Post Syndicated from Grab Tech original https://engineering.grab.com/palana-part-1-secure-platform-for-ai-agents
Abstract
Artificial intelligence (AI) agents are moving from experiments into everyday engineering workflows. They can read code, call application programming interfaces (APIs), run tests, create merge requests, answer Slack messages, and keep long-running state. That makes them useful, but it also changes the risk model – especially as agents get more autonomous in their use of tools. An agent with network access, credentials, tools, and memory is no longer just a chat interface. It is a workload that can act.
The more capability we give to the agents, the more valuable they get – but they also get riskier, and maintaining controls and oversight gets more challenging. We need isolated environments, with clear intentional capabilities added rather than just inheriting “everything on your laptop”.
Palana is Grab’s Kubernetes-native platform for running those workloads safely. It gives each agent an isolated namespace, persistent storage, controlled ingress, proxy-mediated egress, Vault-backed credential injection, large language model (LLM) routing, Git access controls, structured audit logs, and emergency kill switches. It is currently used to run hundreds of agents, including remote development environments, Slack automation, OpenClaw workers, Hermes agents, and other long-running internal systems.
In this post, we share why we built Palana, what it does, and how its architecture lets teams experiment with autonomous agents without giving up control over identity, secrets, network access, and operational visibility.
Introduction
The first wave of AI coding tools lived close to the user: an integrated development environment (IDE) plugin, a chat window, or a command-line assistant running on a developer’s laptop. That model is familiar and easy to adopt, but it has limits. Long-running agents need persistent state. Team workflows need shared access through Slack or web user interfaces (UIs). Security teams need to inspect what an agent is doing, and apply highly granular controls over what an agent can do. Platform teams need a way to stop, resume, update, and audit the workload.
As usage grew, we started seeing the same question in different forms:
How do we let agents do useful work inside the company without treating every new agent as a bespoke infrastructure project?
The answer was not simply to “run agents in containers”. Containers help package the runtime, but they do not answer the harder platform questions:
- Which user does this agent act on behalf of?
- What credentials can it use?
- Can it see another user’s state?
- Can it connect directly to the internet?
- How do we inspect LLM, Git, and Hypertext Transfer Protocol (HTTP) activity after something goes wrong?
- How do we stop an agent quickly without trusting the agent to cooperate?
- How do we give teams a self-service experience without handing them cluster-admin access?
Palana is our answer to those questions.
What Palana is
Palana, an in-house proprietary system built by the CyberSecurity team at Grab, is a secure execution substrate for autonomous and semi-autonomous agents. The name comes from a Sanskrit root associated with protection, maintenance, and care. That maps well to the platform’s purpose: Palana is not trying to be the agent’s brain. It is the environment that contains, observes, and sustains the agent while it works.
At a high level, Palana provides:
- A Kubernetes namespace per agent, with role-based access control (RBAC), resource quotas, network policy, and storage scoped to that agent.
- A command-line and portal experience for creating, running, stopping, configuring, and inspecting agents.
- Persistent
/data storage so long-running agents can preserve memory, caches, repositories, and session state across restarts.
- Browser and shell access for interactive workloads such as Claude Code UI, OpenCode, IDEs, ttyd, or Secure Shell (SSH)-backed development flows.
- LLM access through a LiteLLM wrapper that injects per-agent GrabGPT credentials from Vault.
- HTTP and HTTPS egress through an Envoy and ext-authz proxy path, with Open Policy Agent (OPA) policy checks and structured request logs.
- Proxy-only secrets, where agents can reference placeholder tokens but cannot read the underlying credentials directly.
- Git access through a bastion path so repository operations are attributable and policy-controlled.
- Kill switches and idle shutdown so the control plane can isolate or stop workloads from outside the agent process.
This combination lets Palana support several categories of work:
- Secure OpenClaw and agent-framework testing.
- Cloud development environments accessible from a browser or SSH client.
- Fast prototyping and testing for agentic workloads in a secure environment.
- Slack-connected agents such as cts-aergia and Claude-to-Slack workflows.
- Long-running task agents such as Hermes, Matlock, Butler, and custom team automations.
- Higher-order systems where agentic supervisors launch or route work to scoped agents.
Why we built it
The immediate need came from security research. We wanted a place to run and investigate OpenClaw and related agent frameworks without exposing the broader internal network or placing raw credentials inside the agent runtime. That use case forced us to design for containment from the beginning.
The broader need quickly became developer productivity. Once the basic primitives existed, Palana became useful for remote coding, Slack automation, internal assistants, long-lived experiments, and agentic operational workflows. Grabbers wanted agents that could keep context over days or weeks, run from corporate infrastructure, access approved internal services, and survive laptop sleep, local dependency drift, or network changes.
The security and productivity goals reinforce each other. If the safe path is self-service and ergonomic, teams are more likely to use it. If the productive path is observable and policy-controlled by default, and the appropriate security is baked into the system automatically, platform teams do not have to retrofit controls after adoption.
Design principles
Palana’s architecture follows a few principles that shaped most of the implementation.
Isolation is the unit of trust
Each agent gets its own namespace, service account, storage, network policy, and Vault scope. Agents should not see each other’s pods, secrets, or filesystem state by default. Inter-agent communication is possible, but it goes through explicit peering rules rather than ambient pod-to-pod reachability.
This means the platform does not have to assume every agent framework has perfect multi-tenant isolation internally. A framework designed as a single-user assistant can still be hosted safely by giving each user or worker its own Palana boundary.
Credentials are never given to the agent
Traditional application hosting often gives credentials to the workload as environment variables or mounted files. That is risky for agent workloads because the agent may execute tools, run untrusted code, summarize files, install packages, or expose a web UI.
Palana separates two kinds of secrets:
- Agent-readable secrets live under the agent’s own Vault path and are available only to that agent’s service account.
- Proxy-only secrets are stored under a separate Vault path and are read by the proxy layer, not by the agent.
For proxy-only secrets, the agent sees a placeholder such as TOKEN_GITHUB_PAT or TOKEN_GRABGPT_API_KEY. When an outbound request travels through the proxy path, the proxy replaces the placeholder header with the real credential from Vault. The remote service receives a valid token, but the agent process never stores the token in its own environment or config.
This pattern is especially important for LLMs, source control, API integrations, and browser-like tools where prompt injection or dependency compromise could otherwise expose long-lived credentials.
Egress is a control point
Agents can be useful only if they can call tools and services. Instead of forbidding network access, Palana makes network access observable and policy-mediated.
Agent pods receive proxy configuration automatically. External HTTP and HTTPS traffic flows through Envoy. Envoy asks ext-authz-proxy to identify the calling pod, evaluate policy with OPA, log the request, and optionally inject credentials. HTTPS traffic can be terminated by the proxy’s man-in-the-middle (MITM) listener for header inspection and replacement, with the generated certificate authority (CA) distributed to agent pods.
This gives the platform a place to answer questions that normal Kubernetes networking cannot answer alone:
- Which agent made this request?
- Which user owns that agent?
- Which host and method were requested?
- Was the request allowed or denied?
- Which placeholder credentials were replaced?
- Did the request go to an internal service, an LLM gateway, GitLab, or the public internet?
The control plane must stay outside the agent
Palana assumes an agent might become confused, compromised, or uncooperative. Operational controls therefore live outside the agent process. The operator reconciles namespaces and policies. The proxy controls egress. The portal and pcli (Palana command-line interface) manage lifecycle. The kill switch is enforced with network policy. Idle shutdown is handled by a separate reaper CronJob.
That separation matters. A kill switch that asks the agent to stop is a feature. A kill switch that removes the agent’s network path is a safety control.
Use Kubernetes primitives where they fit
Palana is intentionally Kubernetes-native. Agents are represented by custom resources. The operator reconciles namespaces, RBAC, storage, services, ingress, and network policies. Users can interact through pcli or the portal, while platform engineers can still inspect the underlying Kubernetes objects when debugging.
This gives us a layered experience: simple workflows for users, direct primitives for advanced operators, and infrastructure-as-code for the deployed platform.
Conclusion
By centering the design around isolation, controlled egress, and proxy-mediated secrets, Palana provides a secure foundation for AI agents to operate within Grab. In Part 2, we will dive deeper into the under-the-hood architecture of Palana, exploring how it orchestrates agent lifecycles, handles LLM routing, and maintains operational visibility.
Join us
Grab is Southeast Asia’s leading superapp, serving over 900 cities across eight countries (Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam). Through a single platform, millions of users access mobility, delivery, and digital financial services, including ride-hailing, food delivery, payments, lending, and digital banking via GXS Bank and GXBank. Founded in 2012, Grab’s mission is to drive Southeast Asia forward by creating economic empowerment for everyone while delivering sustainable financial performance and positive social impact.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
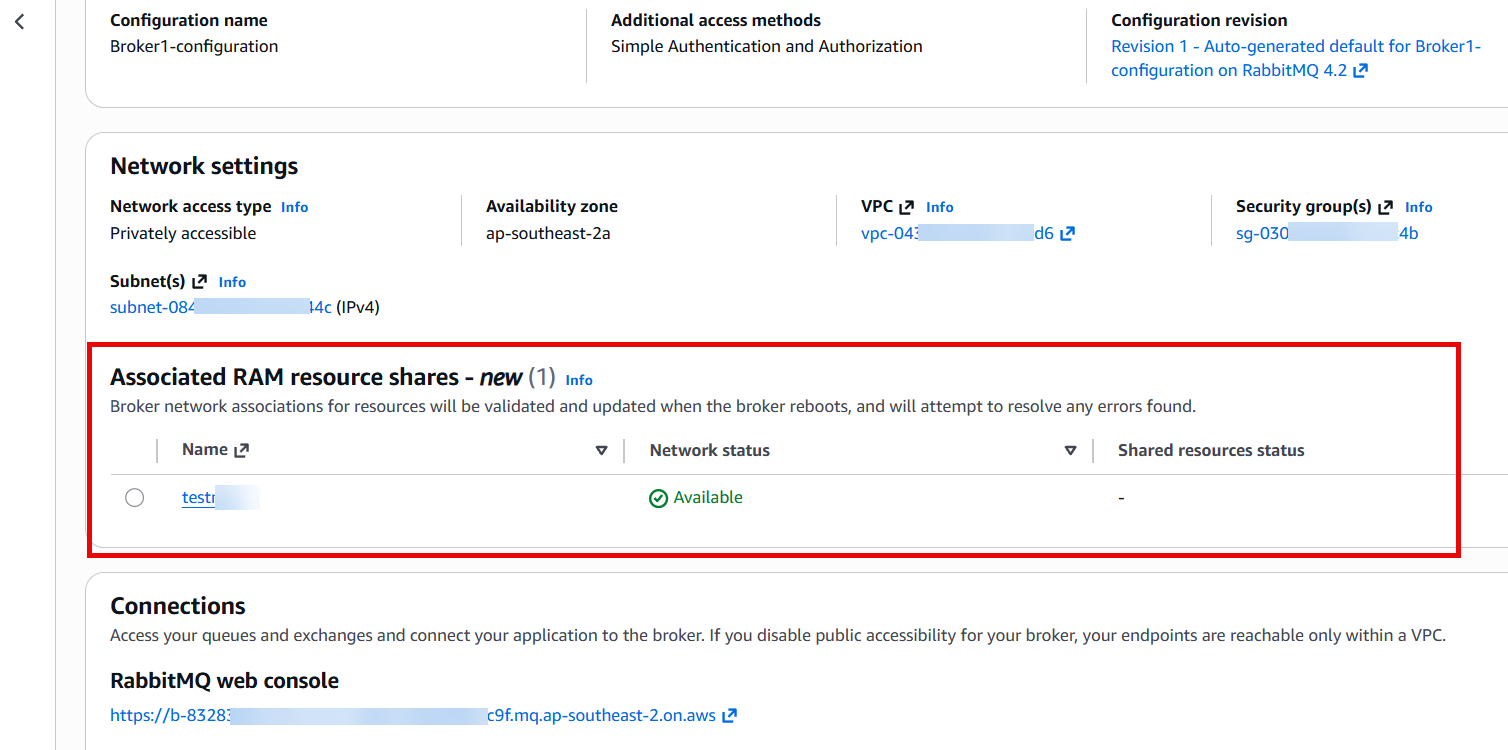
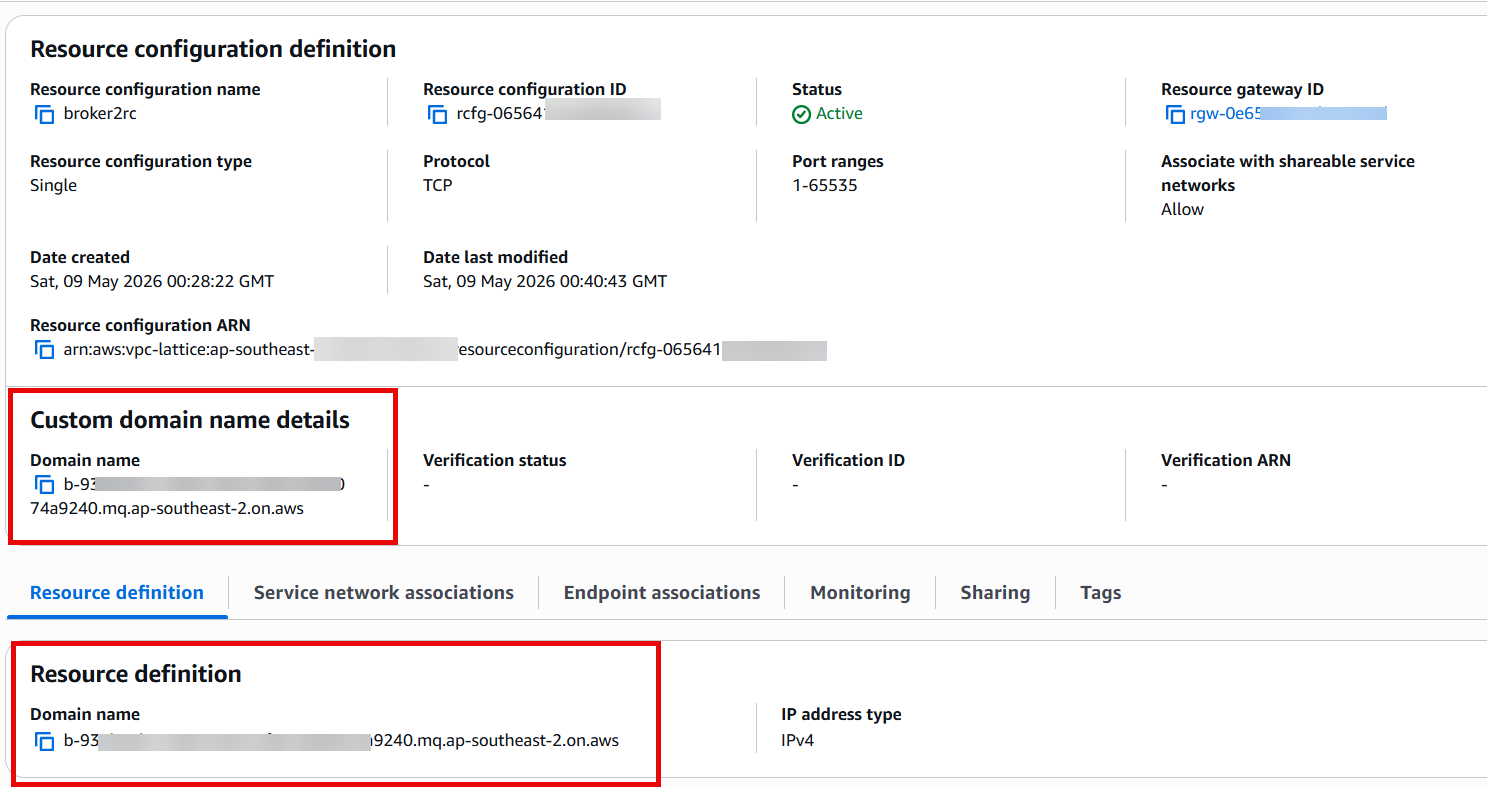 Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint.
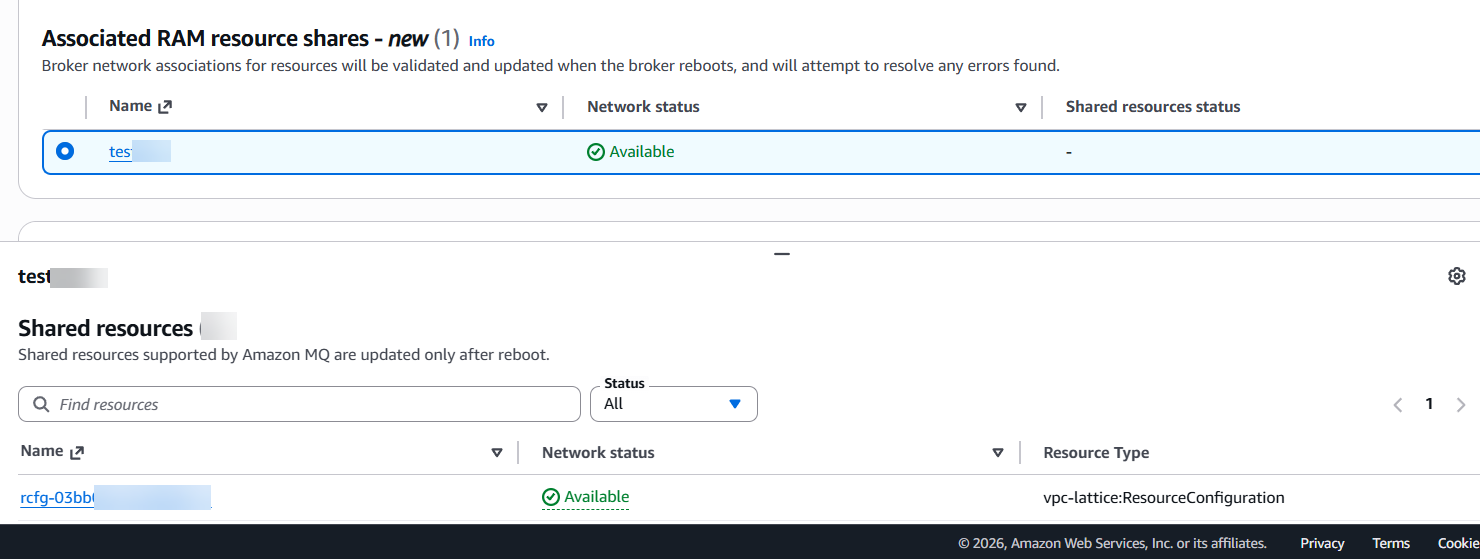
Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint.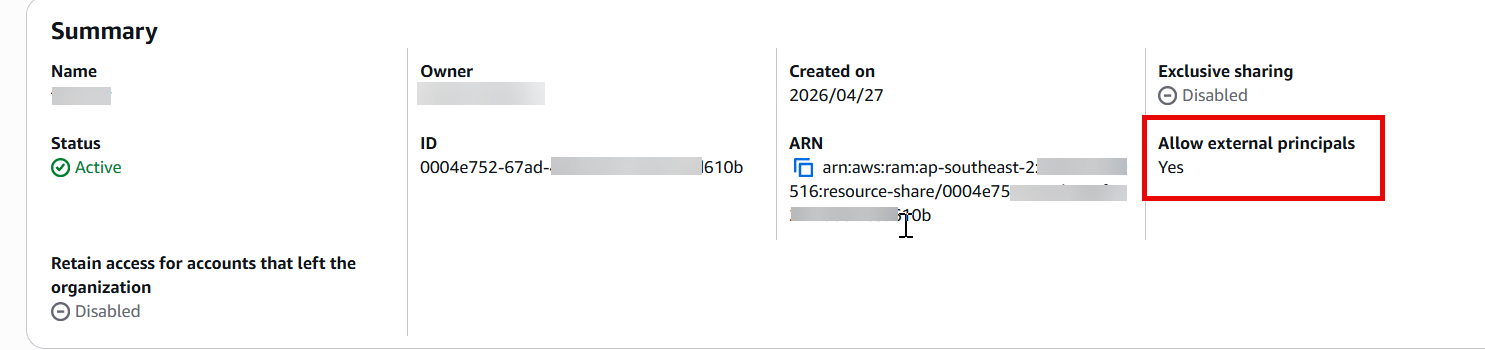 Figure 2: RAM resource share configuration with the Allow external principals option selected.
Figure 2: RAM resource share configuration with the Allow external principals option selected.