Post Syndicated from Manish Kola original https://aws.amazon.com/blogs/big-data/join-streaming-source-cdc-glue/
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, data lakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
Data lakes are not transactional by default; however, there are multiple open-source frameworks that enhance data lakes with ACID properties, providing a best of both worlds solution between transactional and non-transactional storage mechanisms.
Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. However, there is a challenge to ingest datasets, such as Internet of Things (IoT) and clickstreams, at a fast rate with near-real-time delivery SLAs. You will also want to apply incremental updates with change data capture (CDC) from the source system to the destination. To make data-driven decisions in a timely manner, you need to account for missed records and backpressure, and maintain event ordering and integrity, especially if the reference data also changes rapidly.
In this post, we aim to address these challenges. We provide a step-by-step guide to join streaming data to a reference table changing in real time using AWS Glue, Amazon DynamoDB, and AWS Database Migration Service (AWS DMS). We also demonstrate how to ingest streaming data to a transactional data lake using Apache Hudi to achieve incremental updates with ACID transactions.
Solution overview
For our example use case, streaming data is coming through Amazon Kinesis Data Streams, and reference data is managed in MySQL. The reference data is continuously replicated from MySQL to DynamoDB through AWS DMS. The requirement here is to enrich the real-time stream data by joining with the reference data in near-real time, and to make it queryable from a query engine such as Amazon Athena while keeping consistency. In this use case, reference data in MySQL can be updated when the requirement is changed, and then queries need to return results by reflecting updates in the reference data.
This solution addresses the issue of users wanting to join streams with changing reference datasets when the size of the reference dataset is small. The reference data is maintained in DynamoDB tables, and the streaming job loads the full table into memory for each micro-batch, joining a high-throughput stream to a small reference dataset.
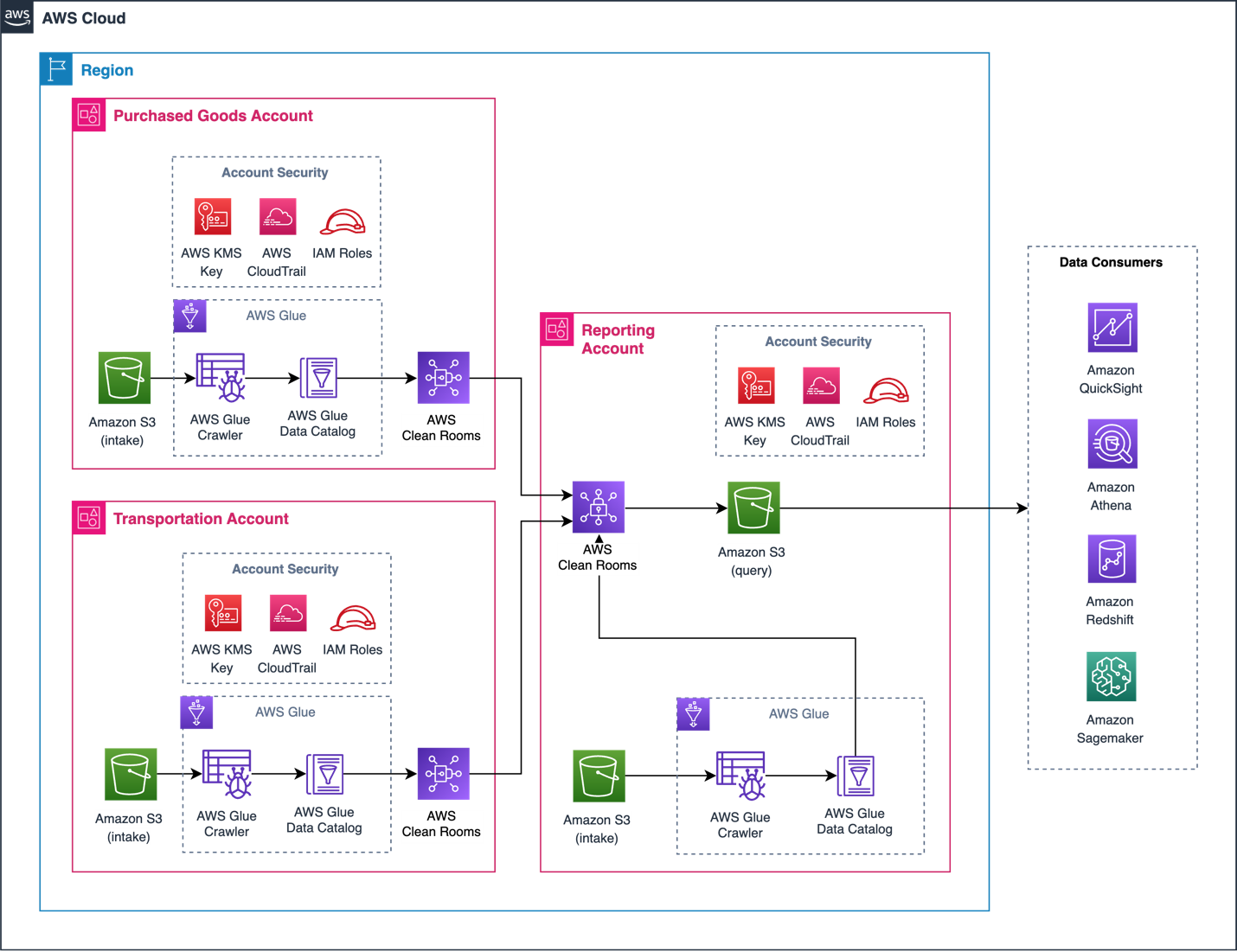
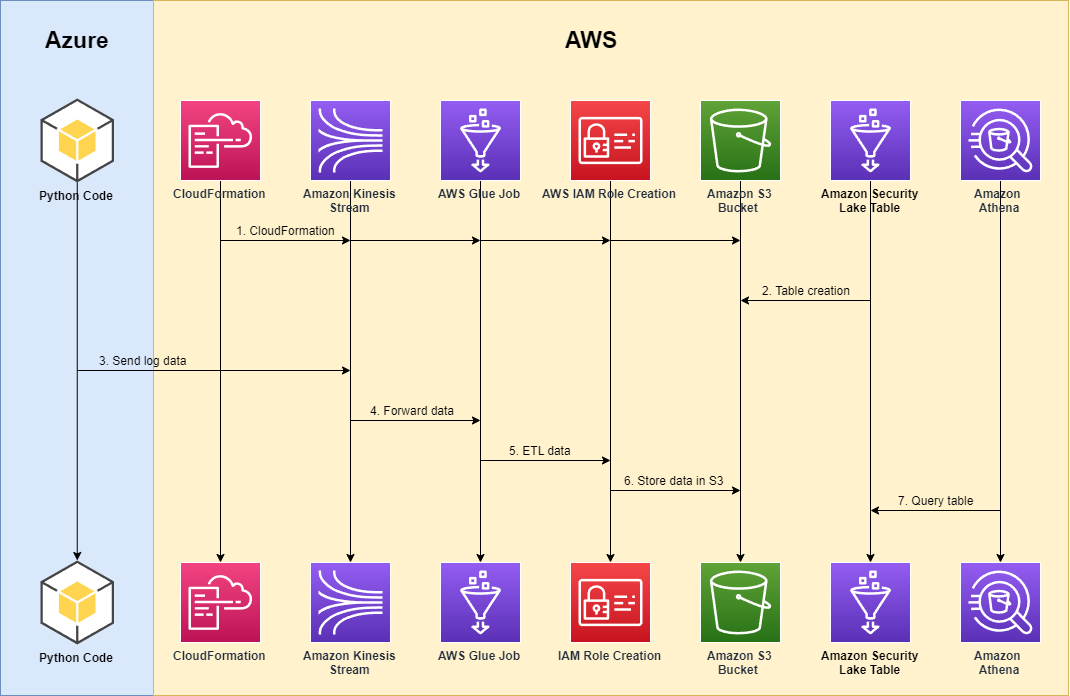
The following diagram illustrates the solution architecture.

Prerequisites
For this walkthrough, you should have the following prerequisites:
Create IAM roles and S3 bucket
In this section, you create an Amazon Simple Storage Service (Amazon S3) bucket and two AWS Identity and Access Management (IAM) roles: one for the AWS Glue job, and one for AWS DMS. We do this using an AWS CloudFormation template. Complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack::

- Choose Next.
- For Stack name, enter a name for your stack.
- For DynamoDBTableName, enter
tgt_country_lookup_table. This is the name of your new DynamoDB table.
- For S3BucketNamePrefix, enter the prefix of your new S3 bucket.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Stack creation can take about 1 minute.
Create a Kinesis data stream
In this section, you create a Kinesis data stream:
- On the Kinesis console, choose Data streams in the navigation pane.
- Choose Create data stream.
- For Data stream name, enter your stream name.
- Leave the remaining settings as default and choose Create data stream.
A Kinesis data stream is created with on-demand mode.
Create and configure an Aurora MySQL cluster
In this section, you create and configure an Aurora MySQL cluster as the source database. First, configure your source Aurora MySQL database cluster to enable CDC through AWS DMS to DynamoDB.
Create a parameter group
Complete the following steps to create a new parameter group:
- On the Amazon RDS console, choose Parameter groups in the navigation pane.
- Choose Create parameter group.
- For Parameter group family, select
aurora-mysql5.7.
- For Type, choose DB Cluster Parameter Group.
- For Group name, enter
my-mysql-dynamodb-cdc.
- For Description, enter
Parameter group for demo Aurora MySQL database.
- Choose Create.
- Select
my-mysql-dynamodb-cdc, and choose Edit under Parameter group actions.
- Edit the parameter group as follows:
| Name |
Value |
| binlog_row_image |
full |
| binlog_format |
ROW |
| binlog_checksum |
NONE |
| log_slave_updates |
1 |
- Choose Save changes.

Create the Aurora MySQL cluster
Complete following steps to create the Aurora MySQL cluster:
- On the Amazon RDS console, choose Databases in the navigation pane.
- Choose Create database.
- For Choose a database creation method, choose Standard create.
- Under Engine options, for Engine type, choose Aurora (MySQL Compatible).
- For Engine version, choose Aurora (MySQL 5.7) 2.11.2.
- For Templates, choose Production.
- Under Settings, for DB cluster identifier, enter a name for your database.
- For Master username, enter your primary user name.
- For Master password and Confirm master password, enter your primary password.
- Under Instance configuration, for DB instance class, choose Burstable classes (includes t classes) and choose db.t3.small.
- Under Availability & durability, for Multi-AZ deployment, choose Don’t create an Aurora Replica.
- Under Connectivity, for Compute resource, choose Don’t connect to an EC2 compute resource.
- For Network type, choose IPv4.
- For Virtual private cloud (VPC), choose your VPC.
- For DB subnet group, choose your public subnet.
- For Public access, choose Yes.
- For VPC security group (firewall), choose the security group for your public subnet.
- Under Database authentication, for Database authentication options, choose Password authentication.
- Under Additional configuration, for DB cluster parameter group, choose the cluster parameter group you created earlier.
- Choose Create database.
Grant permissions to the source database
The next step is to grant the required permission on the source Aurora MySQL database. Now you can connect to the DB cluster using the MySQL utility. You can run queries to complete the following tasks:
- Create a demo database and table and run queries on the data
- Grant permission for a user used by the AWS DMS endpoint
Complete the following steps:
- Log in to the EC2 instance that you’re using to connect to your DB cluster.
- Enter the following command at the command prompt to connect to the primary DB instance of your DB cluster:
$ mysql -h mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com -P 3306 -u admin -p
- Run the following SQL command to create a database:
- Run the following SQL command to create a table:
> use mydev;
> CREATE TABLE country_lookup_table
(
code varchar(5),
countryname varchar(40) not null,
combinedname varchar(40) not null
);
- Run the following SQL command to populate the table with data:
> INSERT INTO country_lookup_table(code, countryname, combinedname) VALUES ('IN', 'India', 'IN-India'), ('US', 'USA', 'US-USA'), ('CA', 'Canada', 'CA-Canada'), ('CN', 'China', 'CN-China');
- Run the following SQL command to create a user for the AWS DMS endpoint and grant permissions for CDC tasks (replace the placeholder with your preferred password):
> CREATE USER repl IDENTIFIED BY '<your-password>';
> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl'@'%';
> GRANT SELECT ON mydev.country_lookup_table TO 'repl'@'%';
Create and configure AWS DMS resources to load data into the DynamoDB reference table
In this section, you create and configure AWS DMS to replicate data into the DynamoDB reference table.
Create an AWS DMS replication instance
First, create an AWS DMS replication instance by completing the following steps:
- On the AWS DMS console, choose Replication instances in the navigation pane.
- Choose Create replication instance.
- Under Settings, for Name, enter a name for your instance.
- Under Instance configuration, for High Availability, choose Dev or test workload (Single-AZ).
- Under Connectivity and security, for VPC security groups, choose default.
- Choose Create replication instance.
Create Amazon VPC endpoints
Optionally, you can create Amazon VPC endpoints for DynamoDB when you need to connect to your DynamoDB table from the AWS DMS instance in a private network. Also make sure that you enable Publicly accessible when you need to connect to a database outside of your VPC.
Create an AWS DMS source endpoint
Create an AWS DMS source endpoint by completing the following steps:
- On the AWS DMS console, choose Endpoints in the navigation pane.
- Choose Create endpoint.
- For Endpoint type, choose Source endpoint.
- Under Endpoint configuration, for Endpoint identifier, enter a name for your endpoint.
- For Source engine, choose Amazon Aurora MySQL.
- For Access to endpoint database, choose Provide access information manually.
- For Server Name, enter the endpoint name of your Aurora writer instance (for example,
mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com).
- For Port, enter
3306.
- For User name, enter a user name for your AWS DMS task.
- For Password, enter a password.
- Choose Create endpoint.
Crate an AWS DMS target endpoint
Create an AWS DMS target endpoint by completing the following steps:
- On the AWS DMS console, choose Endpoints in the navigation pane.
- Choose Create endpoint.
- For Endpoint type, choose Target endpoint.
- Under Endpoint configuration, for Endpoint identifier, enter a name for your endpoint.
- For Target engine, choose Amazon DynamoDB.
- For Service access role ARN, enter the IAM role for your AWS DMS task.
- Choose Create endpoint.
Create AWS DMS migration tasks
Create AWS DMS database migration tasks by completing the following steps:
- On the AWS DMS console, choose Database migration tasks in the navigation pane.
- Choose Create task.
- Under Task configuration, for Task identifier, enter a name for your task.
- For Replication instance, choose your replication instance.
- For Source database endpoint, choose your source endpoint.
- For Target database endpoint, choose your target endpoint.
- For Migration type, choose Migrate existing data and replicate ongoing changes.
- Under Task settings, for Target table preparation mode, choose Do nothing.
- For Stop task after full load completes, choose Don’t stop.
- For LOB column settings, choose Limited LOB mode.
- For Task logs, enable Turn on CloudWatch logs and Turn on batch-optimized apply.
- Under Table mappings, choose JSON Editor and enter the following rules.
Here you can add values to the column. With the following rules, the AWS DMS CDC task will first create a new DynamoDB table with the specified name in target-table-name. Then it will replicate all the records, mapping the columns in the DB table to the attributes in the DynamoDB table.
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "mydev",
"table-name": "country_lookup_table"
},
"rule-action": "include"
},
{
"rule-type": "object-mapping",
"rule-id": "2",
"rule-name": "2",
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "mydev",
"table-name": "country_lookup_table"
},
"target-table-name": "tgt_country_lookup_table",
"mapping-parameters": {
"partition-key-name": "code",
"sort-key-name": "countryname",
"exclude-columns": [
"code",
"countryname"
],
"attribute-mappings": [
{
"target-attribute-name": "code",
"attribute-type": "scalar",
"attribute-sub-type": "string",
"value": "${code}"
},
{
"target-attribute-name": "countryname",
"attribute-type": "scalar",
"attribute-sub-type": "string",
"value": "${countryname}"
}
],
"apply-during-cdc": true
}
}
]
}

- Choose Create task.
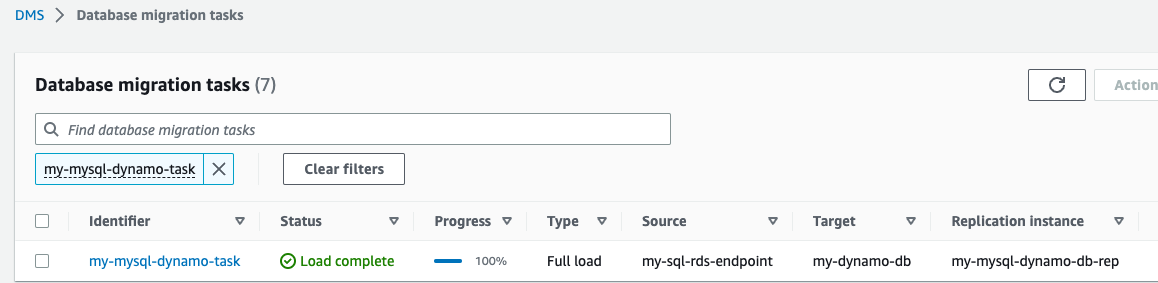
Now the AWS DMS replication task has been started.
- Wait for the Status to show as Load complete.

- On the DynamoDB console, choose Tables in the navigation pane.
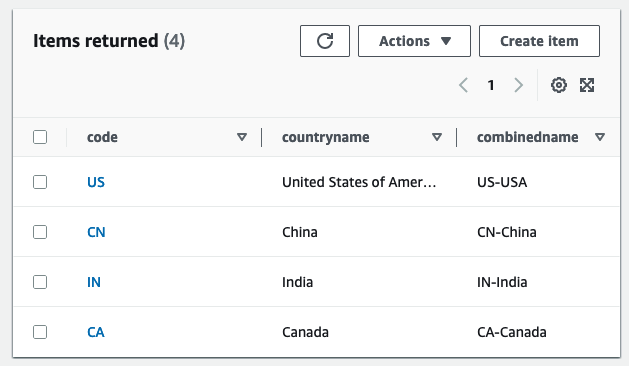
- Select the DynamoDB reference table, and choose Explore table items to review the replicated records.

Create an AWS Glue Data Catalog table and an AWS Glue streaming ETL job
In this section, you create an AWS Glue Data Catalog table and an AWS Glue streaming extract, transform, and load (ETL) job.
Create a Data Catalog table
Create an AWS Glue Data Catalog table for the source Kinesis data stream with the following steps:
- On the AWS Glue console, choose Databases under Data Catalog in the navigation pane.
- Choose Add database.
- For Name, enter
my_kinesis_db.
- Choose Create database.
- Choose Tables under Databases, then choose Add table.
- For Name, enter
my_stream_src_table.
- For Database, choose
my_kinesis_db.
- For Select the type of source, choose Kinesis.
- For Kinesis data stream is located in, choose my account.
- For Kinesis stream name, enter a name for your data stream.
- For Classification, select JSON.
- Choose Next.
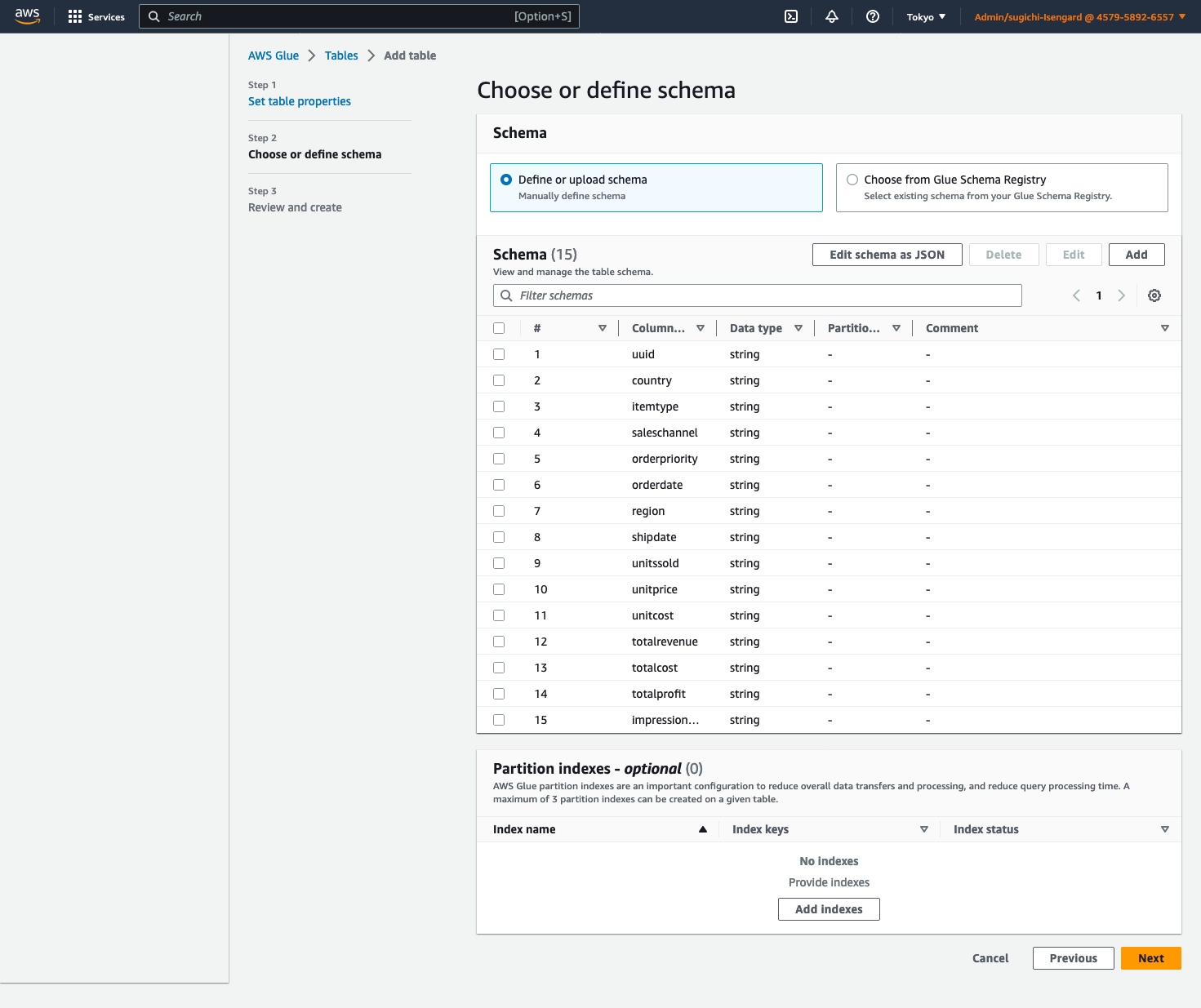
- Choose Edit schema as JSON, enter the following JSON, then choose Save.
[
{
"Name": "uuid",
"Type": "string",
"Comment": ""
},
{
"Name": "country",
"Type": "string",
"Comment": ""
},
{
"Name": "itemtype",
"Type": "string",
"Comment": ""
},
{
"Name": "saleschannel",
"Type": "string",
"Comment": ""
},
{
"Name": "orderpriority",
"Type": "string",
"Comment": ""
},
{
"Name": "orderdate",
"Type": "string",
"Comment": ""
},
{
"Name": "region",
"Type": "string",
"Comment": ""
},
{
"Name": "shipdate",
"Type": "string",
"Comment": ""
},
{
"Name": "unitssold",
"Type": "string",
"Comment": ""
},
{
"Name": "unitprice",
"Type": "string",
"Comment": ""
},
{
"Name": "unitcost",
"Type": "string",
"Comment": ""
},
{
"Name": "totalrevenue",
"Type": "string",
"Comment": ""
},
{
"Name": "totalcost",
"Type": "string",
"Comment": ""
},
{
"Name": "totalprofit",
"Type": "string",
"Comment": ""
},
{
"Name": "impressiontime",
"Type": "string",
"Comment": ""
}
]

-
- Choose Next, then choose Create.
Create an AWS Glue streaming ETL job
Next, you create an AWS Glue streaming job. AWS Glue 3.0 and later supports Apache Hudi natively, so we use this native integration to ingest into a Hudi table. Complete the following steps to create the AWS Glue streaming job:
- On the AWS Glue Studio console, choose Spark script editor and choose Create.
- Under Job details tab, for Name, enter a name for your job.
- For IAM Role, choose the IAM role for your AWS Glue job.
- For Type, select Spark Streaming.
- For Glue version, choose Glue 4.0 – Supports spark 3.3, Scala 2, Python 3.
- For Requested number of workers, enter
3.
- Under Advanced properties, for Job parameters, choose Add new parameter.
- For Key, enter
--conf.
- For Value, enter
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false.
- Choose Add new parameter.
- For Key, enter
--datalake-formats.
- For Value, enter
hudi.
- For Script path, enter
s3://<S3BucketName>/scripts/.
- For Temporary path, enter
s3://<S3BucketName>/temporary/.
- Optionally, for Spark UI logs path, enter
s3://<S3BucketName>/sparkHistoryLogs/.

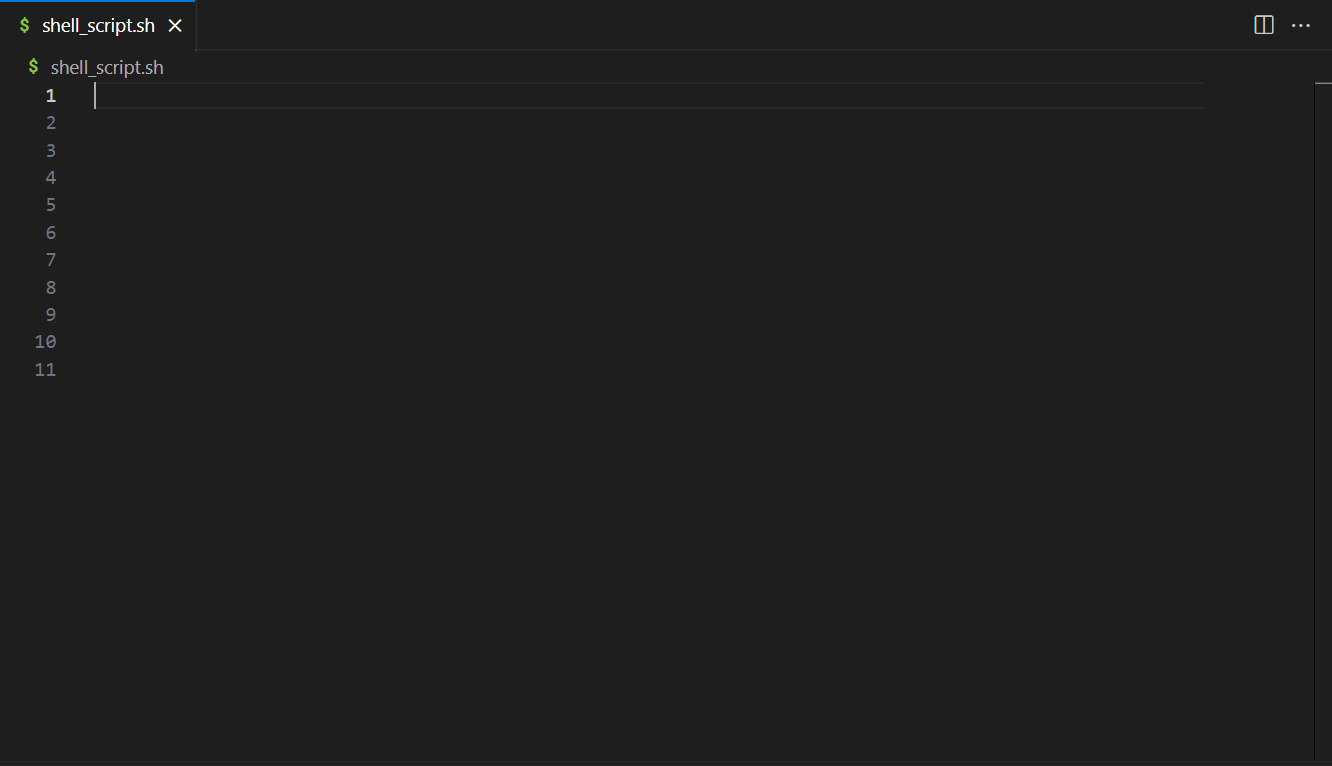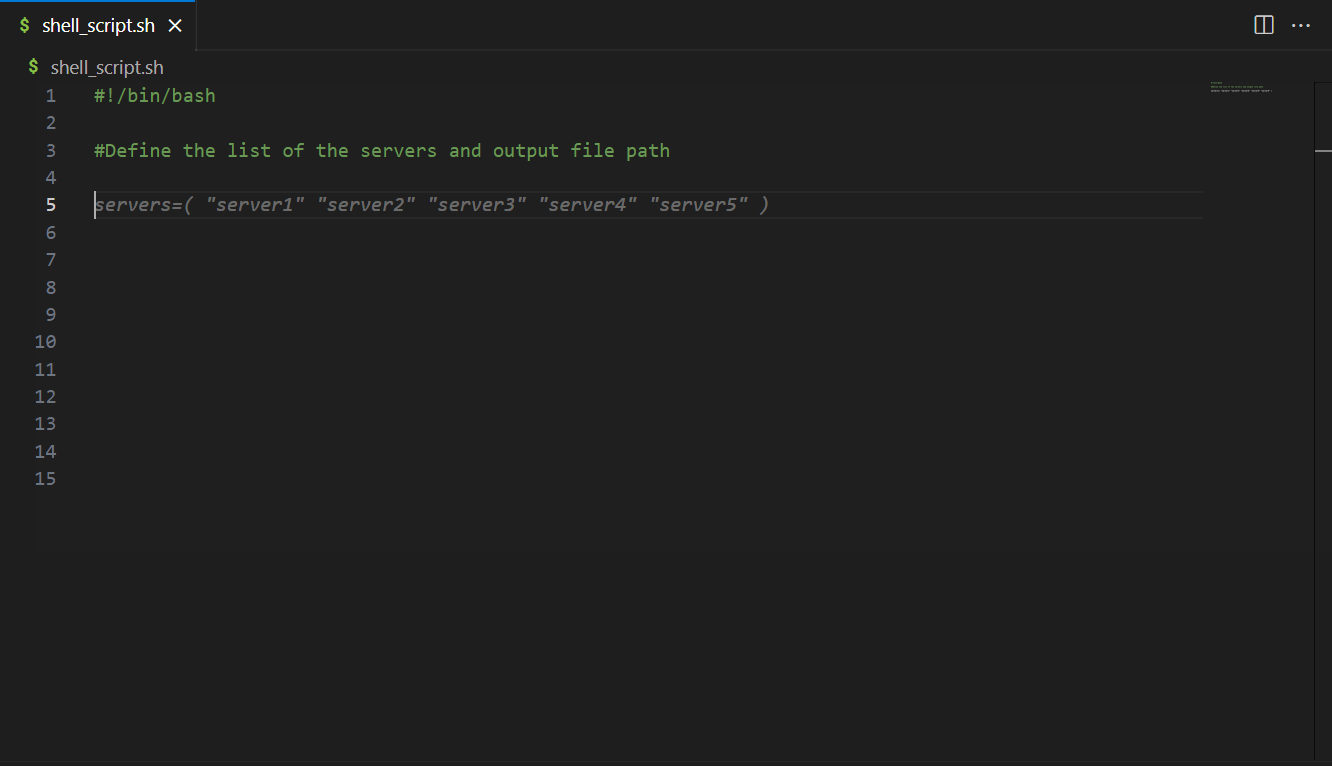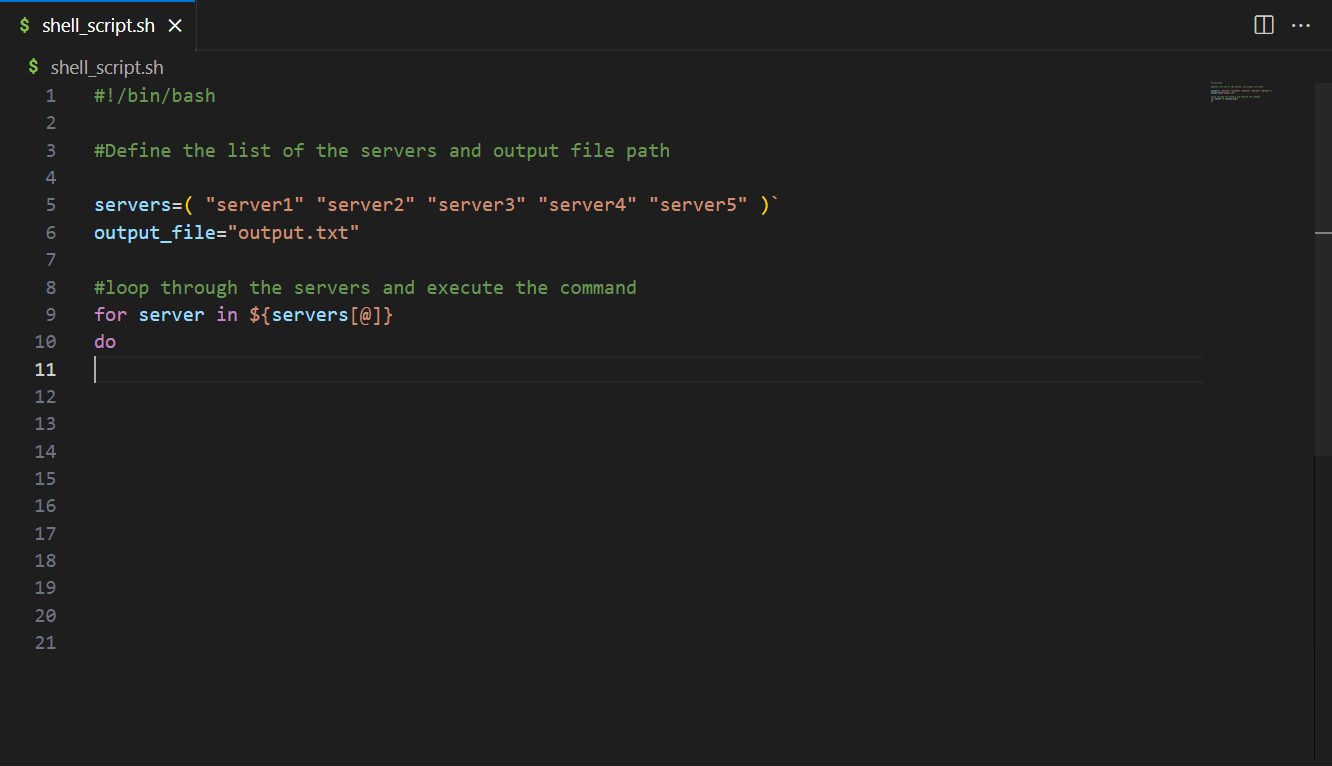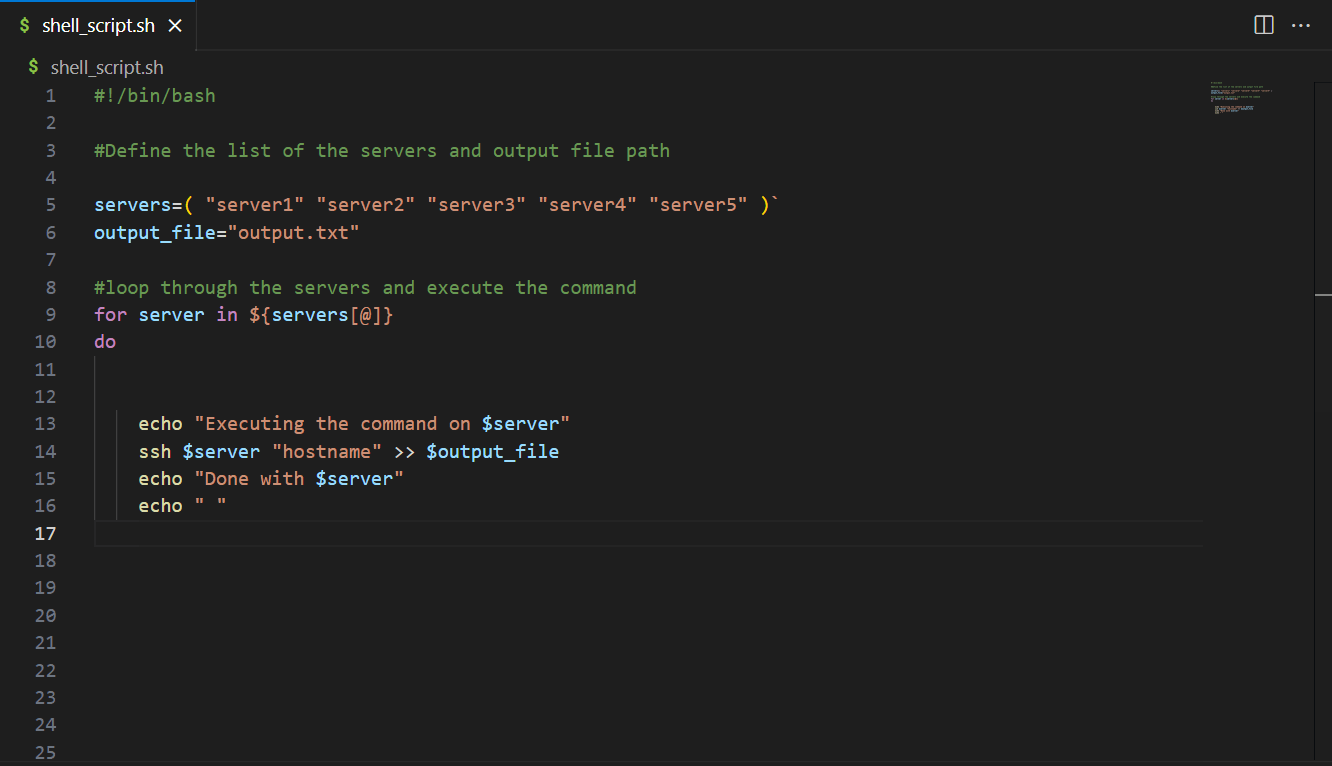
- On the Script tab, enter the following script into the AWS Glue Studio editor and choose Create.
The near-real-time streaming job enriches data by joining a Kinesis data stream with a DynamoDB table that contains frequently updated reference data. The enriched dataset is loaded into the target Hudi table in the data lake. Replace <S3BucketName> with your bucket that you created via AWS CloudFormation:
import sys, json
import boto3
from pyspark.sql import DataFrame, Row
from pyspark.context import SparkContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv,["JOB_NAME"])
# Initialize spark session and Glue context
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# job paramters
dydb_lookup_table = "tgt_country_lookup_table"
kin_src_database_name = "my_kinesis_db"
kin_src_table_name = "my_stream_src_table"
hudi_write_operation = "upsert"
hudi_record_key = "uuid"
hudi_precomb_key = "orderdate"
checkpoint_path = "s3://<S3BucketName>/streamlab/checkpoint/"
s3_output_folder = "s3://<S3BucketName>/output/"
hudi_table = "hudi_table"
hudi_database = "my_kinesis_db"
# hudi options
additional_options={
"hoodie.datasource.hive_sync.use_jdbc": "false",
"hoodie.datasource.write.recordkey.field": hudi_record_key,
"hoodie.datasource.hive_sync.database": hudi_database,
"hoodie.table.name": hudi_table,
"hoodie.consistency.check.enabled": "true",
"hoodie.datasource.write.keygenerator.class": "org.apache.hudi.keygen.NonpartitionedKeyGenerator",
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.NonPartitionedExtractor",
"hoodie.datasource.write.hive_style_partitioning": "false",
"hoodie.datasource.write.precombine.field": hudi_precomb_key,
"hoodie.bulkinsert.shuffle.parallelism": "4",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.write.operation": hudi_write_operation,
"hoodie.datasource.write.storage.type": "COPY_ON_WRITE",
}
# Scan and load the reference data table from DynamoDB into AWS Glue DynamicFrames using boto3 API.
def readDynamoDb():
dynamodb = boto3.resource(“dynamodb”)
table = dynamodb.Table(dydb_lookup_table)
response = table.scan()
items = response[“Items”]
jsondata = sc.parallelize(items)
lookupDf = glueContext.read.json(jsondata)
return lookupDf
# Load the Amazon Kinesis data stream from Amazon Glue Data Catalog.
source_df = glueContext.create_data_frame.from_catalog(
database=kin_src_database_name,
table_name=kin_src_table_name,
transformation_ctx=”source_df”,
additional_options={“startingPosition”: “TRIM_HORIZON”},
)
# As part of batch processing, implement the transformation logic for joining streaming data frames with reference data frames.
def processBatch(data_frame, batchId):
if data_frame.count() > 0:
# Refresh the dymanodb table to pull latest snapshot for each microbatch
country_lookup_df = readDynamoDb()
final_frame = data_frame.join(
country_lookup_df,
data_frame["country"] == country_lookup_df["countryname"],
'left'
).drop(
"countryname",
"country",
"unitprice",
"unitcost",
"totalrevenue",
"totalcost",
"totalprofit"
)
# Script generated for node my-lab-hudi-connector
final_frame.write.format("hudi") \
.options(**additional_options) \
.mode("append") \
.save(s3_output_folder)
try:
glueContext.forEachBatch(
frame=source_df,
batch_function=processBatch,
options={"windowSize": "60 seconds", "checkpointLocation": checkpoint_path},
)
except Exception as e:
print(f"Error is @@@ ....{e}")
- Choose Run to start the streaming job.
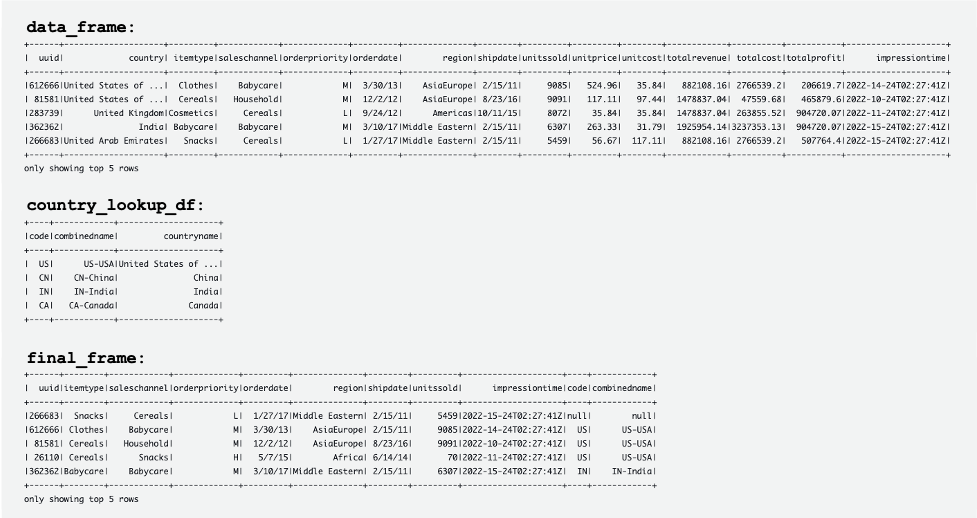
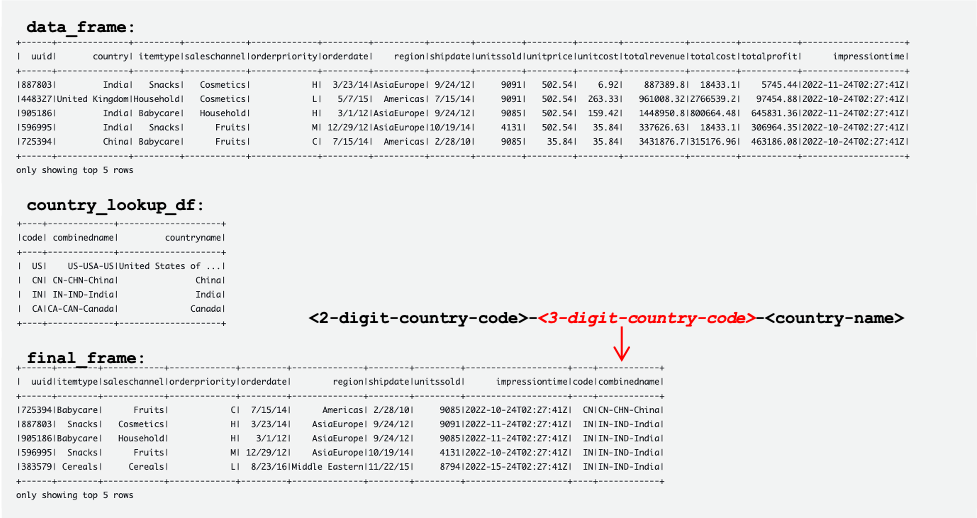
The following screenshot shows examples of the DataFrames data_frame, country_lookup_df, and final_frame.

The AWS Glue job successfully joined records coming from the Kinesis data stream and the reference table in DynamoDB, and then ingested the joined records into Amazon S3 in Hudi format.
Create and run a Python script to generate sample data and load it into the Kinesis data stream
In this section, you create and run a Python to generate sample data and load it into the source Kinesis data stream. Complete the following steps:
- Log in to AWS Cloud9, your EC2 instance, or any other computing host that puts records in your data stream.
- Create a Python file called
generate-data-for-kds.py:
$ python3 generate-data-for-kds.py
- Open the Python file and enter the following script:
import json
import random
import boto3
import time
STREAM_NAME = "<mystreamname>"
def get_data():
return {
"uuid": random.randrange(0, 1000001, 1),
"country": random.choice( [ "United Arab Emirates", "China", "India", "United Kingdom", "United States of America", ] ),
"itemtype": random.choice( [ "Snacks", "Cereals", "Cosmetics", "Fruits", "Clothes", "Babycare", "Household", ] ),
"saleschannel": random.choice( [ "Snacks", "Cereals", "Cosmetics", "Fruits", "Clothes", "Babycare", "Household", ] ),
"orderpriority": random.choice(["H", "L", "M", "C"]),
"orderdate": random.choice( [ "1/4/10", "2/28/10", "2/15/11", "11/8/11", "2/1/12", "2/18/12", "3/1/12", "9/24/12",
"10/13/12", "12/2/12", "12/29/12", "3/30/13", "7/29/13", "3/23/14", "6/14/14",
"7/15/14", "10/19/14", "5/7/15", "10/11/15", "11/22/15", "8/23/16", "1/15/17",
"1/27/17", "2/25/17", "3/10/17", "4/1/17", ] ),
"region": random.choice( ["Asia" "Europe", "Americas", "Middle Eastern", "Africa"] ),
"shipdate": random.choice( [ "1/4/10", "2/28/10", "2/15/11", "11/8/11", "2/1/12", "2/18/12", "3/1/12", "9/24/12",
"10/13/12", "12/2/12", "12/29/12", "3/30/13", "7/29/13", "3/23/14", "6/14/14", "7/15/14",
"10/19/14", "5/7/15", "10/11/15", "11/22/15", "8/23/16", "1/15/17", "1/27/17",
"2/25/17", "3/10/17", "4/1/17", ] ),
"unitssold": random.choice( [ "8217", "3465", "8877", "2882", "70", "7044", "6307", "2384", "1327", "2572", "8794",
"4131", "5793", "9091", "4314", "9085", "5270", "5459", "1982", "8245", "4860", "4656",
"8072", "65", "7864", "9778", ] ),
"unitprice": random.choice( [ "97.44", "117.11", "364.69", "502.54", "263.33", "117.11", "35.84", "6.92", "35.84",
"6.92", "35.84", "56.67", "159.42", "502.54", "117.11", "56.67", "524.96", "502.54",
"56.67", "56.67", "159.42", "56.67", "35.84", "159.42", "502.54", "31.79", ] ),
"unitcost": random.choice( [ "97.44", "117.11", "364.69", "502.54", "263.33", "117.11", "35.84", "6.92", "35.84",
"6.92", "35.84", "56.67", "159.42", "502.54", "117.11", "56.67", "524.96", "502.54",
"56.67", "56.67", "159.42", "56.67", "35.84", "159.42", "502.54", "31.79", ] ),
"totalrevenue": random.choice( [ "1253749.86", "712750.5", "3745117.53", "1925954.14", "30604", "1448950.8",
"689228.96", "22242.72", "145014.56", "23996.76", "961008.32", "337626.63",
"1478837.04", "6075242.57", "887389.8", "742517.05", "3431876.7", "3648085.93",
"161988.86", "673863.85", "1240660.8", "380534.88", "882108.16", "16593.2",
"5255275.28", "463966.1", ] ),
"totalcost": random.choice( [ "800664.48", "405786.15", "3237353.13", "1448320.28", "18433.1", "824922.84",
"226042.88", "16497.28", "47559.68", "17798.24", "315176.96", "234103.77", "923520.06",
"4568591.14", "505212.54", "514846.95", "2766539.2", "2743365.86",
"112319.94", "467244.15", "774781.2", "263855.52", "289300.48", "10362.3",
"3951974.56", "310842.62", ] ),
"totalprofit": random.choice( [ "453085.38", "306964.35", "507764.4", "477633.86", "12170.9", "624027.96",
"463186.08", "5745.44", "97454.88", "6198.52", "645831.36", "103522.86", "555316.98",
"1506651.43", "382177.26", "227670.1", "665337.5", "904720.07", "49668.92", "206619.7",
"465879.6", "116679.36", "592807.68", "6230.9", "1303300.72", "153123.48", ] ),
"impressiontime": random.choice( [ "2022-10-24T02:27:41Z", "2022-10-24T02:27:41Z", "2022-11-24T02:27:41Z",
"2022-12-24T02:27:41Z", "2022-13-24T02:27:41Z", "2022-14-24T02:27:41Z",
"2022-15-24T02:27:41Z", ] ),
}
def generate(stream_name, kinesis_client):
while True:
data = get_data()
print(data)
kinesis_client.put_record(
StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey"
)
time.sleep(2)
if __name__ == "__main__":
generate(STREAM_NAME, boto3.client("kinesis"))
This script puts a Kinesis data stream record every 2 seconds.
Simulate updating the reference table in the Aurora MySQL cluster
Now all the resources and configurations are ready. For this example, we want to add a 3-digit country code to the reference table. Let’s update records in the Aurora MySQL table to simulate changes. Complete the following steps:
- Make sure that the AWS Glue streaming job is already running.
- Connect to the primary DB instance again, as described earlier.
- Enter your SQL commands to update records:
> UPDATE country_lookup_table SET combinedname='US-USA-US' WHERE code='US';
> UPDATE country_lookup_table SET combinedname='CA-CAN-Canada' WHERE code='CA';
> UPDATE country_lookup_table SET combinedname='CN-CHN-China' WHERE code='CN';
> UPDATE country_lookup_table SET combinedname='IN-IND-India' WHERE code='IN';
Now the reference table in the Aurora MySQL source database has been updated. Then the changes are automatically replicated to the reference table in DynamoDB.

The following tables show records in data_frame, country_lookup_df, and final_frame. In country_lookup_df and final_frame, the combinedname column has values formatted as <2-digit-country-code>-<3-digit-country-code>-<country-name>, which shows that the changed records in the referenced table are reflected in the table without restarting the AWS Glue streaming job. It means that the AWS Glue job successfully joins the incoming records from the Kinesis data stream with the reference table even when the reference table is changing.
Query the Hudi table using Athena
Let’s query the Hudi table using Athena to see the records in the destination table. Complete the following steps:
- Make sure that the script and the AWS Glue Streaming job is still working:
- The Python script (
generate-data-for-kds.py) is still running.
- The generated data is being sent to the data stream.
- The AWS Glue streaming job is still running.
- On the Athena console, run the following SQL in the query editor:
select shipdate, unitssold, impressiontime, code,combinedname from <database>.<table>
where combinedname is not null
limit 10;
The following query result shows the records that are processed before the referenced table was changed. Records in the combinedname column are similar to <2-digit-country-code>-<country-name>.

The following query result shows the records that are processed after the referenced table was changed. Records in the combinedname column are similar to <2-digit-country-code>-<3-digit-country-code>-<country-name>.
Now you understand that the changed reference data is successfully reflected in the target Hudi table joining records from the Kinesis data stream and the reference data in DynamoDB.
Clean up
As the final step, clean up the resources:
- Delete the Kinesis data stream.
- Delete the AWS DMS migration task, endpoint, and replication instance.
- Stop and delete the AWS Glue streaming job.
- Delete the AWS Cloud9 environment.
- Delete the CloudFormation template.
Conclusion
Building and maintaining a transactional data lake that involves real-time data ingestion and processing has multiple variable components and decisions to be made, such as what ingestion service to use, how to store your reference data, and what transactional data lake framework to use. In this post, we provided the implementation details of such a pipeline, using AWS native components as the building blocks and Apache Hudi as the open-source framework for a transactional data lake.
We believe that this solution can be a starting point for organizations looking to implement a new data lake with such requirements. Additionally, the different components are fully pluggable and can be mixed and matched to existing data lakes to target new requirements or migrate existing ones, addressing their pain points.
About the authors
 Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects.
Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects.
Santosh Kotagiri is a Solutions Architect at AWS with experience in data analytics and cloud solutions leading to tangible business results. His expertise lies in designing and implementing scalable data analytics solutions for clients across industries, with a focus on cloud-native and open-source services. He is passionate about leveraging technology to drive business growth and solve complex problems.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.






























 Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects.
Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects. Santosh Kotagiri is a Solutions Architect at AWS with experience in data analytics and cloud solutions leading to tangible business results. His expertise lies in designing and implementing scalable data analytics solutions for clients across industries, with a focus on cloud-native and open-source services. He is passionate about leveraging technology to drive business growth and solve complex problems.
Santosh Kotagiri is a Solutions Architect at AWS with experience in data analytics and cloud solutions leading to tangible business results. His expertise lies in designing and implementing scalable data analytics solutions for clients across industries, with a focus on cloud-native and open-source services. He is passionate about leveraging technology to drive business growth and solve complex problems. Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.