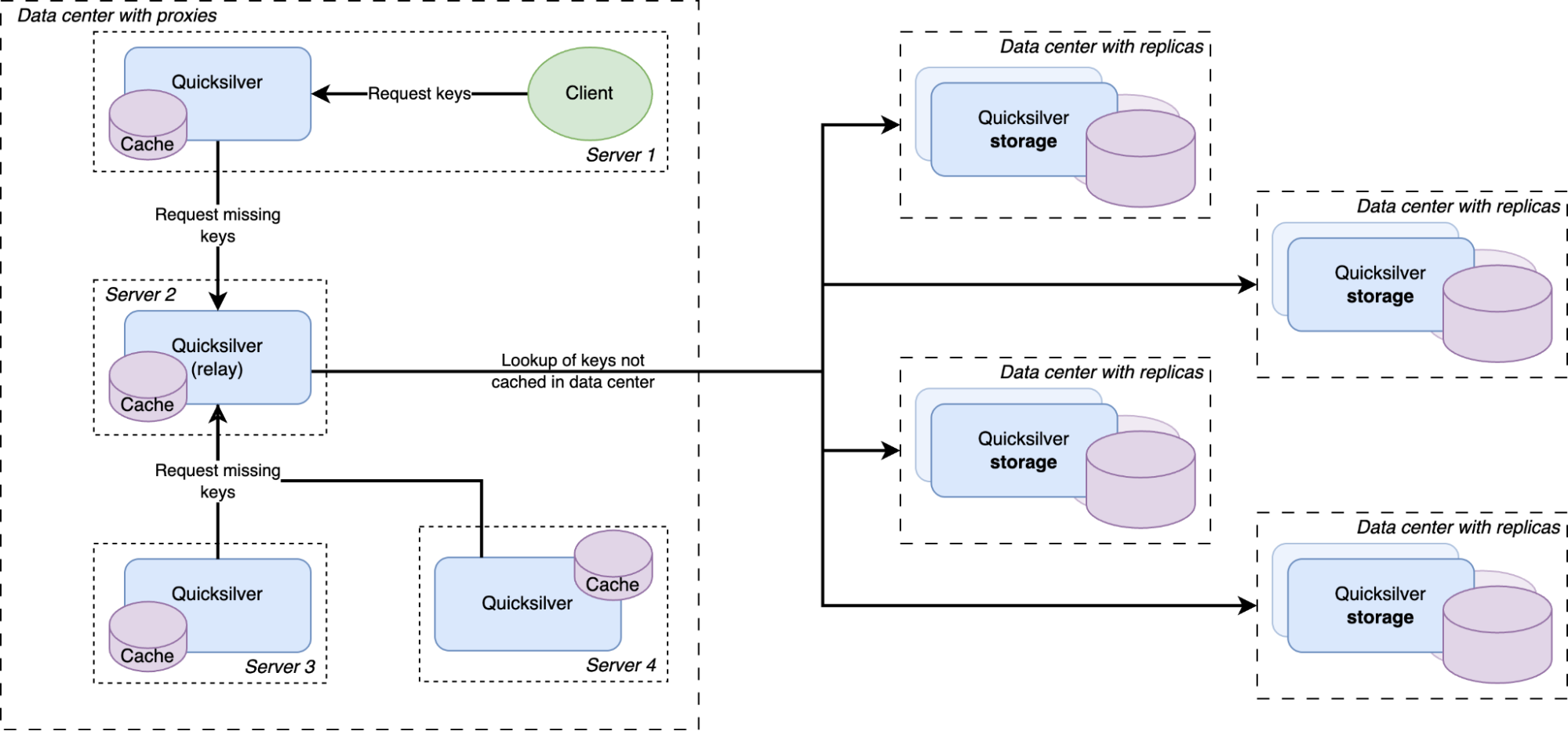
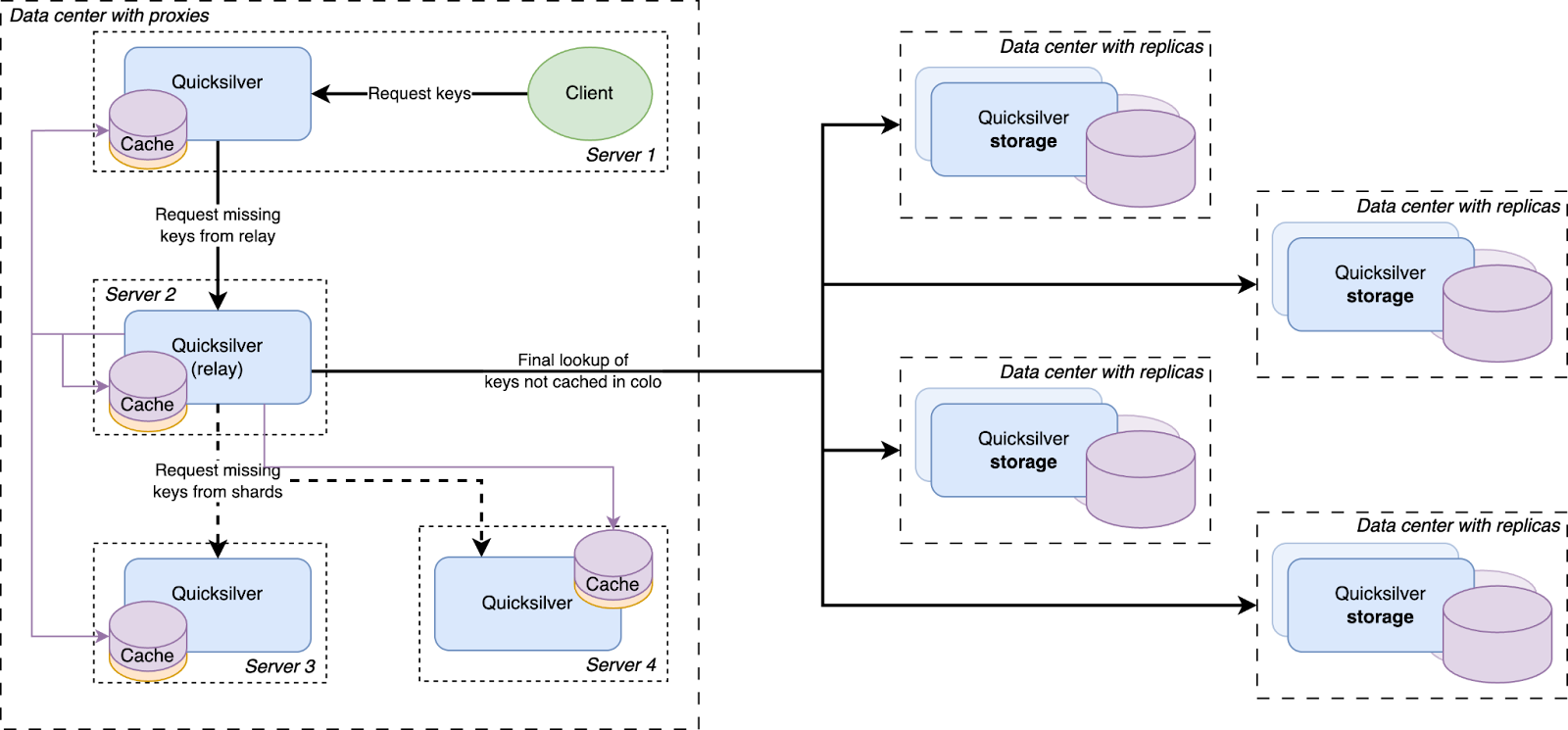
Except for a handful of special storage servers, Quicksilver does not contain the full dataset anymore, but only cache. Any cache misses will be looked up in replicas on our storage servers, which do have the full dataset.
The solution to the scalability problem was brought on by a new insight. As it turns out, numerous key-values were actually almost never used. We call these cold keys. There are different reasons for these cold keys: some of them were old and not well cleaned up, some were used only in certain regions or in certain data centers, and some were not used for a very long time or maybe not at all (a domain name that is never looked up for example or a script that was uploaded but never used).
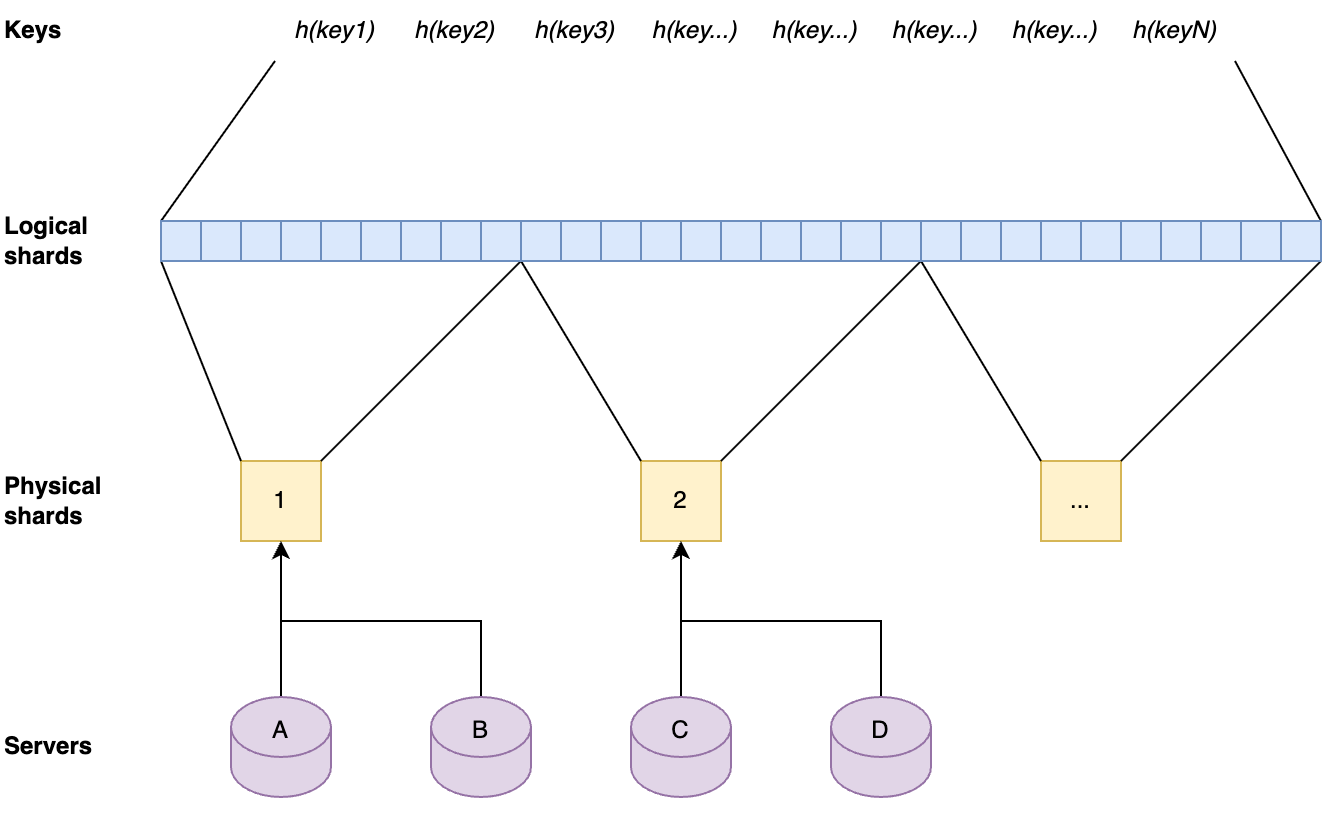
At first, the team had been considering solving our scalability problem by splitting up the entire dataset into shards and distributing those across the servers in the different data centers. But sharding the full dataset adds a lot of complexity, corner cases, and unknowns. Sharding also does not optimize for data locality. For example, if the key-space is split into 4 shards and each server gets one shard, that server can only serve 25% of the requested keys from its local database. The cold keys would also still be contained in those shards and would take up disk space unnecessarily.
Another data structure that is much better at data locality and explicitly avoids storing keys that are never used is a cache. So it was decided that only a handful of servers with large disks would maintain the full data set, and all other servers would only have a cache. This was an obvious evolution from Quicksilver V1.5. Caching was already being done on a smaller scale, so all the components were already available. The caching proxies and the inter-data center discovery mechanisms were already in place. They had been used since 2021 and were therefore thoroughly battle tested. However, one more component needed to be added.
There was a concern that having all instances on all servers connect to a handful of storage nodes with replicas would overload them with too many connections. So a Quicksilver relay was added. For each instance, a few servers would be elected within each data center on which Quicksilver would run in relay mode. The relays would maintain the connections to the replicas on the storage nodes. All proxies inside a data center would discover those relays and all cache misses would be relayed through them to the replicas.
This new architecture worked very well. The cache hit rates still needed some improvement, however.
Prefetching the future
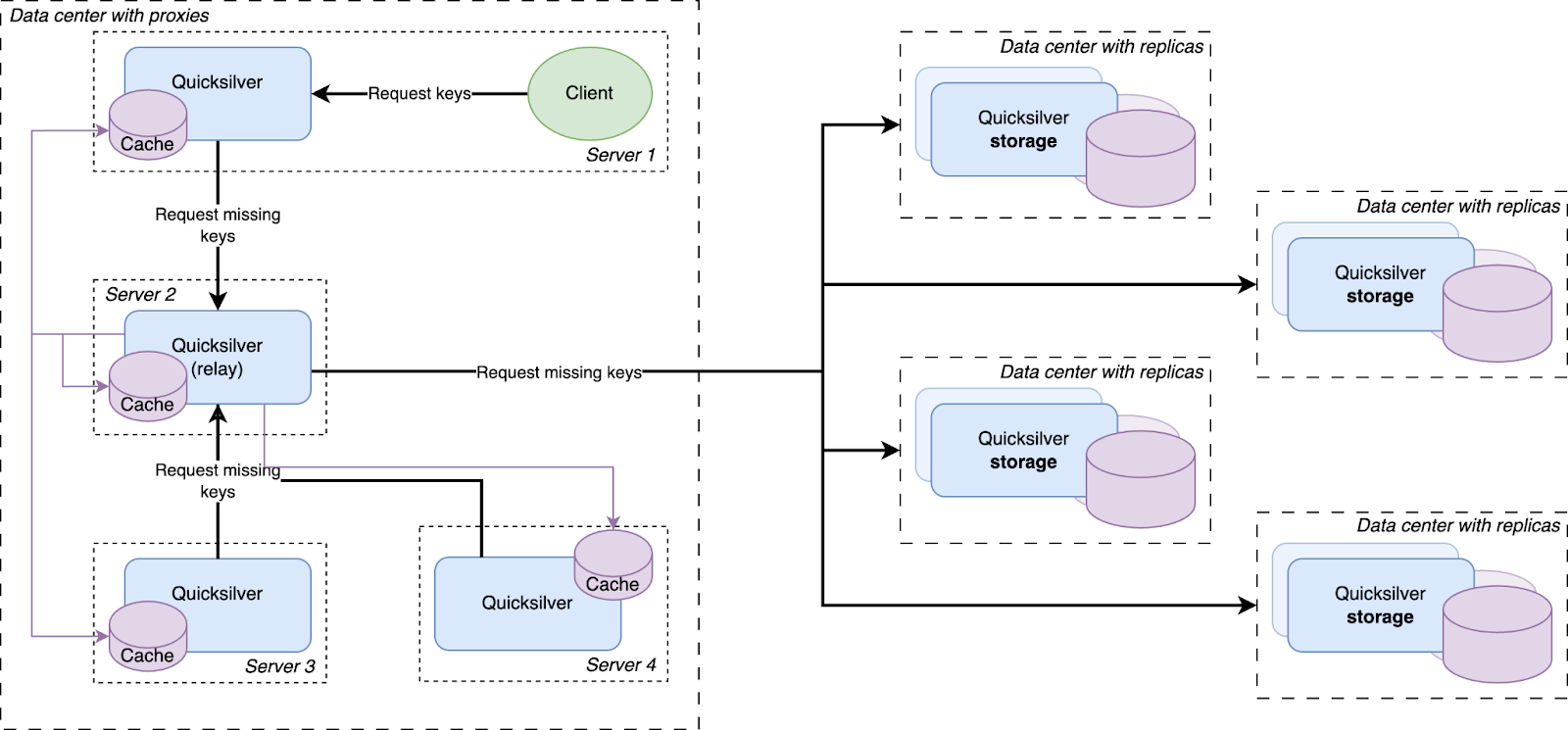
Every resolved cache miss is prefetched by all servers in the data center
We had a hypothesis that prefetching all keys that were cache misses on the other servers inside the same data center would improve the cache hit rate. So an analysis was done, and it indeed showed that every key that was a cache miss on one server in a data center had a very high probability of also being a cache miss on another server in the same data center sometime in the near future. Therefore, a mechanism was built that distributed all resolved cache misses on relays to all other servers.
All cache misses in a data center are resolved by requesting them from a relay, which subsequently forwards the requests to one of the replicas on the storage nodes. Therefore, the prefetching mechanism was implemented by making relays publish a stream of all resolved cache misses, to which all Quicksilver proxies in the same data center subscribe. The resulting key-values were then added to the proxy local caches.
This strategy is called reactive prefetching, because it fills caches only with the key-values that directly resulted from cache misses inside the same data center. Those prefetches are a reaction to the cache misses. Another way of prefetching is called predictive prefetching, in which an algorithm tries to predict which keys that have not yet been requested will be requested in the near future. A few approaches for making these predictions were tried, but they did not result in any improvement, and so this idea was abandoned.
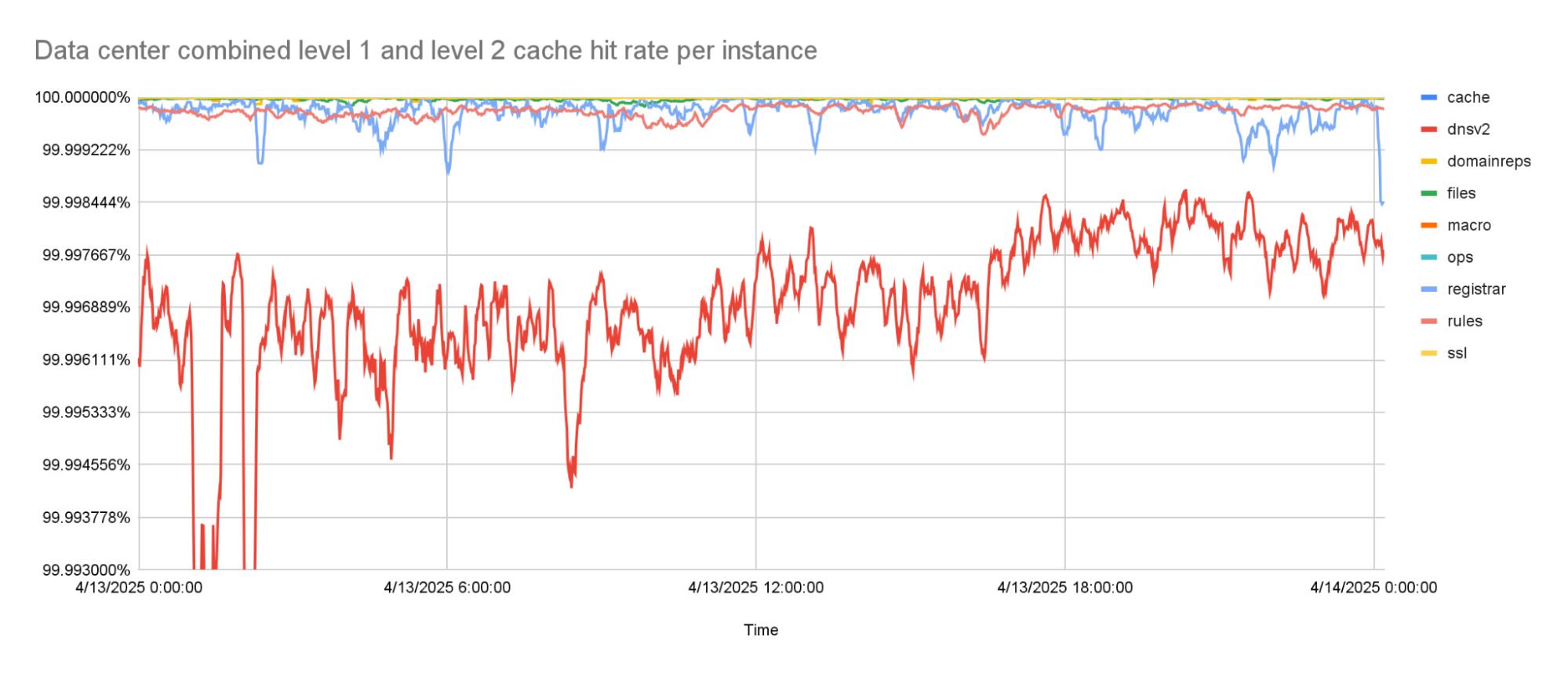
With the prefetching enabled, cache hit rates went up to about 99.9% for the worst performing instance. This was the goal that we were trying to reach. But while rolling this out to more of our network, it turned out that there was one team that needed an even higher cache hit rate, because the tail latencies they were seeing with this new architecture were too high.
This team was using a Quicksilver instance called dnsv2. This is a very latency sensitive instance, because it is the one from which DNS queries are served. Some of the DNS queries under the hood need multiple queries to Quicksilver, so any added latency to Quicksilver multiplies for them. This is why it was decided that one more improvement to the Quicksilver cache was needed.
The level 1 cache hit-rate is 99.9% or higher, on average.
Back to the sharding
Before going to a replica in another data center, a cache miss is first looked up in a data center-wide sharded cache
The instance on which higher cache hit rates were required was also the instance on which the cache performed the worst. The cache works with a retention time, defined as the number of days a key-value is kept in cache after it was last accessed, after which it is evicted from the cache. An analysis of the cache showed that this instance needed a much longer retention time. But, a higher retention time also causes the cache to take up more disk space — space that was not available.
However, while running Quicksilver V1.5, we had already noticed the pattern that caches generally performed much better in smaller data centers as compared to larger ones. This sparked the hypothesis that led to the final improvement.
It turns out that smaller data centers, with fewer servers, generally needed less disk space for their cache. Vice versa, the more servers there are in a data center, the larger the Quicksilver cache needs to be. This is easily explained by the fact that larger data centers generally serve larger populations, and therefore have a larger diversity of requests. More servers also means more total disk space available inside the data center. To be able to make use of this pattern the concept of sharding was reintroduced.
Our key space was split up into multiple shards. Each server in a data center was assigned one of the shards. Instead of those shards containing the full dataset for their part of the key space, they contain a cache for it. Those cache shards are populated by all cache misses inside the data center. This all forms a data center-wide cache that is distributed using sharding.
The data locality issue that sharding the full dataset has, as described above, is solved by keeping the local per-server caches as well. The sharded cache is in addition to the local caches. All servers in a data center contain both their local cache and a cache for one physical shard of the sharded cache. Therefore, each requested key is first looked up in the server’s local cache, after that the data center-wide sharded cache is queried, and finally if both caches miss the requested key, it is looked up on one of the storage nodes.
The key space is split up into separate shards by first dividing hashes of the keys by range into 1024 logical shards. Those logical shards are then divided up into physical shards, again by range. Each server gets one physical shard assigned by repeating the same process on the server hostname.
Each server contains one physical shard. A physical shard contains a range of logical shards. A local shard contains a range of the ordered set that result from hashing all keys.
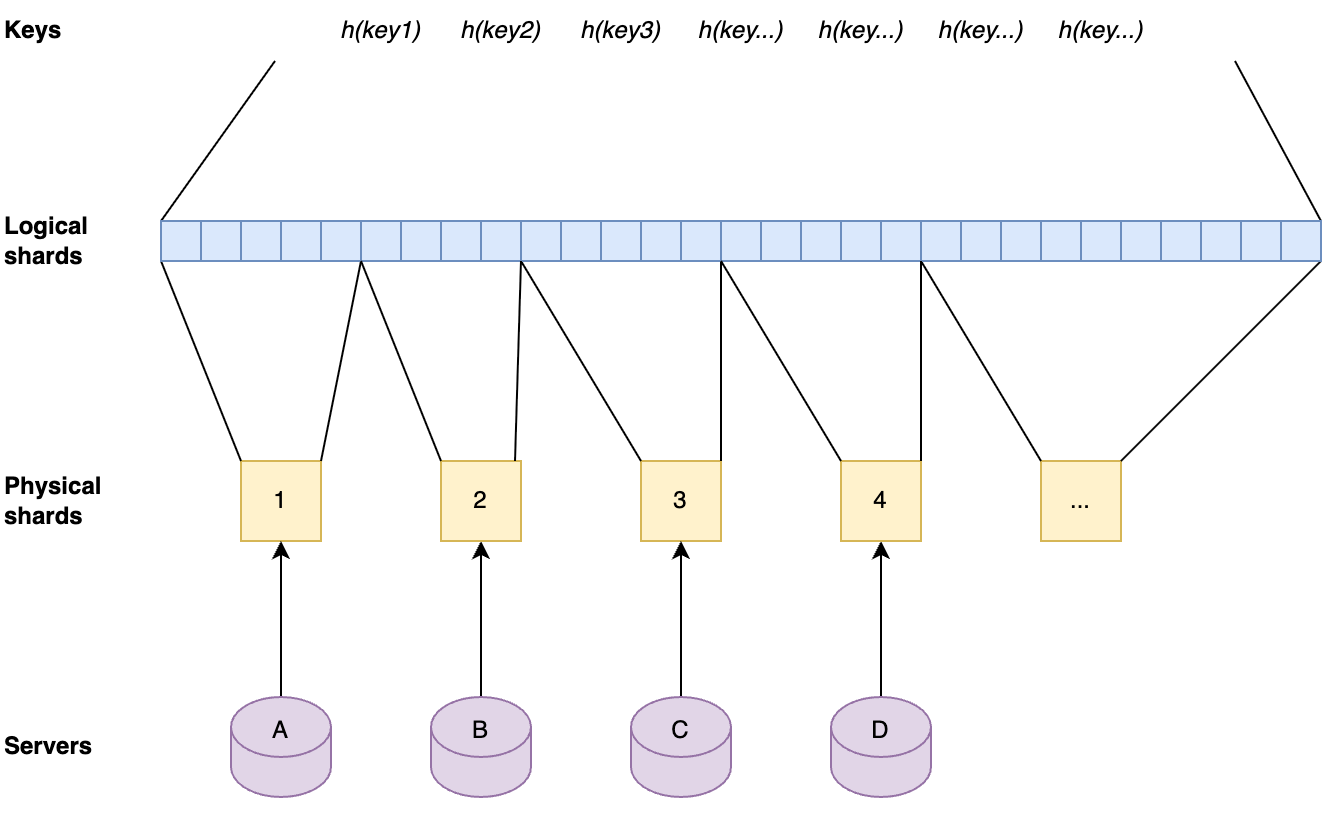
This approach has the advantage that the sharding factor can be scaled up by factors of two without the need for copying caches to other servers. When the sharding factor is increased in this way, the servers will automatically get a new physical shard assigned that contains a subset of the key space that the previous physical shard on that server contained. After this has happened, their cache will contain supersets of the needed cache. The key-values that are not needed anymore will be evicted over time.
When the number of physical shards are doubled the servers will automatically get new physical shards that are subsets of their previous physical shards, therefore still have the relevant key-values in cache.
This approach means that the sharded caches can easily be scaled up when needed as the number of keys that are in Quicksilver grows, and without any need for relocating data. Also, shards are well-balanced due to the fact that they contain uniform random subsets of a very large key-space.
Adding new key-values to the physical cache shards piggybacks on the prefetching mechanism, which already distributes all resolved cache misses to all servers in a data center. The keys that are part of the key space for a physical shard on a particular server are just kept longer in cache than the keys that are not part of that physical shard.
Another reason why a sharded cache is simpler than sharding the full key-space is that it is possible to cut some corners with a cache. For instance, looking up older versions of key-values (as used for multiversion concurrency control) is not supported on cache shards. As explained in an earlier blog post, this is needed for consistency when looking up key-values on different servers, when that server has a newer version of the database. It is not needed in the cache shards, because lookups can always fall back to the storage nodes when the right version is not available.
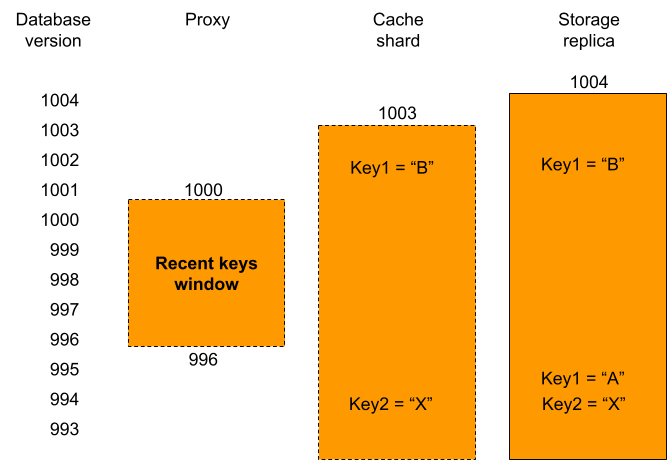
Proxies have a recent keys window that contains all recently written key-values. A cache shard only has its cached key-values. Storage replicas contain all key-values and on top of that they contain multiple versions for recently written key-values. When the proxy, that has database version 1000, has a cache miss for key1 it can be seen that the version of that key on the cache shard was written at database version 1002 and therefore is too new. This means that it is not consistent with the proxy’s database version. This is why the relay will fetch that key from a replica instead, which can return the earlier consistent version. In contrast, key2 on the cache shard can be used, because it was written at index 994, well below the database version of the proxy.
There is only one very specific corner case in which a key-value on a cache shard cannot be used. This happens when the key-value in the cache shard was written at a more recent database version than the version of the proxy database at that time. This would mean that the key-value probably has a different value than it had at the correct version. Because, in general, the cache shard and the proxy database versions are very close to each other, and this only happens for key-values that were written in between those two database versions, this happens very rarely. As such, deferring the lookup to storage nodes has no noticeable effect on the cache hit rate.
Tiered Storage
To summarize, Quicksilver V2 has three levels of storage.
Level 1: The local cache on each server that contains the key-values that have most recently been accessed.
Level 2: The data center wide sharded cache that contains key-values that haven’t been accessed in a while, but do have been accessed.
Level 3: The replicas on the storage nodes that contain the full dataset, which live on a handful of storage nodes and are only queried for the cold keys.
The results
The percentage of keys that can be resolved within a data center improved significantly by adding the second caching layer. The worst performing instance has a cache hit rate higher than 99.99%. All other instances have a cache hit rate that is higher than 99.999%.
The combined level 1 and level 2 cache hit-rate is 99.99% or higher for the worst caching instance.
Final notes
It took the team quite a few years to go from the old Quicksilver V1, where all data was stored on each server to the tiered caching Quicksilver V2, where all but a handful of servers only have cache. We faced many challenges, including migrating hundreds of thousands of live databases without interruptions, while serving billions of requests per second. A lot of code changes were rolled out, with the result that Quicksilver now has a significantly different architecture. All of this was done transparently to our customers. It was all done iteratively, always learning from the previous step before taking the next one. And always making sure that, if at all possible, all changes are easy to revert. These are important strategies for migrating complex systems safely.
And finally, a big thanks to the rest of the Quicksilver team, because we all do this together: Aleksandr Matveev, Aleksei Surikov, Alex Dzyoba, Alexandra (Modi) Stana-Palade, Francois Stiennon, Geoffrey Plouviez, Ilya Polyakovskiy, Manzur Mukhitdinov, Volodymyr Dorokhov.
Today, we’re announcing the preview of Amazon S3 Vectors, a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90 percent. Amazon S3 Vectors is the first cloud object store with native support to store large vector datasets and provide subsecond query performance that makes it affordable for businesses to store AI-ready data at massive scale.
Vector search is an emerging technique used in generative AI applications to find similar data points to given data by comparing their vector representations using distance or similarity metrics. Vectors are numerical representation of unstructured data created from embedding models. You generate vectors using embedding models for fields inside your document and store vectors into S3 Vectors to search semantically.
S3 Vectors introduces vector buckets, a new bucket type with a dedicated set of APIs to store, access, and query vector data without provisioning any infrastructure. When you create an S3 vector bucket, you organize your vector data within vector indexes, making it simple for running similarity search queries against your dataset. Each vector bucket can have up to 10,000 vector indexes, and each vector index can hold tens of millions of vectors.
After creating a vector index, when adding vector data to the index, you can also attach metadata as key-value pairs to each vector to filter future queries based on a set of conditions, for example, dates, categories, or user preferences. As you write, update, and delete vectors over time, S3 Vectors automatically optimizes the vector data to achieve the best possible price-performance for vector storage, even as the datasets scale and evolve.
With S3 Vectors, you can now economically store the vector embeddings that represent massive amounts of unstructured data such as images, videos, documents, and audio files, enabling scalable generative AI applications including semantic and similarity search, RAG, and build agent memory. You can also build applications to support a wide range of industry use cases including personalized recommendations, automated content analysis, and intelligent document processing without the complexity and cost of managing vector databases.
S3 Vectors in action To create a vector bucket, choose Vector buckets in the left navigation pane in the Amazon S3 console and then choose Create vector bucket.
Enter a vector bucket name and choose the encryption type. If you don’t specify an encryption type, Amazon S3 applies server-side encryption with Amazon S3 managed keys (SSE-S3) as the base level of encryption for new vectors. You can also choose server-side encryption with AWS Key Management Service (AWS KMS) keys (SSE-KMS). To learn more about managing your vector bucket, visit S3 Vector buckets in the Amazon S3 User Guide.
Now, you can create a vector index to store and query your vector data within your created vector bucket.
Enter a vector index name and the dimensionality of the vectors to be inserted in the index. All vectors added to this index must have exactly the same number of values.
For Distance metric, you can choose either Cosine or Euclidean. When creating vector embeddings, select your embedding model’s recommended distance metric for more accurate results.
Choose Create vector index and then you can insert, list, and query vectors.
To insert your vector embeddings to a vector index, you can use the AWS Command Line Interface (AWS CLI), AWS SDKs, or Amazon S3 REST API. To generate vector embeddings for your unstructured data, you can use embedding models offered by Amazon Bedrock.
If you’re using the latest AWS Python SDKs, you can generate vector embeddings for your text using Amazon Bedrock using following code example:
# Generate and print an embedding with Amazon Titan Text Embeddings V2.
import boto3
import json
# Create a Bedrock Runtime client in the AWS Region of your choice.
bedrock= boto3.client("bedrock-runtime", region_name="us-west-2")
The text strings to convert to embeddings.
texts = [
"Star Wars: A farm boy joins rebels to fight an evil empire in space",
"Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"Finding Nemo: A father fish searches the ocean to find his lost son"]
embeddings=[]
#Generate vector embeddings for the input texts
for text in texts:
body = json.dumps({
"inputText": text
})
# Call Bedrock's embedding API
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v2:0', # Titan embedding model
body=body)
# Parse response
response_body = json.loads(response['body'].read())
embedding = response_body['embedding']
embeddings.append(embedding)
Now, you can insert vector embeddings into the vector index and query vectors in your vector index using the query embedding:
# Create S3Vectors client
s3vectors_client = boto3.client('s3vectors', region_name='us-west-2')
# Insert vector embedding
s3vectors.put_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
vectors=[
{"key": "v1", "data": {"float32": embeddings[0]}, "metadata": {"id": "key1", "source_text": texts[0], "genre":"scifi"}},
{"key": "v2", "data": {"float32": embeddings[1]}, "metadata": {"id": "key2", "source_text": texts[1], "genre":"scifi"}},
{"key": "v3", "data": {"float32": embeddings[2]}, "metadata": {"id": "key3", "source_text": texts[2], "genre":"family"}}
],
)
#Create an embedding for your query input text
# The text to convert to an embedding.
input_text = "List the movies about adventures in space"
# Create the JSON request for the model.
request = json.dumps({"inputText": input_text})
# Invoke the model with the request and the model ID, e.g., Titan Text Embeddings V2.
response = bedrock.invoke_model(modelId="amazon.titan-embed-text-v2:0", body=request)
# Decode the model's native response body.
model_response = json.loads(response["body"].read())
# Extract and print the generated embedding and the input text token count.
embedding = model_response["embedding"]
# Performa a similarity query. You can also optionally use a filter in your query
query = s3vectors.query_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
queryVector={"float32":embedding},
topK=3,
filter={"genre":"scifi"},
returnDistance=True,
returnMetadata=True
)
results = query["vectors"]
print(results)
To learn more about inserting vectors into a vector index, or listing, querying, and deleting vectors, visit S3 vector buckets and S3 vector indexes in the Amazon S3 User Guide. Additionally, with the S3 Vectors embed command line interface (CLI), you can create vector embeddings for your data using Amazon Bedrock and store and query them in an S3 vector index using single commands. For more information, see the S3 Vectors Embed CLI GitHub repository.
Integrate S3 Vectors with other AWS services S3 Vectors integrates with other AWS services such as Amazon Bedrock, Amazon SageMaker, and Amazon OpenSearch Service to enhance your vector processing capabilities and provide comprehensive solutions for AI workloads.
Create Amazon Bedrock Knowledge Bases with S3 Vectors You can use S3 Vectors in Amazon Bedrock Knowledge Bases to simplify and reduce the cost of vector storage for RAG applications. When creating a knowledge base in the Amazon Bedrock console, you can choose the S3 vector bucket as your vector store option.
In Step 3, you can choose the Vector store creation method either to create an S3 vector bucket and vector index or choose the existing S3 vector bucket and vector index that you’ve previously created.
Using Amazon SageMaker Unified Studio You can create and manage knowledge bases with S3 Vectors in Amazon SageMaker Unified Studio when you build your generative AI applications through Amazon Bedrock. SageMaker Unified Studio is available in the next generation of Amazon SageMaker and provides a unified development environment for data and AI, including building and texting generative AI applications that use Amazon Bedrock knowledge bases.
You can choose your knowledge bases using the S3 Vectors created through Amazon Bedrock when you build generative AI applications. To learn more, visit Add a data source to your Amazon Bedrock app in the Amazon SageMaker Unified Studio User Guide.
Export S3 vector data to Amazon OpenSearch Service You can balance cost and performance by adopting a tiered strategy that stores long-term vector data cost-effectively in Amazon S3 while exporting high priority vectors to OpenSearch for real-time query performance.
This flexibility means your organizations can access OpenSearch’s high performance (high QPS, low latency) for critical, real-time applications, such as product recommendations or fraud detection, while keeping less time-sensitive data in S3 Vectors.
To export your vector index, choose Advanced search export, then choose Export to OpenSearch in the Amazon S3 console.
Then, you will be brought to the Amazon OpenSearch Service Integration console with a template for S3 vector index export to OpenSearch vector engine. Choose Export with pre-selected S3 vector source and a service access role.
It will start the steps to create a new OpenSearch Serverless collection and migrate data from your S3 vector index into an OpenSearch knn index.
Choose the Import history in the left navigation pane. You can see the new import job that was created to make a copy of vector data from your S3 vector index into the OpenSearch Serverless collection.
Now available Amazon S3 Vectors, and its integrations with Amazon Bedrock, Amazon OpenSearch Service, and Amazon SageMaker are now in preview in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Frankfurt), and Asia Pacific (Sydney) Regions.
Quicksilver is a key-value store developed internally by Cloudflare to enable fast global replication and low-latency access on a planet scale. It was initially designed to be a global distribution system for configurations, but over time it gained popularity and became the foundational storage system for many products in Cloudflare.
A previous post described how we moved Quicksilver to production and started replicating on all machines across our global network. That is what we called Quicksilver v1: each server has a full copy of the data and updates it through asynchronous replication. The design served us well for some time. However, as our business grew with an ever-expanding data center footprint and a growing dataset, it became more and more expensive to store everything everywhere.
We realized that storing the full dataset on every server is inefficient. Due to the uniform design, data accessed in one region or data center is replicated globally, even if it’s never accessed elsewhere. This leads to wasted disk space. We decided to introduce a more efficient system with two new server roles: replica, which stores the full dataset and proxy, which acts as a persistent cache, evicting unused key-value pairs to free up some disk space. We call this design Quicksilver v1.5 – an interim step towards a more sophisticated and scalable system.
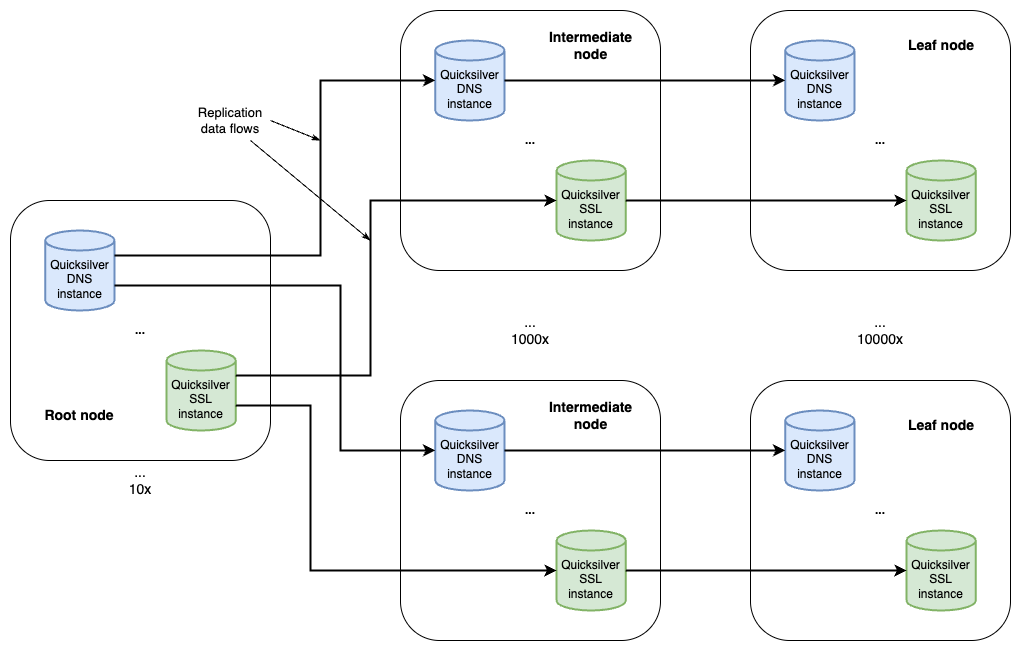
To understand how those two roles helped us reduce disk space usage, we first need to share some background on our setup and introduce some terminology. Cloudflare is architected in a way where we have a few hyperscale core data centers that form our control plane, and many smaller data centers distributed across the globe where resources are more constrained. Quicksilver has dozens of servers in the core data centers with terabytes of storage called root nodes. In the smaller data centers, though, things are different. A typical data center has two types of nodes: intermediate nodes and leaf nodes. Intermediate servers replicate data either from the other intermediate nodes or directly from the root nodes. Leaf nodes serve end user traffic, and receive updates from intermediate servers, effectively being leaves of a replication tree. Disk capacity varies significantly between node types. While root nodes aren’t facing an imminent disk space bottleneck, it’s a definite concern for leaf nodes.
Every server – whether it’s a root, intermediate, or leaf – hosts 10 Quicksilver instances. These are independent databases, each used by specific Cloudflare services or products such as the DNS, CDN or WAF.
Figure 1. Global Quicksilver
Let’s consider the role distribution. Instead of hosting ten full datasets on every machine within a data center, what if we deploy only a few replicas in each? The remaining servers would be proxies, maintaining a persistent cache of hot keys and querying replicas for any cache misses.
Figure 2. Role allocation for different Quicksilver instances
Data centers across our network are very different in size, ranging from hundreds of servers to a single rack with just a few servers. To ensure every data center has at least one replica, the simplest initial step is an even split: on each server, place five replicas of some instances and five proxies for others. The change immediately frees up disk space, as the cached hot dataset on a proxy should be smaller than a full replica. While it doesn’t remove the bottleneck entirely, it could, in theory, lead to an up to 50% reduction in disk space usage. More importantly, it lays the foundation for a new distributed design of Quicksilver, where queries can be served by multiple machines in a data center, paving the way for further horizontal scaling. Additionally, an iterative approach helps to battle-proof the code changes earlier.
Can it even work?
Before committing to building Quicksilver v1.5, we wanted to be sure that the proxy/replica design would actually work for our workload. If proxies needed to cache the entire dataset for good performance, then it would be a dead end, offering no potential disk space benefits. To assess this, we built a data pipeline which pushes accessed keys from all across our network to ClickHouse. This allowed us to estimate typical sizes of working sets. Our analysis revealed that:
in large data centers approximately, 20% of the keyspace was in use
in small data centers this number dropped to just about 1%
These findings gave us confidence that the caching approach should work, though it wouldn’t be without its challenges.
Persistent caching
When talking about caches, the first thing that comes to mind is an in-memory cache. However, this cannot work for Quicksilver for two main reasons: memory usage and the “cold cache” problem.
Indeed, with billions of stored keys, even a fraction of them would lead to an unmanageable increase in memory usage. System restarts should not affect performance, which means that cache data must be preserved somewhere anyway. So we decided to make the cache persistent and store it in the same way as full datasets: in our embedded RocksDB. Thus, cached keys normally sit on disk and can be retrieved on-demand with low memory footprint.
When a key cannot be found in the proxy’s cache, we request it from a replica using our internal distributed key-value protocol, and put it into a local cache after processing.
Evictions are based on RocksDB compaction filters. Compaction filters allow defining custom logic executed in background RocksDB threads responsible for compacting files on disk. Each key-value pair is processed with a filter on a regular basis, evicting least recently used data from the disk when available disk space drops below a certain threshold called a soft limit. To track keys accessed on disk, we have an LRU-like in-memory data structure, which is passed to the compaction filter to set last access date in key metadata and inform potential evictions.
However, with some specific workloads there is still a chance that evictions will not keep up with disk space growth, and for this scenario we have a hard limit: when available disk space drops below a critical threshold, we temporarily stop adding new keys to the cache. This hurts performance, but it acts as a safeguard, ensuring our proxies remain stable and don’t overflow under a massive surge of requests.
Consistency and asynchronous replication
Quicksilver has, from the start, provided sequential consistency to clients: if key A was written before B, it’s not possible to read B and not A. We are committed to maintaining this guarantee in the new design. We have experienced Hyrum’s Law first hand, with Quicksilver being so widely adopted across the company that every property we introduced in earlier versions is now relied upon by other teams. This means that changing behaviour would inevitably break existing functionality and introduce bugs.
However, there is one thing standing in our way: asynchronous replication. Quicksilver replication is asynchronous mainly because machines in different parts of the world replicate at different speeds, and we don’t want a single server to slow down the entire tree. But it turns out in a proxy-replica design, independent replication progress can result in non-monotonic reads!
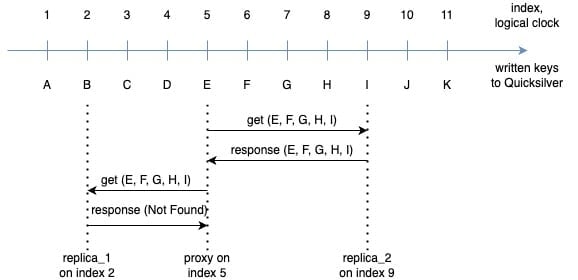
Consider the following scenario: a client sequentially writes keys A, B, C, .. K one after another to the Quicksilver root node. These keys are asynchronously replicated through data centers across our network with varying latency. Imagine we have a proxy on index 5, which has observed keys from A to E, and two replicas:
replica_1 is at index 2 (slightly behind the proxy), having only received A and B
replica_2 at index 9, which is slightly ahead due to a faster replication path and has received all keys from A to I
Figure 3. Asynchronous replication in QSv1.5
Now, a client performs two successive requests on a proxy, each time reading the keys E, F, G, H and I. For simplicity, we assume these keys are not cacheable (for example, due to low disk space). The proxy’s first remote request is routed to replica_2, which already has all keys and responds back with values. To prevent hot spots in a data center, we load balance requests from proxies, and the next one lands on replica_1, which hasn’t received any of the requested keys yet, and responds with a “not found” error.
So, which result is correct?
The correct behavior here is that of Quicksilver v1, which we aim to preserve. If the server on replication index 5 were a replica instead of a proxy, it would have seen updates for keys A through E inclusive, resulting in E being the only key in both replies, while all other keys cannot be found yet. Which means responses from both replica_1 and replica_2 are wrong!
Therefore, to maintain previous guarantees and API backwards compatibility, Quicksilver v1.5 must address two crucial consistency problems: cases where the replica is ahead of the proxy, and conversely, where it lags behind. For now let’s focus on the case where a proxy lags behind a replica.
Multiversion concurrency control
In our example, replica_2 responds to a request from a proxy “from the past”. We cannot use any locks for synchronizing two servers, as it would introduce undesirable delays to the replication tree, defeating the purpose of asynchronous replication. The only option is for replicas to maintain a history of recent updates. This naturally leads us to implementing multiversion concurrency control (MVCC), a popular database mechanism for tracking changes in a non-blocking fashion, where for any key we can keep multiple versions of its values for different points in time.
With MVCC, we no longer overwrite the latest value of a key in the default column family for every update. Instead, we introduced a new MVCC column family in RocksDB, where all updates are stored with a corresponding replication index. Lookup for a key at some index in the past goes as follows:
First we search in the default column family. If a key is found and the write timestamp is not greater than the index of a requesting proxy, we can use it straight away.
Otherwise, we begin scanning the MVCC column family, where keys have unique suffixes based on latest timestamps for which they are still valid.
In the example above, replica_2 has MVCC enabled and has keys A@1 .. K@11 in its default column family. The MVCC is initially empty, because no keys have been overwritten yet. When it receives a request for, say, key H with target index 5, it first makes a lookup in a default column family and finds the given key, but its timestamp is 8, which means this version should not be visible to the proxy yet. It then scans the MVCC, finds no matching previous versions and responds with “not found” to the proxy. Should key H be updated twice at indexes 4 and 8, we would have placed the initial version into MVCC before overwriting it in the default column family, and the proxy would receive the first version in response.
If a key E is requested at index 5, replica_2 can find it quickly in the default column family and return it back to the proxy. There is no need to read from MVCC, as the timestamp of the latest version (5) satisfies the request.
Another corner case to consider is deletions. When a key is deleted and then re-written, we need to explicitly mark the period of removal in MVCC. For that we’ve implemented tombstones – a special value format for absent keys.
Finally, we need to make sure that key history is not growing uncontrollably, using up all of the disk space available. Luckily we don’t actually need to record history for a long period of time, it just needs to cover the maximum replication index difference between any two machines. And in practice, a two-hour interval turned out to be way more than enough, while adding only about 500 MB of extra disk space usage. All records in the MVCC column family older than two hours are garbage collected, and for that again we use custom RocksDB compaction filters.
Sliding window
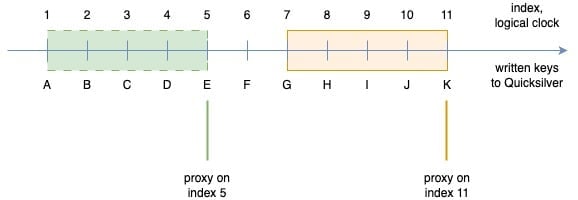
Now we know how to deal with proxies lagging behind replicas. But what about the opposite case, when a proxy is ahead of replicas?
The simplest solution is for replicas to not serve requests with a target index higher than its own. After all, it cannot know about keys from the future, whether they will be added, updated, or removed. In fact, our first implementation just returned an error when the proxy was ahead, as we expected it to happen quite infrequently. But after rolling out gradually to a few data centers, our metrics made it clear that the approach was not going to work.
This led us to analyze which keys are affected by this kind of replication asymmetry. It’s definitely not keys added or updated a long time ago, because replicas would already have the changes replicated. The only problematic keys are those updated very recently, which the proxy already knows about, but the replica does not.
With this insight, we realized that the issue should be solved on the proxies rather than on the replica side. By preserving all recent updates locally, the proxy can avoid querying the replica. This became known as the sliding window approach.
The sliding window retains all recent updates written in a short, rolling timeframe. Unlike cached keys, items in the window cannot be evicted until they move outside of the window. Internally, the sliding window is defined by lower and upper boundary pointers. These are kept in memory, and can easily be restored after a reload from the current database index and the pre-configured window size.
Figure 4. The sliding window shifts when replication updates arrive
When a new update event arrives from the replication layer we add it to the sliding window by moving both the upper and lower boundary one position higher. Thereby, we maintain the fixed size of the window. Keys written before the lower bound can be evicted by the compaction filter, which is aware of current sliding window boundaries.
Negative lookups
Another problem arising with our distributed replica-proxy design is negative lookups – requests for keys which don’t exist in the database. Interestingly, in our workloads we see about ten times more negative lookups than positive ones!
But why is it a problem? Unfortunately, each negative lookup will be a cache miss on a proxy, requiring a request to a replica. Given the volume of requests and proportion of such lookups, it would be a disaster for performance, with overloaded replicas, overused data center networks, and massive latency degradation. We needed a fast and efficient approach to identifying non-existing keys directly at the proxy level.
In v1, negative lookups are the quickest type of requests. We rely on a special probabilistic data structure – Bloom filters – used in RocksDB to determine if the requested key might belong to a certain data file containing a range of sorted keys (called Sorted Sequence Table or SST) or definitely not. 99% of the time, negative lookups are served using only this in-memory data structure, avoiding the need for disk I/O.
One approach we considered for proxies was to cache negative lookups. Two problems immediately arise:
How big is the keyspace of negative lookups? In theory, it’s infinite, but the real size was unclear. We can store it in our cache only if it is small enough.
Cached negative lookups would no longer be served by the fast Bloom filters. We have row and block caches in RocksDB, but the hit rate is nowhere near the filters for SSTs, which means negative lookups would end up going to disk more often.
These turned out to be dealbreakers: not only was the negative keyspace vast, greatly exceeding the actual keyspace (by a thousand times for some instances!), but clients also need lookups to be really fast, ideally served from memory.
In pursuit of probabilistic data structures which could give us a dynamic compact representation of a full keyspace on proxies, we spent some time exploring Cuckoo filters. Unfortunately, with 5 billion keys it takes about 18 GB to have a false positive rate similar to Bloom filters (which only require 6 GB). And this is not only about wasted disk space — to be fast we have to keep it all in memory too!
Clearly some other solution was needed.
Finally, we decided to implement key and value separation, storing all keys on proxies, but persisting values only for cached keys. Evicting a key from the cache actually results in the removal of its value.
But wait, don’t the keys, even stripped of values, take a lot of space? Well, yes and no.
The total size of pure keys in Quicksilver is approximately 11 times smaller than the full dataset. Of course, it’s larger than any representation by probabilistic data structure, but there are some very desirable properties to such a solution. Firstly, we continue to enjoy fast Bloom filter lookups in RocksDB. Another benefit is that it unlocks some cool optimizations for range queries in a distributed context.
We may revisit it one day, but so far it has worked great for us.
Discovery mechanism
Having solved all of the above challenges, one bit remained to be sorted out to make distributed query execution work: how can proxies discover replicas?
Within the local data center it is fairly easy. Each one runs its own consul cluster, where machines are registered as services. Consul is well integrated with our internal DNS resolvers, and with a single DNS request, we can get the names of all replicas running in a data center, which proxies can directly connect to.
However, data centers vary in size, servers are constantly added and removed, and having only local discovery would not be enough for the system to work reliably. Proxies also need to find replicas in other nearby data centers.
We had previously encountered a similar problem with our replication layer. Initially, the replication topology was statically defined in a configuration and distributed to all servers, such that they know from which sources they should replicate. While simple, this approach was quite fragile and tedious to operate. It led to a rigid replication tree with suboptimal overall performance, unable to adapt to network changes.
Our solution to this problem was the Network Oracle – a special overlay network based on a gossip protocol and consisting of intermediate nodes in our data centers. Each member of this overlay constantly exchanges status and metainformation with other nodes, which helps us see active members in near-real time. Each member runs network probes measuring round-trip time to its peers, making it easy to find closest (in terms of RTT) active intermediate nodes to form a low-latency replication tree. Introducing the Network Oracle was a major improvement: we no longer needed to reconfigure the topology, watch intermediate nodes or entire data centers go down, or investigate frequent replication issues. Replication is now a completely self-organized and self-healing dynamic system.
Naturally, we decided to reuse the Network Oracle for our discovery mechanism. It consists of two subproblems: data center discovery and specific service lookup. We use the Network Oracle to find the closest data centers. Adding all machines running Quicksilver to the same overlay would be inefficient because of significant increase of network traffic and message delivery times. Instead, we use intermediate nodes as sources of network proximity information for the leaf nodes. Knowing which data centers are nearby, we can directly send DNS queries there to resolve specific services – Quicksilver replicas in this case.
Proxies maintain a pool of connections to active replicas and distribute requests among them to smooth out the load and avoid hotspots in a data center. Proxies also have a health-tracking mechanism, monitoring the state of connections and errors coming from replicas, and temporarily deprioritizing or isolating potentially faulty ones.
Figure 5. Internal replica request errors
To demonstrate its efficiency, we graphed errors coming from replica requests, which showed that such errors almost disappeared after introducing the new discovery system.
Results
Our objective with Quicksilver v1.5 was simple: gain some disk space without losing request latency, because clients rely heavily on us being fast. While the replica-proxy design delivered significant space savings, what about latencies?
Proxy
Replica
Figure 6. Proxy-replica latency comparison
Above, we have the 99.9% percentile of request latency on both a replica and proxy during a 24-hour window. One can hardly find a difference between the two. Surprisingly, proxies can even be slightly faster than replicas sometimes, likely because of smaller datasets on disk!
Quicksilver v1.5 is released but our journey to a highly scalable and efficient solution is not over. In the next post we’ll share what challenges we faced with the following iteration. Stay tuned!
Thank you
This project was a big team effort, so we’d like to thank everyone on the Quicksilver team – it would not have come true without you all.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
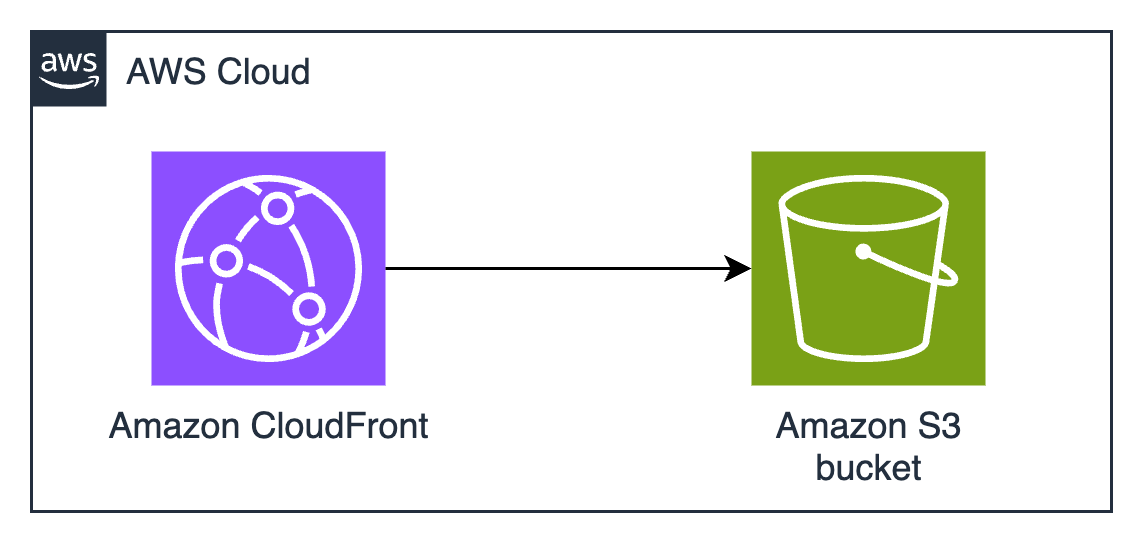
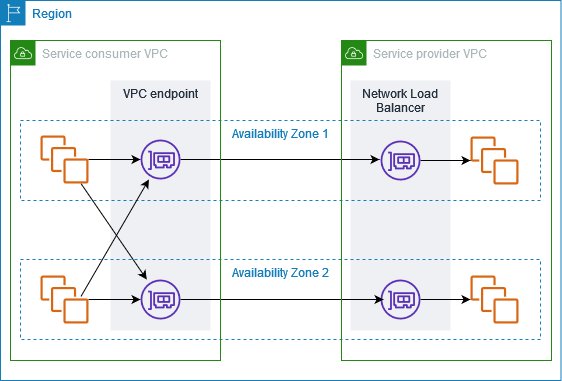
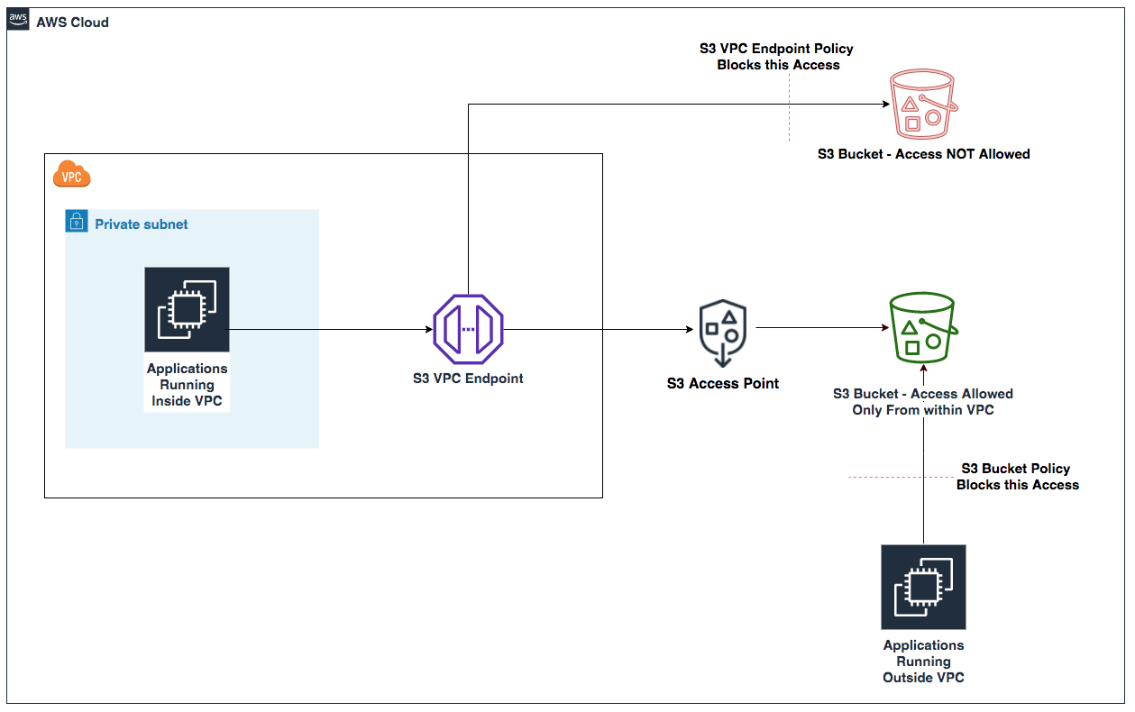
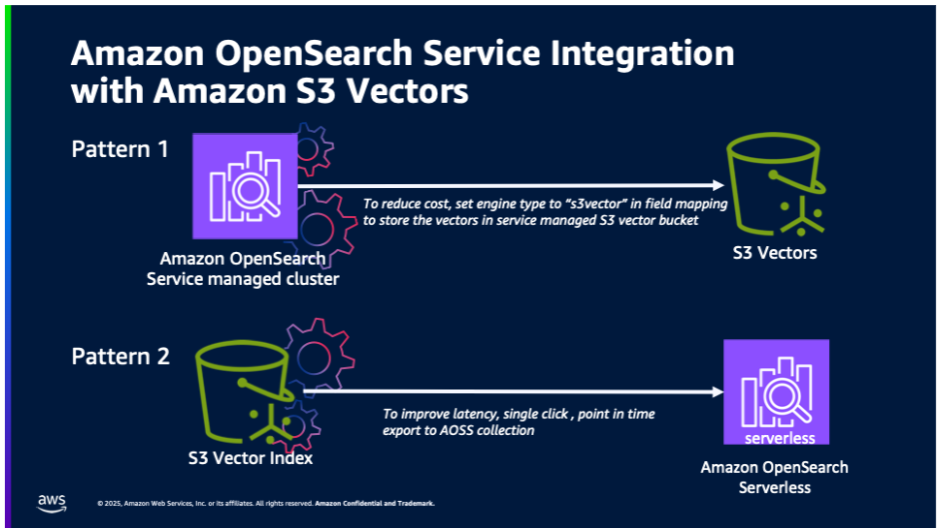
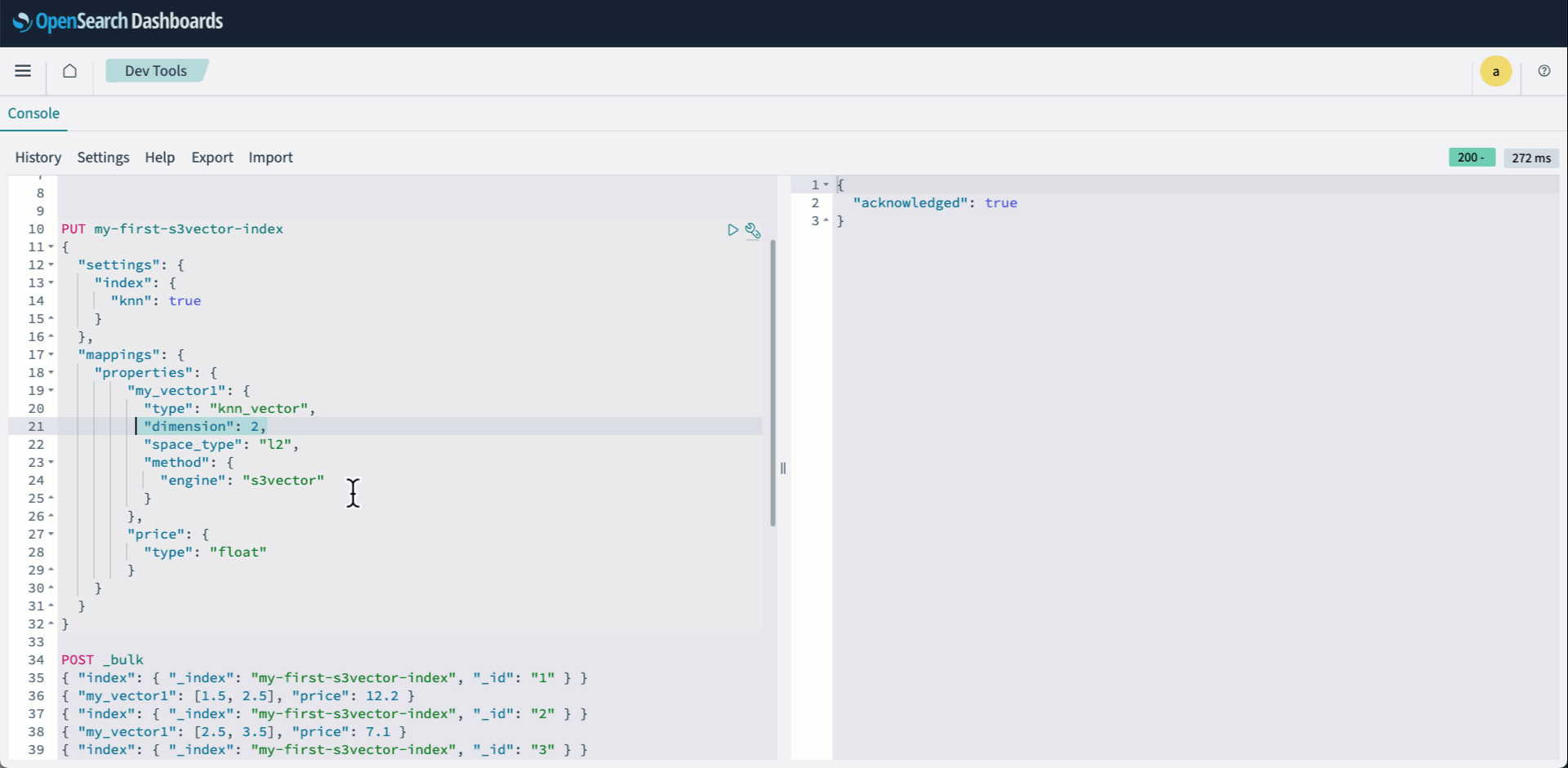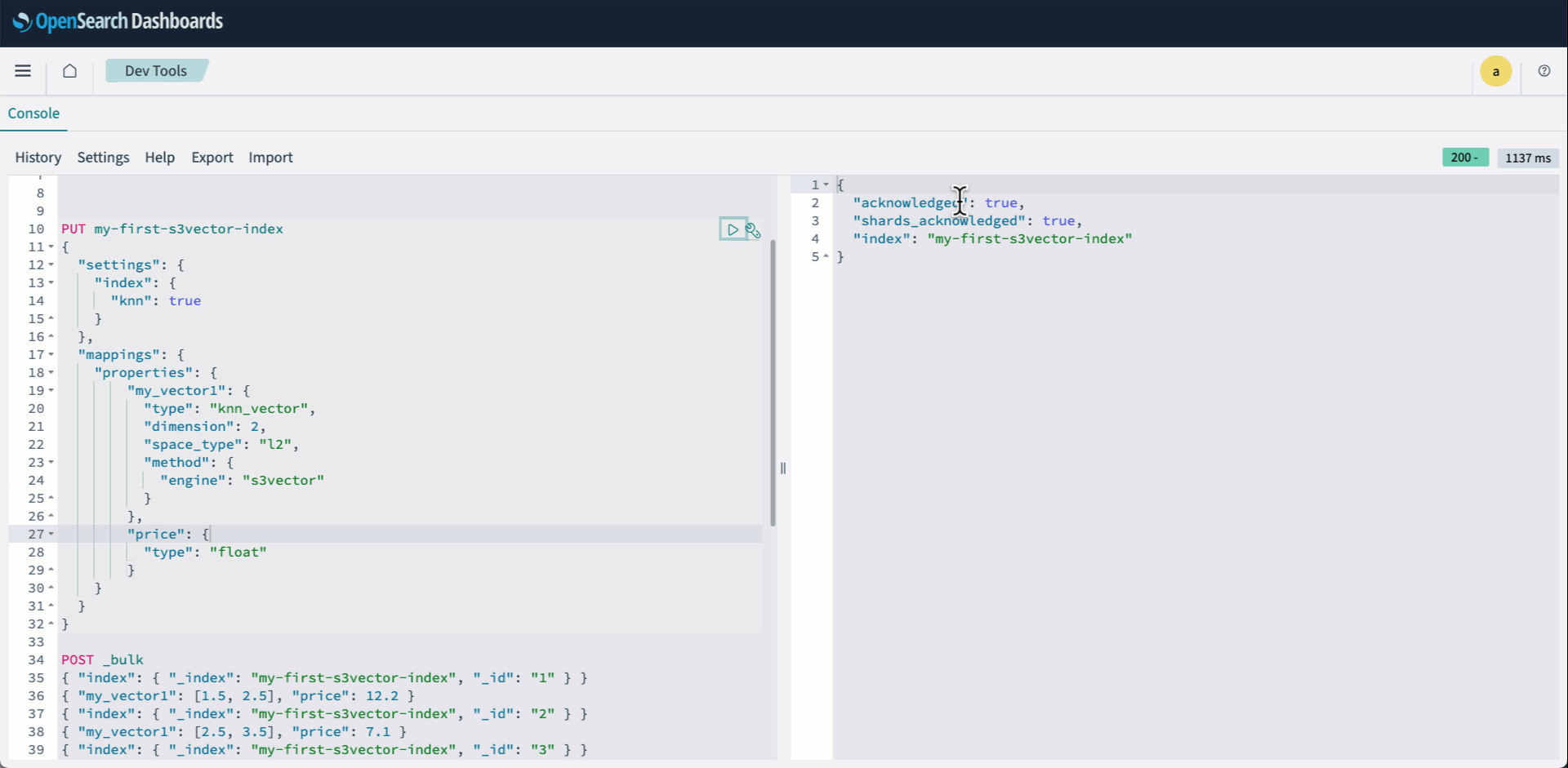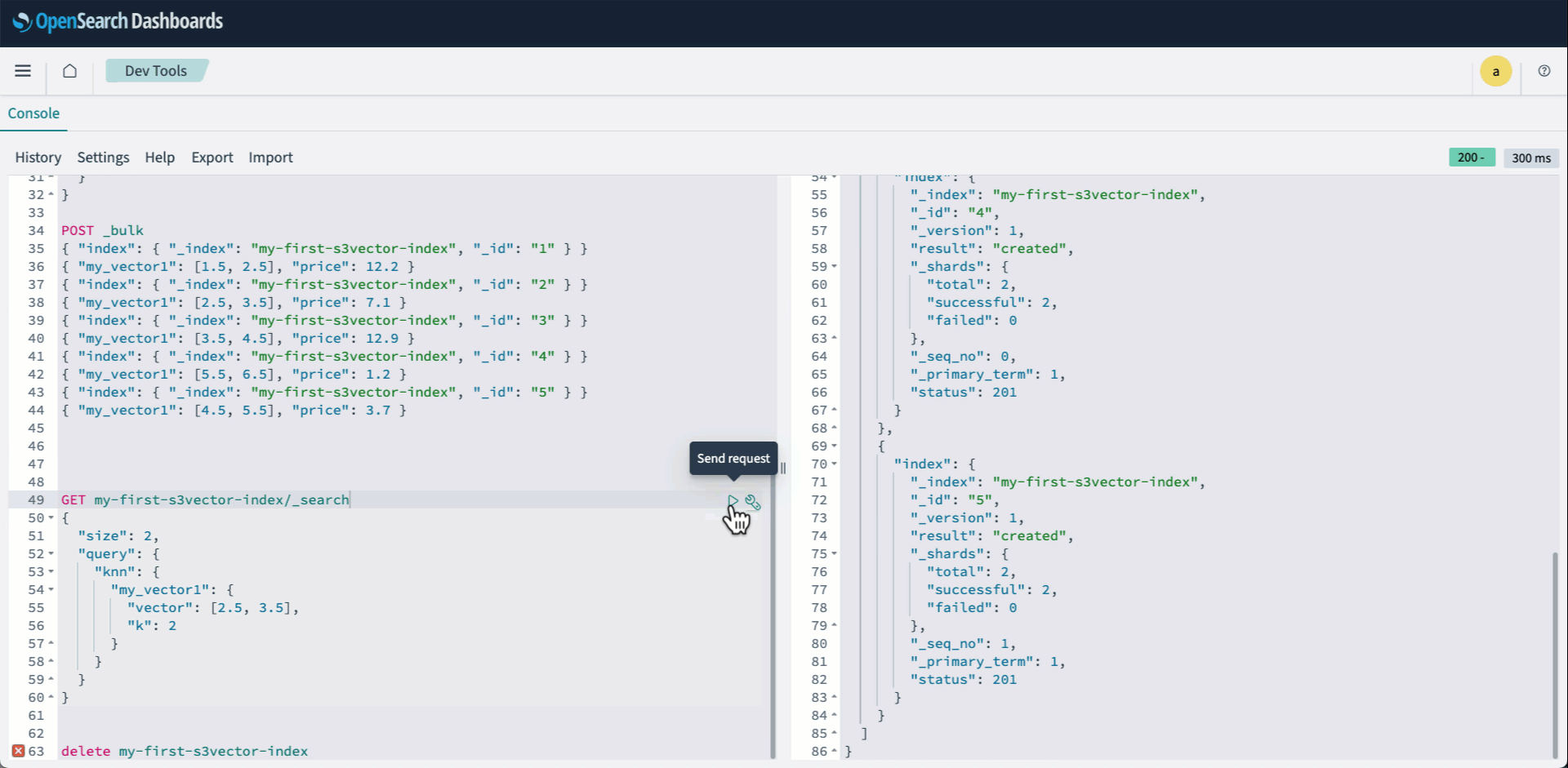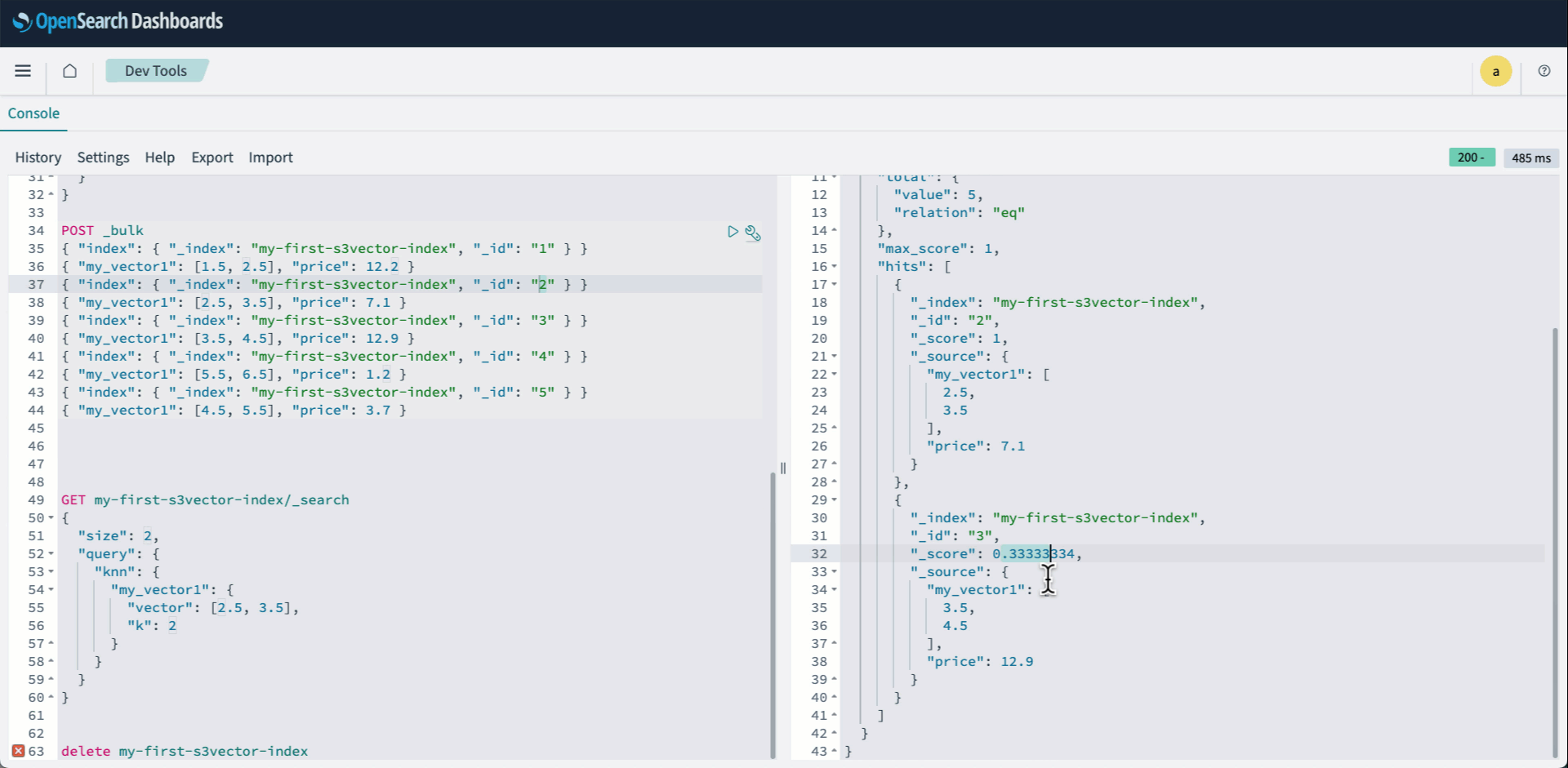
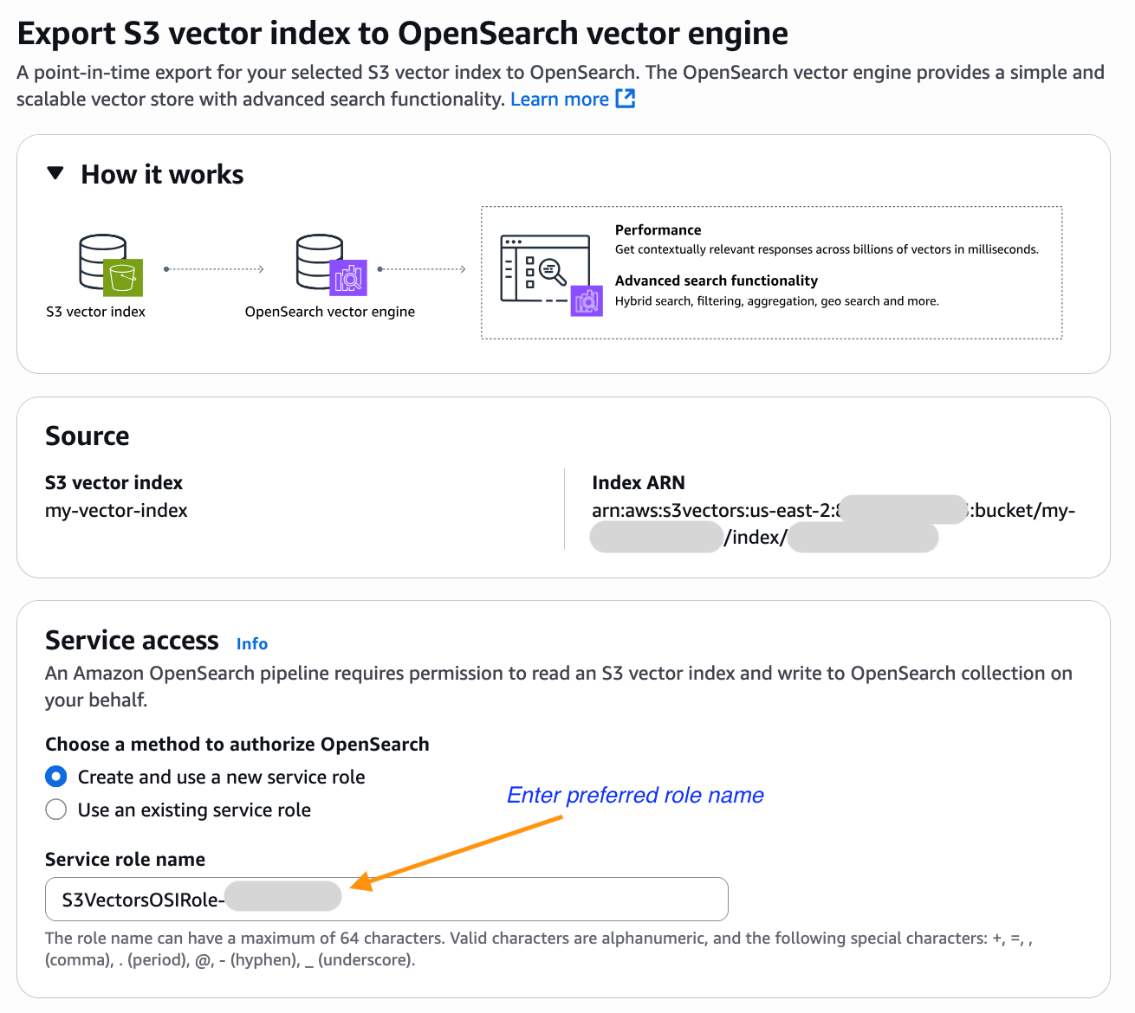
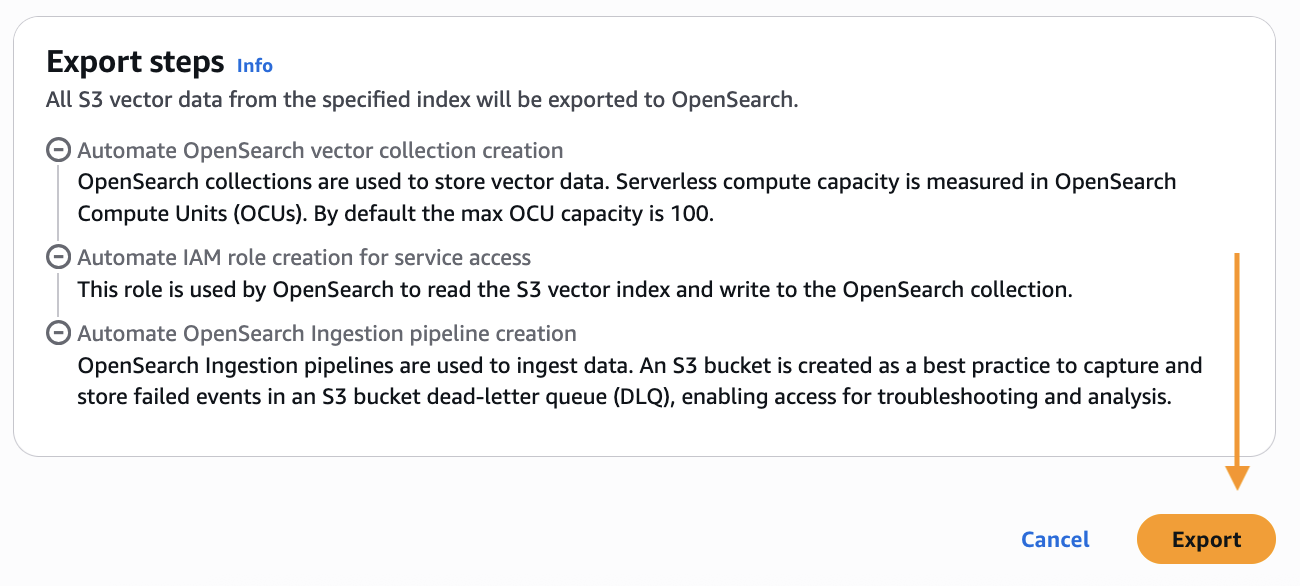
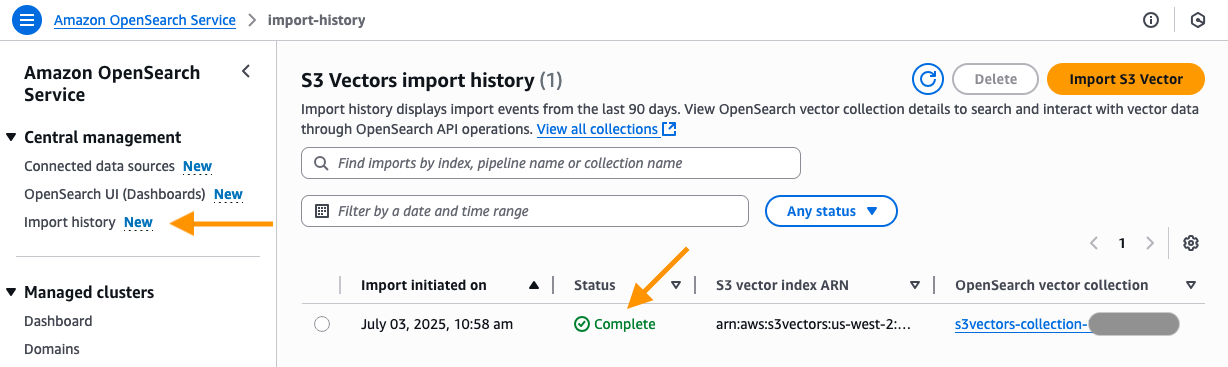
 Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges. Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books. Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems. Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards. Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.
Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.