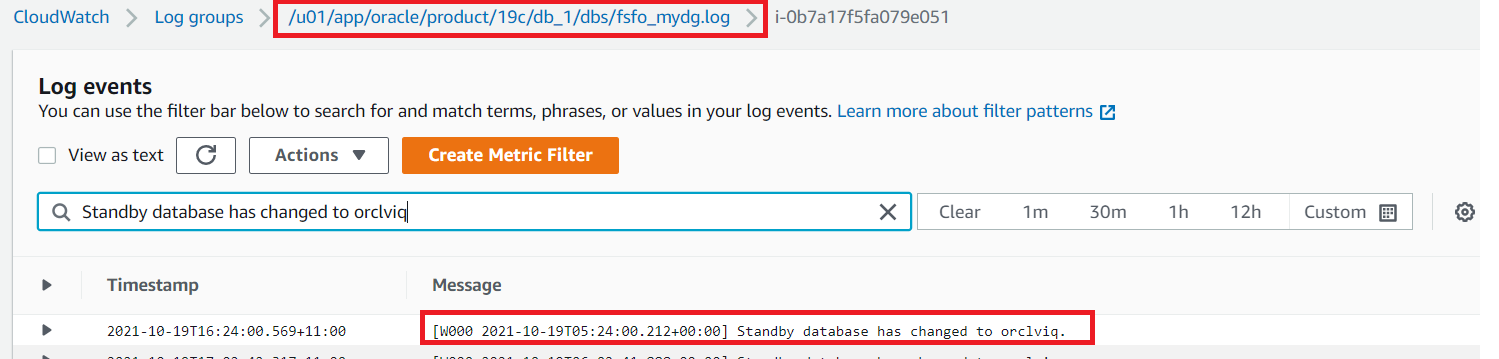
Post Syndicated from Joe Viggiano original https://aws.amazon.com/blogs/security/using-aws-shield-advanced-protection-groups-to-improve-ddos-detection-and-mitigation/
Amazon Web Services (AWS) customers can use AWS Shield Advanced to detect and mitigate distributed denial of service (DDoS) attacks that target their applications running on Amazon Elastic Compute Cloud (Amazon EC2), Elastic Local Balancing (ELB), Amazon CloudFront, AWS Global Accelerator, and Amazon Route 53. By using protection groups for Shield Advanced, you can logically group your collections of Shield Advanced protected resources. In this blog post, you will learn how you can use protection groups to customize the scope of DDoS detection for application layer events, and accelerate mitigation for infrastructure layer events.
What is a protection group?
A protection group is a resource that you create by grouping your Shield Advanced protected resources, so that the service considers them to be a single protected entity. A protection group can contain many different resources that compose your application, and the resources may be part of multiple protection groups spanning different AWS Regions within an AWS account. Common patterns that you might use when designing protection groups include aligning resources to applications, application teams, or environments (such as production and staging), and by product tiers (such as free or paid). For more information about setting up protection groups, see Managing AWS Shield Advanced protection groups.
Why should you consider using a protection group?
The benefits of protection groups differ for infrastructure layer (layer 3 and layer 4) events and application layer (layer 7) events. For layer 3 and layer 4 events, protection groups can reduce the time it takes for Shield Advanced to begin mitigations. For layer 7 events, protection groups add an additional reporting mechanism. There is no change in the mechanism that Shield Advanced uses internally for detection of an event, and you do not lose the functionality of individual resource-level detections. You receive both group-level and individual resource-level Amazon CloudWatch metrics to consume for operational use. Let’s look at the benefits for each layer in more detail.
Layers 3 and 4: Accelerate time to mitigate for DDoS events
For infrastructure layer (layer 3 and layer 4) events, Shield Advanced monitors the traffic volume to your protected resource. An abnormal traffic deviation signals the possibility of a DDoS attack, and Shield Advanced then puts mitigations in place. By default, Shield Advanced observes the elevation of traffic to a resource over multiple consecutive time intervals to establish confidence that a layer 3/layer 4 event is under way. In the absence of a protection group, Shield Advanced follows the default behavior of waiting to establish confidence before it puts mitigation in place for each resource. However, if the resources are part of a protection group, and if the service detects that one resource in a group is targeted, Shield Advanced uses that confidence for other resources in the group. This can accelerate the process of putting mitigations in place for those resources.
Consider a case where you have an application deployed in different AWS Regions, and each stack is fronted with a Network Load Balancer (NLB). When you enable Shield Advanced on the Elastic IP addresses associated with the NLB in each Region, you can optionally add those Elastic IP addresses to a protection group. If an actor targets one of the NLBs in the protection group and a DDoS attack is detected, Shield Advanced will lower the threshold for implementing mitigations on the other NLBs associated with the protection group. If the scope of the attack shifts to target the other NLBs, Shield Advanced can potentially mitigate the attack faster than if the NLB was not in the protection group.
Note: This benefit applies only to Elastic IP addresses and Global Accelerator resource types.
Layer 7: Reduce false positives and improve accuracy of detection for DDoS events
Shield Advanced detects application layer (layer 7) events when you associate a web access control list (web ACL) in AWS WAF with it. Shield Advanced consumes request data for the associated web ACL, analyzes it, and builds a traffic baseline for your application. The service then uses this baseline to detect anomalies in traffic patterns that might indicate a DDoS attack.
When you group resources in a protection group, Shield Advanced aggregates the data from individual resources and creates the baseline for the whole group. It then uses this aggregated baseline to detect layer 7 events for the group resource. It also continues to monitor and report for the resources individually, regardless of whether they are part of protection groups or not.
Shield Advanced provides three types of aggregation to choose from (sum, mean, and max) to aggregate the volume data of individual resources to use as a baseline for the whole group. We’ll look at the three types of aggregation, with a use case for each, in the next section.
Note: Traffic aggregation is applicable only for layer 7 detection.
Case 1: Blue/green deployments
Blue/green is a popular deployment strategy that increases application availability and reduces deployment risk when rolling out changes. The blue environment runs the current application version, and the green environment runs the new application version. When testing is complete, live application traffic is directed to the green environment, and the blue environment is dismantled.
During blue/green deployments, the traffic to your green resources can go from zero load to full load in a short period of time. Shield Advanced layer 7 detection uses traffic baselining for individual resources, so newly created resources like an Application Load Balancer (ALB) that are part of a blue/green operation would have no baseline, and the rapid increase in traffic could cause Shield Advanced to declare a DDoS event. In this scenario, the DDoS event could be a false positive.

Figure 1: A blue/green deployment with ALBs in a protection group. Shield is using the sum of total traffic to the group to baseline layer 7 traffic for the group as a single unit
In the example architecture shown in Figure 1, we have configured Shield to include all resources of type ALB in a single protection group with aggregation type sum. Shield Advanced will use the sum of traffic to all resources in the protection group as an additional baseline. We have only one ALB (called blue) to begin with. When you add the green ALB as part of your deployment, you can optionally add it to the protection group. As traffic shifts from blue to green, the total traffic to the protection group remains the same even though the volume of traffic changes for the individual resources that make up the group. After the blue ALB is deleted, the Shield Advanced baseline for that ALB is deleted with it. At this point, the green ALB hasn’t existed for sufficient time to have its own accurate baseline, but the protection group baseline persists. You could still receive a DDoSDetected CloudWatch metric with a value of 1 for individual resources, but with a protection group you have the flexibility to set one or more alarms based on the group-level DDoSDetected metric. Depending on your application’s use case, this can reduce non-actionable event notifications.
Note: You might already have alarms set for individual resources, because the onboarding wizard in Shield Advanced provides you an option to create alarms when you add protection to a resource. So, you should review the alarms you already have configured before you create a protection group. Simply adding a resource to a protection group will not reduce false positives.
Case 2: Resources that have traffic patterns similar to each other
Client applications might interact with multiple services as part of a single transaction or workflow. These services can be behind their own dedicated ALBs or CloudFront distributions and can have traffic patterns similar to each other. In the example architecture shown in Figure 2, we have two services that are always called to satisfy a user request. Consider a case where you add a new service to the mix. Before protection groups existed, setting up such a new protected resource, such as ALB or CloudFront, required Shield Advanced to build a brand-new baseline. You had to wait for a certain minimum period before Shield Advanced could start monitoring the resource, and the service would need to monitor traffic for a few days in order to be accurate.

Figure 2: Deploying a new service and including it in a protection group with an existing baseline. Shield is using the mean aggregation type to baseline traffic for the group.
For improved accuracy of detection of level 7 events, you can cause Shield Advanced to inherit the baseline of existing services that are part of the same transaction or workflow. To do so, you can put your new resource in a protection group along with an existing service or services, and set the aggregation type to mean. Shield Advanced will take some time to build up an accurate baseline for the new service. However, the protection group has an established baseline, so the new service won’t be susceptible to decreased accuracy of detection for that period of time. Note that this setting will not stop Shield Advanced from sending notifications for the new service individually; however, you might prefer to take corrective action based on the detection for the group instead.
Case 3: Resources that share traffic in a non-uniform way
Consider the case of a CloudFront distribution with an ALB as origin. If the content is cached in CloudFront edge locations, the traffic reaching the application will be lower than that received by the edge locations. Similarly, if there are multiple origins of a CloudFront distribution, the traffic volumes of individual origins will not reflect the aggregate traffic for the application. Scenarios like invalidation of cache or an origin failover can result in increased traffic at one of the ALB origins. This could cause Shield Advanced to send “1” as the value for the DDoSDetected CloudWatch metric for that ALB. However, you might not want to initiate an alarm or take corrective action in this case.

Figure 3: CloudFront and ALBs in a protection group with aggregation type max. Shield is using CloudFront’s baseline for the group
You can combine the CloudFront distribution and origin (or origins) in a protection group with the aggregation type set to max. Shield Advanced will consider the CloudFront distribution’s traffic volume as the baseline for the protection group as a whole. In the example architecture in Figure 3, a CloudFront distribution fronts two ALBs and balances the load between the two. We have bundled all three resources (CloudFront and two ALBs) into a protection group. In case one ALB fails, the other ALB will receive all the traffic. This way, although you might receive an event notification for the active ALB at the individual resource level if Shield detects a volumetric event, you might not receive it for the protection group because Shield Advanced will use CloudFront traffic as the baseline for determining the increase in volume. You can set one or more alarms and take corrective action according to your application’s use case.
Conclusion
In this blog post, we showed you how AWS Shield Advanced provides you with the capability to group resources in order to consider them a single logical entity for DDoS detection and mitigation. This can help reduce the number of false positives and accelerate the time to mitigation for your protected applications.
A Shield Advanced subscription provides additional capabilities, beyond those discussed in this post, that supplement your perimeter protection. It provides integration with AWS WAF for level 7 DDoS detection, health-based detection for reducing false positives, enhanced visibility into DDoS events, assistance from the Shield Response team, custom mitigations, and cost-protection safeguards. You can learn more about Shield Advanced capabilities in the AWS Shield Advanced User Guide.
If you have feedback about this blog post, submit comments in the Comments section below. You can also start a new thread on AWS Shield re:Post to get answers from the community.
Want more AWS Security news? Follow us on Twitter.