Post Syndicated from turnoff.us - geek comic site original http://turnoff.us/geek/clojure-challenge/
Малкият голям човек – детето
Post Syndicated from original https://www.toest.bg/malkiyat-golyam-chovek-deteto/

Според Конвенцията за правата на детето всяко човешко същество под 18 години е дете. Със сигурност обаче всяко човешко същество под 18 години не получава същото човешко отношение, което би получило, ако е над тази възраст. Защо детето е буквално и преносно „малък човек“ и има ли надежда то да стане равноправен член на общността си?
Предварителна бележка: Настоящият текст е наблюдение, а не генерализация. Изключениe от това наблюдение са всички родители и учители, които успешно са преодолели „изконните ценности“, включващи физически наказания, психическо насилие и поколенческа травма. Със сигурност обаче има още много задачи пред настоящите и бъдещите педагози и родители. Усеща се силна нужда от подобряване не само на учебната, но и на обществената среда, включваща всички аспекти на социализирането на децата.
Демонстрация на сила
Отдавна под насилие разбираме не само физическото. УНИЦЕФ, детският фонд на ООН, различава следните видове насилие:
- физическо: всяко неслучайно физическо посегателство над дете от възрастен;
- психическо и емоционално: системно критикуване, засрамване, унижаване, порицаване, заплахи, подигравки, предизвикване на страх и безпокойство, постоянно недоволство от неговото поведение, както и неспособност за подсигуряването на грижа за детето, която да е адекватна за възрастта му; емоционално насилие е включително когато липсва подкрепяща и развиваща среда;
- сексуално насилие;
- неглижиране: действие или бездействие, което лишава детето от грижи за основни нужди, като здраве, образование, емоционална стимулация, адекватно за възрастта му хранене, подсигуряване на дом и условия за живеене, които не застрашават неговото здраве, живот и развитие;
- тормоз (булинг): посегателство през интернет чрез съобщения, обаждания и т.н., които засягат достойнството на жертвата;
- трафик и експлоатация на детски труд.
При съмнение дали дадено поведение или постъпка по отношение на дете е насилие, можем да си зададем въпроса дали бихме си позволили да се държим така с възрастен, или не. Най-често не можем. Не бихме се развикали на подчинен, а бихме опитали с разговор, не бихме обидили директно някого, а бихме му обяснили още веднъж. Бихме потиснали първичната си ярост, за да запазим достойнството на отсрещната страна.
Защо тогава си позволяваме нещо по-различно с децата? Защото са малки. Защото трябва да бъдат възпитани.
Ако си дадем сметка, че всяка негативна реакция на детето е отражение на нещо, случващо се с него, и ѝ отговорим зряло – с търпение и разговор, е много по-вероятно да стигнем до първопричината за тази реакция.
Физическото насилие не е изчезнало въпреки всички регламенти. Единственият начин да го отстраним напълно е да възпитаме и образоваме ново поколение, което се разграничава от методите му.
Емоционалното насилие може да бъде избегнато чрез взаимодействие и комуникация между хората. Както се научаваме да говорим, така възприемаме и тона на общуване на заобикалящите ни. Начинът, по който комуникират родителите и учителите с децата, се попива от самите деца. Така те свикват, че могат да кажат на всеки всичко в лицето, без да се замислят, че не е нужно да са внимателни или да се владеят. Примерът, който получават, е инструментът, с който се сдобиват.
Ефикасност
Неоспоримо е доказано, че добрата среда, спокойствието и приемането водят до много по-успешно усвояване и запаметяване на информация и като цяло – до личностен растеж.
Защо тогава заплахите и наказанията са първичната реакция, която някои възрастни, било то родителите или учители, не могат да превъзмогнат и все още смятат за единствен изход в „напечена“ ситуация?
Възрастните прибягват до тези методи, когато са претоварени и нямат капацитет (време, сили, знания) да реагират по друг начин. Често обаче този тип реакция е резултат от личния им опит, когато са били деца. Всъщност възрастният в този момент действа като детето, което бива наказано. Под стрес родителят/учителят реагира агресивно, което е направило и детето само малко преди това.
Резултатът от поставянето на условия от типа „Ако Х, тогава Y“, в най-добрия случай имат кратко въздействие. „Ако говориш в час, ще получиш забележка!“ Добре, може би час-два или ден-два детето няма да говори. След което поведението дори може да зачести. Това, което се случва обаче, е пълното отписване на детето като непокорно. А всъщност причините за поведението му може да са безброй – като започнем от липсата на концентрация, която може да се корени например в невронетипично поведение, или липсата на интерес поради начина на преподаване, и стигнем до личностни проблеми, които в повечето случаи детето носи от дома си или от приятелската си среда.
Във всички случаи преминаването от забележки към посещения на педагогическия кабинет и въвличане на родителите може да има успех, но само ако зад тези действия стоят адекватни мерки в търсене на първоизточника за поведението, а не да се стига до заклеймяване на детето или отписването му. Дори буквалното отписване – „Търсете друго училище“ са чули не един и двама родители, изправяйки се пред проблеми с детето си, с които дори обучени педагози, изглежда, не могат да се справят. За съжаление обаче, се оказва, че учителите често не могат да превъзмогнат проблемното поведение и дори при положителна промяна ученикът остава черната овца. Друга трудност е и нежеланието на родителите да признаят, че детето им среща препятствия, защото това признание ще ги накара да се сблъскат челно с тези предизвикателства.
Децата от своя страна показват много по-голяма готовност да съдействат, когато разполагат с повече свобода на действие и когато имат правото да участват в процесите, а не да са просто изпълнители или наблюдатели. Обучителният процес в училище често е чисто лекционен. Дори когато учениците не разбират добре нов урок, те не смеят да задават въпроси, с които да си улеснят научаването, защото се страхуват от критика, от лоша оценка или от последващо преднамерено отношение на учителя. Ако ученикът не разбира урока, автоматично в повечето случаи вината пада върху него – не е внимавал, не е учил. Не е рядкост и унижението му пред целия клас с думи като „Ти, ако разбираше, нямаше да си отново в пети клас!“.
Смелостта да задаваме въпроси не се появява от нищото. Можем да я придобием единствено ако се чувстваме сигурни или поне незастрашени от негативни последици.
Уважителни причини
В основата на успешната комуникация стои взаимното уважение. Децата научават в детската градина как да се обръщат към учителите си, минават през периода, в който се учат да употребяват учтивата форма. Следващите нива – начално училище, среден и гимназиален етап, могат постепенно да ги въвеждат в света на възрастните, като им се гласува все по-голямо доверие. Неслучайно от първи до четвърти клас децата биват обгрижвани от малко учители – в идеалния случай преминаването в учебна среда е плавно, на базата на игра и повече внимание.
Натоварването рязко се покачва в пети клас, а отношението към децата става съвсем различно. Автоматично след лятната ваканцията между четвърти и пети клас се очаква да са се сдобили със способността да овладяват множество нови предмети, да могат да разказват, да учат почти академично. Изведнъж изискванията и отношението към тях са станали много по-строги и дори да са се приспособили добре към училищния живот, нерядко децата се задъхват и остават без сили още в първия срок на пети клас. Уви, освен нови отговорности те не са стигнали ново ниво на общуване – остават си същите изпълнители на норми без право на диалогично участие в учебния процес.
Идва зрялата младежка възраст, а с нея и всички предизвикателства на порастването. Бушуват чувства, времето е все по-малко, защото е заето от уроци и извънкласни занимания, а там някъде трябва да има място и за приятели, и за последния училищен етап. Имам ярък спомен за първия път, в който се обърнаха към мен на Вие – точно в гимназията, първата ми учителка по история. Няма място за сравнение с мъчителните часове по химия, в които ме наричаха „момиче“ и никога не чух дори името си. Уважението беше двупосочно, също като неуважението. Училищният ми успех по двата предмета беше най-яркото доказателство за това.
За съжаление, днес дори в университета младите хора не получават нужното уважение. Учтивата форма е изчезнала, заповедният тон (за който в средното училище директорката обяснява, че „учителката така си говори“) е масов и може би единствено профилирането в една наука е разликата със средното образование.
Кога точно децата стават възрастни? В пети клас, когато се научават да са изпълнителни като войници, или в университета, когато вече са пречупени и са се научили, че ако мълчат и правят всичко, което им е казано, ще минат най-лесно между капките? И какви точно възрастни са станали? Уверени, креативни и внимателни?
Последици
Всяка форма на унижение е сравнима с физическа травма. Тя може да доведе до трайно увреждане на нервната, ендокринната и имунната система. Дете, преминало през психически (или физически) тормоз, е предразположено към тревожност, депресия, посттравматично стресово разстройство, разстройство на съня или храненето, та дори към суицидно поведение.
Да не говорим за дългосрочните последици. Същото дете като възрастен ще е неуверен и непълноценен участник в работния и социалния живот, тоест ще сме предначертали неуспешния му професионален и личен път.
Редовно чуваме от учители, че класовете са големи и те нямат възможност за индивидуална работа с учениците. Тук не говорим обаче за извънреден труд или време, а за адекватна и уважителна комуникация. За човешка среда, зачитане, внимание и доверие. Защото децата пропадат, когато не се грижат за тях. Отделените минути за личен разговор както от учител, така и от родител могат да са от ключово значение за по-нататъшното развитие на конфликтна ситуация. Липсата на вяра, че ще бъдат чути, че няма да бъдат съдени за личностните си качества, че ще бъдат оценени като слаби или ще бъдат наказани, е това, което обезсърчава децата и ги убеждава, че ще се провалят.
От позицията на възрастта си имаме привилегията да ни изслушват. Децата, за съжаление, не разполагат с нея. И това трябва да се промени. Ако се почувстват ценени, ще могат да ценят и останалите.
Най-големият комуникационен проблем е, че не слушаме, за да разберем, а слушаме, за да отговорим.
Стивън Кови, педагог, писател и лектор
Светът се променя с бясна скорост. Професиите, в които ще се развиват поколенията, започващи днес образователния си път, все още не са измислени. Подготвена ли е нашата образователна система, за да отговори на тези предизвикателства? Какво може и трябва да се промени? А как?
Веднъж месечно в рубриката „Възможното образование“ ще говорим за промяната – такава, каквато искаме да я видим, за добрите примери и за посоките, в които може би е добре да обърне поглед българската образователна система.
Библиотеката във Варна – рестарт или предизвестен край?
Post Syndicated from Анета Василева original https://www.toest.bg/bibliotekata-vuv-varna-restart-ili-predizvesten-kray/

Новата сграда за Регионалната библиотека на Варна беше една от шумно популяризираните и мъчително потънали в забрава инициативи на предишната общинска власт на града. През 2015 г. се проведе популярен международен архитектурен конкурс, който събра 370 конкурсни предложения от 66 страни, оценени от авторитетно международно жури.
Конкурсът завърши успешно и излъчи за победител холандското студио Architects for Urbanity. През 2016 г. студиото, съставено от млади и амбициозни архитекти, сключи договор за проектиране с Община Варна и започна работа заедно с българските си партньори от варненското студио АМАРХ. През 2018 г. проектът им получи разрешение за строеж. През 2019 г. кметът Иван Портних обяви, че строителството започва, търсят само строител с тръжна процедура. Той обаче разчитал на рамо от държавата както за тази сграда, така и за нова сграда на Математическата гимназия във Варна.
Докато Портних чака подкрепа от държавата, управлявана от неговата партия ГЕРБ и третото правителство на Бойко Борисов, варненската библиотека липсва в инвестиционната програма на Общината, а проектантите алармират, че времето свършва. През 2021 г. разрешителното за строеж на библиотеката наистина изтича. То може да бъде заверено още веднъж за срок от още 3 години – до 2024 г., което тогавашният главен архитект на Варна Виктор Бузев прави.
Междувременно през 2018 г. правителството осигури 43,2 млн. лв. от националния бюджет за община Варна, за да купи „Дупката“ в центъра на града от бизнесмена Георги Гергов. А реконструкцията на 3 километра от злополучния варненски булевард „Васил Левски“ през 2019 г. погълна 113 млн. лв. и се превърна в един от най-скъпите пътни проекти в републиката и непресъхващ извор на трагикомични гафове. За библиотеката по същото време, по изчисления на базата на проекта от 2018 г., бяха нужни около 35 млн. лв. за строителство и 5 млн. лв. за обзавеждане и оборудване. Но те така и не бяха намерени от Портних.
Конкурсът накратко
За архитектурните конкурси в България и конкретно за този за библиотеката във Варна е изписано достатъчно. Самият факт, че това все още е най-популярният архитектурен конкурс в новата ни история, че успя да привлече най-много участници, да разбуни най-много духове и да остане тема за разговор с години, е достатъчен.
Кой
Конкурсът беше организиран от Община Варна със съдействието на КАБ – Варна и независимата архитектурна организация WhAT Association (WhATA)*. Конкурсната програма бе съставена след онлайн анкета, проучваща общественото мнение, нагласи и навици на четене, както и след многобройни консултации с общинските власти и с представители на Регионална библиотека „Пенчо Славейков“ – град Варна, за техните нужди и изисквания.
Къде
За терен на бъдещата библиотека варненските власти определиха общинския паркинг до сградата на Община Варна заради ясната собственост и централното местоположение. Целта им бе да създадат съвременна библиотека в смисъла ѝ на нов тип културно пространство, която като „градска дневна“ да бъде разположена в сърцето на града.
Защо
Конкурсът трябваше да разреши дългогодишен проблем: въпреки че библиотеката на Варна е институция с над 130-годишна история, в момента колекцията ѝ от над 860 000 документа е разпръсната в 6 сгради в различни части на града. Конкурсът за нова сграда целеше да събере библиотеката под един покрив и да осигури безпрепятственото ѝ функциониране, като едновременно с това създаде ново активно обществено пространство.
Ключово послание
От обявяването на конкурса се използваше всеки повод да се подчертае, че бъдещата сграда трябва да демонстрира съвременно отношение към книгите и читателите и да излъчва едно основно послание: „Ние сме модерна, отворена и приятелска институция. Елате да прекарате свободното си време тук.“
Участници
Конкурсът бе обявен в началото на септември 2015 г. и в края на ноември събра 370 конкурсни предложения от 66 страни (около 90 от тях от България), които бяха оценени от международно жури.
Жури
Повечето членове на журито бяха архитекти от популярни студиа с международен опит в проектирането на значими обществени сгради и особено на библиотеки. В журито бяха включени също представители на КАБ – Варна и главният архитект на града.
По време на журирането бяха поканени представители на Регионалната библиотека, включително нейната директорка Емилия Милкова, които даваха мнението си на „потребители“ на бъдещата сграда, без да имат право на глас или да влияят директно на процеса на журиране. Аналогична беше ролята на двама инженери, представители на КИИП (част „Строителни конструкции“ и част „Енергийна ефективност“), които успяха да прегледат разширената селекция от проекти и да напишат ключови препоръки и забележки за тяхната изпълнимост, отношение към противоземетръсните правила в България, енергоефективност и т.н. Писменото становище на специалистите беше взето предвид от журито при разглеждането на всеки проект.
Победителите
Международното жури класира трима победители: младото холандско бюро Architects for Urbanity на първо място, българите от I/O Architects на второ, а на трето – проекта на Spatial Practice от Хонконг. Определени бяха и 2 поощрителни награди: на Stewart Hollenstein от Австралия и на PLUSR Chitecture от Гърция.
Конкурсът носеше духа на времето си, с всичко добро и лошо от това време. Тогава в България все още се градеше доверието към тази най-лека конкурсна форма – отворения, анонимен, едноетапен и безплатен конкурс, който събира стотици участници, хиляди човекочасове архитектурен труд, но не дискриминира никого и дава шанс на младите архитекти, както и на специалисти без опит и реализация.
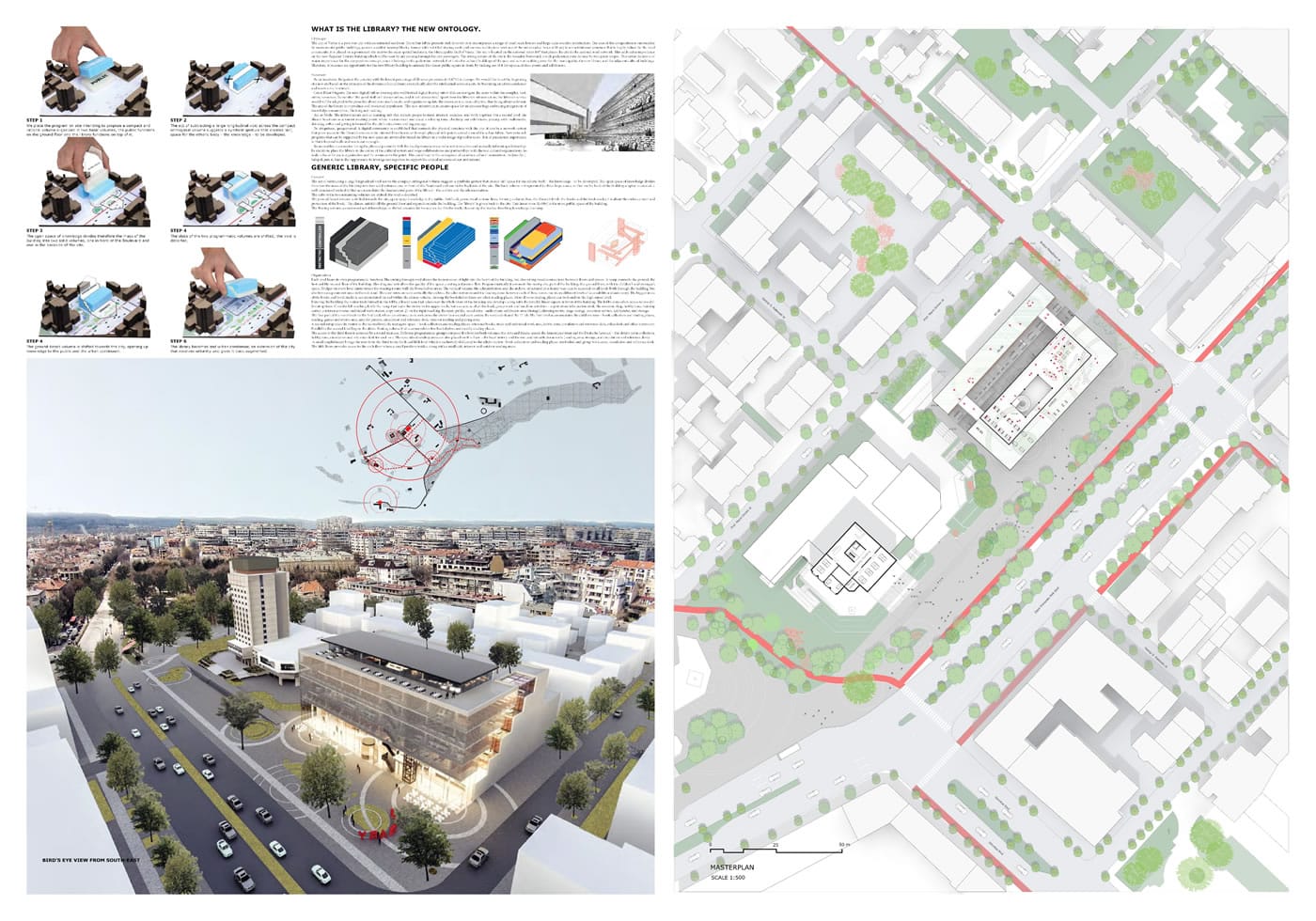


Проектите финалисти в архитектурния конкурс
Една нова библиотека винаги е привлекателна архитектурна задача – още от времената на Франсоа Митеран. През 2015 г. конкурсът за варненската библиотека носеше в себе си оптимизъм и ентусиазъм – наивния оптимизъм на много хора, че властта е разбрала смисъла от архитектурното състезание, а добрите конкурсни практики развиват не само конкурсната култура в България, но и работят за качествена съвременна архитектура и градска среда, разказвайки истории с щастлив край.
А Варна и тогава, и сега има нужда от история с щастлив край.
Но не конкурсът е темата на тази статия.
Проектът накратко
През 2015 г. проектът победител бе избран единодушно от международното жури. Той е неделимо свързан с конкурсната локация, съобразен със заданието и отразява напълно контекста на мястото.
Сградата е на шест етажа, с три подземни нива за паркиране за 300 автомобила, които имат самостоятелен достъп и обслужват голяма част от централната зона на града. Предвидено е библиотеката на Варна да разполага с най-новите технологични въведения, да има 30 места за зареждане на електроавтомобили, велостоянки за 200 велосипеда, както и 24-часова система за връщане на книги. Освен библиотека, сградата представлява и културен център – с амфитеатрална зала с 200 места, 6 помещения за провеждане на събития, картинна галерия на партера, както и редица по-малки помещения за извънкласна дейност и различни прояви. Проектът предвижда обществено достъпен атриум по цялата височина на сградата, който да събира всички, включително деца и младежи, които да прекарват свободното си време там в общуване, четене на книги или работа.
Коментари на журито за проекта победител (сп. „Архитектура“, 2016)
Трине Бертхолд, партньор в schmidt hammer lassen architects, Дания:
Проектът има убедителен разрез: огромна рампа с книги се развива на стъпки през библиотеката. Движението в разреза се възприема като приветлив жест и приканва града и посетителите да влязат в библиотеката. Мащабът на сградата е съобразен с околните сгради, а сградата на Общината остава най-високата точка в района.
Матя Бевк, съосновател на Bevk Perović arhitekti, Словения:
Идеята на проекта е за голяма читалня, която се развива напряко, през целия обем на сградата. Цялата сграда е организирана именно около тези стъпаловидни пространства читални. Те са сърцето на библиотеката – една дневна за посетителите. Сградата има потенциала да създава богат и сложен вътрешен живот, като едновременно с това остава визуално семпла.
Калоян Еревинов, водещ архитект в Zaha Hadid Architects, Китай:
Проектът предлага впечатляващо интериорно решение, отваряне и свързване на центъра на библиотеката с външното пространство. Доминиращият разрез осигурява визуални връзки през сградата и позволява на естествена светлина да достига в дълбочина на обема.
Петр Лешек, съосновател на Projektil architekti, Чехия:
Чиста схема, подходяща за всяка главна улица. Има силно присъствие, но в същото време не доминира над заобикалящата среда. Ще оживи сериозно главната улица. Иконична сграда, но едновременно с това въздействаща на едно деликатно ниво.
Анета Булант-Каменова, съосновател на Bulant & Wailzer, Австрия:
Характерно вътрешно пространство, с възможност за гъвкаво използване и общуване на посетителите. Архитектурата е ясно изразена, неутрална спрямо околната среда, с визуална връзка между външното и вътрешното пространство.
От своята конкурсна фаза до финалното решение с разрешение за строеж проектът остава максимално близко до конкурсната идея, включително визуално, като се съобразява с всички бележки на журито. Това е постижение, за което проектантите трябва да бъдат поздравени.
Но и проектът не е тема на тази статия.





Проектът победител © Architects for Urbanity & AMARCH
Обществото ни днес
В любопитен момент се намира обществото ни днес. И това е така от няколко години. Идеята за прогрес изглежда напълно изчезнала. Въобразяваме си, че сме достигнали някакво ниво и можем да продължим напред, но не! Във всяко нещо, по всяко време напредъкът може да бъде оспорен и мигновено скачаме бодро назад, зачерквайки години бавно и мъчително развитие.
Нещо повече. В днешните времена на социални балони и умиращи авторитети имаме реална криза на доверието в експертността. Протестира се за всичко. В резултат, освен че успешно блокираме безумства в градската среда, също толкова успешно стопираме почти всичко ново, както и крехките, нефелни опити за реформи. Така имаме постоянни дребни информационни бури и скандали, но малко реална промяна, а управляващите стават заложници на общественото мнение и все по-често се чувстват парализирани да прокарват смели визионерски решения.
Новият архитектурен популизъм
Още през 2011 г. в текста си „От плурализъм към популизъм“ холандският архитектурен теоретик и критик Барт Лутсма пише:
Архитектурата се промени: от професия, която правеше обществени сгради, социални и масови жилища, публични пространства, градоустройство и дизайн в служба на по-голяма част от населението във все по-конкретен и вгледан в себе си нишов пазар, обслужващ предимно бизнеса с недвижими имоти, който вече има повече общо с медийната индустрия, отколкото с обществено отговорни задачи.
Лутсма развива теорията за възхода на „пазарния популизъм“, дефиниран от Томас Франк през 2000 г., като част от процеса на индивидуализация и доминиращата парадигма на свободния пазар. Той определя популистите като онези, които се опитват да достигнат до „обикновените хора“, като реагират на техните икономически и социални тревоги чрез „здрав разум“.
Новият архитектурен популизъм обаче добавя още няколко щрихи към този иначе строен икономическо-политически образ на „пазарния популизъм“. Защо? Защото
от 2011 г. до днес социалните мрежи се развиват главоломно и допълнително усложняват отношенията на архитектурата с властта.
Свикнали сме да откриваме популизма в парламентарното ежедневие, около местни избори, както и за прикриване на корупционни практики. Изумително е обаче как той може да засегне нещо толкова безспорно като нова библиотека в третия по големина български град, който вече много години отчаяно се нуждае от такава.
Политиците и Facebook
На 15 декември 2023 г. става ясно, че Община Варна ще кандидатства за 100 млн. лв. от държавния бюджет за 2024 г. с близо 50 обекта, които са от стратегическо значение за развитието на града. „В Общината заварихме липса на проектна готовност. Имаше твърде малко проекти на етап разрешение за строеж“, коментира тогава Благомир Коцев. Новата библиотека е едно от тези изключения – с наличен технически проект и разрешение за строеж. На 20 декември се оказва, че тя е сред „големите проекти, които най-после ще се случат във Варна“ с предвидени 5,5 млн. лв. за поетапно стартиране на строителството.
През януари обаче темата „Да има ли нова библиотека във Варна?“, „Това ли е мястото?”, „Сега ли е моментът?“ е активирана в онлайн дискусии в социални мрежи и Facebook групи.
Мине – не мине време, и се претопля темата за нова библиотека на Варна. Или по-точно абсурдният проект да се застрои една от малкото останали градинки в центъра на Варна.
Това например е мнение на гражданин, споделено във Facebook групата „Варна може да защити Морската си градина /Обновена/“. „Дебатите“ продължават. Дали библиотеката да не се направи в „Дупката“? А в сградата на бившето Руско консулство? А какво ще стане с градинката до паркинга? А с дърветата? И на 11 януари най-неочаквано се оказва, че „случването на настоящия проект за нова сграда на библиотеката във Варна е под въпрос“, а кметът съобщава, че „с обществено обсъждане ще се реши къде да бъде новата сграда на библиотеката във Варна“. На 19 януари варненският заместник-кмет по културата Павел Попов успокоява гражданите, че „новата библиотека не е окончателно затворена страница, предстои решение“, но той самият е разколебан.
Моите колебания са дали реализирането на този скъп проект ще запълни липсите в културната инфраструктура във Варна. Това ще е дворец на книжното тяло, а дали книжното тяло е нещо с бъдеще? Трябва да си отговорим на въпроса дали искаме да създадем такъв дворец.
И така в началото на февруари се оказва, че „Мястото на новата библиотека на Варна отново е на дневен ред“, а има реална вероятност проектът за библиотеката, въпреки отпуснатите средства, да не се осъществи.
Като продължение на предложението си за обществено обсъждане на темата, на 5 февруари 2024 г. варненският кмет Благомир Коцев призова във Facebook своите съграждани да изкажат мнението си дали и каква нова библиотека да получи градът. Там той разумно отбелязва, че
Мястото, където е предвидена да се реализира библиотеката, не може да бъде променяно. То е градска градинка и зелена площ точно до сградата на Общината. Това означава, че ще загубим няколко големи дървета и част от зелените пространства, преди да ги изградим наново, тъй като това е част от проекта.
Дебатът започва директно в социалната мрежа, а кметският пост бързо получи близо 1000 коментара.
За всеки страничен наблюдател ситуацията е съвършено необяснима.
Как е възможно след девет години усилия, започнали в пълен обществен консенсус, след хиляди часове работа на десетки експерти, след международно акламиран конкурс, който приключва без обжалвания и с категоричен победител, след похарчени близо 1 млн. лв. за конкурс, награди и проектиране, при наличието на готов архитектурен проект, неделимо обвързан с една точно определена локация, направен с желание и ентусиазъм и получил разрешение за строеж преди шест години, новата библиотека на Варна отново да бъде под въпрос? При това в ситуация на възможно държавно финансиране.
Това е може би единственият проект на Община Варна, който беше надпартиен и подкрепен от цялата общественост. Ако се загуби насъбраната енергия и свършената до момента работа, това ще е лош сигнал за всяко следващо начинание,
казва в интервю от 20 януари 2024 г. пред „Дарик Варна“ архитект Александър Минчев, един от проектантите на новата библиотека – и е напълно прав.
„Варна има нужда от съвременна библиотека“
беше мотото на архитектурния конкурс през 2015 г. Днес, струва ми се, повече от всякога, Варна има нужда и от мислещи хора, от отговорни експерти и от власт, която не се страхува да вземе стратегически решения, да застане открито зад тях и да ги доведе докрай. Включително да построи една библиотека и най-после да разкаже една история с щастлив край от Варна.
* Авторката участва в организацията на международния конкурс за нова библиотека във Варна (2015) като част от независимата архитектурна група WhAT Association (WhATA). WhATA са автори и на заданието за конкурса. В тази връзка тази статия не е безпристрастна.
Статията е в памет на Емилия Милкова, дългогодишна директорка на Регионална библиотека „Пенчо Славейков“ във Варна и двигател на конкурса за нова сграда на библиотеката в града.
Banana Prices
Post Syndicated from xkcd.com original https://xkcd.com/2892/

Google announces 2024 season of docs
Post Syndicated from LWN.net original https://lwn.net/Articles/961405/
On February 2, Google announced this year’s
“Season of Docs”, a program complementing its Summer of Code program
by providing funding to open source projects to hire technical writers to improve
their documentation. Interested projects have until April 2 to apply.
Google Season of Docs provides direct grants to open source projects to improve their documentation and gives professional technical writers an opportunity to gain experience in open source. Together we raise awareness of open source, of docs, and of technical writing.
Google announces 2024 season of docs
Post Syndicated from daroc original https://lwn.net/Articles/961405/
On February 2, Google announced this year’s
“Season of Docs”, a program complementing its Summer of Code program
by providing funding to open source projects to hire technical writers to improve
their documentation. Interested projects have until April 2 to apply.
Google Season of Docs provides direct grants to open source projects to improve their documentation and gives professional technical writers an opportunity to gain experience in open source. Together we raise awareness of open source, of docs, and of technical writing.
Brennan: What’s Inside a Linux Kernel Core Dump
Post Syndicated from LWN.net original https://lwn.net/Articles/961414/
Stephen Brennan describes
kernel core dumps in excruciating detail.
Kernel core dumps are complex. They are not simply copies of system
memory; they contain plenty of extra metadata which is critical to
understanding their contents. And like any other type of data, the
design of the file formats can enable lots of flexibility and
power. However, due to the broad variety of tools out there, the
diversity of dump formats is overwhelming, and the lack of
documentation or specifications compounds the problem.
Brennan: What’s Inside a Linux Kernel Core Dump
Post Syndicated from corbet original https://lwn.net/Articles/961414/
Stephen Brennan describes
kernel core dumps in excruciating detail.
Kernel core dumps are complex. They are not simply copies of system
memory; they contain plenty of extra metadata which is critical to
understanding their contents. And like any other type of data, the
design of the file formats can enable lots of flexibility and
power. However, due to the broad variety of tools out there, the
diversity of dump formats is overwhelming, and the lack of
documentation or specifications compounds the problem.
GoWin 1U 25GbE Appliance Review This Has Everything Including PoE
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/gowin-1u-25gbe-appliance-review-this-has-everything-including-poe-intel-nvidia/
We check out the new GoWin 1U firewall appliance with 25GbE, 1GbE, 2.5GbE, PoE, lots of CPU performance and storage, and more
The post GoWin 1U 25GbE Appliance Review This Has Everything Including PoE appeared first on ServeTheHome.
Use multiple bookmark keys in AWS Glue JDBC jobs
Post Syndicated from Durga Prasad original https://aws.amazon.com/blogs/big-data/use-multiple-bookmark-keys-in-aws-glue-jdbc-jobs/
AWS Glue is a serverless data integrating service that you can use to catalog data and prepare for analytics. With AWS Glue, you can discover your data, develop scripts to transform sources into targets, and schedule and run extract, transform, and load (ETL) jobs in a serverless environment. AWS Glue jobs are responsible for running the data processing logic.
One important feature of AWS Glue jobs is the ability to use bookmark keys to process data incrementally. When an AWS Glue job is run, it reads data from a data source and processes it. One or more columns from the source table can be specified as bookmark keys. The column should have sequentially increasing or decreasing values without gaps. These values are used to mark the last processed record in a batch. The next run of the job resumes from that point. This allows you to process large amounts of data incrementally. Without job bookmark keys, AWS Glue jobs would have to reprocess all the data during every run. This can be time-consuming and costly. By using bookmark keys, AWS Glue jobs can resume processing from where they left off, saving time and reducing costs.
This post explains how to use multiple columns as job bookmark keys in an AWS Glue job with a JDBC connection to the source data store. It also demonstrates how to parameterize the bookmark key columns and table names in the AWS Glue job connection options.
This post is focused towards architects and data engineers who design and build ETL pipelines on AWS. You are expected to have a basic understanding of the AWS Management Console, AWS Glue, Amazon Relational Database Service (Amazon RDS), and Amazon CloudWatch logs.
Solution overview
To implement this solution, we complete the following steps:
- Create an Amazon RDS for PostgreSQL instance.
- Create two tables and insert sample data.
- Create and run an AWS Glue job to extract data from the RDS for PostgreSQL DB instance using multiple job bookmark keys.
- Create and run a parameterized AWS Glue job to extract data from different tables with separate bookmark keys
The following diagram illustrates the components of this solution.

Deploy the solution
For this solution, we provide an AWS CloudFormation template that sets up the services included in the architecture, to enable repeatable deployments. This template creates the following resources:
- An RDS for PostgreSQL instance
- An Amazon Simple Storage Service (Amazon S3) bucket to store the data extracted from the RDS for PostgreSQL instance
- An AWS Identity and Access Management (IAM) role for AWS Glue
- Two AWS Glue jobs with job bookmarks enabled to incrementally extract data from the RDS for PostgreSQL instance
To deploy the solution, complete the following steps:
- Choose
 to launch the CloudFormation stack:
to launch the CloudFormation stack: - Enter a stack name.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
- Wait until the creation of the stack is complete, as shown on the AWS CloudFormation console.

- When the stack is complete, copy the AWS Glue scripts to the S3 bucket
job-bookmark-keys-demo-<accountid>. - Open AWS CloudShell.
- Run the following commands and replace
<accountid>with your AWS account ID:

aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_1_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_1_job.py
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_2_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_2_job.py
Add sample data and run AWS Glue jobs
In this section, we connect to the RDS for PostgreSQL instance via AWS Lambda and create two tables. We also insert sample data into both the tables.
- On the Lambda console, choose Functions in the navigation pane.
- Choose the function
LambdaRDSDDLExecute.

- Choose Test and choose Invoke for the Lambda function to insert the data.


The two tables product and address will be created with sample data, as shown in the following screenshot.

Run the multiple_job_bookmark_keys AWS Glue job
We run the multiple_job_bookmark_keys AWS Glue job twice to extract data from the product table of the RDS for PostgreSQL instance. In the first run, all the existing records will be extracted. Then we insert new records and run the job again. The job should extract only the newly inserted records in the second run.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Choose the job
multiple_job_bookmark_keys. - Choose Run to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.

- Choose the log stream in the next window to see the output logs printed.

The AWS Glue job extracted all records from the source table product. It keeps track of the last combination of values in the columnsproduct_idandversion.Next, we run another Lambda function to insert a new record. Theproduct_id45 already exists, but the inserted record will have a new version as 2, making the combination sequentially increasing. - Run the
LambdaRDSDDLExecute_incrementalLambda function to insert the new record in theproducttable.

- Run the AWS Glue job
multiple_job_bookmark_keysagain after you insert the record and wait for it to succeed. - Choose the Output logs hyperlink under CloudWatch logs.
- Choose the log stream in the next window to see only the newly inserted record printed.



The job extracts only those records that have a combination greater than the previously extracted records.

Run the parameterised_job_bookmark_keys AWS Glue job
We now run the parameterized AWS Glue job that takes the table name and bookmark key column as parameters. We run this job to extract data from different tables maintaining separate bookmarks.
The first run will be for the address table with bookmarkkey as address_id. These are already populated with the job parameters.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Choose the job
parameterised_job_bookmark_keys. - Choose Run to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.
- Choose the log stream in the next window to see all records from the address table printed.

- On the Actions menu, choose Run with parameters.
- Expand the Job parameters section.
- Change the job parameter values as follows:
- Key
--bookmarkkeywith valueproduct_id - Key
--table_namewith valueproduct - The S3 bucket name is unchanged (
job-bookmark-keys-demo-<accountnumber>)
- Key
- Choose Run job to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.
- Choose the log stream to see all the records from the product table printed.





The job maintains separate bookmarks for each of the tables when extracting the data from the source data store. This is achieved by adding the table name to the job name and transformation contexts in the AWS Glue job script.
Clean up
To avoid incurring future charges, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Select the bucket with job-bookmark-keys in its name.
- Choose Empty to delete all the files and folders in it.
- On the CloudFormation console, choose Stacks in the navigation pane.
- Select the stack you created to deploy the solution and choose Delete.
Conclusion
This post demonstrated passing more than one column of a table as jobBookmarkKeys in a JDBC connection to an AWS Glue job. It also explained how you can a parameterized AWS Glue job to extract data from multiple tables while keeping their respective bookmarks. As a next step, you can test the incremental data extract by changing data in the source tables.
About the Authors
 Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton.
Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton.
 Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.
Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.
GitHub’s Engineering Fundamentals program: How we deliver on availability, security, and accessibility
Post Syndicated from Deepthi Rao Coppisetty original https://github.blog/2024-02-08-githubs-engineering-fundamentals-program-how-we-deliver-on-availability-security-and-accessibility/
How do we ensure over 100 million users across the world have uninterrupted access to GitHub’s products and services on a platform that is always available, secure, and accessible? From our beginnings as a platform for open source to now also supporting 90% of the Fortune 100, that is the ongoing challenge we face and hold ourselves accountable for delivering across our engineering organization.
Establishing engineering governance
To meet the needs of our increased number of enterprise customers and our continuing innovation across the GitHub platform, we needed to address tech debt, improve reliability, and enhance observability of our engineering systems. This led to the birth of GitHub’s engineering governance program called the Fundamentals program. Our goal was to work cross-functionally to define, measure, and sustain engineering excellence with a vision to ensure our products and services are built right for all users.
What is the Fundamentals program?
In order for such a large-scale program to be successful, we needed to tackle not only the processes but also influence GitHub’s engineering culture. The Fundamentals program helps the company continue to build trust and lead the industry in engineering excellence, by ensuring that there is clear prioritization of the work needed in order for us to guarantee the success of our platform and the products that you love.
We do this via the lens of three program pillars, which help our organization understand the focus areas that we emphasize today:
- Accessibility (A11Y): Truly be the home for all developers
- Security: Serve as the most trustworthy platform for developers
- Availability: Always be available and on for developers
In order for this to be successful, we’ve relied on both grass-roots support from individual teams and strong and consistent sponsorship from our engineering leadership. In addition, it requires meaningful investment in the tools and processes to make it easy for engineers to measure progress against their goals. No one in this industry loves manual processes and here at GitHub we understand anything that is done more than once must be automated to the best of our ability.
How do we measure progress?
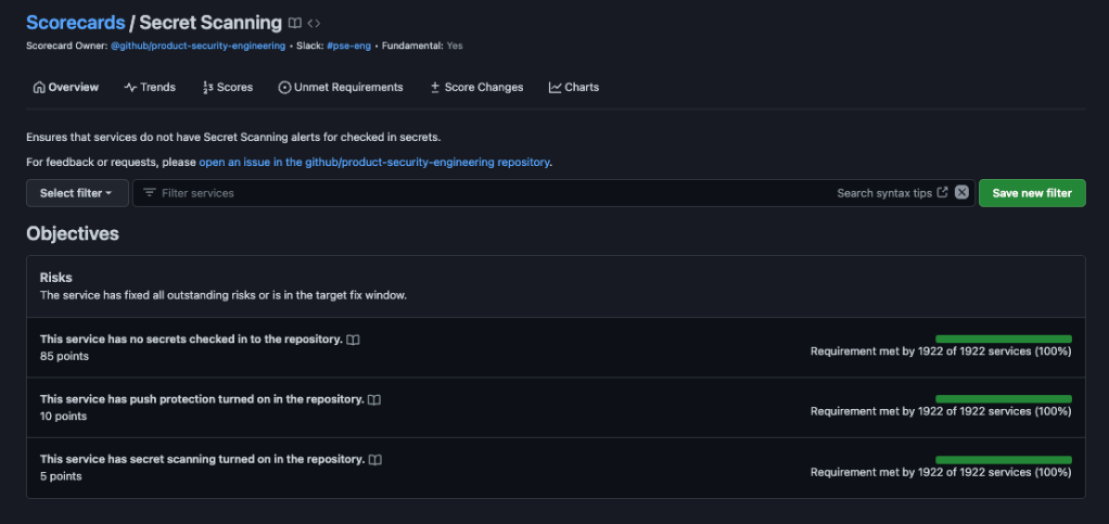
We use Fundamental Scorecards to measure progress against our Availability, Security, and Accessibility goals across the engineering organization. The scorecards are designed to let us know that a particular service or feature in GitHub has reached some expected level of performance against our standards. Scorecards align to the fundamentals pillars. For example, the secret scanning scorecard aligns to the Security pillar, Durable Ownership aligns to Availability, etc. These are iteratively evolved by enhancing or adding requirements to ensure our services are meeting our customer’s changing needs. We expect that some scorecards will eventually become concrete technical controls such that any deviation is treated as an incident and other automated safety and security measures may be taken, such as freezing deployments for a particular service until the issue is resolved.
Each service has a set of attributes that are captured and strictly maintained in a YAML file, such as a service tier (tier 0 to 3 based on criticality to business), quality of service (QoS values include critical, best effort, maintenance and so on based on the service tier), and service type that lives right in the service’s repo. In addition, this file also has the ownership information of the service, such as the sponsor, team name, and contact information. The Fundamental scorecards read the service’s YAML file and start monitoring the applicable services based on their attributes. If the service does not meet the requirements of the applicable Fundamental scorecard, an action item is generated with an SLA for effective resolution. A corresponding issue is automatically generated in the service’s repository to seamlessly tie into the developer’s workflow and meet them where they are to make it easy to find and resolve the unmet fundamental action items.
Through the successful implementation of the Fundamentals program, we have effectively managed several scorecards that align with our Availability, Security, and Accessibility goals, including:
- Durable ownership: maintains ownership of software assets and ensures communication channels are defined. Adherence to this fundamental supports GitHub’s Availability and Security.
- Code scanning: tracks security vulnerabilities in GitHub software and uses CodeQL to detect vulnerabilities during development. Adherence to this fundamental supports GitHub’s Security.
- Secret scanning: tracks secrets in GitHub’s repositories to mitigate risks. Adherence to this fundamental supports GitHub’s Security.
- Incident readiness: ensures services are configured to alert owners, determine incident cause, and guide on-call engineers. Adherence to this fundamental supports GitHub’s Availability.
- Accessibility: ensures products and services follow our accessibility standards. Adherence to this fundamental enables developers with disabilities to build on GitHub.
A culture of accountability
As much emphasis as we put on Fundamentals, it’s not the only thing we do: we ship products, too!
We call it the Fundamentals program because we also make sure that:
- We include Fundamentals in our strategic plans. This means our organization prioritizes this work and allocates resources to accomplish the fundamental goals we each quarter. We track the goals on a weekly basis and address the roadblocks.
- We surface and manage risks across all services to the leaders so they can actively address them before they materialize into actual problems.
- We provide support to teams as they work to mitigate fundamental action items.
- It’s clearly understood that all services, regardless of team, have a consistent set of requirements from Fundamentals.
Planning, managing, and executing fundamentals is a team affair, with a program management umbrella.
Designated Fundamentals champions and delegates help maintain scorecard compliance, and our regular check-ins with engineering leaders help us identify high-risk services and commit to actions that will bring them back into compliance. This includes:
- Executive sponsor. The executive sponsor is a senior leader who supports the program by providing resources, guidance, and strategic direction.
- Pillar sponsor. The pillar sponsor is an engineering leader who oversees the overarching focus of a given pillar across the organization as in Availability, Security, and Accessibility.
- Directly responsible individual (DRI). The DRI is an individual responsible for driving the program by collaborating across the organization to make the right decisions, determine the focus, and set the tempo of the program.
- Scorecard champion. The scorecard champion is an individual responsible for the maintenance of the scorecard. They add, update, and deprecate the scorecard requirements to keep the scorecard relevant.
- Service sponsors. The sponsor oversees the teams that maintain services and is accountable for the health of the service(s).
- Fundamentals delegate. The delegate is responsible for coordinating Fundamentals work with the service owners within their org, supporting the Sponsor to ensure the work is prioritized, and resources committed so that it gets completed.
Results-driven execution
Making the data readily available is a critical part of the puzzle. We created a Fundamentals dashboard that shows all the services with unmet scorecards sorted by service tier and type and filtered by service owners and teams. This makes it easier for our engineering leaders and delegates to monitor and take action towards Fundamental scorecards’ adherence within their orgs.
As a result:
- Our services comply with durable ownership requirements. For example, the service must have an executive sponsor, a team, and a communication channel on Slack as part of the requirements.
- We resolved active secret scanning alerts in repositories affiliated with the services in the GitHub organization. Some of the repositories were 15 years old and as a part of this effort we ensured that these repos are durably owned.
- Business critical services are held to greater incident readiness standards that are constantly evolving to support our customers.
- Service tiers are audited and accurately updated so that critical services are held to the highest standards.
Example layout and contents of Fundamentals dashboard
| Tier 1 Services Out of Compliance [Count: 2] | ||||
| Service Name | Service Tier | Unmet Scorecard | Exec Sponsor | Team |
| service_a | 1 | incident-readiness | john_doe | github/team_a |
| service_x | 1 | code-scanning | jane_doe | github/team_x |
Continuous monitoring and iterative enhancement for long-term success
By setting standards for engineering excellence and providing pathways to meet through standards through culture and process, GitHub’s Fundamentals program has delivered business critical improvements within the engineering organization and, as a by-product, to the GitHub platform. This success was possible by setting the right organizational priorities and committing to them. We keep all levels of the organization engaged and involved. Most importantly, we celebrate the wins publicly, however small they may seem. Building the culture of collaboration, support, and true partnership has been key to sustaining the ongoing momentum of an organization-wide engineering governance program, and the scorecards that monitor the availability, security, and accessibility of our platform so you can consistently rely on us to achieve your goals.
Want to learn more about how we do engineering GitHub? Check out how we build containerized services, how we’ve scaled our CI to 15,000 jobs every hour using GitHub Actions larger runners, and how we communicate effectively across time zones, teams, and tools.
Interested in joining GitHub? Check out our open positions or learn more about our platform.
The post GitHub’s Engineering Fundamentals program: How we deliver on availability, security, and accessibility appeared first on The GitHub Blog.
Backblaze Commits to Routing Security With MANRS Participation
Post Syndicated from Brent Nowak original https://www.backblaze.com/blog/backblaze-commits-to-routing-security-with-manrs-participation/

They say good manners are better than good looks. When it comes to being a good internet citizen, we have to agree. And when someone else tells you that you have good manners (or MANRS in this case), even better.
If you hold your cloud partners to a higher standard, and if you think it’s not asking too much that they make the internet a better, safer place for everyone, then you’ll be happy to know that Backblaze is now recognized as a Mutually Agreed Norms for Routing Security (MANRS) participant (aka MANRS Compliant).
What Is MANRS?
MANRS is a global initiative with over 1,095 participants that are enacting network policies and controls to help reduce the most common routing threats. At a high level, we’re setting up filters to check that network routing information we receive for peers is valid, ensuring that the networks we advertise to the greater internet are marked as owned by Backblaze, and making sure that data that gets out of our network is legitimate and can’t be spoofed.
You can view a full list of MANRS participants here.
What Our (Good) MANRS Mean For You
The biggest benefit for customers is that network traffic to and from Backblaze’s connection points where we exchange traffic with our peering partners is more secure and more trustworthy. All of the changes that we’ve implemented (which we get into below) are on our side—so, no action is necessary from Backblaze partners or users—and will be transparent for our customers. Our Network Engineering team has done the heavy lifting.
MANRS Actions
Backblaze falls under the MANRS category of CDN and Cloud Providers, and as such, we’ve implemented solutions or processes for each of the five actions stipulated by MANRS:
- Prevent propagation of incorrect routing information: Ensure that traffic we receive is coming from known networks.
- Prevent traffic of illegitimate source IP addresses: Prevent malicious traffic coming out of our network.
- Facilitate global operational communication and coordination: Keep our records with 3rd party sites like Peeringdb.com up to date as other operators use this to validate our connectivity details.
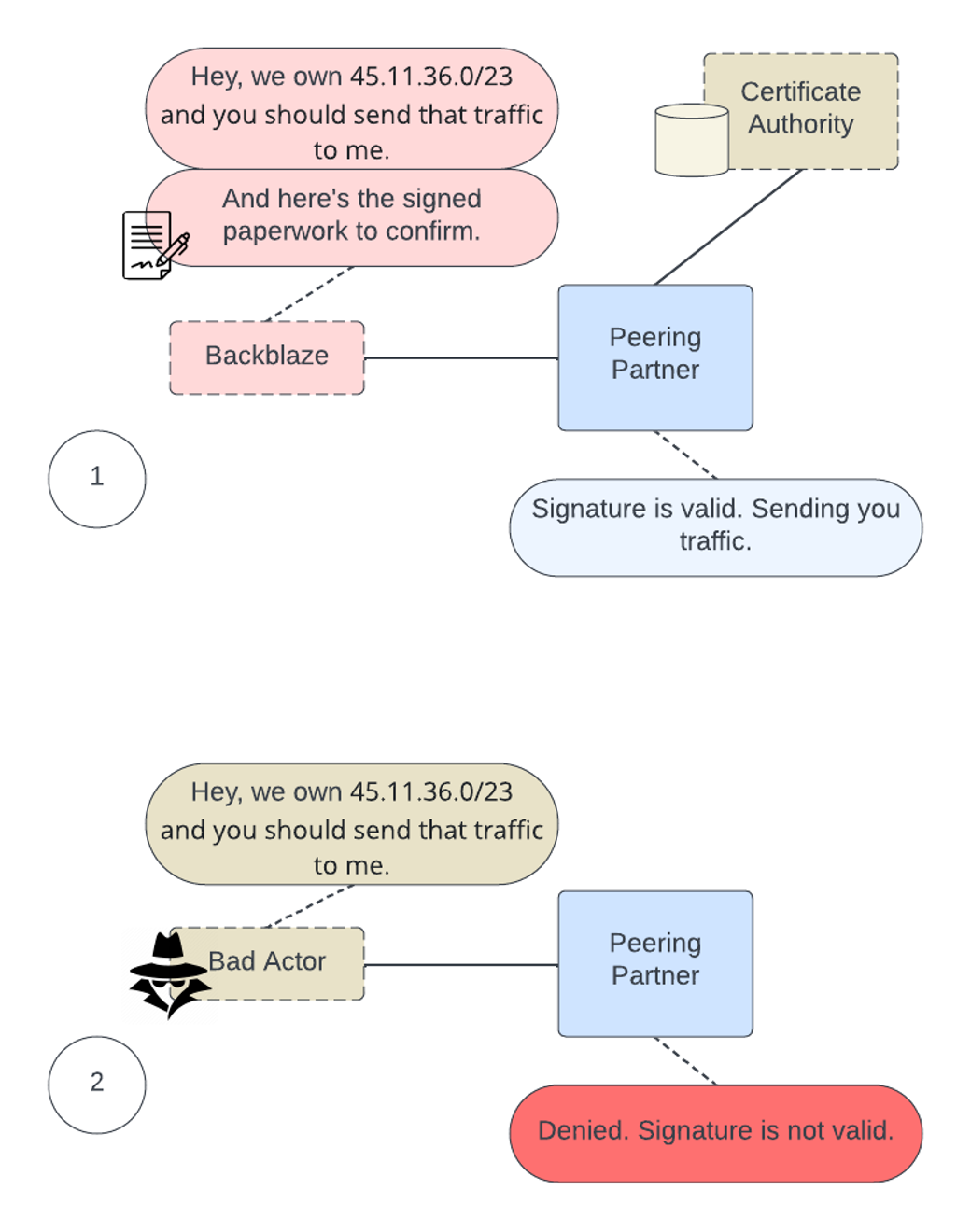
- Facilitate validation of routing information on a global scale: Digitally sign our network objects using the Resource Public Key Infrastructure (RPKI) standard.
- Encourage MANRS adoption: By telling the world, just like in this post!
Digging Deeper Into Filtering and RPKI
Let’s go over the filtering and RPKI details, since they are very valuable to ensuring the security and validity of our network traffic.
Filtering: Sorting Out the Good Networks From the Bad
One major action for MANRS compliance is to validate that the networks we receive from peers are valid. When we connect to other networks, we each tell each other about our networks in order to build a routing table that lets us know the optimal path to send traffic.
We can blindly trust what the other party is telling us, or we can reach out to an external source to validate. We’ve implemented automated internal processes to help us apply these filters to our edge routers (the devices that connect us externally to other networks).
If you’re a more visual learner, like me, here’s a quick conversational bubble diagram of what we have in place.
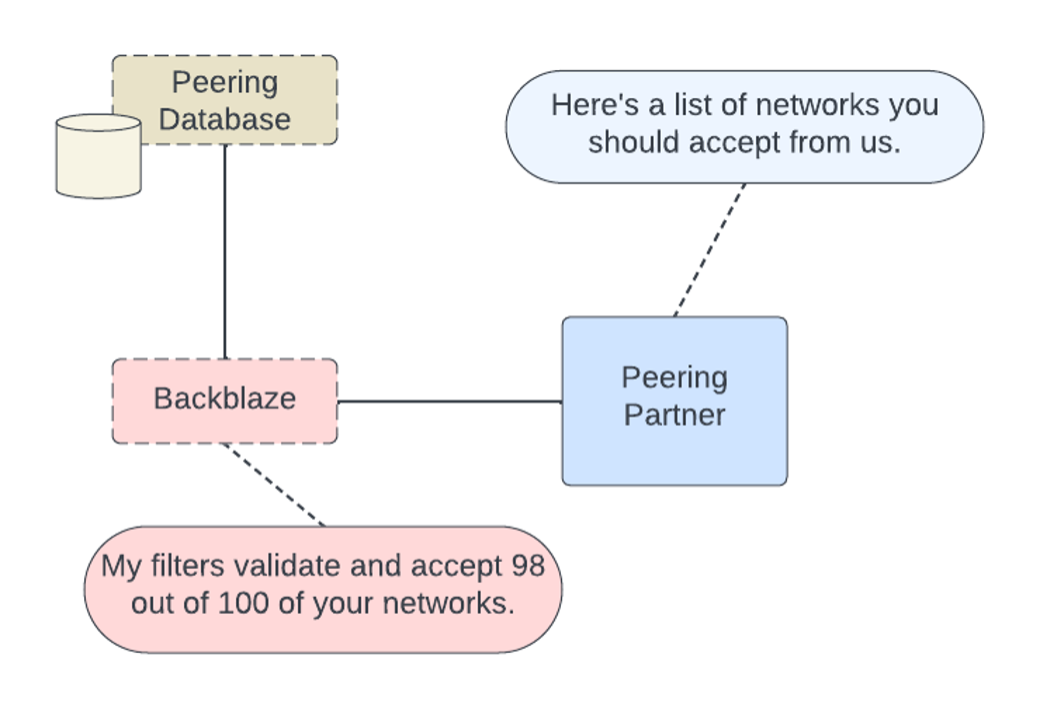
Every edge device that connects to an external peer now has validation steps to ensure that the networks we receive and use to send out traffic are valid. We have automated processes that periodically check and deploy for updates to any lists.
What Is RPKI?
RPKI is a public key infrastructure framework designed to secure the internet’s routing infrastructure, specifically the Border Gateway Protocol (BGP). RPKI provides a way to connect internet number resource information (such as IP addresses) to a trust anchor. In layman’s terms, RPKI allows us, as a network operator, to securely identify whether other networks that interact with ours are legitimate or malicious.
RPKI: Signing Our Paperwork
Much like going to a notary and validating a form, we can perform the same action digitally with the list of networks that we advertise to the greater internet. The RPKI framework allows us to stamp our networks as owned by us.
It also allows us to digitally sign records of our networks that we own, allowing external parties to confirm that the networks that they see from us are valid. If another party comes along and tries to claim to be us, by using RPKI our peering partner will deny using that network to send data to a false Backblaze network.
You can check the status of our RPKI signed route objects on the MANRS statistics website.
What does the process of peering and advertising networks look like without RPKI validation?
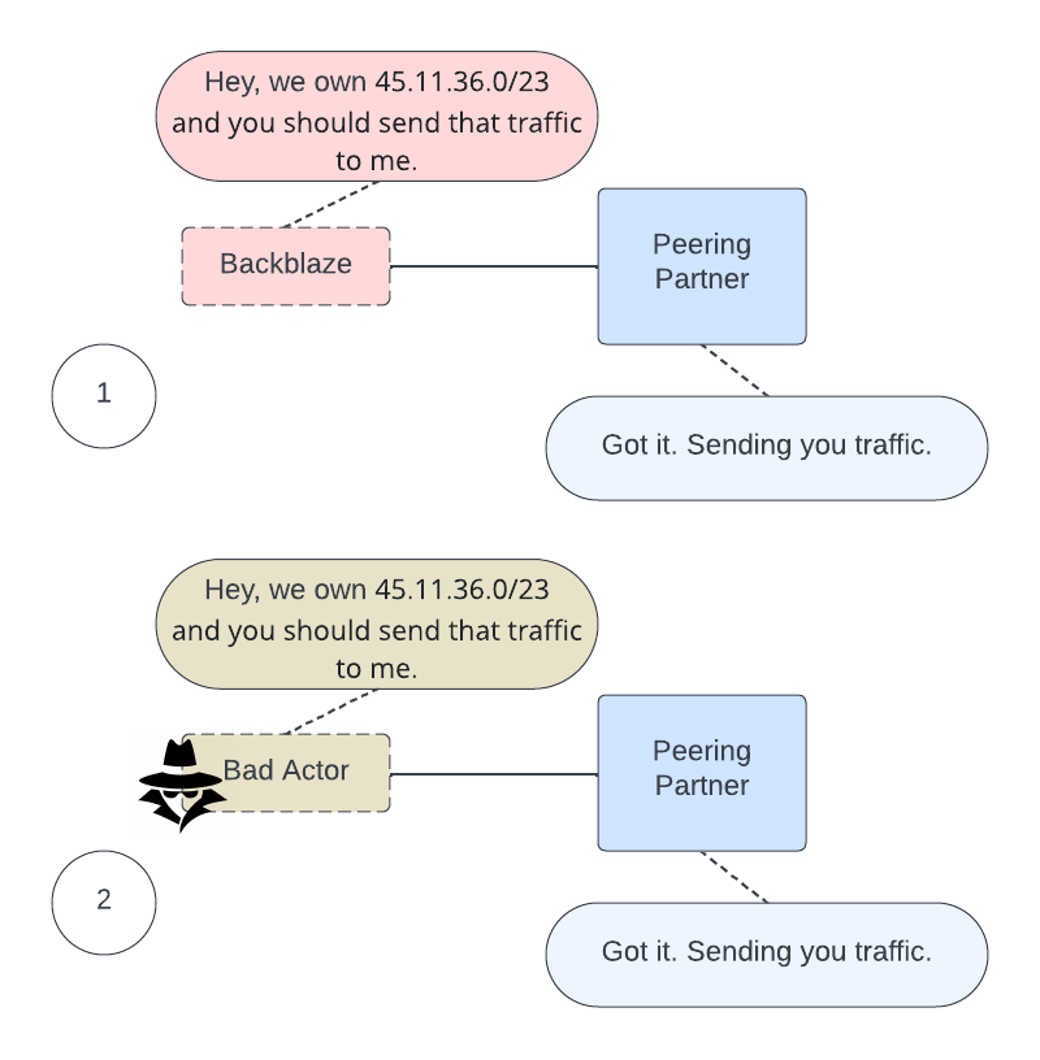
Now, with RPKI, we’ve dotted our I’s and crossed our T’s. A third party certificate holder serves as a validator for the digital certificates that we used to sign our network objects. If anyone else claims to be us, they will be marked as invalid and the peer will not accept the routing information, as you can see in the diagram below.
Mind Your MANRS
Our first value as a company is to be fair and good. It reads: “Be good. Trust is paramount. Build a good product. Charge fairly. Be open, honest, and accepting with customers and each other.” Almost sounds like Emily Post wrote it—that’s why our MANRS participation fits right in with the way we do business. We believe in an open internet, and participating in MANRS is just one way that we can contribute to a community that is working towards good for all.
The post Backblaze Commits to Routing Security With MANRS Participation appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Are you seriously using HACS??!
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=DGA9mRNoTcA
A new CEO for Mozilla
Post Syndicated from LWN.net original https://lwn.net/Articles/961359/
Mitchell Baker has announced
that she is stepping down from the role of Mozilla CEO, effective
immediately. Laura Chambers will be the new CEO “for the remainder of
“.
the year
We’re at a critical juncture where public trust in institutions,
governments, and the fabric of the internet has reached
unprecedented lows. There’s a tectonic shift underway as everyone
battles to own the future of AI. It is Mozilla’s opportunity and
imperative to forge a better future. I’m excited about Laura’s
day-to-day involvement and the chance for Mozilla to achieve
more. Our power lies in the collective effort of people
contributing to something better and I’m eager for Mozilla to meet
the needs of this era more fully.
A new CEO for Mozilla
Post Syndicated from corbet original https://lwn.net/Articles/961359/
Mitchell Baker has announced
that she is stepping down from the role of Mozilla CEO, effective
immediately. Laura Chambers will be the new CEO “for the remainder of
“.
the year
We’re at a critical juncture where public trust in institutions,
governments, and the fabric of the internet has reached
unprecedented lows. There’s a tectonic shift underway as everyone
battles to own the future of AI. It is Mozilla’s opportunity and
imperative to forge a better future. I’m excited about Laura’s
day-to-day involvement and the chance for Mozilla to achieve
more. Our power lies in the collective effort of people
contributing to something better and I’m eager for Mozilla to meet
the needs of this era more fully.
[$] Pitchforks for RDSEED
Post Syndicated from LWN.net original https://lwn.net/Articles/961121/
The generation of random (or, at least, unpredictable) numbers is key to
many security technologies. For this reason, the provision of random data
as a CPU feature has drawn a lot of attention over the years. A proper
hardware-based random-number generator can address the problems that make
randomness hard to obtain in some systems, but only if the manufacturer can
be trusted to not have compromised that generator in some way. A recent
discussion has brought to light a different problem, though: what happens
if a hardware random-number generator can be simply driven into exhaustion?
[$] Pitchforks for RDSEED
Post Syndicated from corbet original https://lwn.net/Articles/961121/
The generation of random (or, at least, unpredictable) numbers is key to
many security technologies. For this reason, the provision of random data
as a CPU feature has drawn a lot of attention over the years. A proper
hardware-based random-number generator can address the problems that make
randomness hard to obtain in some systems, but only if the manufacturer can
be trusted to not have compromised that generator in some way. A recent
discussion has brought to light a different problem, though: what happens
if a hardware random-number generator can be simply driven into exhaustion?
Glibc becomes a CVE Numbering Authority
Post Syndicated from LWN.net original https://lwn.net/Articles/961355/
The GNU C Library project has
been accepted as a CVE Numbering Authority (CNA), meaning that the
project is now in control of the CVE numbers assigned to its code.
As a CNA the glibc security team will be working to improve the
quality and response time of security advisories and mitigations.Over the coming months, the glibc security team will define the
process for the CNA and establish best practices that can also be
used by the rest of the GNU Toolchain.
See this article for some background on
this change.
Glibc becomes a CVE Numbering Authority
Post Syndicated from corbet original https://lwn.net/Articles/961355/
The GNU C Library project has
been accepted as a CVE Numbering Authority (CNA), meaning that the
project is now in control of the CVE numbers assigned to its code.
As a CNA the glibc security team will be working to improve the
quality and response time of security advisories and mitigations.Over the coming months, the glibc security team will define the
process for the CNA and establish best practices that can also be
used by the rest of the GNU Toolchain.
See this article for some background on
this change.
Security updates for Thursday
Post Syndicated from LWN.net original https://lwn.net/Articles/961330/
Security updates have been issued by Debian (chromium), Red Hat (gimp, kernel, kernel-rt, and runc), Slackware (expat), SUSE (libavif), and Ubuntu (linux, linux-aws, linux-aws-5.15, linux-gcp, linux-gcp-5.15, linux-gke,
linux-gkeop, linux-gkeop-5.15, linux-hwe-5.15, linux-ibm, linux-ibm-5.15,
linux-kvm, linux-lowlatency-hwe-5.15, linux-nvidia, linux-oracle,
linux-oracle-5.15, linux, linux-aws, linux-aws-5.4, linux-azure, linux-azure-5.4,
linux-bluefield, linux-gkeop, linux-hwe-5.4, linux-ibm, linux-ibm-5.4,
linux-iot, linux-kvm, linux-oracle, linux-oracle-5.4, linux-xilinx-zynqmp, and linux, linux-aws, linux-gcp, linux-hwe-6.5, linux-laptop,
linux-lowlatency, linux-lowlatency-hwe-6.5, linux-oem-6.5, linux-oracle,
linux-raspi, linux-starfive).