Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/therod/


Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/therod/
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=AAC6Vp655zs
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=uxP36ma_noo
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/07/friday-squid-blogging-squid-inks-fisherman.html
Short video.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Post Syndicated from Йовко Ламбрев original https://toest.bg/editorial-11-16-july-2022/
… ние сме обречени да поправяме къщата, в която живеем – по малко, постепенно и невинаги по най-добрия начин.
Кристиан Таков, 22 март 2017 г.
През седмицата наблюдавахме интересен паралел. В Италия, много подобно на ситуацията у нас, възникна правителствена криза. Премиерът Марио Драги загуби коалиционното си мнозинство и съответно връчи оставката си на президента Серджо Матарела. Оставката обаче не бе приета, а вместо това президентът призова за политическо обсъждане на ситуацията в парламента, което да разясни причините да се стигне дотук. Нека си припомним реакциите на нашия президент, когато правителството на Кирил Петков загуби мнозинство. И да направим нужните сравнения и изводи.

У нас предстои да бъде връчен третият, последен проучвателен мандат за съставяне на кабинет. Дали ще бъде реализиран, предстои да разберем съвсем скоро, но шансовете за ново правителство в рамките на този парламент не са особено големи. Дилемата от днешна гледна точка е дали ще се постигне съгласие за някакво временно управление с прогнозиран живот от няколко месеца, или ще има предсрочни парламентарни избори през октомври. Според Емилия Милчева ключът се държи от „Продължаваме промяната“.
Иначе през седмицата бе направен опит за изпиране на публичния образ на бившия премиер Бойко Борисов. Предизборно. И както подозират не без основание от „Свободна Европа“, вероятно целта е и да се заглушат оценките за България в третия Доклад относно върховенството на закона в Европейския съюз. Схемата е простичка: намира се депутат от ЕНП, който да цитира в Европарламента пасаж от писмо на прокуратурата на Република България, в което се твърди, че съгласно направена експертиза кадрите с кюлчета злато и пачки с 500-еврови банкноти в нощното шкафче на бившия премиер са манипулирани. Медиите безкритично изпапагалстваха „горещата“ новина, гарнирана с твърдението на ГЕРБ за „петорна експертиза“, и така информационното пространство се оказа залято със заглавия, съдържащи изрази като „пълен обрат“ и внушаващи дори, че експертизата е на Европейския парламент.

Именно такива ситуации провокираха Светла Енчева да напише своя критичен материал, озаглавен „Отново за журналистическия мързел. И за обществения интерес“. Макар че конкретният повод за нейния текст е друго събитие, което зае централно място в новините миналата седмица – жестоката катастрофа на бул. „Черни връх“ в столицата, в която загинаха две млади жени. Събитие, което ще продължи да бъде следено и обсъждано включително заради осветлените подозрения за близки връзки между представители на органите на реда с престъпния свят. И именно заради значимостта на развръзката и паметта на загиналите е важно случилото се да не бъде превръщано в медийно шоу.

И съвсем естествено идва мястото и на третата част от поредицата на Йоанна Елми, посветена на манипулативното съдържание в медиите и социалните мрежи. След какво и къде е време да потърсим отговора и на въпроса кой разпространява манипулативното съдържание. А най-важният момент е да осъзнаем, че „потребителите, които консумират и разпространяват такъв тип съдържание, са едновременно жертви и съучастници“.

В рубриката ни „На второ четене“ тази седмица Стефан Иванов се е спрял на три книги вместо на една. Подбраните заглавия са дебютни стихосбирки на три български поетеси, всичките издадени през миналата година. Прочетете какво е решил да сподели Стефан под въздействието на стиховете на Ева Гочева, Калина Линкова и Камелия Панайотова.
Започнах тази редакционна статия с цитат от Кристиан Таков. В понеделник се навършиха пет години от смъртта му. Пет години, през които се питаме какви ли щяха да са коментарите му за всичко, случило се през това време. И друго – дали мъдростта, която носеше, щеше някак да натежи над действителността. Известният юрист, преподавател и общественик е бил и страстен любител фотограф. До 24 юли т.г. на Моста на влюбените до НДК може да разгледате изложбата „Моралът е доброто“ с 60 авторски фотографии на доц. Таков, придружени с негови размисли за правото, справедливостта и обществото.
Да завършим с друг цитат…
Няма покой, стъпил на лъжа, който да трае дълго без употребата на насилие – истината напира, светът напира, природата напира, реалността може да бъде огъната само донякъде и след това се връща като плесница за всички наблизо.

Това пише Нева Мичева в отговор на читателско писмо в рубриката „Говори с Нева“. В есето, озаглавено „Плюс време“, тя размишлява за смирението, примирението и приемането. Всъщност… не съвсем и не само. Но с пожелание за хубаво лято ви изпраща покана за среща във вече празната си пощенска кутия: пишете ѝ, за да продължи да ви отговаря.
Приятно четене!
Post Syndicated from Йоанна Елми original https://toest.bg/koy-razprostranyava-manipulativnoto-sudurzhanie/
Два от най-популярните в България сайтове за дезинформация и конспирации имат почти идентични имена – Bulgarian Times и The Bulgarian Times. Собственик и главен редактор на първия, bultimes.bg, е Константин Петков. На другия, thebulgariantimes.com, собствеността официално не е известна – за него сме писали и в предишни материали от поредицата.
В социалните мрежи всяка статия на bultimes.bg интензивно се разпространява от Петков в множество антисистемни и проруски групи с хиляди последователи.


Същият модел се следва от thebulgariantimes.com, чиито статии се споделят от анонимен профил без снимки и данни на име Dora Yoveva. Това става на ежедневна база, често непосредствено след публикуването на материалите в сайтовете.


В своя сайт Константин Петков публикува най-разнообразни твърдения още от времето на пандемята: от това, че в румънски болници убиват пациенти с COVID-19 през 2021 г., през опровергани изказвания на доц. Анастас Мангъров, до това как Русия успява преди всички да пусне най-ефективната ваксина срещу заболяването. Но манипулативното съдържание далеч не е само открито подвеждащо или невярно – сайтът препечатва изказвания на премиера Борисов, цитира легитимни медии и използва реални събития и новини, за да прокарва определени тези и нагласи.
Две години по-късно темата, разбира се, е друга: Русия ще си връща Аляска, а САЩ иска да заличи не само българското, но дори не разрешава на украинците да мислят и говорят за мир. Западът е в упадък, Русия е силна, Украйна е загубена. Статиите са препечатани от новинарски сайтове – в bultimes.bg почти няма авторско съдържание. Сайтът използва познати похвати: новина от Dir.bg за Зеленски се препечатва и заглавието се променя така, че да се цитира Путин, а повечето от материалите са тълкувани превратно в полза на обрисуването на Русия в положителна светлина.
Така с препубликуване на чуждо съдържание и превратни тълкувания сайтът печели широка популярност и влияние (в т.ч. и за собственика си), а същевременно генерираните кликове носят и добри приходи от реклама – страницата е изпъстрена с банери на GoogleAds. И това е само видимото на повърхността.
За разлика от множество анонимни сайтове, Константин Петков не подвежда своите читатели – той описва медията си като частна, с хумористичен оттенък, и отбелязва, че в секцията „Конспирации“ се публикуват „статии предимно с алтернативно мислене за нещата“. Освен това Петков разграничава сайта си от редица други източници на манипулативна информация със сходни домейни. Но в публичния профил на Петков отсъства всякаква информация за медията му, чиито статии той разпространява в десетки групи ежедневно, достигайки до хиляди потребители.
Така например статия в Bulgaria ON AIR има 184 интеракции във Facebook към 8 юли, докато препечатка на същия материал в сайта на Петков има над 2000. Сред най-честите групи, в които Петков разпространява статиите си, са „Приятели на В.В. Путин в България“, „Ние не искаме война с Русия“, „Подкрепа за Стефан Янев“, „Аз НЯМА да гласувам за Бойко Борисов и ГЕРБ!“, „Строго секретно НЛО извънземни конспирации Бог Вселена тайни и загадки“, „Приятели на Россия!“.
Личният му профил също служи за своеобразна медия, в която обикновено се коментират събитията на деня – в периода от 1 до 4 юли Петков поства над 30 пъти, като повечето публикации са подчертано антизападни и проруски. Личните му постове също се споделят и харесват от десетки. Цената на това влияние не е висока. Дивидентите и последствията обаче са повече от сериозни.
Със сигурност е изкушаващо да обявим потребители като Константин Петков за „платени тролове“, но истината е, че подобни заключения са прибързани и трудни за доказване.
Профилът на Петков от създаването му през 2010 г. досега отразява актуалните конспирации на времето. През 2011 г. Петков публикува антисемитско съдържание, конспирации за намаляване на населението и за НЛО, както и публикации, свързващи американското семейство Буш със сатанистите. През 2012 г. постовете му се въртят около края на света според календара на маите, а от 2013 г. нататък е активен по темата за Сирия. По същото време (съвпадащо с Евромайдана в Украйна) Петков започва активно да публикува съдържание, свързано със Сорос, „еврофашизма“, „нелегалните мигранти“, сравнения на ЕС със СССР, предсказания на Ванга за Русия, пропутински постове. През годините профилът му набира популярност, а през 2016 г. той основава медията си bultimes.bg.
Описанието на bultimes.bg има стилистични прилики с описанието на друг, вече неактивен домейн, bultimes.com, регистриран през 2015 г. и управляван от Крум Фильовски до спирането на дейността пет години по-късно. Последната снимка в Wayback Machine на bultimes.com като действащ сайт е от 30 септември 2020 г. – и съвпадение или не, през септември и октомври същата година са създадени bultimes.info и thebulgariantimes.com, чиито собственици официално не са известни. В допълнение на това, с подобно име са регистрирани други домейни, повечето от които вече неактивни. Скорошни публикувани материали на bultimes.info препращат към други сайтове с проруско и антисистемно съдържание – като например budnaera.com.
В bultimes.info има съдържание не само на български, но и на английски, френски, немски и руски, а в края на статиите се заявява в пряк текст (правописът е запазен):
Ние не разполагаме с ресурсите да проверява информацията, която достига до редакцията и не гарантираме за истинността ѝ, поради което, в края на всяка статия е посочен източникът ѝ, освен ако не е авторска. Възможно е тази статия да не е истина, както и всяка прилика с действителни лица и събития да е случайна.
Напълно идентична формулировка (с все правописните грешки) откриваме в редица други сайтове, публикували не само проруско и антинаучно съдържание, но и препечатки, статии за битови престъпления и конспирации: bulnews.info, bulpress.top (сравнително нискоактивен), bulpress.info (силно про-БСП), patrioti.net, bez-cenzura.info, netvesti.com, actualno.top (неактивен от 2019 г.), bultimes.eu. Част от сайтовете са свързани с т.нар. „ферми за тролове“ в Шумен, където са регистрирани и до днес според проверка на домейните.
Константин Петков препубликува постове на Крум Фильовски още през 2013 г., но на 3 август 2016 г. публично разказва за сериозния разрив между тях. По-долу в коментарите под статуса си Петков заявява, че двамата заедно са движили „Бултаймс“ (bultimes.com), тъй като Фильовски е бил „един от най-добрите приятели“, но впоследствие е откраднал проекта му. Двамата са плащали домейна заедно, а след разрива Фильовски се определя като действителен и реален собственик на bultimes.com, който, както споменахме, е неактивен от 2020 г. насам и е вероятно заместен от thebulgariantimes.com – предвид идентичното лого и описание. Същевременно на 6 октомври 2016 г. Петков регистрира „Константин медия“ ЕООД с 200 лв. начален капитал и създава собствен сайт (bultimes.bg).
Дотук се изчерпват и проверимите факти, а остават въпросите. Свързани ли са тези и други лица помежду си? Организирани ли са, или става въпрос за „тролски войни“, за борба за кликове и приходите от тях, в която автори и имитатори се надпреварват за пазар? Злонамерени ли са действащите лица, или наистина вярват в манипулативното съдържание, което разпространяват? И свързани ли са домейните с идентични имена с едни и същи лица? На своя сайт Петков заявява, че „Bultimes.bg няма нищо общо със сайтовете Bultimes.com, Bultimes.net, Bultimes.eu, Bultimes.info, Thebulgariantimes.com“.
Материали от описаните сайтове са срещани в почти всички проруски групи и групи, насочени срещу антиковидните мерки. Статиите не се разпространяват само от създателите си, нито непременно от фалшиви акаунти, вероятно свързани с тях – макар да разчитат основно на тези техники за достигане до повече потребители.
Има няколко проблема при характеризирането на тези практики. На първо място, не става въпрос единствено за невярна информация, която лесно може да бъде опровергана: препечатките от легитимни медии и цитатите от публични личности съдържат потвърдена информация. Тази истинска информация се смесва с невярна или се тълкува манипулативно, така че да постигне определено внушение.
Следващият въпрос е дали определени практики – като например цитираната по-горе формулировка, че „е възможно статията да не е истина“ – са сигнал за координирана дейност, или просто за копиране на чужди похвати. Същевременно е трудно да се определят мотивите на авторите на подобен тип съдържание: дали става въпрос за умели идеолози, които целят да получат надмощие; за опортюнисти, които печелят пари от провокативно съдържание; или за хора, които искрено вярват в съдържанието, което разпространяват.
Единственото сигурно е, че потребителите, които консумират и разпространяват такъв тип съдържание, са едновременно жертви и съучастници. Манипулацията си играе с често оправдани недоволства срещу институциите и медиите и ги трансформира в антисистемен гняв и апатия – такъв беше случаят с Истанбулската конвенция, Стратегията за детето и здравната криза около COVID-19. Във време на война и нарастваща икономическа несигурност това е особено опасно.
За да се сложи ред в хаоса, трябва да се адресират редица проблеми: липсата на прозрачност на медийната собственост и на ясни правила за администриране на страници в социалните мрежи, както и изобилието от анонимни профили, които системно разпространяват еднородно съдържание. В противен случай печелившите са ясни – хора, които експлоатират слабостите в множество системи и печелят реални пари от още по-реални и наболели проблеми.



Post Syndicated from Нева Мичева original https://toest.bg/plus-vreme/
От доста време си блъскам главата върху следното: как човек може да е сигурен дали в дадена трудна ситуация, направил своя избор (дори и временен), е подходил с примирение или с приемане, и дали не се самозаблуждава, за да си осигури покой.
Умишлено избягвам думата „смирение“, макар да ми е любима, защото се използва твърде често и клиширано напоследък.
Цветелина М.
Колко интересно разполагаш тази главоблъсканица, Цвети. Центърът на въпроса е след събитията, когато изборът вече е направен, поражението (сякаш) е прегърнато и е дошъл моментът за равносметка. Обичайната тревога е как да изтълкуваме най-уместно ситуацията, за да я изведем в наша полза, а ти по-скоро се чудиш как да тълкуваш собственото си поведение в нея, без особен страх от конкретните ѝ последици – едно по-достоевско терзание. Само дето неизвестните тук са прекалено много, за да се стигне до работещ извод: „човек“ помещава твърде широк спектър от възможности и невъзможности, а „трудна ситуация“, „избор“, „самозаблуждение“ и „покой“ може да се дефинират по безброй начини, някои от които – противоположни. (Изключението потвърждава правилото, но да формулираш принцип на самонаблюдаващия се човек в криза е като да изведеш правило от изключения.) Защо обаче не добавим – за разкош – някое и друго разклонение?
Ако бях Шерлок Холмс, щях да започна от сочния паралипсис във второто ти изречение и да стигна до ясно заключение за твоята възраст, произход и кое предпочиташ – сладко или солено, котки или кучета, планина или море. Но тъй като не съм, ще си остана със започването. Паралипсисът е реторичен похват, при който обявяваме, че няма да кажем нещо, след което, привлекли вниманието на събеседниците си, все пак казваме нещото, при което то зрелищно се раздипля пред техните очакващи липса умове и постига двойно по-силен ефект, отколкото ако просто си го бяхме казали. Той е театрален, винаги оцветен в емоция и леко язвителен или комичен според случая, което много ми допада. Да не говорим, че е познат с поне няколко имена, от които избрах това, защото току-що открих, че на зевзешки така се наричало хроничното изтъняване на портфейла – състояние, което ми е свойствено и мило, откак се помня.
Та казваш, значи, че умишлено няма да употребиш „смирение“, като пътем не само употребяваш думата, но и си заплюваш територията ѝ, и теглиш границата под носа на злоупотребяващите с нея. Бих заложила цялото съдържание на припадничавия си портфейл, че смирението е голямата ти тема. Но тъй като тук търсим не решения, а разклонения, ще се насоча другаде. Знакът за равенство между примирението и смирението ми се вижда невъзможен: първото е преглъщане, второто – осъзнаване; първото е пасивно отстъпване пред даденостите, второто – наместване чрез активен разбор на даденостите; първото е потъване, второто – изплуване. Примирението идва от „мир“, а смирението – от „мяра“ според една от теориите, на които попаднах и която най-добре пасва на разбирането ми на двете думи.
Кротостта не е задължително послушание. Да знаеш, че от теб не зависи всичко, не ще рече да знаеш, че от теб не зависи нищо. Ако „примирение“ е да се съгласиш със средата, с която не можеш да излезеш на глава другояче, макар да ти се иска (безсилно отказване), „смирение“ е да се съгласуваш с хората и нещата наоколо чрез постоянното си/им оразмеряване (трезва преценка). Мога да си представя смирено действие, което променя околностите, но не и примирено. „Смирение“, разбира се, е дума, типична за религиозното говорене, в рамките на което неведнъж е означавала именно това, което сега влагам в „примирение“ – не толкова отсъствие на горделивост (тоест на раздуто усещане за себе си в света), колкото отсъствие на личност, на характер (откъде накъде ще имаш мнение и нужди, които не съвпадат с предварително зададените?). Религията обаче върви с цял набор от разбирания и практики, които не владея, както и с политически, икономически и други обвързаности, гмурването в които ще е безкрайно.
А нас тук ни занимава как да направим избор, който не ни е присърце, така че покоят, настъпващ дори след най-неохотно взетото решение, да е автентичен. Може би най-лесният начин да установим дали сме преодолели нещо чрез самозаблуждение, е да видим какво става с преодоляното по-нататък. Няма покой, стъпил на лъжа, който да трае дълго без употребата на насилие – истината напира, светът напира, природата напира, реалността може да бъде огъната само донякъде и след това се връща като плесница за всички наблизо. Ако спокойствието ни е натаманено, доизмислено, причините за предшестващото го безпокойство няма да изчезнат, а ще продължат да действат, докато не се разправим с тях. Комедията е трагедия плюс време, както се казва, откритията са хипотези плюс време, виното е грозде плюс време, и прочее, и прочее. „Плюс време“ е чудесна рецепта за проверка на нещата.
Чудя се дали вариантите за излизането от трудна ситуация са непременно през приемане, а не през отхвърляне (дори безизходиците понякога имат изход – назад до последния кръстопът). И какви ни прави приемането – по-мъдри, по-гъвкави, по-извисени? По-уморени? По-натоварени с чуждо съдържание? По-наплашени? Защо най-често призивът към смирение идва от хора в несмирена позиция, а останалите се връзват? Сами ли се разрешават лесните ситуации и дали въобще не говорим за „ситуация“ само ако има нещо, което препречва гладкия ход на събитията? Не е ли възможно по пътя на самозаблудата да се стигне до хубави и трайни състояния? Колко умуване е твърде много умуване? Как човек може да бъде сигурен в каквото и да било?
Преди няколко дни се върнах от фестивала в Карлови Вари, където наградата на журито спечели филм, в който нищо не се случва. Нищо, свързано с надмогване на спънки, с отсяване на варианти, с целенасочена промяна, избор между алтернативи, среща на различия, среща със себе си. Нищо не се отърква о друго, камо ли да се сблъска с него с хвърчене на искри и парчетии – всичко се точи с анонимността и приспивната равност на индустриален пейзаж през влаков прозорец. За мен цялата тази вътрешна и външна безсъбитийност е една от най-обидните загуби на време (а времето е ключовата съставка на толкова хубави неща, както казахме). Та дано продължим да си блъскаме главите, мила Цвети, да вземаме решения, когато е трудно, а после да се подозираме в склонност към непродуктивно удобство. Така ще стигнем до по-интересни места, отколкото по пътя в обратната посока. Хубаво лято!
Post Syndicated from Стефан Иванов original https://toest.bg/na-vtoro-chetene-tri-bulgarski-debyutni-stihosbirki/
Преди да припомня тези три дебютни книги с поезия, издадени миналата година, е важно да кажа, че едно от последните издания на „Арс“ и Scribens е изцяло благотворителната антология „Поезия срещу войната“. В нея 101 поети (80 от които – български) съжителстват заедно между кориците. Сред тях са Тарас Шевченко, Борис Христов, Юрий Андрухович, Марин Бодаков, Сергий Жадан, Силвия Чолева, Любов Якимчук, Никола Петров и много други. Появата на тази антология е изключително обнадеждаващ факт. Въпреки поляризацията в обществото и в политиката, а донякъде и в културата, поети спонтанно се събират за една ценна и смислена кауза. Като общност.
Едно от най-големите достойнства на издателската група „Арс“/Scribens е именно в последователните ѝ действия през годините по култивиране и подхранване на такава общност. Тя подкрепя и издава дебютанти и организира множество четения, работилници, срещи и разговори. Истинска похвала заслужава работата на Валентин Дишев, Георги Гаврилов, Анна Лазарова и останалите литературни активисти.
изд. Scribens, 2021
 Всяка от трите зрели и хубави дебютни стихосбирки е именно дълга среща и разговор. Още от първите страници от диалога с Ева Гочева се сетих за „Уморени от чудото“, първата стихосбирка на Георги Рупчев, и някак не се учудих, когато Рупчев буквално се появи в стих към края на книгата. Но за да се стигне до него и до преоткриването на тихото чудо, се преминава през целия гръбнак и съдържание на стихотворенията. От изцапаното до бялото и чистото е извървян дълъг път. По него, разбира се, има тъга, но и ясни, лаконични, открити, красиви и болезнено жестоки стихове. В тях София е пространство за едно бездомно всекидневие с множество потни и разплакани часове. Време на раздели и самота.
Всяка от трите зрели и хубави дебютни стихосбирки е именно дълга среща и разговор. Още от първите страници от диалога с Ева Гочева се сетих за „Уморени от чудото“, първата стихосбирка на Георги Рупчев, и някак не се учудих, когато Рупчев буквално се появи в стих към края на книгата. Но за да се стигне до него и до преоткриването на тихото чудо, се преминава през целия гръбнак и съдържание на стихотворенията. От изцапаното до бялото и чистото е извървян дълъг път. По него, разбира се, има тъга, но и ясни, лаконични, открити, красиви и болезнено жестоки стихове. В тях София е пространство за едно бездомно всекидневие с множество потни и разплакани часове. Време на раздели и самота.
Направи ми силно и хубаво впечатление, че това е конкретна, а не абстрактна поезия. Гочева не пише за неща и действия по принцип – не, те имат присъствие и силен образ. Думите ѝ, убеден съм, идват от преработен личен опит. Тя пише толкова уверено за безизходицата, че буквално усещам обнадежденото ѝ облекчение, което със сигурност я е обзело след написването на всяко хубаво стихотворение. Облекчението е заразително. И макар да се чува викът на окосената трева, макар да има атмосфера на паника, болка и тревога, да има памет за скръб, в сърцевината на книгата е жизнеутвърждаващата воля да спасиш собствения си живот. Да го наблюдаваш, да се губиш, да си във ваканция от него, докато го преоткриеш – в цялата му посчупена и сложна прелест.
В поезията на Гочева има уют, а това, че някои от стихотворенията елегантно се стягат като примка, само помага да се усети още по-силно вкусът на близостта и любовта в края на книгата. Когато не се възприемаш като чужденец в собствения си живот, можеш да си опитомиш паяк, да имаш чувство за хумор – и от метрото, куриерските фирми или графитите да изпадаш в пристъп на нежност. Изпитах удоволствие да чета една ненатрапчиво женствена и честна поезия с много въображение, която уверено показва, че е възможно да се живее в режим не на самосаботаж, а на радост и осъществени мечти.
изд. „Арс“, 2021
С Калина имаме общ терапевт – Езика! Заедно се учим и да споделяме открито уязвимостта си, и да пазим животворните тайни на преносните значения. Разпознахме се по сенките. А след тези стихотворения сенките са много по-вежливи с нас.
 Мога само да се съглася с тези думи на Марин Бодаков, редактор на дебютната стихосбирка на Калина Линкова. За някого може и да е неочаквано, но това е една много плътна и искрена поезия, която се основава колкото на аналитичната психология на Юнг, толкова и на изборите, историите и биографията на авторката си. Стихотворенията са фини и точни, но и ненатрапчиво изповедни и интимни.
Мога само да се съглася с тези думи на Марин Бодаков, редактор на дебютната стихосбирка на Калина Линкова. За някого може и да е неочаквано, но това е една много плътна и искрена поезия, която се основава колкото на аналитичната психология на Юнг, толкова и на изборите, историите и биографията на авторката си. Стихотворенията са фини и точни, но и ненатрапчиво изповедни и интимни.
Толкова се радвам, че липсват излишни игри на думи и каламбури. Езиковите открития са по-скоро игри на дълбинен смисъл. Те не са повърхностно шеговити или иронични намигвания. В техния минимализъм има тежест и ангажимент. Те са сериозни – и в това е тяхното достойнство. Стихотворенията се отличават с деликатност и устойчивост, с твърда крехкост. В тях, също както и при Гочева, има и особено сгъстено облекчение. Поетичните образи се родеят с някакъв укротен барок, отказал се от ненужна пищност, но познал блясъка му в пълнота. Много интересен блясък, който сякаш се оттегля, за да се видят нещата такива, каквито са. Без илюзии, но с гласувано доверие.
Стихотворенията скитат между светлосенки от ерудиция, любопитство, тайни и признания. Тази поезия ми припомни, че не само в литературата може да се придава смисъл. При това – без да има нужда от окончателно обяснение. Без да има нужда езикът и разумът да се стискат и да не се пускат в опит да са единствени гаранти за значение в живота. Едни от най-хубавите неща са и едни от най-необяснимите, но това не променя факта, че съществуват. В битката за себе си и в схватката с неназовимото бих казал, че Линкова е победител. От поезията ѝ се усещат цялостност, грижа и топлота. И щастие, което е абсурдно, подобно на всяка една пълноценност. Дано винаги е така.
изд. „Арс“, 2021
 При Камелия Панайотова има една специфична, овладяна, хладна, но и много наситена тъга. Учудващо е колко болезнено и добре узрели са тези стихотворения за един толкова млад и дебютиращ автор. На пръв поглед в тях липсват събития. Най-важното сякаш вече се е случило и на бойното поле на всекидневието има останки, има оцелели и подлежащи на лечение образи, спомени и предизвикателства.
При Камелия Панайотова има една специфична, овладяна, хладна, но и много наситена тъга. Учудващо е колко болезнено и добре узрели са тези стихотворения за един толкова млад и дебютиращ автор. На пръв поглед в тях липсват събития. Най-важното сякаш вече се е случило и на бойното поле на всекидневието има останки, има оцелели и подлежащи на лечение образи, спомени и предизвикателства.
Цялата книга е красноречив и успешен отговор на това как да се скъса с парализиращата тъга. Книгата предоставя достатъчно доказателства, че можеш да се справиш с живота, и то преди той да се справи с теб. Но това не отменя факта, че не е лесно, че има белези и рани, че има минало, от което плачеш. Наистина беше ценно за мен да следя поредицата от озарения на всекидневно ниво, с които е изпъстрена поезията на Панайотова. Как се губят илюзии, но се печелят наслада, усмивка и приемане. Печелят се зрялост и смелост, сила и издръжливост.
Общото между трите книги е, че са несъмнена част от ценната съвременна българска поезия. И също така, че ударението и при трите е поставено върху споделянето. В тях има стремеж към спокойствие, време за себе си и време за проумяване какво въобще става наоколо. Не само в социален, икономически, политически или културен план, но и в личен. Забележително е колко смело и трите авторки гледат към себе си и към най-страшното възможно – и не отвръщат поглед. Това е поезия, която говори за днешния ден и за днешния човек, не само за себе си. Заслужава да я четем, да я чуем, да се вслушаме в нея.
Post Syndicated from Janice Leung original https://aws.amazon.com/blogs/security/aws-achieves-tisax-certification-information-with-very-high-protection-needs-al3/
We’re excited to announce the completion of the Trusted Information Security Assessment Exchange (TISAX) certification on June 30, 2022 for 19 AWS Regions. These Regions achieved the Information with Very High Protection Needs (AL3) label for the control domains Information Handling and Data Protection. This alignment with TISAX requirements demonstrates our continued commitment to adhere to the heightened expectations for cloud service providers. AWS automotive customers can run their applications in the AWS Cloud certified Regions in confidence.
The following 19 Regions are currently TISAX certified:
TISAX is a European automotive industry-standard information security assessment (ISA) catalog based on key aspects of information security, such as data protection and connection to third parties.
AWS was evaluated and certified by independent third-party auditors on June 30, 2022. The Certificate of Compliance demonstrating the AWS compliance status is available on the European Network Exchange (ENX) Portal (the scope ID and assessment ID are SM22TH and AYA2D4-1, respectively) and through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
For up-to-date information, including when additional Regions are added, see the AWS Compliance Program, and choose TISAX.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about TISAX compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Post Syndicated from Janice Leung original https://aws.amazon.com/blogs/security/aws-achieves-hds-certification-to-three-additional-regions/
We’re excited to announce that three additional AWS Regions—Asia Pacific (Korea), Europe (London), and Europe (Stockholm)—have been granted the Health Data Hosting (Hébergeur de Données de Santé, HDS) certification. This alignment with the HDS requirements demonstrates our continued commitment to adhere to the heightened expectations for cloud service providers. AWS customers who handle personal health data can be hosted in the AWS Cloud certified Regions with confidence.
The following 16 Regions are now in scope of this certification:
Introduced by the French governmental agency for health, Agence Française de la Santé Numérique (ASIP Santé), HDS certification aims to strengthen the security and protection of personal health data. Achieving this certification demonstrates that AWS provides a framework for technical and governance measures to secure and protect personal health data, governed by French law.
AWS was evaluated and certified by independent third-party auditors on June 30, 2022. The Certificate of Compliance demonstrating the AWS compliance status is available on the Agence du Numérique en Santé (ANS) website and through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
For up-to-date information, including when additional Regions are added, see the AWS Compliance Program, and choose HDS.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about HDS compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Post Syndicated from Suresh Patnam original https://aws.amazon.com/blogs/big-data/part-2-migrate-a-large-data-warehouse-from-greenplum-to-amazon-redshift-using-aws-sct/
In this second post of a multi-part series, we share best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns. You can check out the first post of this series for guidance on planning, running, and validation of a large-scale data warehouse migration from Greenplum to Amazon Redshift using AWS Schema Conversion Tool (AWS SCT).
Amazon Redshift has two types of clusters: provisioned and serverless. For provisioned clusters, you need to set up the same with required compute resources. Amazon Redshift Serverless can run high-performance analytics in the cloud at any scale. For more information, refer to Introducing Amazon Redshift Serverless – Run Analytics At Any Scale Without Having to Manage Data Warehouse Infrastructure.
An Amazon Redshift cluster consists of nodes. Each cluster has a leader node and one or more compute nodes. The leader node receives queries from client applications, parses the queries, and develops query run plans. The leader node then coordinates the parallel run of these plans with the compute nodes and aggregates the intermediate results from these nodes. It then returns the results to the client applications.
When determining your type of cluster, consider the following:
With AWS SCT extraction agents, you can migrate your source tables in parallel. These extraction agents authenticate using a valid user on the data source, allowing you to adjust the resources available for that user during the extraction. AWS SCT agents process the data locally and upload it to Amazon Simple Storage Service (Amazon S3) through the network (via AWS Direct Connect). We recommend having a consistent network bandwidth between your Greenplum machine where the AWS SCT agent is installed and your AWS Region.
If you have tables around 20 million rows or 1 TB in size, you can use the virtual partitioning feature on AWS SCT to extract data from those tables. This creates several sub-tasks and parallelizes the data extraction process for this table. Therefore, we recommend creating two groups of tasks for each schema that you migrate: one for small tables and one for large tables using virtual partitions.
For more information, refer to Creating, running, and monitoring an AWS SCT data extraction task.
To simplify and modernize your data architecture, consider the following:
In this section, we share best practices for stored procedure migration from Greenplum to Amazon Redshift. Data processing pipelines with complex business logic often use stored procedures to perform the data transformation. We advise using big data processing like AWS Glue or Amazon EMR to modernize your extract, transform, and load (ETL) jobs. For more information, check out Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift. For time-sensitive migration to cloud-native data warehouses like Amazon Redshift, redesigning and developing the entire pipeline in a cloud-native ETL tool might be time-consuming. Therefore, migrating the stored procedures from Greenplum to Amazon Redshift stored procedures can be the right choice.
For a successful migration, make sure to follow Amazon Redshift stored procedure best practices:
sp_. Amazon Redshift reserves the sp_ prefix exclusively for stored procedures. By prefixing your procedure names with sp_, you ensure that your procedure name won’t conflict with any existing or future Amazon Redshift procedure names.You can use IDENTITY columns, system timestamps, or epoch time as an option to ensure uniqueness. The IDENTITY column or a timestamp-based solution might have sparse values, so if you need a continuous number sequence, you need to use dedicated number tables. You can also use of the RANK() or ROW_NUMBER() window function over the entire set. Alternatively, get the high-water mark from the existing ID column from the table and increment the values while inserting records.
Greenplum char and varchar data type length is specified in terms of character length, including multi-byte ones. Amazon Redshift character types are defined in terms of bytes. For table columns using multi-byte character sets in Greenplum, the converted table column in Amazon Redshift should allocate adequate storage to the actual byte size of the source data.
An easy workaround is to set the Amazon Redshift character column length to four times larger than the corresponding Greenplum column length.
A best practice is to use the smallest possible column size. Amazon Redshift doesn’t allocate storage space according to the length of the attribute; it allocates storage according to the real length of the stored string. However, at runtime, while processing queries, Amazon Redshift allocates memory according to the length of the attribute. Therefore, not setting a default size of four times greater helps from a performance perspective.
An efficient solution is to analyze production datasets and determine the maximum byte size length of the Greenplum character columns. Add a 20% buffer to support future incremental growth on the table.
To arrive at the actual byte size length of an existing column, run the Greenplum data structure character utility from the AWS Samples GitHub repo.
The Amazon Redshift numeric data type has a limit to store up to maximum precision of 38, whereas in a Greenplum database, you can define a numeric column without any defined length.
Analyze your production datasets and determine numeric overflow candidates using the Greenplum data structure numeric utility from the AWS Samples GitHub repo. For numeric data, you have options to tackle this based on your use case. For numbers with a decimal part, you have the option to round the data based on the data type without any data loss in the whole number part. For future reference, you can a keep copy of the column in VARCHAR or store in an S3 data lake. If you see an extremely small percentage of an outlier of overflow data, clean up the source data for quality data migration.
While converting SQL scripts or stored procedures to Amazon Redshift, if you encounter unsupported functions, database objects, or code blocks for which you might have to rewrite the query, create user-defined functions (UDFs), or redesign. You can create a custom scalar UDF using either a SQL SELECT clause or a Python program. The new function is stored in the database and is available for any user with sufficient privileges to run. You run a custom scalar UDF in much the same way as you run existing Amazon Redshift functions to match any functionality of legacy databases. The following are some examples of alternate query statements and ways to achieve specific aggregations that might be required during a code rewrite.
The Greenplum function AGE () returns an interval subtracting from the current date. You could accomplish the same using a subset of MONTHS_BETWEEN(), ADD_MONTH(), DATEDIFF(), and TRUNC() functions based on your use case.
The following example Amazon Redshift query calculates the gap between the date 2001-04-10 and 1957-06-13 in terms of year, month, and days. You can apply this to any date column in a table.

If you have a use case to get distinct aggregation in the Count() window function, you could accomplish the same using a combination of the Dense_Rank () and Max() window functions.
The following example Amazon Redshift query calculates the distinct item count for a given date of sale:
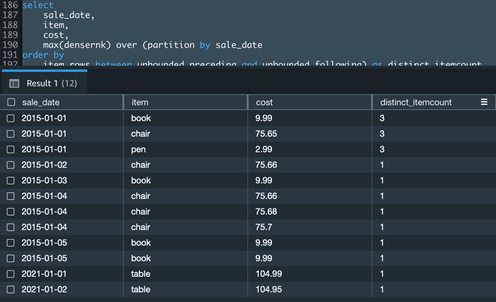
Amazon Redshift aggregate window functions with an ORDER BY clause require a mandatory frame.
The following example Amazon Redshift query creates a cumulative sum of cost by sale date and orders the results by item within the partition:

In Greenplum, STRING_AGG() is an aggregate function, which is used to concatenate a list of strings. In Amazon Redshift, use the LISTAGG() function.
The following example Amazon Redshift query returns a semicolon-separated list of email addresses for each department:

In Greenplum, ARRAY_AGG() is an aggregate function that takes a set of values as input and returns an array. In Amazon Redshift, use a combination of the LISTAGG() and SPLIT_TO_ARRAY() functions. The SPLIT_TO_ARRAY() function returns a SUPER datatype.
The following example Amazon Redshift query returns an array of email addresses for each department:

To retrieve array elements from a SUPER expression, you can use the SUBARRAY() function:

In Greenplum, you can use the UNNEST function to split an array and convert the array elements into a set of rows. In Amazon Redshift, you can use PartiQL syntax to iterate over SUPER arrays. For more information, refer to Querying semistructured data.

You can’t use a window function in the WHERE clause of a query in Amazon Redshift. Instead, construct the query using the WITH clause and then refer the calculated column in the WHERE clause.
The following example Amazon Redshift query returns the sale date, item, and cost from a table for the sales dates where the total sale is more than 100:

Refer to the following table for additional Greenplum date/time functions along with the Amazon Redshift equivalent to accelerate you code migration.
| . | Description | Greenplum | Amazon Redshift |
| 1 | The now() function return the start time of the current transaction |
now () |
sysdate |
| 2 | clock_timestamp() returns the start timestamp of the current statement within a transaction block |
clock_timestamp () |
to_date(getdate(),'yyyy-mm-dd') + substring(timeofday(),12,15)::timetz |
| 3 | transaction_timestamp () returns the start timestamp of the current transaction |
transaction_timestamp () |
to_date(getdate(),'yyyy-mm-dd') + substring(timeofday(),12,15)::timetz |
| 4 | Interval – This function adds x years and y months to the date_time_column and returns a timestamp type |
date_time_column + interval ‘ x years y months’ |
add_months(date_time_column, x*12 + y) |
| 5 | Get total number of seconds between two-time stamp fields | date_part('day', end_ts - start_ts) * 24 * 60 * 60+ date_part('hours', end_ts - start_ts) * 60 * 60+ date_part('minutes', end_ts - start_ts) * 60+ date_part('seconds', end_ts - start_ts) |
datediff('seconds', start_ts, end_ts) |
| 6 | Get total number of minutes between two-time stamp fields | date_part('day', end_ts - start_ts) * 24 * 60 + date_part('hours', end_ts - start_ts) * 60 + date_part('minutes', end_ts - start_ts) |
datediff('minutes', start_ts, end_ts) |
| 7 | Extract date part literal from difference of two-time stamp fields | date_part('hour', end_ts - start_ts) |
extract(hour from (date_time_column_2 - date_time_column_1)) |
| 8 | Function to return the ISO day of the week | date_part('isodow', date_time_column) |
TO_CHAR(date_time_column, 'ID') |
| 9 | Function to return ISO year from date time field | extract (isoyear from date_time_column) |
TO_CHAR(date_time_column, ‘IYYY’) |
| 10 | Convert epoch seconds to equivalent datetime | to_timestamp(epoch seconds) |
TIMESTAMP 'epoch' + Number_of_seconds * interval '1 second' |
The Amazon Redshift Utilities GitHub repo contains a set of utilities to accelerate troubleshooting or analysis on Amazon Redshift. Such utilities consist of queries, views, and scripts. They are not deployed by default onto Amazon Redshift clusters. The best practice is to deploy the needed views into the admin schema.
In this post, we covered prescriptive guidance around data types, functions, and stored procedures to accelerate the migration process from Greenplum to Amazon Redshift. Although this post describes modernizing and moving to a cloud warehouse, you should be augmenting this transformation process towards a full-fledged modern data architecture. The AWS Cloud enables you to be more data-driven by supporting multiple use cases. For a modern data architecture, you should use purposeful data stores like Amazon S3, Amazon Redshift, Amazon Timestream, and others based on your use case.
 Suresh Patnam is a Principal Solutions Architect at AWS. He is passionate about helping businesses of all sizes transforming into fast-moving digital organizations focusing on big data, data lakes, and AI/ML. Suresh holds a MBA degree from Duke University- Fuqua School of Business and MS in CIS from Missouri State University. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Principal Solutions Architect at AWS. He is passionate about helping businesses of all sizes transforming into fast-moving digital organizations focusing on big data, data lakes, and AI/ML. Suresh holds a MBA degree from Duke University- Fuqua School of Business and MS in CIS from Missouri State University. In his spare time, Suresh enjoys playing tennis and spending time with his family.
 Arunabha Datta is a Sr. Data Architect at AWS Professional Services. He collaborates with customers and partners to architect and implement modern data architecture using AWS Analytics services. In his spare time, Arunabha enjoys photography and spending time with his family.
Arunabha Datta is a Sr. Data Architect at AWS Professional Services. He collaborates with customers and partners to architect and implement modern data architecture using AWS Analytics services. In his spare time, Arunabha enjoys photography and spending time with his family.
Post Syndicated from Suresh Patnam original https://aws.amazon.com/blogs/big-data/part-1-migrate-a-large-data-warehouse-from-greenplum-to-amazon-redshift-using-aws-sct/
A data warehouse collects and consolidates data from various sources within your organization. It’s used as a centralized data repository for analytics and business intelligence.
When working with on-premises legacy data warehouses, scaling the size of your data warehouse or improving performance can mean purchasing new hardware or adding more powerful hardware. This is often expensive and time-consuming. Running your own on-premises data warehouse also requires hiring database managers, administrators to deal with outages, upgrades, and data access requests. As companies become more data-driven, reliable access to centralized data is increasingly important. As a result, there is a strong demand for data warehouses that are fast, accessible, and able to scale elastically with business needs. Cloud data warehouses like Amazon Redshift address these needs while eliminating the cost and risk of purchasing new hardware.
This multi-part series explains how to migrate an on-premises Greenplum data warehouse to Amazon Redshift using AWS Schema Conversion Tool (AWS SCT). In this first post, we describe how to plan, run, and validate the large-scale data warehouse migration. It covers the solution overview, migration assessment, and guidance on technical and business validation. In the second post, we share best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns.
Amazon Redshift is an industry-leading cloud data warehouse. Amazon Redshift uses Structured Query Language (SQL) to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes using AWS-designed hardware and machine learning to deliver the best price-performance at any scale.
AWS SCT makes heterogeneous database migrations predictable by automatically converting the source database schema and most of the database code objects, SQL scripts, views, stored procedures, and functions to a format compatible with the target database. AWS SCT helps you modernize your applications simultaneously during database migration. When schema conversion is complete, AWS SCT can help migrate data from various data warehouses to Amazon Redshift using data extraction agents.
The following diagram illustrates our architecture for migrating data from Greenplum to Amazon Redshift using AWS SCT data extraction agents.
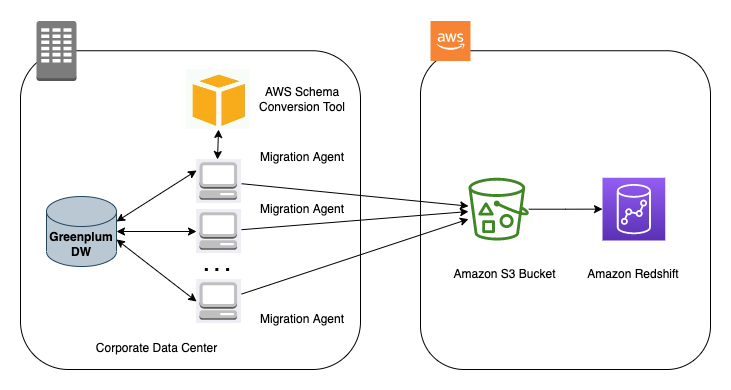
The initial data migration is the first milestone of the project. The main requirements for this phase are to minimize the impact on the data source and transfer the data as fast as possible. To do this, AWS offers several options, depending on the size of the database, network performance (AWS Direct Connect or AWS Snowball), and whether the migration is heterogeneous or not (AWS Database Migration Service (AWS DMS) or AWS SCT).
AWS provides a portfolio of cloud data migration services to provide the right solution for any data migration project. The level of connectivity is a significant factor in data migration, and AWS has offerings that can address your hybrid cloud storage, online data transfer, and offline data transfer needs.
Additionally, the AWS Snow Family makes it simple to get your data into and out of AWS via offline methods. Based on the size of the data, you can use AWS Snowmobile or AWS Snowball if you have petabytes to exabytes of data. To decide which transfer method is better for your use case, refer to Performance for AWS Snowball.
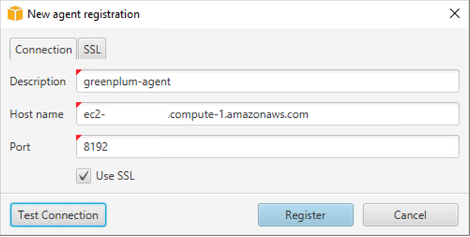
To convert your schema using AWS SCT, you must start a new AWS SCT project and connect your databases. Complete the following steps:










To start your data migration using AWS SCT data extraction agents, complete the following steps:
Now you configure the AWS SCT extractor to perform a one-time data move. You can use multiple extractors when dealing with a large volume of data.

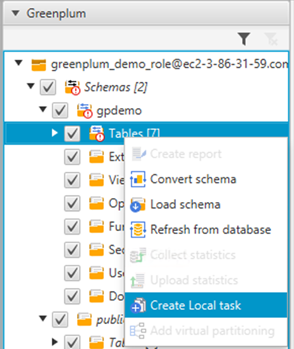



You can choose each task to get a detailed breakdown of its activity. Make sure to examine errors during the extract, upload, and copy process.

You can monitor the status of the tasks, the percentage completed, and the tables that were loaded successfully. You must also verify the count of records loaded into the Amazon Redshift database.

After the initial extracted data is loaded to Amazon Redshift, you must perform data validation tests in parallel. The goal at this stage is to validate production workloads, comparing Greenplum and Amazon Redshift outputs from the same inputs.
Typical activities covered during this phase include the following:
After you successfully migrate the data and validate the data movement, the last remaining task is to involve the data warehouse users in the validation process. These users from different business units across the company access the data warehouse using various tools and methods: JDBC/ODBC clients, Python scripts, custom applications, and more. It’s central to the migration to make sure that every end-user has verified and adapted this process to work seamlessly with Amazon Redshift before the final cutover.
This phase can consist of several tasks:
This business validation phase is key so all end-users are aligned and ready for the final cutover. Following Amazon Redshift best practices enables end-users to fully take advantage of the capabilities of their new data warehouse. After you perform all the migration validation tasks, connect and test every ETL job, business process, external system, and user tool against Amazon Redshift, you can disconnect every process from the old data warehouse, which you can now safely power off and decommission.
In this post, we provided detailed steps to migrate from Greenplum to Amazon Redshift using AWS SCT. Although this post describes modernizing and moving to a cloud warehouse, you should be augmenting this transformation process towards a full-fledged modern data architecture. The AWS Cloud enables you to be more data-driven by supporting multiple use cases. For a modern data architecture, you should use purposeful data stores like Amazon S3, Amazon Redshift, Amazon Timestream, and other data stores based on your use case.
Check out the second post in this series, where we cover prescriptive guidance around data types, functions, and stored procedures.
Suresh Patnam is a Principal Solutions Architect at AWS. He is passionate about helping businesses of all sizes transforming into fast-moving digital organizations focusing on big data, data lakes, and AI/ML. Suresh holds a MBA degree from Duke University- Fuqua School of Business and MS in CIS from Missouri State University. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Arunabha Datta is a Sr. Data Architect at Amazon Web Services (AWS). He collaborates with customers and partners to architect and implement modern data architecture using AWS Analytics services. In his spare time, Arunabha enjoys photography and spending time with his family.
Post Syndicated from LGR original https://www.youtube.com/watch?v=v7EBULRaOnA
Post Syndicated from Grant Willcox original https://blog.rapid7.com/2022/07/15/metasploit-weekly-wrap-up-166/

Community contributor Heyder Andrade added in a new module for a Java deserialization vulnerability in JBOSS EAP/AS Remoting Unified Invoker interface for versions 6.1.0 and prior. As far as we can tell this was first disclosed by Joao Matos in his paper at AlligatorCon. Later a PoC from Marcio Almeida came out that Heyder Andrade used as the basis for his Metasploit module. The exploit allows an unauthenticated attacker with network access to JBOSS EAP/AS <= 6.1.0 Remoting Unified Invoker interface to gain RCE as the user jboss by sending a crafted serialized object to this interface.
Deserialization attacks have certainly been quite popular as of late but we haven’t seen many in JBOSS lately so we appreciate the efforts of these contributors to provide us with some alternative deserialization attacks 🙂
One unauthenticated RCE is nice for a weekly wrapup, but we can always do better. Why not make it two this week? Courtesy of Spencer McIntyre and Altelus1‘s PoC, we now have a Metasploit module for CVE-2022-23642, an unauthenticated RCE in Sourcegraph Gitserver prior to 3.37.0 that allows attackers to execute arbitrary OS commands by modifying the core.sshCommand value within the git configuration. Successful exploitation will allow an unauthenticated attacker to execute commands in the context of the Sourcegraph Gitserver server.
This is another cool attack, as we don’t often see these types of configuration-related issues leading to unauthenticated RCE; typically when they do crop up, there are limitations on what one can do. However in this case we ended up with a full RCE as an unauthenticated user, which goes to show that even less common or more frequently overlooked issues under the right scenario can be exploited to gain privileged access.
Finally, community contributor npm-cesium137-io added a new module to decrypt Citrix Netscaler appliance configuration files and recover secrets encrypted with the KEK encryption scheme, provided you have the key fragment files.
We have heard both from npm-cesium137-io and others that Citrix Netscaler has been seen on a number of pen testing engagements so hopefully this module should assist those pen testing these environments by allowing them to more easily obtain secrets during their engagements.
HTTP::shuffle_get_params, and HTTP::shuffle_post_params that allow users to randomize the order of the POST and GET parameters to evade static signatures.ipv6_neighbor module that caused hosts to be missed when the scanned range was very short due to an adaptive timeout with an insufficient floor value.tftp command stager fail due to a missing tftphost option. This ensures that the tftphost host is set and valid before proceeding with creating the command stager.As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=Aaiovdogn30
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=DBJ0b0FR8_A
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=uuVjcqa9gdA
Post Syndicated from original https://lwn.net/Articles/901059/
A page-table entry (PTE) is relatively small, requiring just eight bytes to refer to a
4096-byte page on most systems. It thus does not seem like a worrisome
level of overhead, and little effort has been made over the kernel’s
history to reduce page-table memory consumption. Those eight bytes can
hurt, though, if they are replicated across a sufficiently large set of
processes. The msharefs
patch set from Khalid Aziz is a revised attempt to address that
problem, but it is proving to be a hard sell in the memory-management
community.
Post Syndicated from original https://lwn.net/Articles/901412/
Security updates have been issued by Debian (webkit2gtk and wpewebkit), Fedora (curl, kernel, openssl1.1, php, subversion, xorg-x11-server, and xorg-x11-server-Xwayland), Oracle (grub2), SUSE (gnutls, kernel, logrotate, oracleasm, p11-kit, and python-PyJWT), and Ubuntu (libhttp-daemon-perl and python2.7, python3.10, python3.4, python3.5, python3.6, python3.8, python3.9).
Post Syndicated from original https://lwn.net/Articles/901367/
The stable kernel updates that were due on July 14 have been delayed for
several days, according to Greg
Kroah-Hartman, due to problems that have come up with the Retbleed
mitigation patches.
The problems are purely due to the fact that we were forced to do
this type of work “in private” with very limited ability for
testing by the normal larger kernel community like we rely on. We
don’t have fancy or huge private testing labs where we can do all
of this work as we are an open source project, and we rely on open
testing in public.
The ongoing problems might yet slow down the 5.19 release as well.
Update: there has actually been a different set of updates
released:
5.18.12,
5.15.55,
5.10.131, and
5.4.206. These revert a single problematic
MTD patch.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}