Post Syndicated from The Atlantic original https://www.youtube.com/shorts/L2clKOwNUac
AMD Ryzen Threadripper 9980X Review Still Better
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/amd-ryzen-threadripper-9980x-review-still-better/
The AMD Ryzen Threadripper 9980X is AMD’s newest 64-core HEDT processor bringing more performance to workstations
The post AMD Ryzen Threadripper 9980X Review Still Better appeared first on ServeTheHome.
How to migrate your Amazon EC2 Oracle Transparent Data Encryption database encryption keystore to AWS CloudHSM
Post Syndicated from Bhushan Bhale original https://aws.amazon.com/blogs/security/how-to-migrate-your-ec2-oracle-transparent-data-encryption-tde-database-encryption-wallet-to-cloudhsm/
July 30, 2025: This post has been republished to migrate the Amazon EC2 Oracle Transparent Data Encryption database encryption keystore to AWS CloudHSM using AWS CloudHSM Client SDK 5.
Encrypting databases is crucial for protecting sensitive data, helping you to be aligned with security regulations and safeguarding against data loss. Oracle Transparent Data Encryption (TDE) is a feature that you can use to encrypt data at rest within an Oracle database. TDE uses envelope encryption. Envelope encryption is when the encryption key used to encrypt the tables of your database is encrypted by a primary key that resides either in a software keystore or on a hardware keystore, such as a hardware security module (HSM). This primary key is non-exportable by design to protect the confidentiality and integrity of your database operation. This gives you a more granular encryption scheme on your data. Hence, TDE for Oracle is a common use case for HSM devices such as AWS CloudHSM.
Oracle TDE supports keystores to securely store the TDE primary encryption keys. You can use either the TDE wallet (software keystore) or external key managers such as an HSM device. In this solution, we show you how to migrate a TDE keystore for an Oracle 19c database installed on Amazon Elastic Compute Cloud (Amazon EC2) from a software-based TDE wallet to AWS CloudHSM.
Using an external key manager, such as CloudHSM, offers several benefits over keeping keys on the Oracle wallet on the host:
- Enhanced security: CloudHSM provides FIPS 140 validated hardware security, keeping the encryption key in a tamper-resistant module.
- Centralized key management: CloudHSM supports centralized management of encryption keys, making it straightforward to rotate, back up, and audit keys.
- Compliance: Your regulatory requirements may include encryption, and using CloudHSM can help you meet these compliance needs.
When you move from one type of keystore to another, new TDE primary keys are created inside the new keystore. To make sure that you have access to backups that rely on your past encryption keys, consider leaving the keystore running for your normal recovery window period or copying existing keys to the new keystore with exact key labels. Being able to access prior primary keys will help avoid data re-encryption.
You can use TDE to encrypt data online or offline. Encrypting TDE tablespace online minimizes disruption to database operations; however, it requires twice the storage space as the tablespace being encrypted, because the encryption process happens on a copy of the original tablespace.
Solution overview
In this solution, you migrate a TDE keystore for an Oracle 19c database from a software-based TDE wallet to CloudHSM, using the steps shown in Figure 1. Start by moving the current encryption keystore, which is your original TDE wallet, to a software wallet. This is done by replacing the PKCS#11 provider of your original HSM with the CloudHSM PKCS#11 software library (steps 1–2), next you reverse migrate to a local wallet (steps 3–5). The third step is to switch the encryption wallet for your database to your CloudHSM cluster (steps 6 and 7). After this process is complete, your database will automatically re-encrypt the data keys using the new primary key.
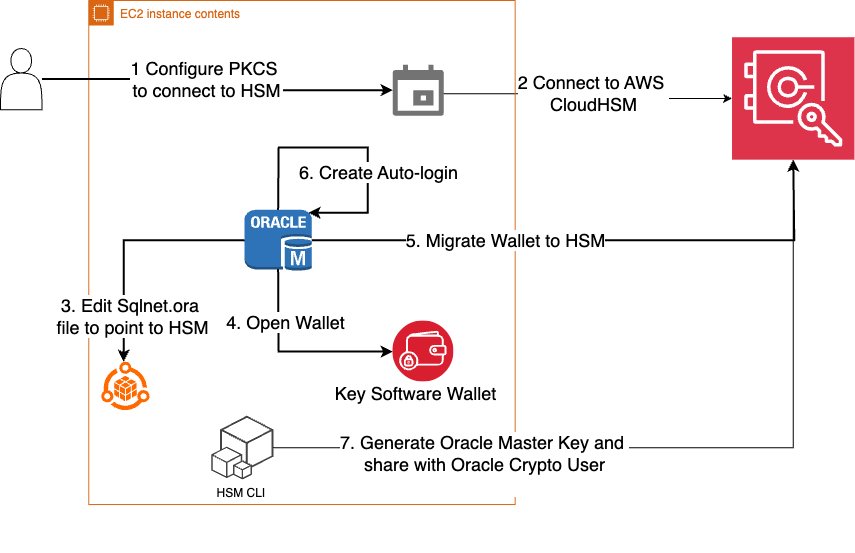
Figure 1: Steps to migrate your EC2 Oracle TDE database encryption wallet to CloudHSM
Note: The following instructions were tested using Oracle version 19c.
Prerequisites
You must have the following prerequisites in place to complete the solution in this post.
- AWS CloudHSM cluster: You need to have a CloudHSM cluster set up and configured with an admin EC2 instance for interacting with CloudHSM following steps and best practices covered in Getting started with AWS CloudHSM.
- Oracle database: Make sure that your Oracle database is up and running. This post assumes that you have an Oracle Database 19c database running on an EC2 Linux instance and there is network connectivity set up to CloudHSM as explained in this Configure the Client Amazon EC2 instance security groups for AWS CloudHSM.
Migrate an Oracle database keystore to a CloudHSM external keystore
As the first step in the migration, you need to migrate your Oracle database keystore to a CloudHSM external keystore. You do this by installing the CloudHSM client and the PKCS#11 library and then configuring the PKCS#11 library to connect to the HSM cluster.
Install the CloudHSM client:
- Install the latest CloudHSM client software on your EC2 instance.
- Configure the client to connect to HSMs in your cluster. For Linux EC2, use the following command:
- Copy the CloudHSM issuing certificate created when you initialized the cluster (
customerCA.crt) to the/opt/cloudhsm/etcfolder. For more information, see Activate the cluster in AWS CloudHSM. - Validate connectivity to the CloudHSM cluster.
- Sign in to the cluster as admin and create a crypto user (e.g.
hsm-crypto-user) and assign it the rolecrypto-user. - Sign in as
hsm-crypto-userand validate the configuration
Install the PKCS#11 Library
- Install the PKCS #11 library for AWS CloudHSM Client SDK 5.
- Configure Oracle to use the PKCS library:
- Copy the PKCS#11 library to the appropriate Oracle folder. Typically, this is:
- Make sure that the folder
/opt/oraclehas the correct ownership, usuallyoracle:dbaasowner:group.
Configure PKCS#11 library to connect to the HSM cluster
Use the following commands:
sudo /opt/cloudhsm/bin/configure-pkcs11 -a <HSM IP addresses>sudo /opt/cloudhsm/bin/configure-pkcs11 --hsm-ca-cert <customerCA certificate file>
Configure the Oracle wallet location
In this section, you configure Oracle to point to CloudHSM using the sqlnet.ora file.
To configure the Oracle wallet location:
- Edit the
sqlnet.oraparameterENCRYPTION_WALLET_LOCATIONto point to the HSM: - Verify that the
WALLET_ROOTparameter is pointing to the current file-based TDE wallet location. This parameter defines the location where the TDE wallet (and other related files) will be stored. You can set it to an existing directory, preferably one in your$ORACLE_BASEor$ORACLE_HOMEdirectory, but other locations are also possible. - Use the following commands to set
WALLET_ROOTif it hasn’t already been set.
Note:
- In Oracle Database 19c and later, the
ENCRYPTION_WALLET_LOCATION. parameter insqlnet.orais deprecated in favor of usingWALLET_ROOTandTDE_CONFIGURATION.- You can also use the
V$ENCRYPTION_WALLETview to check the current keystore location and status.
Point the Oracle database to use a local file-based keystore and CloudHSM
The KEYSTORE_CONFIGURATION attribute within TDE_CONFIGURATION determines the keystore type.
To point the Oracle database:
- Use the following code to point the database to the local keystore and CloudHSM.
- Restart the database to have consistent results.
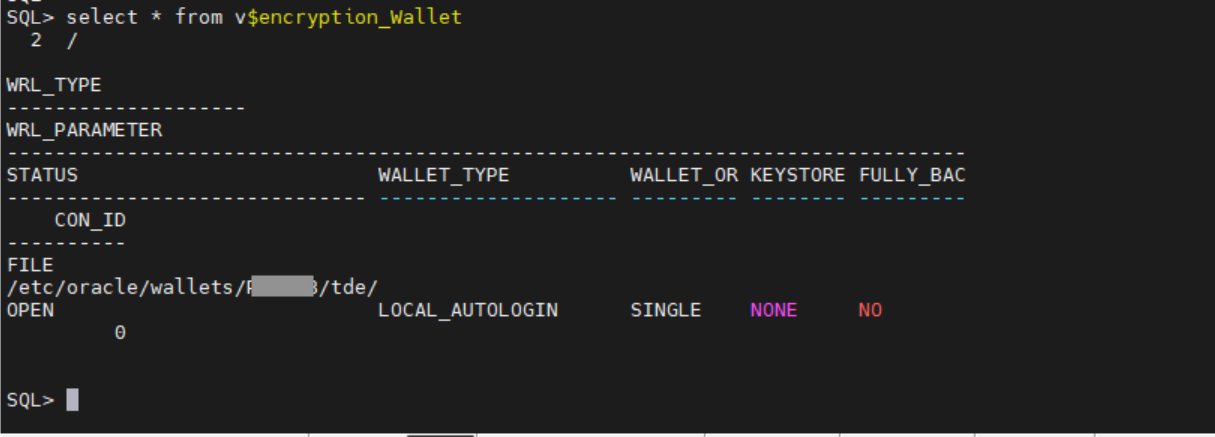
Verify that the keystore file-based wallet is open
To proceed with encryption key migration, you need to check the current keystore status and make sure that the file-based wallet is open.
To verify that the wallet is open:
- Check to see if the file-based wallet is open.

Figure 2: Verify that the wallet status is OPEN
- If the wallet status is not OPEN, use the following command to open it:
Migrate the encryption key to CloudHSM
Use the ADMINISTER KEY MANAGEMENT SET ENCRYPTION KEY command to initiate the TDE primary encryption key migration.
To migrate the encryption key:
- Use the following command to migrate the encryption key:
The parameters used to migrate the encryption key are:
SET ENCRYPTION KEY: Specifies that the command is related to the TDE primary encryption keyIDENTIFIED BY: Specifies the details for migrating the keystore, including the external keystore user and passwordMIGRATE USING: Specifies the password for the file-based wallet containing the primary encryption keyWITH BACKUP: Creates a backup of the keystore before the migration
Verify that the migration is complete
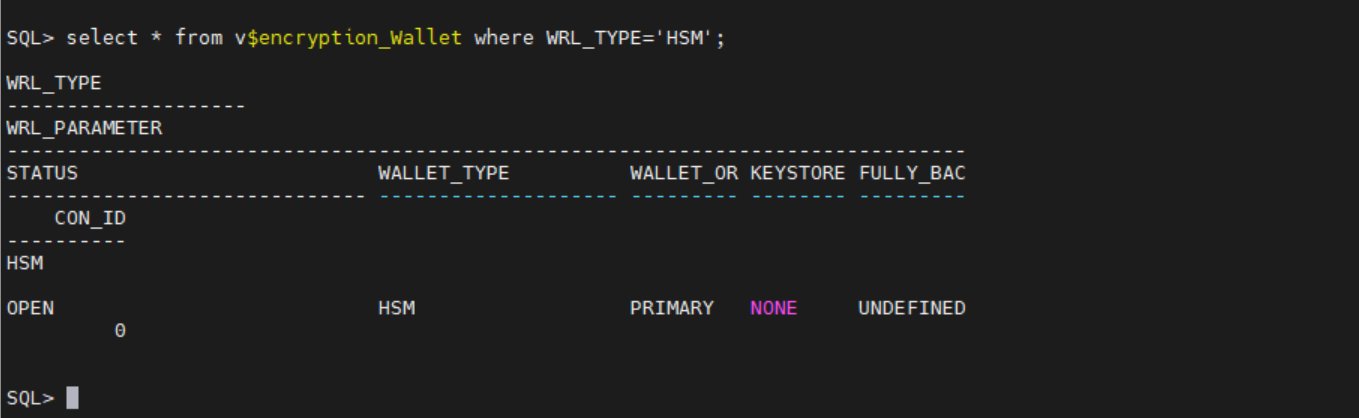
At this point, the migration from Oracle to Cloud HSM should be complete. Use the following steps to verify it.
To verify the migration:
- Check the wallet status again. If the migration was successful, the
WALLET_TYPEwill beHSMand theWALLET_ORwill bePRIMARY.
Figure 3: Verify that WALLET_TYPE and WALLET_OR are correct
- In the wallet is not open, use:
- Verify that the database can access encrypted data without issues, confirming that the migration was successful.
Setup auto-login
Create auto-login to open the wallet during database restarts to connect to AWS CloudHSM.
To set up auto_login:
- Create a new file-based keystore with the same username and password as the CloudHSM crypto user.
- Add the CloudHSM crypto user password to a keystore (TDE wallet).
- The following command creates a new auto-login keystore. This is useful for scenarios where the keystore needs to be accessed without human intervention.
- Open the newly created file based keystore.
Key rotation
Key rotation helps you to adhere to security best practices by providing several data security benefits. Regular rotation of TDE keys reduces the window of opportunity for a bad actor who might have obtained a key, thereby minimizing the impact of a potential breach.
Many established security frameworks and compliance standards—such as PCI DSS and HIPAA—recommend or require regular key rotation to maintain the integrity and confidentiality of encrypted data. By making sure that keys aren’t used indefinitely, you can help reduce the risk of exposure or compromise, which reinforces overall security.
Encryption algorithms can become less secure over time because of advancements in computing power or newly discovered vulnerabilities. By rotating keys regularly, you can transition to stronger encrypting methods as needed, and so improve protection against emerging risks.
When to rotate TDE keys
The frequency of key rotation depends on several factors, including organizational policies, regulatory requirements, and the sensitivity of the data being protected. Here are some common practices:
- Annually: Many organizations rotate TDE keys once a year to align with common compliance requirements.
- Quarterly: For higher-security environments or more sensitive data, rotating keys every quarter can provide an additional layer of security.
- If keys are compromised or suspected to be compromised: If you believe a key to be compromised, rotating that key as soon as possible is recommended to reduce the impact window.
Oracle TDE primary key rotation with an HSM key
In this section, you choose a 32-bit hex value to use as a prefix when generating a key, then use that key to update the Oracle database to use the new primary key.
- Sign in to the database instance as a user who has the
ADMINISTER KEY MANAGEMENTorSYSKMprivilege and execute following command: - Decide on a 32-bit hex value pattern to be used. We used
15A5142C9E2D3C2F18FD435814257DFDin this example. - Add the prefix
ORACLE.TDE.HSM.MKto the hex pattern. - Sign in to CloudHSM and generate a key using the label generated in the previous step.
- Share the key with the Oracle hsm-crypto-user in case the original key was generated through another user.
- Update the Oracle database to use the new primary TDE key.
By following these guidelines, you can enhance the security of your encrypted data, align with regulatory requirements, and maintain robust key management practices.
Conclusion
In this post, we’ve shown you the importance of Transparent Data Encryption (TDE) and the benefits of using an external key manager such as AWS CloudHSM for storing TDE encryption keys. We’ve discussed the benefits of TDE compared to encrypting underlying storage and why using an external key manager is superior to keeping keys on the Oracle wallet on the host. Following these guidelines can help you enhance the security of your encrypted data, align with regulatory requirements, and maintain robust key management practices.
The key takeaways from this post are:
- TDE offers granular encryption, compliance benefits, and robust key management.
- External key managers provide enhanced security, centralized management, improved auditability and scalability.
- Regular rotation of TDE keys is crucial for maintaining security, aligning with regulations, and following recommended practices in key management.
To start securing your Oracle databases with TDE and AWS CloudHSM, visit the AWS Management Console. Follow the steps outlined in this guide to migrate your TDE encryption keystore to AWS CloudHSM and begin rotating your keys regularly to enhance your data security posture. By taking these actions, you can make sure that your sensitive data remains protected, your organization remains aligned with regulations, and you are following the best practices in data encryption and key management.
For more information, see:
- Oracle Documentation on Managing Keystore and TDE Primary Encryption Key
- AWS CloudHSM Documentation
- Oracle Key Documentation
If you have feedback about this post, submit comments in the Comments section below.
Comic for 2025.07.30 – Cheated
Post Syndicated from Explosm.net original https://explosm.net/comics/cheated
New Cyanide and Happiness Comic
Top 5 Unifi Products I Love in 2025!
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=qYfB4M4NlYQ
Optimize traffic costs of Amazon MSK consumers on Amazon EKS with rack awareness
Post Syndicated from Austin Groeneveld original https://aws.amazon.com/blogs/big-data/optimize-traffic-costs-of-amazon-msk-consumers-on-amazon-eks-with-rack-awareness/
Are you incurring significant cross Availability Zone traffic costs when running an Apache Kafka client in containerized environments on Amazon Elastic Kubernetes Service (Amazon EKS) that consume data from Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics?
If you’re not familiar with Apache Kafka’s rack awareness feature, we strongly recommend starting with the blog post on how to Reduce network traffic costs of your Amazon MSK consumers with rack awareness for an in-depth explanation of the feature and how Amazon MSK supports it.
Although the solution described in that post uses an Amazon Elastic Compute Cloud (Amazon EC2) instance deployed in a single Availability Zone to consume messages from an Amazon MSK topic, modern cloud-native architectures demand more dynamic and scalable approaches. Amazon EKS has emerged as a leading platform for deploying and managing distributed applications. The dynamic nature of Kubernetes introduces unique implementation challenges compared to static client deployments. In this post, we walk you through a solution for implementing rack awareness in consumer applications that are dynamically deployed across multiple Availability Zones using Amazon EKS.
Here’s a quick recap of some key Apache Kafka terminology from the referenced blog. An Apache Kafka client consumer will register to read against a topic. A topic is the logical data structure that Apache Kafka organizes data into. A topic is segmented into a single or many partitions. Partitions are the unit of parallelism in Apache Kafka. Amazon MSK provides high availability by replicating each partition of a topic across brokers in different Availability Zones. Because there are replicas of each partition that reside across the different brokers that make up your MSK cluster, Amazon MSK also tracks whether a replica partition is in sync with the most recent data for that partition. This means there is one partition that Amazon MSK recognizes as containing the most up-to-date data, and this is known as the leader partition. The collection of replicated partitions is called in-sync replicas. This list of in-sync replicas is used internally when the cluster needs to elect a new leader partition if the current leader were to become unavailable.
When consumer applications read from a topic, the Apache Kafka protocol facilitates a network exchange to determine which broker currently has the leader partition that the consumer needs to read from. This means that the consumer could be told to read from a broker in a different Availability Zone than itself, leading to cross-zone traffic charge in your AWS account. To help optimize this cost, Amazon MSK supports the rack awareness feature, using which clients can ask an Amazon MSK cluster to provide a replica partition to read from, within the same Availability Zone as the client, even if it isn’t the current leader partition. The cluster accomplishes this by checking for an in-sync replica on a broker within the same Availability Zone as the consumer.
The challenge with Kafka clients on Amazon EKS
In Amazon EKS, the underlying units of computes are EC2 instances that are abstracted as Kubernetes nodes. The nodes are organized into node groups for ease of management, scaling, and grouping of applications on certain EC2 instance types. As a best practice for resilience, the nodes in a node group are spread across multiple Availability Zones. Amazon EKS uses the underlying Amazon EC2 metadata about the Availability Zone that it’s located in, and it injects that information into the node’s metadata during node configuration. In particular, the Availability Zone (AZ ID) is injected into the node metadata.
When an application is deployed in a Kubernetes Pod on Amazon EKS, it goes through a process of binding to a node that meets the pod’s requirements. As shown in the following diagram, when you deploy client applications on Amazon EKS, the pod for the application can be bound to a node with available capacity in any Availability Zone. Also, the pod doesn’t automatically inherit the Availability Zone information from the node that it’s bound to, a piece of information necessary for rack awareness. The following architecture diagram illustrates Kafka consumers running on Amazon EKS without rack awareness.
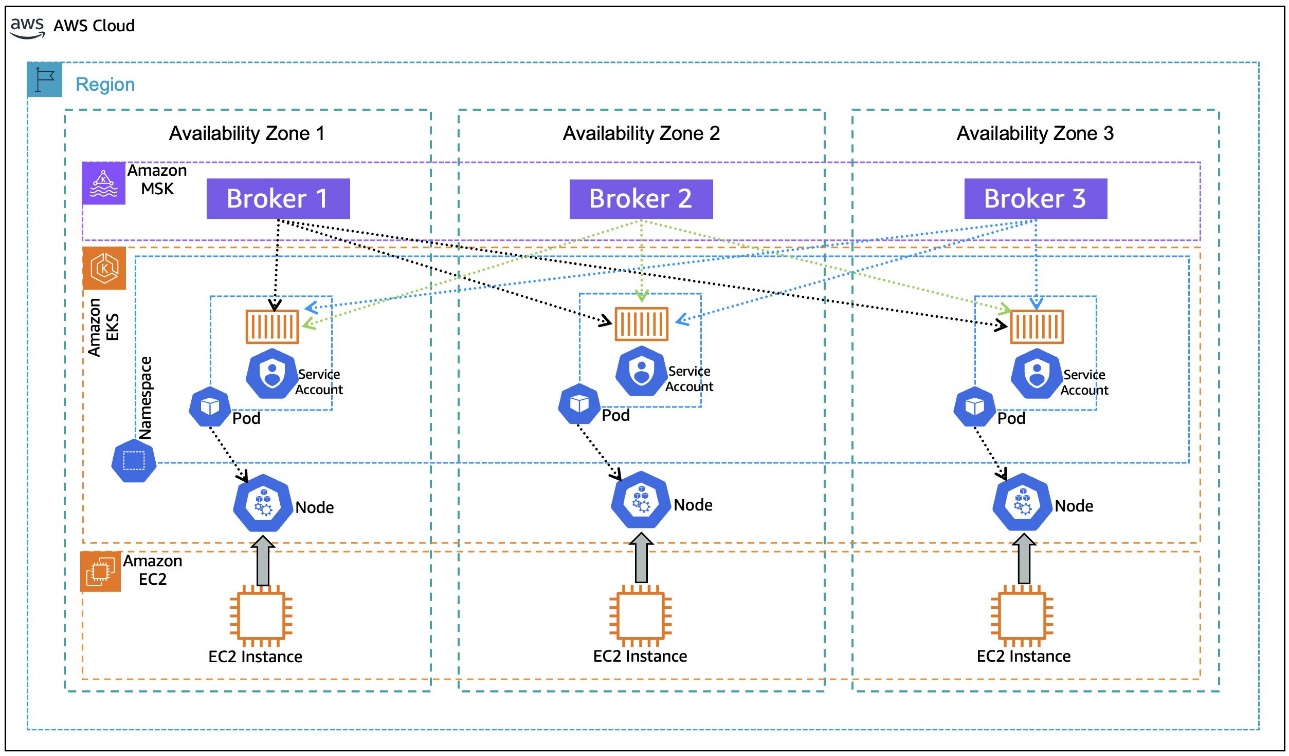
To set the client configuration for rack awareness, the pod needs to know what Availability Zone it’s located in, dynamically, as it is bound to a node. During its lifecycle, the same pod can be evicted from the node it was bound to previously and moved to a node in a different Availability Zone, if the matching criteria permit that. Making the pod aware of its Availability Zone dynamically sets the rack awareness parameter client.rack during the initialization of the application container that is encapsulated in the pod.
After rack awareness is enabled on the MSK cluster, what happens if the broker in the same Availability Zone as the client (hosted on Amazon EKS or elsewhere) becomes unavailable? The Apache Kafka protocol is designed to support a distributed data storage system. Assuming customers follow the best practice of implementing a replication factor > 1, Apache Kafka can dynamically reroute the consumer client to the next available in-sync replica on a different broker. This resilience remains consistent even after implementing nearest replica fetching, or rack awareness. Enabling rack awareness optimizes the networking exchange to prefer a partition within the same Availability Zone, but it doesn’t compromise the consumer’s ability to operate if the nearest replica is unavailable.
In this post, we walk you through an example of how to use the Kubernetes metadata label, topology.k8s.aws/zone-id, assigned to each node by Amazon EKS, and use an open source policy engine, Kyverno, to deploy a policy that mutates the pods that are in the binding state to dynamically inject the node’s AZ ID into the pod’s metadata as an annotation, as depicted in the following diagram. This annotation, in turn, is used by the container to create an environment variable that is assigned the pod’s annotated AZ ID information. The environment variable is then used in the container postStart lifecycle hook to generate the Kafka client configuration file with rack awareness setting. The following architecture diagram illustrates Kafka consumers running on Amazon EKS with rack awareness.
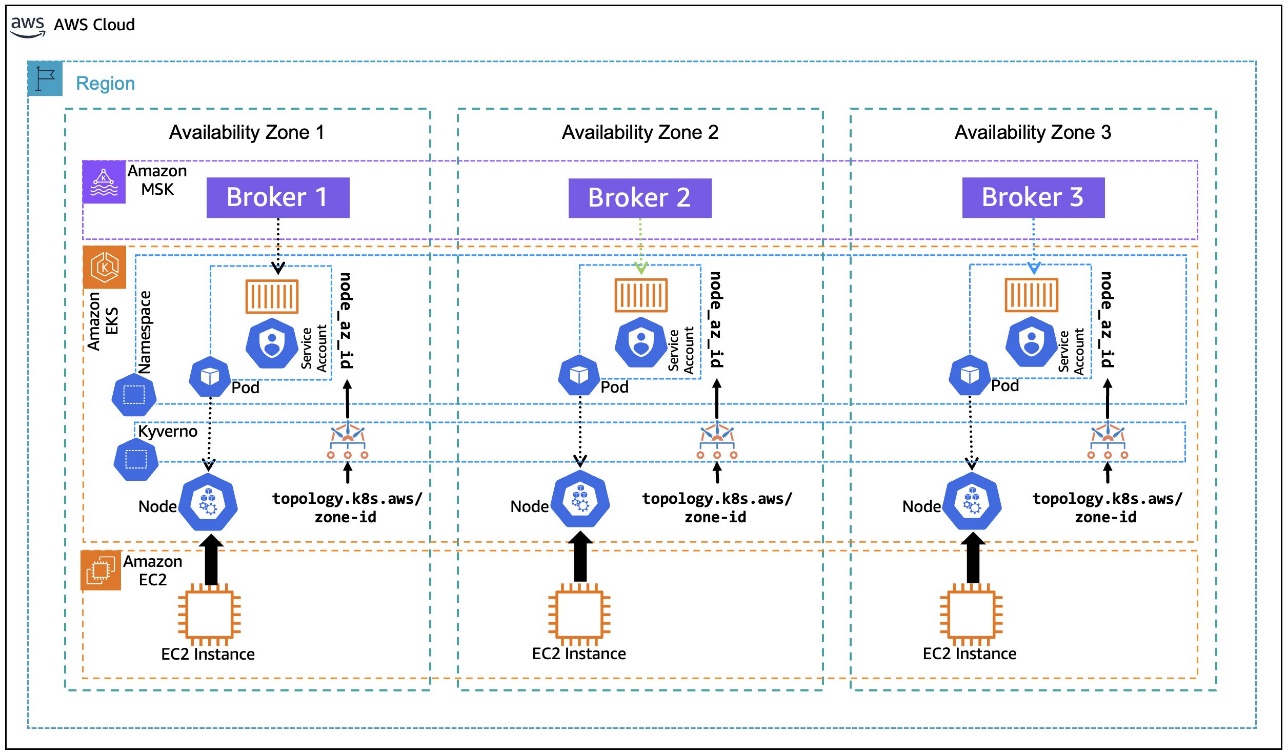
Solution Walkthrough
Prerequisites
For this walkthrough, we use AWS CloudShell to run the scripts that are provided inline as you progress. For a smooth experience, before getting started, make sure to have kubectl and eksctl installed and configured in the AWS CloudShell environment, following the installation instructions for Linux (amd64). Helm is also required to be install on AWS CloudShell, using the instructions for Linux.
Also, check if the envsubst tool is installed in your CloudShell environment by invoking:
If the tool isn’t installed, you can install it using the command:
We also assume you already have an MSK cluster deployed in an Amazon Virtual Private Cloud (VPC) in three Availability Zones with the name MSK-AZ-Aware. In this walkthrough, we use AWS Identity and Access Management (IAM) authentication for client access control to the MSK cluster. If you’re using a cluster in your account with a different name, replace the instances of MSK-AZ-Aware in the instructions.
We follow the same MSK cluster configuration mentioned in the Rack Awareness blog mentioned previously, with some modifications. (Ensure you’ve set replica.selector.class = org.apache.kafka.common.replica.RackAwareReplicaSelector for the reasons discussed there). In our configuration, we add one line: num.partitions = 6. Although not mandatory, this ensures that topics that are automatically created will have multiple partitions to support clearer demonstrations in subsequent sections.
Finally, we use the Amazon MSK Data Generator with the following configuration:
Running the MSK Data Generator with this configuration will automatically create a six-partition topic named MSK-AZ-Aware-Topic on our cluster for us, and it will push data to that topic. To follow along with the walkthrough, we recommend and assume that you deploy the MSK Data Generator to create the topic and populate it with simulated data.
Create the EKS cluster
The first step is to install an EKS cluster in the same Amazon VPC subnets as the MSK cluster. You can modify the name of the MSK cluster by changing that environment variable MSK_CLUSTER_NAME if your cluster is created with a different name than suggested. You can also change the Amazon EKS cluster name by changing EKS_CLUSTER_NAME.
The environment variables that we define here are used throughout the walkthrough.
The last step is to update the kubeconfig with an entry for the EKS cluster:
Next, you need to create an IAM policy, MSK-AZ-Aware-Policy, to allow access from the Amazon EKS pods to the MSK cluster. Note here that we’re using MSK-AZ-Aware as the cluster name.
Create a file, msk-az-aware-policy.json, with the IAM policy template:
To create the IAM policy, use the following command. It first replaces the placeholders in the policy file with values from relevant environment variables, and then creates the IAM policy:
Configure EKS Pod Identity
Amazon EKS Pod Identity offers a simplified experience for obtaining IAM permissions for pods on Amazon EKS. This requires installing an add-on Amazon EKS Pod Identity Agent to the EKS cluster:
Confirm that the add-on has been installed and its status is ACTIVE and that the status of all the pods associated with the add-on is Running.
After you’ve installed the add-on, you need to create a pod identity association between a Kubernetes service account and the IAM policy created earlier:
Install Kyverno
Kyverno is an open source policy engine for Kubernetes that allows for validation, mutation, and generation of Kubernetes resources using policies written in YAML, thus simplifying the enforcement of security and compliance requirements. You need to install Kyverno to dynamically inject metadata into the Amazon EKS pods as they enter the binding state to inform them of Availability Zone ID.
In AWS CloudShell, create a file named kyverno-values.yaml. This file defines the Kubernetes RBAC permissions for Kyverno’s Admission Controller to read Amazon EKS node metadata because the default Kyverno (v. 1.13 onwards) settings don’t allow this:
After this file is created, you can install Kyverno using helm and providing the values file created in the previous step:
Starting with Kyverno v 1.13, the Admission Controller is configured to ignore the AdmissionReview requests for pods in binding state. This needs to be changed by editing the Kyverno ConfigMap:
The kubectl edit command uses the default editor configured in your environment (in our case Linux VIM).
This will open the ConfigMap in a text editor.
As highlighted in the following screenshot, [Pod/binding,*,*] should be removed from the resourceFilters field for the Kyverno Admission Controller to process AdmissionReview requests for pods in binding state.
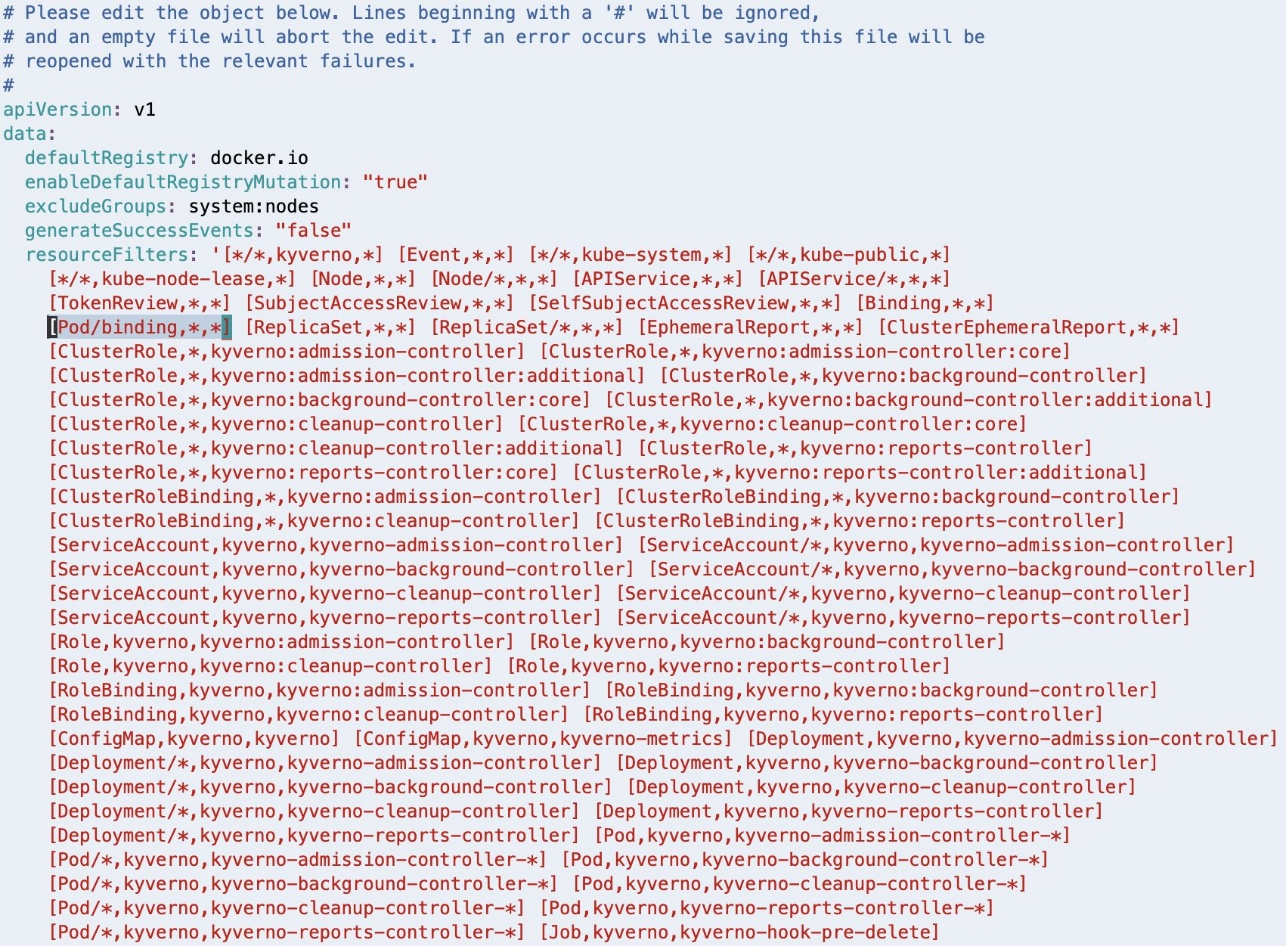
If Linux VIM is your default editor, you can delete the entry using VIM command 18x, meaning delete (or cut) 18 characters from the current cursor position. Save the modified configuration using the VIM command :wq, meaning write (or save) the file and quit.
After deleting, the resourceFilters field should look similar to the following screenshot.
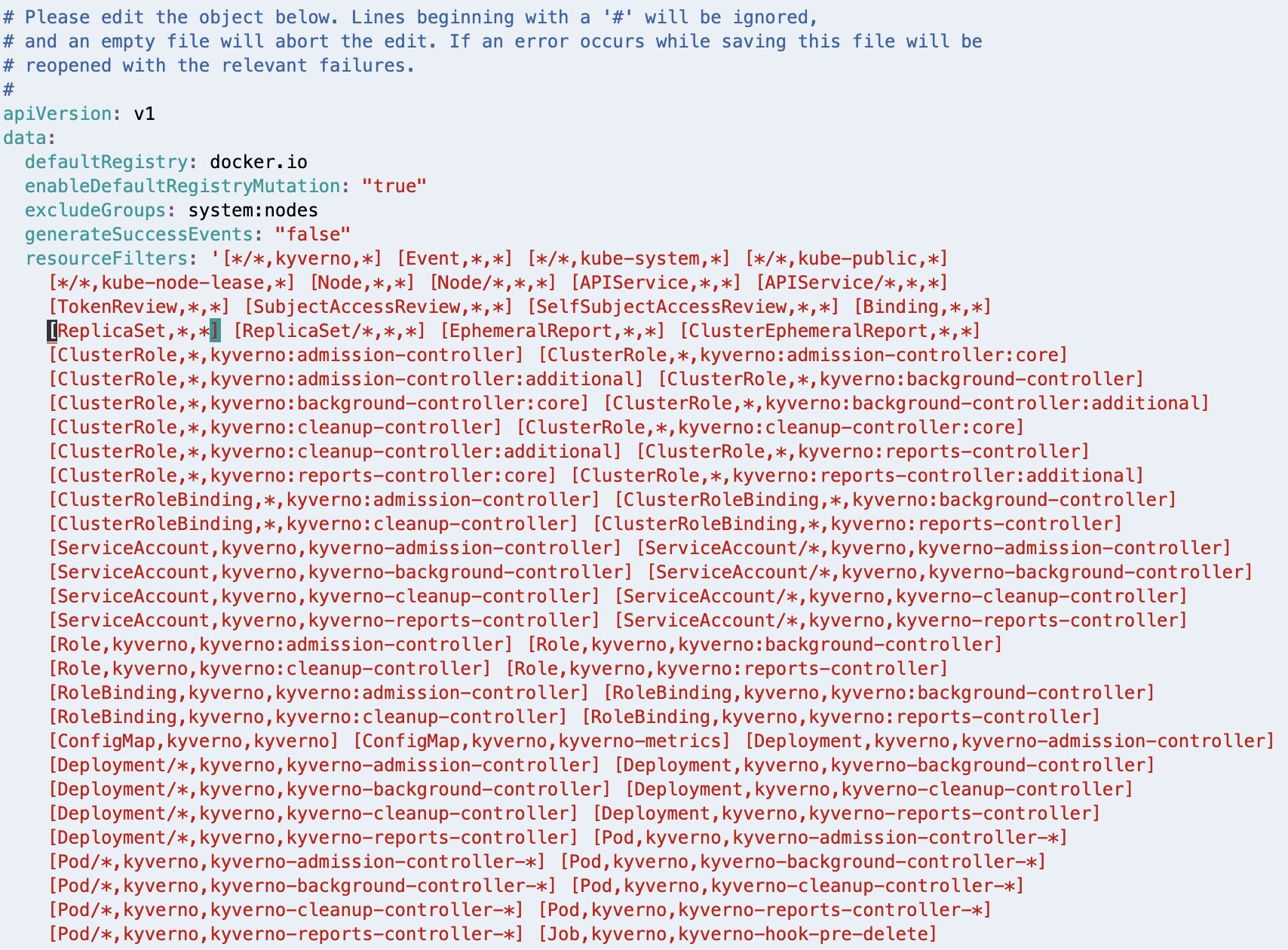
If you have a different editor configured in your environment, follow the appropriate steps to achieve a similar outcome.
Configure Kyverno policy
You need to configure the policy that will make the pods rack aware. This policy is adapted from the suggested approach in the Kyverno blog post, Assigning Node Metadata to Pods. Create a new file with the name kyverno-inject-node-az-id.yaml:
It instructs Kyverno to watch for pods in binding state. After Kyverno receives the AdmissionReview request for a pod, it sets the variable node to the name of the node to which the pod is being bound. It also sets another variable node_az_id to the Availability Zone ID by calling the Kubernetes API /api/v1/nodes/node to get the node metadata label topology.k8s.aws/zone-id. Finally, it defines a mutate rule to inject the obtained AZ ID into the pod’s metadata as an annotation node_az_id.
After you’ve created the file, apply the policy using the following command:
Deploy a pod without rack awareness
Now let’s visualize the problem statement. To do this, connect to one of the EKS pods and check how it interacts with the MSK cluster when you run a Kafka consumer from the pod.
First, get the bootstrap string of the MSK cluster. Look up the Amazon Resource Names (ARNs) of the MSK cluster:
Using the cluster ARN, you can get the bootstrap string with the following command:
Create a new file named kafka-no-az.yaml:
This pod manifest doesn’t make use of the Availability Zone ID injected into the metadata annotation and hence doesn’t add client.rack to the client.properties configuration.
Deploy the pods using the following command:
Run the following command to confirm that the pods have been deployed and are in the Running state:
Select a pod id from the output of the previous command, and connect to it using:
Run the Kafka consumer:
This command will dump all the resulting logs into the file, non-rack-aware-consumer.log. There’s a lot of information in those logs, and we encourage you to open them and take a deeper look. Next, examine the EKS pod in action. To do this, run the following command to tail the file to view fetch request results to the MSK cluster. You’ll notice a handful of meaningful logs to review as the consumer access various partitions of the Kafka topic:
Observe your log output, which should look similar to the following:
You’ve now connected to a specific pod in the EKS cluster and run a Kafka consumer to read from the MSK topic without rack awareness. Remember that this pod is running within a single Availability Zone.
Reviewing the log output, you find rack: values as use1-az2, use1-az4, and use1-az6 as the pod makes calls to different partitions of the topic. These rack values represent the Availability Zone IDs that our brokers are running within. This means that our EKS pod is creating networking connections to brokers across three different Availability Zones, which would be accruing networking charges in our account.
Also notice that you have no way to check which node, and therefore Availability Zone, this EKS pod is running in. You can observe in the logs that it’s calling to MSK brokers in different Availability Zones, but there is no way to know which broker is in the same Availability Zone as the EKS pod you’ve connected to. Delete the deployment when you’re done:
Deploy a pod with rack awareness
Now that you have experienced the consumer behavior without rack awareness, you need to inject the Availability Zone ID to make your pods rack-aware.
Create a new file named kafka-az-aware.yaml:
As you can observe, the pod manifest defines an environment variable NODE_AZ_ID, assigning it the value from the pod’s own metadata annotation node_az_id that was injected by Kyverno. The manifest then uses the pod’s postStart lifecycle script to add client.rack into the client.properties configuration, setting it equal to the value in the environment variable NODE_AZ_ID.
Deploy the pods using the following command:
Run the following command to confirm that the pods have been deployed and are in the Running state:
Verify that Availability Zone Ids have been injected into the pods
Your output should look similar to:
Or:
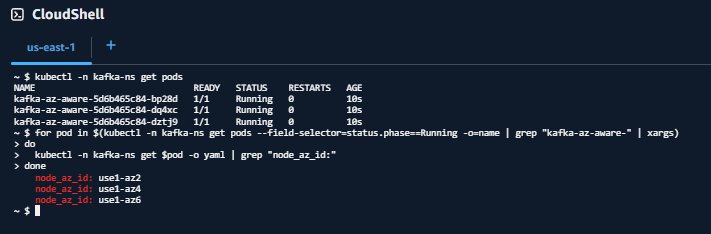
Select a pod id from the output of the get pods command and shell-in to it.
The output of the get $pod command matches the order of results from the get pods command. This matching will help you understand what Availability Zone your pod is running in so you can compare it to log outputs later.
After you’ve connected to your pod, run the Kafka consumer:
Similar to before, this command will dump all the resulting logs into the file, rack-aware-consumer.log. You create a new file so there’s no overlap between the Kafka consumers you’ve run. There’s a lot of information in those logs, and we encourage you to open them and take a deeper look. If you want to see the rack awareness of your EKS pod in action, run the following command to tail the file to view fetch request results to the MSK cluster. You can observe a handful of meaningful logs to review here as the consumer access various partitions of the Kafka topic:
Observe your log output, which should look similar to the following:
For each log line, you can now observe two rack: values. The first rack: value shows the current leader, the second rack: shows the rack that is being used to fetch messages.
For example, look at MSK-AZ-Aware-Topic-5. The leader is identified as rack: use1-az4, but the fetch request is sent to use1-az6 as indicated by to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
You’ll notice something similar in all other log lines. The fetch is always to the broker in use1-az6, which maps to our expectation, given the pod we connected to was in this Availability Zone.
Congratulations! You’re consuming from the closest replica on Amazon EKS.
Clean Up
Delete the deployment when finished:
To delete the EKS Pod Identity association:
To delete the IAM policy:
To delete the EKS cluster:
If you followed along with this post using the Amazon MSK Data Generator, be sure to delete your deployment so it’s no longer attempting to generate and send data after you delete the rest of your resources.
Clean up will depend on which deployment option you used. To read more about the deployment options and the resources created for the Amazon MSK Data Generator, refer to Getting Started in the GitHub repository.
Creating an MSK cluster was a prerequisite of this post, and if you’d like to clean up the MSK cluster as well, you can use the following command:
aws kafka delete-cluster --cluster-arn "${MSK_CLUSTER_ARN}"
There is no additional cost to using AWS CloudShell, but if you’d like to delete your shell, refer to the Delete a shell session home directory in the AWS CloudShell User Guide.
Conclusion
Apache Kafka nearest replica fetching, or rack awareness, is a strategic cost-optimization technique. By implementing it for Amazon MSK consumers on Amazon EKS, you can significantly reduce cross-zone traffic costs while maintaining robust, distributed streaming architectures. Open source tools such as Kyverno can simplify complex configuration challenges and drive meaningful savings.The solution we’ve demonstrated provides a powerful, repeatable approach to dynamically injecting Availability Zone information into Kubernetes pods, optimize Kafka consumer routing, and minimize reduce transfer costs.
Additional resources
To learn more about rack awareness with Amazon MSK, refer to Reduce network traffic costs of your Amazon MSK consumers with rack awareness.
About the authors
 Austin Groeneveld is a Streaming Specialist Solutions Architect at Amazon Web Services (AWS), based in the San Francisco Bay Area. In this role, Austin is passionate about helping customers accelerate insights from their data using the AWS platform. He is particularly fascinated by the growing role that data streaming plays in driving innovation in the data analytics space. Outside of his work at AWS, Austin enjoys watching and playing soccer, traveling, and spending quality time with his family.
Austin Groeneveld is a Streaming Specialist Solutions Architect at Amazon Web Services (AWS), based in the San Francisco Bay Area. In this role, Austin is passionate about helping customers accelerate insights from their data using the AWS platform. He is particularly fascinated by the growing role that data streaming plays in driving innovation in the data analytics space. Outside of his work at AWS, Austin enjoys watching and playing soccer, traveling, and spending quality time with his family.
 Farooq Ashraf is a Senior Solutions Architect at AWS, specializing in SaaS, Generative AI, and MLOps. He is passionate about blending multi-tenant SaaS concepts with Cloud services to innovate scalable solutions for the digital enterprise, and has several blog posts, and workshops to his credit.
Farooq Ashraf is a Senior Solutions Architect at AWS, specializing in SaaS, Generative AI, and MLOps. He is passionate about blending multi-tenant SaaS concepts with Cloud services to innovate scalable solutions for the digital enterprise, and has several blog posts, and workshops to his credit.
Automate data lineage in Amazon SageMaker using AWS Glue Crawlers supported data sources
Post Syndicated from Mohit Dawar original https://aws.amazon.com/blogs/big-data/automate-data-lineage-in-amazon-sagemaker-using-aws-glue-crawlers-supported-data-sources/
The next generation of Amazon SageMaker is the center for all your data, analytics, and AI. Bringing together widely adopted Amazon Web Services (AWS) machine learning (ML) and analytics capabilities, it delivers an integrated experience for analytics and AI with unified access to all your data. From Amazon SageMaker Unified Studio, a single data and AI development environment, you can access your data and use a suite of powerful tools for data processing, SQL analytics, model development, training and inference, and generative AI development.
With data lineage, now part of Amazon SageMaker Catalog, you can centralize lineage metadata of your data assets in a single place. You can track the flow of data over time, determining a clear understanding of where it originated, how it has changed, and its usage across the business. By providing this level of transparency, data lineage helps data consumers gain trust that the data is correct and compliant for their use cases. With data lineage captured at the table, column, and job level, data producers can conduct impact analysis of changes in their data pipelines and respond to data issues when needed, for example, when a column in the resulting dataset is missing the quality required by the business.
Data lineage is a powerful tool that can transform how organizations understand and manage their data flows. In this post, we explore its real-world impact through the lens of an ecommerce company striving to boost their bottom line.
To illustrate this practical application, we walk you through how you can use the prebuilt integration between SageMaker Catalog and AWS Glue crawlers to automatically capture lineage for data assets stored in Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB. Using this workflow, you can capture lineage automatically from additional data sources using AWS Glue crawlers. Refer to the Data lineage support matrix in the SageMaker Unified Studio User Guide for supported sources. We also use SageMaker Unified Studio to navigate these data assets and learn about their origin, transformations, and dependencies, thanks to the lineage metadata captured using the AWS Glue crawlers.
Key features of the SageMaker Catalog lineage graph
In SageMaker Unified Studio, you can explore and discover data assets of your organization suited for your use case. As you dive into these data assets, you can learn more about its business context, schema, quality, and lineage. When you decide to work with a subset of these assets, you can subscribe to them in a self-service fashion and start working with them. For more detail, visit Data discovery, subscription, and consumption in the SageMaker Unified Studio User Guide.
SageMaker Studio provides a visual lineage graph that shows how a data asset has evolved from its source through transformations to its final state. This helps data scientists, engineers, and analysts answer key questions such as:
- Where did this data come from?
- What transformations has it gone through?
- Which downstream assets will be impacted by a change?
With this level of visibility, teams can perform faster impact analysis, find the root cause of data quality issues, and ensure models are built on trusted data. It also supports better collaboration so users can confidently use and share data across the organization. The following screenshot shows how SageMaker Unified Studio visualizes data lineage, making it straightforward to trace data flow and understand dependencies.
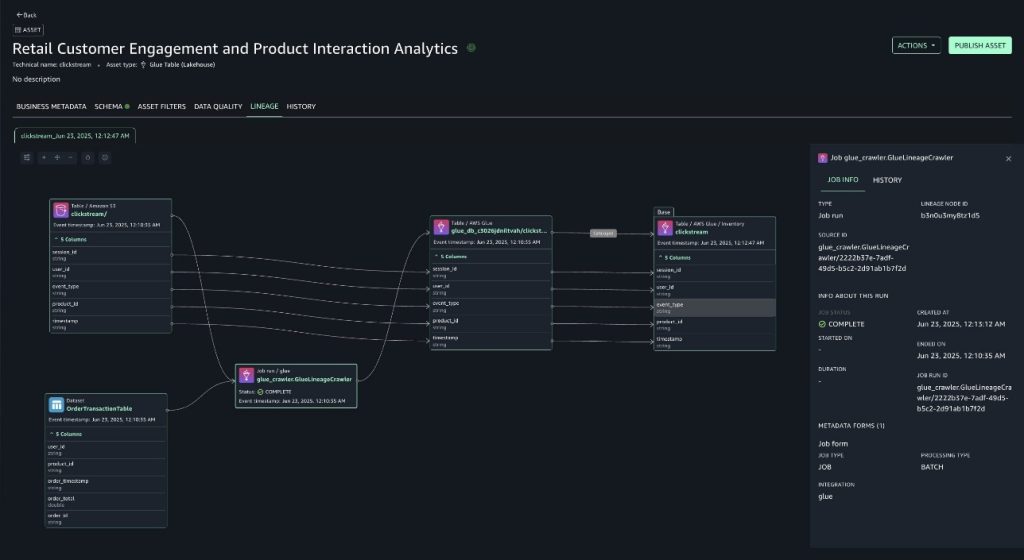
- Column-level lineage – You can expand column-level lineage when available in dataset nodes. This automatically shows relationships with upstream or downstream dataset nodes if source column information is available.
- Column search – If the dataset has more than 10 columns, the node presents pagination to navigate to columns not initially presented. To quickly view a particular column, you can search on the dataset node that lists only the searched column.
- Details pane – Each lineage node captures and displays the following details:
- Every dataset node has three tabs: LINEAGE, SCHEMA, and HISTORY. The HISTORY tab lists the different versions of lineage event captured for that node.
- The job node has a details pane to display job details with the tabs Job info and History. The details pane also captures queries or expressions run as part of the job.
- View dataset nodes only – If you want to filter out the job nodes, you can choose the open view control icon in the graph viewer and toggle the display dataset nodes only, which will remove all the job nodes from the graph and let you navigate only the dataset nodes.
- Version tabs – All lineage nodes in Amazon DataZone data lineage will have versioning, captured as history, based on lineage events captured. You can view lineage at a selected timestamp that opens a new tab on the lineage page to help compare or contrast between the different timestamps.
You can try some of these features as you explore the data assets of this post. To learn more on data lineage in SageMaker, we encourage you to dive deep into the Data lineage in Amazon SageMaker Unified Studio.
Solution overview
Imagine a scenario where an ecommerce company aims to optimize conversion rates and enhance customer experience by gaining deeper insights into the customer journey. They need to connect the dots between user interactions and actual purchases, but with data scattered across multiple sources, where do they begin? This is where data lineage becomes invaluable. To perform their analysis, they need data from two primary sources:
- Clickstream data stored in Amazon S3 (in JSON or Parquet format)
- Transactional order data stored as items in Amazon DynamoDB
To make these datasets discoverable across the business, you need to:
- Create a project in SageMaker Unified Studio that will be used to source and manage the datasets
- Enable data lineage capture in the SageMaker Unified Studio project
- Set up the resources for this use case, which includes an AWS Glue data source (set up in SageMaker Unified Studio) and AWS Glue crawler (set up in AWS Glue)
- Run the AWS Glue crawler to catalog the datasets in AWS Glue Data Catalog
- Source the metadata of the data assets into the SageMaker Catalog by running the data source
- Use SageMaker Unified Studio to navigate through the lineage of the data assets and visualize their origin
- Understand how schema evolution is captured in the data asset’s lineage
Prerequisites
To complete the steps on this post, you need an SageMaker Unified Studio domain already deployed in your AWS account. To get started quickly in a testing environment, we suggest creating your SageMaker domain using the quick setup option as explained in Create an Amazon SageMaker Unified Studio domain – quick setup.

Solution steps
To capture data lineage for AWS Glue tables managed with AWS Glue crawlers using SageMaker Unified Studio, complete the steps in the following sections.
Set up a SageMaker project with SQL capability
In SageMaker Unified Studio, a project profile defines an uber template for projects in your Amazon SageMaker unified domain. By setting up a project with the right tooling (project profile), you will provision resources you can use to work with data, which might include cataloging it in SageMaker, transforming it into new data assets, analyzing it to drive business value, or even use it for ML or AI applications.
To demonstrate data lineage effectively, we use SageMaker SQL analytics project profile for a streamlined setup. Although this profile offers comprehensive data analytics capabilities, we focus specifically on two key components:
- AWS Glue database – A lakehouse for storing and managing technical metadata
- Data source job – Automatically collects and tracks metadata into SageMaker Catalog
We’ve chosen this profile to bypass complex manual configurations so we can focus on the core concepts of data lineage.
To create a new project in your SageMaker domain using the SQL analytics project profile, follow the steps detailed in SQL analytics project profile. Keep all default configurations when creating the project.
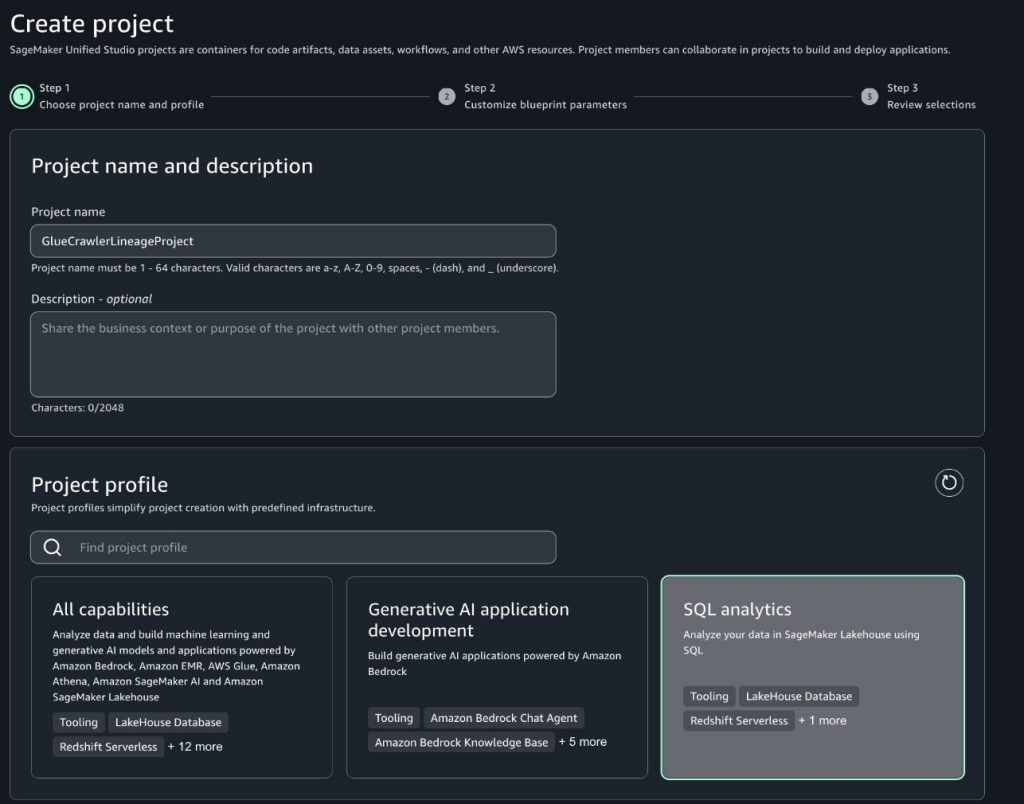
After creating your project in SageMaker Studio, you’ll unlock powerful data lineage capabilities that make tracking and understanding your data flows intuitive. Through the data sourcing feature, you can easily monitor how data moves from source to the AWS Glue database. This visibility becomes particularly valuable when debugging data issues—you can quickly trace data back to its source, understand how changes impact downstream processes, and identify affected analyses or reports. Next, populate the AWS Glue database with sample data to observe these features in action and demonstrate how they can streamline your data operations.
For further guidance on how to access the details of the new SageMaker project, refer to Get project details. After you access the data source details, in the Database name field, take note of the AWS Glue database name associated to the SageMaker project.
Enable data lineage capture in the SageMaker project’s data source
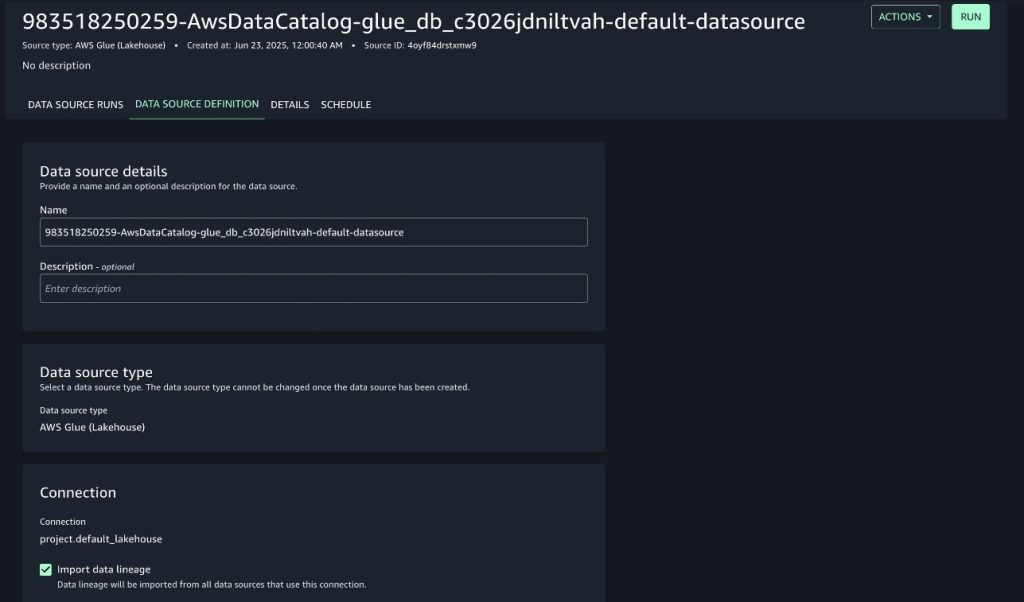
To enable lineage capture, follow these steps:
- Expand the Actions menu, then choose Edit data source.
- Go to the connections and select Import data lineage to configure lineage capture from the source, as shown in the following screenshot.
- Make other changes to the data source fields as desired, then choose Save.
Enabling lineage will make sure the data source job will capture lineage in the next run.
Deploy resources for the use case
Follow these steps:
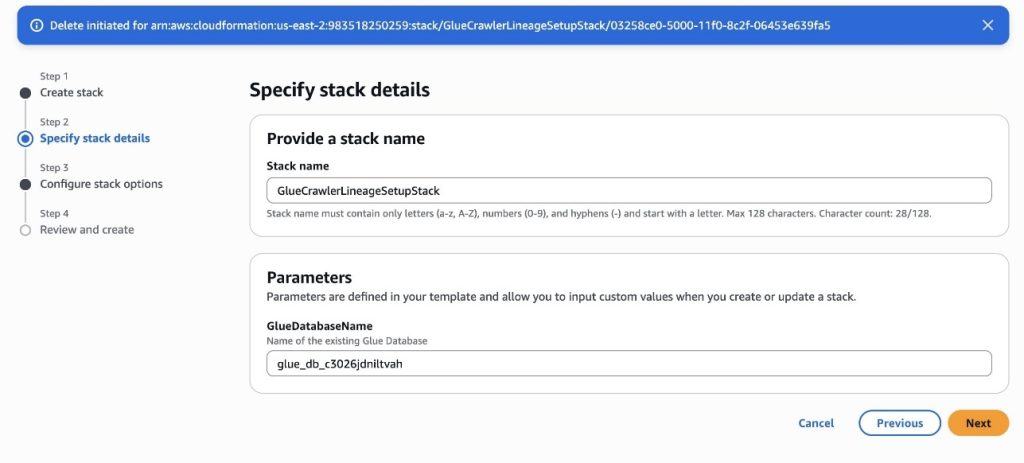
- To deploy the resources required for this post, download the AWS CloudFormation template amazon-datazone-examples in the AWS Samples GitHub repository. Deploy it in your AWS account.
For further guidance on how to deploy a CloudFormation stack, refer to Create a stack from the CloudFormation console. You need to provide a Stack name and the name of the AWS GlueDatabaseName associated to the project of your SageMaker domain, as shown in the following screenshot.
- Choose Next.
The template will deploy the following resources:
- A S3 bucket with a sample file of clickstream data. The bucket name and location of the file will follow the path pattern
s3://ecomm-analytics-<ACCOUNT_ID>-<REGION>/clickstream/<YYYY>/<MM>/<DD>/data.json. The file will contain a sample record with the following structure:
- A DynamoDB table with a sample item of order data (transactions). The table will be named
OrderTransactionTable. The sample item will have the following structure:
- An AWS Glue crawler configured to crawl the S3 bucket and DynamoDB table deployed as part of the stack and store the metadata in the AWS Glue database associated to the SageMaker project. You can access the crawler’s details in the AWS console, as shown in the following screenshot.
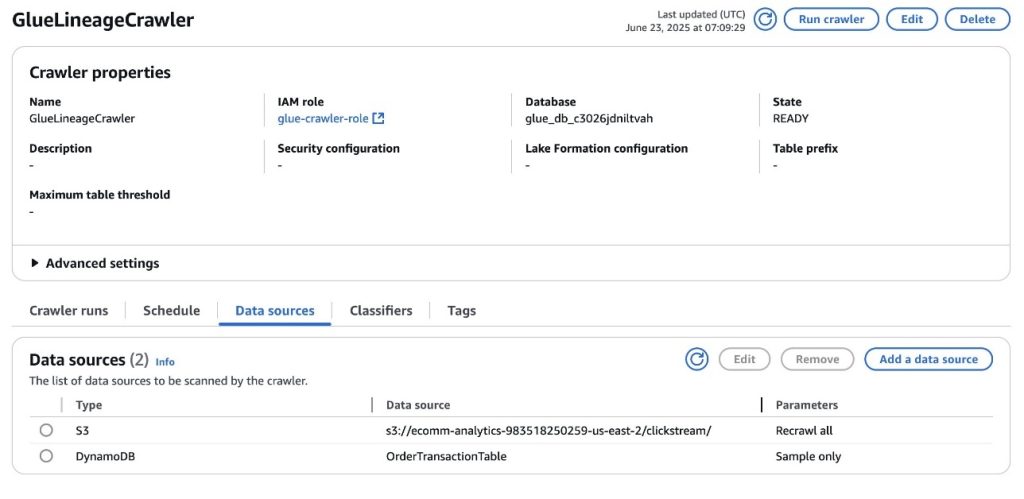
- Two AWS Identity and Access Management (IAM) roles for loading the source data into Amazon S3 and DynamoDB and to use when running the AWS Glue crawler.
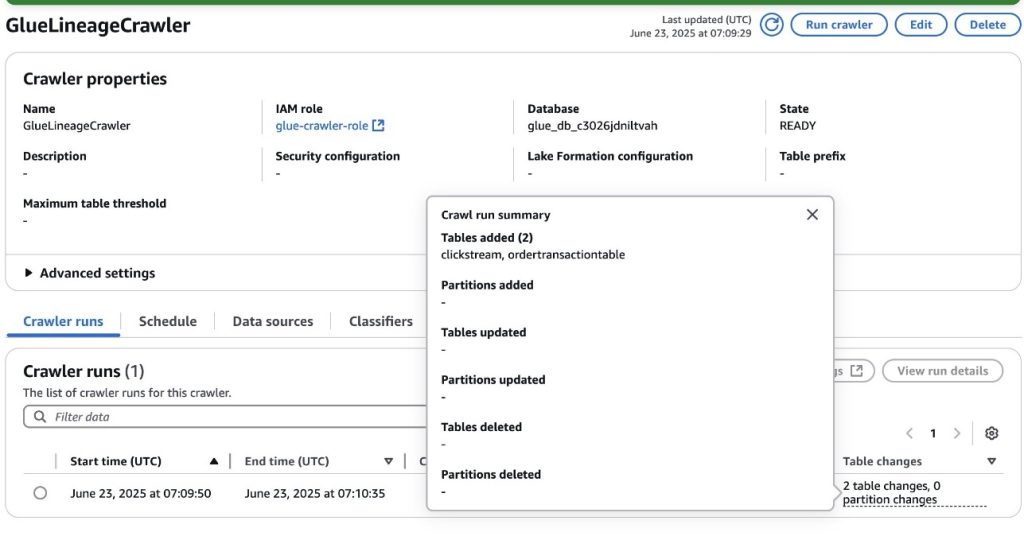
Run the AWS Glue crawler
The AWS Glue crawler deployed in the previous step will allow you to capture metadata from the two data sources, Amazon S3 and DynamoDB, and store it in AWS Glue Data Catalog, specifically in the database associated to the SageMaker project. After the metadata is stored, it will be accessible to SageMaker.
Before running the crawler, you need to provide AWS Lake Formation permissions to the IAM role that the AWS Glue crawler will use to interact with your data source and target AWS Glue database. The following command will grant the permissions needed for the crawler to store metadata into the AWS Glue database of the SageMaker project.
To invoke this command, we recommend using AWS CloudShell on the AWS console as explained in AWS CloudShell Concepts. Update the <REGION>, <ACCOUNT_ID> and <GLUE_DATABASE_NAME> placeholders with the right values for your AWS Region, AWS account ID, and name of the AWS Glue database associated to the SageMaker project.
Next, run the AWS Glue Crawler on the AWS console. After the crawler successfully finishes, two new tables, clickstream and ordertransactiontable, will be created in the AWS Glue database associated to the SageMaker project. Refer to Viewing crawler results and details to learn more about AWS Glue crawler results.
Source metadata from the AWS Glue database into SageMaker
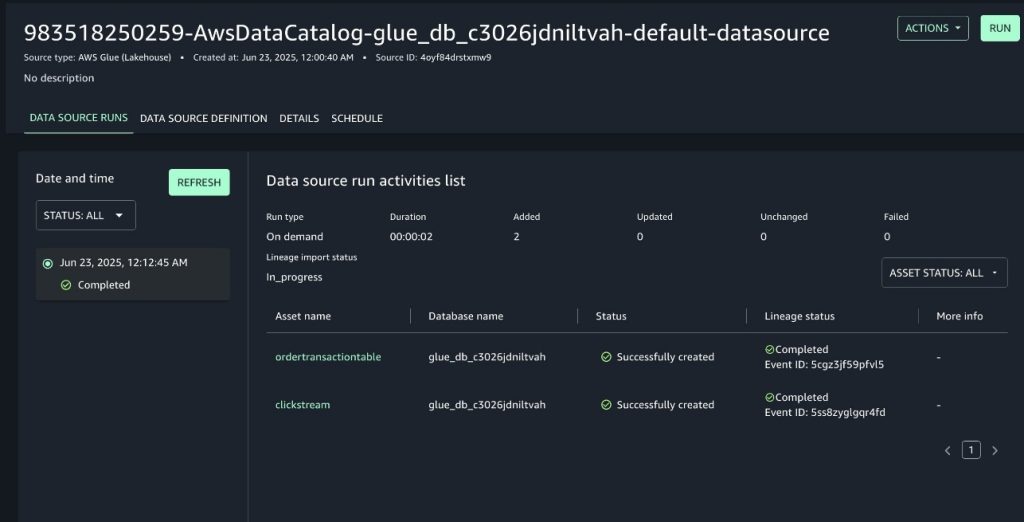
To source metadata from data assets in the AWS Glue database, including their lineage, into SageMaker, use the data source that was deployed as part of the SageMaker project creation.
- To run the data source, go to the data source details page.
- Choose Run. (Data sources can be scheduled to run as well, however, for this demonstration we trigger a manual run).
After the data source run is complete, metadata from both data assets in the AWS Glue database will be imported into the SageMaker domain as the project’s inventory assets. You can find the details of the data source run from within SageMaker Unified Studio, which include:
- The data assets from the AWS Glue database that were ingested into SageMaker.
- The status of the data lineage import for each data asset, which includes an event ID for traceability. This lineage event ID can be used to debug inconsistencies in the resulting lineage graph. You can use the GetLineageEvent API to retrieve the raw payload of the lineage event.
Visualizing the data lineage graph of the data assets in SageMaker Unified Studio
With SageMaker Unified Studio, you have a single place to manage and discover data assets. When accessing a data asset published in the SageMaker central catalog or in your project’s own inventory, you can dive into the asset’s metadata, which includes its schema, business description, custom metadata forms, quality, lineage, and more. To visualize the lineage graph of each data asset of this post, follow these steps:
- In SageMaker Studio, navigate to the Assets section of the SageMaker project details page and choose INVENTORY
- Select the asset that you want to explore. You can also access the asset directly from the data source run by selecting the asset name.
- To view the lineage graph of the data asset up to its origin, shown in the following screenshots, choose the LINEAGE tab.
- For clickstream table (Sourced from S3)
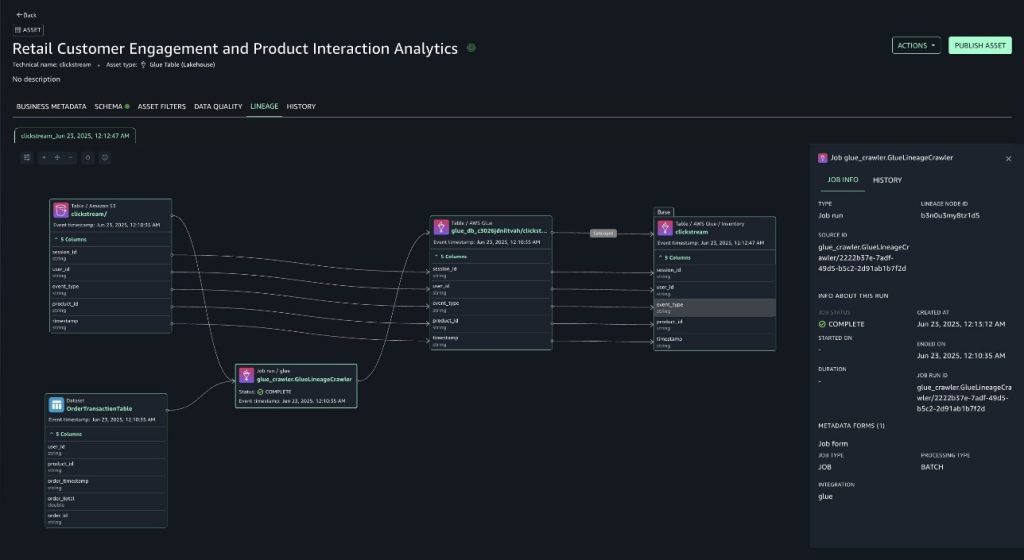
-
- For order transactions table (Sourced from DynamoDB)
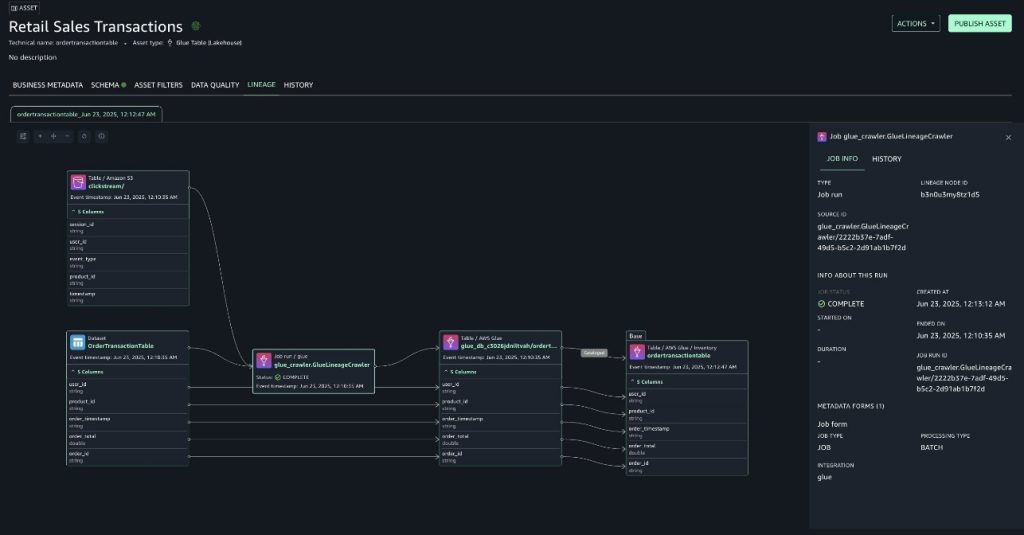
With lineage, you can now confirm that the data originated from sources such as Amazon S3 and Amazon DynamoDB and understand how it has been transformed along the way. Because of this end-to-end visibility, you can trust the data, make informed decisions, and provide compliance with confidence. The lineage graph captures essential metadata that forms the foundation of lineage tracking.
- This includes table schemas, column definitions and their data types.
- Column-level lineage becomes particularly powerful in this context. Imagine your clickstream’s AWS Glue table powers an Amazon QuickSight dashboard analyzing customer purchase patterns and notice discrepancies in your revenue reports. With column lineage, you can instantly trace the source of those columns.
- This granular visibility not only accelerates debugging but also proves invaluable during schema changes, as we show in the following section by changing the source schema.
- The crawler details such as
crawlerRunId(present in the source identifier of the lineage node) and crawler start and end times can be used to debug which crawler runs updated the table.
Understanding your data asset’s schema evolution through lineage in SageMaker Unified Studio
Imagine the order transactions source in DynamoDB was updated with new information. Because this source powers an Amazon QuickSight report for the customer using the AWS Glue database table, it’s important for consumers to know what changes in the data pipeline updated the report.
- Edit the DynamoDB table item with additional columns to learn how lineage graph can be used to view historical updates:
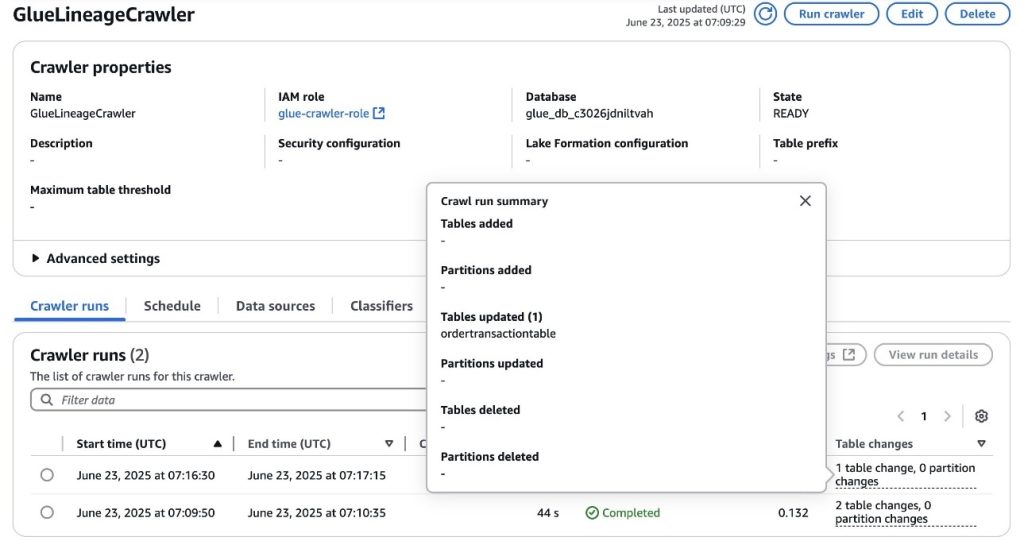
- Enter the
OrderTransactionsCrawlerGlue crawler again on the AWS console. After completion, you’ll notice that it updated theordertransactiontableAWS Glue table, as shown in the following screenshot.
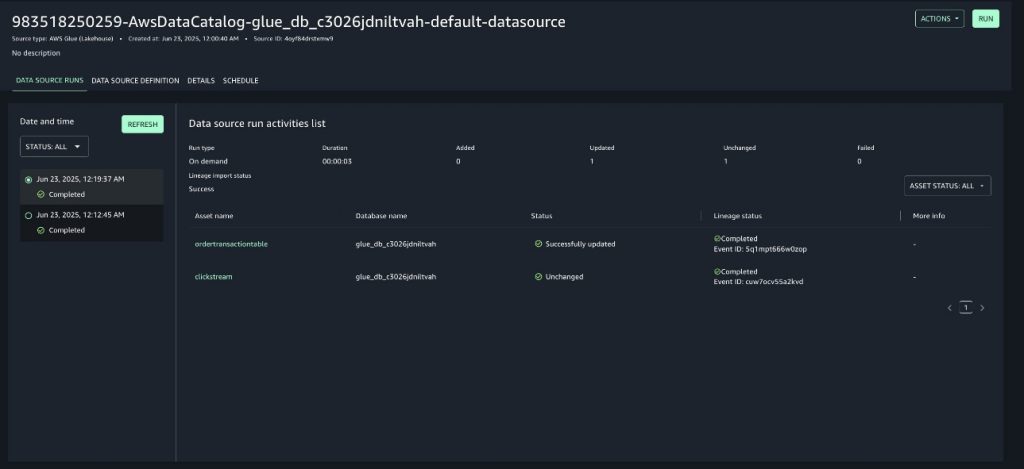
- Run again the data source associated to the project in SageMaker Unified Studio to import the latest metadata into the SageMaker Catalog. After completion, you’ll notice the data source updated the
ordertransactiontabledata asset in the SageMaker Catalog, as shown in the following screenshot.
This section explores how lineage can be useful to track the updates.
Navigate to the ordertransactiontable data asset in SageMaker Catalog by selecting it from the data source run and choose the LINEAGE tab, as shown in the following screenshot.
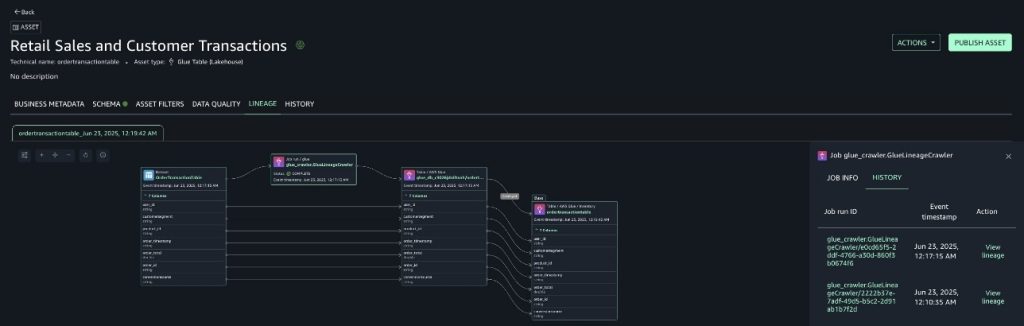
Notice how the new columns are available in the lineage graph. A new crawler run ID is present as the source identifier of the crawler lineage node. The history tab shows multiple crawler runs. You can navigate to check the state of the system during the first run.
Cleanup
After you’re done, we recommend to cleaning up the resources created for this post to avoid unintended charges:
- Delete the inventory assets that were cataloged in the SageMaker project’s inventory, as explained in Delete an Amazon SageMaker Unified Studio asset.
- Delete the SageMaker project that was created as part of this post, as explained in Delete a project.
- Delete the CloudFormation stack that was deployed as part of this post, as explained in Delete a stack from the CloudFormation console.
- The S3 bucket created as part of the CloudFormation stack will remain after its deletion because it contains a data file in it. Empty and delete the bucket, as explained in Deleting a general purpose bucket.
Conclusion
In this post, you were able to explore the data lineage capabilities of Amazon SageMaker, specifically when working with AWS Glue crawlers. You learned how you can set up an AWS Glue crawler to infer metadata from data assets in multiple sources such as Amazon S3 and DynamoDB and store it the AWS Glue Data Catalog. You also imported this metadata, including data lineage, into Amazon SageMaker through the data source capability of a SageMaker project. Finally, you explored the resulting lineage graph of data assets in SageMaker Unified Studio and saw some of the functionalities available to understand the origin path of them, understand how columns are transformed, and what impact looks like when performing changes to any step of the pipeline.We encourage you to now test the capabilities you explored in this post with your own data. By following the pattern presented in this post, many customers have been able to achieve governance of their data lake and lakehouse platforms on top of Amazon SageMaker with data lineage and more.
About the authors
 Mohit Dawar is a Senior Software Engineer at Amazon Web Services (AWS) working on Amazon DataZone. Over the past 3 years, he has led efforts around the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on LinkedIn: Mohit Dawar.
Mohit Dawar is a Senior Software Engineer at Amazon Web Services (AWS) working on Amazon DataZone. Over the past 3 years, he has led efforts around the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on LinkedIn: Mohit Dawar.
 Jose Romero is a Senior Solutions Architect for Startups at Amazon Web Services (AWS) based in Austin, TX, US. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on LinkedIn: Jose Romero.
Jose Romero is a Senior Solutions Architect for Startups at Amazon Web Services (AWS) based in Austin, TX, US. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on LinkedIn: Jose Romero.
✨What’s new in Home Assistant 2025.7? ✨ Part 3
Post Syndicated from Home Assistant original https://www.youtube.com/shorts/KPmIjtD0dfI
The Cameras That Inspire me to Shoot 📸
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=Rx-8C3pTflk
THG Podcast: Butch Cassidy and the Sundance Kid
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=1xDhIerVaxU
Professor Doug Irwin on Trump’s Power Over Trade
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/d9mBX4q8hOQ
We need a European Sovereign Tech Fund (GitHub blog)
Post Syndicated from jzb original https://lwn.net/Articles/1031943/
GitHub director of developer policy, Felix Reda, has published
a blog post about a GitHub-commissioned study by Open Forum Europe, Fraunhofer ISI and
the European University
Institute. The study finds, not surprisingly, “a profound
“; it calls for a European sovereign
mismatch between the importance of open source maintenance and the
public attention it receives
tech fund (STF) modeled after Germany’s Sovereign Tech Agency.
The study proposes two alternative institutional setups for the
EU-STF: either the creation of a centralized EU institution (the
moonshot model), or a consortium of EU member states that provide the
initial funding and apply for additional resources from the EU budget
(the pragmatic model). In both cases, to make the fund a success, the
minimum contribution from the upcoming EU multiannual budget should be
no less than €350 million. This would not be enough to meet the open
source maintenance need, but it could form the basis for leveraging
industry and national government co-financing that would make a
lasting impact.
The European Union is currently starting negotiations for its
2028-2034 budget, the Multiannual
Financial Framework; GitHub and others hope to persuade EU legislators to
include a European STF in that framework.
[$] Extending run-time verification for the kernel
Post Syndicated from daroc original https://lwn.net/Articles/1030685/
There are a lot of things people expect the Linux kernel to do correctly. Some
of these are checked by testing or static analysis; a few are ensured by
run-time verification: checking a live property of a running Linux system. For
example, the scheduler has a handful of different correctness properties that
can be
checked in this way.
Nam Cao posted a
patch series that aims to extend the kinds of properties that the kernel’s
run-time
verification system can check, by adding support for
linear temporal logic (LTL). The patch set has seen eleven revisions since the
first version in March 2025, and recently made it into the linux-next
tree, from where it seems likely to reach the mainline kernel soon.
Научни новини: Комети, мляко без крави и потомство от еднополови родители
Post Syndicated from Михаил Ангелов original https://www.toest.bg/nauchni-novini-kometi-mlyako-bez-kravi-i-potomstvo-ot-ednopolovi-roditeli/
Мляко без крави

Млякото е изключително важна (и вкусна) суровина, която към момента може да се добива само от животни. Отглеждането им ще става все по-трудно и по-скъпо заради очакваните климатични промени и намаляващите водни ресурси и затова интересът към създаването на млечни аналози е изключително голям. Засега най-достъпният метод е биотехнологичното производство на отделните компоненти на млякото, които после да бъдат смесени. А ако се цели производство на млечни субпродукти (например суроватъчни протеини), компонентите могат да бъдат директно вложени в тях, като така се премахва нуждата от разделянето им.
Отделните елементи на млякото, засягащи най-вече вкуса, са: мазнини, казеини (протеините, които формират твърда маса при пресичането на млякото и които са необходими за производството на сирене), суроватъчни протеини (те са по-разтворими и остават в суроватката), захари, витамини и микроелементи.
В последните години няколко компании съобщават, че са решили загадката и имат „биотехнологично мляко“, но за съжаление, никоя от тях не предлага пълна алтернатива. Една от тези компании е Perfect Day (по популярната песен на Lou Reed), основана през 2014 г. Тя работи по B2B модел и предлага своя продукт като суровина на различни компании с цел производство на всякакви хранителни продукти – сладолед, овкусени млека и др.
Зад технологията стои утвърден биотехнологичен модел. Гените за желаните протеини се клонират от първоначалния организъм (в случая крава) в микроорганизъм, който може да се отглежда в биореактори. Perfect Day са избрали за синтез суроватъчния протеин лактоглобулин, а като биологична „фабрика“ – една нишковидна гъба от рода Триходерма. Тези гъби са подходящи за подобен вид производство, тъй като имат свойството да отделят извън клетките си големи количества ензими и с тяхна помощ разграждат целулозата, с която се хранят. Използвайки генетични редакции, учените успяват да ги подлъжат, така че вместо тези хранителни ензими те да синтезират и отделят протеини, чужди за тях.
За съжаление, информацията, която е представена от компанията, може да се окаже не съвсем вярна – това предстои да се установи в дело, заведено преди няколко месеца от две организации – Асоциацията на органичните консуматори (OCA) и GMO/Toxin Free USA.
Perfect Day обявяват съдържание на гъбни протеини от около 7% в своя продукт като следствие от производствения процес. Според ищците независим анализ показва почти обратното – само 13% от продукта представляват рекомбинантен тлактоглобулин, т.е. 87% е съдържанието на гъбни протеини.
Под въпрос е и дали наистина в произведената суровина няма ГМО, тъй като е възможно части от гъбата да не са премахнати при процеса на пречистване. Компанията държи на своя анализ и се позовава на публикувани данни в научна литература, които сочат, че използваната гъба няма известни отрицателни ефекти. Делото ще е интересно, защото може да бъде важно за бъдещето на подобни биотехнологични производства.
Наред със суроватъчните протеини казеините са ключова част от млечните аналози (съставят около 80% от кравето мляко), поради което възможността за техния синтез също представлява голям интерес. В млякото те се намират под формата на агрегати от няколко вида казеин. Важно условие за формирането на тези агрегати е отрицателният заряд на протеините, който те получават чрез фосфорилиране (закрепване на фосфатни групи към тях).
В скорошна публикация са описани два подхода за синтез на фосфорилиран казеин в бактерии. Първият е относително директен – освен гена за казеин от крава се вмъкват и няколко кинази от бактерията Bacillus subtilis. Киназите са ензими, които могат да фосфорилират протеина, закачайки фосфатни групи към него. Второто решение е по-иновативно и се състои в редакция на състава на протеина чрез подмяна на една аминокиселина – серинът се заменя с аспарагинова киселина. Тя има негативен заряд, който ѝ придава свойства, сходни на свойствата на фосфорилирания серин. Екипът нарича този модифициран протеин фосфомиметична версия на казеина, тъй като се държи като него, но няма фосфорилиране.
Според получените резултати от редица тестове, между двата протеина, синтезирани от бактерии, и протеина, извлечен от краве мляко, няма функционална разлика, което звучи обещаващо.
От една страна, е стъпка към чисто практичното приложение на протеина в производство на сирена без използване на животни. Заедно с това показва, че с леки намеси в структурата на протеините може да се получат удачни функционални модификации, чрез които да се опростят подобни производства.
Подобни „прецизни ферментации“ са част от по-общата идея за „клетъчно земеделие“, чиято цел е да се намали използването на животни, като продуктите, традиционно получавани от тях, се заменят с биотехнологични алтернативи. Потенциалът на този нов подход е голям и може да има положително отражение върху много от негативните аспекти на животновъдството – въглеродни емисии, употреба на вода и енергия, заета площ, неетично отглеждане и др. Пълното премахване на животински продукти към момента изглежда много далеч, но на хоризонта се появяват проблясъци като млечните алтернативи или синтетичните месни аналози.
Татко, татко и аз
Размножаването при бозайниците е сравнително праволинейно. Създаването на потомство започва със сливането на две клетки, идващи в общия случай от майката и бащата – процес, който е резултат от милиони години еволюция. Именно поради това намесата в него е изключително трудна и разкриването на всички фини механизми на протичането му е дългогодишна цел на ембриологията. Една от интересните задачи, които са си поставили учените, е да вникнат в процеса на сливане на двете полови клетки и генетичните основи за получаване на новия индивид.
Важен елемент от този процес е епигенетичният феномен „генетичен импринтинг“. След сливането на половите клетки в получената зигота има два набора хромозоми – по един от всеки родител, като всеки се състои от една полова хромозома (X или Y) и няколко автозоми. Тъй като всеки ген е представен от две копия, е нужен прецизен контрол на тяхната активност, за да няма нарушения в развитието на организма. Това е ролята на импринтинга – с помощта на епигенетични механизми някои гени, намиращи се на автозомите, се изключват.
Интересното е, че за разлика от други случаи (например инактивирането на X хромозомите при женските бозайници), в които това се извършва на случаен принцип, при импринтинга има строги правила кои майчини и кои бащини гени ще бъдат изключени. Счита се, че именно поради това няма описани случаи на партеногенеза („непорочно зачатие“) при бозайниците.
Това кара учените да се запитат дали не е възможно изкуствено да се създаде потомство от индивиди от един и същи пол.
Основите на тези опити са поставени през 80-те години на миналия век от английски учени, но резултатите само потвърждават, че наличните към момента технологии не са достатъчни за намеса в специфичния процес на ембриогенеза и в импринтинга. Първият сериозен пробив е направен през 2018 г., когато китайски учени успяват да манипулират ембрионални стволови клетки чрез премахване на няколко ключови гена, които са обект на импринтинг. Най-вероятно поради грубия подход (премахване на цели гени вместо на импринтинга върху тях) от родените 12 мишлета оцеляват само две, при това за по-малко от 48 часа. Въпреки това процедурата е окуражаваща и показва, че с подобни намеси могат да се преодолеят първите критични фази, като образуването на плацентата и началните стадии в развитието на ембриона. В същата публикация е описана сходна технология, чрез която успешно се създават мишки от две майки, даващи нормално потомство след кръстосване с обикновена мишка.
Информация за сходен експеримент бе публикувана и в началото на януари. С помощта на CRISPR/Cas9 китайски учени нарушават функционирането на 20 гена в миши сперматозоиди. Тази намеса е по-успешна – получените мишки оцеляват, но последиците от нея са налице. Животните са по-големи от обикновените, с уголемени органи и по-кратък живот; освен това не са фертилни. Двата експеримента потвърждават сложността на процеса и необходимостта от присъствие на гените.
Промяна на стратегията и сериозна стъпка напред представлява първата яйцеклетка, получена от мъжка стволова клетка.
Разработката, публикувана през 2023 г., е на японски екип, който нарича новата технология „инвитро гаметогенеза“. Процедурата започва със създаване на стволови клетки от възрастни мъжки мишки чрез вземане на материал от опашките им. След това тяхната Y хромозома се премахва и се дублира останалата X, което е една от най-важните стъпки. Така направените XX клетки се имплантират в изкуствено създаден яйчник, където се оформя „мъжката“ яйцеклетка.
След оплождането на тези изкуствени яйцеклетки със сперматозоиди от немодифицирани животни те са имплантирани в сурогатни майки. Получените седем мишки се развиват нормално, без забележими дефекти. Една мъжка и една женска от тях са изпитани за фертилност, като и в двата случая опитите са успешни. Въпреки че само от 1% от имплантираните ембриони се раждат модифицирани мишки, това се оценява като сериозен напредък в полето на репродуктивната генетика.
Разбира се, историята не свършва дотук – в края на миналия месец беше описан нов подход за решаване на тази загадка. Той се базира на модифицирана CRISPR система, редактираща не самия геном, а епигенетичните маркери, които носи ДНК. За получаване на ембрион с генетичен материал от двама бащи се имплантират два сперматозоида в яйцеклетка с премахнато ядро. Така получената „диплоидна“ клетка, която носи два набора хромозоми, се подлага на прецизно насочена редакция, прицелена към алели, които се срещат само на едната хромозома – от единия или от другия татко.
Крайният резултат са две мишлета, които оцеляват и се развиват нормално.
След като достигат полова зрялост, те успяват да създадат потомство с две немодифицирани майки. Този метод изглежда най-щадящ и най-обещаващ, тъй като няма директна намеса в генома, която да бъде предадена на потомството.
Въпреки че може би изглежда малко самоцелно и странно, от манипулирането на половите клетки може да има и преки ползи. Комбинацията от инвитро гаметогенеза и епигенетично редактиране може да бъде важен инструмент за възстановяване на популациите на видове, които са на ръба на изчезването. Макар че най-вероятно няма да може да се пренесе директно от мишки към други видове, натрупаната информация ще помогне за по-бързото и по-лесно разработване на видовоспецифични похвати. Пример са белите носорози, при които инвитро процедурите за оплождане все още не са оптимални.
За добро или лошо, все още сме далеч от прилагането на тези подходи при хора. Дори да приемем, че това би се приело от обществото и се предложи като част от пакетите за репродуктивна помощ, чисто технологично има множество спънки, които трябва да бъдат преодолени. Едната от тях е самото ни познание за гените, подложени на импринтинг – през 2014 г. са били известни около 70, а през 2019 г. броят им надхвърля 200, тоест тепърва се трупат данни. Много е вероятно процедурата да крие рискове, за които все още не подозираме; в повечето публикации полученото потомство не се подлага на тестове за оценка на когнитивните способности. Дискусията доколко етични са подобни технологии, тепърва предстои и няма да бъде лека.
Далечен гост
В необхватните дебри на Космоса има множество обекти, които не обикалят около конкретна звезда, а се движат самотно в пространството между звездните системи. Въпреки че според математическите изчисления те са изключително голям брой, към момента наблюдаването им е доста рядко явление.
В началото на месеца системата за засичане на обекти, представляващи риск за Земята (ATLAS), регистрира ново тяло при преминаването му покрай орбитата на Юпитер.
Траекторията и скоростта му показваха, че идва от пространство извън Слънчевата система и няма да се задържи дълго в нея. Това е едва третият засечен подобен обект, поради което е наречен 3I/ATLAS. Той е по-голям от предишните два, забелязани през 2017 и 2019 г., но точният му размер не може да се определи, защото е активна комета с ядро, обградено от прах (т.нар. кома). Най-вероятно диаметърът му е около 1–2 км, но може да се окаже и към 10 км.

В момента комата е сравнително компактна и опашката ѝ е къса, но най-вероятно с приближаването към Слънцето ще започне да расте. 3I/ATLAS не представлява опасност за Земята и ще прелети на повече от 200 млн. км от нас, преминавайки през орбитата на Марс, без да го застраши. Според сегашните изчисления перихелият (моментът, когато ще е най-близо до Слънцето) ще е на 29 октомври, след което кометата отново ще се отправи към междузвездното пространство в Млечния път. По това време Земята ще бъде от другата страна на Слънцето и няма да е възможно да се правят наблюдения. Орбитите ще позволят това чак през декември, но все още не е ясно дали тогава 3I/ATLAS ще бъде видим.
Поради редкостта на събитието астрономите се възползват от всички налични инструменти.
Телескопът „Хъбъл“ направи наблюдения на 21 юли, а през ноември с негова помощ ще бъдат проведени спектроскопски измервания в ултравиолетовия спектър, които ще определят съотношението между сяра и кислород в кометата. Обсерваторията „Джеймс Уеб“ ще наблюдава обекта през август и декември, измервайки съдържанието на различни вещества в него (вода, амоняк, въглероден диоксид) чрез спектроскопия в инфрачервения спектър.
Тъй като ще прелети най-близо до Марс, учените предвиждат наблюдения и с помощта на изкуствен спътник (MAVEN) в орбита около Червената планета. Измерванията от тези телескопи ще дадат ценна информация за средата, в която се е формирала кометата, и за компонентите, които са присъствали в този момент. Куриозно и за късмет на астрономите, новата обсерватория „Вера Рубин“ също е заснела обекта по време на предварителните ѝ тестове, давайки допълнителни данни отпреди първоначалното му засичане.
Хипотезата за произхода на подобни обекти е, че те се формират в асоциация с някоя звездна система и се движат по дълги орбити около нейната звезда. Но при разминаването с друга звездна система кометите могат да бъдат „издърпани“, което ги изпраща на пътешествие в празното пространство между звездите. Друга възможност е те просто да се откъснат от звездата майка, когато тя започва да губи от масата си и да загива.
Към момента не е ясно откъде точно идва 3I/ATLAS, но учените подозират, че е изключително стар обект.
Предположенията за възрастта му обхващат голям диапазон: според една статия – от 3 до 11 млрд. години, а според друг екип – между 7,6 и 14 млрд. години. Това е впечатляващо, защото може да се окаже, че 3I/ATLAS се е формирал преди нашата Слънчева система. Една от допълнителните улики за произхода на кометата ще бъде и това колко бързо се върти – ако е бързо, най-вероятно е „издърпана“ от друга звезда, а ако е бавно – по-вероятно е просто да е „отплавала“.
Предстои тепърва да разберем още много за тази странстваща комета, но появата ѝ определено предизвика голям интерес в научните среди, което личи от предварителните статии, публикувани само седмици след откритието. Очаква се, че след като обсерваторията „Вера Рубин“ започне своята работа, подобни обекти ще бъдат засичани по-често. Това обаче няма да намали интереса към тях и те ще продължат да пленяват въображението ни.
[$] On becoming a Python contributor
Post Syndicated from jake original https://lwn.net/Articles/1030821/
In the first keynote at
EuroPython 2025 in Prague,
Savannah Bailey described her path to becoming a CPython core developer in
November 2024. She started down that path a few years earlier and her
talk was meant to inspire others—not to slavishly follow hers,
but to create their own. In the talk, entitled “You don’t have to be a compiler engineer
to work on Python”, she had lots of ideas for those who
might be thinking about contributing and are wondering how to do so.
Security updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/1031919/
Security updates have been issued by AlmaLinux (firefox, icu, kernel-rt, libtpms, redis:6, redis:7, and sqlite), Fedora (chromium and cloud-init), Oracle (icu, java-1.8.0-openjdk, java-21-openjdk, kernel, nodejs:22, perl, and sqlite), SUSE (docker, java-1_8_0-openj9, libxml2, python-starlette, and thunderbird), and Ubuntu (cloud-init, linux-azure, linux-azure-5.4, linux-azure-fips, linux-raspi,
linux-raspi-5.4, and perl).
Douglas Irwin and How Trump Weaponized World Trade | The David Frum Show
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=Mv-UTWwu5UM
Cat Eyed Lil: The Cleverest Jewel Thief
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=VdxuUT4da7g
Measuring the Attack/Defense Balance
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/07/measuring-the-attack-defense-balance.html
“Who’s winning on the internet, the attackers or the defenders?”
I’m asked this all the time, and I can only ever give a qualitative hand-wavy answer. But Jason Healey and Tarang Jain’s latest Lawfare piece has amassed data.
The essay provides the first framework for metrics about how we are all doing collectively—and not just how an individual network is doing. Healey wrote to me in email:
The work rests on three key insights: (1) defenders need a framework (based in threat, vulnerability, and consequence) to categorize the flood of potentially relevant security metrics; (2) trends are what matter, not specifics; and (3) to start, we should avoid getting bogged down in collecting data and just use what’s already being reported by amazing teams at Verizon, Cyentia, Mandiant, IBM, FBI, and so many others.
The surprising conclusion: there’s a long way to go, but we’re doing better than we think. There are substantial improvements across threat operations, threat ecosystem and organizations, and software vulnerabilities. Unfortunately, we’re still not seeing increases in consequence. And since cost imposition is leading to a survival-of-the-fittest contest, we’re stuck with perhaps fewer but fiercer predators.
And this is just the start. From the report:
Our project is proceeding in three phases—the initial framework presented here is only phase one. In phase two, the goal is to create a more complete catalog of indicators across threat, vulnerability, and consequence; encourage cybersecurity companies (and others with data) to report defensibility-relevant statistics in time-series, mapped to the catalog; and drive improved analysis and reporting.
This is really good, and important, work.
From coder to mentor: Meet Isabelle
Post Syndicated from Sophie Ashford original https://www.raspberrypi.org/blog/from-coder-to-mentor-meet-isabelle/
We love hearing from members of the community and sharing stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Meet Isabelle, a youth mentor at a library Code Club, whose inspiring story tells how a passion for helping others and a love for reading led back to a childhood interest, shaping an unexpected and rewarding journey.

Saturdays spent at the library
Isabelle’s coding journey began around the age of nine. An avid reader, she regularly attended her local library in Stourbridge with her gran. When they saw there was a Code Club held on a Saturday morning, they both decided it might be a good skill for Isabelle to learn.
“I used to have like an entire folder of all the projects I’d completed. I’ve still got it somewhere in my room!”
She quickly progressed through Scratch, Python, and HTML, even finding herself teaching the adults at the club at some points! But, as secondary school approached, her involvement naturally tapered off as she began to focus on her studies.
A return through volunteering
In secondary school, Isabelle was looking for volunteering opportunities as part of her Duke of Edinburgh (DofE) award. Remembering her positive experiences at the library, and continued love of books, she initially considered volunteering there. Then, she had an idea.
“I suddenly thought ‘What if they still do Code Club?’ I really enjoyed it when I did it and I still remembered enough about it to help others. So, I felt like I could actually be useful instead.”
Isabelle reached out, and thanks to her gran’s long-standing connection with the library, she was remembered and welcomed back. What started as a three-month commitment for her DofE award soon extended to six.
“I really looked forward to each session at the library and decided to stick with it for the whole time.”
Embracing the chaos and connection
Isabelle’s return coincided with the Code Club restarting. Stepping into a mentoring role, she quickly found herself in the thick of it. With five computers and a group of new young people, most of whom had no prior coding experience, the first sessions were a whirlwind.
“It’s like the best kind of chaos. It doesn’t get easier as such. But it’s so fun meeting these new kids, they’re all different and they bounce off each other.”
She works closely with Lucy, the club leader, helping manage the flow of projects and supporting the children as they navigate everything from creating Scratch accounts to tackling challenging projects.

More than just code
While the technical skills are central, Isabelle emphasises that Code Club offers so much more. She’s seen shy children blossom, making new friends and becoming more involved.
“I think there’s the whole element of socialising as well. And beyond coding, kids develop essential IT skills, like learning how to use a mouse and keyboard. Something many who just use tablets and phones don’t know!”
Four years and counting
Isabelle, now preparing to go on to further education, could not have predicted how her mentoring journey would turn out. What began as a three-month DofE requirement has turned into a four-year commitment.
“It has just never been something that I thought ‘oh, I don’t want to do this anymore’. It’s just part of the weekly routine now. It’s been four years and it’s shocking how quickly it’s gone.”
Isabelle’s dedication hasn’t gone unnoticed. She’s built strong bonds with the staff and gained invaluable experience. She’s learned to organise, work in a team, and even run sessions independently, developing skills that will be invaluable for her future.
“I like the bond that I have with the staff and with Lucy. It feels great to be trusted that much and it has just been such a nice experience.”
Lucy, Stourbridge Code Club leader and Library Assistant, shared her experience with the club and collaborating.
“Since Code Club offers so much more than just coding — confidence building, creativity, friendship, etc. — it plays an important role for children and young people in the community. The library is much more than just a place for books, and hosting Code Club here creates a welcoming space where young people can explore technology away from the classroom.”
“Isabelle has been absolutely fantastic both in supporting us with club admin as well as supporting the children with their coding! She understands the projects inside and out and is brilliant at not only solving problems, but also, importantly, encouraging the club to find ways of solving problems themselves. Our Code Club couldn’t have become what it is today without her input!”
Isabelle’s advice for future mentors
As Isabelle prepares to head off to the Bath Spa University to study media communications and publishing, she offers this advice for other young people considering becoming a Code Club mentor…”just go for it!”
Isabelle admits to being anxious at times, but the experience has significantly boosted her confidence.
“It built my confidence a bit more. You make friends along the way and you learn a lot of new things. And don’t worry if you don’t have a lot of coding experience. I don’t think you need it. I had a little bit but I was still basing it mainly off of reading the project instructions. And in all fairness, the instructions are really helpful!”
Mentoring at Code Club isn’t just about teaching, it’s about learning, growing, and connecting. It’s an opportunity to give back, build confidence, and discover the joy in supporting the next generation of digital creators. As Isabelle’s journey shows, sometimes the most rewarding paths are the ones you never planned to take.
Lucy shared why she thinks having youth mentors involved with Code Club is such an important dynamic.
“Youth mentors are great as role models and inspiration for children, and as a young person themselves they build such a great rapport with the club members. A mentor who’s closer to their age often feels more approachable, which helps create a comfortable and encouraging environment for them.”
If Isabelle’s story has inspired you, why not explore the world of coding? You can get started at home with over 250 free projects on the Code Club Projects website.
Looking for a little extra support in your own coding journey or open to mentoring others? Join a Code Club near you to meet a like-minded and supportive community.
The post From coder to mentor: Meet Isabelle appeared first on Raspberry Pi Foundation.